using community structure to control information sharing in online social networks
TRANSCRIPT

Computer Communications 41 (2014) 11–21
Contents lists available at ScienceDirect
Computer Communications
journal homepage: www.elsevier .com/locate /comcom
Using community structure to control information sharing in onlinesocial networks
0140-3664/$ - see front matter � 2014 Elsevier B.V. All rights reserved.http://dx.doi.org/10.1016/j.comcom.2014.01.002
⇑ Corresponding author. Tel.: +1 (514) 398 1465; fax: +1 (514) 398 3883.E-mail addresses: [email protected] (A. Ranjbar), maheswar@
cs.mcgill.ca (M. Maheswaran).
Amin Ranjbar ⇑, Muthucumaru MaheswaranAdvanced Networking Research Lab, School of Computer Science, McGill University, Montreal, QC H3A 2A7, Canada
a r t i c l e i n f o a b s t r a c t
Article history:Received 2 December 2011Received in revised form 7 January 2014Accepted 8 January 2014Available online 18 January 2014
Keywords:Online social networksConfidentialityInformation sharingAccess controlInformation leakage
The dominant role of social networking in the web is turning human relations into conduits of informa-tion flow. This means that the way information spreads on the web is determined to a large extent byhuman decisions. Consequently, information security lies on the quality of the collective decisions madeby the users. Recently, many access control schemes have been proposed to control unauthorizedpropagation of information in online social networks; however, there is still a need for mechanisms toevaluate the risk of information leakage within social networks. In this paper, we present a novel com-munity-centric confidentiality control mechanism for information flow management on the web. Weuse a Monte Carlo based algorithm to determine the potential spread of a shared data object and toinform the user of the risk of information leakage associated with different sharing decisions she canmake in a social network. By using the information provided by our algorithm, the user can curtail shar-ing decisions to reduce the risk of information leakage. Alternatively, our algorithm can provide input fora fully- or semi-automatic sharing decision maker that will determine the outcomes of sharing requests.Our scheme also provides a facility to reduce information flowing to a specific user (i.e., black listing aspecific user). We used datasets from Facebook and Flickr to evaluate the performance of the proposedalgorithms under different sharing conditions. The simulation results indicate that our algorithm caneffectively control information sharing to reduce the risk of information leakage.
� 2014 Elsevier B.V. All rights reserved.
1. Introduction
As online social networks (OSNs) increase in size and morepeople use them as their primary Internet portal, the volume ofinformation shared in OSNs keeps on growing. Information iscreated by different sources in OSNs including people postinginformation in their profile pages, relational information generatedby people initiating connections among themselves, and data feedsgenerated by sensing people’s activities such as gaming and pur-chasing. In any sharing activity, OSNs store and process differentpieces of information: picture files, relationships among people,and sharing preferences regarding data objects. This means thatthe way OSNs are architected and the security primitives built intothem play key roles in defining information security in social web.Consequently, many research thrusts have examined wide-rangingsecurity issues in the context of OSNs [1–6].
While information sharing is vital for socializing online, manysecurity and privacy issues have been raised such as confidential-ity and integrity violations of shared data objects. The main issue
is to ensure users that their privacy and access control require-ments are preserved when information sharing occurs withinOSNs. Recently, users in OSNs have started to become more awareof the risk of unauthorized propagation of their informationthrough social networking sites. To partially answer users concern,several topology-based access control mechanisms for OSNs wereproposed in order to identify authorized users by specifying someconstraints on the social graph [2,3,7–10]. In these schemes, toregulate information sharing, access control rules are defined byidentifying the relationships that users must have in order to ac-cess the shared data.
Because existing techniques only deal with information release,a user might not be able to precisely identify who is authorized tohave access to her data. Even in small social networks, it is difficultfor a user to keep track of the topology of her constantly changingsocial network and to identify users who are actually authorizedeven with simple access rules such as ‘‘friends-of-friends’’. In addi-tion, the user requirements for privacy are constantly changing[11]. This may potentially lead users to losing control of theirshared data and to generating risks of unauthorized informationdissemination related to their access control decisions. A user doesnot have complete knowledge about a set of users authorized byher access control settings and their potential malicious behaviors

12 A. Ranjbar, M. Maheswaran / Computer Communications 41 (2014) 11–21
in releasing her data to unauthorized users [12]. Therefore, it isnecessary to have new access control mechanisms in OSNs inorder to evaluate the potential risks and to make users fully awareof the possible consequences of their decisions in specifying accessrules.
There are two main challenges found in defining new accesscontrol techniques and controlling confidentiality of informationon OSNs. The primary challenge is about enforcing usage condi-tions. The typical corporate information networks [13] such as acourse management network in a university use predefined roles(e.g. professor, teaching assistant, and student) and policies toregulate information flow. For example, a student does not haveaccess to assignments or exams of other students, while studentsappointed as teaching assistants have access to all exams andassignments of specified courses. The employment conditionsof the teaching assistants require them to keep certain informa-tion confidential. Information flow control in such a networkbreaks down if the users fail to abide by the usage conditions.The sharing problem in OSNs, however, is not governed by pre-cise usage policies. The second challenge is that informationsharing in OSNs is not automatically coupled with the level orthe direction of interactions. In analog social networks [14],physical contacts remain as the dominant mechanism for sharinginformation between users. Therefore, people can implicitly con-trol information sharing by avoiding contact with undesirablefriends. The explicit controls are necessary in OSNs to avoidinformation sharing with undesirable friends. Therefore, thereis a need for novel access control techniques that work with min-imal user intervention.
In this paper, we address the two challenges identified above bypresenting a novel community-centric confidentiality controlscheme for OSNs. We develop a new strategy where the eventualinformation distribution is shaped by the initial release of objectsinto the network. Because the initial release is completely con-trolled by the owner, she could shape the information distributionby making appropriate release decisions to minimize possibleinformation leakage. To the best of our knowledge, this is the firstwork proposing an algorithm to closely approximate the exact riskof information leakage associated with user access control deci-sions. Our scheme uses a Monte Carlo method to compute theset of potential users who could receive the data objects belongingto a data owner. Our algorithm can provide input to a fully- orsemi- automatic sharing decision maker that will determine theconsequences of accepting or rejecting sharing requests. In addi-tion, we provide algorithms for preventing information fromreaching certain users by shaping the initial release set. Usingdatasets from Facebook and Flickr, we simulate sharing situationsin social settings and estimate information leakage valuesconsidering that our algorithm controls information sharing.
(a)
Fig. 1. Survey of information sharing on OSNs: (a) When friends share data with you, do yunder no conditions?
Section 2 discusses the secure information sharing problem andassociated security challenges in social networking. In Section 3, anew community-centric confidentiality control mechanism foronline systems is presented. Section 4 presents an analysis of theexperiments performed on information sharing patterns inFacebook and Flickr. Related work is described in Section 5.
2. Information sharing model
One of the important characteristics of OSNs is the privateinformation space it provides for the users joining a network. Afterjoining, users, at their discretion provide access to their friendsusing simple mechanisms provided by the OSN operators. MostOSN operators provide facilities to restrict access to subset offriends, friends, friend-of-friends, or public. These controls onlydeal with information release and expect the user to detect anymisuse and modify the release conditions (for example, block anoffending user from accessing data) [15,16].
Information sharing in OSNs takes place without any formalusage restrictions or guidelines, which is an acceptable and pref-erable approach for OSNs users as shown in Fig. 1. This surveywas conducted to find the value of information sharing on OSNsamong McGill University students from various fields of study.Only 24 percent of participants like explicit sharing conditionswhen they receive data from their friends whereas majority ofthe users prefer to attach specific constraints when they providethe information. This makes policy-based access control less suit-able for OSNs sharing situations. Because information sharing isnot carried out under strict usage conditions in the social net-works, information leakage can occur widely. If an unauthorizeduser has access to the shared data, that object is said to be leakedor that information leakage occurred. Therefore, it is necessary tobe able to compute the risk of information being leaked. Here, weconsider two different use-cases of computing the risk of unau-thorized information leakage:
First, if a user needs to share some information with a subset ofher friends (S1), she should simply set the access control to S1.However, there is a risk of information leakage associated to herdecision for which she does not possess any knowledge. If thereare intense and frequent interactions between S1 and anothersubset of the user’s friends named S2, then the chances that theinformation shared with S1 will leak to the members of S2 is quitehigh. Therefore, there should be a mechanism to compute the riskof information leakage related to the user’s sharing decisions andto provide the subset of the user’s friends who will eventually haveaccess to the shared information. Based on this information, theuser can shape her access control decisions properly.
Second, if a user attempts to black list a specific user (her adver-sary), the only thing she can do in existing OSNs is to add the
(b)
ou prefer when; (b) would you like to share information under specific conditions or

A. Ranjbar, M. Maheswaran / Computer Communications 41 (2014) 11–21 13
adversary to a black list. However, information she shares with herfriends can reach her adversary if the adversary has a significantnumber of common friends with the user. Similarly, there is a needfor a scheme to compute the risk of information leakage to theadversary and also to provide a list of friends who should beblocked in order to minimize the risk.
From the above scenarios, we can observe that the informationleakage problem is similar to the covert channel [17] problem. Ourapproach for information leakage is built on the followingassumptions:
1. All information sharing takes place among users who arepart of the OSN.
2. Users forming the OSN are focused on a specific topic (e.g.,technology analysts). Therefore, when two users interactthey are likely to share information known to them.
3. In OSNs, usage policies are implied and the receivers aretrusted to uphold the norms. We assume that users arenot equally likely to violate these norms.
4. The OSN operator enforces a simple policy that preventsany user more than or equal to K hops away from thesource from accessing or sharing a data that belongs tothe source unless the source has marked that data aspublic.
3. a-myCommunity: a new grouping abstraction
In this section, we first focus on developing an equivalentset of users for information sharing instead of relying solelyon topological information such as friends or friends of friends.This set would be given to a community of friends likely tohave access to the shared information only if a quorum of themis given the information. We can compute the equivalent shar-ing set as a connected component that surrounds a given userbased on the communication patterns observed in the OSN.We refer to this set as the a-myCommunity hereafter. For a gi-ven communication intensity threshold a, our algorithm gives asubgraph which is likely to contain the information that isbeing released by the user. If the user intends to actually re-strict the spread of information to a subset smaller than theset found in this subgraph, then the risk of information leakingoutside the user imposes a restriction that is given by the a va-lue used in the subgraph computation.
Second, we develop a method to compute set of friends whowould leak the shared information to an adversary. For an accept-able threshold of information leakage, our algorithm provides aminimal subset of friends with whom the owner should stop shar-ing in order to prevent the shared information from flowing to theadversary.
3.1. Real life example
In November 2011, one Apple store employee named Crisp wasfired for his critical Facebook posts. He posted negative messagesabout his employer on a Facebook friends’ page assuming it wasa private conversation. A coworker enrolled in the private grouppassed those messages to the Apple store manager [18] who firedCrisp. Although the messages were private, the communicationwas not protected because one of the friends decided to leak it.With all of the existing access control mechanisms in OSNs, Crispwas not able to prevent his posts from leaking to the manager.However, if Crisp knows about the risk of his information leakingout of the desired circle of friends, he can shape the informationspread by not releasing the information to some of his friends.
Because Crisp is only capable of controlling the release ofinformation to his friends, he will use those decisions to maximizethe information spread while the possibility of undesirable leakageis minimized. Better still, if Crisp could find the friends who shouldbe blocked from getting access to the information, he could pre-vent it from flowing to his manager (his adversary) and he wouldnever lose his job.
Accordingly, there is a need for a new scheme like a-myCom-munity on top of existing access control mechanisms in OSNs inorder to compute default sharing sets for users with minimal riskof information leakage. a-myCommunity can be automaticallycomputed for Crisp based on the sharing patterns observed inthe OSN and also notify him if there is a high risk of informationleakage associated to his sharing decisions. However, our schemehas some limitations: first, our algorithm works only if the adver-sary is part of OSNs, in this case Facebook. Second, all informationsharing should take place through OSNs. A user can share theinformation with others who are not part of OSNs by other waysthan using social networking sites (e.g. physical contacts). Ourscheme cannot prevent these types of information leakage.
3.2. Estimating a-myCommunity
The identification of groups and communities inside a networkhas been one of the major topics in social network analysis [13].Communities are subsets of users who are densely connected toeach other. In other words, community members have high levelsof mutual trust and shared interests. Because the concept ofgroups and communities has been used in different fields, thereare various definitions for them in social networks. Here, we tryto specify a community from the point of view of an individualuser. We define myCommunity as the largest subgraph of userswho are likely to receive and hold the information without leaking.That is, myCommunity is defined as a subset of a user’s friendsamong whom there are relatively intense and frequentinteractions.
We represent the social network with a directed weightedgraph SG ¼ ðU; EÞ, where, U is the set of social network users andE is the set of edges representing relationships between the usersof the network. In general, users are not equally likely to sharethe information. Some users are more willing to keep the shareddata item confidential. If we denote Pi as the probability that userui is willing to share the information with some of her friends, Pi
can be computed as follows:
Pi ¼outflow=inflow outflow < inflow
1 outflow > inflow
�ð1Þ
where outflow is the number of interactions user ui has with herfriends, and inflow is the number of interactions ui’s friends havewith her. The weight on an edge between ui and uj (wi;j) representsthe likelihood of two users sharing information along the givenrelationship. Therefore, the probability that user ui shares herinformation with uj is:
pi;j ¼ Pi �wi;j: ð2Þ
We assume that the users’ sharing behavior is consistent in thatuser ui shares all the data she has with user uj with probability pi;j
or not. Although this probability can change with time, it does notdepend on the data being shared. Formally, myCommunity (Mui
) isthe largest subgraph of the social graph (Mui
# SG) including user ui
with the highest probability of information flow from ui to allmembers. Similarly, we define a-myCommunity (MCa
ui) as the
largest subgraph of the social graph (MCaui
# SG) including user ui

14 A. Ranjbar, M. Maheswaran / Computer Communications 41 (2014) 11–21
with the probability of information flow from ui to all membersgreater or equal to the threshold a (MCa
ui¼ f8uj 2 UjPIFi;jÞP ag).
The probability of information flow (PIF) is the probability that useruj will receive the shared data object from the owner ui. It isimportant to note that myCommunity is defined for each userindependently. Within myCommunity, specialized sub-myCom-munities can be defined for specific contexts. It is also possible todevelop aggregations of myCommunities in social neighborhoodsto form ourCommunities.
Because finding the probability of information flow is anNP-hard problem [19], we propose a Monte Carlo based algorithmin order to determine the a-myCommunity for a specific user ui
[20]. We only consider a graph Guias a subgraph of the social graph
for ui (Gui# SG), where Gui
¼ ðUui; EuiÞ is a graph including ui and all
users with the hop distance equal or less than K from ui. If we de-note ui and uj as two users, the hop distance is defined as the small-est number of hops that separate ui and uj on the social graph.Hence, Gui
¼ fuj 2 U; ek 2 Ejjui;ujj 6 Kg, where jui;ujj is the hop dis-tance between ui and uj.
In this algorithm, an information flow scenario gs is randomlygenerated according to the sharing probability on each edge. WithN iterations, bnj ¼ nj=N is an estimation for the probability of infor-mation flow between ui and uj, where nj is the summation of all therandom variables generated in the N iterations. That is, nj repre-sents the number of times uj receives the shared information fromui. Let indicator xk be a random variable indicating whether theinformation sharing occurred on the edge between ui and uj ofthe graph Gui
. That is
xk ¼1 with probability pi;j
0 with probability qi;j:ðqi;j ¼ 1� pi;jÞ
(ð3Þ
Together, the variables x1; x2, . . ., xl generate an informationflow scenario gs of Gui
; gs ¼ ðUui; EsÞ, and Es # Eui
. The Monte-Carlosimulation (MCS) that estimates the a-myCommunity for a specificuser ui is given as follows:
Algorithm 1. Finding a-myCommunity for ui
Input: the social graph SGðU; EÞ and a specific user ui
Output: estimating a-myCommunity for ui.1. Initialize the variable nj to zero: nj 02. Extract the graph Gui
3. Simulate binary random variables xk for each edge ek
(ek 2 Eui ).4. Erase each edge ek if xk ¼ 05. Set Yk;j 1 for all j, if there is a path between ui and uj.
Otherwise, set Yk;j 06. Put nj nj þ Yk;j
7. Repeat step 3–6 N times8. Estimate bnj for all j as bnj nj=N9. Set the probability of information flow between ui and uj asbnj , for all j : PIFi;j ¼ bnj all users with PIFi;j P a as members
of MCaui
3.3. Application: blocking an adversary
One of the possible application of the Algorithm-1 on OSNs suchas Facebook is to find out the minimum set of friends who shouldbe blocked from getting access to the shared information if theowner ui attempts to prevent his or her data object from flowingto a specific user uk. Here, we propose an algorithm in order toprevent the scenario-2 mentioned in previous section.
Algorithm 2. Finding the most effective friend of ui on theprobability of information flow between ui and uk
Input: the social graph SGðU; EÞ; ui and uk
Output: sorted set of ui’s friends based on their effect on PIFi;k.1. for all friends of ui
2. Set the probability of information flow between ui and uj
to 0 : PIFi;j 03. Find the probability of information flow between ui and
uk : aj PIFi;k
4. Find the effect of setting PIFi;j to 0 on PIFi;k : efj a� aj
5. Set the probability of information flow between ui and uj
to the original value6. end for sorted set of ui’s friends based on efj for all j
Algorithm-2 is introduced to find out the most effective friendof ui on the probability of information flow between user ui andher adversary uk. If ui is willing to decrease the probability of infor-mation flow between itself and uk to some new threshold(PIFi;k 6 b), Algorithm-3 provides an estimation for determiningthe minimum set of ui’s friends with whom ui should stop sharing.
Algorithm 3. Finding the set of ui’s friends with whom ui
should stop sharing to have PIFi;k 6 b
Input: the social graph SGðU; EÞ; ui; uk, and bOutput: set of friends with whom ui should stop sharing1:Call Algorithm-2 to rank ui’s friends based on their effect on
PIFi;k
2:repeat3: Set uj as the most effective friend of ui on PIFi;k
4: Set the probability of information flow between ui and uj
to 0 : PIFi;j 05: Add uj to the output set: S S [ uj
6: Put PIFi;k PIFi;k � efj
7: if for all friends of ui; PIFi;j ¼ 0 then S8: else9: continue10: end if11.until PIFi;k 6 bS
To determine the blocking set, we compute the most effectivefriend in terms of information leakage and put that friend in theblocking set. Ideally, we should recompute the most effectivefriend again. However, to avoid the quadratic computational com-plexity we reuse the ranked list of effective friends in this heuristic.In our experiments, the performance difference between the twoschemes are negligible to warrant the additional computationaleffort.
3.4. Analysis: statistical, complexity and security
Now we analyze the properties of our algorithm. Let there be rinformation flow scenarios for each of which we have a path fromui to uj. For such a information flow scenario gq
s , probability of hav-ing a path between ui and uj is given byYðx;kÞ2sharing
pk;x
Yðx;kÞRsharing
ð1� pk;xÞ
In the above expression, ‘‘sharing’’ is the set of edges along whichdata is shared. The nodes controlling the other links are not sharing

A. Ranjbar, M. Maheswaran / Computer Communications 41 (2014) 11–21 15
in the given scenario. To obtain the actual probability of informa-tion flow between ui and uj, we sum all r scenarios that have a pathfrom ui to uj.
Theorem 3.1. The estimated probability of information flow obtainedfrom Algorithm-1 bnj is unbiased and consistent estimation the exactprobability of information flow PIFi;j.
Proof. In each iteration, we declare Yk;j for a user uj as an indicatorrandom variable with
Yk;j ¼1 if there is a path between ui and uj
0 otherwise:
�ð4Þ
Because we use an independent and identical method for gen-erating gs in the N iterations, then Y1;j;Y2;j, . . ., YN;j are independentidentically distributed random variables.
Pr½Yk;j ¼ 1� ¼ PIFi;j: ð5Þ
In the algorithm, nj is the result of a random experiment. Itmeans that we only consider one particular replica of this randomvariable in a specific experiment. Therefore, we have:
nj ¼ Y1;j þ Y2;j þ � � � þ YN;j ð6Þ
where Yk;j; k ¼ 1; . . . ;N, are independent identically distributed bin-ary random variables. We know that the expected value of thesebinary random variables can be computed as:
E½Yk;j� ¼ Pr½Yk;j ¼ 1� ¼ PIFi;j ð7Þ
Accordingly, we have:
E½ bnj � ¼ E½nj=N� ¼ E½ðY1;j þ Y2;j þ � � � þ YN;jÞ=N�
¼XN
k¼1E½Yk;jði; jÞ�=N ¼ PIFi;j ð8Þ
hence, bnj is unbiased estimator of nj. In addition, because Yk;j ¼ Y2k;j,
so we have:
E½Y2k;j� ¼ E½Yk;j� ¼ PIFi;j ð9Þ
and
Var½Yk;j� ¼ E½Y2k;j� � E2½Yk;j� ¼ PIFi;jð1� PIFi;jÞ ð10Þ
Thus,
Var½ bnj � ¼ Var½nj=N� ¼ VarXN
k¼1
Yk;j=N
" #¼XN
k¼1PIFi;jð1� PIFi;jÞ=N2 ¼ PIFi;jð1� PIFi;jÞ=N: ð11Þ
Therefore, our algorithm is not only unbiased, but also has var-iance tending to zero as the number of experiments increases(limN!1Var½ bnj � ¼ 0). In other words, with the increase of N, thevalue of bnj becomes closer and closer to the exact value of the PIFi;j:
limN!1
Pfj bnj � PIFi;jj < eg: ð12Þ
That is, if the replication number N is large enough, any preci-sion requirement e can be accomplished. h
Theorem 3.2. Algorithm-3 is a greedy approximation for finding theminimal subset of ui’s friends who should be blocked in order to havePIFi;k 6 b. The computational complexity of the algorithm is in order ofOðTÞ where T is the number of ui’s friends.
Proof. To determine the minimum subset of ui’s friends withwhom she should stop sharing, we should go through all possiblesubset of ui’s friends, and for every subset, check whether the prob-ability of information flow between ui and uk is less than thethreshold b. In all possible solutions, the minimum subset wouldbe the answer. The running time for this precise algorithm isOð2TÞ. Therefore, we need a heuristic to find out the minimumsubset in a reasonable time.
Our proposed algorithm, at each stage, considers ui’s friendswith the largest effect on PIFi;k. Because Algorithm-3, first, ranksthe ui’s friends based on their effects on the PIFi;k by callingAlgorithm-2, in worst case, it would go through all ui’s friends.Therefore, the Algorithm-3 is a greedy approximation withcomputational complexity of OðTÞ. h
Theorem 3.3. a-myCommunity and blocking list computed based onAlgorithm-1 and Algorithm-3 are upper bounds for topical a-myCom-munity and topical blocking list, respectively.
Proof. With topic based discussions, the probability of informa-tion sharing pi;j between two users ui and uj given by Eq. (2) willbe strictly lower than the value obtained without the topics. Wheninformation flow scenarios are generated the links are sharing withprobabilities pi;j. Therefore, with lower values for pi;j, the informa-tion flow scenarios will have lesser number of sharing edges. Asshown in the beginning of this subsection, the probability of infor-mation leakage is given by all information flow scenarios that havea path between ui and uj. Because the links (or edges) in the infor-mation flow scenarios are sharing with probabilities pi;j, all theinformation flow scenarios that have a path in the topical caseshould have a path in the non topical case. Conversely, all the infor-mation flow scenarios in the non topical case should be present inthe topical case. Therefore, we can say that the PIFi:j values for thetopical case should less be than the values computed for the nontopical case.
From Algorithm-1, a-myCommunity includes all users withPIFi;j P a. Because the topical PIFi;j is less than the non topical one,less number of users can satisfy the constraint (PIFi;j P a.).Therefore, non topical a-myCommunity is always larger than thetopical a-myCommunity. Similarly, we can conclude that thecomputed blocking list on Algorithm-3 is an upper bound for thetopical blocking list. h
Claim 3.1. The risk of information leakage is minimum for the valueof a that minimizes fa� DCðaÞg, where DCðaÞ is the expected changein the a-myCommunity.
Proof. Let the size of a-myCommunity be CðaÞ for a given a and auser ui. Suppose we relax the value of a to a� Da which causesthat the size of a-myCommunity changes to CðaÞ þ DCðaÞ. Thechanged configuration of a-myCommunity brought in new userswho can have the data with a probability of a. Therefore, the num-ber of new users who could hold the data due to the change in avalue is given by fa� DCðaÞg. For the original a-myCommunityof size CðaÞ, the new users introduced by the change in the a valueare the most likely recipients of any leaked data. Therefore, by find-ing a configuration that minimizes fa� DCðaÞg, we can minimizethe risk of information leakage. h
4. Experimental results
In this section, we use extensive simulations to evaluate a-myCommunity estimation schemes and analyze interactions of

16 A. Ranjbar, M. Maheswaran / Computer Communications 41 (2014) 11–21
users inside a-myCommunities. To setup the simulations, we usedtopologies extracted from two different datasets, facebook.com[21], and flickr.com [22]. The Facebook dataset is a collection fromNew Orleans regional network with around 60;290 users,1;545;686 friendships, and 876;993 interactions between theusers. These interactions can be any wall post such as postingvideos, photos, and comments. The other dataset is based on tracescollected from Flickr photo sharing site. While Flickr is an onlinephoto album based social network, users connect with each otherbecause of the quality of the photo albums. Therefore, Flickrpermits users to have two different types of links: links to friendsnamed contacts and links to favorite photos called favorites [22].From this dataset, we extracted a subset of data with 100; 000users, 3;638;215 friendships, and 10;000;000 interactionsbetween the users. Interactions can be sending messages to otherusers, commenting on photos, tagging photos, and choosing favor-ite photos.
Using the friendship traces from both datasets, we constructeda synthetic social network as an undirected graph. It means that ifuser u is friend with user v, user v is also friend with user u. Sim-ilarly, we built an interaction network as a weighted directedgraph using Facebook and Flickr traces. In this network, an edgefrom node u to node v exists if u has an interaction (wall post) withv. We assign a weight on each connection based on the number ofinteractions occurred between two users. Therefore, any edgewould have a weight at least equal to 1. The larger the weight,the larger the probability would be for two users to share informa-tion. We have to mention that we assume all interactions arerelated to one topic. Analyzing interactions based on differenttopics is not in the scope of this paper.
Accordingly, we perform three different groups of studies. Wefirst focus on the distribution of a-myCommunities with differentvalues for a. Next, we evaluate the information leakage in a-myCommunities and analyze the behavior of users inside and withoutside of their communities. Finally, we study the evolution of a-myCommunities over time. We find out how a-myCommunitieswould change in size and members throughout time. We have to
α
α
α
α α
Fig. 2. Distribution of a-myCommu
α
α
α
α
Fig. 3. Distribution of a-myCommunity
mention that we run our algorithm with different number of iter-ations (N ¼ 100;1000;10000;100000). We notice that there is nota significant difference between the results achieved with N equalor greater than 1000. Therefore, N with value of 1000 leads to apromising estimation for our simulations.
4.1. Analysis of a-myCommunity and blocking
In this section, we analyze our algorithms for computinga-myCommunities and blocking lists. We determine the a-myCommunity by considering different hop distance (2-hops or3-hops) for each individual user. We only consider hop distanceequals to 2 or 3, because the hop distance greater than 3 wouldnearly cover the whole network. We first utilize the same a valuefor all users to find out the size of a-myCommunities. Fig. 2 pre-sents the a-myCommunity’s size distribution for different a values(a ¼ 1;0:9; . . . ;0). This figure indicates the maximum, average andminimum size of a-myCommunity with hop distance equals to 2and 3. The larger the value we choose for a, the smaller the sizeof a-myCommunity would be. The reason for this is that thesmaller number of users has enough interactions to be consideredin a-myCommunities with high a values. In addition, the size of a-myCommunities with hop distance equals to 3 is 3 times, for Face-book users, and 2 times, for Flickr users, larger compare to the sizeof a-myCommunities with hop distance equals to 2.
Second, we calculate the chosen value of a for each individualuser. The chosen value of a makes a balance between privacyand publicity for different user. Since relaxing a value results inincreasing the size of a-myCommunity, we choose a value of awhere the a� size of a-myCommunity is maximized. As shownin Fig. 3, the minimum value for a is 0:3, for Facebook users, and0:4 for Flickr users. In addition, we find out the percentage of usershaving the same a value as shown in Fig. 4. We notice that the cho-sen a value for Facebook user is equal to 0:7 as oppose to 0:8 forFlickr users. This is because of the fact that more than 84 percentsof Facebook users have the a value equal or greater than 0:7.
α α
α
nity’s size with equal a value.
α
α
α
α
’s size with the chosen value for a.

α
Fig. 4. Percentage of user with the same a value.
A. Ranjbar, M. Maheswaran / Computer Communications 41 (2014) 11–21 17
Similarly, for more than 67 percents of Flickr users, the a value isequal or greater than 0:8.
To analyze the blocking list scheme, we attempt to figure outhow our algorithm would resist to the changes in the network.We calculate blocking lists for random adversaries for each user,and then change arbitrarily 10;20; . . . ;90;100 percentage of inter-action intensity on edges in both networks. Fig. 5 presents theaverage changes on the size of blocking lists for Facebook andFlickr networks. First, we increase or decrease at random the inter-action intensity of edges in both networks. We notice that changesup to 60 percent of Facebook network, and up to 50 percent ofFlickr network have no effect in the size of the blocking lists. Sec-ond, we only increase arbitrarily the interaction intensity of edgesfor both networks. In this case, the ratio of changes in the size ofblocking lists is two times larger comparing to the first approach.
4.2. Information leakage
We now focus on determining how effective a-myCommunitywould be in preventing information leakage with different valuesfor a. As we mentioned earlier, information leakage occurs whenan authorized user has access to the shared information. To evalu-ate information leakage in a-myCommunities, we analyze theinteractions of members with users outside of communities. Since
Fig. 5. The average ratio of variations in the size of blocking lists by changing theinteraction intensity on edges.
a-myCommunities include users who are likely to hold the sharedinformation without leaking and have relatively intense and fre-quent interactions among each other, we consider the interactionsbetween members and non-members as the information leakage.
To present how effective the information can be protected bythe existing privacy settings in Facebook and Flickr, we try to findout the information leakage if we set the privacy settings to friendsor friends-of-friends. Fig. 6 presents the normalized number ofinteractions occurred inside the privacy setting (friends andfriends-of-friends) and from inside-to-outside of these settings(information leakage). The number of interactions with usersoutside of the privacy settings is around 2 times more than thenumber of interactions occurred within the circle of friends orfriends-of-friends for both Facebook and Flicker users.
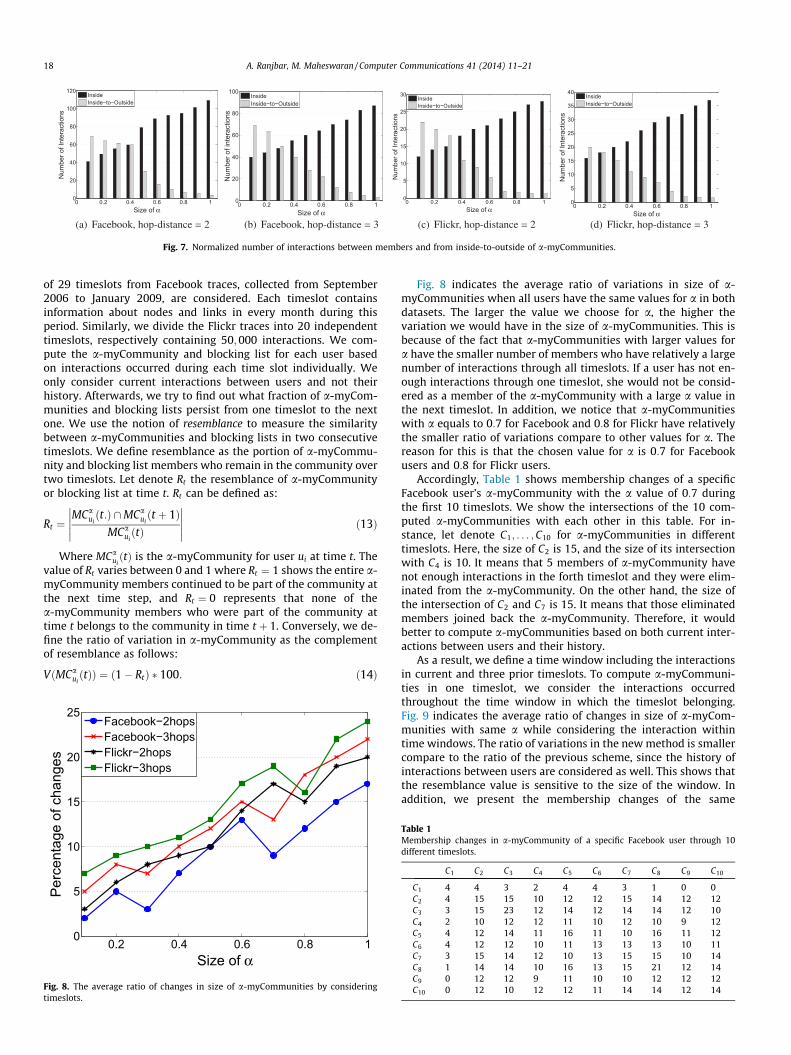
Accordingly, we try to set the privacy settings for each user toa-myCommunity in order to figure out the effectiveness of ourapproach. Fig. 7 indicates the normalized number of interactionsbetween members and from inside-to-outside of a-myCommuni-ties with different values for a. The larger the value we choosefor a, the smaller number of interactions would be between mem-bers and non-members. For instance, the number of interactionsbetween members of a-myCommunities with a value of 1 is 30times more than the number of interactions with non-membersas shown in Fig. 7(a). The information leakage (interactions withoutsiders) is less than one percent of whole interactions when ais equal or greater than 0:7 for Facebook users. Similarly, theinformation leakage is less than one percent for a-myCommunitieswith a equal or greater than 0:8 for Flickr users. It means thata-myCommunity members have tendency to interact more witheach other compare to their other friends and keep the sharedinformation within the community.
4.3. Evolution of myCommunity and blocking list
In this part, we study how a-myCommunities and blocking listsevolve over time. To simulate a-myCommunities evolution, a total
Fig. 6. Normalized number of interactions between members and from inside-to-outside with security setting to ‘‘friends’’ and ‘‘friends of friends’’.
α α α α
Fig. 7. Normalized number of interactions between members and from inside-to-outside of a-myCommunities.
18 A. Ranjbar, M. Maheswaran / Computer Communications 41 (2014) 11–21
of 29 timeslots from Facebook traces, collected from September2006 to January 2009, are considered. Each timeslot containsinformation about nodes and links in every month during thisperiod. Similarly, we divide the Flickr traces into 20 independenttimeslots, respectively containing 50;000 interactions. We com-pute the a-myCommunity and blocking list for each user basedon interactions occurred during each time slot individually. Weonly consider current interactions between users and not theirhistory. Afterwards, we try to find out what fraction of a-myCom-munities and blocking lists persist from one timeslot to the nextone. We use the notion of resemblance to measure the similaritybetween a-myCommunities and blocking lists in two consecutivetimeslots. We define resemblance as the portion of a-myCommu-nity and blocking list members who remain in the community overtwo timeslots. Let denote Rt the resemblance of a-myCommunityor blocking list at time t. Rt can be defined as:
Rt ¼MCa
uiðt:Þ \MCa
uiðt þ 1Þ
MCauiðtÞ
���������� ð13Þ
Where MCauiðtÞ is the a-myCommunity for user ui at time t. The
value of Rt varies between 0 and 1 where Rt ¼ 1 shows the entire a-myCommunity members continued to be part of the community atthe next time step, and Rt ¼ 0 represents that none of thea-myCommunity members who were part of the community attime t belongs to the community in time t þ 1. Conversely, we de-fine the ratio of variation in a-myCommunity as the complementof resemblance as follows:
VðMCauiðtÞÞ ¼ ð1� RtÞ � 100: ð14Þ
α
Fig. 8. The average ratio of changes in size of a-myCommunities by consideringtimeslots.
Fig. 8 indicates the average ratio of variations in size of a-myCommunities when all users have the same values for a in bothdatasets. The larger the value we choose for a, the higher thevariation we would have in the size of a-myCommunities. This isbecause of the fact that a-myCommunities with larger values fora have the smaller number of members who have relatively a largenumber of interactions through all timeslots. If a user has not en-ough interactions through one timeslot, she would not be consid-ered as a member of the a-myCommunity with a large a value inthe next timeslot. In addition, we notice that a-myCommunitieswith a equals to 0:7 for Facebook and 0:8 for Flickr have relativelythe smaller ratio of variations compare to other values for a. Thereason for this is that the chosen value for a is 0:7 for Facebookusers and 0:8 for Flickr users.
Accordingly, Table 1 shows membership changes of a specificFacebook user’s a-myCommunity with the a value of 0:7 duringthe first 10 timeslots. We show the intersections of the 10 com-puted a-myCommunities with each other in this table. For in-stance, let denote C1; . . . ;C10 for a-myCommunities in differenttimeslots. Here, the size of C2 is 15, and the size of its intersectionwith C4 is 10. It means that 5 members of a-myCommunity havenot enough interactions in the forth timeslot and they were elim-inated from the a-myCommunity. On the other hand, the size ofthe intersection of C2 and C7 is 15. It means that those eliminatedmembers joined back the a-myCommunity. Therefore, it wouldbetter to compute a-myCommunities based on both current inter-actions between users and their history.
As a result, we define a time window including the interactionsin current and three prior timeslots. To compute a-myCommuni-ties in one timeslot, we consider the interactions occurredthroughout the time window in which the timeslot belonging.Fig. 9 indicates the average ratio of changes in size of a-myCom-munities with same a while considering the interaction withintime windows. The ratio of variations in the new method is smallercompare to the ratio of the previous scheme, since the history ofinteractions between users are considered as well. This shows thatthe resemblance value is sensitive to the size of the window. Inaddition, we present the membership changes of the same
Table 1Membership changes in a-myCommunity of a specific Facebook user through 10different timeslots.
C1 C2 C3 C4 C5 C6 C7 C8 C9 C10
C1 4 4 3 2 4 4 3 1 0 0C2 4 15 15 10 12 12 15 14 12 12C3 3 15 23 12 14 12 14 14 12 10C4 2 10 12 12 11 10 12 10 9 12C5 4 12 14 11 16 11 10 16 11 12C6 4 12 12 10 11 13 13 13 10 11C7 3 15 14 12 10 13 15 15 10 14C8 1 14 14 10 16 13 15 21 12 14C9 0 12 12 9 11 10 10 12 12 12C10 0 12 10 12 12 11 14 14 12 14

α
Fig. 9. The average ratio of changes in size of a-myCommunities by consideringtime-windows.
Table 2Membership changes in a-myCommunity of a specific Facebook user through 10different time-windows.
C1 C2 C3 C4 C5 C6 C7 C8 C9 C10
C1 49 49 49 49 45 45 49 40 38 38C2 49 58 58 58 55 50 55 55 50 51C3 49 58 61 61 58 61 60 58 58 55C4 49 58 61 68 68 67 68 60 65 65C5 45 55 58 68 75 70 65 59 68 67C6 45 50 61 67 70 70 65 60 65 65C7 49 55 60 68 65 65 65 60 65 65C8 40 55 58 60 59 60 60 60 60 60C9 38 50 58 65 68 65 65 60 69 68C10 38 51 55 65 67 65 65 60 68 75
A. Ranjbar, M. Maheswaran / Computer Communications 41 (2014) 11–21 19
Facebook user’s a-myCommunity based on the new method inTable 2. For example, the size of C4 equals to 68 and its intersectionwith C6 is 67. It means that from timeslot 4 to 6, only one memberwas eliminated and three new members were joined thea-myCommunity.
Similarly, we can define resemblance and ratio of variations forblocking lists. We compute the blocking list for each user by con-sidering both timeslots and time windows. The average ratio ofvariations in size of blocking lists for timeslots method is 33 per-cent compare to 10 percent for time window. Finally, we try to findout whether a set of members who are part of a-myCommunityand blocking list exists in every timeslot or time-window. Wedefine this set of users as the core of the community. When weconsider timeslots, the core for a-myCommunity contains 56percent of members comparing to 73 percent by consideringtime-windows. Further, the core for blocking lists in averageincludes 48 percent of members in the first timeslot and 68 percentof members in the first time-window. Therefore, considering timewindows containing the history of interactions between usersresults in more stable a-myCommunities and blocking lists.
4.4. Summary
From the experimental results we can make the following keyobservations.
� The larger the value of a the smaller the size of a-myCommu-nity. This indicates that interactions is OSNs take place intightly knit groups. These groups, however, may not be cleanlydefined by notions such as friends, or friends-of-friends.
� The chosen a value for Facebook users is about 0:7. Thismeans by choosing 0:7-myCommunities Facebook userscan form communities that are robust in terms of informa-tion sharing. The information discharged into such commu-nities are more likely to be contained within them.Similarly, for the Flickr network, we observed an a value of0:8. Instead of asking the user for an a value the algorithmselect the value yielding a robust configuration.
� Blocking the adversary directly may not prevent flow ofinformation to him. This indicates that users can receiveinformation not only directly from the owner, but also indi-rect ways from common friends. However, the indirect waysmay not cleanly defined by existing notions in OSNs.
� Because interactions are time dependent, we evaluated dif-ferent ways of computing a-myCommunities. By includinghistorical information in the computation process, we wereable to compute relatively stable a-myCommunities.
5. Related work
Recently, Relationship-Based Access Control (ReBAC) was pro-posed in [5,23] to express the access control policies in terms ofinterpersonal relationships between users. ReBAC captures thecontextual nature of relationships in OSNs. PriMa [24] is anotherrecently proposed privacy protection mechanism for OSNs. Thepolicy construction algorithm considers factors such as averageprivacy preference of similar and related users, popularity of theowner, and etc. These factors are then combined to generate accesscontrol rules for profile items. While PriMa is a scheme by whichaccess control policies are automatically constructed for users,our proposed method tries to find out the best sharing set basedon users access control policies [25–27]. Similarly, [28] presentsan adaptive modularity-based method for identifying and tracingcommunity structure of dynamic OSNs. Their algorithm canquickly and efficiently update the network structure, and tracethe evolving of its communities over time. Authors of [6] studiedaccess control policies of data co-owned by multiple parties inOSNs setting, in a way that each co-owner may separately specifyher own privacy preference for the shared data. A voting algorithm,using game theory, was adopted to enable the collective enforce-ment of shared data. A complete survey of several privacy preserv-ing techniques and access control model for OSNs is provided byCarminati et al. [29]. Authors of [30] address the problem of infer-ences of private user attributes from public profile attributes, linksand group memberships in OSNs, whereas the effect of socialrelations on sensitive attribute inference was investigated in [31].
Group-centric models have been proposed for secure informa-tion sharing in [32,33]. The authors focus on authorizations involv-ing the temporal aspect of group membership. In addition, theyproposed super distribution (SD) and micro distribution (MD) assolutions for secure information sharing. In SD algorithm, a singlekey is shared amongst all group users, while in MD algorithm theobjects are individually encrypted for each group user. The limita-tions of SD and MD are addressed in [34] where a new hybridapproach is also proposed as a solution. The usage control basedsecurity framework (UCON) for collaborative applications isproposed in [15]. Authors tried to develop a unified frameworkin order to encompass traditional access control, trust manage-ment, and digital rights management. In their framework, policiescan be specified as attributes for subjects and objects, system attri-butes (e.g. conditional constraints), and user actions (e.g. obliga-tions). They defined not only mutable usage attributes of subjectsand objects, but also persistent attributes (e.g. roles and groupmemberships) as general attributes. In addition, UCON uses condi-tions to support context-based authorizations in improvisedcollaborations [16]. The proposed architecture in [16] uses a hybrid

20 A. Ranjbar, M. Maheswaran / Computer Communications 41 (2014) 11–21
approach of attributes acquisitions and event-based updates inorder to support attribute mutability and decision continuity.
Effectively, Dynamic Coalition Problem (DCP) has beenproposed as a new context to be considered in information sharingchallenges [35–37]. This scheme is about forming a coalition in or-der to solve problems through quick information sharing. Utilizingtrust metrics for imposing access restrictions is similar to multi-le-vel security that is proposed in [2] in order to preserve the trust-worthiness of the users’ data in OSNs. Furthermore, [38,3,39]introduce a new discretionary access control model and a relatedenforcement mechanism for the controlled sharing of informationin online social networks. The new scheme adopts a rule-basedapproach for specifying access policies on information owned bynetwork users. In their scheme, authorized users are denoted interms of the type, depth, and trust level of the relationships exist-ing between nodes in the network. The authors of [40–42,7] at-tempt to advance beyond the access control mechanisms foundin commercial social network systems. They develop a decentral-ized social network system with relationship types, trust metricsand degree-of-separation policies.
Carminati et al. [12] used a probability-based approach like oursto estimate the risk of unauthorized propagation of information inOSNs. They used a probability-based approach to model the likeli-hood that information propagates from one social network user tousers who are not authorized to access it. However, we presenteddifferent algorithms to compute the risk values as probabilities forinformation leakage which can be applied to large scale OSNs. Inaddition, we used real world data sets for Facebook and Flickr toevaluate our schemes which is more representative of online socialnetworks than the syntactic small networks used in [12]. Further-more, the sharing pattern shaping scheme (i.e. the blocking schemeto reduce the risk of information leakage) makes a completedistinction between our work and the work done in [12].
In [43], authors present a new OSN called Persona where usersstate who may have access to their information. This OSN usesattribute-based encryption to hide users’ data and allows usersto apply their own policies over who may view their data. Themetadata calculus for used secure information sharing is presentedin [44]. This scheme models the metadata for security as a vector tosupport different operations. It is shown that, without incurringexponential metadata expansion, it is impossible to achieve stronghomomorphism. In addition, Authors of [45,46] present new tech-niques for controlling the information flow in decentralized sys-tems. In [46], authors introduced a new model for controllinginformation flow in systems with mutual distrust and decentral-ized authority. Their model allows users to share information withdistrusted code and to control how that code propagates theshared information to other users. Srivatsa [45] also presents anew trust management paradigm for securing both intra- and in-ter-organizational information flows against the threat of informa-tion disclosure. They proposed an approach for assessing the risksin terms of trustworthiness and improving risk estimations byinvolving estimates of trust. Their approach also provides a mech-anism for handling risk transfer across organizations and forcingrational entities to be honest. Furthermore, Lockr is proposed in[1] as an access control system in order to improve the privacyof OSNs users. Lockr separates the management of social informa-tion from all other functionality of OSNs by letting users exchangedigitally signed attestations. This feature facilitates the integrationof Lockr’s access control with various centralized or decentralizedonline applications. Finally, the access control paradigm behindthe privacy preservation mechanism of Facebook is discussed in[4]. The authors show how their model can be represented tospecify access control policies through different social factors. Inaddition, the authors proposed a privacy-enhanced visualizationtool, which approximates the extended neighborhood of a user in
such a way that policy assessment can still be conducted in ameaningful manner, while the privacy of other users is preserved[47,11,48,49].
6. Conclusions and future work
This paper is based on the premise that information sharing inan OSN cannot be completely controlled by a single user. For in-stance, Alice can determine the set of friends with whom a pieceof data should be shared in the network. However, Alice does nothave complete control over her friends’ actions. When sharing,she trusts that her friends would adhere to the accepted normswith regard to information usage. Some of her friends may adhereto accepted information usage policies and others may not adhereto them.
We proposed a Monte Carlo based algorithm to compute thesharing subgraph which the information will disperse on the net-work. We refer to such subgraphs as a-myCommunity, where aspecifies the certainty that all members of the subgraph will knowabout the information. We used datasets from Flickr and Facebookto compute a-myCommunities for various a values and blockinglists for different adversaries for each individual users. From theexperiments, we noticed that certain a-myCommunities are morerobust with regard to information leakage. Specifically, we noticedthat the chosen a value for Facebook users is equal or greater than0:7 and for Flickr users is equal or greater than 0:8. With these val-ues, the risk of information leakage would be less than one percent.In addition, we noticed that random changes on interaction inten-sity of edges up to 60 percent for Facebook network and up to 50percent for Flickr network have no effect on the blocking lists.Further, we observed that considering the history of interactionsbetween users results in better estimation of a-myCommunityand blocking lists.
This paper was concerned with developing the notion of a-myCommunity and applying it to datasets extracted from actualOSN activities. The major focus of this study has been to validatethe notion of a-myCommunity by illustrating the community-cen-tric information sharing patterns that actually take place withinOSNs. Also, we developed schemes that will allow a user to shapethe a-myCommunity to fit her intention. For instance, if Alicewants to minimize the possibility of information leaking to hernemesis, with our algorithm, she knows how she should shapeher sharing decisions.
In this paper, we considered a single context. That is all userswere concerned about a single topic. In future studies, we will con-sider various contexts. With a diverse array of topics, the networkbecomes heterogeneous. A conversation between two users couldbe about many topics and modeling how much a particular conver-sation contributes towards the propagation of a information objectbecomes a harder problem.
References
[1] A. Tootoonchian, S. Saroiu, A. Wolman, Y. Ganjali, Lockr: better privacy forsocial networks, in: Proceedings of the Fifth CONEXT, 2009.
[2] B. Ali, W. Villegas, M. Maheswaran, A trust based approach for protecting userdata in social networks, in: Proceedings of the Conference of the Center forAdvanced Studies on Collaborative Research, Richmond Hill, Ontario, Canada,2007.
[3] B. Carminati, E. Ferrari, A. Perego, Enforcing access control in web-based socialnetworks, ACM Trans. Inf. Syst. Secur. (TISSEC) 13 (2009) 6:1–6:38.
[4] P.W.L. Fong, M. Anwar, Z. Zhao, A privacy preservation model for facebook-style social network systems, in: Proceedings of the 14th European Conferenceon Research in Computer Security, Saint-Malo, France, 2009.
[5] P.W.L. Fong, Relationship-based access control: protection model and policylanguage, in: Proceedings of the First ACM Conference on Data and ApplicationSecurity and Privacy (CODASPY), San Antonio, Taxas, USA, 2011, pp. 191–202.
[6] A.C. Squicciarini, M. Shehab, J. Wede, Privacy policies for shared content insocial network sites, VLDB J. 19 (2010) 777–796.

A. Ranjbar, M. Maheswaran / Computer Communications 41 (2014) 11–21 21
[7] B. Carminati, E. Ferrari, R. Heatherly, M. Kantarcioglu, B. Thuraisingham, Asemantic web based framework for social network access control, in:Proceedings of the 14th ACM Symposium on Access Control Models andTechnologies, SACMAT ’09, ACM, Stresa, Italy, 2009, pp. 177–186.
[8] J. Domingo-Ferrer, A. Viejo, F. Sebé, ı. González-Nicolás, Privacyhomomorphisms for social networks with private relationships, Comput.Networks: Int. J. Comput. Telecommun. Networking 52 (2008) 3007–3016.
[9] N. Elahi, M.M.R. Chowdhury, J. Noll, Semantic access control in web basedcommunities, in: Proceedings of the Third International Multi-Conference onComputing in the Global Information Technology (ICCGI), IEEE ComputerSociety, Washington, DC, USA, 2008, pp. 131–136.
[10] S.R. Kruk, S. Grzonkowski, A. Gzella, T. Woroniecki, H. Choi, D-foaf: distributedidentity management with access rights delegation, in: Proceesing of the AsianSemantic Web Conference, Lecture Notes in Computer Science, vol. 4185,Springer, 2006, pp. 140–154.
[11] M. Anwar, P.W.L. Fong, X.-D. Yang, H. Hamilton, Visualizing privacyimplications of access control policies in social network systems, in:Proceedings of the Fourth International Workshop on Data PrivacyManagement (DPM’09), Saint Malo, France, 2009, pp. 106–120.
[12] B. Carminati, E. Ferrari, S. Morasca, D. Taibi, A probability-based approach tomodeling the risk of unauthorized propagation of information in on-line socialnetworks, in: Proceedings of the First ACM Conference on Data and ApplicationSecurity and Privacy, CODASPY ’11, ACM, San Antonio, TX, USA, 2011, pp. 51–62.
[13] S. Wasserman, K. Faust, Social Network Analysis: Methods and Applications,Cambridge University Press, 1994.
[14] D. Easley, J. Kleinberg, Networks, Crowds, and Markets: Reasoning About aHighly Connected World, Cambridge University Press, 2010.
[15] J. Park, R. Sandhu, The uconABC usage control model, ACM Trans. Inf. Syst. Secur.(TISSEC) 7 (2004) 128–174.
[16] X. Zhang, M. Nakae, M.J. Covington, R. Sandhu, Toward a usage-based securityframework for collaborative computing systems, ACM Trans. Inf. Syst. Secur.(TISSEC) 11 (2008) 3:1–3:36.
[17] M. Bishop, Computer Security: Art and Science, Addison-Wesley, 2002.[18] J. Ong, UK tribunal upholds Apple’s firing of retail employee for critical
facebook post, apple insider. <http://www.appleinsider.com/articles/11/11/01/uk_tribunal_upholds_apples_firing_of_retail_employee_for_critical_facebook_post.html>, 2011.
[19] M.R. Garey, D.S. Johnson, Computers and Intractability; A Guide to the Theoryof NP-Completeness, W.H. Freeman & Co., New York, NY, USA, 1990.
[20] I.B. Gertsbakh, Y. Shpungin, Models of Network Reliability: Analysis,Combinatorics, and Monte Carlo, CRC Press, 2010.
[21] B. Viswanath, A. Mislove, M. Cha, K.P. Gummadi, On the evolution of userinteraction in facebook, in: Proceedings of the Second ACM SIGCOMMWorkshop on Social Networks (WOSN), 2009.
[22] M. Cha, A. Mislove, K.P. Gummadi, A measurement-driven analysis ofinformation propagation in the flickr social network, in: Proceedings of the18th International World Wide Web Conference (WWW), 2009.
[23] P.W.L. Fong, I. Siahaa, Relationship-based access control policies and theirpolicy languages, in: Proceedings of the 16th ACM Symposium on AccessControl Models and Technologies (SACMAT’11), Innsbruck, Austria, 2011, pp.51–60.
[24] A. Squicciarini, F. Paci, S. Sundareswaran, Prima: an effective privacyprotection mechanism for social networks, in: Proceedings of the Fifth ACMSymposium on Information, Computer and Communications Security(ASIACCS), Beijing, China, 2010, pp. 320–323.
[25] A. Ranjbar, M. Maheswaran, A case for community-centric controls forinformation sharing on online social networks, in: Proceedings of IEEEGLOBECOM Workshop on Complex and Communication Networks (CCNet),Miami, Florida, USA, 2010.
[26] A. Ranjbar, M. Maheswaran, Blocking in community-centric informationmanagement approaches for the social web, in: Proceedings of IEEE GlobalCommunications Conference (GLOBECOM), Texas, USA, 2011.
[27] A. Ranjbar, M. Maheswaran, Community-centric approaches for confidentialitymanagement in online systems, in: Proceedings of 20th IEEE InternationalConference Computer Communication Networks (ICCCN 2011), Hawaii, USA,2011.
[28] N.P. Nguyen, T.N. Dinh, Y. Xuan, M.T. Thai, Adaptive algorithms for detectingcommunity structure in dynamic social networks, in: Proceedings of the 30thIEEE International Conference on Computer Communications (INFOCOM),Shanghai, China, 2011.
[29] B. Carminati, E. Ferrari, M. Kantarcioglu, B. Thuraisingham., Privacy-awareknowledge discovery: novel applications and new techniques, chapter privacyprotection of personal data in social networks, Chapman and Hall/CRC DataMining and Knowledge Discovery Series, 2010.
[30] E. Zheleva, L. Getoor, To join or not to join: the illusion of privacy in socialnetworks with mixed public and private user profiles, in: Proceedings of the18th International Conference on World Wide Web, WWW ’09, ACM, Madrid,Spain, 2009, pp. 531–540.
[31] J. He, W.W. Chu, Z. Liu, Inferring privacy information from social networks, in:IEEE International Conference on Intelligence and Security Informatics, 2006.
[32] R. Krishnan, R. Sandhu, K. Ranganathan, Pei models towards scalable, usableand high-assurance information sharing, in: Proceedings of the 12th ACMSymposium on Access Control Models and Technologies (SACMAT), 2007.
[33] R. Krishnan, R. Sandhu, J. Niu, W.H. Winsborough, Foundations for group-centric secure information sharing models, in: Proceedings of the 14th ACMSymposium on Access Control Models and Technologies (SACMAT), 2009.
[34] R. Krishnan, R. Sandhu, A hybrid enforcement model for group-centric secureinformation sharing, IEEE International Conference on Computational Scienceand Engineering, 2009, pp. 189–194.
[35] C.E. Phillips Jr., T. Ting, S.A. Demurjian, Information sharing and security indynamic coalitions, in: Proceedings of the Seventh ACM Symposium on AccessControl Models and Technologies (SACMAT), 2002.
[36] V. Atluri, J. Warner, Automatic enforcement of access control policies amongdynamic coalitions, in: International Conference on Distributed Computingand Internet Technology, Bhubaneswar, India, 2004.
[37] J. Warner, V. Atluri, R. Mukkamala, J. Vaidya, Using semantics for automaticenforcement of access control policies among dynamic coalitions, in:Proceedings of the 12th ACM Symposium on Access Control Models andTechnologies (SACMAT), Sophia Antipolis, France, 2007, pp. 235–244.
[38] B. Carminati, E. Ferrari, Access control and privacy in web-based socialnetworks, Int. J. Web Inf. Syst. 4 (2008) 395–415.
[39] B. Carminati, E. Ferrari, J. Cao, K.L. Tan, A framework to enforce access controlover data streams, ACM Trans. Inf. Syst. Secur. (TISSEC) 13 (2010) 2:81–2:831.
[40] B. Carminati, E. Ferrari, A. Perego, Rule-based access control for socialnetworks, in: Proceedings of the IFIP WG 2.12 and 2.14 Semantic WebWorkshop, LNCS, vol. 4278, Springer, Montpellier, France, 2006, pp. 1734–1744.
[41] B. Carminati, E. Ferrari, A. Perego, Private relationships in social networks, in:Proceedings of the IEEE 23rd International Conference on Data EngineeringWorkshop (ICDE2007), Istanbul, Turkey, 2007, pp. 163–171.
[42] B. Carminati, E. Ferrari, Privacy-aware collaborative access control in web-based social networks, in: Proceeedings of the 22nd Annual IFIP WG 11.3Working Conference on Data and Applications Security, Springer-Verlag,London, UK, 2008, pp. 81–96.
[43] R. Baden, A. Bender, N. Spring, B. Bhattacharjee, D. Starin, Persona: an onlinesocial network with user-defined privacy, in: Proceedings of the ACMSIGCOMM Conference on Data Communication, Barcelona, Spain, 2009.
[44] M. Srivatsa, D. Agrawal, S. Reidt, A metadata calculus for secure informationsharing, in: Proceedings of the 16th ACM Conference on Computer andCommunications Security (CCS), Chicago, Illinois, USA, 2009, pp. 488–499.
[45] M. Srivatsa, S. Balfe, K.G. Paterson, P. Rohatgi, Trust management for secureinformation flows, in: Proceedings of the 15th ACM Conference on Computerand Communications Security (CCS), Alexandria, Virginia, USA, 2008, pp. 175–188.
[46] A.C. Myers, B. Liskov, A decentralized model for information flow control, in:ACM Symposium on Operating Systems Principles (SOSP), Saint Malo, France,1997, pp. 129–142.
[47] D. Chakrabarti, C. Faloutsos, Y. Zhan, Visualization of large networks with min-cut plots, a-plots and r-mat, Int. J. Human-Comput. Stud. 65 (2007) 343–445.
[48] M. Anwar, P.W.L. Fong., A visualization tool for evaluating access controlpolicies in facebook-style social network systems, in: Proceedings of the 27thACM Symposium on Applied Computing (SAC’12), Security Track, Riva delGarda, Trento, Italy, 2012.
[49] L. Freeman, Visualizing social networks, J. Social Struct. 1 (2000).