using inverse planning for personalized feedback · using inverse planning for personalized...
TRANSCRIPT

Using Inverse Planning for Personalized Feedback
Anna N. Rafferty Computer Science Department, Carleton College
Rachel A. Jansen Thomas L. Griffiths
Department of Psychology, University of California, Berkeley
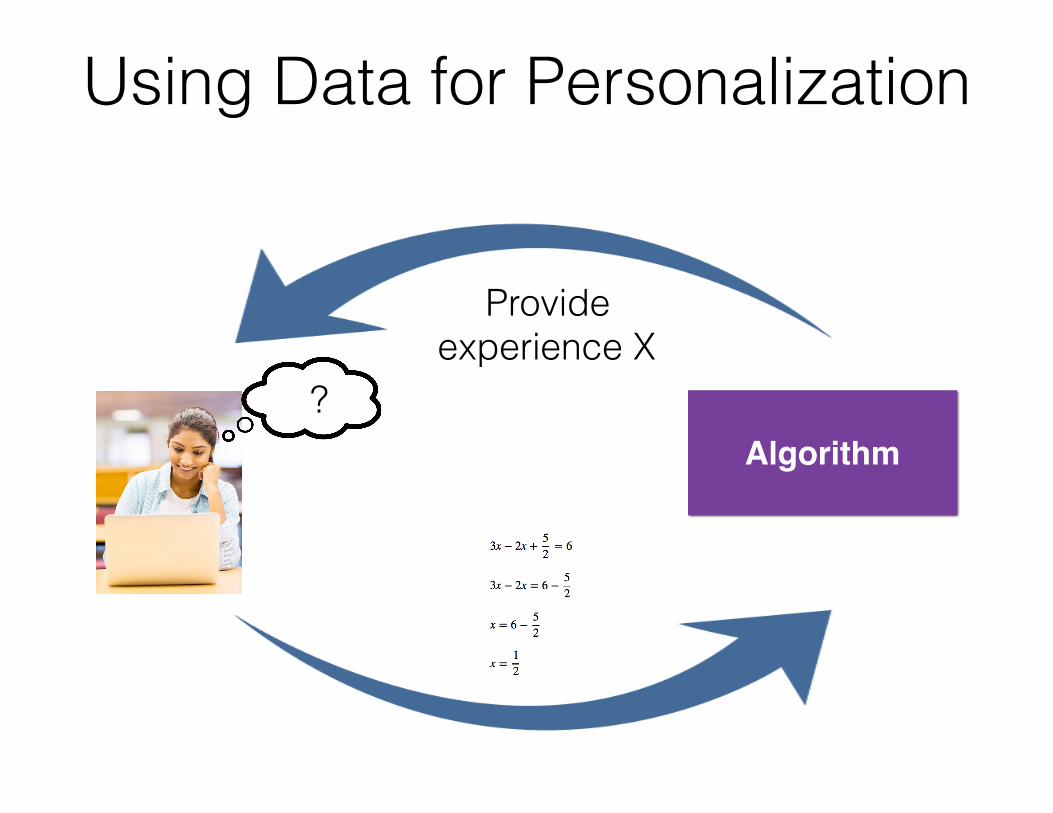
Using Data for Personalization
Algorithm?
Provide experience X

Outline
• Inverse planning: Diagnosing misunderstandings about equation solving
• Developing personalized feedback based on diagnosis
• Testing effectiveness of personalized feedback
• Future directions
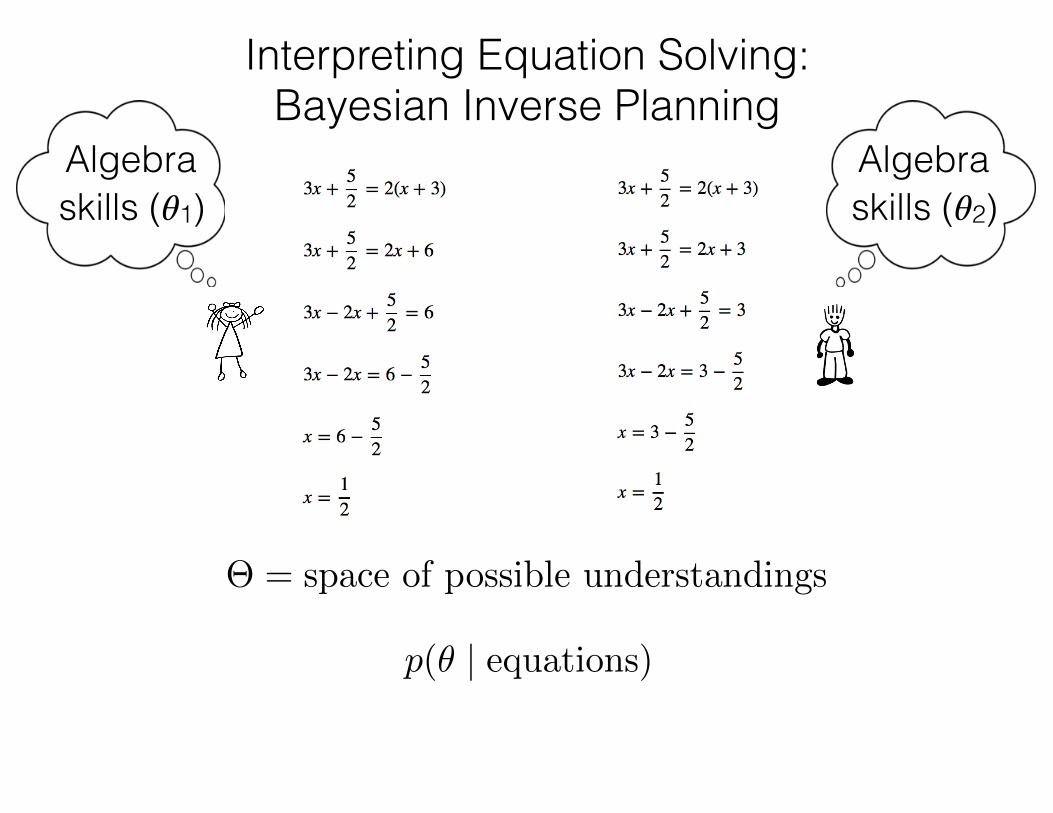
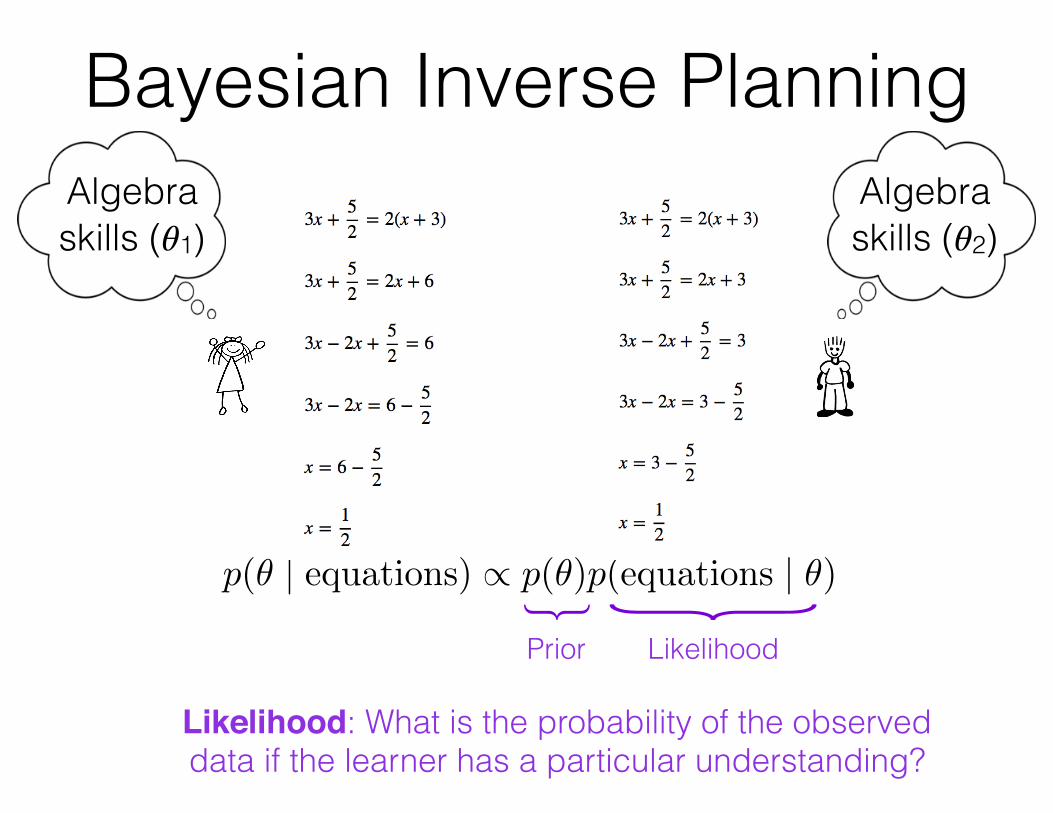
Interpreting Equation Solving: Bayesian Inverse Planning
⇥ = space of possible understandings
p(✓ | equations)
Algebra skills (𝜃1)
Algebra skills (𝜃2)

Representing Understanding: Θ
Conceptual Mal-rules 1+3x => 4x 3(2+5x) => 6+5x
Arithmetic 1+5.9x+3.2x => 1+8.1x -3+5+x => -2+x
Planning 3x+5x+4 = 2 => 3x+4 = -5x+2
e.g., Sleeman, 1984; Payne & Squibb, 1990; Koedinger & MacLaren,1997
✓ 2 ⇥: 6-dimensional vector of parameters related to skill
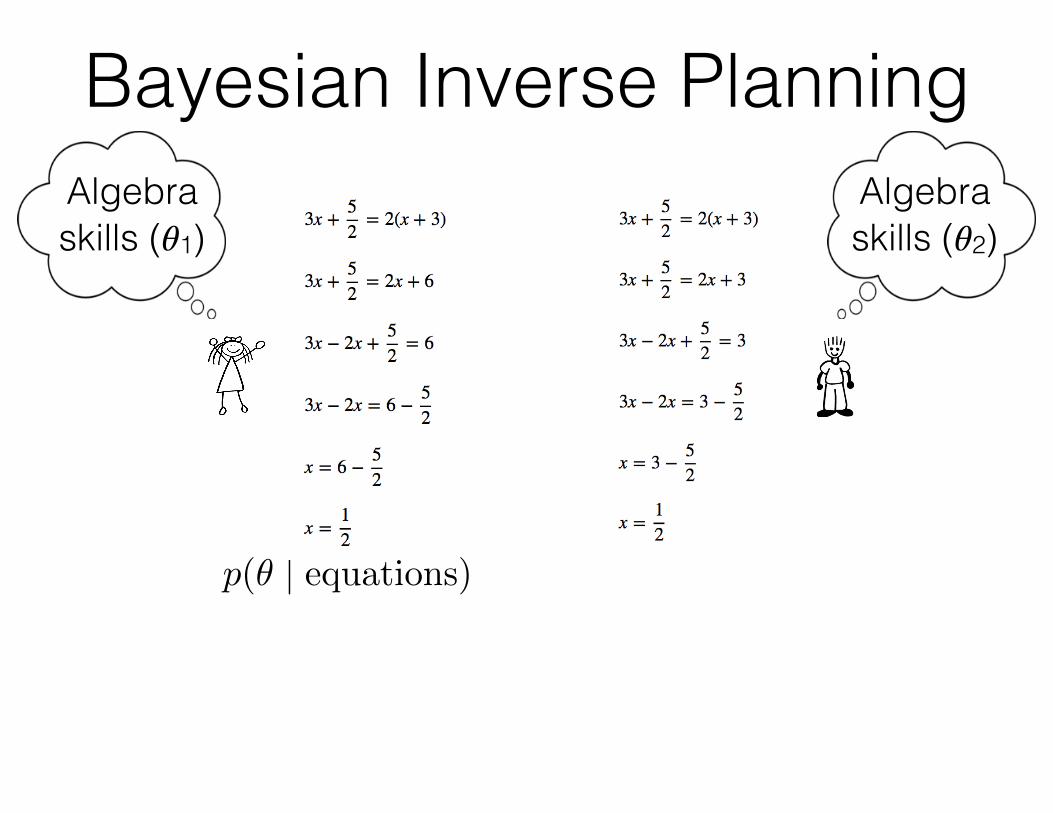
Bayesian Inverse Planning
p(✓ | equations) / p(✓)p(equations | ✓)
Algebra skills (𝜃1)
Algebra skills (𝜃2)
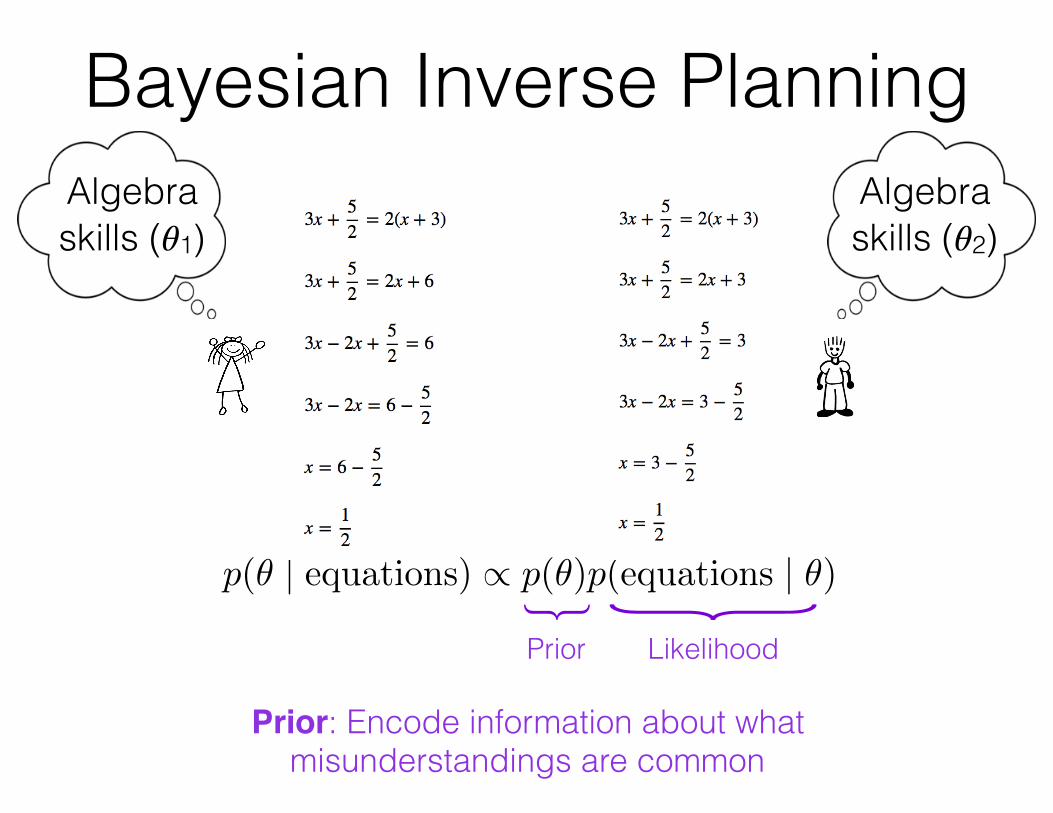
Bayesian Inverse Planning
{Prior
Prior: Encode information about what misunderstandings are common
Likelihood
{p(✓ | equations) / p(✓)p(equations | ✓)
Algebra skills (𝜃2)
Algebra skills (𝜃1)
Bayesian Inverse Planning
Likelihood: What is the probability of the observed data if the learner has a particular understanding?
{Prior Likelihood
{p(✓ | equations) / p(✓)p(equations | ✓)
Algebra skills (𝜃2)
Algebra skills (𝜃1)
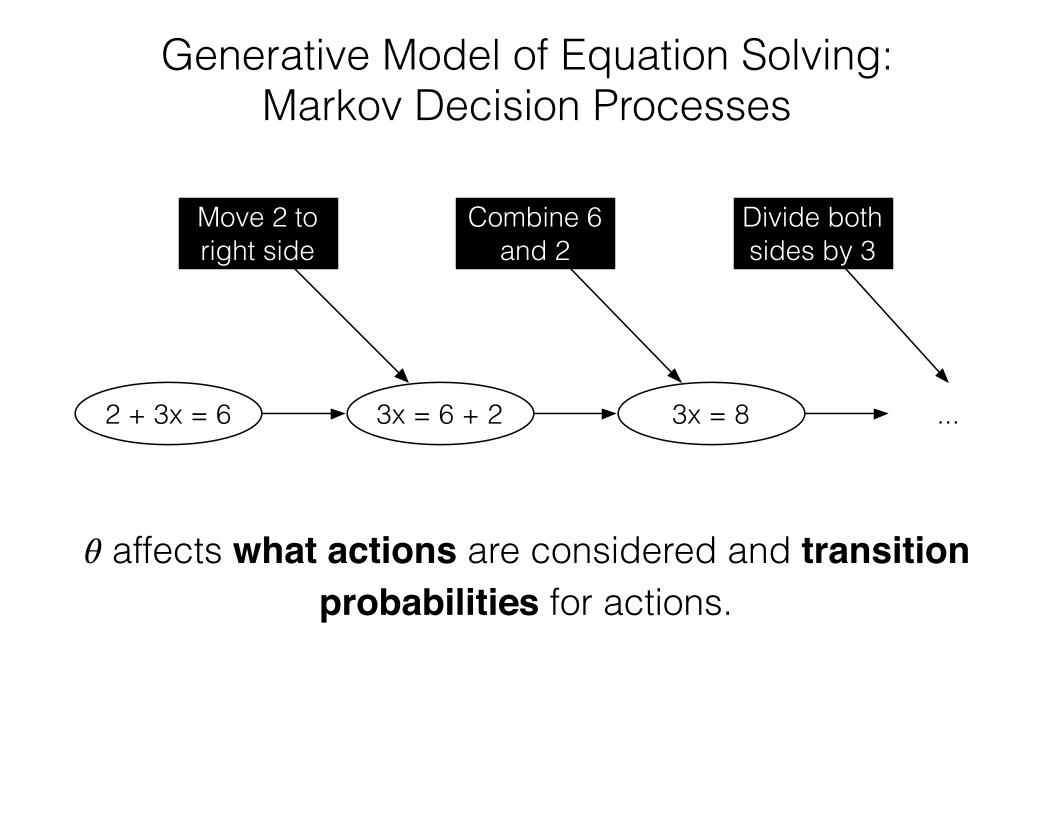
Generative Model of Equation Solving: Markov Decision Processes
2 + 3x = 6 3x = 6 + 2 3x = 8
Move 2 to right side
Combine 6 and 2
Divide both sides by 3
...
𝜃 affects what actions are considered and transition probabilities for actions.

How are Actions Chosen?
Assume a noisily optimal policy:p(a | s) / exp(✓� ·Q(s, a))
Q(s, a) =X
s02S
p(s0|s, a) R(s, a) + �
X
a02A
p(a0|s0)Q(s0, a0)
!Long term expected value:
2 + 3x = 6 3x = 6 + 2 3x = 8
Move 2 to right side
Combine 6 and 2
Divide both sides by 3
...
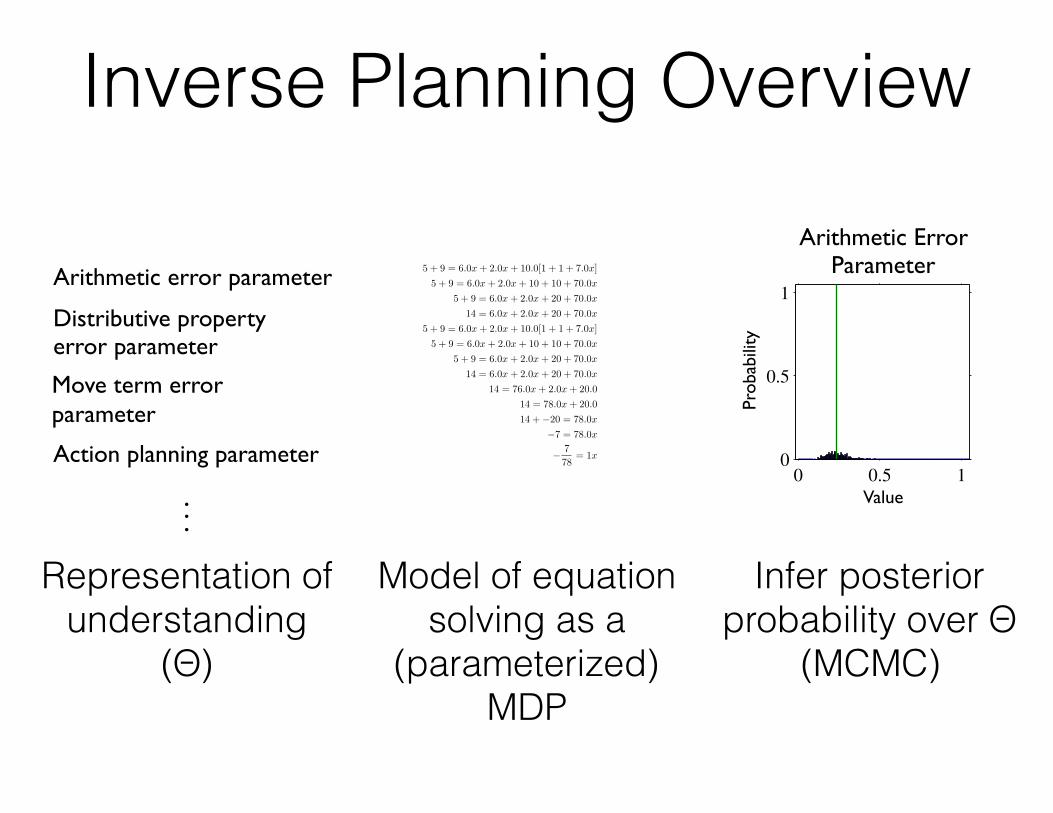
Inverse Planning Overview
5 + 9 = 6.0x + 2.0x + 10.0[1 + 1 + 7.0x]5 + 9 = 6.0x + 2.0x + 10 + 10 + 70.0x
5 + 9 = 6.0x + 2.0x + 20 + 70.0x
14 = 6.0x + 2.0x + 20 + 70.0x
5 + 9 = 6.0x + 2.0x + 10.0[1 + 1 + 7.0x]5 + 9 = 6.0x + 2.0x + 10 + 10 + 70.0x
5 + 9 = 6.0x + 2.0x + 20 + 70.0x
14 = 6.0x + 2.0x + 20 + 70.0x
14 = 76.0x + 2.0x + 20.014 = 78.0x + 20.014 +�20 = 78.0x
�7 = 78.0x
� 778
= 1x
Arithmetic error parameter
Action planning parameter
Distributive property error parameter
Move term error parameter
...
Representation of understanding
(Θ)
Model of equation solving as a
(parameterized) MDP
Infer posterior probability over Θ
(MCMC)
0 0.5 10
0.5
1
Sign Error Parameter
Pro
bab
ilit
y
Value0 1
0
0.5
1
Combine Only Like Parameter
Pro
bab
ilit
y
Value0 0.5 1
0
0.5
1
Reciprocal Error Parameter
Pro
bab
ilit
y
Value0 0.5 1
0
0.5
1
Distributive Error Parameter
Pro
bab
ilit
y
Value0 2 4
0
0.5
1
Planning Parameter
Pro
bab
ilit
yValue
0 0.5 10
0.5
1
Arithmetic Error Parameter
Pro
bab
ilit
y
Value
Arithmetic Error Parameter
Prob
abili
ty
Value

Output for One Learner
How do we turn this into a feedback activity?
0 0.5 1
Value
0
0.5
Pro
bab
ilit
y
Move
0 1
Value
0
0.5
Pro
bab
ilit
yCombine
0 0.5 1
Value
0
0.5
Pro
bab
ilit
y
Divide
0 0.5 1
Value
0
0.5
Pro
bab
ilit
y
Distributive
0 2 4
Value
0
0.5
Pro
bab
ilit
y
Planning
0 0.5 1
Value
0
0.5
Pro
bab
ilit
y
Arithmetic

Feedback Activities
Overview of skills and assessment Text explanation and video from Khan Academy
Targeted practice with fading scaffolding

Testing Personalized Feedback
Session 1: Website Problem
Solving and Multiple Choice Test
Session 3: Website Problem
Solving and Multiple Choice Test
Session 2: Feedback Activity
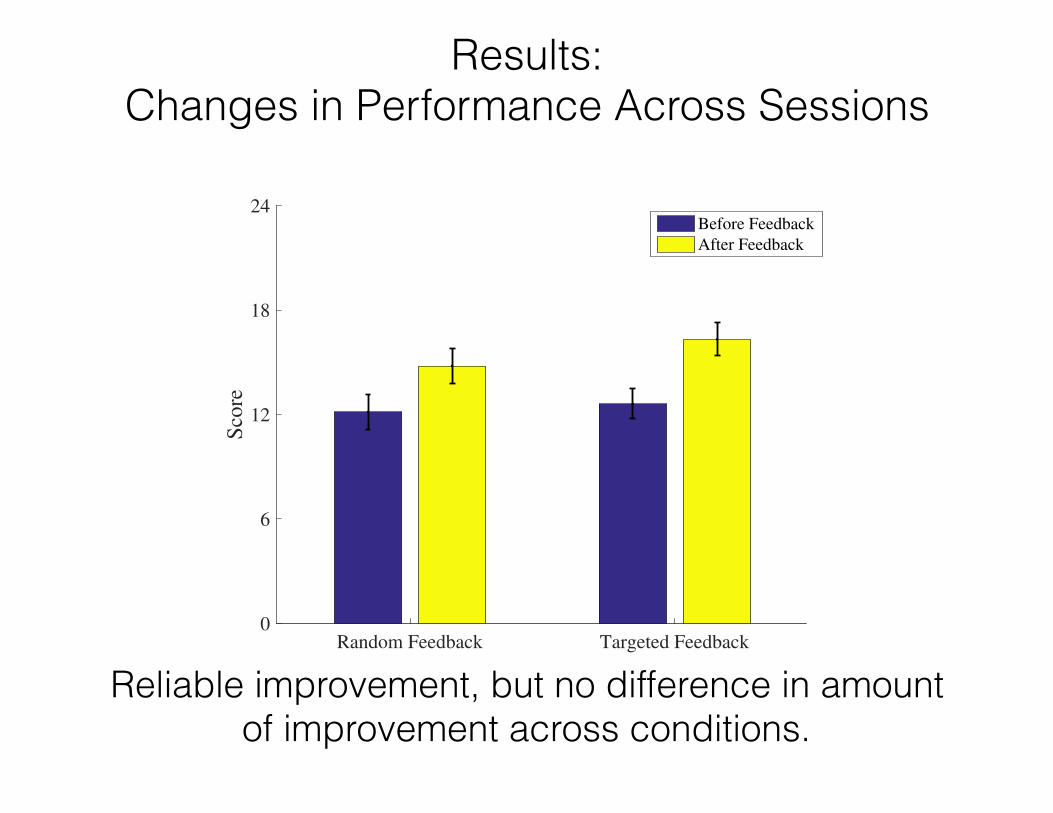
Results: Changes in Performance Across Sessions
Targeted Feedback Random Feedback0
6
12
18
24
Sco
re
Accuracy Improvements by Time and Condition
Before Feedback
After Feedback
Targeted Feedback Random Feedback0
6
12
18
24
Sco
re
Accuracy Improvements by Time and Condition
Before Feedback
After Feedback
Targeted Feedback Random Feedback0
6
12
18
24
Sco
re
Accuracy Improvements by Time and Condition
Before Feedback
After Feedback
Targeted Feedback Random Feedback0
6
12
18
24
Sco
re
Accuracy Improvements by Time and Condition
Before Feedback
After Feedback
Reliable improvement, but no difference in amount of improvement across conditions.
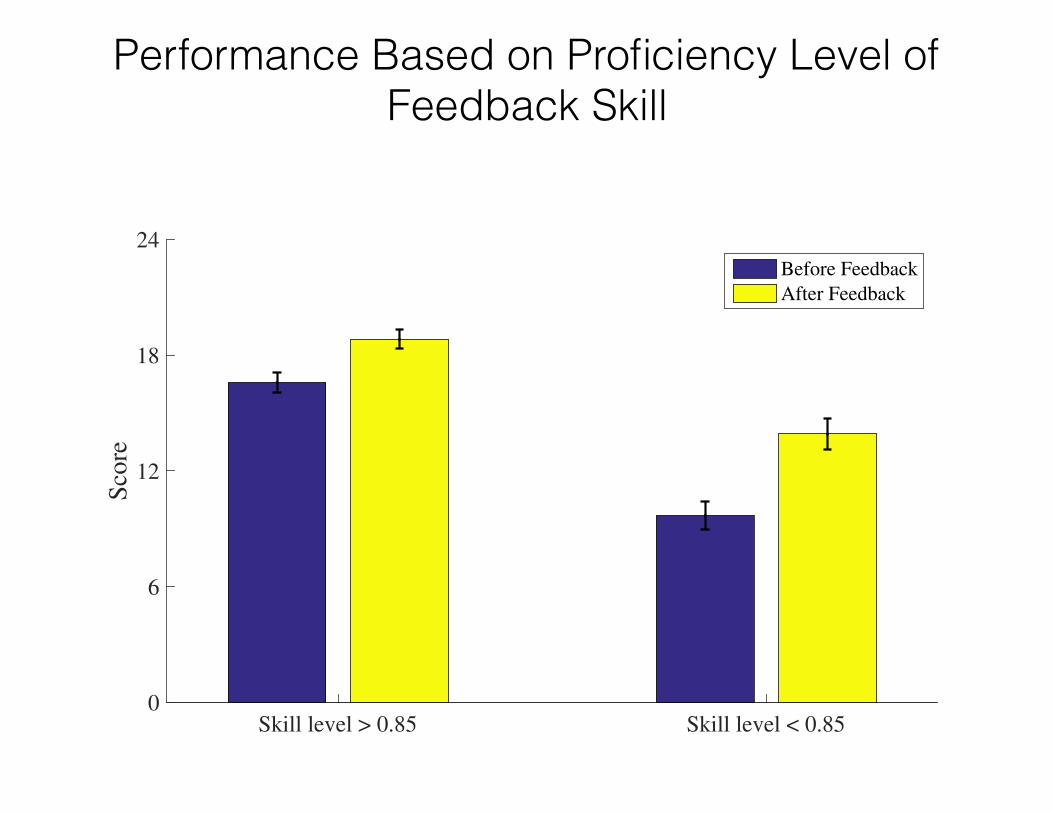
Performance Based on Proficiency Level of Feedback Skill
Skill level > 0.85 Skill level < 0.850
6
12
18
24
Sco
re
Accuracy Improvements by Time and Level of Skill
Before Feedback
After Feedback
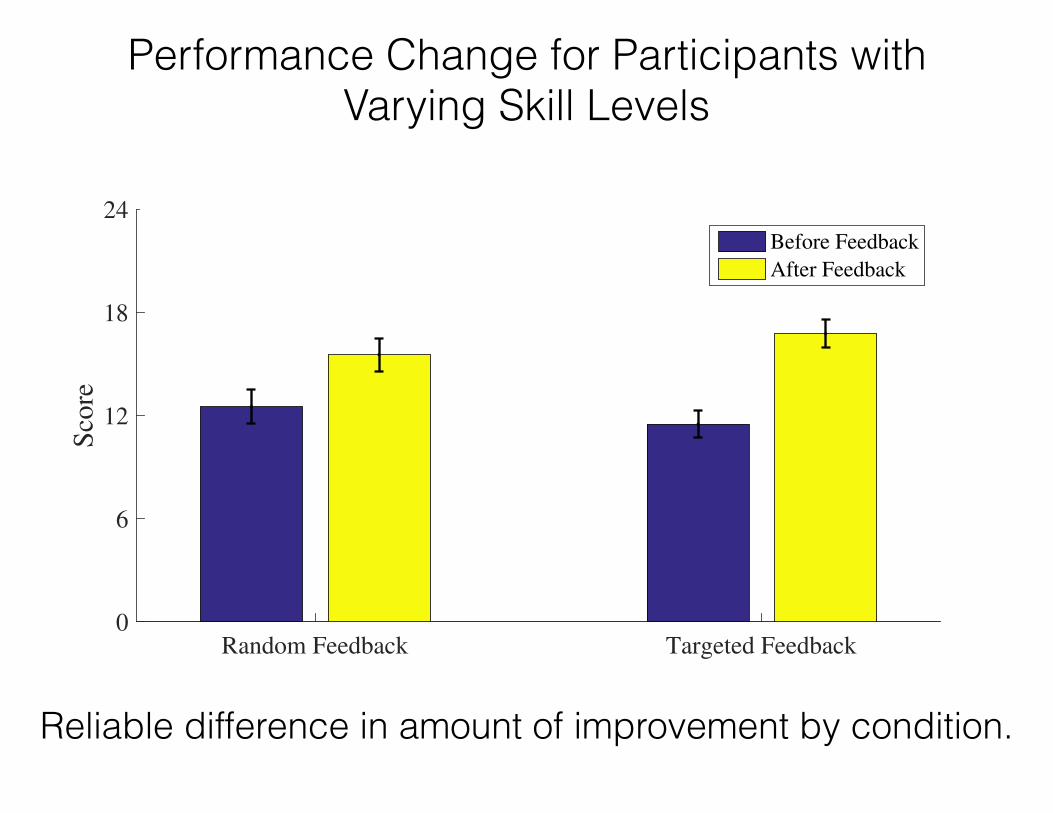
Performance Change for Participants with Varying Skill Levels
Random Feedback Targeted Feedback0
6
12
18
24
Sco
re
Accuracy Improvements by Time and Conditionfor Participants with Some Mastered and Some Unmastered Skills
Before Feedback
After Feedback
Reliable difference in amount of improvement by condition.

Contributions and Next Steps
• Personalization using inverse planning is helpful for learners who struggle with only some skills
• Provides an applied metric assessing the algorithm
• Next steps:
• Greater specificity and more interactivity in feedback
• Longer term interventions

Thank you!
Acknowledgements: Thank you to students Jonathan Brodie and Sam Vinitsky for programming contributions.
Funding: This work is supported by NSF grant number DRL-1420732.
Contact: Anna Rafferty, [email protected]
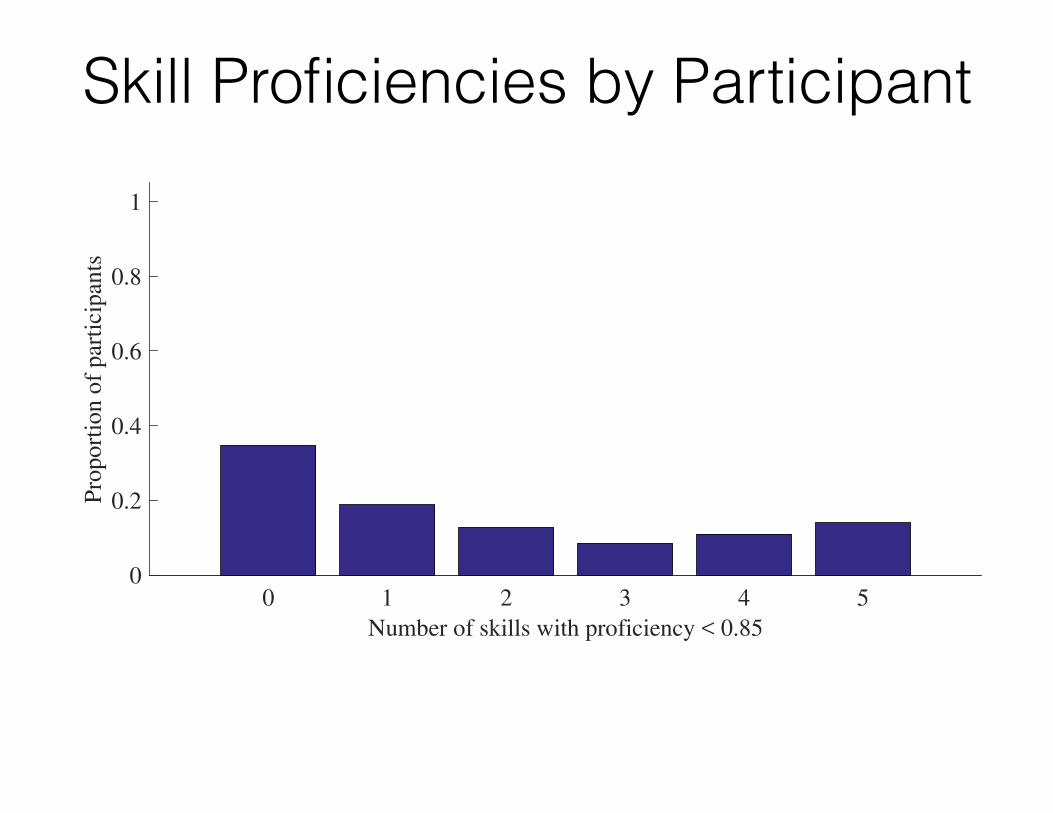
Skill Proficiencies by Participant
0 1 2 3 4 5
Number of skills with proficiency < 0.85
0
0.2
0.4
0.6
0.8
1
Pro
po
rtio
n o
f p
arti
cip
ants
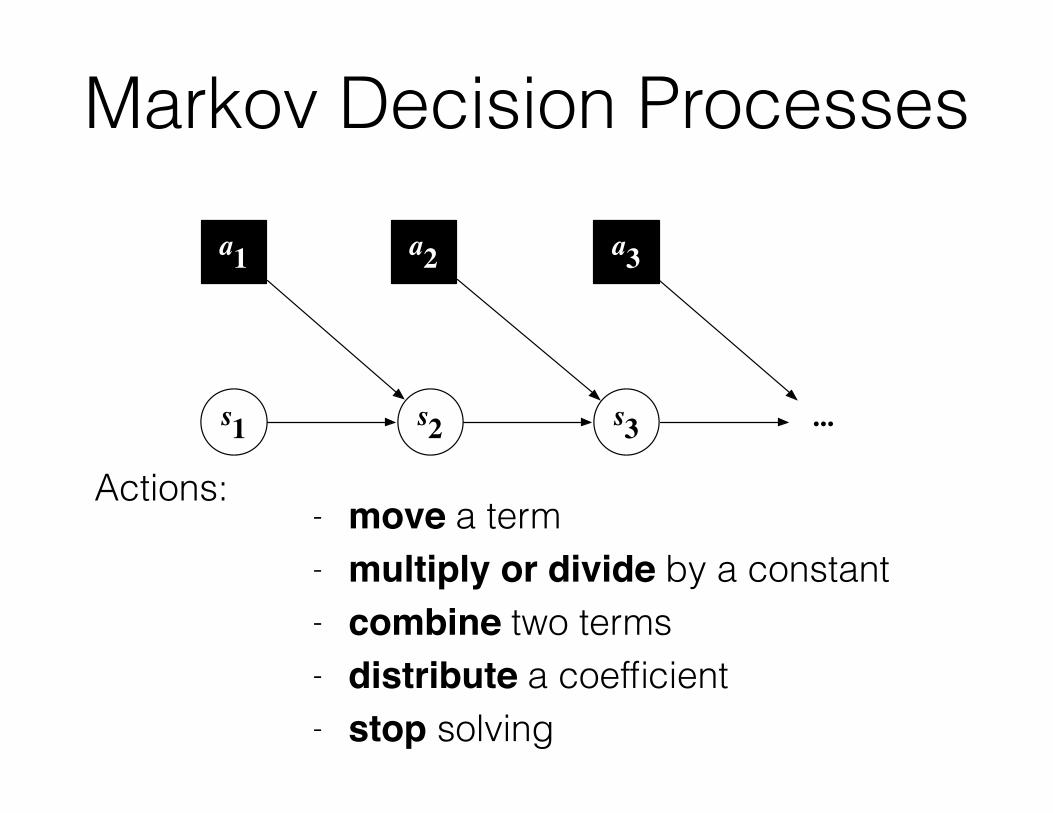
Markov Decision Processesa1 a2 a3
s1 s2 s3 ...
Actions:- move a term - multiply or divide by a constant - combine two terms - distribute a coefficient - stop solving