structural joins: a primitive for efficient xml query pattern matching al khalifa et al., icde 2002
TRANSCRIPT

Structural Joins: A Primitive for Efficient XML
Query Pattern Matching
Al Khalifa et al., ICDE 2002
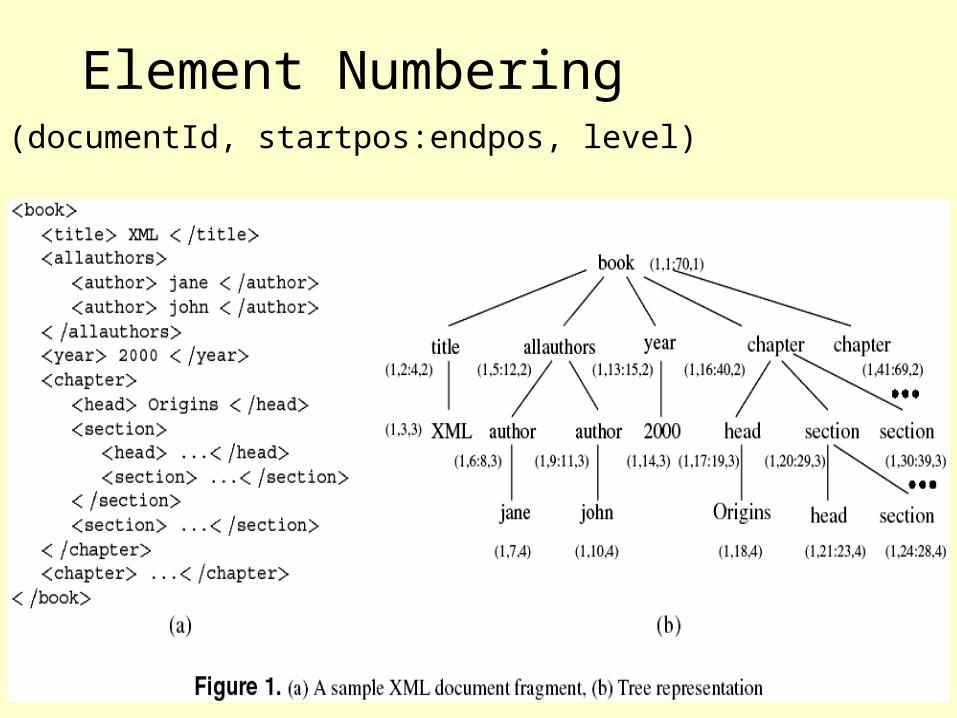
Element Numbering• (documentId, startpos:endpos, level)

Join Conditions Using Numbering
• (D1, S1:E1, L1) (D2, S2:E2, L2)• Ancestor-Descendant
– D1 = D2, S1 < S2 < E2 < E1
• Parent-Child– D1 = D2, S1 < S2 < E2 < E1, L1 + 1 = L2
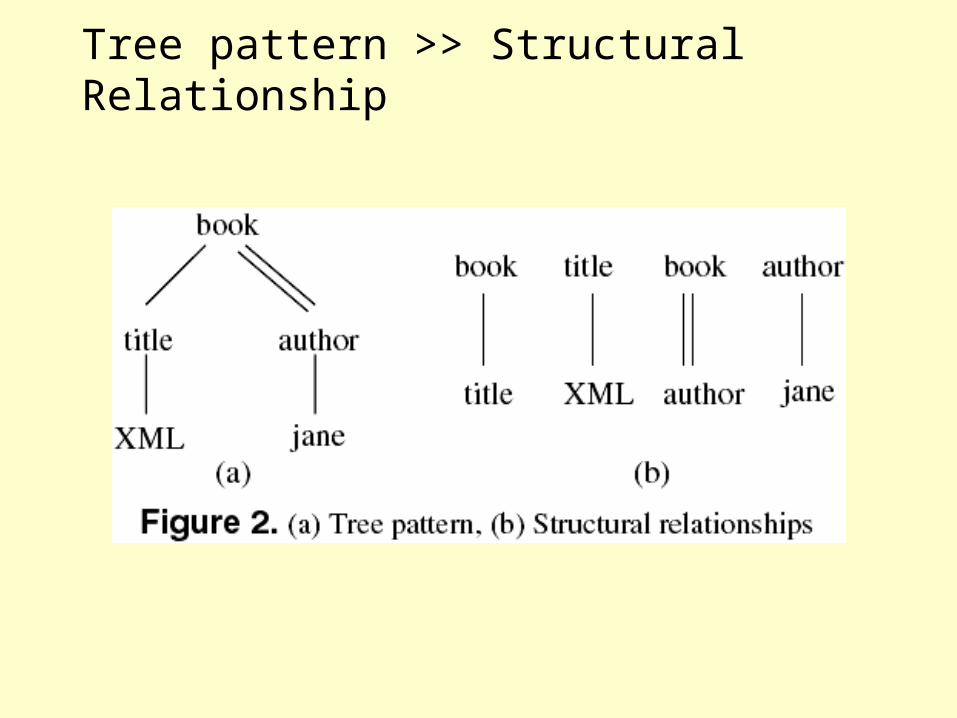
Tree pattern >> Structural Relationship

Structural Join
• Input– 2 element lists
• Ancestor and descendant; parent and child
– Sorted by start position
• Output– Pairs of ancestor/descendant or parent/child– Sorted by first or second element
• 2 algorithms presented– With and without stacks– Both with ordering by ancestor and by descendant
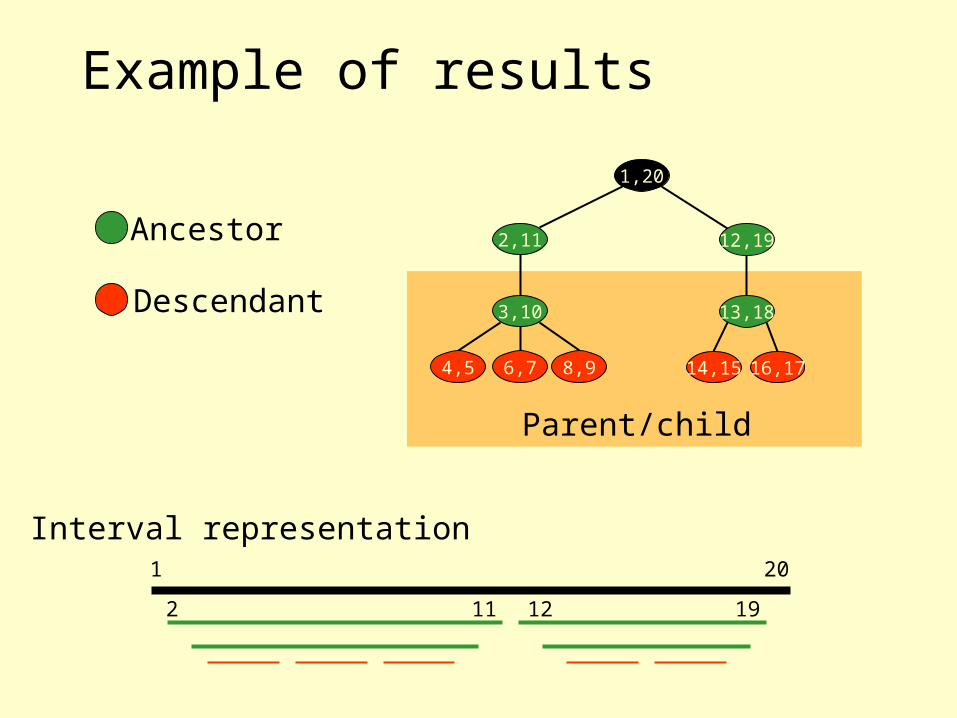
Example of results
2,11
3,10
4,5 6,7 8,9
1,20
Ancestor
Descendant
Parent/child
12,19
13,18
14,15 16,17
1 20
2 11 12 19
Interval representation

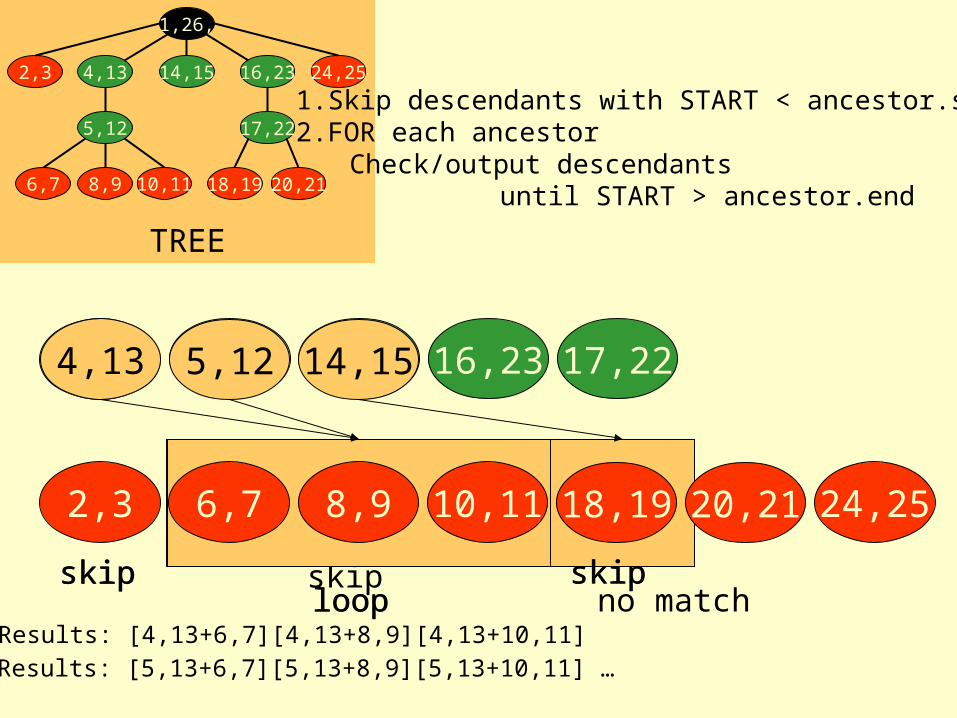
Tree Merge Joinordered by ancestor
4,13 14,155,12 16,23 17,2214,15
skipno match
skiploop
skip
5,124,13
skiploop
skip
TREE
4,13
5,12
6,7 8,9 10,11
1,26,
16,23
17,22
18,19 20,21
2,3 24,2514,15
6,7 8,9 10,11 18,19 20,212,3 24,25
Results: [4,13+6,7][4,13+8,9][4,13+10,11]
Results: [5,13+6,7][5,13+8,9][5,13+10,11] …
1.Skip descendants with START < ancestor.start2.FOR each ancestor
Check/output descendants until START > ancestor.end

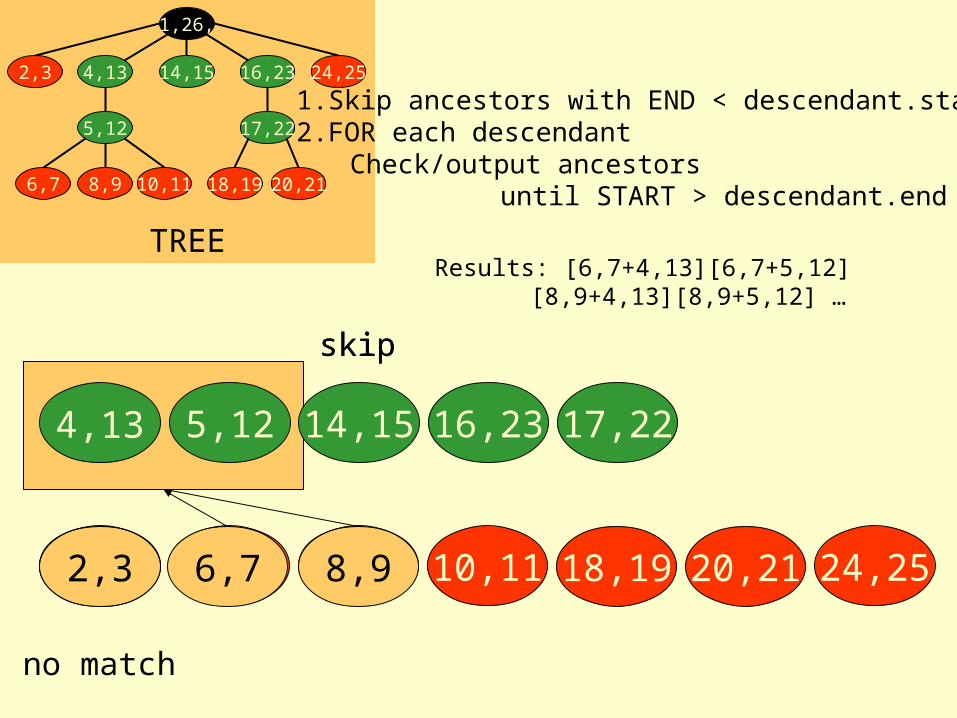
Tree Merge Joinordered by descendant
8,9
skip
8,92,32,3
no match
2,3 6,7
skip
6,7
4,13 14,155,12 16,23 17,22
10,11 18,19 20,21 24,25
TREE
4,13
5,12
6,7 8,9 10,11
1,26,
16,23
17,22
18,19 20,21
2,3 24,2514,15
Results: [6,7+4,13][6,7+5,12][8,9+4,13][8,9+5,12] …
1.Skip ancestors with END < descendant.start2.FOR each descendant
Check/output ancestors until START > descendant.end

Complexity
• For ancestor-descendant relationships:– Tree-Merge-Anc time complexity optimal
• May be quadratic, but proportional to output size
– But can have poor IO performance
• For parent-child relationships– Tree merge cost may still be quadratic, but
output size can only be linear
• Tree-Merge-Desc can be quadratic in output size

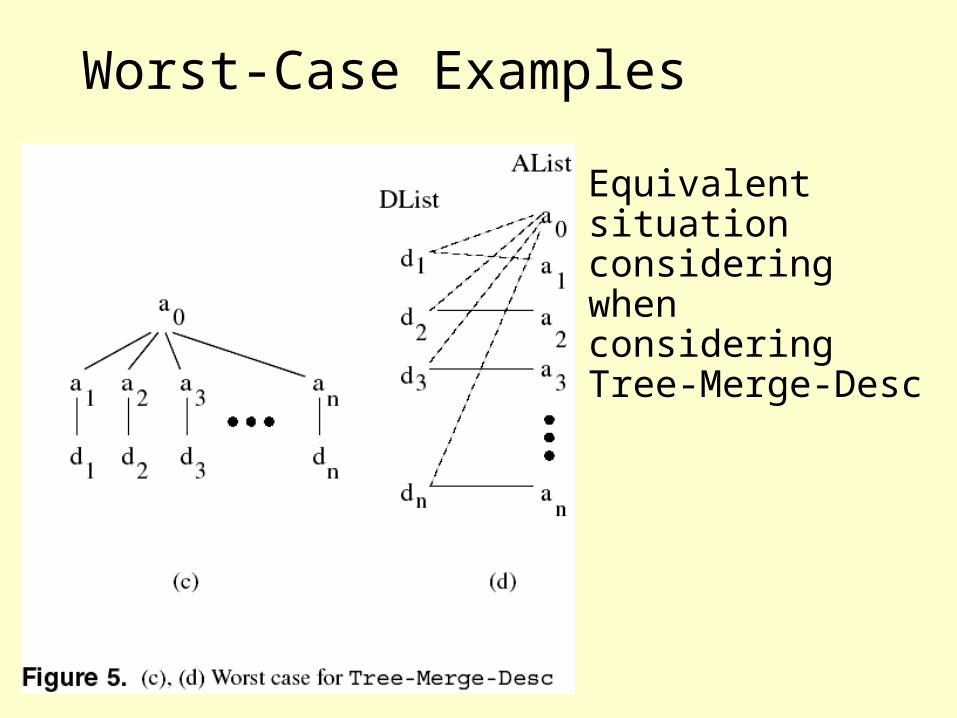
Worst-Case Examples
• a1 has the whole d list as descendants
• a2 has from d2 to d2n-1 as descendantsand so on
• Which means: practically quadratic performance (each ancestor has to check the whole descendant list)
Worst-Case Examples
• Equivalent situation considering when considering Tree-Merge-Desc

Stack-Tree Algorithm
• Basic idea: depth first traversal of XML tree – Linear time with stack size = depth of tree– All ancestor-descendant relationships
appear on stack during traversal– Traverse the lists only once
• Main problem: do not want to traverse the whole database, just nodes in A-list/D-list

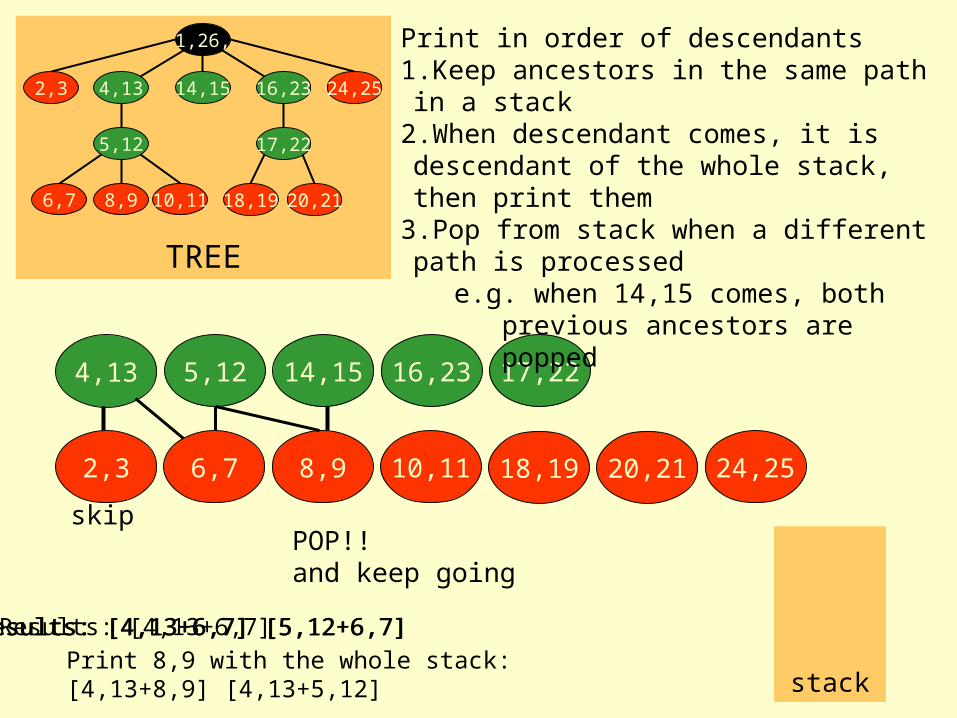
Stack-Tree-Desc
4,13 14,155,12 16,23 17,22
TREE
4,13
5,12
6,7 8,9 10,11
1,26,
16,23
17,22
18,19 20,21
2,3 24,2514,15
6,7 8,9 10,11 18,19 20,212,3 24,25
Print in order of descendants1.Keep ancestors in the same path in a stack
2.When descendant comes, it is descendant of the whole stack, then print them
3.Pop from stack when a different path is processed
e.g. when 14,15 comes, both previous ancestors are popped
stack
skip
Results: [4,13+6,7] 4,13
5,12
Results: [4,13+6,7] [5,12+6,7] 4,13Print 8,9 with the whole stack:[4,13+8,9] [4,13+5,12]
5,12
Results: [4,13+6,7] [5,12+6,7] 4,13
POP!!and keep going
stack

Example of Stack-Tree-Desc Execution

Stack-Tree-Anc
• Basic problem: results from a particular descendant cannot be output immediately– Later descendants may match earlier ancestor
• Solution: keep lists of matching descendant nodes with each stack node– Self-list
• Descendants that match this node• Add descendant node to self-lists of all matching
ancestor nodes
– Inherit list• Inherited from descendants already popped from stack,
to be output after self-list matches are output


Stack-Tree Analysis
• Stack-Tree-Desc– Time complexity (for anc-desc and par-
child)• O(|Alist| + |Dlist| + |OutputList|)
– IO Complexity (for anc-desc and par-child)• O(|Alist|/B + |Dlist|/B + |OutputList|/B)
– Where B is blocking factor
• Stack-Tree-Anc– Requires careful handling of lists– Complexity is same as for Desc case

Performance Study