regression and correlation
TRANSCRIPT

Correlation and Regression

Correlation and Regression
The test you choose depends on level of measurement:
Independent Dependent Test
Dichotomous Interval-Ratio Independent Samples t-testDichotomous
Nominal Interval-Ratio ANOVADichotomous Dichotomous
Nominal Nominal Cross TabsDichotomous Dichotomous
Interval-Ratio Interval-Ratio Bivariate Regression/CorrelationDichotomous

Correlation and Regression
Bivariate regression is a technique that fits a straight line as close as possible between all the coordinates of two continuous variables plotted on a two-dimensional graph--to summarize the relationship between the variables
Correlation is a statistic that assesses the strength and direction of association of two continuous variables . . . It is created through a technique called “regression”

Bivariate Regression
For example:A criminologist may be interested in the relationship between Income and Number of Children in a family or self-esteem and criminal behavior.
Independent Variables
Family Income
Self-esteem
Dependent Variables
Number of Children
Criminal Behavior

Bivariate Regression
For example: Research Hypotheses:
As family income increases, the number of children in families declines (negative relationship).
As self-esteem increases, reports of criminal behavior increase (positive relationship).
Independent Variables
Family Income
Self-esteem
Dependent Variables
Number of Children
Criminal Behavior

Bivariate Regression
For example: Null Hypotheses:
There is no relationship between family income and the number of children in families. The relationship statistic b = 0.
There is no relationship between self-esteem and criminal behavior. The relationship statistic b = 0.
Independent Variables
Family Income
Self-esteem
Dependent Variables
Number of Children
Criminal Behavior

Bivariate Regression Let’s look at the relationship between self-esteem
and criminal behavior. Regression starts with plots of coordinates of
variables in a hypothesis (although you will hardly ever “plot” your data in reality).
The data:
Each respondent has filled out a self-esteem assessment and reported number of crimes committed.

Bivariate RegressionY, crimes
X, self-esteem
10 15 20 25 30 35 40
What do you think the relationship is?
0 1
2
3
4
5
6
7
8
9
10

Bivariate RegressionY, crimes
X, self-esteem
10 15 20 25 30 35 40
Is it positive?
Negative?
No change?
0 1
2
3
4
5
6
7
8
9
10

Bivariate RegressionY, crimes
X, self-esteem
10 15 20 25 30 35 40
Regression is a procedure that fits a line to the data. The slope of that line acts as a model for the relationship between the plotted variables.
0 1
2
3
4
5
6
7
8
9
10

Bivariate RegressionY, crimes
X, self-esteem
10 15 20 25 30 35 40
The slope of a line is the change in the corresponding Y value for each unit increase in X (rise over run).
Slope = 0, No relationship!
Slope = 0.2, Positive Relationship!
1
Slope = -0.2, Negative Relationship!
1
0.5
0 1
2
3
4
5
6
7
8
9
10

Bivariate Regression
The mathematical equation for a line:
Y = mx + b
Where: Y = the line’s position on the vertical axis at any point
X = the line’s position on the horizontal axis at any point
m = the slope of the line
b = the intercept with the Y axis,
where X equals zero

Bivariate Regression
The statistics equation for a line:
Y = a + bx
Where: Y = the line’s position on the vertical axis at any point (value of dependent variable)
X = the line’s position on the horizontal axis at any point (value of the independent variable)
b = the slope of the line (called the coefficient)
a = the intercept with the Y axis,
where X equals zero
^^

Bivariate Regression
The next question:
How do we draw the line???
Our goal for the line:
Fit the line as close as possible to all the data points for all values of X.

Bivariate RegressionY, crimes
X, self-esteem
10 15 20 25 30 35 40
How do we minimize the distance between a line and all the data points?
0 1
2
3
4
5
6
7
8
9
10

Bivariate Regression
• How do we minimize the distance between a line and all the data points?
• You already know of a statistic that minimizes the distance between itself and all data values for a variable--the mean!
• The mean minimizes the sum of squared deviations--it is where deviations sum to zero and where the squared deviations are at their lowest value. (Y - Y-bar)2
•

Bivariate Regression
• The mean minimizes the sum of squared deviations--it is where deviations sum to zero and where the squared deviations are at their lowest value.
• Take this principle and “fit the line” to the place where squared deviations (on Y) from the line are at their lowest value (across all X’s).
(Y - Y)2 Y = line ^ ^

Bivariate Regression
There are several lines that you could draw where the deviations would sum to zero...
Minimizing the sum of squared errors gives you the unique, best fitting line for all the data points. It is the line that is closest to all points.
Y or Y-hat = Y value for line at any X Y = case value on variable Y Y - Y = residual (Y – Y) = 0; therefore, we use (Y - Y)2 …and
minimize that!
^
^
^ ^

Bivariate RegressionY, crimes
X, self-esteem
10 15 20 25 30 35 40
0 1
2
3
4
5
6
7
8
9
10
Illustration of Y – Y
= Yi, actual Y value corresponding w/ actual X
= Yi, line level on Y corresponding w/ actual X
∧
∧
5
-4
Y = 10, Y = 5
Y = 0, Y = 4
∧
∧

Bivariate RegressionY, crimes
X, self-esteem
10 15 20 25 30 35 40
0 1
2
3
4
5
6
7
8
9
10
Illustration of (Y – Y)2
= Yi, actual Y value corresponding w/ actual X
= Yi, line level on Y corresponding w/ actual X
∧
∧
5
-4
(Yi – Y)2 = deviation2 Y = 10, Y = 5 . . . 25
Y = 0, Y = 4 . . . 16
∧
∧
∧
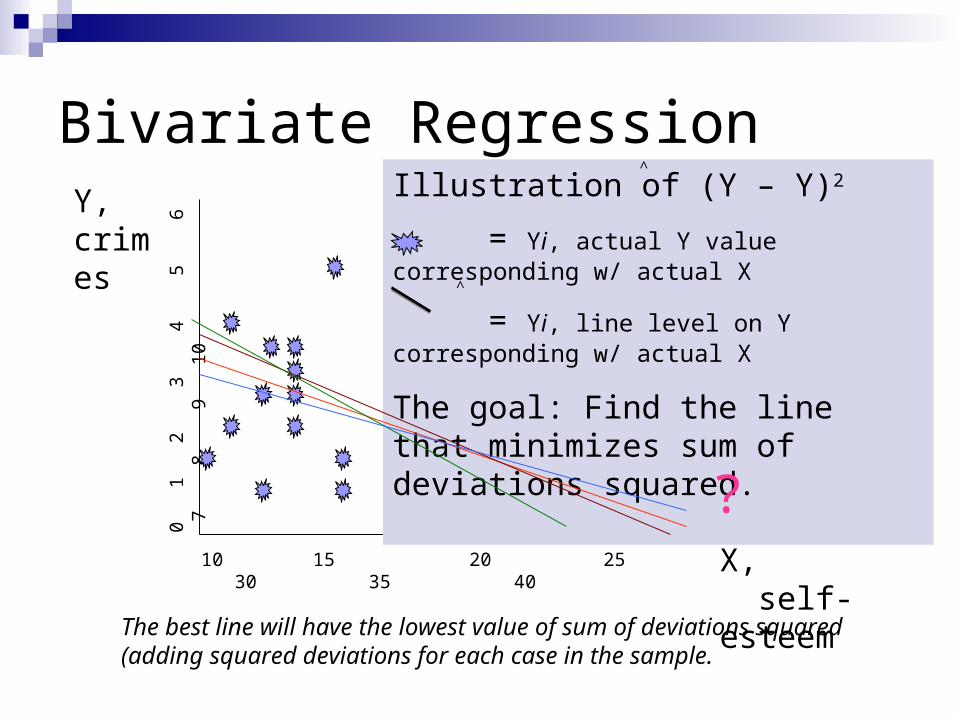
Bivariate RegressionY, crimes
X, self-esteem
10 15 20 25 30 35 40
0 1
2
3
4
5
6
7
8
9
10
Illustration of (Y – Y)2
= Yi, actual Y value corresponding w/ actual X
= Yi, line level on Y corresponding w/ actual X
The goal: Find the line that minimizes sum of deviations squared.
∧
∧
?
The best line will have the lowest value of sum of deviations squared (adding squared deviations for each case in the sample.

Bivariate RegressionY, crimes
X, self-esteem
10 15 20 25 30 35 40
0 1
2
3
4
5
6
7
8
9
10
∧
Y = a + bX∧
∧
e

Bivariate Regression
We use (Y - Y)2 …and minimize that! There is a simple, elegant formula for “discovering”
the line that minimizes the sum of squared errors
((X - X)(Y - Y))
b = (X - X)2 a = Y - bX Y = a + bX This is the method of least squares, it gives our
least squares estimate and indicates why we call this technique “ordinary least squares” or OLS regression
^
^

Bivariate RegressionY
X0 1
1
2
3
4
5
6
7
8
9
10
Considering that a regression line minimizes (Y - Y)2, where would the regression line cross for an interval-ratio variable regressed on a dichotomous independent variable?
^
For example:
0=Men: Mean = 6
1=Women: Mean = 4

Bivariate RegressionY
X0 1
1
2
3
4
5
6
7
8
9
10
The difference of means will be the slope. This is the same number that is tested for significance in an independent samples t-test.
^
0=Men: Mean = 6
1=Women: Mean = 4
Slope = -2 ; Y = 6 – 2X

Correlation This lecture has
covered how to model the relationship between two variables with regression.
Another concept is strength of association.
Correlation provides that.

CorrelationY, crimes
X, self-esteem
10 15 20 25 30 35 40
So our equation is:
Y = 6 - .2X
The slope tells us direction of association… How strong is that?
0 1
2
3
4
5
6
7
8
9
10
^

Correlation1
2
3
4
5
6
7
8
9
1
0
Example of Low Negative Correlation
When there is a lot of difference on the dependent variable across subjects at particular values of X, there is NOT as much association (weaker).
Y
X

Correlation1
2
3
4
5
6
7
8
9
1
0
Example of High Negative Correlation
When there is little difference on the dependent variable across subjects at particular values of X, there is MORE association (Stronger).
Y
X

Correlation
To find the strength of the relationship between two variables, we need correlation.
The correlation is the standardized slope… it refers to the standard deviation change in Y when you go up a standard deviation in X.

Correlation
The correlation is the standardized slope… it refers to the standard deviation change in Y when you go up a standard deviation in X.
(X - X)2
Recall that s.d. of x, Sx = n - 1
(Y - Y)2
and the s.d. of y, Sy = n - 1
Sx Pearson correlation, r = Sy b

Correlation
The Pearson Correlation, r: tells the direction and strength of the relationship between
continuous variablesranges from -1 to +1 is + when the relationship is positive and - when the
relationship is negative the higher the absolute value of r, the stronger the
associationa standard deviation change in x corresponds with r
standard deviation change in Y

Correlation
The Pearson Correlation, r:The pearson correlation is a statistic that is an
inferential statistic too.
r - (null = 0) tn-2 = (1-r2) (n-2)
When it is significant, there is a relationship in the population that is not equal to zero!

Error Analysis
Y = a + bX This equation gives the conditional mean of Y at any given value of X.
So… In reality, our line gives us the expected mean of Y given each value of X The line’s equation tells you how the mean on your dependent variable changes
as your independent variable goes up.
^
Y
X
Y

Error Analysis
As you know, every mean has a distribution around it--so there is a standard deviation. This is true for conditional means as well. So, you also have a conditional standard deviation.
“Conditional Standard Deviation” or “Root Mean Square Error” equals “approximate average deviation from the line.”
SSE ( Y - Y)2
= n - 2 = n - 2
Y
X
Y
^
^

Error Analysis The Assumption of Homoskedasticity:
The variation around the line is the same no matter the X. The conditional standard deviation is for any given value of X.
If there is a relationship between X and Y, the conditional standard deviation is going to be less than the standard deviation of Y--if this is so, you have improved prediction of the mean value of Y by looking at each level of X.
If there were no relationship, the conditional standard deviation would be the same as the original, and the regression line would be flat at the mean of Y.
Y
X
Y Conditional standard deviation
Original standard deviation

Error Analysis
So guess what?
We have a way to determine how much our understanding of Y is improved when taking X into account—it is based on the fact that conditional standard deviations should be smaller than Y’s original standard deviation.

Error Analysis
Proportional Reduction in Error Let’s call the variation around the mean in Y “Error 1.” Let’s call the variation around the line when X is considered
“Error 2.”
But rather than going all the way to standard deviation to determine error, let’s just stop at the basic measure, Sum of Squared Deviations.
Error 1 (E1) = (Y – Y)2 also called “Sum of Squares”
Error 2 (E2) = (Y – Y)2 also called “Sum of Squared Errors”
Y
X
Y Error 2Error 1

R-Squared
Proportional Reduction in Error To determine how much taking X into consideration reduces the
variation in Y (at each level of X) we can use a simple formula:E1 – E2 Which tells us the
proportion or E1 percentage of original
error that is Explained by X.
Error 1 (E1) = (Y – Y)2
Error 2 (E2) = (Y – Y)2
Y
X
Y
Error 2
Error 1

R-squared
r2 = E1 - E2 E1
= TSS - SSE TSS
= (Y – Y)2 - (Y – Y)2
(Y – Y)2
r2 is called the “coefficient of determination”…
It is also the square of the Pearson correlation
Y
X
Y Error 2
Error 1

R-Squared R2:
Is the improvement obtained by using X (and drawing a line through the conditional means) in getting as near as possible to everybody’s value for Y over just using the mean for Y alone.
Falls between 0 and 1 Of 1 means an exact fit (and there is no variation of scores
around the regression line) Of 0 means no relationship (and as much scatter as in the
original Y variable and a flat regression line through the mean of Y)
Would be the same for X regressed on Y as for Y regressed on X
Can be interpreted as the percentage of variability in Y that is explained by X.
Some people get hung up on maximizing R2, but this is too bad because any effect is still a finding—a small R2 only indicates that you haven’t told the whole (or much of the) story with your variable.

Error Analysis, SPSSSome SPSS output (Anti- Gay Marriage regressed on Age):
r2
(Y – Y)2 - (Y – Y)2 (Y – Y)2
196.886 ÷ 2853.286 = .069
Line to the Mean
Data points to the lineData points to the mean
Original SS for Anti- Gay Marriage

Error AnalysisSome SPSS output (Anti- Gay Marriage regressed on Age):
r2
(Y – Y)2 - (Y – Y)2 (Y – Y)2
196.886 ÷ 2853.286 = .069
Line to the Mean
Data points to the lineData points to the mean
0 18 45 89 Age
Strong Oppose 5
Oppose 4
Neutral 3
Support 2
Strong Support 1
Anti- Gay MarriageM = 2.98
Colored lines are examples of:Distance from each person’s data point to the line or model—new, still unexplained error.Distance from line or model to Mean for each person—reduction in error.Distance from each person’s data point to the Mean—original variable’s error.

ANOVA Table
X
YMean
Q: Why do I see an ANOVA Table?
A: We “bust up” variance to get R2. Each case has a value for distance from the line (Y-barcond. Mean) to Y-barbig, and a value for distance from its Y value and the line (Y-barcond. Mean).
Squared distance from the line to the mean (Regression SS) is equivalent to BSS, df = 1. In ANOVA, all in a group share Y-bargroup
The squared distance from the line to the data values on Y (Residual SS) is equivalent to WSS, df = n-2. In ANOVA, all in a group share Y-bargroup
The ratio, Regression to Residual SS, forms an F distribution in repeated sampling. If F is significant, X explains some variation in Y.
BSS
WSS
TSS
Line Intersects Group Means

Dichotomous VariablesY
X0 1
1
2
3
4
5
6
7
8
9
10
Using a dichotomous independent variable, the ANOVA table in bivariate regression will have the same numbers and ANOVA results as a one-way ANOVA table would (and compare this with an independent samples t-test).
^
0=Men: Mean = 6
1=Women: Mean = 4
Slope = -2 ; Y = 6 – 2X
Mean = 5 BSS
WSS
TSS

Regression, Inferential Statistics
Descriptive: The equation for your line
is a descriptive statistic. It tells you the real, best-fitted line that minimizes squared errors.
Inferential: But what about the
population? What can we say about the relationship between your variables in the population???
The inferential statistics are estimates based on the best-fitted line.
Recall that statistics are divided between descriptive and inferential statistics.

Regression, Inferential Statistics
The significance of F, you already understand.
The ratio of Regression (line to the mean of Y) to Residual (line to data point) Sums of Squares forms an F ratio in repeated sampling.
Null: r2 = 0 in the population. If F exceeds critical F, then your variables have a relationship in the population (X explains some of the variation in Y).
Most extreme 5% of F’s
F = Regression SS / Residual SS

Regression, Inferential Statistics What about the Slope or
“Coefficient”? From sample to sample, different
slopes would be obtained. The slope has a sampling
distribution that is normally distributed.
So we can do a significance test. -3 -2 -1 0 1 2 3 z

Regression, Inferential StatisticsConducting a Test of Significance for the slope of the Regression Line
By slapping the sampling distribution for the slope over a guess of the population’s slope, Ho, one determines whether a sample could have been drawn from a population where the slope is equal Ho.
1. Two-tailed significance test for -level = .052. Critical t = +/- 1.963. To find if there is a significant slope in the population,
Ho: = 0Ha: 0 ( Y – Y )2
n Collect Data n - 2n Calculate t (z): t = b – o s.e. = s.e. ( X – X )2
n Make decision about the null hypothesisn Find P-value
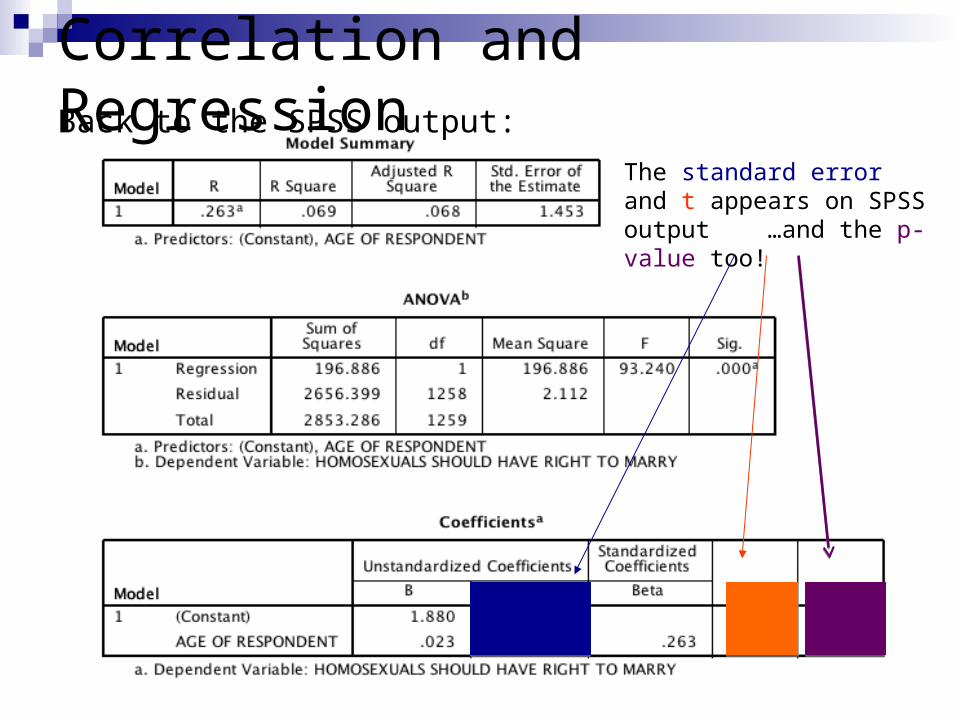
Correlation and RegressionBack to the SPSS output:
The standard error and t appears on SPSS output …and the p-value too!

Correlation and RegressionBack to the SPSS output:
Y = 1.88 + .023X
So the GSS example, the slope is significant. There is evidence of a positive relationship in the population between Age and Anti- Gay Marriage sentiment. 6.9% of the variation in Marriage attitude is explained by age. The older Americans get, the more likely they are to oppose gay marriage.
∧
A one year increase in age elevates “anti” attitudes by .023 scale units. There is a weak positive correlation. A s.d, increase in age produces a .023 s.d. increase in “anti” scale units.