unconstrained static scheduling with communication weights
TRANSCRIPT

JOURNAL OF SCHEDULINGJ. Sched. 2002; 5:359–377 (DOI: 10.1002/jos.114)
Unconstrained static scheduling with communication weights
Vivek Sarkar∗;†
IBM Research; Thomas J. Watson Research Center; P.O. Box 704; Yorktown Heights; NY 10598; U.S.A.
SUMMARY
In this paper, we present some new theoretical results for unconstrained static scheduling with com-munication weights, i.e. multiprocessor scheduling of tasks with no precedence constraints, but witharbitrary communication and computation weights. The results are obtained for a cost function thatextends completion time with a simple model of communication overhead. This cost function and itsvariants have been studied in past work. The main results of this paper are as follows: (1) it is shownthat no single-pass priority-list algorithm can yield a constant performance bound for this cost function,(2) a two-pass approach is proposed as a heuristic solution, (3) the two-pass approach is shown to havea performance bound of (1+ �), where � is the performance bound for the �rst step (scheduling on anunbounded number of processors), and (4) it is shown that no greedy-merge clustering algorithm candeliver a constant performance bound, �, even for the �rst step. We also present some experimentalresults obtained by applying di�erent scheduling algorithms to 150 randomly generated task graphs.Copyright ? 2002 John Wiley & Sons, Ltd.
1. INTRODUCTION
Many optimizing compilers and performance tools used in practice rely on static schedulingat the instruction or task level to deliver improved performance on parallel hardware e.g.References [1–7]. The theoretical foundation for these static scheduling techniques lies inpast research on job-shop scheduling with non-preemptive tasks e.g. References [8, 9]. How-ever, the bulk of past research in scheduling theory has focused on the problem of multi-processor scheduling without communication weights between pairs of tasks. This may haveoccurred in part due to the fact that scheduling is a hard problem even in the absence ofcommunication weights. For example, two-processor scheduling with execution times limitedto equal 1 or 2, but with arbitrary precedence constraints, is known to be an NP-hard problem.Another example of a simple scheduling problem that is known to be NP-hard is n-processorscheduling with arbitrary execution times but without precedence constraints. The researchliterature abounds with several other examples of apparently ‘simple’ scheduling problemsthat are known to be NP-hard e.g. References [10, 11].
∗Correspondence to: Vivek Sarkar, IBM Research, Thomas J. Watson Research Center, P.O. Box 704, YorktownHeights, NY 10598, U.S.A.
†E-mail: [email protected]
Copyright ? 2002 John Wiley & Sons, Ltd.

360 V. SARKAR
Despite these pessimistic NP-hardness results, the good news that has been known for overthree decades [12] is that there exist e�cient greedy algorithms that are guaranteed to yieldconstant performance bounds for multiprocessor scheduling in the absence of communicationweights, e.g. a worst-case performance bound of 4
3 for scheduling without precedence con-straints, and a worst-case performance bound of 2 for scheduling with general precedenceconstraints. These theoretical results on constant performance bounds have a very signi�cantpractical implication—they guarantee that linear speed-up on parallel hardware can always beachieved in the absence of communication weights.However, the reality of current and future parallel hardware is that the cost of data com-
munication is at least as signi�cant as the cost of computation. Therefore, it becomes im-portant to pay attention to communication weights in practice, as has been done by severalrecent static scheduling systems e.g. References [1, 5]. While empirical results have demon-strated the e�ectiveness of these communication-sensitive static scheduling systems, a keyquestion that remains is: what worst-case performance bounds can be guaranteed by schedul-ing theory for these cases of static scheduling with communication weights that are importantin practice? The work reported in References [13, 14] addresses the issue of performancebounds for the case of ‘coarse-grain’ tasks that have bounded communication=computationratios.To address the question of performance bounds for the case of arbitrary communication
and computation weights, we use a simple cost function for communication overhead in thispaper. This cost function has been proposed in earlier work in the literature [15–17], andthe general optimization problem is known to be NP-hard for this cost function. However,to the best of our knowledge, the theoretical performance bounds for this cost function werenot studied in previous work. The goal of this paper is to use this cost function as a casestudy for understanding the theoretical properties of performance bounds for static schedulingwith communication weights. The attractive property of this cost function is that it includescommunication weights; however, its key limitation is that it does not include precedenceconstraints. Analysing performance bounds for more complex communication cost modelswith general precedence constraints, such as the cost functions introduced in Reference [1],is a subject for future work.The main results of this case study are as follows (for the cost function introduced in
Reference [15]):
(1) It is shown that no single-pass priority-list algorithm can have a constant performancebound for the problem of �nding an optimal schedule with communication overhead(Theorem 3.1).
(2) A two-step approach is proposed for solving the problem of multiprocessor schedulingwith communication overhead:
(a) Internalization pre-pass: First, solve the scheduling problem assuming that wehave an unbounded number of virtual processors available (at most n processorswill be used for n tasks).
(b) Processor Assignment: Next, transform a schedule for 6 n virtual processors intoa schedule for p real processors, by simply mapping virtual processors to realprocessors.
Copyright ? 2002 John Wiley & Sons, Ltd. J. Sched. 2002; 5:359–377

UNCONSTRAINED STATIC SCHEDULING WITH COMMUNICATION WEIGHTS 361
(3) The two-step approach is justi�ed by showing that a worst-case performance boundof (1 + �) can be obtained for the full problem, by using an approximation algorithmwith performance bound � for the internalization pre-pass (if one exists), and any listscheduling algorithm for the processor assignment step (Theorem 4.1).
(4) An optimal solution to the internalization pre-pass problem (i.e. with �=1) can beobtained by using the branch-and-bound algorithm proposed in Reference [17]. Whenused in the two-step approach, we obtain a cumulative performance bound of 1+1=2for the scheduling problem. However, the branch-and-bound algorithm is not practicalfor large problem sizes.
(5) A negative theoretical result—it is shown that no algorithm, from a class of greedyclustering algorithms called k-merge, can obtain a constant performance bound � forthe internalization pre-pass problem (Theorem 4.2).
(6) Finally, an e�cient merge-style heuristic algorithm is presented for the internalizationpre-pass. This heuristic algorithm does not have a guaranteed performance bound, butexperimental results show that a two-step approach, consisting of the merge heuristicalgorithm and the LPT-�rst priority-scheduling algorithm, can work well in practice.
The rest of the paper is organized as follows. As background, Section 2 identi�es the classi-cal multiprocessor scheduling problem (with no communication overhead) that is relevant tothis paper. Section 3 discusses the extensions necessary to include communication weights:the model, previous work, and our approach are presented in Sections 3.1, 3.2 and 3.3,respectively. Section 4 contains the result for the (1 + �) performance bound for the two-step approach, as well as the negative result for k-merge algorithms. Section 5 presents ourmerge approximation algorithm for the internalization pre-pass problem. Section 6 containsexperimental results and Section 7 contains our conclusions.
2. MULTIPROCESSOR SCHEDULING—BACKGROUND
In this section, we provide background by identifying the classical multiprocessorscheduling problem (with no communication overhead) that is relevant to this paper. Schedul-ing theory contains a wide range of problems, based on di�erences in machine environ-ments (identical vs non-identical processors, open shop, �ow shop, job shop, etc.), in jobcharacteristics (precedence constraints, resource constraints, preemption, etc.), and in optimal-ity criteria (completion time, tardiness, etc.) [8]. We are generally interested in the problemof automatically mapping tasks in a parallel program to processors in a multiprocessor system,so as to minimize the completion time of the program. The classical scheduling problem thatis relevant to this paper has the following characteristics:
• Machine environment: p identical parallel processors.• Job data: n tasks, 1: : : n, with non-negative execution times t1: : : tn, no precedence con-straints, no preemption.
• Optimality criterion: Minimize the maximum completion time, Cmax, of all n tasks onp processors.
This scheduling problem is known to be NP-hard, and has been extensively studied from theviewpoint of approximation algorithms [8]. In the next section, we discuss how this problem
Copyright ? 2002 John Wiley & Sons, Ltd. J. Sched. 2002; 5:359–377

362 V. SARKAR
Figure 1. The LPT-�rst scheduling algorithm.
is extended to include communication overhead. One of the earliest performance bound resultsfor this problem was presented in Reference [12], where it was shown that
Cmax(LPT)C∗max
643− 13p
where Cmax(LPT) is the completion time obtained by the LPT-�rst approximation algorithmand C∗
max is the optimal completion time. The LPT-�rst approximation algorithm is a simpleO(n log n) list scheduling algorithm in which the priority-list contains tasks in decreasing orderof execution times, i.e. execute the task with the largest processing time (LPT) �rst. Reference[8] discusses other approximation algorithms for this scheduling problem, all of which canobtain slightly better performance bounds than LPT-�rst at the cost of asymptotically largerexecution times.In Figure 1, we give a complete outline of the LPT-�rst algorithm. Step 1 sorts the tasks
in decreasing order of execution times, and initializes the priority-list, L. Step 2 initializesthe heap, H , to the set of pairs {〈0; k〉|16k6p}. The heap data structure [18] supportsinsertions and deletions in O(log n) time, while guaranteeing that the remove top of heapoperation always returns the smallest element in the heap. We use the heap to keep track ofcurrent processor execution times, and to e�ciently determine which processor should get thenext task as dictated by the list scheduling model. A heap element is an ordered pair of theform, 〈tP; k〉, which indicates that processor k will be ready to execute its next task at timetP. Comparison between heap elements is a simple lexicographic comparison of the orderedpairs.The for loop in step 3 processes each task i in the order speci�ed by priority-list L
(decreasing order of execution times). Step 3(a) picks 〈tP; k〉; the smallest entry in heap H .
Copyright ? 2002 John Wiley & Sons, Ltd. J. Sched. 2002; 5:359–377

UNCONSTRAINED STATIC SCHEDULING WITH COMMUNICATION WEIGHTS 363
Step 3(b) performs the main scheduling step by mapping the current task i to processor k.Step 3(c) inserts the heap entry 〈tP + ti; k〉 to re�ect the update in processor k’s executiontime. Finally, step 4 determines the maximum completion time as the max of all processorexecution times in the heap. It is easy to see that the LPT-�rst algorithm presented in Figure1 takes O(n log n) time, by observing that p=O(n) in the worst case.
3. EXTENSIONS FOR COMMUNICATION OVERHEAD
In this section, we discuss the extensions necessary to add communication weights to themodel outlined in Section 2: the model, previous work, and our approach are presented inSections 3.1, 3.2 and 3.3, respectively.
3.1. The model
We extend the scheduling problem considered in the previous section, by specifying a commu-nication cost, cij , for each pair of tasks i and j. We assume that cij = cji and cii=0 ∀16i; j6n.Let e be the number of task pairs {i; j} with a non-zero communication cost i.e. with cij¿0.A solution to the scheduling problem is represented as a mapping S : {1; : : : ; n}→{1; : : : ; p},indicating that task i is to be executed on processor S(i). The inverse mapping, S−1(k),represents the set of tasks mapped onto processor k. We will also use the notation, range(S),to denote the set of processors k such that there exists a task i with S(i)= k.The cost of partition S is de�ned to be F(S)=Tcomm + Cmax, where
Tcomm =∑
{i; j}⊆{1;:::;n}S(i) == S( j)
cij
is the total communication cost incurred, and
Cmax = max16k6p
( ∑i∈S−1(k)
ti
)
is the computation time of the busiest processor [15].Though the cost function is simple, it exhibits the fundamental trade-o� between commu-
nication overhead and parallelism. The communication cost term, Tcomm is minimized (madezero) when all tasks are assigned to the same processor, whereas the computation time term,Cmax, is minimized when tasks are distributed among all processors for the best possible loadbalancing. Note that Cmax and Tcomm have di�erent units, so we might expect the use of anormalizing coe�cient (say, �) in practice to properly weight the two terms, and yield acost function of the form (say), F(S)= �Tcomm + Cmax. For simplicity, we assume that the �coe�cient can be factored into the choice of units, and work with the simpler version of thefunction introduced in Reference [15] for the rest of this paper.It is important to note that the problem of minimizing Cmax, as discussed in the previous
section, is a special case of the problem of minimizing F(S), since F(S)=Cmax if all thecommunication costs are zero. Therefore, the problem of minimizing F(S) is at least as hardas the problem of minimizing Cmax. In particular, both problems are NP-hard. Further, anapproximation algorithm for the problem of minimizing F(S) that has performance bound �,
Copyright ? 2002 John Wiley & Sons, Ltd. J. Sched. 2002; 5:359–377

364 V. SARKAR
must also have performance bound � for the problem of minimizing Cmax. Considering thatthe LPT-�rst approximation algorithm for the problem of minimizing Cmax has a performancebound of �= 4
3 , we would expect to obtain a larger performance bound for the problem ofminimizing F(S).The cost function, F(S)=Tcomm+Cmax was introduced in Reference [15], and has also been
used in References [16, 17]. The major simpli�cation in the cost function is the assumptionthat the total communication overhead is proportional to the total amount of data exchangedamong all processors. This assumption has implications on the following issues:
(1) Precedence constraints among tasks: The model ignores the e�ect of a processorwaiting due to precedence constraints. Therefore, the model is better suited for jobsand mappings in which this waiting rarely occurs, or can be masked by mechanismslike context-switching.
(2) Fixed bandwidth assumption: The model implicitly assumes that all communication isperformed at a �xed bandwidth, by giving Tcomm and Cmax the same unit. For example,if the size of data communicated between tasks i and j is S bytes, and we have abandwidth of B bytes=s, we should set cij = S=B, assuming that the ti values are alsoin seconds. We can also use B=kp, if we want to model the bandwidth increasinglinearly with the number of processors. The optimization problem is only concernedwith the �nal ‘bandwidth-normalized’ cij values.
(3) Inter-processor distances: The model does not account for di�erences in inter-processordistances in estimating communication overhead. Therefore, the model is better suitedfor uniform memory access (UMA) multiprocessors rather than non-uniform memoryaccess (NUMA) multiprocessors.
(4) Dynamic variations in communication load: the model does not consider when thecommunications occur, and therefore ignores the e�ect of possible waiting due toheavy communication loads. Therefore, the model is better suited for jobs in whichthe communication load rarely exceeds the available communication bandwidth in themultiprocessor.
3.2. Previous work
As mentioned earlier, the F(S)=Tcomm+Cmax cost function was introduced in Reference [15].The approach used in Reference [15] was to assume that all task execution times (ti’s) areidentically distributed random variables, and that all communications costs (cij’s) are alsoidentically distributed random variables. Therefore, the problem considered in Reference [15]was to �nd an ‘optimal’ mapping, which yields the smallest expected value of F(S)=Tcomm+Cmax. For this case of ‘randomly generated’ distributed programs, it was shown that the optimalsolution is to either assign all tasks to the same processor or to evenly distribute all tasksamong the given processors, depending on the mean values of the ti random variables andthe cij random variables. However, this result says nothing about what should be done whenthe task execution times and communication costs are �xed (arbitrary) values, rather thanidentically distributed random variables.Our work addresses the problem of minimizing F(S), for given values of task execution
times and communication costs. Though there has been a lot of a notable recent researchthat addresses various scheduling problems in the presence of communication costs (e.g.References [19–22]), Reference [17] is the only reference in previous work that we are aware
Copyright ? 2002 John Wiley & Sons, Ltd. J. Sched. 2002; 5:359–377

UNCONSTRAINED STATIC SCHEDULING WITH COMMUNICATION WEIGHTS 365
Figure 2. Greedy scheduling algorithm from Reference [17].
of that also addressed the general problem of minimizing F(S). Reference [17] presented agreedy algorithm for the problem of mapping the n tasks to p processors, with the goal ofminimizing F(S). Their algorithm is shown in Figure 2. It takes O(p(n+ e)) time, which isO(n3) time in the worst case. It degenerates to LPT-�rst when communication costs are zero.However, no theoretical or experimental results were presented in Reference [17] to indicatehow the algorithm might compare with other static scheduling algorithms. In the next section,we prove that the greedy algorithm in Reference [17] (and any other single-pass priority-listalgorithm) cannot have a constant performance bound, i.e. it can be arbitrarily worse thanoptimal in the worst-case.Reference [17] also contains an optimal branch-and-bound algorithm for the case of an
unbounded number of processors. Experimental results were presented in Reference [17] forsmall communication graphs (with 633 edges) to suggest that the execution time of thebranch-and-bound algorithm will be O(e3) in practice, though it can be exponential in patho-logical cases. It would be interesting to test the algorithm on larger graphs to con�rm theconjecture. Unfortunately, even an O(e3) algorithm is too slow to use in practice on large
Copyright ? 2002 John Wiley & Sons, Ltd. J. Sched. 2002; 5:359–377

366 V. SARKAR
graphs. However, it is possible that a more judicious choice of branching con�gurations andlower bound values in future work may lead to branch-and-bound algorithms that are moree�cient in practice.Finally, it is interesting to note that the unbounded-number-of-processors case lends itself
to a branch-and-bound solution, but the �nite-number-of-processors case does not. The reasonfor this di�erence is due to the resource constraints involved in dealing with a �nite numberof processors.
3.3. Our approach
Since the general scheduling problem is NP-hard, we are interested in e�ciently obtain-ing good approximate solutions. A common class of approximation algorithms used in pastwork is single-pass priority-list algorithms. We de�ne a single-pass priority-list schedul-ing algorithm to be one that maps tasks to processors in a single pass, without back-tracking on previous assignments. In a single-pass priority-list algorithm, the decision tochoose a certain processor for a given task, i, can only be made using execution timesand communication costs involving task i and tasks that have been scheduled by the al-gorithm prior to scheduling task i, and by using a �xed priority-list of tasks that remainsunchanged throughout the scheduling algorithm. We assume that the ordering of tasks inthe priority-list may depend on task execution times, but not on communication costs. (Thereason for not allowing communication costs to be examined when building the priority-list is that the examination of communication costs could then amount to a separate passin the scheduling algorithm, like the internalization pre-pass proposed in this paper, thusyielding a two-pass algorithm.) For example, the two scheduling algorithms from past workdescribed in Figure 1 (LPT-�rst) and in Figure 2 (Greedy) are both single-pass priority-listalgorithms.However, for the scheduling problem with communication weights considered in this paper,
Theorem 3.1 below shows that no single-pass priority-list scheduling algorithm can delivera constant performance bound. This implies that the LPT-�rst algorithm in Figure 1 and theGreedy algorithm in Figure 2 cannot guarantee constant performance bounds as approximationalgorithms for static scheduling with communication weights. (Note that the LPT-�rst algo-rithm only guarantees a constant performance bound for scheduling without communicationweights.)Therefore, we instead propose the following two-step approach for unconstrained static
scheduling with communication weights:
(1) Internalization pre-pass: First, solve the scheduling problem assuming that we havean unbounded number of virtual processors available (at most n will be used). This isa simpler problem than scheduling for p¡n processors.
(2) Processor assignment: Next, transform a schedule for 6n virtual processors into aschedule for p real processors, by simply mapping virtual processors to real processors.Intuitively, the idea here is that if a communication edge, cij , was ‘internalized’ in theprevious step (i.e. tasks i and j were assigned to the same virtual processor), then itshould also be worthwhile to ‘internalize’ the edge if we have fewer processors.
A similar two-pass approach was also proposed in our earlier work [1, 23] for generalprecedence-constrained scheduling with communication weights. However, since the general
Copyright ? 2002 John Wiley & Sons, Ltd. J. Sched. 2002; 5:359–377

UNCONSTRAINED STATIC SCHEDULING WITH COMMUNICATION WEIGHTS 367
problem is harder than the problem considered in this paper, the performance bound resultsfrom this paper do not apply to the problem considered in References [1, 23].
Theorem 3.1A single-pass priority-list algorithm cannot have a constant performance bound for theproblem of scheduling with communication overhead (i.e. the problem of minimizingthe cost function F(S)=Tcomm + Cmax), on a bounded or an unbounded number ofprocessors.
ProofWe perform a proof by contradiction. Assume that there exists a single-pass priority-listalgorithm with a constant performance bound.Let tasks i and j be the �rst pair of tasks to be mapped to di�erent processors, for some
input values {ti} and {cij}. If this is not possible for any input value, then the algorithmmust always be mapping all tasks to the same processor, and hence cannot have a constantperformance bound.Let k be the task that follows j in the priority-list. j cannot always be the last task,
otherwise the previous n − 1 tasks will always be mapped to the same processor, making itimpossible for the algorithm to have a constant performance bound. Therefore, k must existfor some input.We now set cik = cjk =+∞ (i.e. some arbitrarily large cost value). Since the processor
assignment decision of a single-pass priority-list algorithm can only use communication costsinvolving the current task and its preceding tasks, this change in communication costs willnot alter the mappings chosen for tasks i and j. Now, we must have Tcomm =+∞, since thealgorithm must incur the cost of cik or cjk . However, an optimal algorithm could map tasksi; j; k to the same processor, and get Tcomm�+∞, which means that the single-pass priority-listalgorithm cannot have a constant performance bound. Since no assumption was made aboutbounding the number of processors, p, this result holds for any bounded value of p that is¿1, or for the case when p is unbounded.
4. PERFORMANCE BOUNDS
The following theorem states that if the internalization pre-pass step can be solved withperformance bound � (for an unbounded number of processors), and it is followed by anysingle-pass priority-list scheduling algorithm for the processor assignment step, then the re-sulting mapping will have a performance bound of (1+�+O(1=p)) compared to the optimalvalue of F(S) for p processors.
Theorem 4.1De�ne the following solutions (optimal and approximate) to the problem of minimizing F(S):
• S|opt∞ , an optimal solution for an unbounded number of processors• S|�∞|listp , an approximate mapping of the virtual processors in S|�∞ to p real processors,by using any single-pass priority-list scheduling algorithm
Copyright ? 2002 John Wiley & Sons, Ltd. J. Sched. 2002; 5:359–377

368 V. SARKAR
Then,
F(S|�∞|listp )6(1 + �+
1p− 1
)F(S|optp )
for p¿1, and this bound is asymptotically tight for large p.
ProofWe begin by de�ning two additional solutions to the problem of minimizing F(S):
• S|�∞, an approximate solution for an unbounded number of processors with performancebound �; so that S|�∞6�S|opt∞
• S|optp , an optimal solution for p processors
Let the cost functions for S|�∞ and S|�∞|listp be
F(S|�∞) =Cmax|�∞ + Tcomm|�∞
F(S|�∞|listp ) =Cmax|�∞|listp + Tcomm|�∞|listp
We �rst establish a relationship between Cmax|�∞ and Cmax|�∞|listp . Recall that the second stepof our two-step approach maps virtual processors from S|�∞ to the p real processors. Cmax|�∞is the maximum computation time among all virtual processors in S|�∞, and Cmax|�∞|listp is themaximum computation time among all of the p real processors. Therefore, we have
pCmax|�∞|listp 6∑
16i6n︸ ︷︷ ︸Total useful work
ti + (p− 1)Cmax|�∞︸ ︷︷ ︸Maximum total idle time
(1)
since the total useful work and idle time account for the duration of Cmax|�∞|listp on p pro-cessors. Equation (1) actually gives an upper bound for Cmax|�∞|listp . A single-pass priority-listscheduling algorithm cannot have a total idle time larger than (p−1)Cmax|�∞, otherwise someprocessor should have been able to execute a ‘task’ (i.e. a virtual processor) when it was idle.The basic observation about upper bounds, like that of Equation (1), was originally made inReference [12].Rewriting Equation (1) gives us
Cmax|�∞¿(Cmax|�∞|listp −
∑16i6n tip
)p
p− 1 (2)
Now, we start with a simple lower bound for F(S|optp ),
F(S|optp )¿F(S|opt∞ )¿1�F(S|�∞)=
1�(Cmax|�∞ + Tcomm|�∞) (3)
Using the lower bound for Cmax|�∞ from (2) in (3) gives
F(S|optp )¿p
�(p− 1)(Cmax|�∞|listp −
∑16i6n tip
)+1�Tcomm|�∞ (4)
Copyright ? 2002 John Wiley & Sons, Ltd. J. Sched. 2002; 5:359–377

UNCONSTRAINED STATIC SCHEDULING WITH COMMUNICATION WEIGHTS 369
which implies
F(S|optp ) +p
�(p− 1)(∑
16i6n tip
)¿
p�(p− 1) Cmax|
�∞|listp +
1�Tcomm|�∞ (5)
Now, F(S|optp )¿Cmax|optp ¿
∑16i6n tip
so that (5) can be rewritten as
F(S|optp )(1 +
p�(p− 1)
)¿
p�(p− 1) Cmax|
�∞|listp +
1�Tcomm|�∞ (6)
Multiplying Equation (6) by �(p− 1) givesF(S|optp )((p− 1)�+ p)¿pCmax|�∞|listp + (p− 1)Tcomm|�∞ (7)
But Tcomm|�∞¿Tcomm|�∞|listp , since mapping virtual processors to real processors cannotincrease the communication cost term. Therefore, we can rewrite (7) to get
F(S|optp )((1 + �)p− �)¿pCmax|�∞|listp + (p− 1)Tcomm|�∞|listp¿ (p− 1)(Cmax|�∞|listp + Tcomm|�∞|listp )
= (p− 1)F(S|�∞|listp )
Therefore,
F(S|optp )¿(p− 1)
((1 + �)p− �) F(S|�∞|listp )
which leads to our desired result,
F(S|�∞|listp )6(1 + �+
1p− 1
)F(S|optp )
To show that the bound is tight, consider a set of tasks, 1; : : : ; 2p with
• t1 = · · · = tp=T ,• tp+1 = · · · = t2p=T=p,• c(p+1; p+2)= c(p+2; p+3)= · · · = c(2p− 1; 2p)=1, and all other communicationcosts are zero.
An optimal solution for the internalization pre-pass (corresponding to �=1) consists ofp+ 1 virtual processors,
• S|�∞(i)= i; ∀16i6p;• S|�∞(p+ 1)= S|�∞(p+ 2)= · · · = S|�∞(2p)=p+ 1,
and has cost, F(S|�∞)=Cmax|�∞ + Tcomm|�∞=T + 0=T .S|�∞ simply consists of p+1 virtual processors, each with execution time T , and with
no communication costs among them. The computation time achieved by any priority-list
Copyright ? 2002 John Wiley & Sons, Ltd. J. Sched. 2002; 5:359–377

370 V. SARKAR
schedule on p processors will be Cmax|�∞|listp =2T , which is the best we can with the outputof the internalization pre-pass. Since Tcomm|�∞|listp =0, we have F(S|�∞|listp )=2T as well.However, assuming T�p (say T=p2), the optimal schedule on p processors would be
S|optp (i)= S|optp (p+ i)= i; ∀16i6p
so that F(S|optp )=Cmax|optp + Tcomm|optp =(T + T=p) + (p− 1):Therefore,
F(S|�∞|listp )F(S|optp )
=2T
(T + T=P + p− 1) =2−O(1p
)
and we have an example showing that our performance bound is tight for �=1 andasymptotically large p.
Theorem 4.1 supports the two-step approach by showing that a solution to the simplerinternalization pre-pass problem with performance bound �, can be easily made into a solutionto the p-processor scheduling problem with performance bound (1+�). If the problem is smallenough for a branch-and-bound algorithm to be practical, we can get an optimal solution tothe internalization pre-pass problem with �=1, and hence a combined solution that is nomore than a factor of 2 away from optimal in the worst case.In the absence of an e�cient branch-and-bound algorithm, our next hope is to design
an approximation algorithm for the internalization pre-pass, that has a constant worst-caseperformance bound �¿1. Unfortunately, we have some negative theoretical results for thisproblem. In Theorem 3.1, we showed that no single-pass priority-list algorithm can have aconstant performance bound even for the case when p is unbounded i.e. for the internaliza-tion pre-pass. We now establish a similar result for greedy clustering algorithms, which isanother popular class of approximation algorithms used to solve scheduling problems (e.g.see Reference [14]). Figure 3 outlines a general k-merge clustering algorithm that can beused as a heuristic solution for the internalization pre-pass. It starts with the identity mappingS(i)= i, and iteratively attempts to merge a set of tasks that is locally optimal. In general, wecan consider all merge sets with 6k tasks in each iteration (for some k¿2). This k-mergeclustering algorithm takes O(nk+1) time, so we would probably use a small value of k inpractice. However, our negative result is that the k-merge algorithm cannot have a constantperformance bound for any constant value of k.
Theorem 4.2The k-merge clustering algorithm in Figure 3 cannot have a constant performance bound forthe problem of minimizing F(S) on an unbounded number of processors.
ProofConsider a set of n tasks with ti=T; ∀16i6n, and cij =C; ∀i �= j; 16i; j6n. The cost ofthe initial mapping in step 1 of Figure 3, S(i)= i, is
F1 =F(S)=T +
(n
2
)C=T +
n(n− 1)2
C
Copyright ? 2002 John Wiley & Sons, Ltd. J. Sched. 2002; 5:359–377

UNCONSTRAINED STATIC SCHEDULING WITH COMMUNICATION WEIGHTS 371
Figure 3. The k-merge clustering algorithm for the internalization pre-pass.
If we merge any j tasks (26j6k) in the �rst execution of step 2(b)(i) we will obtain a newmapping S ′ with cost
F2 =F(S ′)= jT +
((n
2
)−(j
2
))C
We now constrain C and T , such C=T¡2=j. Doing so allows us to prove that F1¡F2; asfollows:
CT¡2j⇒ jC(j − 1)
2¡T (j − 1)⇒
(j
2
)C¡jT − T ⇒ T¡jT −
(j
2
)C
⇒ T +
(n
2
)C¡jT +
((n
2
)−(j
2
))C ⇒ F1¡F2
Copyright ? 2002 John Wiley & Sons, Ltd. J. Sched. 2002; 5:359–377

372 V. SARKAR
We now further constrain C and T so that C=T =2=(k + 1), which implies that C=T¡2=kand F1¡F2; ∀j; 26j6k. Therefore, the k-merge clustering algorithm must exit the loop (step2(c)) in the very �rst iteration, yielding the initial S(i)= i mapping as the approximatesolution.However, the cost of the ‘coarsest’ mapping (S(i)=1; ∀16i6n) is simply F3 = nT , so
that
F1F3=T + [n(n− 1)=(2)C]
nT⇒ F1F3¿(n− 1)2
CT
⇒ F1F3¿(n− 1)2
2k + 1
⇒ F1F3¿n− 1k + 1
The �nal result F1=F3¿(n − 1)=(k + 1) shows that the k-merge clustering algorithm cannotobtain a constant performance bound, since F1 is the cost of the mapping produced by thek-merge algorithm.
5. APPROXIMATION ALGORITHMS
In this section, we propose heuristic algorithms for the two-step approach discussed inSection 3.3:
(1) Internalization pre-pass: Our solution is to use the merging algorithm described belowin Figure 4.
(2) Processor assignment: Our solution is to simply use LPT-�rst (Figure 1) for this phase.
The experimental results presented in the next section show that our approach performssigni�cantly better than the greedy algorithm in Figure 2. Figure 4 contains our heuris-tic algorithm for the internalization pre-pass problem. The algorithm belongs to the classof k-merge clustering algorithms (with k=2), and therefore cannot have a constantperformance bound in the worst case (Theorem 4.2). However, the experimental resultspresented in the next section indicate that this algorithm works well inpractice.Step 1 initially maps each task to a separate processor in the mapping S: pt(k) and pc(k; l)
contain processor execution times and communication costs, as opposed to the task exe-cution times and communication costs in ti and cij . As written in Figure 4, step 1 takesO(n2) time, though the initialization could also be done in O(n + e) time by using sparserepresentations for cij and p(k; l). Step 2 sorts all non-zero communication edges in de-creasing order of costs, which takes O(e log e) time. Step 3 considers each edge {i; j} (indecreasing order of costs) as a potential candidate for internalization by merging proces-sors S(i) and S(j). Steps 3(a)–(c) compute the new cost function value, F ′, that wouldbe obtained after the merge. If F ′¡F (i.e. the merge yields an improvement in the costfunction), steps (i)–(iv) in 3(d) are performed to actually do the merge in O(n) time.The �nal mapping is available as the algorithm’s output in step 4. Since the loop instep 3 has e iterations, the total execution time of the algorithm in Figure 4 isO(n2 + e log e+ en)=O(n(n+ e)).
Copyright ? 2002 John Wiley & Sons, Ltd. J. Sched. 2002; 5:359–377

UNCONSTRAINED STATIC SCHEDULING WITH COMMUNICATION WEIGHTS 373
Figure 4. Merge: a heuristic algorithm for the internalization pre-pass.
Copyright ? 2002 John Wiley & Sons, Ltd. J. Sched. 2002; 5:359–377

374 V. SARKAR
6. EXPERIMENTAL RESULTS
In this section, we present experimental results for the following scheduling algorithms:
(1) Random mapping—the simplest scheme: just pick a processor randomly for each task!(2) Greedy algorithm—the scheduling algorithm from Reference [17] that was presented
in Figure 2.(3) Merge+ LPT -�rst—the two-pass approach using the merge algorithm (Figure 4) for
the internalization pre-pass, and the LPT-�rst algorithm for the �nal processor assign-ment.
(4) Merge + Greedy—like 3 above, except that the algorithm from Figure 2 is used forthe �nal processor assignment phase. Since the greedy algorithm takes communicationcosts into account, we were curious to see if it would perform better than LPT-�rst inthe second phase.
The parameters used in the experiment were:
• n=512, the number of tasks;• p = 32, the number of processors;• ti ∈ [0 : : : 214], randomly generated execution times from a uniform distribution;• prob=0; 0:001; : : : ; 0:009; 0:01; 0:02; 0:03; 0:04; 0:05, the probability that a communicationedge with non-zero cost is placed between any pair of tasks;
• cij ∈ [0 : : : 214], randomly generated communication costs from a uniform distribution (onlyused for communication edges, as dictated by prob).
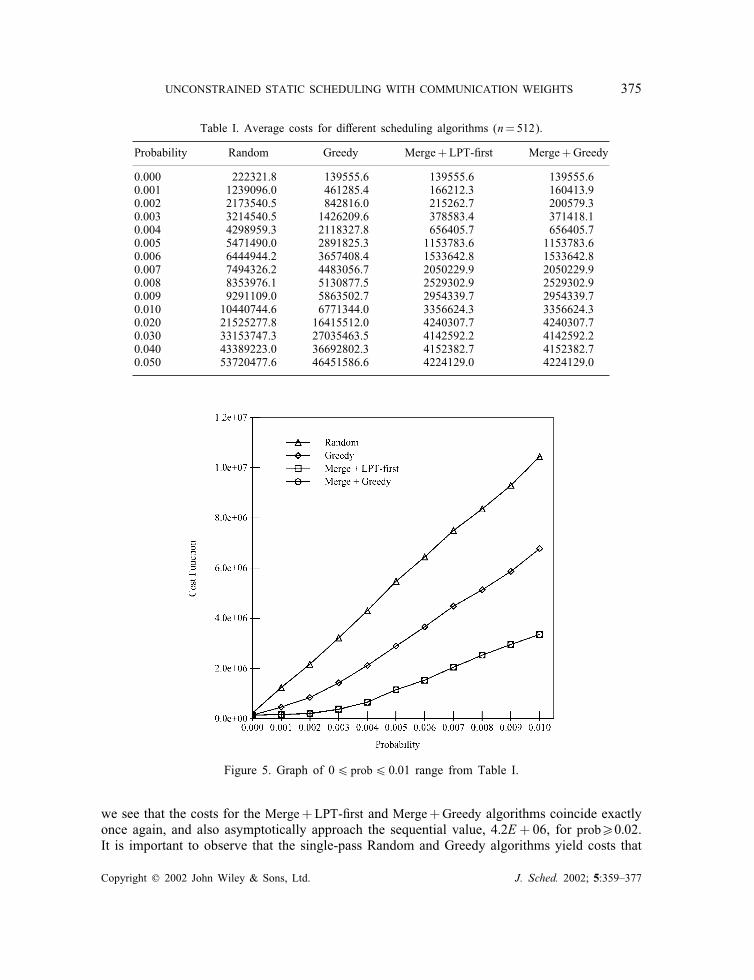
The results of the experiment are summarized in Table I and shown pictorially in Figures5 and 6. The experiment consists of generating a random set of tasks (with execution timesand communication costs based on the parameters described above), running the di�erentalgorithms on the set of tasks, and reporting the cost function values (F(S)) obtained for thedi�erent algorithms. To obtain repeatable results, we performed 10 di�erent trials for eachdata point, and reported the average cost function values obtained. We also measured thestandard deviation in the cost function values, and concluded that 10 was a reasonable choicefor the number of trials because the standard deviation was within 12% of the mean (andusually much less) for all the data points.Figure 5 graphically depicts the range 06prob60:01 in Table I, and illustrates two
important points:
(1) The two-step approach proposed in this paper performed signi�cantly better than thegreedy algorithm proposed in Reference [17].
(2) After using the merge algorithm for the internalization pre-pass (from Figure 4), theLPT-�rst algorithm (from Figure 1) worked equally well as the greedy algorithm (fromFigure 2) for the processor assignment phase. In fact, the Merge+LPT-�rst and Merge+Greedy curves coincide exactly in Figure 5. Therefore, it is better to use the O(n log n)LPT-�rst algorithm, rather than the O(n3) greedy algorithm, in the processor assignmentphase.
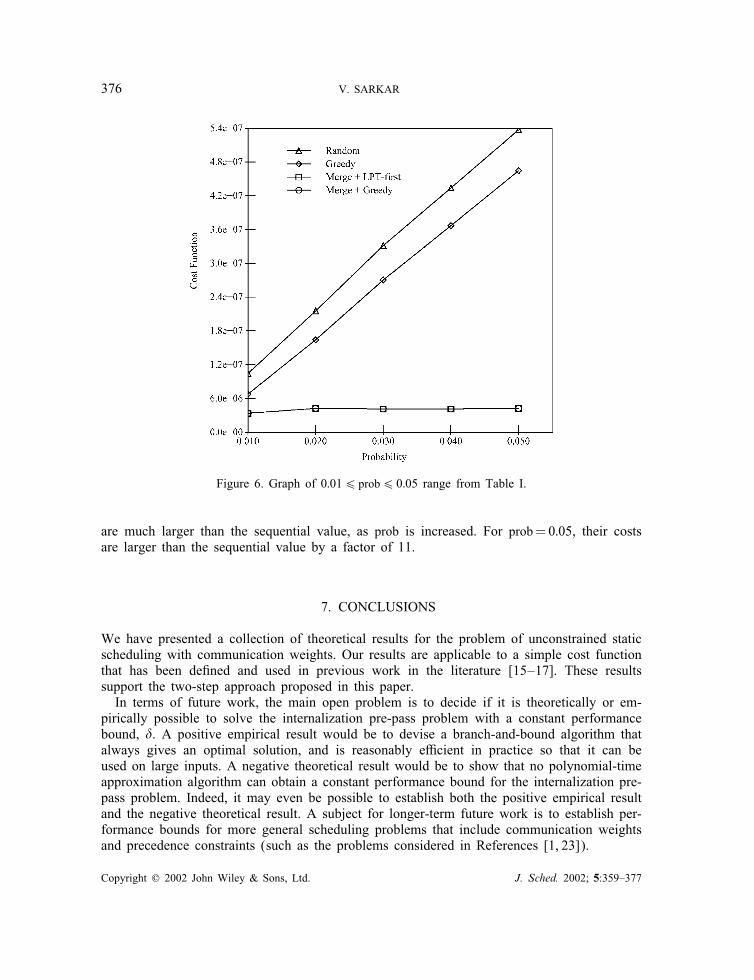
Figure 6 graphically depicts the range 0:016prob60:05 in Table I. For the purpose of com-parison, consider the simple mapping that places all tasks on the same processor. For thissequential case, the average value of F(S) is 21329 =222 =4194304≈ 4:2E +06. In Figure 6,
Copyright ? 2002 John Wiley & Sons, Ltd. J. Sched. 2002; 5:359–377
UNCONSTRAINED STATIC SCHEDULING WITH COMMUNICATION WEIGHTS 375
Table I. Average costs for di�erent scheduling algorithms (n=512).
Probability Random Greedy Merge+LPT-�rst Merge+Greedy
0.000 222321.8 139555.6 139555.6 139555.60.001 1239096.0 461285.4 166212.3 160413.90.002 2173540.5 842816.0 215262.7 200579.30.003 3214540.5 1426209.6 378583.4 371418.10.004 4298959.3 2118327.8 656405.7 656405.70.005 5471490.0 2891825.3 1153783.6 1153783.60.006 6444944.2 3657408.4 1533642.8 1533642.80.007 7494326.2 4483056.7 2050229.9 2050229.90.008 8353976.1 5130877.5 2529302.9 2529302.90.009 9291109.0 5863502.7 2954339.7 2954339.70.010 10440744.6 6771344.0 3356624.3 3356624.30.020 21525277.8 16415512.0 4240307.7 4240307.70.030 33153747.3 27035463.5 4142592.2 4142592.20.040 43389223.0 36692802.3 4152382.7 4152382.70.050 53720477.6 46451586.6 4224129.0 4224129.0
Figure 5. Graph of 06 prob6 0:01 range from Table I.
we see that the costs for the Merge+LPT-�rst and Merge+Greedy algorithms coincide exactlyonce again, and also asymptotically approach the sequential value, 4:2E+06, for prob¿0:02.It is important to observe that the single-pass Random and Greedy algorithms yield costs that
Copyright ? 2002 John Wiley & Sons, Ltd. J. Sched. 2002; 5:359–377
376 V. SARKAR
Figure 6. Graph of 0:016 prob6 0:05 range from Table I.
are much larger than the sequential value, as prob is increased. For prob=0:05, their costsare larger than the sequential value by a factor of 11.
7. CONCLUSIONS
We have presented a collection of theoretical results for the problem of unconstrained staticscheduling with communication weights. Our results are applicable to a simple cost functionthat has been de�ned and used in previous work in the literature [15–17]. These resultssupport the two-step approach proposed in this paper.In terms of future work, the main open problem is to decide if it is theoretically or em-
pirically possible to solve the internalization pre-pass problem with a constant performancebound, �. A positive empirical result would be to devise a branch-and-bound algorithm thatalways gives an optimal solution, and is reasonably e�cient in practice so that it can beused on large inputs. A negative theoretical result would be to show that no polynomial-timeapproximation algorithm can obtain a constant performance bound for the internalization pre-pass problem. Indeed, it may even be possible to establish both the positive empirical resultand the negative theoretical result. A subject for longer-term future work is to establish per-formance bounds for more general scheduling problems that include communication weightsand precedence constraints (such as the problems considered in References [1, 23]).
Copyright ? 2002 John Wiley & Sons, Ltd. J. Sched. 2002; 5:359–377

UNCONSTRAINED STATIC SCHEDULING WITH COMMUNICATION WEIGHTS 377
ACKNOWLEDGEMENTS
The author is grateful to Chandra Chekuri for his feedback on an earlier version of this paper, and tothe anonymous reviewers for their insightful comments and suggestions.
REFERENCES
1. Sarkar V. Partitioning and Scheduling Parallel Programs for Multiprocessors, In the series, ResearchMonographs in Parallel and Distributed Computing. Pitman, London and The MIT Press, Cambridge, MA,1989.
2. McCreary C, Gill H. Automatic determination of grain size for e�cient parallel processing. CACM 1989;32(9):1073–1078.
3. Wu MY, Gajski D. Hypertool: a programming aid for message-passing systems. IEEE Transactions on Paralleland Distributed Systems 1990; 1(3):330–343.
4. Kasahara H, Honda H, Narita S. Parallel processing of near �ne grain tasks using static scheduling on OSCAR(optimally scheduled advanced multiprocessor). Proceedings of Supercomputing ’90, November 1990.
5. Yang T, Gerasoulis A. PYRROS: static task scheduling and code generation for message-passing multiprocessors.Proceedings of the ACM 1992 International Conference on Supercomputing, July 1992.
6. El-Rewini H, Lewis TG, Ali HH. Task Scheduling in Parallel and Distributed Systems. Prentice-Hall:Englewood Cli�s, NJ, 1994.
7. Lee W, Barua R, Frank M, Srikrishna D, Babb J, Sarkar V, Amarasinghe S. Space time scheduling of instruction-level parallelism on a raw machine. Proceedings of the Eighth International Conference on ArchitecturalSupport for Programming Languages and Operating Systems (ASPLOS-VIII), October 1998.
8. Graham RL, Lawler EL, Lenstra JK, Rinnooy Kan AHG. Optimization and approximation in deterministicsequencing and scheduling: a survey. Annals of Discrete Mathematics 1979; 5:287–326.
9. Lawler E, Lenstra JK, Martel C, Simons B, Stockmeyer L. Pipeline scheduling: a survey. Technical Report RJ5738, IBM Research, July 1987.
10. Lenstra JK, Rinnooy Kan AHG. Complexity of scheduling under precedence constraints. Operations Research1978; 26(1).
11. Lenstra JK, Rinnooy Kan AHG, Brucker P. Complexity of machine scheduling problems. Annals of DiscreteMathematics 1977; 4:281–300.
12. Graham RL. Bounds on multiprocessing timing anomalies. SIAM Journal on Applied Mathematics 1969;17(2):416–429.
13. Yang T, Gerasoulis A. List scheduling with and without communication. Parallel Computing Journal 1993;19:1321–1344.
14. Yang T, Gerasoulis A. DSC: scheduling parallel tasks on an unbounded number of processors. IEEETransactions on Parallel and Distributed Systems 1994; 5(9):951–967.
15. Indurkhya B, Stone HS, Lu Xi-Cheng. Optimal partitioning of randomly generated distributed programs. IEEETransactions on Software Engineering 1986; SE-12(3):483–495.
16. Bokhari SH. Partitioning problems in parallel, pipelined, and distributed computing. IEEE Transactions onComputers 1988; C-37:48–57.
17. Girkar M, Polychronopoulos C. Partitioning programs for parallel execution. Proceedings of ACM 1988International Conference on Supercomputing, St. Malo, France, July 1988, 216–229.
18. Floyd RW. Algorithm 245: treesort 3. Communications of the ACM 1964; 7(12).19. Veltman B, Lageweg BJ, Lenstra JK. Multiprocessor scheduling with communication delays. Parallel Computing
1990; 16:173–182.20. Saad R. Scheduling with communication delays. Journal of Combinatorial Mathematics and Combinatorial
Computing 1995; 18:214–224.21. Lenstra JK, Veldhorst M, Veltman B. The complexity of scheduling trees with communication delays. Journal
of Algorithms 1996; 20:157–173.22. Varvarigou TA, Roychowdhury VP, Kailath T, Lawler E. Scheduling in and out forests in the presence of
communication delays. IEEE Transactions on Parallel and Distributed Systems 1996; 7:1065–1074.23. Sarkar V, Hennessy J. Compile-time partitioning and scheduling of parallel programs. Proceedings of the ACM
SIGPLAN ’86 Symposium on Compiler Construction, vol. 21(7), June 17–26, 1986.
Copyright ? 2002 John Wiley & Sons, Ltd. J. Sched. 2002; 5:359–377