vlc 2009 part 2
TRANSCRIPT

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <1>
Variable Length Coding Information entropy
Huffman code vs. arithmetic code Arithmetic coding Why CABAC? Rescaling and integer arithmetic coding Golomb codes Binary arithmetic coding CABAC
112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <2>
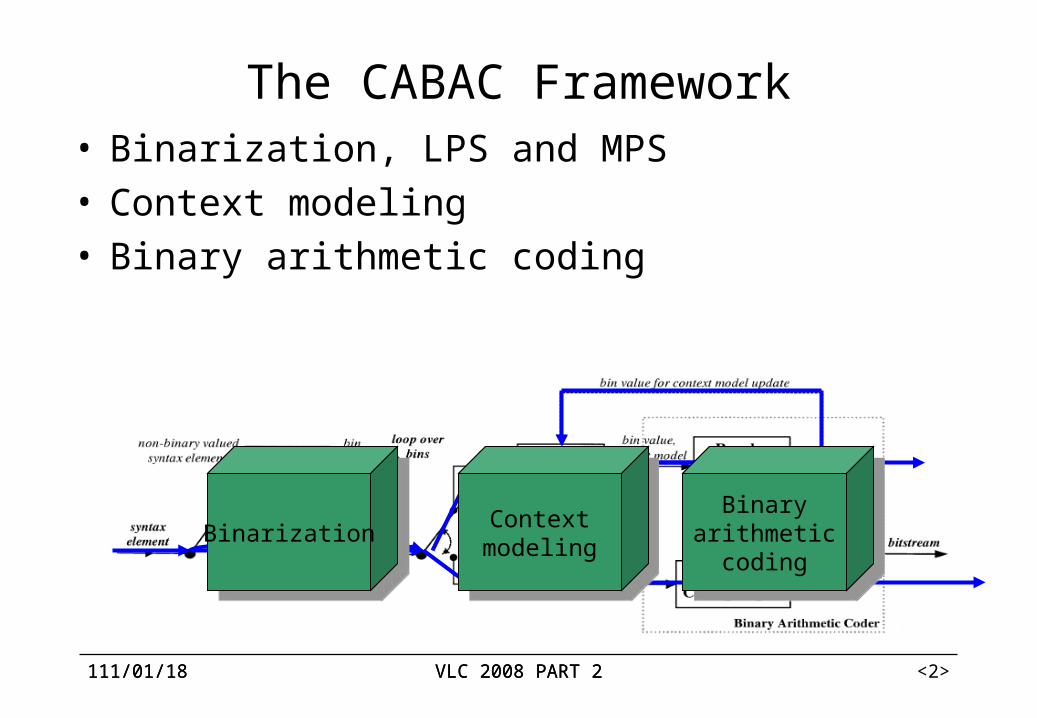
The CABAC Framework• Binarization, LPS and MPS• Context modeling• Binary arithmetic coding
Binarization Contextmodeling
Binaryarithmetic
coding

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <3>
Binary Arithmetic Coding – Word-based to Image-based
Q, QM coders JBIG, JBIG-2 and JPEG-LS
M coder – H.264 Three steps:
modeling statistics-gathering, and coding with many sets of probabilities

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <4>
Binary Arithmetic Coding least probable symbol (LPS) & most probable symbol (MPS) Binary arithmetic is based on the principal of recursive interval
subdivision. Suppose that an estimate of the probability pLPS in (0,0.5] is given and its
lower bound L and its width R. Based on this, the given interval is sub-divided into two sub-intervals: RLPS=R pLPS and the dual interval RMPS=R - RLPS.
In a practical implementation, the main bottleneck in terms of throughput is the multiplication operation required.
Speeding up the required calculation by introducing some approximations of either the range R or of the probability pLPS such that multiplication can be avoided.

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <5>
Binary Coding Binary coding allows a number of
the components of a coder for a multi-symbol alphabet to be eliminated. There is no need for the statistics data structure, since cumulative frequency counts are trivially available.
c0 and c1: the frequencies of symbols zero and one, respectively
One multiplicative operation can be eliminated in the encoder when the LPS is transmitted, and one multiplicative operation avoided in the decoder for the MPS and two for the LPS.
)()()1()(
)or ()or ( symbol observedth the:
symbolth the toup prob cumulative ,)(
, ..., ,2 ,1 ,
)1()1()1()(
)1()1()1()(
101
10
1
nXnnnn
nXnnnn
nn
ln
l
l
nnnX
l
xFluluxFlull
ccddccanx
anpxF
LPSMPSLla
C.context for the LPS theof occurrence theof prob the:
)1(
:symbol LPS theof occurrence the)1(
:symbol MPS theof occurrence thelsubintervalower the toMPS theMap
)1()(
)1()1()(
)1()(
)1()(
CLPS
CLPS
nn
CLPS
nnn
CLPS
nn
nn
p
pRR
pRll
pRR
ll
MPS
LPS

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <6>
Issues in Word-based Models• An efficient data structure is needed to accumulate
frequency counts for a large alphabet.• Multiple coding contexts are necessary, for tokens,
characters, and lengths, for both words and nonwords. Here, a coding context is a conditioning class on which the probability distribution for the next symbol is based.
• An escape mechanism is required to switch from one coding context to another.
• Data structures must be resizable because there is no a priori bound on alphabet size.

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <7>
The Models• The word-based model uses six contexts:
– a zero-order context for words, – a zero-order context for nonwords (sequences of spaces and
punctuation), – a zero-order character context for spelling out new words, – a zero-order character context for spelling out new nonwords,
and – contexts for specifying the lengths of words and of nonwords.

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <8>
The Statistics Module• Managing the data structure that records
cumulative symbol frequencies.
• Encode a symbol s in context C
– lC,s, hC,s and tC: the cumulative frequency counts in context C of symbols respectively prior to and including s, according to some symbol ordering, and tC is the total frequency of all symbols recorded in context C.

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <9>
Performing the Arithmetic• arithmetic_encode(l, h, t): which encodes a symbol implicitly
assumed to have occurred h - l times out of a total of t, and which is allocated the probability range [l/t, h/t).
• [L, L + R), L and R: the current lower bound and range of the coding interval
• L and R: b-bit integers; L is initially 0, and takes on values between 0 and [2b - 2b-2); R is initially 2b-1, and takes on values between 2b-2 + 1 and 2b-1.
• Renormalization: To minimize loss of compression effectiveness due to imprecise division of code space, R should be kept as large as possible.
• This is done by maintaining R in the interval 2b-2 < R 2b-1 prior to each coding step, and making sure that t < 2f, with f b - 2.
0
B=2b-1
¾ B

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <10>
The Q-Coder• Q-Coder is the benchmark• The Q-Coder combines probability estimation and renormalization in
a particularly elegant manner, and implements all operations as table lookups.
• QM Coder: Assume that R(n) has the value close to one, rescale if not
– The probability for context C is updated each time a rescaling take place– It may happen that the symbol assigned to LPS actually occurs more often than
the symbol assigned to MPS. The condition is detected and the assignments are reversed when
CLPS
n
nn
pR
ll
1
:MPSFor
)(
)1()(
CLPSp
CLPS
nCLPS pRp )(
CLPS
n
CLPS
nn
pR
pll
)(
)1()(
)1(
:LPSFor

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <11>
Caveat ! Arithmetic Coding Revisited, ACM Trans on Information Systems, 1998
• For binary alphabets, if there is only one state and if the symbols are independent and can be aggregated into runs, then Golomb or other similar codes should be used.
• For multi-symbol alphabets in which the MPS is relatively infrequent, the error bounds on minimum-redundancy (Huffman) coding are such that the compression loss compared to arithmetic coding is very small.
• If static or semi-static coding (that is, with fixed probabilities) is to be used with such an alphabet, a Huffman coder will operate several times faster than the best arithmetic coding implementations, using very little memory.

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <12>
CABAC Binarization
Huffman treeunary, truncated unary, kth order exp-Golomb, and fixed-
length codes
Context modelingAdaptive probability models
Binary arithmetic coding: M coderTable-based BAC

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <13>
QM-coder: fast, multiplication-free variants of binary arithmetic coder, used in JBIG-2, JPEG-LS, and JPEG-2000
Goal(MM CoderCoder) : design a variation with lower computational complexity of 10% than QM and 20% than Standard-AC, for the total decoder execution time at medium bitrate
Background & GoalBackground & Goal
112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <14>
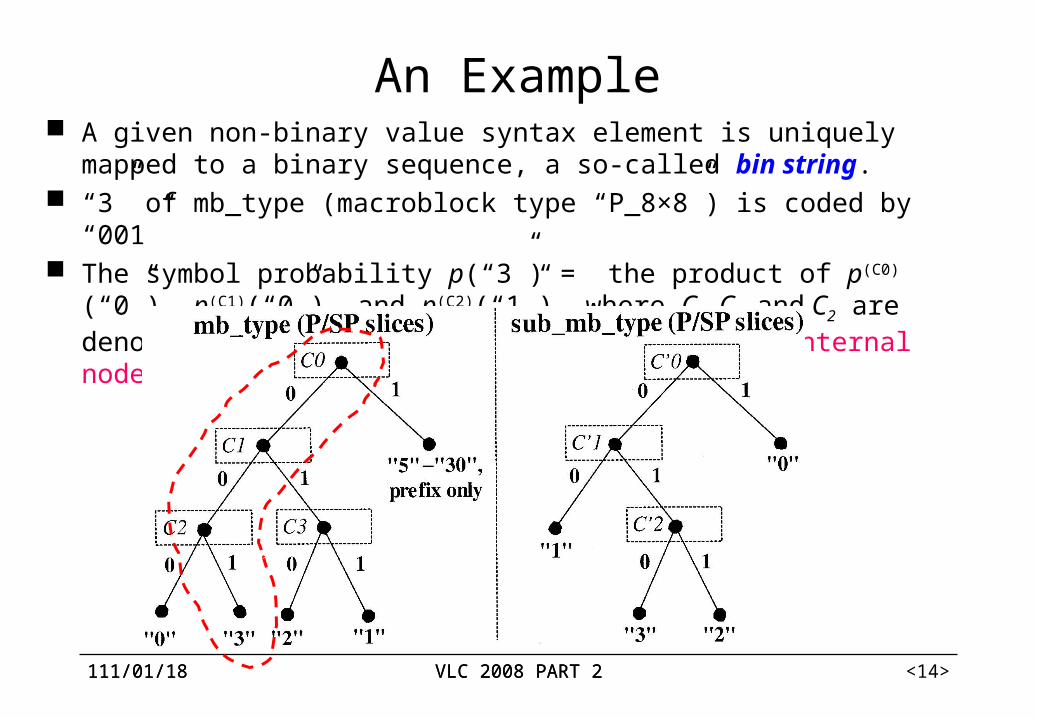
An Example A given non-binary value syntax element is uniquely mapped to a binary sequence,
a so-called bin string. “3” of mb_type (macroblock type “P_8×8”) is coded by “001” The symbol probability p(“3”) = the product of p(C0)(“0”), p(C1)(“0”), and p(C2)(“1”),
where C0, C1, and C2 are denote the binary probability models of the internal nodes.

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <15>
Why Binarization? Adaptive m-ary binary arithmetic coding (m > 2) is in general
requiring at least two multiplication for each symbol to encode as well as a number of fairly operations to perform the probability update.
Fast and multiplication-free variants of binary arithmetic coding. Since the probability of symbols with larger bin strings is typically
very low, the computation overhead is fairly small and can be easily compensated by using a fast binary coding engine.
Binarization enables context modeling on sub-symbol level. For the most frequently observed bins, conditional probability can be used, while less frequently observed bins can be treaded using a joint, typically zero-order probability model.
Independent ormemoryless

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <16>
Binarization Schemes A binary representation for a given non-binary valued syntax element
should be close to a minimum redundancy code. Instead of Huffman tree, the design of CABAC (mostly) relies the (a
few) basic code trees, whose structure enables a simple on-line computation of all code words without the need for storing any tables. Unary code (U) and truncated unary code (TU) The kth order exp-Golomb code (EGk) The fixed-length code (FL)
In addition, there are binarization schemes based on a concatenation of these elementary types.
As an exception, there are five specific binary trees selected manually for the coding of macroblock and sub-macroblock types.

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <17>
Unary and Truncated Unary Binarization unsigned integer valued symbol x 0, the unary code
word consists of x “1” bits plus a terminating “0” bit.U: 5 111110
The truncated unary (TU) code is only defined for x with 0 x S, where for x < S the code is given by the unary code, whereas for x = S the terminating “0” bit is neglected.
S = 9: 6: 1111110
9: 111111111

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <18>
kth order exp-Golomb Binarization The prefix part: a unary code corresponding to the value l(x)=
lg(x/2k+1) The suffix part: is computed as the binary representation of
x+2k(1-2l(x)) using k+l(x) significant bits.

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <19>
Fixed-Length Binarization x, a syntax element, 0 x S: the FL codeword of x is
the binary representation of x with a fixed (minimum) number lFL=lgS of bits.
Typically, FL binarization is applied to syntax elements with a nearly uniform distribution or to syntax elements, where each bit in the FL binary representation represents a specific coding decisions.

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <20>
Concatenation Schemes coded block pattern: Concatenation of
– Prefix: 4-bit FL for luminance– Suffix: TU with S = 2 for chrominance
motion vector difference (mvd): truncated unary / kth order exp-Golomb binarization– the unary code is the simplest prefix-free code– permits a fast adaptation of the individual symbol probabilities
in the sub-sequent context modeling– Prefix: TU with S = 9 for |mvd| < 9– Suffix: EG3 for |mvd - 9| if |mvd| 9– Sign bit
These observations are only accurate for small values of the absolute motion vector differences and transform coefficient levels.

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <21>
Transformed coefficient level– Prefix: TU with S = 14 for |level|– Suffix: EG0 for | level - 14| if |level| 14

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <22>
CABAC Binarization
Huffman treeunary, truncated unary, kth order exp-Golomb, and fixed-
length codes
Context modelingAdaptive probability models
Binary arithmetic codingTable-based BAC

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <23>
Context Modeling To utilize a clean interface between modeling and coding such that
in the modeling stage, a model probability distribution is assigned to the given symbols, which then,
in the subsequent coding stage, drives the actual coding engine to generate a sequence of bits as a coded representation of the symbols according to the model distribution.
F: T C operating on the template T to a related set C={0,…,C-1} of contexts x, a symbol to be coded z, an already coded neighboring symbols in T a conditional probability p(x|F(z)) is estimated by switching between different
probability models Thus, p(x|F(z)) is estimated on the fly by tracking the actual source statistics.

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <24>
Context Modeling (2) τ of different conditional probabilities to be estimated for
an alphabet size of m is equal to τ=C(m-1), it is intuitively clear that the model cost (learning) is proportional toτ.
Increases the # of C, there is a point where overfitting of the model may occur.
In CABAC, only very limited context templates T consisting of a few neighboring of the current symbol to encode are employed such that only a small number of different context models C is used.
Context modeling is restricted to selected bins of the binarized symbols. As a result, the model cost is drastically reduced.
112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <25>
Types of Context Modeling Four basic design types of context models
1st: two neighboring syntax elements in the past of the current syntax element, where the specific definition of the kind of neighborhood depends on the syntax element, e.g.,
112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <26>
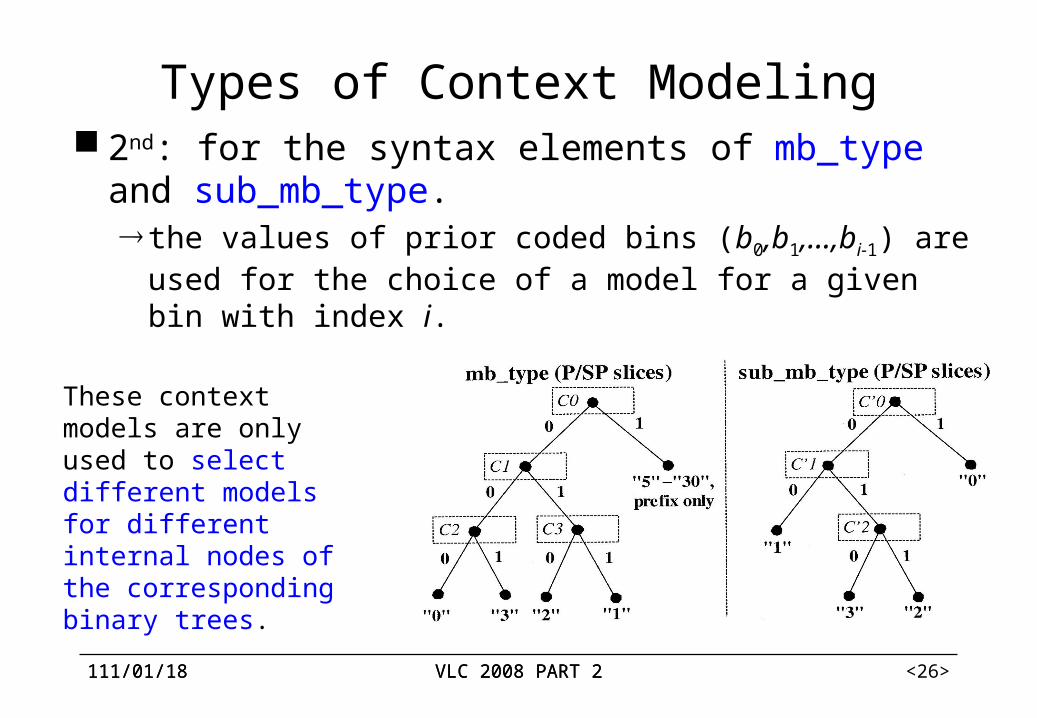
Types of Context Modeling 2nd: for the syntax elements of mb_type and
sub_mb_type. the values of prior coded bins (b0,b1,...,bi-1) are used for the
choice of a model for a given bin with index i.
These context models are only used to select different models for different internal nodes of the corresponding binary trees.

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <27>
3rd and 4th: applied to residual data only. In contrast to all other types of context models, both types depend on the context categories of different block types.
3rd: does not rely on past coded data, but on the position in the scanning path.
4th: involves the evaluation of the accumulated number of encoded (decoded) levels with a specific value prior to the current level bin to encode (decode).
Significant map

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <28>
4th Type• Non-zero levels are coded in reverse order• Each non-zero coefficient is coded by
– abs_m1: |level| – 1• Binarized by unary code• One set of context models for the first bit; One set of context models for
all other bits
– Sign• 5 context models for the first bit of abs_m1
– If all levels coded so far are 1 or -1• Context ID = NumT1 (up to 3)
– If a level greater than 1 has been coded• Context ID = 4.

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <29>
4th Type (2)• 5 context models for the remaining bits of abs_m1:
– NumLgt1: number of coded levels that are greater than 1– Context ID = 5 + min(4, NumLgt1)– NumLgt1 = 0 Context ID = 5– ….– NumLgt1 = 4 Context ID = 9– NumLgt1 = 5 Context ID = 9 …

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <30>
4th Type (3)• Level Coding Example:
– Zigzag scanned result9 0 -5 3 0 0 -1 0 1 0 … 0
– Reverse order of nonzero abs values1 1 3 5 9
– NumLgt1 (before current level)0 0 0 1 2
– Unary code of (abs level – 1)0 0 110 11110 111111110
– Context ID:0 1 2,5 4,6 4,7
112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <31>
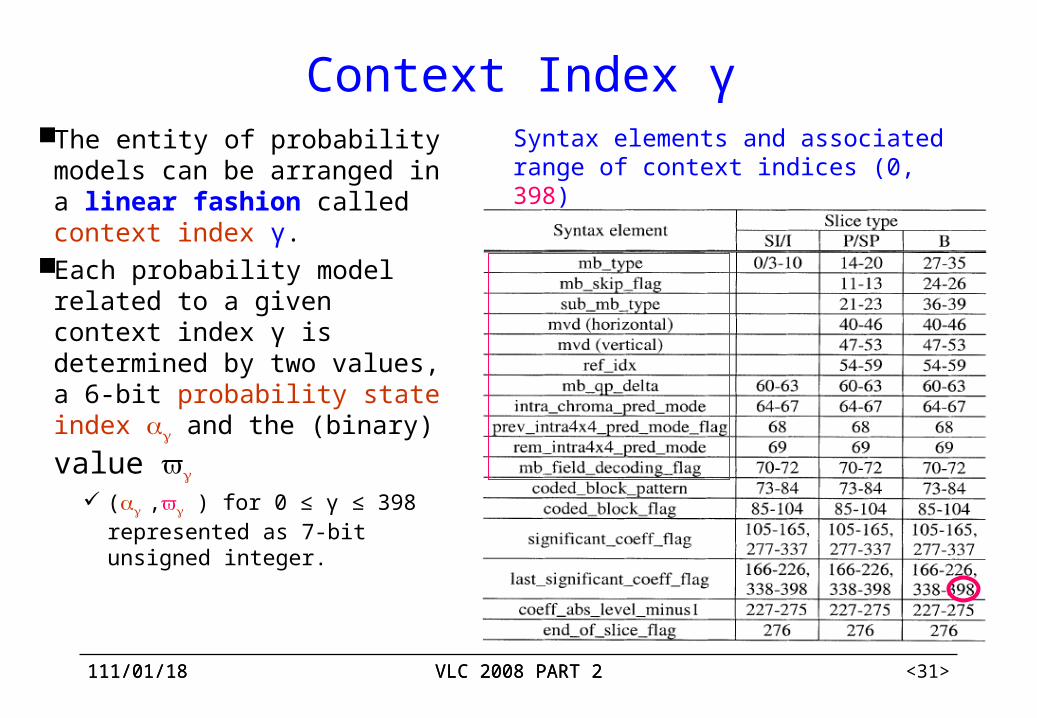
Context Index γThe entity of probability
models can be arranged in a linear fashion called context index γ.
Each probability model related to a given context index γ is determined by two values, a 6-bit probability state index and the (binary) value
( , ) for 0 ≤ γ ≤ 398 represented as 7-bit unsigned integer.
Syntax elements and associated range of context indices (0, 398)

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <32>
0 ~ 72 context indices: related to syntax elements of macroblock, sub-macroblock, prediction modes of special and temporal as well as slice-based and macroblock-based control information.
A corresponding context index γ can be calculated as γ=ΓS+χS.. ΓS: context index offset, the lower value of the range, χS : context index increment of a given syntax element S.
73 ~ 398 context indices: related to the coding of residual data. Significant_coeff_flag and last_significant_coeff_flag are conditioned on the
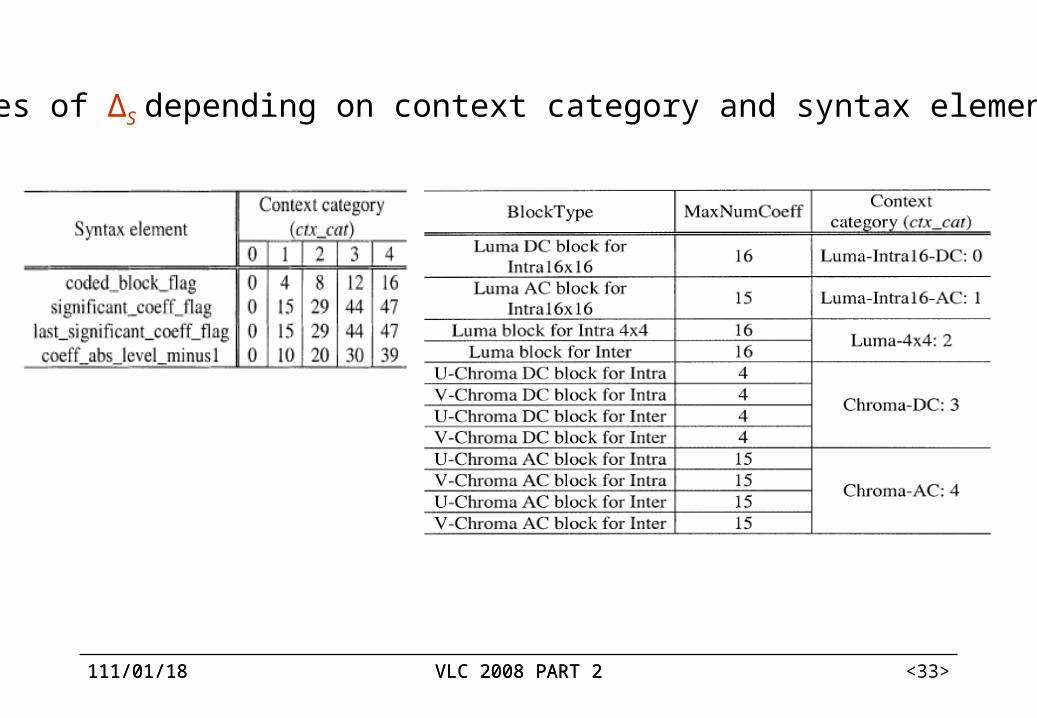
scanning position. Coded_Block_Pattern: γ=ΓS+χS.. Others:γ=ΓS+ΔS(ctx_cat) +χS. Here the context category (ctx_cat) dependent
offset ΔS is employed.
112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <33>
Values of ΔS depending on context category and syntax element
112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <34>
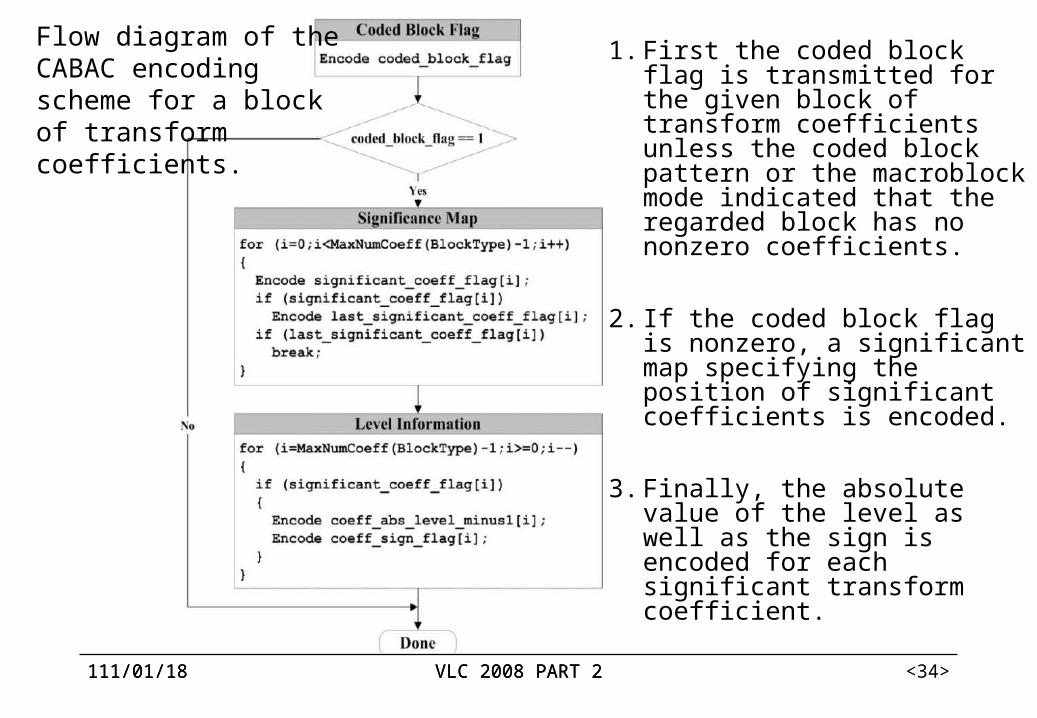
Flow diagram of the CABAC encoding scheme for a block of transformcoefficients.
1. First the coded block flag is transmitted for the given block of transform coefficients unless the coded block pattern or the macroblock mode indicated that the regarded block has no nonzero coefficients.
2. If the coded block flag is nonzero, a significant map specifying the position of significant coefficients is encoded.
3. Finally, the absolute value of the level as well as the sign is encoded for each significant transform coefficient.
112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <35>
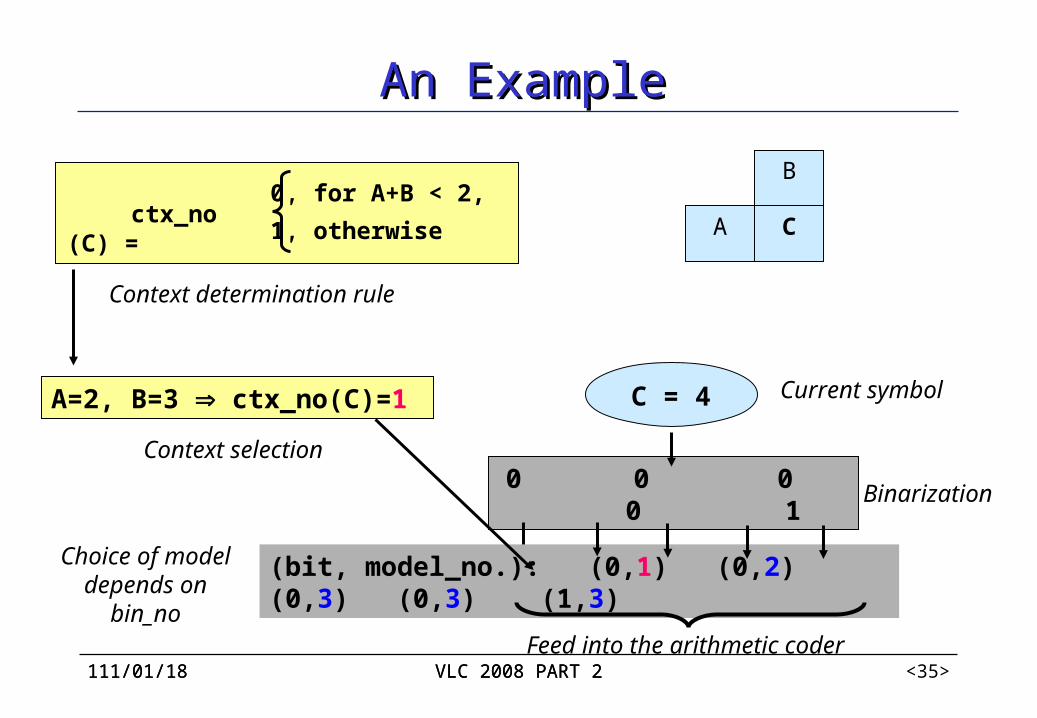
An ExampleAn Example
C
B
A ctx_no (C) =0, for A+B < 2,1, otherwise
Context determination rule
A=2, B=3 ctx_no(C)=1 C = 4
0 0 0 0 1
(bit, model_no.): (0,1) (0,2) (0,3) (0,3) (1,3)
Binarization
Context selection
Choice of model depends on
bin_no
Current symbol
Feed into the arithmetic coder
112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <36>
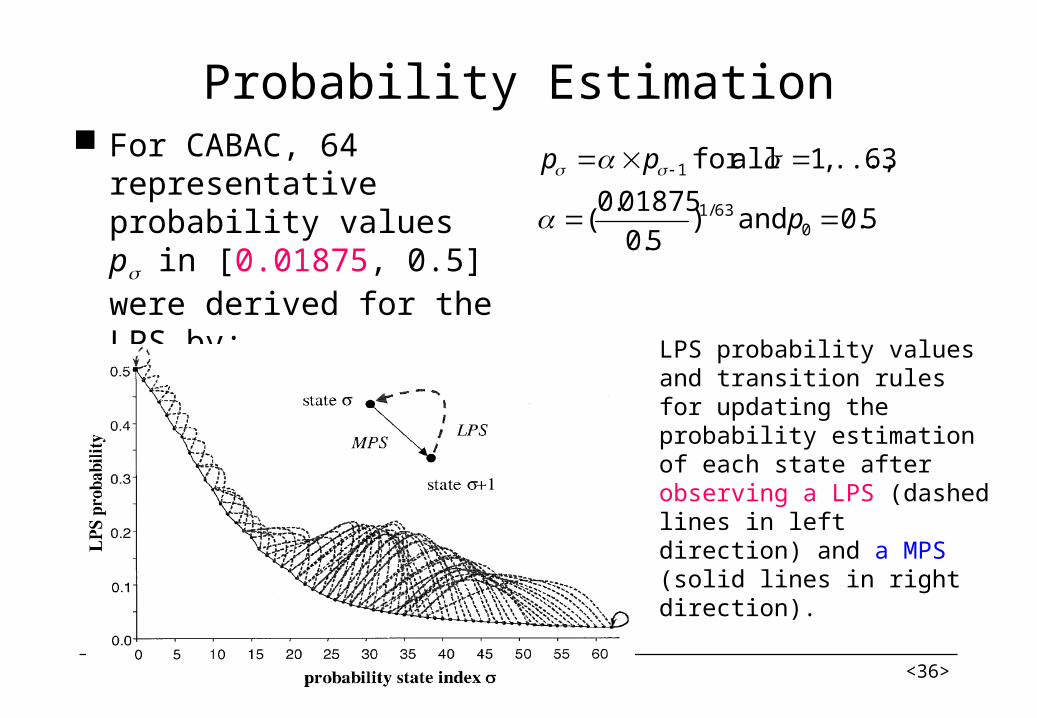
Probability Estimation For CABAC, 64
representative probability values p in [0.01875, 0.5] were derived for the LPS by:
LPS probability values and transition rules for updating the probability estimation of each state after observing a LPS (dashed lines in left direction) and a MPS (solid lines in right direction).
5.0 and )5.0
01875.0(
63 ..., ,1 allfor
063/1
1
p
pp

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <37>
Both the chosen scaling factor α ≈ 0.95 and the cardinality N = 64 of the set probabilities represent a good compromise between the desire for fast adaptation (α 0, small N) and sufficiently stable and accurate estimate (α 1, large N).
As a result of this design, each context model in CABAC can be completely determined by two parameters: its current estimate of the LPS probability and its value of MPS β being either 0 or 1.
For a given probability state, the update depends on the state index and the value of the encoded symbol identified either as a LPS or a MPS. (, ) 6 + 1 bits, 128 values totally.
The derivation of the transition rules for the LPS probability is based on the following relation between a given LPS probability pold and its updated counterpart pnew:
statistics:cLPS/(cLPS+cMPS)But …
cMPS+1cLPS+1
1-(1-pold) TransStateLPS

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <38>
CABAC Binarization
Huffman treeunary, truncated unary, kth order exp-Golomb, and fixed-
length codes
Context modelingAdaptive probability models
Binary arithmetic coding: M coderTable-based BAC
CLPS
nn
CLPS
nnn
CLPS
nn
nn
pRR
pRll
pRR
ll
)1()(
)1()1()(
)1()(
)1()(
)1(
:symbol LPS theof occurrence the)1(
:symbol MPS theof occurrence the

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <39>
M Coder Modulo coder (M coder): project both the legal range [Rmin, Rmax)
of interval width R and the probability range with the LPS onto a small set of representatives Q={Q0,...,QK-1} and P={p0,...,pN-1}, respectively.
So, the multiplication can be approximated by using a table of K N pre-computed product values Qk pn, 0 k K-1 and 0 n N-1.
K= 4 (quantized range values) together with N=64 (LPS related probability values)
Another distinct feature: bypass coding mode (assumed to be uniformly distributed) 2/3
1/35/6
1/61/2
1/2 1/2 1/2
1/2 1/2

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <40>
Conditions for M Coder1. A renormalization strategy is applied to R such that R is forced to stay
within the interval [2b-2, 2b-1) for a given b-bit implementation.
2. The lower bound of the LPS related probability is given by pmin 2-(b-2) to prevent underflow.
3. The probability estimator is realized by a Markov chain, which allows a table-driven implementation of the adaptive probability estimation. Assume that the LPS related probabilities are monotonically
decreasing with increasing state index n, i.e., 0.5 = p0 ... pn ... pN-1 = pmin
The state transition rules are given by at most two tables TransStateLPS and TransStateMPS each having N entries and pointing to the next state for a given entry of a state n with 0 n N-1 and for a observation of a bit identified either as a LPS or MPS, respectively.

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <41>
Conditions for M Coder (2)4. The legal range interval [Rmin, Rmax) = [2b-2, 2b-1) induced
by the renormalization strategy is uniformly quantized into K = 2 cells, where 1 (b-2) and the cells are indexed according to their increasing reconstruction values Q0 < ... < Q < ... < QN-1.
Let TabRangeLPS denote the 2-D table containing the K N product values Q pn = TabRangeLPS[n, k].
112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <42>
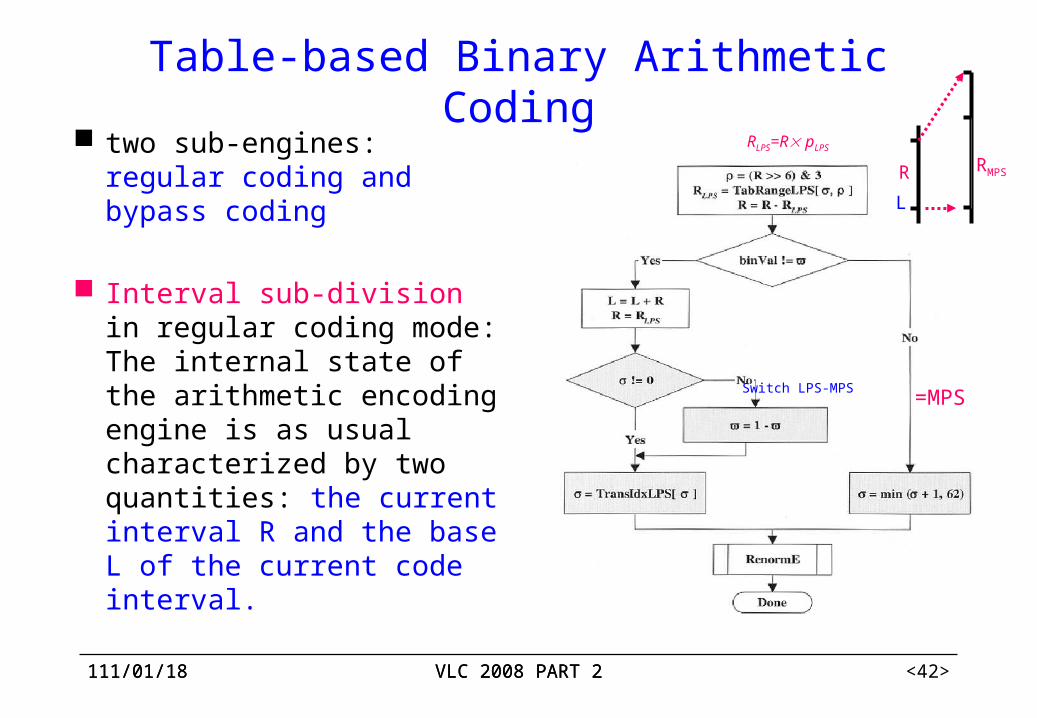
Table-based Binary Arithmetic Coding two sub-engines: regular
coding and bypass coding
Interval sub-division in regular coding mode: The internal state of the arithmetic encoding engine is as usual characterized by two quantities: the current interval R and the base L of the current code interval.
L
R
RLPS=R pLPS RMPS
=MPSSwitch LPS-MPS

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <43>
Table-based Binary Arithmetic Coding First, the current interval R is approximated by a quantized value
Q(R), using an equi-partition of the whole range 28≤ R <29 into four cells. But instead of using the corresponding representative quantized values Q0, Q1, Q2, and Q3. Q(R) is only addressed by its quantizer index ρ, e.g. ρ= (R>>6) & 3.
Thus, this index and the probability state index are used as entries in a 2D table TabRangeLPS to determine (approximate) the LPS related sin-interval range RLPS. Here the table TabRangeLPS contains all 64 4 pre-computed product values pσ Qρ for 0 ≤σ≤ 63, and 0 ≤ ρ≤ 3 in 8 bit precision.
update the probability states i, and renormalize the interval
112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <44>
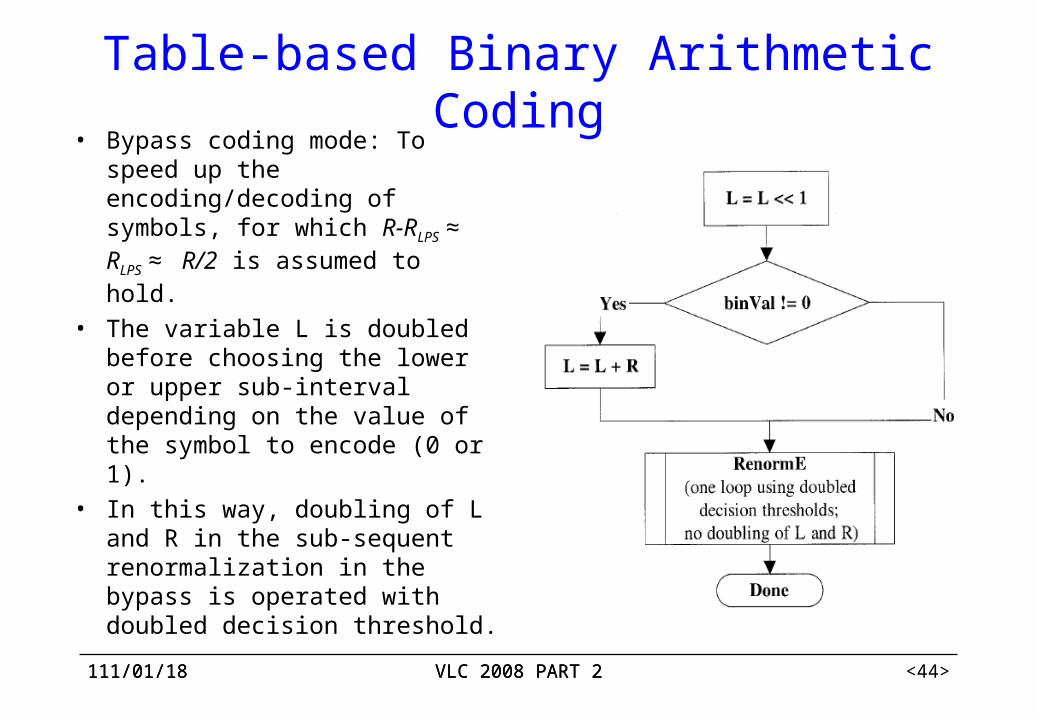
Table-based Binary Arithmetic Coding• Bypass coding mode: To speed up
the encoding/decoding of symbols, for which R-RLPS ≈ RLPS ≈ R/2 is assumed to hold.
• The variable L is doubled before choosing the lower or upper sub-interval depending on the value of the symbol to encode (0 or 1).
• In this way, doubling of L and R in the sub-sequent renormalization in the bypass is operated with doubled decision threshold.

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <45>
Table-based Binary Arithmetic Coding Renormalization and carry-over control: A
renormalization operation after interval sub-division is required whenever the new interval range R no longer stays with its legal range of [28,29).

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <46>
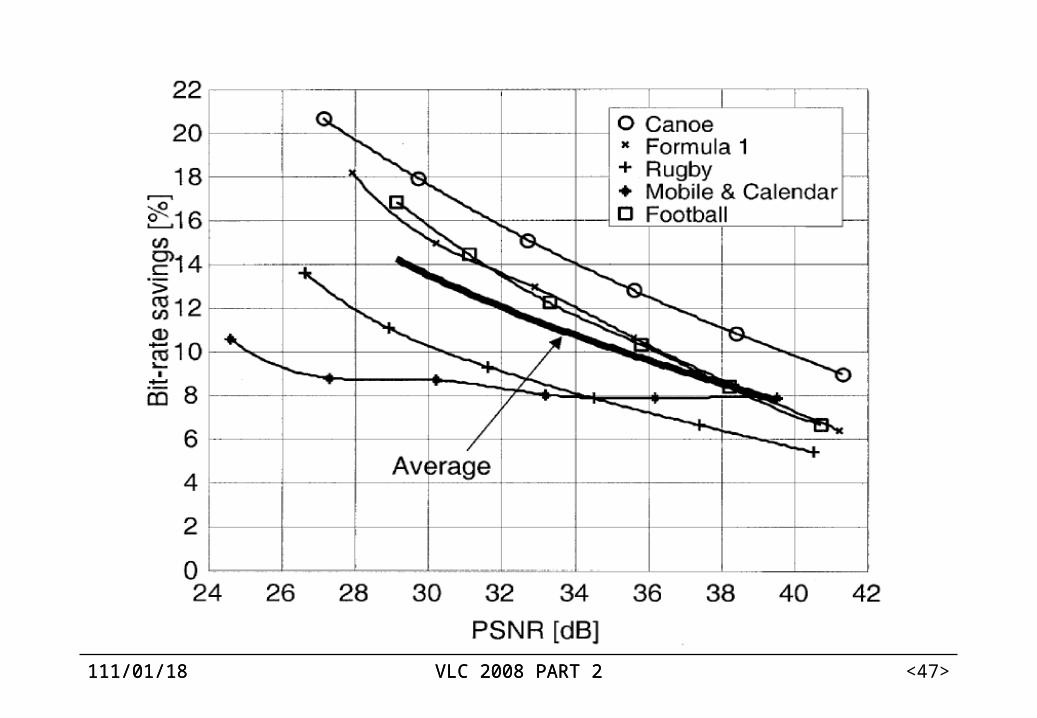
Experimental results CABAC vs. the baseline entropy coding method of H.264/AVC.
zero-order exp-Golomb code: for all syntax elements except the residual data,
CAVLC: for residual data Bit-rate savings of 9% to 14% are achieved, where higher gains
are obtained at lower rates.
112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <47>
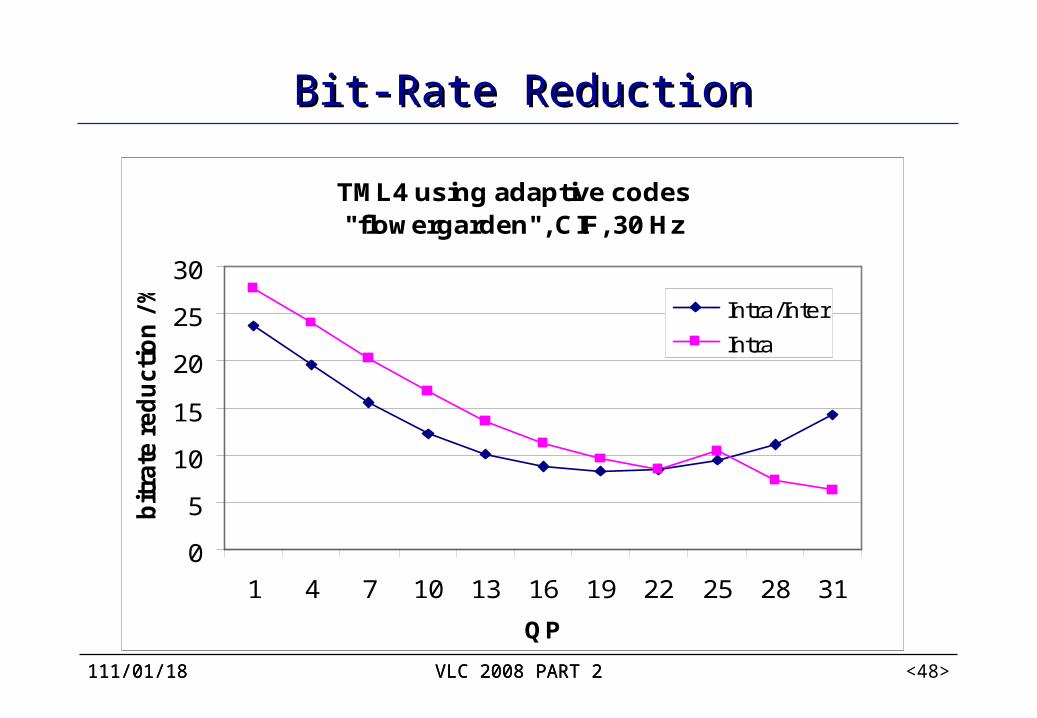
112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <48>
TML4 using adaptive codes"flowergarden", CIF, 30 Hz
0
5
10
15
20
25
30
1 4 7 10 13 16 19 22 25 28 31
QP
bitr
ate
redu
ctio
n / % Intra/Inter
Intra
Bit-Rate ReductionBit-Rate Reduction
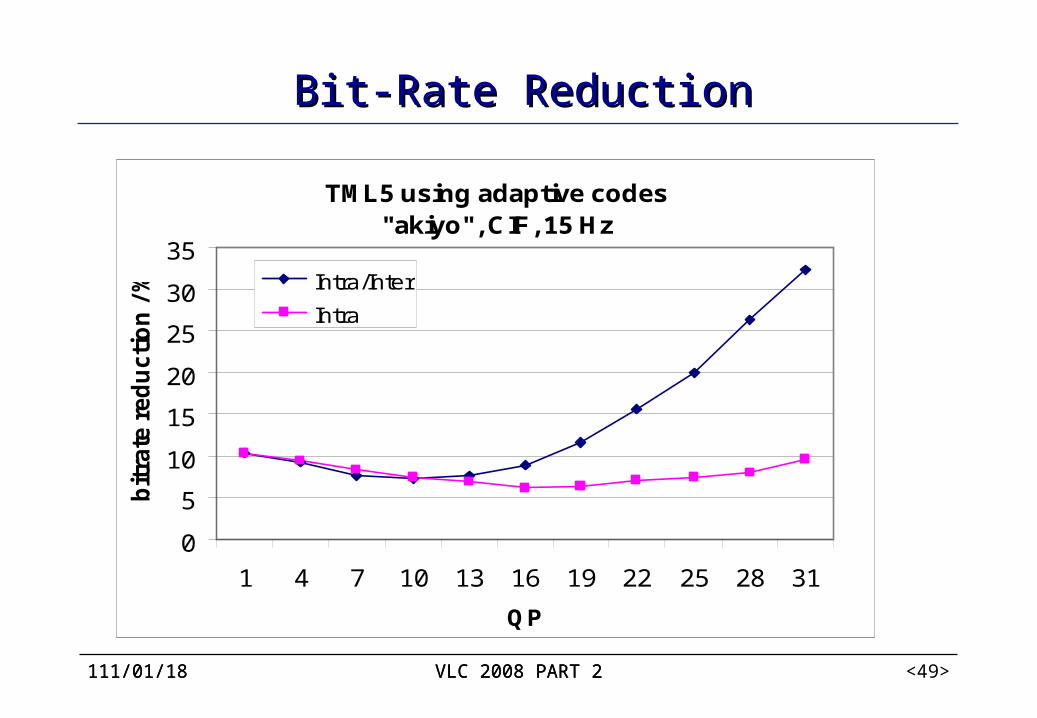
112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <49>
Bit-Rate ReductionBit-Rate Reduction
TML5 using adaptive codes"akiyo", CIF, 15 Hz
0
5
10
15
20
25
30
35
1 4 7 10 13 16 19 22 25 28 31
QP
bitr
ate
redu
ctio
n / %
Intra/InterIntra

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <50>
12 types of transform coefficient blocks are classified into five categories.
For each category, a special set of context models is used for all syntax elements related to residual data.
1. coded_block_pattern• bin indices 0 ~ 3: the context index increment CBP corresponding
to the four 88 luminance blocks, CBP (C, bin_idx) = ((CBP_Bit(A) != 0) ? 0: 1) + 2((CBP_Bit(B) != 0) ? 0: 1)
• indices 4 and 5: related to the two “chrominance” bins in the binarized value of coded_block_pattern.
Context Models for Residual Data
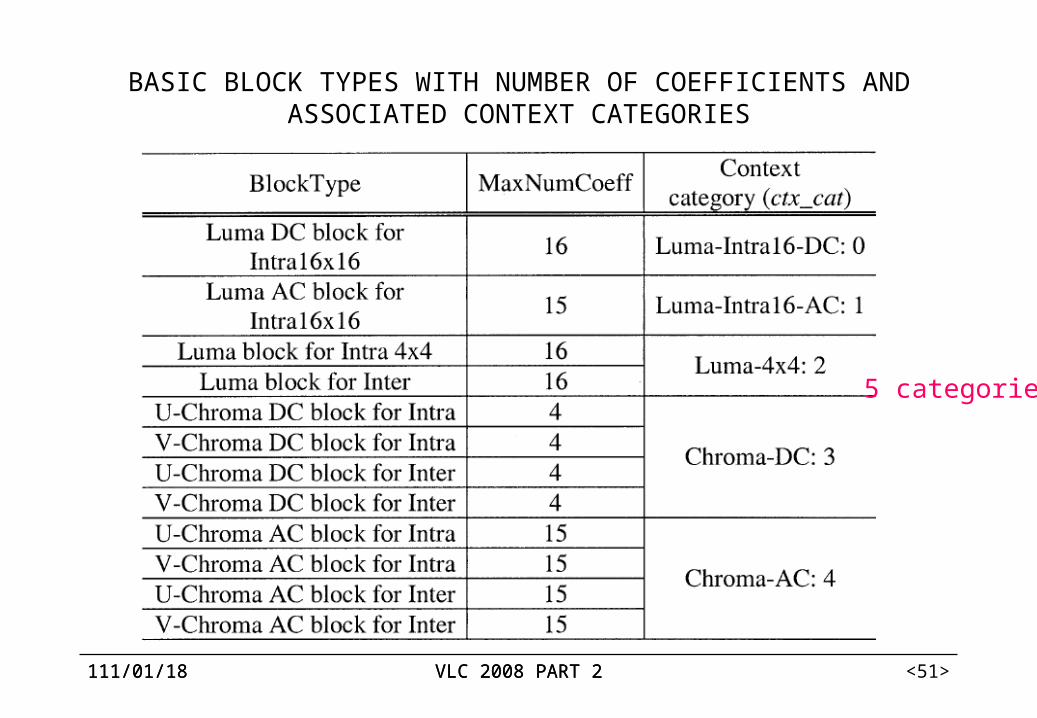
112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <51>
BASIC BLOCK TYPES WITH NUMBER OF COEFFICIENTS AND ASSOCIATED CONTEXT CATEGORIES
5 categories

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <52>
2. Coded Block Flag• Coding of the coded_block_flag utilizes 4 different probability models for
each of the 5 categories, for example, if A and B are of the same typeCBFlag(C) = coded_block_flag(A) + 2 coded_block_flag(B)
• If no neighboring block of the same type exists, it is set to 0. coded_block_flag and significance map: used to indicate the occurrence and
the location of nonzero transform coefficients in a given block.
3. Significant map • up to 15 different probability models are used for both
significant_coeff_flag and last_significant_flag• The choice of the models and the context index increments depend on the
scanning positionSIG (coeff [i]) = LAST (coeff [i] ) = i

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <53>
4. Level information• NumT1(i) denote the accumulated number of already encoded/decoded
trailing 1’s, and let NumLgt1(i) denote the accumulated number of encoded/decoded levels with absolute value greater than 1
Processing in reversescanning order
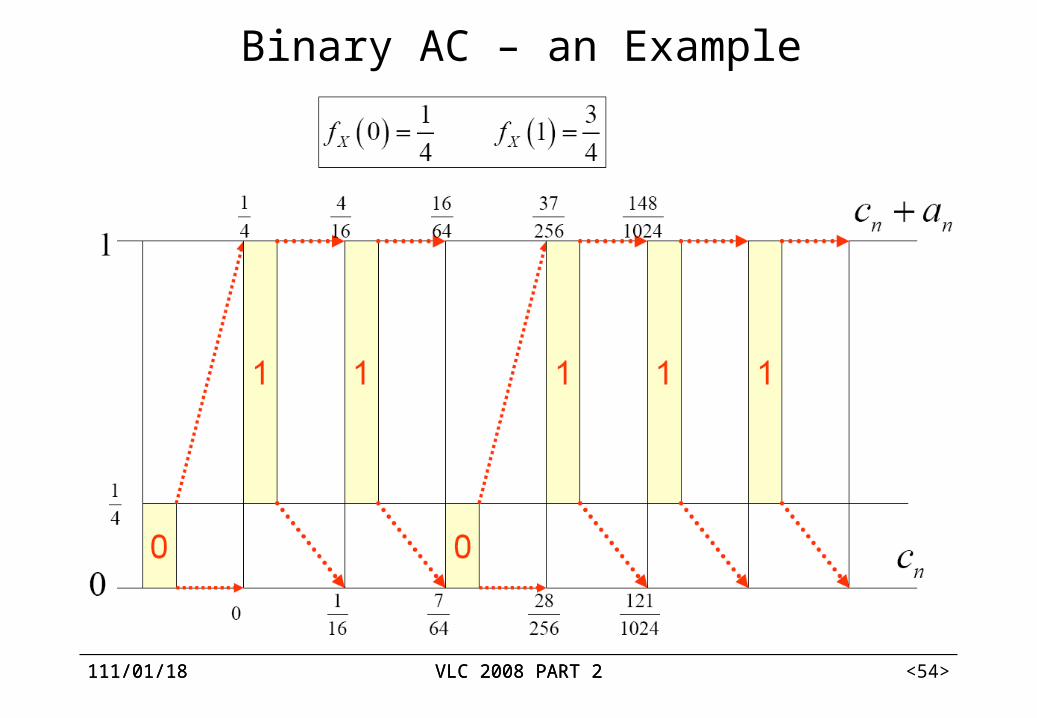
112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <54>
Binary AC – an Example

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <55>
LPS – MPS Switching

112/04/07 VLC 2008 PART 2112/04/07 VLC 2008 PART 2 <56>
Sufficiency of Binary Coders
B = (B0, B1, …, BK-1)