trying to avoid pipeline delays
DESCRIPTION
Trying to avoid pipeline delays. Inter-leafing two sets of operations XY Compute block. Tackled today. Review of coding a hardware circular buffer Roughly understanding where pipeline delays may occur - PowerPoint PPT PresentationTRANSCRIPT

Trying to avoid pipeline delays
Inter-leafing two sets of operationsXY Compute block

04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
2
Tackled today
Review of coding a hardware circular buffer Roughly understanding where pipeline delays
may occur “Refactor” the working code to improve the speed
without spending any time on examining whether delays really there – works at the moment principle
“Refactoring” working code to perform operations using both X and Y ALU’s – in principle twice the speed
04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
3
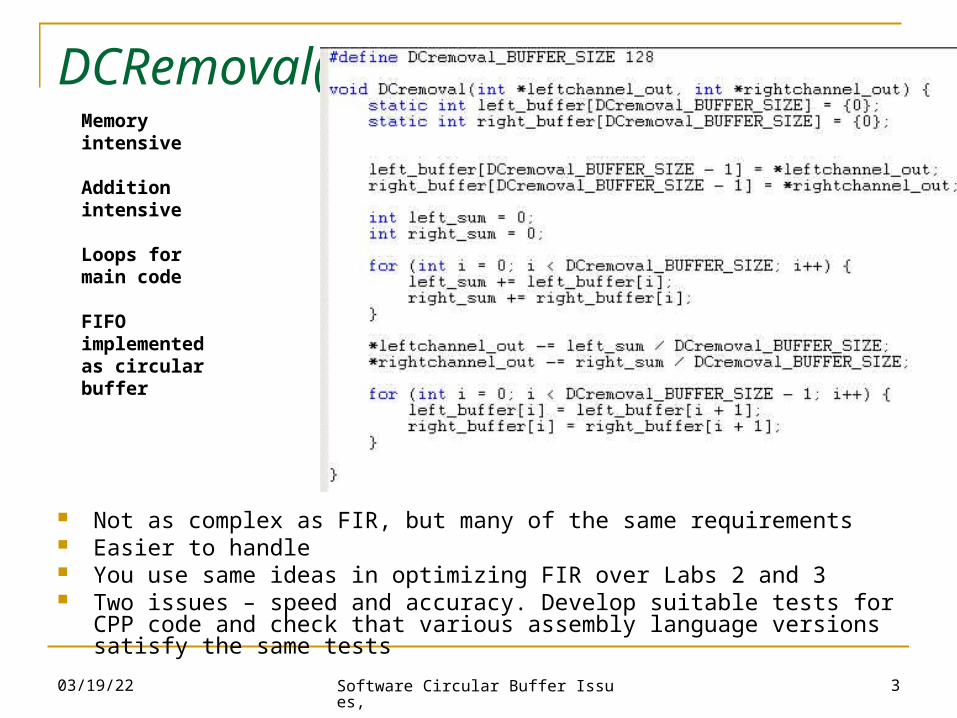
DCRemoval( )
Not as complex as FIR, but many of the same requirements Easier to handle You use same ideas in optimizing FIR over Labs 2 and 3 Two issues – speed and accuracy. Develop suitable tests for CPP code and
check that various assembly language versions satisfy the same tests
Memoryintensive
Additionintensive
Loops formain code
FIFO implementedas circularbuffer

04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
4
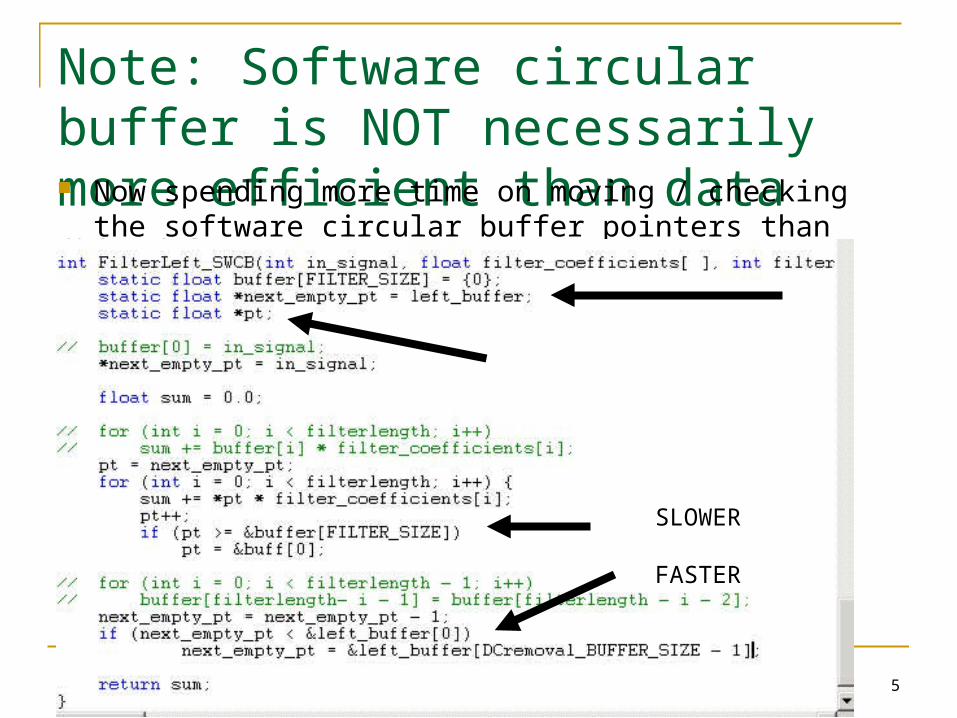
Alternative approach Move pointers rather than memory values In principle – 1 memory read, 1 memory
write, pointer addition, conditional equate
04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
5
Note: Software circular buffer is NOT necessarily more efficient than data moves Now spending more time on moving / checking the software
circular buffer pointers than moving the data?
SLOWER
FASTER

04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
6
Next step – Hardware circular buffer Do exactly the same pointer calculations as with software circular
buffers, but now the calculations are done behind the scenes – high speed – using specialized pointer features
Only available with J0, J1, J2 and J3 registers (On older ADSP-21061 – all pointer registers)
Jx -- The pointer register JBx – The BASE register – set to start of the FIFO array JLx – The length register – set to length of the FIFO array VERY BIG WARNING? – Reset to zero. On older ADSP-21061 it
was very important that the length register be reset to zero, otherwise all the other functions using this register would suddenly start using circular buffer by mistake. Still advisable – but need special syntax for causing circular buffer
operations to occur

04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
7
Store values into hardware FIFO CB instruction ONLY works on POST-
MODIFY operations

04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
8
Next stage in improving code speedHardware circular buffersSet up pointers to buffers
Insert values into buffersSUM LOOPSHIFT LOOPUpdate outgoing parametersUpdate FIFOFunction return
28 Was 43 + N * 4 Was 4 + N * 51 Was 1 + 2 * log2N614 Was 3 + 6 * N2---------------------------37 + 4 N Was 23 + 5 N
N = 128 – instructions = 549 cycles
549 + 300 delay cycle = 879 cyclesDelays are now >50% of useful time
Was 677 + 360 delay cycles = 1011 cycle

04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
9
On TigerSHARC Pipeline Issue After you issue the command to read from memory, then must
wait for value to come
Problem – may be trading memory wait delays for I-ALU delays
Memory pipeline delay
XR5 =CB [J0 += 1];;
XR4 = R4 + R5;;
XR6 = CB [J1 += 1];;
XR7 = R7 + R6;;
No Memory pipeline delay
XR5 =CB [J0 += 1];;
XR6 = CB [J1 += 1];;
XR4 = R4 + R5;;
XR7 = R7 + R6;;

04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
10
Now perform Math operation using circular buffer operation Note the possible memory delays Memory cache helps?
Wait for read ofR2, use it, thenwait for read of R3and then use it

04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
11
Simple interleaving of codePossible saving of memory delays Original order
1234
New order1324

04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
12
Interleaving of codeSame instructions – different orderSet up pointers to buffers
Insert values into buffersSUM LOOPSHIFT LOOPUpdate outgoing parametersUpdate FIFOFunction return
28 Was 43 + N * 4 Was 4 + N * 51 Was 1 + 2 * log2N614 Was 3 + 6 * N2---------------------------37 + 4 N Was 23 + 5 N
N = 128 – instructions = 549 cycles549 + 50 delay cycle = 594 cycles
Delays were 10% of useful time
Was549 + 300 delay cycle = 879 cycles
Delays were >50% of useful time

04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
13
The code is too slow because we are not taking advantage of the available resources Bring in up to 128 bits (4
instructions) per cycle Ability to bring in 4 32-bit values
along J data bus (data1) and 4 along K bus (data2)
Perform address calculations in J and K ALU – single cycle hardware circular buffers
Perform math operations on both X and Y compute blocks
Background DMA activity Off-load some of the processing to
the second processor

04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
14
Understanding how to use MIMD modeProcess left filter in X-Compute, right in Y XR6 = 0;; Puts 0 into XR6 register YR6 = 0;; Puts 0 into YR6 register XYR6 = 0;; Puts 0 into XR6 and YR6 at same
time 1 instruction saved

04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
15
Understanding how to use MIMD modeProcess left filter in X-Compute, right in Y XR6 = R6 + R2;; Adds XR6 + XR2 registers YR6 = R6 + R2;; Adds YR6 + YR2 registers XYR6 = R6 + R2;; Adds XR6 + XR2, AND YR6 + YR2 at
same time N instructions saved

04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
16
Understanding how to use MIMD modeProcess left filter in X-Compute, right in Y XR6 = ASHIFT R6 BY -7;; XR6 = XR6 >> 7 YR6 = ASHIFT R6 BY -7;; YR6 = YR6 >> 7 XYR6 = ASHIFT R6 BY -7;;
XR6 = XR6 >> 7 and YR6 = YR6 >> 7 at same time 1 instruction saved

04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
17
Final operation – dual subtraction

04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
18
MIMD mode
Set up pointers to buffersInsert values into buffersSUM LOOPSHIFT LOOPUpdate outgoing parametersUpdate FIFOFunction return
28 Was 43 + N * 3 Was 4 + N * 51 Was 1 + 2 * log2N614 Was 3 + 6 * N2---------------------------37 + 3 N Was 37 + 4 N
N = 128 – instructions = 421 cycles421 + 180 delay cycles = 590Now delays are 50% of useful time
Was549 + 50 delay cycle = 594 cycles
Delays were 10% of useful time

04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
19
Why no improvement? Extra delays from where?
Back to having towait for R2 to comein from memory beforethe sum can occur

04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
20
The code is too slow because we are not taking advantage of the available resources Bring in up to 128 bits (4
instructions) per cycle Ability to bring in 4 32-bit values
along J data bus (data1) and 4 along K bus (data2)
Perform address calculations in J and K ALU – single cycle hardware circular buffers
Perform math operations on both X and Y compute blocks
Background DMA activity Off-load some of the processing to
the second processor

04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
21
Multiple data busses
Many issues to solve before we can bring in 8 data values per cycle Are the data values aligned so can access 4
values at once? If they are not aligned – what can you do?
One step at a time – Next lecture Lets us bring 1 value in along the J-Data bus and
another in along the K-data bus

04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
22
Exercise on handling interleaving of instructions and X-Y compute operations

04/19/23 Software Circular Buffer Issues, M. Smith, ECE, University of Calgary, Canada
23
Tackled today
Review of coding a hardware circular buffer Roughly understanding where pipeline delays
may occur “Refactor” the working code to improve the speed
without spending any time on examining whether delays really there – works at the moment principle
“Refactoring” working code to perform operations using both X and Y ALU’s – in principle twice the speed