variable-based multi-module data caches for clustered vliw processors enric gibert 1,2, jaume abella...
Post on 20-Dec-2015
228 views
TRANSCRIPT

R
Variable-Based Multi-Module Data Caches for Clustered VLIW Processors
Enric Gibert1,2, Jaume Abella1,2, Jesús Sánchez1,Xavier Vera1, Antonio González1,2
1 Intel Barcelona Research CenterIntel Labs, Barcelona
2 Departament d’Arquitectura de ComputadorsUniversitat Politècnica de Catalunya, Barcelona

Variable-Based Multi-Module Data Caches for Clustered VLIW Processors (PACT’05) 2R
Issue #1: Energy Consumption
• First class design goal• Heterogeneity
– ↓ supply voltage and/or ↑ threshold voltage
• Cache memory ARM10– D-cache 24% dynamic energy
– I-cache 22% dynamic energy
• Heterogeneity can be exploited in the D-cache for VLIW processors
processor front-end
processor back-end
processor front-end
processor back-end
Higher performanceHigher energy
Lower performanceLower energy

Variable-Based Multi-Module Data Caches for Clustered VLIW Processors (PACT’05) 3R
Issue #2: Wire Delays
• From capacity-bound to communication-bound• One possible solution: clustering
• Unified cache clustered VLIW processor– Used as a baseline throughout this work
CLUSTER 1
Reg. FileReg. File
FUsFUs
Global communication buses
CacheCache
Memory buses
…
CLUSTER 2
Reg. FileReg. File
FUsFUs
CLUSTER n
Reg. FileReg. File
FUsFUs

Variable-Based Multi-Module Data Caches for Clustered VLIW Processors (PACT’05) 4R
Contributions
• GOAL: exploit heterogeneity in the L1 D-cache for clustered VLIW processors
• Power-efficient distributed L1 data cache– Divide data cache into two modules and assign each to a cluster
• Modules may be heterogeneous
– Map variables statically between cache modules– Develop instruction scheduling techniques
• Results summary– Heterogeneous distributed data cache good design point– Distributed data cache vs. unified data cache
• Distributed caches outperform unified schemes in EDD and ED
– No single distributed cache configuration is the best• Reconfigurable distributed cache allows additional improvements

Variable-Based Multi-Module Data Caches for Clustered VLIW Processors (PACT’05) 5R
Talk Outline
• Variable-Based Multi-Module Data Cache
• Distributed Cache Configurations
• Instruction Scheduling
• Results
• Conclusions

Variable-Based Multi-Module Data Caches for Clustered VLIW Processors (PACT’05) 6R
L2 D-CACHE
Register buses
load *p
RF
CLUSTER 1
var X
RF
CLUSTER 2
var Y
Variable-Based Multi-Module Cache
FU
RF
CLUSTER 1
FIRSTMODULE
SECONDMODULE
FU
RF
CLUSTER 2
Register buses
L2 D-CACHE
• Memory instructions have a preferred cluster cluster affinity• “Wrong” cluster assignment performance, not correctness
Resume execution
Stall clusters
Empty communication buses
Send request
Access memory
Send reply back
load X
STACKSTACK
HEAP DATAHEAP DATA
GLOBAL DATAGLOBAL DATA
STACKSTACK
HEAP DATAHEAP DATA
GLOBAL DATAGLOBAL DATA
FIR
ST S
PA
CE
SE
CO
ND
SPA
CE
SP1
SP2
distributedstack frames
LogicalAddress Space

Variable-Based Multi-Module Data Caches for Clustered VLIW Processors (PACT’05) 7R
Talk Outline
• Variable-Based Multi-Module Data Cache
• Distributed Cache Configurations
• Instruction Scheduling
• Results
• Conclusions

Variable-Based Multi-Module Data Caches for Clustered VLIW Processors (PACT’05) 8R
Distributed Cache Configurations
8KB8KB 8KB8KB
FAST SLOW
1 R/W 1 R/W
latency ↑energy ↓
FAST
FU+RF
CLUSTER 1
FU+RF
CLUSTER 2
FAST+NONE
FAST
FU+RF
CLUSTER 1
FAST
FU+RF
CLUSTER 2
FAST+FAST
SLOW
FU+RF
CLUSTER 1
FU+RF
CLUSTER 2
SLOW+NONE
SLOW
FU+RF
CLUSTER 1
SLOW
FU+RF
CLUSTER 2
SLOW+SLOW
FAST
FU+RF
CLUSTER 1
SLOW
FU+RF
CLUSTER 2
FAST+SLOW
FIRSTMODULE
FU
RF
CLUSTER 1
SECONDMODULE
FU
RF
CLUSTER 2
Register buses
L2 D-CACHE

Variable-Based Multi-Module Data Caches for Clustered VLIW Processors (PACT’05) 9R
Talk Outline
• Variable-Based Multi-Module Data Cache
• Distributed Cache Configurations
• Instruction Scheduling
• Results
• Conclusions
Variable-Based Multi-Module Data Caches for Clustered VLIW Processors (PACT’05) 10R
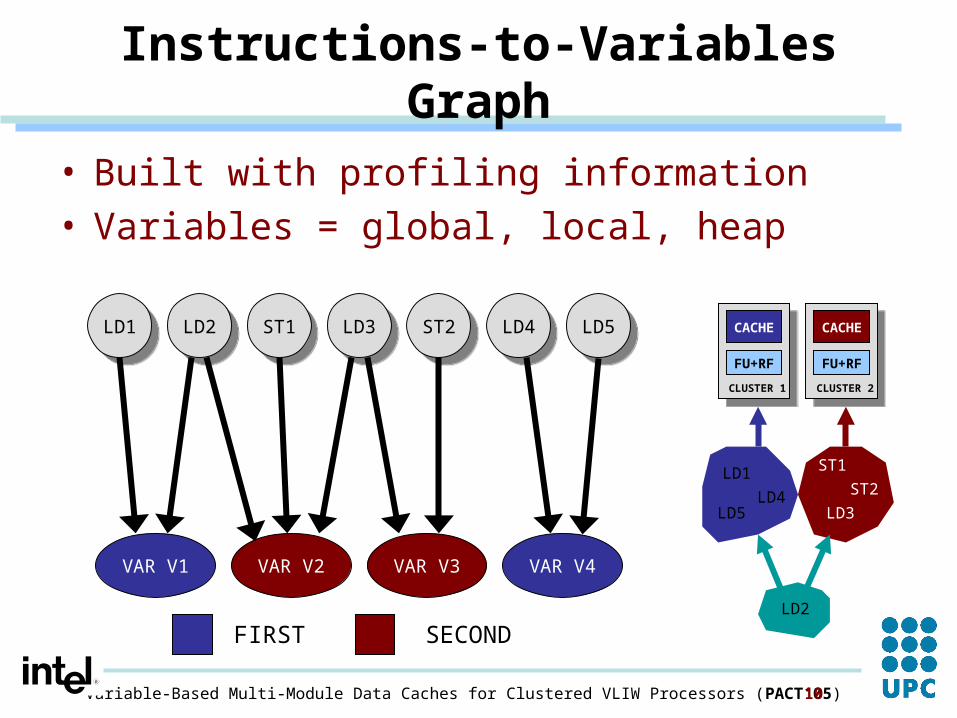
Instructions-to-Variables Graph
• Built with profiling information• Variables = global, local, heap
LD1LD1 LD2LD2 ST1ST1 LD3LD3 ST2ST2 LD4LD4 LD5LD5
VAR V1 VAR V2 VAR V3 VAR V4
FIRST SECOND
CACHE
FU+RF
CLUSTER 1
CACHE
FU+RF
CLUSTER 2
LD2
LD1
LD4LD5
ST1
LD3
ST2
Variable-Based Multi-Module Data Caches for Clustered VLIW Processors (PACT’05) 11R
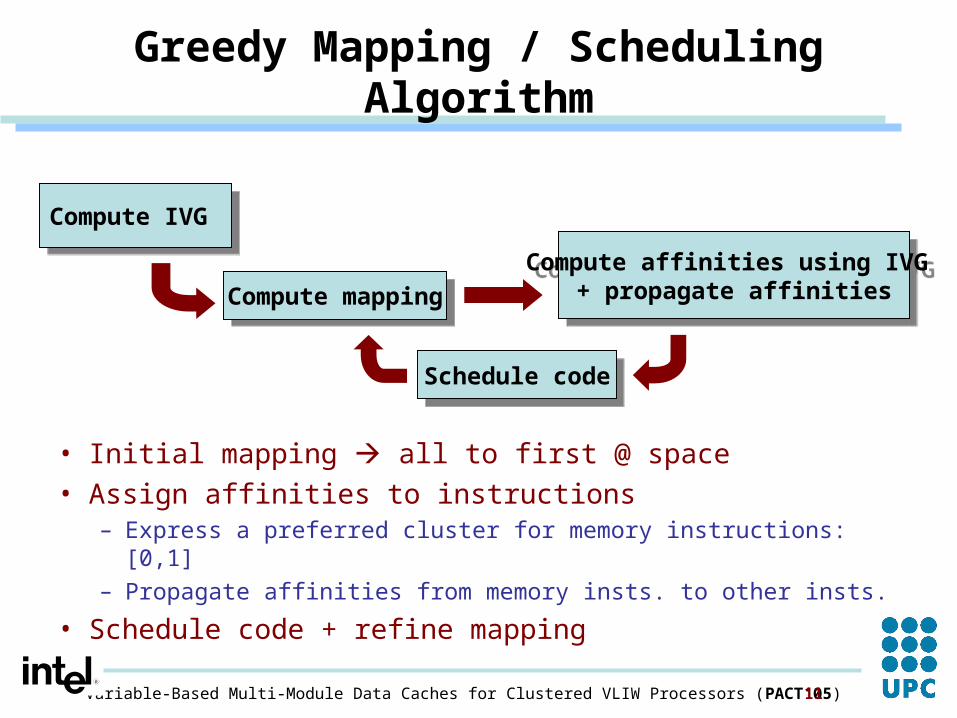
Greedy Mapping / Scheduling Algorithm
• Initial mapping all to first @ space• Assign affinities to instructions
– Express a preferred cluster for memory instructions: [0,1]– Propagate affinities from memory insts. to other insts.
• Schedule code + refine mapping
Compute IVG Compute IVG
Compute mappingCompute mappingCompute affinities using IVG
+ propagate affinities
Compute affinities using IVG + propagate affinities
Schedule codeSchedule code
Variable-Based Multi-Module Data Caches for Clustered VLIW Processors (PACT’05) 12R
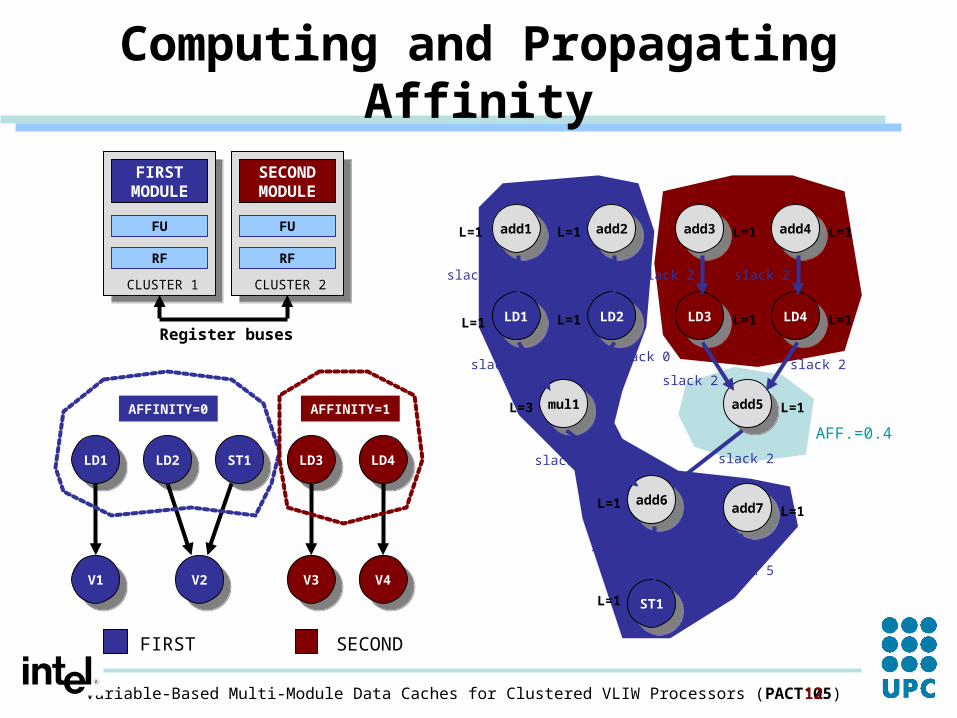
Computing and Propagating Affinity
add1add1
add2add2
LD1LD1
LD2LD2
mul1mul1
add6add6
add7add7
ST1ST1
add3add3
add4add4
LD3LD3
LD4LD4
add5add5
L=1 L=1 L=1 L=1
L=1 L=1 L=1 L=1
L=1
L=1L=1
L=1
L=3
LD1LD1
LD2LD2
LD3LD3
LD4LD4
ST1ST1
V1V1
V2V2
V4V4
V3V3
FIRST SECOND
AFFINITY=0 AFFINITY=1
FIRSTMODULE
FU
RF
CLUSTER 1
Register buses
SECONDMODULE
FU
RF
CLUSTER 2
AFF.=0.4
slack 0 slack 0 slack 2 slack 2
slack 0slack 0
slack 2slack 2
slack 2slack 0
slack 0
slack 5
Variable-Based Multi-Module Data Caches for Clustered VLIW Processors (PACT’05) 13R
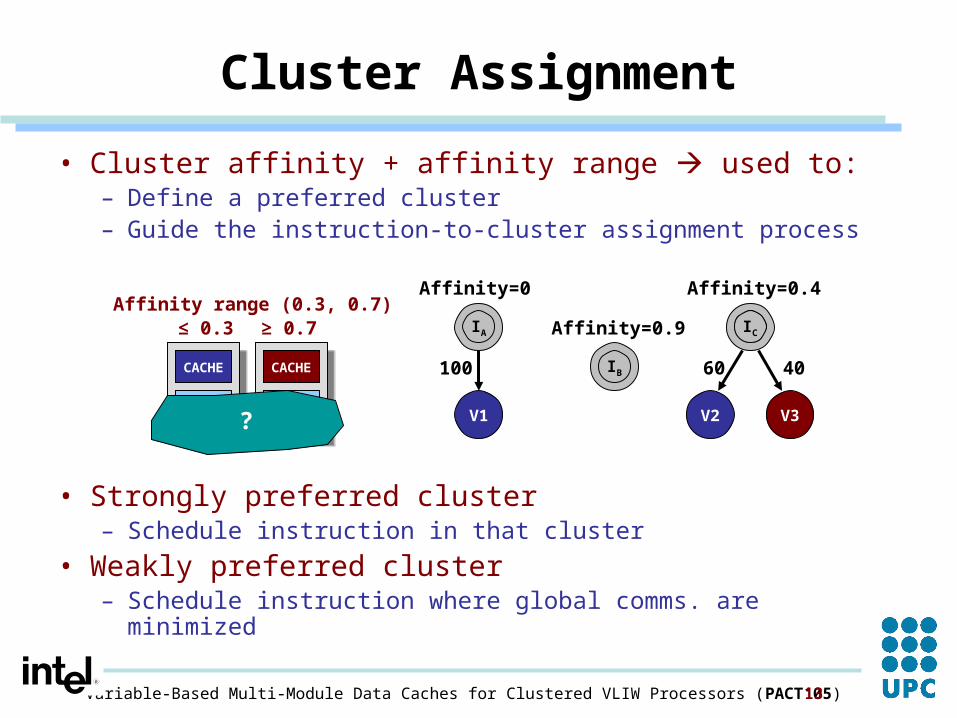
• Cluster affinity + affinity range used to:– Define a preferred cluster– Guide the instruction-to-cluster assignment process
• Strongly preferred cluster– Schedule instruction in that cluster
• Weakly preferred cluster– Schedule instruction where global comms. are minimized
Cluster Assignment
IB
IC
Affinity range (0.3, 0.7)≤ 0.3 ≥ 0.7
CACHE
FU+RF
CLUSTER 1
CACHE
FU+RF
CLUSTER 2V1
IA
100
Affinity=0
Affinity=0.9
V2 V3
60 40
Affinity=0.4
ICIC
?
IA
IB

Variable-Based Multi-Module Data Caches for Clustered VLIW Processors (PACT’05) 14R
Talk Outline
• Variable-Based Multi-Module Data Cache
• Distributed Cache Configurations
• Instruction Scheduling
• Results
• Conclusions

Variable-Based Multi-Module Data Caches for Clustered VLIW Processors (PACT’05) 15R
Evaluation Framework
• IMPACT compiler infrastructure +16 Mediabench• Cache parameters
– CACTI 3.0 + SIA projections + ARM10 datasheets• Data cache consumes 1/3 of the processor energy• Leakage accounts for 50% of the total energy
• Results outline– Distributed cache schemes: F+Ø, F+F, F+S, S+S, S+Ø
• Affinity range• EDD and ED comparison the lower, the better• F+Ø used as baseline throughout presentation
– Comparison with a unified cache scheme• FAST and SLOW unified schemes• State-of-the-art scheduling techniques for these schemes
– Reconfigurable distributed cache
8KB8KB 8KB8KB
FAST SLOW
1 R/WL = 2
1 R/WL = 4
latency x2energy by 1/3
Variable-Based Multi-Module Data Caches for Clustered VLIW Processors (PACT’05) 16R
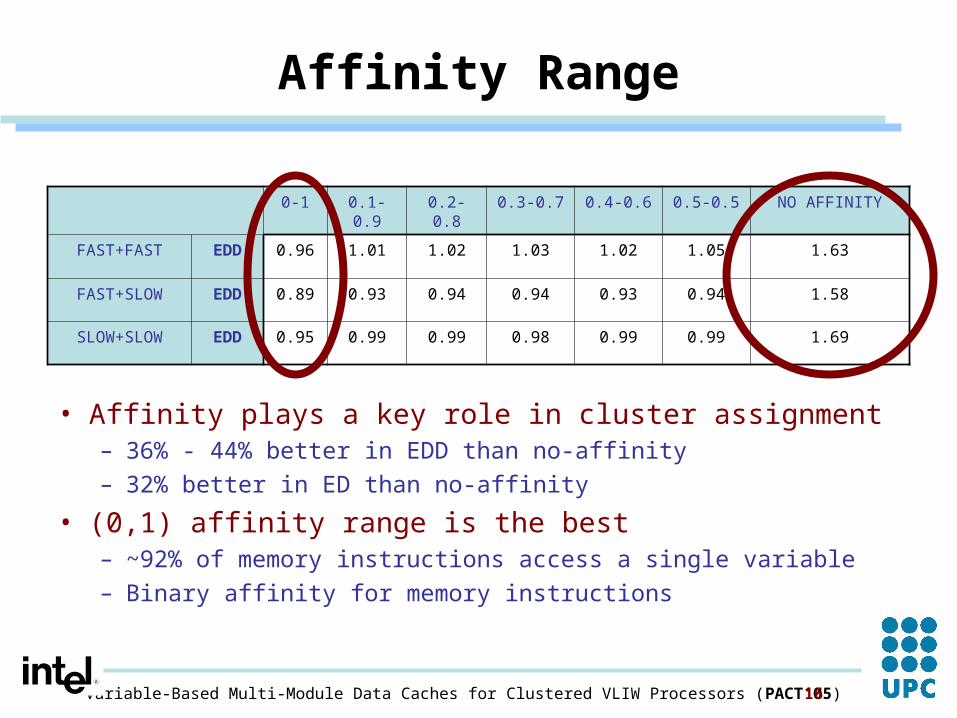
Affinity Range
• Affinity plays a key role in cluster assignment– 36% - 44% better in EDD than no-affinity– 32% better in ED than no-affinity
• (0,1) affinity range is the best– ~92% of memory instructions access a single variable– Binary affinity for memory instructions
0-1 0.1-0.9 0.2-0.8 0.3-0.7 0.4-0.6 0.5-0.5 NO AFFINITY
FAST+FAST EDD 0.96 1.01 1.02 1.03 1.02 1.05 1.63
FAST+SLOW EDD 0.89 0.93 0.94 0.94 0.93 0.94 1.58
SLOW+SLOW EDD 0.95 0.99 0.99 0.98 0.99 0.99 1.69
Variable-Based Multi-Module Data Caches for Clustered VLIW Processors (PACT’05) 17R
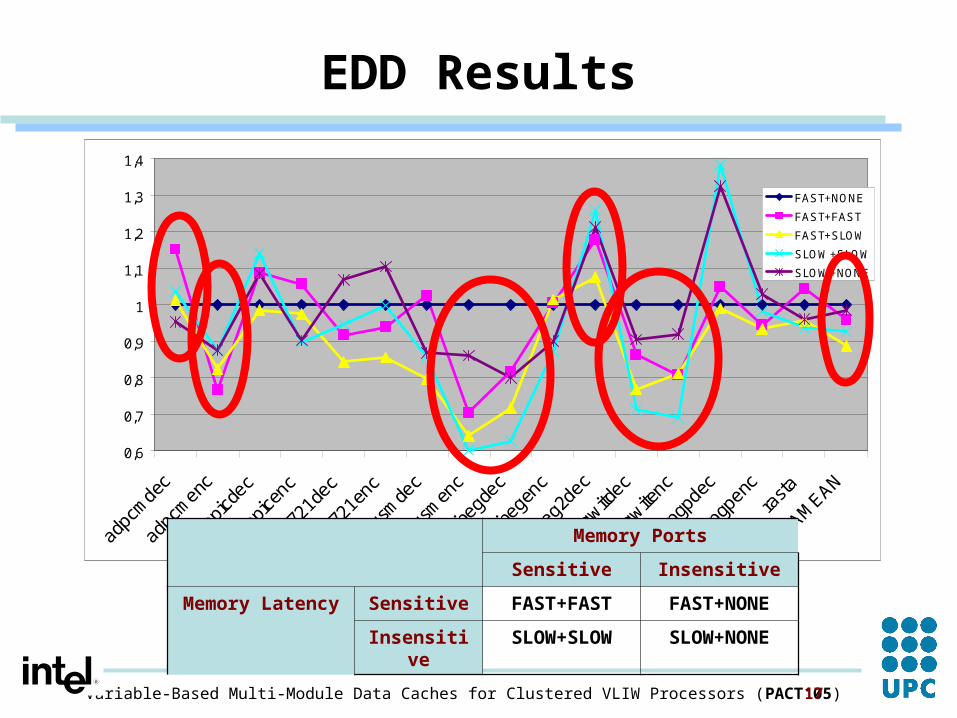
EDD Results
0,6
0,7
0,8
0,9
1
1,1
1,2
1,3
1,4
FAST+NONE
FAST+FAST
FAST+SLOW
SLOW+SLOW
SLOW+NONE
Memory Ports
Sensitive Insensitive
Memory Latency Sensitive FAST+FAST FAST+NONE
Insensitive SLOW+SLOW SLOW+NONE
Variable-Based Multi-Module Data Caches for Clustered VLIW Processors (PACT’05) 18R
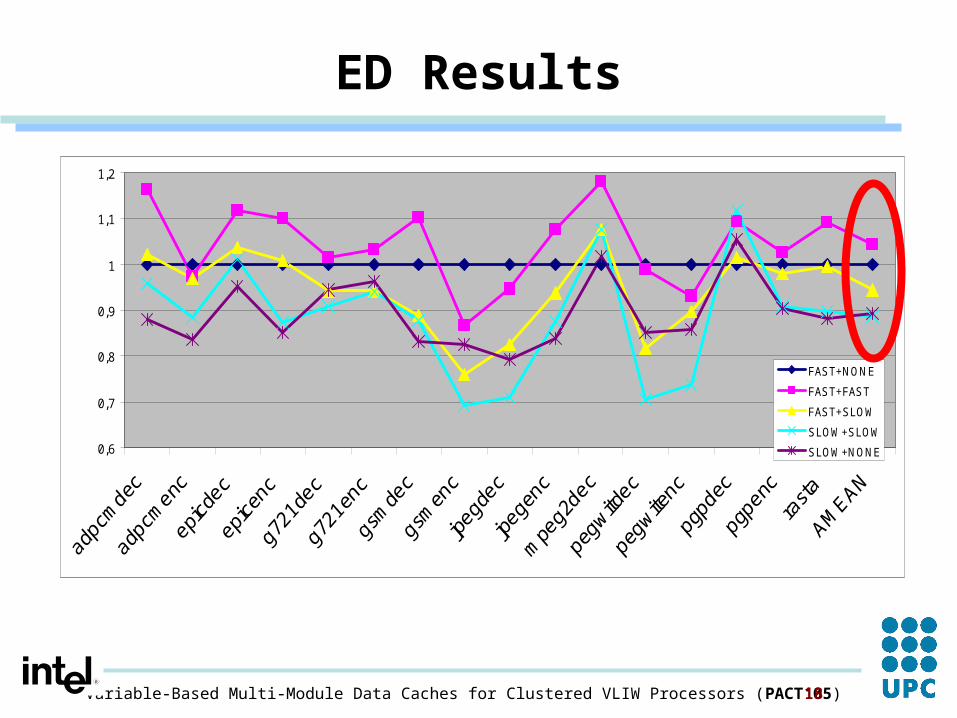
ED Results
0,6
0,7
0,8
0,9
1
1,1
1,2
FAST+NONE
FAST+FAST
FAST+SLOW
SLOW+SLOW
SLOW+NONE
Variable-Based Multi-Module Data Caches for Clustered VLIW Processors (PACT’05) 19R
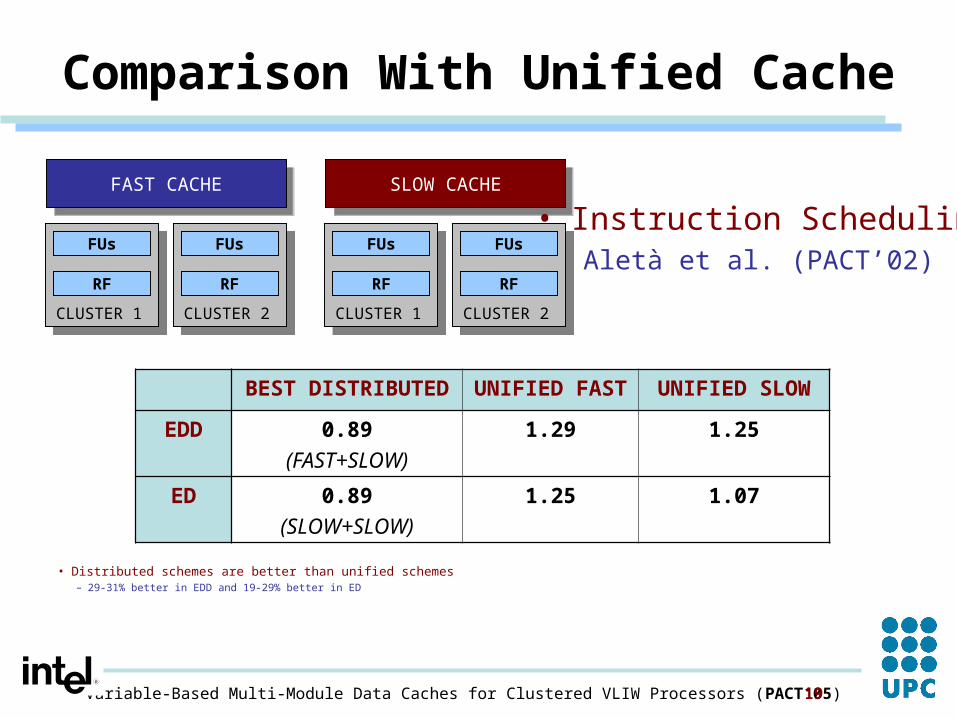
Comparison With Unified Cache
BEST DISTRIBUTED UNIFIED FAST UNIFIED SLOW
EDD 0.89
(FAST+SLOW)
1.29 1.25
ED 0.89
(SLOW+SLOW)
1.25 1.07
• Distributed schemes are better than unified schemes– 29-31% better in EDD and 19-29% better in ED
FUs
RF
CLUSTER 1
FAST CACHEFAST CACHE
FUs
RF
CLUSTER 2
FUs
RF
CLUSTER 1
SLOW CACHESLOW CACHE
FUs
RF
CLUSTER 2
• Instruction SchedulingAletà et al. (PACT’02)

Variable-Based Multi-Module Data Caches for Clustered VLIW Processors (PACT’05) 20R
Reconfigurable Distributed Cache
• The OS can set each module in one state:– FAST mode / SLOW mode / Turned-off
• The OS reconfigures the cache on a context switch– Depending on the applications scheduled in and scheduled out
• Two different VDD and VTH for the cache
– Reconfiguration overhead: 1-2 cycles [Flautner et al. 2002]
• Simple heuristic to show potential– For each application, choose the estimated best cache configuration
BEST
DISTRIBUTED
RECONFIGURABLE SCHEME
EDD 0.89
(FAST+SLOW)
0.86
ED 0.89
(SLOW+SLOW)
0.86

Variable-Based Multi-Module Data Caches for Clustered VLIW Processors (PACT’05) 21R
Talk Outline
• Variable-Based Multi-Module Data Cache
• Distributed Cache Configurations
• Instruction Scheduling
• Results
• Conclusions

Variable-Based Multi-Module Data Caches for Clustered VLIW Processors (PACT’05) 22R
Conclusions
• Distributed Variable-Based Multi-Module Cache– Affinity is crucial for achieving good performance
• 36-44% better in EDD and 32% in ED than no-affinity
– Heterogeneity (FAST+SLOW) is a good design point• 4-11% better in EDD and from 6% worse to 10% better in ED
– No single cache configuration is the best• Reconfigurable cache modules exploit additional 3-4%
• Distributed schemes vs. unified schemes– All distributed schemes outperform unified ones
• 29-31% better in EDD, 19-29% better in ED

R
Q&A