sean mortazavi architect microsoft corporation jeff baxter software developer microsoft corporation...
TRANSCRIPT

Building Supercomputer Applications using Windows HPC 2008
Sean MortazaviArchitectMicrosoft Corporation
Jeff BaxterSoftware DeveloperMicrosoft Corporation
ES13

2
What is High Performance Computing? Windows HPC product overview & demo Programming Model overviews & demo
Parametric Sweeps MPI & MPI.Net Cluster SOA
Cool projects! Parallel Dwarfs Go/Surface/HPC Project
Advanced performance tuning & analysis
Agenda
5
10
30
10
20

3
What is High Performance Computing?
… aka Supercomputing, aka Scientific Computing A Scale out Solution to run on clusters with 10s
to 1000s of nodes Solve large computational problems Commonly associated with science &
engineering HPC also refers to high productivity in recent
years
X64 Server
1991 1998 2008
$40,000,000 $1,000,000 $1,000

4
Classic Scenarios Oil & Gas Auto Aero EDA Gov
Newer Scenarios FinServ Bio Informatics Pharma / Chemistry Digital Content creation
Really New Scenarios (but not really…) Project builds QA testing machine farm Games
Application Scenarios

5
Windows HPC Server 2008
Complete, integrated platform for computational clustering Built on top the proven Windows Server 2008 platform Integrated development environment
Windows Server Operating System
• Secure, Reliable, Tested
• Support for high performance hardware (x64, high-speed interconnects)
HPC Pack
• Job Scheduler• Resource Manager • Cluster Management• Message Passing Interface• SDK
Microsoft Windows HPC Server 2008
• Integrated Solution out-of-the-box
• Leverages investment in Windows administration and tools
• Makes cluster operation easy and secure as a single system

Systems Management
Job & Resource Scheduling
HPCApplication
ModelsStorage
Rapid large scale deployment and built-in diagnostics suite
Integrated monitoring, management and reporting
Familiar UI and rich scripting interface
Integrated security via Active Directory
Support for batch, interactive and service-oriented applications
High availability schedulingInteroperability via OGF’s HPC
Basic Profile
MS-MPI stack based on MPICH2 reference implementation
Performance improvements for RDMA networking and multi-core shared memory
MS-MPI integrated with Windows Event Tracing
Access to SQL, Windows and Unix file servers
Key parallel file server vendor support (GPFS, Lustre, Panasas)
In-memory caching options
Windows HPC Server 2008

7
MPINetwork
PrivateNetwork
PublicNetwork
Corporate IT Infrastructure
Compute NodeHead Node
AD
DNS
DHCP
Windows Update
Monitoring SystemsManagement
Compute Cluster
Typical HPC Cluster Topology
Admin / User Cons
WDS
Job Scheduler
MPI
Management
NAT
Node Manager
MPI
Management
Compute Node
Node Manager
MPI
Management
10s to 1000s
……….

Windows HPCConfiguration, Job & node management, Clusrun, Diagnostics, Reporting
Sean MortazaviArchitectMicrosoft Corporation
demo

Ease of DeploymentSkip/Demo

Ease of DeploymentSkip/Demo

Comprehensive Diagnostics SuiteSkip/Demo

12
Single Management Console
Group compute nodes based on hardware, software and custom attributes; Act on groupings.
Pivoting enables correlating nodes and jobs together
Track long running operations and access operation history
Receive alerts for failures
List or Heat Map view cluster at a glance
Skip/Demo

Integrated MonitoringSkip/Demo

Built-in ReportingSkip/Demo

15
Integrated Job Scheduling
Services oriented HPC apps
Expanded Job Policies
Support for Job Templates
Improve interoperability with mixed IT infrastructure
Skip/Demo

16
Node 1
S0
P0 P1
P2 P3
S1
P0 P1
P2 P3
S2
P0 P1
P2 P3
S3
P0 P1
P2 P3
Node 2
S0
P0 P1
P2 P3
S1
P0 P1
P2 P3
S2
P0 P1
P2 P3
S3
P0 P1
P2 P3
J1 J1
J3
J2
J1: /numsockets:3 /exclusive: falseJ3: /numcores:4 /exclusive: false
J2: /numnodes:1
Windows HPC Server can help your application make the best use of multi-core systems
Node/Socket/Core Allocation
J3
J3 J3J1
Skip/Demo

17
Job Submission: 3 Methods
Command line Job submit /headnode:Clus1 /Numprocessors:124 /nodegroup:Matlab Job submit /corespernode:8 /numnodes:24 Job submit /failontaskfailure:true /requestednodes:N1,N2,N3,N4 Job submit /numprocessors:256 mpiexec \\share\mpiapp.exe [Completel Powershell system mgmt commands are available as well]
using Microsoft.Hpc.Scheduler;class Program{
static void Main(){
IScheduler store = new Scheduler(); store.Connect(“localhost”); ISchedulerJob job = store.CreateJob(); job.AutoCalculateMax = true; job.AutoCalculateMin = true; ISchedulerTask task = job.CreateTask(); task.CommandLine = "ping 127.0.0.1 -n *"; task.IsParametric = true; task.StartValue = 1; task.EndValue = 10000; task.IncrementValue = 1; task.MinimumNumberOfCores = 1; task.MaximumNumberOfCores = 1; job.AddTask(task); store.SubmitJob(job, @"hpc\user“, "p@ssw0rd");
}}
Programmatic Support for C++ & .Net
languages Web Interface
Open Grid Forum: “HPC Basic Profile”

18
NetworkDirect A new RDMA networking interface built for speed and stability
Priorities Comparable with hardware-optimized
MPI stacks Focus on MPI-Only Solution for version 2
Verbs-based design for close fit with native, high-perf networking interfaces
Coordinated w/ Win Networking team’s long-term plans
Implementation MS-MPIv2 capable of 4 networking
paths: Shared Memory
between processors on a motherboard TCP/IP Stack (“normal” Ethernet) Winsock Direct
for sockets-based RDMA New RDMA networking interface
HPC team partners with networking IHVs to develop/distribute drivers for this new interface
User Mode
Kernel Mode
TCP/Ethernet Networking
Kern
el B
y-Pa
ss
MPI AppSocket-Based App
MS-MPI
Windows Sockets (Winsock + WSD)
Networking HardwareNetworking HardwareNetworking Hardware
Networking HardwareNetworking HardwareHardware Driver
Networking HardwareNetworking
HardwareMini-port Driver
TCP
NDIS
IP
Networking HardwareNetworking HardwareUser Mode Access Layer
Networking HardwareNetworking
HardwareWinSock
Direct Provider
Networking Hardware
Networking Hardware
NetworkDirect Provider
RDMA Networking
OS Component
CCP Component
IHV Component(ISV) App

19
What is High Performance Computing? Windows HPC product overview & demo Programming Model overviews & demo
Parametric Sweeps MPI & MPI.Net Cluster SOA
Cool projects! Parallel Dwarfs Go/Surface/HPC Project
Advanced performance tuning & analysis
Agenda
5
10
30
10
20

20
MSFT Parallel Computing Technologies
Task Concurrency
Data Parallelism
Distributed/Cloud Computing
LocalComputing
• Robotics-based manufacturing assembly line
• Silverlight Olympics viewer
• Enterprise search, OLTP, collab
• Animation / CGI rendering• Weather forecasting• Seismic monitoring• Oil exploration
• Automotive control system • Internet –based photo
services
• Ultrasound imaging equipment
• Media encode/decode• Image processing/
enhancement• Data visualization
IFx / CCR
Maestro
TPL / PPL
Cluster-TPL
Cluster-PLINQ
MPI / MPI.Net
WCF
Cluster SOA
WF
PLINQ
TPL / PPL
CDS
OpenMP
21
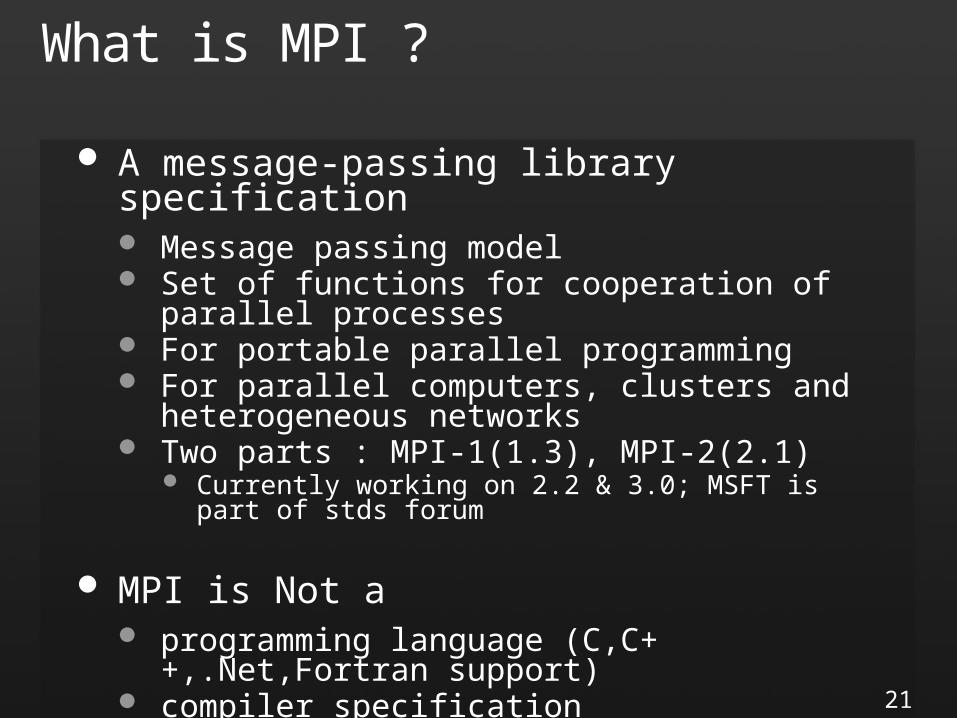
What is MPI ?
A message-passing library specification Message passing model Set of functions for cooperation of parallel processes For portable parallel programming For parallel computers, clusters and heterogeneous
networks Two parts : MPI-1(1.3), MPI-2(2.1)
Currently working on 2.2 & 3.0; MSFT is part of stds forum
MPI is Not a programming language (C,C++,.Net,Fortran support) compiler specification specific product

22
When/Where to Use MPI ?
You need a portable parallel program (w support for clusters)
You are writing a parallel library You have irregular or dynamic
data relationships that do not fit a data parallel model
You care about maximum performance
You need a common Multi-core & Cluster programming model
MSMPI attributes Based on MPICH2
implementation Windows security
model integration Shared memory
performance enhancements
Winsock & Network Direct (RDMA) support

23
“mpiexec -n 8 MyParallelProgram.exe” Every process gets a copy of the executable: Single Program, Multiple
Data (SPMD, though MIMD also possible) They all start executing it Each looks at its own rank to determine which part of the problem to
work on Each process works completely independently of the other processes,
except when communicating The six MPI API’s you “need”:
int MPI_Init(int *argc, char **argv)
int MPI_Comm_size(MPI_Comm comm, int *size)
int MPI_Comm_rank(MPI_Comm comm, int *rank)
int MPI_Send(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)
int MPI_Recv(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status)
int MPI_Finalize(void)
How an MPI Run Works…

24
Features of MPI-1
General features “Communicators” provide message safety API is thread safe Object-based design with language
bindings for C, C++, .Net and Fortran Point-to-point communication
Structured buffers and derived data types, heterogeneity
Modes: normal (blocking and non-blocking), synchronous, ready (to allow access to fast protocols), buffered
Collective Both built-in and user-defined collective operations Large number of data movement routines Subgroups defined directly or by topology
Communication modes Standard mode : MPI
decides buffering. Buffered mode : User
allocates system buffer Synchronous mode :
Synchronize with Receive call
Ready mode : Receive call is already posted

25
Collective CommunicationThe bread & butter of MPI programs
Broadcastint MPI_Bcast(void* buffer, int count,
MPI_Datatype datatype, int root, MPI_Comm comm)
public void Broadcast<T>(ref T value, int root )
A
Broadcast
P0
P1
P2
P3
A
A
A
A
Reduce int MPI_Reduce(void* sendbuf, void* recvbuf,
int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm)
public T Reduce<T>( T value, ReductionOperation<T> op, int root )
Operations : MPI_MAX, MPI_MIN, MPI_SUM, MPI_PROD, MPI_LAND, MPI_BAND, MPI_LOR, MPI_BOR, MPI_LXOR, MPI_BXOR, MPI_MAXLOC, MPI_MINLOC, User Defined
A
B
C
D
P0
P1
P2
P3 Reduce
R

MPI & MPI.NetFluent demoMPI.Net demo
Sean MortazaviArchitectMicrosoft Corporation
demo

Allinea DDT VS Debugger Add-inSkip/Demo

Collective Functions cont.
A B DC A
B
C
D
A
A
A
A
B
B
B
B
C
C
C
C
D
D
D
D
Scatter
Gather
All Gather
A0
A1
A2
A3
B0
B1
B2
B3
C0
C1
C2
C3
D0
D1
D2
D3
A0
B0
C0
D0
A1
B1
C1
D1
A2
B2
C2
D2
A3
B3
C3
D3
All to All
P0
P1
P2
P3
P0
P1
P2
P3

Collective Functions cont.
A
B
C
D
P0
P1
P2
P3
R
A
B
C
D
P0
P1
P2
P3
A
AB
ABC
ABCD
All Reduce R
R
R
Scan

30
Communicator comm = Communicator.world;
string[] hostnames =
comm.Gather(MPI.Environment.ProcessorName, 0);
if (Communicator.world.Rank == 0) {
Array.Sort(hostnames);
foreach(string host in hostnames)
Console.WriteLine(host);
}
C# / MPI.Net exampleGathering Hostnames in MPI.Net
Skip/Demo

31
Optimizing MPI.Net performanceNaïve Point-to-Point Send
public void Send<T>(T value, int dest, int tag)
{
BinaryFormatter format = new BinaryFormatter();
using (MemoryStream stream = new MemoryStream()) {
format.Serialize(stream, value);
unsafe {
fixed (byte* buffer = stream.GetBuffer()) {
Unsafe.MPI_Send(new IntPtr(buffer),
(int)stream.Length, Unsafe.MPI_BYTE, dest,
tag, comm);
}
}
}
}
Serialize
Pin Memory

32
Optimizing MPI.Net performance An optimal Send ?
public void Send<T>(T value, int dest, int tag)
{
if (HasMpiDatatype<T>()) {
unsafe {
fixed (T* valuePtr = &value) {
Unsafe.MPI_Send(new IntPtr(valuePtr), 1,
GetMpiDatatype<T>(), dest, tag, comm);
}
}
} else {
// Serialize and transmit
}
}
C# MPI
short MPI_SHORT
int MPI_INT
float MPI_FLOAT
double
MPI_DOUBLE
Not Valid C#!

0.01
0.1
1
10
100
1.E+00 1.E+01 1.E+02 1.E+03 1.E+04 1.E+05 1.E+06 1.E+07
Throughput (M
bps)
Message Size (Bytes)
NetPI PE Performance
C (Native)
C# (Serialized)

0.01
0.1
1
10
100
1.E+00 1.E+01 1.E+02 1.E+03 1.E+04 1.E+05 1.E+06 1.E+07
Throughput (M
bps)
Message Size (Bytes)
NetPI PE Performance
C (Native)
C# (Primitive)
C# (Serialized)
35
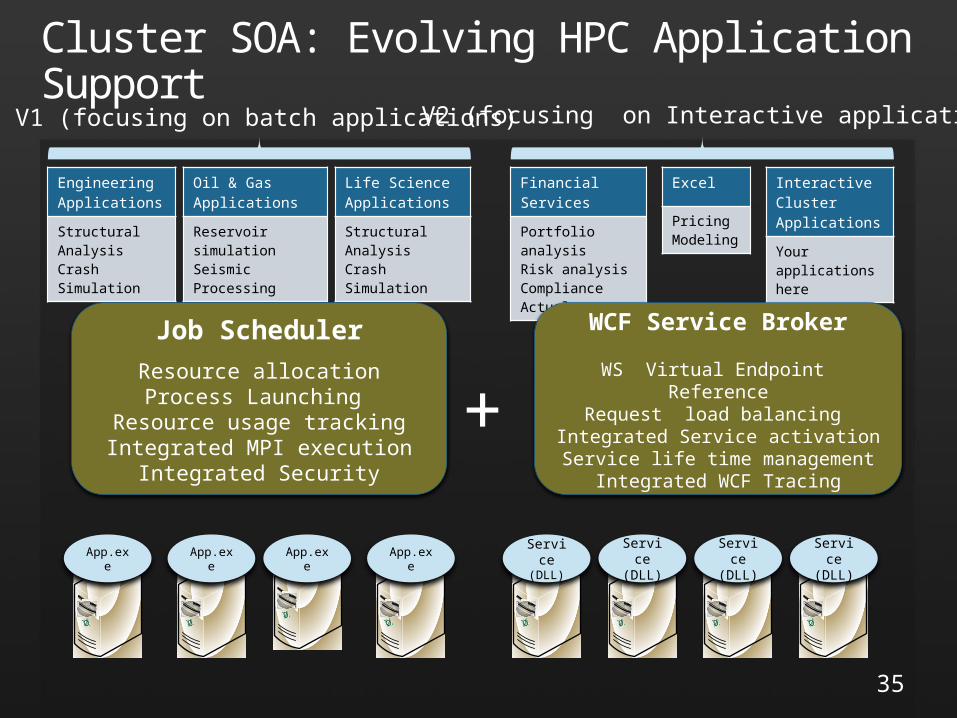
Cluster SOA: Evolving HPC Application Support
App.exe App.exe Service(DLL)
Service(DLL)
Service(DLL)
Service(DLL)
App.exe App.exe
Engineering Applications
Structural AnalysisCrash Simulation
Oil & Gas Applications
Reservoir simulationSeismic Processing
Life Science Applications
Structural AnalysisCrash Simulation
Financial Services
Portfolio analysisRisk analysisComplianceActual
Excel
PricingModeling
Interactive Cluster Applications
Your applications here
V1 (focusing on batch applications) V2 (focusing on Interactive applications)
+Job Scheduler
Resource allocationProcess Launching
Resource usage trackingIntegrated MPI execution
Integrated Security
WCF Service Broker
WS Virtual Endpoint ReferenceRequest load balancing
Integrated Service activationService life time management
Integrated WCF Tracing

36
for (i = 0; i < 100,000,000; i++)
{
r[i] = worker.DoWork(dataSet[i]);
}
reduce ( r );
HPC + WCF Programming Model"Cluster SOA"
Session session = new session(startInfo);
PricingClient client = new PricingClient(
binding, session.EndpointAddress);
for (i = 0; i < 100,000,000, i++)
{
client.BeginDoWork(dataset[i],
new AsyncCallback(callback), i)
}
void callback(IAsyncResult handle)
{
r[inx++] = client.EndDoWork(handle);
}
// aggregate results
reduce ( r );
Sequential
Parallel
37
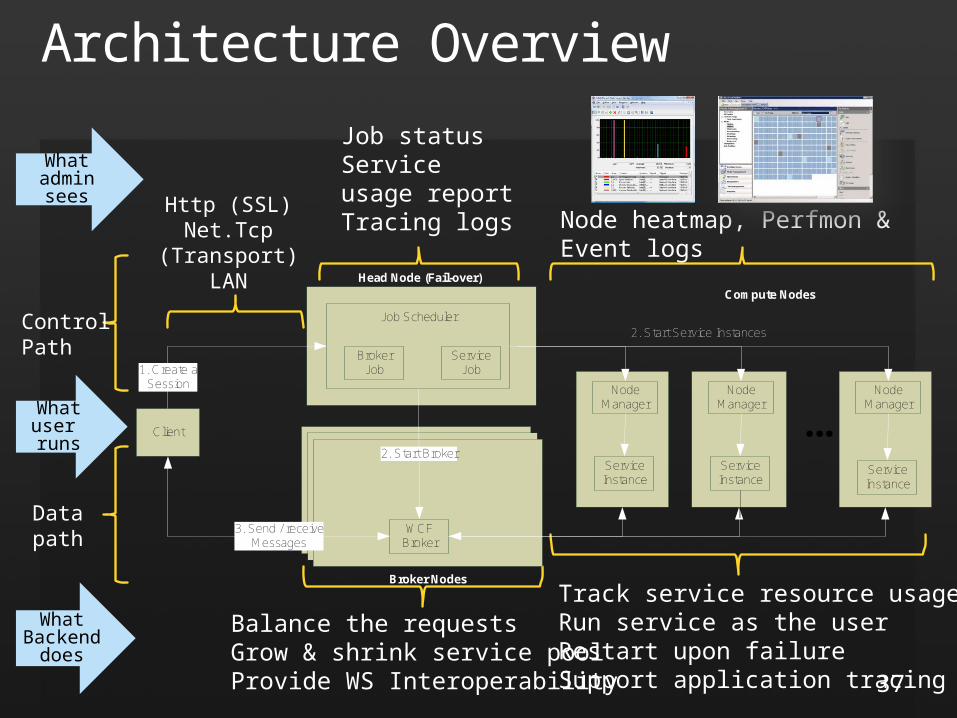
Architecture Overview
Track service resource usageRun service as the userRestart upon failureSupport application tracing
Balance the requestsGrow & shrink service poolProvide WS Interoperability
Node heatmap, Perfmon & Event logs
Job statusService usage reportTracing logs
What Backend
does
What admin sees
What user runs
ControlPath
Data path
Job Scheduler
BrokerJob
ServiceJob
Client
Head Node (Fail-over)
ServiceInstance
Node Manager
WCFBroker
2. Start BrokerServiceInstance
Node Manager
ServiceInstance
Node Manager
2. Start Service Instances
Compute Nodes
1. Create a Session
3. Send / receiveMessages
Broker Nodes
...
Http (SSL)Net.Tcp
(Transport)LAN

38
Invoke any Service Code
ServiceCode
WCFBroker
Using VSTO and HPC WCF API, developers can enhance the Excel’s calculation power by invoking distributed services
Developers use VSTO and SOA API to invoke existing services that are already deployed to the cluster, without having to write any calculation logic or XLLs. As such, the analytics library can be centrally managed, meeting the regulatory requirements…
SOA
APIVSTO
CLR
HPCServiceHost
ServiceCode
CLR
HPCServiceHost
ServiceCode
CLR
HPCServiceHost
ServiceCode
CLR
HPCServiceHost

Cluster SOAParallelizing Excel Calculations
Sean MortazaviArchitectMicrosoft Corporation
demo
40
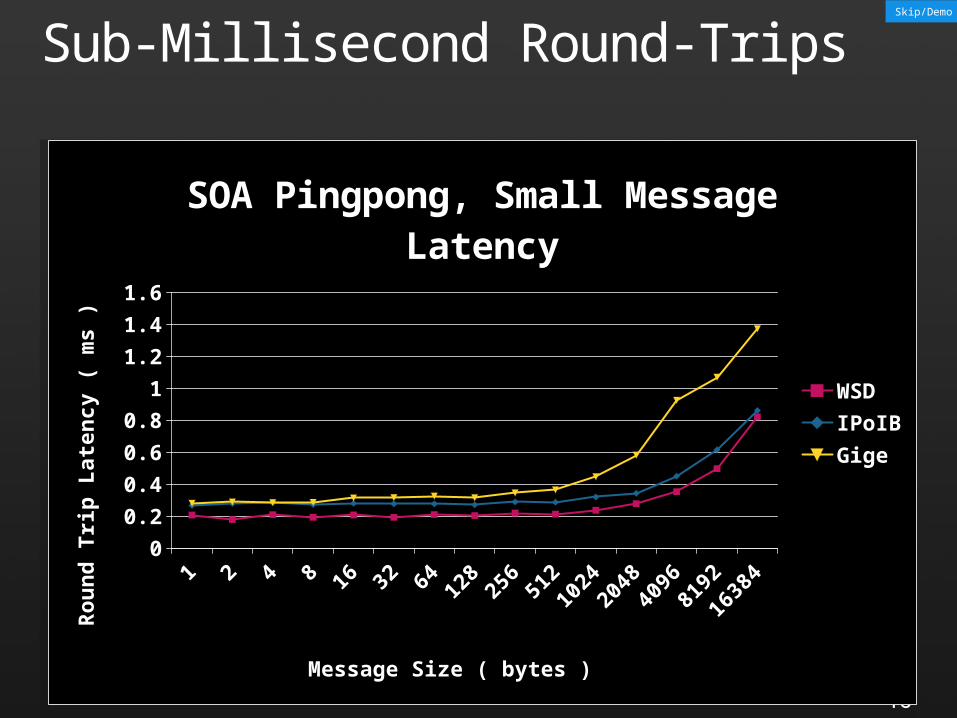
Sub-Millisecond Round-Trips
1 2 4 8 16 32 64128
256512
10242048
40968192
163840
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
SOA Pingpong, Small Message Latency
WSDIPoIBGige
Message Size ( bytes )
Roun
d Tr
ip L
aten
cy (
ms )
Skip/Demo

41
High ThroughputSkip/Demo

42
Solution Benefits
User needs Solution Benefits
Build • Keep the loop & method-call.
• Develop, debug and deploy with VS 2008
• WCF based SOA effectively hides the details for data serialization and distributed computing
• VS 2008 debugs services and clients
Run • Handle sub-second requests efficiently
• Securely run user applications
• Intelligent, dynamic load balancing
• Low round-trip latency
• End-to-end Kerberos with WCF
• Smart, efficient WCF Broker node
Manage • Monitor performance
• Configure infrastructure at a glance
• Perform Diagnostics
• Monitor and report service usage
• Runtime monitoring of performance counters
• Configuration of SOA infrastructure from UI
• Diagnostics report for configuration, connectivity and performance
• Service resource usage reports

Parallel Dwarfs13 kernels parallelized using MSFT technologies
Sean MortazaviArchitectMicrosoft Corporation
demo

44
The “Dwarfs” Colella’s original 7, now 13 kernels that encapsulate a
large spectrum of computing workloads Parallel Dwarfs: Visual Studio solutions that
implement || versions of the dwarfs (13k+ LOC) Languages: C++, C#, (F# soon) Input files: small, medium, large Parallelization technologies:
OpenMP, TPL, MPI, MPI.Net, (ClusterSOA, PPL soon) Results gathering & plotting
Excel, JumpShot, Vampir “Driver” for selecting & running the benchmarks To be released as Open Source
Parallel Dwarfs Project

Dwarf Popularity1
HPC Embed SPEC ML Games DB1 Dense Matrix2 Sparse Matrix3 Spectral (FFT)4 N-Body5 Structured Grid6 Unstructured7 MapReduce8 Combinational9 Nearest Neighbor
10 Graph Traversal11 Dynamic Prog12 Backtrack/ B&B13 Graphical Models14 FSM
Source:“Future of Computer Architecture” by David A. Patterson 45
> >

46
PS1> DwarfBench -Names SpectralMethod -Size medium -Platform managed -Parallel serial,tpl,mpi –PlotExcel
PS1> DwarfBench –Names DenseAlgebra -Size medium -Platform unmanaged,managed -Parallel mpi –PlotVmampir
PS1> DwarfBench –Names *grid* -Size Large -Platform unmanaged -Parallel hybrid –PlotVmampir
Scale: Nearly 300 combinations
Foreach (managed, unmanaged)Foreach (mpi, mpi.net, openmp, tpl, hybrid)
Foreach (input.small, input.medium,input.large) Foreach (one..thirteenth dwarf)
• Run, Trace• Plot Excel, Xperf• Plot Vampir, JumpShot
Support for mixed models:MPI + OpenmpMPI.Net + TPLetc
46
Use the Parallel Dwarfs for:Comparing || technologiesComparing language
featuresBenchmarkingBest practicesStarting templates

13 Visual Studio Solutions
47
StructuredGrid code fragment using MPI.NET
Skip/Demo

Results Summary: -PlotExcel
48
Skip/Demo
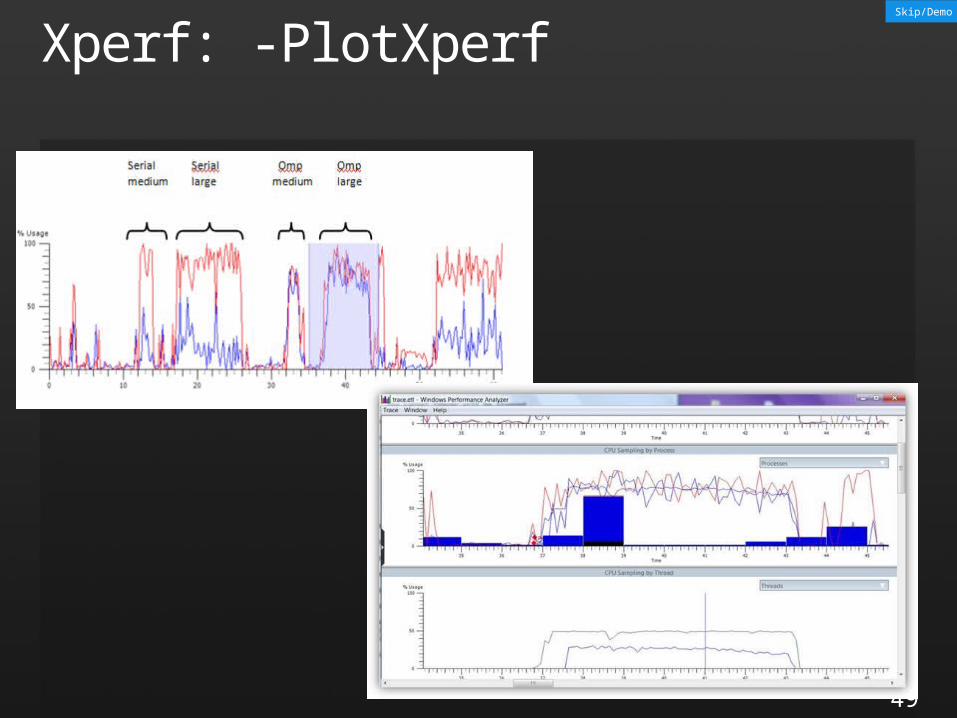
Xperf: -PlotXperf
49
Skip/Demo

JumpShot: -PlotJumpshot -PlotVampir
50
Skip/Demo

51
Much, much harder than chess~ 35 legal moves for chess, 300 for GoPeople look farther ahead in GoGo positions harder to eval: 300k vs 100 / sec
Old vs New EnginesOld code: large, complex, stopped improving despite
faster machinesNew: use statistical models use clusters!
WHPC/Surface/Many Faces of GoSurface for natural game playUses WHPC and MPI for internode communication:
~4K games/sec/coreWon world championships at ICGA last month!
32 core clusterMFOG Will be available for free with Windows HPC
from Smart-games.com Available at the Parallel Computing booth
Go Play against Many Faces and MOGO on Cray CX1!
Go On Computers
Surface Game UI: VectorformGame Engines: SmartGames, MOGO /Irina

52
What is High Performance Computing? Windows HPC product overview & demo Programming Model overviews & demo
Parametric Sweeps MPI & MPI.Net Cluster SOA
Cool projects! Parallel Dwarfs Go/Surface/HPC Project
Advanced performance tuning & analysis
Agenda
5
10
30
10
20

Performance ToolsXperf, Tracing Tools, Vampir
Jeff BaxterPrincipal SDEMicrosoft Corporation
demo

54
Simple ancient algorithm to find number of primes less than a certain number Attributed to Eratosthenes of Cyrene ~ 200BC
Obvious Serial Implementation
Performance Tools DemoSieve of Eratosthones
2 3 4 5 6 7 8 9 10 11 12 13 14
2 3 5 7 9 11 13
2 3 5 7 11 13
Mask off multiples of 2
Mask off multiples of 3
6 primes less than 15

55
Let n be the number of numbers we want to check p be the number of processors
Then each rank has n / p elements Rank 0 has all the primes we need to check
provided n/p > sqrt( n ) Or p < sqrt ( n ) For example:
for 1million elements p must be less than 1000 For 1 trillion elements p must be less than
1 million
Why Broadcast WorksUnder very reasonable assumptions

56
Perfomance Analysis 1Perfmon doesn’t really help
All nodes ~100% cpu
No Disk, Kernel, DPC or ISR time.
No Paging

57
Perfomance Analysis 2Traffic capture doesn’t really help
Data is Interesting but hard to action

58
Perfomance Analysis 3Vampir Shows The Way
Comunicating Ranks MPI Message
Detail
MPI / Application Breakdown
Communicating Ranks
Per–rank timeline
Application / MPI timeline

59
A virtual Visual Studio "HPC Edition" SKU
Languages/RuntimesC++, C#, VBF#, Python, Ruby, JscriptFortran (Intel, PGI)OpenMPMPI, MPI.Net
Team Development
Team portal: version control, scheduled build, bug trackingTest and stress generationCode analysis, Code coveragePerformance analysis
IDERapid application developmentParallel debuggingMultiprocessor buildsWork flow design
.Net FrameworkLINQ: language integrated queryDynamic Language RuntimeFx/JIT/GC improvementsNative support for Web Services
Libs / Tools / Partners
Debug: Allinea, Vampir, …Mathlibs: VNI, NAG, Intel, AMD, …Eng RAD Tools: Matlab, Mathematica, Maple, ISC, …OSS: Tons in every category

60
Trends
Yesterday• Coarse Grained
Parallelism• Big Iron
Today• Chores/Agents• TPL/PPL• PLINQ• OpenMP
Tomorrow• Auto Parallelization• Scale to thousands• Hybrid models
Yesterday• PVM, MP• GAT• Parametric Sweep• 90 others
Today• MPI• MPI.Net• Cluster SOA• Parametric Sweep
Tomorrow• Auto Parallelization• Cluster TPL• Cluster PLINQ• DSM
Day after Tomorrow• Unified Prog Model
Mul
ti-co
reCl
uste
r
•GPU
•Mul
ti-Co
re
•Clu
ster

Resources
Windows HPC www.microsoft.com/hpc
MPI https://computing.llnl.gov/tutorials/mpi
MPI.Net http://www.osl.iu.edu/research/mpi.net Doug Gregor & Andrew Lumsdale
Dwarfs Project www.codeplex.com (soon) Vladimir Safonov & Students at
University of St Petersburg
Go/Surface www.vectorform.com (Surface UI) www.smart-games.com (Many Faces of Go)
Allinea DDT-Lite www.Allinea.com
Vampir http://tu-dresden.de/ Wolfgang Nagel & colleagues at TU
Visual Numerics www.visualnumerics.com
Top 500 benchmark www.top500.org

Evals & Recordings
Please fill
out your
evaluation for
this session at:
This session will be available as a recording at:
www.microsoftpdc.com

Please use the microphones provided
Q&A

© 2008 Microsoft Corporation. All rights reserved. Microsoft, Windows, Windows Vista and other product names are or may be registered trademarks and/or trademarks in the U.S. and/or other countries.The information herein is for informational purposes only and represents the current view of Microsoft Corporation as of the date of this presentation. Because Microsoft must respond to changing market
conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information provided after the date of this presentation. MICROSOFT MAKES NO WARRANTIES, EXPRESS, IMPLIED OR STATUTORY, AS TO THE INFORMATION IN THIS PRESENTATION.


66
Backup

67
Dwarfbench

68
Dwarfs