sound shredding moustafa
TRANSCRIPT

Sound Shredding : Privacy Preserved Audio Sensing
Presenter: Moustafa Alzantot (UCLA)
Sumeet Kumar, et al.Carnegie Melon University

Introduction
Sound sensing can be very useful for context awareness. Identify user location and activities
Potential risks on user’s privacy Speech recognition Speaker identification
How to preserve user privacy without comprising the context awareness accuracy ?

Research Question This paper presents two approaches
for preserving user privacy without significantly decreasing the context recognition accuracy or consuming much battery in Encryption/Decryption.
Sound shredding Sound subsampling

MethodologyActivity context: the place where the activity takes place (e.g. restaurant for dinning)
Context identification process: Audio Data Collection:
35 sounds collected at 8KHz using nexus 4 phone. Feature Extraction:
Sliding window frame (40 ms window , 50%overlap) 12 MFCC features for every window.
Context Recognition: Experiments using both simple KNN, and SVM.

Methodology Sound Subsampling: collection part of raw data.
50% subsampling discarding one frame after every single frame is stored.
Subsampling results in a slight drop in context recognition accuracy.

Methodology Sound Shredding: randomize the audio
frames order in a sound snippet.

Results : Context Recognition Accuracy Collected 35 sound samples in different contexts
(faculty meeting, restaurant, walking, coffee shop)
80% of data for training, 20% for testing. Context recognition accuracy is slightly dropped.
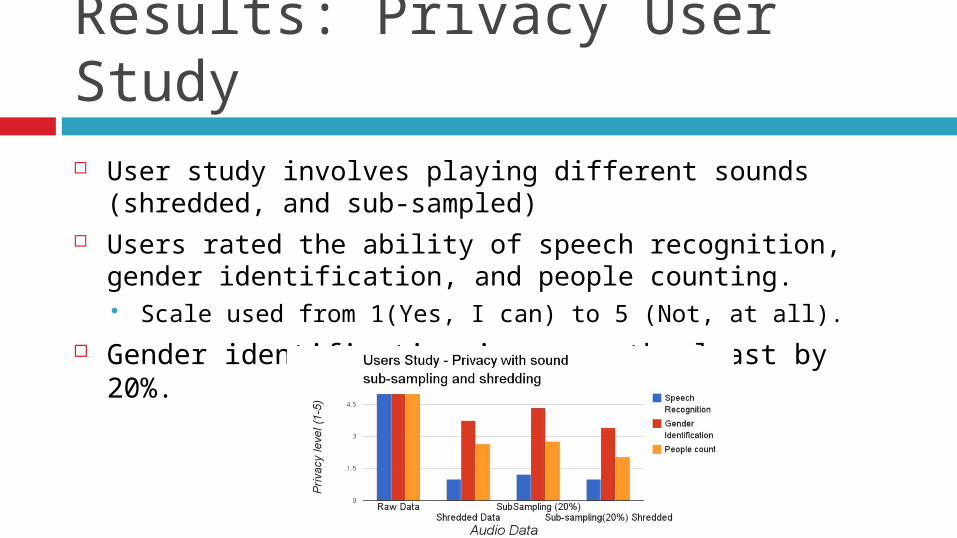
Results: Privacy User Study User study involves playing different sounds (shredded,
and sub-sampled) Users rated the ability of speech recognition, gender
identification, and people counting. Scale used from 1(Yes, I can) to 5 (Not, at all).
Gender identification improves the least by 20%.

Results: Computer Based Recognition

Results: Reconstructing based on frequency content
Number of (10ms) frames in 10 seconds audio snippet = 667 frames. Number of possible orderings = 667! (intractable to break shredding by
bruteforce).
Reconstructing by frequency content Greedly match the left and right edge of subsequent frames in
frequency domain.
Can reconstruct if audio is broken in 5 or less segments

Critique of work(1slide) Sound subsampling alone is not sufficient for
privacy preserving (at least for people counting, and gender identification).
Shredding can be attacked (As they mentioned at the end of paper)
Should compare against other methods (like filtering or perturbing the speech frequency range in the audio collected)