wykład 12 regresja liniowa
DESCRIPTION
Wykład 12 Regresja liniowa. Materiały dotyczące regresji linowej zostały przygotowane w oparciu o materiały Profesora G. P. McCabe z kursu ,, Applied regression analysis’’ na Uniwersytecie Purdue. - PowerPoint PPT PresentationTRANSCRIPT

Wykład 12Regresja liniowa
• Materiały dotyczące regresji linowej zostały przygotowane w oparciu o materiały Profesora G. P. McCabe z kursu ,, Applied regression analysis’’ na Uniwersytecie Purdue.
• Kurs był przygotowany w oparciu o książkę: Kutner, Nachtsheim, Neter and Li, Applied Linear Statistical Models, (5th ed.)

Krzywa wieża w Pizie

Przykład (2)
–Zmienna zależna - nachylenie (Y)
–Zmienna wyjaśniająca - czas (X)
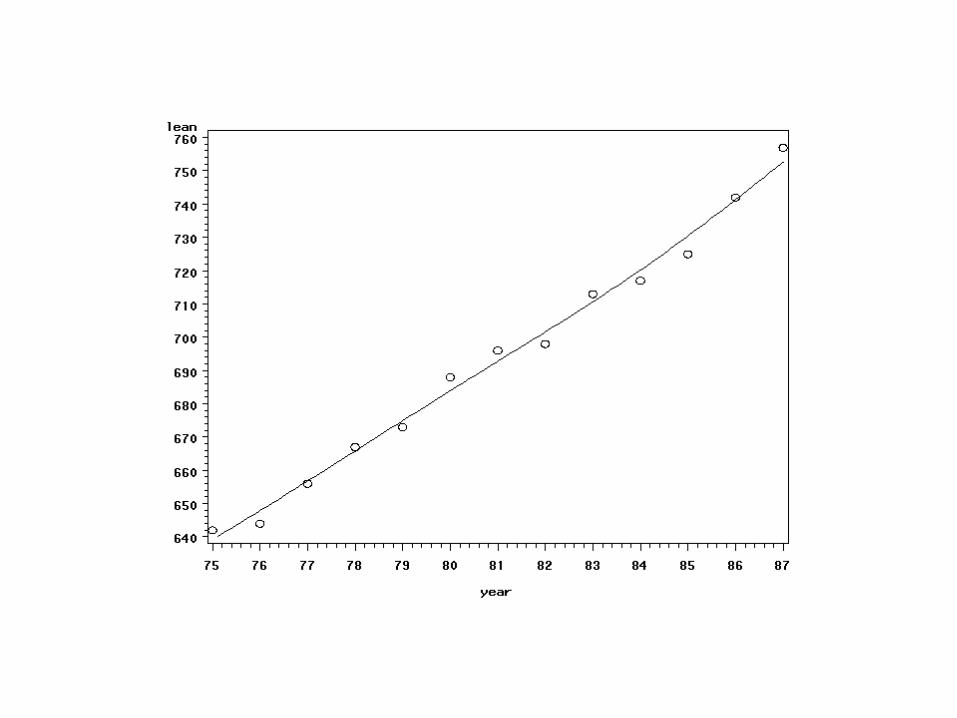
– wykres
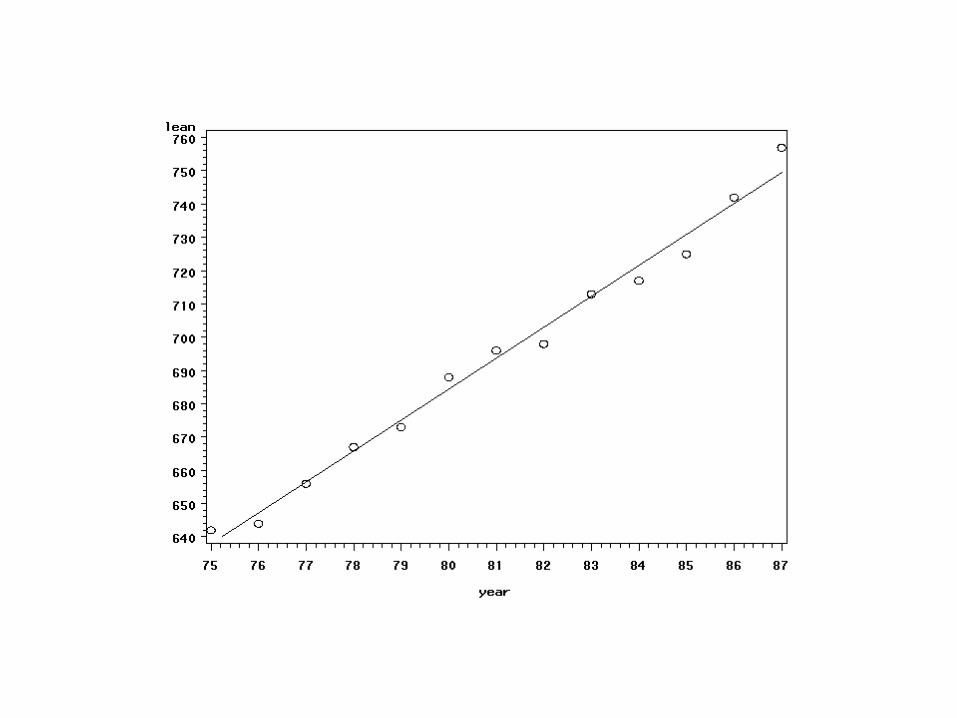
– dopasowanie prostej regresji
– przewidywanie przyszłości

SAS Data Step
data a1; input year lean @@;cards;75 642 76 644 77 656 78 667 79 673 80 68881 696 82 698 83 713 84 717 85 725 86 74287 757 100 .;data a1p; set a1; if lean ne .;

SAS Proc Print
proc print data=a1; run;
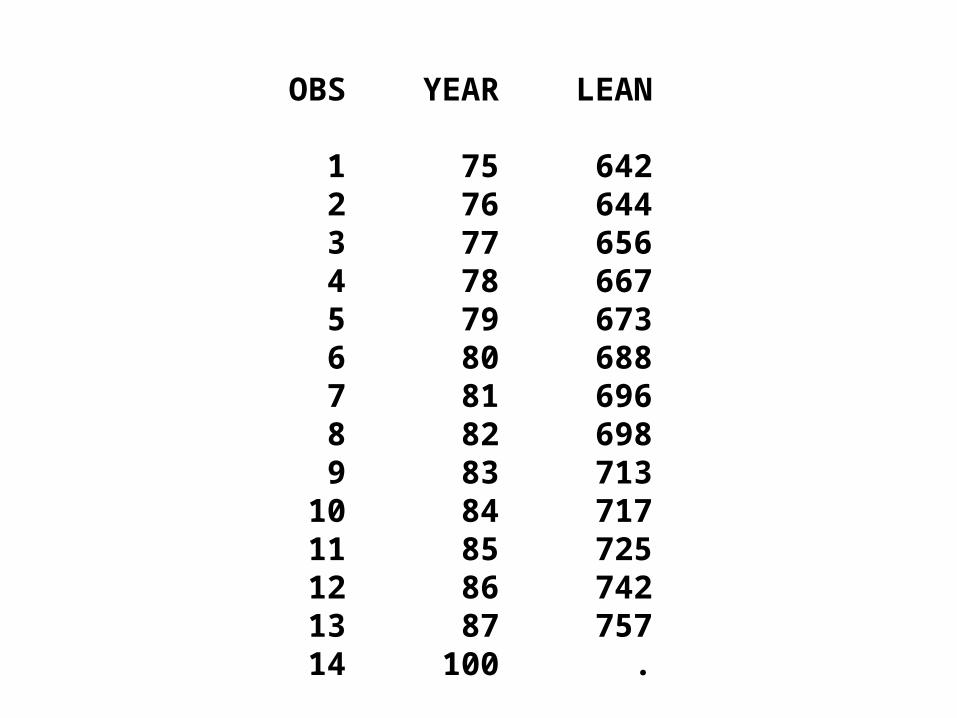
OBS YEAR LEAN
1 75 642 2 76 644 3 77 656 4 78 667 5 79 673 6 80 688 7 81 696 8 82 698 9 83 713 10 84 717 11 85 725 12 86 742 13 87 757 14 100 .

SAS Proc Gplot
symbol1 v=circle i=sm70s;proc gplot data=a1p; plot lean*year; run;
symbol1 v=circle i=rl;proc gplot data=a1p; plot lean*year; run;

SAS Proc Reg
proc reg data=a1; model lean=year/p r; output out=a2 p=pred r=resid; id year;

Parameter Standard Variable DF Estimate Error INTERCEP 1 -61.120879 25.12981850 YEAR 1 9.318681 0.30991420
T for H0:Parameter=0 Prob > |T|-2.432 0.033330.069 0.0001

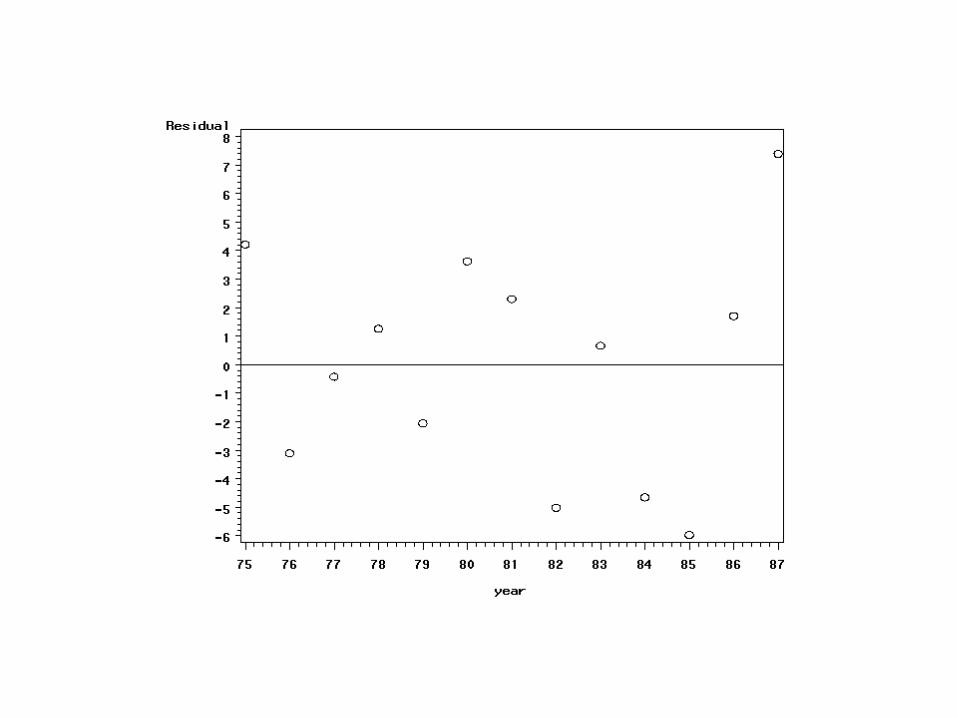
Dep Var Predict Obs YEAR LEAN Value Residual 1 75 642.0 637.8 4.2198 2 76 644.0 647.1 -3.0989 3 77 656.0 656.4 -0.4176 4 78 667.0 665.7 1.2637 5 79 673.0 675.1 -2.0549 6 80 688.0 684.4 3.6264 7 81 696.0 693.7 2.3077 8 82 698.0 703.0 -5.0110 9 83 713.0 712.3 0.6703 10 84 717.0 721.6 -4.6484 11 85 725.0 731.0 -5.9670 12 86 742.0 740.3 1.7143 13 87 757.0 749.6 7.3956 14 100 . 870.7

Struktura danych
• Yi zmienna odpowiedzi (zależna)
• Xi zmienna wyjaśniająca
• dla przypadków i = 1 to n

Prosta regresja liniowa – model statystyczny
• Yi = β0 + β1Xi + ξi
• Yi wartość zmiennej odpowiedzi dla itego
osobnika
• Xi wartość zmiennej wyjaśniającej dla itego osobnika
• ξi zakłócenie losowe z rozkładu normalnego o średniej 0 i wariancji σ2

Parametry
• β0 – punkt przecięcia z osią Y
• β1 - nachylenie
• σ2 - wariancja zakłócenia losowego

Własności modelu
• Yi = β0 + β1Xi + ξi
• E (Yi) = β0 + β1Xi
• Var(Yi|Xi) = var(ξi) = σ2

Dopasowane równanie regresji i reszty
• Ŷi = b0 + b1Xi
• ei = Yi – Ŷi , reszta
• ei = Yi – (b0 + b1Xi)

Wykres reszt
proc gplot data=a2; plot resid*year; where lean ne .; run;

Metoda najmniejszych kwadratów
• Minimalizujemy
• Σ(Yi – (b0 + b1Xi) )2 =∑ei2
• Liczymy pochodne względem b0 i b1
• i przyrównujemy do zera

Rozwiązanie
• Są to równocześnie estymatory największej wiarogodności
XY
XX
YYXX
i
ii
10
21
bb
b

Metoda największej wiarogodności
0
20
40
60
80
100
1st
Q t r
2nd
Q t r
3rd
Q t r
4t h
Q t r
East
West
Nort h
function likelihood 2
1
,~
21
2
1
210
10
210
n
XY
i
ii
iii
fffL
ef
XNY
XY
ii
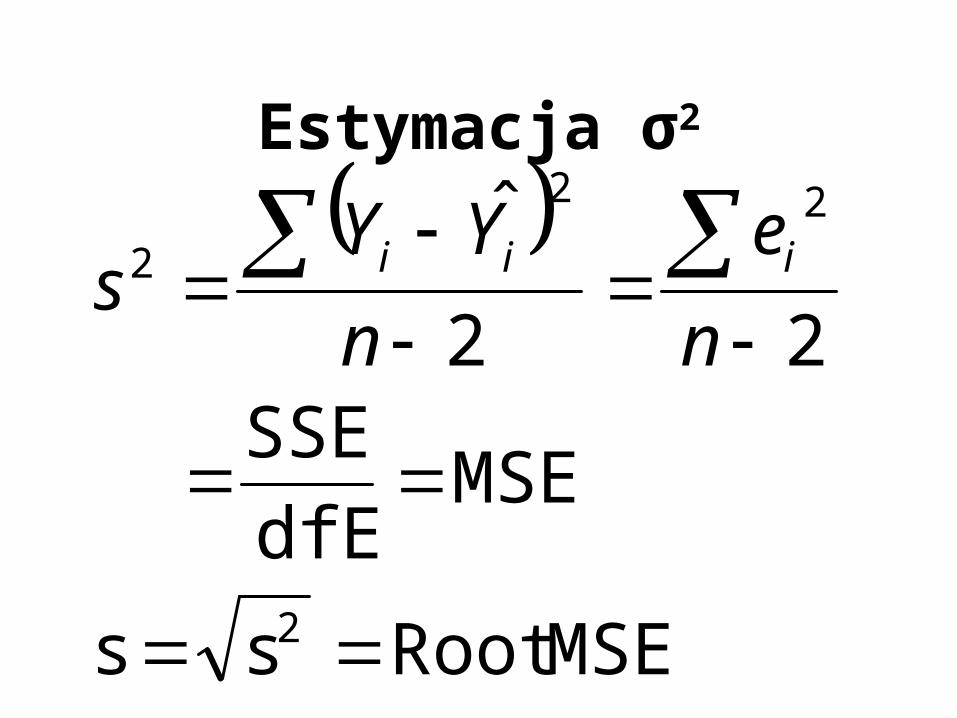
Estymacja σ2
MSERoot ss
MSEdfE
SSE
22
ˆ
2
22
2
n
e
n
YYs iii

Parameter Standard Variable DF Estimate Error INTERCEP 1 -61.120879 25.12981850 YEAR 1 9.318681 0.30991420
Sum of MeanSource DF Squares Square Model 1 15804.48352 15804.48352 Error 11 192.28571 17.48052C Total 12 15996.76923
Root MSE 4.18097 Dep Mean 693.69231 C.V. 0.60271

Teoria dotycząca estymacji β1
• b1 ~ N(β1,σ2(b1))
• gdzie σ2(b1)=σ2 /Σ(Xi – )2
• t=(b1-β1)/s(b1)
• gdzie s2(b1)=s2 /Σ(Xi – )2
• t ~ t(n-2)
X
X

Przedział ufności dla β1
• b1 ± tcs(b1)
• gdzie tc = t(α/2,n-2), kwantyl rzędu
• (1-α/2) z rozkładu Studenta z n-2 stopniami swobody
• 1-α - poziom ufności

Test istotności dla β1
• H0: β1 = 0, Ha: β1 0
• t = (b1-0)/s(b1)
• odrzucamy H0 gdy |t| tc, gdzie
• tc = t(α/2,n-2)
• P = Prob(|z| |t|), gdzie z~t(n-2)

Teoria estymacji β0
• b0 ~ N(β0,σ2(b0))• gdzie σ2(b0)=
• t=(b0-β0)/s(b0)• w s( ), σ2 jest zastąpione przez s2
• t ~ t(n-2)
2
2
2 1
XX
X
ni
0b

Przedział ufności dla β0
• b0 ± tcs(b0)
• gdzie tc = t(α/2,n-2)
• 1-α - poziom ufności

Test istotności dla β0 • H0: β0 = β00, Ha: β0 β00
• t = (b0- β00)/s(b0)
• odrzucamy H0 gdy |t| tc, gdzie
• tc= t(α/2,n-2)
• P = Prob(|z| |t|), gdzie z~t(n-2)

Uwagi (1)
• Normalność b0 and b1 wynika z faktu, że oba te estymatory można przedstawić w postaci liniowej kombinacji Yi, które są niezależnymi zmiennymi o rozkładzie normalnym.

Uwagi (2)
• Na mocy Centralnego Twierdzenia Granicznego, dla dostatecznie dużych rozmiarów prób, estymatory parametrów w regresji liniowej mają rozkład bliski normalnemu, nawet gdy rozkład ξi nie jest normalny. CTG zachodzi gdy wariancja błedu jest skończona. Można wtedy stosować opisane na poprzednich slajdach przedziały ufności i testy istotności.

Uwagi (3)
• Procedury testowania można zmodyfikować tak aby wykrywały alternatywy kierunkowe.
• Ponieważ σ2(b1)=σ2 /Σ(Xi – )2, błąd standardowy b1 można uczynić dowolnie małym zwiększając
• Σ(Xi – )2 .
X
X

SAS Proc Reg
proc reg data=a1; model lean=year/clb;

Parameter StandardVariable DF Estimate Error
Intercept 1 -61.12088 25.12982 year 1 9.31868 0.30991
t Value Pr > |t| 95% Confidence Limits
-2.43 0.0333 -116.43124 -5.8105230.07 <.0001 8.63656 10.00080

Moc dla β1 (1) • H0: β1 = 0, Ha: β1 0• t =b1/s(b1)• tc = t(0.025,n-2)• dla α=.05 , odrzucamy H0 gdy |t| tc
• Potrzebujemy znaleźć P(|t| tc) dla dowolnej wartości β1 0
• gdy β1 = 0, to ``moc’’ wynosi … ?

Moc dla β1 (2)
• t~ t(n-2,δ) – niecentralny rozkład Studenta
• δ= β1/ σ(b1) – parametr niecentralności
• Musimy założyć pewne wartości dla
• σ2(b1)=σ2 /Σ(Xi – )2 i nX

Przykład obliczeń mocy β1
• Załóżmy σ2=2500 , n=25
• i Σ(Xi – )2 =19800
• Tak więc mamy σ2(b1)=σ2 /Σ(Xi – )2= 0.1263
XX

Przykładowe obliczenia mocy (2)
• Rozważmy β1 = 1.5
• Możemy teraz obliczyć δ= β1/ σ(b1)
• t~ t(n-2,δ), chcemy znaleźć P(|t| tc)
• Użyjemy funkcji SAS-a która oblicza dystrybuantę niecentralnego rozkładu Studenta.

data a1; n=25; sig2=2500; ssx=19800; alpha=.05; sig2b1=sig2/ssx; df=n-2; beta1=1.5; delta=beta1/sqrt(sig2b1); tc=tinv(1-alpha/2,df); power=1-probt(tc,df,delta) +probt(-tc,df,delta); output;proc print data=a1;run;

Obs n sig2 ssx alpha 1 25 2500 19800 0.05
sig2b1 df beta1 delta0.12626 23 1.5 4.22137
tc power2.06866 0.98121
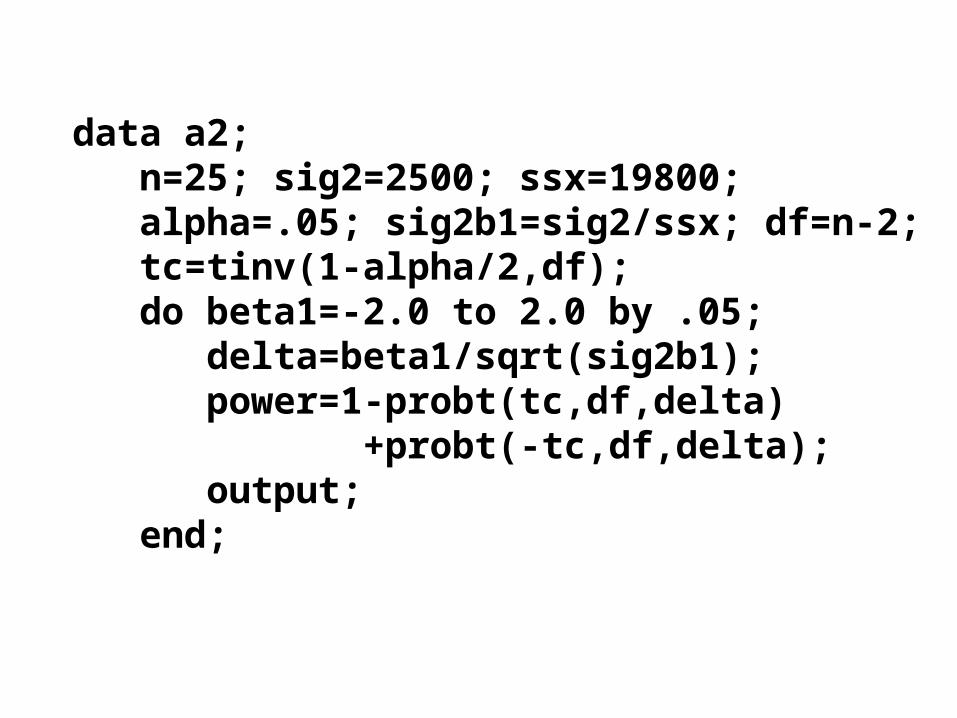
data a2; n=25; sig2=2500; ssx=19800; alpha=.05; sig2b1=sig2/ssx; df=n-2; tc=tinv(1-alpha/2,df); do beta1=-2.0 to 2.0 by .05; delta=beta1/sqrt(sig2b1); power=1-probt(tc,df,delta) +probt(-tc,df,delta); output; end;

title1 'Power for the slope in simple linear regression';symbol1 v=none i=join;proc gplot data=a2; plot power*beta1;proc print data=a2;run;
