recurrent neural networks (rnns) - github pages · recurrent neural networks (rnns) dr. benjamin...
TRANSCRIPT

Recurrent Neural Networks (RNNs)
Dr. Benjamin Roth, Nina Poerner
CIS LMU Munchen
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 1 / 24

Heute
9:15 - 10:00: RNN Basics
10:15 - 11:45: Ubungen: PyTorch, Word2Vec
Statt Ubungsblatt bis nachste Woche durcharbeiten:I http://www.deeplearningbook.org/contents/rnn.html (Abschnitte 10.0
- 10.2.1 (inclusive), 10.7, 10.10)I LSTM: http://colah.github.io/posts/2015-08-Understanding-LSTMs/I GRU: https://towardsdatascience.com/understanding-gru-networks-
2ef37df6c9be/
Nachste Woche:I 9:15 - 10:15: “Journal Club” zu LSTM und GRUI 10:30 - 11:45: Intro Keras
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 2 / 24

Recurrent Neural Networks (RNNs)
Family of neural networks for processing sequential data x(1) . . . x(T ).
Sequences of words, characters, video frames, audio frames, ...
Basic idea: For time step t, compute representation h(t) from currentinput x(t) and previous representation h(t−1).
h(t) = f (h(t−1), x(t); θ)
x(t) can be embeddings, one-hot, output of some previous layer ...
Question: By recursion, what does h(t) depend on?I all previous inputs x(1) . . . x(t)
I the initial state h(0) (typically all-zero, but not necessarily, c.f.encoder-decoder)
I the parameters θ
Question: How does this compare to an n-gram based model?I N-gram based models have limited memory, the RNN has theoretically
(!) unlimited memory
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 3 / 24

Recurrent Neural Networks (RNNs)
Family of neural networks for processing sequential data x(1) . . . x(T ).
Sequences of words, characters, video frames, audio frames, ...
Basic idea: For time step t, compute representation h(t) from currentinput x(t) and previous representation h(t−1).
h(t) = f (h(t−1), x(t); θ)
x(t) can be embeddings, one-hot, output of some previous layer ...
Question: By recursion, what does h(t) depend on?I all previous inputs x(1) . . . x(t)
I the initial state h(0) (typically all-zero, but not necessarily, c.f.encoder-decoder)
I the parameters θ
Question: How does this compare to an n-gram based model?I N-gram based models have limited memory, the RNN has theoretically
(!) unlimited memory
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 3 / 24

Recurrent Neural Networks (RNNs)
Family of neural networks for processing sequential data x(1) . . . x(T ).
Sequences of words, characters, video frames, audio frames, ...
Basic idea: For time step t, compute representation h(t) from currentinput x(t) and previous representation h(t−1).
h(t) = f (h(t−1), x(t); θ)
x(t) can be embeddings, one-hot, output of some previous layer ...
Question: By recursion, what does h(t) depend on?
I all previous inputs x(1) . . . x(t)
I the initial state h(0) (typically all-zero, but not necessarily, c.f.encoder-decoder)
I the parameters θ
Question: How does this compare to an n-gram based model?I N-gram based models have limited memory, the RNN has theoretically
(!) unlimited memory
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 3 / 24

Recurrent Neural Networks (RNNs)
Family of neural networks for processing sequential data x(1) . . . x(T ).
Sequences of words, characters, video frames, audio frames, ...
Basic idea: For time step t, compute representation h(t) from currentinput x(t) and previous representation h(t−1).
h(t) = f (h(t−1), x(t); θ)
x(t) can be embeddings, one-hot, output of some previous layer ...
Question: By recursion, what does h(t) depend on?I all previous inputs x(1) . . . x(t)
I the initial state h(0) (typically all-zero, but not necessarily, c.f.encoder-decoder)
I the parameters θ
Question: How does this compare to an n-gram based model?
I N-gram based models have limited memory, the RNN has theoretically(!) unlimited memory
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 3 / 24

Recurrent Neural Networks (RNNs)
Family of neural networks for processing sequential data x(1) . . . x(T ).
Sequences of words, characters, video frames, audio frames, ...
Basic idea: For time step t, compute representation h(t) from currentinput x(t) and previous representation h(t−1).
h(t) = f (h(t−1), x(t); θ)
x(t) can be embeddings, one-hot, output of some previous layer ...
Question: By recursion, what does h(t) depend on?I all previous inputs x(1) . . . x(t)
I the initial state h(0) (typically all-zero, but not necessarily, c.f.encoder-decoder)
I the parameters θ
Question: How does this compare to an n-gram based model?I N-gram based models have limited memory, the RNN has theoretically
(!) unlimited memory
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 3 / 24

Parameter Sharing
Going from a time step t − 1 to t is parameterized by the sameparameters θ for all t!
h(t) = f (h(t−1), x(t); θ)
Question: Why is parameter sharing a good idea?
I Fewer parametersI Can learn to detect features regardless of their position
F “i went to nepal in 2009” vs. “in 2009 i went to nepal”
I Can generalize to longer sequences than were seen in training
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 4 / 24

Parameter Sharing
Going from a time step t − 1 to t is parameterized by the sameparameters θ for all t!
h(t) = f (h(t−1), x(t); θ)
Question: Why is parameter sharing a good idea?I Fewer parametersI Can learn to detect features regardless of their position
F “i went to nepal in 2009” vs. “in 2009 i went to nepal”
I Can generalize to longer sequences than were seen in training
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 4 / 24
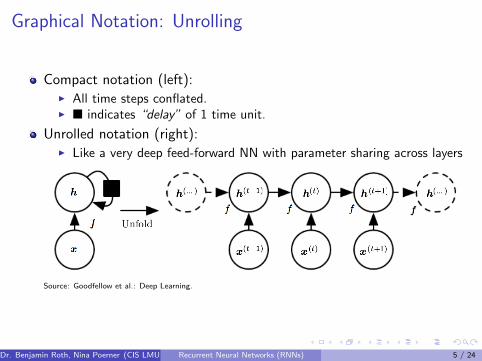
Graphical Notation: Unrolling
Compact notation (left):I All time steps conflated.I � indicates “delay” of 1 time unit.
Unrolled notation (right):I Like a very deep feed-forward NN with parameter sharing across layers
Source: Goodfellow et al.: Deep Learning.
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 5 / 24

Any questions so far?
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 6 / 24

RNN: Output
The output at time t is typically computed from the hiddenrepresentation at time t:
o(t) = f (h(t); θo)
Typically a linear transformation: o(t) = θTo h(t)
Some RNNs compute o(t) at every time step, others only at the lasttime step o(T )
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 7 / 24
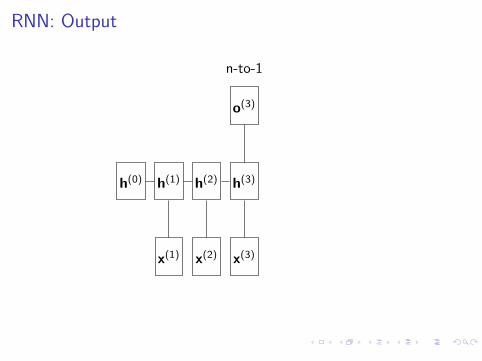
RNN: Output
n-to-1
h(0)
x(1)
h(1)
x(2)
h(2)
x(3)
h(3)
o(3)
Sentiment polarity, topic classification, grammaticality ...
tagging
o(1) o(2)
POS tagging, NER tagging, Language Model ...
tagging (selective)Sequence2Sequence
h(4)
o(4)
h(5)
o(5)
h(6)
o(6)
Decoder
Encoder
Machine Translation, Summarization, Image captioning (encoder CNN) ...
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 8 / 24
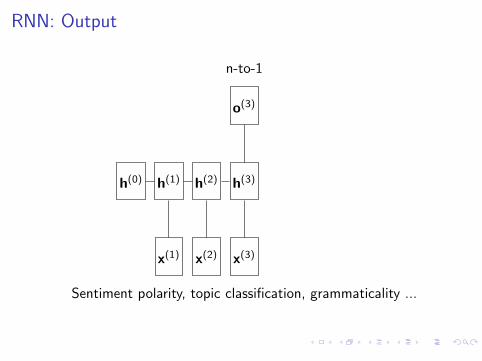
RNN: Output
n-to-1
h(0)
x(1)
h(1)
x(2)
h(2)
x(3)
h(3)
o(3)
Sentiment polarity, topic classification, grammaticality ...
tagging
o(1) o(2)
POS tagging, NER tagging, Language Model ...
tagging (selective)Sequence2Sequence
h(4)
o(4)
h(5)
o(5)
h(6)
o(6)
Decoder
Encoder
Machine Translation, Summarization, Image captioning (encoder CNN) ...
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 8 / 24
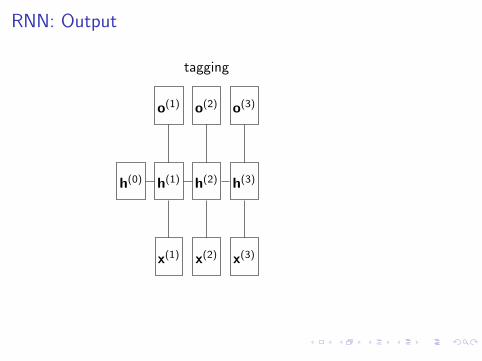
RNN: Output
n-to-1
h(0)
x(1)
h(1)
x(2)
h(2)
x(3)
h(3)
o(3)
Sentiment polarity, topic classification, grammaticality ...
tagging
o(1) o(2)
POS tagging, NER tagging, Language Model ...
tagging (selective)Sequence2Sequence
h(4)
o(4)
h(5)
o(5)
h(6)
o(6)
Decoder
Encoder
Machine Translation, Summarization, Image captioning (encoder CNN) ...
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 8 / 24
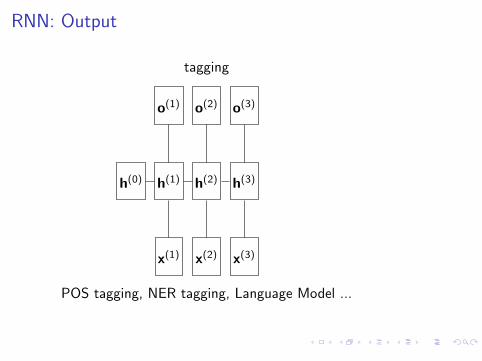
RNN: Output
n-to-1
h(0)
x(1)
h(1)
x(2)
h(2)
x(3)
h(3)
o(3)
Sentiment polarity, topic classification, grammaticality ...
tagging
o(1) o(2)
POS tagging, NER tagging, Language Model ...
tagging (selective)Sequence2Sequence
h(4)
o(4)
h(5)
o(5)
h(6)
o(6)
Decoder
Encoder
Machine Translation, Summarization, Image captioning (encoder CNN) ...
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 8 / 24
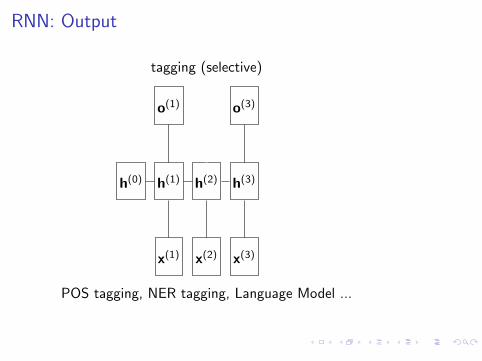
RNN: Output
n-to-1
h(0)
x(1)
h(1)
x(2)
h(2)
x(3)
h(3)
o(3)
Sentiment polarity, topic classification, grammaticality ...
tagging
o(1) o(2)
POS tagging, NER tagging, Language Model ...
tagging (selective)
Sequence2Sequence
h(4)
o(4)
h(5)
o(5)
h(6)
o(6)
Decoder
Encoder
Machine Translation, Summarization, Image captioning (encoder CNN) ...
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 8 / 24
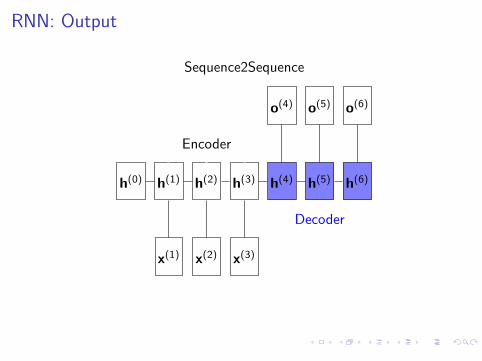
RNN: Output
n-to-1
h(0)
x(1)
h(1)
x(2)
h(2)
x(3)
h(3)
o(3)
Sentiment polarity, topic classification, grammaticality ...
tagging
o(1) o(2)
POS tagging, NER tagging, Language Model ...
tagging (selective)Sequence2Sequence
h(4)
o(4)
h(5)
o(5)
h(6)
o(6)
Decoder
Encoder
Machine Translation, Summarization, Image captioning (encoder CNN) ...
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 8 / 24
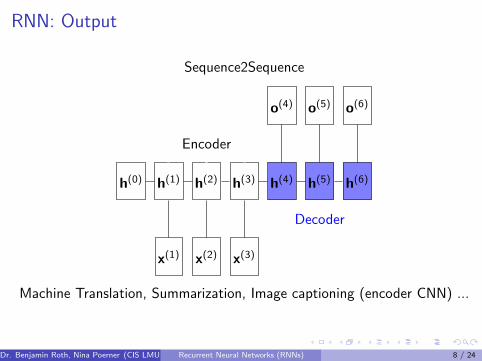
RNN: Output
n-to-1
h(0)
x(1)
h(1)
x(2)
h(2)
x(3)
h(3)
o(3)
Sentiment polarity, topic classification, grammaticality ...
tagging
o(1) o(2)
POS tagging, NER tagging, Language Model ...
tagging (selective)Sequence2Sequence
h(4)
o(4)
h(5)
o(5)
h(6)
o(6)
Decoder
Encoder
Machine Translation, Summarization, Image captioning (encoder CNN) ...
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 8 / 24

Any questions so far?
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 9 / 24

RNN: Loss Function
Loss function:I Several time steps: L(y (1), . . . y (T ); o(1) . . . o(T ))I Last time step: L(y ; o(T ))
Example: POS TaggingI Output o(t) is predicted distribution over POS tags
F o(t) = P(tag =?|h(t))F Typically: o(t) = softmax(θTo h
(t))
I Loss at time t: negative log-likelihood (NLL) of true label y (t)
L(t) = − logP(tag = y (t)|h(t); θo)
I Overall Loss for all time steps:
L =T∑t=1
L(t)
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 10 / 24

RNN: Loss Function
Loss function:I Several time steps: L(y (1), . . . y (T ); o(1) . . . o(T ))I Last time step: L(y ; o(T ))
Example: POS TaggingI Output o(t) is predicted distribution over POS tags
F o(t) = P(tag =?|h(t))F Typically: o(t) = softmax(θTo h
(t))
I Loss at time t: negative log-likelihood (NLL) of true label y (t)
L(t) = − logP(tag = y (t)|h(t); θo)
I Overall Loss for all time steps:
L =T∑t=1
L(t)
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 10 / 24

RNN: Loss Function
Loss function:I Several time steps: L(y (1), . . . y (T ); o(1) . . . o(T ))I Last time step: L(y ; o(T ))
Example: POS TaggingI Output o(t) is predicted distribution over POS tags
F o(t) = P(tag =?|h(t))F Typically: o(t) = softmax(θTo h
(t))
I Loss at time t: negative log-likelihood (NLL) of true label y (t)
L(t) = − logP(tag = y (t)|h(t); θo)
I Overall Loss for all time steps:
L =T∑t=1
L(t)
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 10 / 24

RNN: Loss Function
Loss function:I Several time steps: L(y (1), . . . y (T ); o(1) . . . o(T ))I Last time step: L(y ; o(T ))
Example: POS TaggingI Output o(t) is predicted distribution over POS tags
F o(t) = P(tag =?|h(t))F Typically: o(t) = softmax(θTo h
(t))
I Loss at time t: negative log-likelihood (NLL) of true label y (t)
L(t) = − logP(tag = y (t)|h(t); θo)
I Overall Loss for all time steps:
L =T∑t=1
L(t)
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 10 / 24
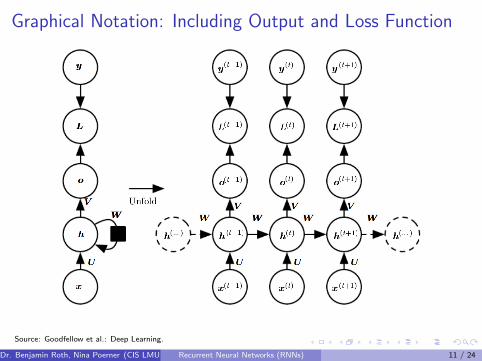
Graphical Notation: Including Output and Loss Function
Source: Goodfellow et al.: Deep Learning.
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 11 / 24

Any questions so far?
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 12 / 24

Backpropagation through time
We have calculated loss L(T ) at time step T and want to updateparameters θi with gradient descent.
For now, imagine that we have time step-specific
“dummy”-parameters θ(t)i , which are identical copies of θi
→ the unrolled RNN looks like a feed-forward-neural-network!
→ we can calculate ∂L(T )
∂θ(t)i
using standard backpropagation
To calculate ∂L(T )
∂θi, add up the “dummy” gradients:
∂L(T )
∂θi=
T∑t=1
∂L(T )
∂θ(t)i
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 13 / 24

Backpropagation through time
We have calculated loss L(T ) at time step T and want to updateparameters θi with gradient descent.
For now, imagine that we have time step-specific
“dummy”-parameters θ(t)i , which are identical copies of θi
→ the unrolled RNN looks like a feed-forward-neural-network!
→ we can calculate ∂L(T )
∂θ(t)i
using standard backpropagation
To calculate ∂L(T )
∂θi, add up the “dummy” gradients:
∂L(T )
∂θi=
T∑t=1
∂L(T )
∂θ(t)i
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 13 / 24

Backpropagation through time
We have calculated loss L(T ) at time step T and want to updateparameters θi with gradient descent.
For now, imagine that we have time step-specific
“dummy”-parameters θ(t)i , which are identical copies of θi
→ the unrolled RNN looks like a feed-forward-neural-network!
→ we can calculate ∂L(T )
∂θ(t)i
using standard backpropagation
To calculate ∂L(T )
∂θi, add up the “dummy” gradients:
∂L(T )
∂θi=
T∑t=1
∂L(T )
∂θ(t)i
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 13 / 24

Truncated backpropagation through time
Simple idea: Stop backpropagation through time after k time steps
∂L(T )
∂θi=
T∑t=T−k
∂L(T )
∂θ(t)i
Question: What are advantages and disadvantages?
I Advantage: Faster and parallelizableI Disadvantage: If k is too small, long-range dependencies are hard to
learn
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 14 / 24

Truncated backpropagation through time
Simple idea: Stop backpropagation through time after k time steps
∂L(T )
∂θi=
T∑t=T−k
∂L(T )
∂θ(t)i
Question: What are advantages and disadvantages?I Advantage: Faster and parallelizableI Disadvantage: If k is too small, long-range dependencies are hard to
learn
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 14 / 24

Any questions so far?
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 15 / 24

Vanilla RNN
h(t) = f (h(t−1), x(t); θ) = tanh(Ux(t) + Wh(h−1) + b)
θ = {W,U,b}
W: Hidden-to-hidden
U: Input-to-hidden
b: Bias term
Vanilla RNN in keras:
vanilla = SimpleRNN(units=10, use_bias = True)
vanilla.build(input_shape = (None, None, 30))
print([weight.shape for weight in vanilla.get_weights()])
[(30, 10), (10, 10), (10,)]
Question: Which shape belongs to which weight?
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 16 / 24

Vanilla RNN
h(t) = f (h(t−1), x(t); θ) = tanh(Ux(t) + Wh(h−1) + b)
θ = {W,U,b}
W: Hidden-to-hidden
U: Input-to-hidden
b: Bias term
Vanilla RNN in keras:
vanilla = SimpleRNN(units=10, use_bias = True)
vanilla.build(input_shape = (None, None, 30))
print([weight.shape for weight in vanilla.get_weights()])
[(30, 10), (10, 10), (10,)]
Question: Which shape belongs to which weight?
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 16 / 24

Bidirectional RNNs
Conceptually: Two RNNs that run in opposite directions over thesame input
Typically, each RNN has its own set of parameters
Results in two sequences of hidden vectors:→h(1) . . .
→h(T ),
←h(1) . . .
←h(T )
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 17 / 24

Before being passed to downstream layers,→h and
←h are typically
concatenated into one representation h, s.t.
dim(h) = dim(→h) + dim(
←h).
Question: Which hidden vectors should we concatenate if we want tocompute a single output (e.g., predict sentiment of sentence)?
I h =→h(T )||
←h(1)
I Because these are the vectors that have “read” the entire sequence
Question: Which hidden vectors should we concatenate in sequencetagging (e.g., to predict POS for word wt)?
I h(t) =→h(t)||
←h(t)
I Left context, right context (including t)
Question: Which hidden vectors should we concatenate to predictsymbol wt (i.e., in a bidirectional language model)?
I
→h(t−1)||
←h(t+1)
I Left context, right context (excluding t)
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 18 / 24

Before being passed to downstream layers,→h and
←h are typically
concatenated into one representation h, s.t.
dim(h) = dim(→h) + dim(
←h).
Question: Which hidden vectors should we concatenate if we want tocompute a single output (e.g., predict sentiment of sentence)?
I h =→h(T )||
←h(1)
I Because these are the vectors that have “read” the entire sequence
Question: Which hidden vectors should we concatenate in sequencetagging (e.g., to predict POS for word wt)?
I h(t) =→h(t)||
←h(t)
I Left context, right context (including t)
Question: Which hidden vectors should we concatenate to predictsymbol wt (i.e., in a bidirectional language model)?
I
→h(t−1)||
←h(t+1)
I Left context, right context (excluding t)
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 18 / 24

Before being passed to downstream layers,→h and
←h are typically
concatenated into one representation h, s.t.
dim(h) = dim(→h) + dim(
←h).
Question: Which hidden vectors should we concatenate if we want tocompute a single output (e.g., predict sentiment of sentence)?
I h =→h(T )||
←h(1)
I Because these are the vectors that have “read” the entire sequence
Question: Which hidden vectors should we concatenate in sequencetagging (e.g., to predict POS for word wt)?
I h(t) =→h(t)||
←h(t)
I Left context, right context (including t)
Question: Which hidden vectors should we concatenate to predictsymbol wt (i.e., in a bidirectional language model)?
I
→h(t−1)||
←h(t+1)
I Left context, right context (excluding t)
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 18 / 24

Before being passed to downstream layers,→h and
←h are typically
concatenated into one representation h, s.t.
dim(h) = dim(→h) + dim(
←h).
Question: Which hidden vectors should we concatenate if we want tocompute a single output (e.g., predict sentiment of sentence)?
I h =→h(T )||
←h(1)
I Because these are the vectors that have “read” the entire sequence
Question: Which hidden vectors should we concatenate in sequencetagging (e.g., to predict POS for word wt)?
I h(t) =→h(t)||
←h(t)
I Left context, right context (including t)
Question: Which hidden vectors should we concatenate to predictsymbol wt (i.e., in a bidirectional language model)?
I
→h(t−1)||
←h(t+1)
I Left context, right context (excluding t)
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 18 / 24

Before being passed to downstream layers,→h and
←h are typically
concatenated into one representation h, s.t.
dim(h) = dim(→h) + dim(
←h).
Question: Which hidden vectors should we concatenate if we want tocompute a single output (e.g., predict sentiment of sentence)?
I h =→h(T )||
←h(1)
I Because these are the vectors that have “read” the entire sequence
Question: Which hidden vectors should we concatenate in sequencetagging (e.g., to predict POS for word wt)?
I h(t) =→h(t)||
←h(t)
I Left context, right context (including t)
Question: Which hidden vectors should we concatenate to predictsymbol wt (i.e., in a bidirectional language model)?
I
→h(t−1)||
←h(t+1)
I Left context, right context (excluding t)
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 18 / 24

Before being passed to downstream layers,→h and
←h are typically
concatenated into one representation h, s.t.
dim(h) = dim(→h) + dim(
←h).
Question: Which hidden vectors should we concatenate if we want tocompute a single output (e.g., predict sentiment of sentence)?
I h =→h(T )||
←h(1)
I Because these are the vectors that have “read” the entire sequence
Question: Which hidden vectors should we concatenate in sequencetagging (e.g., to predict POS for word wt)?
I h(t) =→h(t)||
←h(t)
I Left context, right context (including t)
Question: Which hidden vectors should we concatenate to predictsymbol wt (i.e., in a bidirectional language model)?
I
→h(t−1)||
←h(t+1)
I Left context, right context (excluding t)
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 18 / 24
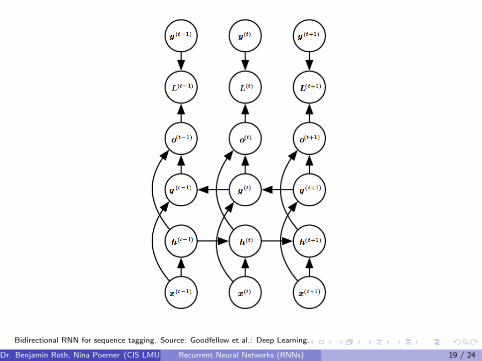
Bidirectional RNN for sequence tagging. Source: Goodfellow et al.: Deep Learning.
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 19 / 24
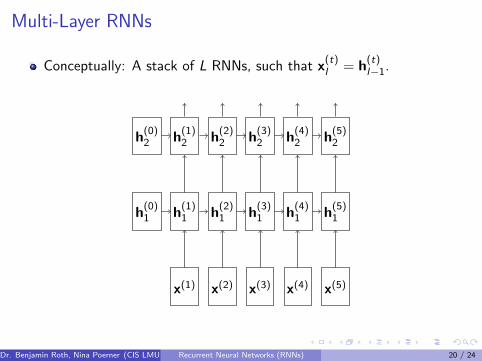
Multi-Layer RNNs
Conceptually: A stack of L RNNs, such that x(t)l = h
(t)l−1.
h(0)1
h(0)2
x(1)
h(1)1
h(1)2
x(2)
h(2)1
h(2)2
x(3)
h(3)1
h(3)2
x(4)
h(4)1
h(4)2
x(5)
h(5)1
h(5)2
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 20 / 24

Feeding outputs back
What do we do if the input sequence x(1) . . . x(T ) is only given attraining time, but not at test time?
Examples: Machine Translation decoder, (generative) language model
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 21 / 24
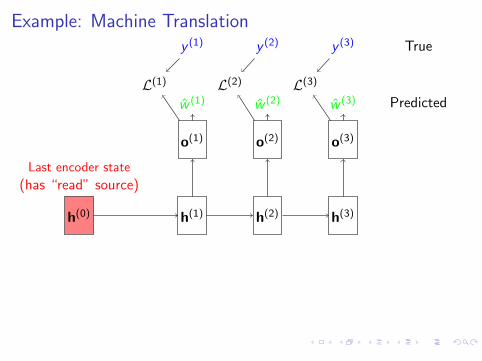
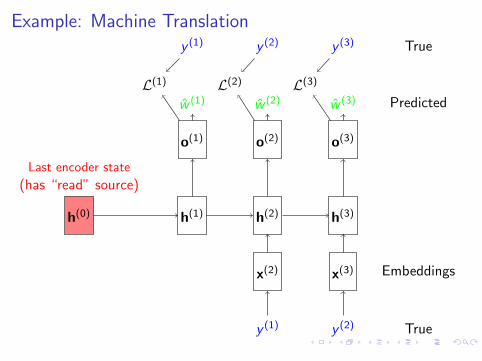
Example: Machine Translation
h(0) h(1)
o(1)
w (1)
y (1)
L(1)
h(2)
o(2)
w (2)
y (2)
L(2)
h(3)
o(3)
w (3)
y (3)
L(3)
Last encoder state
(has “read” source)
Predicted
True
y (1) y (2)
x(2) x(3) Embeddings
Truew (1) w (2) Predicted
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 22 / 24
Example: Machine Translation
h(0) h(1)
o(1)
w (1)
y (1)
L(1)
h(2)
o(2)
w (2)
y (2)
L(2)
h(3)
o(3)
w (3)
y (3)
L(3)
Last encoder state
(has “read” source)
Predicted
True
y (1) y (2)
x(2) x(3) Embeddings
True
w (1) w (2) Predicted
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 22 / 24
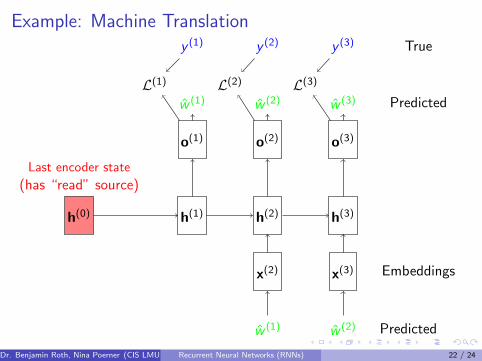
Example: Machine Translation
h(0) h(1)
o(1)
w (1)
y (1)
L(1)
h(2)
o(2)
w (2)
y (2)
L(2)
h(3)
o(3)
w (3)
y (3)
L(3)
Last encoder state
(has “read” source)
Predicted
True
y (1) y (2)
x(2) x(3) Embeddings
Truew (1) w (2) Predicted
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 22 / 24

Oracle
Give Neural Network a signal that it will not have at test time
Can be useful during training (e.g., mix oracle and predicted signalwhen training a generative language model)
Can be used to establish upper bounds of modulesI Example: How much better do Neural MT systems become when they
take the translation of the previous sentence into account?I If we don’t see improvements, this could be because
F the previous sentence contains no useful information in generalF the translation of the previous sentence was not good enough to have a
positive effect
I → provide gold translation of previous sentence as oracle to find upperbound
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 23 / 24

Gated RNNs: Teaser
Vanilla RNNs are not frequently used, becauseI Vanishing/exploding gradients make them difficult to trainI They tend to forget past information quickly
Instead: LSTM, GRU, ... (next week!)
Dr. Benjamin Roth, Nina Poerner (CIS LMU Munchen)Recurrent Neural Networks (RNNs) 24 / 24