temporal fringe pattern analysis with parallel computing
TRANSCRIPT

Temporal fringe pattern analysis with parallel computing
Tuck Wah Ng, Kar Tien Ang, and Gianluca Argentini
Temporal fringe pattern analysis is invaluable in transient phenomena studies but necessitates longprocessing times. Here we describe a parallel computing strategy based on the single-program multiple-datamodel and hyperthreading processor technology to reduce the execution time. In a two-node cluster work-station configuration we found that execution periods were reduced by 1.6 times when four virtual proces-sors were used. To allow even lower execution times with an increasing number of processors, the timeallocated for data transfer, data read, and waiting should be minimized. Parallel computing is found hereto present a feasible approach to reduce execution times in temporal fringe pattern analysis. © 2005Optical Society of America
OCIS codes: 100.2650, 100.3010, 120.3180, 120.3940.
1. Introduction
Optical metrology techniques such as wavefront inter-ferometry, speckle interferometry, moiré, and photoelas-ticity produce fringe patterns. These fringe patterns yieldinformation about phase that can be related to physicalquantities such as displacement, deformation, strain,and shape. There are two general approaches to fringepattern analysis, spatial and temporal. Spatial fringepattern analysis techniques, such as skeletonization,1phase shifting,2 and Fourier transform,3 typically pro-duce the phase modulo 2�. The actual phase valueshave to be computed by a subsequent unwrap oper-ation. Discontinuities and low modulation regions inthe spatial fringe pattern can cause difficulties in thisprocess. Discontinuities arise from factors such asinsufficient sampling, holes, cracks, free surfaces, in-dependent components, and dead pixels. In somemethods, such as speckle interferometry, low-modulation points abound and arise primarily fromthe statistics of the speckle phase.4 Although robustphase-unwrap algorithms that are based on cellularautomata,5 least squares,6 quadratic regularizationfunctionals,7 digital cosine transform,8 and othershave been contemplated, they are still fraught with
some degree of error and are generally time-consuming to implement.
Temporal fringe pattern analysis was first pro-posed by Huntley and Saldner9 to circumvent theproblem of discontinuities and low-modulation datapoints. The original approach of introducing a seriesof phase-shifted fringe patterns at a particular loadinstance has since been further developed by oth-ers.10,11 This methodology, however, necessitates ad-ditional storage and processing. The temporal fastFourier transform approach, first proposed by Ng andChau,12 eliminates such a need. The further use ofcarriers in this method has been demonstrated toimprove the phase derivation accuracy as well as inascertaining whether the deformation phase was in-creasing or decreasing.13 More recently, other tempo-ral fringe pattern analysis approaches that are basedon synchronous detection,14 least-squares fitting,15
and the Hilbert transform16 have been reported.With the advent of affordable high-speed video
camera and pulsed laser sources, optical metrologymethods are now increasingly used for transient phe-nomena studies.17,18 Temporal fringe pattern analy-sis is favorable in such applications because of itsinherent ability to reveal directly the time evolutionof the deformation phase. This scheme, however, ne-cessitates large amounts of computer storage andlong processing times. Ng and Ang19,20 have begun toaddress the storage issue by the introduction of cus-tomized compression schemes. In this research, weinvestigate the use of parallel computing as an ave-nue to reducing temporal fringe analysis periods.
Traditionally programs have been written for se-rial computation, wherein problems are solved by aseries of instructions, executed one after the other, by
T. W. Ng (e-mail, [email protected]) and K. T. Ang are withthe National University of Singapore, Faculty of Engineering, En-gineering Block EA-07-32, 9 Engineering Drive 1, Singapore117576. G. Argentini is with the Riello Group, Department ofInformation and Communication Technology, 35044 Legnago,Verona, Italy.
Received 28 March 2005; accepted 12 July 2005.0003-6935/05/337125-05$15.00/0© 2005 Optical Society of America
20 November 2005 � Vol. 44, No. 33 � APPLIED OPTICS 7125

the CPU. When large amounts of data need to beprocessed, the time requirements scale up accord-ingly. One method for mitigating this is by parallelcomputing. To implement parallel computing, thecomputational problem has to demonstrate charac-teristics such as the ability (a) to be broken apart intodiscrete pieces of work that can be solved simulta-neously and (b) to be executed by multiple programinstructions at any moment in time. In this way theentire problem can be solved more expediently withmultiple computing resources than with a single com-puting resource.
Figure 1(a) shows a typical image recorded withdigital speckle pattern interferometry (DSPI). Theintensity function corresponding to each spatial pointcan be expressed as
i�x, y, k� � iB�x, y� � iM�x, y�cos���x, y�� ��x, y, k��, (1)
where iB�x, y� describes the background intensity,iM�x, y� is related to the local modulation of the pat-tern, and k is the parameter corresponding to thetemporal evolution of loading. The local deformationinformation is contained within the phase ��x, y, k�,and ��x, y� is the random speckle phase. The inten-sity distribution from a single line of data in the DSPIimage, plotted under temporal loading evolution, isgiven in Fig. 1(b). The fringelike features along thetime axis allude to the feasibility of using temporalprocessing to obtain the deformation phase. It alsoalludes to possible benefits from parallel computingto speed up the task.
2. Parallel-Computing Strategy
Parallel computing can be accomplished by differentmodels.21 The well-known models include sharedmemory, threads, message passing, data parallel, hy-brid, single-program multiple data (SPMD), and mul-tiple program multiple data. In the SPMD model asingle program is executed simultaneously by alltasks. Hence the same or different instructions can beexecuted within the same program at any moment intime. SPMD programs usually have the necessarylogic programmed into them to allow different tasks tobranch or conditionally execute parts of the program.
The temporal fringe analysis problem belongs to aclass that is termed embarrassingly parallel. Embar-rassingly parallel computing problems have no com-putational dependence. Hence synchronization ofdata occurs only at the beginning and the end phase.The low communication requirements of embarrass-ingly parallel problems make them particularlysuited for distributed computing implementation ona network of workstations. In addition, embarass-ingly parallel computing problems are easily imple-mentable by the SPMD model.
For parallel computing to work, workstations haveto be linked by interconnection networks. Static linkinterconnects have been used previously but are nowlargely eschewed because of high costs. Currently
most workstations are linked by cluster intercon-nects. The advent of workstation processors with hy-perthreading technology offers the ability to executethreads of multithreaded software applications inparallel.22 Hyperthreading technology essentiallysplits one real physical processor into two virtualprocessors. The operating system, however, usesthese virtual processors as though they are real. Re-cently Argentini23,24 demonstrated the use of this fea-
Fig. 1. Digital speckle interferometry image and the intensitydistribution from a single line of data plotted under temporalloading evolution.
7126 APPLIED OPTICS � Vol. 44, No. 33 � 20 November 2005

ture to parallelize SPMD Matlab computationalprograms in single and clustered workstations withsignificant time-reduction benefits.
3. Performance Verification
A series of 512 temporal simulated intensity speckleinterferometry fringe patterns with 512 � 480 pixelpixel spatial resolution were generated with varyinglevels and directions of deformation phase intro-duced. A speckle frame image is given in Fig. 2(a).The fringe pattern corresponding to a subtractionoperation between the speckle image with load fromanother without load is shown in Fig. 2(b). A constantintensity carrier with time was incorporated.
The hardware comprised two nodes wherein eachnode had two Intel Xeon 3.2 GHz processors and2 GB of RAM on a redundant array of independentdisks (RAID 0). The network comprised a 100 MHzswitch for node connection, and the operating systemwas Windows 2000. Matlab 6.5 does not have a nativesupport for parallel elaboration and multithread-ing.25 Nevertheless it is possible to use a single mas-ter instance to start slave copies on nodes and assigneach of them the same set of instructions to operateon different sets of data. This simulates a SPMDcomputation. This method has the difficulty of ex-changing messages among independent processors.However, this is not an issue here because of theembarrasingly parallel nature of the temporal fringeanalysis scheme.
A master function was written in Matlab to ashared file system so that the generated scripts couldbe executed as slave copies. These copies werelaunched in the background mode for parallel execu-tion. The master program controlled the end of thecomputations by using a simple set of lock files. Oncethe slave finished its task, it canceled its own lock file.The master program was responsible for clocking thetime needed for the essential tasks such as data read-ing, data processing, as well as data transfer andwaiting. The processing algorithm was based on thefast Fourier transform scheme.12,13
4. Results and Discussion
Plots of the measured execution times when a differ-ent number of processors were used are presented inFig. 3. The total execution times were clearly reducedwith an increase in the number of virtual processorson a node. With four virtual processors, for example,the total execution time was found to be reduced by1.6 times. This result confirms the feasibility of usingparallel computing to reduce execution times in tem-poral fringe analysis. A breakdown of the execution-time components reveals some interesting insights.The execution times for processing showed a reducingtrend with an increasing number of virtual proces-sors. This was an expected and logical result. Theexecution time in data transfer and waiting, alterna-tively, showed a corresponding increase with the
Fig. 2. Speckle interferometry intensity fringe patterns with car-rier modulation generated for (a) a single frame and (b) two sub-tracted frames, one with deformation.
Fig. 3. Plots of the measured execution times when a differentnumber of processors are used.
20 November 2005 � Vol. 44, No. 33 � APPLIED OPTICS 7127
number of virtual processors. This result was againexpected since sending and waiting for more blocks ofparallel data would naturally incur more handlingtime. However, the percentage of total execution timeneeded for this was a notable point of concern. Forexample, data transfer and waiting accounted for36% of the total execution time when four virtualprocessors were used. This factor may prove to be abottleneck when one attempts to use more virtualprocessors. The execution time for data reading wasexpected to be fairly constant. Nevertheless a some-what small reducing trend was observed. We believethat this could be attributed to the manner in whichMatlab accesses data blocks from the hard disk.
The parallel-computing performance with N pro-cessors is conveniently measured with the speedupfactor S:
S�N� �t�1�t�N�
, (2)
where t indicates the execution time. The limits of thespeedup factor S= when N processors are used is nor-mally estimated by Amdahl’s law:
S��N� �1
�P�N� � �1 � P�, (3)
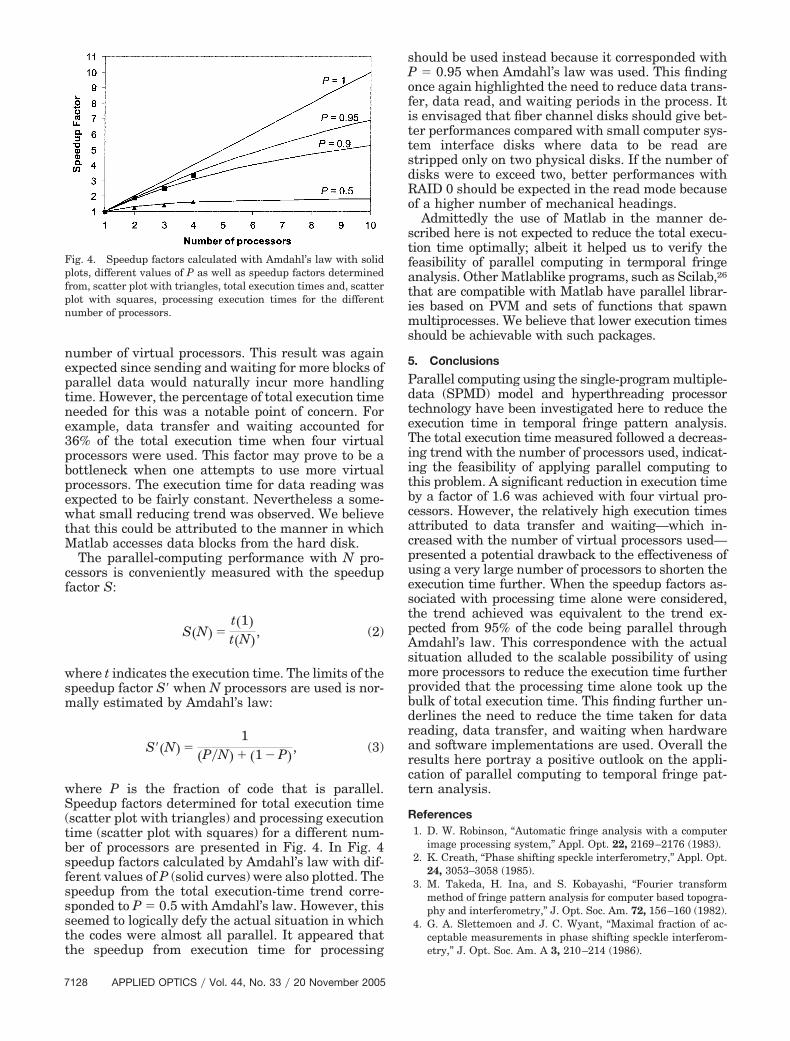
where P is the fraction of code that is parallel.Speedup factors determined for total execution time(scatter plot with triangles) and processing executiontime (scatter plot with squares) for a different num-ber of processors are presented in Fig. 4. In Fig. 4speedup factors calculated by Amdahl’s law with dif-ferent values of P (solid curves) were also plotted. Thespeedup from the total execution-time trend corre-sponded to P � 0.5 with Amdahl’s law. However, thisseemed to logically defy the actual situation in whichthe codes were almost all parallel. It appeared thatthe speedup from execution time for processing
should be used instead because it corresponded withP � 0.95 when Amdahl’s law was used. This findingonce again highlighted the need to reduce data trans-fer, data read, and waiting periods in the process. Itis envisaged that fiber channel disks should give bet-ter performances compared with small computer sys-tem interface disks where data to be read arestripped only on two physical disks. If the number ofdisks were to exceed two, better performances withRAID 0 should be expected in the read mode becauseof a higher number of mechanical headings.
Admittedly the use of Matlab in the manner de-scribed here is not expected to reduce the total execu-tion time optimally; albeit it helped us to verify thefeasibility of parallel computing in termporal fringeanalysis. Other Matlablike programs, such as Scilab,26
that are compatible with Matlab have parallel librar-ies based on PVM and sets of functions that spawnmultiprocesses. We believe that lower execution timesshould be achievable with such packages.
5. Conclusions
Parallel computing using the single-program multiple-data (SPMD) model and hyperthreading processortechnology have been investigated here to reduce theexecution time in temporal fringe pattern analysis.The total execution time measured followed a decreas-ing trend with the number of processors used, indicat-ing the feasibility of applying parallel computing tothis problem. A significant reduction in execution timeby a factor of 1.6 was achieved with four virtual pro-cessors. However, the relatively high execution timesattributed to data transfer and waiting—which in-creased with the number of virtual processors used—presented a potential drawback to the effectiveness ofusing a very large number of processors to shorten theexecution time further. When the speedup factors as-sociated with processing time alone were considered,the trend achieved was equivalent to the trend ex-pected from 95% of the code being parallel throughAmdahl’s law. This correspondence with the actualsituation alluded to the scalable possibility of usingmore processors to reduce the execution time furtherprovided that the processing time alone took up thebulk of total execution time. This finding further un-derlines the need to reduce the time taken for datareading, data transfer, and waiting when hardwareand software implementations are used. Overall theresults here portray a positive outlook on the appli-cation of parallel computing to temporal fringe pat-tern analysis.
References1. D. W. Robinson, “Automatic fringe analysis with a computer
image processing system,” Appl. Opt. 22, 2169–2176 (1983).2. K. Creath, “Phase shifting speckle interferometry,” Appl. Opt.
24, 3053–3058 (1985).3. M. Takeda, H. Ina, and S. Kobayashi, “Fourier transform
method of fringe pattern analysis for computer based topogra-phy and interferometry,” J. Opt. Soc. Am. 72, 156–160 (1982).
4. G. A. Slettemoen and J. C. Wyant, “Maximal fraction of ac-ceptable measurements in phase shifting speckle interferom-etry,” J. Opt. Soc. Am. A 3, 210–214 (1986).
Fig. 4. Speedup factors calculated with Amdahl’s law with solidplots, different values of P as well as speedup factors determinedfrom, scatter plot with triangles, total execution times and, scatterplot with squares, processing execution times for the differentnumber of processors.
7128 APPLIED OPTICS � Vol. 44, No. 33 � 20 November 2005

5. D. C. Ghiglia, G. A. Mastin, and L. A. Romero, “Cellular au-tomata method for phase unwrapping,” J. Opt. Soc. Am. A 4,267–280 (1987).
6. K. M. Hung and T. Yamada, “Phase unwrapping by regionsusing the least-squares approach,” Opt. Eng. 37, 2965–2970(1998).
7. J. L. Marroquin and M. Rivera, “Quadratic regularizationfunctionals for phase unwrapping,” J. Opt. Soc. Am. A 12,2393–2400 (1995).
8. D. Kerr, G. H. Kaufmann, and G. E. Galizzi, “Unwrapping ofinterferometric phase fringe maps by the discrete cosine trans-form,” Appl. Opt. 35, 810–816 (1996).
9. J. M. Huntley and H. Saldner, “Temporal phase unwrappingalgorithm for automated interferogram analysis,” Appl. Opt.32, 3047–3052 (1993).
10. J. M. Kilpatrick, A. J. Moore, J. S. Barton, J. D. C. Jones,M. Reeves, and C. Buckberry, “Measurement of complex sur-face deformation by high-speed dynamic phase-stepped digitalspeckle pattern interferometry,” Opt. Lett. 25, 1068–1070(2000).
11. T. E. Carlsson and A. Wei, “Phase evaluation of speckle pat-terns during continuous deformation by use of phase-shiftingspeckle interferometry,” Appl. Opt. 39, 2628–2637 (2000).
12. T. W. Ng and F. S. Chau, “Automated analysis in digitalspeckle shearing interferometry using an objet step-loadingmethod,” Opt. Commun. 108, 214–218 (1994).
13. T. W. Ng, “Carrier-modulated object step-loading method ofautomated analysis in digital speckle shearing interferome-try,” J. Mod. Opt. 42, 2109–2118 (1995).
14. J. Villa, J. A. Gomez-Pedrero, and J. A. Quiroga, “Sinusoidalleast-squares fitting for temporal fringe pattern analysis,” J.Mod. Opt. 49, 2257–2266 (2002).
15. J. Villa, J. A. Gomez-Pedrero, and J. A. Quiroga, “Synchronous
detection techniques for temporal fringe pattern analysis,”Opt. Commun. 204, 75–81 (2002).
16. V. D. Madjarova, H. Kadono, and S. Toyooka, “Dynamic elec-tronic speckle pattern interferometry (DESPI) phase analysiswith temporal Hilbert transform,” Opt. Express 11, 617–623(2003).
17. E. Astrakharchik-Farrimond, B. Y. Shekunov, P. York, N.B. E. Sawyer, S. P. Morgan, M. G. Somekh, and C. W. See“Dynamic measurements in supercritical flow using instanta-neous phase-shift interferometry,” Exp. Fluids 33, 307–314(2002).
18. D. Ambrosi, D. Paoletti, and G. Schirripa Spagnalo, “Study offree-convective onset on a horizontal wire using speckle pat-tern interferometry,” Int. J. Heat Mass Transfer 46, 4145–4155 (2003).
19. T. W. Ng and K. T. Ang, “Data compression for speckle corre-lation interferometry temporal fringe pattern analysis,” Appl.Opt. 44, 2799–2804 (2005).
20. T. W. Ng and K. T. Ang, “Fourier transform method of datacompression and temporal fringe pattern analysis,” Appl. Opt.(to be published).
21. A. Grama, G. Karypis, V. Kumar, and A. Gupta, An Introduc-tion to Parallel Computing: Design and Analysis of Algo-rithms, 2nd ed. (Addison Wesley, 2003).
22. W. Magro, P. Petersen, and S. Shah, “Hyper-threading tech-nology: impact on computer-intensive workloads,” Intel Tech-nol. J. 6, 58–66 (2002).
23. G. Argentini, “Using virtual processors for SPMD programs,”Comput. Res. Reposit, cs.DC�0312049 (2003).
24. G. Argentini, “Cluster computing performances using virtualprocessors and MATLAB 6.5,” Comput. Res. Reposit. cs.DC�0401006 (2004).
25. www.mathworks.com.26. www.scilab.org.
20 November 2005 � Vol. 44, No. 33 � APPLIED OPTICS 7129