the msr esl assistant: detecting and correcting non-native errors in english
DESCRIPTION
The MSR ESL Assistant: Detecting and correcting non-native errors in English. Michael Gamon, Chris Brockett, William B. Dolan, Jianfeng Gao, Dmitriy Belenko (Microsoft Research), Alexandre Klementiev (University of Illinois at Urbana Champaign), Claudia Leacock (Butler Hill Group). - PowerPoint PPT PresentationTRANSCRIPT

The MSR ESL Assistant: Detecting and correcting non-native errors
in English
Michael Gamon, Chris Brockett, William B. Dolan, Jianfeng Gao, Dmitriy Belenko (Microsoft Research),
Alexandre Klementiev (University of Illinois at Urbana Champaign), Claudia Leacock (Butler Hill Group)

Making NLP useful

Overview• Motivation• Part I: The system
– Error statistics– Different solutions for different errors– Machine learned classifiers for preposition and
determiner errors– Adding a language model and web-based examples
• Part II: Evaluation on native and non-native data• Part III: Usage and interactions

Motivation: The Story of the Disappearing and Reappearing Slide
• 750M people use English as a second or foreign language (vs. 375M as first language)
• 74% of use of English is between non-native speakers
• As many as 300M people study English in China

Error statistics
• Previous studies: – Articles and prepositions account for 20% - 50% of
ESL errors– Prepositions are difficult for learners with various L1
backgrounds

Error statistics
• NICT Japanese Learners of English corpus:– 26.6% of errors are determiner related– 10% of errors are preposition related
• CLEC Chinese Learners’ Corpus:– 10% of errors determiner and number related– 2% preposition related, 5% collocation errors
(which often involve prepositional collocations)

Most frequent errors made by East Asian non-native speakers
• Preposition presence and choice:Finally, the pollution on the world is serious.
• Definite and indefinite determiner presence and choice:We should think whether we have ability to do it well.
• Noun pluralization: So other works couldn't be done in adequate times.
• Gerund/infinitive confusion:So, money is also important in improve people's spirit.
• Auxiliary verb presence and choice:The fire will break out, it can do harmful to people.
• Over-regularized verb inflection: It was builded in 1995.
• Adjective/noun confusion: There was a wonderful women volleyball match between Chinese team and Cuba team.
• Word order (adjective sequences and nominal compounds):A pop British band called "Spice Girl" has sung a song.

Different errors – different solutions
1. Prepositions and articles: much contextual information needed
2. Over-regularized verb morphology: local information is enough
3. Noun number: local information (mass noun, quantifier etc) is enough
• Machine learned approaches for (1), simple heuristics for (2) and (3).
• Total number of error modules: 4 machine-learned modules, 19 heuristic models

Modeling preposition and determiner errors
1. What data?
Domain Sentences
Encarta encyclopedia 487,281
Reuters newswire 567,394
UN proceedings (Hansard) 500,000
Europarl 500,000
Web scraped, using an algorithm similar to STRAND (Resnik and Smith 2003)
500,000
Total 2,554,675

Modeling preposition and determiner errors
1. Preprocessing: tokenization, POStagging2. Heuristic algorithm (based on POS tags): find left edges of
NPs (potential sites for prepositions and articles)3. For each potential site of a preposition or article:
1. Target feature 1: preposition/article present or absent2. Target feature 2: choice of preposition/article (if present)3. Contextual features (POS tags to the left/right, tokens to
the left/right)4. Maximum Entropy classifier

Modeling preposition and determiner errors
Training data: 2.5M sentences: Encarta, Reuters,
UN, EU, web scraped
Classifier Training casesArticle presence/absence 11.9MArticle choice 4.3MPreposition presence/absence 16.1MPreposition choice 6.5M
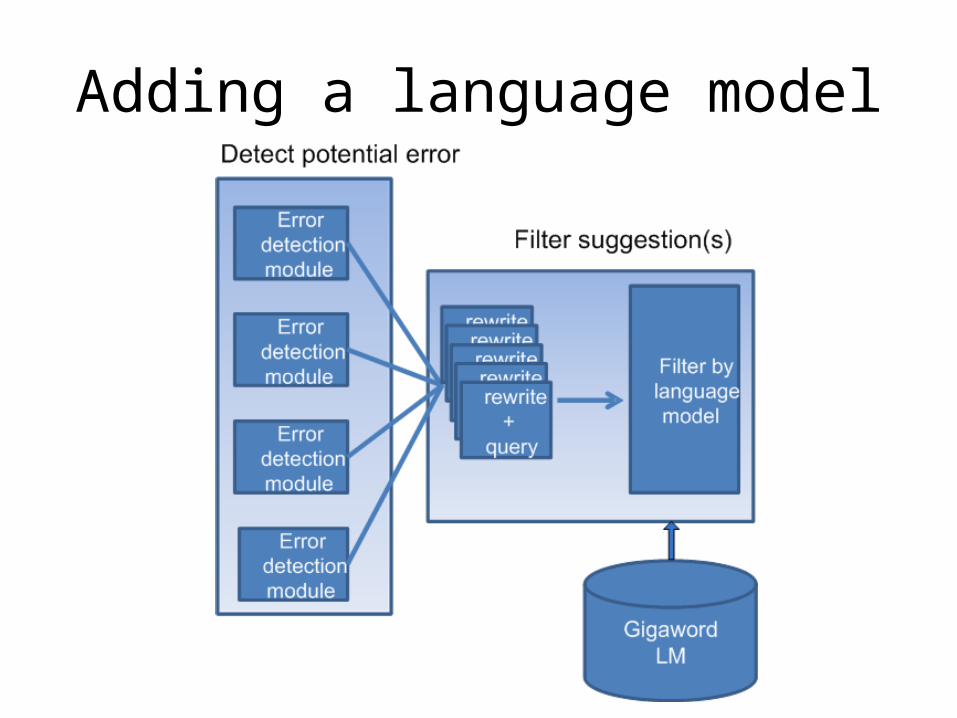
Adding a language model

Adding web search
• Observation: Non-native speakers often use the web to validate word choice

Show suggestions and originals in context

Evaluation (1): native text (correct usage of prepositions and determiners)
• Splitting the original training data into 70% training, 30% test
• Note: classification is split into two questions:1. Should there be a determiner/preposition?2. If yes, which one should it be? (Prepositions:
limiting the set to 12 choices that are common in errors: about, as, at, by, for, from, in, like, of, on, since, to, with, "other“)

Articles: results on native text
Presence/absence Choice model Combined
Accuracy 89.94% 89.66% 86.76%
Baseline 64.04% (no article) 77.73% (definite) 58.91%
Presence/absence model Precision Recall
Presence 87.89% 83.54%
Absence 91.01% 93.54%
Choice model Precision Recall
the 91.48% 95.60%
a/an 81.77% 68.94%

Prepositions: results on native text
Presence/absence Precision Recall
Presence 86.76% 84.66%Absence 89.75% 91.23%
Presence/absence Choice model Combined
Accuracy 88.57% 66.23% 76.77%
Baseline 59.57% (no preposition) 27.07% (of) 42.00%
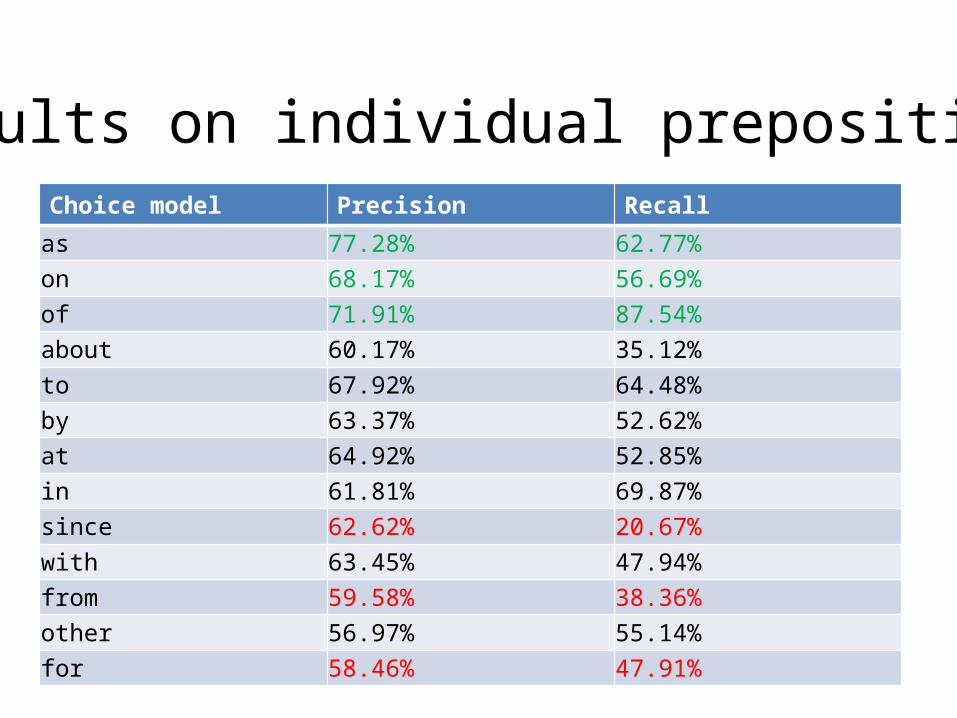
Choice model Precision Recallas 77.28% 62.77%on 68.17% 56.69%of 71.91% 87.54%about 60.17% 35.12%to 67.92% 64.48%by 63.37% 52.62%at 64.92% 52.85%in 61.81% 69.87%since 62.62% 20.67%with 63.45% 47.94%from 59.58% 38.36%other 56.97% 55.14%for 58.46% 47.91%
Results on individual prepositions

Evaluation(2): Human evaluation
1. Spellchecked Chinese Learners’ Corpus (CLEC)2. Test set scraped from the web3. User data

Spellchecked Chinese Learners’ Corpus (CLEC)
• 1 million words of English compositions• collected from Chinese learners of English in
China with differing levels of proficiency:– senior secondary school students– English-major university students– non-English-major university students

Web scraped data
• collected by a vendor for MSR• Scraped from 489 personal web pages and blogs
of non-native speakers/students of English, of Korean, Chinese, or Japanese L1 background
• 6746 sentences, 1k selected randomly for our evaluation
• Education level ranges from high school to graduate school, professionals are also included
• Gender balanced

Intermission: Pie charts

Prepositions
CLEC
good51%
neutral31%
bad18%
CLEC
good34%
neutral39%
bad27%
Web scraped

Articles
good64%
neutral24%
bad12%
CLEC
good68%
neutral20%
bad11%
Web scraped
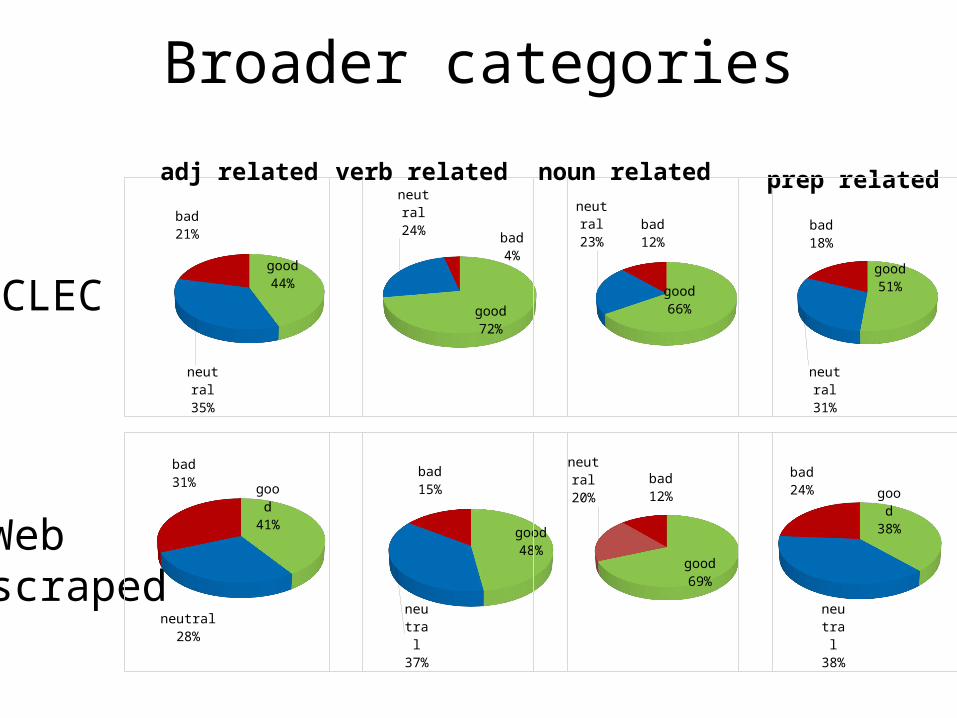
Broader categories
CLEC
Webscraped
good
44%
neu-tral35%
bad21%
good72%
neutral24% bad
4%
good66%
neu-tral23%
bad12%
adj related verb related noun related prep related
good51%
neu-tral31%
bad18%
good
41%
neutral28%
bad31%
good48%
neutral37%
bad15%
good69%
neutral20%
bad12% go
od38%
neutral38%
bad
24%

Usage of the prototype and evaluation of user data
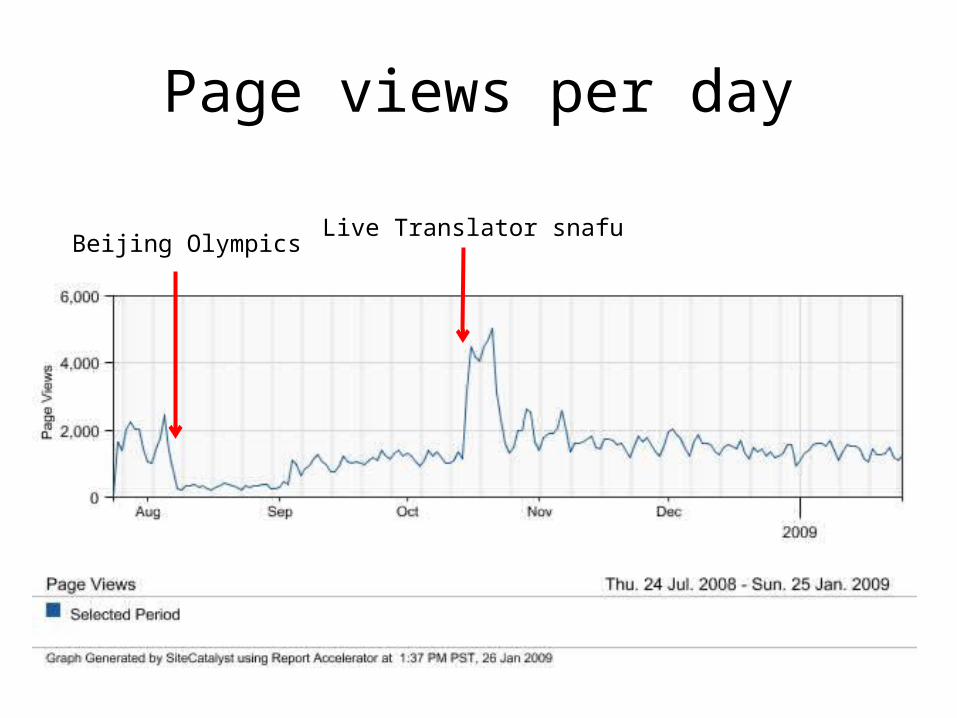
Page views per day
Beijing OlympicsLive Translator snafu

User location
country visits percentageChina 51,285 26.80%United States 28,916 15.10%Taiwan 25,753 13.40%Korea - South 12,934 6.80%Hong Kong 8,826 4.60%Brazil 4,648 2.40%Canada 3,917 2.00%Germany 3,077 1.60%United Kingdom 2,928 1.50%Japan 2,581 1.30%Italy 2,579 1.30%Spain 2,557 1.30%
Russian Federation 2,448 1.30%Saudi Arabia 2.021 1.10%

Users and Sessions
9/24/08 10/24/08 11/24/08 1/7/2009 2/10/20090
5,000
10,000
15,000
20,000
25,000
30,000
Growth of Users
userssessions

Repeat users (2)
once only 2 times or more 3 times or more 4 times or more 5 times or more0
10
20
30
40
50
60
70
80
90
100
Return frequencype
rcen
tage
of t
otal
visi
ts

Return visits

Collected data
Email47%
Non-technical writing24%
Technical writing19%
Unrelated Sentences5%
Other5%
Writing Domains: By Number of Sentences

User interactions

84% of squiggles are examined by the user
Accept39%
Examine suggestion but don't accept
28%
Look at suggestion but don't do any-
thing33%

Are users accepting the right suggestions?
good62%
neutral27%
bad11%
Articles
good44%
neutral42%
bad14%
Prepositions
accepted
good56%
neutral29%
bad15%
Articles
good36%
neutral39%
bad24%
Prepositions
suggested

In summary
• Large market for ESL proofing tools• Detecting and correcting non-native errors is a non-
trivial and interesting research problem• We may already be at a point where the technology
starts to be useful

Some open questions
• How does the accuracy of POStagging influence the accuracy of the overall system?
• How can we best leverage the user behavior as a supervision signal?

Some ideas
• Using web result counts directly as an LM approximation
• Using web result counts as (part of a) supervision signal for ML
• Combining more sources of evidence: LMs trained on different data sets etc
• Build one single model, including LM scores• Active learning to optimize thresholds