unsupervised learning for anomaly intrusion detectionrafea/csce590/spring2015/presentations... ·...
TRANSCRIPT

UNSUPERVISED LEARNING FOR ANOMALY INTRUSION DETECTIONPresented by: Mohamed EL Fadly

Outline
Introduction
Motivation
Problem Definition
Objective
Challenges
Approach
Related Work

Introduction
Anomaly detection is an important problem that has been researched within diverse research areas and application domains.
Many anomaly detection techniques have been specifically developed for certain application domains, while others are more generic.

What are anomalies
Anomaly is a pattern in the data that does not conform to the expected behaviour
Also referred to as outliers, exceptions, peculiarities, surprise, etc.
Anomalies translate to significant (often critical) real life entities Cyber intrusions Credit card fraud

Real World Anomalies
Credit Card Fraud An abnormally high purchase made on a credit card
Cyber Intrusions A web server involved in ftp traffic

Anomaly detection
Anomaly detection triggers alarms when the detected object behaves significantly differently from the predefined normal patterns. Hence, anomaly detection techniques are designed to detect patterns that deviate from an expected normal model built for the data. In cybersecurity, anomaly detection includes the detection of malicious activities, e.g., penetrations and denial of service.
The approach consists of two steps: training and detection.a) In the training step, machine-learning techniques are applied to generate a
profile of normal patterns in the absence of an attack. b) In the detection step, the input events are labeled as attacks if the event
records deviate significantly from the normal profile. Subsequently, anomaly detection can detect previously unknown attacks

Application of Anomaly Detection
Network intrusion detection
Insurance / Credit card fraud detection
Healthcare Informatics / Medical diagnostics
Industrial Damage Detection
Image Processing / Video surveillance
Novel Topic Detection in Text Mining
…

Intrusion Detection
Intrusion Detection: Process of monitoring the events occurring in a computer system or network and analyzing them for intrusions
Intrusions are defined as attempts to bypass the security mechanisms of a computer or network
Challenges Traditional signature-based intrusion detectionsystems are based on signatures of known attacks and cannot detect emerging cyber threats
Substantial latency in deployment of newly created signatures across the computer system
Anomaly detection can alleviate these limitations

Problem Definition
In anomaly detection, labeled data corresponding to normal behavior are usually available, while labeled data for anomaly behavior are not.
Supervised machine-learning methods need attack-free training data. However, this kind of training data is difficult to obtain in real-world network environments. This lack of training data leads to the well-known unbalanced data distribution in machine learning.
In the huge volume of network data, the same malicious data repeatedly occur while the number of similar malicious data is much smaller than the number of normal data. The imbalanced data distribution of normal and anomaly data induces a high false-positive rates (FPRs) of supervised intrusion detection systems (IDSs).

Problem definition
Unsupervised machine learning methods outperform supervised machine-learning methods in updating rules intelligently while the detection rates downgrade.
Thus anomaly detection systems can potentially find new attacks, but they generally have a lower accuracy rate for detection and a higher FAR.
The problem we must solve is how to minimize the false negative and false positive rates while keeping higher accuracy rates

Objective
To propose an unsupervised anomaly detection technique that will produce low false positive rates and to overcome challenges in using labeled data sets for supervised learning, such as time consumption, expensiveness, limitation of expertise, and the accuracy of labels in collecting labeled data.

Why unsupervised
To overcome the problem of using attack-free training data required by supervised learning. Moreover, with the changing network environment or services, patterns of normal traffic will change. The differences between the training and actual data can lead to high FPRs of supervised IDSs.
To address these problems, unsupervised anomaly detection emerges to take unlabeled data as input.
Unsupervised anomaly detection aims to find malicious information buried in cyberinfrastructure even without prior knowledge about the data labels and new attacks. Subsequently, unsupervised anomaly detection methods rely on the following assumptions: normal data covers majority while anomaly data are minor in network traffic flow or audit logs.
That’s why most of the solutions to unsupervised anomaly detection are clustering-based anomaly/outlier detection techniques.
Challenges
1. The key challenge is that the huge volume of data with high-dimensional feature space is difficult to manually analyze and monitor. Such analysis and monitoring requires highly efficient computational algorithms in data processing and pattern learning.
2. Much of the data is streaming data, which requires online analysis.
3. It is also difficult to define a representative normal region or the boundary between normal and outlying behavior. As the concept of an anomaly/outlier varies among application domains
4. The labeled anomalies are not available for training/validation.
5. Training and testing data might contain unknown noises
6. Normal and anomaly behaviors constantly evolve.

Approach
The below aspects should be considered when choosing my approach
1. Nature of input data
2. Availability of supervision
3. Type of anomaly: point, contextual, structural
4. Output of anomaly detection
5. Evaluation of anomaly detection techniques

Input Data
Most common form of data handled by anomaly detection techniques is Record Data Univariate Multivariate
Tid SrcIP Starttime Dest IP Dest
PortNumberof bytes Attack
1 206.135.38.95 11:07:20 160.94.179.223 139 192 No
2 206.163.37.95 11:13:56 160.94.179.219 139 195 No
3 206.163.37.95 11:14:29 160.94.179.217 139 180 No
4 206.163.37.95 11:14:30 160.94.179.255 139 199 No
5 206.163.37.95 11:14:32 160.94.179.254 139 19 Yes
6 206.163.37.95 11:14:35 160.94.179.253 139 177 No
7 206.163.37.95 11:14:36 160.94.179.252 139 172 No
8 206.163.37.95 11:14:38 160.94.179.251 139 285 Yes
9 206.163.37.95 11:14:41 160.94.179.250 139 195 No
10 206.163.37.95 11:14:44 160.94.179.249 139 163 Yes1 0
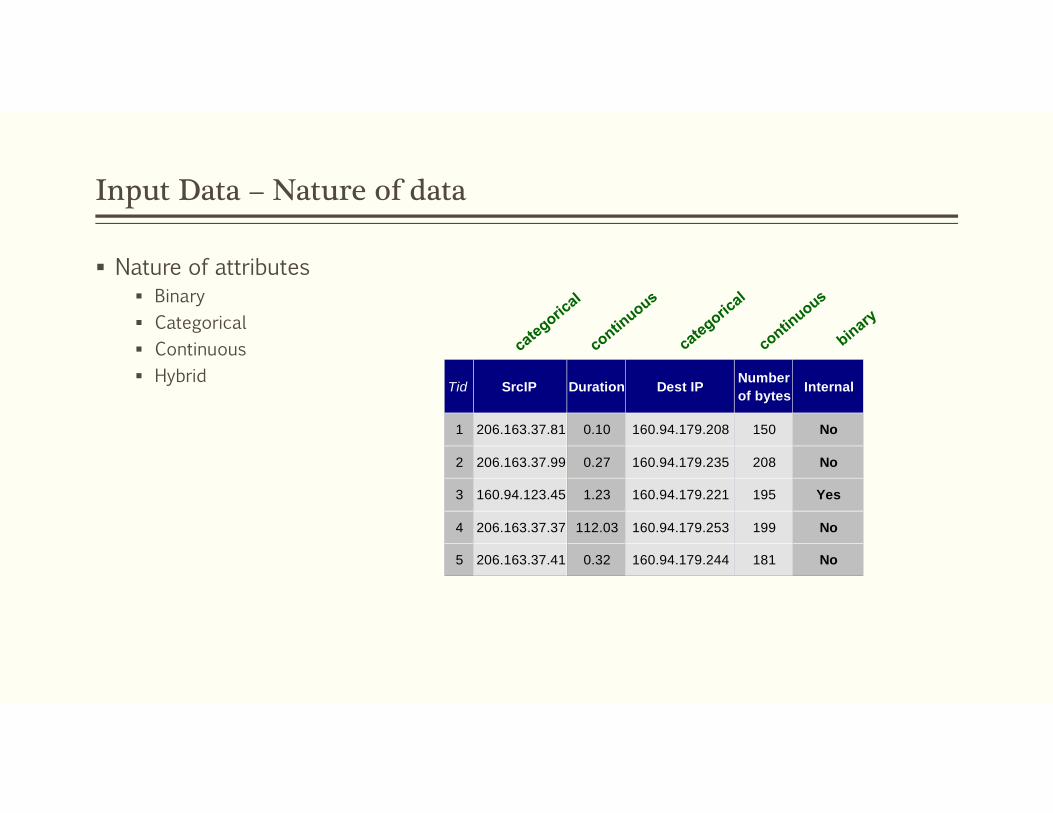
Input Data – Nature of data
Nature of attributes Binary Categorical Continuous Hybrid
Tid SrcIP Duration Dest IP Numberof bytes Internal
1 206.163.37.81 0.10 160.94.179.208 150 No
2 206.163.37.99 0.27 160.94.179.235 208 No
3 160.94.123.45 1.23 160.94.179.221 195 Yes
4 206.163.37.37 112.03 160.94.179.253 199 No
5 206.163.37.41 0.32 160.94.179.244 181 No

Supervision – Data Label
Supervised Anomaly Detection Labels available for both normal data and anomalies
Unsupervised Anomaly Detection No labels assumed; based on the assumption that anomalies are very rare compared to normal data
Semi-supervised Anomaly Detection Labels available only for normal data Use modified classification model to learn the normal behaviour and then detect any deviations
from normal behaviour as anomalous

Type of anomaly
Point Anomalies:
Contextual Anomalies
Collective Anomalies
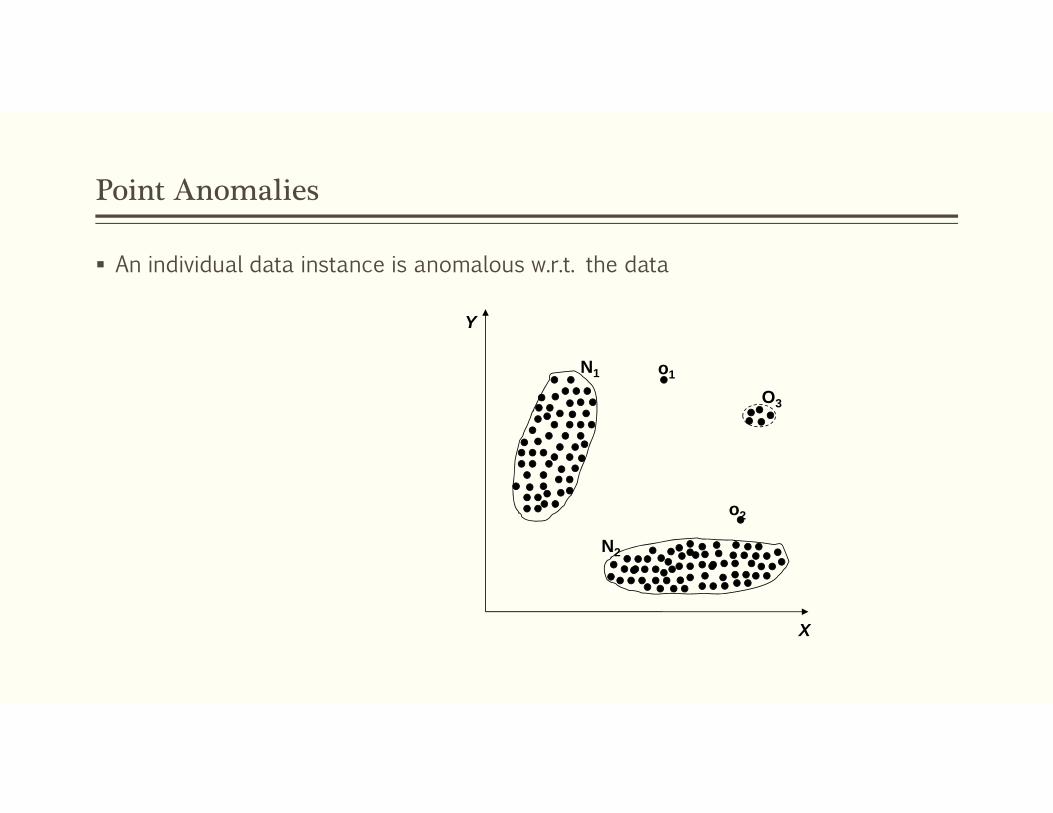
Point Anomalies
An individual data instance is anomalous w.r.t. the data
X
Y
N1
N2
o1
o2
O3
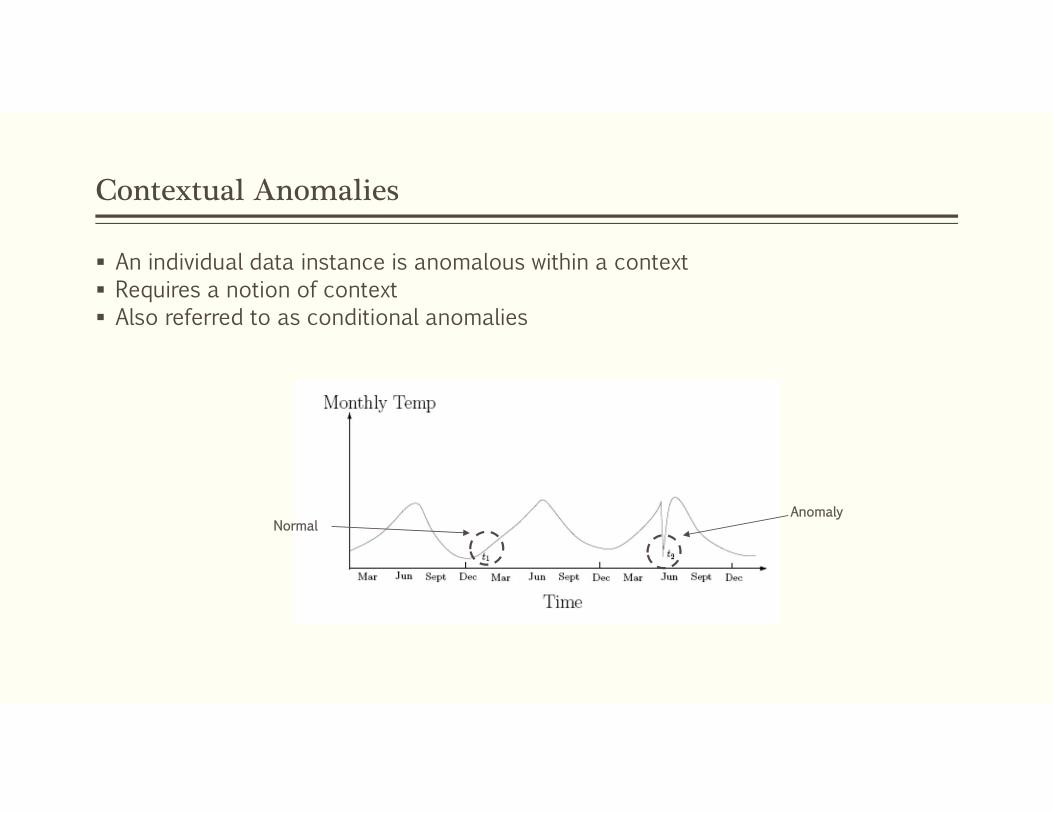
Contextual Anomalies
An individual data instance is anomalous within a context Requires a notion of context Also referred to as conditional anomalies
AnomalyNormal

Collective Anomalies
A collection of related data instances is anomalous Requires a relationship among data instances
Sequential Data Spatial Data Graph Data
The individual instances within a collective anomaly are not anomalous by themselves
Anomalous Subsequence

Output of anomaly Detection
Label Each test instance is given a normal or anomaly label This is especially true of classification-based approaches
Score Each test instance is assigned an anomaly score
Allows the output to be ranked Requires an additional threshold parameter

Evaluation of Anomaly Detection – F-value
Accuracy is not sufficient metric for evaluation Example: network traffic data set with 99.9% of normal data and 0.1% of intrusions Trivial classifier that labels everything with the normal class can achieve 99.9% accuracy !!!!!
Predicted class
Confusion matrix
NC C NC TN FP Actual
class C FN TP
• Focus on both recall and precision– Recall (R) = TP/(TP + FN) – Precision (P) = TP/(TP + FP)
• F – measure = 2*R*P/(R+P)
anomaly class – C
normal class – NC

Evaluation of Outlier Detection – ROC
Standard measures for evaluating anomaly detection problems: Recall (Detection rate) - ratio between the number of correctly detected anomalies and the total number of anomalies False alarm (false positive) rate – ratio between the number of data records from normal class that are misclassified as anomalies and the total number of data records from normal class ROC Curve is a trade-off between detection rate and false alarm rate Area under the ROC curve (AUC) is computed using a trapezoid rule
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1ROC curves for different outlier detection techniques
False alarm rate
Det
ectio
n ra
te
AUC

Possible approach
Anomaly Detection
Contextual Anomaly Detection
Collective Anomaly Detection
Online Anomaly Detection
Distributed Anomaly Detection
Point Anomaly Detection
Classification BasedRule BasedNeural Networks BasedSVM Based
Nearest Neighbor BasedDensity BasedDistance Based
StatisticalParametricNon-parametric
Clustering Based OthersInformation Theory BasedSpectral Decomposition BasedVisualization Based

Clustering Based Techniques
Key assumption: normal data records belong to large and dense clusters, while anomalies belong do not belong to any of the clusters or form very small clustersCategorization according to labels Semi-supervised – cluster normal data to create modes of normal behavior. If a new instance does not belong to any of the clusters or it is not close to any cluster, is anomaly Unsupervised – post-processing is needed after a clustering step to determine the size of the clusters and the distance from the clusters is required fro the point to be anomaly
Anomalies detected using clustering based methods can be: Data records that do not fit into any cluster (residuals from clustering) Small clusters Low density clusters or local anomalies (far from other points within the same cluster)

Clustering Based Techniques
Advantages: No need to be supervised Easily adaptable to on-line / incremental mode suitable for anomaly detection from temporal data
Drawbacks Computationally expensive Using indexing structures (k-d tree, R* tree) may alleviate this problem
In high dimensional spaces, data is sparse and distances between any two data records may become quite similar. Clustering algorithms may not give any meaningful clusters

Related work
1. A Near Real-Time Algorithm for Autonomous Identification and Characterization of Honeypot Attacks
ASIA CCS '15 Proceedings of the 10th ACM Symposium on Information, Computer and Communications Security
Owezarski presents an unsupervised algorithm - called UNADA for Unsupervised Network Anomaly Detection Algorithm - for identification and characterization of security related anomalies and attacks occurring in honeypots.
What is interested that their method does not need any attack signature database, learning phase, or labeled traffic

Related Work
This algorithm has several advantages
1. It works in a completely unsupervised manner, what makes it able to work on top of any monitoring system, and directly usable, without preliminary configuration or knowledge.
2. It combines robust clustering techniques to avoid classical issues of clustering algorithms, e.g. sensitivity to initial configuration, the required a priori indication of the number of clusters to be identified, or the sensitivity of results when using less pertinent features.
3. It automatically builds simple and small signatures fully characterizing attacks; theses signature can then be used in a filtering security device.
4. It is designed to run in real time by making possible to take advantage of the parallelism of their clustering approach.

Evaluation – true Positive rates vs False alarms
They run their algorithm on the honeypot traffic traces gathered at the University of Maryland
They compare the performance of UNADA against three previous approaches for unsupervised anomaly detection:
DBSCAN-based, k-means-based, and PCA-based
outliers detection.

Related Work
2- Enhancing One-class Support Vector Machines for Unsupervised Anomaly DetectionProceeding ODD '13 Proceedings of the ACM SIGKDD Workshop on Outlier Detection and Description
Amer et.al have applied apply two modifications in order to make one-class SVMs more suitable for unsupervised anomaly detection: Robust one class SVMs and eta one-class SVMs.
The key idea of both modifications is, that outliers should contribute less to the decision boundary as normal instances.
Experiments performed on datasets from UCI machine learning repository show that their modifications are very promising: Comparing with other standard unsupervised anomaly detection algorithms, the enhanced one-class SVMs are superior on two out of four datasets.
In particular, the proposed eta oneclass SVM has shown the most promising results.

Results
Comparing the AUC of SVM based algorithms against other anomaly detection algorithms
Dataset used for evaluation
ROC Curve

Related Work
An Unsupervised Anomaly Detection Engine With an Efficient Feature set for AODV
Published in: Information Security and Cryptology (ISCISC), 2013 10th International ISC Conference
They proposed an anomaly detection engine by collecting decent features and applying robust PCA on the data set.
The results showed their features can detect much more attacks either by applying PCA or by applying robust PCA.
Their contribution in using the Robust PCA, through having an unsupervised algorithm that detect anomaly more accurate.
The robust PCA can form the baseline profile even by existence of malicious nodes in the learning phase
Their results show robust PCA cannot be affected by outlier data within the network

References
1- Philippe Owezarski. 2015. A Near Real-Time Algorithm for Autonomous Identification and Characterization of Honeypot Attacks. In Proceedings of the 10th ACM Symposium on Information, Computer and Communications Security (ASIA CCS '15). ACM, New York, NY, USA, 531-542.
2- Mennatallah Amer, Markus Goldstein, and Slim Abdennadher. 2013. Enhancing one-class support vector machines for unsupervised anomaly detection. In Proceedings of the ACM SIGKDD Workshop on Outlier Detection and Description (ODD '13). ACM, New York, NY, USA, 8-15
3- Houri Zarch, M.K.; Abedini, M.; Berenjkoub, M.; Mirhosseini, A., "An unsupervised anomaly detection engine with an efficient feature set for AODV," Information Security and Cryptology (ISCISC), 2013 10th International ISC Conference on , vol., no., pp.1,6, 29-30 Aug. 2013
4- Sumeet Dua and Xian Du. Data Mining and Machine Learning in cybersecurity. April 25, 2011 by Auerbach Publications
5- Varun Chandola, Arindam Banerjee, and Vipin Kumar. 2009. Anomaly detection: A survey. ACM Comput. Surv. 41, 3, Article 15 (July 2009), 58 pages
6- Yingbing Yu. 2012. A survey of anomaly intrusion detection techniques. J. Comput. Sci. Coll. 28, 1 (October 2012), 9-17.
7- Phil Simon. Too Big to Ignore: The Business Case for Big Data. Wiley, 2013
8- Taiwo Oladipupo Ayodele. New Advances in Machine Learning. InTech, 2010.
9- Harjinder Kaur, Gurpreet Singh, Jaspreet Minhas, “A Review of Machine Learning based Anomaly Detection Techniques”