xml query processing talk prepared by bhavana dalvi (05305001) uma sawant (05305903)
TRANSCRIPT

XML Query Processing
Talk prepared by
Bhavana Dalvi (05305001)Uma Sawant (05305903)

Structural Joins: A Primitive for Efficient XML Query Pattern
Matching
Al Khalifa, H. Jagadish,N. Koudas, J. Patel
D. Srivastava, Yuquing Wu ICDE 2002
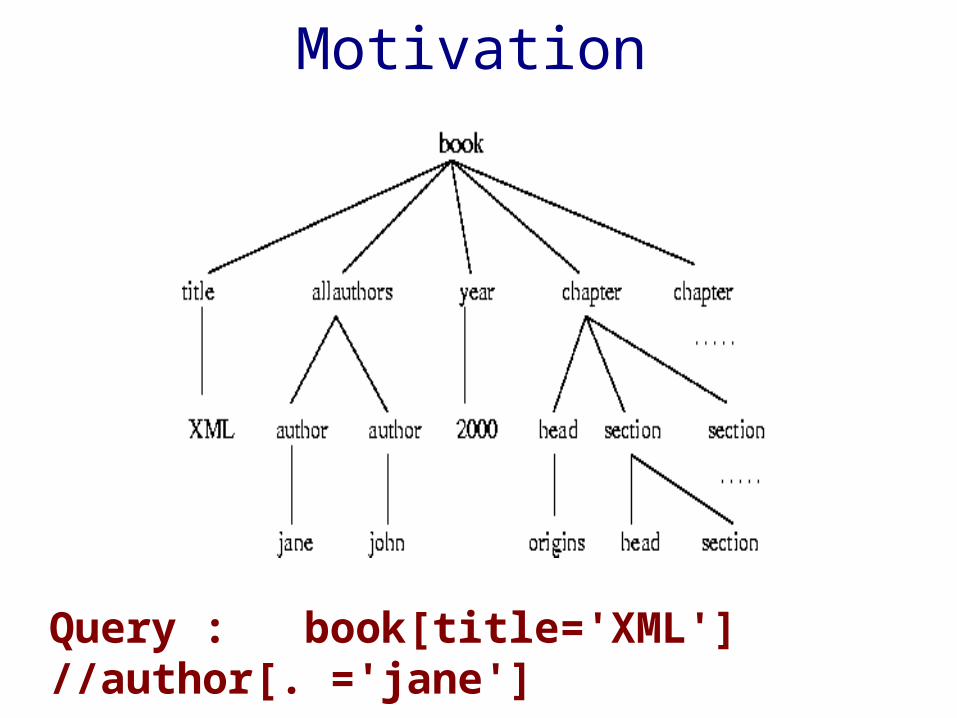
Motivation
Query : book[title='XML'] //author[. ='jane']
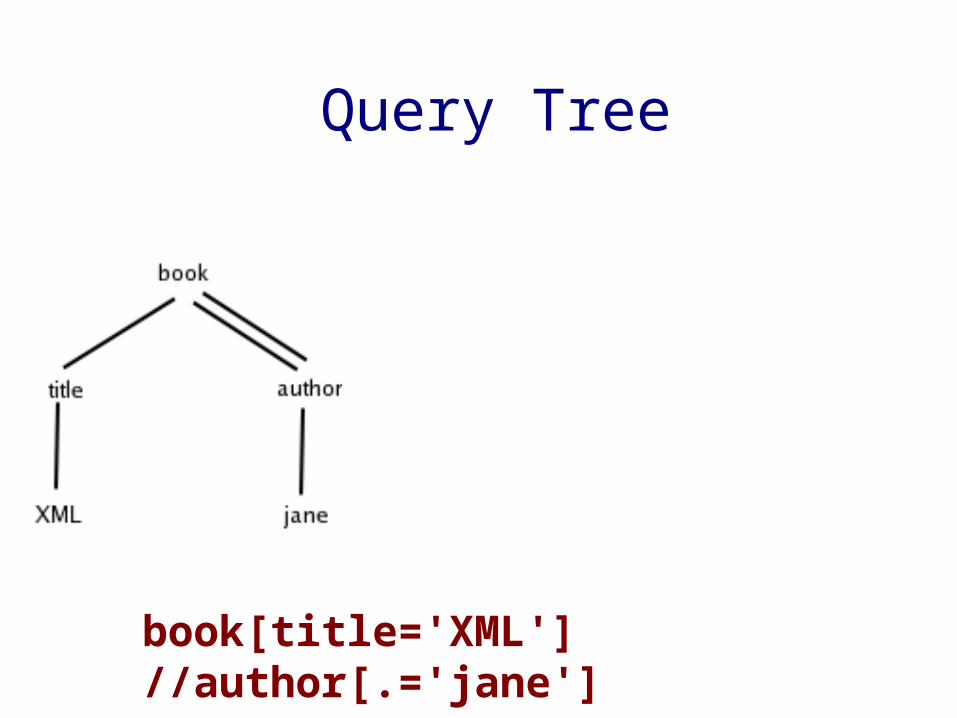
Query Tree
book[title='XML'] //author[.='jane']
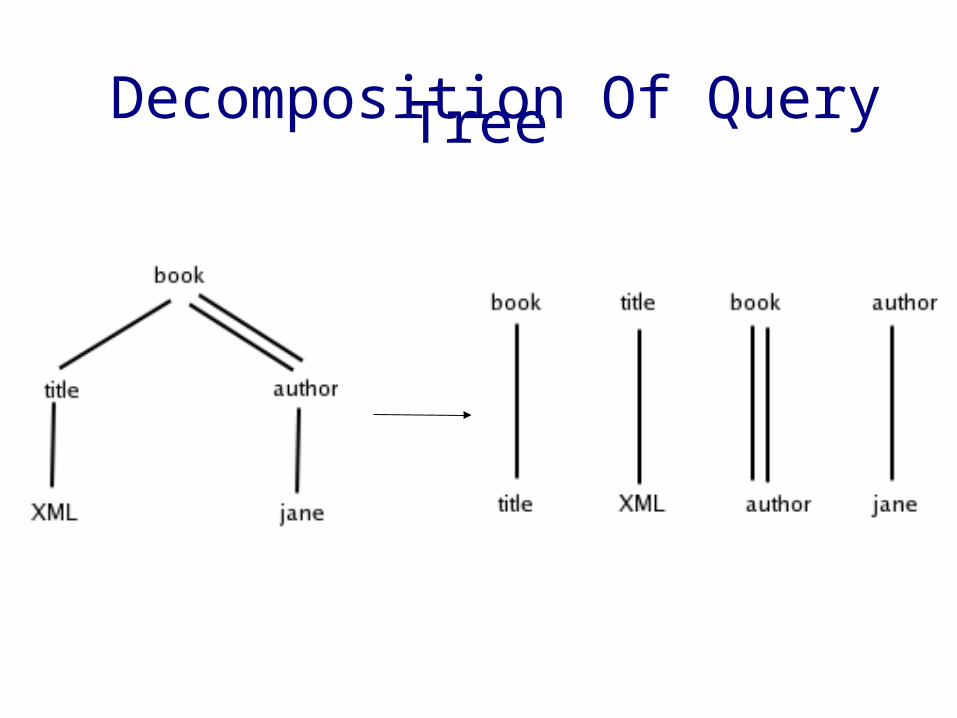
Decomposition Of Query Tree

Evaluation of Query
• Matching each of the binary structural relationships against database.• Stitching together these basic matches

Different ways of matchingstructural relationships
• Tuple-at-a-time approach➢ Tree traversal➢ Using child & parent pointers➢ Inefficient because complete pass through data
• Pointer based approach➢ Maintain (Parent,Child) pairs & identifying (ancestor,descendants) : Time complexity➢ Maintain (ancestor,descendant) pairs : space complexity➢ Either case is infeasible

Solution: Set-at-a-time approach
Uses mechanism ➢ Positional representation of occurrences of XML
elements and string values➢ Element
• 3 tuple (DocId, StartPos:EndPos, LevelNum) ➢ String• 3 tuple (DocId, StartPos, LevelNum)

Positional Representation

Structural Relationship Test
• (D1, S1:E1, L1) (D2, S2:E2, L2)• Ancestor-Descendant
➢ D1 = D2, S1 < S2, E2 < E1
• Parent-Child➢ D1 = D2, S1 < S2, E2 < E1, L1 + 1 = L2

Goal
• Given ancestor-descendant (or parent-child) structural relationship (e1,e2), find all node pairs which satisfy this

• Traditional merge join➢ Does equi-join on doc-id➢ Tests for inequalities on cross-product of two sets
• Multi-Predicate Merge Join (MPMGJN)➢ MPMGJN uses Positional representation➢ Better than traditional merge join➢ Applies multiple predicates simultaneously➢ Still lot of unnecessary computation and I/O
Previous Approaches

Need of better I/O and CPU optimal
algorithm

Solution: Structural Joins
• Set-at-a-time approach• Uses positional representation of XML elements.• I/O and CPU optimal
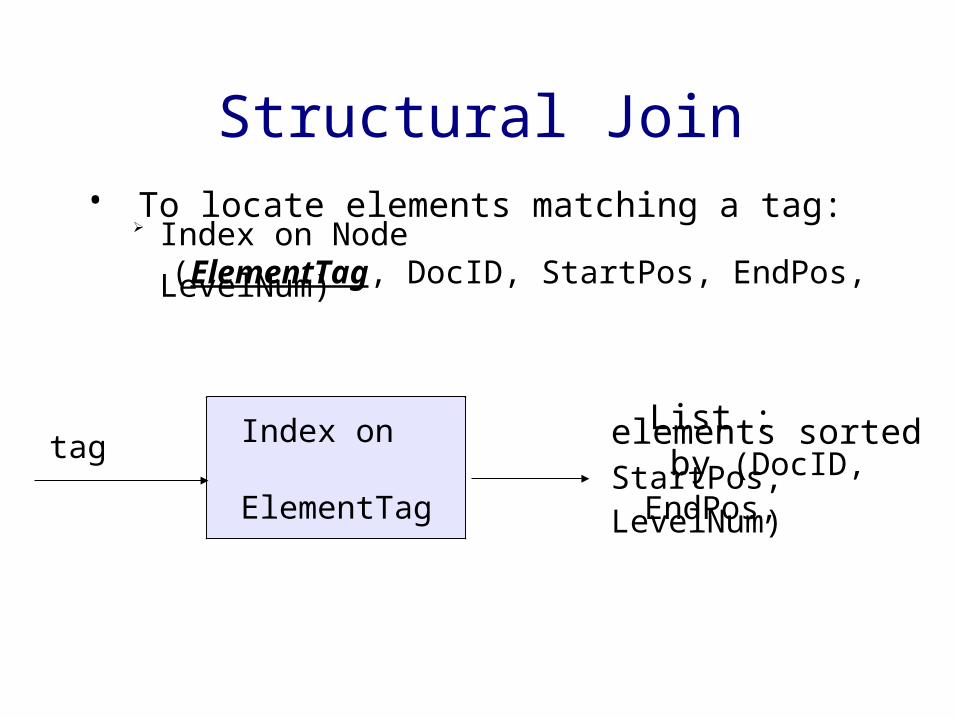
Structural Join• To locate elements matching a tag:
➢ Index on Node (ElementTag, DocID, StartPos, EndPos, LevelNum)
Index on ElementTag
tag List : elements sorted by (DocID, StartPos, EndPos, LevelNum)

Structural Join
• Goal: join two lists based on either parent-child or ancestor-descendant
• Input : ➢ AList (a.DocID, a.StartPos : a.EndPos, d.LevelNum)➢ DList (d.DocID, d.StartPos : d.EndPos, d.LevelNum)
• Output can be sorted by ➢ Ancestor: (DocID, a.StartPos, d.StartPos), or➢ Descendant: (DocID, d.StartPos, a.StartPos)

Two families of structural join algorithms
• Tree-merge Algorithm : MPMGJN is member of this family• Stack-tree Algorithm

Algorithm Tree-Merge-Anc
• Output : ordered by ancestors• Algorithm :
Loop through list of ancestors in increasing order of startPos
➢ For each ancestor, skip over unmatchable descendants➢ check for ancestor-descendant relationship ( or parent-child relationship )➢ Append result to output list

Worst case for Tree-Merge-Anc
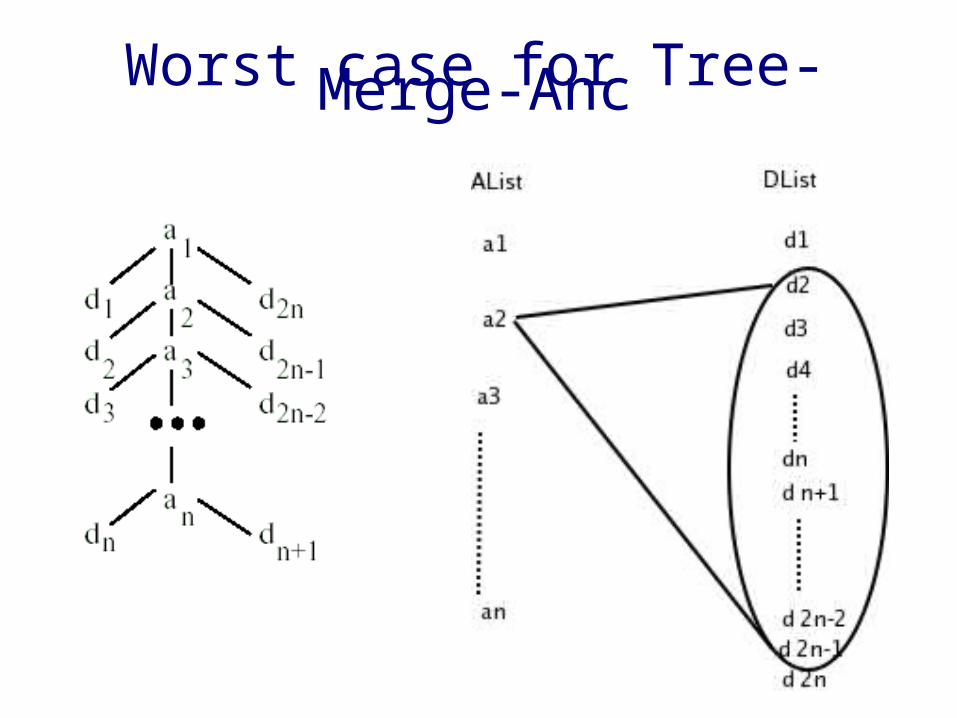
Worst case for Tree-Merge-Anc
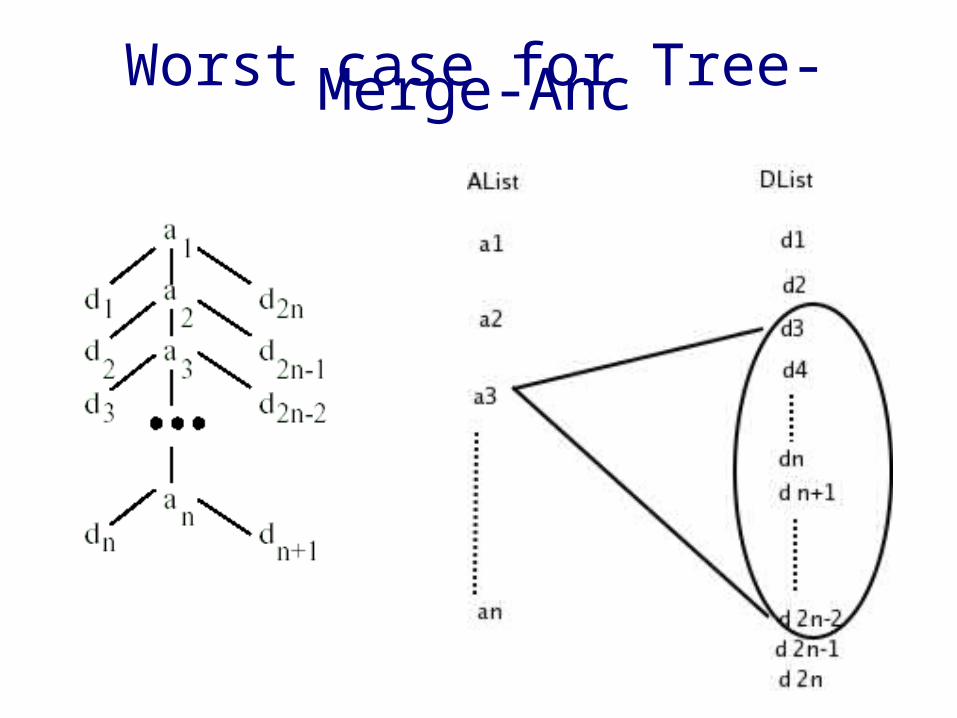
Worst case for Tree-Merge-Anc
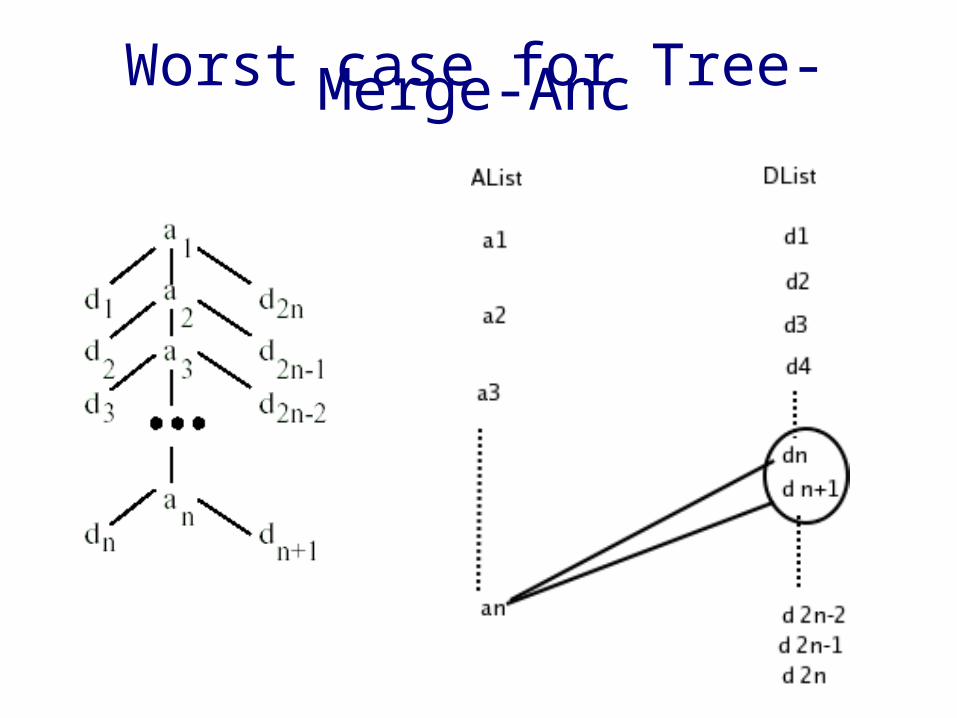
Worst case for Tree-Merge-Anc

Analysis• Ancestor-descendent relationship
➢ |Output List| = O(|AList| * |DList|)➢ Time complexity is optimal O( |AList| * |DList| )➢ But poor I/O performance
• Parent-child relationship➢ |Output List| = O(|AList| + |DList|)➢ Time complexity is O (|AList| * |DList| )

Tree-Merge-Desc Algorithm
• Output : ordered by descendants• Algorithm :
Loop over Descendants list in increasing order of startPos➢ For each descendant, skip over unmatchable ancestors➢ check for ancestor-descendant relationship
( or parent-child relationship )➢ Append result to output list

Worst case for Tree-Merge-Desc
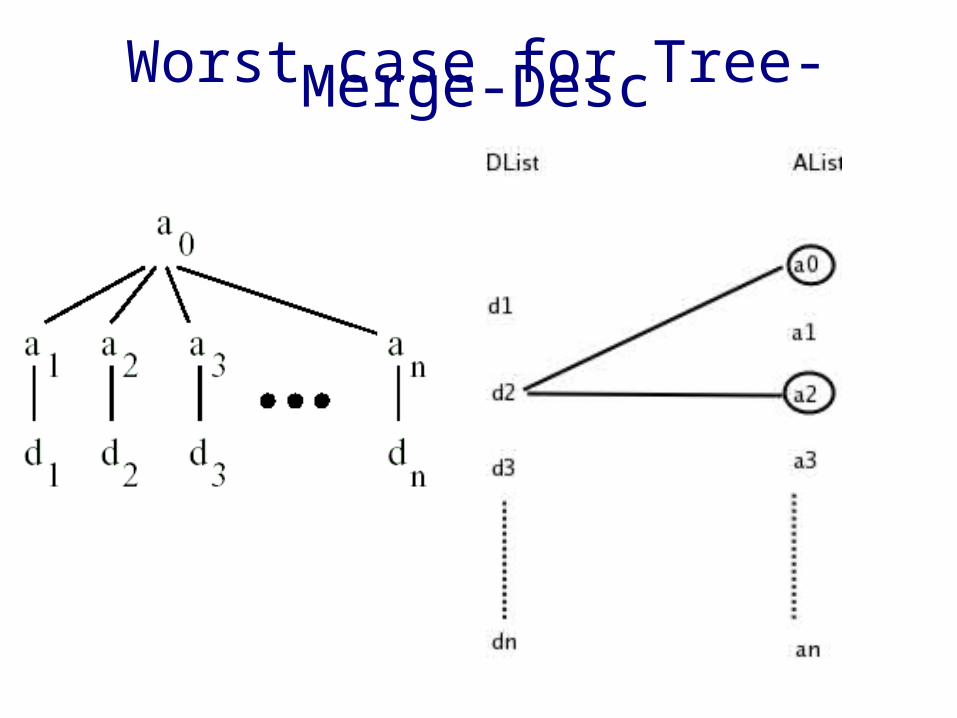
Worst case for Tree-Merge-Desc
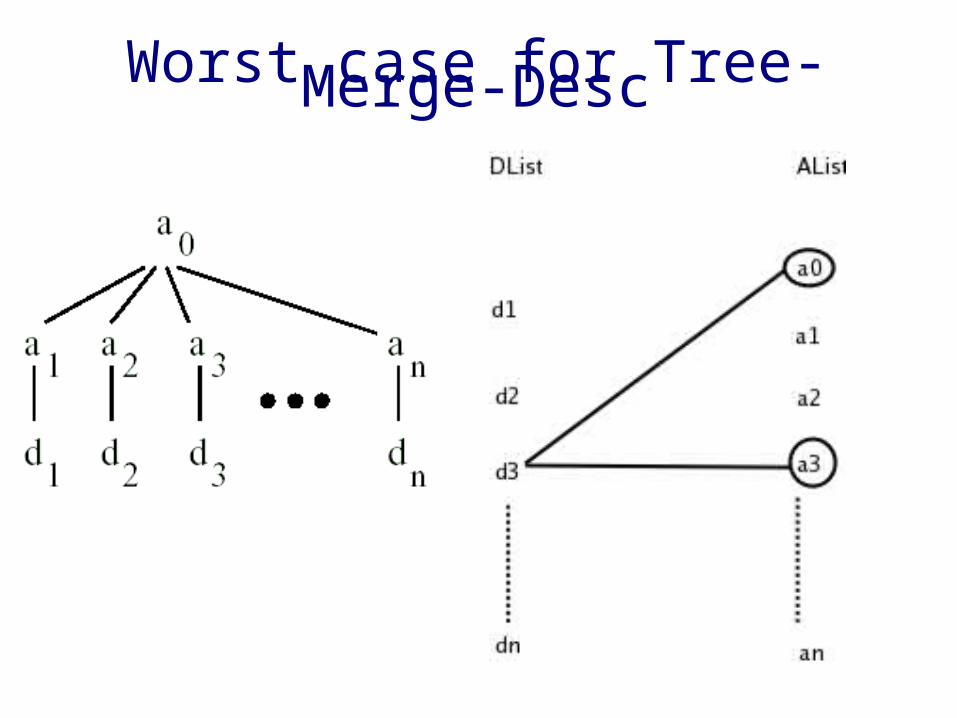
Worst case for Tree-Merge-Desc
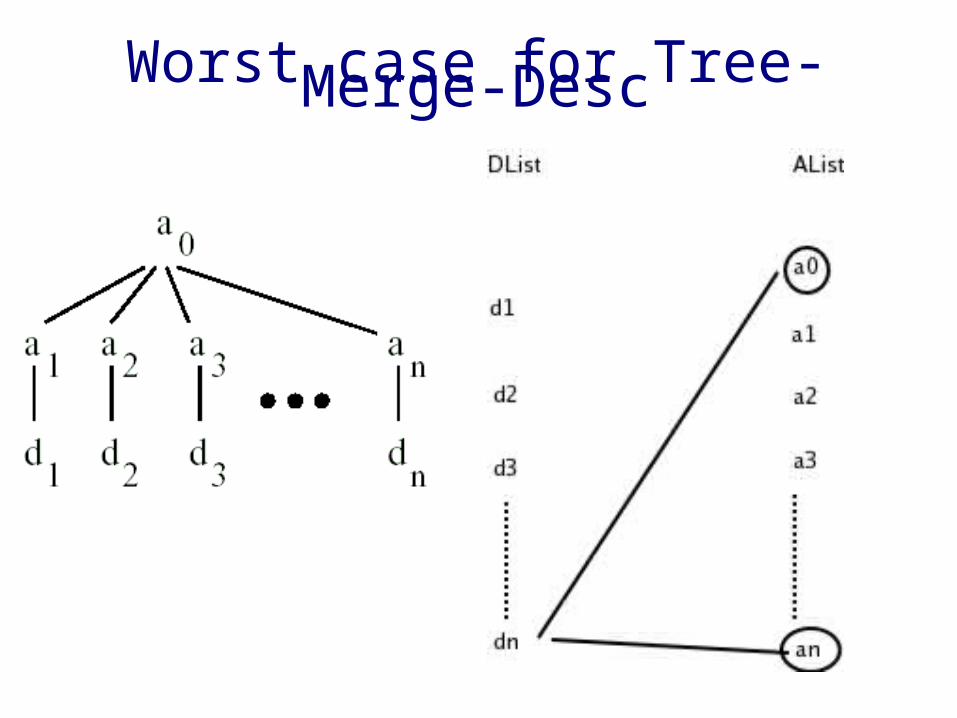
Worst case for Tree-Merge-Desc

Analysis
• Ancestor-descendent relationship➢ |Output List| = O( |AList| * |DList| )➢ Time Complexity :
O( |AList| * |DList| )
• Parent-child relationship➢ |Output List| = O(|AList| + |DList|)➢ Space and Time complexities are
O (|AList| * |DList| )

• Tree-Merge algorithms are not I/O optimal • Repetitive accesses to Anc or Desc list

Motivation for Stack-TreeAlgorithm
• Basic idea: depth first traversal of XML tree ➢ takes linear time with stack of size equal to tree depth➢ all ancestor-descendant relationships appear on stack during traversal
• Main problem: do not want to traverse the whole database, just nodes in Alist or Dlist• Solution : Stack-Tree algorithm
➢ Stack: Sequence of nodes in Alist

Stack-Tree-Desc
• Initialize start pointers (a*, d*, s->top)• While input lists are not empty and stack is not empty
➢ if new nodes (a* and d*) are not descendants of current s->top, pop the stack➢ else
if a* is ancestor of d*, push a* on stack and increment a* else
➔ compute output list for d* , by matching with all nodes in current stack, in bottom-up order➔ Increment d* to point to next node
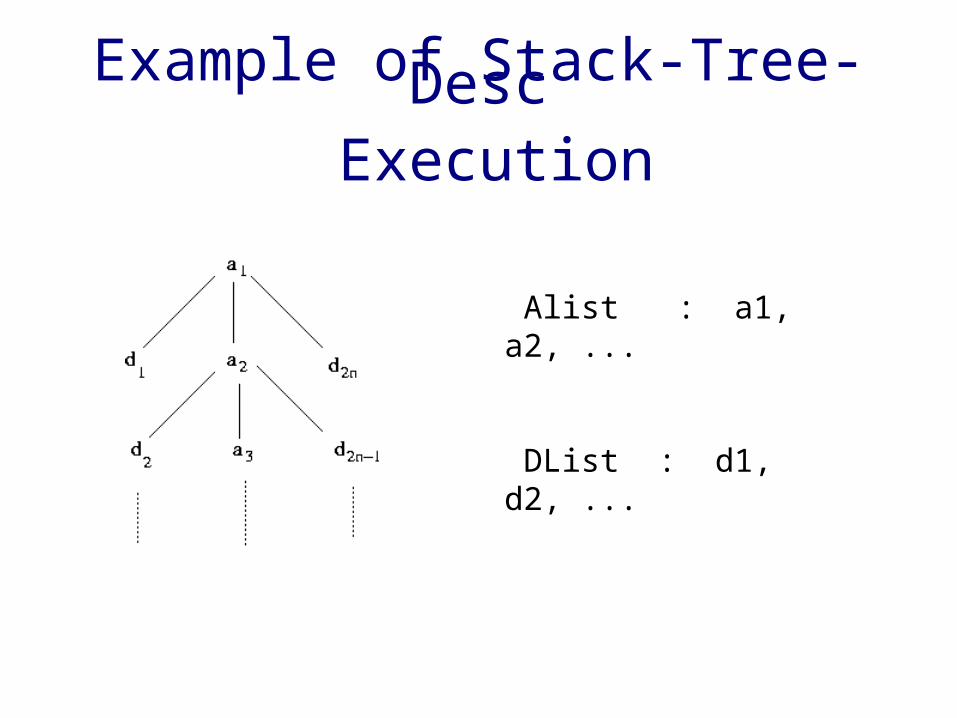
Example of Stack-Tree-Desc Execution
Alist : a1, a2, ...
DList : d1, d2, ...
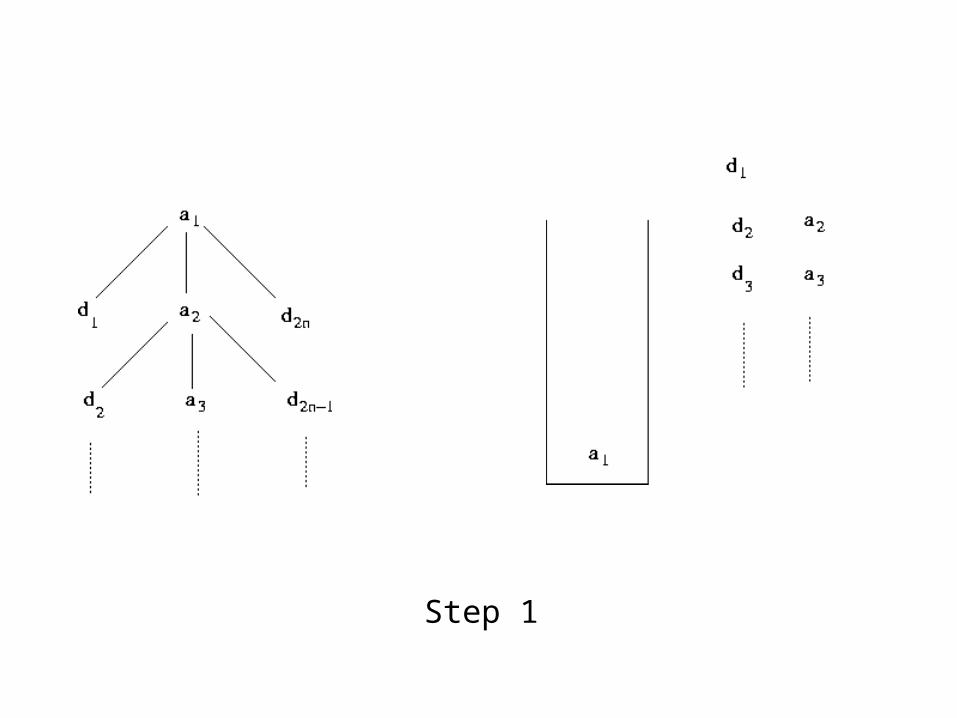
Step 1
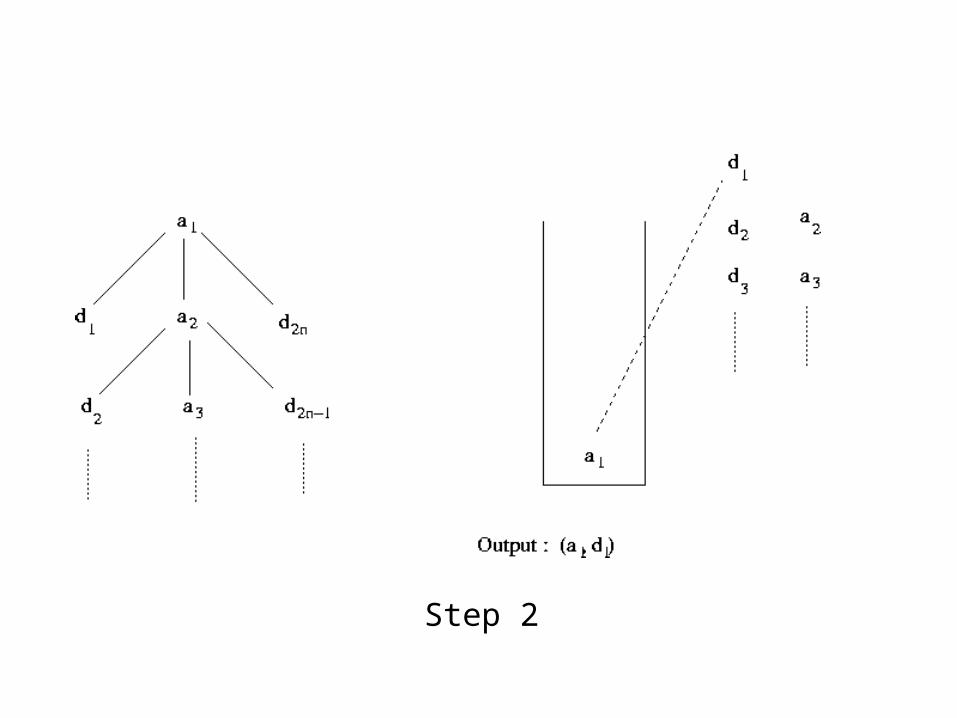
Step 2
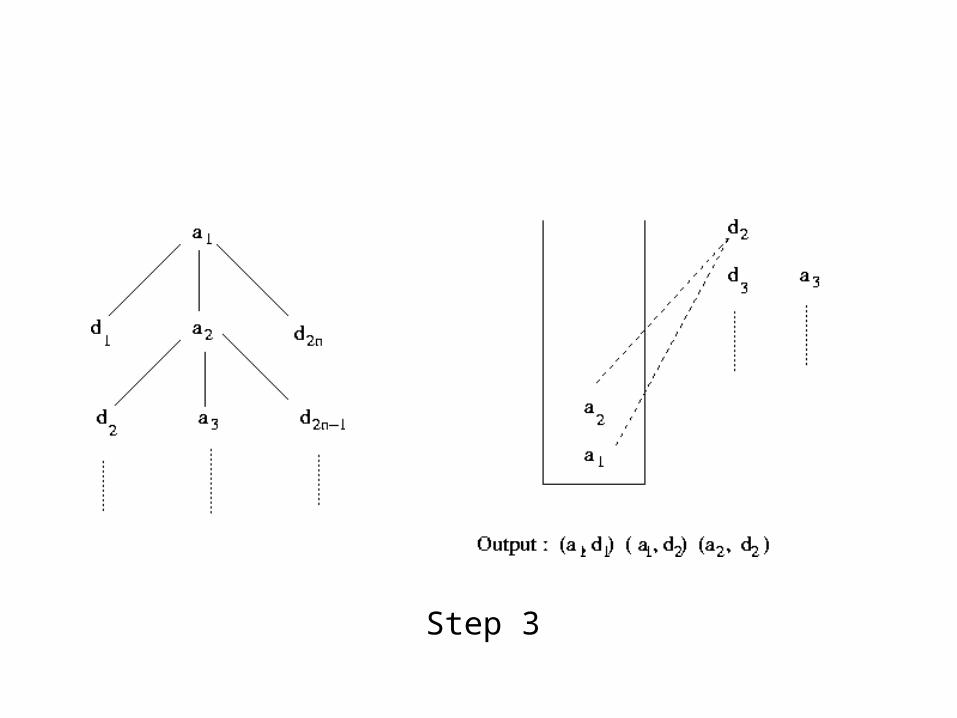
Step 3


Stack-Tree-Desc Analysis
* Time complexity (for anc-desc and parent-child) O(|AList| + |DList| + |OutputList|)
* I/O Complexity (for anc-desc and par-child) O(|AList| / B + |DList| / B + |OutputList| / B)
➢ Where B is blocking factor

Stack-Tree-Anc• Output ordered by ancestors• Cannot use same algorithm, as in Stack-Tree-Desc• Basic problem: results from a particular descendant cannot be output immediately
➢ Later descendants may match earlier ancestor, hence have to be output first

Stack-Tree-Anc
• Solution: keep lists of matching descendant nodes with each stack node
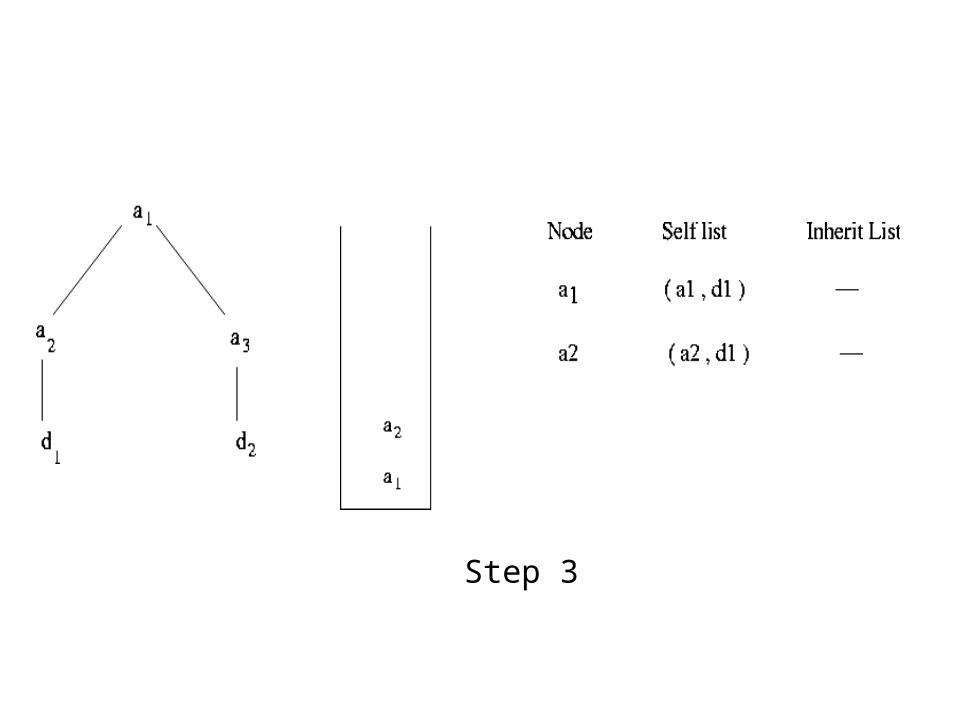
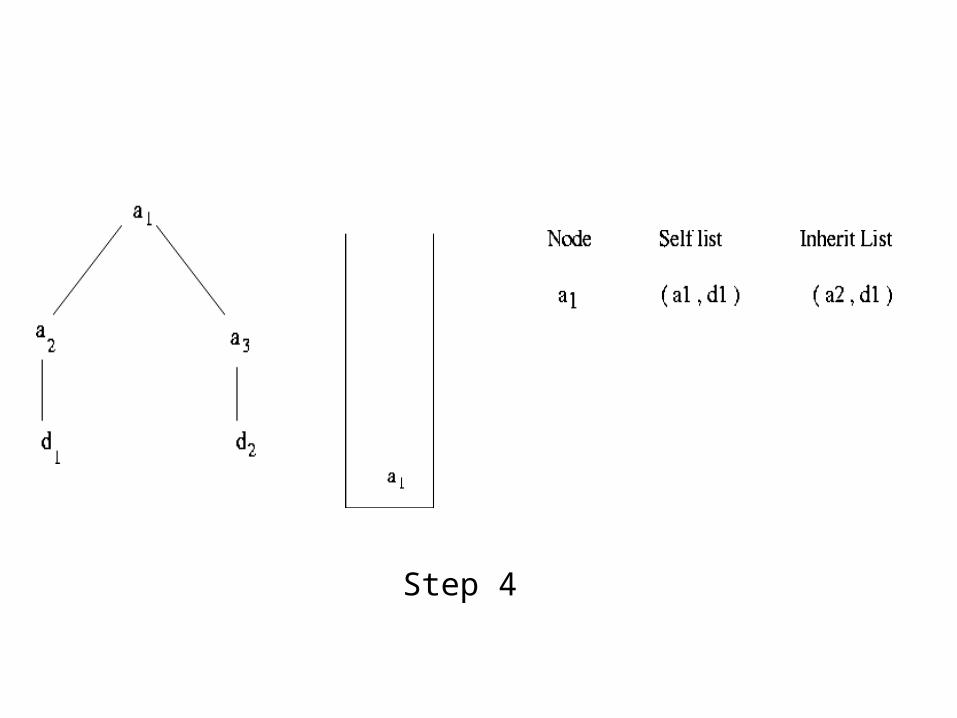
➢ Self-list Descendants that match this node Add descendant node to self-lists of all matching ancestor nodes
➢ Inherit list Inherited from nodes already popped from stack, to be output after self-list matches are output

Algorithm Stack-Tree-Anc● Initialize start pointers (a*, d*, s->top)● While the input lists are not empty and the stack is not empty
• if new nodes (a* and d*) are not descendants of current s->top, pop the stack (p* = popped ancestor node)
➢ Append p* . inherit_list to p* . self_list➢ Append resulting list to (s->top) . inherit_list
• else ➢ if a* is ancestor of d*, push a* on stack and increment a*➢ else
Append corresp. tuple to self list of all nodes in stack Increment d* to point to next node
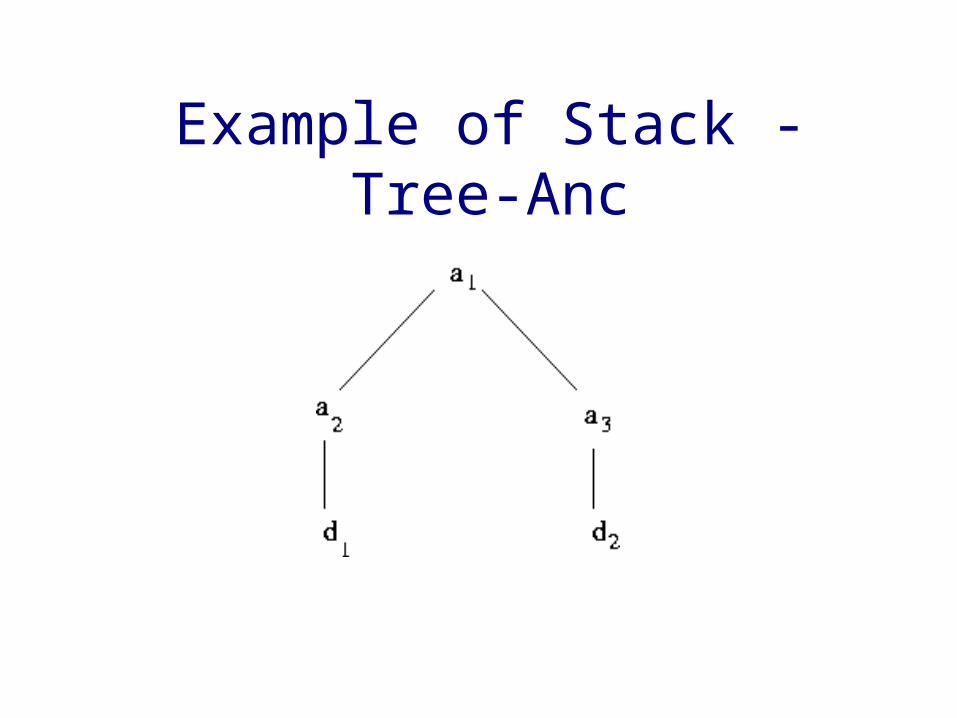
Example of Stack -Tree-Anc
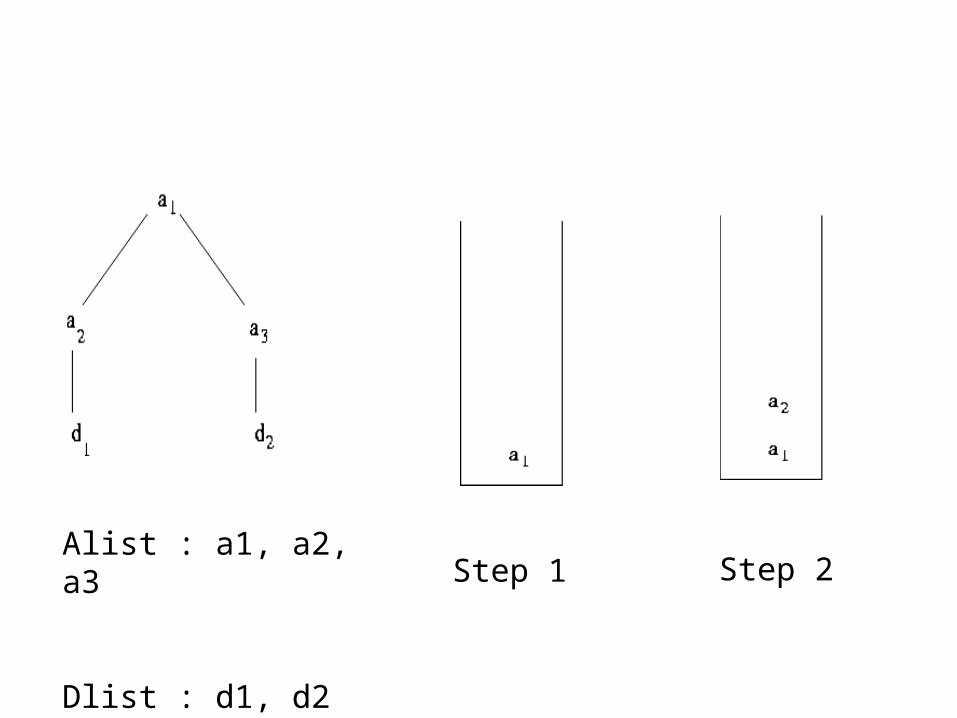
Step 1 Step 2Alist : a1, a2, a3
Dlist : d1, d2
Step 3
Step 4

Step 5

• Final output is : (a1 , d1) , (a1 , d2) , (a2 , d1) , (a3 , d2)

Stack-Tree-Anc Analysis
• Requires careful handling of lists (linked lists)• Time complexity (for anc-desc and parent-child relation)
O(|AList| + |DList| + |OutputList|)• Careful buffer management needed

Performance Study
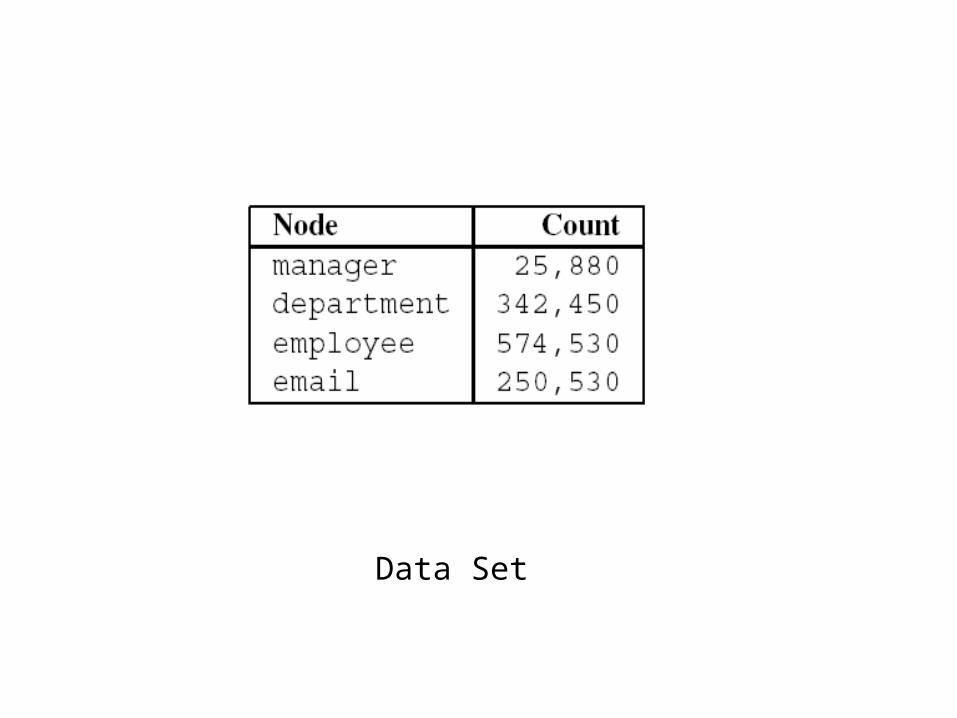
Data Set
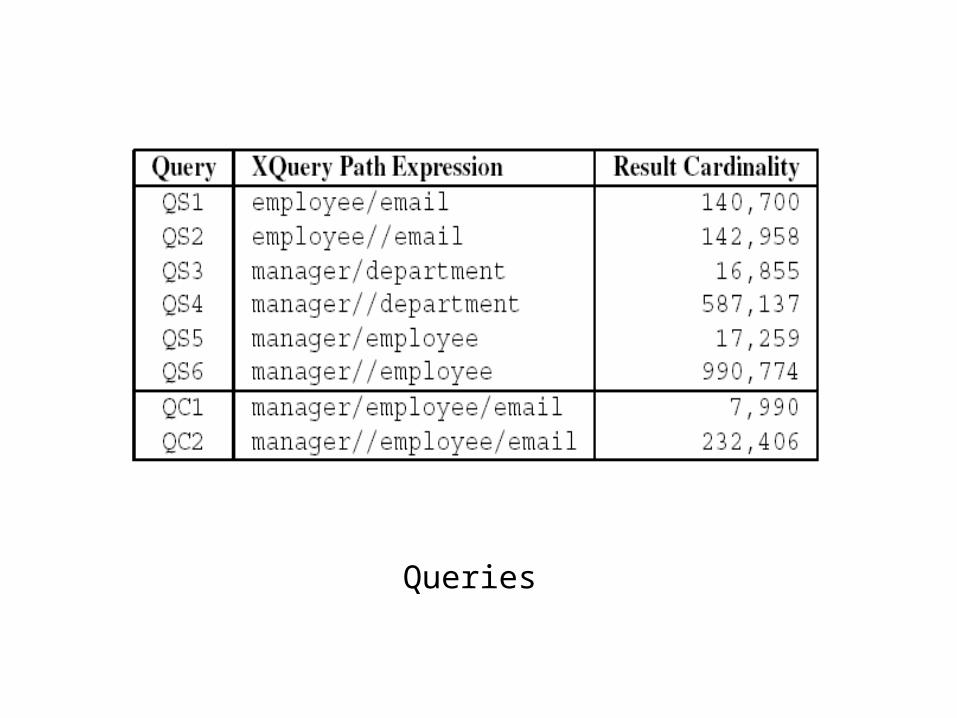
Queries
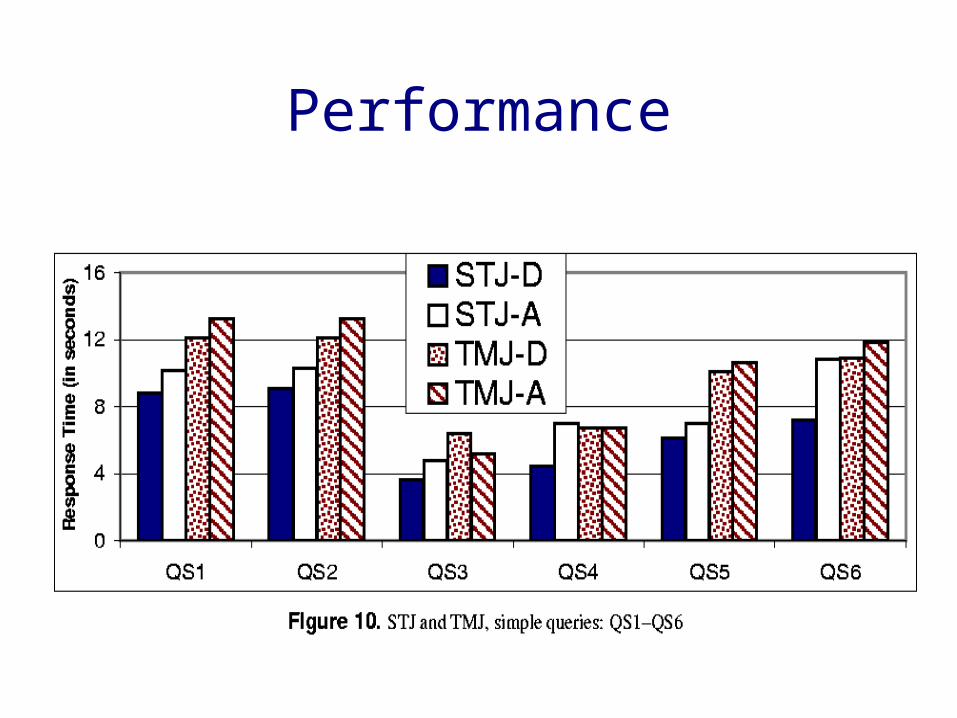
Performance
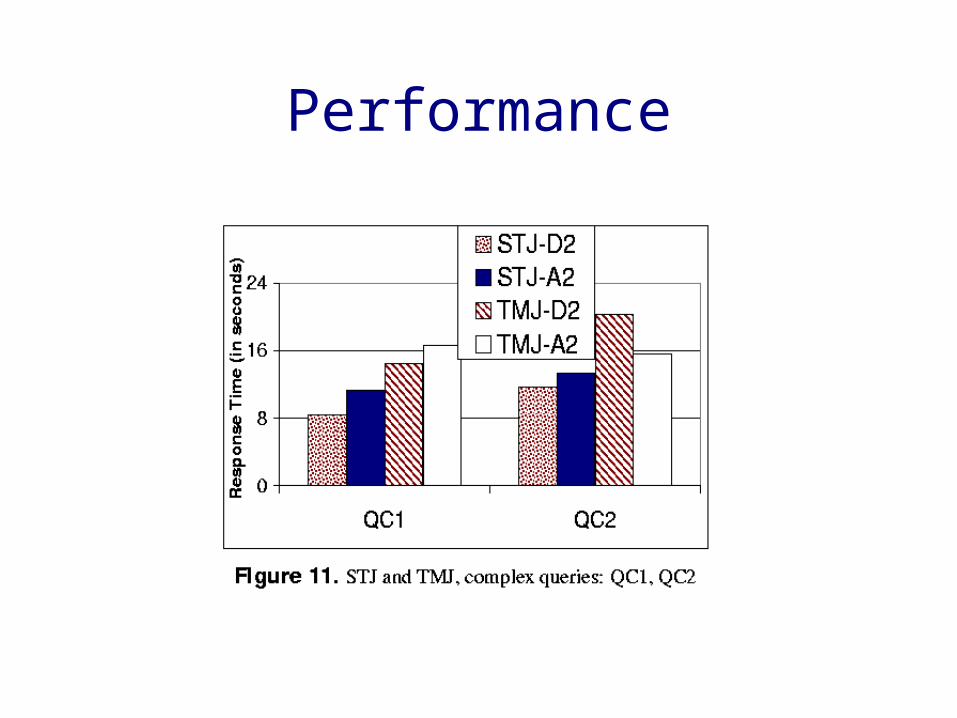
Performance

Conclusion
• The performance of the traversal-style algorithms degrades considerably with the size of the dataset.
• Performance of STJD is superior compared to others (STJA, TMJA, TMJD).

ORDPATHs: Insert Friendly XML Node
Labels
Patrik O'Neil, Elizabeth O'NeilShankar Pal, Istvan Cseri,
Gideon Schaller, Nigel Westbury
(SIGMOD 2004)

Motivation
• Previous schemes adequate for static XML data.• But poor response for arbitrary inserts• Relabeling of many nodes is necessary• Hence if data is not static, need for an insert-friendly labeling method.
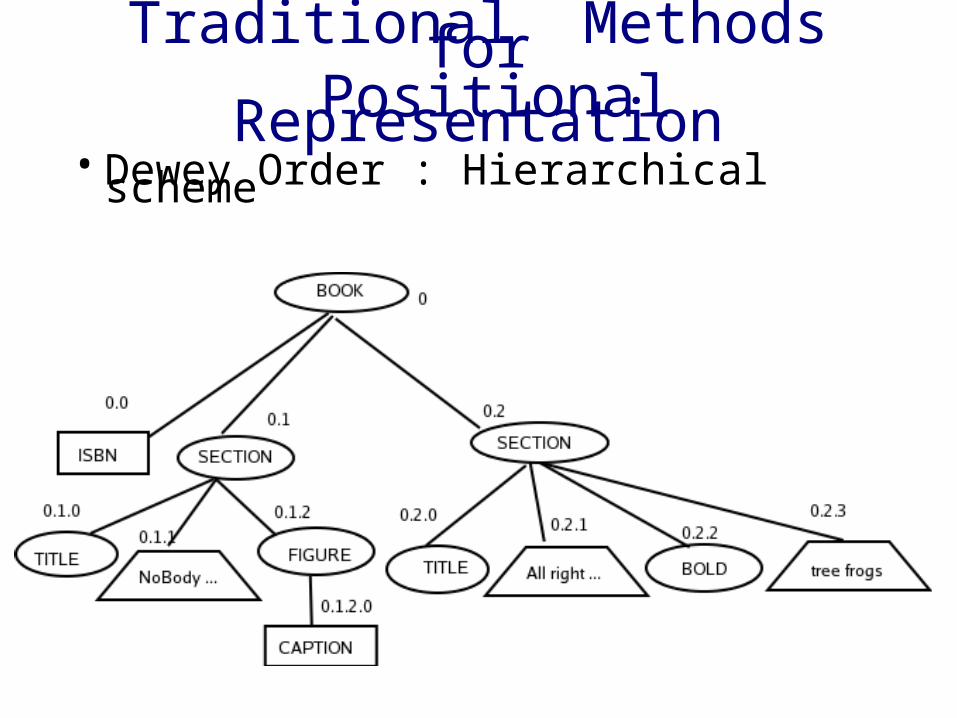
Traditional Methods for Positional Representation
• Dewey Order : Hierarchical scheme

• Is independent of database schema• Allows efficient access through Dewey List
indexing• But arbitrary inserts are costly.
Dewey ID representation

Solution: ORDPATH
• Similar to Dewey ID• Differs in initial labeling & encoding scheme• Provides efficient insertion at any position in tree• Encodes the path efficiently to give maximum possible compression• Byte by Byte comparison : to get proper document order• Supports extremely high performance query plans

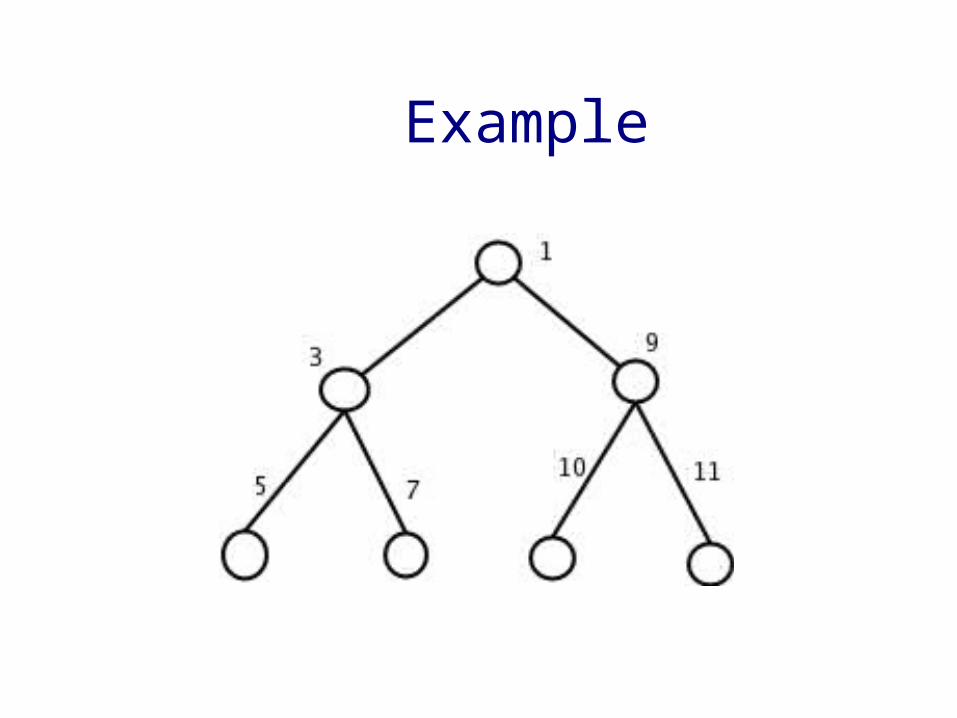
Example

• Initial Load: only positive and odd integers are assigned.
• Later Insertions: even-numbered and negative integer components

ORDPATH : Primary key
Relational node table

Compressed ORDPATH Format
• Li: Length in bits of successive Oi bitstring➢ Uses prefix free encoding
• Oi(Ordinal): Variable length representation of node depending on Li
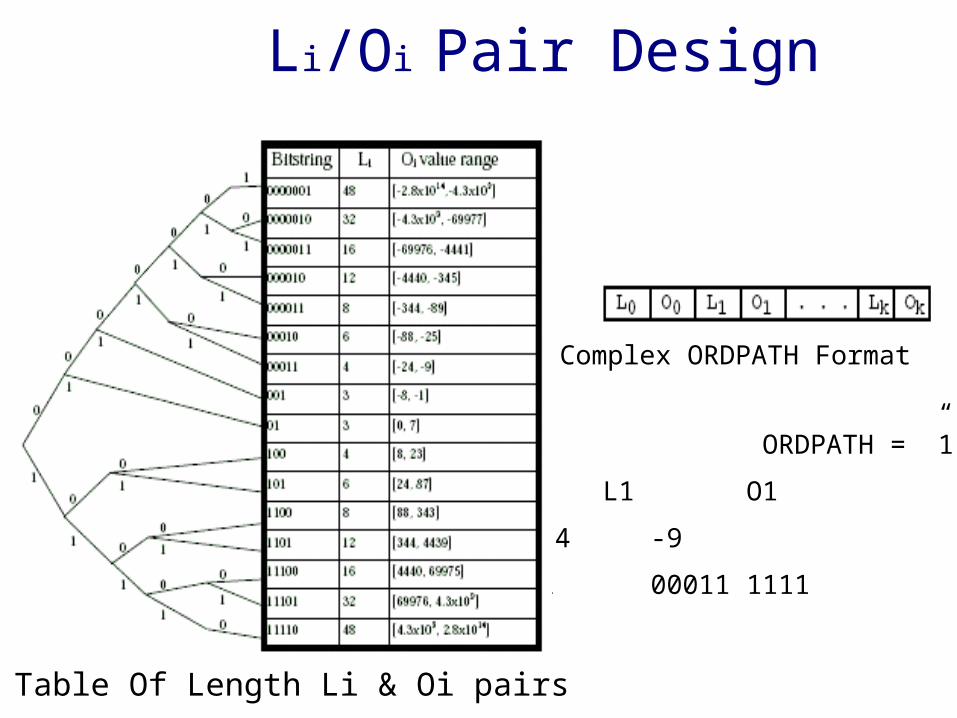
Li/Oi Pair Design
ORDPATH = ”1.-9” L0 O0 L1 O1 3 1 4 -9 01 001 00011 1111
Complex ORDPATH Format
Table Of Length Li & Oi pairs

Comparing ORDPATH values
• Simple bitstring comparison yields document order• Ancestor-descendent relationships
– X is strict substring of Y implies that X is ancestor of Y

ORDPATH InsertionsInsertions at extreme ends• Right of all: Add 2 to last ordinal of last child• Left of all: Add -2 to last ordinal of first child

Other insertions
Arbitrary insertions:➢ Careting in : Create a component with even ordinal falling between final ordinals of two siblings.➢ Append with a new odd component➢ Depth of tree remains constant

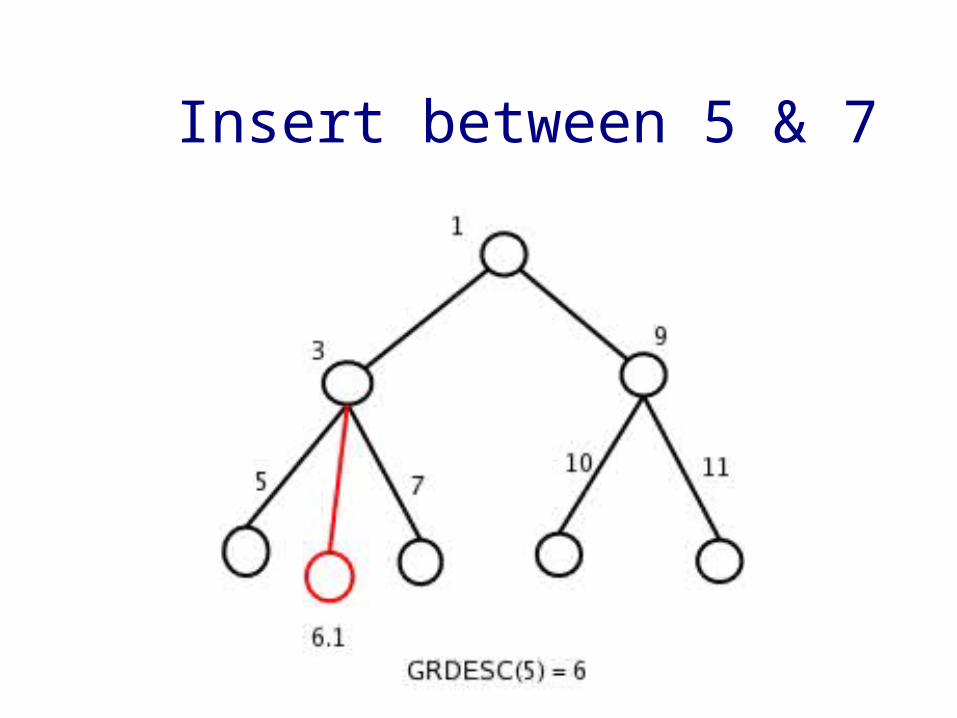
Example
• Adding a node under 5 between 5.5 & 5.7 -->
➢ Create a new caret 6 (5 < 6 < 7)➢ New siblings are 5.6.1, 5.6.3, ....

We can caret in entire subtree

Use of ORDPATH representation in Query plans

ORDPATH Primitives
• PARENT(ORDPATH X).➢ Parent of X➢ Remove rightmost component of X (odd)➢ Remove all rightmost even ordinals➢ e.g. PARENT(1.3.2.2.1) = (1.3)
• GRDESC(ORDPATH X)➢ Smallest ORDPATH-like value greater than any descendent of X➢ Increment last ordinal component of X➢ e.g. GRDESC(1.3.1) = (1.3.2)

Secondary Indices
• Element and Attribute TAG indexsupporting fast look up of elements and attributesby name.
• Element and Attribute VALUE indexsupporting fast look up of elements and attributesby value

Query Plans
Query : //Book//Publisher[.=”xyz”]
• Plan-1 : #descendants are small➢ Retrieve all book elements(sec. Index on Attribute TAG) & all descendants (Using GRDESC(X))
• Plan-2 : #descendants are large➢ Separate sequences of Book & Publisher [value=”xyz”] (sec. Index on Attribute value)➢ Join by ancestor//descendent

Query plans contd...
• Plan-3: #descendants are extremely small➢ Start at publisher & look for a Book element as
ancestor (Using PARENT(X))

Insert Friendly Ids
• Generate labels to reflect document order but not path information
➢ Pass through XML tree in document order.➢ Generate single component L0/O0 pairs with ordinals = 1, 3, 5, 7...➢ Later insertions: ORDPATH careting-in Method
--> Multiple even Oi components
• Short ID : Primary key in Node table• No relabeling required on inserts
Example
Insert between 5 & 7

Insert children of 6.1

Conclusion• Thus ORDPATH suggests an hierarchical naming scheme.
• Supports insertion of nodes at arbitrary positions without relabeling
• ORDPATH primitives along with secondary indices leads to efficient query plans

References
• Structural Joins: A Primitive for Efficient XML Query Pattern Matching, D. Srivastava, S. Al-Khalifa, H.V. Jagadish, N. Koudas, J.M. Patel, Y.Wu, ICDE 2002.
• ORDPATHs: Insert-Friendly XML Node Labels, Patrick E. O'Neil, Elizabeth J. O'Neil, Shankar Pal, Istvan Cseri, Gideon Schaller, Nigel Westbury, SIGMOD 2004.
• On Supporting Containment Queries in Relational Database Management Systems, Chun Zhang, Jerey Naughton, David DeWitt, Qiong Luon, Guy Lohmano, SIGMOD 2001.

Thank You !

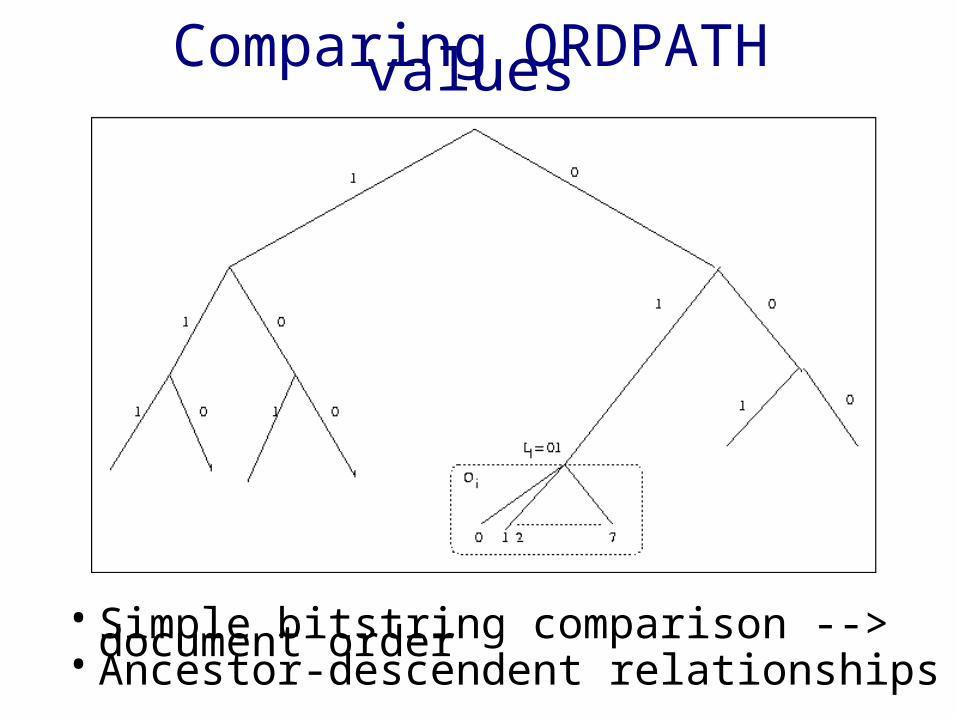
Comparing ORDPATH values
• Simple bitstring comparison --> document order• Ancestor-descendent relationships

ORDPATH Length• Worst case: small fanout at each level (2)
• Proved result:➢ Avg. depth P(n) of such tree obeys inequality : P(n) <= 1 + 1.4 log2(n)
● If max. depth = d, max. degree = t then max. bitlength L of labels is bounded:
d.log2(t) – 1 <= L <= 4dlog2(t)


Traditional Merge Join vs. MPMGJN
Performance Study
Data Tree