rakuten techconf2015.baiji.he.bigdataforsmallstartupandbeyond
TRANSCRIPT


Big Data for Small Startup
and Beyond
Baiji He
Director of Data Engineering
Rakuten Marketing

My Background
• Director of data engineering, Rakuten Marketing
• Employee no.1, chief data architect, Deep Forest Media
• Worked in Yahoo! Strategic Data Solutions for 6 years
• Early adopter of Hadoop (in 2007)
• Graduated from Tsinghua University

What We Do
• We help advertisers to:
– Engage consumer
– Drive revenue
– Build brand loyalty
• How we do it:
– Cross channel
– Cross device
– Programmatic, real time bidding solution
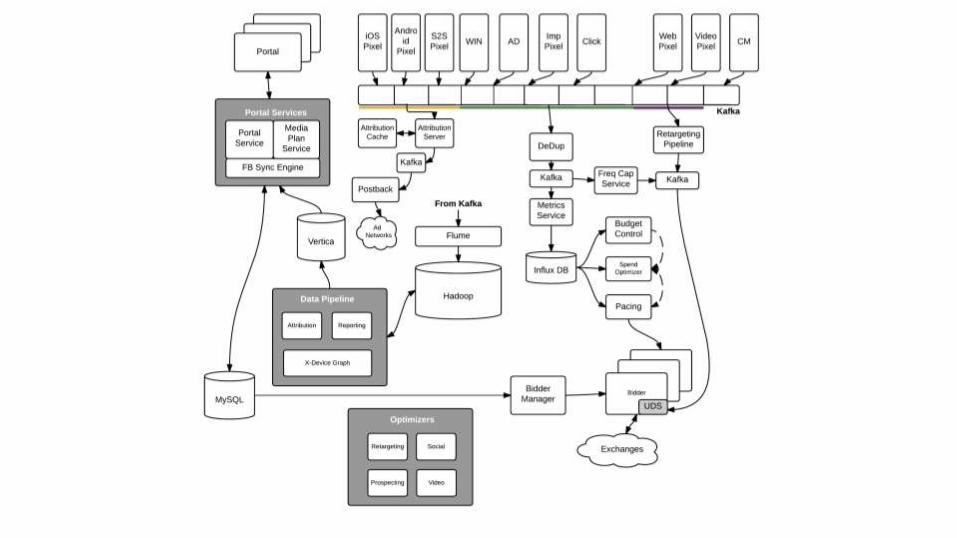

Big Data Challenges
• Velocity: Respond to bid requests in 10s of ms
• Variety: RTB, Ad Serving, SDK, 3rd party data
• Volume: 10+TB per day
• Complexity: multiple databases for different
requirements
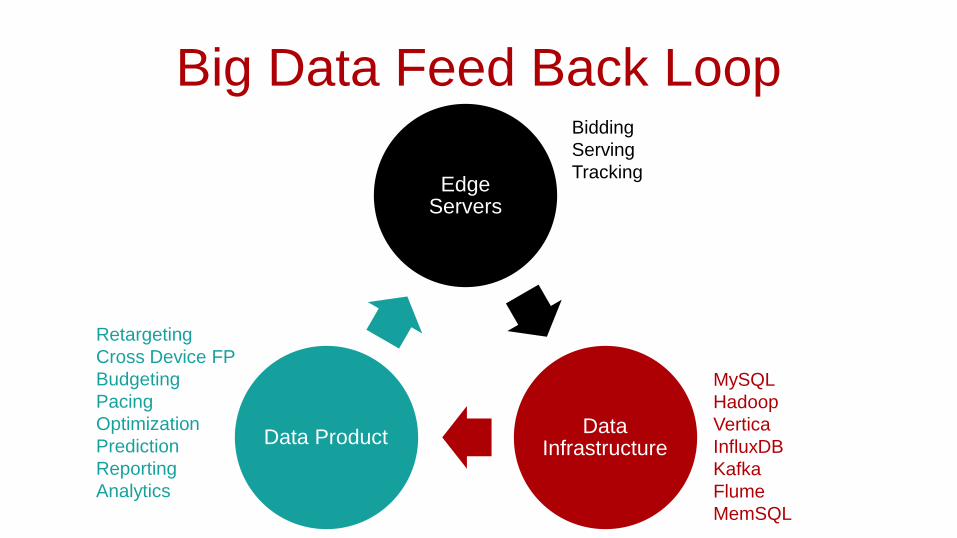
Big Data Feed Back Loop
Edge Servers
Data Infrastructure
Data Product
Bidding
Serving
Tracking
MySQL
Hadoop
Vertica
InfluxDB
Kafka
Flume
MemSQL
Retargeting
Cross Device FP
Budgeting
Pacing
Optimization
Prediction
Reporting
Analytics

Data Collection
• Flume-ng
– Distributed, reliable, configurable log collecting system
– Works well with HDFS, Kafka, HBase
– Can create flexible data flow with its components:
• Source, channel, sink
• Interceptor, channel selector, sink processor

Data Collection
• Kafka
– More general purpose messaging system
– Multiple consumers pull data independently
– API in many languages

Data Format
• Avro
– Data serialization format for collecting raw data
– Schema bring some cleanliness to data
– Schema evolution
– Works well with Hadoop / Impala / Spark

Data Format
• Parquet
– De facto columnar storage format
– Highly efficient for analytical queries
– Works well with Hadoop / Impala / Spark

Batch Data Pipeline
• Hive
– On M/R, Tez or Spark
• Map Reduce
• Spark
– Most flexible, replacing M/R
• Impala
– Fastest on data up to 10s GB

Real Time Data Pipeline
• Custom Golang code
– Built into our edge servers
• Flume Interceptor
– As low latency as storm
– Simple event enriching/transforming/validating
• Spark Streaming
– Micro batch processing
– Aggregating, Windowing, Joining

Data Serving
• Custom code + RocksDB
– Highly optimized for low latency requirement
• Aerospike
– Distributed in-memory NoSQL & key value store
• MemSQL
– Hybrid, distributed in-memory SQL database
• Vertica
– Column-oriented SQL database

Analytics
• Cloudera Impala
– Hadoop native
– Can be used as soon as data lands in HDFS
• Vertica
– Faster than Impala
• Spark
– In memory and flexible
– RDD, DataFrame, Spark SQL

Reporting
• Custom Dashboards
– Use Vertica for fast response and concurrency
– Home grown for slicing/dicing/rolling up/drilling down
• Tableau
– Can use data from either Vertica or Impala
• Canned reports
– Batch jobs, sent by emails

Monitoring
• Earlier: Carbon + Whisper + Graphite
• Now: InfluxDB + Grafana
– Simple configuration
– Written in Golang
– Active community
– Cluster mode (experimental)

What is not being used currently?
• Storm
• Kudu
• Solr
• HBase
• Cassandra
• …...
• But who knows? We are open minded.

We Are Hiring
• Data Infrastructure
• Data Integration
• User Data Service
• Cross Device
• Content Recommendation

