sébas&en coue-e stas&ques cm1 m1 se, bgs, vvt, … · test unilatéral et test bilatéral...
TRANSCRIPT
Sébas&enCoue-e
Sta&s&quesCM1M1SE,BGS,VVT,AGES

Testssta&s&quessimples,univariésoubivariés
Sta&s&quesmul&variées
ANOVA2facteurs
ANCOVAMANOVA
ACPDFAAFC
Séance1Séance2
Séance3 Séance4
Révision:Qu’estcequ’untest Testsunivariés testsbivariés
Mul&variéeexploratoire:ACP
2wANOVAANCOVAMANOVA
Clustering:DFA AFC
t(v) = z0
z²1 + z²2 + … + z²v
v √

Statistiques inférentielles et tests simples
CM1
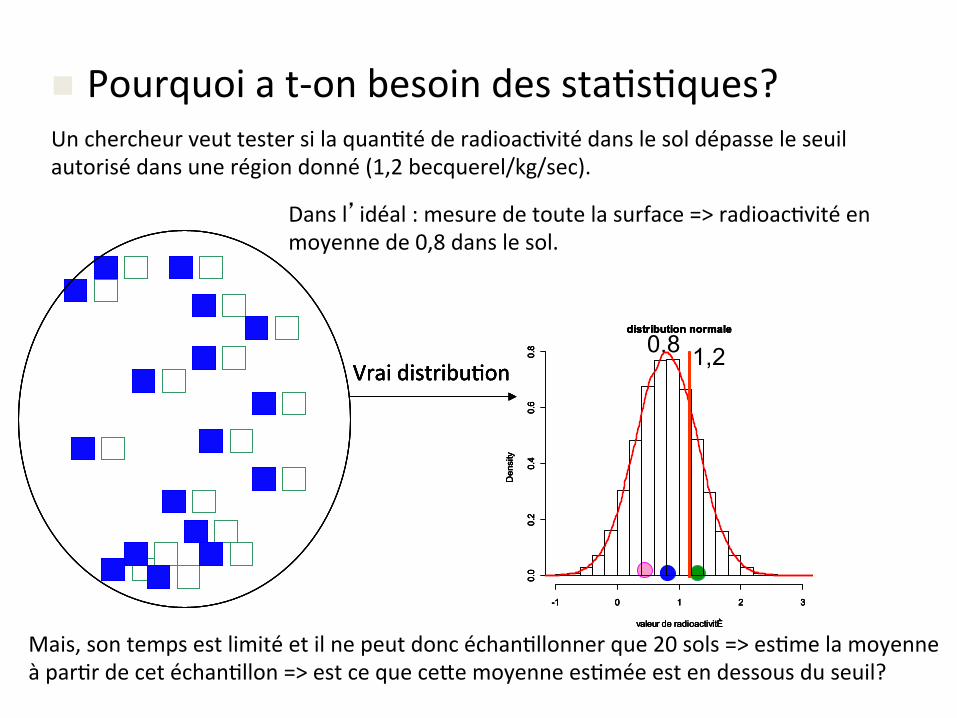
n Pourquoiat-onbesoindessta&s&ques?Unchercheurveuttestersilaquan&téderadioac&vitédanslesoldépasseleseuilautorisédansunerégiondonné(1,2becquerel/kg/sec).
Dansl’idéal:mesuredetoutelasurface=>radioac&vitéenmoyennede0,8danslesol.
distribution normale
valeur de radioactivitÈ
Den
sity
-1 0 1 2 3
0.0
0.2
0.4
0.6
0.8
Vraidistribu&on0.8
Mais,sontempsestlimitéetilnepeutdoncéchan&llonnerque20sols=>es&melamoyenneàpar&rdecetéchan&llon=>estcequece-emoyennees&méeestendessousduseuil?
1,2 distribution normale
valeur de radioactivitÈ
Den
sity
-1 0 1 2 3
0.0
0.2
0.4
0.6
0.8
Vraidistribu&on
distribution normale
valeur de radioactivitÈ
Den
sity
-1 0 1 2 3
0.0
0.2
0.4
0.6
0.8
Vraidistribu&on
distribution normale
valeur de radioactivitÈ
Den
sity
-1 0 1 2 3
0.0
0.2
0.4
0.6
0.8
Vraidistribu&on

Lesparamètresdesdistribu&ons(moyenne,variance,médiane,etc.)sontes&mésàpar&rdedonnéesrécoltéespourdeséchan&llonsaléatoiresreprésentantlespopula&onssta&s&ques.Autrementdit,unéchan&llonaléatoirepermetd’obtenirunees&ma&onx,Var,…desparamètresvrais,μ,σ²…delapopula&onsta&s&que.
Population statistique, N, µ, σ²
1
Echantillon 1, n1, x1, Var1
k Echantillon k, nk, xk, Vark
Echantillon 2, n2, x2, Var2 2
n Pourquoiat-onbesoindessta&s&ques?

n Pourquoiat-onbesoindessta&s&ques?
Carontravaillegénéralementàpar&rd’unéchan&llonetonneconnaitpaslesparamètresdelapopula&on.Onessayedoncde&reruneconclusionsurlapopula&onàpar&rdecetéchan&llon…Echan&llon=>approxima&on!
=>Lestestssta&s&quesperme-entde&rerdesconclusionsàpar&rd’unéchan&llonsachantqu’ilyaunrisqued’erreur.
Exempleprécédent=>plusl’échan&llonestgrandetplusl’es&ma&ondesparamètresestprécise

n Choixd’hypothèses
Ils’agitdefaireunchoixentreplusieurshypothèses,toutenassociantcechoixavecdesrisquesd’erreur.•Lechercheurestappeléàprendredesdécisionssurlabasederésultatsexpérimentaux,enétantconscientqu’ilyaunrisqued’erreurliéàl’incer&tudedesobserva&onsoudesrésultatsexpérimentaux.Avantdeprendreunetelledécision,iltesteraunehypothèsesta&s&quecorrespondantàsonproblèmebiologique•L’issuedeceteststa&s&queindiqueraquelledécisionilconvientdeprendre.
Lestestssta&s&quessontu&liséslorsqu’onchercheàsavoirsiunecertainehypothèserela&veàlapopula&onestcompa&bleavecl’informa&ondisponibleàpar&rdel’échan&llon.
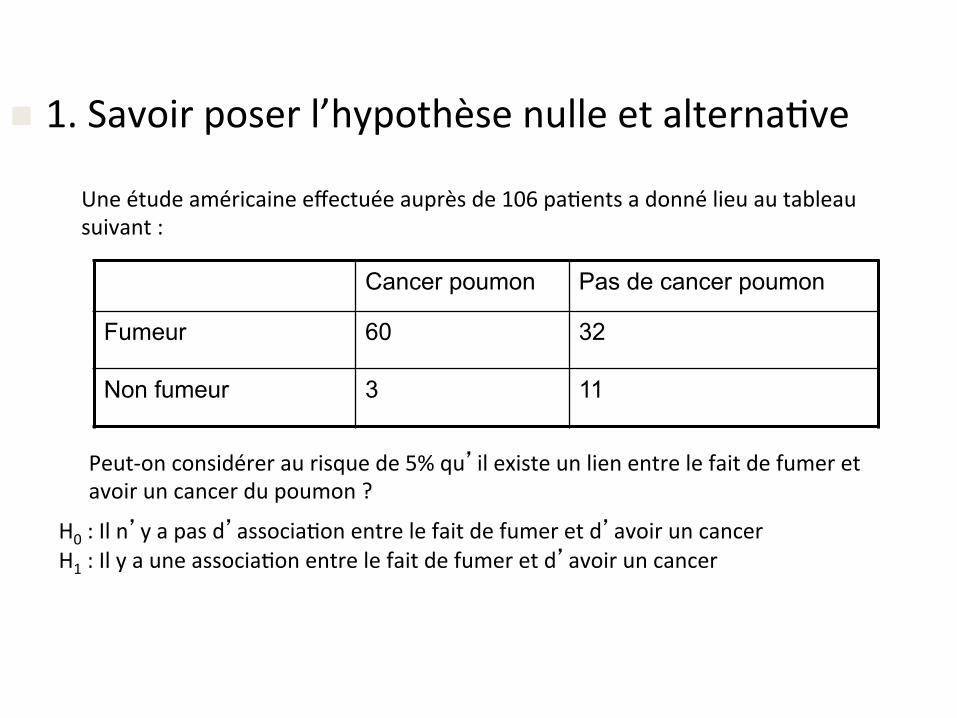
n 1.Savoirposerl’hypothèsenulleetalterna&ve
Uneétudeaméricaineeffectuéeauprèsde106pa&entsadonnélieuautableausuivant:
Peut-onconsidéreraurisquede5%qu’ilexisteunlienentrelefaitdefumeretavoiruncancerdupoumon?
Cancer poumon Pas de cancer poumon
Fumeur 60 32
Non fumeur 3 11
H0:Iln’yapasd’associa&onentrelefaitdefumeretd’avoiruncancerH1:Ilyauneassocia&onentrelefaitdefumeretd’avoiruncancer

n 1.Savoirposerl’hypothèsenulleetalterna&ve
Danstouslescas,l’hypothèsetestée,ouhypothèseprincipale,ouhypothèsenulleH0,formulel’absencededifférenceoul’absencederela&on(lavaria&onestdueauhasard):c’estellequel’onrejeBeraouacceptera.

n Plusieurshypothèsesalterna&vespossibles:testunilatéralettestbilatéral
H1:Ilyauneassocia&onposi&veentrelefaitdefumeretd’avoiruncancer(plusjefumeplusj’aidechanced’avoiruncancer)H1:Ilyauneassocia&onnéga&veentrelefaitdefumeretd’avoiruncancer(moinsjefumeetplusj’aidechanced’avoiruncancer)
H0:Iln’yapasd’associa&onentrelefaitdefumeretd’avoiruncancerH1:Ilyauneassocia&onentrelefaitdefumeretd’avoiruncancer
Testunilatéralettestbilatéral:c’estlaformula&ondel’hypothèsecontraire,H1,quidéterminesiuntestestunilatéraloubilatéral.•Danslecasdelacomparaisondedeuxgroupesparexemple,onréaliseuntestbilatéral(“two-tailedtest”)lorsqu’onchercheunedifférenceouliaisonsanssepréoccuperdusens.•Onréaliseplutôtuntestunilatéral(“one-tailedtest”)lorsquenotrehypothèsebiologiquenes’intéressequ’auxdifférencesouauxrela&onsayantunsignedonné.
LechoixdeH1doitsefaireAVANTl’expérience!!!
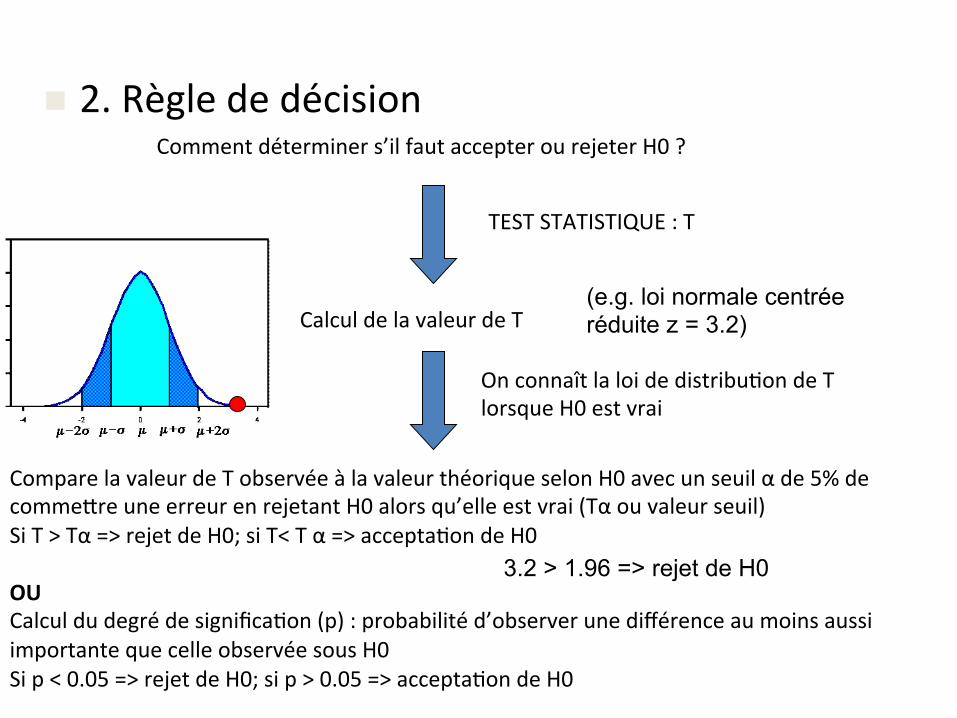
n 2.RèglededécisionCommentdéterminers’ilfautaccepterourejeterH0?
TESTSTATISTIQUE:T
CalculdelavaleurdeT
Onconnaîtlaloidedistribu&ondeTlorsqueH0estvrai
ComparelavaleurdeTobservéeàlavaleurthéoriqueselonH0avecunseuilαde5%decomme-reuneerreurenrejetantH0alorsqu’elleestvrai(Tαouvaleurseuil)SiT>Tα=>rejetdeH0;siT<Tα=>accepta&ondeH0OUCalculdudegrédesignifica&on(p):probabilitéd’observerunedifférenceaumoinsaussiimportantequecelleobservéesousH0Sip<0.05=>rejetdeH0;sip>0.05=>accepta&ondeH0
(e.g. loi normale centrée réduite z = 3.2)
3.2 > 1.96 => rejet de H0
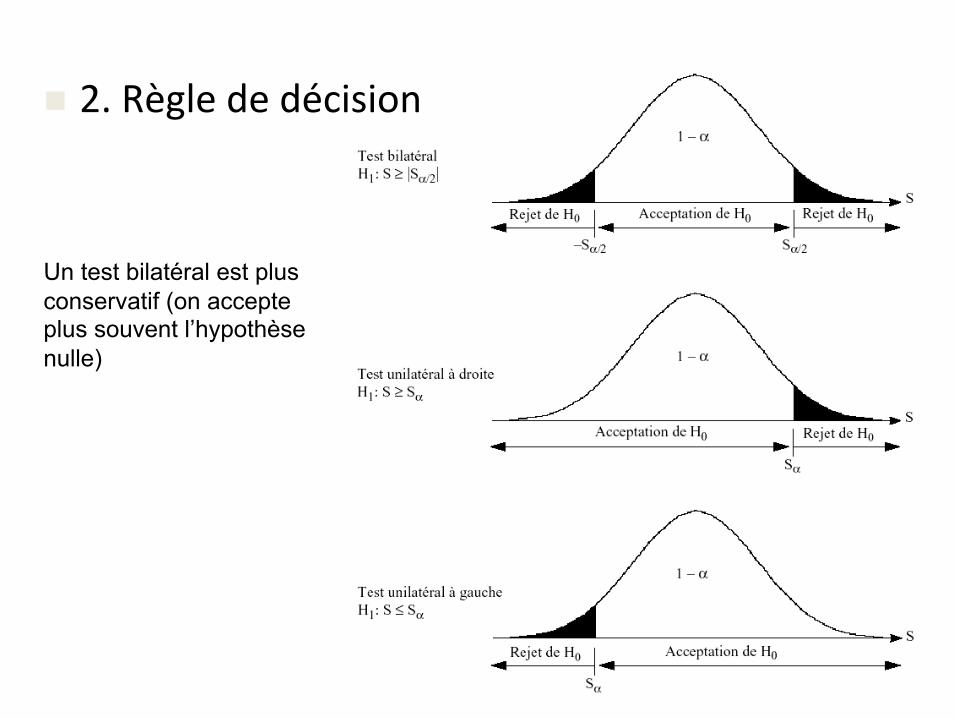
n 2.Règlededécision
Un test bilatéral est plus conservatif (on accepte plus souvent l’hypothèse nulle)
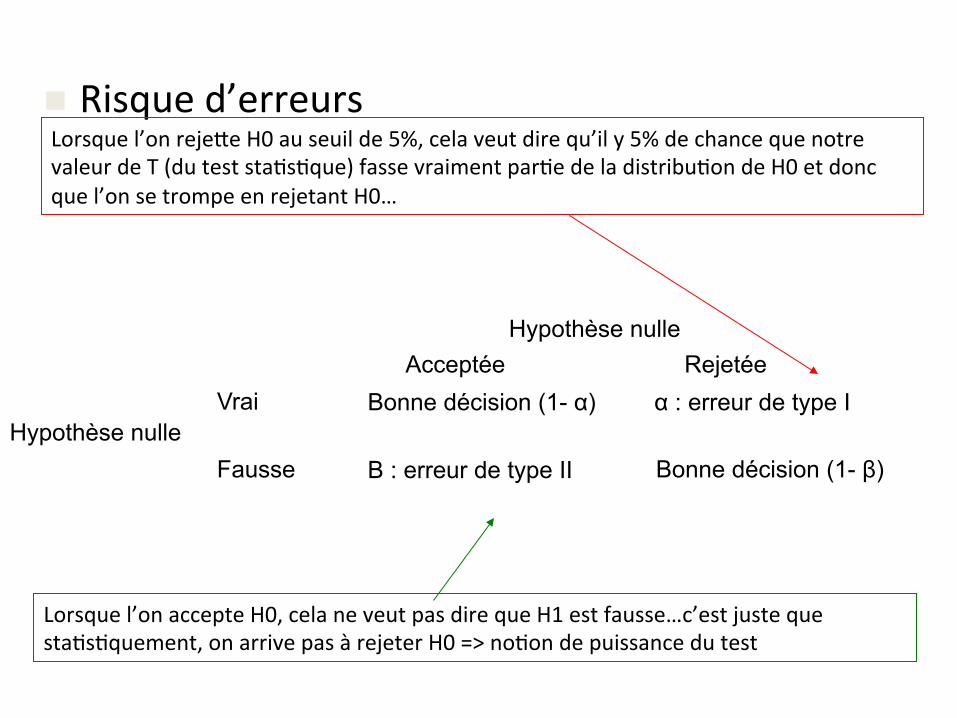
n Risqued’erreurs
Hypothèse nulle
Hypothèse nulle Vrai
Fausse
Acceptée Rejetée Bonne décision (1- α)
Bonne décision (1- β)
Lorsquel’onaccepteH0,celaneveutpasdirequeH1estfausse…c’estjustequesta&s&quement,onarrivepasàrejeterH0=>no&ondepuissancedutest
Β : erreur de type II
Lorsquel’onreje-eH0auseuilde5%,celaveutdirequ’ily5%dechancequenotrevaleurdeT(duteststa&s&que)fassevraimentpar&edeladistribu&ondeH0etdoncquel’onsetrompeenrejetantH0…
α : erreur de type I

• Les questions à se poser pour identifier le bon test statistique
1. Iden&fierlesvariables
=>Est-cequelesvariablessontqualita&vesouquan&ta&ves?=>Est-cequejepeuxexpliquerunevariableparuneouplusieursautres?(unevariableàexpliquerouvariabledépendanteetuneouplusieursvariablesexplica&vesouvariableindépendante)
2.Essayezdereprésentergraphiquementlejeudedonnées
=>Deuxvariablesqualita&ves:camemberts,tableauxdecon&ngence…=>Chi-deux,testdeFisher=>Deuxvariablesquan&ta&ves:nuagedepoints….=>régressioncorréla&on=>Unevariablequan&ta&veàexpliquerplusaumoinsunevariablequalita&ve:boxplot,moyenne….=>analysedevariance,régressionmul&ple…

3.Unefoisletestchoisi,vérifiezlescondi&onsd’applica&ondutest
-Indépendancedesdonnées(no&ondedonnéesappariés,ouderépé&&on) -Loidedistribu&ondesdonnées(loinormaleouautre?oupasdedistribu&onévidente)=>testsparamétriquesounonparamétriques
+autreshypothèsesplusspécifiquesàchaquetestserontvusplustard….
n Lesques&onsàseposerpouriden&fierlebonteststa&s&que
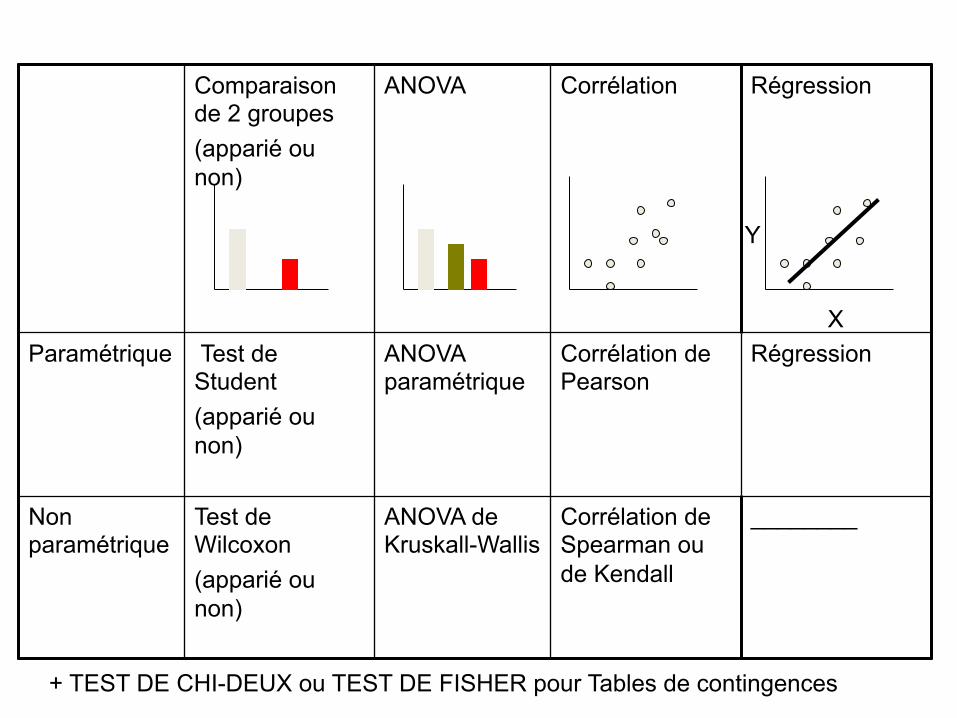
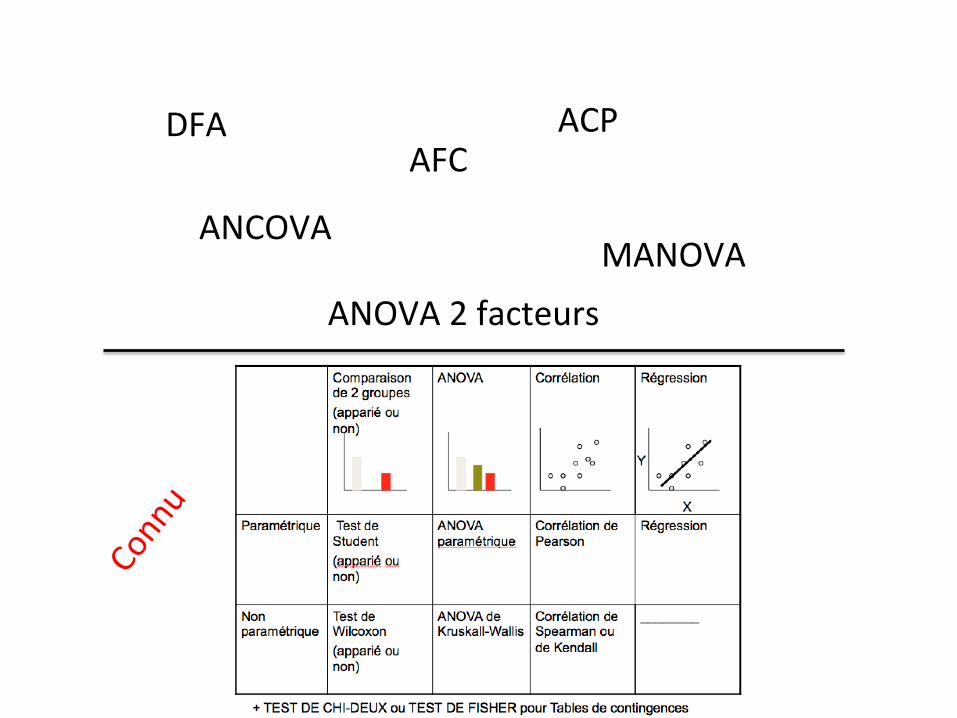
Comparaison de 2 groupes (apparié ou non)
ANOVA Corrélation Régression
Paramétrique Test de Student (apparié ou non)
ANOVA paramétrique
Corrélation de Pearson
Régression
Non paramétrique
Test de Wilcoxon (apparié ou non)
ANOVA de Kruskall-Wallis
Corrélation de Spearman ou de Kendall
________
X
Y
+ TEST DE CHI-DEUX ou TEST DE FISHER pour Tables de contingences

• Différences entre un test paramétrique et non paramétrique
Ø Untestparamétriquerequiertunmodèleàfortescontraintes(normalitédesdistribu&ons,égalitédesvariances)pourlequellesmesuresdoiventavoirétéréaliséesdansuneéchelleaumoinsd'intervalle.Ceshypothèsessontd'autantplusdifficilesàvérifierqueleseffec&fsétudiéssontplusréduits=>sieffec&fréduit,ilestplusprudentd’u&liseruntestnon-paramétrique
Ø Untestnonparamétriqueestuntestdontlemodèleneprécisepaslescondi&onsquedoiventremplirlesparamètresdelapopula&ondontaétéextraitl'échan&llon.Celan’enlèvepaslebesoind’unebonnestratégied’échan&llonnage(individusindépendantsetprisaléatoirement)
n Différencesentreuntestnonappariéetapparié
Ø Touslestestspartentduprincipequelesobserva&onssontindépendantes(individusprisaléatoirementdanslapopula&on)
Ø Danscertainscas,lesobserva&onssontfaitessurlemêmeindividuousurdesindividusquinesontpasprisaléatoirement(mêmefamille,mêmeorigineetc…)=>ceBeindépendancedoitêtrepriseencomptepardestestsappariés

n Exemples:Exo3:unchercheursouhaitepouvoiriden&fierlesexedechacalàpar&rdemachoireretrouvéedanslanature.Afindesavoirsicelaestpossible,ilmesurelalongueurdelamâchoireinférieure(enmm)de10chacalsmâleset10chacalsfemellesconservéesauBri&shMuseum.•mâles120107110116114111113117114112•femelles110111107108110105107106111111
Exo4
Exo5:deséchan?llonsdecrèmeprélevésdans10laiteriessontdivisésendeuxpar?es.L’uneestenvoyéeaulaboratoire1etl’autreaulaboratoire2pourencompterlesbactéries.Résultats(103bact/ml):lab1:11.7,12.1,13.3,15.1,15.9,15.3,11.9,16.2,15.1,13.8lab2:10.9,11.9,13.4,15.4,14.8,14.8,12.3,15.0,14.2,13.2

Exo7:Unchercheursouhaitetesterl’effetdedifférentesconcentra&onettypedesucresurlacroissance,(mesuréeparlalongueurenmm)depe&tspois.Pourchaquetraitement,lechercheuraprisauhasard10grainesdepe&tspois.
control 2% glucose 2% fructose 1%glucose+1%fructose2% sucrose75 57 58 58 6267 58 61 59 6670 60 56 58 6575 59 58 61 6365 62 57 57 6471 60 56 56 6267 60 61 58 6567 57 60 57 6576 59 57 57 6268 61 58 59 67
Exo8:onamesurélahauteur(enmètres)de12arbresselondeuxméthodesdifférentes,avantetaprèslacoupedel’arbre.debout=20.4,25.4,25.6,25.6,26.6,28.6,28.7,29.0,29.8,30.5,30.9,31.1aba-u=21.7,26.3,26.8,28.1,26.2,27.3,29.5,32.0,30.9,32.3,32.3,31.7

Unseuléchan&llon=>testdeconformitéàunemoyennethéorique
Exemple:contrôledesteneursennitratesde30eauxdesourced’unerégiondonnée(mgNO3/l),norme=25mg/l37;21;0;19;1;5;0;13;1;20;34;19;17;74;28;34;61;15;35;55;28;10;69;48;63;8;18;34;18;90Est-cequeletauxdenitratesestconformeàlanorme?
ns
mx
ns
mxt
xx
obs 21
−=
−= Degrédeliberté=n-1
n Testdestudent
Histogram of distribution
distribution
Den
sity
-4 -2 0 2 4
0.0
0.2
0.4
-4 -2 0 2 4
0.0
0.4
0.8
distribution
pt(d
istri
butio
n, d
dl)
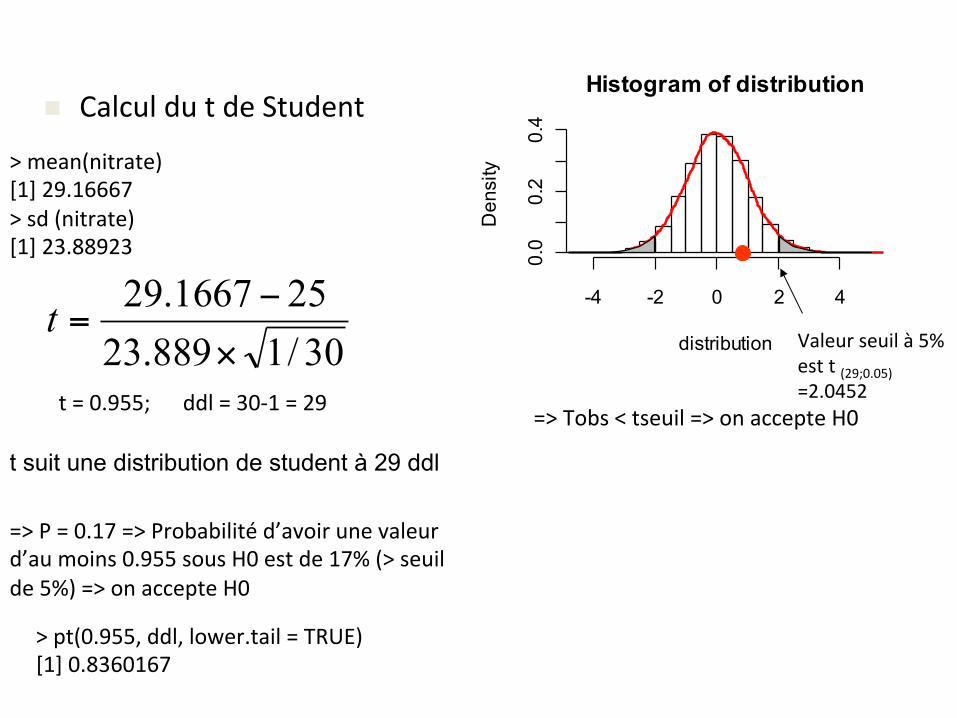
n CalculdutdeStudent
>mean(nitrate)[1]29.16667>sd(nitrate)[1]23.88923
30/1889.23251667.29
×
−=t
t=0.955;ddl=30-1=29
t suit une distribution de student à 29 ddl
=>P=0.17=>Probabilitéd’avoirunevaleurd’aumoins0.955sousH0estde17%(>seuilde5%)=>onaccepteH0
Valeurseuilà5%estt(29;0.05)=2.0452
=>Tobs<tseuil=>onaccepteH0
>pt(0.955,ddl,lower.tail=TRUE)[1]0.8360167
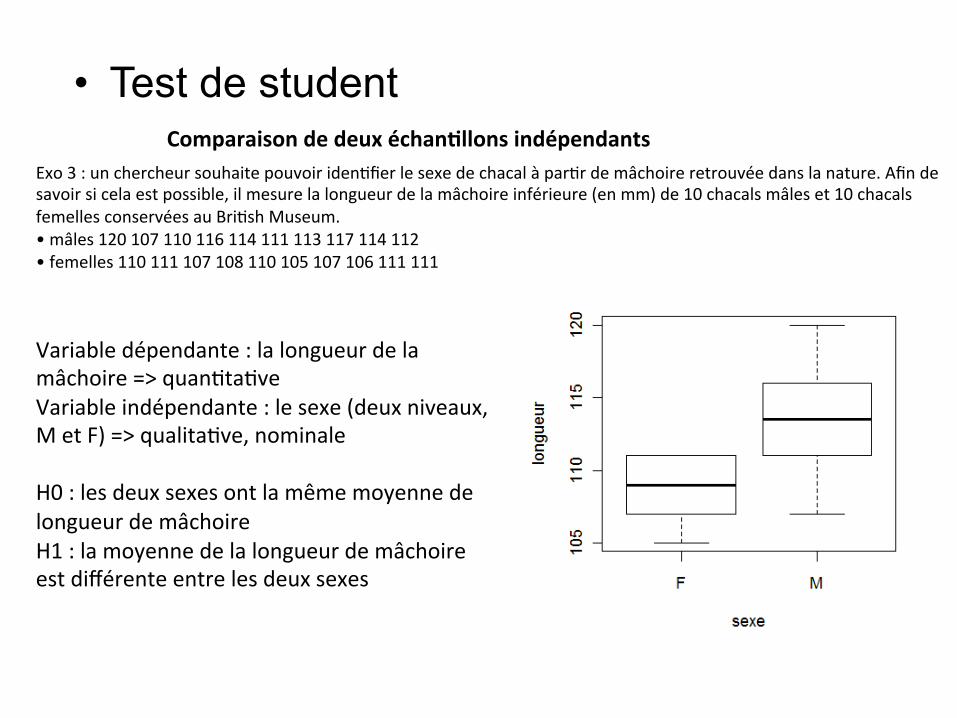
• Test de student Comparaisondedeuxéchan&llonsindépendants
Exo3:unchercheursouhaitepouvoiriden&fierlesexedechacalàpar&rdemâchoireretrouvéedanslanature.Afindesavoirsicelaestpossible,ilmesurelalongueurdelamâchoireinférieure(enmm)de10chacalsmâleset10chacalsfemellesconservéesauBri&shMuseum.•mâles120107110116114111113117114112•femelles110111107108110105107106111111
Variabledépendante:lalongueurdelamâchoire=>quan&ta&veVariableindépendante:lesexe(deuxniveaux,MetF)=>qualita&ve,nominaleH0:lesdeuxsexesontlamêmemoyennedelongueurdemâchoireH1:lamoyennedelalongueurdemâchoireestdifférenteentrelesdeuxsexes

( )
⎟⎟⎠
⎞⎜⎜⎝
⎛+×
−
yx
obs
nns
yxt11ˆ2
( ) ( )211
ˆ22
2
−+
−+−=
yx
yyxx
nnsnsn
s
Degrédeliberté=nx+ny-2
avec
• Test de student Principe:oncomparel’écartentrelesdeuxmoyennesà0aprèsl’avoirstandardiséparlavarianceintragroupe
MoyenneX=108.6(femme)MoyenneY=113.4(homme)
VarianceX=5.16(femme)VarianceY=13.82(homme)
( )( )221
yx
obs
ssn
yxt+
−Sinx=ny
Tobs=(108.6-113.4)/racine(1/10*(5.16+13.82))=4.8/1.377=-3.48
Tobsce-evaleursta&s&quesuituneloidestudentdeddl=18tseuil0.05=2.1009
Tobs>tseuil=>onreje-el’hypothèsenulle=>ilexistedesdifférencesdemoyennes

SORTIER>t.test(longueur~sexe,alterna&ve='two.sided',conf.level=.95,+var.equal=TRUE,data=exo3cour)
TwoSamplet-testdata:longueurbysexet=-3.4843,df=18,p-value=0.002647alterna&vehypothesis:truedifferenceinmeansisnotequalto095percentconfidenceinterval:-7.694227-1.905773samplees&mates:meaningroupFmeaningroupM108.6113.4
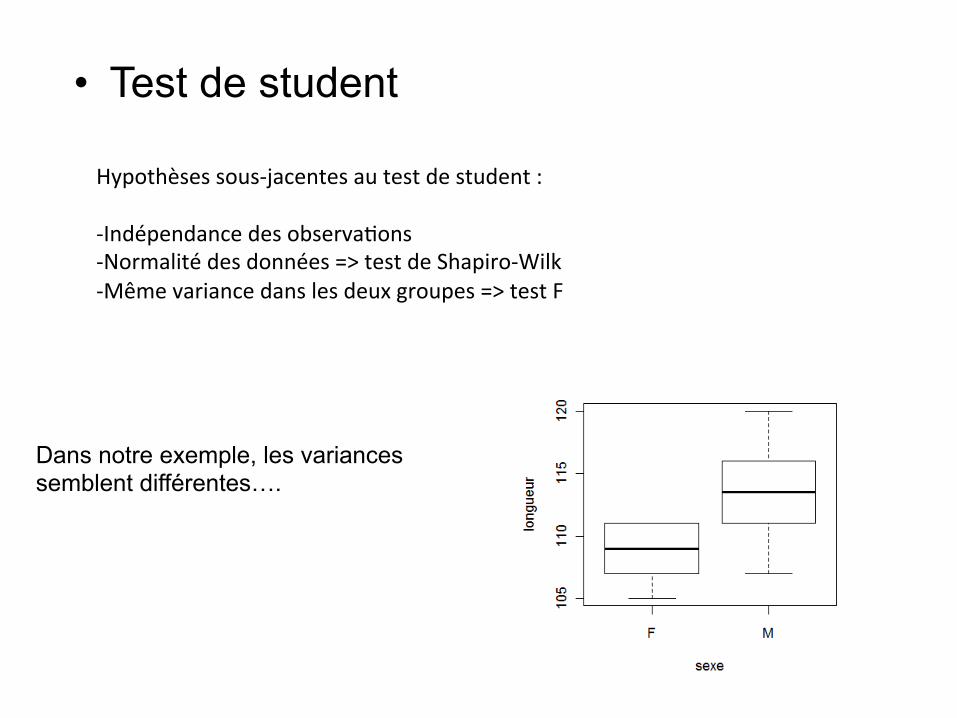
• Test de student
Hypothèsessous-jacentesautestdestudent:- Indépendancedesobserva&ons- Normalitédesdonnées=>testdeShapiro-Wilk- Mêmevariancedanslesdeuxgroupes=>testF
Dans notre exemple, les variances semblent différentes….

n Commenttesterl’hétérogénéitédesvariances?=>testFFISHER-SNEDECOR
H0:VAR1=VAR2H1:VAR1>VAR2(sachantquevar1estplusgrandequevar2)LerapportdedeuxvariancessuituneloidetypeF(loiasymétrique,Fdoitêtreplusgrandque0)aveccommedegrésdeliberté(ddldelavariancemax;ddlvarmin)Fobs=VARmaximale/VARminimale
Dansnotreexemple:VarianceX=5.16(femme);VarianceY=13.82(homme)Fobs[9;9]=13.82/5.16=2.68 Fseuil0.05[9;9]=3.18=>Lesvariancesnesontpassignifica&vementdifférentesauseuilde5%

Comparaisondedeuxéchan&llonsindépendantsavecvariancehétérogène
( )
⎟⎟⎠
⎞⎜⎜⎝
⎛+
−
y
y
x
x
obs
ns
ns
yxt22
Enfaitc’estleddlquiestvraimentmodifiéetquiprendencomptenonseulementleseffec&fsmaiségalementlavaleurdesvariancesdechaqueéchan&llon
n TestdeWelchsivariancehétérogène
NOTE:Pardéfaut,Reffectuecetestetiln’estdoncpasindispensabledetesterl’hétérogénéitédesvariances

SORTIER>t.test(longueur~sexe,alterna&ve='two.sided',conf.level=.95,+var.equal=FALSE,data=exo3cour)
WelchTwoSamplet-testdata:longueurbysexet=-3.4843,df=14.894,p-value=0.00336alterna&vehypothesis:truedifferenceinmeansisnotequalto095percentconfidenceinterval:-7.738105-1.861895samplees&mates:meaningroupFmeaningroupM108.6113.4

n Testdestudentappariésidonnéesnonindépendantes
exemple:onamesurélahauteur(enmètres)de12arbresselondeuxméthodesdifférentes,avantetaprèslacoupedel’arbre.debout=20.4,25.4,25.6,25.6,26.6,28.6,28.7,29.0,29.8,30.5,30.9,31.1aba-u=21.7,26.3,26.8,28.1,26.2,27.3,29.5,32.0,30.9,32.3,32.3,31.7debout-aba-u=-1.3-0.9-1.2-2.50.41.3-0.8-3.0-1.1-1.8-1.4-0.6

n Testdestudentappariésidonnéesnonindépendantes
Principe:unindividudel’échan&llonestuncouple.Testerl’hypothèse«laméthodedecoupen’apasd’effet»contrel’hypothèse«laméthodedecoupeauneffetposi&f»,c’esttesterl’hypothèse«lamoyennedesdi=xi-yiestnulle»contrel’hypothèse«lamoyennedesdi=xi-yiestposi&veounéga&ve».
•di=xi-yiestlaréalisa&ond’unevariablealéatoiredemoyenne0etdevarianceσ2.Onveutcomparerlamoyennededà0.Onu&liseletesttdeStudentavecddl(n-1),nétantlenombredecoupleici12
nsmtd
d2
=Moyenne différence = -1.075 Variance différence = 1.326
t = (1.075-0)/racine(1.326/12) = -3.23
t suit une loi de Student à 11 ddl tseuil 0.05 = 2.201 tobs > tseuil => on rejette l’hypothèse nulle

SORTIER:>t.test(exo4cour$avant,exo4cour$apres,alterna&ve='two.sided',+conf.level=.95,paired=TRUE)
Pairedt-testdata:exo4cour$avantandexo4cour$aprest=-3.2343,df=11,p-value=0.007954alterna&vehypothesis:truedifferenceinmeansisnotequalto095percentconfidenceinterval:-1.8065536-0.3434464samplees&mates:meanofthedifferences-1.075

n Sidistribu&onnonnormales=>testsnonparamétrique:testdeWilcoxonouMann-Whitney
GroupeA ****** GroupeB******
123456789101112
Variabledépendante=duretédusilex=>variablequan&ta&ve(rang)Variableindépendante=région(2niveaux)=>variablequalita&venominale
=>Testnonparamétriquecarlesrangsnereprésententpasunevariablecon&nue

Pourungroupe,pourchaqueobserva&on,oncomptelenombred’observa&onsdansl’autregroupequiontunrangplusgrand.PourgroupeA:rang1:0;rang2:0;rang3:0,rang5:1,rang6:1,rang8:2,lasommeC=4PourgroupeB:C=3+5+6+6+6+6=32
n CalculdutestdeWilcoxonouMann-Whitney
GroupeA****** GroupeB******
123456789101112
Lasta&s&queU(lavaleurdeClapluspe&te)suitunedistribu&ondeChi-Deuxsieffec&f>30,sinonu&lisa&ond’unetable(ousimplementdelavaleurdepdonnéeparlelogiciel!)

SORTIER:>regionA=c(1,2,3,5,6,8)>regionB=c(4,7,9,10,11,12)>wilcox.test(regionA,regionB)Wilcoxonranksumtestdata:regionAandregionBW=4,p-value=0.02597alterna&vehypothesis:trueloca&onshi�isnotequalto0

n Donnéesappariéesexemple:deséchan?llonsdecrèmeprélevésdans10laiteriessontdivisésendeuxpar?es.L’uneestenvoyéeaulaboratoire1etl’autreaulaboratoire2pourencompterlesbactéries.Résultats(103bact/ml):lab1:11.7,12.1,13.3,15.1,15.9,15.3,11.9,16.2,15.1,13.8lab2:10.9,11.9,13.4,15.4,14.8,14.8,12.3,15.0,14.2,13.2lab1-lab2:0.80.2-0.1-0.31.10.5-0.41.20.90.6
Hypothèsenulle:lesigneseraaléatoirement+ou-(doncavec½quecesoit+ou-)3signesnéga&fs/10=>u&lisa&ondelaloibinomiale
=>Testsimple=testdesigne(sihasard=>autantde+quede-)
1719,021
21
!7!3!10
21
21 7373
310 =⎟
⎠
⎞⎜⎝
⎛⎟⎠
⎞⎜⎝
⎛⎟⎠
⎞⎜⎝
⎛=⎟⎠
⎞⎜⎝
⎛⎟⎠
⎞⎜⎝
⎛=Cp

n TestdeWilcoxonappariéMAISilsepourraitquelesigne+soitenvironunefoissurdeuxmaisquelesdifférencesdansunsenssoientplusfaiblesenvaleurabsoluequelesdifférencesdansl’autresens.
⇒ TestdeWilcoxonapparié
S-=sommedesrangsdesignenéga&f:1+3+4=8S+=sommedesrangsdesigneposi&f=47OnprendlavaleurdeSlapluspe&tepourconstruireunesta&s&queTquel’ontestesurunetableT(oudirectementvaleurdepdonnéeparlelogiciel!).
lab1-lab2:0.80.2-0.1-0.31.10.5-0.41.20.90.6rangs:72139541086
Onrangelesvaleursabsoluesdesdifférencesenordrecroissant:

SORTIER:>lab1=c(11.7,12.1,13.3,15.1,15.9,15.3,11.9,16.2,15.1,13.8)>lab2=c(10.9,11.9,13.4,15.4,14.8,14.8,12.3,15.0,14.2,13.2)>wilcox.test(lab1,lab2,paired=TRUE)Wilcoxonsignedranktestdata:lab1andlab2V=47,p-value=0.04883alterna&vehypothesis:trueloca&onshi�isnotequalto0

Comparaison de 2 groupes (apparié ou non)
ANOVA Corrélation Régression
Paramétrique Test de Student (apparié ou non)
ANOVA paramétrique
Corrélation de Pearson
Régression
Non paramétrique
Test de Wilcoxon (apparié ou non)
ANOVA de Kruskall-Wallis
Corrélation de Spearman ou de Kendall
________
X
Y
+ TEST DE CHI-DEUX ou TEST DE FISHER pour Tables de contingences
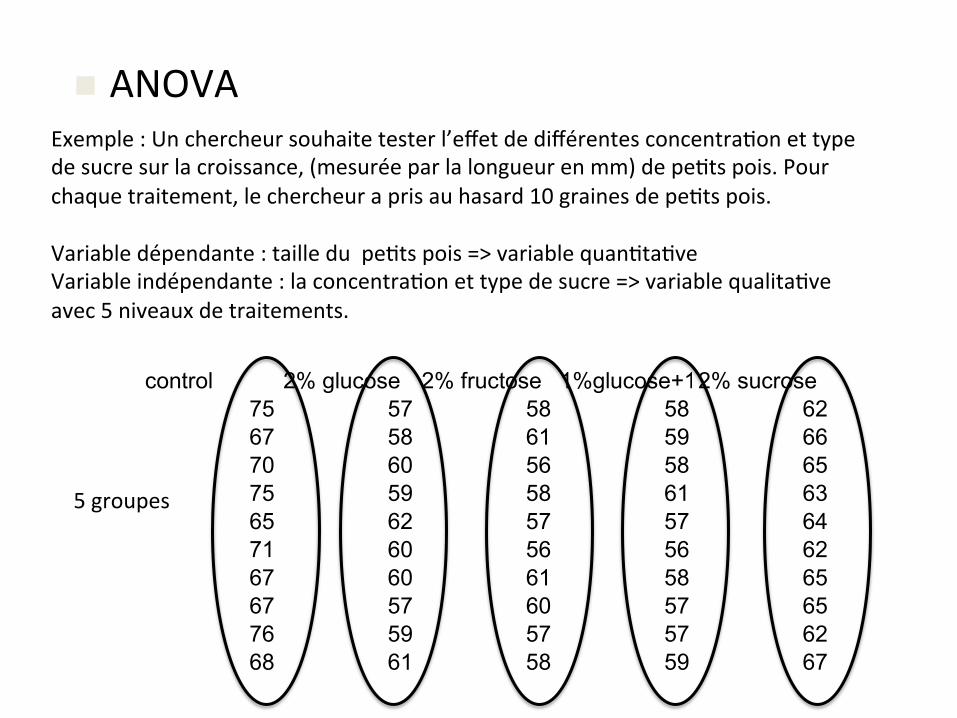
n ANOVAExemple:Unchercheursouhaitetesterl’effetdedifférentesconcentra&onettypedesucresurlacroissance,(mesuréeparlalongueurenmm)depe&tspois.Pourchaquetraitement,lechercheuraprisauhasard10grainesdepe&tspois.Variabledépendante:tailledupe&tspois=>variablequan&ta&veVariableindépendante:laconcentra&onettypedesucre=>variablequalita&veavec5niveauxdetraitements.
control 2% glucose 2% fructose 1%glucose+1%fructose2% sucrose75 57 58 58 6267 58 61 59 6670 60 56 58 6575 59 58 61 6365 62 57 57 6471 60 56 56 6267 60 61 58 6567 57 60 57 6576 59 57 57 6268 61 58 59 67
5groupes
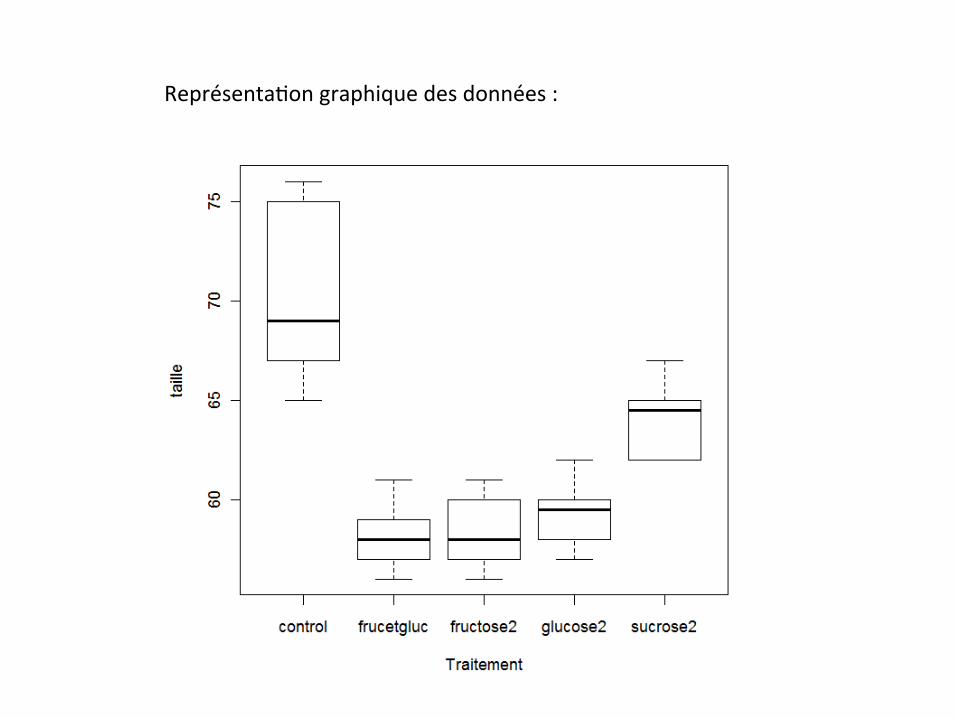
Représenta&ongraphiquedesdonnées:

n ANOVAHypothèsenulle:iln’yapasd’effetdutraitementsurlacroissancedupoisHypothèsealterna&ve:ilyauneffetdutraitementsurlacroissancedupois
Principe:s’iln’yapasd’effetsdutraitement,alorslavarianceentrelesgroupesestdemêmeordredegrandeurquelavarianceàl’intérieurdesgroupes…
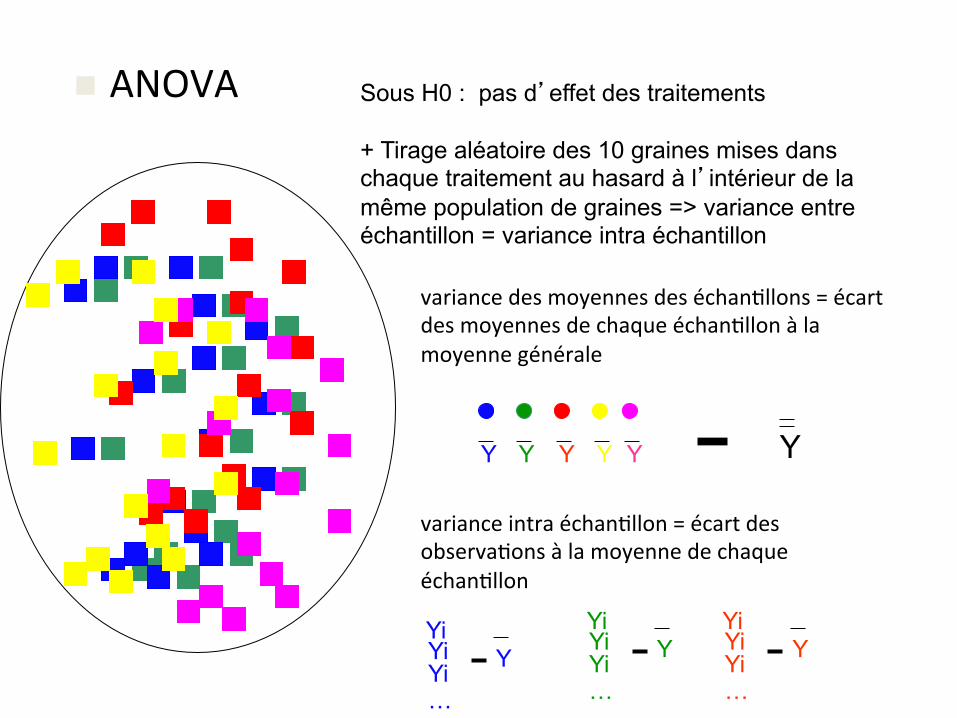
n ANOVA Sous H0 : pas d’effet des traitements + Tirage aléatoire des 10 graines mises dans chaque traitement au hasard à l’intérieur de la même population de graines => variance entre échantillon = variance intra échantillon
Y Y Y Y Y Y
variancedesmoyennesdeséchan&llons=écartdesmoyennesdechaqueéchan&llonàlamoyennegénérale
varianceintraéchan&llon=écartdesobserva&onsàlamoyennedechaqueéchan&llon
Yi Yi Yi …
Y Yi Yi Yi …
Y Yi Yi Yi …
Y

n ANOVAOnsaitparailleursquethéoriquementlavariancedesmoyennes=
nY
22 σ
σ =Si l’hypothèse nulle est vraie alors : Variance intra-groupe = Variance inter-groupe * n => Tester si le rapport de ces deux variances = 1 par un test-F
( )211
1 ∑=
=−
−ai
i i YYa
Approcheplusmathéma&que…..
Varianceintra-groupe(variancerésiduelle)=(a=nombredegroupe)(c’estunemoyennedelavarianceintra-groupe)
Varianceinter-groupe=(a=nombredegroupe)
( ) ( )∑∑=
=
=
=−
−
ai
i
nj
j iij YYna 1
2
111
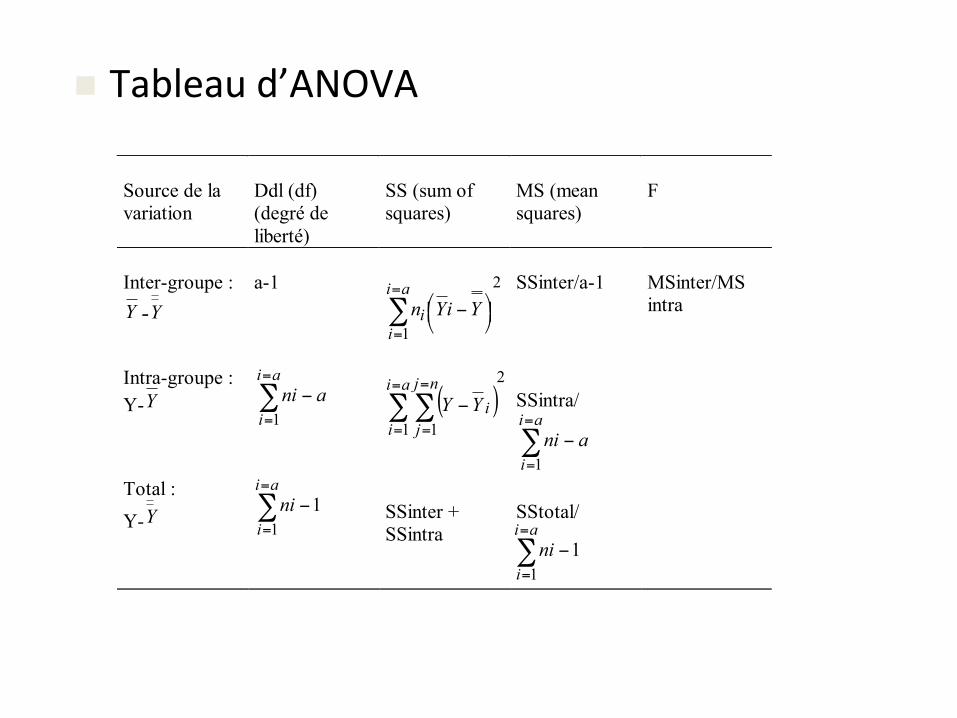
n Tableaud’ANOVA
Source de la variation
Ddl (df) (degré de liberté)
SS (sum of squares)
MS (mean squares)
F
Inter-groupe : Y -Y
a-1
2
1∑=
=⎟⎠⎞⎜
⎝⎛ −
ai
ii YiYn
SSinter/a-1
MSinter/MS intra
Intra-groupe : Y-Y ∑
=
=
−ai
iani
1 ( )
2
1 1∑∑=
=
=
=
−ai
i
nj
jiYY
SSintra/
∑=
=
−ai
iani
1
Total : Y-Y
∑=
=
−ai
ini
11
SSinter + SSintra
SStotal/
∑=
=
−ai
ini
11
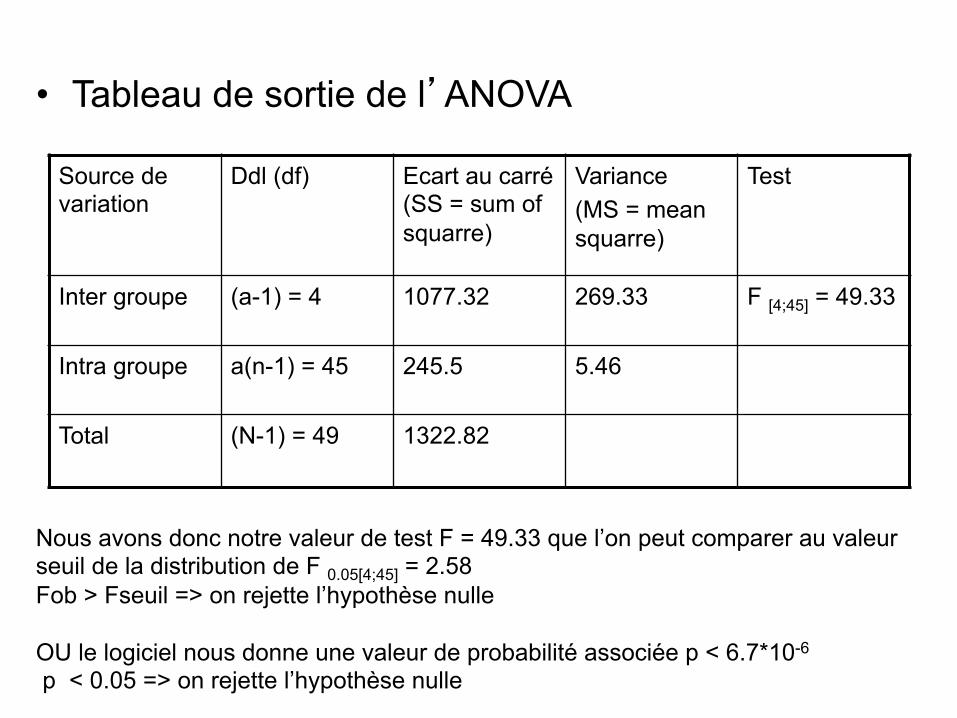
• Tableau de sortie de l’ANOVA
Source de variation
Ddl (df) Ecart au carré (SS = sum of squarre)
Variance (MS = mean squarre)
Test
Inter groupe (a-1) = 4 1077.32 269.33 F [4;45] = 49.33
Intra groupe a(n-1) = 45 245.5 5.46
Total (N-1) = 49 1322.82
Nous avons donc notre valeur de test F = 49.33 que l’on peut comparer au valeur seuil de la distribution de F 0.05[4;45] = 2.58 Fob > Fseuil => on rejette l’hypothèse nulle OU le logiciel nous donne une valeur de probabilité associée p < 6.7*10-6
p < 0.05 => on rejette l’hypothèse nulle

SORTIER:summary(AnovaModel.2) DfSumSqMeanSqFvaluePr(>F)Traitement41077.3269.33049.368 6.737e-16***Residuals45245.55.456---Signif.codes:0'***'0.001'**'0.01'*'0.05'.'0.1''1

• Comparaisons de moyenne post-hoc (après ANOVA)
Dansnotreexemple,l’ANOVAnouspermetdeconclurequ’ilexistedesdifférencessignifica&vesentrelesmoyennesdemestraitementsEtapesuivante:quellessontlesmoyennesquidifférententreelles?Unesolu&on:fairepleindetestdestudentdecomparaisonsdemoyennes….MAISonaugmentenotreerreurdetype1(direquedesdifférencessontsignifica&vesalorsqu’ellesn’ensontpas).Testdecomparaisonmul&pleàpostériori=>demoyennespost-hoc(onverracestestsavecdesapplica&ons)
TestdeTukeyHSD(leplusconserva&f)(celuiu&liséparRpardéfaut)LSD(leastsignificantdifference)(trèspeuconserva&f!)testdeStudentNewmanskeuls(moyennementconserva&f)

SORTIEDER:LinearHypotheses:Es&mate lwr uprfrucetgluc-control==0-12.1000-15.0680-9.1320fructose2-control==0-11.9000-14.8680-8.9320glucose2-control==0-10.8000-13.7680-7.8320sucrose2-control==0-6.0000-8.9680-3.0320fructose2-frucetgluc==00.2000-2.76803.1680glucose2-frucetgluc==01.3000-1.66804.2680sucrose2-frucetgluc==06.10003.13209.0680glucose2-fructose2==01.1000-1.86804.0680sucrose2-fructose2==05.90002.93208.8680sucrose2-glucose2==04.80001.83207.7680>cld(.Pairs)#compactle-erdisplayfrucetglucfructose2glucose2sucrose2control"a""a" "a""b""c"
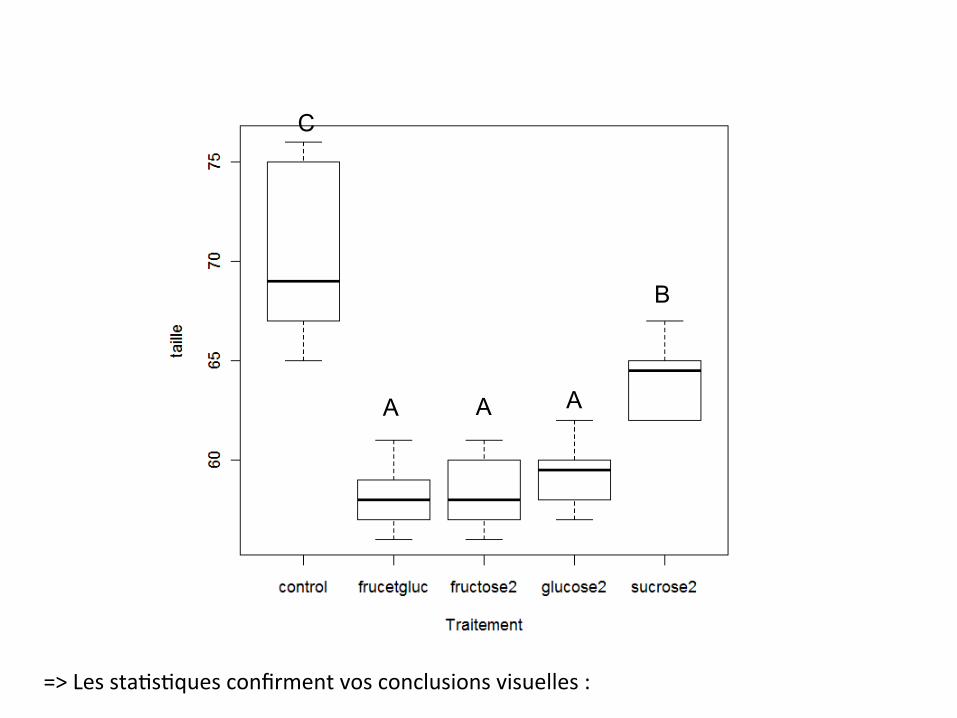
C
B
A A A
=>Lessta&s&quesconfirmentvosconclusionsvisuelles:

• Hypothèses sous-jacentes à l’ANOVA
1. Indépendance des observations 2. Normalité des données 3. Homogénéité des variances (des différents
groupes) (homoscédasticité) Vérification visuelle des hypothèses par de graphiques appropriés que nous verrons avec la régression
n Sinonrespectdeshypothèses=>onessayedetransformerlesdonnéespourqueleshypothèsessoientrespectées
n OU=>testsnonparamétriques:ANOVAdeKRUSKALL-WALLIS

• ANOVA DE KRUSKALL-WALLIS
PRINCIPE : tester la différence de mode pour des données transformées en rangs 1. On transforme les données en rang 2. On calcule la variance attendue de la somme des rangs sous l’hypothèse nulle
(pas de différences entre groupes) 3. On obtient la statistique H qui peut être comparée à une distribution de chi-deux
de (a-1) ddl (même si effectif des groupes petit (5))
Sor&edeR:kruskal.test(taille~Traitement,data=ANOVACOUR)
Kruskal-Wallisranksumtestdata:taillebyTraitementKruskal-Wallischi-squared=38.4368,df=4,p-value=9.105e-08***
Comparaison de 2 groupes (apparié ou non)
ANOVA Corrélation Régression
Paramétrique Test de Student (apparié ou non)
ANOVA paramétrique
Corrélation de Pearson
Régression
Non paramétrique
Test de Wilcoxon (apparié ou non)
ANOVA de Kruskall-Wallis
Corrélation de Spearman ou de Kendall
________
X
Y
+ TEST DE CHI-DEUX ou TEST DE FISHER pour Tables de contingences

Etude de la liaison entre deux variables
Une des variable n’est pas distribuée normalement (ou la distribution est inconnue), Le nombre d’observations est très faible, Une des variables est mesurée sur une échelle semi-quantitative (rang)
Les deux variables sont parfaitement quantitatives et distribuées normalement
Corrélation paramétrique
Corrélation non-paramétrique

Etude de la liaison entre deux variables
Pour que les statistiques soient applicables il faut qu’au moins une des variables soit aléatoire
Cas 1: une variable est aléatoire, l’autre contrôlée Exemple: l’intensité de l’assimilation chlorophyllienne (V.A.) en fonction de l’éclairement (V.C.)
Cas 2: les deux variables sont aléatoires Exemple: abondance de la récolte viticole (V.A.) en fonction du nombre de jours d’ensoleillement (V.A.)
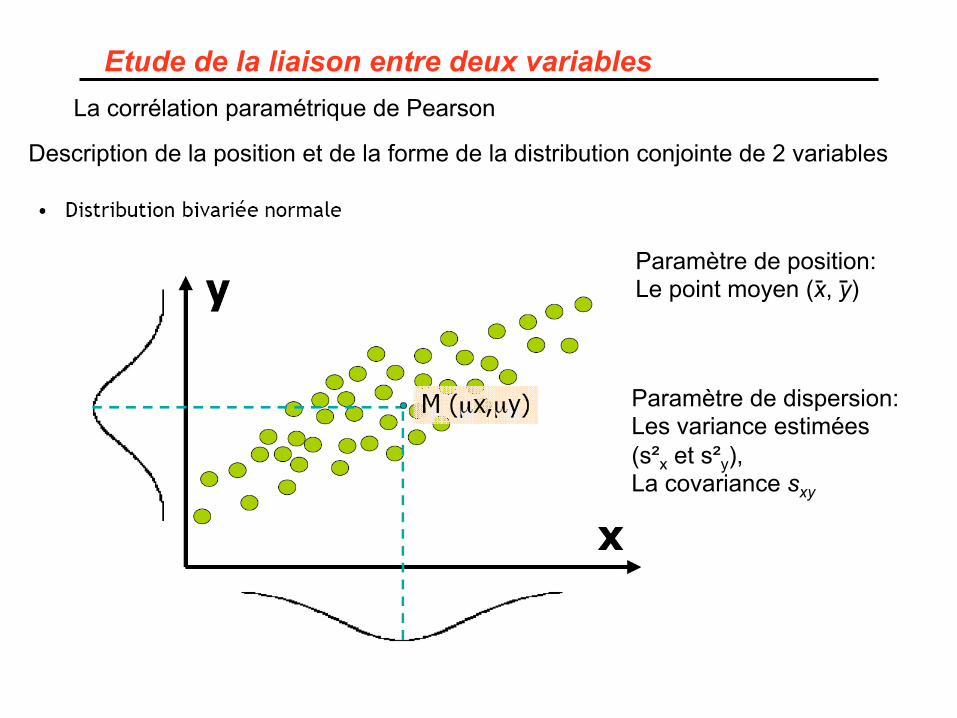
Etude de la liaison entre deux variables La corrélation paramétrique de Pearson
Description de la position et de la forme de la distribution conjointe de 2 variables
Paramètre de position: Le point moyen (x, y)
Paramètre de dispersion: Les variance estimées (s²x et s²y), La covariance sxy

Etude de la liaison entre deux variables
La variance estimée de x
s²x = Σ (xi – x)² , v = (n – 1) 1 v
n
i = 1
La variance estimée de y
s²y = Σ (yi – y)² , v = (n – 1) 1 v
n
i = 1
La covariance estimée de x et y
sxy = Σ (xi – x)(yi – y) , v = (n – 1) 1 v
n
i = 1
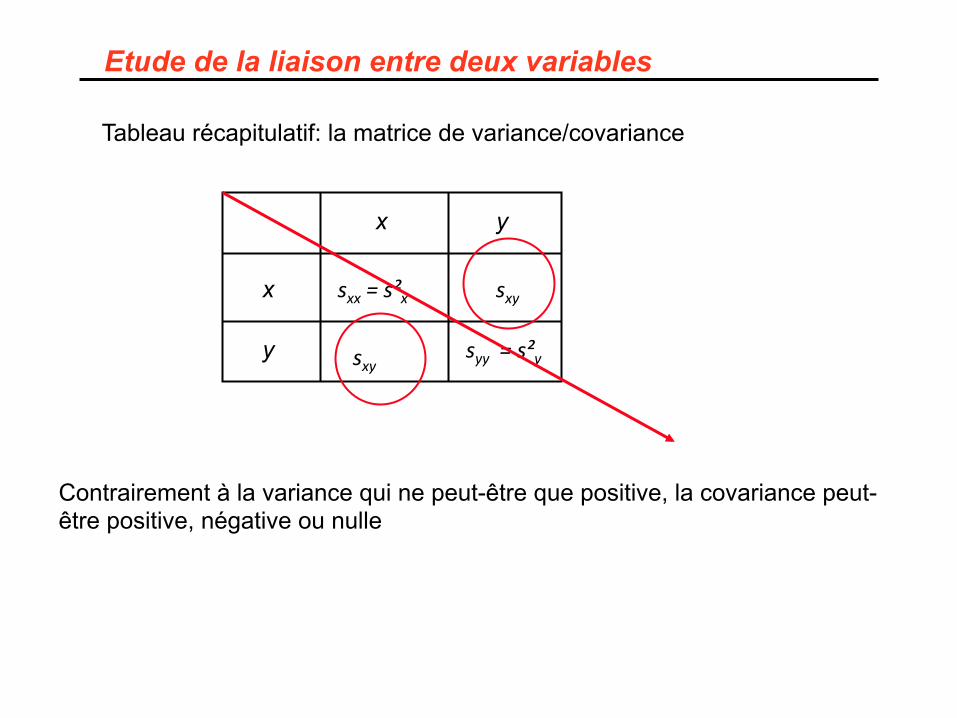
Etude de la liaison entre deux variables
Tableau récapitulatif: la matrice de variance/covariance
x y
x
y
sxx=s²x
sxy syy
sxy
=s²y
Contrairement à la variance qui ne peut-être que positive, la covariance peut-être positive, négative ou nulle

La covariance nous renseigne sur l’inclinaison du nuage de points, mais elle ne nous donne pas d’idée de l’intensité de la liaison existant entre x et y.
Etude de la liaison entre deux variables
y
x
A
B Les nuages de points A et B montrent la même intensité de liaison mais les covariances sont différentes
Il faut trouver une autre mesure qui nous renseignera sur l’intensité de la relation

Etude de la liaison entre deux variables La corrélation linéaire de Pearson
La covariance mesure la dispersion conjointe des deux variables quantitatives (x et y) autour de leur moyenne
La corrélation linéaire de Pearson mesure la liaison linéaire entre deux variables quantitatives x et y
Le calcul de la corrélation linéaire se fait suivant plusieurs étapes:
1 – transformation de x et y en variables centrées réduites
x’i = xi - x
sx y’i =
yi - y sy
2 – calcul de la covariance entre ces nouvelles variables
sx’y’ = Σ (x’i – x’)(y’i – y’) , v = (n – 1) 1 v
n
i = 1

sx’y’ = Σ (x’i – x’)(y’i – y’) 1 v
n
i = 1
Etude de la liaison entre deux variables La corrélation linéaire de Pearson
rxy = Σ - 0 - 0 1 v
n
i = 1
yi - y sy
xi - x sx
Moyenne des variables centrées réduites = 0
sysx rxy =
1 v (yi – y) Σ (xi – x)
sxsy
sxy =
(yi – y) Σ (xi – x) =
(yi – y)² √Σ (xi – x)²

Etude de la liaison entre deux variables La corrélation linéaire de Pearson
• Exemple
On cherche à voir si la tension artérielle Y est corrélée à l’âge X.
y = 13,5 x = 35 ans
Quel est le coefficient de corrélation?
rxy = sxy/sxsy
= 10/256 = 0,03
sx=4,sy=64,sxy=10

Etude de la liaison entre deux variables La corrélation linéaire de Pearson
Tableau récapitulatif: la matrice de corrélation
x y
x
y
rxx=1
rxy ryy
rxy
=1
Les valeurs de la diagonale sont des « 1 » puisque les variables sont centrées réduites
r = +1 ou r = -1 si les points forment une droite sur le diagramme bivarié
Le signe de r est le même que celui de la covariance et indique le sens de la relation (positive ou négative)
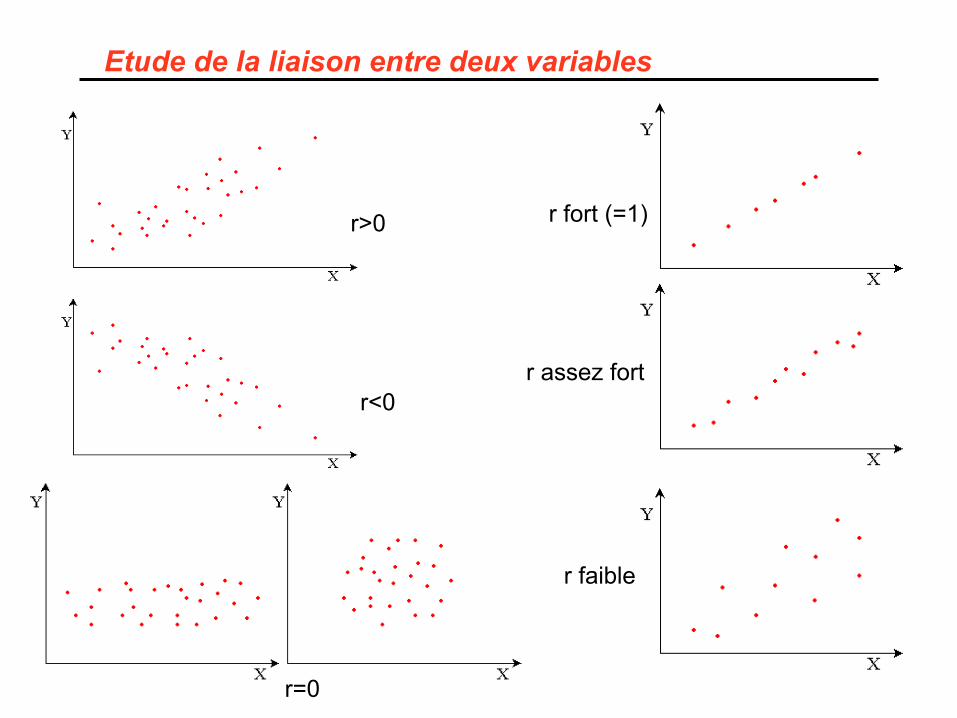
Etude de la liaison entre deux variables
r>0
r<0
r=0
r fort (=1)
r assez fort
r faible

Etude de la liaison entre deux variables
Le test de signification du r de Pearson
On peut montrer que: si les deux variables sont quantitatives si la distribution est bi-normale si les observations sont indépendantes
alors
t = rxy √n - 2
√1 – r²xy
On test l’hypothèse nulle d’absence de corrélation dans la population statistique d’où est tiré l’échantillon
H0: ρxy = 0
n – 2 ddl

Etude de la liaison entre deux variables
La corrélation non-paramétrique On rappelle que le coefficient de corrélation linéaire de Pearson et son test, ne sont pas appropriés dans les circonstances suivantes: • au moins une des variables est semi-quantitative (rangs) • les variables ne sont pas distribuées normalement • le nombre d’observations est faible
Dans ces cas, on utilise un coefficient de corrélation de rangs, souvent testés par permutations
rs ou ρ de Spearman
Consiste en : • remplacer les valeurs numériques par les rangs • calculer la formule de la corrélation de Pearson entre les variables ainsi formées • tester la signification du coefficient en ayant recourt à une table appropriée
Le τ de Kendall Une fois encore, il mesure le degré de liaison entre les deux variables
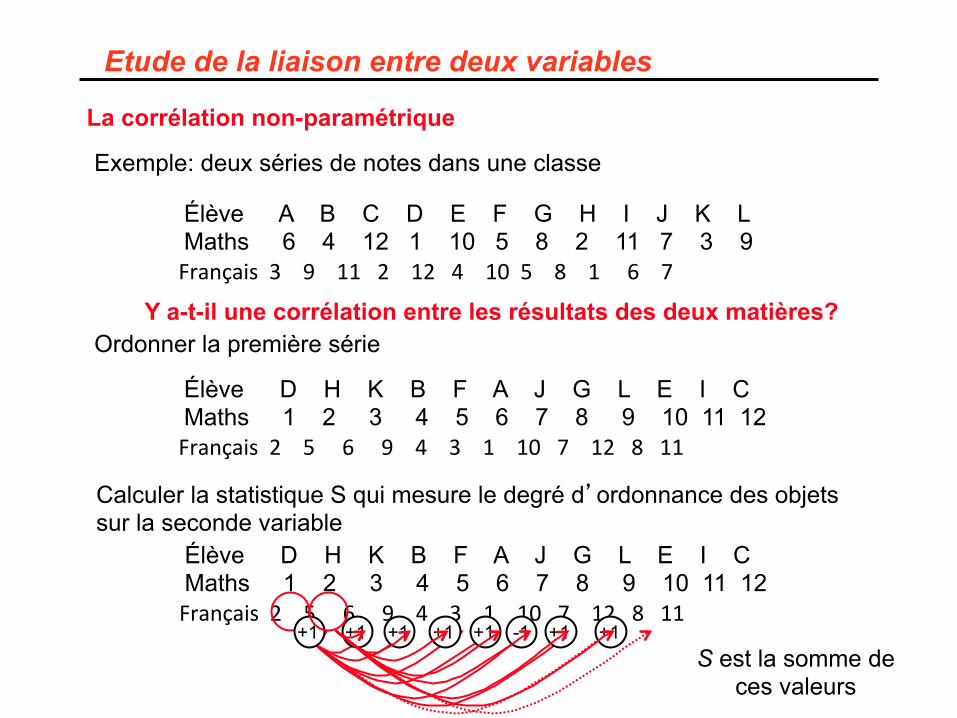
Etude de la liaison entre deux variables
La corrélation non-paramétrique
Exemple: deux séries de notes dans une classe
Élève A B C D E F G H I J K L Maths 6 4 12 1 10 5 8 2 11 7 3 9 Français391121241058167
Ordonner la première série
Élève D H K B F A J G L E I C Maths 1 2 3 4 5 6 7 8 9 10 11 12 Français256943110712811
Y a-t-il une corrélation entre les résultats des deux matières?
Calculer la statistique S qui mesure le degré d’ordonnance des objets sur la seconde variable
Élève D H K B F A J G L E I C Maths 1 2 3 4 5 6 7 8 9 10 11 12 Français256943110712811
+1 -1 +1 +1 +1 +1 +1 +1 S est la somme de
ces valeurs

Etude de la liaison entre deux variables
La corrélation non-paramétrique
τ = 2S
n(n – 1)
Élève D H K B F A J G L E I C Maths 1 2 3 4 5 6 7 8 9 10 11 12 Français256943110712811
S = 28
τ = 0,424
Application sous
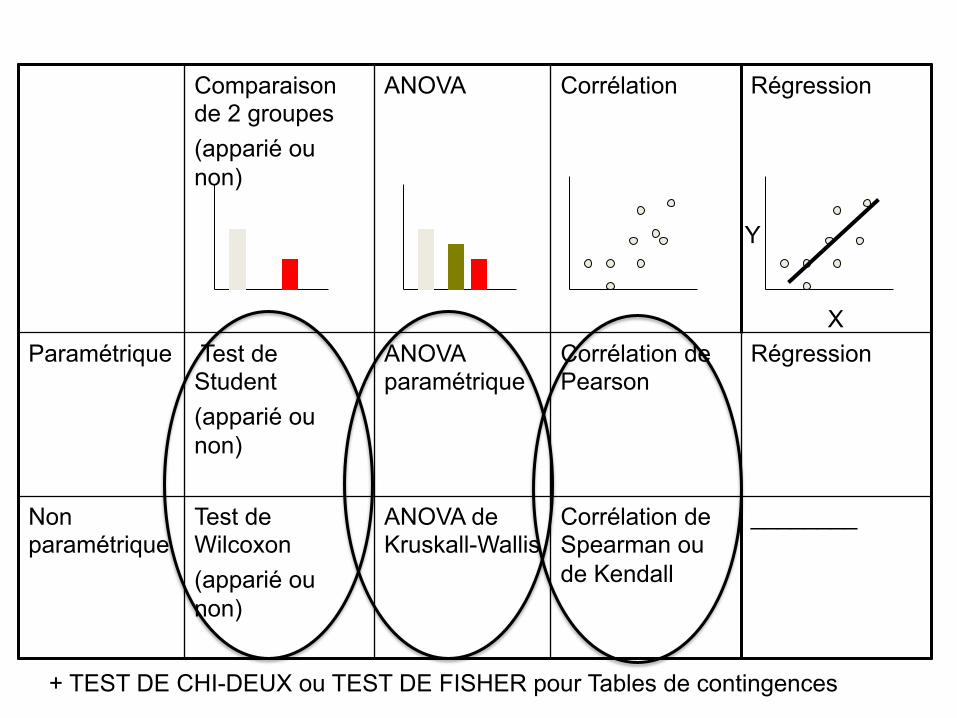
Comparaison de 2 groupes (apparié ou non)
ANOVA Corrélation Régression
Paramétrique Test de Student (apparié ou non)
ANOVA paramétrique
Corrélation de Pearson
Régression
Non paramétrique
Test de Wilcoxon (apparié ou non)
ANOVA de Kruskall-Wallis
Corrélation de Spearman ou de Kendall
________
X
Y
+ TEST DE CHI-DEUX ou TEST DE FISHER pour Tables de contingences
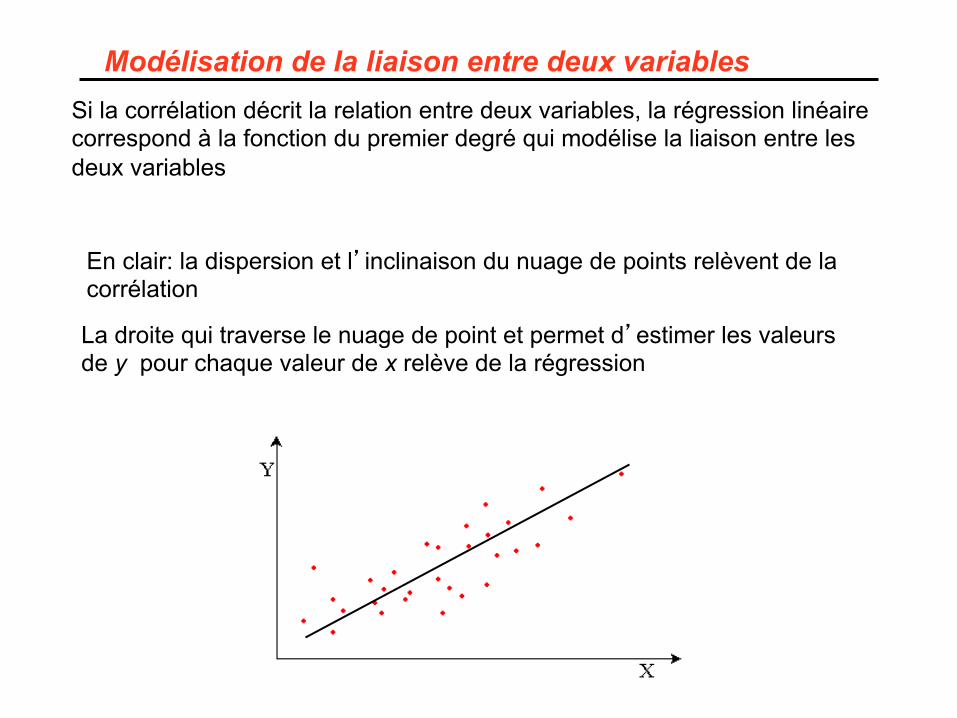
Modélisation de la liaison entre deux variables Si la corrélation décrit la relation entre deux variables, la régression linéaire correspond à la fonction du premier degré qui modélise la liaison entre les deux variables
En clair: la dispersion et l’inclinaison du nuage de points relèvent de la corrélation
La droite qui traverse le nuage de point et permet d’estimer les valeurs de y pour chaque valeur de x relève de la régression
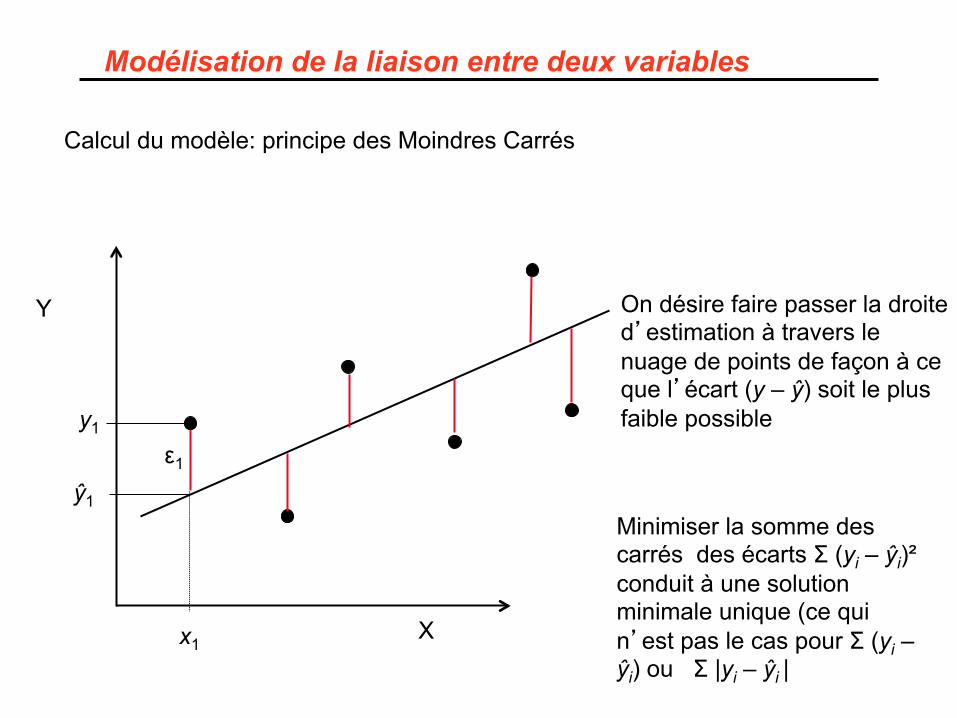
Modélisation de la liaison entre deux variables
Calcul du modèle: principe des Moindres Carrés
Y
X
y1
ŷ1
x1
On désire faire passer la droite d’estimation à travers le nuage de points de façon à ce que l’écart (y – ŷ) soit le plus faible possible
Minimiser la somme des carrés des écarts Σ (yi – ŷi)² conduit à une solution minimale unique (ce qui n’est pas le cas pour Σ (yi – ŷi) ou Σ |yi – ŷi |
ε1
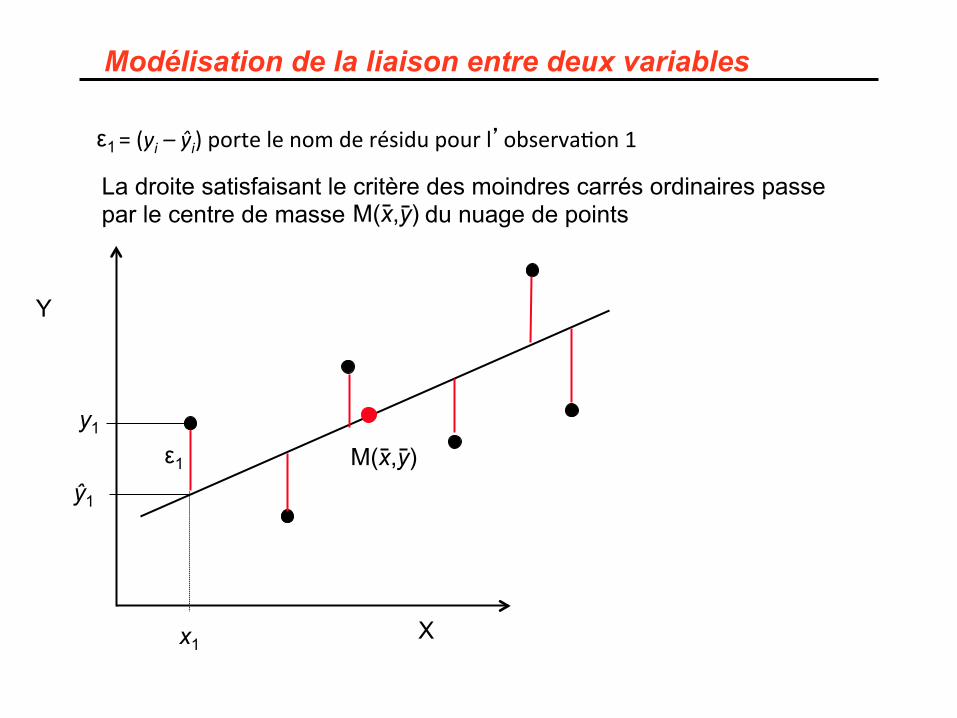
Modélisation de la liaison entre deux variables
ε1 =(yi–ŷi)portelenomderésidupourl’observa&on1
Y
X
y1
ŷ1
x1
ε1 M(x,y)
La droite satisfaisant le critère des moindres carrés ordinaires passe par le centre de masse du nuage de points M(x,y)

Modélisation de la liaison entre deux variables
Calcul de deux paramètres de la droite de régression: la pente et l’ordonnée à l’origine
Fonction du premier degré y = ax + b, ici, ŷ = ax + b
Ainsipourchaquerésidu(yi–ŷi)=[yi–(axi+b)]DonclasommedescarrésàminimiserestΣ(yi–ŷi)²=Σ[yi–(axi+b)]²n
i = 1
n
i = 1
On trouve le minimum d’une fonction en égalant sa dérivée première à zéro
sy
a = nΣxiyi - ΣxiΣyi
nΣ(xi²) – Σ(xi)² or sxy =
nΣxiyi - ΣxiΣyi
n(n – 1) et s²x =
nΣ(xi²) – Σ(xi)² n(n – 1)
donc a = sxy
s²x
de plus rxy =
sxy
sxsy ainsi a =
rxysxsy
s²x = rxy
sy
sx
et rxy = a sx

Modélisation de la liaison entre deux variables
Calcul de deux paramètres de la droite de régression: la pente et l’ordonnée à l’origine
Fonction du premier degré y = ax + b, ici, ŷ = ax + b
Ainsipourchaquerésidu(yi–ŷi)=[yi–(axi+b)]DonclasommedescarrésàminimiserestΣ(yi–ŷi)²=Σ[yi–(axi+b)]²n
i = 1
n
i = 1
On trouve le minimum d’une fonction en égalant sa dérivée première à zéro
Pour l’ordonnée à l’origine: b = y – ax On peut calculer l’ordonnée à l’origine à partir de la pente a et du centre de masse (x, y) du nuage de points
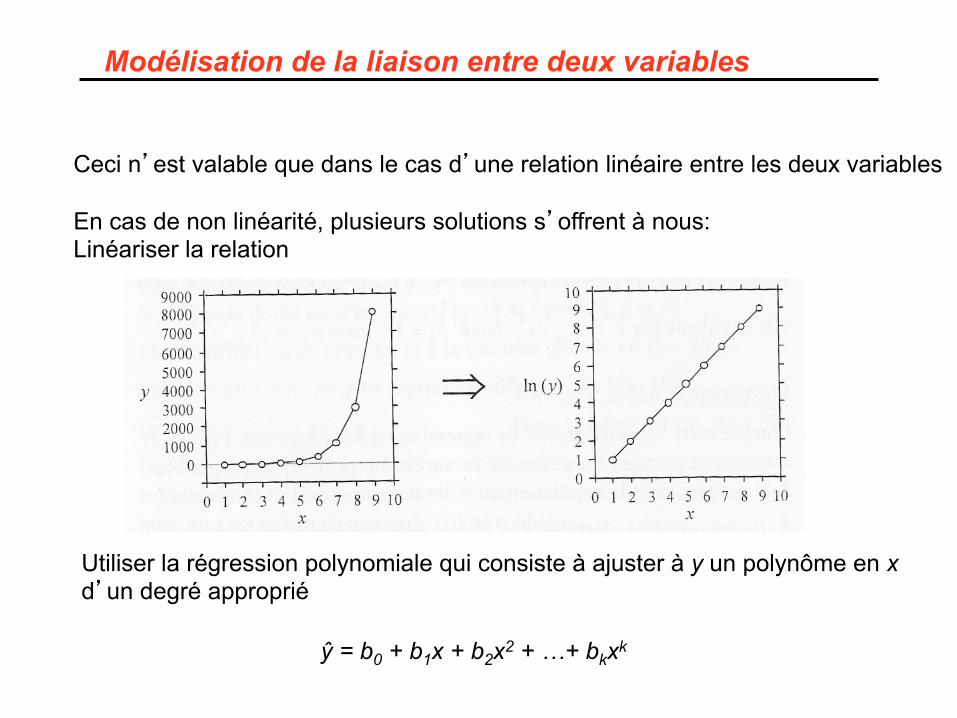
Modélisation de la liaison entre deux variables
Ceci n’est valable que dans le cas d’une relation linéaire entre les deux variables En cas de non linéarité, plusieurs solutions s’offrent à nous: Linéariser la relation
Utiliser la régression polynomiale qui consiste à ajuster à y un polynôme en x d’un degré approprié
ŷ = b0 + b1x + b2x2 + …+ bkxk
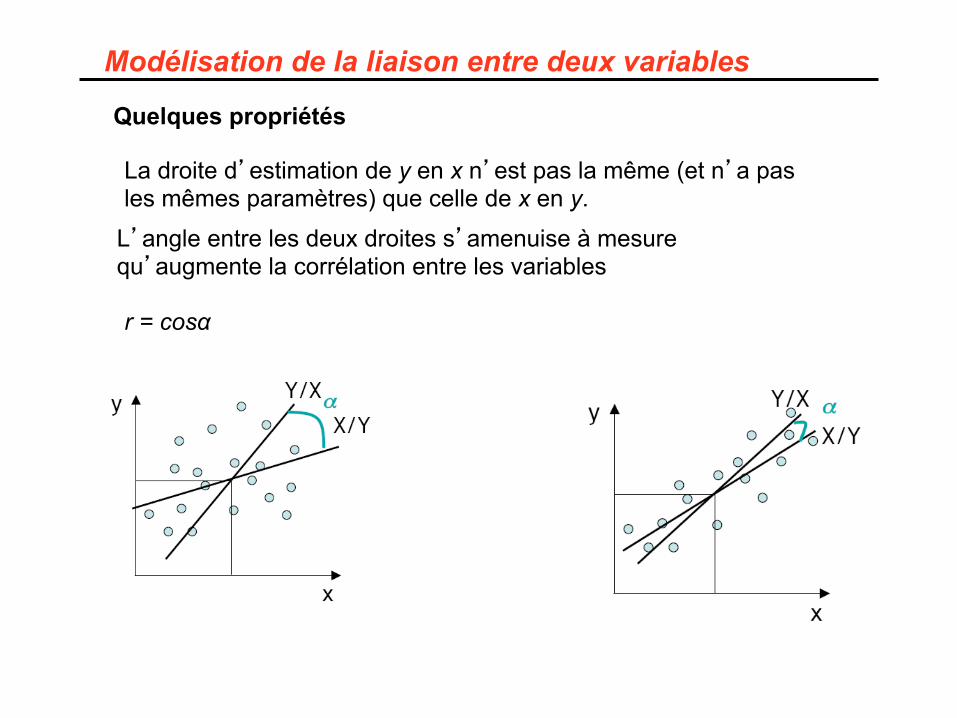
Modélisation de la liaison entre deux variables
Quelques propriétés
La droite d’estimation de y en x n’est pas la même (et n’a pas les mêmes paramètres) que celle de x en y.
L’angle entre les deux droites s’amenuise à mesure qu’augmente la corrélation entre les variables
r = cosα
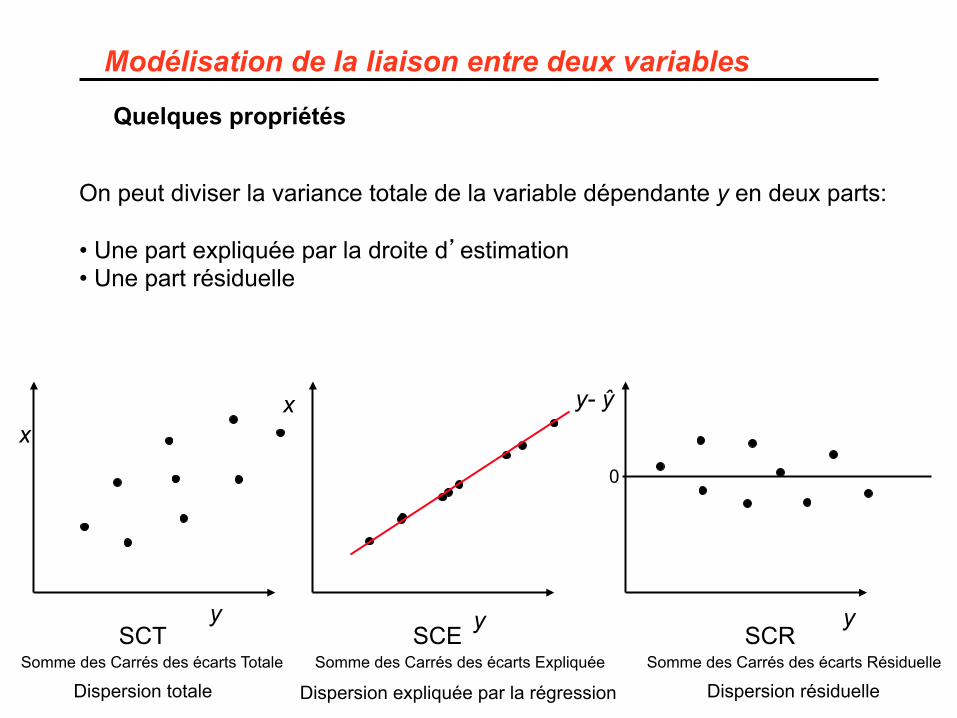
Modélisation de la liaison entre deux variables
Quelques propriétés
On peut diviser la variance totale de la variable dépendante y en deux parts: • Une part expliquée par la droite d’estimation • Une part résiduelle
0
y
y- ŷ x
y
x
y SCT Somme des Carrés des écarts Totale
Dispersion totale
SCE Somme des Carrés des écarts Expliquée
Dispersion expliquée par la régression
SCR Somme des Carrés des écarts Résiduelle
Dispersion résiduelle

Modélisation de la liaison entre deux variables
Le coefficient de détermination
Coeff. de détermination = SCE SCT = r²xy
Le coefficient de détermination mesure la proportion de la variance y expliquée par x
Par l’étude du rapport de la variance expliquée par la régression et de la variance due aux erreurs, on peut également estimer l’intervalle de confiance et tester la signification de la pente de la droite de régression. On peut aussi estimer l’intervalle de confiance de l’ordonnée à l’origine.

Modélisation de la liaison entre deux variables
En résumé:
Pour bien présenter le résultat de la liaison entre deux variables, il est important de préciser
• La taille de l’échantillon
• La valeur du coefficient de corrélation r
• La significativité du coefficient de corrélation r
• En cas de régression, l’équation de la droite du modèle linéaire
• La valeur du coefficient de détermination r²
• Eventuellement, la significativité de la pente de la droite de régression