slide 2 collecting, storing and analyzing big data
TRANSCRIPT


Agenda
Collecting → Storing → Processing → Analyzing → Learning → Reacting
Data engineering process: 3 tasks
1. Collectinga. Conceptsb. Technology
2. Storinga. Big Data Storage Conceptsb. Big Data Storage Technology
3. Processinga. Big Data Processing Conceptsb. Big Data Processing Technology
Data Science/Machine Learning process: 3 tasks
4) Analyzing → 5) Learning → 5) Reacting

Big Data Analytics Lifecycle
Collecting
Storing
Processing

(Collecting) → Storing → Processing → Analyzing → Learning → Reacting

Collecting

Collecting tools
Batch collecting: Apache Sqoop ( from DBMS to Apache Hadoop)
Real-time collecting: RFX-tracking (from stream data to Apache Kafka)

Collecting → (Storing) → Processing → Analyzing → Learning → Reacting

Storing Concepts
Clusters
File Systems and Distributed File Systems
NoSQL
Sharding
Replication
Sharding and Replication
CAP Theorem
ACID
BASE

Clusters

NoSQL

Sharding


Replication (Master-Slave)

Replication (Peer-to-Peer)
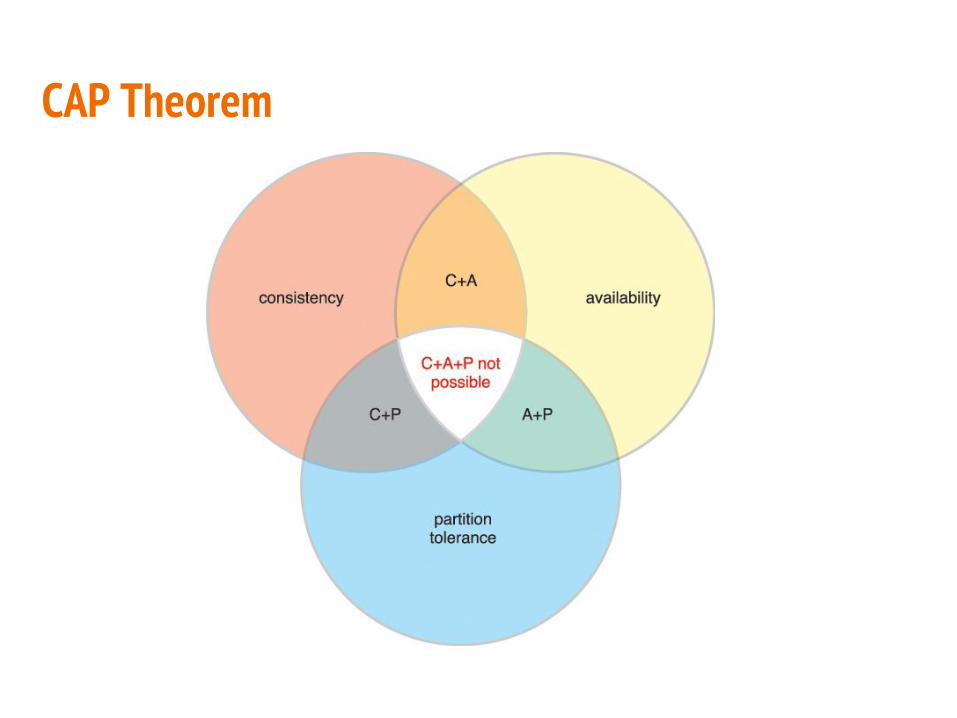
CAP Theorem


Collecting → Storing → (Processing) → Analyzing → Learning → Reacting

Processing concepts
Parallel Data Processing
Distributed Data Processing
Hadoop
Processing Workloads
Cluster
Processing in Batch Mode
Processing in Realtime Mode

Parallel Data Processing
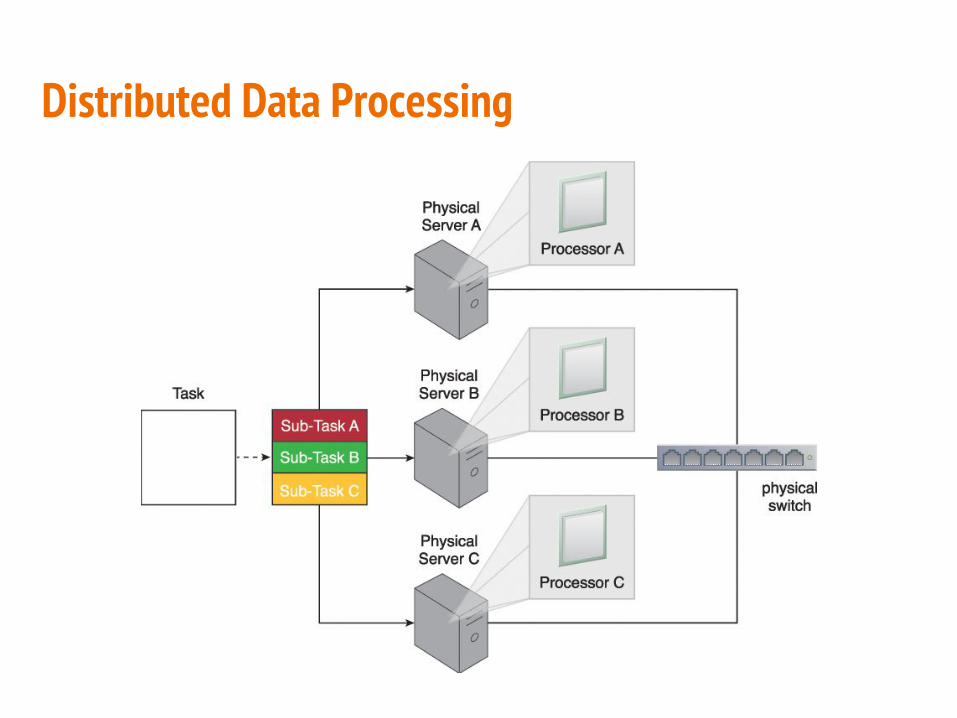
Distributed Data Processing

Hadoop
Hadoop is a versatile framework that provides both processing and storage capabilities

Batch processing (offline processing)

Transactional processing

Cluster

Map and Reduce Tasks

Processing in Realtime Mode

Tools

When standard relational database (Oracle,MySQL, ...) is not good enough
the “analytic system” MySQL database from a startup, tracking all actions in mobile games: iOS, Android, ...

3 common problems in Big Data System
1. Size: the volume of the datasets is a critical factor.2. Complexity: the structure, behaviour and permutations of the datasets is
a critical factor.3. Technologies: the tools and techniques which are used to process a
sizable or complex dataset is a critical factor.

What is Apache Phoenix ?
Apache Phoenix is a SQL skin over HBase. It means scaling Phoenix just like scale-up and scale-out the Hbase

PhoenixSQL Engine

Interesting features of Apache Phoenix ● Embedded JDBC driver implements the majority of java.sql interfaces, including
the metadata APIs.● Allows columns to be modeled as a multi-part row key or key/value cells.● Full query support with predicate push down and optimal scan key formation.● DDL support: CREATE TABLE, DROP TABLE, and ALTER TABLE for
adding/removing columns.● Versioned schema repository. Snapshot queries use the schema that was in
place when data was written.● DML support: UPSERT VALUES for row-by-row insertion, UPSERT SELECT for
mass data transfer between the same or different tables, and DELETE for deleting rows.
● Limited transaction support through client-side batching.● Single table only - no joins yet and secondary indexes are a work in progress.● Follows ANSI SQL standards whenever possible● Requires HBase v 0.94.2 or above ● 100% Java


the Phoenix table schema

Setting JDBC Phoenix Driver

Phoenix and SQL tool in Eclipse 4

Phoenix vs Hive (running over HDFS and HBase)
http://phoenix.apache.org/performance.html
Performance: Phoenix vs Hive

Readings
1. https://medium.baqend.com/real-time-stream-processors-a-survey-and-decision-guidance-6d248f692056#.s00ac9xtu
2. https://medium.baqend.com/nosql-databases-a-survey-and-decision-guidance-ea7823a822d#.pn63unwx6
3. https://www.infoq.com/articles/apache-kafka4. https://docs.google.com/document/d/1ZtEhLw3lrQSeNWVEJkKLLy8B8t9zA
0MGRqmCOV3_hsA/edit?usp=sharing