redshift deep dive
TRANSCRIPT

Sao Paulo

Amazon Redshift Deep Dive
Eric FerreiraAWS
Wanderlei PaivaMovile
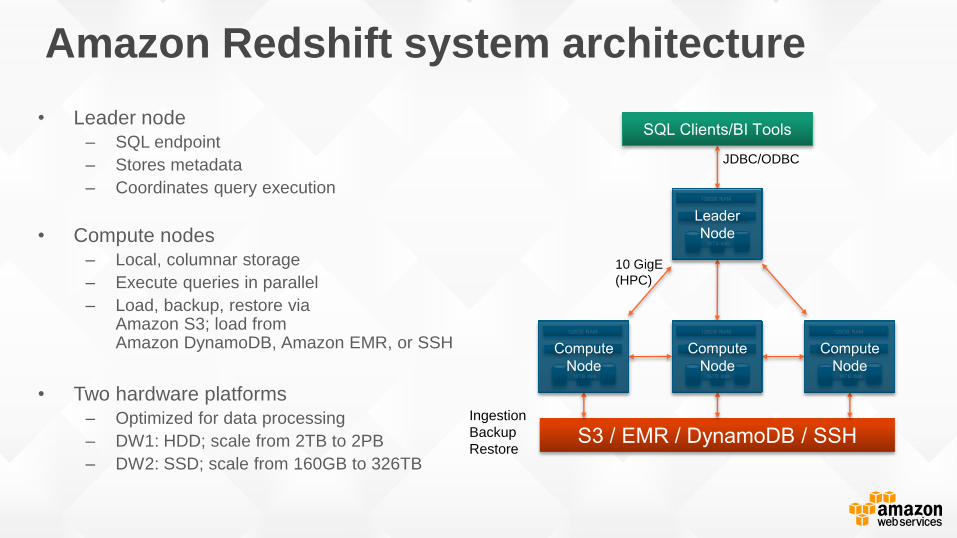
Amazon Redshift system architecture
• Leader node– SQL endpoint
– Stores metadata
– Coordinates query execution
• Compute nodes– Local, columnar storage
– Execute queries in parallel
– Load, backup, restore via Amazon S3; load from Amazon DynamoDB, Amazon EMR, or SSH
• Two hardware platforms– Optimized for data processing
– DW1: HDD; scale from 2TB to 2PB
– DW2: SSD; scale from 160GB to 326TB
10 GigE
(HPC)
Ingestion
Backup
Restore
JDBC/ODBC

A deeper look at compute node architecture
• Each node is split into slices– One slice per core
– DW1 – 2 slices on XL, 16 on 8XL
– DW2 – 2 slices on L, 32 on 8XL
• Each slice is allocated memory,
CPU, and disk space
• Each slice processes a piece of
the workload in parallel
Leader Node

Implications for ingestion

Use multiple input files to maximize
throughput• Use the COPY command
• Each slice can load one file at
a time
• A single input file means only
one slice is ingesting data
• Instead of 100MB/s, you’re
only getting 6.25MB/s

Use multiple input files to maximize
throughput• Use the COPY command
• You need at least as many input files as you have slices
• With 16 input files, all slices are working so you maximize throughput
• Get 100MB/s per node; scale linearly as you add nodes

Primary keys and manifest files
• Amazon Redshift doesn’t enforce primary key constraints– If you load data multiple times, Amazon Redshift won’t complain
– If you declare primary keys in your DML, the optimizer will expect the data to be unique
• Use manifest files to control exactly what is loaded and how to respond if input files are missing– Define a JSON manifest on Amazon S3
– Ensures the cluster loads exactly what you want

Analyze sort/dist key columns after every load
• Amazon Redshift’s query
optimizer relies on up-to-
date statistics
• Maximize performance by
updating stats on sort/dist
key columns after every
load

Automatic compression is a good thing (mostly)
• Better performance, lower costs
• COPY samples data automatically when loading into an empty table
– Samples up to 100,000 rows and picks optimal encoding
• If you have a regular ETL process and you use temp tables or staging tables, turn off automatic compression
– Use analyze compression to determine the right encodings
– Bake those encodings into your DML

Be careful when compressing your sort keys
• Zone maps store min/max per block
• Once we know which block(s) contain the
range, we know which row offsets to scan
• Highly compressed sort keys means many
rows per block
• You’ll scan more data blocks than you need
• If your sort keys compress significantly
more than your data columns, you may
want to skip compression

Keep your columns as narrow as possible
• During queries and ingestion,
the system allocates buffers
based on column width
• Wider than needed columns
mean memory is wasted
• Fewer rows fit into memory;
increased likelihood of
queries spilling to disk

Customer Testimony .
Wanderlei Paiva

“Com os serviços da AWS
pudemos dosar os investimento
iniciais e prospectar os custos
para expansões futuras”
• Líder em Mobile Commerce na América Latina
– 50 Milhões de pessoas usam serviços Movile todo mês
– Estamos conectados a + de 70 Operadoras em toda
América
– + de 50 Bilhões de transações por ano
– + de 700 colaboradores em 11 escritórios (AL e EUA)
• PlayKids
– 10M de downloads / 3M usuários ativos
– Conteúdo licenciado em 27 países e usuários em 102
países (6 idiomas: português, inglês, espanhol, alemão,
francês e chines)
– App #1 top grossing for Kids in Apple Store
“O Redshift nos
permitiu
transformar dados
em informações
self-service” - Wanderley Paiva
Database Specialist
PlayKids iFood MapLink Apontador
Rapiddo Superplayer Cinepapaya ChefTim
e

O Desafio
• Escalabilidade
• Disponibilidade
• Centralização dos dados
• Custos reduzidos e
preferencialmente diluído

Solução
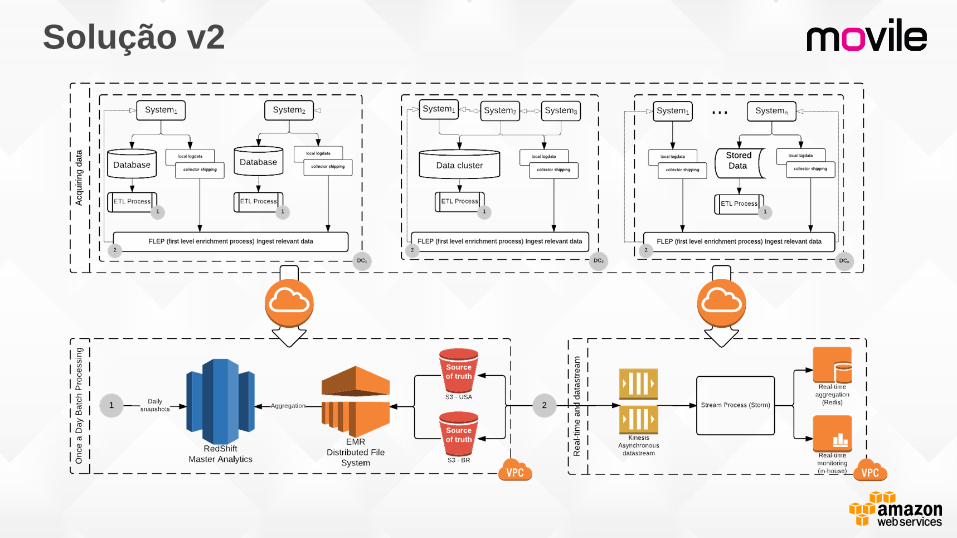
Solução v2

Expanding Amazon Redshift’s query
capabilities

New SQL functions
• We add SQL functions regularly to expand Amazon Redshift’s query
capabilities
• Added 25+ window and aggregate functions since launch, including:– APPROXIMATE_COUNT
– DROP IF EXISTS, CREATE IF NOT EXISTS
– REGEXP_SUBSTR, _COUNT, _INSTR, _REPLACE
– PERCENTILE_CONT, _DISC, MEDIAN
– PERCENT_RANK, RATIO_TO_REPORT
• We’ll continue iterating but also want to enable you to write your own

User Defined Functions
• We’re enabling User Defined Functions (UDFs) so you can
add your own– Scalar and Aggregate Functions supported
• You’ll be able to write UDFs using Python 2.7– Syntax is largely identical to PostgreSQL UDF Syntax
– System and network calls within UDFs are prohibited
• Comes with Pandas, NumPy, and SciPy pre-installed– You’ll also be able import your own libraries for even more flexibility

Scalar UDF example – URL parsing
CREATE FUNCTION f_hostname (VARCHAR url)
RETURNS varchar
IMMUTABLE AS $$
import urlparse
return urlparse.urlparse(url).hostname
$$ LANGUAGE plpythonu;

Multidimensional indexing
with space filling curves

You’re a small Internet bookstore
• You’re interested in
how you’re doing– Total sales
– Best customers
– Best-selling items
– Top-selling author this
month
• A row store with
indexes works well
Orders
Product
Time
Customer
Site

You get a little bigger
• Your queries start taking
longer
• You move to a column store
• Now you have zone maps,
large data blocks, but no
indexes
• You have to choose which
queries you want to be fast
10 | 13 | 14 | 26 |…
… | 100 | 245 | 324
375 | 393 | 417…
… 512 | 549 | 623
637 | 712 | 809 …
… | 834 | 921 | 959

Today’s state of the art: Zone maps, sorting,
projections
• Zone maps store the min/max values for every block in memory
• Works great for sorted columns
– O(log n) access to blocks
• Doesn’t work so well for unsorted columns
– O(n) access
• Projections are multiple copies of data sorted different ways
– Optimizer decides which copy to use for responding to queries
– Loads are slower
– Gets unwieldy quickly. If you have 8 columns, you need have 8 factorial (40,320) combinations.
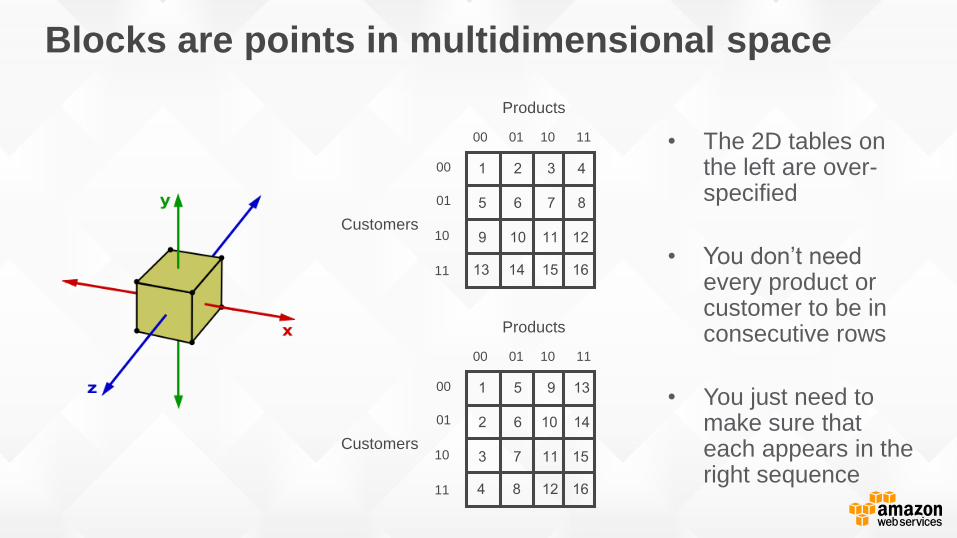
Blocks are points in multidimensional space
00 01 10 11
00
01
10
11
Customers
Products
00 01 10 11
00
01
10
11
Customers
Products
• The 2D tables on the left are over-specified
• You don’t need every product or customer to be in consecutive rows
• You just need to make sure that each appears in the right sequence

Space filling curves
00 01 10 11
00
01
10
11
Customers
Products
• You need a way of traversing the space that preserves order
• And you need to touch every point in the space
• You need a space filling curve– There are many of these, for example the
curve on the right
• Products appear in order as do customers and you don’t favor one over the other
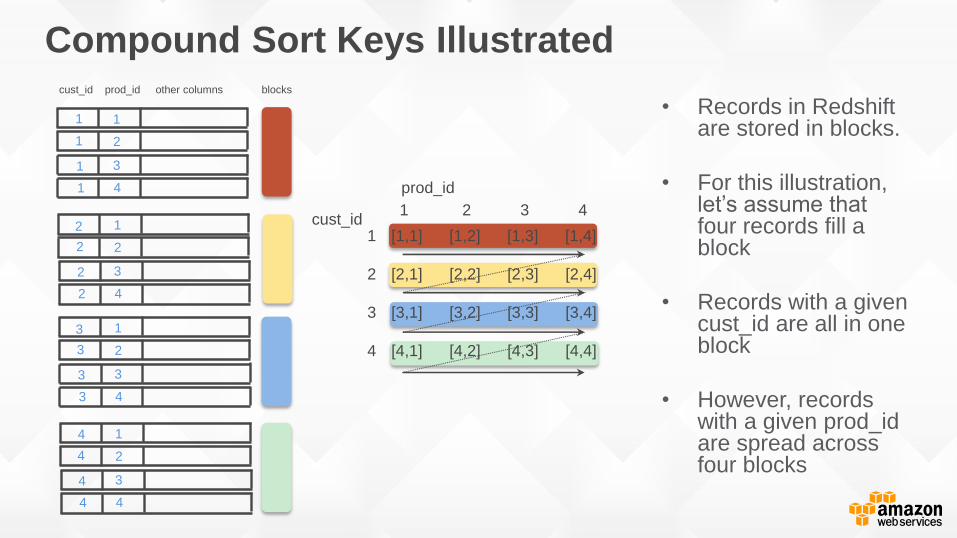
Compound Sort Keys Illustrated
• Records in Redshift are stored in blocks.
• For this illustration, let’s assume that four records fill a block
• Records with a given cust_id are all in one block
• However, records with a given prod_idare spread across four blocks
1
1
1
1
2
3
4
1
4
4
4
2
3
4
4
1
3
3
3
2
3
4
3
1
2
2
2
2
3
4
2
1
1 [1,1] [1,2] [1,3] [1,4]
2 [2,1] [2,2] [2,3] [2,4]
3 [3,1] [3,2] [3,3] [3,4]
4 [4,1] [4,2] [4,3] [4,4]
1 2 3 4
prod_id
cust_id
cust_id prod_id other columns blocks
1 [1,1] [1,2] [1,3] [1,4]
2 [2,1] [2,2] [2,3] [2,4]
3 [3,1] [3,2] [3,3] [3,4]
4 [4,1] [4,2] [4,3] [4,4]
1 2 3 4
prod_id
cust_id
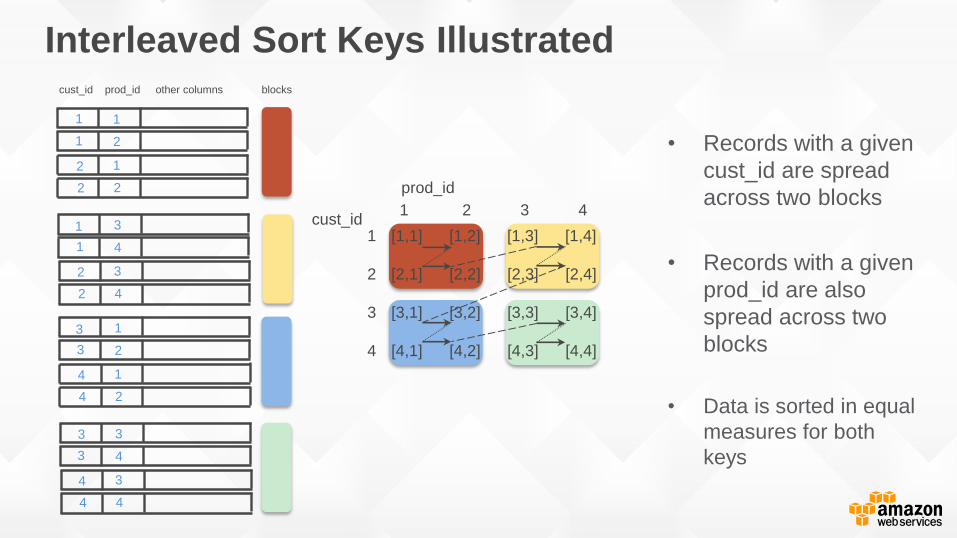
Interleaved Sort Keys Illustrated
• Records with a given
cust_id are spread
across two blocks
• Records with a given
prod_id are also
spread across two
blocks
• Data is sorted in equal
measures for both
keys
1
1
2
2
2
1
2
3
3
4
4
4
3
4
3
1
3
4
4
2
1
2
3
3
1
2
2
4
3
4
1
1
cust_id prod_id other columns blocks

How to use the feature
• New keyword ‘INTERLEAVED’ when defining sort keys– Existing syntax will still work and behavior is unchanged
– You can choose up to 8 columns to include and can query with any or all of them
• No change needed to queries
• We’re just getting started with this feature– Benefits are significant; load penalty is higher than we’d like and we’ll fix that quickly
• Will be available in a couple of weeks and we’d love to get your feedback
[[ COMPOUND | INTERLEAVED ] SORTKEY ( column_name [, ...] ) ]

Migration Considerations

Forklift = BAD

Typical ETL/ELT
• One file per table, maybe a few if too big
• Many updates (“massage” the data)
• Every job clears the data, then load
• Count on PK to block double loads
• High concurrency of load jobs
• Small table(s) to control the job stream

Two Questions to ask
• Why you do what you do?– Many times they don’t even know
• What is the customer need ?– Many times needs do not match practice
– You might have to add other AWS solutions

On Redshift
• Updates are delete + insert– Deletes just mark rows for deletion
• Commits are expensive– 4GB write on 8XL per node
– Mirrors WHOLE dictionary
– Cluster-wide Serialized

On Redshift
• Not all Aggregations created equal– Pre aggregation can help
• Concurrency should be low
• No dashboard connected directly to RS
• WLM only parcels RAM to sessions, not priority
• Compression is for speed as well
• Distkey, Sortkey and datatypes are important

Not all MPP/Columnar are the same
• Only RS can DIST STYLE ALL and have a copy
per node (not per slice/core)
• Some columnar DB have a row-based version of
data on insert. Or a option for it
• RS does not charge millions of dollars and come
do the work for you.
Open Source Tools
• https://github.com/awslabs/amazon-redshift-utils
• Admin Scripts– Collection of utilities for running diagnostics on your Cluster
• Admin Views– Collection of utilities for managing your Cluster, generating Schema
DDL, etc
• Column Encoding Utility– Gives you the ability to apply optimal Column Encoding to an
established Schema with data already loaded


Sao Paulo