zbigniew s. szewczak podstawy systemów operacyjnychzssz/pso2003/wyk10/wyk10.pdf · ☛ramka ofiara...
TRANSCRIPT

Toruń, 2003
Zbigniew S. Szewczak Podstawy Systemów Operacyjnych
Wykład 10
Pamięć wirtualna.

Pamięć wirtualna
☛ Podstawy☛ Stronicowanie na żądanie☛ Sprawność stronicowania na żądanie☛ Zastępowanie stron☛ Algorytmy zastępowania stron☛ Przydział ramek☛ Szamotanie☛ Inne rozważania☛ Segmentacja na żądanie

Podstawy
☛ Wykonywane rozkazy muszą rezydować wpamięci, jednak cały program nie musi☛ programy często zawierają fragmenty obsługi sytuacji
wyjątkowych☛ tablice, listy mają zwykle nadmiar przydzielonej pamieci☛ pewne możliwości programu są rzadko stosowane
☛ Zalety programu częściowo rezydującego☛ brak ograniczeń na pamięć☛ więcej programów: lepsze wykorzystanie procesora☛ mniejsza liczba operacji we/wy dla załadowania programu
więc program wykonuje się szybciej

Podstawy (c.d.)
☛ Pamięć wirtualna (ang. virtual memory ) – pozwalana odseparowanie pamięci logicznej użytkownika odpamięci fizycznej☛ Można jedynie część programu załadować do pamięci w celu
wykonania☛ Logiczna przestrzeń adresowa procesu może dlatego być
znacznie większa niż fizyczna przestrzeń adresowa☛ Potrzeba wymiany stron między dyskiem a pamięcią
☛ Pamięć wirtualną można zaimplementować jako:☛ Stronicowanie na żądanie (ang. demand paging)☛ Segmentacja na żądanie (ang. demand segmentation) np.OS/2

Stronicowanie na żądanie
☛ Nigdy nie dokonuje się wymiany strony wpamięci jeśli nie jest to konieczne - proceduraleniwej wymiany (ang. lazy swapper)☛ Mniej operacji we/wy☛ Mniej pamięci☛ Szybsza reakcja☛ Więcej użytkowników
☛ Jeśli strona jest potrzebna ⇒ odwołaj się☛ niepoprawne odwołanie ⇒ abort☛ brak strony w pamięci ⇒ sprowadź z stronę do pamięci
☛ Zgodność z Zasadą lokalności odniesień

Stronicowanie na żądanie (c.d.)
☛ Proces jest traktowany jako ciąg stron☛ Procedura wymiany dotyczy całego procesu☛ Procedura stronicująca (ang. pager) dotyczy
poszczególnych stron procesu☛ Gdy proces ma zostać wprowadzony do pamięci,
wówczas procedura stronicująca zgaduje jakiestrony będą w użyciu przed ponownymzaładowaniem na dysk (ang. swap space)
☛ Nigdy nie dokonuje się wymiana całego procesudlatego używamy określenia stronicowanie(ang. page) zamiast wymiana (ang. swap)

Bit poprawności
☛ Z każdą pozycją w tablicy stron stowarzyszony jestbit poprawności (ang. valid-invalid bit): 1 ⇒ wpamięci, 0 ⇒ poza pamięcią
☛ Początkowo bit poprawności ustawiany jest na 0dla wszystkich pozycji
☛ Przykład 1
11
1
0
00
Μ
Nr ramki bit poprawności
tablica stron

Brak strony☛ Implementacja bitu poprawności wymaga
wsparcia ze strony sprzętu☛ Jeśli wystąpi odwołanie do strony z bitem 0,
sprzęt stronicujący spowoduje przejście dosystemu operacyjnego : błąd zwany brakiemstrony (ang. page-fault)
☛ Procedura obsługi braku strony:☛ System opercyjny sprawdza wewnętrzną tablicę oraz
decyduje że :☛ jeśli odwołanie niedozwolone - kończy proces☛ jeśli odwołanie dozwolone tylko zabrakło strony w pamięci to
sprowadza tę stronę

Brak strony (c.d.)
☛ Procedura obsługi braku strony (c.d.):☛ System znajduje wolną ramkę na liście wolnych ramek☛ System wczytuje stronę z dysku do wolnej ramki☛ System wstawia bit 1 w tablicy stron☛ System wykonuje przerwany rozkaz
☛ Czyste stronicowanie na żądanie (ang. puredemand paging): Nigdy nie sprowadzaj stronydo pamięci wcześniej niż jest to niezbędne

Co się stanie gdy zabrakniewolnej ramki?
☛ Zastąpienie strony - szukamy strony w pamięciktóra nie jest używana i zapisujemy na dyska☛ wydajność – potrzebny jest taki algorytm, który zminimalizuje
liczbę braków strony
☛ Pewne strony mogą być sprowadzane do pamięcipo kilka razy
☛ Może się okazać, że kilka stron w pamięci jestpotrzebnych do wykonania jednego rozkazu☛ MVC (przenieś znaki), EX (wykonaj)☛ sposób adresowania - np. pośrednie, autoincrement (PDP-11)☛ Wn. Sposób zastąpienia strony zależy od architektury
komputera

Sprawność stronicowania nażądanie
☛ Prawdopodobieństwo braku strony p☛ jeśli p=0 to brak braku stron☛ jeśli p=1 to każde odwołanie generuje brak strony
☛ Efektywny czas dostępu (EAT)☛ EAT = (1-p) * cd + p* czas obsługi strony☛ cd - czas dostępu do pamięci (10 do 200 ns)☛ czas obsługi strony
☛ obsługa przerwania wywołanego brakiem strony (1 do 100 µs)☛ czytanie strony☛ wznowienie procesu(1 do 100 µs)

Prefiksy metryczne
☛ 10^-3 - mili (m); 10^3 - kilo (k)☛ 10^-6 - micro (µ); 10^6 - Mega (M)☛ 10^-9 - nano (n); 10^9 - Giga (G)☛ 10^-12 - pico (p); 10^12 - Tera (T)☛ 10^-15 - femto (f); 10^15 - Peta (P)☛ 10^-18 - atto (a); 10^18 - Exa (E)☛ 10^-21 - zepto (z); 10^21 - Zetta (Z)☛ 10^-24 - yocto (y); 10^24 - Yotta (Y)

Przykłady wykorzystania
☛ 1.7 yg - masa protonu☛ 1 as - czas przejścia światła przez atom☛ 1 pg - masa bakterii☛ 1 µL - kropelka wody☛ 1 Ms - 11,6 dni☛ 0,3 Gm - sekunda świetlna☛ 9,5 Pm - rok świetlny☛ 1 ZL - objętość Pacyfiku☛ 1 YL - pojemność Ziemii

Czas obsługi braku strony☛ Przejście do systemu operacyjnego☛ Przechowanie kontekstu☛ Określenie, że przerwanie to brak strony☛ Określenie dopuszczalności i położenia strony☛ Czytanie z dysku do wolnej ramki☛ Przydzielenie procesora w trakcie transferu☛ Przerwanie we/wy po transferze strony☛ Odebranie sterowania i przełączenie kontekstu☛ Skorygowanie tablicy stron☛ Czekanie na przydział procesora i wznowienie

Stronicowanie na żądanie -przykład
☛ cd = 100 ns☛ czytanie strony z dysku twardego
☛ opóźnienie (ang. latency) - 8ms☛ przeszukiwanie (ang. seek) - 15ms☛ przesyłanie (ang. transfer) - 1ms
☛ Czytanie strony = 25 ms = 25000000ns EAT = (1 – p) *(100) + p *(25000000)
=100 + 24999900*p ns☛ Wn. EAT jest proporcjonalny do p (page-fault
rate) dlatego rozsądnym jest utrzymywaniemałego prawdopodobieństwa p braku strony

Tworzenie procesu
☛ Podczas tworzenia procesu pamięć wirtualnapozwala na realizację
☛ kopiowania przy zapisie (ang. copy-on-write)
☛ odwzorowania plików do pamięci (ang. memory-mappedfiles)
☛

Kopiowanie przy zapisie
☛ Kopiowanie przy zapisie umożliwia procesowipotomnemu jak i rodzicowi dzielenie tych samychstron w pamięci
☛ Jeśli któryś z nich modyfikuje stronę to jest onakopiowana
☛ Kopiowanie przy zapisie poprawia wydajnośćtworzenia procesów np. Linux, W2K, Solaris 2
☛ Wolne strony są alokowane z puli wyzerowanych stron(ang. zero-fill-on-demand)
☛ vfork - rodzic jest zawieszony i potomek używa jegoprzestrzeni adresowej, np. funkcja systemowa exec

Odwzorowanie plików do pamięci
☛ We/wy na pliki odwzorowane w pamięci todostęp do bloków danych dyskowychwymapowanych na strony
☛ Plik jest początkowo czytany jako żądanie strony☛ Blok danych o wielkości strony zostaje wczytany☛ Operacje we/wy na pliku to we/wy na pamięci☛ Uproszczenie dostępu do pliku, bez wywołań
systemowych read(), write()☛ Wiele procesów może korzystać z pliku dzieląc
strony w pamięci☛ Solaris 2

Zastępowanie stron
☛ Ochrona przed nadprzydziałem (ang. over-allocation) pamięci przez dodanie do obsługibraku strony możliwości zastąpienia strony (ang.page replacement).
☛ Zlokalizowanie potrzebnej strony na dysku☛ Odnalezienie wolnej ramki
☛ jeśli ramka istnieje - zostaje użyta☛ w przeciwnym razie typowanie ramki ofiary (ang. victim)☛ ramka ofiara zapisana na dysk; zmiana w tablicy stron
☛ Wczytanie potrzebnej strony☛ Wznowienie procesu

Zastępowanie stron (c.d.)
☛ Gdy nie ma wolnych ramek - potrzebne jestdwukrotne przesyłanie stron a w konsekwencjiwydłużenie efektywnego czasu dostępu
☛ Zastosowanie bitu modyfikacji(zabrudzenia)(ang. modify (dirty) bit ) do zredukowania czasudostępu - tylko strony zmodyfikowane sązapisywane na dysk

Zastępowanie stron (c.d.)
☛ Zastępowanie stron jest podstawą stronicowaniana żądanie i dopełnia rozdzielenie pamięcilogicznej od fizycznej
☛ Z pomocą tego mechanizmu otrzymujemywielką pamięć wirtualną używając mniejszejpamięci fizycznej
☛ Dwa główne problemy☛ algorytm przydziału ramek (ang. frame-allocation
algorithm)☛ algorytm zastępowania stron (ang. page-replacement
algorithm)

Algorytmy zastępowania stron
☛ Minimalizacja częstości braków stron (ang. page-fault rate)
☛ Algorytm ocenia się na podstawie wykonania go napewnym ciągu odniesień (ang. reference string) dopamięci i zsumowaniu liczby braków stron w tymciągu
☛ Dla zilustrowania algorytmów zastępowania stronbędziemy używać pamięci z trzema wolymi ramkamioraz następujacego ciągu odniesień7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1.

Algorytm zastępowania FIFO
☛ Algorytm FIFO (ang. First-In-First-Out)stowarzysza z każdą ze stron czas kiedy zostałaona sprowadzona do pamięci
☛ Jeśli trzeba zastąpić stronę to zastępowana jestnajstarsza ze stron
☛ Implementuje się za pomocą kolejek FIFO
☛ Dla ciągu odniesień z trzema ramkami mamy15 braków stron (w tym trzy początkowe brakistron)
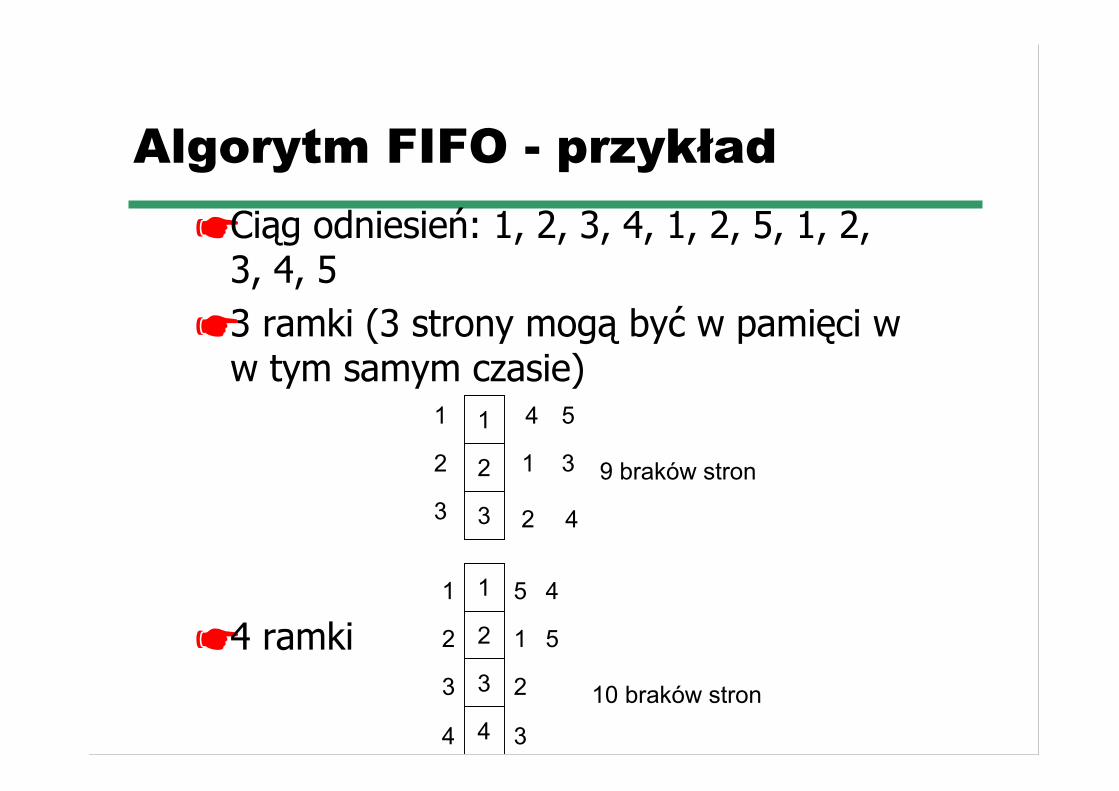
Algorytm FIFO - przykład☛ Ciąg odniesień: 1, 2, 3, 4, 1, 2, 5, 1, 2,
3, 4, 5☛ 3 ramki (3 strony mogą być w pamięci w
w tym samym czasie)
☛ 4 ramki
1
2
3
1
2
3
4
1
2
5
3
4
9 braków stron
1
2
3
1
2
3
5
1
2
4
5
10 braków stron4 34

Anomalia Belady’ego
☛ Anomalia Belady’ego (ang. Belady’s anomaly)odzwierciedla fakt, że w niektórych algorytmachzastępowania stron współczynnik braków stronmoże wzrastać ze wzrostem wolnych ramek(mimo, że intuicja zdaje się sugerować, żezwiekszenie pamięci procesu powinno polepszyćjego działanie)
☛ Poszukiwanie optymalnego algorytmuzastępowania stron, który cechuje najniższywspólczynnik braków stron

Algorytm optymalny
☛ Zastąp tę stronę, która najdłużej nie będzieużywana; nazywany OPT lub MIN
☛ Przykład 3 ramek 7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1
☛ Nie ma anomalii Belady’ego
1
2
3
7
9 page faults
0
1
2
0
1
2
0
3
2
4
3
2
0
3
2
0
1
7
0
1

Algorytm optymalny (c.d.)
☛ Bardzo trudny do realizacji bo wymaga wiedzy oprzyszłej postaci ciągu odniesień (podobnie jakprzy planowaniu procesora metodą SJF)
☛ Używany głównie w studiach porównawczych☛ wiedza o tym, że jakiś algorytm odbiega od optymalnego o
12,3% a średnio jest od niego gorszy o 4,7% może okazaćsię cenną

Algorytm LRU
☛ Zastąp tę stronę, która najdawniej była użyta(ang. Least Recently Used)
☛ Przykład 3 ramek 7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1
☛ Nie jest dotknięty anomalią Belady’ego☛ Odwracalność
1
2
3
7
12 page faults
0
1
2
0
1
2
0
3
4
0
3
4
0
2
4
3
2
0
3
2
1
3
2
1
0
2
1
0
7
1
2
3

Algorytm LRU - przykład
☛ Ciąg odniesień: 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5☛ Zastępujemy najdawniej używaną stronę
1
2
3
5
4
4 3
5

Algorytm LRU (c.d.)
☛ Dwie implementacje☛ Liczniki - do każdej pozycji w tablicy stron dołączamy rejestr
czasu użycia, do procesora zaś dodajemy zegar logiczny lublicznik. Wskazania zegara są zwiększane wraz z każdymodniesieniem do pamięci. Ilekroć występuje odniesienie dopamięci, tylekroć zawartość rejestru zegara jest kopiowana dorejestru czasu użycia należącego do danej strony w tablicy stron
☛ Stos - przy każdym odwołaniu do strony jej numer wyjmuje sięze stosu i umieszcza na szczycie - najlepsza implementacja todwukierunkowa lista ze wskaźnikami do czoła i do końca
☛ najwyżej 6 zmian wskaźników☛ nie jest potrzebne przeszukiwanie listy

Algorytmy stosowe
☛ Algorytm stosowy (ang. stack algorithm) to takialgorytm dla którego zbiór stron w pamięci wprzypadku n ramek jest podzbiorem zbioru stronw pamięci w przypadku n+1 ramek
☛ Przykład: LRU☛ Własności: klasa algorytmów stosowych nie jest
dotknięta anomalią Belady’ego

Algorytmy przybliżające LRU☛ Bit odniesienia (ang. reference bit)
☛ Z każdą stroną stowarzyszamy na początku bit 0☛ Czytanie lub pisanie na stronie ustawia bit na 1☛ Zastąp stronę stronę jeśli ma bit 0
☛ nie można poznać porządku użycia stron
☛ Algorytm drugiej szansy (ang. second chance)☛ Algorytm FIFO (wymaga zegara)☛ Gdy strona (FIFO) ma bit odniesienia = 1 to strona dostaje
drugą szansę na pobyt w pamięci:☛ bit odniesienia = 0 i czas przybycia = bieżący☛ zostawia się stronę w pamięci☛ zastępuje się następną w porządku FIFO stronę według
powyższych zasad

Ulepszony algorytm drugiejszansy☛ (x,y) - x - bit odniesienia, y- bit modyfikacji☛ 4 klasy (od najniższej)
☛ (0,0) - nie używana ostatnio i nie zmieniana: najlepszaofiara
☛ (0,1) - nie używana ostatnio ale zmieniona: gorsza ofiarabo wymaga zapisu na dysk
☛ (1,0) - używana ostatnio i czysta: może być wkrótce użyta☛ (1,1) - używana ostatnio i zmieniana - najgorsza ofiara,
prawdopodobnie będzie zaraz użyta
☛ Algorytm drugiej szansy ale zastępujemypierwszą napotkaną stronę z najniższejniepustej klasy (x,y)

Algorytmy zliczające
☛ Wprowadzamy liczniki odwołań do każdej zestron
☛ Algorytm LFU (ang. least frequently used) -zastąp stronę najrzadziej używaną
☛ Algorytm MFU (ang. most frequently used) -uzasadnia się tym, że strona z najmniejsząwartością licznika została prawdopodobniedopiero co sprowadzona i będzie jeszczeużywana
☛ Implementacja kosztowana i nie przybliżajądobrze algorytmu OPT

Algorytmy buforowania stron
☛ Zanim usunie się z pamięci ramkę ofiarę wczytuje sięnową stronę do którejś z wolnych ramek
☛ Nie trzeba czekać na zakończenie zapisywania stronyofiary aby wznowić proces
☛ Z chwilą zapisania do swapu ramki ofiary dołączanajest ona do listy wolnych ramek
☛ Rozwinięcie tej idei: lista zmodyfikowanych stron☛ gdy urządzenie stronicujące jest wolne (ang. idle) zmodyfikowna
strona jest zapisywana na dysk
☛ Lista wolnych stron wraz listą odwiedzających stron☛ VAX/VMS - ramka ofiara (FIFO) może być użyta

Przydział ramek
☛ Każdy proces wymaga minimalnej liczby ramek☛ Przykład: IBM 370 – 6 ramek potrzebnych do
wykonania rozkazu typu SS MVC:☛ rozkaz długośći 6 bajtów może zajmować 2 strony☛ dane wejściowe (256 znaków) mogą zajmować 2 strony☛ obszar na który przesyłamy może zajmować 2 strony☛ gdy MVC jest argumentem rozkazu EXECUTE jeszcze 2!
☛ Dwa główne schematy przydziału☛ przydział stały (ang. fixed allocation)☛ przydział priorytetowy (ang. priority allocation)

MVC - Move Characters
☛ MVC D1(L,B1), D2(B2)☛ prześlij pole danych o długości L z pod adresu
wyznaczonego przez zawartość rejestru B2 powiększonegoo przesunięcie D2 pod adres (B1)+D1
☛ Przykład☛ L=08, B1=x’B’, D1=001,B2=x’B’,D2=000☛ MVC 1(8,11), 0(11) - format Assemblera☛ D207B001B000 - format maszynowy☛ rejestr 11 zawiera x’358’; pod adresem 358 mamy:
00F1F2F3F4F5F6F7F8F9☛ po wykonaniu MVC mamy pod adresem 358 :
000000000000000000

EX - Execute
☛ EX R1, D2(X2,B2)☛ do bitów 8-15 rozkazu z pod adresu (X2)+(B2)+D2 są
dodawane logicznie bity 24-31 rejestru R1 i takzmodyfikowany rozkaz jest wykonywany
☛ Przykład☛ pod adresem 3820 mamy D2FFB001B000; R11=x’358’,
pod adresem 358 mamy 00F1F2F3F4F5F6F7F8F9☛ R1=3, X2=0, B2=x’A’, D2=000, R10 = x’00003820’☛ EX 1,0(0,10) - format Assemblera☛ 4410A000 - format maszynowy☛ po wykonaniu EX mamy pod adresem 358:
0000000000F5F6F7F8

Przydział stały
☛ Przydział równy (ang. equal allocation) - np. jeślimamy 100 ramek i 5 procesów, to każdy procesmoże dostać 20 ramek
☛ Przydział proporcjonalny (ang. proportionalallocation) - każdemu procesowi przydziela siędostępną pamięć proporcjonalnie do jegorozmiaru

Przydział proporcjonalny
☛ Przykład☛ s(i) rozmiar pamięci wirtualnej procesu P(i)☛ S = s(1)+s(2)+....+s(n)☛ m - całkowita liczba ramek☛ procesowi P(i) przydzielamy a(i)~ m*(s(i)/S) ramek
☛ m=64,n=2, s(1)=10, s(2)=127☛ a(1)= 64*(10/137) ~ 5 ramek☛ a(2)= 64*(127/137) ~ 59 ramek

Przydział priorytetowy
☛ Zastosowanie metody przydziałuproporcjonalnego, w którym liczba ramek zależynie od względnych rozmiarów procesu, lecz odpriorytetów procesów albo od kombinacjirozmiaru i priorytetu
☛ Jeśli proces Pi generuje błąd braku strony☛ wybierz do zastąpienia jedną z jego ramek☛ wybierz do zastąpienia ramkę procesu o niższym
priorytecie

Porównanie przydziaługlobalnego i lokalnego
☛ Zastępowanie globalne (ang. globalreplacement) – umożliwia procesom wybórramki ze zbioru wszystkich ramek, nawet gdyramka jest w danej chwili przydzielona doinnego procesu: jeden proces może zabraćramkę drugiemu procesowi
☛ Zastępowanie lokalne (ang. local replacement) –wybór ograniczony do zbioru ramekprzydzielonych do danego procesu
☛ Lepszą przepustowość systemu daje globalne -zastępowanie lokalne ma mniejszy zakres

Szamotanie
☛ Jeśli proces nie ma “wystarczająco dość” ramekto współczynnik braków stron jest znaczny.Powoduje to:☛ słabe wykorzystanie CPU☛ system operacyjny reaguje: trzeba zwiększyć
wieloprogramowość i podnieść wykorzystanie CPU☛ nowy procesy z kolejki procesów gotowych staje się
aktywnym
☛ Szamotanie (ang. trashing) - proces się szamocejeśli spędza więcej czasu na stronicowaniu niżna wykonaniu

Przyczyna szamotania
☛ System operacyjny nadzoruje wykorzystaniejednostki centralnej
☛ Jeśli jest ono za małe planista przydziałuprocesora zwiększa stopień wieloprogramowości
☛ Strony zastępowane są według globalnegoalgorytmu bez brania po uwagę do jakichprocesów należą
☛ Procesom zaczyna brakować stron☛ Procesy ustawiają się w kolejce do urządzenia
stronicującego☛ Planista opróżnia kolejkę procesów gotowych

Powstrzymanie szamotania
☛ Zmniejszenie stopnia wieloprogramowości☛ Lokalny (lub priorytetowy) algorytm
zastępowania☛ jeśli proces zaczyna się szamotać nie może on kraść ramek
innemu procesowi bo może on też zacząć się szamotać
☛ Trzeba dostarczyć procesowi potrzebne ramki☛ Należy zabezpieczyć się przed możliwością
wystapienia braku ramek

Model strefowy a chaos☛ Model strefowy (ang. locality model) zakłada, że
w trakcie wykonania przechodzi się z jednejstrefy programu do innej, gdzie przez strefęprogramu rozumie się zbiór stron pozostajacychwe wspólnym użyciu
☛ Ogólnie ujmując, program składa się z wieluróżnych stref, które mogą na siebie zachodzić
☛ Strefy programu są określne przez jegostrukturę oraz strukturę jego danych
☛ Model strefowy neguje losowość programów☛ System operacyjny nie radzi sobie z chaosem

Model zbioru roboczego☛ Założenie: procesy mają charakter strefowy☛ D - parametr do definiowania okna roboczego
(ang. working-set window) oznaczający ustalonąliczbę ostatnich odniesień do stron
☛ WS(i) - zbiór roboczy (ang. working-set)procesu P(i) - całkowita liczba odniesień dostron w ostatnich D jednostkach czasu☛ za małe D nie obejmie całego zbioru roboczego☛ za duże D to będzie zachodzić na kilka stref programu☛ nieskończone D - wszystkie strony użyte przez proces
☛ Szamotanie jeśli WS(1)+..+WS(n) > #(pamięć)- należy zawiesić w takiej sytuacji jakiś proces

Utrzymanie śladu zbioruroboczego
☛ Trudno jest utrzymać ślad zbioru roboczego☛ Model zbioru roboczego można przybliżać z
pomocą zegara generującego przerwania wstałych odstępach czasu oraz bitu odniesienia
☛ Przykład D=10000☛ przerwania zegarowe co 5000 odniesień☛ dwa bity przechowywane w pamięci dla każdej strony☛ po wystąpieniu przerwania zegara kopiuje się i zeruje
wartości bitów odniesień wszystkich stron☛ jeśli wystąpi brak strony to badamy bit odniesienia i dwa
bity w pamięci: conajmiej jeden ustawiony bit określazbiór roboczy

Utrzymanie śladu zbioruroboczego - przykład (c.d.)
☛ Wada: nie można powiedzieć, w którym miejscuprzydziału 5000 odniesień wystąpiło daneodniesienie
☛ Można zwiekszyć historię odniesień (t.j. ilośćbitów z 2 do 10) i liczbę przerwań ( np. co 1000odniesień)
☛ Wada: zwiększony koszt obsługi

Częstość braków stron
☛ Metodą mierzenia szamotania jest mierzenieczęstości braków stron (ang. page-faultfrequency - PFF)☛ ustala się górną i dolną granicę pożądanego poziomu
braków stron☛ jeśli proces przekracza górną granicę do dostaje dodatkową
ramkę☛ jeśli częstość występowania braków stron spada poniżej
dolnej granicy to usuwa się ramkę z procesu, którego tenobjaw dotyczy

Przykłady implementacjipamięci wirtualnej
☛ WNT☛ stronicowanie na żądanie☛ clustering - każdy proces ma przypisany minimalny i
maksymalny zbiór roboczy: jeśli proces ma zbiór roboczybliski maksymalnemu i złapie błąd strony musi zgodnie zlokalną polityką zastępowania wyznaczyć ramkę ofiarę;jeśli proces ma zbiór roboczy bliski minimalnemu możedostać ramkę z globalnej listy wolnych ramek
☛ Konkretny sposób wyboru strony do usunięciaze zbioru roboczego jest zależny od typuprocesora

Przykłady implementacjipamięci wirtualnej (c.d.)
☛ W2K☛ 4GB pamięci dla procesu w tym 2GB - W2K, 2*64KB - pointers☛ stany stron
☛ dostępne - nieużywane przez dany proces☛ zarezerwowane - ciągły zbiór stron nie wliczany do quoty zanim
użyty (np. przy zapisie do pamięci)☛ powierzone (ang. commited) - np. strony w chwili zapisywania do
pliku na dysku
☛ Solaris 2☛ wartość progowa (ang. threshold) wolnej pamięci zwana lostfree
poniżej której proces zwany pageout zaczyna stronicowanie (1/64pamięci fizycznej); pageout weryfikuje pamięć 4 razy na sekundę

Stronnicowanie wstępne
☛ Stronicowanie wstępne (ang. prepaging) -jednorazowe wprowadzenie do pamięciwszystkich potrzebnych stron procesu zapobiegawysokiej aktywności stronicowania we wstępnejfazie procesu
☛ W systemach implementujących model zbioruroboczego dla każdego procesu przechowujesię listę stron jego zbioru roboczego
☛ Przełączenie kontekstu: zapamiętanie listy stron(np. w przypadku I/O) oraz wczytanie stron z tejlisty przed restartem

Rozmiar strony
☛ Rozmiary stron są potęgami 2: od 4096 (2^12)do 4194304 (2^22) bajtów
☛ Wybór rozmiaru strony☛ minimalizacja fragmentacji wewnętrznej - małe strony☛ małe strony - wzrasta wielkość tablicy stron☛ duże strony - minimalizacja czasu operacji we/wy☛ małe strony - lepsza lokalizacja

Rozmiar strony (c.d.)
☛ Obserwuje się tendencję do wybieraniawiększych stron
☛ Intel 80386 - 4KB; Motorola 68030 - od 256B do32KB
☛ Wzrost szybkości procesorów i pojemnościpamięci jest szybszy niż wzrost szybkościdysków
☛ Z punktu widzenia wydajności systemu brakistron są kosztowne
☛ Większy rozmiar strony = większa fragmentacjawewnętrzna

Przykładowe rozmiary stron
☛ Atlas - 512 48b słów☛ Honeywell-Multics - 1024 36b słów☛ IBM 370/XA/ESA - 4KB☛ VAX - 512B☛ IBM AS/400 - 512B☛ DEC Alpha - 8KB☛ MIPS - 4KB☛ UltraSPARC - 8KB do 4MB☛ Pentium - 4KB lub 4MB☛ PowerPC - 4KB

Współczynnik trafień dla TLB
☛ Współczynnik trafień dla TLB (ang. TLB reach)odnosi się do ilości pamięci dostępnej za pomocąTLB (tzn. liczby pozycji w TLB razy rozmiar strony)
☛ Najlepiej mieć zbiór roboczy w TLB☛ Jak zwiększyć współczynnik trafień TLB?
☛ powiększyć rozmiar strony☛ wiele rozmiarów stron (UltraSPARC - 8KB, 64KB, 512KB,
4MB)
☛ Konieczność obsługi TLB (musi zawierać rozmiarstrony) przez system operacyjny w przypadku wielurozmiarów stron

Odwrócona tablica stron☛ Odwrócona tablica stron nie zawiera pełnych
informacji o logicznej przestrzeni adresowejprocesu potrzebnych przy stronicowaniu
☛ W stronicowaniu na żądanie wprowadza sięzewnętrzną tablicę stron procesu do którejodwołanie następuje w przypadku braku strony
☛ Zewnętrzne tablice stron podlegają równieżstronicowaniu
☛ Zarządca pamięci wirtualnej może spowodowaćkolejny brak strony wprowadzając potrzebnązewnętrzną tablicę stron aby zlokalizować stronęwirtualną na dysku

Struktura programu☛ Struktura programu zerowania tablicy
☛ int A[][] = new int[128][128];☛ Strona długości 128 słów☛ System operacyjny alokuje mniej niż 128 ramek☛ Program 1:
for (int j = 0; j < A.length; j++ )for (int i = 0; i < A.length; i++ )A[i][ j] = 0;
128 x 128 braków stron (A w pamięci jest wierszami)

Struktura programu (c.d.)☛ Struktura programu zerowania tablicy
☛ int A[][] = new int[128][128];☛ Strona długości 128 słów☛ System operacyjny alokuje mniej niż 128 ramek☛ Program 2:
for (int i = 0; i < A.length; i++ )for (int j = 0; j < A.length; j++ )A[i][ j] = 0;
128 braków stron (A w pamięci jest wierszami)

We/wy a ramki
☛ Proces wysyła zamówienie na we/wy i ustawiasię w kolejce do urządzenia we/wy
☛ Procesor zostaje przydzielony innym procesom☛ Zaczynają występować braki stron☛ W wyniku działania algorytmu globalnego
zastępowania stron jeden z procesów zastępujestronę zawierającą bufor we/wy procesuczekającego w kolejce we/wy
☛ Zamówienie na we/wy zaczyna być realizowanedo ramki innego procesu

We/wy a ramki (c.d.)
☛ Zakaz wykonywania operacji we/wy wprost dopamięci użytkownika☛ duże nakłady przy kopiowaniu
☛ Blokowanie stron w pamięci☛ każda ramka ma bit blokowania☛ stron zablokowanych nie wolno zastępować☛ strona jest odblokowywana po zakończeniu operacji
we/wy
☛ pula wolnych stron jest zbyt mała?☛ proces próbuje zablokować zbyt wiele stron?

Segmentacja na żądanie
☛ Jeśli występuje niedostatek sprzętu do realizacjipamięci wirtualnej stosuje się segmentację nażądanie (ang. demand segmentation)
☛ OS/2 zamiast stronami przydziela pamięćsegmentami opisanymi za pomocą deskryptorówsegmentów (ang. segment descriptors)
☛ Deskryptor segmentu zawiera bit poprawnościwskazujący dla każdego segmentu czy znajdujesię on w danej chwili w pamięci☛ Jeśli segment jest w pamięci głównej, kontynuacja☛ W przeciwnym razie przerwanie brak segmentu

Podsumowanie (1)
☛ Potrzeba wykonania procesów których logicznaprzestrzeń adresowa jest większa niż dostępnafizyczna przestrzeń adresowa
☛ Można użyć nakładek ale jest to bardzo trudne☛ Pamięć wirtualna umożliwia wykonywanie
bardzo dużych procesów zwalniającjednocześnie programistę od kłopotówzwiązanych z brakiem pamięci

Podsumowanie (2)
☛ Czyste stronicowanie na żądanie (ang. puredemand paging) polega na nie sprowadzaniustrony do pamięci dopóty, dopóki nie ma do niejodniesienia
☛ Potrzebne są algorytmy zastępownia stron wpamięci☛ FIFO - anomalia Belady’ego☛ optymalne zastępowanie OPT - wymaga wiedzy o
przyszłości☛ Algorytm LRU przybliża OPT ale jest trudny w realizacji☛ Większość algorytmów oparta o algorytm drugiej szansy

Podsumowanie (3)
☛ Polityka przydziału ramek uzupełnia algorytmzastępowania stron☛ przydział stały lub dynamiczny
☛ Proces powinien mieć przydzieloną liczbę ramekwystarczającą dla bieżącego zbioru roboczego,w przeciwnym razie nastąpi szamotanie
☛ Rozważenia wymaga również:☛ rozmiar strony☛ blokowanie stron w pamięci (np. dla operacji we/wy)