the mpack library: a multiple precision version of blas...
TRANSCRIPT

symbol1-1.eps
The MPACK library: A multiple precisionversion of BLAS and LAPACK
中田アングリーバード真秀(NAKATA AngryBirds Maho)
RIKEN, Advanced Center for Computing and Communication
2013/11/19 SC13 BoF
1 / 30

symbol1-1.eps
My Angry Birds Score
(In 2013/10/17, I’m ranked 582 out of 36,586,460 players)
2 / 30

symbol1-1.eps
Introduction: BLAS, LAPACK, and MPACK
3 / 30

symbol1-1.eps
What are the BLAS and LAPACK?
BLAS: A reference implementation of basic linear algebraoperations like: matrix-matrix, matrix-vector, andvector-vector multiplication and manipulation, and use thisas a building block.LAPACK: Using BLAS, it solves linear problems,eigenvalue problems, least square fitting and many more.These libraries are de facto standard of dense linearNumber of accesses of LAPACK web page: 118,181,573(Data as of Sat Jun 29 14:21:36 EDT 2013)In Top500, hand-optimization of a BLAS routine called“dgemm” is important.✞✝ ☎✆The BLAS and LAPACK are very important libraries
4 / 30

symbol1-1.eps
What are the BLAS and LAPACK?
BLAS: A reference implementation of basic linear algebraoperations like: matrix-matrix, matrix-vector, andvector-vector multiplication and manipulation, and use thisas a building block.LAPACK: Using BLAS, it solves linear problems,eigenvalue problems, least square fitting and many more.These libraries are de facto standard of dense linearNumber of accesses of LAPACK web page: 118,181,573(Data as of Sat Jun 29 14:21:36 EDT 2013)In Top500, hand-optimization of a BLAS routine called“dgemm” is important.✞✝ ☎✆The BLAS and LAPACK are very important libraries
4 / 30

symbol1-1.eps
What the BLAS and LAPACK cannot do
✞✝ ☎✆Arbitrary precision calculation ← A survey shows 4% ofvery frquently, 7% of frequently, and 11% of sometimesusers use more than double precision 1.Handling sparse matrix and vectors: ← This is out of ourscope
1http://icl.cs.utk.edu/lapack-forum/survey/lapack-scalapack-display-q.cgi5 / 30

symbol1-1.eps
What the BLAS and LAPACK cannot do
✞✝ ☎✆Arbitrary precision calculation ← A survey shows 4% ofvery frquently, 7% of frequently, and 11% of sometimesusers use more than double precision 1.Handling sparse matrix and vectors: ← This is out of ourscope
1http://icl.cs.utk.edu/lapack-forum/survey/lapack-scalapack-display-q.cgi5 / 30

symbol1-1.eps
What the BLAS and LAPACK cannot do
✞✝ ☎✆Arbitrary precision calculation ← A survey shows 4% ofvery frquently, 7% of frequently, and 11% of sometimesusers use more than double precision 1.Handling sparse matrix and vectors: ← This is out of ourscope
1http://icl.cs.utk.edu/lapack-forum/survey/lapack-scalapack-display-q.cgi5 / 30

symbol1-1.eps
The MPACK : Multiple precision version of BLAS and LAPACK✞✝ ☎✆http://mplapack.sourceforge.net/
NAKATA, Maho @ RIKEN
MPACK: multiple precision version of BLAS and LAPACK.Providing Building block, reference implementation, andApplication Program Interface (API).0.8.0 (2012/12/25); Status: MBLAS completed, and 100MLAPACK routines.Extensive testing: preparing test cases for all calculations.Multi-platform:Linux/BSD/Mac/Win/NVIDIA GPU/Intel Xeon PhiFive supported multiple precision types: GMP, MPFR, quadrupleprecision (binary128), DD, QD, and doubleWritten in C++: easier programming.Distributed under: 2-clause BSD license, redistribution,modification are permitted.
6 / 30

symbol1-1.eps
My contribution
I have been developing a high precision linear algebrapackage based on BLAS and LAPACK and this library isopened to public.My scopes are towards “error free computation” or“numerical validation of computation”.Splitting task to easier participation: HPC people areinterested in acceleration, PDE people are interested insolving in just higher precision, etc by defining API.Wide application fields: (i) numerically hard problems:eigenvalue problem, partial differential equations etc, (ii)Computer-Assisted Proofs (iii) casual debugging:verification of values, can change precision at runtime etc,etc.
7 / 30

symbol1-1.eps
My contribution
I have been developing a high precision linear algebrapackage based on BLAS and LAPACK and this library isopened to public.My scopes are towards “error free computation” or“numerical validation of computation”.Splitting task to easier participation: HPC people areinterested in acceleration, PDE people are interested insolving in just higher precision, etc by defining API.Wide application fields: (i) numerically hard problems:eigenvalue problem, partial differential equations etc, (ii)Computer-Assisted Proofs (iii) casual debugging:verification of values, can change precision at runtime etc,etc.
7 / 30

symbol1-1.eps
My contribution
I have been developing a high precision linear algebrapackage based on BLAS and LAPACK and this library isopened to public.My scopes are towards “error free computation” or“numerical validation of computation”.Splitting task to easier participation: HPC people areinterested in acceleration, PDE people are interested insolving in just higher precision, etc by defining API.Wide application fields: (i) numerically hard problems:eigenvalue problem, partial differential equations etc, (ii)Computer-Assisted Proofs (iii) casual debugging:verification of values, can change precision at runtime etc,etc.
7 / 30

symbol1-1.eps
My contribution
I have been developing a high precision linear algebrapackage based on BLAS and LAPACK and this library isopened to public.My scopes are towards “error free computation” or“numerical validation of computation”.Splitting task to easier participation: HPC people areinterested in acceleration, PDE people are interested insolving in just higher precision, etc by defining API.Wide application fields: (i) numerically hard problems:eigenvalue problem, partial differential equations etc, (ii)Computer-Assisted Proofs (iii) casual debugging:verification of values, can change precision at runtime etc,etc.
7 / 30

symbol1-1.eps
My contribution
I have been developing a high precision linear algebrapackage based on BLAS and LAPACK and this library isopened to public.My scopes are towards “error free computation” or“numerical validation of computation”.Splitting task to easier participation: HPC people areinterested in acceleration, PDE people are interested insolving in just higher precision, etc by defining API.Wide application fields: (i) numerically hard problems:eigenvalue problem, partial differential equations etc, (ii)Computer-Assisted Proofs (iii) casual debugging:verification of values, can change precision at runtime etc,etc.
7 / 30

symbol1-1.eps
Dealing with round-off error by multiple precision calculation
Floating point numbers: approximation of the real numberson computer.Round-off error can occur in each operation.
a + (b + c) ! (a + b) + c
1 + 0.0000000000000001 = 1 in double precision
(one possible) solution: higher/multiple precision (MP)calculation
✞✝ ☎✆A brute force method for against round-off error by employing MP
8 / 30

symbol1-1.eps
Dealing with round-off error by multiple precision calculation
Floating point numbers: approximation of the real numberson computer.Round-off error can occur in each operation.
a + (b + c) ! (a + b) + c
1 + 0.0000000000000001 = 1 in double precision
(one possible) solution: higher/multiple precision (MP)calculation
✞✝ ☎✆A brute force method for against round-off error by employing MP
8 / 30

symbol1-1.eps
Dealing with round-off error by multiple precision calculation
Floating point numbers: approximation of the real numberson computer.Round-off error can occur in each operation.
a + (b + c) ! (a + b) + c
1 + 0.0000000000000001 = 1 in double precision
(one possible) solution: higher/multiple precision (MP)calculation
✞✝ ☎✆A brute force method for against round-off error by employing MP
8 / 30

symbol1-1.eps
IEEE 754: Standard for Binary Floating-Point Arithmetic
754-2008 IEEE Standard for Floating-Point ArithmeticMost used; fast(on Core i7 920: ∼40GFlops; RADEONHD7970 ∼1TFlops)significant digits 16 binary64 (double precision) 64bit
a = ±!
12 +
d222 +
d323 + · · · + d52
252
"× 2e, d = 0 or 1,
e = −1022 ∼ 1023(Partially taken from Wikipedia: http://en.wikipedia.org/wiki/IEEE_754-2008).
9 / 30

symbol1-1.eps
IEEE 754: Standard for Binary Floating-Point Arithmetic
754-2008 IEEE Standard for Floating-Point ArithmeticMost used; fast(on Core i7 920: ∼40GFlops; RADEONHD7970 ∼1TFlops)significant digits 16 binary64 (double precision) 64bit
a = ±!
12 +
d222 +
d323 + · · · + d52
252
"× 2e, d = 0 or 1,
e = −1022 ∼ 1023(Partially taken from Wikipedia: http://en.wikipedia.org/wiki/IEEE_754-2008).
9 / 30

symbol1-1.eps
IEEE 754: Standard for Binary Floating-Point Arithmetic
754-2008 IEEE Standard for Floating-Point ArithmeticMost used; fast(on Core i7 920: ∼40GFlops; RADEONHD7970 ∼1TFlops)significant digits 16 binary64 (double precision) 64bit
a = ±!
12 +
d222 +
d323 + · · · + d52
252
"× 2e, d = 0 or 1,
e = −1022 ∼ 1023(Partially taken from Wikipedia: http://en.wikipedia.org/wiki/IEEE_754-2008).
9 / 30

symbol1-1.eps
IEEE 754: Standard for Binary Floating-Point Arithmetic
754-2008 IEEE Standard for Floating-Point ArithmeticMost used; fast(on Core i7 920: ∼40GFlops; RADEONHD7970 ∼1TFlops)significant digits 16 binary64 (double precision) 64bit
a = ±!
12 +
d222 +
d323 + · · · + d52
252
"× 2e, d = 0 or 1,
e = −1022 ∼ 1023(Partially taken from Wikipedia: http://en.wikipedia.org/wiki/IEEE_754-2008).
9 / 30

symbol1-1.eps
There are many multiple precision arithmetic libraries
The GMP is a free library for arbitrary precision arithmetic,operating on signed integers, rational numbers, andfloating point numbers.
TThe MPFR library is a C library for multiple-precisionfloating-point computations with correct rounding.
10 / 30

symbol1-1.eps
There are many multiple precision arithmetic libraries
binary128, so called “quad double” definied in IEEE 7542008.
QD library: double-double (quad-double) precision : 32(64) decimal significant digit.
11 / 30

symbol1-1.eps
There are many multiple precision arithmetic libraries
binary128, so called “quad double” definied in IEEE 7542008.
QD library: double-double (quad-double) precision : 32(64) decimal significant digit.
11 / 30

symbol1-1.eps
There are many multiple precision arithmetic libraries
binary128, so called “quad double” definied in IEEE 7542008.
QD library: double-double (quad-double) precision : 32(64) decimal significant digit.
11 / 30

symbol1-1.eps
There are many multiple precision arithmetic libraries
12 / 30

symbol1-1.eps
What is the MPACK library?
13 / 30

symbol1-1.eps
The MPACK : Multiple precision version of BLAS and LAPACK✞✝ ☎✆http://mplapack.sourceforge.net/
NAKATA, Maho @ RIKEN
MPACK: multiple precision version of BLAS and LAPACK.Providing Building block, reference implementation, andApplication Program Interface (API).0.8.0 (2012/12/25); Status: MBLAS completed, and 100MLAPACK routines.Extensive testing: preparing test cases for all calculations.Multi-platform:Linux/BSD/Mac/Win/NVIDIA GPU/Intel Xeon PhiFive supported multiple precision types: GMP, MPFR, quadrupleprecision (binary128), DD, QD, and doubleWritten in C++: easier programming.Distributed under: 2-clause BSD license, redistribution,modification are permitted.
14 / 30

symbol1-1.eps
Naming rule of routines
Change in Prefixfloat, double→ “R”eal,complex, double complex→ “C”omplex.
daxpy, zaxpy→ Raxpy, Caxpydgemm, zgemm→ Rgemm, Cgemmdsterf, dsyev→ Rsterf, Rsyevdzabs1, dzasum→ RCabs1, RCasum
15 / 30

symbol1-1.eps
Supported routines in MBLAS 0.8.0
LEVEL1 MBLASCrotg Cscal Rrotg Rrot Rrotm CRrot Cswap
Rswap CRscal Rscal Ccopy Rcopy Caxpy RaxpyRdot Cdotc Cdotu RCnrm2 Rnrm2 Rasum iCasum
iRamax RCabs1 Mlsame Mxerbla
LEVEL2 MBLASCgemv Rgemv Cgbmv Rgbmv Chemv Chbmv Chpmv RsymvRsbmv Ctrmv Cgemv Rgemv Cgbmv Rgemv Chemv ChbmvChpmv Rsymv Rsbmv Rspmv Ctrmv Rtrmv Ctbmv CtpmvRtpmv Ctrsv Rtrsv Ctbsv Rtbsv Ctpsv Rger CgeruCgerc Cher Chpr Cher2 Chpr2 Rsyr Rspr Rsyr2Rspr2
LEVEL3 MBLASCgemm Rgemm Csymm Rsymm Chemm Csyrk Rsyrk CherkCsyr2k Rsyr2k Cher2k Ctrmm Rtrmm Ctrsm Rtrsm
16 / 30
symbol1-1.eps
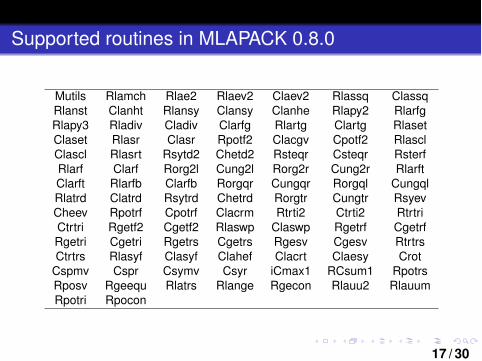
Supported routines in MLAPACK 0.8.0
Mutils Rlamch Rlae2 Rlaev2 Claev2 Rlassq ClassqRlanst Clanht Rlansy Clansy Clanhe Rlapy2 RlarfgRlapy3 Rladiv Cladiv Clarfg Rlartg Clartg RlasetClaset Rlasr Clasr Rpotf2 Clacgv Cpotf2 RlasclClascl Rlasrt Rsytd2 Chetd2 Rsteqr Csteqr RsterfRlarf Clarf Rorg2l Cung2l Rorg2r Cung2r RlarftClarft Rlarfb Clarfb Rorgqr Cungqr Rorgql CungqlRlatrd Clatrd Rsytrd Chetrd Rorgtr Cungtr RsyevCheev Rpotrf Cpotrf Clacrm Rtrti2 Ctrti2 RtrtriCtrtri Rgetf2 Cgetf2 Rlaswp Claswp Rgetrf CgetrfRgetri Cgetri Rgetrs Cgetrs Rgesv Cgesv RtrtrsCtrtrs Rlasyf Clasyf Clahef Clacrt Claesy Crot
Cspmv Cspr Csymv Csyr iCmax1 RCsum1 RpotrsRposv Rgeequ Rlatrs Rlange Rgecon Rlauu2 RlauumRpotri Rpocon
17 / 30

symbol1-1.eps
Programming details
Use INTEGER, REAL, COMPLEX, LOGICAL type.MP libs are renamed using “typedef”. REAL→ mpf_class,qd_real, dd_real etc.We support GMP, MPFR, QD, DD, binary128 and doubleWe can program like “double” of C++(eg. SDPA-DD and-GMP)
18 / 30

symbol1-1.eps
Implimentation of MBLAS by example
Caxpy: Complex version of axpy
void Caxpy(INTEGER n, COMPLEX ca, COMPLEX * cx, INTEGER incx, COMPLEX * cy, INTEGER incy){
REAL Zero = 0.0;if (n <= 0)
return;if (RCabs1(ca) == Zero)
return;INTEGER ix = 0;INTEGER iy = 0;if (incx < 0)
ix = (-n + 1) * incx;if (incy < 0)
iy = (-n + 1) * incy;for (INTEGER i = 0; i < n; i++) {
cy[iy] = cy[iy] + ca * cx[ix];ix = ix + incx;
19 / 30

symbol1-1.eps
Implimentation of MLAPACK by exampleRsyev; diagonalization of real symmetric matrices
Rlascl(uplo, 0, 0, One, sigma, n, n, A, lda, info);}
//Call DSYTRD to reduce symmetric matrix to tridiagonal form.inde = 1;indtau = inde + n;indwrk = indtau + n;llwork = *lwork - indwrk + 1;Rsytrd(uplo, n, &A[0], lda, &w[0], &work[inde - 1], &work[indtau - 1],
&work[indwrk - 1], llwork, &iinfo);//For eigenvalues only, call DSTERF. For eigenvectors, first call//DORGTR to generate the orthogonal matrix, then call DSTEQR.
if (!wantz) {Rsterf(n, &w[0], &work[inde - 1], info);
} else {Rorgtr(uplo, n, A, lda, &work[indtau - 1], &work[indwrk - 1], llwork,
&iinfo);Rsteqr(jobz, n, w, &work[inde - 1], A, lda, &work[indtau - 1], info);
}//If matrix was scaled, then rescale eigenvalues appropriately.
if (iscale == 1) {if (*info == 0) {
20 / 30

symbol1-1.eps
Quality assurance of MBLAS and MLAPACK✞✝ ☎✆Note: BLAS does only algebraic operations
Take the origianl version as reference. Then compareMPFR+MPC version, to check if the results are reasonable.Then do again for MPFR+MPC/QD, /DD, ...Not sufficient for MLAPACK of course.for (int k = MIN_K; k < MAX_K; k++) {for (int n = MIN_N; n < MAX_N; n++) {for (int m = MIN_M; m < MAX_M; m++) {
...for (int lda = minlda; lda < MAX_LDA; lda++) {for (int ldb = minldb; ldb < MAX_LDB; ldb++) {for (int ldc = max(1, m); ldc < MAX_LDC; ldc++) {
Rgemm(transa, transb, m, n, k, alpha, A, lda, B, ldb, beta, C, ldc);dgemm_f77(transa, transb, &m, &n, &k, &alphad, Ad, &lda,
Bd, &ldb, &betad, Cd, &ldc);...
diff = vec_diff(C, Cd, MAT_A(ldc, n), 1);if (fabs(diff) > EPSILON) {
printf(‘‘#error %lf!!\n’’, diff);errorflag = TRUE;
}
21 / 30

symbol1-1.eps
Feature: dynamic change precision for GMP andMPFR
An example of change precision at execution : Inversion of theHilbert matrix.
$ ./hilbert_mpfr...1norm(I-A*invA)=1.8784847910273908e-73$ MPACK_MPFR_PRECISION=1024;$ export MPACK_MPFR_PRECISION ; ./hilbert_mpfr...1norm(I-A*invA)=1.9318639065194500e-226
22 / 30

symbol1-1.eps
Performance of Raxpy : vector operation
on Intel Core i7 920 (2.6GHz) / Ubuntu 10.04 / gcc 4.4.3
y← αx + y
Raxpy performance in Flops. multithread by OpenMP inparenthesis
MP Library(sign. digs.) Flops (OpenMP)DD(32) 130(570)MQD(64) 13.7(67)M
GMP(77) 11.3(45)MGMP(154) 7.6(32)MMPFR(154) 3.7(17)M
GotoBLAS(16) 1.5G
23 / 30

symbol1-1.eps
Performance of Rgemv : Matrix-vector operation
on Intel Core i7 920 (2.6GHz) / Ubuntu 10.04 / gcc 4.4.3
y← αAx + βy
Rgemv performance in Flops.MP Library(sign. digs.) Flops (OpenMP)
DD(32) 140MQD(64) 13M
GMP(77) 11.1MMPFR(77) 4.7MGMP(154) 7.1MMPFR(154) 3.7M
GotoBLAS(16) 3.8G
24 / 30

symbol1-1.eps
Performance of Rgemm : Matrix-matrix operation
on Intel Core i7 920 (2.6GHz) / Ubuntu 10.04 / gcc 4.4.3
Rgemm performance in Flops.
C ← αAB + βC
MP Library(sign. digs.) Flops (OpenMP)DD(32) 136 (605)MQD(64) 13.9 (63)M
GMP(77) 11.5 (44)MMPFR(77) 4.6 (20)MGMP(154) 7.2 (28) MMPFR(154) 3.7 (16) M
GotoBLAS(16) 42.5G
25 / 30

symbol1-1.eps
Matrix-Matrix operation Performance of Rgemm indouble-double on NVIDIA C2050
CUDA 3.2, NVIDIA C2050, 16GFlops-26GFlops:
0
5
10
15
20
25
0 1000 2000 3000 4000 5000 6000
GFLOPS
Dimension
QuadMul−Sloppy, QuadAdd−Cray KernelQuadMul−Sloppy, QuadAdd−Cray TotalQuadMul−FMA, QuadAdd−Cray Kernel
QuadMul−FMA, QuadAdd−Cray TotalQuadMul−Sloppy, QuadAdd−IEEE Kernel
QuadMul−Sloppy, QuadAdd−IEEE TotalQuadMul−FMA, QuadAdd−IEEE Kernel
QuadMul−FMA, QuadAdd−IEEE Total
Best paper: A Fast implementation of matrix-matrix product in double-double precision on NVIDIA C2050 and
application to semidefinite programming in The Third International Conference on Networking and Computing.
26 / 30

symbol1-1.eps
Perfomance of Rgemm :matrix-matrix operation: indouble-double on Westmere EP
Intel Composer, Intel WestmereEP, 40 cores, 2.4GHz: apporx5GFlops
27 / 30

symbol1-1.eps
Perfomance of Rgemm :matrix-matrix operation: indouble-double on Magnycours 48cores
GCC 4.6, Magny cours 2.4GHz, 48 cores : approx 3GFlops
28 / 30

symbol1-1.eps
Perfomance of Rgemm :matrix-matrix operation: inbinary128 on Magnycours 48cores
GCC 4.6, Magny cours 2.4GHz, 48 cores : approx 0.3GFlops
29 / 30
symbol1-1.eps
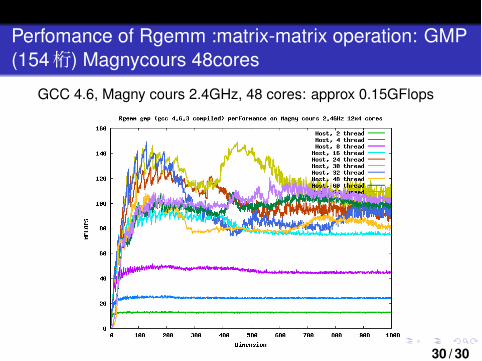
Perfomance of Rgemm :matrix-matrix operation: GMP(154桁) Magnycours 48cores
GCC 4.6, Magny cours 2.4GHz, 48 cores: approx 0.15GFlops
30 / 30