zipf's law for indian languages
TRANSCRIPT

This article was downloaded by: [Ondokuz Mayis Universitesine]On: 06 November 2014, At: 06:23Publisher: RoutledgeInforma Ltd Registered in England and Wales Registered Number: 1072954Registered office: Mortimer House, 37-41 Mortimer Street, London W1T 3JH, UK
Journal of Quantitative LinguisticsPublication details, including instructions for authors andsubscription information:http://www.tandfonline.com/loi/njql20
Zipf's Law for Indian LanguagesB. D. Jayaram a & M. N. Vidya aa Central Institute of Indian Languages , Karnataka, IndiaPublished online: 10 Oct 2008.
To cite this article: B. D. Jayaram & M. N. Vidya (2008) Zipf's Law for Indian Languages,Journal of Quantitative Linguistics, 15:4, 293-317, DOI: 10.1080/09296170802326640
To link to this article: http://dx.doi.org/10.1080/09296170802326640
PLEASE SCROLL DOWN FOR ARTICLE
Taylor & Francis makes every effort to ensure the accuracy of all the information(the “Content”) contained in the publications on our platform. However, Taylor& Francis, our agents, and our licensors make no representations or warrantieswhatsoever as to the accuracy, completeness, or suitability for any purposeof the Content. Any opinions and views expressed in this publication are theopinions and views of the authors, and are not the views of or endorsed byTaylor & Francis. The accuracy of the Content should not be relied upon andshould be independently verified with primary sources of information. Taylor andFrancis shall not be liable for any losses, actions, claims, proceedings, demands,costs, expenses, damages, and other liabilities whatsoever or howsoever causedarising directly or indirectly in connection with, in relation to or arising out of theuse of the Content.
This article may be used for research, teaching, and private study purposes.Any substantial or systematic reproduction, redistribution, reselling, loan, sub-licensing, systematic supply, or distribution in any form to anyone is expressly

forbidden. Terms & Conditions of access and use can be found at http://www.tandfonline.com/page/terms-and-conditions
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014

Zipf’s Law for Indian Languages*
B. D. Jayaram and M. N. VidyaCentral Institute of Indian Languages, Karnataka, India
ABSTRACT
The present paper attempts to study the application of Zipf’s law for Indian languages. Itexamines the rank-frequency distribution in four Indian languages representing twoIndo-Aryan and two Dravidian languages. The sample texts were drawn from fivedifferent genres viz., aesthetics, commerce, natural physical and professional sciences,official and media languages, and social sciences. The rank-frequency distributions wereanalysed for fitting the distribution by using Altmann Fitter software where it fitted thetruncated zeta distribution defined as
Px ¼1
xaT; x ¼ 1; 2; . . . ;R
where R is the truncation parameter and T is the normalizing constant. The analysisshows that rank-frequency distribution follows Zipf’s law.
INTRODUCTION
In the domain of quantitative linguistics, word counting is perhaps themost popular discipline. This is supported by the fact that words aresimply ‘‘given’’ in the text: everybody can count them but especiallycomputers. Only genuine linguists consider the fact that a word is a verycomplex entity whose definition is not unique. Nevertheless, counting‘‘words’’ and preparing frequency dictionaries belong to the daily jobs of
*Address correspondence to: B. D. Jayaram, Research Officer, Central Institute of IndianLanguages, Manasagangotri, Hunsar Road, Mysore 570006, Karnataka, India.E-mail: jayaram/[email protected]
Journal of Quantitative Linguistics2008, Volume 15, Number 4, pp. 293–317DOI: 10.1080/09296170802326640
0929-6174/08/15040293 � 2008 Taylor & Francis
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014

computer linguists performing them without even any preliminaryhypothesis. However, the counting of words always has a practicalpurpose: it is useful for language teaching and grammatical studies. Thetheoretical use of word frequencies presupposes at least one hypothesiswhose validity should be corroborated by the word count. The founderof this kind of thinking was Zipf (1935, 1949) who set up a number ofhypotheses concerning word frequency. Today his heritage has twodirections: frequentistic and synergetic linguistics. However, theranking of words made popular by him has been initiated by Estoup(1916). Today it is an extensive discipline, perhaps the most pursued onein quantitative linguistics (cf. Kohler, 1995; Baayen, 2001; Glottometrics3–5, 2002). Zipf’s original idea of using the harmonic series and thepower series for capturing the relationship of rank and frequency hasbeen:
1. Replaced by the zeta distribution which is simply normalized andtruncated if necessary.
2. Replaced by a number of different models all of which represent amodification or a generalization of his original idea.
There is such an abundance of models that one automatically suspectsthat the researchers did not work with homogeneous (but mixed) data, orthat they did not care for a fruitful definition of the word, or that theysimply tried to find the best fitting distribution not caring for thetheoretical background.Word counting in Indian languages has a short and rather poor
tradition. There are some older publications on Bengali (Dabbs, 1966),Gujarati (Pandit, 1965), Hindi (Ghatage, 1964) and Urdu (Barker et al.,1969), Malayalam (Ghatage, 1994), Oriya (Kelkar, 1994) and somenewer ones, but the discipline as a whole begins to flourish due to theemployment of computers (cf. Jayaram, 2005; Jayaram & Rajyashree,2001).In the present study we want to examine the rank-frequency
distribution in four Indian languages and show:
1. That it abides by Zipf’s law; no modification is necessary.2. That the parameter a of the distribution strongly depends on the
repeat rate of the empirical distribution which can be used forestimation purposes.
294 B. D. JAYARAM & M. N. VIDYA
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014

DATA SOURCE
The sample texts in the present investigation are drawn from the IndianLanguage Written Corpora maintained by the Central Institute of IndianLanguages,Mysore. This corpus is of a general type covering all the genres ofthe language. The criteria considered for the categorization of the languageinto different genres were informational, administrative, instructional, andimaginative. Thus the data were collected under five main categories:
1. aesthetics,2. commerce,3. natural physical and professional sciences,4. official and media languages, and5. social sciences.
These were further subdivided into 76 text categories. The period of thecorpus was restricted to one decade, i.e. texts published between 1981 and1990 were included and it represents the contemporary Indian language(Jayaram & Rajyashree, 2001).
METHOD AND DATA FOR THE PRESENT INVESTIGATION
From the corpus of different Indian languages available at the CentralInstitute of Indian Languages, four languages were selected to representIndo-Aryan and Dravidian families of languages. The languages are Hindiand Marathi representing Indo-Aryan, and Kannada and Telugu represent-ing Dravidian. The sample text files, varying from five to 12, were selected atrandom from each genre of the four languages depending on the number ofsample texts available under each genre. The data from each text wasanalysed to obtain rank and frequency of words by developing a programwritten in Perl language. This rank-frequency data was further analysed forfitting the distribution by using Altmann-Fitter software.Adhering to the principle of economy we restricted our search to the
original Zipfian approach and fitted iteratively the right-truncated zetadistribution defined as
Px ¼1
xaT; x ¼ 1; 2; . . . ;R ð1Þ
ZIPF’S LAW FOR INDIAN LANGUAGES 295
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014

where R is the truncation parameter at the right-hand side of thedistribution and T is the normalizing constant
T ¼XR
j¼1j�a
which can be expressed by means of Riemann’s zeta function or byLerch’s function.
RESULTS AND DISCUSSIONS
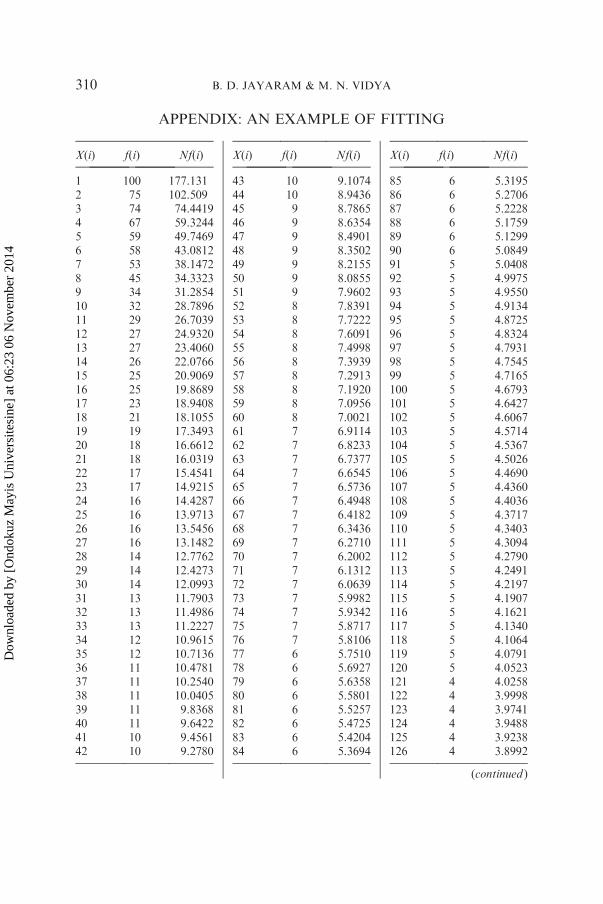
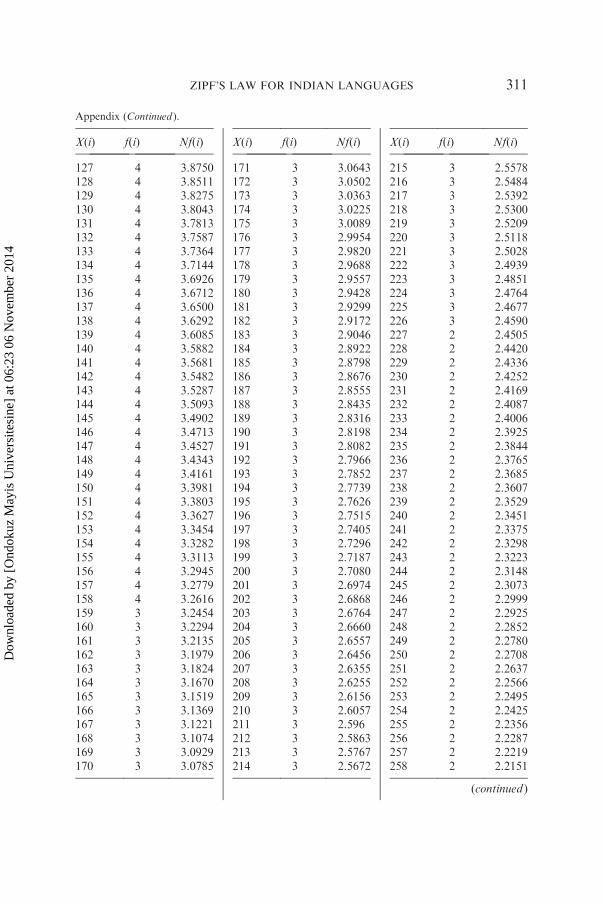
The analysis of data was carried out using Altmann-Fitter software.Altmann-Fitter is an interactive program for fitting theoretical univariatediscrete probability functions to empirical frequency distributions usingmethods of iterative optimization based on the simplex algorithm byNelder-Mead. Fitting starts with the common point estimates and isoptimized successively. Goodness of fit is determined by the chi-squaretest and the associated probability. An example of fitting is shown in thetable in the Appendix.The empirical repeat rate has been computed for each text according to
RR ¼ 1
N 2
XR
x¼1f 2x ð2Þ
where N is the number of all words in the text (¼ text length, number oftokens), R is the maximal rank, i.e. the number of types, identical withthe truncation parameter of the Zipf distribution, and fx is the absolutefrequency at rank x. This index lies in the interval h1/R, 1i but in long-taildata it is usually so small that ‘‘optically’’ it is not very expressive.Besides, it is not directly comparable. Therefore one usually takes the‘‘relative repeat rate’’ according to McIntosh (1967), defined as
RRrel ¼1�
ffiffiffiffiffiffiffiRRp
1� 1=ffiffiffiffiRp ð3Þ
The values of RRrel can be found in the last column of all tables.The results are presented in the following 20 tables analysing the texts
for each language and genre separately (four languages and five genres).
296 B. D. JAYARAM & M. N. VIDYA
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014
The tables present the values of parameters a and R (representing thetruncation parameter, i.e. the number of types), the corresponding degrees offreedom, w2 values with probability, the sample text size (N), repeat rate andrelative repeat rate. It can be seen from the result that all texts from eachlanguage and each genre follow the right-truncated zeta distribution exceptfor one text in the category of Telugu–Commerce. The degrees of freedomstrongly differ from the number of types (R) because many classes have beenpooled in order to attain the necessary expected frequency.In order to show the output of the exact analysis the data from one text
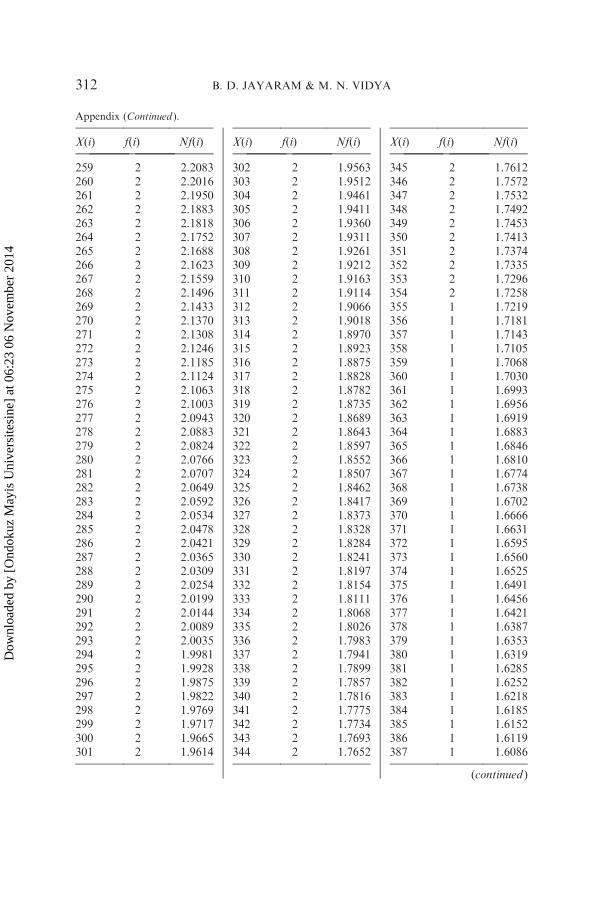
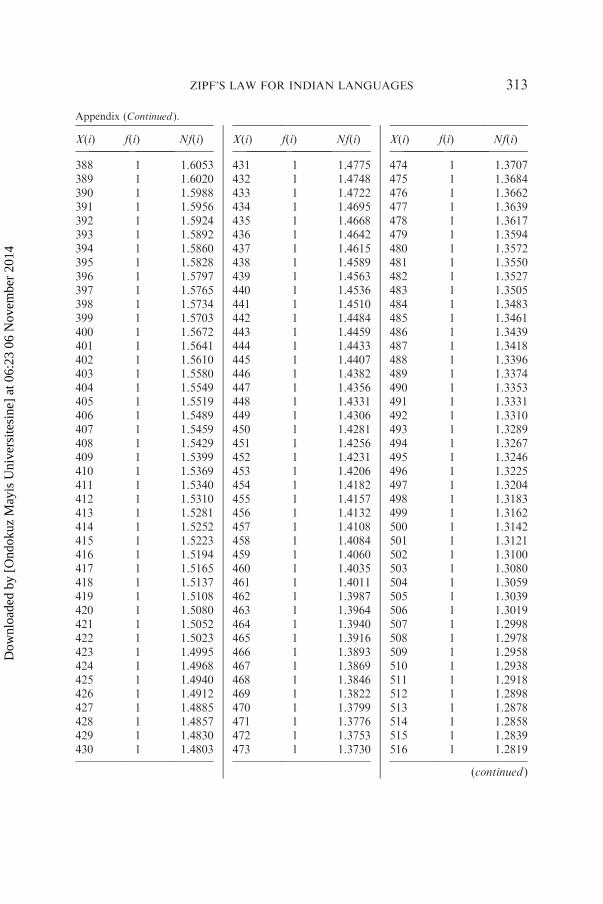
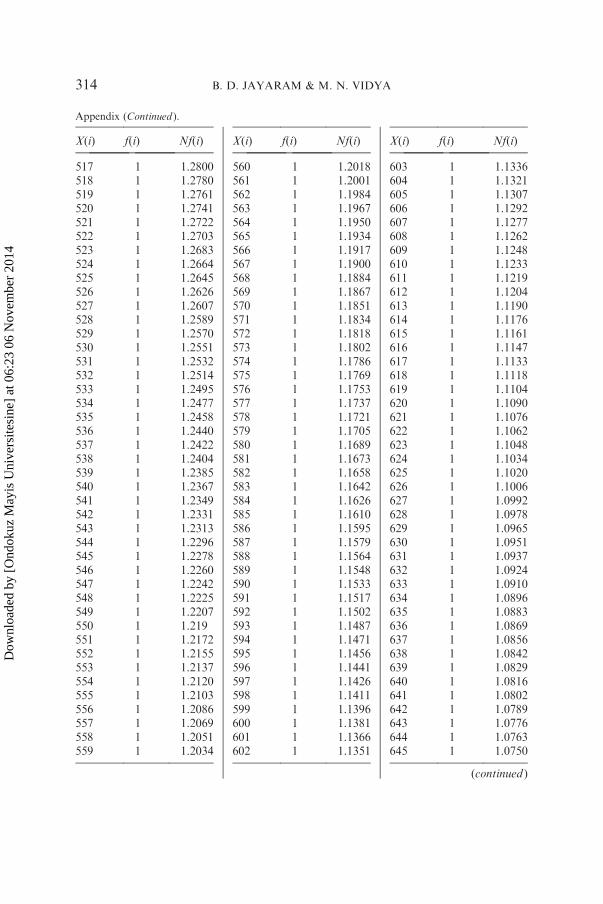
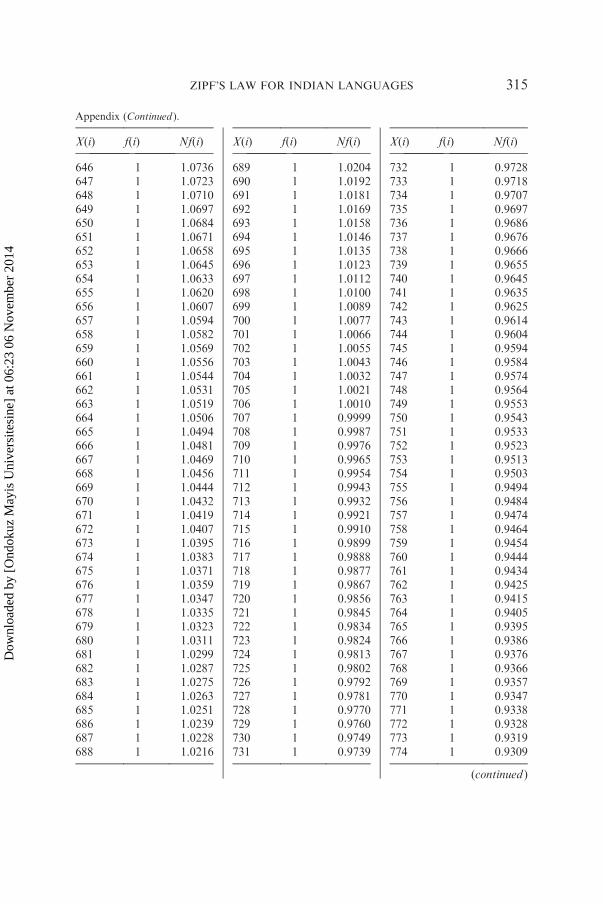
has been analyzed in detail by giving the rank of each word and itsfrequency and also the expected frequency obtained by using the right-truncated zeta distribution. The result of this analysis is shown in thegraph, which indicates that rank-frequency data follows Zipf’s first law.Detailed analysis of one sample text of aesthetics from Hindi is shown in
the Appendix and graphically presented in Figure A1 (bilogarithmic scale).
THE BEHAVIOUR OF PARAMETER a
Having obtained very positive fittings of the right-truncated Zipf (¼ zeta)distribution to 195 data sets from four languages, we see that theparameter a variates in the interval h0.46, 0.88i. We know that it dependson the form of the empirical distribution but its estimation is not simplebecause of the normalizing constant which is itself a function of a. Inaddition, it must be estimated in each case separately if one does not usea software package. On the other hand, each parameter of the
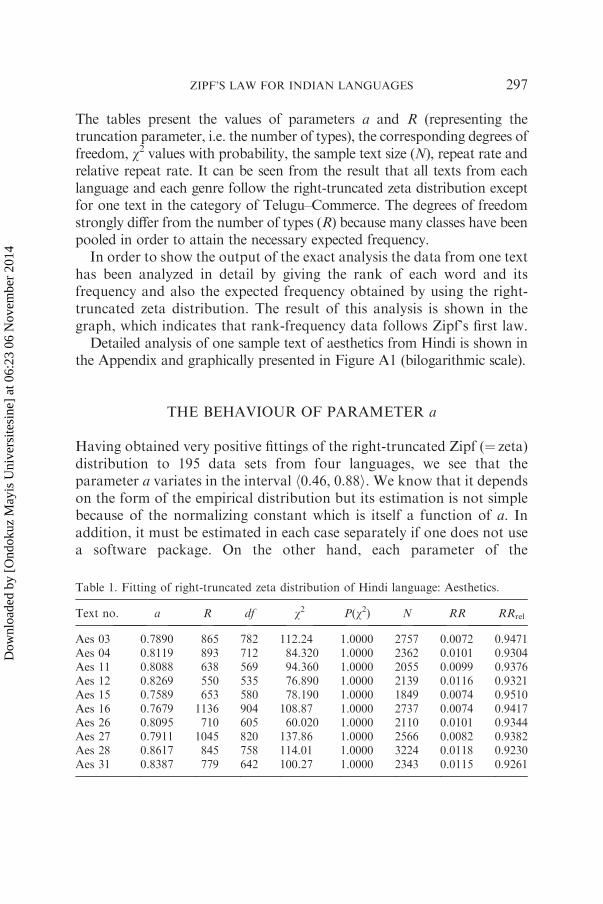
Table 1. Fitting of right-truncated zeta distribution of Hindi language: Aesthetics.
Text no. a R df w2 P(w2) N RR RRrel
Aes 03 0.7890 865 782 112.24 1.0000 2757 0.0072 0.9471Aes 04 0.8119 893 712 84.320 1.0000 2362 0.0101 0.9304Aes 11 0.8088 638 569 94.360 1.0000 2055 0.0099 0.9376Aes 12 0.8269 550 535 76.890 1.0000 2139 0.0116 0.9321Aes 15 0.7589 653 580 78.190 1.0000 1849 0.0074 0.9510Aes 16 0.7679 1136 904 108.87 1.0000 2737 0.0074 0.9417Aes 26 0.8095 710 605 60.020 1.0000 2110 0.0101 0.9344Aes 27 0.7911 1045 820 137.86 1.0000 2566 0.0082 0.9382Aes 28 0.8617 845 758 114.01 1.0000 3224 0.0118 0.9230Aes 31 0.8387 779 642 100.27 1.0000 2343 0.0115 0.9261
ZIPF’S LAW FOR INDIAN LANGUAGES 297
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014
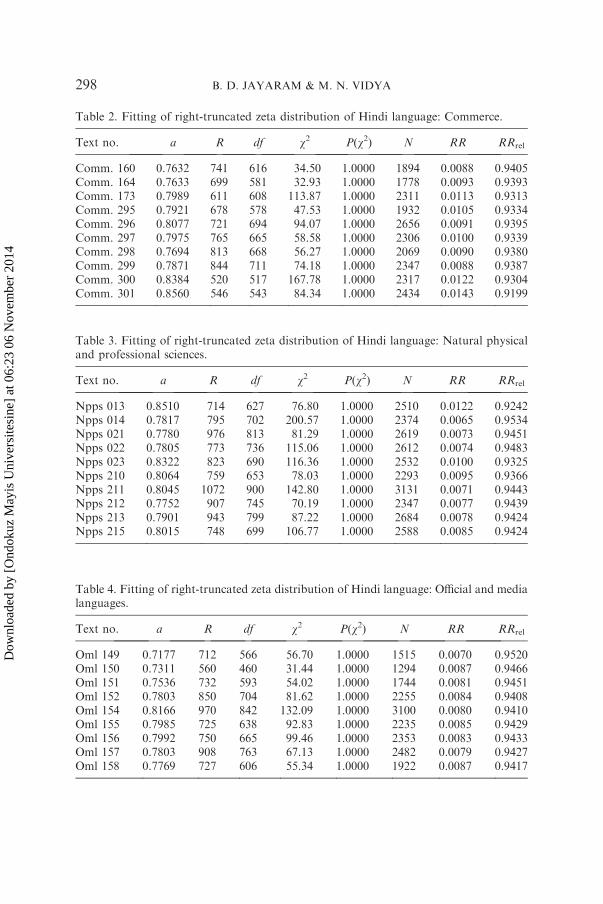
Table 2. Fitting of right-truncated zeta distribution of Hindi language: Commerce.
Text no. a R df w2 P(w2) N RR RRrel
Comm. 160 0.7632 741 616 34.50 1.0000 1894 0.0088 0.9405Comm. 164 0.7633 699 581 32.93 1.0000 1778 0.0093 0.9393Comm. 173 0.7989 611 608 113.87 1.0000 2311 0.0113 0.9313Comm. 295 0.7921 678 578 47.53 1.0000 1932 0.0105 0.9334Comm. 296 0.8077 721 694 94.07 1.0000 2656 0.0091 0.9395Comm. 297 0.7975 765 665 58.58 1.0000 2306 0.0100 0.9339Comm. 298 0.7694 813 668 56.27 1.0000 2069 0.0090 0.9380Comm. 299 0.7871 844 711 74.18 1.0000 2347 0.0088 0.9387Comm. 300 0.8384 520 517 167.78 1.0000 2317 0.0122 0.9304Comm. 301 0.8560 546 543 84.34 1.0000 2434 0.0143 0.9199
Table 3. Fitting of right-truncated zeta distribution of Hindi language: Natural physicaland professional sciences.
Text no. a R df w2 P(w2) N RR RRrel
Npps 013 0.8510 714 627 76.80 1.0000 2510 0.0122 0.9242Npps 014 0.7817 795 702 200.57 1.0000 2374 0.0065 0.9534Npps 021 0.7780 976 813 81.29 1.0000 2619 0.0073 0.9451Npps 022 0.7805 773 736 115.06 1.0000 2612 0.0074 0.9483Npps 023 0.8322 823 690 116.36 1.0000 2532 0.0100 0.9325Npps 210 0.8064 759 653 78.03 1.0000 2293 0.0095 0.9366Npps 211 0.8045 1072 900 142.80 1.0000 3131 0.0071 0.9443Npps 212 0.7752 907 745 70.19 1.0000 2347 0.0077 0.9439Npps 213 0.7901 943 799 87.22 1.0000 2684 0.0078 0.9424Npps 215 0.8015 748 699 106.77 1.0000 2588 0.0085 0.9424
Table 4. Fitting of right-truncated zeta distribution of Hindi language: Official and medialanguages.
Text no. a R df w2 P(w2) N RR RRrel
Oml 149 0.7177 712 566 56.70 1.0000 1515 0.0070 0.9520Oml 150 0.7311 560 460 31.44 1.0000 1294 0.0087 0.9466Oml 151 0.7536 732 593 54.02 1.0000 1744 0.0081 0.9451Oml 152 0.7803 850 704 81.62 1.0000 2255 0.0084 0.9408Oml 154 0.8166 970 842 132.09 1.0000 3100 0.0080 0.9410Oml 155 0.7985 725 638 92.83 1.0000 2235 0.0085 0.9429Oml 156 0.7992 750 665 99.46 1.0000 2353 0.0083 0.9433Oml 157 0.7803 908 763 67.13 1.0000 2482 0.0079 0.9427Oml 158 0.7769 727 606 55.34 1.0000 1922 0.0087 0.9417
298 B. D. JAYARAM & M. N. VIDYA
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014
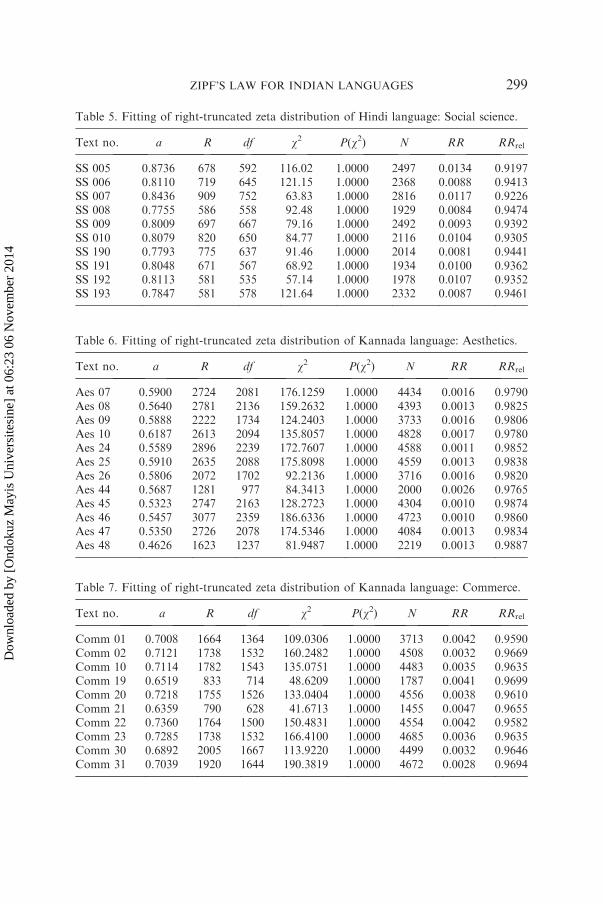
Table 5. Fitting of right-truncated zeta distribution of Hindi language: Social science.
Text no. a R df w2 P(w2) N RR RRrel
SS 005 0.8736 678 592 116.02 1.0000 2497 0.0134 0.9197SS 006 0.8110 719 645 121.15 1.0000 2368 0.0088 0.9413SS 007 0.8436 909 752 63.83 1.0000 2816 0.0117 0.9226SS 008 0.7755 586 558 92.48 1.0000 1929 0.0084 0.9474SS 009 0.8009 697 667 79.16 1.0000 2492 0.0093 0.9392SS 010 0.8079 820 650 84.77 1.0000 2116 0.0104 0.9305SS 190 0.7793 775 637 91.46 1.0000 2014 0.0081 0.9441SS 191 0.8048 671 567 68.92 1.0000 1934 0.0100 0.9362SS 192 0.8113 581 535 57.14 1.0000 1978 0.0107 0.9352SS 193 0.7847 581 578 121.64 1.0000 2332 0.0087 0.9461
Table 6. Fitting of right-truncated zeta distribution of Kannada language: Aesthetics.
Text no. a R df w2 P(w2) N RR RRrel
Aes 07 0.5900 2724 2081 176.1259 1.0000 4434 0.0016 0.9790Aes 08 0.5640 2781 2136 159.2632 1.0000 4393 0.0013 0.9825Aes 09 0.5888 2222 1734 124.2403 1.0000 3733 0.0016 0.9806Aes 10 0.6187 2613 2094 135.8057 1.0000 4828 0.0017 0.9780Aes 24 0.5589 2896 2239 172.7607 1.0000 4588 0.0011 0.9852Aes 25 0.5910 2635 2088 175.8098 1.0000 4559 0.0013 0.9838Aes 26 0.5806 2072 1702 92.2136 1.0000 3716 0.0016 0.9820Aes 44 0.5687 1281 977 84.3413 1.0000 2000 0.0026 0.9765Aes 45 0.5323 2747 2163 128.2723 1.0000 4304 0.0010 0.9874Aes 46 0.5457 3077 2359 186.6336 1.0000 4723 0.0010 0.9860Aes 47 0.5350 2726 2078 174.5346 1.0000 4084 0.0013 0.9834Aes 48 0.4626 1623 1237 81.9487 1.0000 2219 0.0013 0.9887
Table 7. Fitting of right-truncated zeta distribution of Kannada language: Commerce.
Text no. a R df w2 P(w2) N RR RRrel
Comm 01 0.7008 1664 1364 109.0306 1.0000 3713 0.0042 0.9590Comm 02 0.7121 1738 1532 160.2482 1.0000 4508 0.0032 0.9669Comm 10 0.7114 1782 1543 135.0751 1.0000 4483 0.0035 0.9635Comm 19 0.6519 833 714 48.6209 1.0000 1787 0.0041 0.9699Comm 20 0.7218 1755 1526 133.0404 1.0000 4556 0.0038 0.9610Comm 21 0.6359 790 628 41.6713 1.0000 1455 0.0047 0.9655Comm 22 0.7360 1764 1500 150.4831 1.0000 4554 0.0042 0.9582Comm 23 0.7285 1738 1532 166.4100 1.0000 4685 0.0036 0.9635Comm 30 0.6892 2005 1667 113.9220 1.0000 4499 0.0032 0.9646Comm 31 0.7039 1920 1644 190.3819 1.0000 4672 0.0028 0.9694
ZIPF’S LAW FOR INDIAN LANGUAGES 299
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014
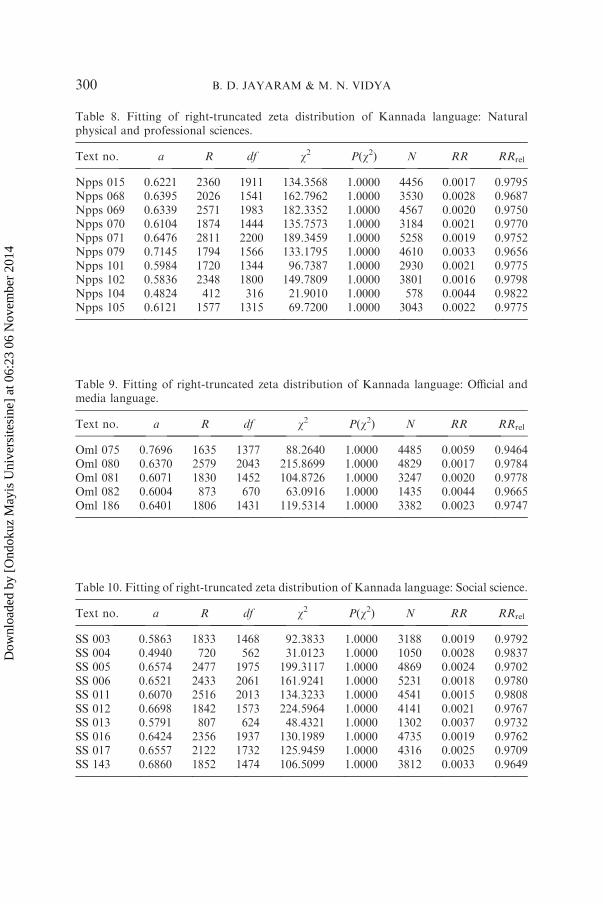
Table 8. Fitting of right-truncated zeta distribution of Kannada language: Naturalphysical and professional sciences.
Text no. a R df w2 P(w2) N RR RRrel
Npps 015 0.6221 2360 1911 134.3568 1.0000 4456 0.0017 0.9795Npps 068 0.6395 2026 1541 162.7962 1.0000 3530 0.0028 0.9687Npps 069 0.6339 2571 1983 182.3352 1.0000 4567 0.0020 0.9750Npps 070 0.6104 1874 1444 135.7573 1.0000 3184 0.0021 0.9770Npps 071 0.6476 2811 2200 189.3459 1.0000 5258 0.0019 0.9752Npps 079 0.7145 1794 1566 133.1795 1.0000 4610 0.0033 0.9656Npps 101 0.5984 1720 1344 96.7387 1.0000 2930 0.0021 0.9775Npps 102 0.5836 2348 1800 149.7809 1.0000 3801 0.0016 0.9798Npps 104 0.4824 412 316 21.9010 1.0000 578 0.0044 0.9822Npps 105 0.6121 1577 1315 69.7200 1.0000 3043 0.0022 0.9775
Table 9. Fitting of right-truncated zeta distribution of Kannada language: Official andmedia language.
Text no. a R df w2 P(w2) N RR RRrel
Oml 075 0.7696 1635 1377 88.2640 1.0000 4485 0.0059 0.9464Oml 080 0.6370 2579 2043 215.8699 1.0000 4829 0.0017 0.9784Oml 081 0.6071 1830 1452 104.8726 1.0000 3247 0.0020 0.9778Oml 082 0.6004 873 670 63.0916 1.0000 1435 0.0044 0.9665Oml 186 0.6401 1806 1431 119.5314 1.0000 3382 0.0023 0.9747
Table 10. Fitting of right-truncated zeta distribution of Kannada language: Social science.
Text no. a R df w2 P(w2) N RR RRrel
SS 003 0.5863 1833 1468 92.3833 1.0000 3188 0.0019 0.9792SS 004 0.4940 720 562 31.0123 1.0000 1050 0.0028 0.9837SS 005 0.6574 2477 1975 199.3117 1.0000 4869 0.0024 0.9702SS 006 0.6521 2433 2061 161.9241 1.0000 5231 0.0018 0.9780SS 011 0.6070 2516 2013 134.3233 1.0000 4541 0.0015 0.9808SS 012 0.6698 1842 1573 224.5964 1.0000 4141 0.0021 0.9767SS 013 0.5791 807 624 48.4321 1.0000 1302 0.0037 0.9732SS 016 0.6424 2356 1937 130.1989 1.0000 4735 0.0019 0.9762SS 017 0.6557 2122 1732 125.9459 1.0000 4316 0.0025 0.9709SS 143 0.6860 1852 1474 106.5099 1.0000 3812 0.0033 0.9649
300 B. D. JAYARAM & M. N. VIDYA
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014
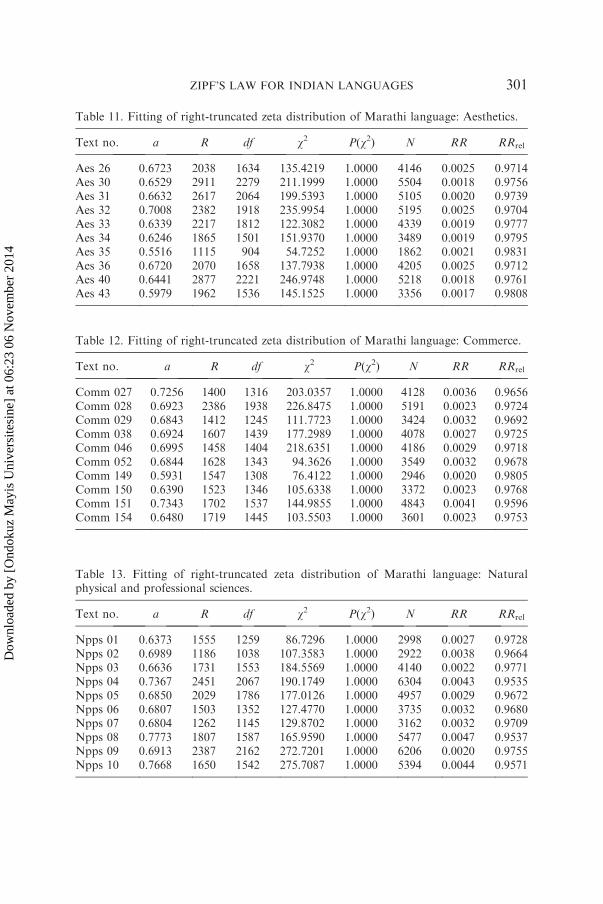
Table 11. Fitting of right-truncated zeta distribution of Marathi language: Aesthetics.
Text no. a R df w2 P(w2) N RR RRrel
Aes 26 0.6723 2038 1634 135.4219 1.0000 4146 0.0025 0.9714Aes 30 0.6529 2911 2279 211.1999 1.0000 5504 0.0018 0.9756Aes 31 0.6632 2617 2064 199.5393 1.0000 5105 0.0020 0.9739Aes 32 0.7008 2382 1918 235.9954 1.0000 5195 0.0025 0.9704Aes 33 0.6339 2217 1812 122.3082 1.0000 4339 0.0019 0.9777Aes 34 0.6246 1865 1501 151.9370 1.0000 3489 0.0019 0.9795Aes 35 0.5516 1115 904 54.7252 1.0000 1862 0.0021 0.9831Aes 36 0.6720 2070 1658 137.7938 1.0000 4205 0.0025 0.9712Aes 40 0.6441 2877 2221 246.9748 1.0000 5218 0.0018 0.9761Aes 43 0.5979 1962 1536 145.1525 1.0000 3356 0.0017 0.9808
Table 12. Fitting of right-truncated zeta distribution of Marathi language: Commerce.
Text no. a R df w2 P(w2) N RR RRrel
Comm 027 0.7256 1400 1316 203.0357 1.0000 4128 0.0036 0.9656Comm 028 0.6923 2386 1938 226.8475 1.0000 5191 0.0023 0.9724Comm 029 0.6843 1412 1245 111.7723 1.0000 3424 0.0032 0.9692Comm 038 0.6924 1607 1439 177.2989 1.0000 4078 0.0027 0.9725Comm 046 0.6995 1458 1404 218.6351 1.0000 4186 0.0029 0.9718Comm 052 0.6844 1628 1343 94.3626 1.0000 3549 0.0032 0.9678Comm 149 0.5931 1547 1308 76.4122 1.0000 2946 0.0020 0.9805Comm 150 0.6390 1523 1346 105.6338 1.0000 3372 0.0023 0.9768Comm 151 0.7343 1702 1537 144.9855 1.0000 4843 0.0041 0.9596Comm 154 0.6480 1719 1445 103.5503 1.0000 3601 0.0023 0.9753
Table 13. Fitting of right-truncated zeta distribution of Marathi language: Naturalphysical and professional sciences.
Text no. a R df w2 P(w2) N RR RRrel
Npps 01 0.6373 1555 1259 86.7296 1.0000 2998 0.0027 0.9728Npps 02 0.6989 1186 1038 107.3583 1.0000 2922 0.0038 0.9664Npps 03 0.6636 1731 1553 184.5569 1.0000 4140 0.0022 0.9771Npps 04 0.7367 2451 2067 190.1749 1.0000 6304 0.0043 0.9535Npps 05 0.6850 2029 1786 177.0126 1.0000 4957 0.0029 0.9672Npps 06 0.6807 1503 1352 127.4770 1.0000 3735 0.0032 0.9680Npps 07 0.6804 1262 1145 129.8702 1.0000 3162 0.0032 0.9709Npps 08 0.7773 1807 1587 165.9590 1.0000 5477 0.0047 0.9537Npps 09 0.6913 2387 2162 272.7201 1.0000 6206 0.0020 0.9755Npps 10 0.7668 1650 1542 275.7087 1.0000 5394 0.0044 0.9571
ZIPF’S LAW FOR INDIAN LANGUAGES 301
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014
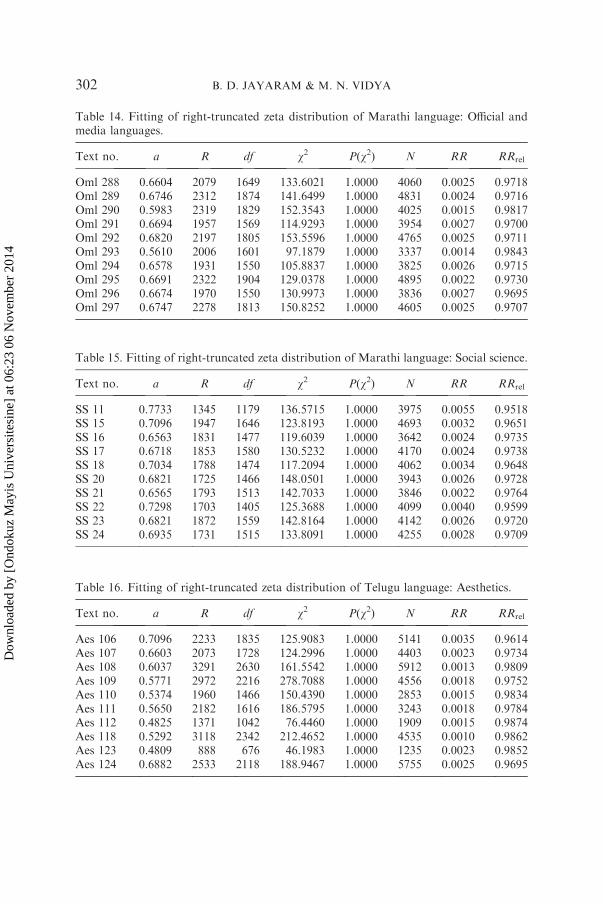
Table 14. Fitting of right-truncated zeta distribution of Marathi language: Official andmedia languages.
Text no. a R df w2 P(w2) N RR RRrel
Oml 288 0.6604 2079 1649 133.6021 1.0000 4060 0.0025 0.9718Oml 289 0.6746 2312 1874 141.6499 1.0000 4831 0.0024 0.9716Oml 290 0.5983 2319 1829 152.3543 1.0000 4025 0.0015 0.9817Oml 291 0.6694 1957 1569 114.9293 1.0000 3954 0.0027 0.9700Oml 292 0.6820 2197 1805 153.5596 1.0000 4765 0.0025 0.9711Oml 293 0.5610 2006 1601 97.1879 1.0000 3337 0.0014 0.9843Oml 294 0.6578 1931 1550 105.8837 1.0000 3825 0.0026 0.9715Oml 295 0.6691 2322 1904 129.0378 1.0000 4895 0.0022 0.9730Oml 296 0.6674 1970 1550 130.9973 1.0000 3836 0.0027 0.9695Oml 297 0.6747 2278 1813 150.8252 1.0000 4605 0.0025 0.9707
Table 15. Fitting of right-truncated zeta distribution of Marathi language: Social science.
Text no. a R df w2 P(w2) N RR RRrel
SS 11 0.7733 1345 1179 136.5715 1.0000 3975 0.0055 0.9518SS 15 0.7096 1947 1646 123.8193 1.0000 4693 0.0032 0.9651SS 16 0.6563 1831 1477 119.6039 1.0000 3642 0.0024 0.9735SS 17 0.6718 1853 1580 130.5232 1.0000 4170 0.0024 0.9738SS 18 0.7034 1788 1474 117.2094 1.0000 4062 0.0034 0.9648SS 20 0.6821 1725 1466 148.0501 1.0000 3943 0.0026 0.9728SS 21 0.6565 1793 1513 142.7033 1.0000 3846 0.0022 0.9764SS 22 0.7298 1703 1405 125.3688 1.0000 4099 0.0040 0.9599SS 23 0.6821 1872 1559 142.8164 1.0000 4142 0.0026 0.9720SS 24 0.6935 1731 1515 133.8091 1.0000 4255 0.0028 0.9709
Table 16. Fitting of right-truncated zeta distribution of Telugu language: Aesthetics.
Text no. a R df w2 P(w2) N RR RRrel
Aes 106 0.7096 2233 1835 125.9083 1.0000 5141 0.0035 0.9614Aes 107 0.6603 2073 1728 124.2996 1.0000 4403 0.0023 0.9734Aes 108 0.6037 3291 2630 161.5542 1.0000 5912 0.0013 0.9809Aes 109 0.5771 2972 2216 278.7088 1.0000 4556 0.0018 0.9752Aes 110 0.5374 1960 1466 150.4390 1.0000 2853 0.0015 0.9834Aes 111 0.5650 2182 1616 186.5795 1.0000 3243 0.0018 0.9784Aes 112 0.4825 1371 1042 76.4460 1.0000 1909 0.0015 0.9874Aes 118 0.5292 3118 2342 212.4652 1.0000 4535 0.0010 0.9862Aes 123 0.4809 888 676 46.1983 1.0000 1235 0.0023 0.9852Aes 124 0.6882 2533 2118 188.9467 1.0000 5755 0.0025 0.9695
302 B. D. JAYARAM & M. N. VIDYA
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014
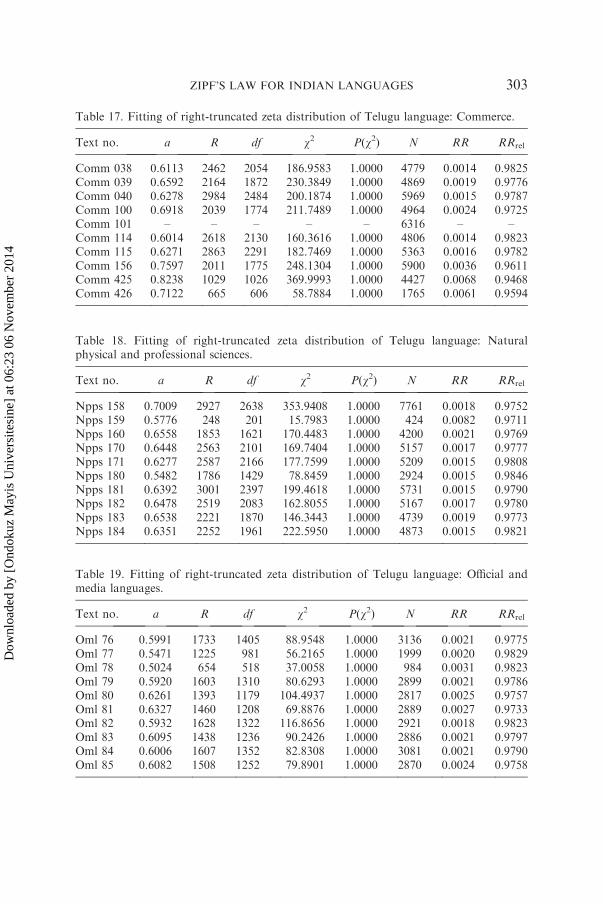
Table 17. Fitting of right-truncated zeta distribution of Telugu language: Commerce.
Text no. a R df w2 P(w2) N RR RRrel
Comm 038 0.6113 2462 2054 186.9583 1.0000 4779 0.0014 0.9825Comm 039 0.6592 2164 1872 230.3849 1.0000 4869 0.0019 0.9776Comm 040 0.6278 2984 2484 200.1874 1.0000 5969 0.0015 0.9787Comm 100 0.6918 2039 1774 211.7489 1.0000 4964 0.0024 0.9725Comm 101 – – – – – 6316 – –Comm 114 0.6014 2618 2130 160.3616 1.0000 4806 0.0014 0.9823Comm 115 0.6271 2863 2291 182.7469 1.0000 5363 0.0016 0.9782Comm 156 0.7597 2011 1775 248.1304 1.0000 5900 0.0036 0.9611Comm 425 0.8238 1029 1026 369.9993 1.0000 4427 0.0068 0.9468Comm 426 0.7122 665 606 58.7884 1.0000 1765 0.0061 0.9594
Table 18. Fitting of right-truncated zeta distribution of Telugu language: Naturalphysical and professional sciences.
Text no. a R df w2 P(w2) N RR RRrel
Npps 158 0.7009 2927 2638 353.9408 1.0000 7761 0.0018 0.9752Npps 159 0.5776 248 201 15.7983 1.0000 424 0.0082 0.9711Npps 160 0.6558 1853 1621 170.4483 1.0000 4200 0.0021 0.9769Npps 170 0.6448 2563 2101 169.7404 1.0000 5157 0.0017 0.9777Npps 171 0.6277 2587 2166 177.7599 1.0000 5209 0.0015 0.9808Npps 180 0.5482 1786 1429 78.8459 1.0000 2924 0.0015 0.9846Npps 181 0.6392 3001 2397 199.4618 1.0000 5731 0.0015 0.9790Npps 182 0.6478 2519 2083 162.8055 1.0000 5167 0.0017 0.9780Npps 183 0.6538 2221 1870 146.3443 1.0000 4739 0.0019 0.9773Npps 184 0.6351 2252 1961 222.5950 1.0000 4873 0.0015 0.9821
Table 19. Fitting of right-truncated zeta distribution of Telugu language: Official andmedia languages.
Text no. a R df w2 P(w2) N RR RRrel
Oml 76 0.5991 1733 1405 88.9548 1.0000 3136 0.0021 0.9775Oml 77 0.5471 1225 981 56.2165 1.0000 1999 0.0020 0.9829Oml 78 0.5024 654 518 37.0058 1.0000 984 0.0031 0.9823Oml 79 0.5920 1603 1310 80.6293 1.0000 2899 0.0021 0.9786Oml 80 0.6261 1393 1179 104.4937 1.0000 2817 0.0025 0.9757Oml 81 0.6327 1460 1208 69.8876 1.0000 2889 0.0027 0.9733Oml 82 0.5932 1628 1322 116.8656 1.0000 2921 0.0018 0.9823Oml 83 0.6095 1438 1236 90.2426 1.0000 2886 0.0021 0.9797Oml 84 0.6006 1607 1352 82.8308 1.0000 3081 0.0021 0.9790Oml 85 0.6082 1508 1252 79.8901 1.0000 2870 0.0024 0.9758
ZIPF’S LAW FOR INDIAN LANGUAGES 303
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014

distribution must be expressible by means of some functions, e.g.moments. But in long-tail data like word frequencies, moments are notvery useful as characteristics. Hence we try to find a simple function ofthe empirical data which could be associated with the parameter a. Tothis end we consider the relative repeat rate as given in equation (2) andempirically in the last columns of all tables.If one inserts the points in a co-ordinate system, one sees at once that a
is evidently linked with RRrel. The supposed dependence has the form ofa concave monotone decreasing curve. In order to obtain this curve weuse the Wimmer-Altmann approach of modelling and consider therelative rate of change of the dependent variable y (here a) proportionalto the change of the independent variable x (here RRrel) which has aminimum (m) and a maximum (M) and set
y0
y¼ b
x�m� a
M� xð4Þ
which results in
y ¼ CðM� xÞaðx�mÞb ð5Þ
Setting the integration constant C¼ 1 in order to save a parameter wecan get different curves according to our aim. If we insert the empiricalminimum and maximum of RRrel we obtain
y ¼ ð0:993� xÞ0:1478ðx� 0:915Þ�0:0532
yielding a determination coefficient D¼ 0.885.
Table 20. Fitting of right-truncated zeta distribution of Telugu language: Social science.
Text no. a R df w2 P(w2) N RR RRrel
SS 113 0.4925 1040 797 59.3842 1.0000 1480 0.0020 0.9862SS 116 0.6069 4454 3555 270.4227 1.0000 8052 0.0010 0.9836SS 117 0.4716 1133 871 53.6187 1.0000 1581 0.0017 0.9877SS 119 0.4953 1782 1382 84.0987 1.0000 2593 0.0013 0.9880SS 120 0.5855 3774 2936 234.6003 1.0000 6306 0.0010 0.9843SS 121 0.5691 3971 3074 222.8190 1.0000 6416 0.0010 0.9844SS 122 0.6108 3920 3092 236.1613 1.0000 6990 0.0012 0.9816SS 139 0.6076 1535 1253 99.6624 1.0000 2843 0.0021 0.9797SS 153 0.6362 2436 1958 159.4437 1.0000 4665 0.0017 0.9782SS 154 0.4634 2335 1972 88.0498 1.0000 3628 0.0008 0.9929
304 B. D. JAYARAM & M. N. VIDYA
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014
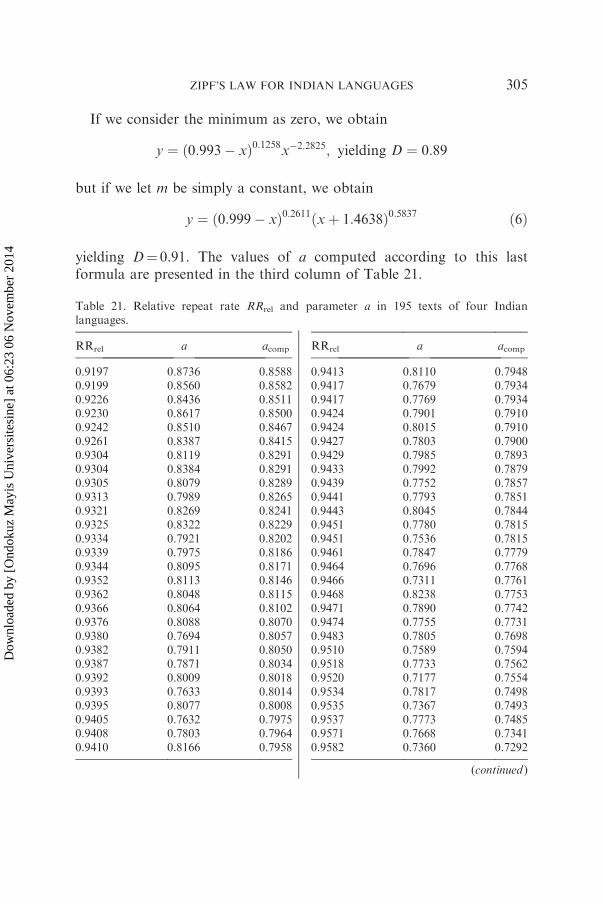
If we consider the minimum as zero, we obtain
y ¼ ð0:993� xÞ0:1258x�2:2825; yielding D ¼ 0:89
but if we let m be simply a constant, we obtain
y ¼ ð0:999� xÞ0:2611ðxþ 1:4638Þ0:5837 ð6Þ
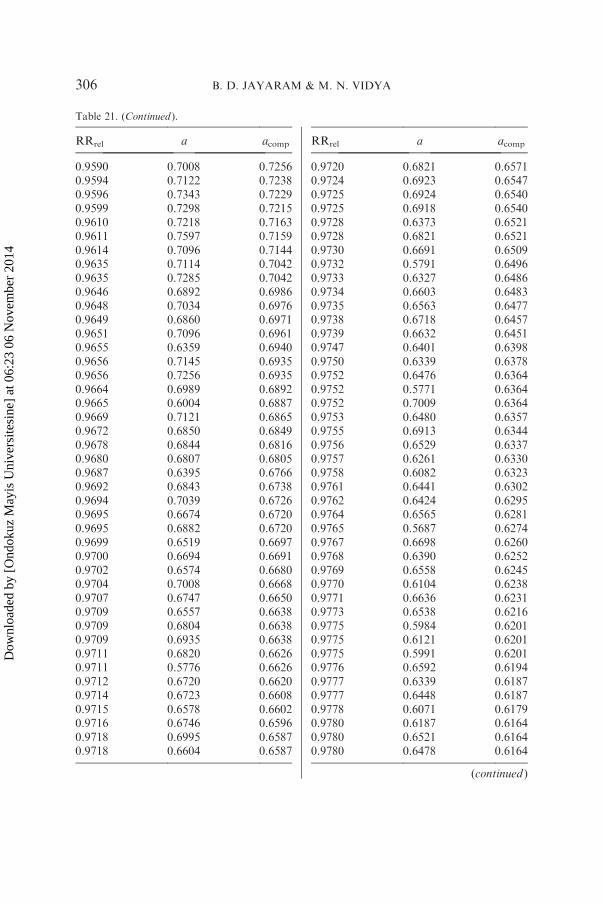
yielding D¼ 0.91. The values of a computed according to this lastformula are presented in the third column of Table 21.
Table 21. Relative repeat rate RRrel and parameter a in 195 texts of four Indianlanguages.
RRrel a acomp
0.9197 0.8736 0.85880.9199 0.8560 0.85820.9226 0.8436 0.85110.9230 0.8617 0.85000.9242 0.8510 0.84670.9261 0.8387 0.84150.9304 0.8119 0.82910.9304 0.8384 0.82910.9305 0.8079 0.82890.9313 0.7989 0.82650.9321 0.8269 0.82410.9325 0.8322 0.82290.9334 0.7921 0.82020.9339 0.7975 0.81860.9344 0.8095 0.81710.9352 0.8113 0.81460.9362 0.8048 0.81150.9366 0.8064 0.81020.9376 0.8088 0.80700.9380 0.7694 0.80570.9382 0.7911 0.80500.9387 0.7871 0.80340.9392 0.8009 0.80180.9393 0.7633 0.80140.9395 0.8077 0.80080.9405 0.7632 0.79750.9408 0.7803 0.79640.9410 0.8166 0.7958
RRrel a acomp
0.9413 0.8110 0.79480.9417 0.7679 0.79340.9417 0.7769 0.79340.9424 0.7901 0.79100.9424 0.8015 0.79100.9427 0.7803 0.79000.9429 0.7985 0.78930.9433 0.7992 0.78790.9439 0.7752 0.78570.9441 0.7793 0.78510.9443 0.8045 0.78440.9451 0.7780 0.78150.9451 0.7536 0.78150.9461 0.7847 0.77790.9464 0.7696 0.77680.9466 0.7311 0.77610.9468 0.8238 0.77530.9471 0.7890 0.77420.9474 0.7755 0.77310.9483 0.7805 0.76980.9510 0.7589 0.75940.9518 0.7733 0.75620.9520 0.7177 0.75540.9534 0.7817 0.74980.9535 0.7367 0.74930.9537 0.7773 0.74850.9571 0.7668 0.73410.9582 0.7360 0.7292
(continued )
ZIPF’S LAW FOR INDIAN LANGUAGES 305
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014
RRrel a acomp
0.9590 0.7008 0.72560.9594 0.7122 0.72380.9596 0.7343 0.72290.9599 0.7298 0.72150.9610 0.7218 0.71630.9611 0.7597 0.71590.9614 0.7096 0.71440.9635 0.7114 0.70420.9635 0.7285 0.70420.9646 0.6892 0.69860.9648 0.7034 0.69760.9649 0.6860 0.69710.9651 0.7096 0.69610.9655 0.6359 0.69400.9656 0.7145 0.69350.9656 0.7256 0.69350.9664 0.6989 0.68920.9665 0.6004 0.68870.9669 0.7121 0.68650.9672 0.6850 0.68490.9678 0.6844 0.68160.9680 0.6807 0.68050.9687 0.6395 0.67660.9692 0.6843 0.67380.9694 0.7039 0.67260.9695 0.6674 0.67200.9695 0.6882 0.67200.9699 0.6519 0.66970.9700 0.6694 0.66910.9702 0.6574 0.66800.9704 0.7008 0.66680.9707 0.6747 0.66500.9709 0.6557 0.66380.9709 0.6804 0.66380.9709 0.6935 0.66380.9711 0.6820 0.66260.9711 0.5776 0.66260.9712 0.6720 0.66200.9714 0.6723 0.66080.9715 0.6578 0.66020.9716 0.6746 0.65960.9718 0.6995 0.65870.9718 0.6604 0.6587
RRrel a acomp
0.9720 0.6821 0.65710.9724 0.6923 0.65470.9725 0.6924 0.65400.9725 0.6918 0.65400.9728 0.6373 0.65210.9728 0.6821 0.65210.9730 0.6691 0.65090.9732 0.5791 0.64960.9733 0.6327 0.64860.9734 0.6603 0.64830.9735 0.6563 0.64770.9738 0.6718 0.64570.9739 0.6632 0.64510.9747 0.6401 0.63980.9750 0.6339 0.63780.9752 0.6476 0.63640.9752 0.5771 0.63640.9752 0.7009 0.63640.9753 0.6480 0.63570.9755 0.6913 0.63440.9756 0.6529 0.63370.9757 0.6261 0.63300.9758 0.6082 0.63230.9761 0.6441 0.63020.9762 0.6424 0.62950.9764 0.6565 0.62810.9765 0.5687 0.62740.9767 0.6698 0.62600.9768 0.6390 0.62520.9769 0.6558 0.62450.9770 0.6104 0.62380.9771 0.6636 0.62310.9773 0.6538 0.62160.9775 0.5984 0.62010.9775 0.6121 0.62010.9775 0.5991 0.62010.9776 0.6592 0.61940.9777 0.6339 0.61870.9777 0.6448 0.61870.9778 0.6071 0.61790.9780 0.6187 0.61640.9780 0.6521 0.61640.9780 0.6478 0.6164
(continued )
Table 21. (Continued ).
306 B. D. JAYARAM & M. N. VIDYA
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014

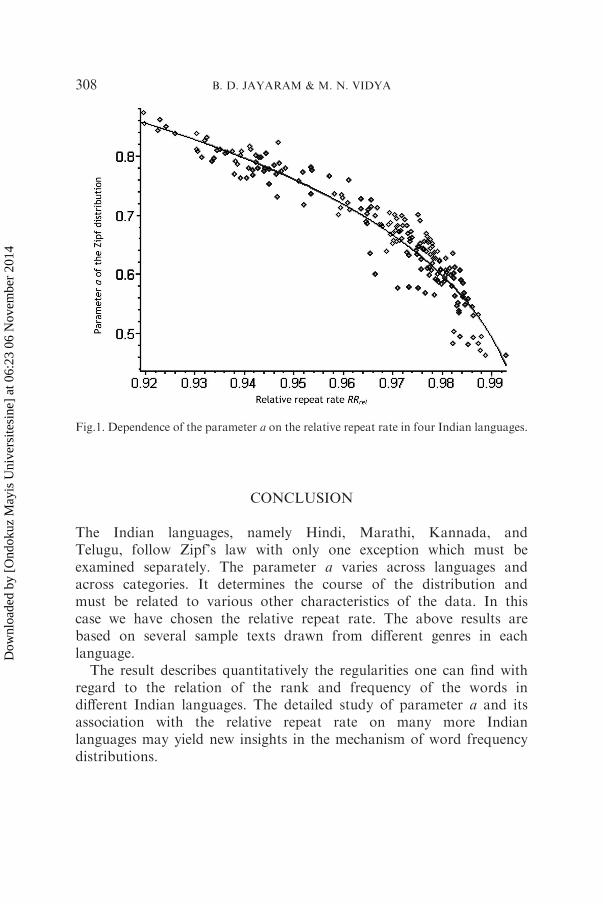
The graphical representation can be found in Figure 1.We suppose that if a rank-frequency distribution of words follows the
Zipf (zeta) distribution, then its parameter a can be estimated for anylanguage from formula (6) by simply substituting the value of the relativerepeat rate of the sample for x. This is a different approach to theestimation but it shows at the same time that the characteristics of arank-frequency distribution must be interrelated.
RRrel a acomp
0.9782 0.6271 0.61490.9782 0.6362 0.61490.9784 0.6370 0.61340.9784 0.5650 0.61340.9786 0.5920 0.61190.9787 0.6278 0.61110.9790 0.5900 0.60880.9790 0.6392 0.60880.9790 0.6006 0.60880.9792 0.5863 0.60720.9795 0.6221 0.60490.9795 0.6246 0.60490.9797 0.6095 0.60330.9797 0.6076 0.60330.9798 0.5836 0.60250.9805 0.5931 0.59680.9806 0.5888 0.59600.9808 0.6070 0.59430.9808 0.5979 0.59430.9808 0.6277 0.59430.9809 0.6037 0.59350.9816 0.6108 0.58750.9817 0.5983 0.58660.9820 0.5806 0.58400.9821 0.6351 0.58310.9822 0.4824 0.58230.9823 0.6014 0.58140.9823 0.5024 0.58140.9823 0.5932 0.58140.9825 0.5640 0.57960.9825 0.6113 0.57960.9829 0.5471 0.5759
RRrel a acomp
0.9831 0.5516 0.57410.9834 0.5350 0.57130.9834 0.5374 0.57130.9836 0.6069 0.56940.9837 0.4940 0.56850.9838 0.5910 0.56750.9843 0.5610 0.56270.9843 0.5855 0.56270.9844 0.5691 0.56170.9846 0.5482 0.55970.9852 0.5589 0.55360.9852 0.4809 0.55360.9860 0.5457 0.54520.9862 0.5292 0.54300.9862 0.4925 0.54300.9874 0.5323 0.52940.9874 0.4825 0.52940.9877 0.4716 0.52590.9880 0.4953 0.52220.9887 0.4626 0.51350.9929 0.4634 0.4485
Table 21. (Continued ).
ZIPF’S LAW FOR INDIAN LANGUAGES 307
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014
CONCLUSION
The Indian languages, namely Hindi, Marathi, Kannada, andTelugu, follow Zipf’s law with only one exception which must beexamined separately. The parameter a varies across languages andacross categories. It determines the course of the distribution andmust be related to various other characteristics of the data. In thiscase we have chosen the relative repeat rate. The above results arebased on several sample texts drawn from different genres in eachlanguage.The result describes quantitatively the regularities one can find with
regard to the relation of the rank and frequency of the words indifferent Indian languages. The detailed study of parameter a and itsassociation with the relative repeat rate on many more Indianlanguages may yield new insights in the mechanism of word frequencydistributions.
Fig.1. Dependence of the parameter a on the relative repeat rate in four Indian languages.
308 B. D. JAYARAM & M. N. VIDYA
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014

REFERENCES
Baayen, R. H. (2001). Word Frequency Studies. Dordrecht: Kluwer.Barker, M. A., Hamdani, J. H., & Dihlavi, K. M. S. (1969). An Urdu Newspaper Word
Count. Montreal: Institute of Islamic Studies, McGill University.Dabbs, J. A. (1966). Word Frequencies in Newspaper Bengali. Texas: A & M
University.Estoup, J. B. (1916). Gammes stenographiques. Methode et exercises pour l’acquisition de
la vitesse. Paris: Institut stenographique.Ghatage, A. M. (Ed.) (1964). Phonemic and Morphemic Frequencies in Hindi. Poona:
Deccan College Postgraduate and Research Institute.Ghatage, A. M. (1994). Phonemic and Morphemic Frequency Count in Malayalam.
Mysore: Ciil.Glottometrics 3–5. (2002). To Honor G. K. Zipf. Ludenscheid: RAM.Jayaram, B. D. (2005). Corpora in Indian languages. In G. Altmann, V. Levickij & V.
Perebyinis (Eds), Problems of Quantitative Linguistics (pp. 323–329). Chernivcy:Ruta.
Jayaram, B. D., & Rajyashree, K. S. (2001). Indian language corpora development. Paperpresented in Language Engineering in South Asian Languages, NCST, Mumbai,India, 23–25 April 2001.
Kelkar, A. R. (1994). Phonemic and Morphemic Frequency Count in Oriya. Mysore:Ciil.
Kohler, R. (1995). Bibliography of Quantitative Linguistics. Amsterdam: Benjamins.McIntosh, R. P. (1967). An index of diversity and the relation to certain concepts of
diversity. Ecology, 48, 392–404.Pandit, P. W. (1965). Phonemic and Morphemic Frequencies of the Gujarati Language.
Poona: Deccan College Postgraduate and Research Institute.Zipf, G. K. (1935). The Psycho-biology of Language. Boston: Houghton Mifflin.Zipf, G. K. (1949). Human Behavior and the Principle of the Least Effort. An Introduction
to Human Ecology. New York: Hafner.
ZIPF’S LAW FOR INDIAN LANGUAGES 309
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014
APPENDIX: AN EXAMPLE OF FITTING
X(i) f(i) Nf(i)
1 100 177.1312 75 102.5093 74 74.44194 67 59.32445 59 49.74696 58 43.08127 53 38.14728 45 34.33239 34 31.285410 32 28.789611 29 26.703912 27 24.932013 27 23.406014 26 22.076615 25 20.906916 25 19.868917 23 18.940818 21 18.105519 19 17.349320 18 16.661221 18 16.031922 17 15.454123 17 14.921524 16 14.428725 16 13.971326 16 13.545627 16 13.148228 14 12.776229 14 12.427330 14 12.099331 13 11.790332 13 11.498633 13 11.222734 12 10.961535 12 10.713636 11 10.478137 11 10.254038 11 10.040539 11 9.836840 11 9.642241 10 9.456142 10 9.2780
X(i) f(i) Nf(i)
43 10 9.107444 10 8.943645 9 8.786546 9 8.635447 9 8.490148 9 8.350249 9 8.215550 9 8.085551 9 7.960252 8 7.839153 8 7.722254 8 7.609155 8 7.499856 8 7.393957 8 7.291358 8 7.192059 8 7.095660 8 7.002161 7 6.911462 7 6.823363 7 6.737764 7 6.654565 7 6.573666 7 6.494867 7 6.418268 7 6.343669 7 6.271070 7 6.200271 7 6.131272 7 6.063973 7 5.998274 7 5.934275 7 5.871776 7 5.810677 6 5.751078 6 5.692779 6 5.635880 6 5.580181 6 5.525782 6 5.472583 6 5.420484 6 5.3694
X(i) f(i) Nf(i)
85 6 5.319586 6 5.270687 6 5.222888 6 5.175989 6 5.129990 6 5.084991 5 5.040892 5 4.997593 5 4.955094 5 4.913495 5 4.872596 5 4.832497 5 4.793198 5 4.754599 5 4.7165100 5 4.6793101 5 4.6427102 5 4.6067103 5 4.5714104 5 4.5367105 5 4.5026106 5 4.4690107 5 4.4360108 5 4.4036109 5 4.3717110 5 4.3403111 5 4.3094112 5 4.2790113 5 4.2491114 5 4.2197115 5 4.1907116 5 4.1621117 5 4.1340118 5 4.1064119 5 4.0791120 5 4.0523121 4 4.0258122 4 3.9998123 4 3.9741124 4 3.9488125 4 3.9238126 4 3.8992
(continued )
310 B. D. JAYARAM & M. N. VIDYA
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014
X(i) f(i) Nf(i)
127 4 3.8750128 4 3.8511129 4 3.8275130 4 3.8043131 4 3.7813132 4 3.7587133 4 3.7364134 4 3.7144135 4 3.6926136 4 3.6712137 4 3.6500138 4 3.6292139 4 3.6085140 4 3.5882141 4 3.5681142 4 3.5482143 4 3.5287144 4 3.5093145 4 3.4902146 4 3.4713147 4 3.4527148 4 3.4343149 4 3.4161150 4 3.3981151 4 3.3803152 4 3.3627153 4 3.3454154 4 3.3282155 4 3.3113156 4 3.2945157 4 3.2779158 4 3.2616159 3 3.2454160 3 3.2294161 3 3.2135162 3 3.1979163 3 3.1824164 3 3.1670165 3 3.1519166 3 3.1369167 3 3.1221168 3 3.1074169 3 3.0929170 3 3.0785
X(i) f(i) Nf(i)
171 3 3.0643172 3 3.0502173 3 3.0363174 3 3.0225175 3 3.0089176 3 2.9954177 3 2.9820178 3 2.9688179 3 2.9557180 3 2.9428181 3 2.9299182 3 2.9172183 3 2.9046184 3 2.8922185 3 2.8798186 3 2.8676187 3 2.8555188 3 2.8435189 3 2.8316190 3 2.8198191 3 2.8082192 3 2.7966193 3 2.7852194 3 2.7739195 3 2.7626196 3 2.7515197 3 2.7405198 3 2.7296199 3 2.7187200 3 2.7080201 3 2.6974202 3 2.6868203 3 2.6764204 3 2.6660205 3 2.6557206 3 2.6456207 3 2.6355208 3 2.6255209 3 2.6156210 3 2.6057211 3 2.596212 3 2.5863213 3 2.5767214 3 2.5672
X(i) f(i) Nf(i)
215 3 2.5578216 3 2.5484217 3 2.5392218 3 2.5300219 3 2.5209220 3 2.5118221 3 2.5028222 3 2.4939223 3 2.4851224 3 2.4764225 3 2.4677226 3 2.4590227 2 2.4505228 2 2.4420229 2 2.4336230 2 2.4252231 2 2.4169232 2 2.4087233 2 2.4006234 2 2.3925235 2 2.3844236 2 2.3765237 2 2.3685238 2 2.3607239 2 2.3529240 2 2.3451241 2 2.3375242 2 2.3298243 2 2.3223244 2 2.3148245 2 2.3073246 2 2.2999247 2 2.2925248 2 2.2852249 2 2.2780250 2 2.2708251 2 2.2637252 2 2.2566253 2 2.2495254 2 2.2425255 2 2.2356256 2 2.2287257 2 2.2219258 2 2.2151
(continued )
Appendix (Continued ).
ZIPF’S LAW FOR INDIAN LANGUAGES 311
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014
X(i) f(i) Nf(i)
259 2 2.2083260 2 2.2016261 2 2.1950262 2 2.1883263 2 2.1818264 2 2.1752265 2 2.1688266 2 2.1623267 2 2.1559268 2 2.1496269 2 2.1433270 2 2.1370271 2 2.1308272 2 2.1246273 2 2.1185274 2 2.1124275 2 2.1063276 2 2.1003277 2 2.0943278 2 2.0883279 2 2.0824280 2 2.0766281 2 2.0707282 2 2.0649283 2 2.0592284 2 2.0534285 2 2.0478286 2 2.0421287 2 2.0365288 2 2.0309289 2 2.0254290 2 2.0199291 2 2.0144292 2 2.0089293 2 2.0035294 2 1.9981295 2 1.9928296 2 1.9875297 2 1.9822298 2 1.9769299 2 1.9717300 2 1.9665301 2 1.9614
X(i) f(i) Nf(i)
302 2 1.9563303 2 1.9512304 2 1.9461305 2 1.9411306 2 1.9360307 2 1.9311308 2 1.9261309 2 1.9212310 2 1.9163311 2 1.9114312 2 1.9066313 2 1.9018314 2 1.8970315 2 1.8923316 2 1.8875317 2 1.8828318 2 1.8782319 2 1.8735320 2 1.8689321 2 1.8643322 2 1.8597323 2 1.8552324 2 1.8507325 2 1.8462326 2 1.8417327 2 1.8373328 2 1.8328329 2 1.8284330 2 1.8241331 2 1.8197332 2 1.8154333 2 1.8111334 2 1.8068335 2 1.8026336 2 1.7983337 2 1.7941338 2 1.7899339 2 1.7857340 2 1.7816341 2 1.7775342 2 1.7734343 2 1.7693344 2 1.7652
X(i) f(i) Nf(i)
345 2 1.7612346 2 1.7572347 2 1.7532348 2 1.7492349 2 1.7453350 2 1.7413351 2 1.7374352 2 1.7335353 2 1.7296354 2 1.7258355 1 1.7219356 1 1.7181357 1 1.7143358 1 1.7105359 1 1.7068360 1 1.7030361 1 1.6993362 1 1.6956363 1 1.6919364 1 1.6883365 1 1.6846366 1 1.6810367 1 1.6774368 1 1.6738369 1 1.6702370 1 1.6666371 1 1.6631372 1 1.6595373 1 1.6560374 1 1.6525375 1 1.6491376 1 1.6456377 1 1.6421378 1 1.6387379 1 1.6353380 1 1.6319381 1 1.6285382 1 1.6252383 1 1.6218384 1 1.6185385 1 1.6152386 1 1.6119387 1 1.6086
(continued )
Appendix (Continued ).
312 B. D. JAYARAM & M. N. VIDYA
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014
X(i) f(i) Nf(i)
388 1 1.6053389 1 1.6020390 1 1.5988391 1 1.5956392 1 1.5924393 1 1.5892394 1 1.5860395 1 1.5828396 1 1.5797397 1 1.5765398 1 1.5734399 1 1.5703400 1 1.5672401 1 1.5641402 1 1.5610403 1 1.5580404 1 1.5549405 1 1.5519406 1 1.5489407 1 1.5459408 1 1.5429409 1 1.5399410 1 1.5369411 1 1.5340412 1 1.5310413 1 1.5281414 1 1.5252415 1 1.5223416 1 1.5194417 1 1.5165418 1 1.5137419 1 1.5108420 1 1.5080421 1 1.5052422 1 1.5023423 1 1.4995424 1 1.4968425 1 1.4940426 1 1.4912427 1 1.4885428 1 1.4857429 1 1.4830430 1 1.4803
X(i) f(i) Nf(i)
431 1 1.4775432 1 1.4748433 1 1.4722434 1 1.4695435 1 1.4668436 1 1.4642437 1 1.4615438 1 1.4589439 1 1.4563440 1 1.4536441 1 1.4510442 1 1.4484443 1 1.4459444 1 1.4433445 1 1.4407446 1 1.4382447 1 1.4356448 1 1.4331449 1 1.4306450 1 1.4281451 1 1.4256452 1 1.4231453 1 1.4206454 1 1.4182455 1 1.4157456 1 1.4132457 1 1.4108458 1 1.4084459 1 1.4060460 1 1.4035461 1 1.4011462 1 1.3987463 1 1.3964464 1 1.3940465 1 1.3916466 1 1.3893467 1 1.3869468 1 1.3846469 1 1.3822470 1 1.3799471 1 1.3776472 1 1.3753473 1 1.3730
X(i) f(i) Nf(i)
474 1 1.3707475 1 1.3684476 1 1.3662477 1 1.3639478 1 1.3617479 1 1.3594480 1 1.3572481 1 1.3550482 1 1.3527483 1 1.3505484 1 1.3483485 1 1.3461486 1 1.3439487 1 1.3418488 1 1.3396489 1 1.3374490 1 1.3353491 1 1.3331492 1 1.3310493 1 1.3289494 1 1.3267495 1 1.3246496 1 1.3225497 1 1.3204498 1 1.3183499 1 1.3162500 1 1.3142501 1 1.3121502 1 1.3100503 1 1.3080504 1 1.3059505 1 1.3039506 1 1.3019507 1 1.2998508 1 1.2978509 1 1.2958510 1 1.2938511 1 1.2918512 1 1.2898513 1 1.2878514 1 1.2858515 1 1.2839516 1 1.2819
(continued )
Appendix (Continued ).
ZIPF’S LAW FOR INDIAN LANGUAGES 313
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014
X(i) f(i) Nf(i)
517 1 1.2800518 1 1.2780519 1 1.2761520 1 1.2741521 1 1.2722522 1 1.2703523 1 1.2683524 1 1.2664525 1 1.2645526 1 1.2626527 1 1.2607528 1 1.2589529 1 1.2570530 1 1.2551531 1 1.2532532 1 1.2514533 1 1.2495534 1 1.2477535 1 1.2458536 1 1.2440537 1 1.2422538 1 1.2404539 1 1.2385540 1 1.2367541 1 1.2349542 1 1.2331543 1 1.2313544 1 1.2296545 1 1.2278546 1 1.2260547 1 1.2242548 1 1.2225549 1 1.2207550 1 1.219551 1 1.2172552 1 1.2155553 1 1.2137554 1 1.2120555 1 1.2103556 1 1.2086557 1 1.2069558 1 1.2051559 1 1.2034
X(i) f(i) Nf(i)
560 1 1.2018561 1 1.2001562 1 1.1984563 1 1.1967564 1 1.1950565 1 1.1934566 1 1.1917567 1 1.1900568 1 1.1884569 1 1.1867570 1 1.1851571 1 1.1834572 1 1.1818573 1 1.1802574 1 1.1786575 1 1.1769576 1 1.1753577 1 1.1737578 1 1.1721579 1 1.1705580 1 1.1689581 1 1.1673582 1 1.1658583 1 1.1642584 1 1.1626585 1 1.1610586 1 1.1595587 1 1.1579588 1 1.1564589 1 1.1548590 1 1.1533591 1 1.1517592 1 1.1502593 1 1.1487594 1 1.1471595 1 1.1456596 1 1.1441597 1 1.1426598 1 1.1411599 1 1.1396600 1 1.1381601 1 1.1366602 1 1.1351
X(i) f(i) Nf(i)
603 1 1.1336604 1 1.1321605 1 1.1307606 1 1.1292607 1 1.1277608 1 1.1262609 1 1.1248610 1 1.1233611 1 1.1219612 1 1.1204613 1 1.1190614 1 1.1176615 1 1.1161616 1 1.1147617 1 1.1133618 1 1.1118619 1 1.1104620 1 1.1090621 1 1.1076622 1 1.1062623 1 1.1048624 1 1.1034625 1 1.1020626 1 1.1006627 1 1.0992628 1 1.0978629 1 1.0965630 1 1.0951631 1 1.0937632 1 1.0924633 1 1.0910634 1 1.0896635 1 1.0883636 1 1.0869637 1 1.0856638 1 1.0842639 1 1.0829640 1 1.0816641 1 1.0802642 1 1.0789643 1 1.0776644 1 1.0763645 1 1.0750
(continued )
Appendix (Continued ).
314 B. D. JAYARAM & M. N. VIDYA
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014
X(i) f(i) Nf(i)
646 1 1.0736647 1 1.0723648 1 1.0710649 1 1.0697650 1 1.0684651 1 1.0671652 1 1.0658653 1 1.0645654 1 1.0633655 1 1.0620656 1 1.0607657 1 1.0594658 1 1.0582659 1 1.0569660 1 1.0556661 1 1.0544662 1 1.0531663 1 1.0519664 1 1.0506665 1 1.0494666 1 1.0481667 1 1.0469668 1 1.0456669 1 1.0444670 1 1.0432671 1 1.0419672 1 1.0407673 1 1.0395674 1 1.0383675 1 1.0371676 1 1.0359677 1 1.0347678 1 1.0335679 1 1.0323680 1 1.0311681 1 1.0299682 1 1.0287683 1 1.0275684 1 1.0263685 1 1.0251686 1 1.0239687 1 1.0228688 1 1.0216
X(i) f(i) Nf(i)
689 1 1.0204690 1 1.0192691 1 1.0181692 1 1.0169693 1 1.0158694 1 1.0146695 1 1.0135696 1 1.0123697 1 1.0112698 1 1.0100699 1 1.0089700 1 1.0077701 1 1.0066702 1 1.0055703 1 1.0043704 1 1.0032705 1 1.0021706 1 1.0010707 1 0.9999708 1 0.9987709 1 0.9976710 1 0.9965711 1 0.9954712 1 0.9943713 1 0.9932714 1 0.9921715 1 0.9910716 1 0.9899717 1 0.9888718 1 0.9877719 1 0.9867720 1 0.9856721 1 0.9845722 1 0.9834723 1 0.9824724 1 0.9813725 1 0.9802726 1 0.9792727 1 0.9781728 1 0.9770729 1 0.9760730 1 0.9749731 1 0.9739
X(i) f(i) Nf(i)
732 1 0.9728733 1 0.9718734 1 0.9707735 1 0.9697736 1 0.9686737 1 0.9676738 1 0.9666739 1 0.9655740 1 0.9645741 1 0.9635742 1 0.9625743 1 0.9614744 1 0.9604745 1 0.9594746 1 0.9584747 1 0.9574748 1 0.9564749 1 0.9553750 1 0.9543751 1 0.9533752 1 0.9523753 1 0.9513754 1 0.9503755 1 0.9494756 1 0.9484757 1 0.9474758 1 0.9464759 1 0.9454760 1 0.9444761 1 0.9434762 1 0.9425763 1 0.9415764 1 0.9405765 1 0.9395766 1 0.9386767 1 0.9376768 1 0.9366769 1 0.9357770 1 0.9347771 1 0.9338772 1 0.9328773 1 0.9319774 1 0.9309
(continued )
Appendix (Continued ).
ZIPF’S LAW FOR INDIAN LANGUAGES 315
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014
X(i) f(i) Nf(i)
775 1 0.9300776 1 0.9290777 1 0.9281778 1 0.9271779 1 0.9262780 1 0.9253781 1 0.9243782 1 0.9234783 1 0.9225784 1 0.9215785 1 0.9206786 1 0.9197787 1 0.9188788 1 0.9178789 1 0.9169790 1 0.9160791 1 0.9151792 1 0.9142793 1 0.9133794 1 0.9124795 1 0.9115796 1 0.9106797 1 0.9097798 1 0.9088799 1 0.9079800 1 0.9070801 1 0.9061802 1 0.9052803 1 0.9043804 1 0.9034
X(i) f(i) Nf(i)
805 1 0.9025806 1 0.9016807 1 0.9007808 1 0.8999809 1 0.8990810 1 0.8981811 1 0.8972812 1 0.8964813 1 0.8955814 1 0.8946815 1 0.8938816 1 0.8929817 1 0.8920818 1 0.8912819 1 0.8903820 1 0.8895821 1 0.8886822 1 0.8878823 1 0.8869824 1 0.8861825 1 0.8852826 1 0.8844827 1 0.8835828 1 0.8827829 1 0.8818830 1 0.8810831 1 0.8802832 1 0.8793833 1 0.8785834 1 0.8777
X(i) f(i) Nf(i)
835 1 0.8768836 1 0.8760837 1 0.8752838 1 0.8744839 1 0.8735840 1 0.8727841 1 0.8719842 1 0.8711843 1 0.8703844 1 0.8694845 1 0.8686846 1 0.8678847 1 0.8670848 1 0.8662849 1 0.8654850 1 0.8646851 1 0.8638852 1 0.8630853 1 0.8622854 1 0.8614855 1 0.8606856 1 0.8598857 1 0.8590858 1 0.8582859 1 0.8574860 1 0.8567861 1 0.8559862 1 0.8551863 1 0.8543864 1 0.8535865 1 0.8527
Appendix (Continued ).
Sample size N¼ 2757, a¼ 0.7891, R¼ 865, DF¼ 782, X2¼ 112.24, P*1.00.
316 B. D. JAYARAM & M. N. VIDYA
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014
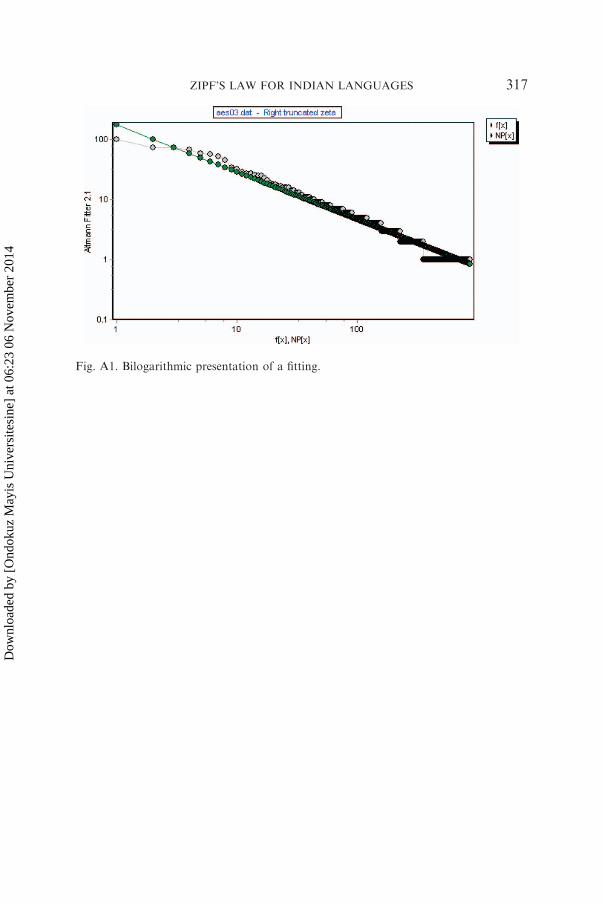
Fig. A1. Bilogarithmic presentation of a fitting.
ZIPF’S LAW FOR INDIAN LANGUAGES 317
Dow
nloa
ded
by [
Ond
okuz
May
is U
nive
rsite
sine
] at
06:
23 0
6 N
ovem
ber
2014