won kim: on optimizing an sql-like nested query.pdf
TRANSCRIPT

On Optimizing an SQL-like Nested Query
WON KIM
IBM Research
SQL is a high-level nonprocedural data language which has received wide recognition in relational databases. One of the most interesting features of SQL is the nesting of query blocks to an arbitrary depth. An SQL-like query nested to an arbitrary depth is shown to be composed of five basic types of nesting. Four of them have not been well understood and more work needs to be done to improve their execution efficiency. Algorithms are developed that transform queries involving these basic types of nesting into semantically equivalent queries that are amenable to efficient processing by existing query-processing subsystems. These algorithms are then combined into a coherent strategy for processing a general nested query of arbitrary complexity.
Categories and Subject Descriptors: H.2.4 [Information Systems]: Systems-query processing
General Terms: Algorithms, Languages
Additional Key Words and Phrases: Relational database, nested query, join, divide, aggregate function, predicate
1. INTRODUCTION
A principal advantage of the relational model of data [7-lo] is that it allows the user to express the desired results of a query in a high-level nonprocedural data language without specifying the access paths to stored data. E.F. Codd proposed the relational calculus [7] and the relational algebra [lo] for concisely specifying a complex query against the database. However, the mathematics of the relational calculus and the relational algebra is not easy for nontechnical users of a database system to grasp, and their use as data languages may be limited. As a result, much work has been done to develop a data language which is as powerful as the relational calculus and the relational algebra and which is easy for nontechnical users to learn and use. One such data language that has come to be well received is SQL [5,6]. SQL is a block-structured, calculus-based language which has been implemented in the SEQUEL system [l], System R [2], and ORACLE [23]. SQL- like data languages have also been implemented in ZETA [ll, 151, MRDS [22], and DB-85 [14].
Much of this work was done as a part of this author’s Ph.D. thesis research in the Computer Science Department at the Universi y of Illinois, Urbana-Champaign, and was supported in part by an IBM graduate fellowship and in part by National Science Foundation Grant US NSF-MCS80-01561. Author’s address: IBM Research, 5600 Cottle Road, San Jose, CA 95193. Permission to copy without fee all or part of this material is granted provided that the copies are not made or distributed for direct commercial advantage, the ACM copyright notice and the title of the publication and its date appear, and notice is given that copying is by permission of the Association for Computing Machinery. To copy otherwise, or to republish, requires a fee and/or specific permission. 0 1982 ACM 0362-5915/82/0900-0443 $00.75
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982, Pages 443-469.

444 ’ Won Kim
One of the more interesting features of SQL is the nesting of query blocks to an arbitrary depth. Without this capability, the power of SQL is severely restricted. However, techniques which have been used to implement this feature in existing systems are in general inefficient and, in view of the popularity of SQL-like data languages, it is imperative to develop efficient methods of processing nested queries. This paper shows that a query nested to an arbitrary depth is composed of five basic types of nesting and that the reason for the less-than-satisfactory performance of nested queries in existing systems is that four of the five basic types of nesting have not been well understood. It develops algorithms which transform nested queries to equivalent, nonnested queries which the query- processing subsystems (often called the optimizers) are designed to process more efficiently. The algorithms are based on alternative ways of interpreting the operations of queries which involve the four types of nesting, and may often improve the performance of nested queries by orders of magnitude. Further, these algorithms are directly applicable to the processing of queries expressed in such highly developed, non-SQL-like data languages as QUEL, which is supported by INGRES [21].
This paper presumes that the reader is familiar with the syntax of SQL, as well as with the basic concepts and terminology of relational databases.
The illustrative examples used in this paper are based on the following database of suppliers, parts, projects, and shipments:
SUPPLIER @NO, SNAME, SLOC, SBUDGET) PART (PNO, PNAME, DIM, PRICE, COLOR) PROJECT (JNO, JNAME, PNO, JBUDGET, JLOC) SHIPMENT (SNO, PNO, JNO, QTY)
Each SUPPLIER tuple contains the number (identifier), name, location, and budget of a supplier. Each PART tuple contains the number (identifier), name, dimension, unit price, and color of a part. A PROJECT tuple has fields for the number (identifier), name, budget, and location of a project, along with the part number of a part it uses. A SHIPMENT tuple has fields for a supplier number, along with the part number, project number, and quantity of the part the supplier supplies.
Throughout this paper Ri denotes a relation in the database, Ck the k th column of a relation, and B the size in pages of available main-memory buffer space.
This paper is organized as follows: Section 2 presents a new scheme for classifying a nested query into one of five basic types. Algorithms for transforming a nested query of one of four basic nesting types into its semantically equivalent, nonnested form are developed and illustrated in Sections 3-5. Section 6 indicates potential performance improvements that these algorithms can bring about. Section 7 shows how these algorithms may be merged into a coherent strategy for processing a general SQL-like nested query of arbitrary complexity.
2. NESTING OF QUERY BLOCKS
The fundamental structure of an SQL-like query is syntactically represented by a query block which consists of SELECT, FROM, and WHERE clauses. The WHERE clause specifies the predicates which tuples of the relation indicated in
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

On Optimizing an SQL-like Nested Query - 445
the FROM clause must satisfy. A predicate is of the form [Ri.Ck op X], where X is a constant or a list of constants, and op is a scalar comparison operator (=, l=, >, >=, <, <=) or a set membership operator (IS IN, IS NOT IN). The SELECT clause specifies the columns of the relation to be output and operations on the columns. The following two examples illustrate the basic structure of an SQL-like query.
Example 1. Find the supplier numbers of suppliers which supply parts whose part number is Pl.
SELECT SNO FROM SHIPMENT WHERE PNO = ‘Pl’;
Example 2. Find the highest part number of parts whose unit price is greater than 25.
SELECT MAX(PN0) FROM PART WHERE PRICE > ‘25’;
As long as the predicates in the WHERE clause are restricted to the simple predicates of the form [Ri.Ck op X], only single-relation queries can be formu- lated. If n-relation queries which require relational join and division operations are to be formulated, more general predicates must Be allowed. The simple predicates can only be extended in three ways.
(1) Nested predicate. X may be replaced by Q, an SQL-like query block, to yield a predicate of the form [Ri.Ck op Q]. The op may be a scalar or set membership operator. The predicate may also take the form [Q op Ri.Ck]. The set membership operator is then replaced by the set containment operator (CONTAINS, DOES NOT CONTAIN). The two forms of the predicate are symmetric, so the latter will not be further considered.
(2) Join predicate. X may be replaced by Rj.Ch to yield a predicate of the form [Ri. Ck OP Rj. Ch], in which Ri 1~ Rj and the op is a scalar comparison operator.
(3) Division predicate. Ri. Ck and X may be replaced by query blocks Qi and Qj, respectively, to yield a predicate of the form [Qi op Qi]. The op may be a scalar comparison operator, set comparison operator (=, #), or set membership and containment operator. As will be seen later, Qj (or Qi) may be a constant or a list of constants, provided that Qi (or Qi) has in its WHERE clause a join predicate which references the relation of the outer query block.
For simplicity, the op in a join predicate is assumed to be an equality operator in this paper. The join predicate [Ri.Ck = Rj.Ch] indicates that each tuple of Ri is to be joined with all tuples of Rj whose Ch column values are equal to the Ck column value of the Ri tuple. The next example illustrates the use of a join predicate in formulating a two-relation query.
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

446 * Won Kim
Example 3. Find the supplier numbers of suppliers which supply parts whose unit price is higher than 25:
SELECT SNO FROM SHIPMENT, PART WHERE SHIPMENT.PNO = PART.PNO AND
PRICE > ‘25’;
Note that a query which requires joining two relations has been expressed using one join predicate. A query which joins n relations can be written using a conjunction of n - 1 join predicates in the WHERE clause. An n-relation query which joins n relations via n - 1 join predicates and contains no nested or division predicates is termed a canonical n-relation query. As shown later in this section, it is possible to write a query which joins relations without the use of join predicates.
Examples 4 through 7 later in this section illustrate uses of nested predicates, and Example 8 shows a query which makes use of a division predicate.
Besides providing the capability for expressing a canonical n-relation query, the generalized predicates allow the user to nest query blocks to an arbitrary depth. For the following discussion, however, a query is assumed to be of nesting depth one. That is, a query consists of an outer block and an inner block. (The query blocks Qi and Qj in a division predicate are the left- and right-hand sides of the inner block.) Further, it is assumed that the WHERE clause of the outer block contains only one nested predicate or division predicate. These assumptions cause no loss of generality, as is shown in Section 7. Finally, as in SQL, it is assumed that only one column name may be specified in the SELECT clause of a query block that is nested within another query block.
It is clear that, of the three types of generalized predicates defined above, only the nested predicate and the division predicate give rise to the nesting of query blocks. A nested predicate may cause one of four basic types of nesting, according to whether the inner query block Q has in the WHERE clause a join predicate that references the relation of the outer query block and whether the column name in the SELECT clause of Q has associated with it an aggregate function (SUM, AVG, MAX, MIN, COUNT). A division predicate yields a fifth basic nesting. It appears that the present specification of SQL gives rise to no other basic nesting types. However, it does not appear that an extra nesting type will
enhance the power of SQL-like data languages. The remainder of this section will illustrate these five basic nesting types and, for later use, develop graphical representations for them.
A nested predicate gives rise to type-A nesting if the inner query block Q does not contain a join predicate that references the relation of the outer query block and the SELECT clause of Q indicates an aggregate function associated with the column name. Note that if Q does not contain in the WHERE clause a join predicate that references the relation of the outer query block, Q may be completely evaluated independently of the outer query block. Moreover, when the SELECT clause of Q specifies an aggregate function, the result of evaluating
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

On Optimizing an SQL-like Nested Query l 447
Q will be a single constant rather than a list of constants. A type-A nesting of depth 1 is illustrated by the following example.
Example 4. Find the supplier numbers of suppliers which supply parts whose part number is the highest of those parts whose unit price is greater than 25.
SELECT SNO FROM SHIPMENT WHERE PNO = (SELECT MAX(PN0)
FROM PART WHERE PRICE > ‘25’) ;
There is only one way to process a type-A nested query on a single processor. The inner block has to be evaluated first. The nested predicate of the outer block then becomes a simple predicate, since Q can be replaced by a constant. The outer block then is no longer nested and can be processed completely.
A type-A nested query (predicate) of depth 1 is graphically represented as follows. The graphical representation for a query will be called the query graph for the query.
The left-hand node represents the outer block (which requires access to Ri), and the right-hand node the inner block (which references R;). The arc represents the nested predicate and is labeled ‘A’ followed by the column name that appears in the SELECT clause of the inner query block. In general, if the WHERE clause of the outer block consists of n nested predicates, n arcs leading to n right-hand nodes emanate from one left-hand node.
A nested predicate yields a type-N nesting, if Q does not contain a join predicate that references the relation of the outer query block and the column name in the SELECT clause of Q does not have an aggregate function associated with it. The result of evaluating the Q of a type-N nested predicate is a list of constants, and, as in a type-A nested query, Q may be completely evaluated independently of the outer query block. The following example illustrates a type-N nesting.
Example 5. Find the supplier numbers of suppliers which supply parts whose unit price is greater than 25.
SELECT SNO FROM SHIPMENT WHERE PNO IS IN (SELECT PNO
FROM PART WHERE PRICE > ‘25’) ;
Note that Examples 3 and 5 show two different formulations of the same query. This observation has some interesting implications, as can be seen in Section 3.
The System R approach to processing the above query is first to process the inner query block Q in order to replace the type-N nested predicate, PNO IS IN Q, with a simple predicate PNO IS IN X, where X is the result of evaluating Q, and then to completely process the resulting nonnested query.
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

448 * Won Kim
The query graph for a type-N nested query of depth 1 is
A type-N nested query in which the op of the nested predicate is the set noninclusion operator (IS NOT IN) requires a different treatment from a type-N nested query involving the set inclusion operator (IS IN), as is shown in Section 3. This special type-N nested query is represented by a straight arc labeled ‘Nx’.
A type-N nested query of depth n(n >= 1) is defined as a nested query whose query graph consists of only straight arcs labeled ‘N’. The following is the query graph for a type-N nested query of depth 2.
A nested predicate gives rise to a type-J nesting when the WHERE clause of Q contains a join predicate that references the relation of the outer query block and the column name in the SELECT clause of Q is not associated with an aggregate function, The next example illustrates a type-J nesting.
Example 6. Find the supplier numbers of suppliers which supply projects that are located in New York and whose project numbers are the same as the supplier numbers.
SELECT SNO FROM SHIPMENT WHERE PNO IS IN (SELECT PNO
FROM PROJECT WHERE SHIPMENT.SNO = PROJECT.JNO AND
JLOC = ‘NEW YORK’) ;
The following is the query graph for a type-J nested query of depth 1.
a3 Ri.C,=Ri.C,
The straight arc is labeled ‘N’, since except for the presence of a join predicate in the inner block, a type-J nested query has the same form as a type-N nested query. The circular arc, labeled with a join predicate, links the two query blocks that the join predicate references.
The query graph for a type-J nested query of depth 1 involving the set noninclusion operator is shown in the following.
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

On Optimizing an SQL-like Nested Query l 449
Ri.C,=Rj.C,
A type-J nested query of depth n(n >= 1) is defined as a nested query whose query graph consists of at least one circular arc and no straight arc labeled ‘A’. The following is the query graph for a type-J nested predicate of depth 2.
@-3+AyJ
R,.C,=R,.C,
A type-JA nesting results from a nested predicate if the WHERE clause of Q contains a join predicate that references the relation of the outer query block and an aggregate function is associated with the column name in the SELECT clause of Q. The next example illustrates a type-JA nesting.
Example 7. Find the supplier numbers of suppliers which supply parts whose part numbers are the highest of those parts used by each of the projects located in New York.
SELECT SNO FROM SHIPMENT WHERE PNO = (SELECT MAX( PNO)
FROM PROJECT WHERE PROJECT.JNO = SHIPMENT.JNO AND
JLOC = ‘NEW YORK’);
The query graph for a type-JA nested predicate of depth 1 is
@yg
Ri.C,=Rj.C,
The straight arc joining the two nodes is labeled ‘A’. The circular arc connects the two query blocks referenced in the join predicate.
A type-JA nested query of depth n(n >= 1) is defined as a nested query whose query graph exhibits at least one circular arc and at least one straight arc labeled ‘A’, as shown below.
R,.C,=R,.C,
A join predicate and a division predicate together give rise to a type-D nesting, if the join predicate in either Qi or Qj (or both) references the relation of the outer block. As the next example shows, a type-D nested query expresses the relational division operation.
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

450 - Won Kim
Example 8. Find the names of suppliers which supply all red parts that are priced higher than 25.
SELECT SNAME FROM SUPPLIER WHERE (SELECT PNO
FROM SHIPMENT WHERE SHIPMENT.SNO = SUPPLIER.SNO)
CONTAINS
( SELECT PNO FROM PART WHERE COLOR = ‘RED’ AND
PRICE > ‘25’) ;
The division predicate in this query specifies the division of TMPl (SNO, PNO) by TMP2 (PNO), where TMPl is obtained by projecting the SHIPMENT relation over the SNO and PNO columns, and TMP2 by evaluating the right- hand side of the division predicate.
The query graph for a type-D nested query of depth 1 is
The straight arc is labeled ‘D’. One straight arc leads to two right-hand nodes, since the inner block consists of two query blocks, Qi and Qj . The top right-hand node is the left-hand side of the division predicate. The circular arc connects the outer block and the left-hand side of the division predicate.
Both sides of the inner block of a type-D nested query may contain join predicates which link them to the outer block. However, a division predicate in which neither query block contains a join predicate that references the outer block is meaningless. The reason is that a predicate is a condition which is imposed on tuples of the relation indicated in the FROM clause of the query block, and a division predicate which does not contain a join predicate which references the relation is either always true or always false.
The System R technique for processing a nested query in which the WHERE clause of the inner query block contains a join predicate that references the relation of the outer query block (that is, types J, JA, and D) is the conceptually simple, nested-iteration method [16-18, 20, 241. This method suggests the com- plete processing of the inner query block for each tuple of the relation of the outer query block. For example, the query of Example 6 may be processed by the nested-iteration method by fetching each SHIPMENT tuple, isolating its SNO column value for substitution in the join predicate of the inner query block, evaluating the inner query block (which by now is free of any join predicate that references the relation of the outer query block), and reducing the type-J nested predicate of the original query to a simple predicate PNO IS IN X, where X is the result of evaluating the inner query block for a particular SNO value of the SHIPMENT tuple.
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

On Optimizing an SQL-like Nested Query * 451
Although it provides a convenient way of viewing the semantics of a nested query, the nested-iteration method is an inefficient way to evaluate it in a paged- memory environment. In fact, the main thrust of this paper is the development of algorithms for transforming, with some intermediate query processing, a nested query of various types to a semantically equivalent canonical form which can be evaluated more efficiently. This is illustrated in Section 6.
3. PROCESSING A TYPE-N OR TYPE-J NESTED QUERY
Examples 3 and 5 have shown that some query may be expressed in its canonical form or type-N nested form. The equivalence of the two forms of the same query has been recognized by others [see 12, Chap. 71. However, some important questions which arise have not been investigated. Can a type-N nested query of depth n - 1 be transformed to a semantically equivalent canonical n-relation query, and vice versa? Which of the two forms of the query can be more efficiently processed?
First, Lemma 1 establishes the equivalence of the canonical and type-N nested form of a two-relation query in which the op is not the set noninclusion operator, IS NOT IN.
Let Q1 be
SELECT RieCk FROM Ri, Rj WHERE Ri.Ch = Rj.Cm
And let Qz be
SELECT Ri.Ck FROM R, WHERE Ri.Ch ISIN (SELECT R,.Cm
FROM Rj);
LEMMA 1. Q1 and Q2 are equivalent; that is, they yield the same result.
PROOF. By definition, the inner block of Q2 can be evaluated independently of the outer block and the result of evaluating it is X, a list of values in the C, column of Rj. Qz is then reduced to
SELECT Ri.Ck FROM Ri WHERE Ri.Ch ISIN X;
The predicate Ri. G, IS IN X is satisfied only if X contains a constant 3c such that Ri.Ch = X. That is, it can be satisfied only for those tuples of Ri and Rj which have common values in the Ch and C, columns, respectively. The join predicate Ri. Ch = Rj. C, specifies exactly this condition. Cl
Lemma 1 implies one important assumption. The result of evaluating the inner block of Qz is X, a list of values in the C, column of Rj. Since the list is obtained by projecting R; over the C, column, in general it will contain duplicate values. But the effect of the simple predicate Ri. Ch IS IN X is to implicitly remove any redundant values from X. However, the join predicate Ri. Ch = Rj. C, of Q1 does not imply removal of duplicate values from the C, column of Rj and the result of &I reflects their presence. Therefore, it is assumed throughout this paper that, if
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

452 * Won Kim
a canonical n-relation query has been obtained from a type-N or type-J nested query and if and only if the op of the nested predicate is IS IN, it is processed by first restricting and projecting the relation which corresponds to the relation of the inner query block in the nested query (e.g., Rj in Q1) and then removing duplicate values from the resulting unary (i.e., single-column) relation before joining it with the relation which corresponds to the relation of the outer query block in the nested query (e.g., Ri in Q1). This assumption guarantees the correctness of Lemma 1 and appears to be reasonable, since the relation which results from projecting and restricting a relation is usually much smaller than the initial relation, and the cost of joining reduced relations is, therefore, usually smaller than the cost of joining unreduced relations.
It is also important to recognize that Lemma 1 establishes only that the type- N nested form of a query in which the op of the nested predicate is the set inclusion operator can be transformed to its canonical form. Lemma 1 does not apply when the op of the nested predicate is the set noninclusion operator, as is shown later. Further, the canonical form of a query cannot in general be trans- formed to the type-N nested form. This is because only one column (the join column) is allowed in the SELECT clause of the inner block [6]. If, for example, the SELECT clause of Q1 contained Rj.Cq hs well as Ri.Ck, it would not be possible to express the query in the nested form. Lemma 1 can be readily extended to type-N nested predicate in which the op is a scalar comparison operator.
The scalar comparison operator becomes the op of the join predicate in the canonical form of the query. It is assumed that the result of evaluating the inner query block is always a single constant. If it is desirable to be able to abort the query when the inner query block yields a list of constants, the canonical equivalent must be processed as if the op is IS IN.
Lemma 1 suggests Algorithm NEST-N-J for transforming a type-N nested query of depth n - 1 to its canonical form.
Algorithm NEST-N-J
(1) Combine the FROM clauses of all query blocks into one FROM clause. (2) AND the WHERE clauses of all query blocks into one WHERE clause. (3) Replace [Ri. C,, op (SELECT Rj. C,] by a join predicate [Ri. CI, new-op Rj. .C,], and
AND it to the combined WHERE clause obtained on step 2. Note that if op is IS IN, the corresponding new-op is ‘=‘; otherwise, new-op is the same as op.
(4) Retain the SELECT clause of the outermost query block.
Algorithm NEST-N-J attaches no significance to join predicates. A type-J nested query can also be transformed to its canonical form by the algorithm. The join predicate in the inner block which references the outer block is ANDed to other simple predicates on step 2. The following example illustrates Algorithm NEST-N-J.
Example9 SELECT Ri.Ck FROM Ri WHERE Ri.Ch IS IN (SELECT Rj.Cm
FROM Rj WHERE Ri.Cn=Rj.CP);
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

On Optimizing an SQL-like Nested Query * 453
The canonical form of this query is shown below:
SELECT Ri.Ck FROM Rip Rj WHERE Ri.Ch = Rj.Cm AND
Ri.Cn = Rj.Cp;
The query joins relations Ri and Rj, on (Ch, C,) and (Cm, C,) columns, respectively. The process of transforming a type-N or type-J nested query of depth n to its
canonical equivalent can be viewed as one of eliminating all straight or circular arcs as well as all but the leftmost node on the query graph for the nested query.
A type-N nested query in which the op in the nested predicate is the set noninclusion operator requires a careful, special consideration. Consider the following query.
Example 10. Find the names of suppliers that do not supply parts whose part number is Pl.
SELECT SNAME FROM SUPPLIER WHERE SNO IS NOT IN (SELECT SNO
FROM SHIPMENT WHERE PNO = ‘Pl’) ;
It is important to understand that the following query is not equivalent to the above query.
SELECT SNAME FROM SUPPLIER WHERE SNO IS IN (SELECT SNO
FROM SHIPMENT WHERE PNO l= ‘PI’);
Further, as pointed out in 1121, the operation of the query may be viewed as fetching each SUPPLIER tuple, checking whether the supplier supplies part Pl, and, if not, outputting the supplier name. This alternate interpretation of the query results in the formulation of a type-D nested query.
SELECT SNAME FROM SUPPLIER WHERE (SELECT PNO
FROM SHIPMENT WHERE SHIPMENTSNO = SUPPLIER.SNO)
DOES NOT CONTAIN Pl;
As is shown in Section 5, efficient processing of a type-D nested query in general requires sorting the relation of the left-hand side of the inner block, the SHIPMENT relation in the present example. The equivalent type-N nested form of the query, on the other hand, requires sequentially scanning the SHIPMENT relation only once. Therefore, the type-D nested form of the query is not helpful. However, the type-N nested form also suffers if X, the result of evaluating the inner block, is large compared with B, the size of main-memory buffer space.
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

454 * Won Kim
A potentially better method of processing the above query when the result of evaluating the inner block is large is a special merge join of X and SUPPLIER. Both relations are first sorted in SNO-column order and then simultaneously scanned to find SUPPLIER tuples which have SNO values that are not shared by X. X and SUPPLIER may be said to be ‘antijoined’ by the antijoin predicate l(SUPPLIER.SNO = XSNO). The above query may then be transformed to its pseudocanonical form as follows,
SELECT SNAME FROM SUPPLIER, X WHERE l(SUPPLIER.SNO = X.SNO);
The set noninclusion operator in a type-N or type-J nested query requires an extension to Algorithm NEST-N-J. Now [Ri.Ck IS NOT IN (SELECT Rj.Ch] is replaced by the antijoin predicate l(Ri.Ck = Rj.Ch) and ANDed to the merged WHERE clause obtained on steps 2 and 3 of the algorithm.
The result of a query is independent of the order in which its predicates are evaluated. However, an antijoin predicate must be evaluated only after all join predicates have been evaluated. The following query explains this point.
SELECT Ri.Ck FROM WHERE ii:.& IS NOT IN (SELECT RjaCm
FROM Rj WHERE RjeCn = Ri.Cp);
The operation of the query may be thought of as fetching each tuple of Ri, retrieving all tuples of Rj whose C, column values are the same as the C, column value of the Ri tuple (i.e., if Rj.Cn = Ri.Cp), and outputting the C’k column of the Ri tuple if its C,, column value is not found in the C,,, column of the retrieved Rj tuples ,(i.e., if I( Ri.Ch = Rj.Cm)). Notice how the join predicate, Rj.Cn = Ri.Cp, is evaluated before the antijoin predicate, l(Ri.Ch = Rj.Cm) (implied in Ri.Ch IS NOT IN (SELECT Rj.Cm) for each value in the C, column of Ri.
4. PROCESSING’A TYPE-JA NESTED QUERY
A new algorithm for processing a type-JA nested query is developed in this section. The algorithm not only improves the performance of a type-JA nested query but also appears to be easy to implement. Lemma 2 provides the basis for the algorithm. An algorithm similar to the one described in this section has been independently developed by Epstein in the context of the QUEL data language
c131. Let Q3 be
SELECT R, . G FROM Ri WHERE Ri. CA = (SELECT AGG(Rj. Cm)
FROM R, WHERE R,.Cm = Ri.Cp);
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

On Optimizing an SQL-like Nested Query * 455
Further, let Q4 be
SELECT R, . Ck FROM Ri WHERE Ri.Ch = (SELECT RI.&
FROM R1 WHERE Rt.CI = Ri.Cp);
where Rt(C1, C,) is obtained by
Rt(C1, Cz) = (SELECT Rj.Cn, AGG(Rj.Cm) FROM Rj GROUP BY Rj*Cn);
LEMMA 2. Q3 and Q4 are equivalent, that is, they produce the same result.
PROOF. It is shown in Section 2 that the operation of Q3 may be thought of as first fetching a tuple of Ri and all tuples of Rj whose C,, column values are the same as the C, column value of the Ri tuple, then applying the aggregate function AGG on the C,,, column of the Rj tuples to obtain a constant X, and, finally, outputting the Ck value of the Ri tuple if x = C,, column value of the Ri tuple. Now RI is a binary relation of each distinct value in the C,, column of Rj and the corresponding value obtained by applying the aggregate function AGG on the Rj tuples. Then it is clear that the query may be processed by fetching each tuple of Ri, then fetching the Rt tuple whose Cl column has the same value as the C, column of the Ri tuple, and outputting the Ck column value of the Ri tuple if the C2 column value of the Rt tuple is the same as the C,, value of the Ri tuple. But this is exactly the operation of Q4. Cl
Note that Q3 is type-JA nested, but Q4 is type-J nested and can be transformed to its canonical form by Algorithm NEST-N-J. Since the op of the type-J nested predicate is the scalar equality operator, rather than the set inclusion operator IS IN, the problem of removing duplicates from Rt does not arise here. In other words, the straight arc labeled ‘A’ on the query graph for Q3 is replaced by a straight arc labeled ‘N’, and the circular arc is retained.
Lemma 2 directly leads to an algorithm which transforms a type-JA nested query of depth 1 to an equivalent type-J nested query of depth 1. Consider the following query.
SELECT R,. C,,+z FROM R, WHERE R,.C,,+I = (SELECT AGG(R~.C,+I)
FROM Rz WHERE R,.C, = R,.C, AND
Rz.Cz = R,.C2 AND
Rz.C,, = R,.C,,);
Algorithm NEST-JA
(1) Generate a temporary relation Rt( Cl, . . . , C,, C,,,,) from R2 such that each C,,+l column value of Rt is a constant obtained by applying the aggregate function AGG OP
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

456 - Won Kim
the C,,,, column of the Rz tuples which share a common value in columns C1 through C,,. In other words, the primary key of Rt is its lirst n columns. Rt can be obtained by
RttCl,..., C,, C,+l) = (SELECT Cl,. . . , C,, AGG(C,+l) FROM RZ GROUP BY C,, . . . , Cn) ;
(2) Transform the inner block of the initial query by changing all references to Rz columns in join predicates that reference R, to corresponding RI columns. The initial type-JA nested query is now type-J nested, since the aggregate function in the SELECT clause has been replaced by a simple reference to the C,+1 column of Rt.
SELECT RI. C, +2 FROM RI WHERE Rl.C,,+l = (SELECT Rt.C,+l
FROM Rt WHERE R1.G =R,.C, AND
RI.& =Rl.Cz AND
Rt.C,, = RI.&);
In order to extend Lemma 2 to an algorithm for transforming a type-JA nested query of depth n(n >= 1) to an equivalent, type-J nested query, it is instructive to consider first the transformation of a type-JA nested query of depth 2. A type- JA nested query of depth 2 has at least one circular arc on its query graph and one or both of the straight arcs must be labeled ‘A’. Therefore, there are 3 types of type-JA nested query of depth 2, as illustrated below.
type JA(NA)
QeQs
tvw JA(AA)
QQa
type JA(AN)
0
It is clear that Algorithm NEST-JA, when applied to the two right-hand nodes, transforms a type-JA(NA) nested query to an equivalent type-J query of depth 2 shown below.
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

On Optimizing an SQL-like Nested Query * 457
Similarly, it transforms a type-JA(AA) nested query to an equivalent type- JA(AN) nested query. A type-JA(AN) nested query can be transformed to a type-JA query of depth 1 if Algorithm NEST-N-J is first applied to the two innermost blocks (i.e., the two rightmost nodes on the query graph). The next example illustrates this.
Example 11. The following is a type-JA(AA) nested query of depth 2.
SELECT Ri.Ck FROM Ri WHERE Ri. CA = (SELECT AGG(R,.C,)
FROM Rj WHERE RjsCn = (SELECT AGG(Rk. C,)
FROM Rk WHERE Rk.Cq = Ri.Cr));
First, a temporary relation &(Cr, Cz) is obtained by step 1 of Algorithm NEST- JA.
Rt,(Cl, Cz) = (SELECT Rk . C, , AGG (Rk . C,, FROM & GROUP BY Rk.C9);
By step 2 of Algorithm NEST-JA, the innermost block is transformed to
SELECT R~I < Cz FROM Rt1 WHERE Rtl.CI = Ri.Cr;
The initial type-JA(AA) nested query is now type-JA(AN) nested. The two inner blocks of the type-JA(AA) nested query can then be transformed to its canonical form by Algorithm NEST-N-J, yielding the following type-JA nested query of depth 1.
SELECT FROM WHERE
Ri. Ck R, Ri. Ch = (SELECT AGG(Rj.C,!
FROM Rj, Rtl WHERE Rt1.G = R,.C, AND
Rt1.c~ = Rj.Cn);
Next, another temporary relation, Rtz(G, C2), is obtained by step 1 of &ofithm
NEST-JA.
R&Cl, Cz) = (SELECT R~I.CI, AGG(Rj.Cm) FROM &I, Rj WHERE Rj.Cn = Rtl.Cz GROUP BY Ro.C,);
By another application of step 2 of Algorithm NEST-JA, the initial query is transformed to an equivalent type-J query of depth 1.
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.
458 * Won Kim
SELECT Ri.Ck FROM Ri WHERE Ri.Ch = (SELECT Rt2.c~
FROM WHERE ilZ.Cl = Ri.Cr);
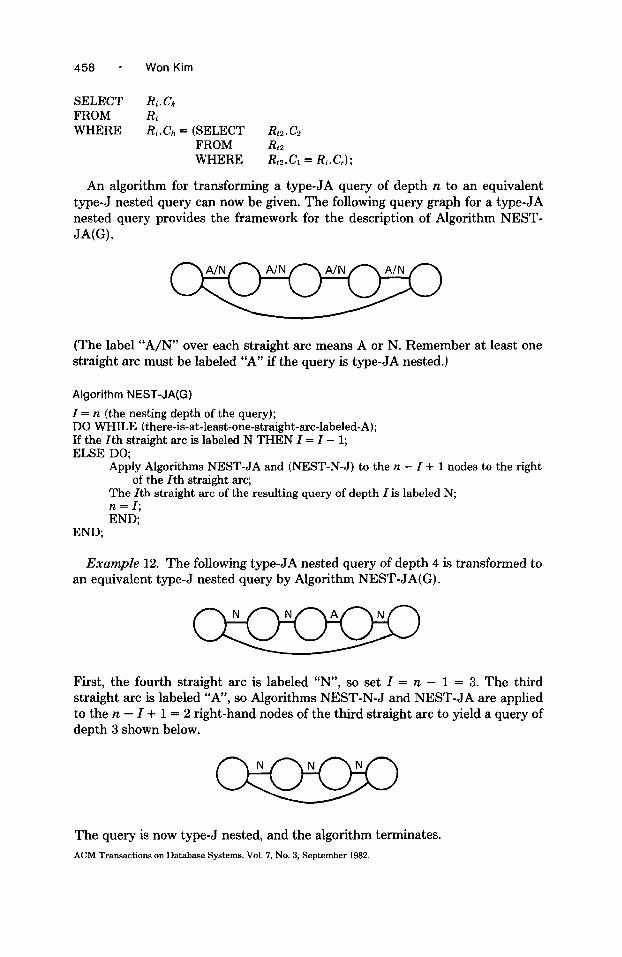
An algorithm for transforming a type-JA query of depth n to an equivalent type-J nested query can now be given. The following query graph for a type-JA nested query provides the framework for the description of Algorithm NEST- JA(G).
(The label “A/N” over each straight arc means A or N. Remember at least one straight arc must be labeled “A” if the query is type-JA nested.)
Algorithm NEST-JA(G)
I = n (the nesting depth of the query); DO WHILE (there-is-at-least-one-straight-arc-labeled-A); If the Ith straight arc is labeled N THEN I = I - 1; ELSE DO;
Apply Algorithms NEST-JA and (NEST-N-J) to the n - I + 1 nodes to the right of the Ith straight arc;
The Zth straight arc of the resulting query of depth I is labeled N; n = I; END;
END;
Example 12. The following type-JA nested query of depth 4 is transformed to an equivalent type-J nested query by Algorithm NEST-JA(G).
c First, the fourth straight arc is labeled “N”, so set I = n - 1 = 3. The third straight arc is labeled “A”, so Algorithms NEST-N-J and NEST-JA are applied to the n - I + 1 = 2 right-hand nodes of the third straight arc to yield a query of depth 3 shown below.
The query is now type-J nested, and the algorithm terminates.
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

On Optimizing an SQL-like Nested Query * 459
5. PROCESSING A TYPE-D NESTED QUERY
As far as this author is aware, none of the currently operational relational database systems supports the division predicate. However, it is often necessary to formulate a query that requires division of one relation by another relation, and it does appear that the relational division operation can be efficiently performed. A more efficient algorithm than the nested-iteration method for processing a type-D nested query can be found by, once again, recognizing an alternate interpretation of the operation of the query. The algorithm is based on Lemma 3. Let Q5 be the following query.
SELECT Ri.Ck FROM Ri WHERE (SELECT Rj.Ch
FROM WHERE z.Cn=Ri.Cp)
OP (SELECT Rk . C, FROM Rd;
Further, let Q6 be SELECT Ri.Ck FROM Ri WHERE Ri.C,, = (SELECT Cl
FROM RI) ;
where Rt is obtained as
R,(G) = (SELECT Rj.Cn FROM Rj RX WHERE (SELECT Rj.Cb
FROM RjRY WHERE RY.C,, = RX.C,)
(SELECT Yi:. c, FROM Rk) ;
LEMMA 3. Q5 and Qs are equivalent, that is, they produce the same result.
PROOF. As has been shown, the operation of Q5 may be thought of as fetching each tuple of Ri and checking whether the division predicate is satisfied by the C, column value of the tuple. But what if there is a list of the C,, column values of Rj which satisfy the division predicate? Then all that needs to be done is to fetch each Ri tuple and determine whether the C,, column value of the tuple is in the list. But this is precisely the operation of Qs, since Rt is just such a list. 0
Note that the initial type-D nested query has been transformed to an equivalent type-N nested query. The fact that the op of the type-N nested predicate is the scalar equality operator, rather than the set inclusion operator IS IN, means that the type-N nested query may be transformed to its canonical equivalent form without having to remove duplicates from Rt. In terms of query graphs, the straight arc labeled “D” on the query graph for the initial query is replaced by a straight arc labeled “N”, the two right-hand-side nodes are replaced by one node,
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

460 l Won Kim
and the circular arc on the initial query graph is eliminated. It should be clear that the initial query could have been directly transformed to its canonical form. The following example illustrates Lemma 3.
Example 13. Find the names of suppliers which supply all red parts.
SELECT SNAME FROM SUPPLIER WHERE (SELECT PNO
FROM SHIPMENT WHERE SHIPMENT. SNO = SUPPLIER. SNO)
= (SELECT PNO FROM PART WHERE COLOR = ‘RED’) ;
The query is equivalent to
SELECT SNAME FROM SUPPLIER WHERE SNO IS IN (SELECT SNO
FROM TMP) ;
where the temporary relation TMP(SN0) is obtained by
TMP(SN0) = (SELECT SNO FROM SHIPMENT SX WHERE (SELECT PNO
FROM SHIPMENT SY =
WHERE SX.SNO = SY.SNO) (SELECT PNO FROM PART WHERE COLOR = ‘RED’);
The query which generates the temporary relation Rt is simply an SQL-like formulation of the relational division operator. Lemma 3 provides the basis for Algorithm NEST-D, which transforms a general type-D nested query to an equivalent canonical two-relation query. Consider the following query which requires dividing Rz( Cl, . . . , CL) by R3(C1, . . . , C,), where n > m.
SELECT RI. C, FROM RI WHERE (SELECT Rz. Cl
FROM RZ WHERE R2.G = R,.Cz AND
Rz.Cz = R1.G AND
Rz.C,, = RI.&) =
(SELECT R3. CI FROM RS WHERE R3.C2 = R,.G AND
R3.C3 = R,.Cz AND
R3.C,,, = R,.C,);
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

On Optimizing an SQL-like Nested Query 461
Algorithm NEST-D
(1) Generate a temporary relation &I(& . . . , C,) by
Rtl(C1, . . . , Cm) = (SELECT Cl, . . . , C, FROM Rx);
Also generate a temporary relation Rt2(C1, . . . , C,) by
RdG, . . . , C,,) = (SELECT C,, . . . , C, FROM Rz) ;
(2) Divide Rt2(C1, . . . . C,) by Rtl(G, . . . . C,). The result is a new temporary relation RtdCm+~, . . . , Cd.
(3) Transform the initial query to its canonical equivalent by first dropping the query block on RS, replacing all references to columns of RP to corresponding columns of Rt3 in the query block on Rz, and eliminating the SELECT and FROM clauses of the query block on RP. The FROM clause of the resulting canonical query must now include Rt3 as well.
SELECT R, . C, FROM R,, Rt3 WHERE RI.C,+I =RmC,,,+l AND
R1.C,,,+2 = Rta.Cm+z AND
R,.C, = Rt3.G;
6. RATIONALE FOR TRANSFORMING NESTED QUERIES
What is the reason for transforming a nested query to its canonical equivalent? The answer is that the optimizers in currently operational relational database systems that support SQL-like query languages have been designed to evaluate the canonical form of multiple-relation queries and they resort solely to the nested-iteration method for evaluating the nested form of the queries. The nested- iteration method is efficient only for a limited set of query and database charac- teristics, as is shown in this section.
A generally more effective strategy for evaluating a nested query (of arbitrary depth and complexity) is to transform it to its canonical form and have the optimizer determine an optimal set of algorithms and access paths for evaluating it. The System R optimizer, for example, considers both the nested-iteration method and the merge-join method, as well as all possible “reasonable” orders in which relations may be scanned, in processing a canonical n-relation query [19]. Whereas the nested-iteration method of joining two relations requires the inner relation to be retrieved as many times as there are tuples that satisfy predicates on the outer relation, the merge-join requires both relations to be simultaneously retrieved only once, provided that the relations are first sorted in join-column order. It appears that the equivalence-transformation approach developed in this paper may be adopted as the foundation for an optimizer of SQL-like queries and the nested-iteration method may then be used to augment the performance of the optimizer for the rather special situations for which the latter method is more efficient.
This section analyzes and compares the costs of processing types N, J, JA, and D nested queries using the System R approach and the transformation algorithms presented in this paper. For simplicity, nested queries of depth greater than 1 are
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

462 * Won Kim
not considered. Ri denotes the relation of the outer query block, Rj the relation indicated in the FROM clause of the inner block, and Rt the temporary relation obtained by an intermediate processing on Rj . Pk is the size (in pages) of relation Rk, and Nk the number of tuples in Rk. fi denotes the fraction of the tuples of Ri that satisfy all simple predicates on Ri, and Jk,, the number of distinct values in the C, column of Rk. Further, it is assumed that a (B - l)-way multiway merge sort is used, which requires 2.P-log~-,P page I/OS to sort a relation R [3, 41. This section takes page I/OS as the primary measure of performance of a query, and assumes, for expository simplicity, that Ri and Rj are sequentially scanned.
System R evaluates a type-N nested query by first evaluating the inner query block in order to reduce the nested predicate to an equivalent, simple predicate, and by then evaluating the outer query block. As long as Rt, the unary relation obtained by evaluating the inner query block, is small enough to fit into B - 1 pages of the main memory buffer, clearly the System R approach is optimal: Rj needs to be fetched only once to generate R,; and also Ri once, one page at a time into the remaining buffer page, to compare against Rt. The System R method costs at most
Pj + Pi page fetches
If, however, Rt is larger than B - 1 pages, this approach can cause serious thrashing, since Rt has to be fetched once for each tuple of Ri that satisfies all other simple predicakes on Ri. Then it costs up to
Pj + Pt + Pi + fi*Ni.P, page I/OS,
where the first two terms are the cost of generating Rt. In contrast, if the type-N nested query is transformed to its canonical equivalent
to merge join Ri and Rt, the total cost is
Pj + Pt + 2’Pt’ logs-1Pt + Pi + Ptl + 2*Ptl’ lo@-1Ptl + Pt + Ptl,
where the first three terms are the cost of generating R1 and removing duplicates from it, the next three terms are the cost of restricting and projecting Ri into Rn and sorting it, and the last two terms are the cost of merge joining Rt and Rtl. The cost of removing duplicates from Rc is subsumed by the cost of merge-joining Rt with Rtl, since Rt needs to be sorted for the merge-join anyway. Note that the total cost expressed in the above formula may be further reduced since Rt may be reduced in size by removal of duplicates.
Intuitively, the nested-iteration method of processing a nested query of any type will tend to be efficient and will obviate the need to transform the query, if (1) Pt is “large” (which increases the cost of sorting Rt for the merge-join, thereby placing the transformation approach at a disadvantage) and (2) fi.Ni is very “small” (around 2. logB--l P,), so that the nested-iteration method will not require R, to be retrieved as many times as it is required to sort Rt. However, these represent a very small subset of the set of all possible query and database characteristics. The following example compares the performance of the two methods for a type-N nested query.
Example 14. Suppose B = 6, Pi = 100, fi- Ni = 500, Pj = 100, and Pt = 20. The nested-iteration method may cost 10,220 page fetches. If Rtl, the temporary
ACM Transactions 3x1 Database Systems, Vol. 7, NO. 3, September 1932.

On Optimizing an SQL-like Nested Query * 463
relation generated by reducing Ri, is 50 pages and a five-way merge-sort is used to sort Rtl and Rt, the transformation approach costs total 720 page I/OS.
Now let us consider the cost of processing nested queries in which the inner query block contains a join predicate Ri. C,, = R,. C,,,, that is, types J, JA, and D nested queries, by the nested-iteration method. The drawback of the nested- iteration method is that, by definition, it requires Rj to be retrieved potentially very many times: fi’ Ni times if there is no index on the C, column of Rj, and up to min( fi.Ni, Jjm) times if C, is indexed. If the index on the C, column is clustered, that is, if the tuples of Rj that share the same key value are stored physically “close” together, only ( Pj/Jjm 1 pages may need to be retrieved each time. If the index on C, is not clustered, min( 1 Nj/ Jjm 1, Pj) pages must be fetched each time.
The total cost of processing types J, JA, or D nested queries by the transfor- mation approach proposed in this paper consists simply of the cost of generating a temporary relation Rt and merge-joining it with Ri. For a type-J nested query, the cost of generating R1 is
Pj + Pt + 2-P,’ logs-1Pt,
where the last term is the cost of removing duplicates from Rt. Since duplicates are removed from Rt by sorting it, only Ri (or, more likely, Rtl, obtained by restricting and projecting Ri) needs to be sorted for the merge-join.
Example 15. Let Pi = Pj = 50, Pt = 20, B = 6, and fi*Ni = 500. The nested- iteration approach costs 10,120 page fetches for a type-J nested query. If a five- way external merge-sort technique is used to sort Rt and Ri in join-column order and Ri is not reduced in size by restriction and projection, the transformation approach costs 550 page I/OS.
The penalty for transforming a type-JA nested query to an equivalent type-J nested query has been shown to be the cost of generating temporary relation RL by evaluating a query with a GROUP BY clause on the relation(s) of the inner query block. System R uses one of two methods in implementing the GROUP BY construct [19]. One is to use an index on the GROUP BY column. The other is to sort the relation in GROUP BY column order. Therefore, the intermediate- processing penalty can be seen to be
min(Pj, 2-Pn-lOgs-1Pn + Pj) + Pt,
where RQ is the reduced relation which results from restricting and projecting Rj. The reader may easily verify that Rt thus obtained is free of duplicates and is in join-column order; that is, Rt need not be sorted to be merge-joined with Ri.
Example 16. Consider Q3 and Q4 of Section 4. Let P, = 50, Pj = 30, Pt = 5, B = 6, and fi. Ni = 100. The nested-iteration method of processing Q3 is, in the worst case, 50 + 100.30 = 3050 page fetches. If a five-way merge-sort technique is used (to generate Rt and to merge-join Ri and Rt), it costs 560 page I/OS to sort Ri and Rj. The merge-join of Ri and Rt costs additional 55 page fetches. So Q4 incurs 615 page fetches. Note that the cost may be even smaller if Ri is first reduced by restriction and projection and the resulting reduced relation is sorted for the merge-join.
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

464 * Won Kim
Recall that a type-D nested query contains two inner query blocks, which reference Rj and Rk, respectively. Assume for expository simplicity that the query block on Rj has in its WHERE clause a join predicate Ri. C, = Rj.Cm, where Ri is the relation of the outer query block. The query block on Rk is assumed to contain only simple predicates, so that it may be processed only once to yield a unary relation Rt3. Then the nested-iteration method of processing a type-D nested query requires, for each tuple of Ri that satisfies simple predicates on Ri, retrieval of not only Rj but also Rt3.
In order to transform a type-D nested query to a semantically equivalent type- N nested query, one of the two relations in the inner query block must be relationally divided by the other. The binary division of a relation of degree 2, Rj (Cl, Cz), by a unary relation Rk( Cz) yields a unary relation Rt( C1 ). The quotient Rt can then be merge-joined with Ri.
R, can be obtained by grouping the dividend Ri by the values in the C1 column, and extracting the C1 values from each group of tuples that contain in the Cz column all the values of Rk. Since the dividend needs to be grouped by be values of the quotient column, sorting of the dividend relation in quotient-column order, as well as the divisor relation, has been suggested as a method for computing relational division [20]. Therefore, the cost of generating Rt for a type-D nested query is
Pi+ Pa+ 2*Ptz*lOgB-lPa + Pk+Pfi + 2*Pt3*lOgB-1Pt3
+Pt‘i! + Pt3+Pt+ Pi+ Ptl+ 2’Ptl’lOgB-1 Ptl+ Ptl+ Pt, I
where the first six terms are the cost of generating temporary relations Rti and Rf3 from the two inner relations of the division predicate, the next three terms are the cost of dividing Rti by Rt3 and generating the quotient Rt, and the last five terms are the cost of merge-joining Rt and Rtl. As was the case with a type-JA nested query, the quotient R, is also free of duplicates and is in join-column order to be merge-joined with Rtl.
Example 17. Let Pi = 50, Pj = Pn = 30, pt = 5, Pk = Pts = 1, B = 4, and fig Ni = 1000. The nested-iteration method of processing a type-D nested query requires, in the worst case, 50 + 1000.30 + 1 = 30051 page fetches. If a three-way merge- sort technique is used to sort Rt3 and R a, it costs 296 page I/OS to generate the quotient of dividing Rti by Rt3. Further, it costs 400 page I/OS to sort Ri. So the cost of merge-joining Ri and Rt is 400 + 50 + 5 = 455. The total cost of processing the type-D nested query by the algorithms of this paper is 296 + 455 = 751 page I/OS.
7. PROCESSING A GENERAL NESTED QUERY
So far it has been assumed for simplicity that the WHERE clause of a query block contains only one nested or division predicate. In general, however, a query block may be nested to an arbitrary depth and contain an arbitrary number of any type of predicates. This section presents a coherent strategy for processing such a general query.
It has been shown that a type-N or type-J nested query may be transformed directly to an equivalent canonical query (Algorithm NEST-N-J). A type-JA
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

On Optimizing an SQL-like Nested Query * 465
nested query may be converted to a type-J nested query once query blocks with an aggregate function in the SELECT clause have been evaluated (Algorithm NEST-JA(G)). And a type-D nested query can be transformed to its canonical form once the relational division operation it implies has been performed (Algo- rithm NEST-D). What this means is that a nested predicate which gives rise to a type-N, type-J, or type-JA nesting and a division predicate which results in a type-D nesting may each be replaced by a set of join predicates. Further, it was shown in Section 2 that a nested predicate which yields a type-A nesting must be replaced by a simple predicate. Algorithm NEST-G, which replaces all nested predicates and division predicates in the WHERE clause of the outermost block of a general nested query with a set of join predicates and simple predicates, emerges immediately from these observations. The algorithm is described below in terms of the query graph for a general query.
Algorithm NEST-G
(1) Transform each type-A predicate to a simple predicate by completely evaluating the query block Q represented by the right-hand node on the query graph for the subquery (predicate). If Q is itself nested, Algorithm NEST-G is invoked recursively on Q. Once Q has been evaluated, Q and the straight arc labeled ‘A’, leading to Q from the outermost query block, are eliminated from the initial query graph.
(2) Transform each typedA nested subquery to an equivalent type-N or type-J subquery by Algorithm NEST-JA(G). If the right-hand node of the circular arc is further nested, Algorithm NEST-G may be invoked recursively on the node. The query graph for the resulting type-N or type-J nested subquery replaces the query graph for the initial type-JA subquery.
(3) Transform each type-D nested subquery to its canonical form by Algorithm NEST-D. If either of the two right-hand nodes on the query graph of the subquery is further nested, Algorithm NEST-G may be recursively invoked on the node. Once the division predicate has been replaced by an appropriate set of join predicates, the two right- hand nodes and both the straight arc and the circular arc leading to them are removed from the query graph of the initial subquery.
(4) Transform the resulting query, which consists only of type-N and type-J subqueries, to an equivalent canonical query by Algorithm NEST-N-J.
Example 18. This example illustrates Algorithm NEST-G. The following is a general nested query of considerable complexity.
SELECT R, . Cl FROM RI WHERE R,.Cz ISIN (SELECT Rz.Cz
FROM RP WHERE Rz.Cs = (SELECT AGG(R3. C’s)
FROM WHERE i&L, = RI.&)
AND Rz. Cq IS IN (SELECT Rd. C., FROM Rd)
AND R, . Cz = (SELECT AGG(R5. Cs) FROM R5 WHERE R5.G IS NOTIN (SELECT Rs.Gj
FROM Rs)) AND (SELECT R7.G
FROM WHERE ::.Cs = R1.G)
(SELECT= Rs. CB FROM Rd;
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.
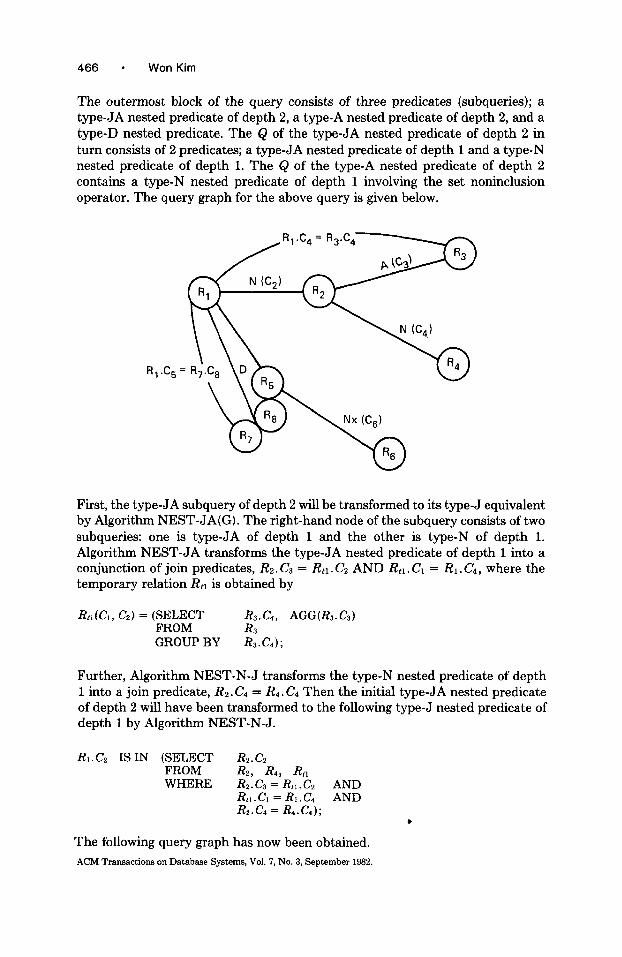
466 * Won Kim
The outermost block of the query consists of three predicates (subqueries); a type-JA nested predicate of depth 2, a type-A nested predicate of depth 2, and a type-D nested predicate. The Q of the type-JA nested predicate of depth 2 in turn consists of 2 predicates; a type-JA nested predicate of depth 1 and a type-N nested predicate of depth 1. The Q of the type-A nested predicate of depth 2 contains a type-N nested predicate of depth 1 involving the set noninclusion operator. The query graph for the above query is given below.
First, the type-JA subquery of depth 2 will be transformed to its type-J equivalent by Algorithm NEST-JA(G). The right-hand node of the subquery consists of two subqueries: one is type-JA of depth 1 and the other is type-N of depth 1. Algorithm NEST-JA transforms the type-JA nested predicate of depth 1 into a conjunction of join predicates, &. C3 = RH. CZ AND Rtl . Cl = RI. Cd, where the temporary relation Rn is obtained by
R~(G, Cd = WCLECT Rs.Cd, AGG(R3.W FROM GROUP BY &4,;
Further, Algorithm NEST-N-J transforms the type-N nested predicate of depth 1 into a join predicate, Rz.Cd = Rd.Cd Then the initial type-JA nested predicate of depth 2 will have been transformed to the following type-J nested predicate of depth 1 by Algorithm NEST-N-J.
RI.C~ ISIN (SELECT R2.C2 FROM R2, R4, R~I WHERE Rz. Cs = R,, . Cz AND
Rt,.Cl = R,.Cd AND Rz.Cd = R4.1-24);
l
The following query graph has now been obtained.
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

On Optimizing an SQL-like Nested Query * 467
R,.C, = R,,.C,
AND R,,.C, = R,.C,
AND R2.C, = R,.C,
Next, the type-A subquery of depth 2 is evaluated. The right-hand node of the subquery is itself type-N nested. A recursive call of Algorithm NEST-G trans- forms the node to
SELECT AGG(&,. C’s) FROM Rs, RG WHERE l(Rs.CG = &.C6);
The transformed node is then evaluated to a constant X, and the nested predicate of the initial type-A subquery becomes a simple predicate, RI. C3 = x. The resulting query graph is shown below.
R, .Cg = R,, .C2
AND R,,.C, = R,,C,
AND R2.C4 = R,.C,
AND R,.C,=x
Then, the type-D subquery is evaluated so as to replace the division predicate with a join predicate by Algorithm NEST-D. The resulting join predicate is RI. CS = Rn. Cl, where the unary relation Ra(C,) is the quotient of dividing RT(CB, CT)
by RdCs). ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

468 * Won Kim
The resulting query is type-J nested and Algorithm NEST-N-J can be used to transform it into its canonical equivalent, shown in the following.
SELECT RI. C, FROM R,, Rtl, Rtz WHERE R,.Cz= Rz.Cz AND
R2.Ca= Rt1.G AND Rtl.C,=R1.C., AND R2.C4= R4.G AND R,.Cs=x AND R,.Cs = R,.C,;
8. SUMMARY
The fundamental structure of an SQL-like, block-structured data language has been analyzed. A query nested to an arbitrary depth has been shown to be composed of five basic types of nesting. Four of them have not been well understood and their present implementation suffers from the use of the ineffi- cient nested-iteration method. Alternate ways of interpreting the operations of queries that involve these types of nesting have provided the basis for algorithms which transform the queries to equivalent, nonnested queries that existing optim- izers are designed to process more efficiently. The algorithms have been shown to improve the performance of nested queries often by orders of magnitude. Finally, they have been combined into a coherent strategy for completely pro- cessing a general query of arbitrary complexity.
ACKNOWLEDGMENTS
I am grateful to Prof. David Kuck (Department of Computer Science, University of Illinois, Urbana) and Dr. Mario Schkolnick (IBM Research, San Jose) for their many valuable comments on the presentation and technical accuracy of this paper. I also thank the referees for their incisive comments about the treatment of duplicates and the analysis of the transformation algorithms in earlier versions of this paper, which helped to considerably improve the presentation of Sections 6 and 7.
REFERENCES
1. ASTRAHAN, M.M., AND CHAMBERLIN, D.D. Implementation of a structured English query language. Commun. ACM 18, lO(Oct. 1975), 580-588.
2. ASTRAHAN, M.M., ET AL. System R: Relational approach to database management. ACM Trans. Database Syst. 1,2(June 1976), 97-137.
3. BLASGEN, M.W., AND ESWARAN, K.P. On the evaluation of queries in relational data base systems. IBM Res. Rep. RJ1745, IBM Research, San Jose, Calif., April 1976.
4. BLASGEN, M.W., AND ESWARAN, K.P. Storage and access in relational data bases. IBM Syst. J. 16,4, 1977, 363-377.
5. BOYCE, R.F., AND CHAMBERLIN, D.D. SEQUEL: A structured English query language. In PFOC. ACM SZGMOD Workshop Data Descrfption, Access and Control (Ann Arbor, Mich., May l-3), ACM, New York, 1974, pp. 249-264.
6. CHAMBERLIN, D.D., ET AL. SEQUELB: A unified approach to data definition, manipulation, and control. IBM J. Res. Dev. (Nov. 1976), 560-575.
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982.

On Optimizing an SQL-like Nested Query * 469
7. CODD, E.F. A relational model of data for large shared data banks. Commun. ACM 13, G(June 1970), 377-387.
8. CODD, E.F. A database sublanguage founded on the relational calculus. In Proc. ACM SZGFZ- DET Workshop on Data Description, Access and Control (San Diego, Nov. ll-12), ACM, New York, 1971, pp. 35-68.
9. CODD, E.F. Further normalization of the data base relational model. In Data Base Systems, Cow-ant Computer Science Symposia, Vol. 6, Prentice-Hall, Englewood Cliffs, N.J., 1971.
10. CODD, E.F. Relational completeness of data base sublanguages. In Data Base Systems, Cow-ant Computer Science Symposia, Vol. 6, Prentice-Ha& Englewood Cliffs, N.J., 1971.
11. CZARNIK, B., SCHUSTER, S., AND TSICHRITZIS, D. ZETA: A relational data base management system. In Proc. ACM Pacific Regional Conf (San Francisco, April 17-18), ACM, New York, 1975, pp. 21-25.
12. DATE, C.J. An Introduction to Database Systems (2nd ed.). Addison-Wesley, Reading, Mass., 1977.
13. EPSTEIN, R. Techniques for processing of aggregates in relational database systems. ERL/UCB Memo M79/8, Electronics Research Laboratory, Univ. California, Berkeley, Feb. 1979.
14. LIEN, Y.E. Design and implementation of a relational database on a minicomputer. In Proc. ACMAnnuaZ Conf (Seattle, Oct. 16-19), ACM, New York, 1977, pp. 16-22.
15. MYLOPOULOS, J., SCHUSTER, S., AND TSICHRITZIS, D. A multi-level relational system. In Proc. 1975 AFZPS Nut. Computer Conf., Vol. 44. AFIPS Press, Arlington, Va., pp. 403-408.
16. PALERMO, F.P. A data base search problem. IBM Res. Rep. RJ1072, San Jose, Calif., July 1972. 17. ROTHNIE, J.B. An approach to implementing a relational data base management system. In
Proc. ACMSZGMOD Workshop Data Description, Access and Control. (Ann Arbor, Mich., May l-3), ACM, New York, 1974, pp. 277-294.
18. ROTHNIE, J.B. Evaluating inter-entry retrieval expressions in a relational data base management system. In Proc. 1975 AFZPS Nat. Computer Conf., Vol. 44. AFIPS Press, Arlington, Va., pp. 417-423.
19. SELINGER, P.G., ET AL. Access path selection in a relational database system. In Proc. Inter. Conf Management of Data (ACM) (Boston, Mass., May 1979), 23-34.
20. SMITH, J.M., AND CHANG, P.Y. Optimizing the performance of a relational algebra database interface. Commun. ACM 18, lO(Oct. 1975), 568-579.
21. Stonebraker, M., Wong, E., Kreps, P., and Held, G. The design and implementation of INGRES. ACM Trans. Database Syst. I,3 (Sept. 1976), 189-222.
22. WEELDREYER, J.A., AND FRIESEN, O.D. Multics relational data store: An implementation of a relational data base manager. In Proc. 11th Hawaii Int. Conf. Systems Science, 1978, pp. 52-66.
23. WEISS, H.M. The ORACLE data base management system. Mini-Micro Syst. (Aug. 1980), 111-114.
24. WONG, E., AND YOUSSEFI, K. Decomposition-A strategy for query processing. ACM Trans. Database Syst. 1,3(Sept. 1976), 223-241.
Received February 1981; revised May 1981; accepted July 1981
ACM Transactions on Database Systems, Vol. 7, No. 3, September 1982