tag-based algorithms can predict human ratings of which objects a picture shows
TRANSCRIPT

Multimed Tools Appl (2012) 59:441–462DOI 10.1007/s11042-011-0761-x
Tag-based algorithms can predict human ratingsof which objects a picture shows
Viktoria Pammer · Barbara Kump ·Stefanie Lindstaedt
Published online: 23 February 2011© Springer Science+Business Media, LLC 2011
Abstract Collaborative tagging platforms allow users to describe resources withfreely chosen keywords, so called tags. The meaning of a tag as well as the preciserelation between a tag and the tagged resource are left open for interpretationto the user. Although human users mostly have a fair chance at interpreting thisrelation, machines do not. In this paper we study the characteristics of the problemto identify descriptive tags, i.e. tags that relate to visible objects in a picture. Weinvestigate the feasibility of using a tag-based algorithm, i.e. an algorithm that ignoresactual picture content, to tackle the problem. Given the theoretical feasibility ofa well-performing tag-based algorithm, which we show via an optimal algorithm,we describe the implementation and evaluation of a WordNet-based algorithm asproof-of-concept. These two investigations lead to the conclusion that even relativelysimple and fast tag-based algorithms can yet predict human ratings of which objects apicture shows. Finally, we discuss the inherent difficulty both humans and machineshave when deciding whether a tag is descriptive or not. Based on a qualitativeanalysis, we distinguish between definitional disagreement, difference in knowledge,disambiguation and difference in perception as reasons for disagreement betweenraters.
Keywords Semantic annotation · Image tagging behaviour · Descriptive tags ·Flickr · WordNet
V. Pammer (B) · S. LindstaedtKnow-Center, Inffeldgasse 21a, 8010 Graz, Austriae-mail: [email protected], [email protected]
S. Lindstaedte-mail: [email protected]
B. KumpKnowledge Management Institute, Graz University of Technology, Tübingen, Germanye-mail: [email protected]

442 Multimed Tools Appl (2012) 59:441–462
1 Introduction
Social software and collaborative tagging platforms have sprung up everywhere onthe web. They enable users to describe photos, news, blogs, research publications andweb bookmarks with freely chosen keywords, so called tags, and to share both theircontent and their tags with other users. Exemplary platforms are Flickr1 for photos,Digg2 for news, Technorati3 for blogs, CiteULike4 for research publications, orDelicious5 for web bookmarks. The appeal of tagging lies in its simplicity for the tagproducer, who can attach any keyword he or she deems appropriate to a resource. Noexplanation of the exact meaning of the tag has to be provided and no rules restrictingthe vocabulary have to be adhered to. This ease of use on the tag producer’s sidecreates a disadvantage on the side of the tag consumer. The (human or machine)tag consumer who wants to use other people’s tags has to interpret the given tags. Ithas been shown that also humans have difficulty in using tags, for instance in orderto find appropriate tags to formulate queries [6]. However, typically humans seemto be able to make sense of tags in general, and certainly to a larger extent thanmachines. Consequently, significant research is directed towards understanding tagsand tagging behaviour in collaborative tagging platforms, typically with the long-termgoal of providing better automated means to benefit from the rich content availablein such platforms (Section 3).
In this paper, we analyse the semantics of a specific relation between tags andpictures, namely the “shows”-relation which expresses that a tag refers to an entitywhich is visible on the picture. We present a problem analysis (Section 4) anddiscussion (Section 6) of the challenge of identifying such a relation. Furthermore,we describe a theoretical upper-limit for tag-based algorithms attempting to identifythe “shows”-relation and a proof-of-concept implementation and its evaluation(Section 5). This paper represents a significant revision and extension of our ownwork [12].
2 Problem statement and motivation
In this paper we specifically investigate the “shows”-relation between a picture anda tag. The “shows”-relation can be verbalised as “Picture <X> shows a(n) <tag>”where “<X>” stands for a specific picture, and “<tag>” stands for a specific tag.For instance, one could say “The picture in Fig. 1 shows a flower”. For brevity, weoften refer to tags in a “shows”-relation with a picture as “descriptive tags”. The“shows”-relation asserts that there is some part on the picture on which a real-worldinstance corresponding to the tag is visible, but the exact part is not further specified.Note that we do not differentiate between the case where the tag denotes a concept
1www.flickr.com2www.digg.com3www.technorati.com4www.citeulike.com5www.delicious.com

Multimed Tools Appl (2012) 59:441–462 443
Fig. 1 Only part of the tagsdescribe the content of thepicture. Other tags describewhere it was taken and whichcamera calibration was used.Lower- and uppercase writingwas taken over from theoriginal Flickr tags. The Flickrpage of this photo is onlineat http://flickr.com/photos/sevenbrane/2631266076/. Thephoto is licensed under theCreative Commons http://creativecommons.org/licenses/by-nc/2.0/deed.en
Given tags:Flower Garten garden
Haus Liebermann Malve Weitwinkelhollyhock wide angle WannseeGermany NaturesFinest
Tags probably describing content:Malve hollyhock FlowerGarten garden Haus Liebermann
and an instance of this concept is visible on the picture (e.g., “castle”6), and the casewhere the tag denotes an instance and this instance is visible on the picture (e.g.,“Versailles”7).
The core of our research is the observation that not all tags attached to apicture describe the visible content of the picture [2, 6]. In collaborative taggingenvironments, people tag not only what is visible on a picture (e.g., “Eiffel Tower”).Often, tags describe the context in which the picture was taken (e.g., “Paris trip”,“holiday”), describe the picture as such (e.g., “impressive”, “high”), or express theuser’s likes or dislikes (e.g., “wow!”). As a concrete example, consider Fig. 1. It showsa picture taken from Flickr, with flowers, a garden and a house at the background.However, some of the tags assigned to the picture (visible in the box above the photoin Fig. 1) clearly do not denote content of the picture.
Our goal is to devise an algorithm that can identify the “shows”-relation. Suchan algorithm would be useful for instance to give a quick overview of the visualcontent of a picture repository. The rationale for investigating to what extent a tag-based algorithm can achieve this goal is that tag-analysis is computationally easier
6For instance, “castle” is a tag of http://www.flickr.com/photos/katclay/4361062759/. This pictureshows a particular castle, apparently in Wales. Many objects are castles.7“Versailles” is a tag of http://www.flickr.com/photos/followingtheequator/2655044746 for instance.This picture shows the castle Versailles. There is only one real-world object that “is” Versailles.

444 Multimed Tools Appl (2012) 59:441–462
and faster than image analysis. In the long run, it seems plausible to imagine a tag-based algorithm to monitor the image repository of a collaborative tagging platform,and inform interested parties about changing content. Image classification could thenbe applied specifically to (picture, tag) pairs for which a low performance of the tag-based algorithm is known.
Given the question “Does the tag describe an object that is visible on the picture?”for a specific (picture, tag) pair, the following two research questions are treated inthis paper. (1) Assuming an agent knows from which data source a (picture, tag)
pair comes from but sees only the tag, how well can the agent guess whether thetag describes a visible object on the picture? (Section 5). We answer this questionby determining the optimal performance of a tag-based algorithm on a test set, andby implementing and evaluating a WordNet-based algorithm. (2) Why is it difficultto decide which tags describe objects on a picture and which not? (Section 6). Weanswer this question based on an analysis of disagreements between human raters aswell as disagreements between human raters and a tag-based algorithm.
3 Related work
Because of the lack of explicitly given precise meaning of tags and their relationto tagged resources, significant research is directed toward automatically assigningmore precise semantics to tags. On the one hand, researchers have tried to deriveontologies from the folksonomic structures relating users, tags and resources whichunderlie collaborative tagging systems. For instance, Mika [8] derives light-weightontologies directly from folksonomies, such that they represent a community’s viewon a topic. A different approach is taken by Schmitz [14], who uses WordNet to lay anontology over the tags by mapping tags to concepts in WordNet. Mika’s and Schmitz’approaches can be said to inhabit the two extremes of a continuous spectrum, whereat the one side semantics is added bottom-up, using only available data to infersemantics, while at the other end available structures of background knowledgeare made use of, which already embodies part of the vision of the Semantic Web.Rattenbury et al. [13] infer whether a tag describes an event or a location based oncharacteristics of the temporal and spatial distribution of tags. Under the aspect ofthe semantics of the relation between tags and resources, tags that describe a locationor an event also inherently differ in the relation they can have to a picture. Thiswork can therefore be seen as dealing, similar to our work, with the semantics of therelation between tags and tagged resources.
From a different angle, Sun and Bhowmick [16] investigate visual-representativetags, i.e. tags that describe visually similar pictures. According to this definition, avisually representative tag is for instance “sunset” (on a data set retrieved fromFlickr), since all pictures tagged with sunset look very similar in terms of colourdistribution, etc. A visually not representative tag is for instance “people”, sincepictures tagged with “people” are visually very different from each other. Thus,descriptive tags provide a complementary approach to clustering “similar pictures”,namely by the kind of objects that are visible on the pictures.
Golder and Hubermann [6] describe the kinds of tags encountered within col-laborative tagging systems. According to them, tags can identify who or what theresource is about, the kind of the resource (e.g., article, picture, example), who owns

Multimed Tools Appl (2012) 59:441–462 445
the resource, or characteristics of the resource (e.g., awesome, interesting), etc. Thekinds of tags can also be seen as different relations between tags and resources:For example, tags that identify the owner of a picture can be regarded as relatingto the picture via an “owned-by” relation. However, the authors do not discuss thedifficulty in deciding which relation holds between a tag and a tagged resource, northe possibilities to automatically identify this relation. Bechhofer et al. [2] categorisedifferent kinds of semantic annotations. Semantic annotations are different from tagsinsofar as the first unambiguously define the meaning of each tag (the tag “becomes”a concept) and the meaning of each relation between a tag and a resource. Oneof the possible meanings of a relation cited in the paper by Bechhofer is “instancereference”, which is one of the two things the “shows”-relation can be. By instancereference, the authors mean a semantic annotation where a digital resource (e.g.,a URI, a picture, some text) refers to a real-world entity (e.g., Versailles) which isannotated with the concept to which it belongs (e.g., a picture showing Versailles isannotated with the concept “castle”).
In coordinated image labelling efforts the goal to create training sets for automaticclassifiers predefines the semantics of the relation between labels and images in thata correct label describes an object visible on the labelled picture. Hence, in such asetting the question to automatically identify descriptive tasks we ask in this paperis irrelevant. Nonetheless, also in image labelling settings the difficulty of decidingwhat actually is on a picture has been recognised (e.g., [17]). We therefore think thatin particular the analysis of what makes this task hard for humans (Section 6) may beinsightful for other researchers dealing with image labelling situations.
4 Human ratings as gold standard
In order to test a tag-based algorithm that decides which of a picture’s tags aredescriptive, a gold standard test set must be developed. The gold standard test setcontains pictures, their tags, and for each (picture, tag) pair a rating whether the tagis descriptive with regard to the picture. Technically, such a test set can be createdby getting a data set of pictures and their tags, and one human rating for each(picture, tag) pair. However, in order to serve as test set in the scientific sense, itis necessary to ensure that the human ratings in the test set are reliable.
Two aspects of reliability are taken into account, namely retest reliability andinter-rater reliability. In this context, retest reliability refers to the stability of thejudgements of a human rater over time and their independency of confoundingvariables (e.g., mood of the rater, day of the week). Would a rater come to the sameconclusion about a (picture, tag) pair two weeks after his or her first judgement? Thesecond aspect of reliability, inter-rater reliability, refers to the extent to which ratersagree. Would two raters come to the same conclusion about the same (picture, tag)
pair?
4.1 Method
4.1.1 Rating procedure
Two human raters participated in our investigation. Both Rater 1 and Rater 2 werenative German speakers with a good command of English. In order to define the

446 Multimed Tools Appl (2012) 59:441–462
relation “this picture shows a(n) <tag>”, for each (picture, tag) pair, a rating has tobe made whether the tag describes an object that is visible on the picture. A ratingwith regard to one picture and one tag therefore consists of deciding either: “yes, thistag describes an object visible on the picture” (positive decision) or “no, this tag doesnot describe an object visible on the picture” (negative decision). For the preparationof the gold standard test set, the ratings were performed by human raters. Obviously,the same rating procedure can be followed by algorithms.
4.1.2 Data sets
As data source for our study we chose Flickr, an online photo sharing and manage-ment platform which provides pictures and tags given both by picture owners andvisitors. Pictures on Flickr mostly show everyday objects that are also visible to thehuman eye and are mostly made by handheld cameras. The dominant language oftags is (currently) English [15].
For the analyses, a set of 500 publicly available pictures rated as “most interesting”were downloaded on July 3, 2008 from Flickr using the Flickr API.8,9 Pictureswithout tags were removed from the dataset, which left 405 photos. The thuscompiled data set (Set A) consists of 3862 (picture, tag) pairs. For investigating thereliability of the human rating, a data set (Set B) was created as subset of Set A. 20pictures were randomly chosen from Set A, and finally Set B consists of 20 picturescorresponding to 189 (picture, tag) pairs.
Rater 1 was provided with a table of all (picture, tag) pairs from Set A, and withall 405 pictures that built the basis for Set A. Rater 1 was instructed to rate each(picture, tag) pair according to the above described rating procedure. The decisionwas noted in a table next to the pair (picture, tag). This procedure was repeated forall 405 pictures, i.e. for all 3862 (picture, tag) pairs. Set A together with Rater 1’sratings constitutes the gold standard test set.
4.1.3 Quantifying the agreement between dif ferent rating sources
If two (human or machine) raters agree, this means that both raters decide for a(picture, tag) pair either “yes, the picture shows a <tag>”, or both decide “no,the picture does not show a <tag>”. If the same rater gives a judgement at twodifferent points in time, the same terminology applies. Disagreement means thatone of the raters decides “yes, the picture shows a <tag>” while the other ratercomes to the conclusion “no, the picture does not show a <tag>”. Aggregated over asample of tags, the extent of agreement and disagreement can be visualised by meansof a contingency table. The percentage of agreement of two raters is the ratio ofjudgements where both raters agree to the total number of judgements in percentage.Moreover, we use the contingency coefficient � to measure the agreement anddisagreement.
8http://www.flickr.com/services/api/9The procedure of downloading the most recent and “most interesting” pictures was chosen in orderto avoid querying for specific topics (tags) or users. Getting random samples from Flickr is not reallypossible since Flickr’s database is only accessible via API, such that specific queries need to beformulated in order to access data.

Multimed Tools Appl (2012) 59:441–462 447
The � coefficient is appropriate for comparing the degree of association betweentwo binary (=dichotomous) variables [4, p.30f]. The binary variable in our case isthe yes/no decision taken with respect to a (picture, tag) pair. In its computationand interpretation, � is equal to the popular Pearson correlation coefficient r. Thevalues of � range from −1 to +1. For our purposes � = +1 can be interpreted asperfect agreement, which means that the raters agree for all rating decisions. Perfectdisagreement is indicated by � = −1 and means that two raters disagree for all ratingdecisions. A coefficient � = 0 means that the rating decisions of two raters are notsystematically connected at all. In other words, if � = 0, the decision of one rater(whether a tag refers to an object visible on a picture) cannot be predicted fromthe other rater’s decision. The value of � cannot be interpreted as linear, e.g., acorrelation of 2� cannot be interpreted as correlation that is twice as high as �.Moreover, the value of � does not necessarily indicate the percentage of agreementsand disagreements among two raters. It is possible that two sets of (picture, tag)
pairs judged by two raters have equal percentages of agreement and disagreementbut result in different values for �. This is due to the fact that � takes into accountthe baseline distribution of the binary variable (yes/no decisions) in the judgementsof each rater. Similar to Pearson’s r, the coefficient � allows testing for statisticalsignif icance. We denote the statistical significance in our paper by p < x for eachachieved correlation �, which means that the probability that � has been obtained bychance p is smaller than the value x. For instance, p < .05 means that the probabilitythat the contingency between two variables is due to chance is lower that 5%.
4.2 Descriptive results
Rater 1 rated 782 (20.3%) out of 3862 tags in Set A to describe visible objects onthe corresponding picture. In the retest reliability test, Rater 1 rated 35 (19.2%) outof 182 tags in Set B to describe visible objects on the corresponding picture. In theinter-rater reliability test, Rater 2 rated 40 (22.2%) out of 189 tags in Set B to describevisible objects on the corresponding picture.
4.3 Reliability of ratings
4.3.1 Retest reliability
For investigating retest-reliability, Rater 1 was asked to repeat part of her ratingstwo weeks after she had performed the rating procedure on Set A. The repeatedratings were given on Set B (189 (picture, tag) pairs, a subset of Set A). At the timethe retest ratings of Rater 1 were given, one of the pictures was not online anymore.Therefore, Rater 1 rated only 182 (picture, tag) pairs in the retest trial. 173 (95.1%)of the 182 (picture, tag) pairs were rated the same in both ratings, which correspondsto � = 0.84 (p < .01). This indicates high retest reliability.
4.3.2 Inter-rater reliability
In order to assess inter-rater reliability, Rater 2 was asked to rate the tags assigned tothe pictures in Set B. These ratings were compared with the original ratings of Rater1 on Set A. Overall, 189 (picture, tag) pairs were judged by both raters. Rater 1 and

448 Multimed Tools Appl (2012) 59:441–462
Rater 2 agreed on 175 (92.6%) out of 189 tags. The agreement of the two raters wastherefore � = 0.77 (p < .01). This indicates also high inter-rater reliability.
4.4 Discussion
4.4.1 Low overall number of descriptive tags
The low percentage of tags which are considered to refer to something visible ona picture (about 20%, see Section 4.2) is remarkable. Given that our test designtargets a different question, we are unable to draw concrete conclusions from this.We can only hypothesize that people may feel that describing the actual content ofthe picture in words is redundant and hence prefer to add information that cannotbe gained from the picture itself. However, it would be interesting to relate thislow number of descriptive tags to different motivations for tagging. So far, existingresearch on tagging motivation has mostly studied the influence of motivation on theamount of tags [1, 10]. Golder and Hubermann’s different kinds of tags in [6] can berelated to motivations, but no quantification is given as to which motivation prevailsunder which circumstances, and to what extent.
4.4.2 Sample size for reliability testing
Concerning the size of Set B as sample for the retest and inter-rater reliability testing,it is in general standard to use only a sub-set of the original sample [18]. As a rule,the authors recommend to test reliability with a sample size of 10–25% of the originalsample ([18, p.167]). This would have been 40–100 pictures with 380–960 tags in ourcase. However, these rules stem from the social sciences where sample sets can be assmall as only a handful of samples, and where typically more than two categories areused. For example, in [7] the total sample size is only 25 transcripts. Moreover, the �
coefficient that we used for computing the agreement between raters also takes intoaccount the sample size: the lower the sample size, the higher the required value ofthe coefficient in order to achieve statistical significance. In other words, with largesample sizes, statistical significance can also be achieved with lower coefficients [3].Thus we conclude that from an inference-statistical perspective, the sample sizesof Set A and Set B are sufficient to test our hypotheses of inter-rater and retestreliability.
4.4.3 Implications for algorithmic ratings
The reliability results have several implications for the design of any algorithm thattries to predict or simulate human ratings of which tags are descriptive of a pictureand which are not. If the ratings would differ substantially across time or differentraters, this would indicate that descriptive tags can only be identified by taking intoaccount additional information such as personal opinions, or the situation in whichthe rating procedure takes place. If specifically inter-rater reliability was low, it wouldbe doubtable that the problem of automatically determining descriptive tags can beanswered on a general basis, and any algorithm trying to imitate human ratings wouldhave to be personalised.
Since retest and inter-rater reliability are sufficiently high, the human ratings onSet A can be considered as reliable. Hence, the test set can be used as gold standardagainst which to evaluate algorithmic ratings.

Multimed Tools Appl (2012) 59:441–462 449
5 A tag-based algorithm
Assuming an agent only sees the tags, without the picture, how well can it guess whichtags will describe visible entities on the picture? As motivated above, by posing thisquestion we want to study whether by tag-analysis, which is computationally fasterthan image-analysis, it would be possible to get an overview of the visual content ina collaborative tagging platform for pictures.
5.1 Quantifying the limitation of a tag-based algorithm
A tag-based algorithm has knowledge about the (meaning of) tags and may addition-ally have prior knowledge about the pictures to be expected. In order to quantify thelimitations of any tag-based algorithm on Set A with respect to the ratings of Rater 1,an optimal algorithm was constructed. The algorithm is optimal in the sense that noother tag-based algorithm can exist which agrees better with Rater 1’s ratings on SetA. The optimal algorithm always decides exactly like Rater 1, except for tags wherethe human rater gives alternating decisions. In these cases, the optimal algorithmgoes for the majority of decisions. If there is a draw, the optimal algorithm chooses“no”. The latter is an arbitrary decision by the authors of the study.
To give some examples, the tag “leaves” occurred five times, and Rater 1 decidedfour of the times that the tag described objects visible on the picture. The optimalalgorithm stays with the majority of decisions and always decides “yes” for the tag“leaves”. The tag “morning dew” occurred two times, and Rater 1 decided once for“yes” and once for “no”. In this case the optimal algorithm chooses “no”.
The agreement between the optimal algorithm and Rater 1’s ratings on Set Ais � = 0.94 (p < .01). In concrete numbers, the optimal algorithm agreed with thehuman rater on 3783 (98.0%) of 3862 tags. This very high correlation indicates thatin a fixed environment, e.g., within one platform, the patterns of usage are consistentenough to make an informed guess about whether a tag represents a visible entityor not.
5.2 Algorithm design
Given the theoretical feasibility of a well-performing tag-based algorithm, we im-plemented and evaluated a WordNet-based algorithm (WN-Algorithm) as proof-of-concept. In line with previous findings [15] we assumed that WordNet refers to asufficient amount of words used as tags in Flickr. Additionally, it was assumed thatWordNet was an appropriate structure to solve the given problem, namely to decidewhether a tag describes image content or not.
As was already seen, a tag-based algorithm deterministically guesses, given a tag,whether it will be visible on a given (indeed on any) picture. In order to performwell, such an algorithm must have a general knowledge about the meaning of tags,i.e. which tags describe concepts that can in principle be visible on a picture, as wellas some knowledge about the domain, i.e. what kinds of objects can be expected tobe photographed. For instance, the tag “Africa” in Flickr mostly seem to mean “Thisphoto was taken in Africa.”, while in a database of satellite photos it would probablymean “The continent Africa is visible on the photo.”.

450 Multimed Tools Appl (2012) 59:441–462
5.2.1 WordNet
The knowledge about meanings of words, and the general frequency of their occur-rence are both encoded in WordNet [9],10 a lexical database of English. For instance,WordNet encodes that the word “wood” may mean either the material or a forestamongst other things, but that mostly the former is meant in English. Additionally,WordNet maps English words (nouns, adjectives, adverbs, verbs) to sets of syn-onyms. This means that one lexical entry can relate to multiple sets of synonyms, andone set of synonyms can relate to multiple lexical entries. For instance “fire” belongsto the set of synonyms that describes the concept of “an event of something burning”as well as to the set of synonyms that describe “feelings of great warmth” etc. A setof synonyms is additionally described by a short verbal description. Synonyms anddescription together build a concept (called “synset” in WordNet’s terminology).Concepts are related to each other via hierarchical relations (hyper/hyponymy fornouns, in analogy troponymy for verbs), part-of relations (meronymy), the relationbetween opposites (antonymy) or instance relationship. For example, “Eve” is aninstance of the concept “woman”.
5.2.2 Disambiguation
Every tag must be disambiguated, i.e. it must be decided which of a tag’s possiblymany meanings the algorithm shall assume, before deciding whether it is a descriptivetag or not. In most cases, the WN-Algorithm performs disambiguation by mappingeach tag simply to the concept it most frequently stands for which is encoded inWordNet. Additionally, the authors decided to consider each word that can be eitheran adjective or a noun as an adjective. WordNet does not encode which of these usesis most frequently used. This decision affects words like e.g., “pedestrian” or “giant”.Finally, the WN-Algorithm contains a short stop- and a short gowordlist which areused to catch frequent disambiguation errors.
The relevant point is to understand that this disambiguation procedure is a simpleheuristic. This potentially affects the proposed algorithm whenever the meaningchosen by the WN-Algorithm does not correspond to the prevalent meaning of atag in Flickr.
5.2.3 Rules
The knowledge which concepts denote entities likely to be visible and which do not isencoded into rules based on the underlying knowledge structure, i.e. WordNet. Rulesin the WN-Algorithm are formulated as decision criteria in terms of the WordNethierarchy. Note that the decision criteria (WordNet concepts) have been chosen suchthat after disambiguation has been performed, any single tag can only trigger a singlerule. The hierarchy is travelled from top to down. At appropriate levels, rules specifywhether all concepts11 and instances12 in the subtree below denote visible entities on
10http://wordnet.princeton.edu/11A concept refers to an idea of something. A concept often refers to something abstract, e.g., “love”or to a group of real world entities, e.g., “flower”.12An instance refers to a specific entity in the real world, e.g., “Big Ben” is an instance of the concept“clock tower”.

Multimed Tools Appl (2012) 59:441–462 451
Table 1 All rules of the WN-Algorithm
Rule name Decision (yes/no)
Stopwordlist NoGowordlist YesTag is not in WordNet NoAdjectives and adverbs NoThing / object / matter / process YesInstances of artefact YesInstances of other NoOther No
For each rule, “yes” in the decision column means that if the rule is applied, the WN-Algorithmdecides that the tag in question is a descriptive tag in any (picture, tag) pair. Conversely, “no” in thedecision column means that if the rule is applied, the WN-Algorithm decides that the tag in questionis not a descriptive tag in any (picture, tag) pair
any given picture or not. The WordNet-based rules are preceded by a preprocessingstage in which stemming (stripping tags off eventual suffixes) is performed. Thedefault decision for any input is negative, i.e. if no other rule applies to a tag, thetag is judged by the WN-Algorithm to not represent a visible object.
All rules in the WN-Algorithm are listed in Table 1 and elaborated below.
Stop- and go-wordlist Both the stop- and the go-wordlist have been compiled fromvarious sample data during development (not from Set A), and therefore contain alsotags that do not appear in Set A. For tags in the stop-wordlist, the WN-Algorithmalways decides that the tag is not a descriptive tag, and for tags in the go-wordlist theWN-Algorithm always decides that the tag is indeed a descriptive tag.
Most of the tags in the stop- and go-wordlist result from wrong disambiguation,i.e. the dominating meaning given by WordNet runs counter the dominant meaninga tag has in the context of Flickr. For instance, while WordNet ranks the meaningof “church” as “Christian church community” as most frequent, it should rather beinterpreted as denoting a building in the majority of cases in Flickr. Therefore, thestop- and gowordlist conceptually belongs to the disambiguation step in the WN-Algorithm.
Tag is not in WordNet The rule is read as “If the tag does not occur in WordNet,then decide that it is not a descriptive tag”. Tags that are not in WordNet maybe in another language than English, English but wrongly spelt, proper names,nicknames, recently created words, or complete phrases, etc. Some examples are tagslike “wow!” or “It starts getting peculiar”.13
Adjectives and adverbs The rule is read as “If a tag could be an adjective oradverb, then decide that the tag is not a descriptive tag”. Exemplary tags are “great”,“awesome”, “red”, but also “pedestrian” or “giant”. Typically, such tags describequalities/properties of the picture itself or of objects on the picture. Conceptually,
13http://www.flickr.com/photos/bradi/2631548160/

452 Multimed Tools Appl (2012) 59:441–462
this “rule” belongs to the disambiguation step in the WN-Algorithm (see discussionin Section 5.2.2 above).
Thing The rule is read as “If the tag’s dominant meaning according to WordNet isa hyponym of the concept ’Thing, a separate and self-contained entity’, then decidethat the tag is indeed a descriptive tag”. This rule applies, for instance, to tags thatdescribe body parts, such as “feet”, or to tags that describe bodies of water, such as“lagoon” or “lake”, etc.
Object The rule is read as “If the tag’s dominant meaning according to WordNetis a hyponym of the concept ‘Object, thing that can cast a shadow’, then decide thatthe tag is indeed a descriptive tag”. Animals, buildings, geological formations such asbeaches, caves or mountains are hyponyms of “Object”.
Matter The rule is read as “If the tag’s dominant meaning according to WordNetis a hyponym of the concept ’Matter, that which has mass and occupies space’, thendecide that the tag is indeed a descriptive tag”. This rule applies to tags that describefood or various materials, such as “ice”, “clay”, etc.
Process The rule is read as “If the tag’s dominant meaning according to WordNetis a hyponym of the concept ’Process, a sustained phenomenon’, then decide that thetag is indeed a descriptive tag”. This rule is applied to tags like “clouds”, “rain”, and“sunlight”.
Instances The rule is read as “If the tag’s dominant meaning according to WordNetcorresponds to an instance of a concept in WordNet, then decide that the tag isnot a descriptive tag, except if the tag corresponds to an instance of the concept’artefact’ ”. For instance, “mozart” is a tag that corresponds to an instance of aWordNet concept other than “artefact”. It denotes Salzburg’s famous composerWolfgang Amadeus Mozart, and is an instance of the concept “composer” and,farther up the hierarchy, “person”. Of course, it is theoretically possible that a pictureshows Mozart. However, a search for pictures tagged with “mozart” in Flickr returnsmostly pictures taken in Salzburg, from opera performances evidently of Mozart’splays, etc., but few pictures that show Mozart himself. Instances of the concept“artefact” are for example “eiffel tower” or “golden gate bridge”, and these indeedmostly show the expected artefact.
Other If, given a (picture, tag) pair, no rule applies to the tag, then the WN-Algorithm decides that the tag does not describe an object visible on the picture.
5.3 Algorithm evaluation
The WN-Algorithm’s ratings were compared with Rater 1’s ratings on Set A. Anoverview of the results is given in Table 2. The agreement between the implementedalgorithm and the Test Set is � = 0.55 (p < .01). Out of 3862 (picture, tag) pairs, theWN-Algorithm agreed with Rater 1’s ratings on Set A on 3290 pairs (84.9%) anddisagreed on 572 pairs.
Multimed Tools Appl (2012) 59:441–462 453
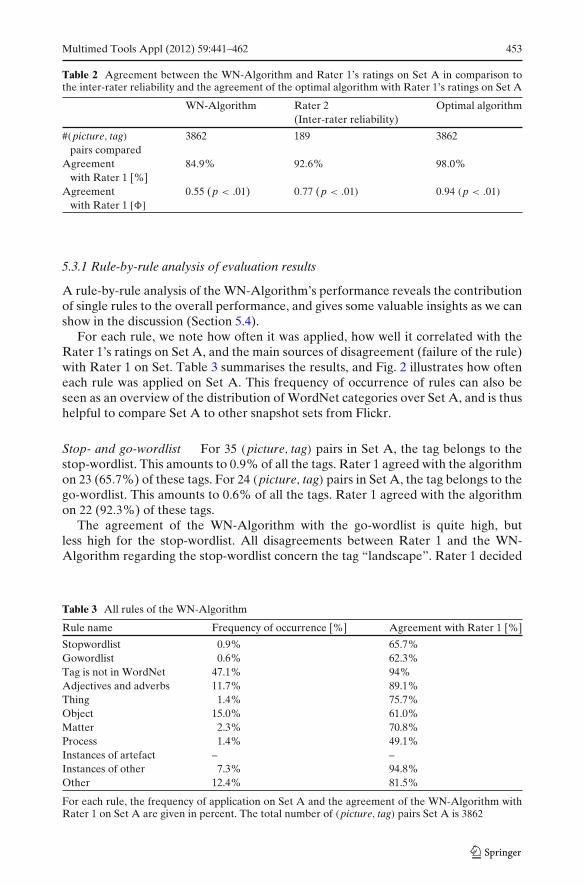
Table 2 Agreement between the WN-Algorithm and Rater 1’s ratings on Set A in comparison tothe inter-rater reliability and the agreement of the optimal algorithm with Rater 1’s ratings on Set A
WN-Algorithm Rater 2 Optimal algorithm(Inter-rater reliability)
#(picture, tag) 3862 189 3862pairs compared
Agreement 84.9% 92.6% 98.0%with Rater 1 [%]
Agreement 0.55 (p < .01) 0.77 (p < .01) 0.94 (p < .01)
with Rater 1 [�]
5.3.1 Rule-by-rule analysis of evaluation results
A rule-by-rule analysis of the WN-Algorithm’s performance reveals the contributionof single rules to the overall performance, and gives some valuable insights as we canshow in the discussion (Section 5.4).
For each rule, we note how often it was applied, how well it correlated with theRater 1’s ratings on Set A, and the main sources of disagreement (failure of the rule)with Rater 1 on Set. Table 3 summarises the results, and Fig. 2 illustrates how ofteneach rule was applied on Set A. This frequency of occurrence of rules can also beseen as an overview of the distribution of WordNet categories over Set A, and is thushelpful to compare Set A to other snapshot sets from Flickr.
Stop- and go-wordlist For 35 (picture, tag) pairs in Set A, the tag belongs to thestop-wordlist. This amounts to 0.9% of all the tags. Rater 1 agreed with the algorithmon 23 (65.7%) of these tags. For 24 (picture, tag) pairs in Set A, the tag belongs to thego-wordlist. This amounts to 0.6% of all the tags. Rater 1 agreed with the algorithmon 22 (92.3%) of these tags.
The agreement of the WN-Algorithm with the go-wordlist is quite high, butless high for the stop-wordlist. All disagreements between Rater 1 and the WN-Algorithm regarding the stop-wordlist concern the tag “landscape”. Rater 1 decided
Table 3 All rules of the WN-Algorithm
Rule name Frequency of occurrence [%] Agreement with Rater 1 [%]
Stopwordlist 0.9% 65.7%Gowordlist 0.6% 62.3%Tag is not in WordNet 47.1% 94%Adjectives and adverbs 11.7% 89.1%Thing 1.4% 75.7%Object 15.0% 61.0%Matter 2.3% 70.8%Process 1.4% 49.1%Instances of artefact – –Instances of other 7.3% 94.8%Other 12.4% 81.5%
For each rule, the frequency of application on Set A and the agreement of the WN-Algorithm withRater 1 on Set A are given in percent. The total number of (picture, tag) pairs Set A is 3862

454 Multimed Tools Appl (2012) 59:441–462
Fig. 2 Frequency of WN-Algorithm’s rules on Set A
that this was an object on the picture, while the WN-Algorithm always decided theopposite.
Overall, these two rules were only applied very infrequently, and did not con-tribute significantly to the success of the WN-Algorithm. This is an important point,since if stop- and go-wordlists were vital to the success of the WN-Algorithm, thiswould amount to a brute-force approach that would not easily be generalisable.
Tag is not in WordNet This rule applies to 1819 (picture, tag) pairs (47.1% of 3862pairs), for which the WN-Algorithm always decided that the tag does not show avisible object on the picture. Rater 1 agreed with this decision in 1709 cases (94.0%).
Hence, the main reason for the WN-Algorithm to decide that a tag is notdescriptive is because it is not contained in WordNet. The success of this rule isimportant, since it indicates that WordNet is an appropriate knowledge structurefor an tag-based algorithm that tries to tackle the given problem.
Adjectives and adverbs 450 tags from the Test Set are counted as adjectives bythe WN-Algorithm. This amounts to 11.7% of all the tags. Rater 1 agreed with thealgorithm on 401 (89.1%) of these tags.
Disagreement mostly occurs because of wrong disambiguation, i.e. the decisionthat a tag is an adjective or adverb is wrong. Given the word “pedestrian” forinstance, the WN-Algorithm decides that this is an adjective and therefore does notdenote a visible object on the picture. However, in many (picture, tag) pairs takenfrom Flickr, if the tag is “pedestrian” it is used as noun, and denotes a person that iswalking.

Multimed Tools Appl (2012) 59:441–462 455
The high agreement between Rater 1 and the WN-Algorithm indicates that thisrule is very useful for rejecting tags that describe something which is not visible on apicture. However, it must be said that most of the tags to which this rule is appliedare adjectives. The test set is not conclusive on adverbs, since too few are contained.
Thing This rule applies to 52 (picture, tag) pairs in Set A (1.4%). Rater 1 agreedwith the algorithm on 40 (75.5%) of these pairs. On Set A, the “Thing”- rule appliesmostly to tags that describe various body parts such as face, feet, fingers, head, andbodies of water such as lagoon, lake, ocean, sea.
All disagreements between Rater 1 and the WN-Algorithm in these cases stemfrom the fact that the WN-Algorithm does not take the actual picture into account(algorithmic limitation). For example, the tag “feet” is assigned to a picture that doesnot actually show feet.14
Object This rule applies to 579 (picture, tag) pairs in Set A (15.0%). As areminder, animals, buildings and geological formations such as beaches, caves, etc.are hyponyms of “Object”. Rater 1 agreed with the algorithm on only 353 (61.0%)of these pairs.
This is one of the rules that seem most intuitively correct, and yet the agreementbetween Rater 1 and the WN-Algorithm is quite low. This rule is used quite often,so improving it would improve the overall performance of the WN-Algorithm. Someerroneous judgements of this rule are due to the fact that the WN-Algorithm does nottake the actual content of a picture into account (algorithmic limitation). However,disagreements between Rater 1 and the WN-Algorithm in case of this rule run alsothrough all other reasons for disagreement (definitional disagreement, difference inknowledge, disambiguation, difference in perception) discussed in Section 6 below.
Matter This rule applies to 89 (picture, tag) pairs in Set A (2.3%). Rater 1 agreedwith the algorithm on only 63 (70.8%), of these pairs.
Disagreements between Rater 1 and the WN-Algorithm again run through thewhole spectrum of reasons for disagreement (definitional disagreement, difference inknowledge, disambiguation, difference in perception) discussed in Section 6 below.
Process This rule applies to 53 (picture, tag) pairs in Set A (1.4%). The top mostfrequent tags to which this rule applies on Set A are “clouds”, “rain”, and “sunlight”.Rater 1 agreed with the algorithm on only 26 (49.1%), of these tags.
The performance of this rule is quite low, but on the other hand this rule is alsoapplied only very rarely which would make improving this rule specifically not apriority.
Most of the disagreements between Rater 1 and the WN-Algorithm again eitherstem from the WN-Algorithm’s algorithmic limitation of not considering actualpicture content, or from one of the other reasons for disagreement (definitionaldisagreement, difference in knowledge, disambiguation, difference in perception)discussed in Section 6 below. However, a minority of disagreements occur becauseWordNet puts not only natural occurrences like “rain” and “clouds” in the category
14http://www.flickr.com/photos/95197744@N00/2631322270

456 Multimed Tools Appl (2012) 59:441–462
of “Process, a sustained phenomenon” but also real processes (in the sense ofsomething happening over time, with a possibly visible outcome). Such words canby definition not denote visible entities on a picture. An example is “erosion”.15
Instances Set A contains one (picture, tag) pair where the tag refers to an instanceof an artefact. For 268 (picture, tag) pairs, the tag corresponds to instances ofWordNet concepts other than artefacts. This amounts to 7.3% of all the (picture, tag)
pairs. Rater 1 agreed with the algorithm on 254 (94.8%) of these cases.
Other To 480 (picture, tag) pairs, none of the above rules applied. The top mostfrequent tags to which the default (negative) decision was applied in Set A were“beauty”, “canon”, “explore”, “nature”, “portrait”, “reflection”, “summer”, and“Wednesday”. Rater 1 agreed on 391 (81.5%) tags with the algorithm’s decision.
5.4 Discussion
5.4.1 Assessing the WN-Algorithm’s performance
The agreement of 84.9% (� = 0.55) between Rater 1 and the WN-Algorithm ispositive (the ratings of Rater 1 can be predicted by looking at the ratings of theWN-Algorithm, or vice versa), and reasonably high. However, in order to interpretwhether this agreement between Rater 1 and the WN-Algorithm on Set A really con-stitutes a “good” result, it is necessary to set it into the context of the baselines givenby the inter-rater reliability and the optimal algorithm: The two human raters agreeto 92.6% (� = 0.77), and the optimal algorithm achieves an agreement of 98.0%(� = 0.94) with Rater 1. We therefore interpret the WN-Algorithm’s performanceas satisfactory. When improving it we would target a performance similar to that ofthe inter-rater agreement.
5.4.2 Algorithmic limitation
Two crucial assumptions underlie the WN-Algorithm. The first assumption is that theactual picture content can be disregarded to some extent in order to decide whether atag is descriptive or not with respect to the given picture. Our studies above indicatethe fundamental limitations of such a tag-based algorithm (Section 5.1) and show thatin spite of ignoring such a significant piece of information, namely the actual picturecontent, in general good decisions can be made (Section 5.3). A closer look throughthe rule-by-rule analysis of the WN-Algorithm’s performance (Section 5.3.1) revealsthat there is some difference in performance between the single rules. It seems thatthe WN-Algorithm does sufficiently well in distinguishing those tags that can inprinciple describe visible entities (like “feet”) from those that cannot describe visibleentities (like “beauty”). On the other hand, erroneous judgements are made by theWN-Algorithm when a tag that can in principle describe visible entities is assignedto a picture on which this entity is not visible. For instance the tag “hotel” denotes
15The picture shows a rock formation created by the process of erosion: http://www.flickr.com/photos/38381877@N00/2632589512.

Multimed Tools Appl (2012) 59:441–462 457
something which could be a visible entity on any picture but there are pictures taggedwith “hotel” on which no hotel is visible.16 This algorithmic limitation could beovercome, for instance, by appending an image-processing component to rules thatlead to a positive decision, e.g., the “Object”-rule.
5.4.3 WordNet as source of background knowledge
The second assumption is that WordNet is an appropriate source of backgroundknowledge for taking these decisions. The overall good performance of the WN-Algorithm supports this in principle. However, when analysing the (poor) perfor-mance of the “Process”-rule, it becomes apparent that WordNet is probably not theperfect knowledge structure for the given task. As has been analysed in depth froma theoretical, philosophically motivated viewpoint in [5], the taxonomy (hierarchy ofconcepts) in WordNet is not always rigorous. This can be explained by the fact thathistorically WordNet has grown into a taxonomy from a loosely organised semanticnetwork for English. In the “Process”-rule, this becomes apparent in that bothpossibly visible things like clouds as well as clearly invisible things like the processof erosion appear under the same top-level category. Given WordNet as backgroundknowledge structure, the performance of the WN-Algorithm could only be improvedin this regard by creating more fine-grained rules. The obvious downside of suchan approach is of course that, if taken to the extreme, it leads to stop- and go-wordlists. The alternative solution for such problems could be to use another sourceof structured background knowledge such as OpenCyc [11]. Finally, we note thatFlickr and WordNet cover pictures of everyday life and commonplace knowledge.We hypothesize that for specialised domains, a domain ontology would be necessary,which should be similar to WordNet in that it includes references from concepts towords (e.g., labels, comments, synonyms).
5.4.4 Generalisability
Whenever experiments or evaluations are based on samples from a population, 3862(picture, tag) pairs from Flickr in our case, the question arises whether the results canbe generalised to other samples of the same population, or to the entire population.
The first indicator for generalisability of our results are the good retest and inter-rater reliability computed on the test set. The second indicator for generalisabilityis that Set A shows a similar tag distribution with respect to WordNet categorieswhen compared to a data set of approximately 52 million photos described in [15].The authors mapped tags into WordNet categories such as Location, Artefact orObject, Person or Group, Action or Event and Time (cited in descending order offrequency). On their data set, 48% of the tags are not contained in WordNet (com-pared to 45% on our dataset). Approximately 15% fall into the categories “Artefactor Object” and “Person or Group” in the data set of [15]. These numbers compareto the numbers encompassed by the WN-Algorithm’s category of “Object”, whichencompasses 15.2% of Set A. These two numbers compare only in approximation, as
16This picture shows the ocean, a piece of beach and a bird but not a hotel: http://flickr.com/photos/26079103@N00/2630745505.

458 Multimed Tools Appl (2012) 59:441–462
we do not know precisely which WordNet categories fall into the categories referredto in [15]. However, both numbers point at the same order of magnitude. We can alsoroughly compare the 20.3% of content-describing tags from Set A to this number.Again, this comparison is very approximate, probably even more than the previousone, since we do not know, for instance, whether all tags in the cited categories reallydescribe objects visible on the corresponding picture, and which of the tags in theother categories describe visible objects. However, again both numbers point at thesame order of magnitude. This indicates that Set A is representative concerningthe distribution of tags over the underlying knowledge structure WordNet, and thatour results can be generalised to other representative data sets from Flickr.
6 Why is it difficult to decide what a picture shows?
Notwithstanding the algorithmic limitation leading to wrong ratings of the WN-Algorithm (discussed in Section 5.4), it has turned out that there is also some inherentdifficulty in the task to decide which tags are descriptive of a picture’s content andwhich are not.
The example in Fig. 1 can be used to illustrate part of this difficulty. The algorithmdescribed above determines that “Fig. 1 shows a flower, a garden and a hollyhock”. Inaddition to this, Rater 1 identified the tags “Malve” and “Garten”, the German wordsfor “hollyhock” and “garden” respectively, as descriptive tags. The other ratingscoincide. Looking at the picture, one could conjecture that in addition also “HausLiebermann” is a descriptive tag if it is the name of the house. Then, we do notknow whether Rater 1 does not know “Haus Liebermann”, or whether she knows“Haus Liebermann” and rejects the tag because the house on the picture is not “HausLiebermann”.
In a qualitative analysis we studied the (picture, tag) pairs on which Rater 1 andRater 2, or Rater 1 and WN-Algorithm, disagreed. The following list of reasons fordisagreement between (human and algorithmic) raters is the condensed output ofthis analysis. These reasons for disagreement illustrate at the same time the inherentdifficulty in distinguishing descriptive from non-descriptive tags given a (picture, tag)
pair.
Definitional disagreement Two raters have a different definition of what “an ob-ject” on a picture is. This is a foundational source of disagreement, since the problemwe wanted an algorithm to solve was exactly to decide on which tags describe objectsvisible on a picture. Examples of this are the tags “agriculture” (e.g., for a pictureshowing a field of corn) or “feeling stitchy” (which was a writing embroidered onlinen on the picture in question), on which the two human raters disagreed. Otherexamples of definitional disagreement are disagreements over whether a ferret isactually a pet,17 or whether a picture really shows sunlight.18
17The picture shows a ferret: http://flickr.com/photos/77651361@N00/2631585847.18The picture shows a daisy on a sunlit background: http://www.flickr.com/photos/7845858@N05/2631348902.

Multimed Tools Appl (2012) 59:441–462 459
Difference in knowledge This may happen with technical terms, uncommon Eng-lish terms, or terms in an unknown foreign language. Examples are the terms “man-grove”,19 “hydrangea”20 or “jetty”.21 This error can also be made by algorithmicraters if the used background knowledge does not contain terms of specific language,or technical terms, or is not specific enough.
Disambiguation When a tag can have multiple meanings, a rater needs to disam-biguate first before a decision can be made. Raters may disagree over the meaningthey assign to a tag. In general human raters use picture context as well as a vastamount of background knowledge to disambiguate whereas an algorithmic raterdisambiguates according to strict rules and only limited background knowledge.
Difference in perception An object might have been overlooked, such as a spiderweb,22 or a guitar on a dark background.23 Such differences may occur systematicallywhen raters have different visual capabilities, have access to the same picture indifferent resolutions, on different devices that represent some colours more or lessclearly, etc.
Moreover, humans occasionally make unsystematic erroneous ratings that stemfrom negligence. However, it can be assumed that the test set contains sufficientlyfew such erroneous judgements because of the high retest reliability.
Note that when looking at an erroneous judgement it is not always obviouswhether the judgement is really erroneous. Consider as example a picture with alittle girl on a swing.24 Rater 1 has decided that the tag “girl” does not denote anobject visible on the picture. Since the girl is in the centre of the picture we couldsafely assume that this judgement was an error of negligence. On the other hand, itis also be possible that the rater was simply cautious and did not want to commit toknowing that the child on the picture was indeed a girl.
7 Conclusion
We investigated the question of deciding which of a picture’s tags describe visibleentities depicted on it from multiple angles. On the one hand, we researched whetheran agent can guess whether a tag describes a visible object on a picture givenincomplete information. In our investigations, the information was incomplete inthat it contained background information about the data source, and the tag but notthe picture. First, we studied a tag-based algorithm that was optimised for the given
19A tropical maritime tree, see e.g., http://flickr.com/photos/7486128@N03/263179298020A flower, see e.g., http://www.flickr.com/photos/mbgrigby/2930572161/21A landing wharf, a structure where ships lie alongside to in order to load or discharge freight orpassengers, see e.g., http://www.flickr.com/photos/71298168@N00/2630153723.22The picture shows a flower with a butterfly, and a barely visible spider http://flickr.com/photos/18718027@N00/2631263572.23The guitar is barely visible between the grass and on top a very dark picture http://www.flickr.com/photos/52752598@N00/2630825364.24http://www.flickr.com/photos/29905372@N00/2631336870

460 Multimed Tools Appl (2012) 59:441–462
test set. Given that the optimal algorithm was able to achieve a very high agreementwith human ratings, a simple practical tag-based algorithm, the WN-Algorithm, wasimplemented as proof-of-concept. The first main result of our work lies in showingthat despite the WN-Algorithm’s relatively simple structure, it yet has a high agree-ment with human ratings. On the other hand, a qualitative analysis of disagreementsbetween the two human raters, and between a human rater and the WN-Algorithm,led to the insight that identifying descriptive tags reliably is not a clear-cut task evenfor humans, because of differences in definition, knowledge, disambiguation, andperception. A good generalisability of our results can be assumed (i) because of thesatisfactory retest and inter-rater reliability testings performed on the test set, and(ii) because our data set shows a similar tag distribution with respect to WordNetcategories when compared to a dataset of approximately 52 million photos describedin [15].
Based on a detailed rule-by-rule analysis of the WN-Algorithm’s performance, itis possible to identify weak points of the algorithm and to derive pointers for futurework. One reason for low performance is the central algorithmic limitation of theWN-Algorithm of not taking actual picture content into account (e.g., “Object”-rule). This points toward investigating combinations of tag and image analysismethods to identify descriptive tags. Some erroneous ratings of the WN-Algorithmalso seem to stem from a confusion in the WordNet taxonomy itself (e.g., “Process”-rule). In order to remedy this source of error, a different background knowledgestructure should be experimented with. Looking farther ahead, a generalisation ofidentifying content-descriptive tags from pictures to arbitrary resources, such as webbookmarks, would be interesting but would require more research of the matter.
Acknowledgements The Know-Center is funded within the Austrian COMET Program—Competence Centers for Excellent Technologies—under the auspices of the Austrian FederalMinistry of Transport, Innovation and Technology, the Austrian Federal Ministry of Economy,Family and Youth and by the State of Styria. COMET is managed by the Austrian ResearchPromotion Agency FFG.
References
1. Ames M, Naaman M (2007) Why we tag: motivations for annotation in mobile and online media.In: CHI ’07: proceedings of the SIGCHI conference on Human factors in computing systems.ACM, New York, pp 971–980
2. Bechhofer S, Carr L, Goble CA, Kampa S, Miles-Board T (2002) The semantics of semanticannotation. In: On the move to meaningful internet systems, 2002—DOA/CoopIS/ODBASE2002 Confederated International Conferences DOA, CoopIS and ODBASE 2002. Springer,London, pp 1152–1167
3. Blanche MT, Durrheim K, Painter D (eds) (2006) Research in practice—applied methods for thesocial sciences. University of Cape Town Press
4. Cohen J, Cohen P, West SG, Aiken LS (2003) Applied multiple regression/correlation analysisfor the behavioral sciences. Lawrence Erlbaum Associates. ISBN: 0805822232
5. Gangemi A, Guarino N, Oltramari R (2001) Conceptual analysis of lexical taxonomies: thecase of wordnet top-level. In: Proceedings of the international cnference on formal ontologyin information systems. ACM Press, pp 285–296
6. Golder SA, Hubermann BA (2006) Usage patterns of collaborative tagging systems. J Inf Sci32(2):198–208
7. Kurasaki KS (2000) Intercoder reliability for validating conclusions drawn from open-endedinterview data. Field Methods 12(3):179–194

Multimed Tools Appl (2012) 59:441–462 461
8. Mika P (2005) Ontologies are us: a unified model of social networks and semantics. In: Gil Y,Motta E, Benjamins VR, Musen MA (eds) International semantic web conference. Lecture notesin computer science, vol 3729. Springer, pp 522–536
9. Miller GA (1995) Wordnet: a lexical database for english. Commun. ACM 38(11):39–4110. Nov O, Naaman M, Ye C (2008) What drives content tagging: the case of photos on flickr. In: CHI
’08: proceeding of the twenty-sixth annual SIGCHI conference on Human factors in computingsystems. ACM, New York, pp 1097–1100
11. OpenCyc (2010) http://www.opencyc.org/. Last visited: 10 Aug 201012. Pammer V, Kump B, Lindstaedt S (2009) On the feasibility of a tag-based approach for de-
ciding which objects a picture shows: an empirical study. In: Semantic multimedia. Proceed-ings of 4th International Conference on Semantic and Digital Media Technologies, SAMT2009. Lecture notes in computer science, vol 5887/2009. Graz, Austria, 2–4 Dec 2009. SpringerBerlin/Heidelberg, pp 40–51
13. Rattenbury T, Good N, Naaman M (2007) Towards automatic extraction of event and placesemantics from flickr tags. In: SIGIR ’07: proceedings of the 30th annual international ACMSIGIR conference. ACM Press, New York, pp 103–110
14. Schmitz P (2006) Inducing ontology from flickr tags. In: Proceedings of the collaborative webtagging workshop at WWW2006. Edinburgh, Scotland
15. Sigurbjörnsson B, van Zwol R (2008) Flickr tag recommendation based on collective knowledge.In: Huai J, Chen R, Hon H-W, Liu Y, Ma W-Y, Tomkins A, Zhang X (eds) (2008) WWW. ACM,pp 327–336
16. Sun A, Bhowmick SS (2009) Image tag clarity: in search of visual-representative tags for socialimages. In: WSM ’09: proceedings of the first SIGMM workshop on Social media. ACM, NewYork, pp 19–26
17. Volkmer T, Thom JA, Tahaghoghi SMM (2007) Modeling human judgment of digital imageryfor multimedia retrieval. IEEE Trans Multimedia 9(5):967–974
18. Wimmer RD, Dominick JR (2006) Mass media research: an introduction, 8th edn. ThomsonWadsworth
Viktoria Pammer is a postdoctoral researcher at the Know-Center in the department “KnowledgeServices”. In the past, she has researched automatic support for domain modeling in descriptionlogics, automatic tag recommendation to support content annotation, and the usage of both semanticmodels and tags as background knowledge in intelligent work-integrated learning systems. Hercurrent work areas include the automatic creation of background knowledge for intelligent systemsby observing and logging users interaction with software systems in the work context.ViktoriaPammer holds both an MsC and a PhD in computer science from the Graz University of Technology(Austria).

462 Multimed Tools Appl (2012) 59:441–462
Barbara Kump is a postdoctoral researcher at the Know-Center in the department “KnowledgeServices” and at the Graz University of Technology, in the Institute for Knowledge Management.Barbara Kump studied Psychology at the University of Graz, Austria, with a focus on CognitivePsychology and Work Psychology (Diploma in 2006). Her work in the past has covered domainmodeling for adaptive work-integrated learning systems and evaluating such domain models. Currentwork topics of Barbara Kump include reflective learning at work, the adaptive delivery of learningcontent, and the evolution of content (text, tags, structured knowledge) over time through usage ina community.
Stefanie Lindstaedt is head of the division Knowledge Services at the Know-Center in Graz andis scientific coordinator of the EU project MIRROR. In these roles she is responsible for themanagement of many large, multi-firm projects and the scientific strategy of the division. Stefanieis also assistant professor at the Knowledge Management Institute of the Technical University Graz.For more than 10 years she has been leading interdisciplinary, international projects in the fields ofknowledge management, semantic systems and software engineering. She holds a PhD and a M.S.both in Computer Science from the University of Colorado at Boulder (USA).