構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
TRANSCRIPT

構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
清水昌平
大阪大学 産業科学研究所
行動計量学会第40回大会 チュートリアル2012年9月13日, 新潟県立大学
チュートリアル後の訂正や引用文献リストは以下にアップ予定http://www.ar.sanken.osaka-u.ac.jp/~sshimizu/bsj2012.html

Abstract
• 統計的因果推論– 因果関係についてデータから推測する方法論
– 「何かを変化させて、何か他のものが変化したら」前者が原因で、後者が結果
• フレームワーク:– 因果の定義:反実仮想モデル
– 因果を数学的に記述: 構造方程式モデル
• 因果関係をデータから探索する方法を概観
2

イントロ

因果関係の解明
• ある変数を変化させると、他の変数はどう変化?
– この薬を飲ませると、あの病気が治る?
– セロトニンを増やすと、うつ症状が改善?
– 研究開発費を増やすと、利益は減る?
• 因果関係の連鎖(=因果構造)の解明
– 現象の仕組みの理解
– 病気の治療法
– 薬効・副作用の予測
– 経営方針・政策の評価
4

データから因果関係を推定
• 方法1: ランダム化のあるデータ(実験データ)による方法
– 患者をランダムにグループ分け+強制: 薬を飲む vs 飲まない
– データ: 飲んだかどうか + 治癒したかどうか
– 2つのグループの治癒割合を比較: 違いがあれば、薬のせい
– 倫理・コストの問題
• 方法2: ランダム化がないデータ(観察データ)による方法
– 薬を飲むかどうかは患者の選択に任せる
– データ:飲んだかどうか + 治癒したか
– 違いがあっても、薬のせいかは不明: 追加の仮定・情報が必要
実験の優先順位将来の観察のデザイン
観察データによる仮説の探索
5

観察データから因果に関する仮説を探索
• 観察データ+仮定因果構造
– どんな仮定の下で何が導けるか?
• 最近の発展: 連続変数
– 「線形+ガウス性」から「線形+非ガウス性」へ
– 従来より格段に多くの情報をデータから引き出せる
6
データ行列X
サンプル
変数
推定
x4
x21
x3x57
x83
x15
+仮定

Contents
• 第1部: 構造方程式モデルによる因果推論の基礎– 1.1 反実仮想モデルによる因果の定義
– 1.2 データ生成過程のモデルとしての構造方程式モデル
– 1.3 構造方程式モデルで因果を数学的に記述
• 第2部: 因果構造探索における最近の発展– 2.1 基本問題設定+従来法
– 2.2 最近の発展:非ガウス性の利用 (基礎編)
– 2.3 拡張編
7

第1部:構造方程式モデルによる
因果推論の基礎

1.1 反実仮想モデルによる因果の定義
David Hume (1766)
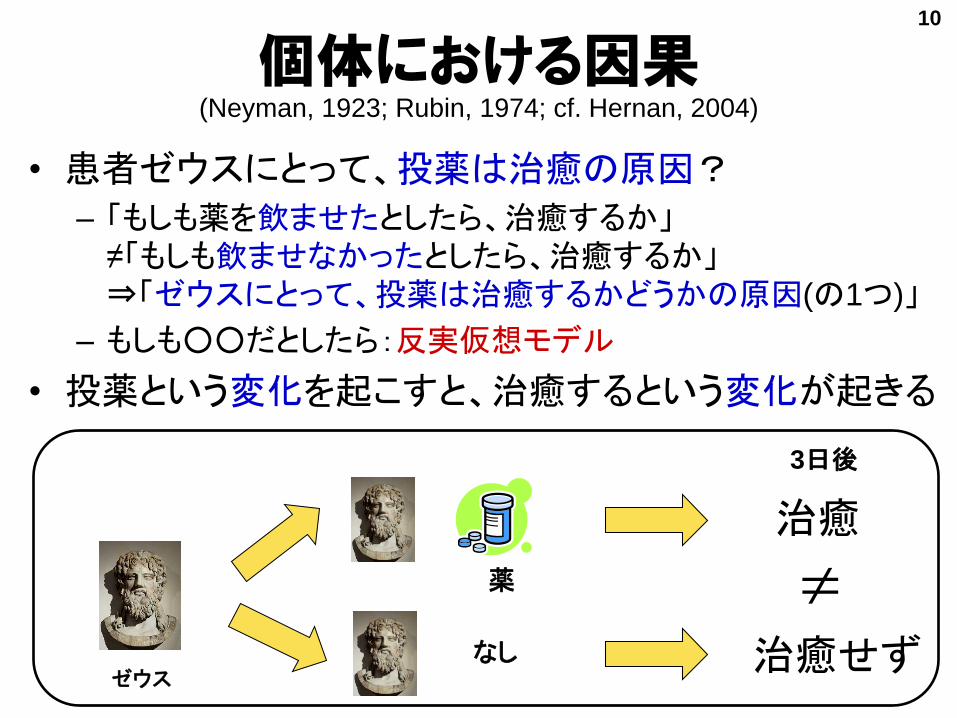
個体における因果(Neyman, 1923; Rubin, 1974; cf. Hernan, 2004)
• 患者ゼウスにとって、投薬は治癒の原因?
– 「もしも薬を飲ませたとしたら、治癒するか」≠「もしも飲ませなかったとしたら、治癒するか」⇒「ゼウスにとって、投薬は治癒するかどうかの原因(の1つ)」
– もしも○○だとしたら:反実仮想モデル
• 投薬という変化を起こすと、治癒するという変化が起きる
薬
治癒
治癒せずなし
3日後
ゼウス
10
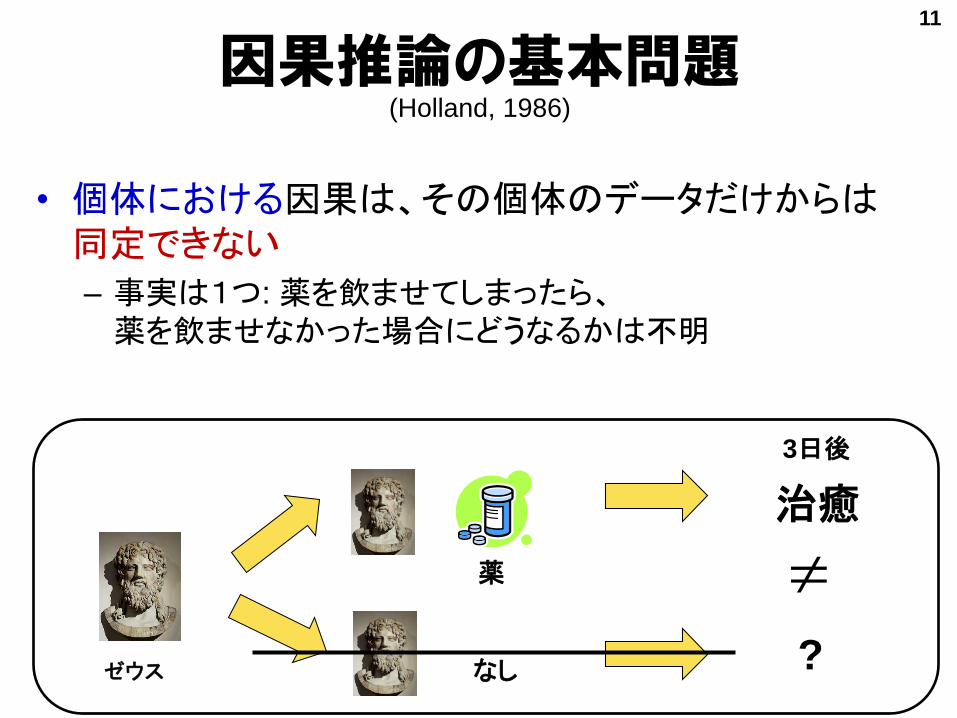
因果推論の基本問題(Holland, 1986)
• 個体における因果は、その個体のデータだけからは同定できない
– 事実は1つ: 薬を飲ませてしまったら、薬を飲ませなかった場合にどうなるかは不明
薬
治癒
?なし
3日後
ゼウス
11
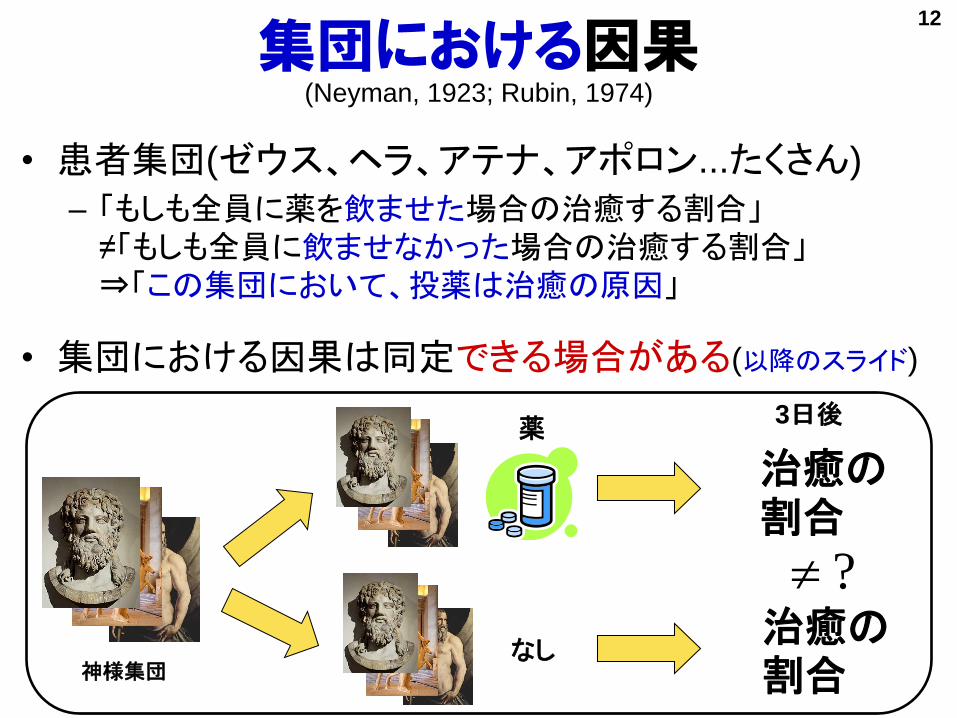
集団における因果(Neyman, 1923; Rubin, 1974)
• 患者集団(ゼウス、ヘラ、アテナ、アポロン...たくさん)
– 「もしも全員に薬を飲ませた場合の治癒する割合」≠「もしも全員に飲ませなかった場合の治癒する割合」⇒「この集団において、投薬は治癒の原因」
• 集団における因果は同定できる場合がある(以降のスライド)
3日後薬
治癒の割合
治癒の割合
なし
?
神様集団
12

1.2 データ生成過程のモデル:構造方程式モデル

構造方程式モデル (Bollen, 1989; Pearl, 2000)
• データ生成過程のモデル
– 変数の「値」が、どういう過程を経て生成されるか
• 構造方程式:変数の「値」の決定関係を表す
– 治癒 = f(薬,それ以外)
– 𝑦 = 𝑓𝑦 𝑥, 𝑒𝑦» 左辺を右辺で定義する: 単なる等式ではない
» 𝑒𝑦: yの値を決定するために必要な要因全て(x以外): 重症度や環境
),( yy
x
exfy
ex
x (薬)
y (治癒)
構造方程式 パス図
14
xe
ye
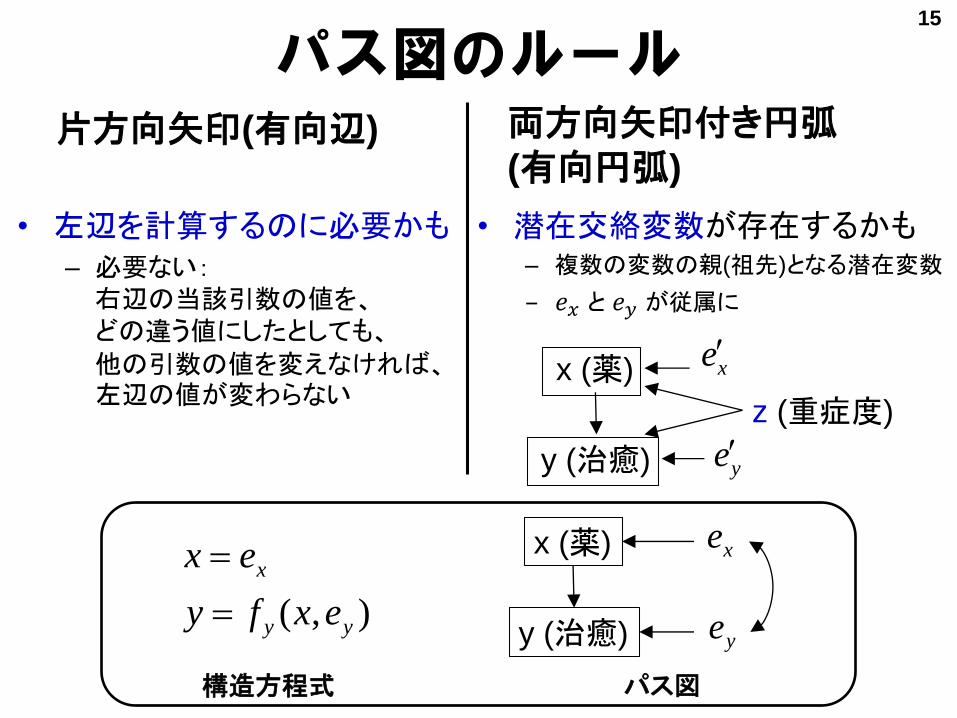
パス図のルール片方向矢印(有向辺)
• 左辺を計算するのに必要かも– 必要ない:右辺の当該引数の値を、どの違う値にしたとしても、他の引数の値を変えなければ、左辺の値が変わらない
両方向矢印付き円弧(有向円弧)
• 潜在交絡変数が存在するかも– 複数の変数の親(祖先)となる潜在変数
– 𝑒𝑥 と 𝑒𝑦 が従属に
),( yy
x
exfy
ex
x (薬)
y (治癒)
構造方程式 パス図
x (薬)
y (治癒)
z (重症度)
15
xe
ye
ye
xe
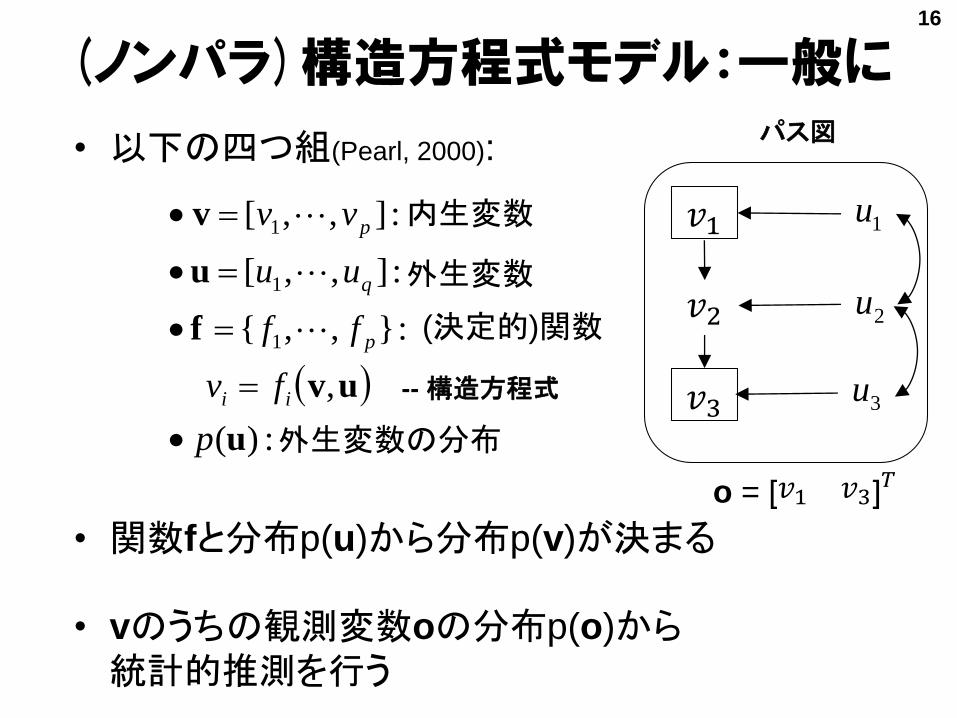
(ノンパラ)構造方程式モデル:一般に
• 以下の四つ組(Pearl, 2000):
• 関数fと分布p(u)から分布p(v)が決まる
• vのうちの観測変数oの分布p(o)から統計的推測を行う
:)(
,
:},,{
:],,[
:],,[
1
1
1
u
uv
f
u
v
p
fv
ff
uu
vv
ii
p
q
p
-- 構造方程式
内生変数
外生変数
(決定的)関数
外生変数の分布
16
𝑣1
𝑣2
パス図
2u
1u
o = [𝑣1 𝑣3]𝑇
𝑣3 3u

1.3 構造方程式モデルを用いて集団における因果を記述

介入 (Pearl, 2000)
• 介入: 変数の値を(他の変数に依らず=強制で)固定する– 薬を飲ませる:do(薬=飲む) or do(x=1)
– xの構造方程式を「x=1」に取り換える
• 介入前のデータ生成過程 (観察データ)
• 介入後のデータ生成過程𝑀𝑥=1
),( yy
x
exfy
ex
x (薬)
y (治癒)
𝑒𝑥
𝑒𝑦構造方程式 パス図(因果グラフ)
),(
1
yy exfy
x
x (薬)
y (治癒)
1
𝑒𝑦
自律性の仮定:他の関数は変わらない
(強制的に投薬した場合の仮想集団)
18

介入後の分布 (Pearl, 2000)
• 介入後のyの分布 := 介入後のモデル 𝑀𝑥=1での分布
• もし介入後のyの分布が違うxの値cとdがあれば、「この集団において、xはyの原因」と言う
ypxdoypxM 1
:1|
dxdoypcxdoyp ||
),(
1
yy exfy
x
x (薬)
y (治癒)
1
𝑒𝑦
構造方程式 因果グラフ(パス図)
19
介入後のモデル𝑀𝑥=1
𝑀𝑥=1

例
• 投薬は治癒の原因:
• 投薬の効果がある:
飲まない薬治癒
飲む薬治癒
dop
dop
|
|
飲まない薬治癒
飲む薬治癒
dop
dop
|
|
20

定量化: 因果効果(Rubin, 1974; Pearl, 2000)
• 変数xの値をcからdに変化させた時に、変数yの値が平均的にどのくらい変化するか
• 変化させる:do(x=c)をした後、cをdに変える
• 分散で測る:
cxdoyEdxdoyE ||:)( 因果効果平均
21
cxdoyVardxdoyVar ||

例1• xを定数 c から d へ変化させたときの yへの因果効果
= E( y | 母集団全員のxをdにする )
- E( y | ・・・ xをcにする )
=
=
=
yyxyyx ecbEedbE
cdbyx
cxdoyEdxdoyE ||
yyx
x
exby
ex
モデル1:
x
y
ex
ey yyx exby
dx
モデル1’:
x
y
d
ey
22
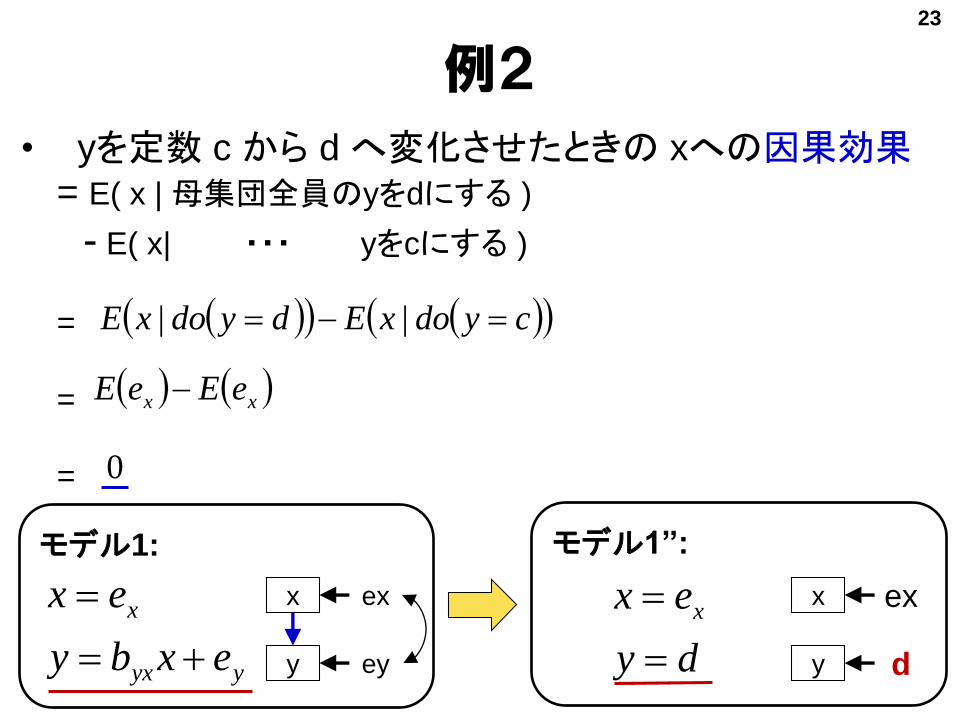
例2
• yを定数 c から d へ変化させたときの xへの因果効果= E( x | 母集団全員のyをdにする )
- E( x| ・・・ yをcにする )
=
=
=
xx eEeE
0
cydoxEdydoxE ||
yyx
x
exby
ex
モデル1:
x
y
ex
ey dy
ex x
モデル1’’:
x
y
ex
d
23
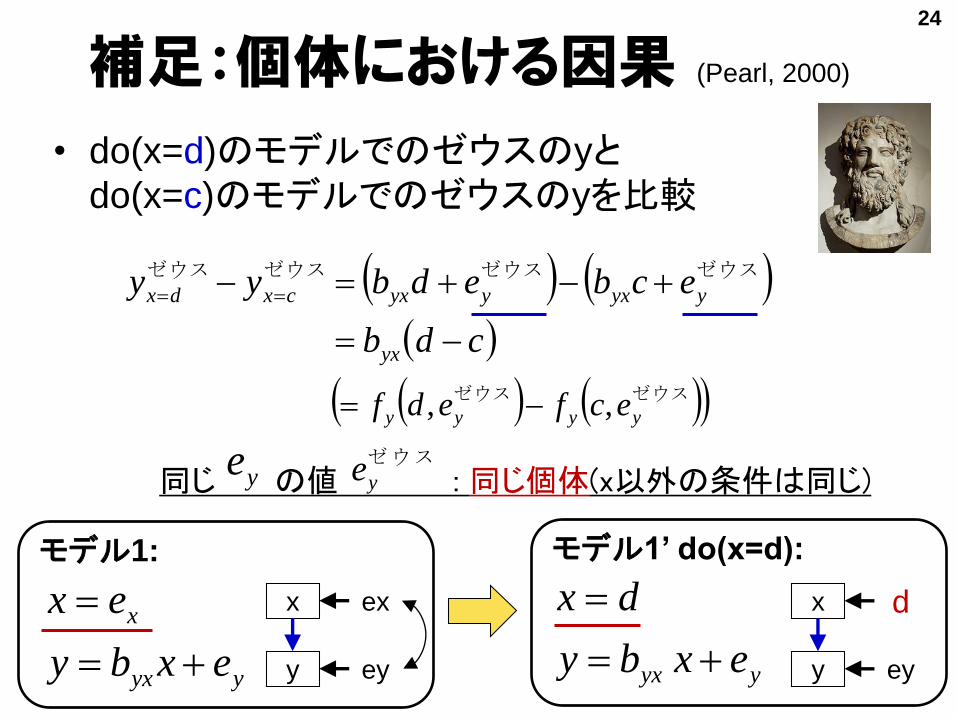
同じ の値 : 同じ個体(x以外の条件は同じ)
補足:個体における因果 (Pearl, 2000)
• do(x=d)のモデルでのゼウスのyとdo(x=c)のモデルでのゼウスのyを比較
cdb
ecbedbyy
yx
yyxyyxcxdx
ゼウスゼウスゼウスゼウス
yyx
x
exby
ex
モデル1:
x
y
ex
ey yyx exby
dx
モデル1’ do(x=d):
x
y
d
ey
ye ゼウスye
24
ゼウスゼウスyyyy ecfedf ,,

総合効果・直接効果・間接効果
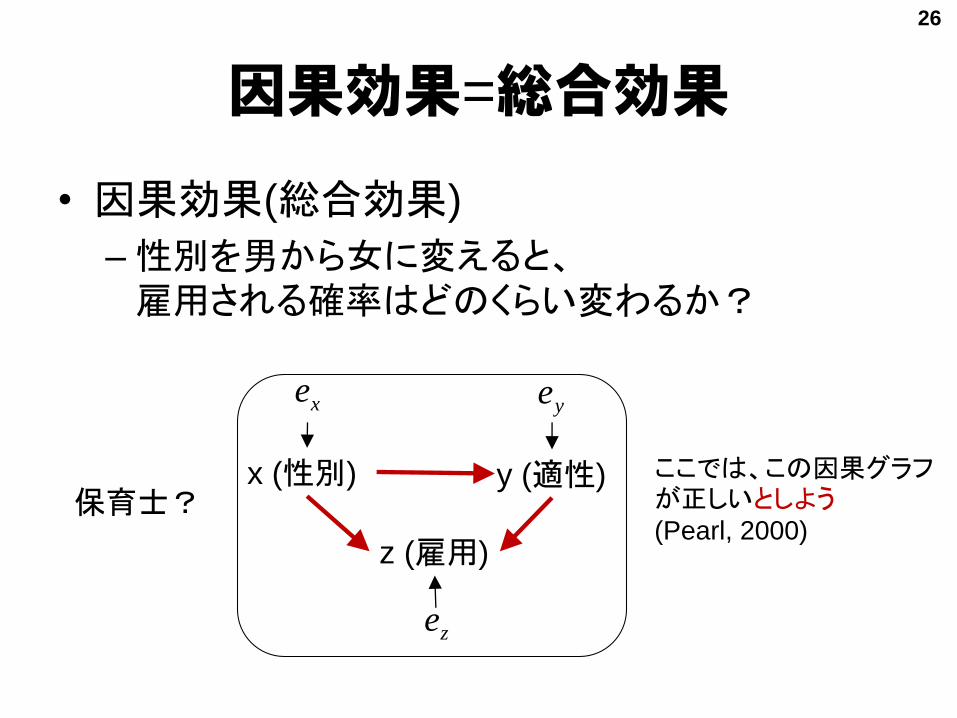
因果効果=総合効果
• 因果効果(総合効果)
–性別を男から女に変えると、雇用される確率はどのくらい変わるか?
ここでは、この因果グラフが正しいとしよう(Pearl, 2000)
x (性別) y (適性)
z (雇用)
26
xeye
ze
保育士?
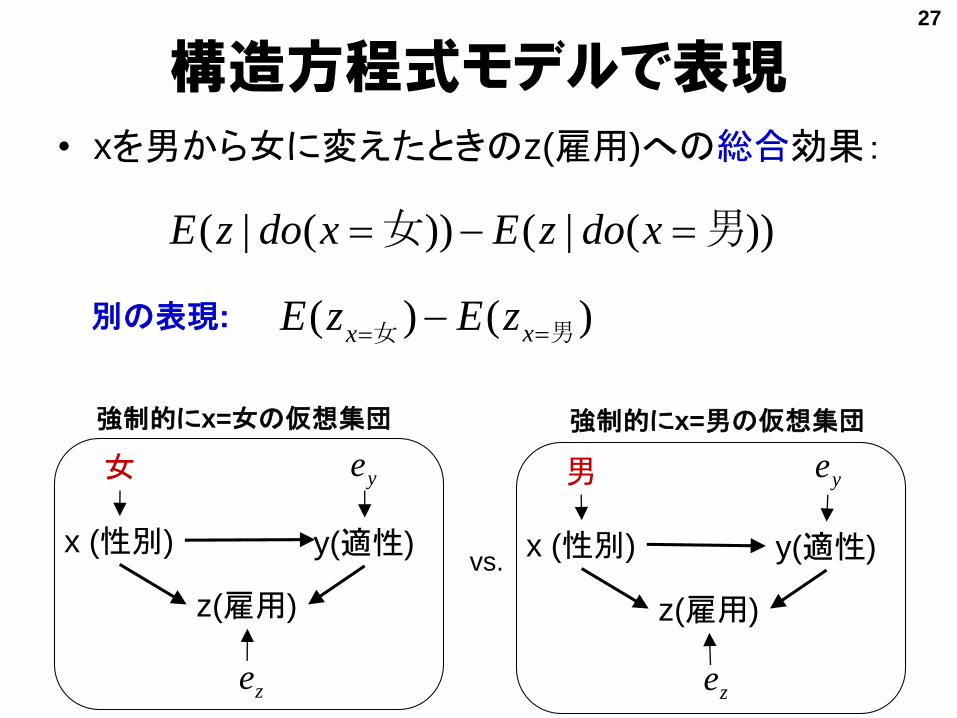
構造方程式モデルで表現• xを男から女に変えたときのz(雇用)への総合効果:
))(|())(|( 男女 xdozExdozE
x (性別) y(適性)
z(雇用)
女
強制的にx=女の仮想集団
x (性別) y(適性)
z(雇用)
男
強制的にx=男の仮想集団
)()( 男女
xxzEzE別の表現:
27
ye
zeze
ye
vs.

直接効果
• 直接効果: 性別は男から女に変えるが、適性は変えないとき、雇用される確率はどのくらい変わるか?
– これが大きいと、性差別がある
x (性別) y (適性)
z (雇用)
28
ye
ze
ye

構造方程式モデルで表現(Robins & Greenland, 1992; Pearl, 2001)
• xを男から女に変えたときのz(雇用)への直接効果:
)()( , 男女 男 xyyx zEzE
x
x (性別) y(適性)
z(雇用)
女
強制的にx=女, の仮想集団
x (性別) y(適性)
z(雇用)
男
強制的にx=男の仮想集団男
xyy
𝐲𝐱=男
29
zeze
ye
vs.
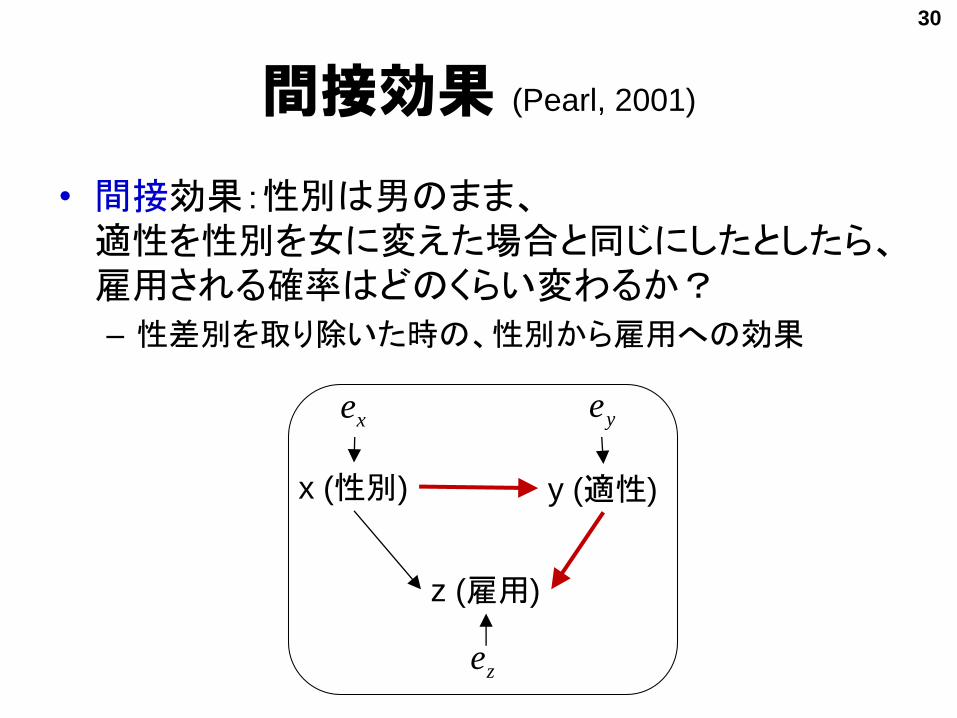
間接効果 (Pearl, 2001)
• 間接効果:性別は男のまま、適性を性別を女に変えた場合と同じにしたとしたら、雇用される確率はどのくらい変わるか?
– 性差別を取り除いた時の、性別から雇用への効果
x (性別) y (適性)
z (雇用)
30
ye
ze
xe
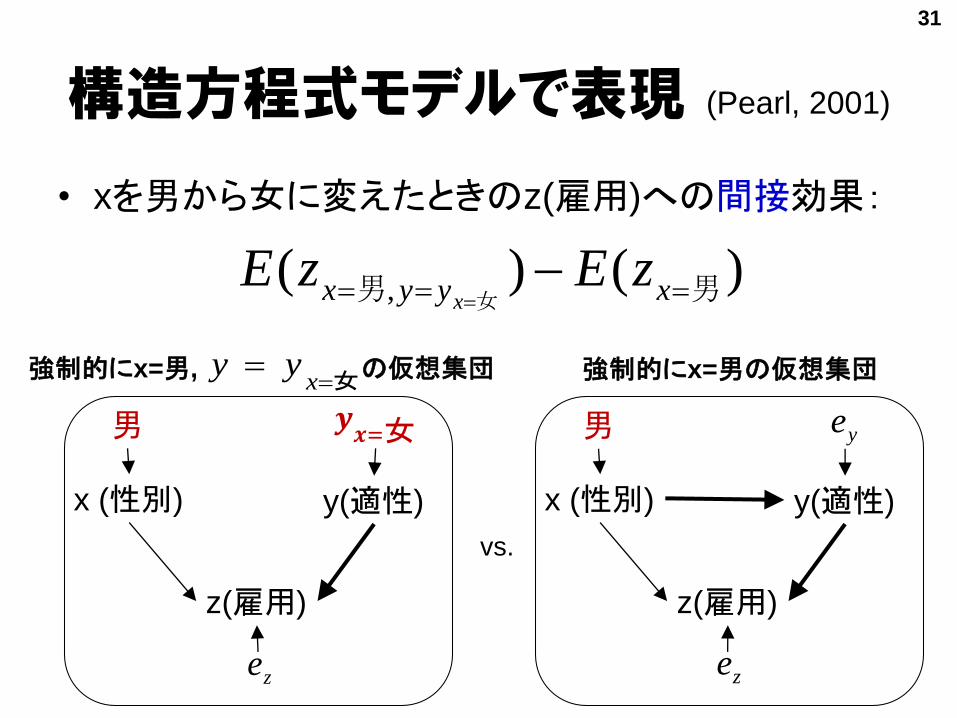
構造方程式モデルで表現 (Pearl, 2001)
• xを男から女に変えたときのz(雇用)への間接効果:
)()(, 男男 女
xyyx
zEzEx
x (性別) y(適性)
z(雇用)
男
x (性別) y(適性)
z(雇用)
男
強制的にx=男の仮想集団
𝒚𝒙=女
強制的にx=男, の仮想集団女
x
yy
31
ze ze
ye
vs.
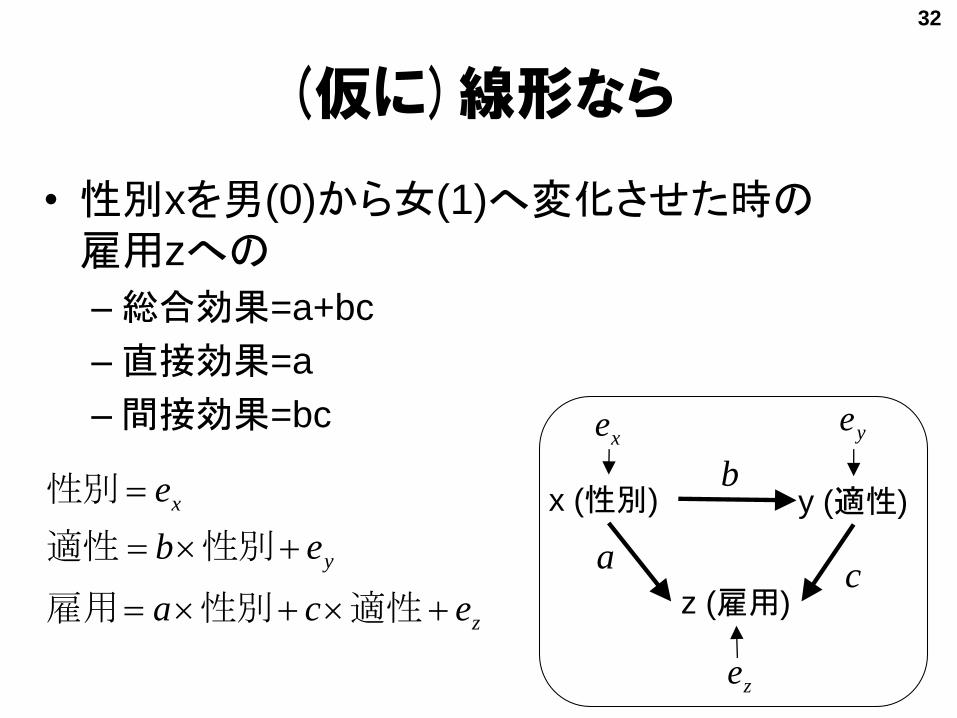
• 性別xを男(0)から女(1)へ変化させた時の雇用zへの
–総合効果=a+bc
–直接効果=a
–間接効果=bc
(仮に)線形なら
x (性別) y (適性)
z (雇用)z
y
x
eca
eb
e
適性性別雇用
性別適性
性別
a
b
c
32
xe ye
ze

因果効果の識別性(推定可能性)

因果構造(因果グラフ・パス図)が既知の場合
34

因果効果の識別性:doのない形にかけるか?
• 非巡回で交絡変数がない場合(Pearl, 1995):
• 証明:
yy exfy
dx
,
モデル1’ do(x=d):
x
y
d
dxyEdxdoyE |)(|
yy edfE
dxdoyE
,
|
等しい
yy
x
exfy
ex
,
モデル1:
x
y
35
ye ye
xe
yy
yy
yy
edfE
dxedfE
dxexfEdxyE
,
|,
|,|
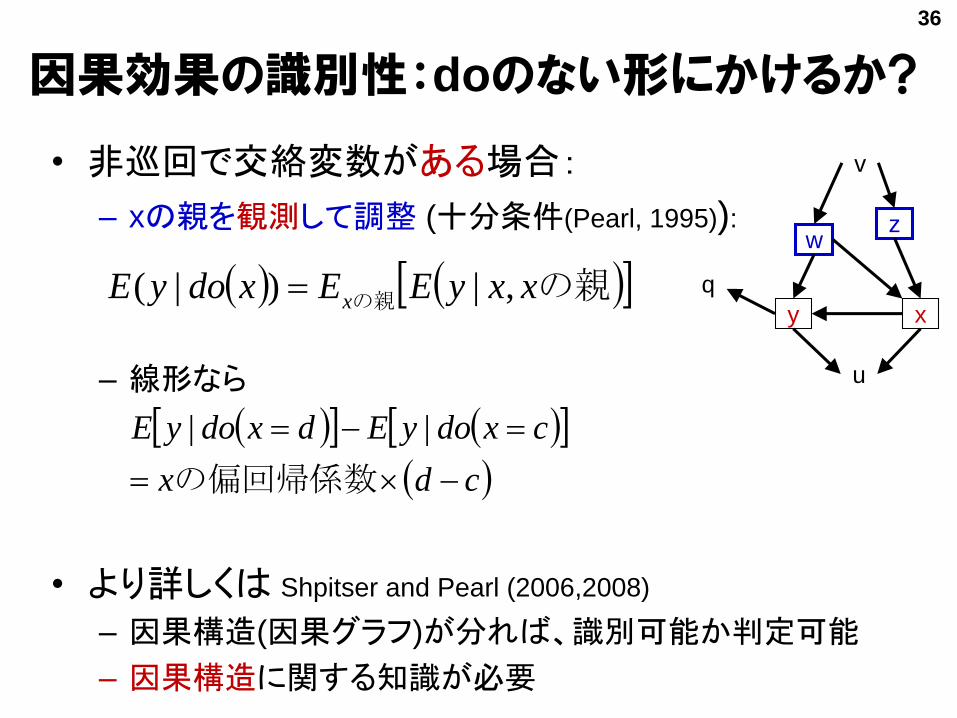
因果効果の識別性:doのない形にかけるか?
• 非巡回で交絡変数がある場合:
– xの親を観測して調整 (十分条件(Pearl, 1995)):
– 線形なら
• より詳しくは Shpitser and Pearl (2006,2008)
– 因果構造(因果グラフ)が分れば、識別可能か判定可能
– 因果構造に関する知識が必要
の親の親 xxyEExdoyEx
,|)|( y x
zw
u
v
q
cdx
cxdoyEdxdoyE
の偏回帰係数
||
36
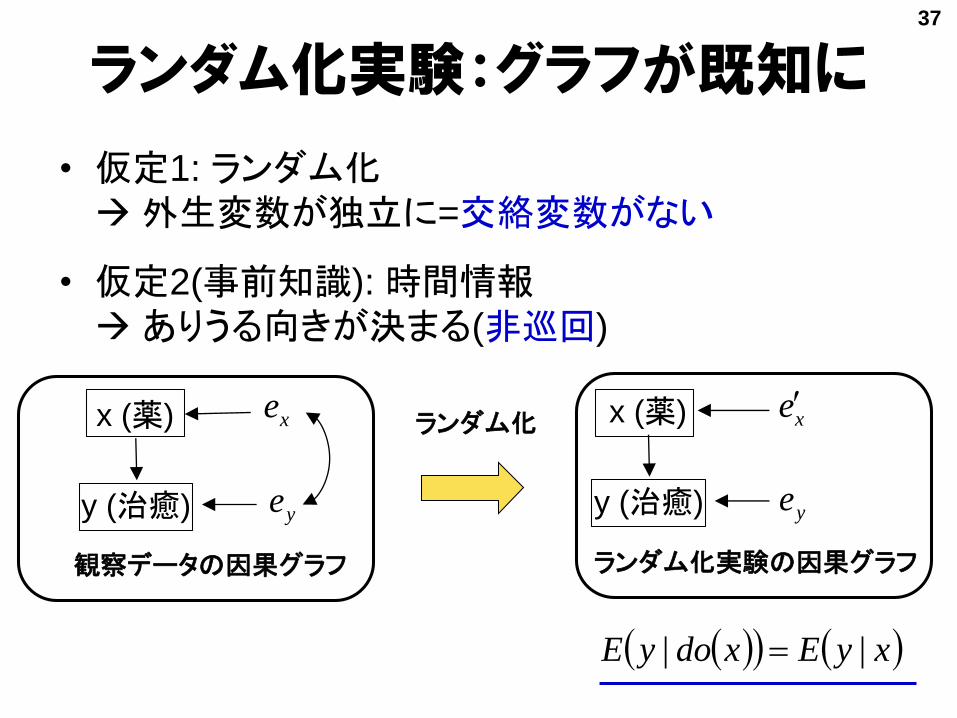
ランダム化実験:グラフが既知に
• 仮定1: ランダム化外生変数が独立に=交絡変数がない
• 仮定2(事前知識): 時間情報ありうる向きが決まる(非巡回)
x (薬)
y (治癒)
観察データの因果グラフ
x (薬)
y (治癒)
ランダム化実験の因果グラフ
ランダム化
xyExdoyE ||
37
ye
xe
ye
xe

因果効果の推定には因果構造に関する情報が必要
• いつもランダム化できるとは限らない
– 倫理
– コスト
• ランダム化のないデータ=観察データに基づいて因果構造を推定する必要
• 因果構造自体も興味の対象
38

補足: 予測との目的の違い
• 予測: 何かを観測したとき、他の何かはどのくらいか?– 薬を飲んだ時、治癒する確率は?
– 推定したい量:
条件付き期待値: E( 治癒 | 薬=飲む)
• 因果: 何かを変化させると、他の何かがどう変化するか– 薬を飲ませると、治癒する確率はどう変わる?
– 推定したい量:因果効果: E[ 治癒 | do( 薬 = 飲む ) ]
– E[ 治癒 | do( 薬 = 飲まない ) ]
• 多くの場合: E[ 治癒 | do( 薬 = 飲む ) ] E( 治癒 | 薬=飲む)
39

第2部:因果構造探索における最近の発展
- 観察データに基づいて -
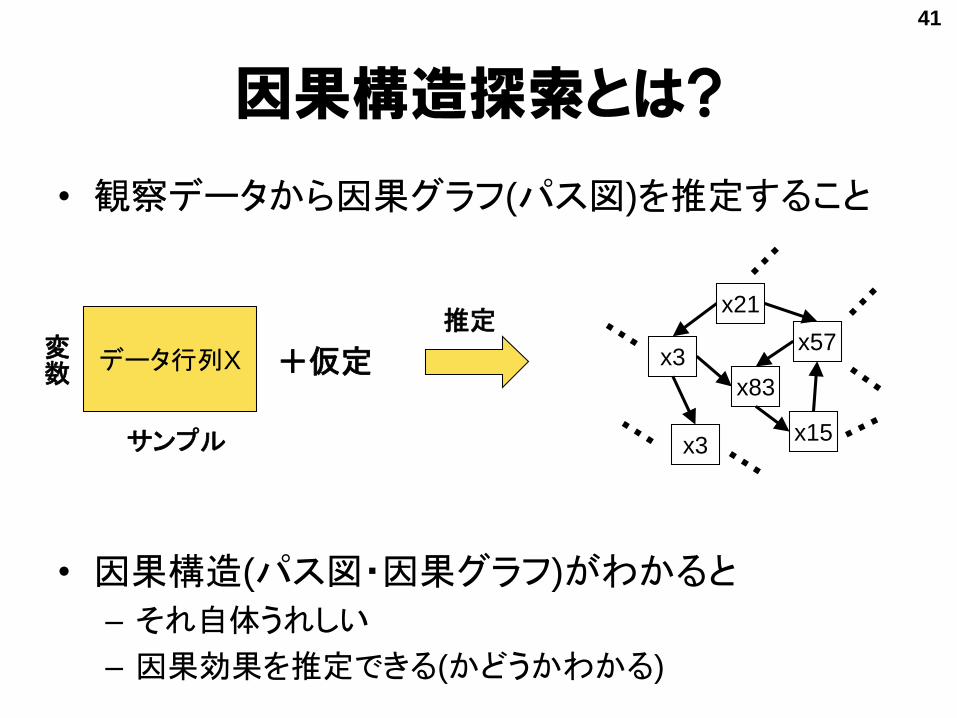
因果構造探索とは?
• 観察データから因果グラフ(パス図)を推定すること
• 因果構造(パス図・因果グラフ)がわかると
– それ自体うれしい
– 因果効果を推定できる(かどうかわかる)
データ行列X
サンプル
変数
推定
x3
x21
x3x57
x83
x15
+仮定
41

因果構造探索のフレームワーク
• 観察データ+仮定 因果構造(因果グラフ)
• 仮定: 因果の定義・データ生成過程に関する制約
• 条件付きの主張:
– もし「これこれ」の仮定を受け入れるなら、このデータと組み合わせて、「これこれ」の因果構造が示唆される
• 検証可能な仮定を検証: 検定・実験による確認
42
事前知識分析者の判断

期待される応用分野

生命科学(Sachs et al. Science, 2005; Smith NeuroImage, 2012;
Maathuis et al. Nature Methods, 2010; Peer et al. Cell, 2011)
• 脳領域ネットワーク– 変数:脳領域
– 脳画像データ(MEG, fMRI)
• 遺伝子/タンパク質ネットワーク– 変数: 遺伝子/タンパク質
– マイクロアレイ/フローサイトメトリー
• システムの理解・治療法の開発– 実験は難しい and/or 高コスト
– 観察データ分析に基づいて実験の優先順位
• 因果効果の有無の予測, 患者とnon-患者の違い
44
脳ネットワーク(Ramsey et al., 2009)
タンパク質ネットワーク(Sachs et al., 2005)

• 実験は難しい
• 経済学– Ferkingsta et al. Energy Economics. 2011
– Moneta et al. Oxford Bulletin of Economics and Statistics, 2012
• 行動遺伝学– Ozaki et al. Behavior Genetics, 2009, 2010
• 心理学– Takahashi et al., Japanese Psychological Research, 2012
– von Eye et al., Int. Journal of Behavioral Development, 2012
• 環境学– D. Niyogi et al. Water Resources Research , 2012
利益(t)
社会科学45
雇用(t)
売上(t)
R&D(t)
雇用(t+1)
売上(t+1)
R&D(t+1)
利益(t+1)
雇用(t+2)
売上(t+2)
R&D(t+2)
利益(t+2)
(Moneta et al., 2012)

最近の発展の概要
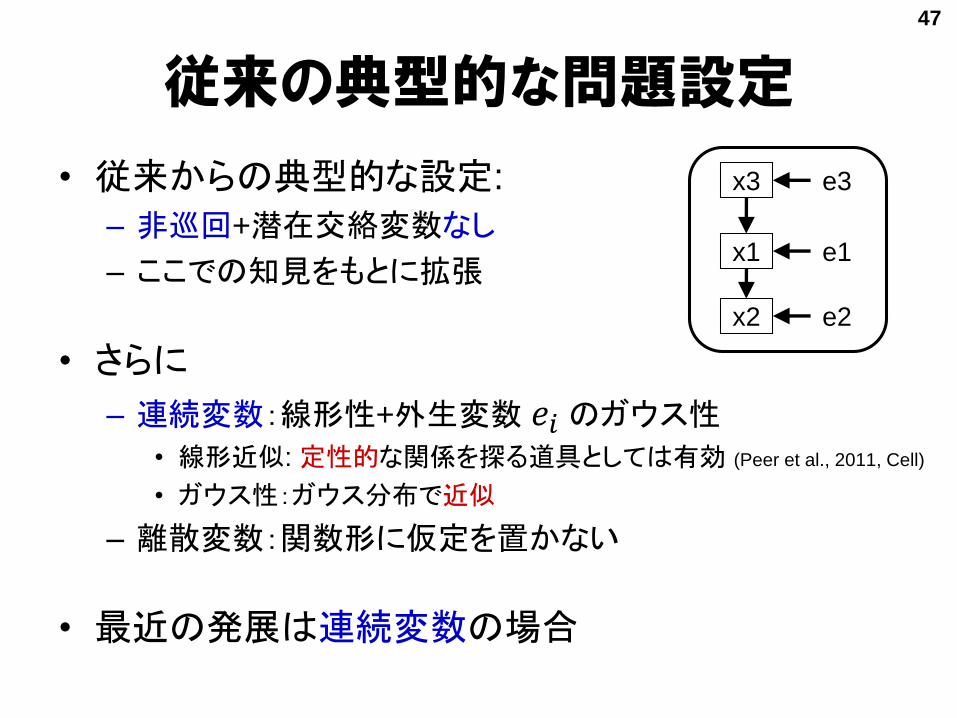
従来の典型的な問題設定
• 従来からの典型的な設定:
– 非巡回+潜在交絡変数なし
– ここでの知見をもとに拡張
• さらに
– 連続変数:線形性+外生変数 𝑒𝑖 のガウス性• 線形近似: 定性的な関係を探る道具としては有効 (Peer et al., 2011, Cell)
• ガウス性:ガウス分布で近似
– 離散変数:関数形に仮定を置かない
• 最近の発展は連続変数の場合
47
x3
x1
e3
e1
x2 e2

最近の発展の概要 (1/2)
• データ行列 X が次のどちらかのデータ生成過程からランダムに生成されたとしよう :
ここで 𝑒1 と 𝑒2 は独立な潜在変数 (外生変数: かく乱項、誤差)
• データ行列Xのみを用いて、データXを生成したのがモデル1 なのかモデル2 なのかを同定したい
or
21212
11
exbx
ex
22
12121
ex
exbx
モデル 1: モデル 2:
x1
x2
e1
e2
x1
x2
e1
e2
0, 1221 bb
48

最近の発展の概要 (2/2)
• 「同定はできない」と長らく思われていた
• 実は、「ほとんどの場合に同定可能」ということが最近分かってきた (Shimizu et al., 2005; 2006)
– 𝑒1 と 𝑒2がガウス分布に従うとダメ
• 非線形+加法誤差でもポジティブな結果(Hoyer et al., 2009; Zhang & Hyvarinen, 2009; Peters et al., 2011)
or
2122
11
exfx
ex
22
121
ex
exfx
モデル 3: モデル 4:
x1
x2
e1
e2
x1
x2
e1
e2
49

2.1 基本問題の定式化
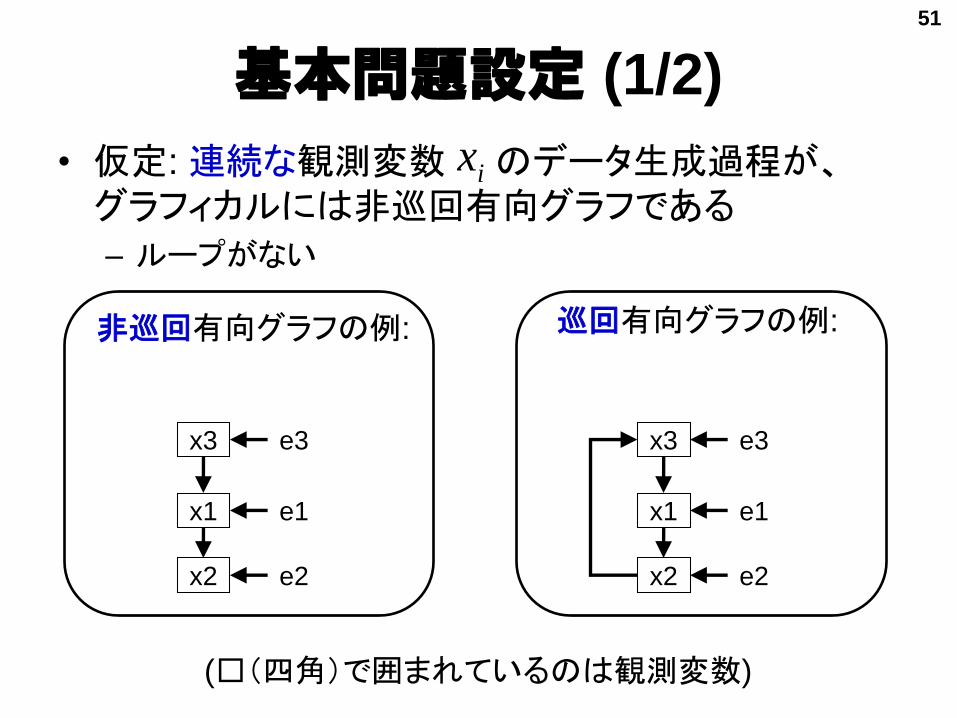
基本問題設定 (1/2)
• 仮定: 連続な観測変数 のデータ生成過程が、グラフィカルには非巡回有向グラフである
– ループがない
x3
x1
e3
e1
x2 e2
x3
x1
e3
e1
x2 e2
非巡回有向グラフの例: 巡回有向グラフの例:
ix
(□(四角)で囲まれているのは観測変数)
51

基本問題設定 (2/2)
• さらに、 の線形関係を仮定すると、次の線形・非巡回・潜在交絡変数なしモデルを得る:
– 𝑘 𝑖 : 𝑥𝑖 の生成順序
– 𝑏𝑖𝑗: パス係数
– 𝑒𝑖 は、モデル内で規定されない連続な潜在変数:ここでは、外生変数と呼ぶ (かく乱変数、誤差変数).
– 𝑒𝑖 は、非ゼロの分散を持ち、互いに独立
eBxx i
ikjk
jiji exbx )()(
or
ix
52
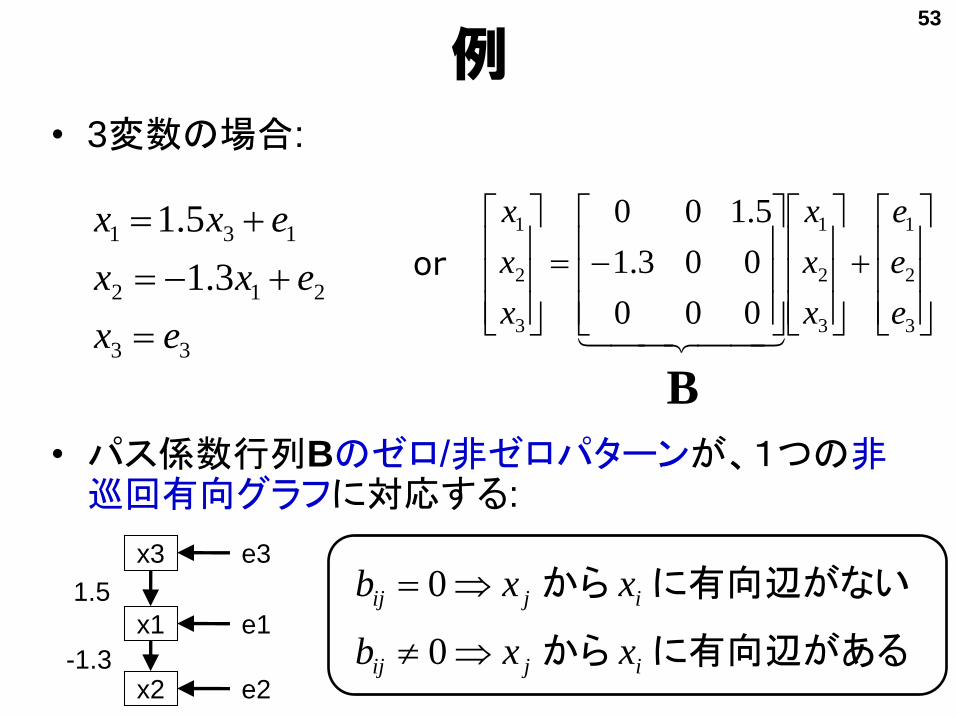
• 3変数の場合:
• パス係数行列Bのゼロ/非ゼロパターンが、1つの非巡回有向グラフに対応する:
例
3
2
1
3
2
1
3
2
1
000
003.1
5.100
e
e
e
x
x
x
x
x
x
x3
x1
e3
e1
x2 e2
1.5
-1.3
B33
212
131
3.1
5.1
ex
exx
exx
or
に有向辺がないから ijij xxb 0
に有向辺があるから ijij xxb 0
53

2
1
3
2
1
3
2
1
3
03.10
005.1
000
e
e
e
x
x
x
x
x
x
非巡回性の仮定
• 非巡回の場合は、パス係数行列Bを下三角にするような変数 の生成順序𝑘 𝑖 が必ず存在する (Bollen, 1989).
0
0
x3
x1
e3
e1
x2
1.5
-1.3
0 0
0
0
置換後B
e2
ix
3
2
1
3
2
1
3
2
1
000
003.1
5.100
e
e
e
x
x
x
x
x
x
B
00
).(
,,
.3)2(,2)1(,1)3(
213
半順序逆はない
の祖先でもよいがは、 xxx
kkk
そういう生成順序𝑘 𝑖 は:
54
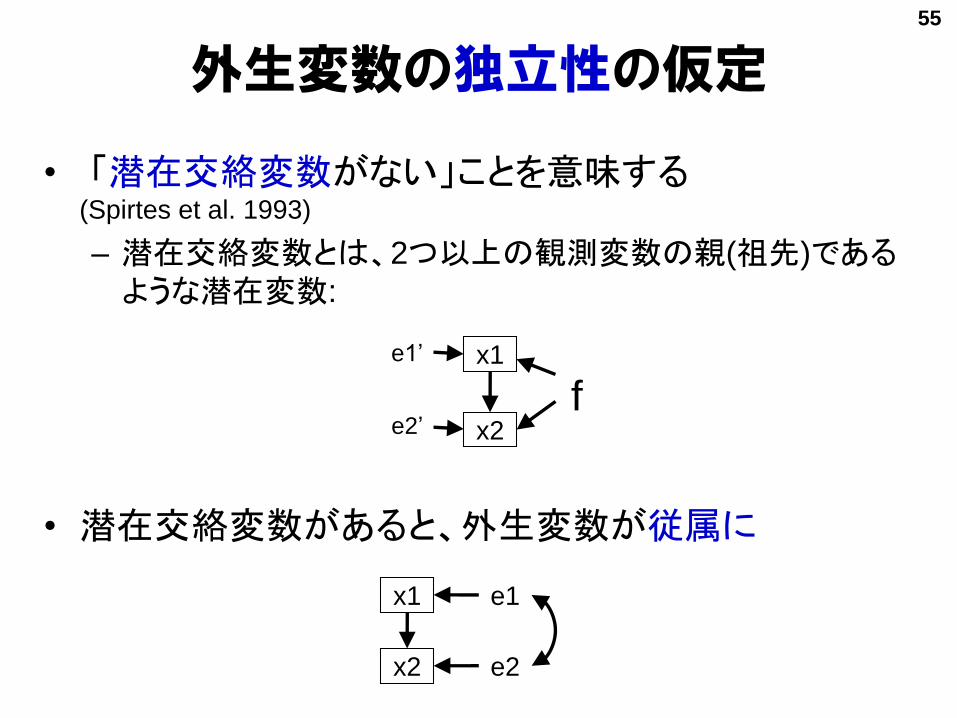
外生変数の独立性の仮定
• 「潜在交絡変数がない」ことを意味する(Spirtes et al. 1993)
– 潜在交絡変数とは、2つ以上の観測変数の親(祖先)であるような潜在変数:
• 潜在交絡変数があると、外生変数が従属に
x1
x2f
e1’
e2’
x1
x2
e1
e2
55

• 仮定:データ行列 X は、このモデルからランダムに生成される:
• Goal: データ行列Xの情報のみを使って、パス係数行列 B を推定する!
– Bのゼロ/非ゼロパターンが、1つの有向非巡回グラフに対応する
基本問題設定 (3/3):
「線形+非巡回+潜在交絡なし」モデルの推定
eBxx x1
x2
e1
e2
21b
56
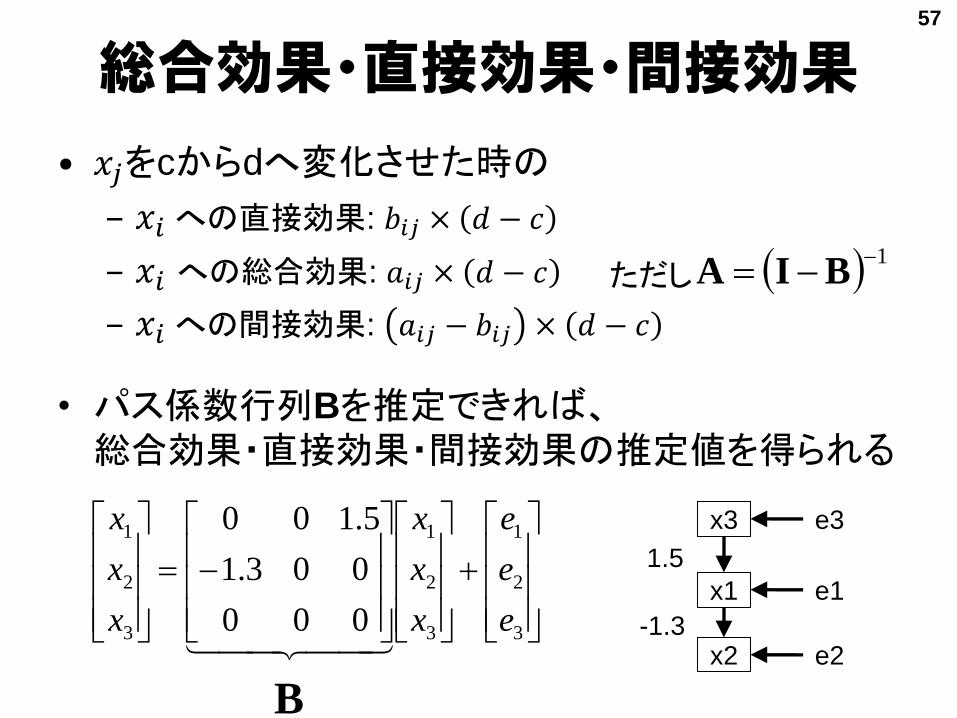
総合効果・直接効果・間接効果
• 𝑥𝑗をcからdへ変化させた時の
– 𝑥𝑖 への直接効果: 𝑏𝑖𝑗 × 𝑑 − 𝑐
– 𝑥𝑖 への総合効果: 𝑎𝑖𝑗 × 𝑑 − 𝑐
– 𝑥𝑖 への間接効果: 𝑎𝑖𝑗 − 𝑏𝑖𝑗 × 𝑑 − 𝑐
• パス係数行列Bを推定できれば、総合効果・直接効果・間接効果の推定値を得られる
57
3
2
1
3
2
1
3
2
1
000
003.1
5.100
e
e
e
x
x
x
x
x
x
x3
x1
e3
e1
x2 e2
1.5
-1.3
B
1 BIAただし

従来法の問題点: 識別性がない

パス係数行列 B の識別性
• 「Bが識別可能」 「p(x)からBが一意に決定される」
– Bのゼロ/非ゼロパターン=因果構造(因果グラフ・パス図)
• 「線形・非巡回・潜在交絡なし」の構造方程式モデル:
– Bとp(e)から観測変数の分布p(x)が決まる
– 異なるB に対してp(x) (or p(x)の特性)が異なれば,
Bは一意に決まる
eBxx x1
x2
e1
e2
21b
59
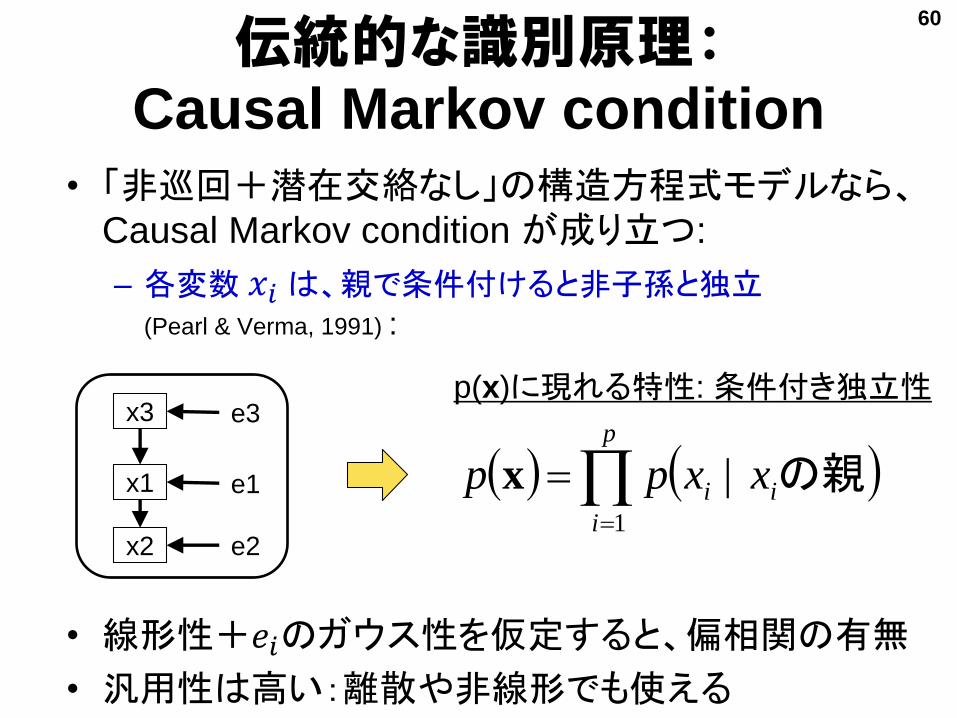
伝統的な識別原理:Causal Markov condition
• 「非巡回+潜在交絡なし」の構造方程式モデルなら、Causal Markov condition が成り立つ:
– 各変数 𝑥𝑖 は、親で条件付けると非子孫と独立(Pearl & Verma, 1991) :
• 線形性+𝑒𝑖のガウス性を仮定すると、偏相関の有無
• 汎用性は高い:離散や非線形でも使える
p
i
ii xxpp1
| の親x
x3
x1
e3
e1
x2 e2
60
p(x)に現れる特性: 条件付き独立性
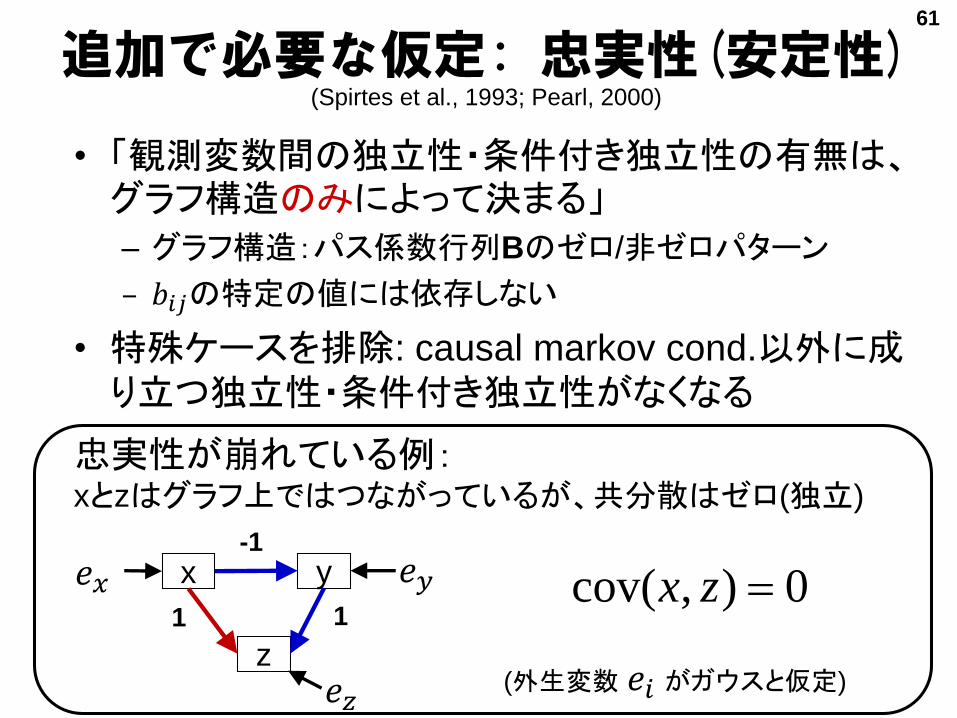
追加で必要な仮定: 忠実性(安定性)(Spirtes et al., 1993; Pearl, 2000)
• 「観測変数間の独立性・条件付き独立性の有無は、グラフ構造のみによって決まる」
– グラフ構造:パス係数行列Bのゼロ/非ゼロパターン
– 𝑏𝑖𝑗の特定の値には依存しない
• 特殊ケースを排除: causal markov cond.以外に成り立つ独立性・条件付き独立性がなくなる
61
忠実性が崩れている例:xとzはグラフ上ではつながっているが、共分散はゼロ(独立)
x y𝑒𝑥 𝑒𝑦
z
1
-1
1
𝑒𝑧
0),cov( zx
(外生変数 𝑒𝑖 がガウスと仮定)

例: Causal Markov Cond.では識別できない追加:62
x3
x1
x2
データXで成り立つ条件付き独立性:
𝒙𝟐と𝒙𝟑が独立 | 𝒙𝟏データXが生成される
x3
x1
x2
x3
x1
x2
x3
x1
x2
x3
x1
x2
真
データで成り立つのと同じ条件付き独立性を与えるモデルを列挙
まとめる
復元できない:識別性なし
この3つが全部そう
ここまでが限界

Causal Markov condition
に基づく推定法
• 条件付き独立性+忠実性に基づく方法(Spirtes & Glymour, 1991)
– 多くのモデルが、観測変数 𝑥𝑖 間に同じ条件付き独立性を与え、等しくデータにフィットしてしまう
• 外生変数 𝑒𝑖がガウスであろうとなかろうと
• さらにガウス性を仮定して情報量基準を用いて比較する方法 (Chickering, 2002)
– 多くのモデルが同じ観測変数の分布を与え、等しくデータにフィットしてしまう。
• 多くの場合、パス係数行列Bは一意に決まらない
63

• 有向辺の向きが反対の2つのモデル:
• どちらのモデルでも、(条件付き)独立になる変数はない:
• 𝑒𝑖 がガウスなら、どちらのモデルも同じガウス分布を与える:
例: ガウス性を仮定しても
08.0,cov 21 xx
212
11
8.0 exx
ex
22
121 8.0
ex
exx
モデル 1: モデル 2:
x1
x2
e1
e2
x1
x2
e1
e2
1varvar 21 xx ,021 eEeE
64
18.0
8.01
0
0~
2
1N
x
x

2.2 最近の発展: 非ガウス性に基づく方法

非ガウス性に基づくアプローチ
• モデル識別にデータの非ガウス性を利用する(Bentler, 1983; Mooijaart, 1985; Dodge and Rousson; 2001)
• 外生変数 𝑒𝑖が非ガウスなら、パス係数行列Bを識別可能(一意に推定可能) (Shimizu et al., 2005; 2006)
• 非ガウス因果構造探索の適用されている分野の例:– 脳 (Smith et al., 2011; Ramsey et al., 2011; Faes et al., 2010)
– 遺伝子 (Sogawa et al., 2011)
– 経済学 (Moneta et al., 2012; Ferkingsta et al. 2011)
– 行動遺伝学 (Ozaki et al , 2009; 2011)
– 心理学(Takahashi et al. 2012; von Eye et al, 2012)
66
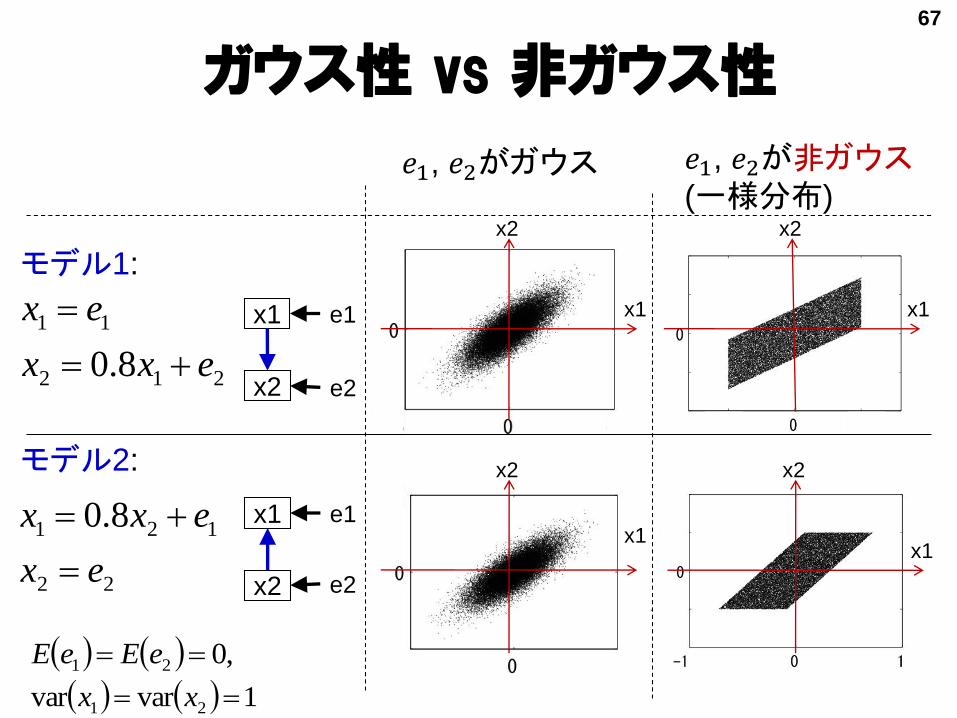
ガウス性 vs 非ガウス性
𝑒1, 𝑒2がガウス 𝑒1, 𝑒2が非ガウス(一様分布)
モデル1:
モデル2:
x1
x2
x1
x2
e1
e2
x1
x2
e1
e2
x1
x2
x1
x2
x1
x2
212
11
8.0 exx
ex
22
121 8.0
ex
exx
1varvar 21 xx
,021 eEeE
67

• Linear Non-Gaussian Acyclic Model:
ここで
– の生成順序
– 外生変数 (攪乱項、誤差項)は
• 分散が非ゼロ
• 非ガウスな密度関数+互いに独立.
• データXからBが識別可能(一意に推定可能)
LiNGAMモデル(Shimizu, Hyvarinen, Hoyer & Kerminen, 2005; 2006)
ie
eBxx i
ikjk
jiji exbx )()(
or
ixik :
68

LiNGAMモデルの識別性
69

LiNGAMモデルの識別性
• LiNGAMモデルは識別可能.
–データXからBを一意に推定できる.
• 証明には独立成分分析の結果を利用
–独立成分分析 (Hyvarinen et al., 2001):
Independent component analysis (ICA)
• 非ガウス因子分析!?
70

独立成分分析モデル (ICAモデル)(Jutten & Herault, 1991; Comon, 1994)
• 観測変数ベクトルxのデータ生成過程:
ここで– 潜在変数(独立成分) 𝑠𝑖は分散が非ゼロ、非ガウスな密度関数、 互いに独立
– 混合行列 A = [𝑎𝑖𝑗]は正方行列でフル列ランク
• 混合行列Aは(列の置換PとスケーリングDを除いて)識別可能:
Asx
p
j
jiji sax1
or
APDA ica
71

独立成分分析(ICA)と因子分析との関連
• ICAは因子分析の一種:因子が独立・誤差項なし
• 因子分析: ガウス性 (or 共分散行列で推定)
– 因子が無相関
– 因子回転Tの不定性: 制約(情報)が足りない
• 独立成分分析(ICA): 非ガウス性
– 因子が独立
– 因子回転の不定性なし
72
APDA ica
Asx
APDTA 因子分析(T: 直交行列)

独立と無相関
• 変数xとyが「独立」:
• xとyが「無相関」:
• 「独立」の方が強い条件: 制約がたくさん– ガウスだと、独立=無相関
• 独立成分分析(ICA)モデルは、「非ガウス+独立」を利用して識別可能になる: No 因子回転!
0 yExExyE
0 ygExfEygxfE
任意の有界な関数fとgについて
73

「 は独立」
独立性の評価指標
• 相互情報量
– ここでHはエントロピー
• 「相互情報量 = 0」
xx HxHIp
i
i 1
)(
)(log xx pEH
74
xI
pxxx ,,, 21

ICAモデルの推定• 多くの推定法が推定するのは復元行列
(Hyvarinen et al., 2001)
• 推定される独立成分の相互情報量(or その近似)を最小化 :
• 復元行列Wは、行の並び替えPとスケーリングDを除いて推定される:
• 推定アルゴリズム (Hyvarinen, 1999; Amari, 1998)
– セミパラメトリック: 分布形を特定する必要はない
xWs icaˆ
:1 AW
1 PDAPDWWica
sWAsx1
75

LiNGAMモデルに戻ろう

LiNGAMモデルの識別性(1/3):
ICAで「半分」同定できる
• LiNGAMモデルはICAモデルの特殊形
– 観測変数 𝑥𝑖 は非ガウス+独立な外生変数 𝑒𝑖 の線形結合:
• ICAで を同定できる.
– P: 未知の置換行列
– D: 未知のスケーリング行列(対角)
• Bを同定するにはPとDを求める必要がある.
eWAe
eBIxeBxx
1
1)(
)( BIPDPDWW ica
BIW
77

)( BIDDWPDWPWP ica
LiNGAMモデルの識別性(2/3):
置換行列を定める (1/6)
• ICAが推定するのは– P : 置換行列; D: スケーリング行列 (対角)
• 置換 をキャンセルするような置換行列 を求めたい(つまり となるような )
• 以下が証明できる(Shimizu et al., 2005) (次のスライドで説明) :
– もし , つまり, の行に置換が施されないなら,
は対角成分にゼロが一つも無い (定義より明らか).
– もし , つまり, の行に何らかの置換が施されたなら,
の対角成分に少なくとも一つはゼロがある
)( BIPDPDWW ica
IPP
P
IPP
icaWP
IPP
icaWP
I
P
DW
DW
P
78

LiNGAMモデルの識別性(2/3):
置換行列を定める (2/6)
• 定義より の対角成分は全て1– Bの対角成分は全てゼロ
• 非巡回性の仮定より、Bを下三角行列にするような変数の生成順序k(1)…k(p)が必ず存在する. その時 も下三角.
• なので、以下では一般性を失わずに, を下三角と仮定する:
1**
01*
001
W
0 0
0対角成分にゼロがない!
BIW
BIW
W
79
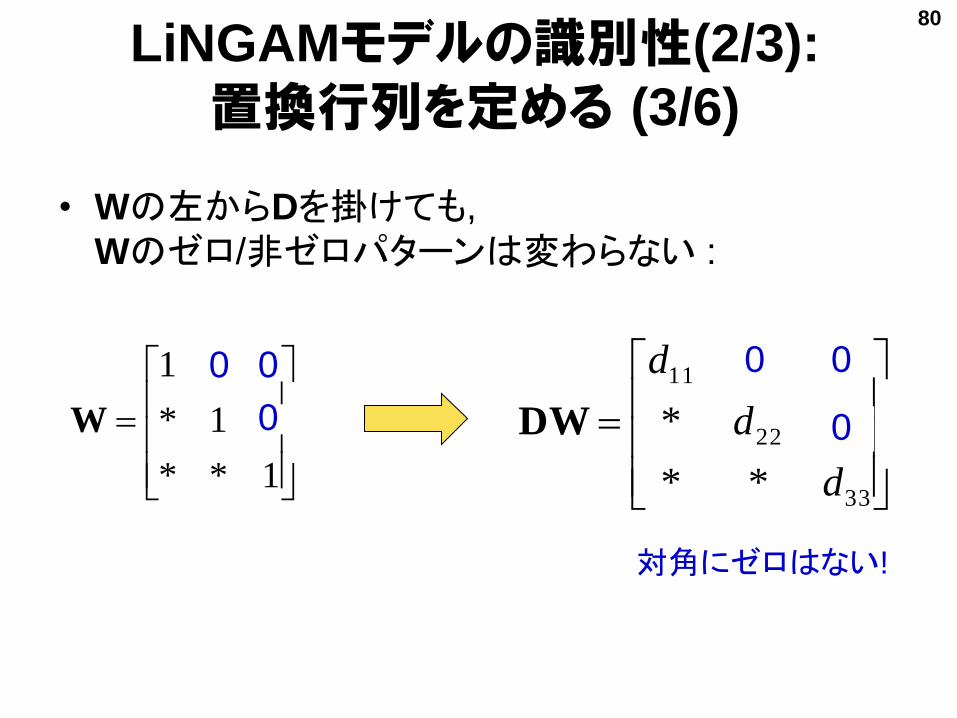
LiNGAMモデルの識別性(2/3):
置換行列を定める (3/6)
• Wの左からDを掛けても,
Wのゼロ/非ゼロパターンは変わらない :
33
22
11
**
0*
00
d
d
d
DW 0
0 0
1**
01*
001
W
0 0
0
対角にゼロはない!
80

33
11
22
12
**
00
0*
d
d
d
DWP
LiNGAMモデルの識別性 (2/3):
置換行列を定める (4/6)
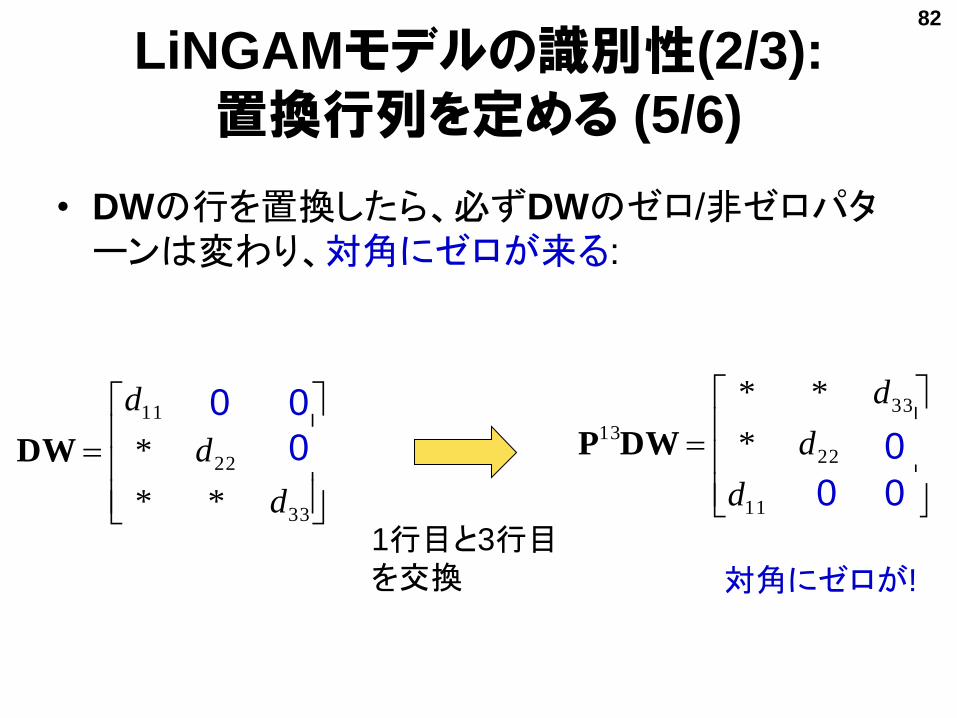
• DWの行を置換したら、必ずDWのゼロ/非ゼロパターンは変わり、対角にゼロが来る:
33
22
11
**
0*
00
d
d
d
DW 0
0 0 0
00
1行目と2行目を交換 対角にゼロが!
81
• DWの行を置換したら、必ずDWのゼロ/非ゼロパターンは変わり、対角にゼロが来る:
33
22
11
**
0*
00
d
d
d
DW
00
0*
**
11
22
33
13
d
d
d
DWP
LiNGAMモデルの識別性(2/3):
置換行列を定める (5/6)
0
0 0
0
0
1行目と3行目を交換 対角にゼロが!
0
82

LiNGAMモデルの識別性(2/3):
置換行列を定める (6/6)
• の対角にゼロが来ないような置換行列 を探せば、それが求めたい である (Shimizu et al., 2005).
• というわけで、置換の不定性を解くことができて、以下を得る:
icaWP
P
BIDDWPDWPWP ica
I
83
P

LiNGAMモデルの識別性(3/3):
スケーリング行列を定める
• ここまで解いた:
• すると,
• の各行を対応する対角成分で割ればI-B つまり B を得る:
B)D(IWP ica
icaWPD diag
icaWP
BIB)D(IDWPWP 11diag icaica
84

LiNGAMモデルの推定
1. ICA-LiNGAMアルゴリズム
2. DirectLiNGAMアルゴリズム
85

LiNGAMモデルの尤度(Hyvarinen et al., 2010)
• 生成順序𝑘 𝑖 が与えられた時の対数尤度 :
• 生成順序𝑘 𝑖 を求める必要
–総当たりで探すのは大変: p!通り
• 分布を特定しなくても良い方法がbetter
t i i
i
i
T
ii T
ttpL
logloglog
xbxX
s i
2 =1
Txi t( ) -b0,i
Tx( )
2
t
åここで ,ii epp
86
2つの推定アルゴリズム
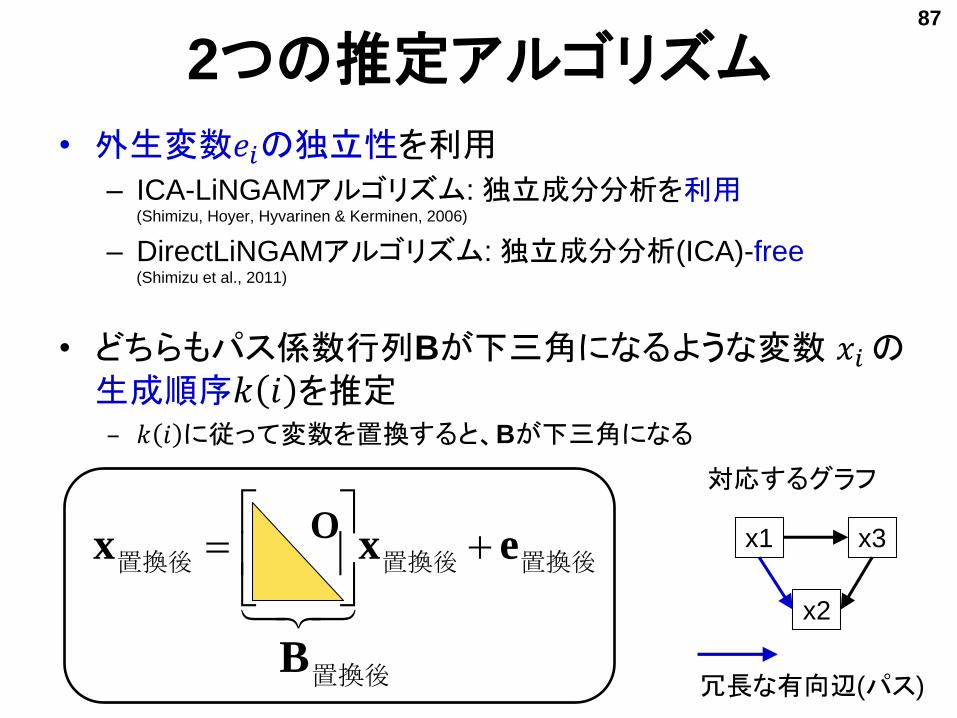
• 外生変数𝑒𝑖の独立性を利用
– ICA-LiNGAMアルゴリズム: 独立成分分析を利用(Shimizu, Hoyer, Hyvarinen & Kerminen, 2006)
– DirectLiNGAMアルゴリズム: 独立成分分析(ICA)-free(Shimizu et al., 2011)
• どちらもパス係数行列Bが下三角になるような変数 𝑥𝑖の生成順序𝑘 𝑖 を推定– 𝑘 𝑖 に従って変数を置換すると、Bが下三角になる
置換後置換後置換後 exx
置換後B
O
x2
x3x1
冗長な有向辺(パス)
対応するグラフ
87

生成順序𝑘 𝑖 を見つけてしまえば
• 既存のスパース回帰を使って枝刈り
• 例: adaptive lasso (Zou, 2006)で1行ずつ枝刈り
x2
x3x1
x2
x3x1O0
0*
* *
*
枝刈り
の親候補の親候補 ii xj ij
ij
xj
jijiolsb
bxbx
:
2
: )(ˆ
88
置換後置換後置換後 exx
置換後B

LiNGAMモデルの推定法
1. ICA-LiNGAMアルゴリズム
2. DirectLiNGAMアルゴリズム

1. ICA-LiNGAMアルゴリズムの流れ(Shimizu, Hoyer, Hyvarinen, & Kerminen, JMLR, 2006)
1. ICA + 置換でBを推定
冗長な有向辺(パス)
x3
x2x1
x3x3 23b13b
2. Bが下三角になるように置換
x1 x2
90

1. ICAを使って推定(ここでは, FastICA (Hyvarinen, 1999))
2. の対角成分を絶対値の意味でできるだけ大きくするような置換行列 を見つける:
3. の各行を対応する対角成分で割ると, I-Bの推定値を得て、 を得る.
ICA-LiNGAMアルゴリズム(1/2):
ステップ1: Bの推定
iiicaWP
PP ˆ
1minˆ
B)PD(IPDWW ica
icaWP ˆ
Hungarian alg.(Kuhn, 1955)
P
icaWP ˆˆ
B̂
91
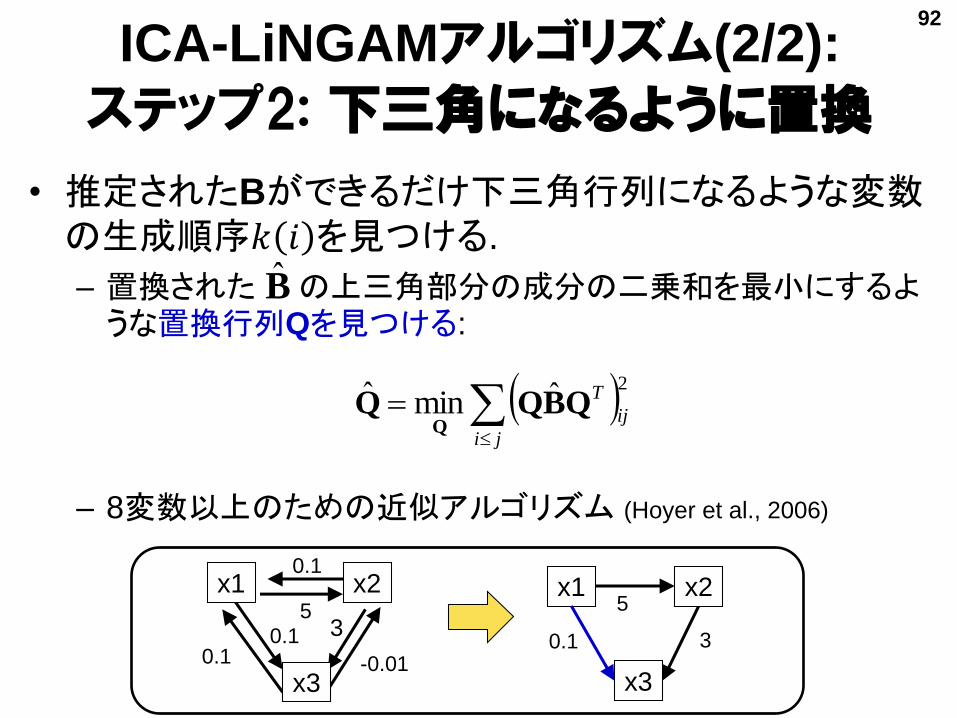
ICA-LiNGAMアルゴリズム(2/2):
ステップ2: 下三角になるように置換
• 推定されたBができるだけ下三角行列になるような変数の生成順序𝑘 𝑖 を見つける.
– 置換された の上三角部分の成分の二乗和を最小にするような置換行列Qを見つける:
– 8変数以上のための近似アルゴリズム (Hoyer et al., 2006)
ji
ij
T2
ˆminˆ QBQQQ
x3
x2x1
x3x30.1
0.1 3
0.1
0.1 3
55
-0.01
x1 x2
B̂
92

ICA-LiNGAMアルゴリズムの性質
• ICA-LiNGAMアルゴリズム = ICA + 置換×2
– ICAの推定法を利用することで計算効率が良い
• 潜在的な問題
– ICAは(パラメータ空間での)反復推定法:
• 初期値やステップサイズが悪いと局所解に落ちるかもしれない
– 置換アルゴリズムがスケール不変でない:
• 変数のスケールを変えると推定値も変わりうる
93

LiNGAMモデルの推定法
1. ICA-LiNGAMアルゴリズム
2. DirectLiNGAMアルゴリズム
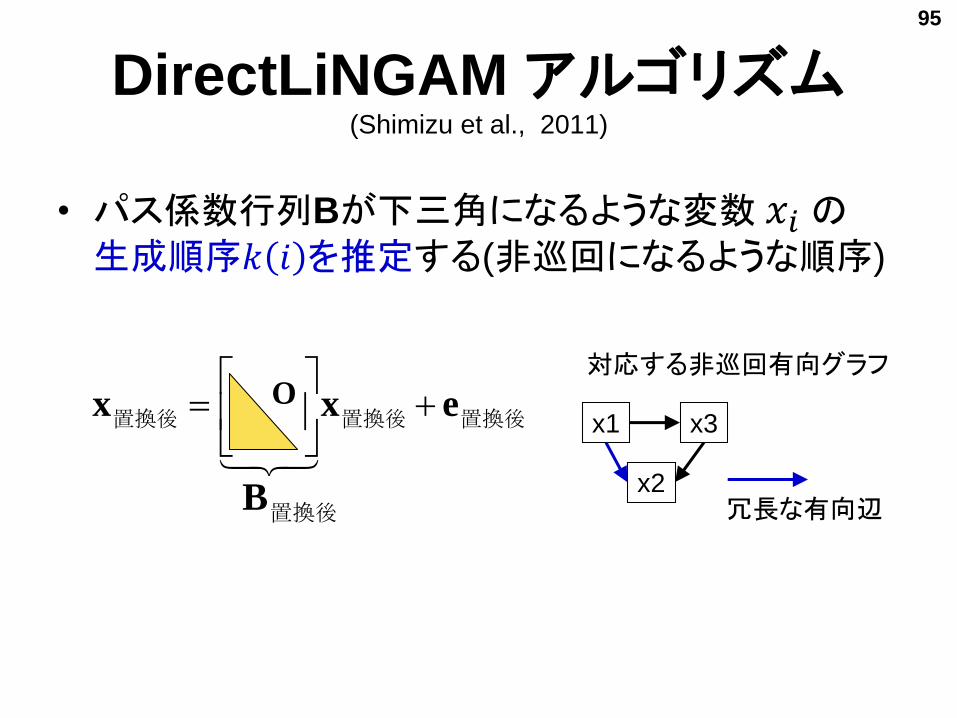
DirectLiNGAM アルゴリズム(Shimizu et al., 2011)
• パス係数行列Bが下三角になるような変数 𝑥𝑖 の生成順序𝑘 𝑖 を推定する(非巡回になるような順序)
置換後B
O
x2
x3x1
冗長な有向辺
対応する非巡回有向グラフ
95
置換後置換後置換後 exx
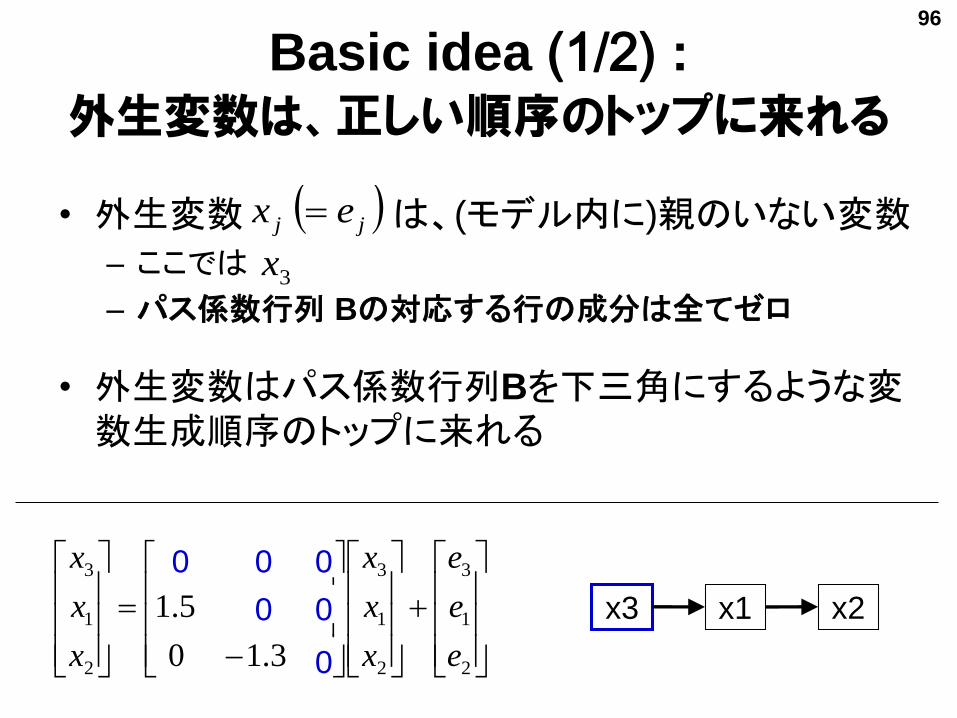
Basic idea (1/2) :外生変数は、正しい順序のトップに来れる
• 外生変数 は、(モデル内に)親のいない変数
– ここでは
– パス係数行列 Bの対応する行の成分は全てゼロ
• 外生変数はパス係数行列Bを下三角にするような変数生成順序のトップに来れる
2
1
3
2
1
3
2
1
3
03.10
005.1
000
e
e
e
x
x
x
x
x
x
0
0
0
0
00
x3 x1 x2
jj ex
3x
96

Basic idea (2/2): 外生変数 の成分を取り除く
• 他の変数 を外生変数 に回帰して残差 を計算する
– 残差 も、LiNGAMモデルを形成する
– 残差の生成順序は、元の観測変数の順序と同じ
• 残差 が外生なので、 はトップから2番目に来れる)3(
1r 1x
3x
)2,1(3 iri
3x)2,1( ixi
2
1
3
2
1
3
2
1
3
03.10
005.1
000
e
e
e
x
x
x
x
x
x 0
0
0 0
0
0
00
2
1
)3(
2
)3(
1
)3(
2
)3(
1
03.1
00
e
e
r
r
r
r 0 0
)3(
2r)3(
1rx3 x1 x2
3
2
3
1 rr と
0
97
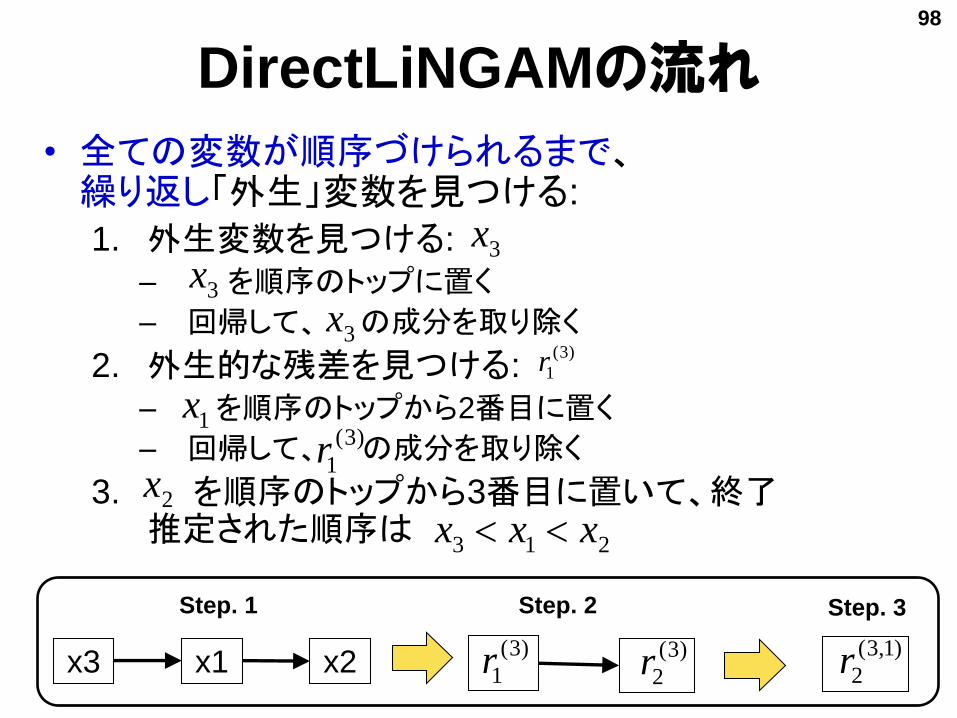
• 全ての変数が順序づけられるまで、繰り返し「外生」変数を見つける:
1. 外生変数を見つける:
– を順序のトップに置く
– 回帰して、 の成分を取り除く
2. 外生的な残差を見つける:
– を順序のトップから2番目に置く
– 回帰して、 の成分を取り除く
3. を順序のトップから3番目に置いて、終了推定された順序は
DirectLiNGAMの流れ
3x
)3(
1r
3x
)3(
2r)3(
1rx3 x1 x2)1,3(
2r
3x
1x
)3(
1r
2x
213 xxx
Step. 1 Step. 2 Step. 3
98

定理1: 「 はその残差
のどれとも独立 ( は 以外全部)」 「 は外生変数」
• LiNGAMモデルにおいて
• 実際のデータ解析では、残差と最も独立な観測変数を見つけることによって、外生変数を同定する
外生変数の同定
j
j
ji
i
j
i xx
xxxr
)var(
)cov( ,jx
jxi j
99

)var(
var
)var(
),cov(1
)var(
),cov(
,
1
2122
1
1212
1
1
122
)1(
2
12
x
xbx
x
xxb
xx
xxxr
xx
に回帰して を
2
1212
1
1
122
)1(
2
12
)var(
),cov(
,
e
xbx
xx
xxxr
xx
に回帰してを
外生変数の同定 (2変数の場合)
ii) は外生変数でないi) は外生変数
02121212
11
bexbx
ex
)( 11 ex 1x
22
122121 0
ex
bxbx
は独立でないと )1(
21 rxは独立と )1(
21 rx
1e
1e
100
残差

1
1
22
1
1212
1
1
122
)1(
2
12
)var(
var
)var(
),cov(1
)var(
),cov(
,
ex
xx
x
xxb
xx
xxxr
xx
に回帰してを
22
1212121 0
ex
bexbx
Darmois-Skitovitch’ theorem:
変数 と を次のように定義する:
Darmois-Skitovitch’ theorem(Darmois, 1953; Skitovitch, 1953)
ii) は外生変数でない1x
は独立でないと )1(
21 rx
p
j
jj
p
j
jj eaxeax1
22
1
11 ,
1x
ここで は独立な確率変数.
もし となるような非ガウスな があれば、と は独立でない
je
ie021 iiaa
1x 2x
1
12b
2x
101

独立性の評価• 非線形相関(独立の必要条件)
• 残差について和をとって:
• 相互情報量:
– ノンパラ推定(Bach & Jordan, 2002; Gretton et al.. 2005; Kraskov et al., 2004)
– サンプルサイズが十分あればベター(Sogawa et al., 2010; Entner et
al., 2011)
tanh,corr )( grgx j
ij
ji
j
ij
j
ij rxgrgxT )()( ,corr,corr
102
j
i
jj
ijj
i
j
r
xHrHxH
r
xI )(

DirectLiNGAMの大事な性質
• DirectLiNGAM は次の2つを繰り返す:
– 単回帰
– 変数と残差の独立性評価
• アルゴリズムについてのパラメータがない
– ステップサイズ、初期値、収束基準
• モデルが正しくサンプルサイズが十分にあれば、変数の数と同じステップ数で正しい解に収束することを保証できる(収束はいつもする)
103
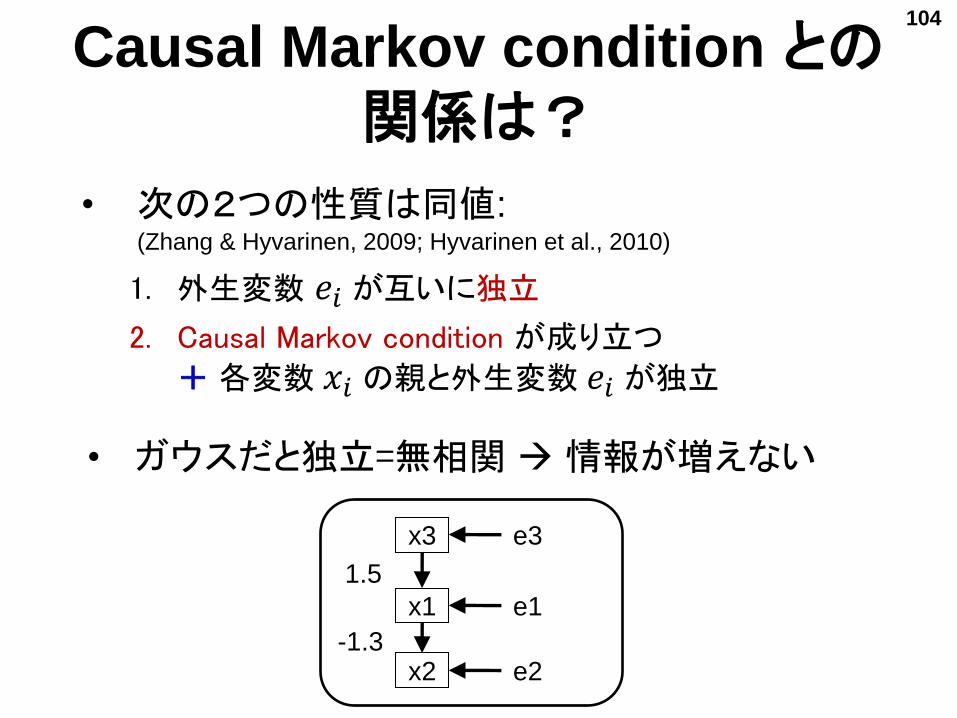
Causal Markov condition との関係は?
• 次の2つの性質は同値:(Zhang & Hyvarinen, 2009; Hyvarinen et al., 2010)
1. 外生変数 𝑒𝑖 が互いに独立
2. Causal Markov condition が成り立つ
+ 各変数 𝑥𝑖 の親と外生変数 𝑒𝑖 が独立
• ガウスだと独立=無相関 情報が増えない
x3
x1
e3
e1
x2 e2
1.5
-1.3
104

仮定の崩れの検出と統計的信頼性評価

検証可能な仮定を検定
• 外生変数 𝑒𝑖 の非ガウス性: 𝑒𝑖のガウス性検定
• 仮定の崩れの検出:– 外生変数 𝑒𝑖の独立性
• すべての仮定が正しければ、 𝑒𝑖 は独立になるはず
– 全体的適合度(高次モーメント構造)(Shimizu & Kano, 2008; Ozaki et al., 2010)
• 検定のロジックでは、モデルを積極的には採用できないが…
• 実験できれば実験で確認
106

例:潜在交絡変数の検出(Entner et al., 2011)
• 潜在交絡変数(非ガウス)の例
• 定理:
• LiNGAMによって推定される 𝑒𝑖の独立性検定
107
x2 x1
f1
21211212
11111
efxbx
efx
「潜在交絡変数がない」
「LiNGAMモデルが成立」
e1e2

統計的信頼性の評価
• 推定結果の統計的信頼性評価が必要– 標本変動
– 非ガウス性が小さいとモデルが識別不能に近づく
• ブートストラップ法によるアプローチ:– サンプルサイズが小さいか非ガウス性が小さいかすれば、ブートストラップ標本についてのLiNGAMの結果は大きくばらつくはず(Komatsu et al., 2010; Hyvarinen et al., 2010; Thamvitayakul et al., 2012)
x2
x3x1
x2
x3x1
….
p値=0.23 p値=0.18 >0.05
108

2.3 拡張モデル
潜在交絡変数・巡回・複数データセット・変数グループ・時系列・非線形

潜在交絡変数
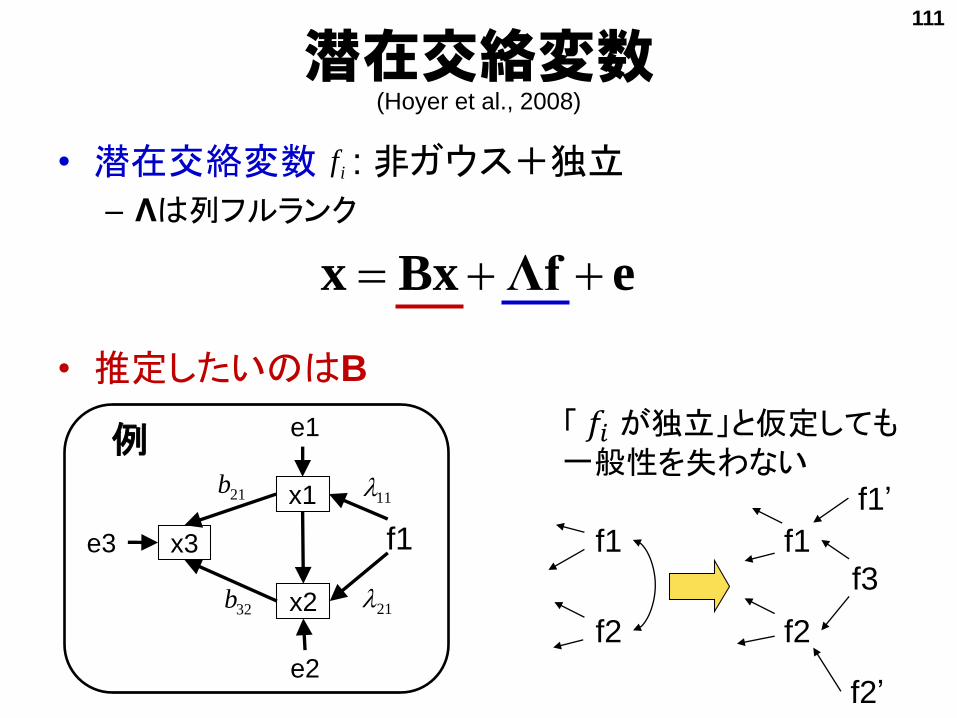
潜在交絡変数(Hoyer et al., 2008)
• 潜在交絡変数 : 非ガウス+独立
– Λは列フルランク
• 推定したいのはB
eΛfBxx
f1
f2
f1
f2
f3
f1’
f2’
x3
x2
x1
e2
e1
e3
21b
32b 21
11
「 𝑓𝑖 が独立」と仮定しても一般性を失わない
例
f1
111
if
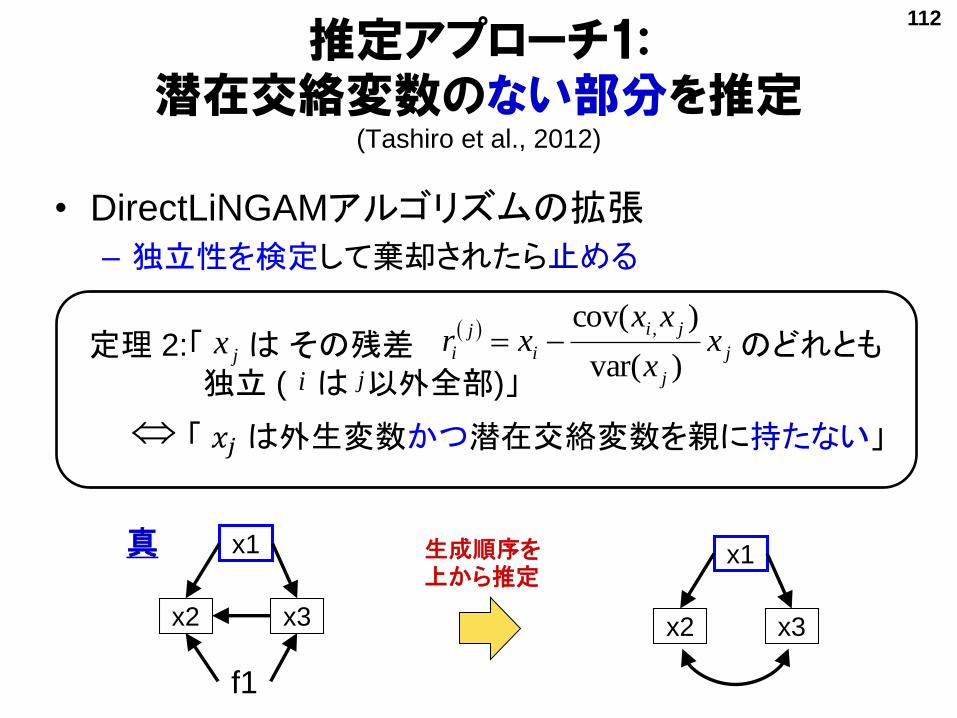
• DirectLiNGAMアルゴリズムの拡張
– 独立性を検定して棄却されたら止める
定理 2:「 は その残差 のどれとも独立 ( は 以外全部)」
推定アプローチ1: 潜在交絡変数のない部分を推定
(Tashiro et al., 2012)
j
j
ji
i
j
i xx
xxxr
)var(
)cov( ,
jx
i j
x2
x1
x3 x2
x1
x3
生成順序を上から推定
真
f1
112
「 𝑥𝑗 は外生変数かつ潜在交絡変数を親に持たない」
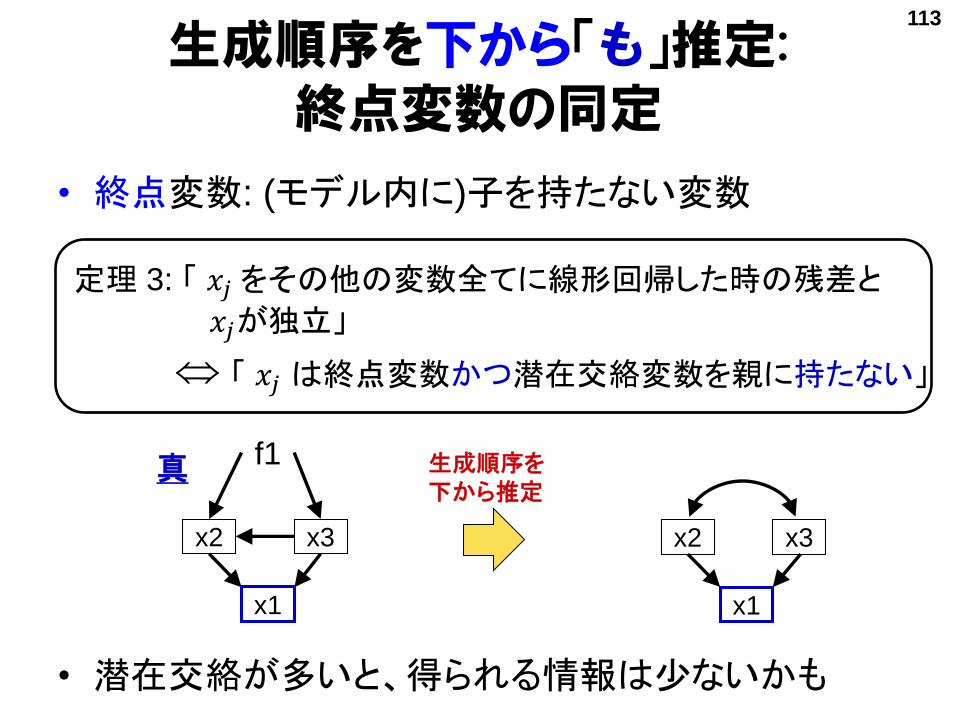
• 終点変数: (モデル内に)子を持たない変数
• 潜在交絡が多いと、得られる情報は少ないかも
「 𝑥𝑗 は終点変数かつ潜在交絡変数を親に持たない」
定理 3: 「 𝑥𝑗 をその他の変数全てに線形回帰した時の残差と
𝑥𝑗が独立」
生成順序を下から「も」推定: 終点変数の同定
x2 x3
x1
x2 x3
x1
生成順序を下から推定
真 f1
113

推定アプローチ2:
潜在交絡変数を陽にモデリング(Hoyer et al., 2008)
• ICA-LiNGAMアルゴリズムの拡張
– ICA(独立成分分析)の一種 (Lewicki et al., 2000)として解く
• 難しさ: 推定されたAのどの列がeにどの列がfに対応?
– 対応が一意に定まらないことがある(置換の不定性)
– Aのゼロ・非ゼロパターンから定まるのは例えばいつ?(次のスライド)
As
f
eΛBIBIx
11eΛfBxx
-- ICA (独立成分の方が多い)
114
--潜在交絡変数ありのLiNGAM
非ガウス (一様分布)
x2
x1
e1,e2, f1がガウス
x2
• Aのゼロ・非ゼロパターンからグラフは識別可能– 𝑥𝑖, 𝑓𝑖に忠実性を仮定
• 課題: 効率のよい推定アルゴリズムは発展途上
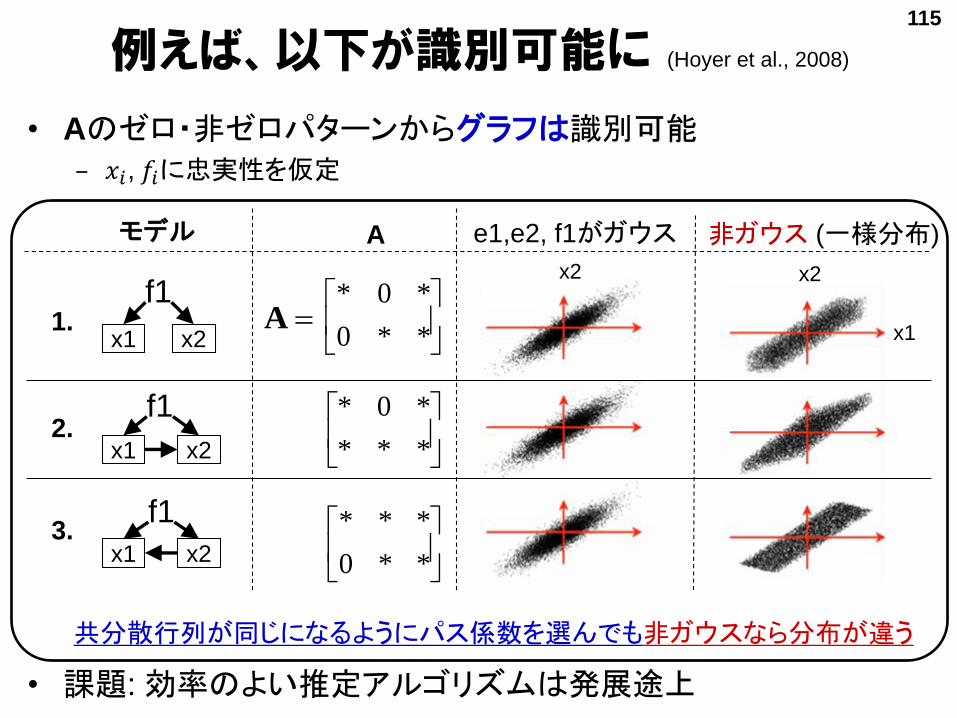
例えば、以下が識別可能に (Hoyer et al., 2008)
115
x1 x2
f1
x1 x2
f1
x1 x2
f1
モデル
1.
2.
3.
共分散行列が同じになるようにパス係数を選んでも非ガウスなら分布が違う
**0
*0*
***
*0*
**0
***
A
A

巡回モデル
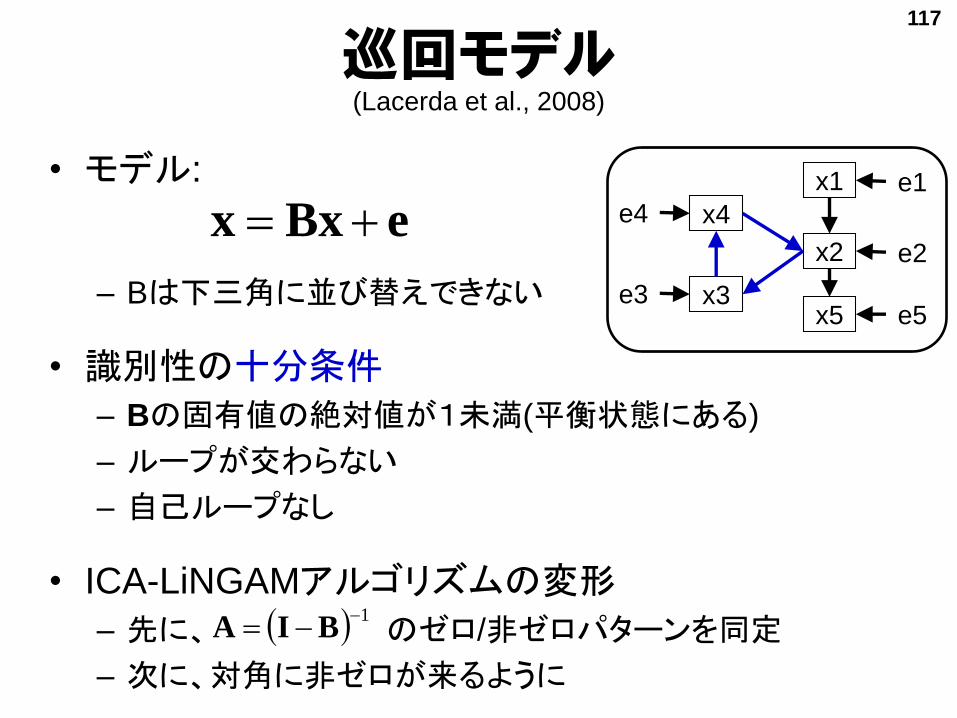
巡回モデル(Lacerda et al., 2008)
• モデル:
– Bは下三角に並び替えできない
• 識別性の十分条件
– Bの固有値の絶対値が1未満(平衡状態にある)
– ループが交わらない
– 自己ループなし
• ICA-LiNGAMアルゴリズムの変形
– 先に、 のゼロ/非ゼロパターンを同定
– 次に、対角に非ゼロが来るように
x1
x2
e1
e2
x5 e5
x4e4
x3e3
eBxx
117
1 BIA

複数データセット
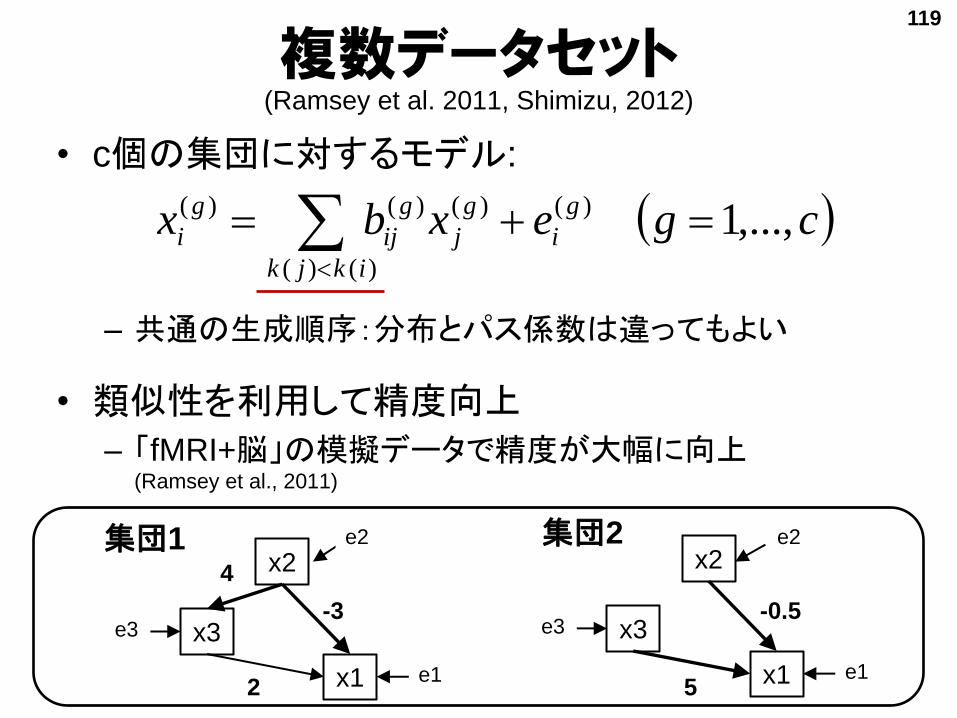
複数データセット(Ramsey et al. 2011, Shimizu, 2012)
• c個の集団に対するモデル:
– 共通の生成順序:分布とパス係数は違ってもよい
• 類似性を利用して精度向上
– 「fMRI+脳」の模擬データで精度が大幅に向上(Ramsey et al., 2011)
cgexbx g
i
ikjk
g
j
g
ij
g
i ,...,1)(
)()(
)()()(
x3
x1
x2
e1
e2
e3
4
-3
2
x3
x1
x2
e1
e2
e3-0.5
5
集団1 集団2
119

変数グループ間の解析
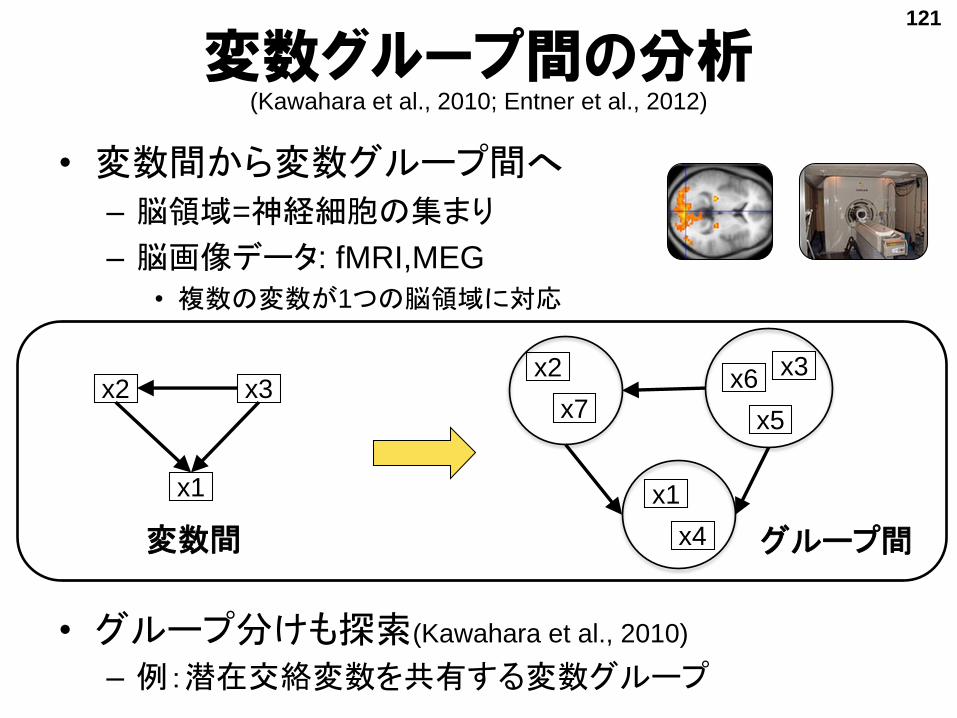
• 変数間から変数グループ間へ
– 脳領域=神経細胞の集まり
– 脳画像データ: fMRI,MEG
• 複数の変数が1つの脳領域に対応
• グループ分けも探索(Kawahara et al., 2010)
– 例:潜在交絡変数を共有する変数グループ
変数グループ間の分析(Kawahara et al., 2010; Entner et al., 2012)
x2
x7x6
x5
x1
x4
x3x2 x3
x1
変数間 グループ間
121

時系列

時系列(Hyvarinen et al., 2008;2010)
• LiNGAM+自己回帰モデル
– 瞬間的因果構造:LiNGAM
– 時間的決定関係:自己回帰モデル
– 測定間隔と相互作用のスピード
– 計量経済学• 構造型ベクトル自己回帰モデル
(Swanson & Granger, 1997)
– 推定• 自己回帰モデルの残差にLiNGAMをかける
)()()(0
tttk
exBx
x1(t)x1(t-1)
x2(t-1) x2(t)
e1(t-1)
e2(t-1)
e1(t)
e2(t)
123

非線形

• 「非線形+加法の外生変数」のモデル: – 非巡回・潜在交絡変数なし
• 「外生変数の独立性」の推定原理が使える– いくつかの非線形性と外生変数の分布を除いて、一意に推定可能
(Zhang & Hyvarinen, 2009; Peters et al., 2011)
– 課題:計算負荷高い(7,8変数ぐらいまで?)+大サンプルサイズ必要?
• 巡回・潜在交絡・時系列(Mooij et al., 2011; Zhang et al., 2010; Peters et al., 2012)
非線形+加法の外生変数
iiiii
iiii
exffx
exfx
の親
の親
1,
1
2,
-- Hoyer et al. (2008)
-- Zhang et al. (2009)
1.
2.
125

• 非巡回 + 潜在交絡変数なし:
– Causal Markov Conditionを利用 (Spirtes & Glymour, 1991)
– 「外生変数の独立性」の推定原理は使えない
– ノンパラメトリック独立性・条件付き独立性検定(Gretton, 2010; Sun et al., 2007)
• 潜在交絡・巡回・時系列(Spirtes et al., 1995; Richardson, 1996; Chu & Glymour, 2008; Entner & Hoyer, 2010)
• 多くの場合、一意に同定できないが、関数形について仮定をおかないのであれば、この系統
– 歴史的には、この系統が先
関数形がノンパラメトリック
iiii exfx ,の親
126

そのほかの話題

• 背景知識を探索に生かす(推定精度を上げる)– Inazumi et al. (2010).
• ベイズ: – Hoyer and Hyttinen (2009); Henao and Winther (2010,2011);
Mooij et al. (2010)
• 離散変数: 関数形に制約– Peters et al. (2010,2011); Inazumi et al. (2011).
• モデル誤特定への頑健性– 実は外生変数のいくつかがガウス(Hoyer et al., 2008)
• 因果と予測: 因果についての知識を予測にどう生かす?– Tillman and Spirtes (2010); Schölkopf et al. (2012)
そのほかの話題128

まとめ
• 因果分析のフレームワーク
– 反実仮想モデルによる因果の定義
– 因果を記述する道具: 構造方程式モデル
• 因果構造探索における最近の発展
– 非ガウス性の利用は、因果構造の同定に役立つ
– 非ガウスデータは多くの応用分野で見られる
– 非ガウス性を用いるアプローチは有望な選択肢の一つ
• プログラムや論文: http://www.ar.sanken.osaka-
u.ac.jp/~sshimizu/lingampapers.html
129

因果推論に関するレビュー
• 因果推論全般
– J. Pearl. Causal inference in statistics: An overview. Statistics Surveys
3: 96--146, 2009.
• 因果構造探索
– P. Spirtes, C. Glymour, R. Scheines, and R. E. Tillman. Automated
search for causal relations: Theory and practice. In Heuristics,
Probability, and Causality, College Publications, pp. 467-506, 2010.
• 因果構造探索法の応用(生命科学・社会科学)
– 脳: S. M. Smith. The future of FMRI connectivity. NeuroImage 62(2):
1257--1266, 2012.
– 遺伝子: P. Bühlmann. Causal statistical inference in high dimensions.
Mathematical Methods of Operations Research, 2012. In press.
– 経済: A. Moneta, N. Chlaß, D. Entner, and P. O. Hoyer. Causal search in
structural vector autoregressive models. In JMLR Workshop and
Conference Proceedings, Causality in Time Series, 12: 95-118, 2011.
• ソフトウェア(無料): TETRAD (http://www.phil.cmu.edu/projects/tetrad/).
130