risc vs cisc Ð iron lawelec3441/sp19/handout/l05-pipeline-4up.pdf · computer architecture...
TRANSCRIPT
Computer Architecture
ELEC3441
Lecture 5 – Pipelining
Dr. Hayden Kwok-Hay So
Department of Electrical and
Electronic Engineering
RISC vs CISC – Iron Law
2nd sem., '18-19 ENGG3441 - HS 2
Microarchitecture CPI Cycle Time
CISC >1 short
RISC – single cycle unpipelined
1 long
RISC – pipelined 1 short
CPUTime =# of instruction
program×
# of cycle
instruction×
time
cycle
L4
L5,6
Pipeline Motivation – Buying
Food from Canteen
n Getting food from canteen involves 3 steps:• Place order (P)
• Pickup food (F)
• Pickup drink (D)
n If there is only 1 customer:• P è F è D
n How to serve 2 customer?
2nd sem., '18-19 ENGG3441 - HS 3
time
Order Food Drink Order Food Drink
Order Food Drink1 customer
2 customers
Slow
Food Ordering – Pipeline
n Serving one after one è Slow:• Assume each step take 1 unit of time, then
• N customers è 3N units of time
n Better solution: Pipeline• Overlap different steps in parallel
• N customers è 2 + N units of time
2nd sem., '18-19 ENGG3441 - HS 4
timeP F D
4 customers(pipeline)
4 customers(no pipeline)
P F D P F D P F D
P F D
P F D
P F D
P F D
Pre-requisite: All steps
must be able to operate
independently in parallel
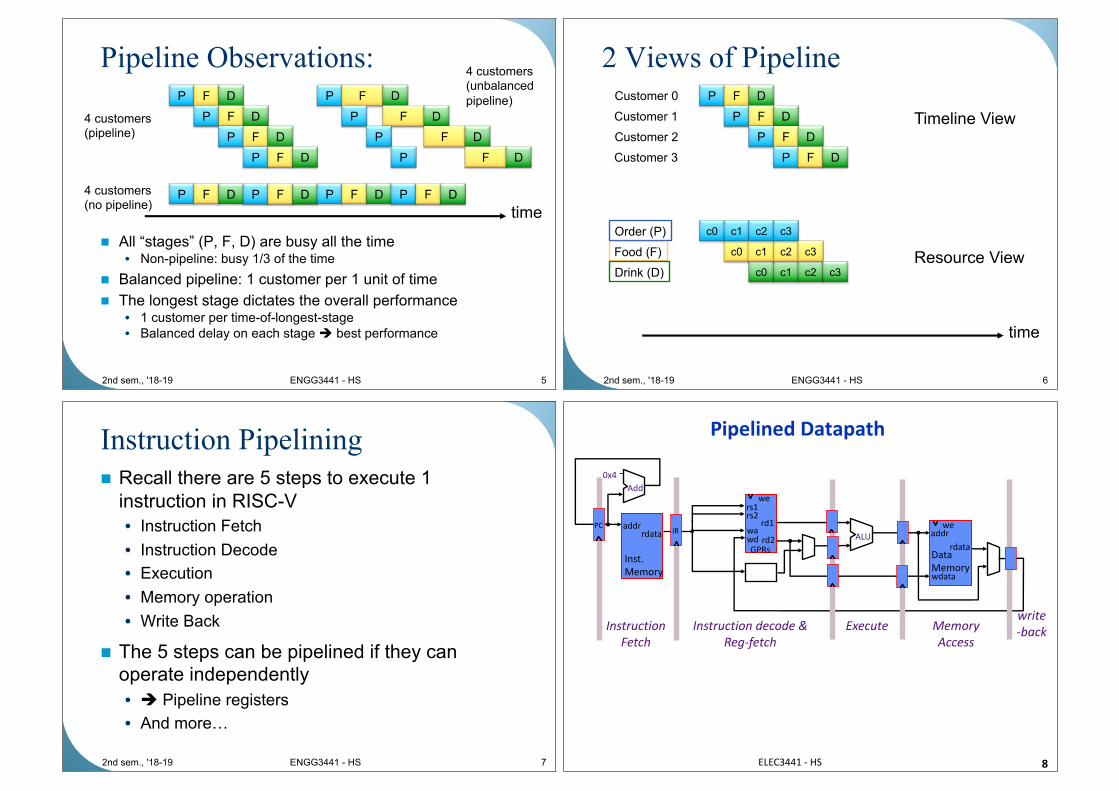
Pipeline Observations:
n All “stages” (P, F, D) are busy all the time• Non-pipeline: busy 1/3 of the time
n Balanced pipeline: 1 customer per 1 unit of time
n The longest stage dictates the overall performance• 1 customer per time-of-longest-stage
• Balanced delay on each stage è best performance
2nd sem., '18-19 ENGG3441 - HS 5
timeP F D
4 customers(pipeline)
4 customers(no pipeline)
P F D P F D P F D
P F D
P F D
P F D
P F D
P F D
P F D
P F D
P F D
4 customers(unbalanced
pipeline)
2 Views of Pipeline
2nd sem., '18-19 ENGG3441 - HS 6
Customer 0 P F D
P F DCustomer 1
P F DCustomer 2
P F DCustomer 3
c0
c0
c0
c1
c1
c1
c2
c2
c2
c3
c3
c3
Order (P)
Food (F)
Drink (D)Resource View
Timeline View
time
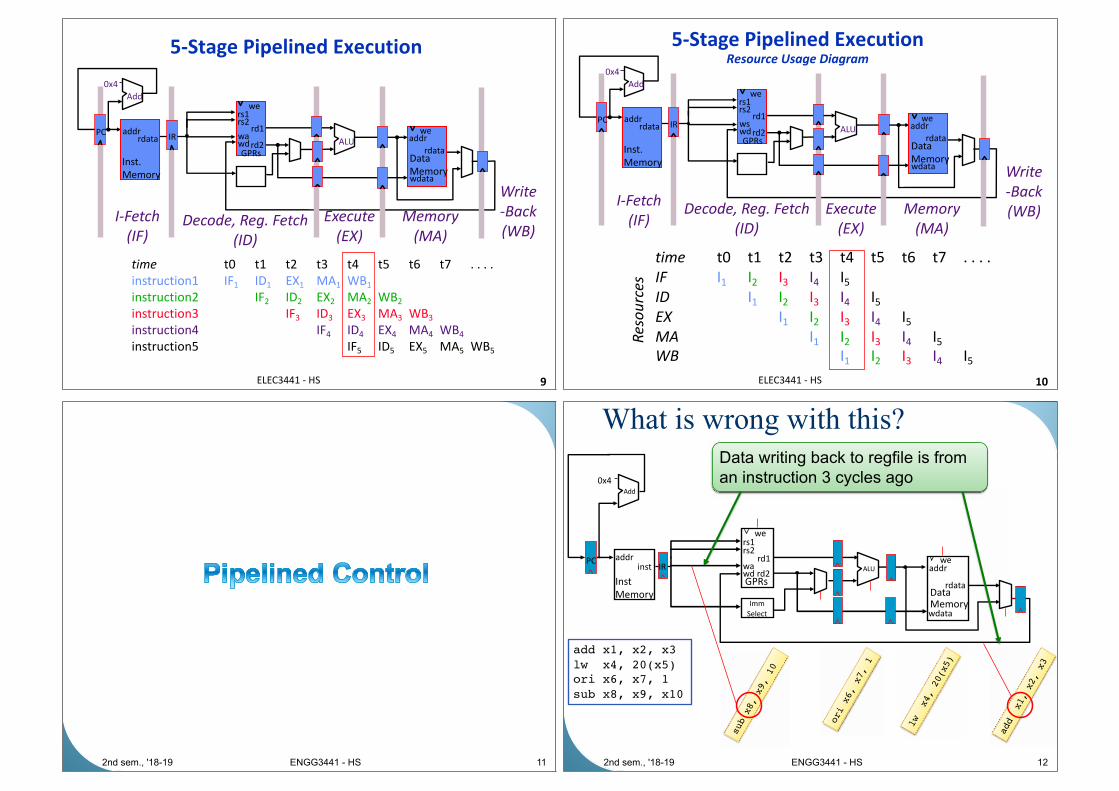
Instruction Pipelining
n Recall there are 5 steps to execute 1
instruction in RISC-V
• Instruction Fetch
• Instruction Decode
• Execution
• Memory operation
• Write Back
n The 5 steps can be pipelined if they can
operate independently
• è Pipeline registers
• And more…
2nd sem., '18-19 ENGG3441 - HS 7 ELEC3441 - HS
Pipelined Datapath
8
write
-backInstruction
Fetch
ExecuteInstruction decode &
Reg-fetch
Memory
Access
addr
wdata
rdataData
Memory
we
ALU
0x4
Add
addrrdata
Inst.
Memory
rd1
GPRs
rs1rs2
wawd rd2
we
IRPC
ELEC3441 - HS
5-Stage Pipelined Execution
9
time t0 t1 t2 t3 t4 t5 t6 t7 . . . .
instruction1 IF1 ID1 EX1 MA1 WB1
instruction2 IF2 ID2 EX2 MA2 WB2
instruction3 IF3 ID3 EX3 MA3 WB3
instruction4 IF4 ID4 EX4 MA4 WB4
instruction5 IF5 ID5 EX5 MA5 WB5
Write
-Back
(WB)I-Fetch
(IF)
Execute
(EX)Decode, Reg. Fetch
(ID)
Memory
(MA)
addr
wdata
rdataData
Memory
we
ALU
0x4
Add
addrrdata
Inst.
Memory
rd1
GPRs
rs1rs2
wawdrd2
we
IRPC
ELEC3441 - HS
5-Stage Pipelined ExecutionResource Usage Diagram
10
time t0 t1 t2 t3 t4 t5 t6 t7 . . . .
IF I1 I2 I3 I4 I5
ID I1 I2 I3 I4 I5
EX I1 I2 I3 I4 I5
MA I1 I2 I3 I4 I5
WB I1 I2 I3 I4 I5
Re
sou
rce
s
Write
-Back
(WB)I-Fetch
(IF)Execute
(EX)
Decode, Reg. Fetch
(ID)
Memory
(MA)
addr
wdata
rdataData
Memory
we
ALU
0x4
Add
addrrdata
Inst.
Memory
rd1
GPRs
rs1rs2
wswdrd2
we
IRPC
2nd sem., '18-19 ENGG3441 - HS 11
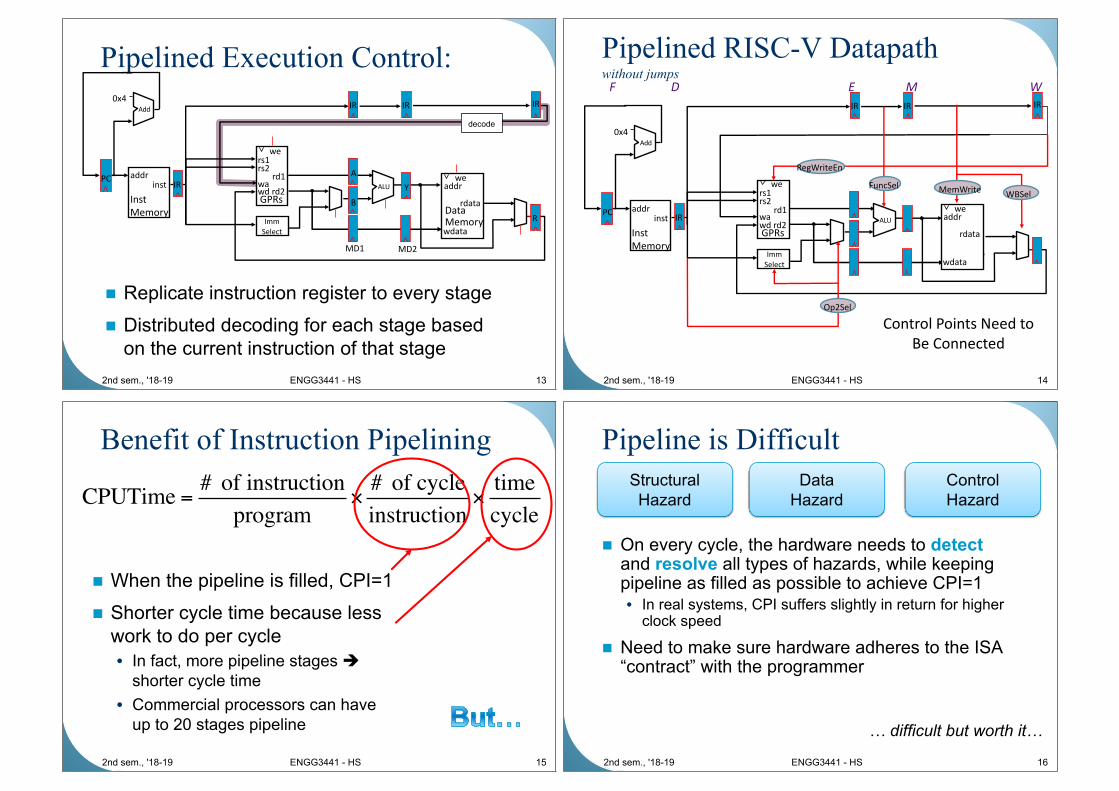
What is wrong with this?
12
PC addrinst
Inst
Memory
0x4
Add
IR
Imm
Select
ALU
rd1
GPRs
rs1rs2
wawd rd2
we
wdata
addr
wdata
rdataData Memory
we
Data writing back to regfile is from
an instruction 3 cycles ago
add x1, x2, x3
lw x4, 20(x5)
ori x6, x7, 1
sub x8, x9, x10
add x1, x2, x3
lw
x4, 20(x5)
orix6, x7, 1
sub x8, x9, 10
2nd sem., '18-19 ENGG3441 - HS
Pipelined Execution Control:
n Replicate instruction register to every stage
n Distributed decoding for each stage based
on the current instruction of that stage
13
IRIR IR
PCA
B
Y
R
MD1 MD2
addrinst
Inst
Memory
0x4
Add
IR
Imm
Select
ALU
rd1
GPRs
rs1rs2
wawd rd2
we
wdata
addr
wdata
rdataData Memory
we
decode
2nd sem., '18-19 ENGG3441 - HS
Pipelined RISC-V Datapathwithout jumps
14
IRIR IR
PC addrinst
Inst
Memory
0x4Add
IR
Imm
Select
ALU
rd1
GPRs
rs1rs2
wawd rd2
we
Data Memorywdata
addr
wdata
rdata
we
FuncSelWBSel
MemWrite
RegWriteEn
F D E M W
Control Points Need to
Be Connected
Op2Sel
2nd sem., '18-19 ENGG3441 - HS
Benefit of Instruction Pipelining
n When the pipeline is filled, CPI=1
n Shorter cycle time because less
work to do per cycle
• In fact, more pipeline stages è
shorter cycle time
• Commercial processors can have
up to 20 stages pipeline
15
CPUTime =# of instruction
program×
# of cycle
instruction×
time
cycle
2nd sem., '18-19 ENGG3441 - HS
Pipeline is Difficult
n On every cycle, the hardware needs to detectand resolve all types of hazards, while keeping pipeline as filled as possible to achieve CPI=1• In real systems, CPI suffers slightly in return for higher
clock speed
n Need to make sure hardware adheres to the ISA “contract” with the programmer
2nd sem., '18-19 ENGG3441 - HS 16
Structural
Hazard
Data
Hazard
Control
Hazard
… difficult but worth it…

Structural Hazard
n Structural hazard arises when more than 1
pipeline stages require access to the same
physical hardware
n Solutions:
1. Add extra copies of the resource
2. Change resource so that it can handle concurrent use
3. Require different stages to access hardware at
different time
• Stall one (some) of the conflicting stages
• Avoid the concurrent use
2nd sem., '18-19 ENGG3441 - HS 17
Structural Hazard Ex – Memory n Physically there is only 1
main memory in a computer• Holds instruction and data
n During run-time, both IF and MEM stages need access to the main memory• è structural hazard
n Solution so far: “replicate” the memory• Instruction + Data memory
• Reality: Inst + Data Cache
2nd sem., '18-19 ENGG3441 - HS 18
i0 i1 i2 i3 i4 i5
i0 i1 i2 i3 i4 i5
i0 i1 i2 i3 i4 i5
i0 i1 i2 i3 i4 i5
i0 i1 i2 i3 i4 i5
IF
ID
EX
MEM
WB
t0 t1 t2 t3 t4 t5 t6 t7 t8 t9
Structural Hazard Ex – Regfilen Physically there is only
1 register file
n During run-time, there are chances that both ID and WB stages need access to the regfile• ID: read regfile (rs1, rs2)
• WB: write regfile (rd)
• è structural hazard
n Solution so far: regfilesupports concurrent read and write
2nd sem., '18-19 ENGG3441 - HS 19
i0 i1 i2 i3 i4 i5
i0 i1 i2 i3 i4 i5
i0 i1 i2 i3 i4 i5
i0 i1 i2 i3 i4 i5
i0 i1 i2 i3 i4 i5
IF
ID
EX
MEM
WB
t0 t1 t2 t3 t4 t5 t6 t7 t8 t9
2nd sem., '18-19 ENGG3441 - HS 20

Data Hazardn Data hazard arises when pipeline stages
access data location in ways that are incompatible with the ISA contract with the programmer
n Technically 3 types of hazards• Read After Write hazards (RAW)
• Write After Read hazards (WAR)
• Write After Write hazards (WAW)
n What may go wrong?• RAW: a later read happens before an earlier write
• WAR: a later write happens before an earlier read
• WAW: a later write happens before an earlier write
n Data hazard happens on register AND memory locations
n In our 5-stage pipeline, only RAW can happen
2nd sem., '18-19 ENGG3441 - HS 21
x1 ß x0 + 10
x4 ß x1 + 17
x4 ß x2 + x3
x2 ß x4 + 1
RAW
WAWWAR
ELEC3441 - HS
Data Hazard Example
22
time t0 t1 t2 t3 t4 t5 t6 t7 . . . .
x1 ß x0 + 10 IF1 ID1 EX1 MA1 WB1
x4 ß x1 + 17 IF2 ID2 EX2 MA2 WB2
Write
-Back
(WB)I-Fetch
(IF)
Execute
(EX)Decode, Reg. Fetch
(ID)
Memory
(MA)
addr
wdata
rdataData
Memory
we
ALU
0x4
Add
addrrdata
Inst.
Memory
rd1
GPRs
rs1rs2
wawdrd2
we
IRPC
new val of x1 calculated
writes val of x1
old val of x1 read
Resolving Data Hazards
n Strategy 1: Stalling
• Wait for the result to be available by freezing
earlier pipeline stages
• è Interlocks
n Strategy 2: Data Forwarding
• Route data as soon as possible after it is calculated to the earlier pipeline stage
• è bypass
232nd sem., '18-19 ENGG3441 - HS
Feedback to Resolve Hazards
§ Later stages provide dependence information to
earlier stages which can stall (or kill) instructions
24
FB1
stage1
stage2
stage3
stage4
FB2 FB3 FB4
• Controlling a pipeline in this manner works provided the instruction at stage i+1 can complete without any interference from instructions in stages 1 to i
(otherwise deadlocks may occur)
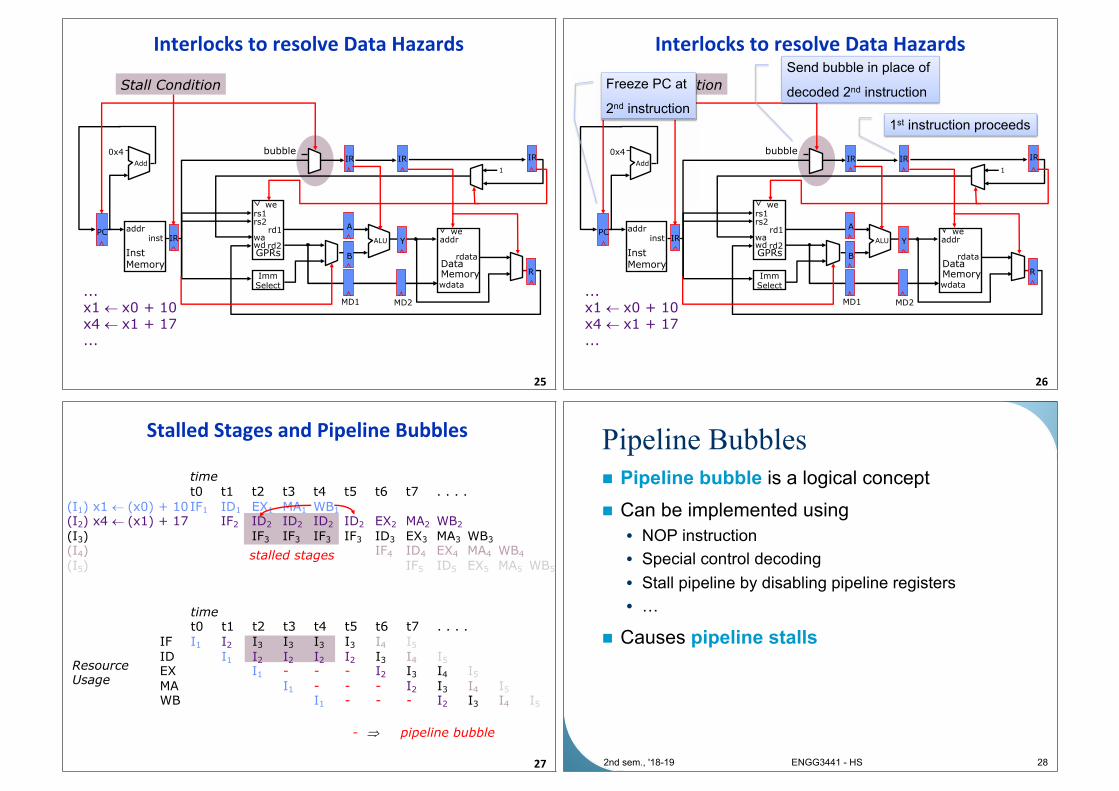
Interlocks to resolve Data Hazards
25
IRIR IR
1
PCA
B
Y
R
MD1 MD2
addrinst
Inst
Memory
0x4
Add
IR
ImmSelect
ALU
rd1
GPRs
rs1rs2
wawd rd2
we
wdata
addr
wdata
rdataData Memory
we
bubble
...
x1 ¬ x0 + 10
x4 ¬ x1 + 17
...
Stall Condition
Interlocks to resolve Data Hazards
26
IRIR IR
1
PCA
B
Y
R
MD1 MD2
addrinst
Inst
Memory
0x4
Add
IR
ImmSelect
ALU
rd1
GPRs
rs1rs2
wawd rd2
we
wdata
addr
wdata
rdataData Memory
we
bubble
...
x1 ¬ x0 + 10
x4 ¬ x1 + 17
...
Stall Condition
Send bubble in place of
decoded 2nd instruction
1st instruction proceeds
Freeze PC at
2nd instruction
Stalled Stages and Pipeline Bubbles
27
stalled stages
timet0 t1 t2 t3 t4 t5 t6 t7 . . . .
IF I1 I2 I3 I3 I3 I3 I4 I5
ID I1 I2 I2 I2 I2 I3 I4 I5
EX I1 - - - I2 I3 I4 I5
MA I1 - - - I2 I3 I4 I5
WB I1 - - - I2 I3 I4 I5
time
t0 t1 t2 t3 t4 t5 t6 t7 . . . .
(I1) x1 ¬ (x0) + 10IF1 ID1 EX1 MA1 WB1
(I2) x4 ¬ (x1) + 17 IF2 ID2 ID2 ID2 ID2 EX2 MA2 WB2
(I3) IF3 IF3 IF3 IF3 ID3 EX3 MA3 WB3
(I4) IF4 ID4 EX4 MA4 WB4
(I5) IF5 ID5 EX5 MA5 WB5
Resource Usage
- Þ pipeline bubble
Pipeline Bubbles
n Pipeline bubble is a logical concept
n Can be implemented using
• NOP instruction
• Special control decoding
• Stall pipeline by disabling pipeline registers
• …
n Causes pipeline stalls
282nd sem., '18-19 ENGG3441 - HS

Bubbles turns into NOPs
2nd sem., '18-19 ENGG3441 - HS 29
addi x1, x0, 10
addi x4, x1, 17
ori x6, x7, 1
sub x8, x9, x10
addi x1, x0, 10
NOP
NOP
NOP
addi x4, x1, 17
ori x6, x7, 1
sub x8, x9, x10
Hazards due to Loads & Stores
30
...
M[x1+7] ß x2
x4 ß M[x3+5]
...
IRIR IR
1
PCA
B
Y
R
MD1 MD2
addrinst
Inst
Memory
0x4Add
IR
Imm
Select
ALU
rd1
GPRs
rs1rs2
wawd rd2
we
wdata
addr
wdata
rdataData Memory
we
bubble
Stall Condition
Is there any possible data hazard
in this instruction sequence?
What if
x1+7 = x3+5 ?
Load & Store Hazards
31
However, the hazard is avoided because our memory
system completes writes in one cycle !
Load/Store hazards are sometimes resolved in the
pipeline and sometimes in the memory system itself.
More on this later in the course.
...
M[x1+7] ß x2
x4 ß M[x3+5]
...
x1+7 = x3+5 è data hazard
Pipeline CPI Examples
32
Time
3 instructions finish in 3 cycles
CPI = 3/3 =1
Inst 1
Inst 2
Inst 3
3 instructions finish in 4 cycles
CPI = 4/3 = 1.33
Inst 1
Inst 2
Inst 3
Bubble
Inst 1
Inst 2
Inst 3
Bubble 1
Bubble 2
Measure from when first instruction finishes
to when last instruction in sequence finishes.
3 instructions finish in 5cycles
CPI = 5/3 = 1.67
Inst 3
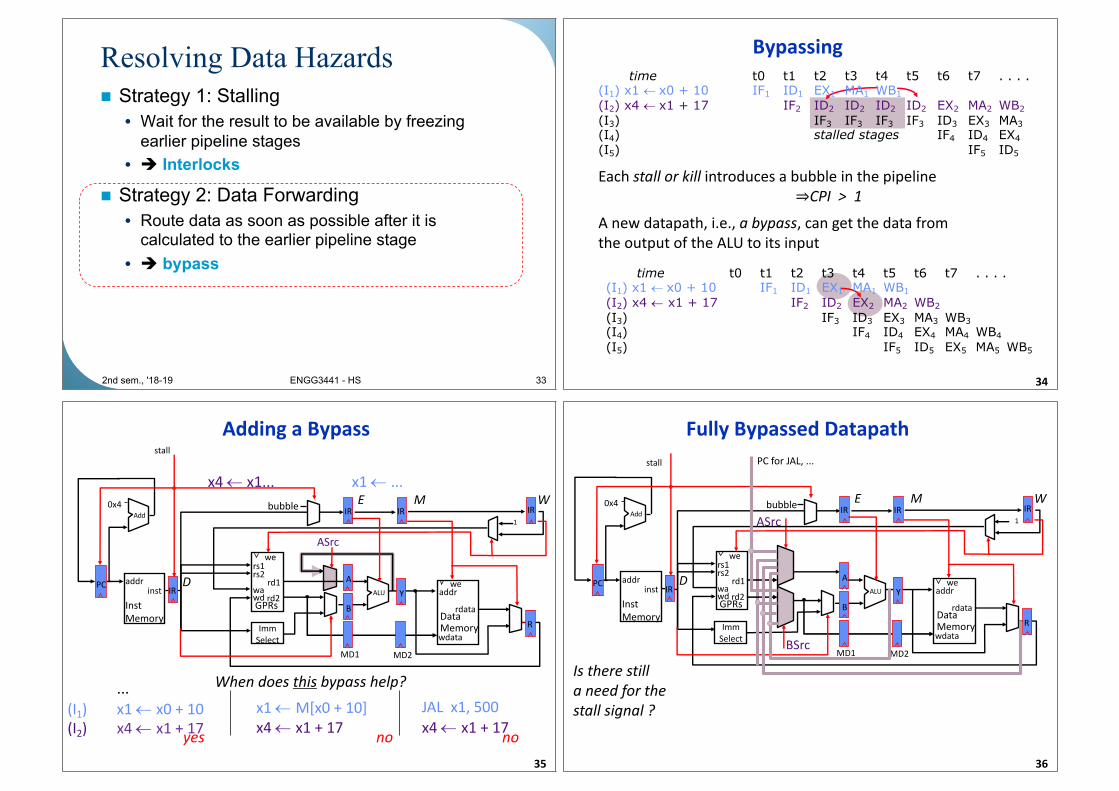
Resolving Data Hazards
n Strategy 1: Stalling
• Wait for the result to be available by freezing
earlier pipeline stages
• è Interlocks
n Strategy 2: Data Forwarding
• Route data as soon as possible after it is calculated to the earlier pipeline stage
• è bypass
332nd sem., '18-19 ENGG3441 - HS
Bypassing
34
Each stall or kill introduces a bubble in the pipeline
⇒CPI > 1
time t0 t1 t2 t3 t4 t5 t6 t7 . . . .(I1) x1 ¬ x0 + 10 IF1 ID1 EX1 MA1 WB1
(I2) x4 ¬ x1 + 17 IF2 ID2 ID2 ID2 ID2 EX2 MA2 WB2
(I3) IF3 IF3 IF3 IF3 ID3 EX3 MA3
(I4) stalled stages IF4 ID4 EX4
(I5) IF5 ID5
time t0 t1 t2 t3 t4 t5 t6 t7 . . . .(I1) x1 ¬ x0 + 10 IF1 ID1 EX1 MA1 WB1
(I2) x4 ¬ x1 + 17 IF2 ID2 EX2 MA2 WB2
(I3) IF3 ID3 EX3 MA3 WB3
(I4) IF4 ID4 EX4 MA4 WB4
(I5) IF5 ID5 EX5 MA5 WB5
A new datapath, i.e., a bypass, can get the data from
the output of the ALU to its input
Adding a Bypass
35
ASrc
...
(I1) x1 ¬ x0 + 10
(I2) x4 ¬ x1 + 17
x4 ¬ x1...� x1 ¬ ...
IRIR IR
PCA
B
Y
R
MD1 MD2
addrinst
Inst
Memory
0x4Add
IR
Imm
Select
ALU
rd1
GPRs
rs1rs2
wawd rd2
we
wdata
addr
wdata
rdataData Memory
we
1
bubble
stall
D
E M W
When does this bypass help?
x1 ¬ M[x0 + 10]
x4 ¬ x1 + 17
JAL x1, 500
x4 ¬ x1 + 17yes no no
Fully Bypassed Datapath
36
ASrcIRIR IR
PCA
B
Y
R
MD1 MD2
addrinst
Inst
Memory
0x4Add
IR ALU
Imm
Select
rd1
GPRs
rs1rs2
wawd rd2
we
wdata
addr
wdata
rdataData Memory
we
1
bubble
stall
D
E M W
PC for JAL, ...
BSrc
Is there still
a need for the
stall signal ?
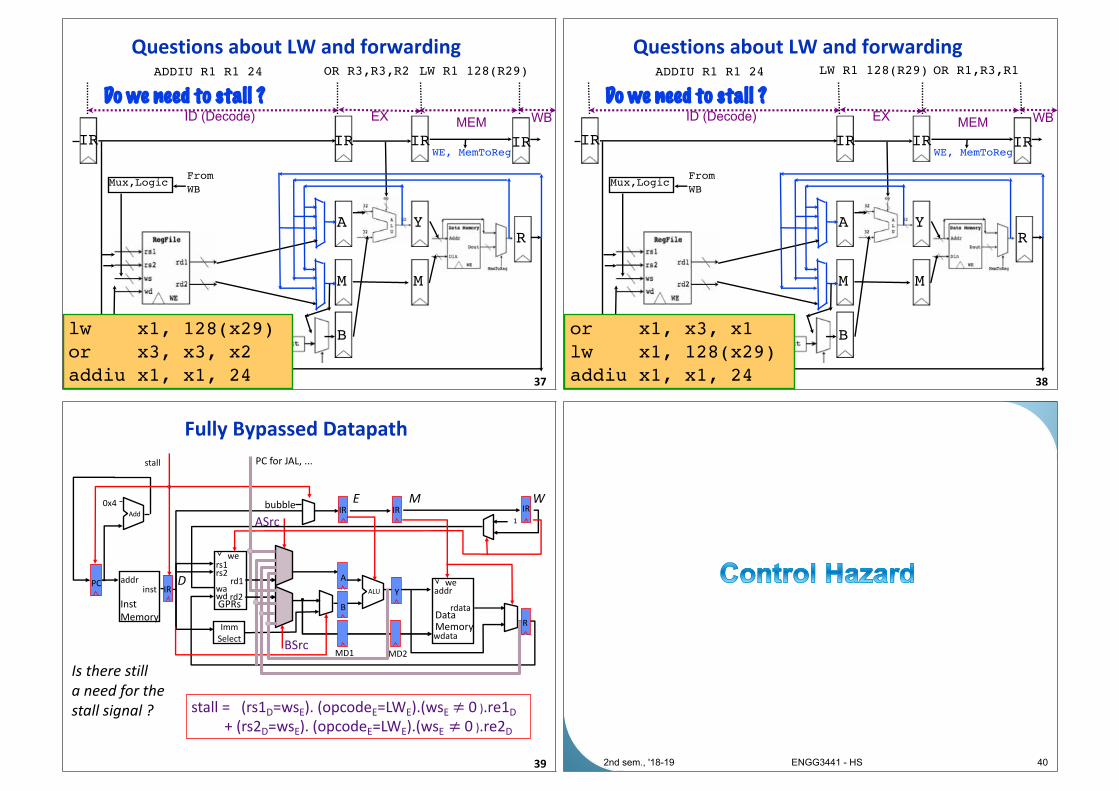
Mux,Logic
IR IR
B
A
M
IR
Y
M
IR
R
WE, MemToReg
ID (Decode) EXMEM WB
From
WB
ADDIU R1 R1 24 LW R1 128(R29)
Do we need to stall ?
OR R3,R3,R2
Questions about LW and forwarding
37
lw x1, 128(x29)
or x3, x3, x2
addiu x1, x1, 24
Mux,Logic
IR IR
B
A
M
IR
Y
M
IR
R
WE, MemToReg
ID (Decode) EXMEM WB
From
WB
ADDIU R1 R1 24 LW R1 128(R29)
Do we need to stall ?
OR R1,R3,R1
Questions about LW and forwarding
38
or x1, x3, x1
lw x1, 128(x29)
addiu x1, x1, 24
Fully Bypassed Datapath
39
ASrcIRIR IR
PCA
B
Y
R
MD1 MD2
addrinst
Inst
Memory
0x4Add
IR ALU
Imm
Select
rd1
GPRs
rs1rs2
wawd rd2
we
wdata
addr
wdata
rdataData Memory
we
1
bubble
stall
D
E M W
PC for JAL, ...
BSrc
Is there still
a need for the
stall signal ? stall = (rs1D=wsE). (opcodeE=LWE).(wsE ≠ 0 ).re1D
+ (rs2D=wsE). (opcodeE=LWE).(wsE ≠ 0 ).re2D
2nd sem., '18-19 ENGG3441 - HS 40

Control Hazard
n Control hazards occur as a result of branches and jumps• next instruction not necessarily at PC+4
n Unconditional jumps:• Next instruction is determined by the jump instruction
n Conditional branches:• Next instruction depends on result of branch comparison
n Possible solutions:• Stall
• Change ISA
• (forward)• Speculation
n Important questions to ask yourself:
2nd sem., '18-19 ENGG3441 - HS 41
When do we know the address of next instruction to execute?
What happen to the instructions in the rest of the pipeline?
PCPC
Pipelining Branches
42
IR
PC addrinst
Inst
Memory
0x4
Add
IR
Imm
Select
ALU
rd1
GPRs
rs1rs2
wawd rd2
we
wdata
addr
wdata
rdata
we
F D E M W
Bcomp?Br Logic
Add
PCSel
Data Memory
Calc target addr
Take branch?
Select correct target depending on Bcomp
Challenge: Does not know target address until EX stage
IR IR
2nd sem., '18-19 ENGG3441 - HS
Not so good solution – Stalling
n Stalling:• Wait 2 cycles
• Fetch the correct target after address calculation is completed in EX stage
n Stalling doesn’t quite work:• The hardware doesn’t know it is a branch instruction until ID
stage è What should happen at t2?
• Huge performance penalty if hardware always stall 2 cycles regardless of instruction è 3x cycle time
2nd sem., '18-19 ENGG3441 - HS 43
time
t0 t1 t2 t3 t4 t5 t6 t7 . . . .
(I1) 096: ADD IF1 ID1 EX1 MA1 WB1
(I2) 100: BEQ +200 IF2 ID2 EX2 MA2 WB2
(I3) 104: ADD - - - - -
(I4) 108: ADD - - - - - -(I5) 300: SUB IF5 ID5 EX5 MA5 WB5
Solution 1: Change ISA
n Expose the fact that there is pipeline in hardware
n Change ISA: The 2 instructions following branch
will ALWAYS be executed regardless of the
branch comparison result
n The extra cycle when an instruction is always
executed regardless of the comparison result is
called a branch delay slot
n Compiler may insert useful instructions in the
branch delay slot or NOPs
• e.g. instruction that may be executed regardless of the
branch target
2nd sem., '18-19 ENGG3441 - HS 44

Branch Delay Slot Example
n Instructions in delay slot must not affect the
branch decision
• e.g. in above: they cannot modify x1
n Is the value of x4 ok?
2nd sem., '18-19 ENGG3441 - HS 45
addi x2, x1, 4
lw x4, 16(x2)
beq x1, x0, err
ok: add x5, x3, x4
ori x6, x0, 23
…
err: sub x5, x3, x4
beq x1, x0, err
addi x2, x1, 4
lw x4, 16(x2)
ok: add x5, x3, x4
ori x6, x0, 23
…
err: sub x5, x3, x4
delayslot
Original Rearranged
Real Processor: MIPS-I
n The first generation of MIPS processor has 1
delay slot defined
n Brach decision is moved to ID stage
• Only support very simple branch:
• beqz on 1 register
n Compiler must find instruction to fill the delay
slot or put NOP
2nd sem., '18-19 ENGG3441 - HS 46
Microprocessor without
Interlocked Pipeline Stages
Solution 2: Speculate + Killn Step 1: Speculate that the instruction in delay
slots will be executed.
n Step 2: Determine at EX stage:• if branch taken, then kill the instructions in IF and
ID stage
• if branch not taken, then do nothing
n Pro: Waste cycles only in cases when branch taken
n Cons: complicate hardware• interact with stall
• Branch/Jump in delay slots?
2nd sem., '18-19 ENGG3441 - HS 47
Killing instructions in IF, ID
2nd sem., '18-19 ENGG3441 - HS 48
time
t0 t1 t2 t3 t4 t5 t6 t7 . . . .
(I1) 096: ADD IF1 ID1 EX1 MA1 WB1
(I2) 100: BEQ +200 IF2 ID2 EX2 MA2 WB2
(I3) 104: ADD IF3 ID3 - - -
(I4) 108: ADD IF4 - - - - -(I5) 300: SUB IF5 ID5 EX5 MA5 WB5
time
t0 t1 t2 t3 t4 t5 t6 t7 . . . .
(I1) 096: ADD IF1 ID1 EX1 MA1 WB1
(I2) 100: BEQ +200 IF2 ID2 EX2 MA2 WB2
(I3) 104: ADD IF3 ID3 EX3 MA3 WB3
(I4) 108: ADD IF4 ID4 EX4 MA4 WB4
(I5) 112: SLL IF5 ID5 EX5 MA5 WB5
Branch taken
Kill instructions
in pipeline
Branch not taken
Instructions
continue
new
instruction
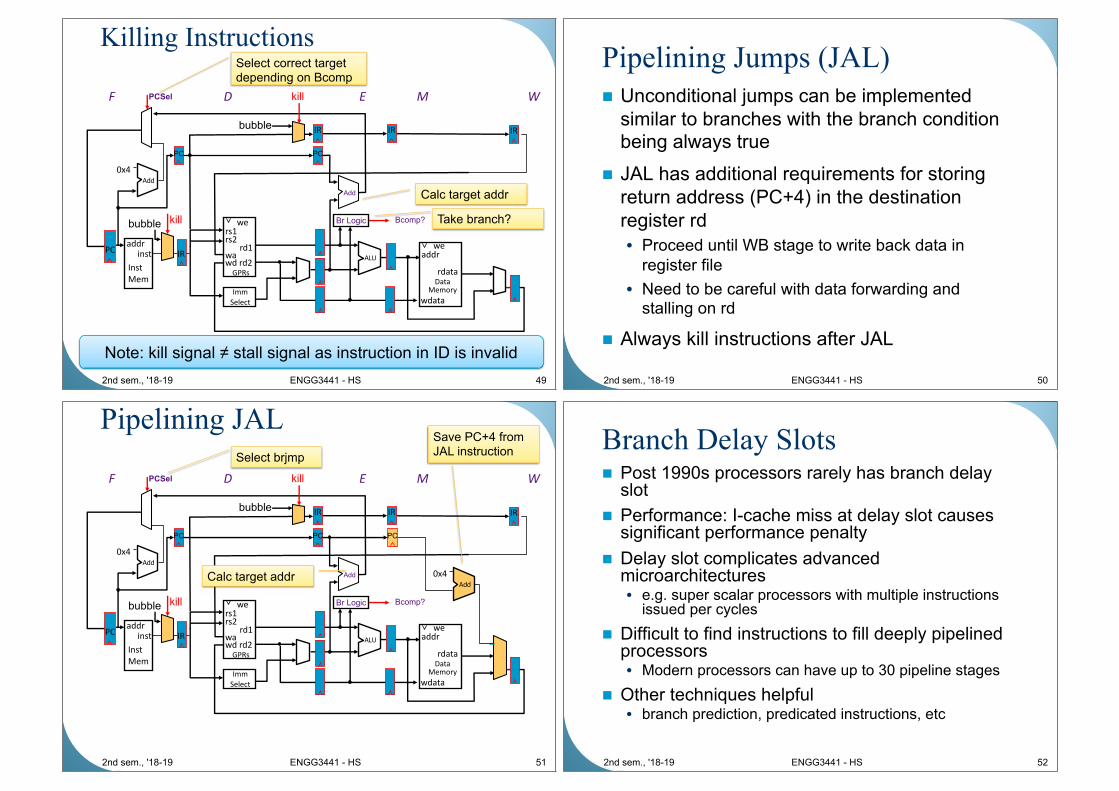
PCPC
Killing Instructions
49
PCaddr
inst
Inst
Mem
0x4
Add
IR
Imm
Select
ALU
rd1
GPRs
rs1rs2
wawd rd2
we
wdata
addr
wdata
rdata
we
F D E M W
Bcomp?Br Logic
Add
PCSel
Data Memory
Calc target addr
Take branch?
Select correct target depending on Bcomp
Note: kill signal ≠ stall signal as instruction in ID is invalid
bubble kill
IR IR IRbubble
kill
2nd sem., '18-19 ENGG3441 - HS
Pipelining Jumps (JAL)
n Unconditional jumps can be implemented
similar to branches with the branch condition
being always true
n JAL has additional requirements for storing
return address (PC+4) in the destination
register rd
• Proceed until WB stage to write back data in
register file
• Need to be careful with data forwarding and stalling on rd
n Always kill instructions after JAL
2nd sem., '18-19 ENGG3441 - HS 50
PCPC PC
Pipelining JAL
51
PCaddr
inst
Inst
Mem
0x4
Add
IR
Imm
Select
ALU
rd1
GPRs
rs1rs2
wawd rd2
we
wdata
addr
wdata
rdata
we
F D E M W
Bcomp?Br Logic
Add
PCSel
Data Memory
Save PC+4 from JAL instruction
Select brjmp
bubble kill
IR IR IRbubble
kill
Calc target addr 0x4
Add
2nd sem., '18-19 ENGG3441 - HS
Branch Delay Slotsn Post 1990s processors rarely has branch delay
slot
n Performance: I-cache miss at delay slot causes significant performance penalty
n Delay slot complicates advanced microarchitectures• e.g. super scalar processors with multiple instructions
issued per cycles
n Difficult to find instructions to fill deeply pipelined processors• Modern processors can have up to 30 pipeline stages
n Other techniques helpful• branch prediction, predicated instructions, etc
2nd sem., '18-19 ENGG3441 - HS 52

In Conclusions…
n Pipeline is a well-studied digital system design technique
n Pipelining allows concurrent execution of multiple steps
n 5-stages of RISV-V pipeline:• Instruction Fetch
• Instruction Decode
• Instruction Execute
• Memory Access
• Write Back
n 3 Types of Hazards• Structural hazard
• Data hazard
• Control hazard
532nd sem., '18-19 ENGG3441 - HS 54
Acknowledgementsn These slides contain material developed and
copyright by:
• Arvind (MIT)
• Krste Asanovic (MIT/UCB)
• Joel Emer (Intel/MIT)
• James Hoe (CMU)
• John Kubiatowicz (UCB)
• David Patterson (UCB)
n MIT material derived from course 6.823
n UCB material derived from course CS152, CS252
2nd sem., '18-19 ENGG3441 - HS