vorlesung - pub.informatik.uni-wuerzburg.de · deduktive datenbanken sommersemester 2012 auch das...
TRANSCRIPT

Vorlesung
Deduktive Datenbanken
Prof. Dr. Dietmar Seipel
Universität Würzburg
Sommersemester 2012

Deduktive Datenbanken Sommersemester 2012
Inhaltsverzeichnis
1 Datenbanken und DATALOG 41
1.1 Grundbegriffe des relationalen Datenmodells. . . . . . . . . . . 42
1.1.1 Relationen und Relationenschemata. . . . . . . . . . . . 42
1.1.2 Relationale Anfragesprachen. . . . . . . . . . . . . . . . 48
1.2 Die deduktive Datenbanksprache DATALOG . . . . . . . . . . . . 58
1.2.1 Regeln und Fakten. . . . . . . . . . . . . . . . . . . . . 64
1.2.2 Integritätsbedingungen und Default Negation. . . . . . . 88
1.2.3 BUILT–IN–Prädikate . . . . . . . . . . . . . . . . . . . . 97
1.2.4 Aggregationsfunktionen. . . . . . . . . . . . . . . . . . 103
Prof. Dr. Dietmar Seipel 1

Deduktive Datenbanken Sommersemester 2012
2 Die deklarative Programmiersprache PROLOG 110
2.1 Grundlegende Strukturen. . . . . . . . . . . . . . . . . . . . . . 116
2.1.1 Klauseln . . . . . . . . . . . . . . . . . . . . . . . . . . 119
2.1.2 Datentypen. . . . . . . . . . . . . . . . . . . . . . . . . 136
2.2 Programmierstrukturen. . . . . . . . . . . . . . . . . . . . . . . 164
2.2.1 Rekursion. . . . . . . . . . . . . . . . . . . . . . . . . . 166
2.2.2 Prädikatenorientiertes, relationales Programmieren . . . . 184
2.2.3 Backtracking und der Cut. . . . . . . . . . . . . . . . . 199
2.3 Die interne PROLOG–Datenbank. . . . . . . . . . . . . . . . . . 215
2.4 Datenbanken und PROLOG . . . . . . . . . . . . . . . . . . . . . 241
2.4.1 ODBC–Zugriff auf eine relationale Datenbank. . . . . . . 243
2.4.2 Das deduktive Mini–DBMS DDBASE . . . . . . . . . . . 249
Prof. Dr. Dietmar Seipel 2

Deduktive Datenbanken Sommersemester 2012
2.5 GUI–Programmierung in XPCE–PROLOG . . . . . . . . . . . . . 278
2.6 Datenstrukturen, Kontrollstrukturen und Algorithmen. . . . . . . 289
2.6.1 Suche in Graphen. . . . . . . . . . . . . . . . . . . . . . 290
2.6.2 Sortierverfahren . . . . . . . . . . . . . . . . . . . . . . 297
2.6.3 Binäre Suchbäume. . . . . . . . . . . . . . . . . . . . . 304
2.6.4 Hierarchische Daten. . . . . . . . . . . . . . . . . . . . 314
2.6.5 Diagnoseregeln in DATALOG∗ . . . . . . . . . . . . . . . 347
2.7 Vergleich mit DATALOG . . . . . . . . . . . . . . . . . . . . . . 353
Prof. Dr. Dietmar Seipel 3

Deduktive Datenbanken Sommersemester 2012
3 Definite Logikprogramme 380
3.1 Syntax. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 383
3.1.1 Klauseln und Regeln. . . . . . . . . . . . . . . . . . . . 384
3.1.2 Definite Logikprogramme, DATALOG . . . . . . . . . . . 393
3.1.3 Substitutionen und Unifikation. . . . . . . . . . . . . . . 399
3.1.4 Herbranduniversum, Herbrandbasis, Grundinstanz. . . . 431
3.2 Die modelltheoretische Semantik. . . . . . . . . . . . . . . . . . 440
3.2.1 Herbrandinterpretationen und Herbrandmodelle. . . . . . 445
3.2.2 Logische Konsequenzen. . . . . . . . . . . . . . . . . . 460
3.3 Beweistheorie: Bottom–Up. . . . . . . . . . . . . . . . . . . . . 471
3.3.1 Der KonsequenzoperatorTP . . . . . . . . . . . . . . . . 474
3.3.2 Iteration desTP –Operators. . . . . . . . . . . . . . . . . 492
Prof. Dr. Dietmar Seipel 4

Deduktive Datenbanken Sommersemester 2012
3.3.3 Forward Chaining: Beweisbäume. . . . . . . . . . . . . 515
3.3.4 Der verallgemeinerte KonsequenzoperatorTPbu,Ptd. . . . 519
3.4 Fixpunkttheorie auf Partialordnungen. . . . . . . . . . . . . . . 532
3.5 Beweistheorie: Top–Down. . . . . . . . . . . . . . . . . . . . . 533
3.5.1 Backward Chaining: Suchbäume und Beweisbäume. . . . 534
3.5.2 SLD–Resolution und SLD–Bäume. . . . . . . . . . . . . 545
3.5.3 SLDNF–Resolution . . . . . . . . . . . . . . . . . . . . 577
Prof. Dr. Dietmar Seipel 5

Deduktive Datenbanken Sommersemester 2012
4 Datenstrukturen und Programmstrukturen für Logikprogra mme 591
4.1 Datenstrukturen in PROLOG . . . . . . . . . . . . . . . . . . . . 592
4.1.1 Terme und Goals. . . . . . . . . . . . . . . . . . . . . . 593
4.1.2 Logikprogramme als Klauseln oder als Terme. . . . . . . 627
4.1.3 Die Field Notation für komplexe Objekte. . . . . . . . . 649
4.2 Kontrollstrukturen und Meta–Prädikate von PROLOG . . . . . . . 670
4.2.1 Finden aller Lösungen. . . . . . . . . . . . . . . . . . . 671
4.2.2 Filter und Transformationen. . . . . . . . . . . . . . . . 682
4.2.3 Schleifen und Verzweigungen. . . . . . . . . . . . . . . 686
4.3 Struktureigenschaften von Logikprogrammen. . . . . . . . . . . 705
4.4 Äquivalenz und Transformation von Logikprogrammen. . . . . . 735
Prof. Dr. Dietmar Seipel 6

Deduktive Datenbanken Sommersemester 2012
5 Auswertungsmethoden und Programmoptimierung für DATALOG 779
Prof. Dr. Dietmar Seipel 7

Deduktive Datenbanken Sommersemester 2012
6 Default Negation und normale Logikprogramme 780
6.1 DATALOGnot – DATALOG mit Default Negation. . . . . . . . . . 793
6.1.1 Syntax und Semantik (Modelltheorie). . . . . . . . . . . 793
6.1.2 Die Closed–World–Annahme. . . . . . . . . . . . . . . 800
6.2 Stratifizierte Auswertung von DATALOGnot . . . . . . . . . . . . 804
6.2.1 Abhängigkeitsgraphen und Stratifizierung. . . . . . . . . 805
6.2.2 Die KonsequenzoperatorenTP undT ′
P . . . . . . . . . . 826
6.2.3 Das perfekte Modell. . . . . . . . . . . . . . . . . . . . 841
6.2.4 Ontologie–Analyse in DATALOG∗ . . . . . . . . . . . . . 872
6.3 Stabile und wohlfundierte Modelle. . . . . . . . . . . . . . . . . 894
6.3.1 Stabile Modelle. . . . . . . . . . . . . . . . . . . . . . . 896
6.3.2 Berechnungsfolgen für stabile Modelle. . . . . . . . . . 921
6.3.3 Das wohlfundierte Modell. . . . . . . . . . . . . . . . . 932Prof. Dr. Dietmar Seipel 8

Deduktive Datenbanken Sommersemester 2012
7 Disjunktive Logikprogramme 978
Literatur 979
Index 981
Prof. Dr. Dietmar Seipel 9

Deduktive Datenbanken Sommersemester 2012
Prof. Dr. Dietmar Seipel 10

Deduktive Datenbanken Sommersemester 2012
Vorwort
Deduktive Datenbanken entstehen durch die Integration von
2 Logikprogrammierungund
2 Datenbanktechnologie.
Die darauf aufbauendenDBLP–Systemekönnen z.B.
2 komplexe, wissensbasierte Systeme,
2 intelligente, entscheidungsunterstützende Systeme (Expertensysteme) und
2 Semantic Web–Anwendungen
unterstützen.
Prof. Dr. Dietmar Seipel 1

Deduktive Datenbanken Sommersemester 2012
Logikprogrammierung und Datenbanken
Logikprogrammierung in PROLOG:
2 Vereinfachung von Techniken des Theorembeweisens 1970
−→ effiziente und einfachere Programmierung
relationales Datenmodell:
2 Vereinfachung des hierarchischen und des Netzwerkdatenmodells
−→mengenorientierte, deklarative Datenmanipulation
kommerzielle Nutzung: 1980
Logikprogrammierung in DATALOG:
2 mächtige, deklarative Datenbankanfragesprache seit 1980
−→ Anfrageoptimierung möglich
Prof. Dr. Dietmar Seipel 2

Deduktive Datenbanken Sommersemester 2012
Auch das japanische Fifth–Generation–Projekt hat DBLP–Systeme für
Anwendungen aus derkünstlichen Intelligenz (KI)propagiert.
2 Diese erfordern extrem viele Deduktionen pro Zeiteinheit,und
2 sie greifen auf ein relationales Datenmodell zur Speicherung großer
Datenmengen zurück.
Kombination:
2 Datenbanktechnologie für effizienten Zugriff und zuverlässigen Update
persistenter Daten,
2 Logikprogrammierung als homogener, ausdrucksmächtiger Formalismus zur
Formulierung von Anfragen, Integritätsbedingungen und prozeduralen
Komponenten, und für deklarative Programmier–Frontends für Datenbanken.
Prof. Dr. Dietmar Seipel 3
Deduktive Datenbanken Sommersemester 2012
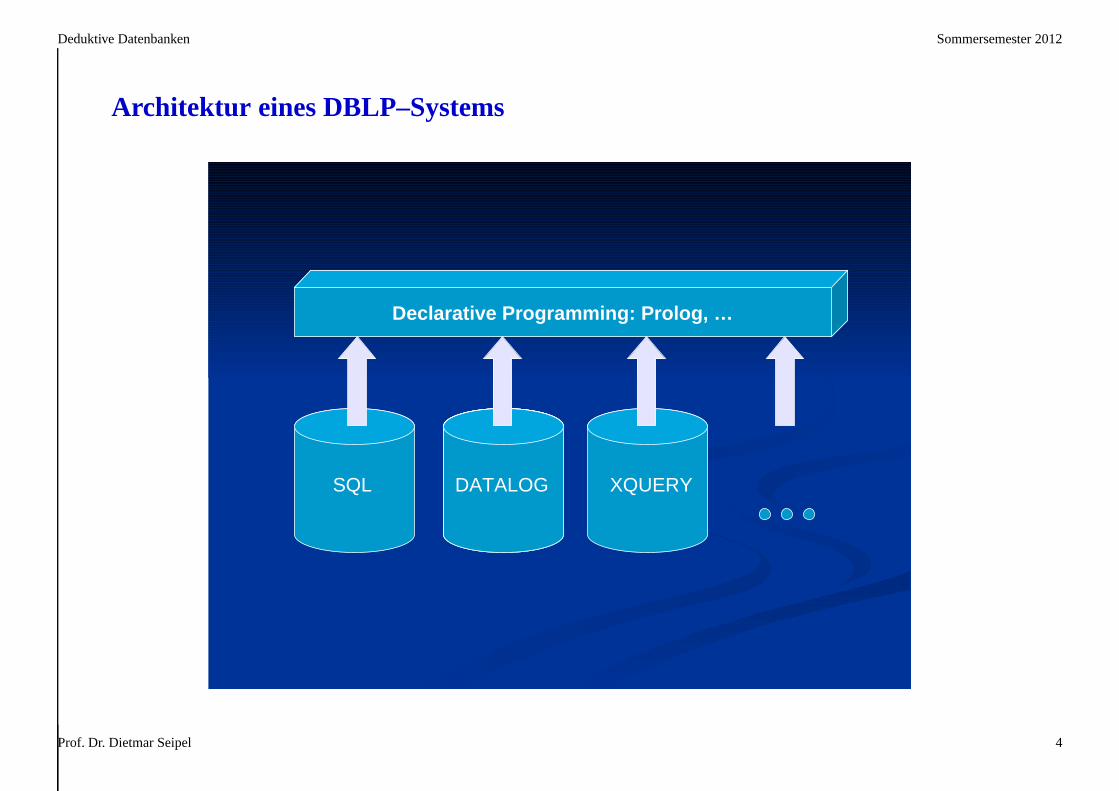
Architektur eines DBLP–Systems
������������� ������ ������ ��
��� ������� ���
Prof. Dr. Dietmar Seipel 4
Deduktive Datenbanken Sommersemester 2012
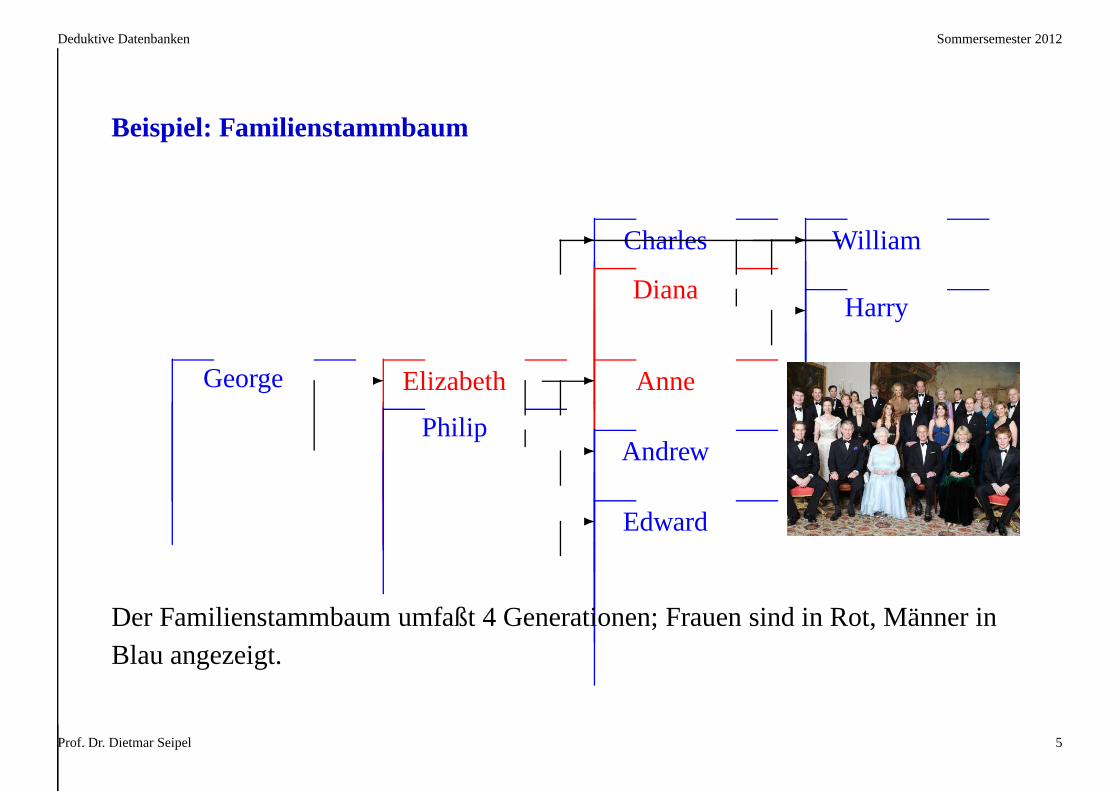
Beispiel: Familienstammbaum
George Elizabeth
Philip
Charles
Diana
Anne
Andrew
Edward
William
Harry
-
-
-
-
- -
-
Der Familienstammbaum umfaßt 4 Generationen; Frauen sind in Rot, Männer inBlau angezeigt.
Prof. Dr. Dietmar Seipel 5
Deduktive Datenbanken Sommersemester 2012
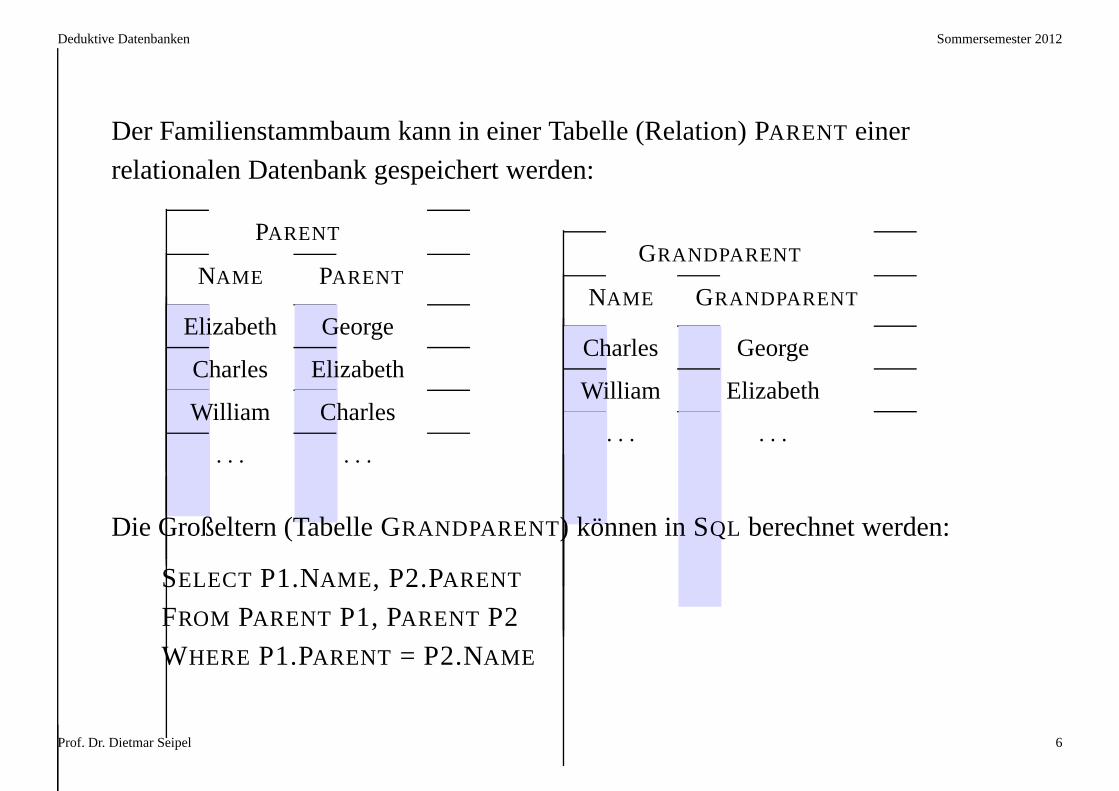
Der Familienstammbaum kann in einer Tabelle (Relation) PARENT einer
relationalen Datenbank gespeichert werden:
PARENT
NAME PARENT
Elizabeth George
Charles Elizabeth
William Charles
. . . . . .
GRANDPARENT
NAME GRANDPARENT
Charles George
William Elizabeth
. . . . . .
Die Großeltern (Tabelle GRANDPARENT) können in SQL berechnet werden:
SELECT P1.NAME , P2.PARENT
FROM PARENT P1, PARENT P2
WHERE P1.PARENT = P2.NAME
Prof. Dr. Dietmar Seipel 6

Deduktive Datenbanken Sommersemester 2012
Die Vorfahren einer Person können in SQL nicht berechnet werden:
ANCESTOR
NAME ANCESTOR
William George
. . . . . .
In einem DBLP–System kann man diese aber mittelsrekursiver
DATALOG–Regeln berechnen:
ancestor(X ,Z )← parent(X ,Z ),
ancestor(X ,Z )← parent(X ,Y ) ∧ ancestor(Y ,Z ).
Eine PersonZ ist ein Vorfahre einer PersonX,
2 falls Z ein Elternteil vonX ist (erste Regel), oder
2 falls Z ein Vorfahre eines ElternteilsY vonX ist (zweite Regel).
X
Y
Z
parent
ancestor
ancestor
6
6I
Prof. Dr. Dietmar Seipel 7

Deduktive Datenbanken Sommersemester 2012
Anwendungsbereiche von DBLP
2 Datenbanken mit komplexen Strukturen (Hierarchien, XML )
2 komplexe, wissensbasierte Systeme,
regelbasierte Systeme, Diagnosesysteme (Medizin, Technik)
2 Datenintegration
2 Semantic Web
2 Default Reasoning, Answer Set Programming (ASP)
2 symbolische Informationsverarbeitung, Parsing
2 Graphenprobleme und kombinatorische Probleme
(Spiele wie Sudoku oder Minesweeper, etc.)
Prof. Dr. Dietmar Seipel 8
Deduktive Datenbanken Sommersemester 2012
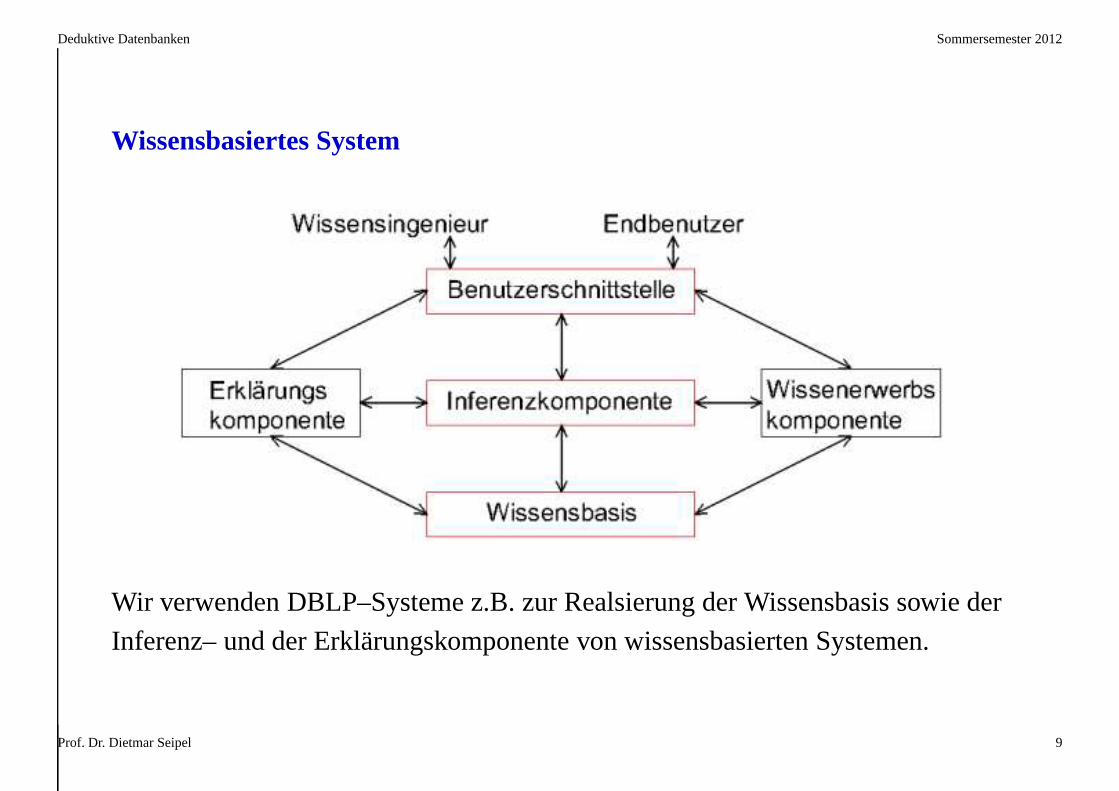
Wissensbasiertes System
Wir verwenden DBLP–Systeme z.B. zur Realsierung der Wissensbasis sowie der
Inferenz– und der Erklärungskomponente von wissensbasierten Systemen.
Prof. Dr. Dietmar Seipel 9

Deduktive Datenbanken Sommersemester 2012
Semantic Web
Knowledge Engineering im Semantic Web basiert auf Ontologien und Logik und
kann von Techniken aus dem Bereich der Deduktiven Datenbanken und der
Logikprogrammierung unterstützt werden.
Die Semantic Web Rule Language (SWRL) baut Regeln aus der
Logikprogrammierung in OWL–Ontologien ein.
Deduktionsaufgaben:
2 Unterstützung derAnfrageauswertung;
2 in derWissensmodellieung: Analyse der Struktur von Ontologien im
Hinblick auf Anomalien.
Prof. Dr. Dietmar Seipel 10

Deduktive Datenbanken Sommersemester 2012
DBLP–Anwendungen in Würzburg
2 Software Engineering:Analyse und Refaktorisierung von
– Programm–Quellcode (PROLOG, JAVA , PHP, COBOL),
– Datenbankanwendungen (Schema und Embedded SQL–Code) und
– Ontologien (OWL, SWRL) im Semantic Web
2 Bio–Informatik:Management komplexer XML–Daten,
z.B. im Rahmen der Pathway–Analyse
2 Sprachwissenschaften:
Parsing, Analyse und Aufbereitung von Textdaten, oft in XML
2 Analyse–Tools:
– Taktikanalyse imSport(Tennis, Basketball)
– Stocktool: Chartanalyse und Visualisierung
Prof. Dr. Dietmar Seipel 11

Deduktive Datenbanken Sommersemester 2012
DBMS–Eigenschaften von DBLP–Systemen
2 Datenintegration, Datenunabhängigkeit/Datenabstraktion:
Wissen aus Fakten (Tupeln von Relationen) und Regeln (Methoden)
2 Datenintegrität:
wie bei relationalen DBMS + erweiterte Ausdrucksmächtigkeit
2 Datenpersistenz, Datensicherheit, Datenschutz:
vom zugrunde liegenden relationalen DBMS übernommen
2 deklarative Anfragesprache:
ausdrucksmächtig, Zugriffsoptimierung auch für rekursive Regeln
Prof. Dr. Dietmar Seipel 12
Deduktive Datenbanken Sommersemester 2012
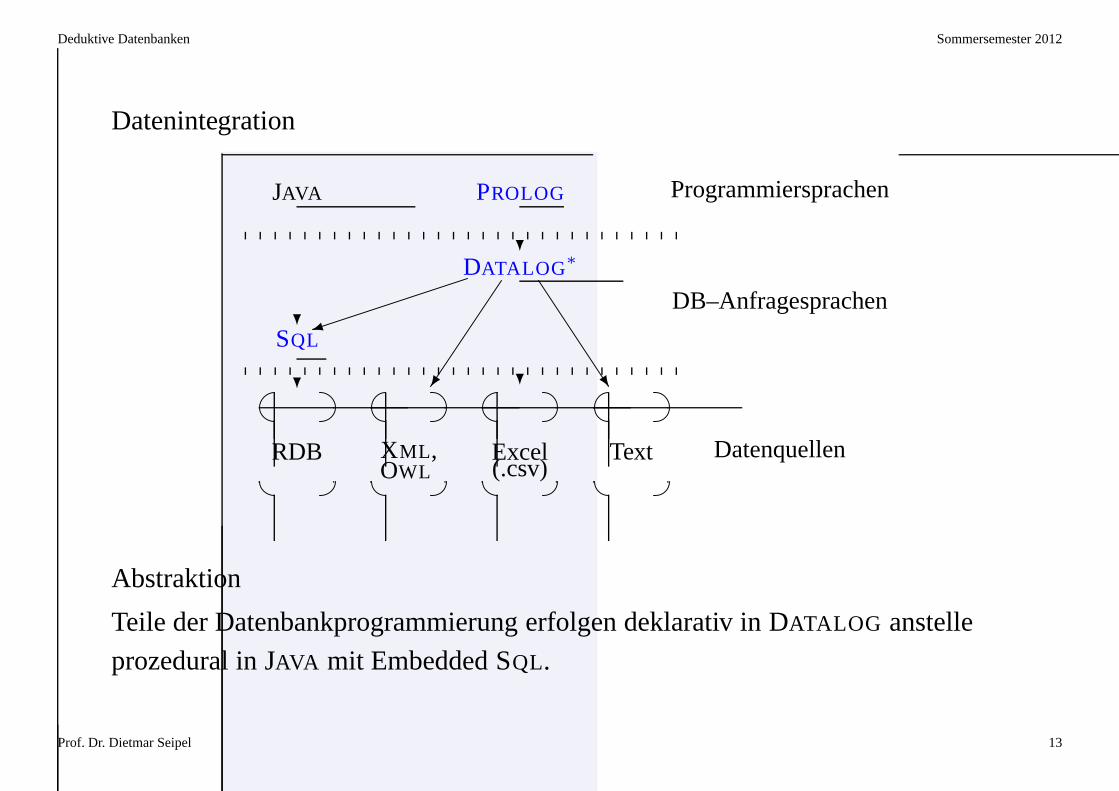
Datenintegration
)
? � ? ^
?
?SQL
DATALOG∗
JAVA PROLOG
Datenquellen
DB–Anfragesprachen
Programmiersprachen
RDB XML ,OWL
Excel(.csv)
Text
Abstraktion
Teile der Datenbankprogrammierung erfolgen deklarativ inDATALOG anstelle
prozedural in JAVA mit Embedded SQL.
Prof. Dr. Dietmar Seipel 13

Deduktive Datenbanken Sommersemester 2012
PROLOG
Man kann mit PROLOG (im Gegensatz zur “reinen” Logikprogrammierung) auch
2 prozedural
2 mit Seiteneffekten und
2 mit globalen Variablen (realisiert mit Hilfe vonassert undretract)
programmieren.
PROLOG–Implementierungen wie – z.B. SWI/XPCE–PROLOG – besitzen
umfangreiche Programmbibliotheken und Erweiterungen:
2 Datenstrukturen und Algorithmen, Kombinatorik,
2 Datenbank– und Web–Programmierung,
2 komfortable GUI–Programmierung, etc.
Prof. Dr. Dietmar Seipel 14

Deduktive Datenbanken Sommersemester 2012
Die einfache Handhabung vonTermenalsDatenstrukturund die mächtige,
eingebauteKontrollstrukturdesBacktrackingssind Features, die PROLOG im
Vergleich zu anderen Programmiersprachen auszeichnen.
PROLOG ist sehr gut zur eingebetten Datenbankprogrammierung geeignet.
Im Datenbankkontext wird häufig eine eingeschränkte Version benutzt, die
DATALOG genannt wird – die Basis der deduktiven Datenbanken.
2 PROLOG und DATALOG sind deklarative Sprachen, mit denen man auf
Datenbanken und XML–Dokumenten operieren kann.
2 Relationen und komplexe Objekte (wie z.B. XML–Dokumente) können in
sehr natürlicher Weise als Terme repräsentiert werden.
2 Mithilfe deklarativer Regeln können wir auch Integritätsbedingungen und
Inferenzregeln zur Ableitung von Schlußfolgerungen aus der gegebenen
Information repräsentieren.
Prof. Dr. Dietmar Seipel 15

Deduktive Datenbanken Sommersemester 2012
Datenbankprogrammierung
2 Man kann aus PROLOG heraus über eine SQL–Schnittstelle mittels ODBC
auf relationale Datenbanken zugreifen.
2 Die Verbindung von PROLOG und DATALOG erlaubt eine sehr komfortable
Programmierung von Datenbankanwendungen.
2 Der von Embedded SQL (JDBC, ODBC) bekannte Mismatch zwischen
– der Datenbanksprache SQL und
– der Host–Programmiersprache (z.B. JAVA oder C++)
kann hier vermieden werden.
Prof. Dr. Dietmar Seipel 16
Deduktive Datenbanken Sommersemester 2012
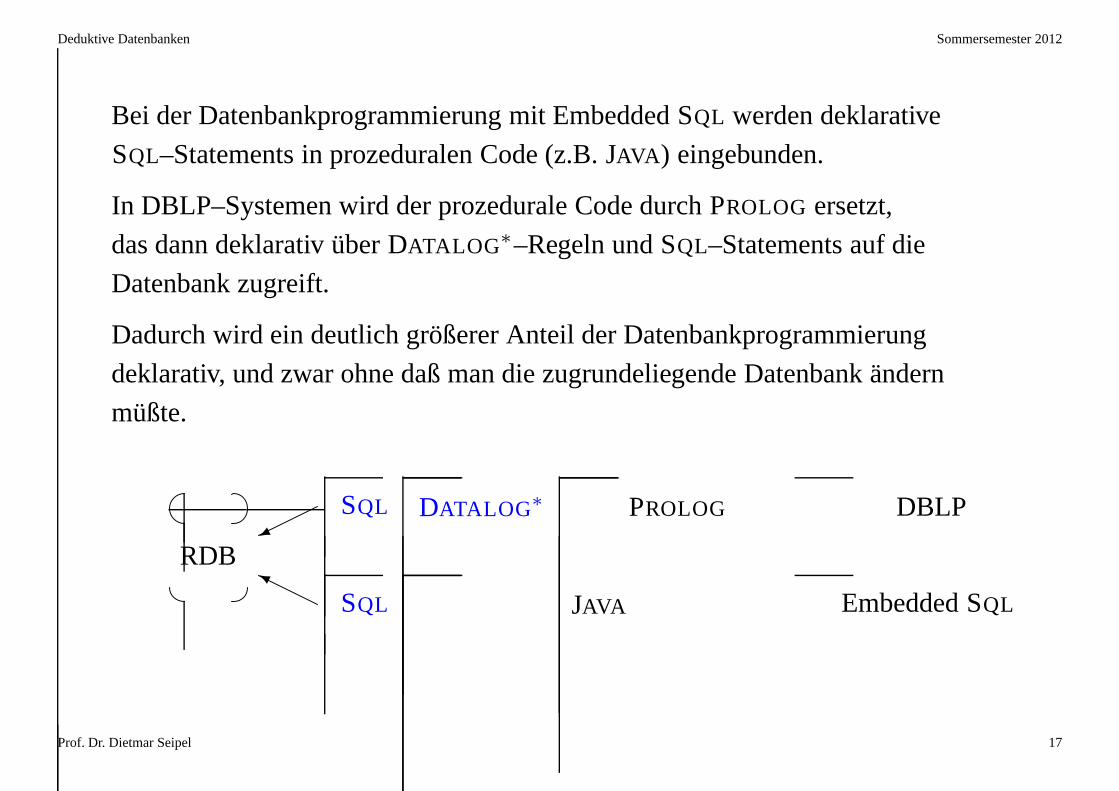
Bei der Datenbankprogrammierung mit Embedded SQL werden deklarative
SQL–Statements in prozeduralen Code (z.B. JAVA ) eingebunden.
In DBLP–Systemen wird der prozedurale Code durch PROLOG ersetzt,
das dann deklarativ über DATALOG∗–Regeln und SQL–Statements auf die
Datenbank zugreift.
Dadurch wird ein deutlich größerer Anteil der Datenbankprogrammierung
deklarativ, und zwar ohne daß man die zugrundeliegende Datenbank ändern
müßte.
SQL JAVA Embedded SQLY
�SQL DATALOG∗ PROLOG DBLP
RDB
Prof. Dr. Dietmar Seipel 17

Deduktive Datenbanken Sommersemester 2012
APIs und Tools für PROLOG
2 SWI–PROLOG–Libraries (/usr/lib/pl-x.y.z/library):
lists.pl, ordsets.pl, ugraphs.pl, odbc.pl, sgml.pl, . . . ,
andere PROLOG–Libraries: loops.pl, . . .
2 XPCE–PROLOG–Libraries für SWI–PROLOG:
(/usr/lib/pl-x.y.z/xpce/prolog/lib):
WWW, HTML , Charts, . . .
2 DISLOG Developers’ Kit (DDK) für SWI–PROLOG::
Units (~DisLog/sources):
– basic_algebra, nm_reasoning, xml, databases,
– development, stock_tool, projects, linguistics, biology_and_medicine.
SWI–PROLOG ist in C geschrieben.
Prof. Dr. Dietmar Seipel 18

Deduktive Datenbanken Sommersemester 2012
DDK (D ISL OG Developers’ Toolkit)
eine große PROLOG–Bibliothek mit Algorithmen und Datenstrukturen für
verschiedenste Anwendungen, einschließlich Datenbanken, nicht–montones
Schließen (NMR), WWW, XML und Software Engineering
2 DDBASE:
ein PROLOG–basiertes deduktives Datenbanksystem mit Anbindung an
relationale Datenbanken (MySQL) und verschiedene ASP–Systeme
2 FNQuery/ PL4XML:
eine deklarative, PROLOG–basierte XML–Anfrage–, Transformations– und
Update–Sprache
2 DATALOG∗ :
eine mit PROLOG verwobene Erweiterung von DATALOG
Prof. Dr. Dietmar Seipel 19

Deduktive Datenbanken Sommersemester 2012
Andere Systeme zur Logikprogrammierung
2 deduktive Datenbanksysteme:
CORAL, LDL, Lola, ADITI
2 Systeme für Answer Set Programming (ASP):
dlv, Smodels, XSB, Lola,Cmodels, ASAT
2 PROLOG–Systeme:
SWI, SICStus, Visual PROLOG, IF PROLOG, Mercury
2 Constraint–logische Programmierung (CLP):
Eclipse, Chip, Minerva
2 Funktional–logische Programmierung (FLP):
Curry
Prof. Dr. Dietmar Seipel 20

Deduktive Datenbanken Sommersemester 2012
Themengebiete der Vorlesung
2 Grundlagen von DATALOG und PROLOG
2 das deduktive Datenbanksystem DDBASE
2 FNQuery, DATALOG∗
2 effiziente Auswertung von Logikprogrammen
2 weitere Sprachkonstrukte:
– Built–In–Prädikate, Aggregationsfunktionen
– Negation und Disjunktion
−→ Answer Set Programming (ASP), DISLOG
2 Anwendungen
Prof. Dr. Dietmar Seipel 21

Deduktive Datenbanken Sommersemester 2012
Kapitel 1 und 2: DATALOG und PROLOG
DATALOG und PROLOG sind – auf einem Domänenkalkül basierende – logische
Programmiersprachen, die sich syntaktisch sehr ähneln undsich semantisch (in
der Auswertung) unterscheiden.
2 DATALOG ist eine deklarative Datenbanksprache.
2 Es erweitert die relationale Datenbanksprache SQL (Tupelkalkül) um
Rekursion. Nicht–rekursive DATALOG–Anfragen kann man leicht nach SQL
übersetzen – und umgekehrt.
2 DATALOG kann – ähnlich wie SQL – effizient mengen–orientiert ausgewertet
werden.
2 Für praktische Anwendungen braucht man oft zusätzliche Features, wie
Built–In–Prädikate, komplexe Typen, Aggregation und Default Negation, die
nicht von allen Systemen unterstützt werden.
Prof. Dr. Dietmar Seipel 22

Deduktive Datenbanken Sommersemester 2012
PROLOG ist eine deklarative Programmiersprache:
2 Wegen ihrer Kompaktheit und weitgehenden Ungetyptheit kann sie sehr gut
alsSkripting–Spracheverwendet werden.
2 Konstruktehöherer Ordnung(Funktionale) erlauben sehr viel Abstraktion
und selbst–definierte Kontrollstrukturen.
2 Die Programmierung istrelationalmit eingebautemBacktracking, und es
wird häufigRekursionverwendet.
Im Vergleich zu DATALOG
2 bietet PROLOG deutlich mehr syntaktische Features, aber dafür weniger
semantische Alternativen;
2 ist die tupel–orientierte Auswertung von PROLOG weniger effizient und
terminiert für rekursive Programme manchmal nicht.
Prof. Dr. Dietmar Seipel 23

Deduktive Datenbanken Sommersemester 2012
PROLOG–Programmierung
2 Wir zeigen auf, wie PROLOG in Verbindung mit relationalen Datenbanken
benutzt werden kann.
2 Zur Datenhaltung in PROLOG selbst kann die interne PROLOG–Datenbank
verwenden. Auf deren Basis wurde auch das deduktive
Mini–Datenbanksystem DDBASE entwickelt.
2 XPCE–PROLOG bietet viele weitere Features (GUI–,
Web–Programmierung), die noch nicht im Sprachstandard vonPROLOG
enthalten sind.
2 Wir zeigen verschiedene Anwendungen von PROLOG: Sortieren und Suchen
(auch in Graphen), Analyse hierarchischer Daten, medizinische Diagnose.
Für praktische Anwendungen ist oft die Verbindung von PROLOG, DATALOG und
Datenbanken (relational oder XML ) sehr sinnvoll (DBLP–Systeme).
Prof. Dr. Dietmar Seipel 24

Deduktive Datenbanken Sommersemester 2012
Anwendungsbeispiel: Stücklistenauflösung
Die Stücklistenauflösung dient in der Betriebswirtschaftslehre der Ermittlung der
in einer Planperiode erforderlichen Bedarfsmengen an Werkstoffen und Teilen.
components(C1, C2:Q2):
Ein Werkteil vom TypC1 enthältQ2 Komponenten vom TypC2.
a
b c
d e f
2 3
4 5 6 7
R
R R
components(a, b:2).
components(a, c:3).
components(b, d:4).
components(b, e:5).
components(c, e:6).
components(c, f:7).
Dann hat ein komplexes Teil vom Typa z.B. folgende Stückliste:
[d:8, e:28, f:21].
Prof. Dr. Dietmar Seipel 25

Deduktive Datenbanken Sommersemester 2012
Die persistente Speicherung und Verwaltung der Teilehierarchie kann in einer
relationalen Datenbank erfolgen, aus der dann die Faktencomponents(C1,
C2:Q2) extrahiert werden:
a
b c
d e f
2 3
4 5 6 7
R
R R
COMPONENTS
C1 C2 Q2
a b 2
a c 3
b d 4
b e 5
c e 6
c f 7
Das in PROLOG implementierte deduktive Datenbanksystem DDBASE kann über
ODBC auf relationale Datenbanken zugreifen.
Prof. Dr. Dietmar Seipel 26
Deduktive Datenbanken Sommersemester 2012
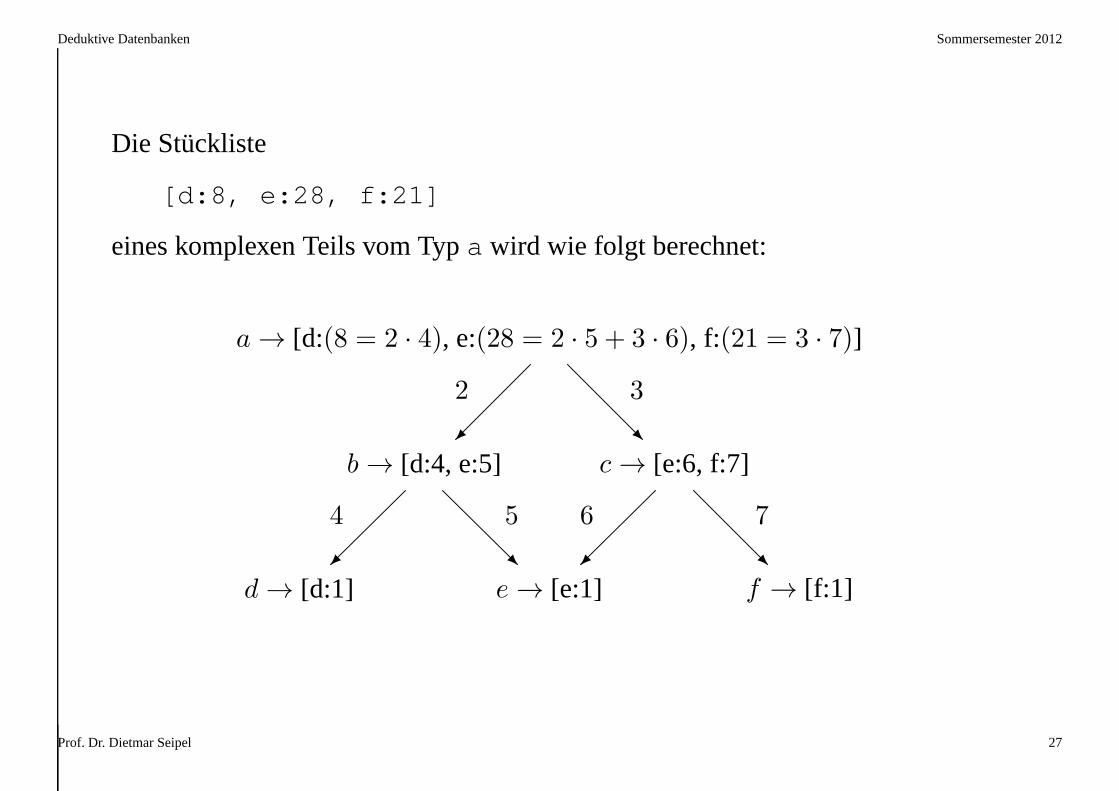
Die Stückliste
[d:8, e:28, f:21]
eines komplexen Teils vom Typa wird wie folgt berechnet:
a→ [d:(8 = 2 · 4), e:(28 = 2 · 5 + 3 · 6), f:(21 = 3 · 7)]
b→ [d:4, e:5] c→ [e:6, f:7]
d→ [d:1] e→ [e:1] f → [f:1]
2 3
4 5 6 7
R
R R
Prof. Dr. Dietmar Seipel 27

Deduktive Datenbanken Sommersemester 2012
Die Berechnung der Stücklisten für beliebig komplexe (tiefe) Teile ist nur in
Embedded SQL möglich, nicht aber in SQL. In PROLOG reicht dagegen das
folgende, kompakte Logikprogramm zur Stücklistenaggregation schon aus:
parts_of(C1, C2:Q2) :-
( not(components(C1, _)) -> C2:Q2 = C1:1
; ddbase_aggregation( [Cb, sum(Qa*Qb)],
( components(C1, Ca:Qa),
parts_of(Ca, Cb:Qb) ), [C2, Q2] ) ).
(If->Then;Else):
2 FallsC1 keine Komponenten hat, so wirdC1:1 berechnet.
2 Andernfalls ermitteltddbase_aggregation/3 für alle Komponenten
Ca:Qa vonC1 wieviele TeileCb:Qb diese enthalten und berechnet die
SummeQ2 über alleQa*Qb.
Prof. Dr. Dietmar Seipel 28

Deduktive Datenbanken Sommersemester 2012
Kapitel 3: Syntax und Semantik (Theorie)
2 Die syntaktischen Grundbausteine von DATALOG und PROLOG stammen aus
der Prädikatenlogik: Terme, Atome und Klauseln. Letztere werden für
Fakten, Regeln und Anfragen verwendet.
2 Die Semantik von DATALOG kann mittels Inferenzmethoden
(beweis–theoretisch:TP , SLD/SLDNF), modell–theoretisch oder mittels
eines Fixpunktansatzes beschrieben werden.
2 In der Praxis wird bei DATALOG die Bottom–Up–Inferenzmethode des
TP–Operators – basierend aufHyperresolution– zur Bestimmung aller
ableitbaren Fakten verwendet.
2 Für PROLOG ist die Top–Down–Inferenzmethode derSLDNF–Resolution
die grundlegenede Auswertungsmethode für Anfragen; allerdings muß sie
dann um außer–logische Features mit Seiteneffekten erweitert werden.
Prof. Dr. Dietmar Seipel 29

Deduktive Datenbanken Sommersemester 2012
Kapitel 4: Daten– und Programmstrukturen für P ROLOG
2 Es gibt nur eine Reihe von Basis–Datentypen. Aber man kann beliebige
komplexe Strukturen als Terme (ein wichtiger Spezialfall sind Listen) in
PROLOG repräsentieren.
2 Sehr geeignet sind dabei Terme, die XML–Elemente repräsentieren,
da man dann entsprechende Anfrage–, Transformations– und
Update–Sprachen wie FNQuery verwenden kann.
2 Neben Schleifen und Verzweigungen kann man vielfältige, weitere
Kontrollstrukturenauf der Basis von Meta–Prädikaten realisieren.
Typisch sind Konstrukte zum Finden aller Antworten auf eineAnfrage sowie
Filter und Transformationen für Listen.
2 Die (rekursive) Struktur von PROLOG–Programmen kann gut analysiert
werden, und es können Äquivalenz–Transformationen zur
Programm–Optimierung – speziell für DATALOG – eingesetzt werden.
Prof. Dr. Dietmar Seipel 30

Deduktive Datenbanken Sommersemester 2012
Kapitel 5: Auswertungsmethoden für DATALOG
2 Man kann DATALOG–Programme leicht in relationen–algebraische
Ausdrücke übersetzen, die man dann sehr effizient auf der Basis relationaler
Datenbanken auswerten kann.
2 Für spezielle, häufig auftretende DATALOG–Programme kann man Anfragen
mit Wavefront–Methoden relationen–algebraisch auswerten.
2 Die Ketten–Normalisierungsmethode kann beliebige DATALOG–Programme
mit genau einer linear–rekursiven Regeln mittels einer graph–basierten
Analyse auf diese Form bringen.
2 Die Magic–Sets–Methode transformiert ein DATALOG–Programm bezüglich
einer Anfrage durch Nachahmung der SLD–Resolution in ein
DATALOG–Programm (Source–to–Source–Transformation), das zielgerichtet
und effizienter bottom–up ausgewertet werden kann.
2 In der Literatur findet man viele weitere Auswertungsmethoden.
Prof. Dr. Dietmar Seipel 31

Deduktive Datenbanken Sommersemester 2012
Kapitel 6: Default Negation in Logikprogrammen
2 Praktische Anwendungen erfordern Default Negation, Aggregation,
Built–In– und oft auch Meta–Prädikate.
2 Häufig können solche LogikprogrammeP stratifiziertausgewertet werden:
– Falls sich ein FaktA auf die Negation eines anderen FaktsB bezieht, so
muß zuerstB ausgewertet werden. Erst dann kann man per
Closed–World–Annahmeentscheiden, ob die Negation vonB gilt.
– Auch im Falle von Meta–Prädikaten versucht man so vorzugehen.
Die so berechnete intuitive Semantik nennt man dasperfekteModell MP .
Ohne Default Negation istMP das eindeutige minimale Modell.
2 Manchmal bezieht sich ein Fakt auf die Negation eines anderen Fakts,
mit dem es wechselseitigrekursivist, und man kann nicht stratifizieren.
Dann arbeitet man mitstabilenModellen, die durch einen Fixpunkt–Ansatz
definiert werden, oder mit demwohlfundiertenModellWP .
Prof. Dr. Dietmar Seipel 32

Deduktive Datenbanken Sommersemester 2012
Anwendungsbeispiel: Studium
Kurse (mit ECTS–Punkten) und Prüfungen:
course(’ADS’, under_graduate, 10).
course(’SWT’, under_graduate, 10).
course(’DB1’, under_graduate, 5).
course(’DB2’, graduate, 5).
course(’DDB’, graduate, 9).
exam(’Mary’, ’ADS’, 2007-02-05).
exam(’Mary’, ’SWT’, 2007-07-05).
exam(’Mary’, ’DB1’, 2008-02-05).
exam(’Mary’, ’DB2’, 2009-02-05).
Diese Fakten könnten in der Erweiterung DATALOG∗ von DATALOGnot auch
durch eine Anfrage an eine relationale Datenbank gewonnen werden.
Prof. Dr. Dietmar Seipel 33

Deduktive Datenbanken Sommersemester 2012
Ein Student kommt an dem Tag ins Hauptstudium (graduate), andem er
180 ECTS–Punkte im Grundstudium (under_graduate) erreicht:
exam(Student, Course, Level, Date, ECTS) :-
exam(Student, Course, Date),
course(Course, Level, ECTS).
graduate(Student, Date) :-
ddbase_aggregate( [Student, max_date(D), sum(E)],
exam(Student, _, under_graduate, D, E),
Tuples ),
member([Student, Date, Total], Tuples),
Total >= 180.
Das Prädikatddbase_aggregate/3 bestimmt für alle Studierenden das
maximale Datum und die Summe der ECTS–Punkte ihrer Prüfungen.
Prof. Dr. Dietmar Seipel 34

Deduktive Datenbanken Sommersemester 2012
Wenn man die Studierenden im Grund– bzw. Hauptstudium zählen will,
dann muß man zuerst alle graduate–Studierenden bestimmen;
alle anderen Studierenden sind dann under_graduate:
under_graduate(Student) :-
student(Student),
not(graduate(Student)).
graduate(Student) :-
graduate(Student, Date).
Aus technischen Gründen muß man in der Regel für under_graduate mit der
Projektion von graduate auf die Studierenden arbeiten.
Diese stratifizierte Auswertung bestimmt in DATALOG∗ dasperfekteModell.
Prof. Dr. Dietmar Seipel 35

Deduktive Datenbanken Sommersemester 2012
Das generische Prädikat “count_students/2” wendet “graduate/1”
bzw. “under_graduate/1” auf alle Studierenden an und zählt die Hits:
count_students(Pred, N) :-
member(Pred, [graduate, under_graduate])
ddbase_aggregate( [length(Student)],
call(Pred, Student),
[[N]] ).
Durch “call(Pred, Student)” wird das Argument Predicate zum
Prädiaktensymbol des Aufrufs “Pred(Student)” gemacht, was man in
PROLOG direkt nicht schreiben darf.
Nachdem die Liste “Students” aller entsprechenden Studierenden berechnet
wurde, wird mittels “length(Students, N)” deren Länge “N” ermittelt.
Prof. Dr. Dietmar Seipel 36

Deduktive Datenbanken Sommersemester 2012
Das rekursive Prädikat supports bestimmt Kurse, welche andere Kurse (transitiv)
unterstützen:
supports(C1, C2) :-
supports(C1, C3),
supports(C3, C2).
supports(’DB1’, ’DDB’).
supports(’SWT’, ’DB1’).
supports(’ADS’, ’SWT’).
Die transitive Verketteng ist eine der häufigsten Formen vonRekursionin
deduktiven Datenbanken.
Um effizient zu sein müssen rekursive Logikprogramme geschickt ausgewertet
werden, da sonst sehr viel Redundanz entstehen kann.
Prof. Dr. Dietmar Seipel 37

Deduktive Datenbanken Sommersemester 2012
DATALOG –Erweiterungen
2 Aktuelle DATALOG–Systeme erlauben nur konjunktive Regelrümpfe mit
Default Negation und elementaren Built–In–Prädikaten sowie einfache
Aggregation.
2 In der hier verwendeten Erweiterung DATALOG∗ sind beliebige
PROLOG–Regeln mit beliebigen Meta–Prädikaten erlaubt, die aber –anders
als in PROLOG – bottom–up ausgewertet werden.
2 Dadurch kann man viele Sachverhalte in DATALOG∗ deutlich komfortabler
ausdrücken als in DATALOG, und man kann externe Tools gut einbinden.
2 Momentan erlaubt DATALOG∗ wie die meisten DATALOG–Systeme nur
stratifizierte Meta–Prädikate – mit Default Negation und Aggregation als
Spezialfällen.
Prof. Dr. Dietmar Seipel 38

Deduktive Datenbanken Sommersemester 2012
DATALOG ∗ vs. PROLOG
2 Viele DATALOG∗–Programme – wie z.B. obiges Programm zum Studium –
könnten auch direkt in PROLOG ausgewertet werden.
2 Die tupel–orientierte PROLOG–Auswertung wäre allerdings weniger effizient
als die mengen–orientierte DATALOG∗–Auswertung.
2 Außerdem würde die PROLOG–Auswertung nicht mehr terminieren,
sobald die supports–Relation zyklisch würde.
2 Manche Anwendungen – wie z.B. Diagnose–Systeme – erforderndie
mengen–orientierte DATALOG∗–Auswertung.
Prof. Dr. Dietmar Seipel 39

Deduktive Datenbanken Sommersemester 2012
Kapitel 7: Disjunktive Logikprogramme (DLPs)
2 DLPs erlauben Disjunktion in Regelköpfen zur Formulierungunsicheren
Wissens. Typische Beispiele sind unsichere Diagnoseregeln,
Graphenprobleme und kombinatorische Probleme, wie etwa Spiele.
2 Die Semantik eines Negations–freien DLPs ist durch die minimalen
Herbrandmodelle gegeben, die mittels der beiden VerallgemeinerungenT sP
undT iP desTP –Operators bestimmt werden können.
2 Wenn zusätzlich Default Negation auftritt, so werden wieder diestabilen
bzw. (als Erweiterung) diepartiell–stabilenModelle herangezogen:
– Ohne Negation entsprechen beide den minimalen Modellen.
– Ohne Disjunktion istWP das kleinste partiell–stabile Modell.
– Falls zuätzlich die Negation stratifiziert ist, so istMP das eindeutige
stabile bzw. partiell–stabile Modell.
Prof. Dr. Dietmar Seipel 40