© chinese university, cse dept. distributed systems / 9 - 1 distributed systems topic 9: time,...
Post on 21-Dec-2015
220 views
TRANSCRIPT

© Chinese University, CSE Dept. Distributed Systems / 9 - 1
Distributed Systems
Topic 9: Time, Coordination and Replication
Dr. Michael R. LyuComputer Science & Engineering Department
The Chinese University

© Chinese University, CSE Dept. Distributed Systems / 9 - 2
Outline
1 Time
2 Coordination
3 Replication The gossip architecture The process groups approach
4 Summary

© Chinese University, CSE Dept. Distributed Systems / 9 - 3
1 Time
The notation of time– story: 12/9/1949
External synchronization Internal synchronization Physical clocks and their synchronization Logical time and logical clocks

© Chinese University, CSE Dept. Distributed Systems / 9 - 4
1.1 Synchronizing Physical Clocks
Computer each contain their physical clock. Physical clock is limited by its resolution - the
period between updates of the clock register. Clock drift often happens to physical clocks. To compensate for clock drifts, computers are
synchronized to a time service, e.g., UTC - Coordinated universal time.
Several other algorithms for synchronization.

© Chinese University, CSE Dept. Distributed Systems / 9 - 5
1.1 Compensating for Clock Drift
S(t) = H(t) + (t); S = application time, H = hardware clock time, = compensating factor.
Assuming linear relation (t) = aH(t) + b. Let the value of the software clock be Tskew when H
= h, and let the actual time be Treal. If S is to give the actual time after N further ticks,
we have
Tskew = (1 + a)h + b, and Treal + N = (1 + a)(h + N) + b. a = (Treal - Tskew) / N and b = Tskew - (1 + a)h

© Chinese University, CSE Dept. Distributed Systems / 9 - 6
1.1 Cristian’s Clock Synchronization
Let the time returned in S’s message mt be t. P should set its clock to t + Tround/2.
The time by S’s clock when the reply message arrives is [t + min, t + Tround - min], with width Tround - 2 min and accuracy ±(Tround/2 - min).

© Chinese University, CSE Dept. Distributed Systems / 9 - 7
1.1 The Berkeley Algorithm
A coordinator computer is chosen to act as the master. Master periodically polls to slaves whose clocks are to be synchronized.
The master estimates their local clock times by observing the round-trip times, and it averages the values obtained.
The master takes a fault-tolerant average. Should the master fail, then another can be
elected to take over.

© Chinese University, CSE Dept. Distributed Systems / 9 - 8
1.1 The Network Time Protocol
NTP distributes time information to provide:– a service to synchronize clients in Internet– a reliable service that survives loss of connection– a frequent resynchronization for client’s clock drift– protection against interference with time server
NTP service is provided by various servers: – Primary servers, secondary servers, and servers
of other levels (called strata). Synchronization subnet: the servers which are
connected in a logical hierarchy.

© Chinese University, CSE Dept. Distributed Systems / 9 - 9
1.1 NTP Synchronization Modes
Estimating delay and offset in NTP protocol:– a = Ti-2 - Ti-3
– b = Ti –Ti-1
– di = a + b
– oi = (a-b)/2
NTP servers synchronize in three modes:–Multicast mode
–Procedure-call mode
–Symmetric mode

© Chinese University, CSE Dept. Distributed Systems / 9 - 10
1.2 Logical Time and Logical Clocks
The order of the events – two events occurred in the order they appear in a
process.
– event of sending occurred before event of receiving.
happened-before relation, denoted by HB1: If process p: x p y, then x y.
HB2: For any message m, send(m) rcv(m),
HB3: If x, y and z are events such that x y and y z, then x z.
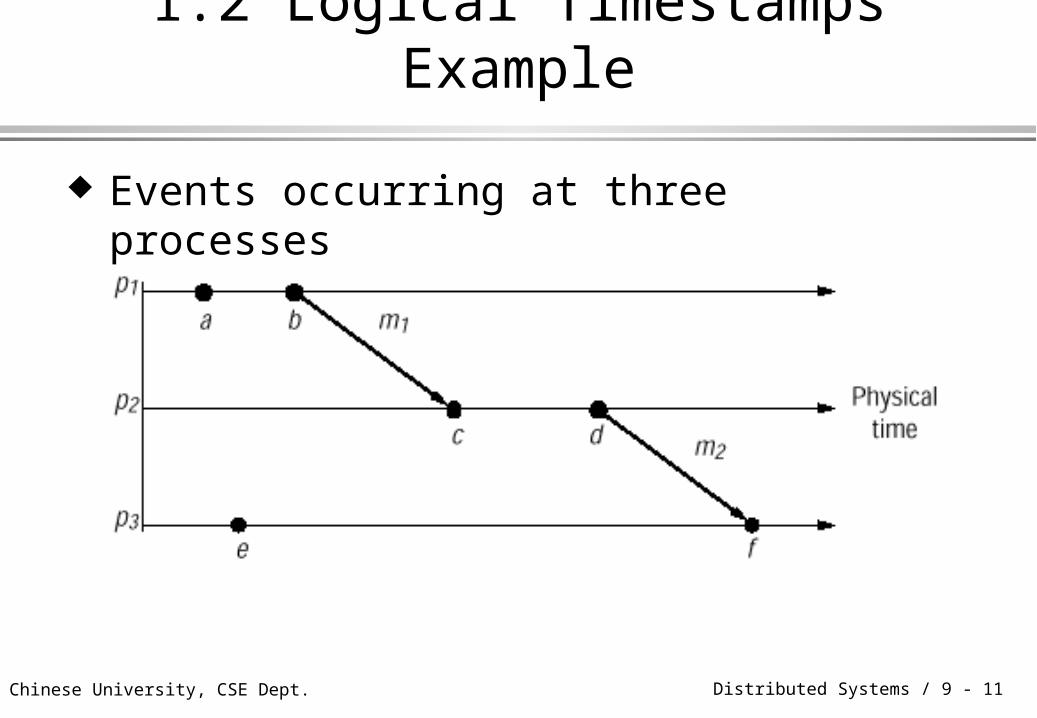
© Chinese University, CSE Dept. Distributed Systems / 9 - 11
1.2 Logical Timestamps Example
Events occurring at three processes

© Chinese University, CSE Dept. Distributed Systems / 9 - 12
1.2 Logical Timestamps
Logical clock - a monotonically increasing software counter.
Cp: logical clock for process p; Cp(a): timestamp of event a at p; C(b): timestamp of event b
LC1: event issued at process p: Cp := Cp + 1
LC2: a) p sends message m to q with value t = Cp
b) Cq := max(Cq,t) and applies LC1 to rcv(m). If a b then C(a) < C(b), but not visa versa! Total order logical clock and vector clock.

© Chinese University, CSE Dept. Distributed Systems / 9 - 13
1.2 Logical Timestamps Example
Events occurring at three processes
1 2
3 4
51
3
6
=> 7

© Chinese University, CSE Dept. Distributed Systems / 9 - 14
2 Coordination
Distributed processes need to coordinate their activities.
Distributed mutual exclusion is required for safety, liveness, and ordering properties.
Election algorithms: methods for choosing a unique process for a particular role.

© Chinese University, CSE Dept. Distributed Systems / 9 - 15
2.1 Distributed Mutual Exclusion
The basic requirements for mutual exclusion:– ME1 (safety): At most one process may execute
in the critical section (CS) at a time.– ME2 (liveness): A process requesting entry to the
CS is eventually granted.– ME3 (ordering): Entry to the CS should be
granted in happened-before order. The central server algorithm. A ring-based algorithm. A distributed algorithm using logical clocks.

© Chinese University, CSE Dept. Distributed Systems / 9 - 16
2.2 Elections
An election is a procedure carried out to choose a process from a group.
A ring-based election algorithm. The bully algorithm.

© Chinese University, CSE Dept. Distributed Systems / 9 - 17
3 Replication
Replication is the maintenance of on-line copies of data and resources
For performance, availability, fault tolerance. Basic Architectural Model. Consistency and request ordering. The gossip architecture. The process group approach.

© Chinese University, CSE Dept. Distributed Systems / 9 - 18
3 Bulletin Board Example

© Chinese University, CSE Dept. Distributed Systems / 9 - 19
3 Replication Issues
Replica management models consider trade-off between accuracy and response time.
– Simple asynchronous model
– Totally synchronous model
– Quorum-based schemes
– Causality-ordered
Multicast updates to a process group. Read/write ratio.

© Chinese University, CSE Dept. Distributed Systems / 9 - 20
3.1 Basic Architectural Model

© Chinese University, CSE Dept. Distributed Systems / 9 - 21
3.1 The Gossip Architecture

© Chinese University, CSE Dept. Distributed Systems / 9 - 22
3.1 The Primary Copy Model

© Chinese University, CSE Dept. Distributed Systems / 9 - 23
3.2 Consistency and Request Ordering
Criteria: correctness vs. expenses. Total, causal, and sync ordering requirements. Implementing request ordering. Implementing total ordering. Implementing causal ordering with vector
timestamps.

© Chinese University, CSE Dept. Distributed Systems / 9 - 24
3.2.1 Total, Causal, and Sync Ordering
Let r1 and r2 be requests. Total ordering: Either r1 is processed before r2
or r2 is processed before r1, at all RMs. Causal ordering: If r1 happened-before r2 then
r1 is processed before r2 at all RMs. FIFO ordering: If r1 is issued before r2 then r1
is processed before r2 at all RMs. Sync-ordering: If r1 is sync-ordered, then
either r1 is processed before r2 at all RMs or r2 is processed before r1 at all RMs.

© Chinese University, CSE Dept. Distributed Systems / 9 - 25
3.2.1 Example 1

© Chinese University, CSE Dept. Distributed Systems / 9 - 26
3.2.1 Example 2

© Chinese University, CSE Dept. Distributed Systems / 9 - 27
3.2.2 Implementing Request Ordering
Hold-back: A received request is not processed by RM until ordering constraints can be met.
Stable message: all prior requests processed. Hold-back queue vs. delivery queue. Safety property: no message will be delivered
out of order by being prematurely transferred. Liveness property: no message should wait on
the hold-back queue forever.

© Chinese University, CSE Dept. Distributed Systems / 9 - 28
3.2.3 Implementing Total Ordering
Basic approach: assign totally ordered identifiers to requests.
Sequencer Distributed agreement in assigning request ids.
© Chinese University, CSE Dept. Distributed Systems / 9 - 29
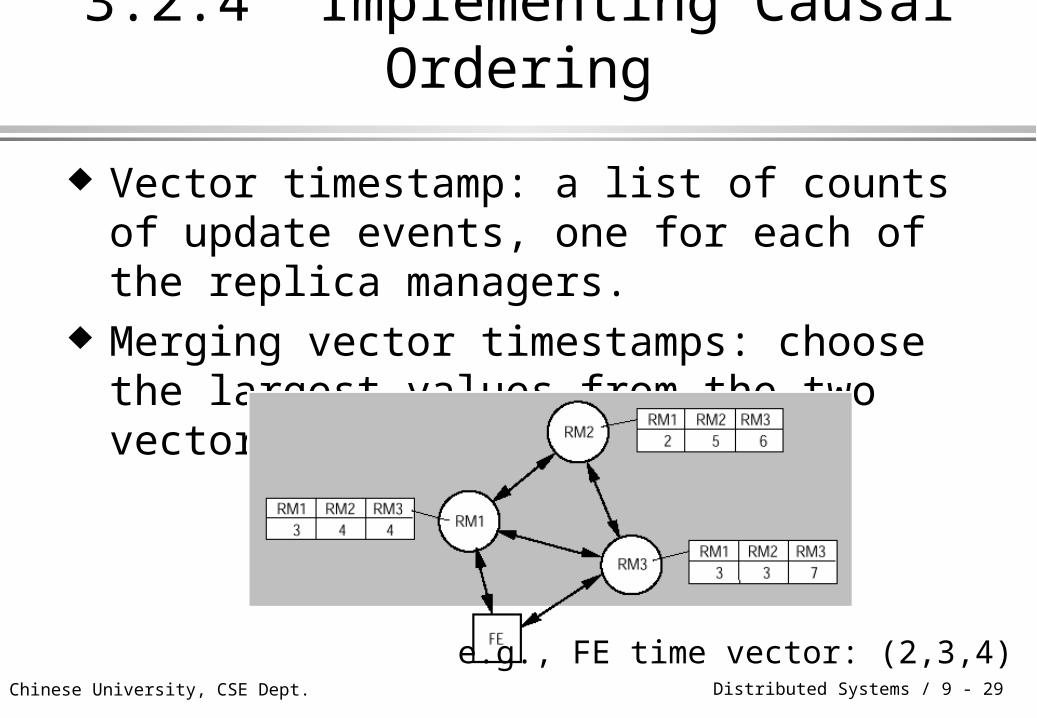
3.2.4 Implementing Causal Ordering
Vector timestamp: a list of counts of update events, one for each of the replica managers.
Merging vector timestamps: choose the largest values from the two vectors, component-wise.
e.g., FE time vector: (2,3,4)
© Chinese University, CSE Dept. Distributed Systems / 9 - 30
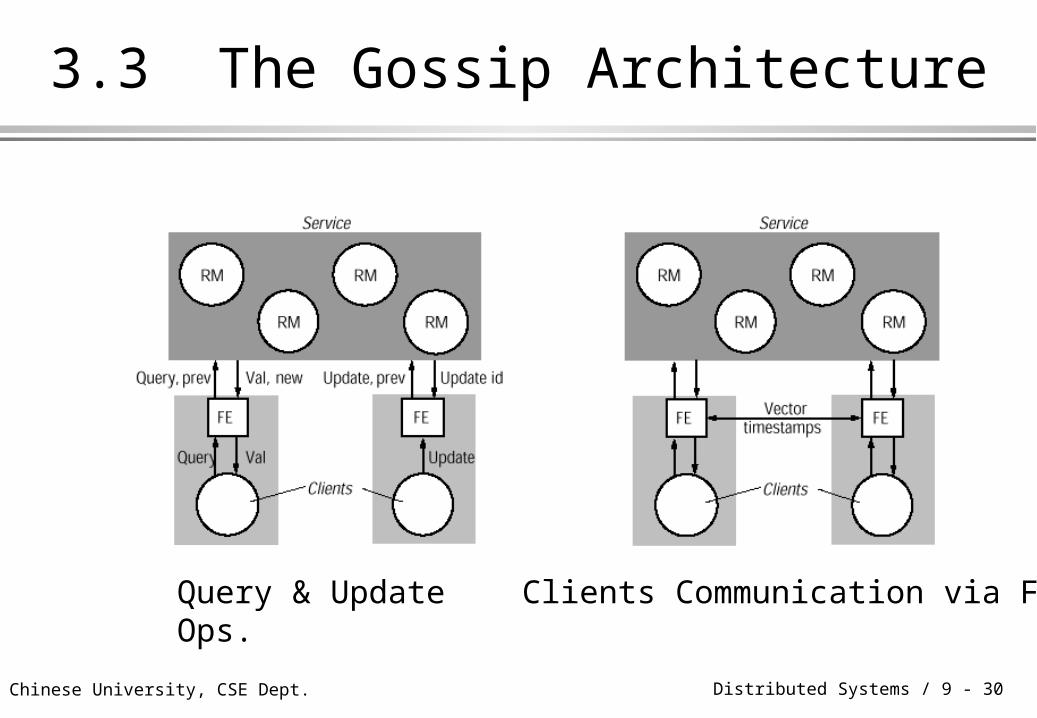
3.3 The Gossip Architecture
Query & Update Ops. Clients Communication via FE

© Chinese University, CSE Dept. Distributed Systems / 9 - 31
3.4 Process Group Approach
Process group and group communication. Group structure
– peer group
– server group
– client-server group
– subscription group
– hierarchical groups

© Chinese University, CSE Dept. Distributed Systems / 9 - 32
3.4 Process Group Services
Group membership management– Create
– Join
– Leave
Group address expansion Multicast communication
– unreliable multicast
– reliable multicast
– atomic multicast

© Chinese University, CSE Dept. Distributed Systems / 9 - 33
3.4 Multicast Communication
Sample multicasting operationvoid Multicast (in orderType order, in groupId group, in msg m, in int nReplies, out msgSeq replies) raises (…);
Order types:– unordered
– total ordering
– causal ordering
– sync-ordering

© Chinese University, CSE Dept. Distributed Systems / 9 - 34
4 Summary
Timing issues– Synchronizing physical clocks.
– Logical time and logical clocks.
Distributed coordination and mutual exclusions.
Replication to providing good performance, high
availability and fault tolerance.
The gossip approach and the process group
approach.
CORBA replication service is a research topic.