what we learn with pleasure we never forget. alfred mercier smitha n pai
TRANSCRIPT

Static HashingWhat we learn with pleasure we never forget.
Alfred Mercier
Smitha N Pai

Static Hashing• Identifiers are stored in fixed sized table called hash table.• Arithmetic function f is used to determine the address or
location of an identifier, x in the table.• f(x) gives the home or hash address of x in the table• The hash table ht is stored in sequential memory
locations that are partitioned into b buckets ht[0] ht[1], ht[b-1].
• Each bucket has s slots• s=1 means each bucket holds one record• Hash function is used to transform the identifier x into an
address in the hash table• f(x) maps the set of possible identifiers onto integers 0
through b-1

• Identifier density is the ratio of n/T where n is the number of identifiers in the table. T represents the set of all possible identifiers including the ones which may not exist in real life situation
• The loading density or loading factor of a hash table is n/sb
• Hash function may map several identifiers into the same bucket.
• Two identifiers i1 and i2 are synonym wth respect to f if f(i1)=f(i2)
• An overflow occurs when we hash a new identifier i into a full bucket
• A collision occurs when we hash two non identical identifiers into the same bucket
• When bucket size is 1, collision and overflows occur simultaneously
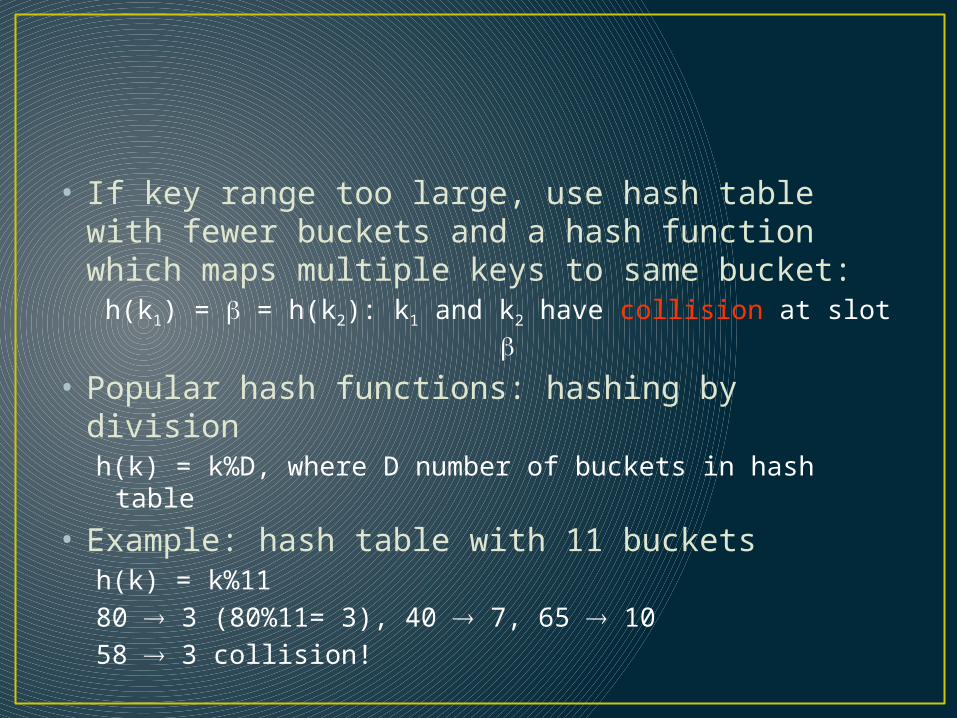
• If key range too large, use hash table with fewer buckets and a hash function which maps multiple keys to same bucket:
h(k1) = = h(k2): k1 and k2 have collision at slot
• Popular hash functions: hashing by divisionh(k) = k%D, where D number of buckets in hash table
• Example: hash table with 11 bucketsh(k) = k%1180 3 (80%11= 3), 40 7, 65 1058 3 collision!
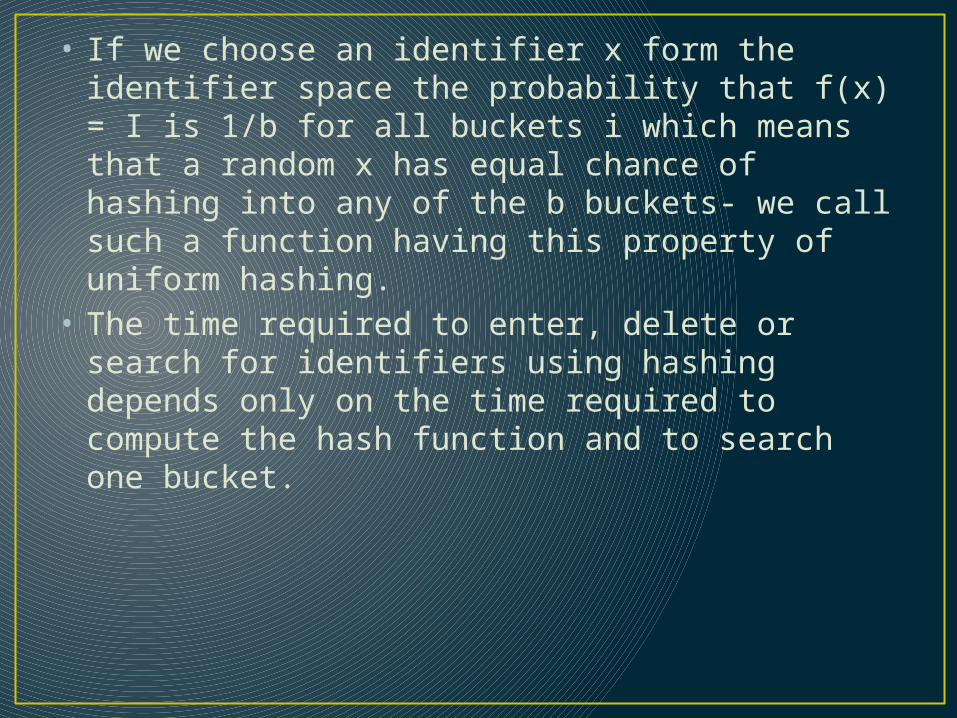
• If we choose an identifier x form the identifier space the probability that f(x) = I is 1/b for all buckets i which means that a random x has equal chance of hashing into any of the b buckets- we call such a function having this property of uniform hashing.
• The time required to enter, delete or search for identifiers using hashing depends only on the time required to compute the hash function and to search one bucket.

Uniform Hashing function• Midsquare- Square the identifier and using
appropriate number of bits from the middle of the square to obtain the bucket address
• Since middle bits fo the square depend upon all the characters in an identifier there is a high probability that different identifiers will produce different hash addresses even when some characters are same
• Number of bits used depends on the table size• If r bits are used then the range of values is 2 r
• Size of hash table should be power of 2
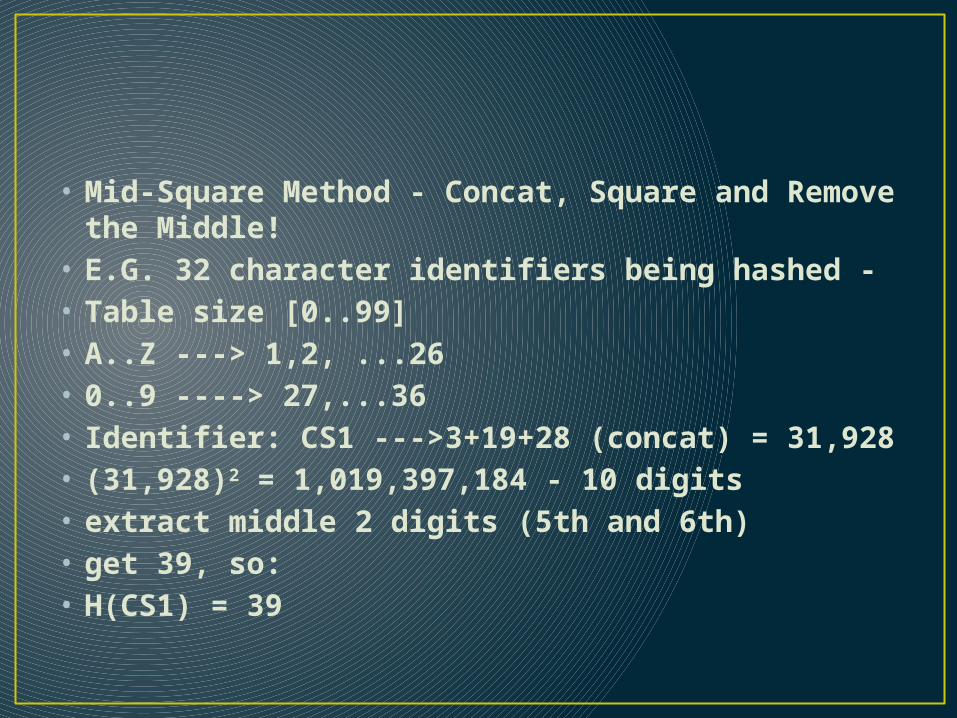
• Mid-Square Method - Concat, Square and Remove the Middle!
• E.G. 32 character identifiers being hashed -• Table size [0..99]• A..Z ---> 1,2, ...26• 0..9 ----> 27,...36• Identifier: CS1 --->3+19+28 (concat) = 31,928• (31,928)2 = 1,019,397,184 - 10 digits• extract middle 2 digits (5th and 6th)• get 39, so:• H(CS1) = 39

Division• Divide the identifier x by some number M and use
the remainder as the hash address for x• F(x)= x%M
• Bucket address range from 0 to M-1 where M is the table size
• Choice of M results in a biased use of hash table when several of the identifiers in use have the same result
• With M=2, odd keys are mapped to odd buckets and even keys to even
• Choose M as a prime number • Value of M should be such that it has no prime
divisors less than 20

• E.g. - Table size of 100• 3 Digit numbers are the keys• 999 possible items• Indices 0..99 on the table• 999 % 100 = 99 (100 is Table size)• 524 % 100 = 24• 199 % 100 = 99 (COLLISION)

0 01 912 923 04 05 506 07 08 09 010 011 4112 1213 5814 0
Basic Division Method-H(Key) = Key % 15,Values to be hashed all > 00 indicates null value - or nothing there Results after hashing 41, 58, 12, 92, 50 and 91:This is a nice distribution of values, no collisions!

0 3060 (collision)
1 02 03 04 0
5 2050 (collision)
6 07 08 09 0
10 1040, 70 (collisions)
11 012 013 014 0
Conclusion: % 15 is a BAD HASHFUNCTION for this particular set of values!In general: Choose the nearest prime number 1.5 times greater than the size of the data set you are hashing!
Now with values 10, 20, 30, 40, 50, 60, 70

Folding• Partition the identifier x into several parts. All
except for the last one have the same length• Add the parts together to obtain the hash address• Shift folding• Shift all parts except for the last one so that the least
significant bit of each part lines up with the corresponding bit of the last part. Add the parts together to obtain f(x)
• Folding at the boundaries• Reverses every other partition before adding• Add the partitions which gives the hash address

Folding Method: Chopping the key k into two parts and adding yields the following hash addresses:
H(3205)=32+05=37,H(7148)=71+48=19,H(2345)=23+45=68
Observe that the leading digit 1 in H(7148) is ignored. Alternatively, one may want to reverse the second part before adding, thus producing the following hash addresses:
H(3205)=32+50=82, H(7148)=71+84=55,H(2345)=23+54=77
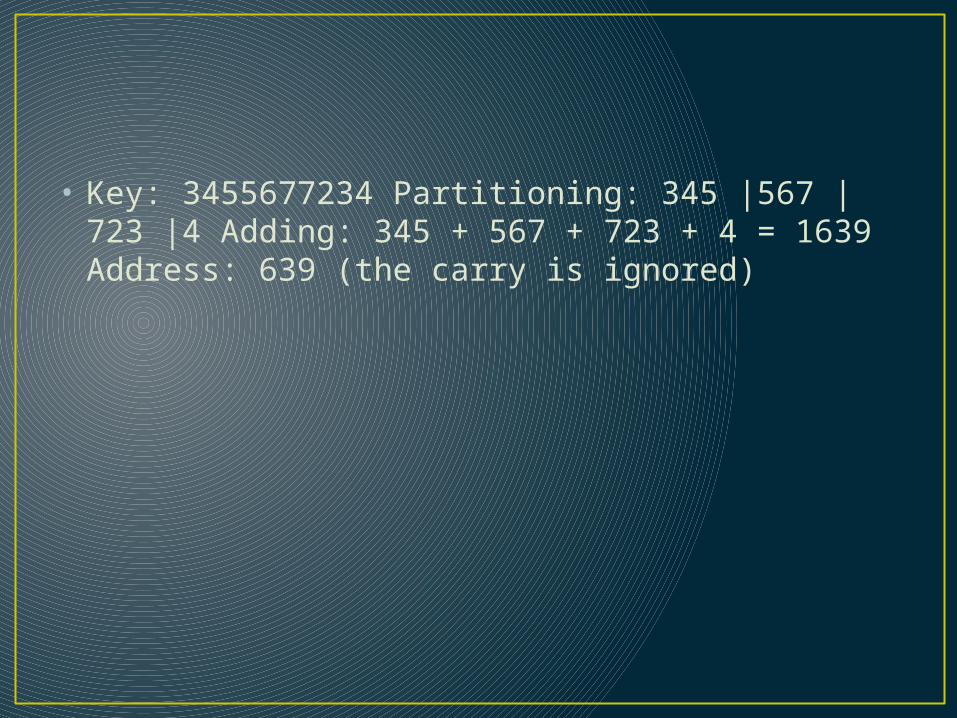
• Key: 3455677234 Partitioning: 345 |567 | 723 |4 Adding: 345 + 567 + 723 + 4 = 1639 Address: 639 (the carry is ignored)
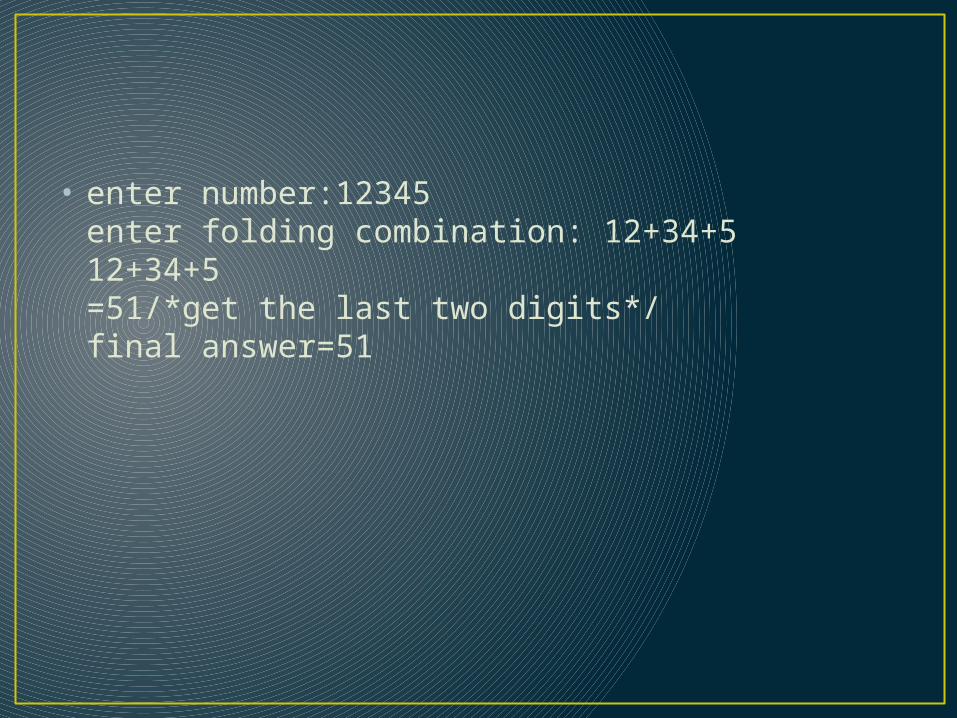
• enter number:12345enter folding combination: 12+34+512+34+5=51/*get the last two digits*/final answer=51

Digit Analysis• Used with static files- in which all the identifiers
are know in advance• Transform the identifiers into numbers using some
radix r• Examine the digit of each identifier, deleting those
digits that have the most skewed distributions• Continue deleting the digits until the number of
remaining digits is small enough to give an address in the range of the hash table
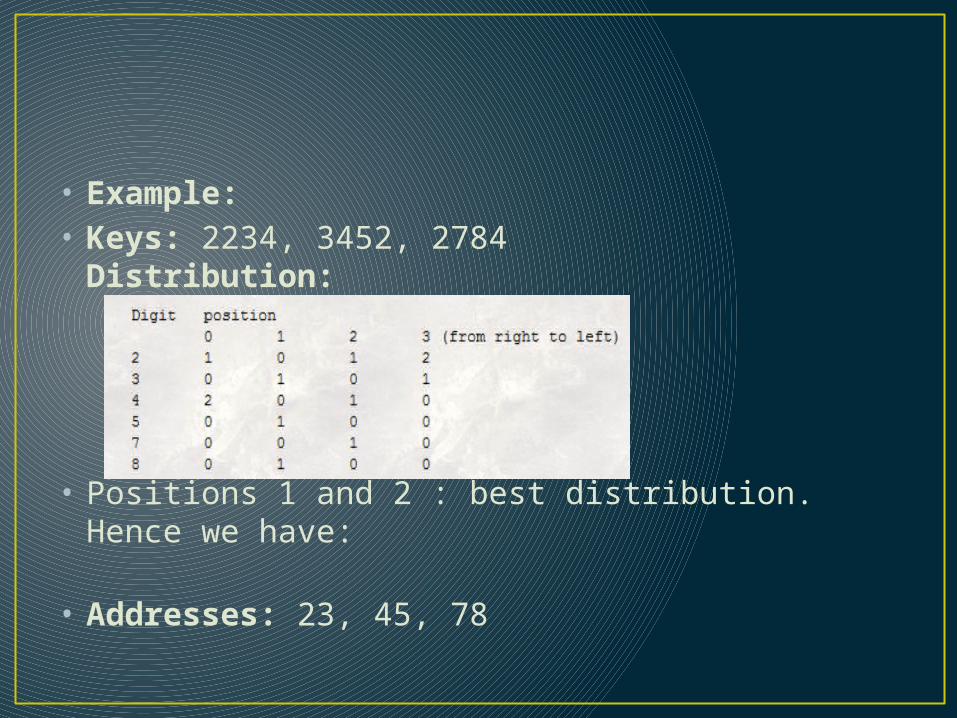
• Example:• Keys: 2234, 3452, 2784
Distribution:
• Positions 1 and 2 : best distribution. Hence we have:
• Addresses: 23, 45, 78

• Handling Collisions - Techniques:• Two Major Strategies:• 1) Open Addressing - Find another spot in
the "Table" (same contiguous address space) • 2) Chaining - Find another spot outside the
"Table"• Open Addressing Techniques:• a) Linear Probing - search sequentially (with wrap-
around) until you find the first vacant slot• b) Quadratic Probing -
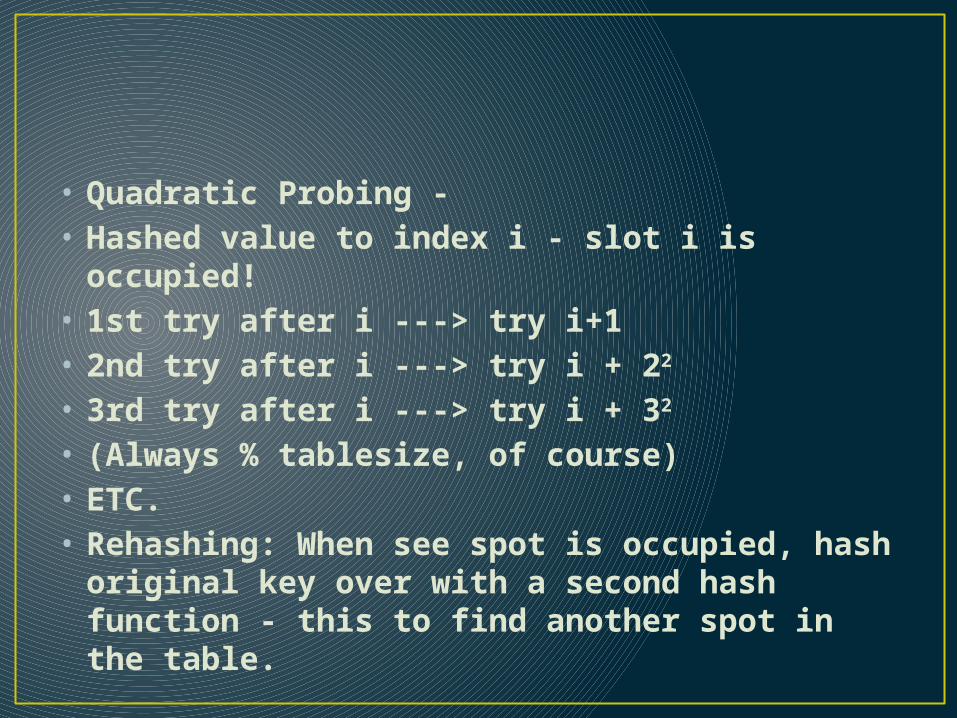
• Quadratic Probing - • Hashed value to index i - slot i is occupied!• 1st try after i ---> try i+1• 2nd try after i ---> try i + 22
• 3rd try after i ---> try i + 32
• (Always % tablesize, of course)• ETC.• Rehashing: When see spot is occupied, hash
original key over with a second hash function - this to find another spot in the table.

• Chaining Techniques:• This technique "Chains" the item that
collided to a location outside the "Table" - to another block of memory
• (It is done with Dynamic, Extendible Hashing Techniques)
• Problems with both Open Addressing and Chaining - can have very long searches for an item that collided a bunch with other items!

0
1
2
.... ..... .....
38 160 H(160)=38
39 204 H(204)=38
40 219 H(219)=38
41 119 H(119)=39
42 412 H(412)=39
43 390 H(390)=39
44 263 H(263)=40
.... ..... ......
size
Open Addressing with Linear ProbingClustering can occur :Suppose keys 160, 204, 219, 119, 412, 390, 263 are loaded and H is biased for returning 38-40!
Conclusion: Clustering can occur due to a biased hash function with linear probing as a collision resolution technique!

0 4612 133 3456 247 908910
0
1
2
3
X - Initial hash position, plus 4th, 8th, 12th.... probes
4
1st, 3rd, 5th, 7th, 9th.... probes after collision at position 3
5
6
7
2nd, 6th, 10th.... probes after collision at position 3
Quadratic Probing:H(Key) = Key %11, Hashing values 13, 3, 24, 46, 90:Note the wraparound calculations!
Also, quadratic probing may never "get anywhere"-
H(K) = K % 8 ......

Linear probing• Compute f(x) for identifier x and then examine the
hash table buckets ht[f(x)+j)%TABLE_SIZE] for 0<=j<=TABLE_SIZE
• Outcomes• Bucket contains x. Already in the table, -Report duplicate
identifier or update information in the other fields of the element• Bucket contains the empty string- Bucket is empty and we
may inset the new element into it• Bucket contains a nonempty string other than x- Proceed
ot the examine the next bucket• Return to home bucket ht[f(x)](j=TABLE_SIZE) –Home
bucket is being examined for the second time and all remaining buckets have been examined. –Table is full and we report an error condition and exit
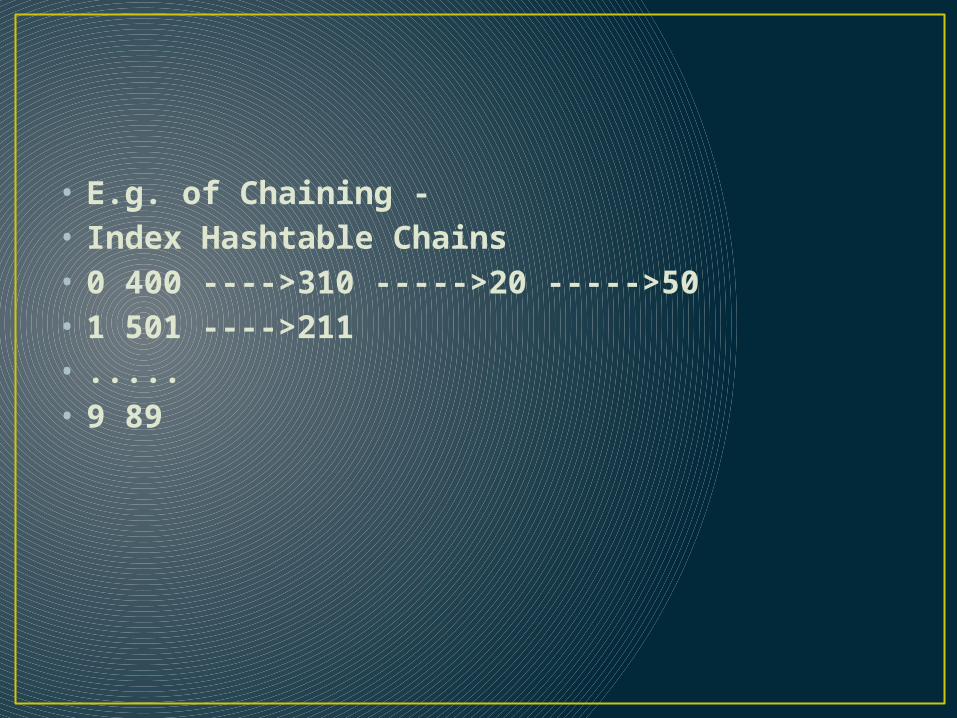
• E.g. of Chaining -• Index Hashtable Chains• 0 400 ---->310 ----->20 ----->50 • 1 501 ---->211• .....• 9 89