universidad nacional autónoma de nicaragua unan … · • la función de distribución acumulada...
TRANSCRIPT

Universidad Nacional Autónoma de NicaraguaUNAN-Managua
Curso de Estadística
UNIDAD III
Variables Aleatorias
Y
Distribuciones de probabilidades
Estudiantes:
FAREM-Carazo
Profesor:
MSc. Julio Rito
Vargas Avilés.
II Semestre 2010
Año académico:
La duración de las clases prácticas será de 90 mínutosininterrumpidas. Durante este tiempo se irán realizando lasprácticas, las tareas y el Trabajo de curso.
Paquetes Informáticos
PROFESOR
Material Bibliográfico
Fuentes Estadísticas
PAGINA W E BPAGINA W E B
Aula Virtual
Clases Practicas
CONSULTAS VIRTUALES
BLOG (PÁGINA WEB)

3
Variable aleatoria
• El resultado de un experimento aleatorio puede ser descrito en ocasiones como una cantidad numérica.
• En estos casos aparece la noción de variable aleatoria– Función que asigna a cada suceso un número real
• Las variables aleatorias pueden ser discretas o continuas.
• En las siguientes transparencias vamos a recordar conceptos de temas anteriores, junto con su nueva designación. Los nombres son nuevos. Los conceptos no.

Definición
• El conjunto de pares ordenados (x,f(x)) es una función deprobabilidad o distribución de probabilidad de la variablealeatoria discreta X si, para cada resultado posible x:
1. f(X)≥0 (todos los f(x) son positivos o cero)
2. ∑f(x)=1 (la suma de todos los f(x) es igual a la prob. total1)
3. P(X=x)=f(x)

Ejemplo 1
• Una empresa importadora recibe 8 microcomputadoras de lascuales tres están defectuosas. Las cuales son enviadas a undistribuidor. Un turista compra aleatoriamente dosmicrocomputadoras de ese lote. Encuentre la distribución deprobabilidad para el número de microcomputadorasdescompuestas.
Sea X: la variable aleatoria, cuyos valores x son los posiblesnúmeros de computadoras defectuosas compradas por elturista. Entonces x puede ser cualquiera de los números 0,1,2.

Solución
28
10
!6!2
!8!3!2
!5
!3!0
!3
2
8
2
5
0
3
)0(
xf
28
15
!6!2
!8!4!1
!5
!2!1
!3
2
8
1
5
1
3
)1(
xf
28
3
!6!2
!8!5!0
!5
!1!2
!3
2
8
0
5
2
3
)2(
xf
x 0 1 2
f(x) 10/28 15/28 3/28
0.00
0.10
0.20
0.30
0.40
0.50
0.60
1 2 3
f(x)
f(x)
0 1 2 x

Ejemplo 2
• El 50% de los automóviles que renta una agencia de turismoson de diesel, encuentre la distribución de probabilidad delnúmero de automóviles diesel entre los próximos 4automóviles que se renta en esta agencia.
Sea X: la variable aleatoria, cuyos valores x son los posiblesautomóviles diesel que se rentan para turistas. Entonces xpuede ser cualquiera de los números 0,1,2,3,4.

0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
0.40
1 2 3 4 5
f(x)
f(x)
SoluciónYa que la probabilidad de rentar un modelo diesel
O de gasolina es 0.5. Los 24 puntos del espacio
muestral tienen la misma posibilidad de ocurrir.
42
4
)(x
xf
x 0 1 2 3 4
f(x) 1/16 4/16 6/16 4/16 1/16
0 1 2 3 4 x
16
1
16
!4!0
!4
2
0
4
)0(4
xf
16
4
16
!3!1
!4
2
1
4
)1(4
xf
16
6
16
!2!2
!4
2
2
4
)2(4
xf
16
4
16
!1!3
!4
2
3
4
)3(4
xf
16
1
16
!0!4
!4
2
4
4
)4(4
xf

9
Función de probabilidad (V. Discretas)
• Asigna a cada posible valor de una variable discreta su probabilidad.
• Recuerda los conceptos de frecuencia relativa y diagrama de barras.
• Ejemplo
– Número de caras al lanzar 3 monedas. 0%
5%
10%
15%
20%
25%
30%
35%
40%
0 1 2 3

10
Función de distribución (V. discreta)
• La función de distribución acumulada F(x) de una variable aleatoria discreta X, cuya función de probabilidad es f(x) es:
– A los valores extremadamente bajos les corresponden valores de la función de distribución cercanos a cero.
– A los valores extremadamente altos les corresponden valores de la función de distribución cercanos a uno.
xtfxXPxFxt
- para )()()(
11
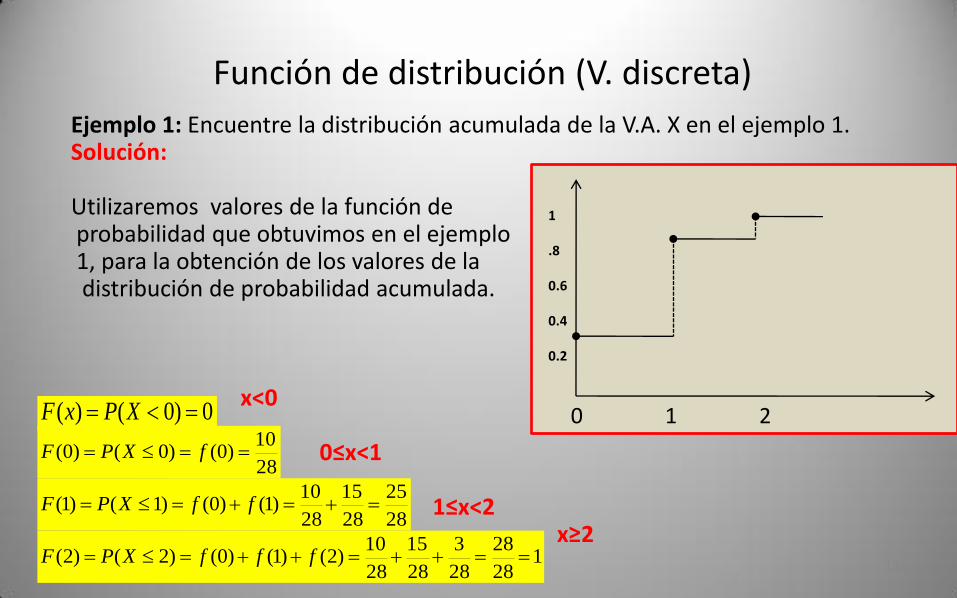
Función de distribución (V. discreta)
Ejemplo 1: Encuentre la distribución acumulada de la V.A. X en el ejemplo 1. Solución:
Utilizaremos valores de la función deprobabilidad que obtuvimos en el ejemplo 1, para la obtención de los valores de la distribución de probabilidad acumulada.
x<0
0≤x<1
1≤x<2 x≥2
28
10)0()0()0( fXPF
28
25
28
15
28
10)1()0()1()1( ffXPF
128
28
28
3
28
15
28
10)2()1()0()2()2( fffXPF
0 1 2
1
.8
0.6
0.4
0.2
0)0()( XPxF
12
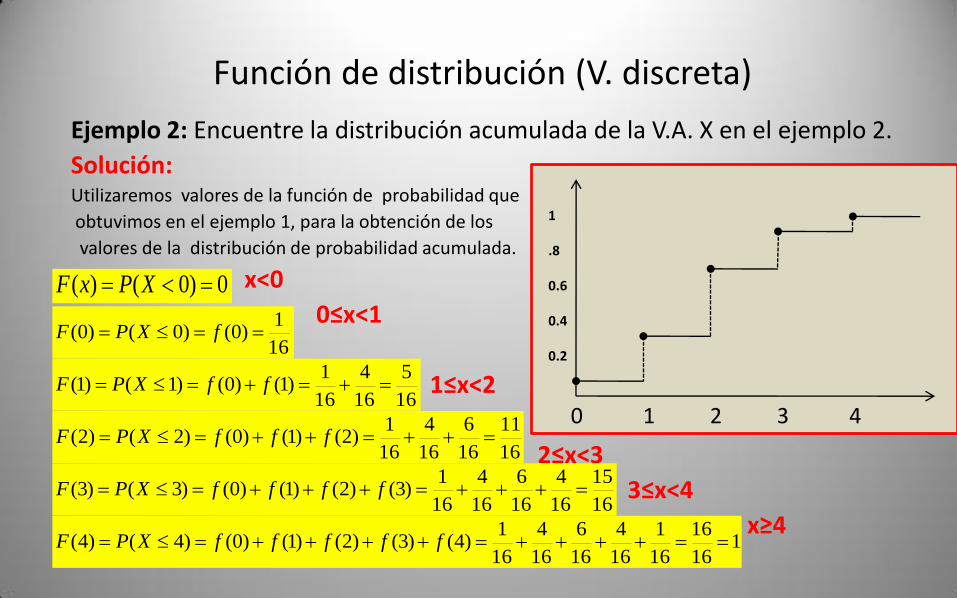
Función de distribución (V. discreta)
Ejemplo 2: Encuentre la distribución acumulada de la V.A. X en el ejemplo 2.
Solución:Utilizaremos valores de la función de probabilidad que
obtuvimos en el ejemplo 1, para la obtención de los
valores de la distribución de probabilidad acumulada.
x<0
0≤x<1
1≤x<2
2≤x<3
3≤x<4
x≥4
16
1)0()0()0( fXPF
16
5
16
4
16
1)1()0()1()1( ffXPF
16
11
16
6
16
4
16
1)2()1()0()2()2( fffXPF
16
15
16
4
16
6
16
4
16
1)3()2()1()0()3()3( ffffXPF
116
16
16
1
16
4
16
6
16
4
16
1)4()3()2()1()0()4()4( fffffXPF
0 1 2 3 4
1
.8
0.6
0.4
0.2
0)0()( XPxF

Tema 5: Modelos probabilísticos
13
Valor esperado y varianza de una v.a. X
• Valor esperado
Sea X una V.A. Discreta, con distribución de probabilidad f(x). La media o Valor esperado de X es:
E*X+= μ=∑x(fx)Ejemplo 1: Encuentre el valor esperado de Licenciadoen Turismo que forman parte de comité de tresmiembros que se seleccionan al azar de un grupo de 3Licenciado en Turismo y cuatro Administradores deEmpresas.

Tema 5: Modelos probabilísticos
14
Valor esperado y varianza de una v.a. X
Si se realizan los cálculos correspondientes. Se obtiene lo siguiente:
E(x)=(0)(4/35) +(1)(18/35)+(2)(12/35)
+ (3)(1/35)= 0+0.51+0.69+0.086
E(x)= 1.29
35
4
!4!3
!7!1!3
!4
!3!0
!3
3
7
3
4
0
3
)0(
xf
35
18
!4!3
!7!2!2
!4
!2!1
!3
3
7
2
4
1
3
)1(
xf
35
12
!4!3
!7!3!1
!4
!1!2
!3
3
7
1
4
2
3
)2(
xf
35
1
!4!3
!7!4!0
!4
!0!3
!3
3
7
0
4
3
3
)3(
xf
x 0 1 2 3
f(x) 4/35 18/35 12/35 1/35

Tema 5: Modelos probabilísticos
15
Valor esperado y varianza de una v.a. X
• Varianza
– Se representa mediante VAR*X+ o σ2
– Es el equivalente a la varianza
– Se llama desviación típica a σ

Tema 5: Modelos probabilísticos
16
Algunos modelos de v.a.
• Hay v.a. que aparecen con frecuencia en diferentes las Ciencias.– Experimentos dicotómicos.
• Bernoulli
– Contar éxitos en experimentos dicotómicos repetidos:• Binomial• Poisson (sucesos raros)• Distribución Hipergeométrica
– Y en otras muchas ocasiones…• Distribución normal (gaussiana, campana,…)• Distribución t student (aproximamente normal) • Distribución Chi cuadrada, F de Snedecor
• El resto del tema está dedicado a estudiar estas distribuciones especiales.

Tema 5: Modelos probabilísticos
17
Distribución de Bernoulli
• Tenemos un experimento de Bernoulli si al realizar un experimentos sólo son posibles dos resultados:– X=1 (éxito, con probabilidad p)– X=0 (fracaso, con probabilidad q=1-p)
• Lanzar una moneda y que salga cara.– p=1/2
• Elegir una persona de la población y que esté enfermo.– p=1/1000 = prevalencia de la enfermedad
• Aplicar un tratamiento a un enfermo y que éste se cure.– p=95%, probabilidad de que el individuo se cure
• Como se aprecia, en experimentos donde el resultado es dicotómico, la variable queda perfectamente determinada conociendo el parámetro p.

Tema 5: Modelos probabilísticos
18
Ejemplo de distribución de Bernoulli.
• Se ha observado estudiando 2000 accidentes de tráfico con impacto frontal y cuyos conductores no tenían cinturón de seguridad, que 300 individuos quedaron con secuelas. Describa el experimento usando conceptos de v.a.
• Solución.– La noción frecuentista de probabilidad nos permite aproximar la probabilidad
de tener secuelas mediante 300/2000=0,15=15%
– X=“tener secuelas tras accidente sin cinturón” es variable de Bernoulli
• X=1 tiene probabilidad p ≈ 0,15• X=0 tiene probabilidad q ≈ 0,85

Tema 5: Modelos probabilísticos
19
Ejemplo de distribución de Bernoulli.
• Se ha observado estudiando 2000 accidentes de tráfico con impacto frontal y cuyos conductores sí tenían cinturón de seguridad, que 10 individuos quedaron con secuelas. Describa el experimento usando conceptos de v.a.
• Solución.– La noción frecuentista de probabilidad nos permite aproximar la probabilidad
de quedar con secuelas por 10/2000=0,005=0,5%
– X=“tener secuelas tras accidente usando cinturón” es variable de Bernoulli
• X=1 tiene probabilidad p ≈ 0,005• X=0 tiene probabilidad q ≈ 0,995

Tema 5: Modelos probabilísticos
20
Observación• En los dos ejemplos anteriores hemos visto cómo enunciar los resultados de
un experimento en forma de estimación de parámetros en distribuciones de Bernoulli.– Sin cinturón: p ≈ 15%– Con cinturón: p ≈ 0,5%
• En realidad no sabemos en este punto si ambas cantidades son muy diferentes o aproximadamente iguales, pues en otros estudios sobre accidentes, las cantidades de individuos con secuelas hubieran sido con seguridad diferentes.
• Para decidir si entre ambas cantidades existen diferencias estadísticamente significativas necesitamos introducir conceptos de estadística inferencial(extrapolar resultados de una muestra a toda la población).
21
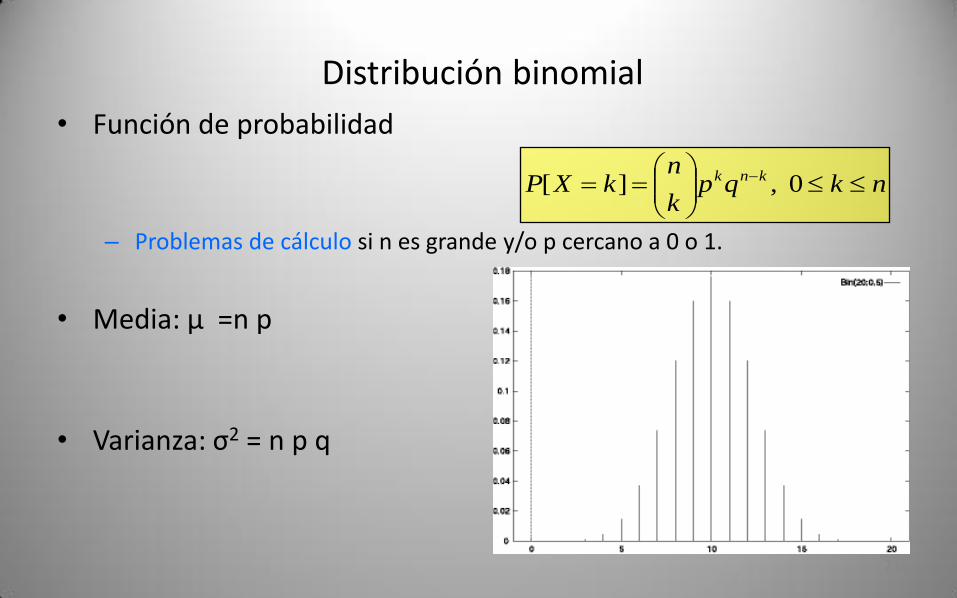
Distribución binomial
• Función de probabilidad
– Problemas de cálculo si n es grande y/o p cercano a 0 o 1.
• Media: μ =n p
• Varianza: σ2 = n p q
nkqpk
nkXP knk
0 ,][

Tema 5: Modelos probabilísticos
22
Distribución Binomial
• Si se repite un número fijo de veces, n, un experimento de Bernoulli con parámetro p, el número de éxitos sigue una distribución binomial de parámetros (n,p).
• Lanzar una moneda 10 veces y contar las caras.– Bin(n=10,p=1/2)
• Cuál es la probabilidad de obtener al menos 4 caras en 10 lanzamientos de una moneda
P(X≤4) =F(4)=CDF.BINOM(4,10,0.5)=0.376953• Lanzar una moneda 100 veces y contar las caras.
– Bin(n=100,p=1/2)– Difícil hacer cálculos con esas cantidades. El modelo normal será más adecuado.
• El número de personas que enfermará (en una población de 500.000 personas) de una enfermedad que desarrolla una de cada 2000 personas.
– Bin(n=500.000, p=1/2000)» Difícil hacer cálculos con esas cantidades. El modelo de Poisson será más adecuado.
23
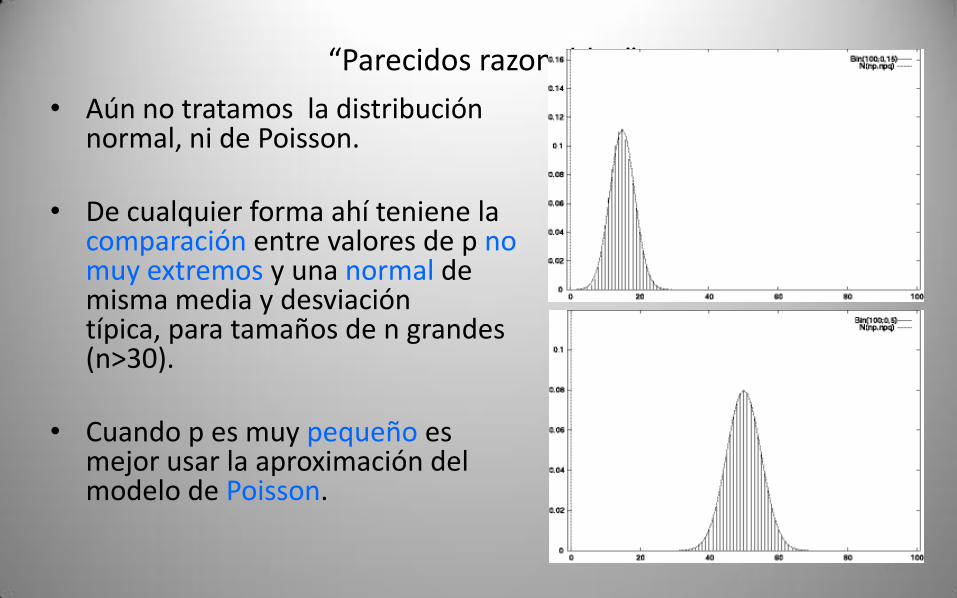
“Parecidos razonables”
• Aún no tratamos la distribución normal, ni de Poisson.
• De cualquier forma ahí teniene la comparación entre valores de p no muy extremos y una normal de misma media y desviación típica, para tamaños de n grandes (n>30).
• Cuando p es muy pequeño es mejor usar la aproximación del modelo de Poisson.

24
Distribución de Poisson
• También se denomina de sucesos raros.
• Se obtiene como aproximación de una distribución binomial con la misma media, para ‘n grande’ (n>30) y ‘p pequeño’ (p<0,1).
• Queda caracterizada por un único parámetro μ (λ) (que es a su vez su media y varianza.)
• Función de probabilidad:
,...2,1,0 ,!
][ kk
ekXPk

Tema 5: Modelos probabilísticos
25
Ejemplos de variables de Poisson
• El número de individuos que será atendido un día cualquiera en el servicio de urgencias del hospital clínico universitario.– En Managua hay 1,000.000 habitantes (n grande)– La probabilidad de que cualquier persona tenga un accidente es pequeña, pero no
nula. Supongamos que es 3/10000– Bin(n=1,000.000,p=3/10000) ≈ Poisson(μ=np=300)
• Sospechamos que diferentes hospitales pueden tener servicios de traumatología de diferente “calidad” (algunos presentan pocos, pero creemos que aún demasiados, enfermos con secuelas tras la intervención). Es dificil compararlos pues cada hospital atiende poblaciones de tamaños diferentes (ciudades, pueblos,…)– Tenemos en cada hospital n, nº de pacientes atendidos o nº individuos de la población
que cubre el hospital.– Tenemos p pequeño calculado como frecuencia relativa de secuelas con respecto al
total de pacientes que trata el hospital, o el tamaño de la población,…– Se puede modelar mediante Poisson(μ=np)

Tema 5: Modelos probabilísticos
26
Distribución Hipergeométrica
• La distribución de probabilidad de la variable aleatoriahipergeométrica X, el números de éxitos en una muestraaleatoria de tamaño n seleccionada a N resultados posibles, delos cuales k son considerados como éxitos y N-k como fracasoses:
n0,1,2,.., x,),,;(
n
N
xn
kN
x
k
knNxh
N
nk
N
k
N
kn
N
nN1
1
2

Ejemplo• Un crucero que llega San Juan del Sur trae 50 turistas
Europeos, de los cuales 5 tienen VIH, si 10 de los los turistasestablecen relaciones sentimentales con personasnicaragüenses, cual es la probabilidad de que exactamente 2de ellos tienen VIH.
N=300; n=30 ; k=10, x=2
0.20983972
!40!10
!50!37!8
!45
!3!2
!5
10
50
210
550
2
5
)5;10;50;2(
h

Ejemplo• Cual es la probabilidad que una mesera se niegue a servir
bebidas alcohólicas únicamente a dos menores de edad, si verifica aleatoriamente sólo cinco de 9 estudiantes de los cuales 4 no tienen la edad suficiente.
N=9; n=5 ; k=4, x=2
476.0126
106
!4!5
!9!2!3
!5
!2!2
!4
5
9
25
49
2
4
)4;5;9;2(
x
h
29
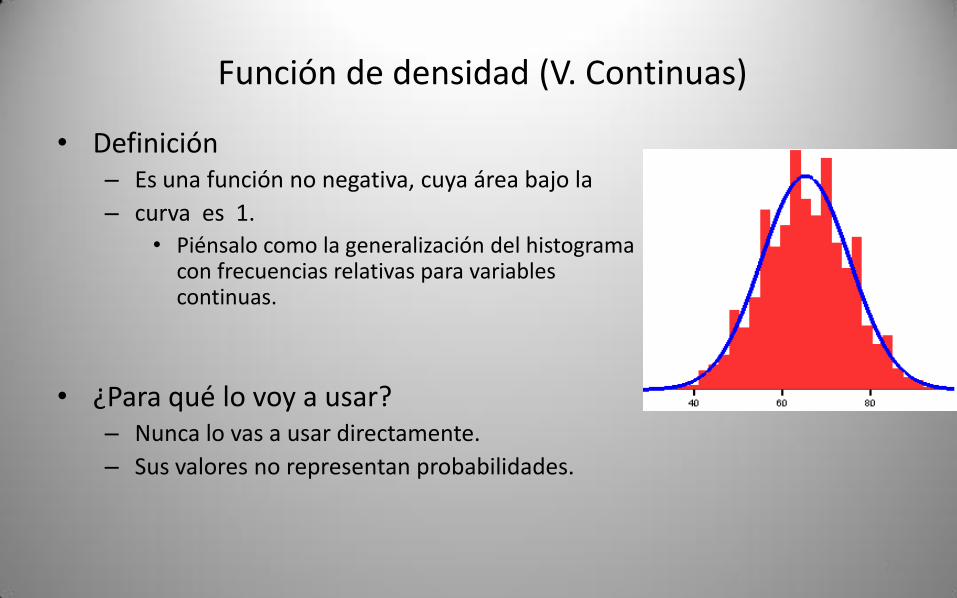
Función de densidad (V. Continuas)
• Definición– Es una función no negativa, cuya área bajo la
– curva es 1.
• Piénsalo como la generalización del histograma con frecuencias relativas para variables continuas.
• ¿Para qué lo voy a usar?– Nunca lo vas a usar directamente.
– Sus valores no representan probabilidades.
30
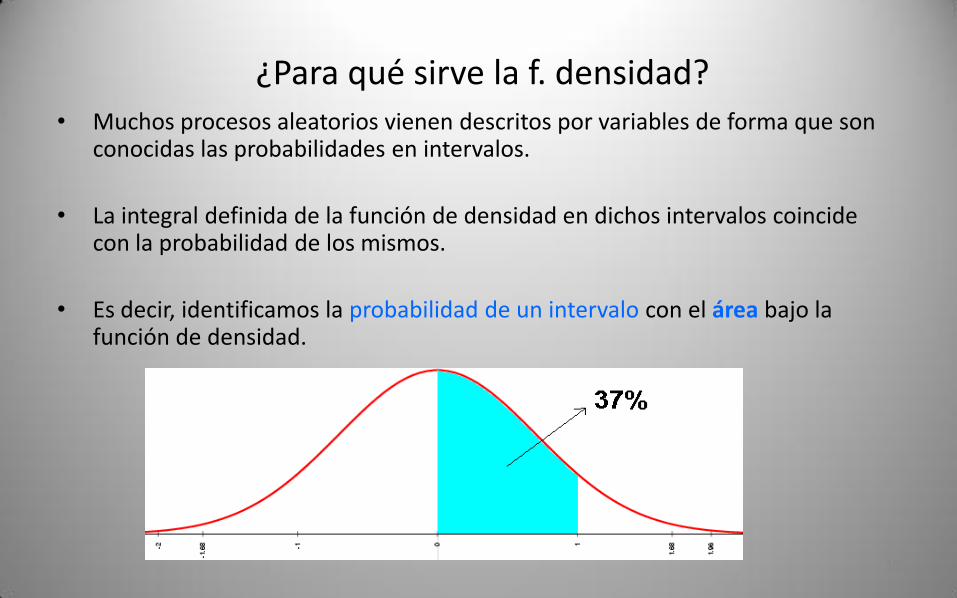
¿Para qué sirve la f. densidad?• Muchos procesos aleatorios vienen descritos por variables de forma que son
conocidas las probabilidades en intervalos.
• La integral definida de la función de densidad en dichos intervalos coincide con la probabilidad de los mismos.
• Es decir, identificamos la probabilidad de un intervalo con el área bajo la función de densidad.

32
Distribución normal o de Gauss
• Aparece de manera natural:– Errores de medida.
– Distancia de frenado.
– Altura, peso, propensión al crimen…
– Distribuciones binomiales con n grande (n>30) y ‘p ni pequeño’ (np>5) ‘ni grande’ (nq>5).
• Está caracterizada por dos parámetros: La media, μ, y la desviación típica, σ.
• Su función de densidad es:
2
2
1
2
1)(
x
exf
33
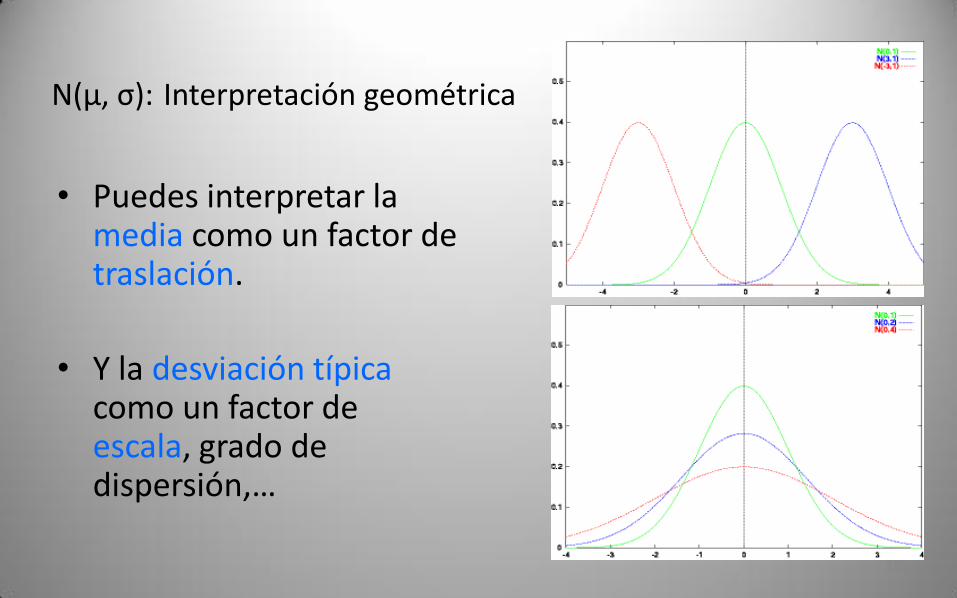
N(μ, σ): Interpretación geométrica
• Puedes interpretar la media como un factor de traslación.
• Y la desviación típicacomo un factor de escala, grado de dispersión,…
34
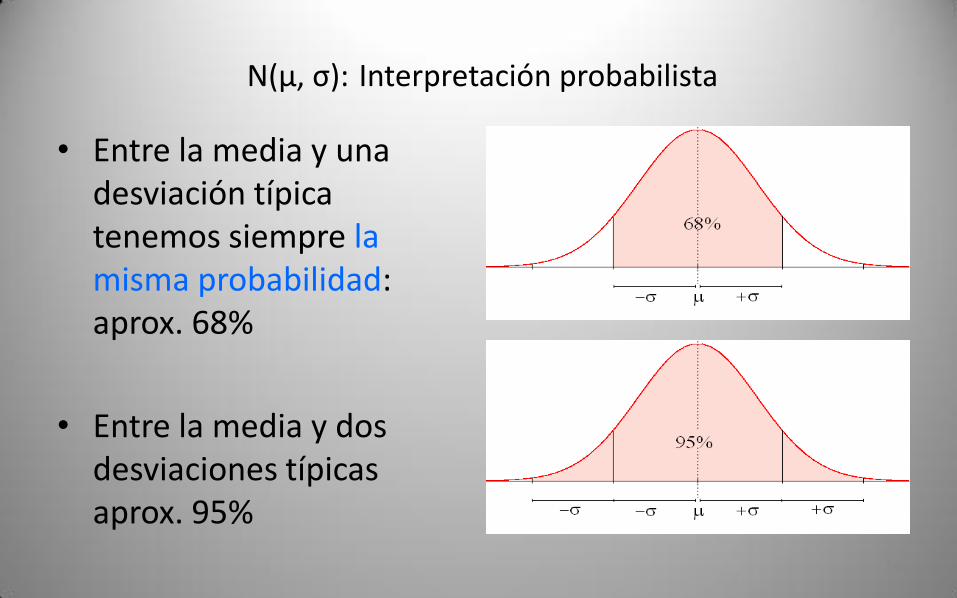
N(μ, σ): Interpretación probabilista
• Entre la media y una desviación típica tenemos siempre la misma probabilidad: aprox. 68%
• Entre la media y dos desviaciones típicas aprox. 95%

Tema 5: Modelos probabilísticos
35
Algunas características• La función de densidad es simétrica, mesocúrtica y unimodal.
– Media, mediana y moda coinciden.
• Los puntos de inflexión de la función de densidad están a distancia σ de μ.
• Si tomamos intervalos centrados en μ, y cuyos extremos están…– a distancia σ, tenemos probabilidad 68%– a distancia 2 σ, tenemos probabilidad 95%– a distancia 2’5 σ tenemos probabilidad 99%
• No es posible calcular la probabilidad de un intervalo simplemente usando la primitiva de la función de densidad, ya que no tiene primitiva expresable en términos de funciones ‘comunes’.
• Todas las distribuciones normales N(μ, σ), pueden ponerse mediante una traslación μ, y un cambio de escala σ, como N(0,1). Esta distribución especial se llama normal tipificada.– Justifica la técnica de tipificación, cuando intentamos comparar individuos diferentes obtenidos de sendas
poblaciones normales.

36
Tipificación• Dada una variable de media μ y desviación típica σ, se denomina valor
tipificado,z, de una observación x, a la distancia (con signo) con respecto a la media, medido en desviaciones típicas, es decir
• En el caso de variable X normal, la interpretación es clara: Asigna a todo valor de N(μ, σ), un valor de N(0,1) que deja exáctamente la misma probabilidadpor debajo.
• Nos permite así comparar entre dos valores de dos distribuciones normales diferentes, para saber cuál de los dos es más extremo.
xz
37
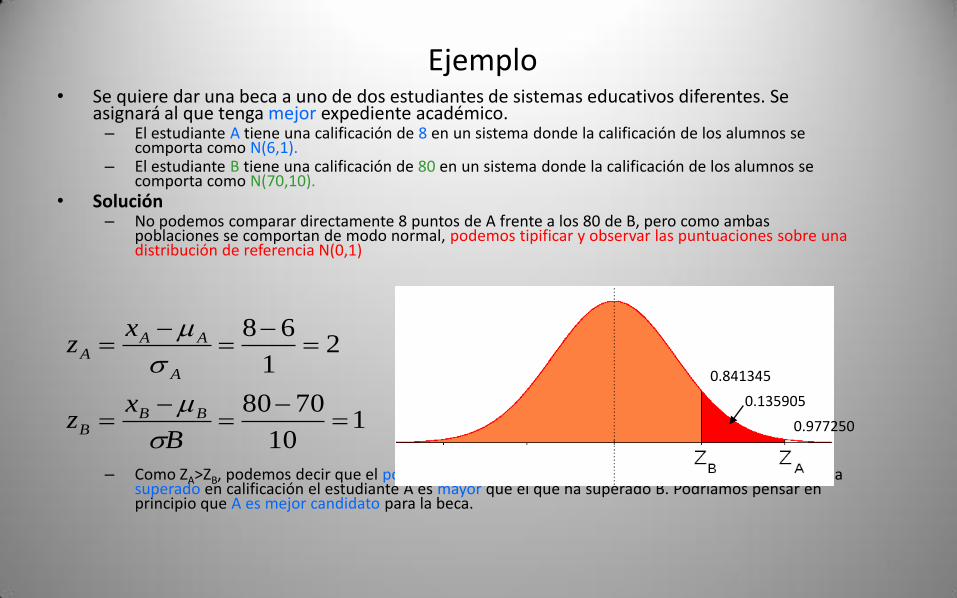
Ejemplo• Se quiere dar una beca a uno de dos estudiantes de sistemas educativos diferentes. Se
asignará al que tenga mejor expediente académico.– El estudiante A tiene una calificación de 8 en un sistema donde la calificación de los alumnos se
comporta como N(6,1).– El estudiante B tiene una calificación de 80 en un sistema donde la calificación de los alumnos se
comporta como N(70,10).• Solución
– No podemos comparar directamente 8 puntos de A frente a los 80 de B, pero como ambas poblaciones se comportan de modo normal, podemos tipificar y observar las puntuaciones sobre una distribución de referencia N(0,1)
– Como ZA>ZB, podemos decir que el porcentaje de compañeros del mismo sistema de estudios que ha superado en calificación el estudiante A es mayor que el que ha superado B. Podríamos pensar en principio que A es mejor candidato para la beca.
110
7080
21
68
B
xz
xz
BBB
A
AAA
0.841345
0.977250
0.135905

Tema 5: Modelos probabilísticos
¿Por qué es importante la distribución normal?
• Las propiedades que tiene la distribución normal son interesantes, pero todavía no hemos hablado de por qué es una distribución especialmente importante.
• La razón es que aunque una v.a. no posea distribución normal, ciertos estadísticos/estimadores calculados sobre muestras elegidas al azar sí que poseen una distribución normal.
• Es decir, tengan las distribución que tengan nuestros datos, los ‘objetos’ que resumen la información de una muestra, posiblemente tengan distribución normal (o asociada).
39
Veamos aparecer la distribución normal
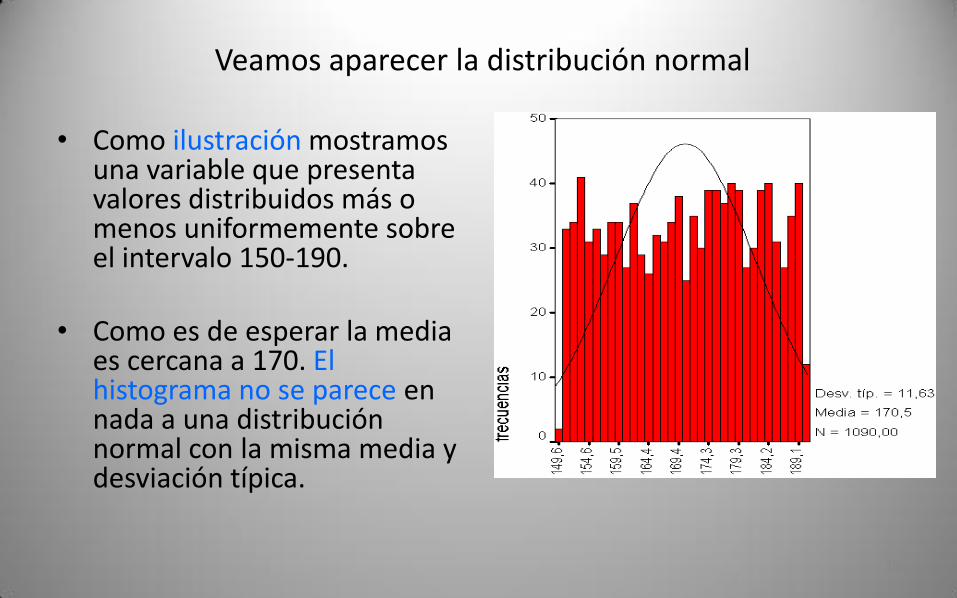
• Como ilustración mostramos una variable que presenta valores distribuidos más o menos uniformemente sobre el intervalo 150-190.
• Como es de esperar la media es cercana a 170. El histograma no se parece en nada a una distribución normal con la misma media y desviación típica.

40
• A continuación elegimos aleatoriamente grupos de 10 observaciones de las anteriores y calculamos el promedio.
• Para cada grupo de 10 obtenemos entonces una nueva medición, que vamos a llamar promedio muestral.
• Observa que las nuevas cantidades están más o menos cerca de la media de la variable original.
• Repitamos el proceso un número elevado de veces. En la siguiente transparencia estudiamos la distribución de la nueva variable.
Muestra
1ª 2ª 3ª185 190 179
174 169 163
167 170 167
160 159 152
172 179 178
183 175 183
188 159 155
178 152 165
152 185 185
175 152 152
173 169 168 …

41
• La distribución de los promedios muestrales sí que tiene distribución aproximadamente normal.
• La media de esta nueva variable (promedio muestral) es muy parecida a la de la variable original.
• Las observaciones de la nueva variable están menos dispersas. Observa el rango. Pero no sólo eso. La desviación típica es aproximadamente ‘raiz de 10’ veces más pequeña. Llamamos error estándar a la desviación típica de esta nueva variable.
• Nada de lo anterior es casualidad.

42
Teorema central del límite• Dada una v.a. cualquiera, si extraemos muestras de
tamaño n, y calculamos los promedios muestrales, entonces:
• dichos promedios tienen distribución aproximadamente normal;
• La media de los promedios muestrales es la misma que la de la variable original.
• La desviación típica de los promedios disminuye en un factor “raíz de n” (error estándar).
• Las aproximaciones anteriores se hacen exactas cuando n tiende a infinito.
– Este teorema justifica la importancia de la distribución normal.
– Sea lo que sea lo que midamos, cuando se promedie sobre una muestra grande (n>30) nos va a aparecer de manera natural la distribución normal.

Tema 5: Modelos probabilísticos
Distribuciones asociadas a la normal
• Cuando queramos hacer inferencia estadística hemos visto que la distribución normal aparece de forma casi inevitable.
• Dependiendo del problema, podemos encontrar otras (asociadas):– X2 (chi cuadrado)– t- student– F-Snedecor
• Estas distribuciones resultan directamente de operar con distribuciones normales. Típicamente aparecen como distribuciones de ciertos estadísticos.
• Veamos algunas propiedades que tienen (superficialmente). Para más detalles consultad el manual.
• Sobre todo nos interesa saber qué valores de dichas distribuciones son “atípicos”.– Significación, p-valores,…
44
Chi cuadrado
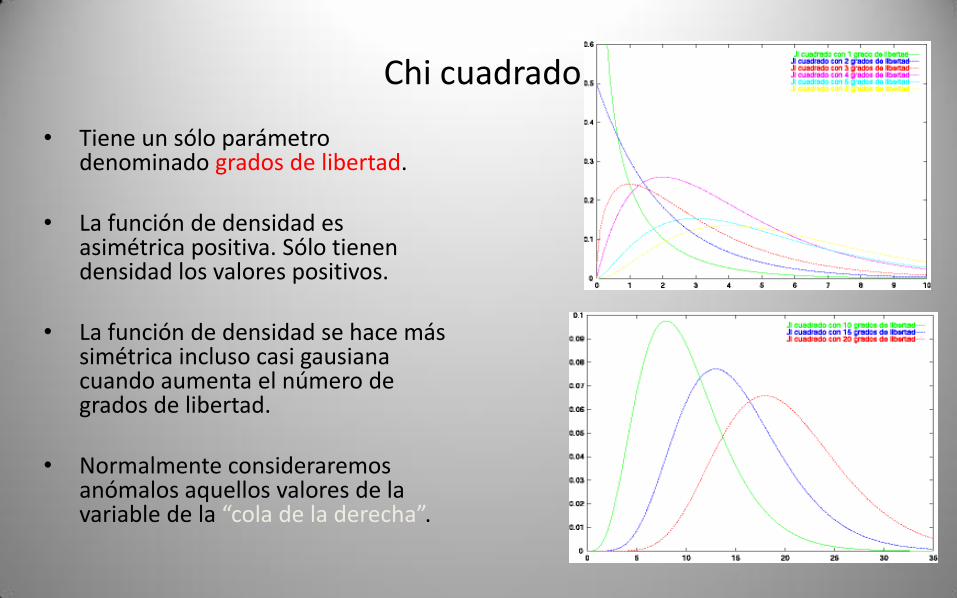
• Tiene un sólo parámetro denominado grados de libertad.
• La función de densidad es asimétrica positiva. Sólo tienen densidad los valores positivos.
• La función de densidad se hace más simétrica incluso casi gausianacuando aumenta el número de grados de libertad.
• Normalmente consideraremos anómalos aquellos valores de la variable de la “cola de la derecha”.
45
T de Student
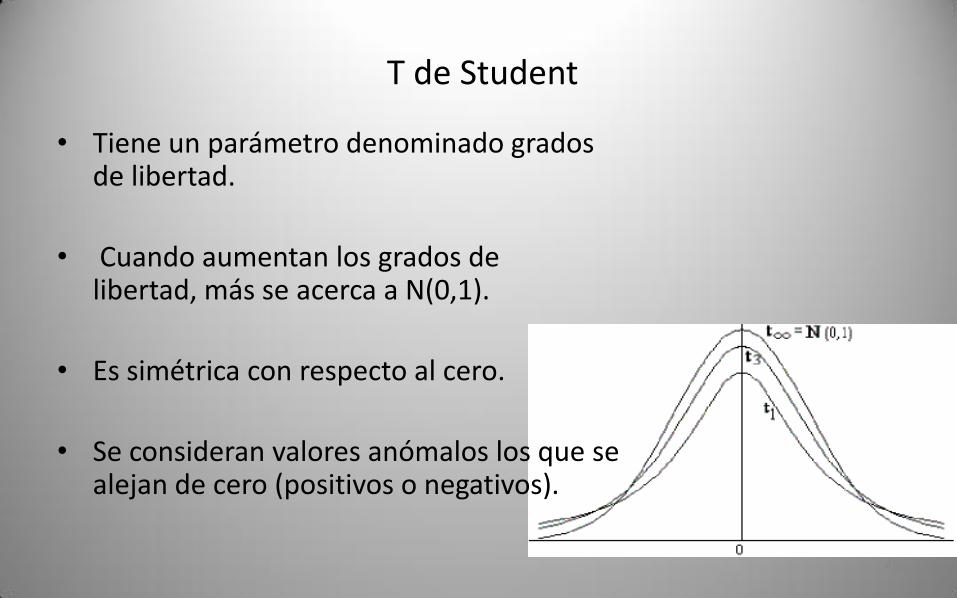
• Tiene un parámetro denominado grados de libertad.
• Cuando aumentan los grados de libertad, más se acerca a N(0,1).
• Es simétrica con respecto al cero.
• Se consideran valores anómalos los que se alejan de cero (positivos o negativos).
46
F de Snedecor
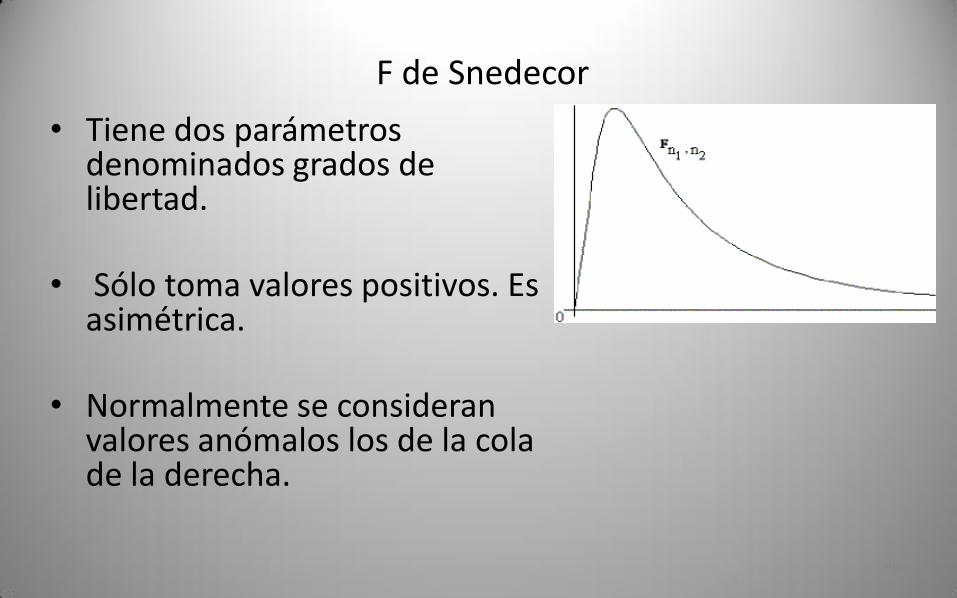
• Tiene dos parámetros denominados grados de libertad.
• Sólo toma valores positivos. Es asimétrica.
• Normalmente se consideran valores anómalos los de la cola de la derecha.