structured flowcharts for multiprocessing
TRANSCRIPT

C,+mpr+rcr L+.¢lua+ic~. x+ o[ $. p p -+++~+ -'2 P~ tN)~+6-H'~<I ~ I I+H-t12!+*/~4Q ~1 II ~T P~r,-'amon P r ~ . L i d l q - ~ P r t n ! c d ~n G r e : l ; Br~tarn
S T R U C T U R E D F L O W C H A R T S F O R M U L T I P R O C E S S I N G *
A. TONI COHEN
The Pennsylvania State University. Delaware County Campus. Media. Pennsylvania. U.S.A.
and
LEON" S. LEVY
University of Delaware, Newark. Delaware. U.S.A.
(Received 15 December 1976: in recised form 17 February 1978: receit'ed for puhlication 22 March 1978)
Abstract--We present a flowchart language for parallel processing: in addition to the "standard" components, our flowcharts contain fork. join and synchronizing nodes. Extending the work of Mills, we suggest restrictions on controlling computation flow and show that any proper program can be algorithmically transformed to an equivalent structured program•
Control structures Flov, chart lnterprocess communication Multiprocessing Structured programming
1. I N T R O D U C T I O N
TWO AREAS which have been of great interest in recent years are structured programming [I-5] and multiprocessing [6-18]. In this paper, we formalize a flowchart language for parallel computation, suggest restrictions on controlling computation flow and, extending the work of Mills [19] and Bohm and Jacopini [20], show that any proper program can be structured according to these restrictions.
There are inherent limitations to the speed-up achievable by strictly sequential com- puter systems, even multiprogrammed ones, since data transfer between components must involve transmission over finite distances. Thus, it seems likely that continued significant increases in system speeds will result from multiprocessing rather than from hardware improvements. The use of parallelism will enhance performance capabilities by increasing throughput and, thus, allowing systems to handle greater computational loads.
Multiprocessing, to be fully effective, must allow communication between concurrently- executing processes. In particular, any one of several competing processes must be able to preempt any of its competitors, suspending their execution, during the (finite) time necessary for it to complete some indivisible action.
Including communication capabilities in a language greatly increases the complexity of its control structures and makes disciplined programming practices particularly desir- able. The rationale for structured programming is both straightforward and convincing. Experience (with sequential systems) has shown that, from the programmer's point of view, the need for debugging is minimized and correctness proofs are easier to formulate; from the user's viewpoint, the restricted format greatly simplifies understanding the process. We believe that these arguments will hold even more strongly in multiprocessing systems.
The need for shared resources and the desirability of control structuring can be sum- marized as follows: Multiprocessing is desirable and should include facilities for interpro- cess communication. Undisciplined use of the available control structures is undesirable and a set of restrictions for controlling computation flow should be formulated.
We first define a language which allows concurrent execution of processes. In addition to the standard sequential control structures, it includes primitives which (1) cause com- putation flow to fork, thus creating a new process; (2) cause computation flow to join, thus destroying an existing process; (3) allow either of two concurrently-executing pro- cesses to temporarily block the other.
* Partially supported by NSF grant MCS 77-04834.
ct. 3a--A 209

210 A. TONI COHEN and LEON S. LEVY
We next define structured programs in our language. In essence, we say that the following are structured: (1) any structured sequential program; (2) any combinat ion of structured programs along the principle of D-chart combinations [21]: (3) a descrip- tion of the parallel execution of two structured programs; (4) the program resulting from placing a monitor on two structured subprograms of a structured program.
These restrictions were chosen pragmatically. Structuring must involve some loss of efficiency, since it limits the use of available control structures [22]. At the same time, lack of discipline increases the likelihood of errors and decreases clarity. We allow the use of parallelism in non-communicat ing programs only when it is possible to impose well-nestedness: in other cases, we force execution to proceed sequentially. We relax the requirement of well-nestedness to allow communicat ion between structured subpro- grams.
2. P R E L I M I N A R I E S
The usual structured version S(P) of a sequential program P is equivalent to the unstructured program in the sense that (a) if, on given input, P has the execution sequence s, . , . s , of (uninterpreted) functions and predicates, then, on the same data, S(P) has the execution sequence CoSlC, . . . s,c,, where the c~ are (possibly empty) control constructs; and (b) the functions computed by P and S(P) are identical. In the case of parallel programs, in general neither P nor S(P) determines a unique sequence of functions and predicates since the relative speeds of unsynchronized parallel segments are unconstrained.
However, for given input, each of P and S(P) determines a set of possible computat ion sequences, Seq(P) and Seq(S(P)). Each sequence in Seq(P) is a permutat ion of every other sequence in Seq(P); similarly, each sequence in Seq(S(P)) is a permutat ion of every other sequence in Seq(S(P)). Further, the computed function is the same for all sequences in Seq(P) and Seq(S(P)).
Our structuring algorithm develops a structured program S(P) from given P which retains as much parallelism as possible while satisfying a set of structural constraints. Thus, if Cot~qt2.. . t,c, is an execution sequence of Seq(S(P)), the algorithm insures that t~t2.. , t, is a sequence of Seq(P).
Definition 1. A (directed) graph, G = (V,E,V~,VI) is
(a) a set V of vertices or nodes: (b) a s e t E ___ V x V ~ V x V x V of edges; (c) a set V~ c_ V of initial nodes, with indegree 0; (d) a set V I ~_ V of final nodes, with outdegree 0.
If e = (vt,vz)*, then v~ is the source of e and v2 is the sink of e. We denote the source of e by D(e) since it is an element of the domain of the relation V x V: similarly, the sink of e is in the range of V x V and is designated R(e). If e = (v~,v2,v3), then e is a complex edge, v, is the source of e, denoted D(e), and v2 and v 3 are the sinks of e, denoted R~(e) and R2(e).
A graph is 1,1 if it is single entry, single exit; that is, if G = (V,E[v~,,[vs-}), where v~ is the unique initial node with outdegree 1, and vf is the unique final node, with indegree 1.
A labelled graph, GL ---- (G,Lv,L~) is a graph G = (V,E,V~,V I) with labelling functions Lv:V---~ T, where T is a set of node types, and LE:E~-4*A, where A is an alphabet of edge labels, and such that no two distinct edges have the same label and nodes of each type have the proper indegree and outdegree. The node types we use, with associated indegree and outdegree, are shown in Fig. 1.
* F o l l o w i n g s t anda rd no ta t ion , we use capi ta l let ters to ind ica te sets, lower case let ters to indica te e lements of sets.
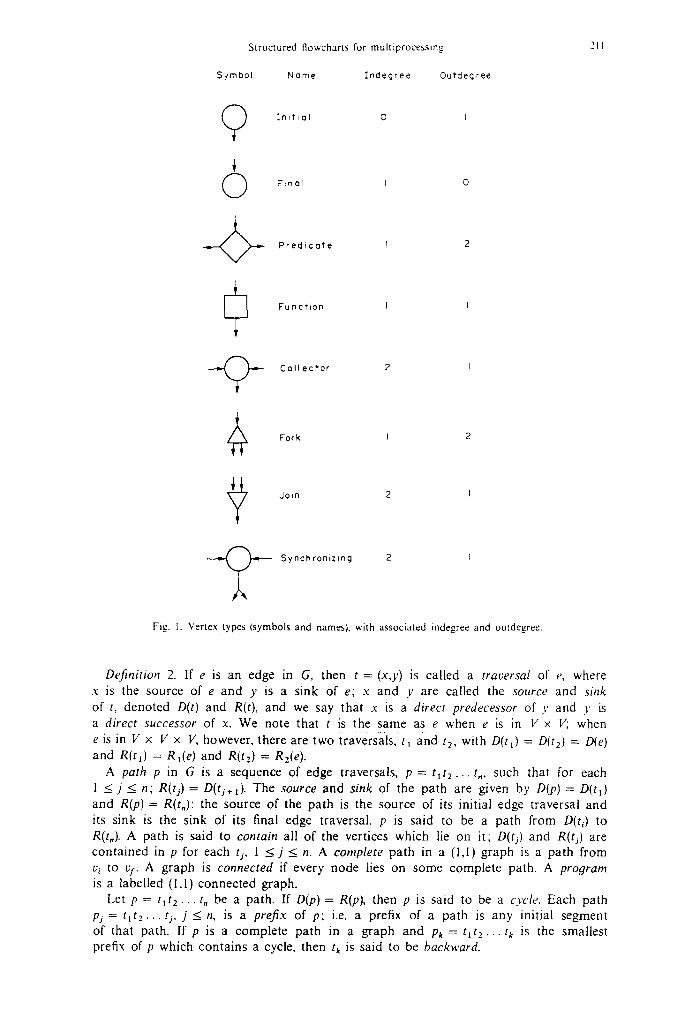
Structured flowcharts for muhiprocessing 211
Symbol Name Indegree Outdegree
~nit~al 0 t
Ftnal I 0
Pred ica te I 2
Function [ I
Col lec tor 2 I
Fork I 2
dora 2 I
* ~ Synchronizing 2 I
Fig. 1. Vertex types (symbols and namesL with associated indegree and outdegree.
Definition 2. If e is an edge in G, then t = (x,y) is cal led a traversal of e, where x is the source of e and y is a sink of e; x and y are cal led the source and sink of t, deno ted D(t) and R(t), and we say that x is a direct predecessor of 3' and y is a direct successor of x. We note that t is the same as e when e is in V x V; when
e is in V x V x V, however, there are two t raversals , t~ and t2, with D(tO = D(t2) = D(e) and R(tt) = Rl(e) and R(t2) = Rz(e).
A path p in G is a sequence of edge t raversals , p = q t z . . . t , , such that for each 1 <_j < n; R(tj) = D(t~÷t), The source and sink of the pa th are given by D(p) = D(tl) and R(p) = R(t,): the source of the pa th is the source of its ini t ial edge t raversa l and its s ink is the sink of its final edge traversal , p is said to be a pa th from D(h) to R(t,). A pa th is said to contain all of the vertices which lie on it; D(tj) and R(tj) are con t a ined in p for each tj, 1 < j _< n. A complete pa th in a (1,I) g raph is a pa th from vi to v:. A graph is connected if every node lies on some comple t e path. A program is a label led (1,1) connec ted graph.
Let p = t t t 2 . . , t, be a path . If D(p) = R(p), then p is said to be a cycle. Each pa th p~ = t~ t2 . . , t~, j < n, is a prefix of p; i.e. a prefix of a pa th is any ini t ial segment of that path. If p is a comple t e pa th in a g raph and Pk = t a t z . . , tk is the smal les t prefix of p which con ta ins a cycle, then tk is said to be backward.

212
Example 1.
A. TONI COHEN and LEON S. LEvY
@l
G:
G is labelled, (1,1) and connected and is therefore a program, e5 has source D(e 5) = s
and sinks R l ( e s ) = J r and R 2 ( e s ) = j 2 . s is a direct predecessor of j l and j2 and j l and j2 are both direct successors of s.
The sequence ete2e4eveseve9eloe15 is a complete path of G. p contains the cycle Pl = eves, with D(Pt) = R(pl) = c. The path P2 = e leze4eves is a prefix of p; since P2 ends in a cycle, es is backward.
Definit ion 3. For each fork node v in a graph G, the scope of v is the set of nodes up to and including the set of join nodes which "balance" v. Formally, v' is within the scope of v if either (a) there is a path p --- t l t z . . . t , from v to v' which contains at least as many fork nodes as joins and if no proper prefix of p contains exactly as many fork nodes as jo ins; or (b) v' = v.
Informally, a segment is a p rogram wi thout initial and final nodes. (Strictly speaking, it is not a p rog ram since it is not even a labelled graph, but what has been called a partial 9raph). The source of a segment is the sink of its initial edge; its sink is the source of its final edge. If m and m' are distinct segments of P, m is said to contain m' if every edge of m' is an edge of m. A segment of P is max ima l if it is not conta ined in any other segment of P; it is minimal if it does not contain any other segment of P.
Definit ion 4. The marking of a graph is a map m: E---.N, assigning to each edge e of G a natural number re(e), called the mark ing of e. The set of all markings is denoted M, and M = N ~ (where the no ta t ion x y denotes the set of all functions from y to x). The mark ing of a p rogram is the mark ing of its graph. The initial markin 9 m~ of a p rog ram has m~(e) = 1 if e is ou tgo ing f rom the initial node or f rom a synchroniz- ing node; otherwise, m~(e) = O.
• A step s applied at node v of a p rogram is a relat ion from mark ing to marking (S ~_ M x M, where S is the set of steps) which alters the mark ing of incoming and outgoing edges of v in accordance with Lv(v) as shown in Fig. 2. A step applied at a node whose incoming and outgoing edges do not have appropr ia te markings is said to be undefined.
An execut ion sequence ex is a sequence of (one or more) steps. If ex = s l s 2 . . , s,, then length (ex) = n. We write mex to denote the marking which results from applying ex to m.

Structured flo~,charts for multiprocessing 213
If ex is an execution sequence and there is no node at which a step can be applied to extend ex (because incoming edges have too-small markings), then ex is said to terminate. If ex terminates with m~ex(e) = I whenever e is ou tgoing from a synchronizing node or incoming to Q, and 0 otherwise, then ex terminates properly, since this corre- sponds to a computa t ion which has moved through the p rogram from input to output. If ex terminates, but not properly, then ex is said to block. A program P is said to be blocking if any of its execution sequences block; otherwise, all execution sequences which terminate do so properly, and P is non-blocking.
Name Change to incoming edges Change to outgoing edges
initial final predicate - 1 ( + 1,0) or (0, + 1) function - 1 + 1 collector ( - 1,0) or ( 0 , - 1) + 1 fork - 1 ( + 1,+ 1) join ( - 1 , - 1) + 1 synchronizing ( - 1,0) or ( 0 , - 1) + I
Fig. 2. Node types with changes allowed when a step is applied at the given node.
Example 2. For the graph G of Example 1, the scope o f f l is {fl,jl,j2,c,s,fn,p,f2,f3,j31; the scope o f f 2 is {f2,s,jl,j2,j31 the scope o f f 3 is {f3,s,jl,j2,j3'~. The maximal segment has source f l and sink j3.
The initial mark ing is given by mi(et) = mi(es) = I and mi(e) = 0 for all other edges e. Only one step, s~, is defined on G with mark ing ml; the result of applying s~ to t'l is m l, with ml(e2)= ml(e3)= ml(es)= 1 and rn l ( e )= 0 for all other e. Two steps are defined on G with marking m, : s2, applied at j l and s3, applied at j2. If ex = sis2, then m2 = miex has m2(e3) = rex(e4) = 1 and m2(e) = 0 for all other e.
The only two sets of execution sequences which terminate are:
(1) f 1,j l,(c,p) +,f2,s,j2,fi~,f3,j3 and (2) f l,j2,fn,f3,s,jl,(c,p) +,f2,j3,
where each step is named with the node at which it is applied. Both 1 and 2 terminate properly, so G is non-blocking.
Definition 5. If P is any program, the unsynchronized underlying program of P, U(P), is derived from P by removing all synchroniz ing nodes, together with their incoming and outgoing edges, and replacing their direct predecessors and direct successors with no-ops (where a no -op is represented by the identity function). Informally, U(P) is P with all synchroniz ing machinery removed, so that the several processes represented by the concur ren t paths are not in communica t ion with one another.
The scope of synchroniz ing node v is the set of nodes which are conta ined in some path from v to itself. Each maximal segment of U(P) which is within the scope of v in P is called a critical section of r,. We say the critical sections of v are synchronized by u.
Two edges el and e2 are said to be concurrent if they have a unique least c o m m o n ancestor (edge) whose sink is a fork node f and if every path from el to e2 or from e 2 to e 1 contains f. Informally, this definition asserts that e~ and e2 may be traversed in parallel and that there is no path within the scope of f which contains both e~ and e 2 (SO that no traversal of e2 is ever defined as a result of a traversal of el).

214
Example 3.
A. To,~l COHEN and LEON S. LEVY
U(P) :
Q
b ¢
d
5 E
The following pairs of edges of U(P) are concurrent:
(fix). (h.f), (h,g). (h.]). (h.l), (c.d), (c,e), (c,h), (c,k). (d.e), (d,f), (d,9), (d,j), (d,/), (e,f). (e,a), (e.h), (e,j), (e,I), (fg), (fj), (fl), (g,h), (g,k), (hd), (h,/), (j,k).
The scope o f f l in U(P) is I f l , f2 , f3 , j l , j2 , j3 , fn l , fn2~ the scope o f f 2 is [f2, j l , j2}; the scope o f f 3 is If3,j l , j2~. The scope of sl in P is [sl,j4,j5,fnl,fn2,f4,f51 and the critical sections of sl are [fnl] and [fn2].
Programs, as defined, allow more concurrency and communicat ion between processes than is desirable. We wish to consider only those programs which intuition tells us "work properly".
Definition 6. A proper program is a program in which:
(1) for each execution sequence ex and each edge e, 0 _< mlex(e) <_ 1; (2) along each complete path, the number of fork nodes equals the number of join
nodes; and (3) if t' is a synchronizing node, the direct predecessors of t" are fork nodes and the
direct successors of v are join nodes.
Restriction 1 simplifies the control of processes executing the program since at most one process can be associated with an edge at any given time. There is no need for a queue structure to control the sequencing of concurrently active processes through the nodes of the program. In fact, this restriction insures that, if processes A and B are traversing the same path in a program, their relative order will be maintained. Restriction 2 forces each path through each loop to contain the same number of fork nodes as of joins. Since concurrent loop entries are prohibited as a consequence of restriction 1, the set of exits from each loop must also be mutually exclusive (concurrent exits would be possible only if more forks than joins were encountered by some path). Finally, restriction 3 limits the use of synchronizing nodes, forcing them to be used only as monitors.
We note that restriction 1 is really a consequence of previous definitions.

Struc tured flov, char ts For mul t ip roces s ing 215
3. S T R U C T U R E D P R O G R A M S
Our parallel flowcharts are intended to be practical representations. As such. the~ differ markedly from the various theoretical models of parallel computation, although their development was particularly influenced by UCLA graphs [23], and parallel flow- chart schemata [24]. (The control structures described by Dennis [25] provide a more hardware-oriented approach.)
In addition to Mills' sequential constructs [19], our structured programs use P AR ALLELDO and SYNCHRONIZE. The latter component indicates communication between concurrently-executing processes: we assume the existence of a genie (or arbiter) within the underlying machine to implement the communication (methods of synchroniz- ing cooperating sequential processes are discussed in [11], [12], and [21]).
We define structured programs with concurrency and synchronization. The definition given below is an extension of the usual context-free form of definition in which D-charts are specified, and only items 6 and 7 of our definition require comment (since the D-chart definition is precisely items 1-5 and 8 of ours). In choosing the PARELLELDO, we have given a minimal parallelism in terms of which more complex parallelism can be built by cascade composition. This minimal parallelism is related to greater parallel- isms as the conditional is related to the CASE statement, and our algorithms can be extended to include greater parallelism. The synchronization construct is a model of the monitor concept, albeit without procedures, and is perhaps closer to Dijkstra's ori- ginal description of a secretary [26]. Again, our synchronizer can only control two competing segments, but the obvious generalizations can be handled as the generalized parallelism, mutatis mutandis.
A structured program is a structured segment with initial and final nodes adjoined, where we define structured segments recursively:
Definition: (1) --, is structured; [empty segment] (2) -----15]----, is structured; [function] (3) if---*f--, and ---'g---' are structured segments, then so is ----'f--*g--'; [concatenation] (4) if--~f--~ and ---~g--" are structured segments and p is a predicate, then
is s t ruc tu red ; C i f thene lse ]
(5) i f f is a structured segment and p is a predicate, then
is s t r uc tu red ; [ .whi ledo]
(6) if f and g are structured segments, then
9 is s t ruc tu red ; [ p a r a l l e l d o ]
(7) i f f is a structured segment of the form
f (
h I - .
) J

216 A. To~T COHEN and LEO~ S. LEvY
with g and h structured subsegments, then
f \ J
~s s t ruc tured; [synchronize]
(8) Nothing else is structured. Theorem l: If P is a structured program, then P is non-blocking. Proof: The only way that a program can block is for all edges in the graph with
marking greater than zero to have join nodes as sinks, since any other node can allow execution to continue. We can argue by structural induction that structured programs are non-blocking. Surely, the first five constructs in the definition cannot introduce blocking since they do not introduce join nodes.
As far as the sixth construct is concerned, i f f and 9 are independently non-blocking, then paral[eldo (fg) must be non-blocking, since this construct starts with a fork which updates the graph marking so that f a n d 9 can be stepped. Neither f n o r 9 is blocking, so they will either continue to have nodes which can be stepped or update the marking so that the join node at their output can be stepped.
The critical sections of synchronizing nodes are partially ordered with respect to containment: given any two critical sections csl, cs2 of a proper structured program, csl is contained with cs2, or cs2 is contained within csl or csl and cs2 are disjoint (see Example 9). And, again by structural induction, if P is a non-blocking program and 9 and h are non-blocking segments in P, then the program derived from P by synchronizing 9 and h is non-blocking.
4. I N F O R M A L D E S C R I P T I O N O F S T R U C T U R I N G A L G O R I T H M
The structuring algorithm first considers the unsynchronized underlying program U(P) of a program P. After U(P) is structured, the synchronizing machinery is forced to become well-nested and P itself is structured. If P is non-blocking, the algorithm con- structs S(P), a structured program equivalent to P. Else, if P is blocking, the algorithm so indicates.
We introduce the algorithm by giving several examples, showing the step-by-step construction of the structured equivalent of each program.
Example 4: Forcing forks and joins to be well-nested
P :
S (P):
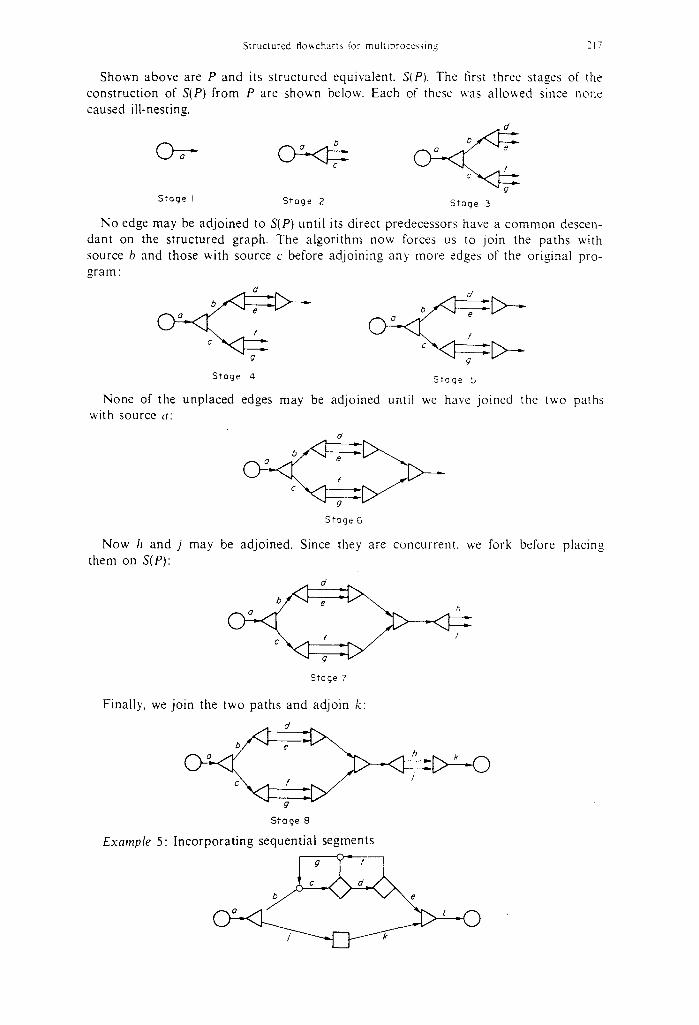
S t r u c t u r e d f l owcha r t s J'or m u l t i p r o c e s d n g 217
Shov,'n above are P and its structured equivalent. S(P). The first three stages of the construction of S(P) from P are shown below. Each of these was allowed since none caused ill-nesting.
d
/
Stage I Stage 2 Stage 3
No edge may be adjoined to S(P) until its direct predecessors have a common descen- dant on the structured graph. The algorithm now forces us to join the paths with source b and those with source c before adjoining an> more edges of the original pro- gram:
/
Stage 4 Stage 5
None of the unplaced edges may be adjoined until we have joined the two paths with source a:
o'
Stage ro
Now t, and j may be adjoined. Since they are concurrent, we fork before placing them on S(P)
a h
Stage 7
Finally, we join the two paths and adjoin k:
b d
Stage 8
Example 5: Incorporat ing sequential segments
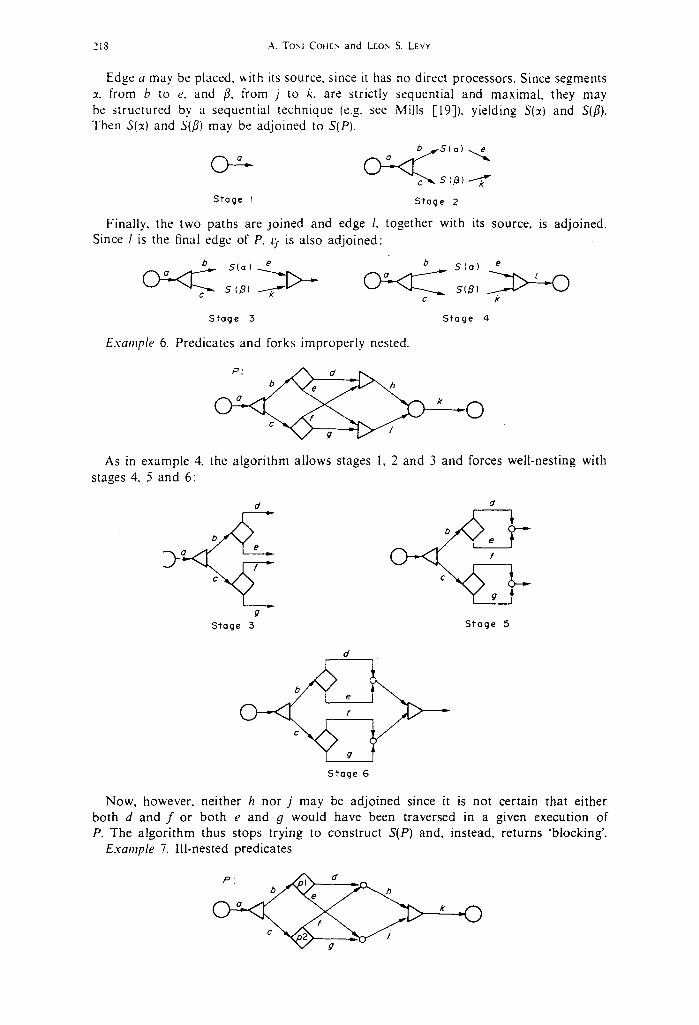
218 A. Toxl COHEN and LEON S. LEVY
Edge a may be placed, v, i th its source, since it has no direct processors. Since segments :c from b to e, and fl, from j to k, are strictly sequential and maximal, they may be structured by a sequential technique (e.g. see Mills [19]), yielding S(:d and S(fl). Then S(:z) and S(fl) may be adjoined to S(P).
Stage I
~ , . S ( a ) o - - 4 .
( ~ ~ s (~1 .I;," Stage 2
Finally, the two paths are joined and edge l, together with its source, is adjoined. Since l is the final edge of P, q is also adjoined:
b S(a) e b SIo) e
¢ k
Stage 3 Stage 4
Example 6. Predicates and forks improperly nested.
P: d
~ " ~ ) ~ ~
As in example 4, the algorithm allows stages 1, 2 and 3 and forces well-nesting with stages 4, 5 and 6:
d d
0 e
C
g Stage 3 Stage 5
d
Stage 6
Now, however, neither h nor j may be adjoined since it is not certain that either both d and f or both e and g would have been traversed in a given execution of P. The algorithm thus stops trying to construct S(P) and, instead, returns 'blocking'.
Example 7. Ill-nested predicates
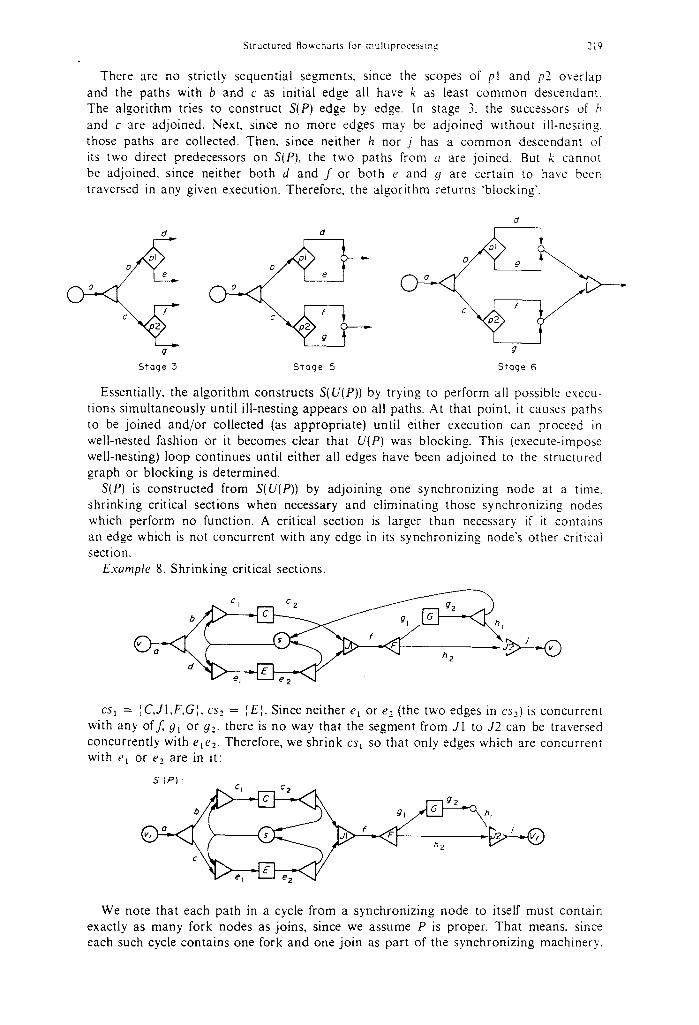
Structured flowcharts for muhiprocessing 219
There are no strictly sequential segments, since the scopes of pl and p2 overlap and the paths with b and c as initial edge all have k as least common descendant. The algorithm tries to construct S(P) edge by edge. In stage 3, the successors of b and c are adjoined. Next. since no more edges may be adjoined without ill-nesting, those paths are collected. Then, since neither h nor j has a common descendant of its two direct predecessors on S(P), the two paths from a are joined. But k cannot be adjoined, since neither both d and f or both e and g are certain to have been traversed in any given execution. Therefore, the algorithm returns "blocking'.
d d d
b e b
c
9
Stage 3 Stoge 5 Stoge 6
Essentially, the algorithm constructs S(U(P)) by trying to perform all possible execu- tions simultaneously until ill-nesting appears on all paths. At that point, it causes paths to be joined and/or collected (as appropriate) until either execution can proceed in well-nested fashion or it becomes clear that U(P) was blocking. This (execute-impose well-nesting) loop continues until either all edges have been adjoined to the structured graph or blocking is determined.
S(P) is constructed from S(U(P)) by adjoining one synchronizing node at a time, shrinking critical sections when necessary and eliminating those synchronizing nodes which perform no function. A critical section is larger than necessary if it contains an edge which is not concurrent with any edge in its synchronizing node's other critical sect ion,
Example 8. Shrinking critical sections.
C I C 2
csl = [C, J1,F,G}, cs2 = [El. Since neither el or ez (the two edges in cs2) is concurrent with any o f f g~ or g2, there is no way that the segment from J l to J2 can be traversed concurrently with ere2. Therefore, we shrink csl so that only edges which are concurrent with et or ez are in it:
S (P) :
-- ~ [ ~ ~ ~ "4 h 2 V" v
We note that each path in a cycle from a synchronizing node to itself must contain exactly as many fork nodes as joins, since we assume P is proper. That means, since each such cycle contains one fork and one join as part of the synchronizing machinery.

220 A. TONI COHEN and LEON S. LEVY
that the part of the cycle which is in U(P) must contain exactly as many forks and joins. It also means that the scopes of synchronizing nodes cannot overlap; if csl and cs2 are critical sections of distinct synchronizing nodes, either they are disjoint or one must be a subset of the other.
Example 9. Synchronizing nodes with overlapping scopes occur only in non-proper programs.
G ' ~ e ~ .._
The cycle (9bcf) with source and sink sl contains 2 join nodes and only one fork. This would be impossible if P were proper.
Assume the critical sections of one synchronizing node (s2) are subsets of the critical sections of another (sl). Then s2 is unnecessary, since its function is already being fulfilled by sl.
Example 10. Nested critical sections.
S (P):
5. THE STRUCTURING ALGORITHM
As shown below, the definitions of proper and non-blocking programs severely limit the amount of interaction which can occur between the scopes of distinct fork nodes or between the scopes of fork nodes and predicate nodes. The structuring algorithm makes use of several properties of proper non-blocking programs which are inherent in the definitions, but not immediately obvious.
Proposition 1. Each cycle of a proper program contains exactly as many fork nodes as joins.
Proof: Let P be proper with cycle pl. Each complete path through P contains exactly as many fork nodes as joins. Since whenever p = p2,pl,p3 is a complete path of P, p' = p2,pl,pl,p3 is also, pl clearly contains the same number of forks as of joins.
Proposition 2. Concurrent entries to any cycle of a proper program are impossible. Proof: (by contradiction). Assume P has a cycle p with at least two concurrent entry
edges. P may be stepped so that the edges of p have total marking 2 and, then, so that one edge of p has marking 2. Since P is proper, this is impossible.
Proposition 3. If P is a proper non-blocking program with fork node v, then the several paths descendant from any predicate node pl within the scope of v must have a common descendant within the scope of v.
Proof: (by contradiction). Assume that p and p' are paths from pl to two distinct join nodes, j l and j2, within the scope of v. Then P must block at either j l or j2.

Structured ftov, charts for multiprocessing 221
Proposition 4. In proper non-blocking programs, no cycle within the scope of a fork node f l may contain J 'l .
Proof: (by contradiction). Let t, be the immediate predecessor of f l in p. If r is within the scope of f l , there must be a path p from f l to r which contains a join or collecting node. If p contains a join node, p must be blocking (since that join can never be stepped). Else, if p contains no joins, the shortest cycle from f l to itself which contains p {the concatenation of p with (r,fl)) contains more forks than joins, which is impossible since p is proper.
Proposition 5. Let p be a cycle in a proper non-blocking program p and let k be a cycle in p. Then p/k, the portion of p lying in k, contains exactly as many fork nodes as joins.
Proof: By Proposition 1, k contains exactly as many fork nodes as joins. If k contains no forks, the result follows trivially. Else, let f l be any fork encountered on p/k and consider k to have D(k) = R(k) = f l . Let Px be the shortest prefix of k containing exactly as many fork nodes as joins, so that R(pl) = j l , a join node. One incoming edge to j l is on Pl. The other must be a descendant of f l since concurrent entries to cycles are impossible (Proposition 2). We shall show that all paths from f l to c s (the final node) contain j l .
Assume there is a path P2 from f l to r r which does not contain j l . Then there is a node el descendant from f l which is the last node contained in both Pl and P2. el must be either a fork or a predicate. By Proposit ion 3, el cannot be a predicate since not all paths descendant from it pass through j l . Thus, t,l must be a fork node.
Consider P3, the path from f l to j l which contains vl. P3 must contain a join j' to balance vl (since otherwise the cycle from f l to itself containing vl must have more forks than joins) and the other incoming edge to j ' must be a descendant of vI. We can proceed inductively, considering next the cycle from vl to itself which contains j l , to reach the conclusion that no path through a cycle may exit that cycle via a fork node.
Since we have already shown that a path can exit via a predicate node only after passing through the same number of fork nodes as of joins, the proposit ion is proved.
Informally, Proposit ion 3 asserts that each predicate node in a proper non-blocking program must be the source of a segment, and that there can be no interaction between the scopes of predicates* and forks (i.e. one must be properly contained within the other or they must be disjoint).
The extent of Proposit ion 4 can best be understood by considering the segment below. Node :~ must be a fork or a predicate, since only these two node types have outdegree 2. Similarly, /3 must be either a collecting node or a join (,6 cannot be a synchronizing node since its immediate successor is not a join), fi cannot be a join since in that case the program must block before ~ is ever stepped; so it must be a collector. But in that case f l might be stepped twice before j l is stepped once, giving c a marking of 2.
* We have not defined the scope of a predicate of a fork.
Q
node, but it~ definition is analogous to that of the scope

222 A. To>q COHEN and LEON S. LEVY
Finally, we note that, as a consequence of Proposit ion 5, concurrent entries to or exits from cycles are impossible in proper non-blocking programs.
The algorithm is first applied to the unsynchronized underlying program U(P) of a program P. and then to S(U(P)), to yield S(P). We assume the following data are available:
1. The sets of direct predecessors and direct successors of each edge; 2. The node-type of the sink of each edge of U(P); 3. All concurrent /non-current information for U(P); that is, for each pair e,e' of edges,
either concurrent (e,e') or non-concurrent (e,e'): 4. For each edge e of U(P),
(a) the Boolean function PLACEABLE(e) which has value 1 if e may be immediately adjoined to (the partially constructed) S(P) and 0 otherwise; (b) the three-valued function TRAVERSED(e), with value 0 if e has not yet been adjoined to S(P), I if e has been adjoined and surely traversed (i.e. if it is not on one path of an ifthenelse) and '? if e has been adjoined but not surely traversed; (c) the Boolean function BACKWARD(e), which has value 1 if e is backward, and 0 otherwise: (d) the identities and final edges of all strictly sequential segments of U(P) whose initial edge is e;
5. A stack containing the names of all edges of U(P) which have two direct predecessors and which have been adjoined to S(P) but not yet "balanced". (This stack will be popped to determine which paths get joined or collected when well-nesting is being imposed);
6. For each synchronizing node s, the scope of s and the two critical sections of s; 7. The partial ordering on critical sections: for each pair csl, cs2 of critical sections,
exactly one of csl c cs2, cs2c_csl, incomparable(csl.cs2).
Macro-algori thm
1. While not all edges of U(P) have been adjoined to S(P) (a) Determine which edges are placeable, or return 'blocking' if that is established; (b) If any edges are placeable, adjoin them to S(P); else, join or collect to impose
well-nesting or, if blocking is established, return "blocking'; 2. While not all synchronizing nodes of P have been adjoined to S(P), adjoin any un-
placed synchronizing node, adjusting its scope as necessary, or discard it if it serves no function. We first present the construction of S(U(P))in detail:
While not all edges of U(P) have been adjoined to S(P)
1. For each unadjoined edge e, e is placeable if and only if (a) e has no direct predecessors; or (b) e's one direct predecessor has been traversed and, if e is backward, the sink of
its direct successor must be the source of a segment whose sink is the source of e's direct predecessor [i.e., e is not placeable if its adjunction would cause the scope of a fork' node to overlap a cycle-]" or
(c) one of e's two direct predecessors is backward and the other has been traversed; or
(d) there is a traversed edge on S(P) which is a descendant of both of e's two direct predecessors '
If e's one direct predecessor has been traversed, e is backward and would cause the scope of a fork node to overlap a cycle, then return 'blocking'•
2. If any edges are placeable, then for each placeable edge e (a) adjoin e's source; structure and adjoin the maximal strictly sequential segment
with initial edge e, forking first if several concurrent edges are made placeable as direct successors of an edge on S(P);
Structured flowcharts for multiprocessmg 223
(b) Set P L A C E A B L E ( d ) to 0, T R A V E R S E D ( e ' ) to 1 for each e' in the jus t -adjo ined segment :
(c) if the final edge of the jus t -adjo ined segment has two direct successors, stack its name:
else if the stack is emp ty then return "blocking' : else pop the stack. Assume the edge whose name was popped is e. that e has sink r and that the las t -adjoined successors of e are j and k. ((3)' if either j or k is backward , re turn: (b') if C O N C U R R E N T ( j , k ) then join j and k:
else (i) collect j and k; (ii) for all edges e' within the scope of t:. set T R A V E R S E D ( U ) to ?.
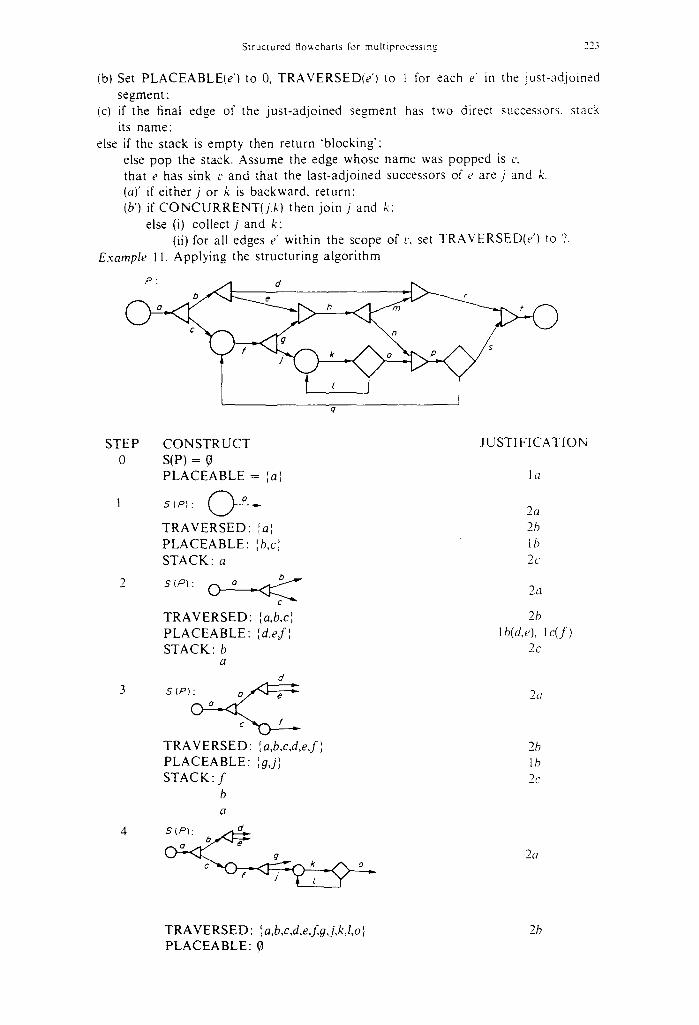
Example 11. Applying the s t ructur ing a lgor i thm
o / , ' " , , 4 - - _ ~ e
q
STEP C O N S T R U C T o s (P) = 0
P L A C E A B L E = la[
1 S ( P I : @ - - , , -
T R A V E R S E D : {al P L A C E A B L E : Ib,c~j S T A C K : a
2 s(P) : o O
T R A V E R S E D : ~a,b,c'~ P L A C E A B L E : [ d, ef ', S T A C K : b
a
d 3 S(P): O/~e
T R A V E R S E D : ~,a,b,c,d,e,f~ P L A C E A B L E : ',g,J] S T A C K : f
b a
4 s(Pl: .,~.d
O
J U S T I F I C A T I O N
1(3
2(3 2b lb 2c
2a
2b lh(d,e), l c ( f )
2c
2~
2b lb 2c
2(3
¢ -
T R A V E R S E D : ~a,b,c,d,e,fg,j,k,l,o~ P L A C E A B L E : 0
2b

224 A. Toni COHEN and LEON S. LE~
STEP
5
C O N S T R U C T
STACK: b
S(P): D ~
STACK: a d
.S" (P) : D ~ =
PLACEABLE: 0
STACK: 0 d
S(P): b ~ ~ > ~ =
o 9 _
PLACEABLE: [/i]
S(P):
l
TRAVERSE D: la,b,c,d,e,fg,h,j,k,l,ol PLACEABLE: {m,nl STACK : /1
9 s(P): d
o
TRAVERSE D: [a,b.c.d,eJlgdl.j,k,Lm,n,ol PLACEABLE: Ip,rl STACK : h
10 s(Pl : . m • a g -
• , y C y o TRAVERSED: la,bx,d,e,fg,h,j,k,l,m,n,o,p,r] PLACEABLE: 'tsl Return 'blocking', since adjunction of q is dis- allowed: the partial graph with initial edge f and final edge p is not a segment•
J U S T I F I C A T I O N
2(POP)
2b'
2(POP)
2b'
2(POP)
2a
2b lb 2c
2a
2b ld
2b
2b lb
The algorithm above constructs S(U(P)) or returns "blocking', as appropriate. If S(U(P)) has been completed, we apply the algorithm below to construct S(P).
While not all synchronizing nodes have been adjoined to S(P), nondeterministically select any unadjoined synchronizing node s, with critical sections csl and cs2.

Structured flowcharts t~or multiprocessmg 225
(a) Remove from each of csl. cs2 all nodes which are not concurrent with some node of the other critical section, i.e. shrink the critical sections to eliminate unnecessary synchronization, eliminating s if the critical sections become empty:
tb) If there is a synchronizing node s' on S(P) such that the two critical sections of s (s') are subsets of the two critical sections of s' (s), then eliminate s (s') since s' Is) is already fulfilling its function.
Finally. we show that. if the structuring algorithm completes, then S(P) is equivalent to P and that the algorithm returns "blocking' exactly when P is blocking.
Theorem 2. If the structuring algorithm constructs S(P), then S(P) halts exactly when P does, and computes the same function.
Sketch of prooJ': S(P), as constructed, is simulating a generalized computation of P. At each stage when P is able to proceed, we adjoin the corresponding edges in S(P). Thus each path p in S(P) corresponds to a path p' in P and computes the same function. Further, each cycle along p corresponds to a cycle in p' and computes the same partial function. Thus S(P) halts exactly' when P does and computes the same function.
Theorem 3. A proper program is blocking if and only if the structuring algorithm so indicates by returning 'blocking'.
Proof: If P is blocking, then the structuring algorithm will so indicate. Assume the contrary. Then P is blocking, but the structuring algorithm completes, yielding a struc- tured program Q equivalent to P. But if Q is equivalent to P, then O must block. This is impossible, since (by Theorem 1) no structured program is blocking.
We sketch the proof of the converse: If the algorithm indicates that P is blocking, then P is indeed blocking. The structuring algorithm, in producing S(P), is in some sense a generalized execution of P. So long as the computation of P proceeds, the construction of S(P) does also. Hence, if the algorithm constructing S(P) returns 'blocking', it must be because P has, in fact, blocked.
S U M M A R Y
The well-known Bohm-Jacopini structuring theorem for sequential programs is gener- alized to concurrent programs as follows: We define concurrent programs as flowcharts with the usual sequential constructs, concurrency (provided by fork and join constructs) and mutual exclusion (provided by a synchronizing construct). Concurrent programs are said to be structured if they are constructed by an extension of D-chart methods which includes the concurrent programming constructs.
We show that every structured program is non-blocking (Theorem I). Since it is easy to construct concurrent programs which do block, it is clear that there must be some restriction on the types of programs to which a structuring theorem can apply. The appropriate class are the proper, non-blocking programs, where a proper program is, informally, one whose parallelism is limited and whose fork and join nodes have been used as intended, although not necessarily in a structured manner. Theorems 2 and 3 together comprise the structuring theorem. The proof is by an algorithm which, given a program P, determines if P is blocking and, if it is not, constructs an equivalent structured program.
C O N C L U S I O N
The structured programming revolution has very convincingly shown that program- ming is an inherently challenging task. Accordingly, a very disciplined methodology is required to bring the programming activity within the range of the limited human intellect. If all of the foregoing is important for sequential programs, then it is even more vital for programs with concurrency.
What we have done is to generalize the basic theorem of sequential structured pro- gramming to concurrent programming. Assuming that our generalization is the appro- priate one, it remains to use this theorem as the basis for a concurrent generalization of the sequential programming methodology. CL 3 4

226 A. TONI COHEN and LEON S. LEvY
.4cknowledqement--The authors wish to thank the referee for his careful and constructive comments.
R E F E R E N C E S
1. 13. S. Baker. An algorithm for structuring flowgraphs. J. Assoc. Comp,~t. Mach. 24. 98-120 (1977). 2. J. Bruno and K. Steiglitz. The expression of algorithms by charts. J. Assoc. Comput. Maeh. 19, 517-525
(1972). 3. O. H. Dahl, E. W. Dijkstra and C. A. R. Hoare, Str,~ctured Programming. Academic Press, New York
(1972). 4. S. R. Kosaraju. On structuring flowcharts, Proc. 8th Ann. Assoc. Comput. Mach. Syrup. on Theory o]"
Computation. pp. 92-100. 5. H. D. Mills, The new math of computer programming. Comm. Assoc. Comput. Mach. 18, 43-48 (1975). 6. Arvind and K. P. Gostelow, A computer capable of exchanging processors for time, Proc. IFIP Congr.
(1977). 7. Arvind, K. P. Gostetow and W. Plouffe. Indeterminacy, monitors and dataflow, 6th Ann. Syrup. on Op.
Syst. Principles (1977). 8. E. A. Ashcroft, Proving assertions about parallel programs. J. Comput. Syst. Sci. 10. 110-135 (1975). 9. J. L. Baer, D. P. Bovet and G. Estrin, Legality and other properties of graph models of parallel compu-
tations, J. Assoc. Comput. Mach. 17. 543-554 (1970). 10. A. T. Cohen, A unified treatment of graph theoretic models for parallel computation, Ph.D. thesis. Univ.
of Delaware (1976). 1 I. E. W. Dijkstra, Cooperating sequentiaL processes, in Programmin 9 Languages. pp. 44-112. Academic Press,
New York (1968). 12. J. R. Jump and P. S. Thiagarajan. On the interconnection of asynchronous control structures, J. Assoc.
Comput. Mach. 22, 596-612 (1975). 13. T. Kimura, An algebraic system for process structuring and interprocess communication, Proc. 8th ,,Inn.
Syrup. on Theory qf" Computing. pp. 92-100 (1976). 14. S. R. Kosaraju, Limitations of Dijkstra's semaphore primitives and Petri nets, Hopkins Comput. Research
Rept. 25, The Johns Hopkins Univ. (1973). 15. D. B. Lomet, Process structuring, synchronization and recovery using atomic actions, I.B.M. Research
Rept. RC6287 (11/76). 16. R. E. Miller, A comparison of some theoretical models of parallel computation. IEEE Trans. Comput.
22. 7t0-717 (1973). 17. S. Owicki and D. Gries, Verifying properties of parallel programs: an axiomatic approach, Comm. Assoc.
Comput. Mach. 19, 279-285 (1976). 18. L. Presser. MuLtiprogramming coordination. Comp. Sure. 7, 21-44 (1975}. 19. H. D. Mills. Mathematical foundations for structured programming. FSC 72-6012 (Fed. Syst. Div.. IBM
Corp.. Gaithersburg. MD)(1972). 20. C. Bohm and G. Jacopini, Flow diagrams, turing machines and languages with only two formation
rules, Comm. Assoc. Comput. Mach. 9. 366-371. 21. S. R. Kosaraju. Analysis of structured programs, J. Comput. Syst, Sci. 9, 232-255 (1974). 22. R. A. deMillo, S. C. Eisenstat and R. J. Lipton. Space-time trade-offs in structured programming. Proc.
1976 Conj. on lnf Sci. S)'st.. pp. 431-434. The Johns Hopkins Univ. (1976). 23. I. Gostelow. V. Cerf, G. Estrin and S. Volanski. Proper termination of flow-of-control in programs involv-
ing concurrent processes. Proc. Assoc. Comput. Maeh. 742-754 (1972). 24. R. M. Karp and R. E. Miller, Properties of a model for parallel computations: determinacy', termination,
queueing, Sianz J. Appl. Math. 14, 1390-1411 (1966). 25. J. B. Dennis, Modular asynchronous control structures for a high performance processor, Record, Proj.
MAC Cot~ on Concurrent Syst. and Parallel Computations, pp. 55-80. Assoc. Comput. Mach., N.Y. (1970). 26. E. W. Dijkstra. Hierarchical ordering of sequential processes, in Operatin 9 Systems Techniques, pp. 72-93.
Academic Press, New York (1972).
About the Author--A. To,~I COHEN received her M.S. and Ph.D. in Computer Science from the University of Delaware (1972 and 1976). Her undergraduate work was done at Mount Holyoke College (B.A. in Mathematics. 1959). Her research interests include parallel processing and programming methodology.
She is currently Assistant Professor of Computer Science at The Pennsylvania State University, assigned to the Delaware County Campus, a position she has held since 1976. Her previous employment was as a programmer/consultant at Lincoln University during the 1975-76 academic year.
About the Author--LEON S. LEvy received his degree in Computer and Information Science from the University of Pennsylvania in 1970. He is currently Associate Professor of Computer Science at the University of Delaware. His research interests include programming 'methodology and the foundations of Computer Science.
Prior to attending the University of Pennsylvania, Dr. Levy held several positions in industry: Senior staff engineer at Hughes Aircraft Company, Manager of Computers and Displays section at Aerospace Corporation, and Senior engineer at IBM.
Dr. Levy is the co-author of General Computer Science (Merrill & Co., 1976) and author of a forthcoming Wiley text on Discrete Structures.