semeval - aspect based sentiment analysis
DESCRIPTION
Explains the Aspect Based Sentiment Analysis task of SemEval 2014 and the top scoring approaches.TRANSCRIPT

SemEval 2014
Aspect Based Sentiment Analysis - Task Overview
Aditya Joshi, IIIT Hyderabad
With Sandeep, Sai Praneeth, Satarupa

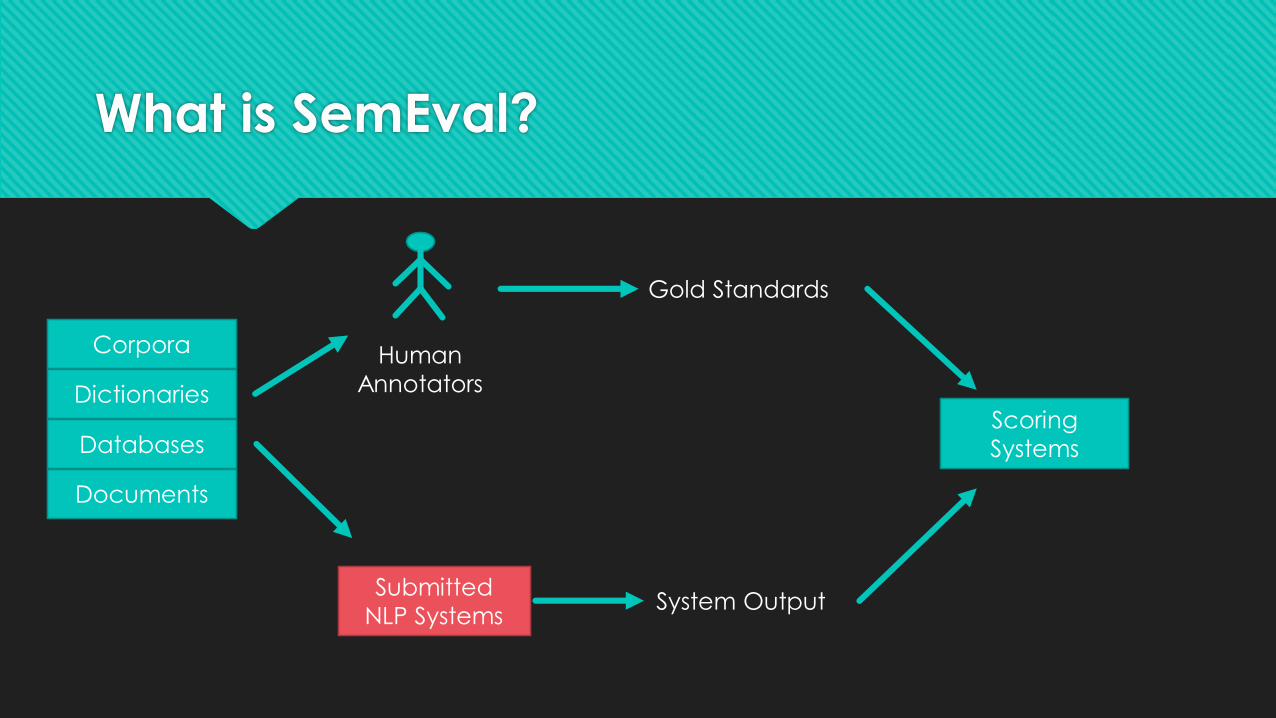
What is SemEval?
Ongoing series of evaluations of computational semantic analysis systems
Evolved from the SensEval word sense evaluation series.
Evaluations are intended to explore the nature of meaning in language
What is SemEval?
Corpora
Dictionaries
Databases
Documents
Human
Annotators
Submitted
NLP Systems
Gold Standards
System Output
Scoring
Systems

SemEval 2014
1. Evaluation of Compositional Distributional Semantic Models on Full Sentences through Semantic Relatedness and Entailment
2. Grammar Induction for Spoken Dialogue Systems
3. Cross-Level Semantic Similarity
4. Aspect Based Sentiment Analysis
5. L2 Writing Assistant
6. Supervised Semantic Parsing of Spatial Robot Commands
7. Analysis of Clinical Text
8. Broad-Coverage Semantic Dependency Parsing
9. Sentiment Analysis in Twitter
10. Multilingual Semantic Textual Similarity

Aspect Based Sentiment Analysis
Task 4 (ABSA)
Subtask 1
Aspect term extraction
Subtask 2
Aspect term polarity
Subtask 3
Aspect category detection
Subtask 4
Aspect category polarity
"I liked the service and
the staff, but not the desserts”
{service: positive, staff:
positive, desserts: negative}
{service: positive, food: negative}{service quality, food}

Approaches

Aspect Term Extraction
• Improvement over Hu and Liu 2004
• Dependency labels (amod, nsubj) are used to filter
• Also use seed lexicons and forbidden words
Noun Extraction Based Approaches
• Trained CRF(DLIREC)/Markov Tagger(NRC) along with manually created Dependency Rules
Labelling Approaches
• Assign labels to each word in the review.
• Features (IITP) : local context, POS, stop words, length
• Word2Vec based approach(Blinov)
Classification Based Approaches

Polarity Detection
• DCU (Dublin) used MPQA (Wilson 2005), SentiWordNet, General Inquirer, Bing Liu (2004). Normalized the lexicon scores.
• Trained SVM Based on individual lexicon scores as well as POS Tags
Classification Approach
• iTac (Breman) used Stanford Sentiment Tree.
• Traverse parse tree from aspect towards root and take the first non-neutral label.
• Accuracy of 62% on Restaurant dataset and 52% on Laptops.
Sentiment Tree
• A window of words around aspect term (or dependent tokens) are looked up in the SentiWordNet. Teams expanded the lexicon using Wordnet.
Simple Lexicon Lookup

Top System – NRC Canada
Compiled a large corpora of reviews (unlabeled).
These lexicons will be used in the further stages.
Gathered Amazon and Yelp Ratings. Learnt the word sentiments considering 1-2 star
reviews as negatives and 4-5 star as positives.
score(w) = PMI (w, +) – PMI (w, -)
PMI (w, +) = 𝑙𝑜𝑔2𝑓𝑟𝑒𝑞 𝑤,+ ∗𝑁
𝑓𝑟𝑒𝑞 𝑤 ∗𝑓𝑟𝑒𝑞 (+)(pointwise mutual information)
where N = total tokens in corpus, freq(w) = frequency of term w in the corpus, freq (w, +) =
frequency of w in positive reviews. freq(+) = total number of tokens in positive reviews.

Top System – NRC Canada
Developed in-house entity tagging system.
Cleaned tokenized sentences are tagged with two possible tags – O : outside, T : aspect
term. T can be a phrase upto 5 tokens. Used a semi-Markov Tagger (Sarawagi and Cohen,
2004).
Emission Features : couple the tag sequence y to input w.
Transition Features : couple the tags with tags. If current tag is yj , transition tamplates are
short n-grams of tag identities yj; yj-1; yj-2
The approach was coupled with a simpler structured perceptron. However this didn’t
affect the results.
Produced best results – 80.19% F-Score for Restaurants, 68.57% for laptops.

Top System – NRC Canada
For Aspect Term Polarity, trained a linear SVM. Features:-
Surface Features : unigrams, bigrams extracted from a term
Lexicon Features : number of positive and negative tokens, sum of token scores, max score
Parse Features : POS N-grams, context target bigrams
For category classification, used 5 binary one-vs-all SVM classifiers. Parameter was
optimized after cross-validation across all categories individually. Obtained F-score of 88%.

Top System – DCU Dublin
Attained top position in aspect term polarity detection (subtask 2).
Employed four lexicons :- MPQA (Wilson 2005), SentiWordNet, General Inquirer, Bing Liu’s
Lexicon. Normalized all the scores in range [-1, 1]
For a word, these four scores are summed to arrive at a score in range [-4, 4]
Domain specific words were manually added. E.g. mouthwatering, watery, better-
configured.
As aspect term governs the sentiment as well, it’s distance to the sentiment term is
considered in terms of (i) Token Distance, (ii) Discourse Chunk Distance (Tofiloski 2009), and
(iii) Dependency Path Distance.
Trained an SVM with bag of n-gram features. Parameters are decided in a 5-fold cross
validation on the training data. Extra features include distance weighted sum of positive,
negative scores. Test accuracy was 81%.

SemEval 2015
Opinion Target (may be review entity or the aspect term)
Aspect Category (Prices, Food, Service, Ambience, Misc)
Sentiment Polarity (+, -, neutral, conflict)
Offsets (begin and end) of opinion target.
http://alt.qcri.org/semeval2015/task12/

SemEval 2014 Proceedings are available at : http://alt.qcri.org/semeval2014/cdrom/