卒業論文 マルチエージェント強化学習 における...
TRANSCRIPT

卒業論文
マルチエージェント強化学習
における Profit Sharing の
有効性検証~追跡問題を例に~
高知大学 理学部 数理情報科学科
本田研究室
B033G014N 内海 朋秀
2007年2月8日
1

要旨 強化学習とは,報酬という特別な入力を手がかりに,エージェントが試行錯誤を通じて
環境に適応した行動決定戦略を追求する機械学習システムある。そのため強化学習は「何
をしてほしいか」という学習目標を報酬に反映させるだけで,「その実現方法」を学習シス
テムに自動的に獲得させることが出来る。このことから強化学習は,工学的応用の観点か
らも非常に魅力的な枠組みといえる。強化学習をより実用的なものにするために強化学習
をマルチエージェントシステムへ拡張させた場合を考えた。 マルチエージェントシステムとは,複数のエージェントが様々な情報を共有して,協力
しながら目標を達成するシステムのことである。強化学習をマルチエージェントシステム
に拡張するにあたって,あるエージェントが目標を達成し報酬を得た場合,他のエージェ
ントに間接報酬を与える。このことにより,協調的な動きを学習したり,学習速度が速く
なるといった可能性がある。反面,問題点として,システム全体の挙動に悪影響を及ぼす
可能性もでてくる。この問題を抑制する間接報酬の与え方として,マルチエージェント系
における Profit Sharing の合理性定理[宮崎他 99]がある。 本研究では,マルチエージェント強化学習問題における,エージェント数が多い場合の
間接報酬の効果の検証及び,学習された行動ルールにおける協調性の検証を、学習アルゴ
リズムに Profit Sharing を用いて行った。 これらを検証するための問題として追跡問題を用いた。追跡問題とは複数の追跡者エー
ジェントが,逃亡者エージェントを捕獲するという問題である。追跡問題は,マルチエー
ジェント系におけるベンチマークの一つとして知られており,アルゴリズムの評価,エー
ジェント間の協調などに関する多くの研究の対象になっている。 実験結果から Profit Sharing の合理性定理は有効であると判断でき,強化学習をマルチ
エージェントシステムに拡張させた場合の問題点を解決できることが分かった。またエー
ジェントの行動する順番を予め決めておくだけで,エージェントが自動的に協調的動作を
獲得してくれることが分かった。しかし,複雑な問題の場合,合理性定理が保証できる間
接報酬の値が,小さすぎて学習速度の向上はあまり期待できないということも分かった。
2

目次
1. はじめに・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・1 2. エージェントと強化学習
2.1 エージェントとは・・・・・・・・・・・・・・・・・・・・・・・・2 2.2 強化学習とは・・・・・・・・・・・・・・・・・・・・・・・・・・2 2.3 強化学習の枠組み・・・・・・・・・・・・・・・・・・・・・・・・3 2.4 強化学習の目的・・・・・・・・・・・・・・・・・・・・・・・・・3 2.5 強化学習の学習法・・・・・・・・・・・・・・・・・・・・・・・・3 2.6 応用上期待できること・・・・・・・・・・・・・・・・・・・・・・4
3. マルチエージェントシステム 3.1 なぜマルチエージェントシステムか・・・・・・・・・・・・・・・・5 3.2 マルチエージェントのシングルエージェントと比べた利点・・・・・・5 3.3 強化学習のマルチエージェントシステムへの拡張
3.3.1 なにを共有するのか・・・・・・・・・・・・・・・・・6 3.3.2 情報の共有(報酬配分)による利点と問題点・・・・・・7
4. Profit Sharing 4.1 Profit Sharing とは・・・・・・・・・・・・・・・・・・・・・・・8 4.2 迂回系列とは・・・・・・・・・・・・・・・・・・・・・・・・・・8 4.3 合理性定理を満たす強化関数・・・・・・・・・・・・・・・・・・・9 4.4 学習アルゴリズム・・・・・・・・・・・・・・・・・・・・・・・10 4.5 マルチエージェント問題への拡張 4.5.1 マルチエージェント系における合理性定理・・・・・・11 4.5.2 実装上のポイント・・・・・・・・・・・・・・・・・11 4.5.3 学習アルゴリズム・・・・・・・・・・・・・・・・・11
5. 複雑なマルチエージェント問題における強化学習 5.1 追跡問題への応用
5.1.1 追跡問題とは・・・・・・・・・・・・・・・・・・・13 5.1.2 問題設定・・・・・・・・・・・・・・・・・・・・・13
5.2 間接報酬の値による学習効率~エージェント数が多い場合~ 5.2.1 実験条件・・・・・・・・・・・・・・・・・・・・・15 5.2.2 結果及び考察・・・・・・・・・・・・・・・・・・・16 5.3 学習された行動ルールにおける協調性 5.3.1 実験条件・・・・・・・・・・・・・・・・・・・・・17 5.3.2 結果及び考察・・・・・・・・・・・・・・・・・・・18
6.まとめ・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・21
3

謝辞・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・22 参考文献・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・23 付録 A. プログラムリスト
A-1 エージェント数 6 の場合の追跡問題・・・・・・・・・・・・・・・24 A-2 エージェント数 2 の場合の追跡問題・・・・・・・・・・・・・・・44
B. 実験結果の詳細・・・・・・・・・・・・・・・・・・・・・・・・・・・・67
4

1. はじめに
強化学習(reinforcement learning)とは,報酬(reward)という特別な入力を手がかり
として環境に適応する教師無し機械学習の一種である。強化学習の目的は,出来るだけ多
くの報酬を出来るだけ早く獲得することである。最終的に多くの報酬を得るために最適性
を重視した接近を環境同定型(代表的な手法:TD 法,Q-learning)と呼び,学習途中でも
報酬を得る効率性を重視した接近を経験強化型(代表的な手法:Profit Sharing)と呼んで
いる。 また最近では,複雑かつ動的な問題を多くの自立的なエージェントが何らかの協調動作
をすることで解決しようと研究が進められており,マルチエージェント系における協調的
行動の実現は,工学的及び認知科学的観点から興味ある話題である。しかし,これらの多
くは人間が設定した行動群によって制御されており,対象やタスク,個体間の相互作用が
複雑になるにつれて,その設計が困難になる。そのため,エージェント自身の学習や適応
能力が求められている。このような背景からマルチエージェント系における強化学習が注
目されている。 本研究では,Profit Sharing を用いて強化学習をマルチエージェント問題に適応する際に
生じる利点と問題点の検証を行った。具体的には,あるエージェントが目標を達成して報
酬を得た場合,他のエージェントにも間接報酬を与えることによって,協調行動の学習,
学習速度の向上といった利点が得られているかどうかの検証,また,大きすぎる間接報酬
による解の劣化を防ぐためにマルチエージェント系における Profit Sharing の合理性定理
[宮崎他 99]の有効性の検証を行った。 以下2章では,エージェントと強化学習について述べる。3章では,強化学習のマルチ
エージェント問題への拡張について論じる。4章では,検証に用いる Profit Sharing 学習
法の合理性定理と,マルチエージェント系における Profit Sharingの合理性定理を述べる。
5章では,本研究で扱う問題説明と各実験の条件,結果及び考察を述べる。6章は結論で,
本研究の成果のまとめ,今後の研究方針について論じる。
5

2. エージェントと強化学習
2.1 エージェントとは エージェント(agent)とは,一般的な意味では自分の代わりになにかを行ってくれる代
理人のことをいう。例えば,旅行代理店の店員がその例にあたり,自分の代わりにホテル
の予約や切符の手配をしてくれる。 また,情報科学の世界では自立的に動作するソフトウェアのことである。そのメカニズ
ムは図2.1に示すように,エージェントはある環境をセンサである受容器(detector)を
用いて知覚(percept)し,効果器(effector)を通して行動(action)するものである。こ
のとき,知覚した情報を実際の行動に変換する知的メカニズムもエージェントの構成要素
となる。人間の処理に例えていうならば,目から情報を知覚し,それを脳で処理して,そ
の結果を筋肉に伝えて行動するものと捉えることができる。また,ロボットをイメージす
るならば,受容器はカメラや赤外線センサに相当し,効果器はアームや車輪などのモータ
に相当する。そして,これらのエージェントが集まった集団をマルチエージェント(multi agent)と呼ぶ。
知的メカニズム 受容器 効果器
行動 知覚
環境
エージェント
図2.1 基本的なエージェントのフレームワーク
2.2 強化学習とは 強化学習とは,報酬という特別な入力を手がかりに,エージェントが試行錯誤を通じて
環境に適応した行動決定戦略を追求する機械学習システム(machine learning system)で
ある。そのため強化学習は「何をしてほしいか」という学習目標を報酬に反映させるだけ
で,「その実現方法」を学習システムに自動的に獲得させることが出来る。
6

強化学習の枠組み 強化学習の枠組みを図2.1に示す。学習主体「エージェント」と制御対象「環境」は
以下のやり取りを行い学習する。 (1) エージェントは時刻 t において環境の状態 tx を観測し,それに応じて確率的方策
),( axπ に基づき意思決定を行い,行動 ta を出力する。 (2) エージェントの行動により,環境は 1+tx へ状態遷移し,その遷移に応じた報酬 tR を
エージェントに与える。 (3) エージェントは与えられた報酬 tR を用いて方策 ),( axπ を更新する。
(4) 時刻 t を 1+t に進めて(1)へ戻る。
方策
),( axπ
報酬 tR行動 ta状態観測 tx
環境
(制御対象)
エージェント
(学習主体)
図2.2 強化学習の枠組み
2.3 強化学習の目的 2.3の(1)~(4)を1ステップと呼び,エージェントは利得(return:最も単純
な場合,報酬の総計)の最大化を目的として,1ステップごとに状態観測から行動出力へ
のマッピング(方策(policy)と呼ばれる)を改善しながら,目標達成への最適な方策を獲
得する。 2.4 強化学習の学習法 前に述べたように強化学習の目的は,出来るだけ多くの報酬を出来るだけ早く獲得する
ことである。最終的に多くの報酬を得るために最適性を重視した接近を環境同定型(代表
的な手法:TD 法,Q-learning)と呼び,学習途中でも報酬を得る効率性を重視した接近を
7

経験強化型(代表的な手法:Profit Sharing)と呼ぶ。 2.5 応用上期待できること 強化学習に期待される応用分野としては,以下のようなものがある。 ・制御プログラミングの自動化・省略化 環境に不確実性や計測不能な未知のパラメータが存在すると,タスクの達成方法やゴー
ルへの到達方法は設計者にとって自明ではない。よってロボットへタスクを遂行するため
の制御規則をプログラミングすることは設計者にとって重労働である。ところが,達成す
べき目標を報酬によって指示することは前記に比べれば遥かに簡単である。そのため,タ
スク遂行のためのプログラミングを強化学習で自動化することにより,設計者の負担軽減
が期待できる。十分に優れた性能を持つ強化学習エージェントをコントローラとして1つ
だけ開発しておけば,あとはロボットの目的に応じて報酬の与え方だけを設計者が設定す
るだけで,あらゆる種類のロボットの制御方法を同一のコントローラによって自動的に獲
得できる。 ・ハンドコーティングよりも優れた解 試行錯誤を通じて学習するため,人間のエキスパートが得た解よりも優れた解を発見す
る可能性がある。特に不確実性(摩擦やガタ,振動,誤差など)や計測が困難な未知のパ
ラメータが多い場合,人間の常識では対処しきれないことが予想され,強化学習の効果が
期待できる。エキスパートの制御規則を学習初期状態に設定して,それを改善する場合と,
全くのゼロから学習を開始し,設計者にとっては意外な新しい解を発見する場合とが考え
られる。 ・自律性と想定外の環境変化への対応 機械故障などの急激な変化やプラントの経年変化のような暖慢な変化など,予め事態を
予測してプログラミングしておくことが困難な環境変化に対しても自動的に追従すること
がきたいできる。特に宇宙や海底など,通信が物理的に困難な場合や,通信ネットワーク
制御のように現象のダイナミクスが人間にとって速すぎる場合において,強化学習の自律
的な適応能力が特に威力を発揮する。
8

3. マルチエージェントシステム
3.1 なぜマルチエージェントシステムか 近年,インターネットやマルチメディアなどの発展によって情報やデータは分散化・巨
大化するだけでなく,その種類も増え,われわれを取り囲む環境は大規模かつ複雑化して
いる。そのため,このような環境に対処するシステムも大規模・複雑化し,従来の中央集
権型システム(centralized system)では限界が生じてきた。これはハードウェアやソフト
ウェア技術の問題というよりは,分散した大量の情報を一箇所に集め,それを元に処理す
る方法自体に限界があることを表している。特に頻繁に変化する環境では正確な情報をつ
ねに一箇所に集めることはできず,適切な対処が難しくなる。 このような問題に対処するために,分散したものは分散したものとして処理する分散制
御型システム(decentralized system)が着目され,様々なシステムが開発され始めている。
例えば,車の交通をスムーズにするための信号機では,センターにすべての情報を集めて
各信号の色を決定するのではなく,局所的に(例えば,信号機という単位で)処理を行う
研究がなされている。このような例以外にも,回線に集中する接続を分散させる電話回線
網の制御,群知能ロボットによるロバストコントロールや高度な協調作業,航空管制の制
御・管理など,様々なものが考えられる。 ここで,中央集権型システムと分散制御型システムをエージェントの観点から見ると,
前者は1台のシステムで作動していることからシングルエージェントシステム(single agent system),一方,後者は複数のシステムがやり取りを行うことからマルチエージェン
トシステム(multi agent system)と捉えることができる。このように捉えると,マルチエ
ージェントシステムはシングルエージェントシステムでは対処困難な問題に対して,柔軟
に取り組める可能性を持っているといえる。 3.2 マルチエージェントのシングルエージェントと比べた利点 マルチエージェントシステムにはどのような利点があるのだろうか。シングルエージェ
ントシステムと比べてつぎのようなものがある。 ・問題解決能力 まず,最初の利点は,問題解決能力(problem solving ability)の向上である。例えば,
1個体のエージェントではできないことが,複数集まることによってできるようになる可
能性がある。あるいは,1個体の能力が低くても複数が協力することでより高度な仕事を
達成できる可能性もある。また,他のエージェントと競い合わせることによって,1個体
の場合よりも学習が促進され,効率的かつ効果的な学習が可能となる場合がある。
9

・適応能力 つぎの利点は,適応能力(adaptability)である。例えば,問題規模の拡大,問題対象の
変更,あるいは,問題自体の複雑化に対して,マルチエージェントシステムでは,新たに
エージェントを追加したり,エージェント間の相互作用を動的に調整することによってう
まく対処できる可能性がある。特に,後者はサッカーのように相手によってチームの戦略
を変える場合などが当てはまる。 ・ロバスト性 さらに,ロバスト性(robustness)もマルチエージェントシステムの利点である。例え
ば,あるエージェントがプログラムの暴走や故障などで使いものにならなくなっても,他
のエージェントが代役をすることで,マルチエージェントシステム全体の処理の停止を防
ぐことが可能になる。このような故障などに対する強さを表すロバスト性は,対故障性,
頑健性,安定性,あるいは信頼性という言葉で表す場合がある。 ・並列性 マルチエージェントシステムの利点には,並列性(parallelism)もある。例えば,エー
ジェント間の整合性をとる処理(あるいは,オーバヘッド)が少ない問題の場合,エージ
ェントは並列かつ非同期に動作できるので,全体の処理の高速化と効率の向上をはかるこ
とができる可能性が高い。 ・モジュール性 最後の利点は,モジュール性(modulability)である。マルチエージェントシステムはエ
ージェント単位でモジュール化されているので,始めからシステムの詳細設計をしなくて
も,設計済みのエージェントを再利用あるいは組み合わせることで設計コストと時間を低
く抑えることができる可能性がある。また,システムのテストや維持管理もエージェント
単位で簡単に行うことができる。 3.2 強化学習のマルチエージェントシステムへの拡張 3.2.1 なにを共有するのか マルチエージェントシステムとは図3.1に示すように,複数のエージェントが様々な
情報を共有して協力しながら目標を達成するシステムである。ここで,強化学習を行う場
合に実際に共有する情報は,エージェントが知覚した情報,行った行動,得た報酬を表す
瞬間的な情報,エージェントが学習して獲得した政策を意味する知識的な情報,そして,
エージェントが経験した「知覚,行動,報酬」の3つの組を連続して集めたエピソードな
どの経験的な情報の3種類が考えられる。
10

図3.1 強化学習におけるマルチエージェントシステム
3.2.2 情報の共有(報酬配分)による利点と問題点 図3.2のように,あるエージェントが目標を達成して報酬を得た場合,他のエージェ
ントに間接報酬を与える。利点としては,エージェントが協調的な動きを学習したり,学
習速度が速くなるといった可能性がある。しかし,反面問題点として,大きすぎる間接報
酬を与えることは解の劣化をまねく可能性がある。これは,報酬獲得に貢献していないエ
ージェントにも間接報酬を与えることによって好ましくない方策を強化してしまう可能性
があるためである。
エージェント
エージェント
エージェント
エージェント協力
ゴール
(目標)
報酬
直接報酬 協力していない
エージェント エージェント
エージェント
経験的情報
知識的情報
瞬間的情報
(目標)
ゴール
間接報酬
図3.2 マルチエージェントシステムにおける報酬配分
11

4. Profit Sharing 4.1 Profit Sharing とは
Profit Sharing[Grefenstette 88]は,遺伝的アルゴリズム(genetic algoeithm,GA)を併
用するクラシファイアシステムでの信用割当(credit assignment)の方法として 1980 年
代後半に提唱された。現在 Profit Sharing は GA だけではなく強化学習の枠組みにおいて
も利用され,さらにマルチエージェント環境においても有用であると期待されている。 Profit Sharing では,ある感覚入力 x に対して実行可能な行動 a の組のことをルール i(if r
x then というルールをa xa と書く)という。すべてのルール にはルールの重み が
存在し,エージェントは各ルールの重み の値に従って確率的に行動を選択し実行する。
ir irS
i
i
rS
学習の方法は,報酬に至るエピソードにおけるルール系列を記憶しておき,報酬が得ら
れた時点で記憶してある系列上のルールの重み を次式(4.1)に従って一括して強化
する。
rS
.1,...,1,0, −=+= WifSS irr ii (4.1)
ここで, はエピソード系列上の 番目のルールの重み, は強化関数と呼ばれ,報酬か
ら ステップ前の強化値を表す。
irS i if
i 4.2 迂回系列とは あるエピソードで,同一の感覚入力に対して異なるルールが選択されているとき,その
間のルール系列を迂回系列(detour)と呼ぶ。例えば図4.1のようなエピソード
( yaxazbybxa ⋅⋅⋅⋅ )には,迂回系列( xazbyb ⋅⋅ )が存在する。
図4.1 エピソードと迂回系列の例
a
エピソード
迂回系列
a a a b b yy x x z 報酬
12
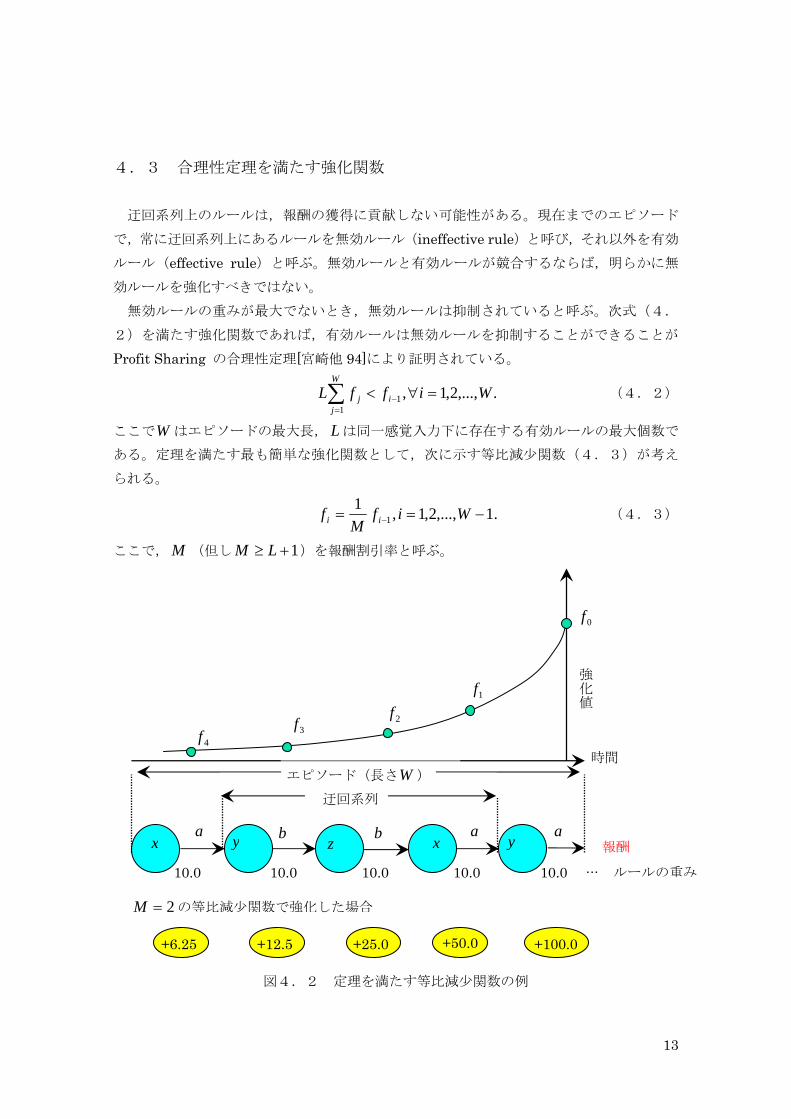
4.3 合理性定理を満たす強化関数 迂回系列上のルールは,報酬の獲得に貢献しない可能性がある。現在までのエピソード
で,常に迂回系列上にあるルールを無効ルール(ineffective rule)と呼び,それ以外を有効
ルール(effective rule)と呼ぶ。無効ルールと有効ルールが競合するならば,明らかに無
効ルールを強化すべきではない。 無効ルールの重みが最大でないとき,無効ルールは抑制されていると呼ぶ。次式(4.
2)を満たす強化関数であれば,有効ルールは無効ルールを抑制することができることが
Profit Sharing の合理性定理[宮崎他 94]により証明されている。
(4.2) .,...,2,1,1
1 WiffLW
jij =∀<∑
=−
ここでW はエピソードの最大長, は同一感覚入力下に存在する有効ルールの最大個数で
ある。定理を満たす最も簡単な強化関数として,次に示す等比減少関数(4.3)が考え
られる。
L
.1,...,2,1,11 −== − Wif
Mf ii (4.3)
ここで,M (但し 1+≥ LM )を報酬割引率と呼ぶ。
強化値
図4.2 定理を満たす等比減少関数の例
時間
a
エピソード(長さW )
迂回系列
報酬
10.0 10.0 10.0 10.0 10.0 ... ルールの重み
2=M の等比減少関数で強化した場合
+6.25 +12.5 +25.0 +50.0 +100.0
0f
1f
2f3f
4f
ab
a a by y x xz
13

例えば,図4.2に示すようなエピソードを 2=M の等比減少関数を用いて強化した場
合(但し初期報酬値 とする),ルール1000 =f yaのルールの重み(110.0)は,迂回系列上
のルール ybのルールの重み(22.5)よりも大きくなり,確かに無効ルールを抑制できてい
る。 4.4学習アルゴリズム Profit Sharing の学習アルゴリズムを以下の図4.3に示す。
図4.3 Profit Sharing の学習アルゴリズム
(1). を任意に初期化 i
i
rS
(2). 各エピソードに対して繰り返し: (a). ,W を初期化 ir (b). エピソードの各ステップに対し繰り返し:
(ⅰ). から導かれる方策を用いて状態rS x での行動 を選択するa
(ⅱ). 行動 をとり、次状態a x′ を観測 Rと報酬
xar =0 (ⅲ). すべての i に対して を保存 1+← ii とし,
とし以下の処理を行う (ⅳ). の場合,0≠R Rf =0
.1,...,1,0, −=+= WifSS irr ii
.1,...,2,1,11 −== − Wif
Mf ii 但し, とする
;1, +=′← WWxx (ⅴ). が終端状態ならば繰り返しを終了 (c). x
14

4.5 マルチエージェントシステムへの拡張 4.5.1 マルチエージェント系における合理性定理 大きすぎる間接報酬を与えることは3.2.2で述べたように解の劣化につながる可能
性がある。そこで,報酬 R を割り引いた値 )0( ≥μμR を間接報酬として与えてやる。マル
チエージェント系における Profit Sharing の合理性定理[宮崎他 99]によると,次式(4.
4)を満たすμ の範囲で間接報酬 Rμ を与えれば間接報酬による解の劣化を避けることがで
きる。
.
)1(11
10
LnM
M
Mw
W −⎟⎟⎠
⎞⎜⎜⎝
⎛⎟⎠⎞
⎜⎝⎛−
−<μ (4.4)
ここで,W は直接報酬を獲得したエージェントの最大エピソード長, は直接報酬を獲得
したエージェント以外の強化区間,
0WM は競合数, はエージェントの個数, は同一感覚
入力下に存在する有効ルールの最大個数である。 n L
4.5.2 実装上のポイント 一般に L の値は学習以前には知ることはできない。しかし, の値が最大となるのは,
唯一の無効ルールと競合した場合なので,実装上は
L1−= ML とすれば十分である。
一般にW の値は学習以前に知ることはできないが,実装上はW を任意の値に設定し,あ
る時点でのエピソードが 1+≥ LM を超えた場合には 0=μ とし,間接報酬を与えなければ
十分である。 1−= ML ,さらに とし,間接報酬による強化を直接報酬による強化と同じ強化 WW =0
区間まで許した場合,(4.4)式は以下の式(4.5)のように簡略化される。
.)1)(1(
1−−
<nM Wμ (4.5)
4.5.3 学習アルゴリズム 個のエージェントを用いたマルチエージェント問題における Profit Sharing の学習ア
ルゴリズムを以下の図4.4に示す。 n
15

(1). を任意に初期化 ir
S
(2). 各エピソードに対して繰り返し: (a). ,W を初期化 ir (b). エピソードの各ステップに対し繰り返し: (ⅰ). 個の中から任意に行動するエージェントを選ぶ n
(ⅱ). 選ばれたエージェントは から導かれる方策を用いて状態ir
S
x での行動 を選択する a
図4.4 マルチエージェント問題における Profit Sharing の学習アルゴリズム
(ⅱ). 行動 をとり,次状態a x′ を観測 Rと報酬
xar =0 (ⅲ). すべての i に対して を保存 1+← ii とし,
(ⅳ). の場合,以下の処理を行う 0≠R
選択されたエージェント,
WWRf a == ,0
それ以外のエージェント,
)(),0( 000 WWWWRf a ≤=≥= μμ
)1)(1(1
−−<
nM Wμ とする 但し、
.1,...,1,0, −=+= WifSS irr ii
.1,...,2,1,11 −== − Wif
Mf ii 但し, とする
;1, +=′← WWxx (ⅴ).
(c). が終端状態ならば繰り返しを終了 x
16

5. 複雑なマルチエージェント問題における強化学習
5.1 追跡問題への応用 5.1.1 追跡問題とは 追跡問題(Pursuit Problem)[Benda 85]は,マルチエージェント系におけるベンチマー
クの一つとして知られており,アルゴリズムの評価,エージェント間の協調などに関する
多くの研究の対象になっている。追跡問題には,研究者独自の設定に伴う数多くのバリエ
ーションがあるが,本論文では,5.1.2の設定にもとづく。 5.1.2 問題設定 図5.1に示すような 格子状の環境を設定し,ここに複数の追跡者(Hunter)エー
ジェントとひとつの逃亡者(Prey)エージェントをランダムに配置する。これを初期状態
とする。行動の順番と1ステップの定義は,実験1では,ランダムに選ばれたエージェン
トがひとつ行動した単位時間を1ステップと呼ぶ。実験2では,エージェントが行動する
順番は予め決められており全てのエージェントが行動した単位時間を 1 ステップと呼ぶ。
また,各エージェントがとりうる行動は,{上,下,左,右}の方向に 1 セル進むか,または停止
の5種類から選択される。ある行動を選んだ際にエージェント同士が衝突する場合,衝突
したエージェントは 1 ステップ前の位置に戻るものとする。また,格子の外枠は壁とし,
各エージェントは壁を越えることはできないとする。
ll ×
追跡者の視界は で与え,自分の周囲,横方向にVX セル,縦方向にVY セルが見
えるものとする。追跡者エージェントが各ステップで観測できる状態は,自分の視界内に
存在する他の追跡者及び逃亡者の向き{上,右上,右,右下,下,左下,左,左上}と視野外の9通りの
組み合わせである。エージェントは追跡者と逃亡者を識別できるものとするが,外枠の壁
は知覚できないものとする。
VYVX ×
目標状態は,図5.2に示すように,予め設定した数の追跡者が逃亡者に隣接した時と
する。ここでいう隣接とは,逃亡者の上下左右のいずれかのセルに追跡者が存在すること
を指す。追跡者から見て逃亡者が斜めのセルに存在する時は隣接したとはみなさない。目
標を達成した場合に最後に行動した追跡者エージェントに報酬を与える。
17

図5.1の青い四角は追跡者エージェント,赤いは四角は逃亡者,オレンジの矢印はエ
ージェントのとりうる行動,黄色の矢印は横,縦それぞれの視野の範囲VX ,VY ,シアン
と水色の領域がエージェントの視野の範囲を表している。
図5.1 追跡問題の枠組み
図5.2 捕獲の例
VY
VX
18

5.2 実験1 間接報酬の値による学習効率~エージェント数が多い場合~ 5.2.1 実験条件 まず,間接報酬μ の値の変化に伴う学習効率の違いを比較するために,追跡者エージェ
ントを6個用いて以下の実験を行った。 表5.1の設定で,μ の値を変えながらそれぞれの値で 20 試行した平均値を比較し検証
した。図5.3は実験1の枠組みを示しており,青は追跡者,赤は逃亡者,水色は逃亡者
に対する視野の範囲を表している。
図5.3 実験1の枠組み
表5.1 実験1の実験条件 各項目 内容
追跡者の数 6 間接報酬μ の値 0,0.0016*,0.01,0.03,0.1,0.2,0.4,1.0 視野の範囲( ) VYVX × 4×4(対逃亡者) 状態数 9(逃亡者に対する状態数) マップサイズ 13×13 環境の初期状態 ランダム 目標状態 逃亡者に 4 辺で隣接(壁を用いても良い) 最大エピソード数 1000 最大ステップ数 10000 *赤字は定理の保証する最大値
19

5.2.2 結果及び考察
図5.4に実験 1 の結果をまとめたグラフを示す。ここで,グラフの横軸はμ の値
で,縦軸は捕獲できないエピソードが無くなるまでの必要学習回数である。この数値が
小さいほど早く学習が進んでいて良い結果といえる。 青線は各μ の値での 20 回試行を繰り返した必要学習回数の平均値でありエラーバー
は標準偏差である。赤の実線及び点線はμ =0 とし,間接報酬を与えなかった場合の必要
学習回数と標準偏差を表している。縦のオレンジの点線までが合理性定理が保証する μの値である。 このグラフからμ の値を大きくしすぎると学習が遅くなっていることが分かる。これ
は,間接報酬の値を大きくしすぎたため捕獲に貢献していないエージェントの行動まで
強化してしまったためであると考えられる。また,μ の範囲が合理性定理が保証する値
までは,確かに良い結果が出ていてマルチエージェント系における合理性定理は確かに
有効であるといえる。最も良い結果が出ているのは,合理性定理が保証する 0016.0=μ の
時で,標準偏差,学習速度ともに若干良い値となっている。しかし,エージェントの数
が多く,行動の選択肢も多いこの問題では,定理の保証できるμの値が 0.0016 と非常に
小さく間接報酬による学習速度の向上というメリットまで薄れてしまっている。
図5.4 μ の値の変化に伴う学習効率
捕獲できないエピソードが無くなる
までの必要学習回数
0.00001 0.0001 0.001 0.01 0.1 1
300
200
100
μ
20

5.3 実験2 学習された行動ルールにおける協調性 5.3.1 実験条件 次に,学習された行動ルールにおけるエージェント間の協調動作を検証するために以下
の実験を行った。 エージェント間の協調動作を検証しやすくするため,追跡者エージェントの数は2個と
した。これらのエージェントが行動する順番は予め決められているものとする。また,捕
獲直前のエージェント間の協調動作を検証しやすくするため,視野の範囲を逃亡者に対し
ては7×7で与え,他の追跡者に対しては1×1で与えた。目標状態は逃亡者に2個の追
跡者が隣接することである。このためすべてのエージェントは必ず捕獲に貢献しているの
で,μ の値は 1.0 とし直接報酬と同じ値の間接報酬を与えた。
表5.2の設定で 20 回分の学習された行動ルールを検証した。図5.4は実験2の枠組
みを示しており,青は追跡者,赤は逃亡者,水色は逃亡者に対する視野の範囲,黄色は他
の追跡者に対する視野の範囲を表している。
図5.4 実験2の枠組み
21

表5.2 実験2の実験条件 各項目 内容
追跡者の数 2 間接報酬μ の値 1.0 視野の範囲(VX ) VY× 7×7(対逃亡者),1×1(対追跡者) 状態数 9×9 マップサイズ 15×15 環境の初期状態 ランダム 目標状態 逃亡者に 2 辺で隣接 最大エピソード数 2000 最大ステップ数 1000 5.3.2 結果及び考察 エージェントの協調動作を確認するために図5.5のような場合における各エージェン
トの行動選択確率を検証した。エージェントの番号は各ステップにおいての行動順序を表
している。但し,状態観測は図5.5の状態で同時に行うものとする。
2
1
図5.5 エージェントの協調動作が必要な状態の例
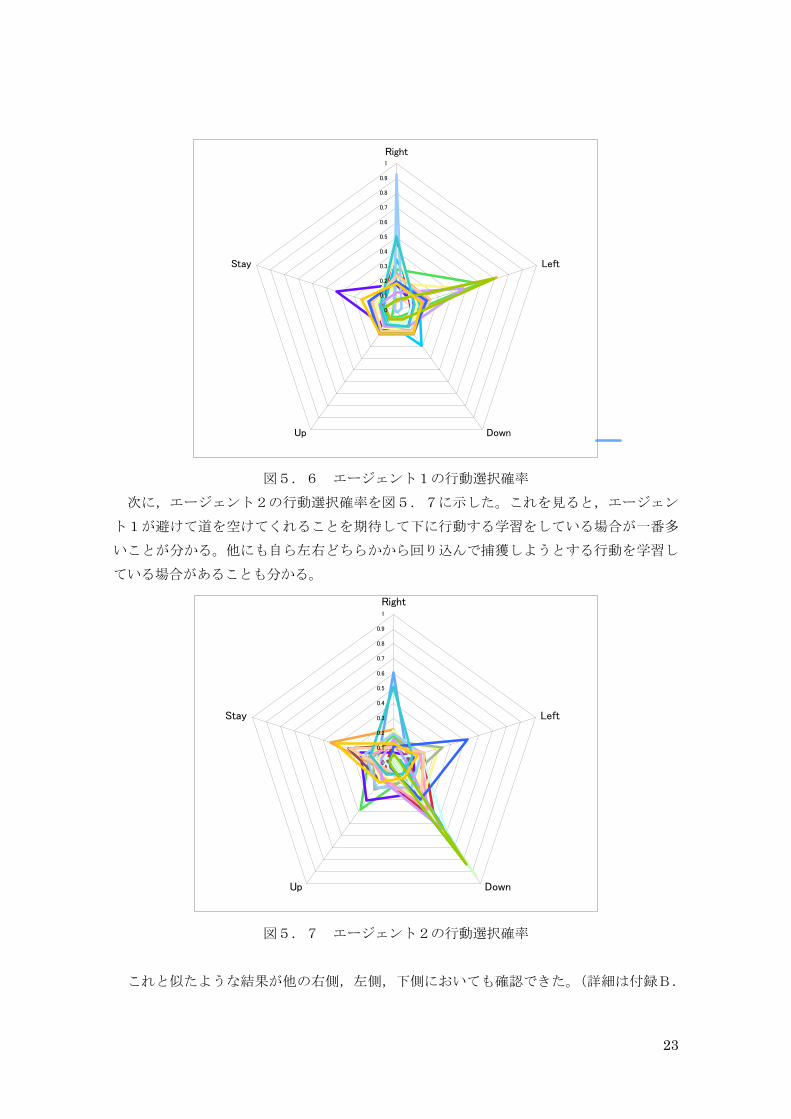
まず,最初に行動するエージェント1の行動選択確率を図5.6に示した。線の色が 20種類あるのは,20 試行それぞれで学習された行動選択確率を示している。これを見ると,
右,または左に避けて相手のエージェントと協力して捕獲しようとするような動きを学習
している場合が多いことが分かる。
22
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Right
Left
DownUp
Stay
図5.6 エージェント1の行動選択確率
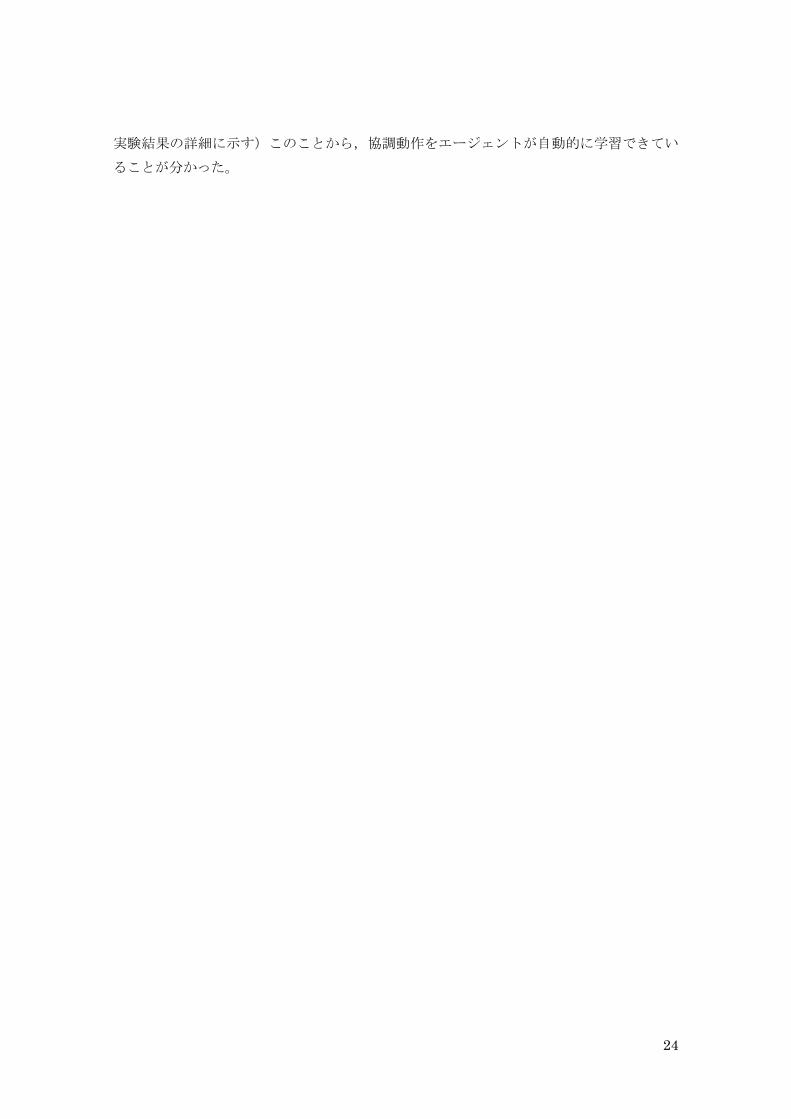
次に,エージェント2の行動選択確率を図5.7に示した。これを見ると,エージェン
ト1が避けて道を空けてくれることを期待して下に行動する学習をしている場合が一番多
いことが分かる。他にも自ら左右どちらかから回り込んで捕獲しようとする行動を学習し
ている場合があることも分かる。
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Right
Left
DownUp
Stay
図5.7 エージェント2の行動選択確率
これと似たような結果が他の右側,左側,下側においても確認できた。(詳細は付録B.
23
実験結果の詳細に示す)このことから,協調動作をエージェントが自動的に学習できてい
ることが分かった。
24

6. まとめ
本研究では,マルチエージェントシステムにおける強化学習の利用例として,マルチエ
ージェント強化学習における Profit Sharing の有効性検証を行った。 マルチエージェント系におけるベンチマークとしても知られる追跡問題を用いて,間接
報酬の効果と協調動作の学習について検証を行った結果,複雑なマルチエージェント問題
においてもマルチエージェント系における Profit Sharing の合理性定理[宮崎他 99]をも
ちいることにより,間接報酬を与えたことによる解の劣化を防ぐことが可能なことが分か
った。しかし,複雑な問題においては,定理の保証できる間接報酬の値があまりにも小さ
いため学習速度の向上というメリットも薄れてしまうことも分かった。また,学習された
行動ルールからエージェント間の協調動作を検証したところ,予め行動する順番さえ与え
ておけば,エージェントが自動的に協調動作を学習してくれることが分かった。 今後の課題として,エージェントに与える状態数を増やしてより詳しい環境の状態をエ
ージェントに与えてやることによって,さらに質の高い協調動作を学習させることが期待
できる。しかし,与える状態数の増加に伴う学習に必要な時間及び,必要なメモリ数の増
加という問題を解決することも必要となってくる。
25

謝辞 本研究に際して,数々の丁寧なご指導をしていただいた理学部数理情報科学科本田理恵助
教授に感謝の意を表し,心からお礼申し上げます。また,研究に関して様々な相談や協力
をしていただいた同研究室の皆様にもここでお礼申し上げます。ここに謹んで謝辞を申し
上げます。
26

参考文献 [Benda 85] Benda,M.,Jagannathan,V.,and Dodhiawalla,R.:On optimal
cooperation of knowledge sources,Technical Report BCS-G2010-28,Boeing AI Center,Boeing Computer Services,Bellevue,WA(1985)
[Grefenstette 88] Grefenstette,J.J.:Credit assignment in rule discovery systems based on genetic algorithms,Machine Learning,Vol.3,pp.225~245(1988)
[宮崎他 94] 宮崎和光,山村雅幸,小林重信:強化学習における報酬割当の理論的考察,
人工知能学会誌,Vol.9 No.4,pp.580~587(1994) [宮崎他 99] 宮崎和光,荒井幸代,小林重信:Profit Sharing を用いたマルチエージェント
強化学習における報酬配分の理論的考察,人工知能学会誌,Vol.14 No. 6,
pp.148~156(1999) [Richard,Andrew 98] Richard S.Sutton and Andrew G.Barto:強化学習,(三上貞芳&
皆川雅章 共訳),(森北出版,2000) [高玉 03] 高玉圭樹:マルチエージェント学習―相互作用の謎に迫る―,(コロナ社,2003)
27

付録 A.プログラムリスト A-1. エージェント数 6 の場合の追跡問題 import java.awt.*; import java.awt.event.*; import javax.swing.*; import java.io.*; public class PSm3 extends JFrame implements ActionListener,Runnable{ MyCanvas c1; JButton b1,b3; Thread t1; int width =800; int height=800; boolean KissOfDeath; int i0,i1,j0,j1; int an=6; /*エージェントの数*/ int am=5; /*行動の数*/ int sn=10; /*状態の数*/ int w=3; /*強化区間*/ int st; /*状態*/ int sa=0; /*選択されたエージェント*/ int a; /*選択された行動*/ int ra; /*実行した行動*/ int maxstep=10000; /*最大ステップ数*/ int maxepisode=1000; /*最大エピソード数*/ String logfile="07.02.6-1."+maxstep+"."+maxepisode+"log.d"; /* 実験デ
ータ保存ファイル名*/ String weightfile="07.02.6-1."+maxstep+"."+maxepisode+"weight.d"; /* 学習デ
ータ保存ファイル名*/ double r=0; /*報酬*/ int mp=10; /*初期配置の最大値*/ int ax; /*初期配置*/ int ay; /*初期配置*/ Rule rule;
28

Map map; Agent [] h = new Agent[an]; Agent ta ; Episod eps; int step; int episode; int NN = 50000; int [] epscap = new int [NN]; int [] stepcap = new int [NN]; int capno = 0; PSm3() { super(); setTitle("Profit Sharing"); setBounds( 0, 0, 1200, 600); Container c = getContentPane(); BorderLayout layout = new BorderLayout(); c.setLayout(layout); i0=10; j0=10; i1=810; j1=810; KissOfDeath = false; c1 = new MyCanvas(); c.add(c1,layout.CENTER); JPanel jc= new JPanel(); b1 = new JButton("GO/STOP"); b1.addActionListener(this); jc.add(b1, new BorderLayout().WEST); b3 = new JButton("reset"); b3.addActionListener(this); jc.add(b3, new BorderLayout().EAST); c.add(jc,layout.SOUTH); episode=0; rule = new Rule(an,sn,am,w); rule.readsrdata("ProfitSharing/07.01.23-2.10000.1000weight.d");
29

} public static void main(String args[]){ JFrame f = new PSm3(); f.setDefaultCloseOperation( JFrame.EXIT_ON_CLOSE ); f.setSize( 1200, 600); f.setVisible( true ); } public void actionPerformed(ActionEvent ev) { if (ev.getSource() == b1) { KissOfDeath = ! KissOfDeath; if (KissOfDeath){ t1 = new Thread(this); t1.start(); } } else if (ev.getSource() == b3) { c1.repaint(); } } public void run(){ try { while(KissOfDeath && episode<maxepisode){ r=0; map = new Map(15,15); //map.show(); /*h[0] = new Agent(4,4,map,false,0); h[1] = new Agent(10,4,map,false,1); h[2] = new Agent(4,10,map,false,2); h[3] = new Agent(10,10,map,false,3); h[4] = new Agent(7,4,map,false,4); h[5] = new Agent(7,10,map,false,5); ta = new Agent(7,7,map,true,0);*/ h[0] = new
30

Agent(getNextRand(mp)+2,getNextRand(mp)+2,map,false,0); ax = getNextRand(mp)+2; ay = getNextRand(mp)+2; while(ax==h[0].x && ay==h[0].y){ ax = getNextRand(mp)+2; ay = getNextRand(mp)+2; } h[1] = new Agent(ax,ay,map,false,1); ax = getNextRand(mp)+2; ay = getNextRand(mp)+2; while((ax==h[0].x && ay==h[0].y)||(ax==h[1].x && ay==h[1].y)){ ax = getNextRand(mp)+2; ay = getNextRand(mp)+2; } h[2] = new Agent(ax,ay,map,false,2); ax = getNextRand(mp)+2; ay = getNextRand(mp)+2; while((ax==h[0].x && ay==h[0].y)||(ax==h[1].x && ay==h[1].y)|| (ax==h[2].x && ay==h[2].y)){ ax = getNextRand(mp)+2; ay = getNextRand(mp)+2; } h[3] = new Agent(ax,ay,map,false,3); ax = getNextRand(mp)+2; ay = getNextRand(mp)+2; while((ax==h[0].x && ay==h[0].y)||(ax==h[1].x && ay==h[1].y)|| (ax==h[2].x && ay==h[2].y)||(ax==h[3].x && ay==h[3].y)){ ax = getNextRand(mp)+2; ay = getNextRand(mp)+2; } h[4] = new Agent(ax,ay,map,false,4);
31

ax = getNextRand(mp)+2; ay = getNextRand(mp)+2; while((ax==h[0].x && ay==h[0].y)||(ax==h[1].x && ay==h[1].y)|| (ax==h[2].x && ay==h[2].y)||(ax==h[3].x && ay==h[3].y)|| (ax==h[4].x && ay==h[4].y)){ ax = getNextRand(mp)+2; ay = getNextRand(mp)+2; } h[5] = new Agent(ax,ay,map,false,5); ax = getNextRand(mp)+2; ay = getNextRand(mp)+2; while((ax==h[0].x && ay==h[0].y)||(ax==h[1].x && ay==h[1].y)|| (ax==h[2].x && ay==h[2].y)||(ax==h[3].x && ay==h[3].y)|| (ax==h[4].x && ay==h[4].y)||(ax==h[5].x && ay==h[5].y)){ ax = getNextRand(mp)+2; ay = getNextRand(mp)+2; } ta = new Agent(ax,ay,map,true,0); eps = new Episod(an); step=0; while(r==0 && step<maxstep){ sa=getNextRand(an); st = h[sa].getstate(ta); a = rule.selectaction(sa,st); ra = h[sa].move(a,map,sa); a = ra; eps.hozon(sa,st,a); r = h[sa].getreward(an,h,ta,map); if(step%an==0){ a=getNextRand(am);
32

ta.move(a, map,0); } step++; if (episode%1==0) { c1.repaint(); t1.sleep(200); } } if(r!=0){ rule.kyouka(r,sa, eps); c1.repaint(); System.out.println("episode="+episode+"で捕獲"+" step="+step); epscap[capno]=episode; stepcap[capno]=step; capno++; } episode++; } rule.hyojiSr(); savelogdata(logfile); rule.saveweightdata(weightfile); } catch(Exception e){ System.out.println(e); } } class MyCanvas extends JLabel{ MyCanvas(){ } public void paintComponent(Graphics g ){ showmap(g); }
33

public void showmap(Graphics g){ int x0=10; int y0=10; int w=480; int h=480; float dw=w/(float)map.width; float dh=h/(float)map.height; g.setColor(Color.LIGHT_GRAY); g.fillRect(x0,y0,w,h); g.setColor(Color.BLACK); g.drawString("agent="+sa,510,10); g.drawString("selectaction="+a,510,30); g.drawString("action="+ra,510,50); g.drawString("episode="+episode+" step="+step,510,90); String stra,strs; for(int i=0;i<an;++i){ g.drawString("agentid="+i+" length="+eps.length[i],510,110+60*i); stra=""; strs=""; for(int j=0;j<eps.length[i];++j){ strs+=eps.sn[i][j]; stra+=eps.acn[i][j]; } g.drawString(strs,510,130+60*i); g.drawString(stra,510,150+60*i); } int jstart=10; int istart=800; for(int i=0;i<an;++i){ istart=800; g.drawString("agentid="+i,istart,jstart); jstart+=20; String strsr;
34

for(int j=0;j<am;++j){ istart=800; g.setColor(Color.BLACK); g.drawString("a"+j,istart,jstart); istart+=60; for(int k=0;k<sn;++k){ if(rule.sr[i][k][j]==10.){ g.setColor(Color.BLACK); }else g.setColor(Color.RED); strsr=Math.round(rule.sr[i][k][j]*10000)/10000.+" "; g.drawString(strsr,istart,jstart); istart+=60; } jstart+=20; } } for (int j=0;j<map.height;++j) { for (int i=0;i<map.width;++i) { if (map.st[i][j]==1) g.setColor(Color.BLACK); else if (map.st[i][j]>=2) g.setColor(Color.BLUE); else if (map.st[i][j]==-1) g.setColor(Color.RED); else g.setColor(Color.LIGHT_GRAY); g.fillRect((int)(x0+dw*i), (int)(y0+dh*j), (int)(dw), (int)(dh)); if (map.st[i][j]>=2){ g.setColor(Color.YELLOW); g.drawString(""+(map.st[i][j]-2),(int)(x0+dw*(i+0.5)),(int)(y0+dh*(j+0.5))); } } } g.setColor(Color.BLACK); for(int i=0;i<map.width+1;++i) g.drawLine((int)(x0+dw*i), y0, (int)(x0+dw*i),
35

y0+h); for(int j=0;j<map.height+1;++j) g.drawLine(x0,(int)(y0+dh*j), x0+w,(int)(y0+dh*j)); } } public int getNextRand(int n){ int a; double r=Math.random(); a=(int)(Math.abs(r-0.0000000001)/(1.0/n)); return a; } public void savelogdata(String logfile){ try{ BufferedWriter bo = new BufferedWriter(new FileWriter(logfile)); for(int i=0;i<capno;++i){ String logdata="episode= "+epscap[i]+" step= "+stepcap[i]; bo.write(logdata); bo.newLine(); } bo.close(); } catch(Exception e){System.out.println(e);} } } public class Agent { int st; /*座標*/ int x; /*x 座標*/ int y; /*y 座標*/ boolean target;
36

int vx=4; /*横の視野*/ int vy=4; /*縦の視野*/ Agent(){ } Agent(int x0, int y0, Map map,boolean ta,int id){ set(x0,y0,map,ta,id); } public void set (int x0, int y0, Map map,boolean ta,int id){ x=x0; y=y0; target = ta; if(target){ map.st[x][y]=-1; this.st=-1; } else{ map.st[x][y]=id+2; this.st=id; } } public void set (int x0, int y0, Map map,int id){ x=x0; y=y0; if(target){ map.st[x][y]=-1; this.st=-1; } else{ map.st[x][y]=id+2; this.st=id; } }
37

public void show(){ System.out.println("("+x+","+y+")"); } public int move(int a, Map map,int id){ int apx,apy; apx = this.x; apy = this.y; switch(a){ case 0: apx++; break; case 1: apx--; break; case 2: apy++; break; case 3: apy--; break; case 4: break; } if(map.st[apx][apy]==0){ map.st[x][y]=0; this.set(apx, apy, map,id); }else { } int an = a; return an; }
38

public int getstate(Agent tg){ int dx,dy; int s=9; //8 1 2 //7 0 3 //6 5 4 //otherwise 9 dx = tg.x - this.x; dy = tg.y - this.y; if(dx >= -vx && dx <= vx && dy >= -vy && dy <= vy){ if (dx==0){ if(dy==0) s=0; else if(dy<0) s=1; else if(dy>0) s=5; } else if (dx>0){ if(dy<0) s=2; else if(dy==0) s=3; else if(dy>0) s=4; } else if (dx<0){ if(dy<0) s=8; else if(dy==0) s=7; else if(dy>0) s=6; } } else s=9; return s; } int agentContactsPrey(Agent tg){ int ans = 0; int dx,dy;
39

dx = Math.abs(tg.x - this.x); dy = Math.abs(tg.y - this.y); if((dx==0 && dy==1) || (dx==1 && dy==0)) ans=1; else ans=0; return ans; } int targetContactswall(Map map){ int tcw = 0; if(map.st[this.x][this.y-1]==1) ++tcw; if(map.st[this.x][this.y+1]==1) ++tcw; if(map.st[this.x-1][this.y]==1) ++tcw; if(map.st[this.x+1][this.y]==1) ++tcw; return tcw; } public boolean hokaku(int anum,Agent[] ag,Map map){ int count = 0; int wcount; boolean ans; wcount = this.targetContactswall(map); for(int i=0;i<anum;++i){ count += ag[i].agentContactsPrey(this); } if(count==4){ ans = true; }else if(count==3 && wcount==1){ ans = true; }else if(count==2 && wcount==2){ ans = true; }else ans = false;
40

return ans; } public double getreward(int anum,Agent[] ag,Agent ta,Map map){ double reward=0; if(ta.hokaku(anum,ag,map)==true){ reward=100; } return reward; } } public class Episod { int NN=50000; int AN=10; int [][] sn = new int [AN][NN]; int [][] acn = new int [AN][NN]; int [] length = new int [NN]; int anum; Episod(int an){ anum = an; for(int i=0;i<anum;++i){ length[i] = 0; } } public void hozon(int agid,int s,int ac){ int i = length[agid]; sn[agid][i] = s; acn[agid][i] = ac; length[agid] += 1;
41

} public void hyouji(){ String stra,strs; for(int i=0;i<anum;++i){ System.out.println("agentid="+i+" length="+length[i]); stra=""; strs=""; for(int j=0;j<length[i];++j){ strs+=sn[i][j]; stra+=acn[i][j]; } System.out.println(strs); System.out.println(stra); } } } public class Map { int NN=100; int width; /*行の数*/ int height; /*列の数*/ int [][] st= new int[NN][NN]; /*座標*/ Map (int w, int h){ width = w; height = h; refresh(); } public void refresh(){ int i,j; for(i=0;i<width;i++){ for(j=0;j<height;j++){
42

st[i][j]=0; } } for(i=0;i<width;i++){ st[i][0]=1; st[i][height-1]=1; } for(j=0;j<height;j++){ st[0][j]=1; st[width-1][j]=1; } } public void show() { String str; for (int j=0;j<height;++j) { str=""; for (int i=0;i<width;++i) { if (st[i][j]==0) str+=" "; else if (st[i][j]==1) str+="W "; else if (st[i][j]>=2) str+="H"+(st[i][j]-2); else if (st[i][j]==-1) str+="T "; else str+="? "; } System.out.println(str); } } } import java.io.*; import java.util.StringTokenizer; public class Rule {
43

int NN = 10; double [][][] sr = new double [NN][NN][NN]; /*ルールの重み*/ int anum; /*エージェントの数*/ int stnum; /*状態の数*/ int actnum; /*行動の数*/ int w; /*直接報酬を得たエージェントの強化区間*/ int w0; /*それ以外のエージェントの強化区間*/ //int [] aw = new int [NN]; Rule(int an,int sn,int acn, int wn){ anum = an; stnum = sn; actnum = acn; w = wn-1; w0 = w; this.init(); } public void init(){ for(int i=0;i<anum;++i){ for(int j=0;j<stnum;++j){ for(int k=0;k<actnum;++k){ sr[i][j][k] = 10.0; } } } } public void kyouka(double r,int agid,Episod eps){ int MM = 50000; double [] f = new double [MM]; double rfirst; int wa; int s;
44

int ac; int wend; int wstart; wa = eps.length[agid]; for(int l=0;l<anum;++l){ if(l==agid){ wend = wa-1-w; wstart=wa-1; rfirst = r; }else{ wend = eps.length[l]-1-w0; wstart=eps.length[l]-1; rfirst = r*myu(); } if (wend<0) wend = 0; for(int i=wstart;i>=wend;--i){ s = eps.sn[l][i]; ac = eps.acn[l][i]; if(i==wstart){ f[i] = rfirst; }else f[i] = f[i+1]/actnum; sr[l][s][ac]+=f[i]; } } } public double myu(){ double u; u = (1/(((Math.pow(actnum,w+1)-1)*(anum-1))))*0.99999; return u; } public int selectaction(int agid, int statas){
45

int a; double r = Math.random(); double sumsr=0.0; for(int k=0;k<actnum;++k){ sumsr += sr[agid][statas][k]; } double [] sradd = new double [actnum+1]; sradd[0]=0; for (int i=1;i<actnum+1;++i){ sradd[i]=sradd[i-1]+sr[agid][statas][i-1]; } for(int i=0;i<actnum;++i){ sradd[i]/=sumsr; } a=0; for (int i=0;i<actnum;++i){ if (r>sradd[i] && r<=sradd[i+1]){ a=i; } } return a; } public void hyojiSr(){ String strsr; for(int i=0;i<anum;++i){ System.out.println("agentid="+i); for(int j=0;j<actnum;++j){ strsr=""; for(int k=0;k<stnum;++k){ strsr+=Math.round(sr[i][k][j]*10000)/10000.+" "; }
46

} } } public void saveweightdata(String weightfile){ try{ BufferedWriter bo = new BufferedWriter(new FileWriter(weightfile)); for(int i=0;i<anum;++i){ String agentdata="agentid="+i; bo.write(agentdata); bo.newLine(); for(int j=0;j<actnum;++j){ String weightdata=""; for(int k=0;k<stnum;++k){ weightdata+=Math.round(sr[i][k][j]*10000)/10000.+" "; } bo.write(weightdata); bo.newLine(); } } bo.close(); } catch(Exception e){System.out.println(e);} } public void readsrdata(String srfile){ String linedata; String [] str = new String[100]; int length; int i=-1; int j=0; int k=0; try{
47

BufferedReader bi = new BufferedReader(new FileReader(srfile)); while((linedata=bi.readLine())!=null){ StringTokenizer st= new StringTokenizer(linedata, " "); int l=0; while (st.hasMoreTokens()) { str[l]=st.nextToken(); str[l].trim(); l++; } length=l; if(length!=1){ for(j=0;j<length;j++){ sr[i][j][k]=Double.parseDouble(str[j]); } k++; }else { i++; k=0; } } bi.close(); } catch(Exception e){System.out.println(e);} } } A-2. エージェント数 2 の場合の追跡問題 import java.awt.*; import java.awt.event.*; import javax.swing.*;
48

import java.io.*; public class PSm4 extends JFrame implements ActionListener,Runnable{ MyCanvas c1; JButton b1,b3; Thread t1; int width =800; int height=800; boolean KissOfDeath; int i0,i1,j0,j1; int an=2; /*エージェントの数*/ int am=5; /*行動の数*/ int sn=100; /*状態の数*/ int tavx=7; /*ターゲットに対する横の視野*/ int tavy=7; /*ターゲットに対する縦の視野*/ int avx=1; /*他のエージェントに対する横の視野*/ int avy=1; /*他のエージェントに対する縦の視野*/ int w=5; /*強化区間*/ int st1; /*状態*/ int st2; int sa=0; /*選択されたエージェント*/ int a; /*選択された行動*/ int a1; int a2; int ra1; /*実行した行動*/ int ra2; int maxstep=1000; /*最大ステップ数*/ int maxepisode=2000; /*最大エピソード数*/ String logfile="07.02.4-1."+maxstep+"."+maxepisode+"log.d"; /* 実験結
果保存ファイル名*/ String weightfile="07.02.4-1."+maxstep+"."+maxepisode+"weight.d"; /* 学習デ
ータ保存ファイル名*/ double r=0; /*報酬*/ int mp=14; /*初期配置の最大値*/ int ax; /*初期配置*/
49

int ay; Rule2 rule2; Rule2 rule; Map map; Agent [] h = new Agent[an]; Agent ta ; Episod eps; int step; int episode; int NN = 50000; int [] epscap = new int [NN]; int [] stepcap = new int [NN]; int capno = 0; PSm4() { super(); setTitle("Profit Sharing"); setBounds( 0, 0, 1200, 600); Container c = getContentPane(); BorderLayout layout = new BorderLayout(); c.setLayout(layout); i0=10; j0=10; i1=810; j1=810; KissOfDeath = false; c1 = new MyCanvas(); c.add(c1,layout.CENTER); JPanel jc= new JPanel(); b1 = new JButton("GO/STOP"); b1.addActionListener(this); jc.add(b1, new BorderLayout().WEST); b3 = new JButton("reset"); b3.addActionListener(this); jc.add(b3, new BorderLayout().EAST); c.add(jc,layout.SOUTH);
50

episode=0; rule2 = new Rule2(an,sn,am,w); rule = new Rule2(an,10,am,w); /*rule.readsrdata("07.01.27-21sr.1000.300weight.d"); for(int i=0;i<an;++i){ for(int j=0;j<10;++j){ for(int k=0;k<am;++k){ for(int l=0;l<10;++l){ rule2.sr[i][j+l*10][k]=rule.sr[i][j][k]; } } } }*/ rule2.readsrdata("ProfitSharing/07.01.29-53.1000.2000weight.d"); //rule2.hyojiSr(); } public static void main(String args[]){ JFrame f = new PSm4(); f.setDefaultCloseOperation( JFrame.EXIT_ON_CLOSE ); f.setSize( 1200, 600); f.setVisible( true ); } public void actionPerformed(ActionEvent ev) { if (ev.getSource() == b1) { KissOfDeath = ! KissOfDeath; if (KissOfDeath){ t1 = new Thread(this); t1.start(); } } else if (ev.getSource() == b3) { c1.repaint(); }
51

} public void run(){ try { while(KissOfDeath && episode<maxepisode){ r=0; map = new Map(17,17); /*h[0] = new Agent(2,3,map,false,0); h[1] = new Agent(7,12,map,false,1); ta = new Agent(6,8,map,true,0);*/ h[0] = new Agent(getNextRand(mp)+1,getNextRand(mp)+1,map,false,0); ax = getNextRand(mp)+1; ay = getNextRand(mp)+1; while(ax==h[0].x && ay==h[0].y){ ax = getNextRand(mp)+1; ay = getNextRand(mp)+1; } h[1] = new Agent(ax,ay,map,false,1); ax = getNextRand(mp)+1; ay = getNextRand(mp)+1; while((ax==h[0].x && ay==h[0].y)||(ax==h[1].x && ay==h[1].y)){ ax = getNextRand(mp)+1; ay = getNextRand(mp)+1; } ta = new Agent(ax,ay,map,true,0); eps = new Episod(an); step=0; while(r==0 && step<maxstep){ a=getNextRand(am); ta.move(a,map,0); st1 = h[0].getstate(ta,tavx,tavy)+h[0].getstate(h[1],avx,avy)*10; a1 = rule2.selectaction(0,st1); st2 =
52

h[1].getstate(ta,tavx,tavy)+h[1].getstate(h[0],avx,avy)*10; a2 = rule2.selectaction(1,st2); ra1 = h[0].move(a1,map,0); a1 = ra1; eps.hozon(0,st1,a1); ra2 = h[1].move(a2,map,1); a2 = ra2; eps.hozon(1,st2,a2); r = h[1].getreward(an,h,ta,map); step++; if (episode%1==0) { c1.repaint(); t1.sleep(500); } } if(r!=0){ rule2.kyouka(r,1, eps); c1.repaint(); System.out.println("episode="+episode+"で捕獲"+" step="+step); epscap[capno]=episode; stepcap[capno]=step; capno++; }else{ epscap[capno]=episode; stepcap[capno]=step; capno++; } episode++; } rule2.hyojiSr(); savelogdata(logfile); rule2.saveweightdata(weightfile); } catch(Exception e){ System.out.println(e);
53

} } class MyCanvas extends JLabel{ MyCanvas(){ } public void paintComponent(Graphics g ){ showmap(g); } public void showmap(Graphics g){ int x0=10; int y0=10; int w=480; int h=480; float dw=w/(float)map.width; float dh=h/(float)map.height; g.setColor(Color.LIGHT_GRAY); g.fillRect(x0,y0,w,h); g.setColor(Color.BLACK); g.drawString("agent=0",510,10); g.drawString("selectaction="+a1,510,30); g.drawString("action="+ra1,510,50); g.drawString("agent=1",510,70); g.drawString("selectaction="+a2,510,90); g.drawString("action="+ra2,510,110); g.drawString("episode="+episode+" step="+step,510,150); String stra,strs; for(int i=0;i<an;++i){ stra=""; strs=""; for(int j=0;j<eps.length[i];++j){ strs+=eps.sn[i][j]; stra+=eps.acn[i][j]; }
54

} int jstart=10; int istart=800; for(int i=0;i<an;++i){ istart=800; g.drawString("agentid="+i,istart,jstart); jstart+=20; String strsr; for(int j=0;j<am;++j){ istart=800; g.setColor(Color.BLACK); g.drawString("a"+j,istart,jstart); istart+=60; for(int k=0;k<sn;++k){ if(rule2.sr[i][k][j]==10.){ g.setColor(Color.BLACK); }else g.setColor(Color.RED); strsr=Math.round(rule2.sr[i][k][j]*10000)/10000.+" "; g.drawString(strsr,istart,jstart); istart+=60; } jstart+=20; } } for (int j=0;j<map.height;++j) { for (int i=0;i<map.width;++i) { if (map.st[i][j]==1) g.setColor(Color.BLACK); else g.setColor(Color.LIGHT_GRAY); g.fillRect((int)(x0+dw*i), (int)(y0+dh*j), (int)(dw), (int)(dh)); } } for (int j=0;j<map.height;++j) {
55

for (int i=0;i<map.width;++i) { if (map.st[i][j]>=2) { g.setColor(Color.CYAN); int vxmin=i-tavx; int vxmax=i+tavx; int vymin=j-tavy; int vymax=j+tavy; if(vxmin<1) vxmin=1; if(vxmax>map.width-2) vxmax=map.width-2; if(vymin<1) vymin=1; if(vymax>map.height-2) vymax=map.height-2; for(int ii=vxmin;ii<=vxmax;++ii){ for(int jj=vymin;jj<=vymax;++jj){ g.fillRect((int)(x0+dw*ii), (int)(y0+dh*jj), (int)(dw), (int)(dh)); } } } } } for (int j=0;j<map.height;++j) { for (int i=0;i<map.width;++i) { if (map.st[i][j]>=2) { g.setColor(Color.BLUE); g.fillRect((int)(x0+dw*i), (int)(y0+dh*j), (int)(dw), (int)(dh)); g.setColor(Color.YELLOW); g.drawString(""+(map.st[i][j]-2),(int)(x0+dw*(i+0.5)),(int)(y0+dh*(j+0.5))); } else if (map.st[i][j]==-1) {
56

g.setColor(Color.RED); g.fillRect((int)(x0+dw*i), (int)(y0+dh*j), (int)(dw), (int)(dh)); } } } g.setColor(Color.BLACK); for(int i=0;i<map.width+1;++i) g.drawLine((int)(x0+dw*i), y0, (int)(x0+dw*i), y0+h); for(int j=0;j<map.height+1;++j) g.drawLine(x0,(int)(y0+dh*j), x0+w,(int)(y0+dh*j)); } } public int getNextRand(int n){ int a; double r=Math.random(); a=(int)(Math.abs(r-0.0000000001)/(1.0/n)); return a; } public void savelogdata(String logfile){ double sumstep = 0; double v=0; for(int j=0;j<capno;++j){ sumstep += stepcap[j]; } sumstep = sumstep/capno; for(int k=0;k<capno;++k){ v += Math.pow(sumstep-stepcap[k],2); } v = Math.sqrt(v/capno);
57

try{ BufferedWriter bo = new BufferedWriter(new FileWriter(logfile)); for(int i=0;i<capno;++i){ String logdata="episode= "+epscap[i]+" step= "+stepcap[i];//+" average= "+sumstep+" v= "+v; bo.write(logdata); bo.newLine(); } bo.close(); } catch(Exception e){System.out.println(e);} } } package Agent2ver; public class Agent { int st; /*座標*/ int x; /*x 座標*/ int y; /*y 座標*/ boolean target; Agent(){ } Agent(int x0, int y0, Map map,boolean ta,int id){ set(x0,y0,map,ta,id); } public void set (int x0, int y0, Map map,boolean ta,int id){ x=x0; y=y0;
58

target = ta; if(target){ map.st[x][y]=-1; this.st=-1; } else{ map.st[x][y]=id+2; this.st=id; } } public void set (int x0, int y0, Map map,int id){ x=x0; y=y0; if(target){ map.st[x][y]=-1; this.st=-1; } else{ map.st[x][y]=id+2; this.st=id; } } public void show(){ System.out.println("("+x+","+y+")"); } public int move(int a, Map map,int id){ int apx,apy; apx = this.x; apy = this.y; switch(a){
59

case 0: apx++; break; case 1: apx--; break; case 2: apy++; break; case 3: apy--; break; case 4: break; } if(map.st[apx][apy]==0){ map.st[x][y]=0; this.set(apx, apy, map,id); }else { } int an = a; return an; } public int getstate(Agent tg,int viewx,int viewy){ int vx,vy; int dx,dy; int s=9; //8 1 2 //7 0 3 //6 5 4 //otherwise 9 vx = viewx; vy = viewy; dx = tg.x - this.x;
60

dy = tg.y - this.y; if(dx >= -vx && dx <= vx && dy >= -vy && dy <= vy){ if (dx==0){ if(dy==0) s=0; else if(dy<0) s=1; else if(dy>0) s=5; } else if (dx>0){ if(dy<0) s=2; else if(dy==0) s=3; else if(dy>0) s=4; } else if (dx<0){ if(dy<0) s=8; else if(dy==0) s=7; else if(dy>0) s=6; } } else s=9; return s; } int agentContactsPrey(Agent tg){ int ans = 0; int dx,dy; dx = Math.abs(tg.x - this.x); dy = Math.abs(tg.y - this.y); if((dx==0 && dy==1) || (dx==1 && dy==0)) ans=1; else ans=0; return ans; } public boolean hokaku(int anum,Agent[] ag,Map map){
61

int count = 0; boolean ans; for(int i=0;i<anum;++i){ count += ag[i].agentContactsPrey(this); } if(count==2){ ans = true; }else ans = false; return ans; } public double getreward(int anum,Agent[] ag,Agent ta,Map map){ int reward=0; if(ta.hokaku(anum,ag,map)==true){ reward=100; } return reward; } } public class Episod { int NN=50000; int AN=10; int [][] sn = new int [AN][NN]; int [][] acn = new int [AN][NN]; int [] length = new int [NN]; int anum; Episod(int an){ anum = an; for(int i=0;i<anum;++i){
62

length[i] = 0; } } public void hozon(int agid,int s,int ac){ int i = length[agid]; sn[agid][i] = s; acn[agid][i] = ac; length[agid] += 1; } public void hyouji(){ String stra,strs; for(int i=0;i<anum;++i){ System.out.println("agentid="+i+" length="+length[i]); stra=""; strs=""; for(int j=0;j<length[i];++j){ strs+=sn[i][j]; stra+=acn[i][j]; } System.out.println(strs); System.out.println(stra); } } } public class Map { int NN=100; int width; /*行の数*/ int height; /*列の数*/ int [][] st= new int[NN][NN]; /*座標*/ Map (int w, int h){
63

width = w; height = h; refresh(); } public void refresh(){ int i,j; for(i=0;i<width;i++){ for(j=0;j<height;j++){ st[i][j]=0; } } for(i=0;i<width;i++){ st[i][0]=1; st[i][height-1]=1; } for(j=0;j<height;j++){ st[0][j]=1; st[width-1][j]=1; } } public void show() { String str; for (int j=0;j<height;++j) { str=""; for (int i=0;i<width;++i) { if (st[i][j]==0) str+=" "; else if (st[i][j]==1) str+="W "; else if (st[i][j]>=2) str+="H"+(st[i][j]-2); else if (st[i][j]==-1) str+="T "; else str+="? ";
64

} System.out.println(str); } } } import java.io.*; import java.util.StringTokenizer; public class Rule2 { int NN = 101; double [][][] sr = new double [NN][NN][NN]; /*ルールの重み*/ int anum; /*エージェントの数*/ int stnum; /*状態の数*/ int actnum; /*行動の数*/ int w; /*直接報酬を得たエージェントの強化区間*/ int w0; /*それ以外のエージェントの強化区間*/ //int [] aw = new int [NN]; Rule2(int an,int sn,int acn, int wn){ anum = an; stnum = sn; actnum = acn; w = wn-1; w0 = w; this.init(); } public void init(){ for(int i=0;i<anum;++i){ for(int j=0;j<stnum;++j){ for(int k=0;k<actnum;++k){
65

sr[i][j][k] = 10.0; } } } } public void kyouka(double r,int agid,Episod eps){ int MM = 50000; double [] f = new double [MM]; double rfirst; int wa; int s; int ac; int wend; int wstart; wa = eps.length[agid]; for(int l=0;l<anum;++l){ if(l==agid){ wend = wa-1-w; wstart=wa-1; rfirst = r; }else{ wend = eps.length[l]-1-w0; wstart=eps.length[l]-1; rfirst = r*myu(); } if (wend<0) wend = 0; for(int i=wstart;i>=wend;--i){ s = eps.sn[l][i]; ac = eps.acn[l][i]; if(i==wstart){ f[i] = rfirst; }else f[i] = f[i+1]/actnum; sr[l][s][ac]+=f[i];
66

} } } public double myu(){ double u; u = (1/(((Math.pow(actnum,w+1)-1)*(anum-1))))*0.99999; u = 1.0; return u; } public int selectaction(int agid, int statas){ int a; double r = Math.random(); double sumsr=0.0; for(int k=0;k<actnum;++k){ sumsr += sr[agid][statas][k]; } double [] sradd = new double [actnum+1]; sradd[0]=0; for (int i=1;i<actnum+1;++i){ sradd[i]=sradd[i-1]+sr[agid][statas][i-1]; } for(int i=0;i<actnum;++i){ sradd[i]/=sumsr; } a=0; for (int i=0;i<actnum;++i){ if (r>sradd[i] && r<=sradd[i+1]){ a=i; } } return a;
67

} public void hyojiSr(){ String strsr; for(int i=0;i<anum;++i){ System.out.println("agentid="+i); for(int j=0;j<actnum;++j){ strsr=""; for(int k=0;k<stnum;++k){ strsr+=Math.round(sr[i][k][j]*10000)/10000.+" "; } } } } public void saveweightdata(String weightfile){ try{ BufferedWriter bo = new BufferedWriter(new FileWriter(weightfile)); for(int i=0;i<anum;++i){ String agentdata="agentid="+i; bo.write(agentdata); bo.newLine(); for(int j=0;j<actnum;++j){ String weightdata=""; for(int k=0;k<stnum;++k){ weightdata+=Math.round(sr[i][k][j]*10000)/10000.+" "; } bo.write(weightdata); bo.newLine(); } } bo.close();
68

} catch(Exception e){System.out.println(e);} } public void readsrdata(String srfile){ String linedata; String [] str = new String[100]; int length; int i=-1; int j=0; int k=0; try{ BufferedReader bi = new BufferedReader(new FileReader(srfile)); while((linedata=bi.readLine())!=null){ StringTokenizer st= new StringTokenizer(linedata, " "); int l=0; while (st.hasMoreTokens()) { str[l]=st.nextToken(); str[l].trim(); l++; } length=l; if(length!=1){ for(j=0;j<length;j++){ sr[i][j][k]=Double.parseDouble(str[j]); } k++; }else { i++; k=0; }
69

} bi.close(); } catch(Exception e){System.out.println(e);} } }
70
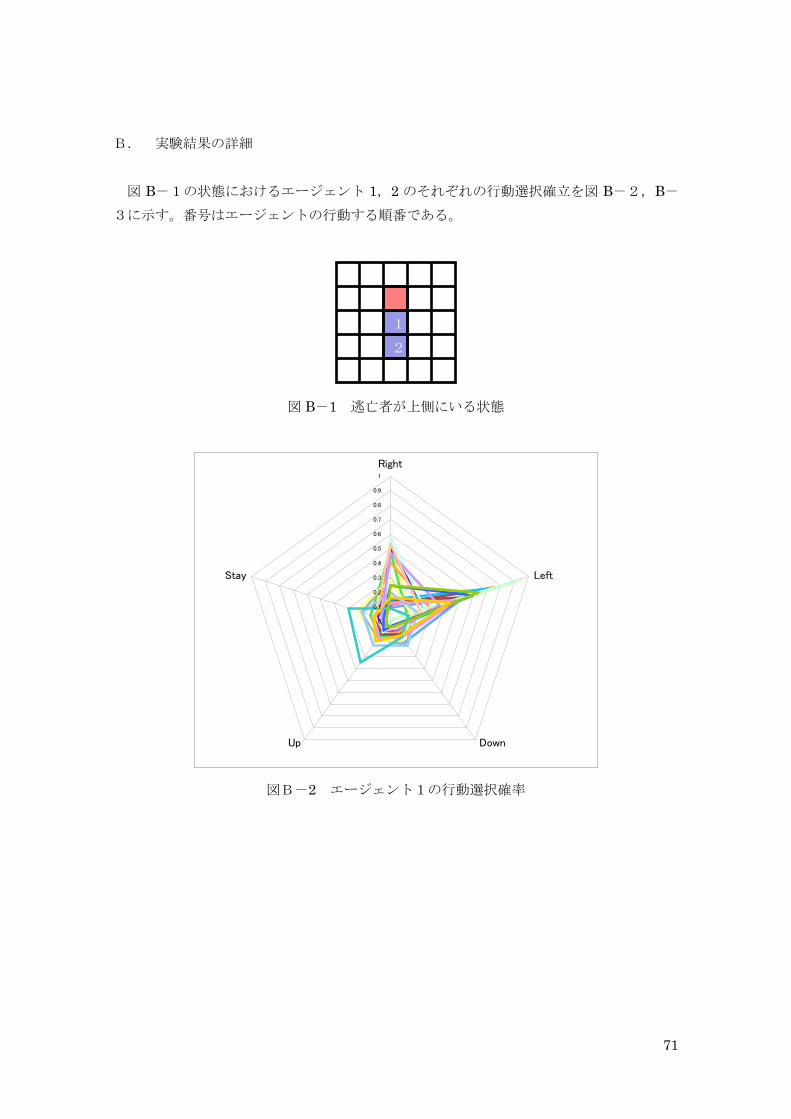
B. 実験結果の詳細 図 B-1の状態におけるエージェント 1,2 のそれぞれの行動選択確立を図 B-2,B-
3に示す。番号はエージェントの行動する順番である。
2
1
図 B-1 逃亡者が上側にいる状態
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Right
Left
DownUp
Stay
図B-2 エージェント1の行動選択確率
71

0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Right
Left
DownUp
Stay
図B-3 エージェント2の行動選択確率
図 B-4の状態におけるエージェント 1,2 のそれぞれの行動選択確立を図 B-5,B-
6に示す。番号はエージェントの行動する順番である。
2 1
図 B-4 逃亡者が右側にいる状態
72
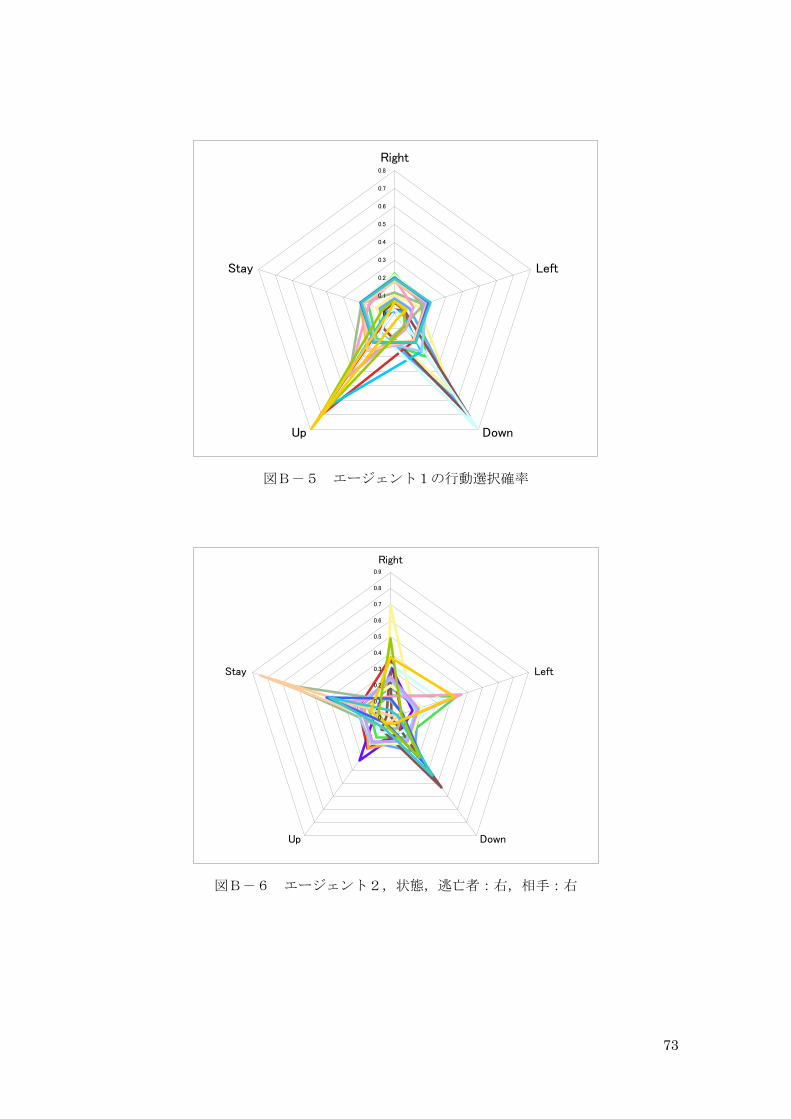
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Right
Left
DownUp
Stay
図B-5 エージェント1の行動選択確率
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Right
Left
DownUp
Stay
図B-6 エージェント2,状態,逃亡者:右,相手:右
73

図 B-7の状態におけるエージェント 1,2 のそれぞれの行動選択確立を図 B-8,B-
9に示す。番号はエージェントの行動する順番である。
1 2
図 B-7 逃亡者が左側の状態
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Right
Left
DownUp
Stay
図B-8 エージェント1の行動選択確率
74

0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Right
Left
DownUp
Stay
図B-9 エージェント2の行動選択確率
75