saliency-based models of image content and their application to auto-annotation by semantic...
TRANSCRIPT

Saliency-based Models of Image Content and their
Application to Auto-Annotation by Semantic
PropagationJonathon S. Hare and Paul H. Lewis
Intelligence, Agents, Multimedia GroupDepartment of Electronics and Computer Science
University of Southampton{jsh02r, phl}@ecs.soton.ac.uk

Introduction
• Image search is much easier if all of the images in a collection have adequate annotations
• Annotating images manually is a time-consuming and laborious process
• We propose a simple method for automatic image annotation based on the idea that visually similar images should have similar annotations
• Visual similarity is assessed using local descriptors of salient regions in an information model
• We also address how the quality of the automatic annotations can be assessed

Image Auto-AnnotationPropagating the Semantics (I)• Simple idea based on propagating semantics
between visually similar images
• Image content is modelled using concepts from information theory
• Modelling the images in this way allows us to assess image similarity in a well-founded framework
• We tried two models:
• Vector-Space
• Latent Semantic Indexing

Image Auto-AnnotationPropagating the Semantics (II)• A training corpus of pre-annotated images is
created
• An unannotated image is compared to images in the training corpus using the information models to find visually similar images
• The annotations from a number of the closest visually similar images in the training corpus are then applied, or propagated, to the unannotated image

Information TheoryModelling Textual Information::vector-spaces
• A common approach to modelling documents containing textual information is to use a vector-space
• Each document is represented by a vector of term-occurrences
• Each element of the vector is the count of the number of times the corresponding term occurred in the document
• Similar documents should have similar vectors
• i.e. the angle between vectors is small

Information TheoryModelling Textual Information::latent semantic indexing
• LSI takes the vector-space model a step further
• LSI attempts to deal with issues of synonymy and polysemy between terms by using linear algebra
• Term-occurrence vectors are arranged in a term-document matrix and factored using SVD
• Using the resulting matrices from the SVD it is possible to create a rank-k estimate of the original term-document matrix
• Queries can be performed in the k-subspace instead of the original space

Modelling ImagesRepresenting Images using Textual Information Models
• Salient regions are found in the image from peaks in a difference-of-Gaussian pyramid
• Local descriptors (SIFT) are calculated for each region
• The feature descriptors are quantised by assigning them to the closest visual terms in a predefined vocabulary
• Term-occurrence vectors are calculated

ExperimentationDataset
• Test dataset consisted of 697 annotated photographic images
• Original annotations were processed to remove plurals and correct mistakes
• 170 processed annotation terms in total
• Training and test sets were created by randomly cutting the dataset into halves

ExperimentationEvaluation Technique::considerations (I)
• For any auto-annotation system to be worthwhile it must perform better than if the annotations were guessed based on the empirical distribution of keywords in the training set

ExperimentationEvaluation Technique::considerations (II)
• Images in the training set may have been incorrectly annotated
• For comparative purposes this is not a problem as all algorithms have to deal with the same data
• However, the reported overall performance is likely to be less than it would be with correct annotations

ExperimentationEvaluation Technique::performance measure
• A reasonable assumption to make of an annotation algorithm should be that it will return approximately the correct number of annotations
• Previous auto-annotation work has used the normalised score measure developed by Barnard et al.
• However, this measure does not sufficiently weight incorrect guesses, resulting in many more guessed annotations than correct annotations when the score is maximised
r = Number of correctly predicted annotations
n = Number of actual true annotations
w = Number of wrongly predicted annotations
N = Number of terms in annotation vocabulary

ExperimentationEvaluation Technique::performance measure
• We have instead adopted the use of precision and recall to measure performance
• Unlike in retrieval, we want both high precision and high recall
r = Number of correctly predicted annotations
n = Number of actual true annotations
w = Number of wrongly predicted annotations
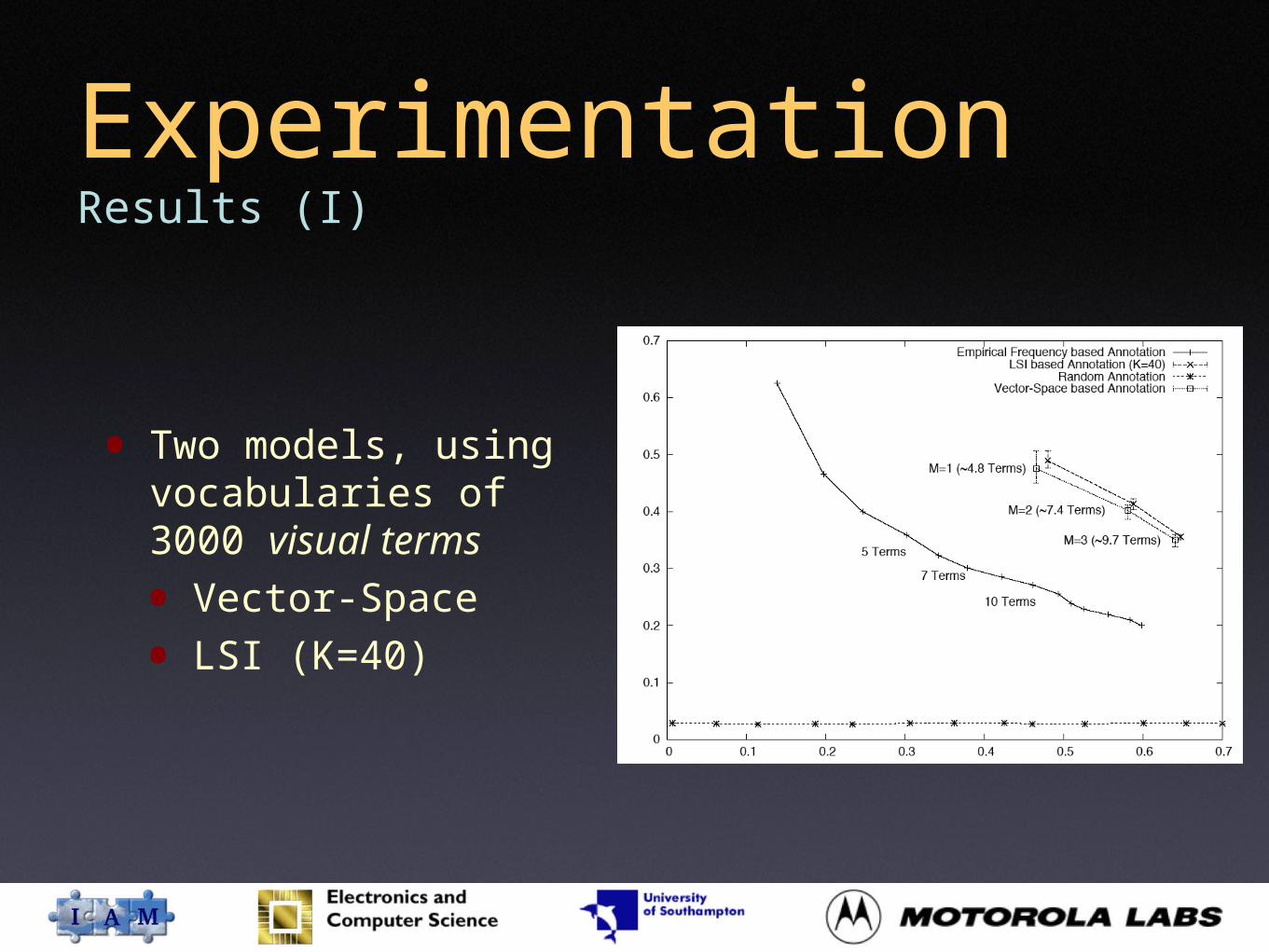
ExperimentationResults (I)
• Two models, using vocabularies of 3000 visual terms
• Vector-Space
• LSI (K=40)
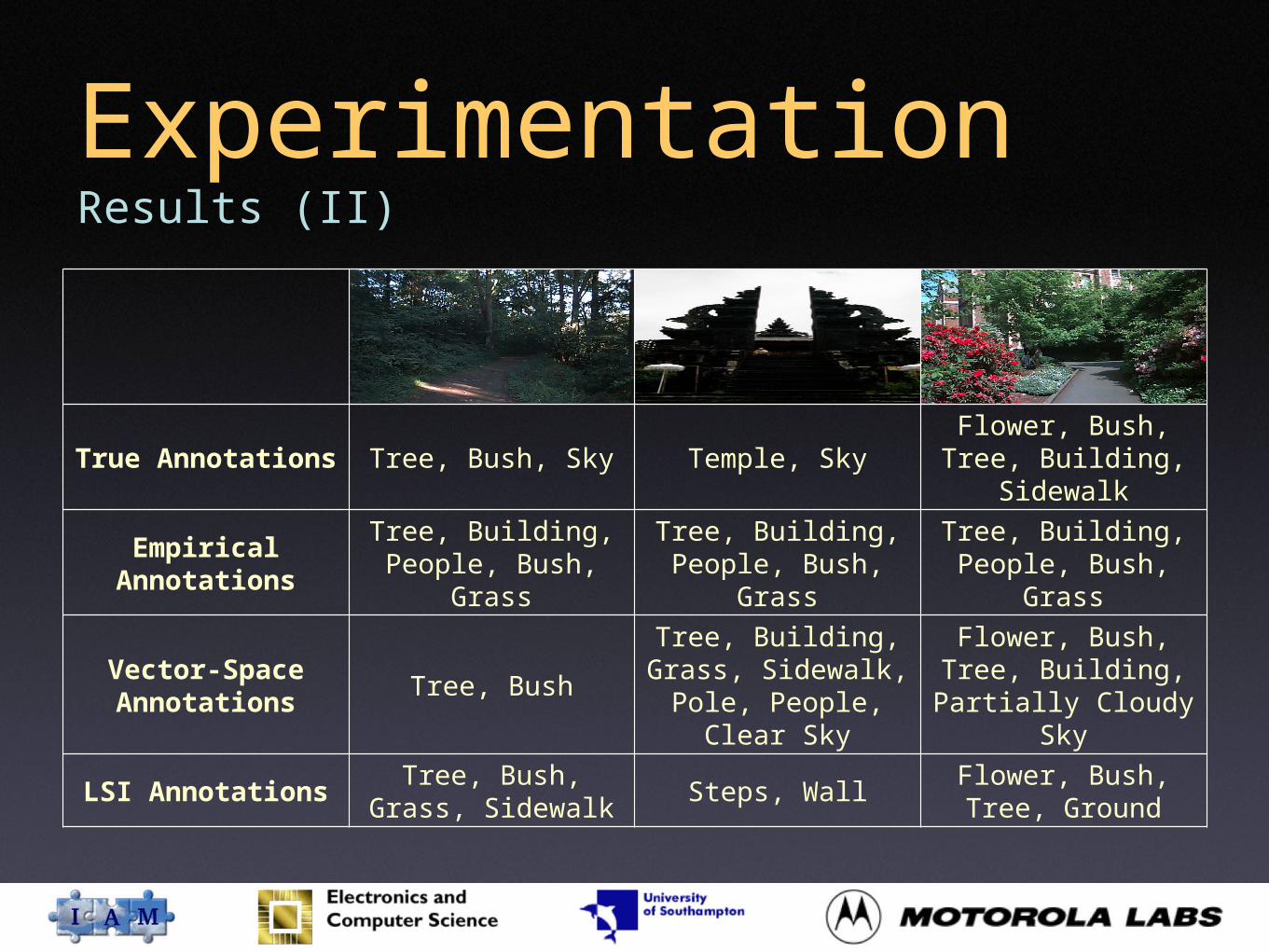
ExperimentationResults (II)
True Annotations Tree, Bush, Sky Temple, SkyFlower, Bush, Tree, Building, Sidewalk
Empirical Annotations
Tree, Building, People, Bush, Grass
Tree, Building, People, Bush, Grass
Tree, Building, People, Bush, Grass
Vector-Space Annotations
Tree, Bush
Tree, Building, Grass, Sidewalk,
Pole, People, Clear Sky
Flower, Bush, Tree, Building, Partially
Cloudy Sky
LSI AnnotationsTree, Bush, Grass,
SidewalkSteps, Wall
Flower, Bush, Tree, Ground

Future Work(I)
• Our current annotation approach is slightly deficient in that it doesn’t allow us to select individual terms
• This needs to be addressed
• This work used a fixed number of images from which to draw the annotations
• It is possible that this number could be chosen dynamically for each unannotated image, based on the similarity between its vector representation and the vectors of the training images

Future Work(II)
• The SIFT local descriptor is generated from grey-level information only
• The addition of other local descriptors may improve performance
• A local colour descriptor is currently planned

Conclusions
• The results show promise for our relatively simple auto-annotation technique
• The LSI based method marginally outperforms the vector-space approach
• This result confirms the findings of our work on image retrieval using the two approaches