survey on parallel/distributed search engines
TRANSCRIPT

Survey on Parallel/Distributed Search Engines
Yu Liu@NII
Sep. 20th, 2013
Yu Liu@NII Survey on Parallel/Distributed Search Engines

Background
In web search, the information retrieval system needs
Crawling billions of documents stored on millions ofcomputers;
Indexing, ranking, clustering TBs of documents;
Responding thousands of quires at same time;
I did this survey also for finding parallel/distributed applicationsthat related to my current research.
Yu Liu@NII Survey on Parallel/Distributed Search Engines

Background
In web search, the information retrieval system needs
Crawling billions of documents stored on millions ofcomputers;
Indexing, ranking, clustering TBs of documents;
Responding thousands of quires at same time;
Such tasks can (almost) only be done in a parallel/distributed way.The basic idea of a distributed search engine:
many machines work on one task to get it done quicker thanone large machine alone
batter fault tolerance (continue operating properly in theevent of the failure)
Yu Liu@NII Survey on Parallel/Distributed Search Engines

Distributed (Web) Search Engine
Definition
Distributed search engine is a search engine model in which thetasks of Web crawling, indexing and query processing aredistributed among multiple computers and networks.
Yu Liu@NII Survey on Parallel/Distributed Search Engines

Distributed Crawling/Indexing/Ranking
Relative simple, e.g., Goog’s MapReduce1 based approach
1MapReduce:Simplified Data Processing on Large Clusters.
Jeffrey Dean and Sanjay Ghemawat, OSDI’04
Yu Liu@NII Survey on Parallel/Distributed Search Engines

Distributed Crawling/Indexing/Ranking
Relative simple, e.g., Goog’s MapReduce1 based approach
1MapReduce:Simplified Data Processing on Large Clusters.
Jeffrey Dean and Sanjay Ghemawat, OSDI’04
Yu Liu@NII Survey on Parallel/Distributed Search Engines

Distributed Indexing
(Pic. from Dean and Ghemawat (OSDI’04))
Yu Liu@NII Survey on Parallel/Distributed Search Engines

Distributed Search/Query
An Informal Defination
Finding information form multiple “nodes” where searchableresources(indices/documents) are stored.
Each “node” only contains a part of the whole resources, andreturn a partial result.
A final result is produced by aggregating all partial results.
Federated search is an example: each “node” is a search engine,
(Pic. from Wikipedia)
Yu Liu@NII Survey on Parallel/Distributed Search Engines

Distributed Search/Query
Peer-to-Peer search is a decentralized search engine technology.
(Pic. from YaCy)
Yu Liu@NII Survey on Parallel/Distributed Search Engines

Some Examples of Search Engines that SupportDistributed Search/Query
Google’s search engine and Microsoft Bing ...(of course)
Indri : http://www.lemurproject.org/indri.php
Apache Sola/Lucent): http://lucene.apache.org/
YaCy (P2P): http://yacy.net/
Grub (P2P) Grub.org...
Yu Liu@NII Survey on Parallel/Distributed Search Engines

Challenges in Distributed Search
Distributed search applications must carry out three additional,important functions 2:
Resource representation: Generating a description of theresource (documents) stored in each nodeE.g., a language model description, generated by query-basedsampling
Resource selection: Selecting some resources based o theirdescriptionsE.g.,top-k ranked (query-likelihood) nodes
Result merging: Merging the ranked results list form multiplenodesRelated to situations of query model and global statistics
2Text book: Search Engines – Information Retrieval in Practice, by W.BruceCroft, et al.
Yu Liu@NII Survey on Parallel/Distributed Search Engines

Challenges in Distributed Search
For the three important functions
Better resource representation:
Resource selection: better replication, partitioning ofindices/documents and ranking of search results
Result merging: better effectiveness
Yu Liu@NII Survey on Parallel/Distributed Search Engines

Challenges in Distributed Search
More concret examples of Solr– limitations to distributed search:
Each document indexed must have a unique key. If Solrdiscovers duplicate document IDs, Solr selects the firstdocument and discards subsequent ones.
Inverse-document frequency (IDF) calculations cannot bedistributed.
The index for distributed searching may become momentarilyout of sync if a commit happens between the first and secondphase of the distributed search.
Distributed searching supports only sorted-field faceting, notdate faceting
The number of shards is limited by number of charactersallowed for GET method’s URI
Update commands may be sent to any server with distributedindexing configured correctly.
Yu Liu@NII Survey on Parallel/Distributed Search Engines

Challenges in Distributed Search
Relation between my research:
Index updating — incremental MapReduce computation
Base Data already existMapReduce provides parallel processing functionalityIncremental computation makes computation efficient
Currently, our study hasn’t considered the problem of “momentarily out of sync”.
Yu Liu@NII Survey on Parallel/Distributed Search Engines
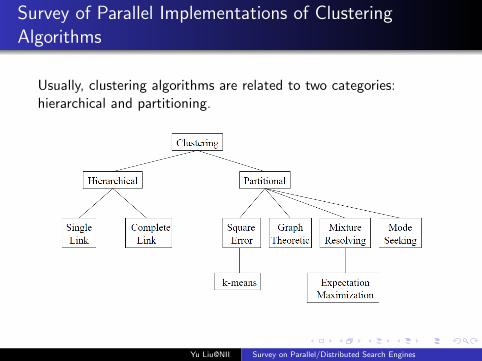
Survey of Parallel Implementations of ClusteringAlgorithms
Usually, clustering algorithms are related to two categories:hierarchical and partitioning.
Yu Liu@NII Survey on Parallel/Distributed Search Engines

Hierarchical clustering
A hierarchical clustering is a sequence of partitions in which eachpartition is nested into the next partition in the sequence.
Hierarchical clusterings generally fall into twocategories:Top-down and Bottom-up.
The more popular hierarchical agglomerative clustering(HAC)algorithms use a bottom-up approach to merge itemsinto a hierarchy of clusters.
Yu Liu@NII Survey on Parallel/Distributed Search Engines
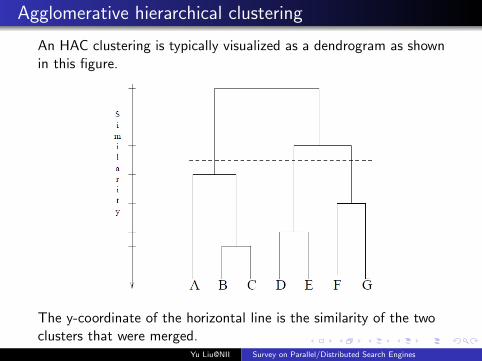
Agglomerative hierarchical clustering
An HAC clustering is typically visualized as a dendrogram as shownin this figure.
The y-coordinate of the horizontal line is the similarity of the twoclusters that were merged.
Yu Liu@NII Survey on Parallel/Distributed Search Engines

The sequential and parallel implementations of hierarchicalclustering
Methods to determine the distances between clusters (Olson 95)[1]
Graph methods
Single linkAverage linkComplete link
Geometric methods
CentroidMedian (group-average)Minimum Variance
Yu Liu@NII Survey on Parallel/Distributed Search Engines

Yu Liu@NII Survey on Parallel/Distributed Search Engines

Single-link Algorithm (naive)
Naive single-link algorithm performs O(N3) time and O(N2)space3
3Introduction to Information Retrieval. ISBN: 0521865719, pp381.Yu Liu@NII Survey on Parallel/Distributed Search Engines

Single-link Algorithm O(N2)
An efficient single-link algorithm using a next-best-merge array(NBM) as a optimization4:
4Introduction to Information Retrieval. ISBN: 0521865719, pp386.Yu Liu@NII Survey on Parallel/Distributed Search Engines

Complexity
Table : Comparison of HAC algorithms.
method combination similarity time complexity optimal
single-link max inter-similarity of any 2 O(N2) yescomplete-link min inter-similarity of any 2 O(N2logN) nomedian average of all sims O(N2logN) nocentroid average inter-similarity O(N2logN) no
In practice, the difference in complexity is rarely a concern whenchoosing one of the algorithms. For most cases of documentsclustering, median is a good choice.
Yu Liu@NII Survey on Parallel/Distributed Search Engines

The Complexity
Efficient single-link algorithm uses O(N2) time and O(N2) space,the situations are similar with other algorithms [Olson 94].A possible problem for MapReduce implementation is that usuallythe input is very huge and far beyond the local memory. Evenrequirement of N2/p memory for a cluster-node is still notacceptable.
Yu Liu@NII Survey on Parallel/Distributed Search Engines

Parallel HAC Algorithms
There are a lot of studies of parallel HAC algorithms, on SIMDarray processors, n-hypercube, n-butterfly and PRAM.(Li, Fang89[3], Li 90[2]) And basically they can compute in O(N2/p) time.Manoranjan Dash et al., introduced an approach to compute inO(N2/cp) time (Dash Manoranjan 04)[4]
Yu Liu@NII Survey on Parallel/Distributed Search Engines

Mapreduec-able ?
There is no real parallel implementation of HAC on MapReduce.
Some approaches of MapReduce to reduce thesize(dimensions) of input data to fit the local memory
Some approaches use buckshot approach to improve k-means
Apache Mahout project has a fake MapReduceimplementation 5
5http://mahout.apache.org/Yu Liu@NII Survey on Parallel/Distributed Search Engines

Difficulties for parallelization with MapReduce
A single similarity matrix must be kept consistent among allcomputing-nodes, which requires communication whenever updatesare performed. But there is no Broadcast method for MapReduce.
Input data are initially split to each computing-node
N × N pairwise bottom level items of the dendrogram can becompute by matrix-multiply approach of MapReduce
Parallel N-1 times merge operations are not known, currently.
Yu Liu@NII Survey on Parallel/Distributed Search Engines

Yu Liu@NII Survey on Parallel/Distributed Search Engines