quantum-assisted cluster analysis · 1 quantum-assisted cluster analysis florian neukart* 1, david...
TRANSCRIPT

1
Quantum-assistedclusteranalysisFlorianNeukart*1,DavidVonDollen1,ChristianSeidel2
1VolkswagenGroup,RegionAmericas2VolkswagenData:Lab
AbstractWe present an algorithm for quantum-assisted cluster analysis (QACA) that makes use of thetopologicalpropertiesofaD-Wave2000Qquantumprocessingunit(QPU).Clusteringisaformofunsupervisedmachinelearning,whereinstancesareorganizedintogroupswhosememberssharesimilarities.Theassignmentsare,incontrasttoclassification,notknownapriori,butgeneratedbythealgorithm.Weexplainhowtheproblemcanbeexpressedasaquadraticunconstrainedbinaryoptimization (QUBO) problem, and show that the introduced quantum-assisted clusteringalgorithm is, regarding accuracy, equivalent to commonly used classical clustering algorithms.Quantum annealing algorithms belong to the class of metaheuristic tools, applicable for solvingbinary optimization problems. Hardware implementations of quantum annealing, such as thequantum annealing machines produced by D-Wave Systems [1], have been subject to multipleanalyses in research,with theaimof characterizing the technology’susefulness foroptimization,sampling,andclustering[2–16,38].Ourfirstandforemostaimistoexplainhowtorepresentandsolve parts of these problemswith the help of theQPU, andnot to prove supremacy over everyexistingclassicalclusteringalgorithm.
1 IntroductionQuantum annealing is a class of algorithmicmethods andmetaheuristic tools for solving search oroptimizationproblems.Thesearchspacefortheseproblemsusuallyconsistsoffindingaminimumormaximumofacostfunction.Insearchingasolutionspaceforaproblem,quantumannealingleveragesquantum-mechanical superpositionof states,where thesystem followsa time-dependentevolution,wheretheamplitudesofcandidatestateschangeinaccordanceofthestrengthofthetransversefield,whichallowsforquantumtunnelingbetweenstates.Followinganadiabaticprocess,aHamiltonianisfoundwhosegroundstatecloselydescribesasolutiontotheproblem[1,2,28].
Quantum annealing machines produced by D-Wave Systems leverage quantum annealing via itsquantum processor or QPU. The QPU is designed to solve an Ising model, which is equivalent tosolvingquadraticunconstrainedbinaryoptimization(QUBO)problems,whereeachqubitrepresentsavariable,andcouplersbetweenqubitsrepresentthecostsassociatedwithqubitpairs.TheQPUisaphysical implementation of an undirected graph with qubits as vertices and couplers as edgesbetweenthem.ThefunctionalformoftheQUBOthattheQPUisdesignedtominimizeis:*Correspondingauthor:[email protected]

2
𝑂𝑏𝑗 𝑥, 𝑄 = 𝑥( ∙ 𝑄 ∙ 𝑥
(1)
where𝑥isavectorofbinaryvariablesof size𝑁, and𝑄isan𝑁×𝑁real-valuedmatrixdescribing therelationship between the variables. Given the matrix𝑄, finding binary variable assignments tominimize theobjective function inEquation2 is equivalent tominimizingan Isingmodel, aknownNP-hardproblem[16,17].
2 ClassicalclusteringInclusteranalysis,theaimistogroupsetsofobjects,i.e.,pointsorvectorsin𝑑-dimensionalspace,suchthat some objects within one group can be clearly distinguished from objects in another group. Anadditional taskmay be the ability to quickly assign new objects to existing groups (clusters), i.e., bycalculatingthedistancetoapreviouslycalculatedcluster-centroidinsteadofrunningthere-runningthecompleteclusteringalgorithm.
Clustering isa formofunsupervisedmachine learning,andused to findrepresentativecaseswithinadata set for supporting data reduction, orwhen needing to identify data not belonging to any of thefoundclusters[29].Clusteringhelpsto identify instancessimilar tooneanother,andtoassignsimilarinstances to a candidate cluster. A set of clusters is considered to be of high quality if the similaritybetweenclusters is low,yetthesimilarityof instanceswithinacluster ishigh[30].Thegroupsare, incontrarytoclassification,notknownapriori,butproducedbytherespectiveclusteringalgorithm[31].Clustering is, amongst others, supported by self-organizing feature maps, centroid-based algorithms[32],distribution-basedalgorithms,density-basedalgorithms,orthogonalpartitioningclustering.
Weonlyexplainoneverycommonalgorithmindetail–self-organizingfeaturemaps–asthisclassicalalgorithmsharessomesimilaritiestotheintroducedquantum-assistedclusteringalgorithm.
2.1 Self-organizingfeaturemapSelf-organizingfeaturemaps(SOFMs)areusedtoprojecthigh-dimensionaldataontoalow-dimensionalmapwhiletryingpreservetheneighboringstructureofdata.Thismeansthatdatacloseindistanceinan𝑛-dimensional space shouldalso stay close indistance in the low-dimensionalmap– theneighboringstructureiskept.SOFMsinventor,TeuvoKohonen,wasinspiredbythesensoryandmotorpartsofthehumanbrain[33].

3
n1
n2n3
n4
n5
n6
n7n8
n9
n10
n11n12
n13n14
n15
n16
n17n18
n19
n21
n22n23
n24
n25
n26
n27n28
n29
nn
x4x3x2x1
wn13x3
wn14x4
wn13x1
wn13x2
n20
Fig.1–Selforganizingfeaturemap
Fig.1–Selforganizingfeaturemap–theschemeofaSOFMshowsthateverycomponentof the inputvector𝑥is represented by an input neuron and is connectedwith the above low-(two-) dimensionallayer.Duringalearningphase,theweightvectorsofaSOFMareadaptedinaself-organizingway[34].As other Artificial Neural Networks (ANNs), the SOFM consists of neurons(𝑛/, … , 𝑛1), each having aweightvector𝑤4andadistancetoaneighborneuron.Thedistancebetweentheneurons𝑛4and𝑛6 is𝑛46,.AsFig.1–shows,eachneuronisallocatedapositioninthelow-dimensionalmapspace.AsinallotherANNs,initiallytheneuronweightsarerandomized.Duringlearning,thesimilarityofeachinputvectorto theweightsof all neuronson themap is calculated,meaning that allweight vectors are comparedwith the input vector𝑑 ∈ 𝐷 . The SOMs learning algorithm therefore belongs to the group ofunsupervised learning algorithms. The neuron showing the highest similarity, having the smallestdistance𝑑9:;<< to𝑑 ∈ 𝐷isthenselectedasthewinningneuron𝑛=41(Eq.3)[35]:
𝑑9:;<< = 𝑑{(𝑑 ∈ 𝐷,/?6?1:41 𝑤6)}
(2)
Weightsofthewinningneuronareadapted,aswellastheweightsoftheneighborneuronsutilizingtheneighborhood function𝜑1and the learning rate𝜇. The neighborhood function has the followingcharacteristics[35]:
• 𝜇hasitscenteratthepositionof𝑛=41andisamaximumthere.• Theneighboringneuronsareconsideredaccordingtoaradius.Withinthisradius,fordistances
smallerthan𝑟,𝜑1leadstooutcomesgreaterthanzero,andfordistancesgreaterthan𝑟,ittakesonavalueofzero.

4
ChoosingaGaussianfunctionfulfilsalltherequirementsinthiscase.TheadaptionoftheweightsisthencarriedoutasdescribedinEq.3:
𝑤4(DE/) = 𝑤4
(D) + 𝜇𝜑1 𝑤1GHI,𝑤4D , 𝑟 𝑑 ∈ 𝐷 − 𝑤4
(D)
(3)
Duringtraining,thelearningrateandtheneighborhoodradiushastobereducedineachiteration,doneby𝜎(DE/)(Eq.4)[35,37]:
𝜎(DE/) = 𝜎9 ∗𝜎M𝜎9
(DE/)/(DE/)O
(4)
where𝜎9representsthestartingvalueand𝜎M theendingvalue,alsobeingthefunctionvalueof𝑡(+1)M .
2.2 SimilaritiestoSOFMandquantum-assistedclusteringIn theexampledepicted inFig.1, theSOFMisa two-dimensional latticeofnodes,anddependingonapresented instance,differentnodeswill firewithdifferentstrengths.Theones firingwith thegreatestamplitudegivetheclusterassignment.TheQACAworkssimilar inthesensethatthetwo-dimensionaltopologicalpropertiesof theD-Waveareexploited for clusterassignments.Assumingweembed two-dimensional clusters on the chip (higher-dimensional structures can be mapped as well – see theexplanationsinchapter3),anassignmentofclusterpointstoqubitsmaylookasdescribedinFig.2:

5
Fig.2–Qubitsandclusters
Fig. 2 shows schematically thatqubits1 –8, and17, 18, 21would “fire”, thus take the value1 in theresult-vector,andqubits9–16and19,20,22–24wouldnotfire,thustakethevalue0.Weneedtosetthecouplingsaccordingly,sothatwhenacandidateinstanceisfedintothecluster-form(see3.2,Fig.3)andembeddedontotheQPU,theresultallowsusidentify“areas”ofactivityorgroupsofqubitssetto1forsimilarinstances.
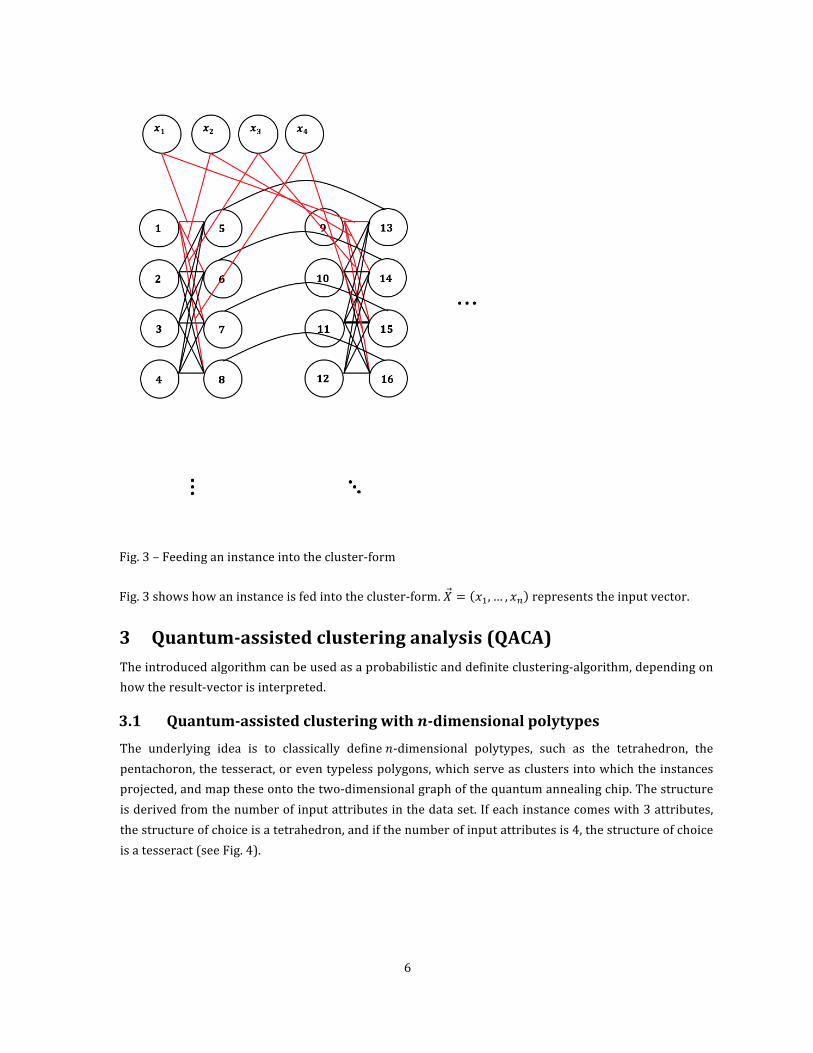
6
Fig.3–Feedinganinstanceintothecluster-form
Fig.3showshowaninstanceisfedintothecluster-form.𝑋 = 𝑥/, … , 𝑥1 representstheinputvector.
3 Quantum-assistedclusteringanalysis(QACA)Theintroducedalgorithmcanbeusedasaprobabilisticanddefiniteclustering-algorithm,dependingonhowtheresult-vectorisinterpreted.
3.1 Quantum-assistedclusteringwith𝒏-dimensionalpolytypesThe underlying idea is to classically define𝑛-dimensional polytypes, such as the tetrahedron, thepentachoron,thetesseract,oreventypelesspolygons,whichserveasclustersintowhichtheinstancesprojected,andmaptheseontothetwo-dimensionalgraphofthequantumannealingchip.Thestructureisderivedfromthenumberofinputattributesinthedataset.Ifeachinstancecomeswith3attributes,thestructureofchoiceisatetrahedron,andifthenumberofinputattributesis4,thestructureofchoiceisatesseract(seeFig.4).
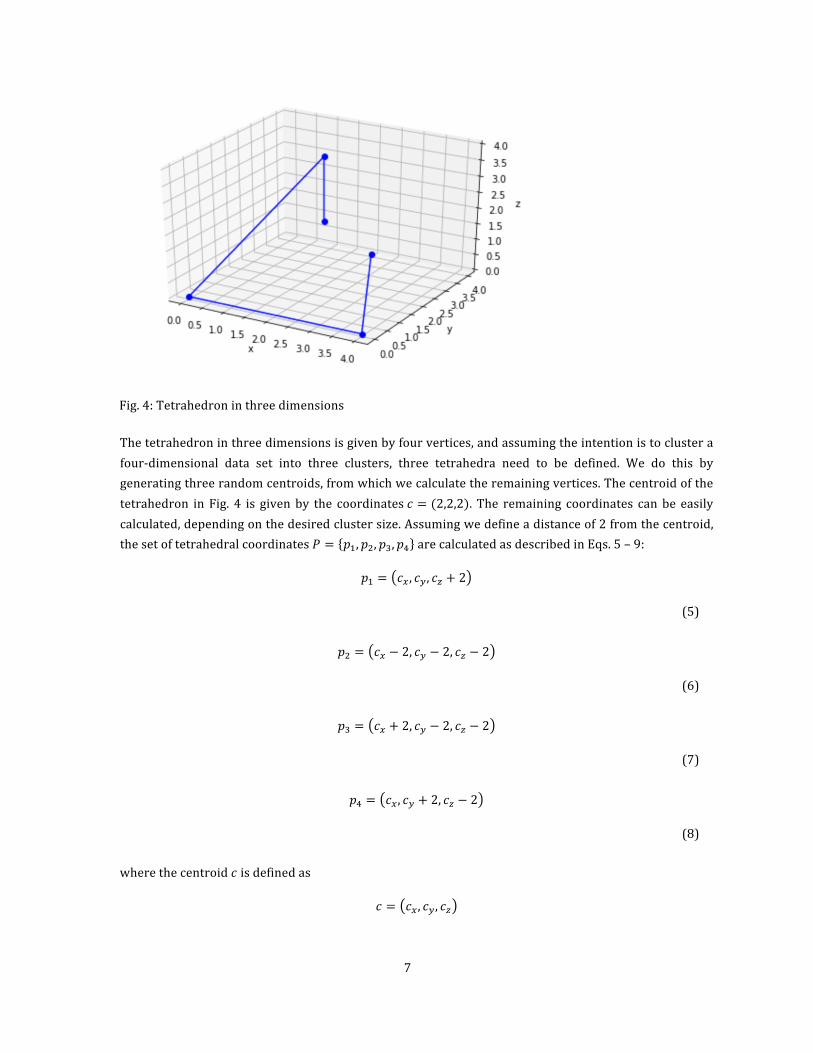
7
Fig.4:Tetrahedroninthreedimensions
Thetetrahedroninthreedimensionsisgivenbyfourvertices,andassumingtheintentionistoclusterafour-dimensional data set into three clusters, three tetrahedra need to be defined. We do this bygeneratingthreerandomcentroids,fromwhichwecalculatetheremainingvertices.Thecentroidofthetetrahedron in Fig. 4 is givenby the coordinates𝑐 = (2,2,2). The remaining coordinates canbe easilycalculated,dependingonthedesiredclustersize.Assumingwedefineadistanceof2fromthecentroid,thesetoftetrahedralcoordinates𝑃 = 𝑝/, 𝑝X, 𝑝Y, 𝑝Z arecalculatedasdescribedinEqs.5–9:
𝑝/ = 𝑐[, 𝑐\, 𝑐] + 2
(5)
𝑝X = 𝑐[ − 2, 𝑐\ − 2, 𝑐] − 2
(6)
𝑝Y = 𝑐[ + 2, 𝑐\ − 2, 𝑐] − 2
(7)
𝑝Z = 𝑐[, 𝑐\ + 2, 𝑐] − 2
(8)
wherethecentroid𝑐isdefinedas
𝑐 = 𝑐[, 𝑐\, 𝑐]

8
(9)
Asthisapproachdoesnotgeneralizetootherpolytypes,thethree-dimensionaltetrahedronservesonlyas an example. Another way of defining clusters is by typeless polygons, based on randomly chosencoordinates fromwithin a range of𝑚𝑖𝑛(𝑥)and𝑚𝑎𝑥(𝑥). Due to the innerworkings of the introducedalgorithm strongly overlapping clusters can be seen as probabilistic clustering, and clusters withinclusterswouldhelptoidentifyclustersindatasetssuchasdescribedinFig.5:
Fig.5:Somenon-lineardatasetsandsomewaystoclusterthem[36]
Dependingonhowfarwemovetheclustersapart, the lessprobabilisticQACAbecomes,asthefarthertheclustersareapart, thesmaller theprobabilityofoverlappingclustersbecomes. If, classically (non-quantum),clustersdonotoverlapatall,wefinddefiniteclusterassignmentsforeachoftheinstances.Togive a first indication about howwe define probability in terms of the introduced quantum-assistedclusteringalgorithm,weconsiderdefinitestatesofqubitspost-measurement.Eachqubitcanbeinoneofthestates𝑆 = −1,1 .Themorequbitsofacluster𝑘[ ∈ 𝐾 = 𝑘d, … , 𝑘:e/ takethestate1foraspecificinstance𝑖[ ∈ 𝐼 = 𝑖d, … , 𝑖<e/ , the more probable it is that the instance𝑖[is a member of𝑘[ . What’sparticularly elegant about this approach is that if clusters do not overlap in space, the nature of ouralgorithmstillallowsforprobabilisticclustering(andtosolvenon-linearproblemsasdepictedinFig.3).However,thefartherapartwemovetheclusters,themoretherespectiveclustercoordinatesdifferfromeachother,andthemorelikelyitisthatwefinddefiniteassignments.Weinitializetheclustersbasedon𝑛-dimensionaltypelesspolygonsasdescribedinAlgorithm1:

9
Algorithm1Clusterdefinitionbasedon𝒏-dimensionaltypelesspolygons
Initialize:𝒊𝒄,𝒏𝒗,𝑴,𝒊E,𝒓𝒎𝒊𝒏,𝒓𝒎𝒂𝒙Foreach𝒌 ∈ 𝑴:
Foreach𝒗 ∈ 𝑵𝒗:𝒗𝒙𝒄 = 𝒓𝒂𝒏𝒅 𝒓𝒎𝒊𝒏, 𝒓𝒎𝒂𝒙 𝒗𝒚𝒄 = 𝒓𝒂𝒏𝒅 𝒓𝒎𝒊𝒏, 𝒓𝒎𝒂𝒙 𝒗𝒛𝒄 = 𝒓𝒂𝒏𝒅 𝒓𝒎𝒊𝒏, 𝒓𝒎𝒂𝒙
𝒓𝒎𝒊𝒏 = 𝒓𝒎𝒊𝒏 + 𝒊E ∗ 𝝐𝒓𝒎𝒂𝒙 = 𝒓𝒎𝒂𝒙 + 𝒊E ∗ 𝝐
Breakdown𝒊𝒄:theinitialcoordinateforclustervertexcalculations,givenbyEq.8.𝒏𝒗:setofallverticespercluster,i.e.,fourverticespercluster:𝑵𝒗 = 1,2,3,4 .𝒌:cluster𝑴:setofallclusters,i.e.,threeclusters:𝑴 = {1,2,3}.𝒊E:incrementbywhichthecoordinaterangeforfindingrandomverticesisshifted,givenbyEq.9.𝒓𝒎𝒊𝒏:minimumrangevalue for findingrandomverticeswhichdefineacluster. Initializedas𝒓𝒎𝒊𝒏 =𝒊𝒄.𝒓𝒎𝒂𝒙:maximumrangevalueforfindingrandomverticeswhichdefineacluster.Initializedas𝒓𝒎𝒂𝒙 =𝒓𝒎𝒊𝒏 + 𝒊E.𝒗𝒙𝒄, 𝒗𝒚𝒄 , 𝒗𝒛𝒄: x,y, z coordinatesof thevertex𝑣in the𝑐Dxcluster. In the introducedexamplespace is3-dimensional,butthealgorithmgeneralizesto𝑛-dimensionalspace,andevencomplexmanifolds.𝝐:slidingfactor.
𝑖y = min(𝑋)
(10)
𝑖E =max 𝑋 − min(𝑋)
𝑚
(11)
where𝑋isthematrixofinputattributesand𝑚thenumberofclusters.InAlg.1,weassigncoordinatestoeachvertexofan𝑛-dimensionaltypelesspolygon.Foreachcluster,weshiftthecoordinaterange𝑟 =𝑟:41, 𝑟:;[ by the increment𝑖Eand a sliding factor𝜖,which is increases or decreases in coordinationwithdesiredinter-clusterdistances.Weemphasizethatlargeinter-clusterdistances,i.e.intheEuclideansense,donotnecessarilyimplydefiniteclusterassignments.Foraninstance𝑖[ ,theintroducedalgorithmmaystillcalculateacertainprobabilityof𝑖[belongingtocluster𝑘/,butalsoto𝑘[ ,evenwhen𝑘/and𝑘[donotoverlapin𝑛-dimensionalspace.
3.2 QUBO-formandembeddingWepresenttheproblemtotheD-WaveinQUBO-form.ThedefinitionofthematrixinQUBO-formisdoneintwosteps.

10
1. ThefirststepisindefiningamatrixinQUBO-formorwhatwecallacluster-form(CF).TheCFisdefinedonlyonce for all presented instances, and subsequentlymodifiedas instances are fedintoit.Itisworthpointingoutanothermajordifferencetoclassicalclusteringalgorithmssuchask-meansorself-organizingfeaturemaps: insteadoftrainingregimes, i.e., iterativedistance-basedcalculationofcentroids,orstrengtheningtheweightsofnearestneighborsaroundafiringneuron,weonlyneedtoallocateinstancestotheCFoncetoobtaintheclusterassignment.The QUBO-matrix is an upper triangular𝑁×𝑁-matrix defined by𝑖 ∈ 0, … , 𝑁 − 1 by𝑗 ∈ 0, … , 𝑁 − 1 . In thedemonstratedexample,eachentry is initializedwith0,andsubsequentlyupdated with the values calculated for the CF, which come from Alg. 1. The CF will hold allvaluesof theverticesbasedon thesimplecalculations inAlg.1.Whilecalculatingeachvertexcoordinate𝑣[y, 𝑣\y, 𝑣]y , we also assign an ID to each of these and store this information in alookup-table.The𝑥-coordinate in firstvertex in the first cluster isgiven the ID1:𝑣[/(ormoreaccurately:𝑣/�
/ , where the exponent defines the cluster, and the subscript the vertex number
andtherespectivecoordinate), the𝑦-coordinate inthefirstvertexof thefirstclustertheID2,and so on. We additionally create a list𝐿of length𝑙 = 𝑛� ∗ 𝑚, which contains a list of thecoordinate values, i.e., the first three entries of this list give the𝑥, 𝑦, 𝑧coordinates of the firstvertex in the first cluster. The values in𝐿may also be scaled as described in Eq. 20, but thisstronglydependsfromthevarianceinthedataset.Wedefinethenumberofverticesas𝑛�and𝑚thenumberofclusters.Additionally,westore thequbit-to-clusterassignments ina lookup-table𝐷intheform 𝑘/: 0,1,2 , 𝑘X: 3,4,5 , … , 𝑘1: 𝑞[eY, … , 𝑞[e/ thatweuseinstep2.Weassign𝑘[astheclusternumber,andqubitsaregivenbytherespectivearrays.TheCFisthendefinedasdescribedinEq.12:
CF i, j =
CF i, j − L�X + L�X , ifc1
CF i, j + L�X + L�X , ifc2
CF i, j , otherwise
(12)where
c1:S/ ≡ SXandi ≤ j(13)
andc2:S/¬≡ SXandi ≤ j
(14)
InEqs.13and14theconditionsforassigningpositiveornegativesignstoanentryaredefined.
Ifc1 ismet,ourtestsshowthatsettingtherespectiveentriesto0 insteadof− L�X + L�X may
providebetterresults,butthereisanoticeablevarianceoverdifferingdatasets.Thebasicideais to iterate over the qubit-IDs of each cluster, and to compare if the set of qubit IDsS/is

11
identicaltothesetofqubitIDsSX. If thesetsareidentical,negativeintra-clustercouplingsareset, and if not, positive inter-cluster couplings are set. The reason for this is that once weintroduce an instance to the CF. The coupling-strengths values around the most probablecluster’squbitsarelowered,andinthesameinstancethevaluestheinter-clustercouplingshelpto raise the entries of the remaining clusters. This results in lower probability of the mostprobableclustersbeingactivated.
2. Thesecondstepisiteratingoverallcluster-instances:theinstancesarefedintothecluster-formonebyone,andeachoftheresultinginstance-clustermatrices(ICM)areembeddedontheQPU.Foreachcluster,wegooverthenumberofverticesandcalculateadistancefromeachattribute-coordinate toeachcluster-coordinate.Thenumberofqubitsperclustermustbeamultipleofthenumberofdatasetattributes,i.e.,whenthedatasetisthree-dimensional,aclustermayberepresentedby3qubits(point),6qubits(line),9qubits(triangle),andsoon.Ifaclusterina3-dimensionalspaceisdefinedby6points,werequire18qubitstorepresentitontheQPU.Foreachoftheclustercoordinates,wenowcalculatethedistancetoeachinstanceandupdatethelist𝐿accordingly.𝐿,asdefinedinstep1,wasusedtodefinethecluster-formandwassetwithnegative intra-cluster couplings, and positive inter-cluster couplings. For each instance,𝐿isupdatedasdescribedinAlg.2:Algorithm2Instancetoclusterdistancecalculation
Load:𝑫, 𝑳, 𝒊𝒙Initialize:cc=0Foreach𝒌 ∈ 𝑫:
Foreach𝒒𝒖𝒃𝒊𝒕 ∈ 𝒌:𝑳 𝒒𝒖𝒃𝒊𝒕 = 𝑳 𝒒𝒖𝒃𝒊𝒕 − 𝒊[𝒄𝒄]𝟐𝒄𝒄 = 𝒄𝒄 + 𝟏If𝒄𝒄 == 𝒅:
cc=0
Breakdown𝑫:Clusterdictionary𝐷: 𝑘/: 0,1,2 , 𝑘X: 3,4,5 , … , 𝑘1: 𝑞[eY, … , 𝑞[e/ 𝑳:Listwithqubit-IDsandtheirvaluesasinitializedinthecluster-form𝒊𝒙:aninstance𝒄𝒄: coordinate counter. Counts up to 3 if the instance has 3 coordinates, up to 4 with 4coordinates,andsoon𝒅:numberofdimensionsperinstance𝒌:key/clusterin𝐷𝒒𝒖𝒃𝒊𝒕:thequbitIDsperentryin𝐷𝑳[𝒒𝒖𝒃𝒊𝒕]:thevalueof𝐿atentry𝑞𝑢𝑏𝑖𝑡WithAlg.2,thedistancefromaninstance𝑖[toanypoint inanyclusterinthecluster-formiscalculated.Oncethisisdone,theICMisupdatedasdescribedinEqs.15–20:

12
CF 𝑖, 𝑗 =
CF 𝑖, 𝑗 − 𝐿4X + 𝐿6X , 𝑖𝑓𝑐1CF 𝑖, 𝑗 − 𝐿4 ∗ 𝐿6 , 𝑖𝑓𝑐2CF 𝑖, 𝑗 + 𝐿4X + 𝐿6X , 𝑖𝑓𝑐3CF 𝑖, 𝑗 + 𝐿4 ∗ 𝐿6 , 𝑖𝑓𝑐4
CF 𝑖, 𝑗 , 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒
(15)where
𝑐1:𝑆/ ≡ 𝑆X𝑎𝑛𝑑𝑖 < 𝑗(16)
and𝑐2:𝑆/ ≡ 𝑆X𝑎𝑛𝑑𝑖 = 𝑗
(17)and
𝑐3:𝑆/¬≡ 𝑆X𝑎𝑛𝑑𝑖 < 𝑗(18)
and𝑐3:𝑆/¬≡ 𝑆X𝑎𝑛𝑑𝑖 = 𝑗
(19)
ThelaststepbeforeembeddingtheproblemontotheQPUisscalingthevaluesintheICM,whichisdoneaccordingtoEq.20:
𝑥9y;<M¯ =𝑥4 − 𝑚𝑒𝑎𝑛(𝑥)
𝜎 𝑥
(20)
where𝜎 𝑥 isthestandarddeviation.Thefeaturesarecenteredtothemeanandscaledtounitvariance.
OncetheICMhasbeenprocessed,thespin-directionsprovidedintheresult-vectortelluswhichqubitsare “turned on”, and which are “turned off”. Three ways to extract the cluster assignments areprobabilisticanddefinite:
1. Definite:Fortheturned-onqubits,therespectivevaluesof𝐿areextracted,andbylookingup𝐷wecanidentifytheclusterthisqubitbelongsto.In𝐷,wecanfindthequbitspercluster,andfromtheresult-vectorwegettheturned-on.WelookuptherespectiveIDsin𝐿,andsumthevaluesovertheremainingqubits.Thelowestsumof“on”-qubitvaluesperclustergivestheclusterassignment.
2. Probabilistic1:Thenumberofturned-onqubitspercluster,asdefinedbyqubit-assignmentsin𝐷,iscounted.Thepercentageof turned-onqubitsper clustergives theprobabilistic assignmentsof aninstancetoclusters.
3. Probabilistic2:Fortheturned-onqubits,therespectivevaluesof𝐿areextracted,andbylookingup𝐷wecanidentifytheclusterthisqubitbelongsto.In𝐷,wecanfindthequbitspercluster,andfromtheresult-vectorwegettheturned-on.WelookuptherespectiveIDsin𝐿,andsumthevaluesover

13
theremainingqubits.Thepercentageofturned-onqubits-valuesperclustergivestheprobabilisticassignmentsofaninstancetoclusters.
4 ExperimentalresultsandconclusionsOurintentionwastoobtaintheresultswithouthavingtosplittheQUBOsothatasingularembeddingispossible.WeverifiedQACAwithcommonlyusedlow-dimensionalverificationdatasets,suchastheIris data set. For verification, we chose Expectation Maximization, k-means, and Self-OrganizingFeatureMaps,allthreeknowntoperformwellontheIrisdataset.WeranQACA5timesandaveragedtheperformance,asduetotherandomnessinthecluster-formtheresultscanvary. Inbrackets,weprovide the individual cluster assignments. The accuracy is defined as percentage of correctlyassignedinstances,andthecluster-assignmentisdefinite(Tbl.1).
EM k-means SOFM QACA
Accuracyin% 86 89.7 70.7 Avg.:~85.6
Ind.:(87.33(131),90(135),83.33(125),80(120),87.33(131))
Tbl.1-Algorithmcomparison
Some example results for the “Probabilistic 2”-method,which is as accurate as the definite resultsdescribedinTbl.1whenassigninghighestprobabilitytoaninstance,areasfollows(Tbl.2):
instance 0 probabilities: 1.06, 20.96, 77.97 instance 1 probabilities: 1.06, 20.96, 77.97 instance 2 probabilities: 2.62, 20.99, 76.38 instance 3 probabilities: 0.76, 20.92, 79.83 instance 4 probabilities: 1.06, 20.96, 77.97 instance 5 probabilities: 4.019, 23.99, 80.02 ... Tbl.2–Probabilisticassignments
Summing up, the quantum-assisted clustering algorithm can compete with classical algorithms intermsof accuracy, andsometimesoutperforms theonesused for comparisonon the testdata sets.However, theresultsstronglyvarydependingonthecluster-form,andbetterways forcluster-forminitializationhavetobefound.

14
5 FutureworkInourfuturework,weintendtofurtherexploitthechiptopologytoidentifyclusterassignments.ByidentifyingwhereontheQPUwecanfindtheturned-onqubits,animplementationoffullfeaturemapshouldbepossible.
AcknowledgmentsThanksgo toVWGroupCIOMartinHofmannandVWGroupRegionAmericasCIOAbdallahShanti,who enable our research. Special thanks go to Sheir Yarkoni of D-Wave systems whose valuablefeedbackhelpedustopresentourresultscomprehensibly.
References[1] D-Wave(2017): Quantum Computing, How D-Wave Systems Work [04-24-2017]; URL:
https://www.dwavesys.com/quantum-computing
[2] M. Benedetti, J.R.-Gmez, R. Biswas, A. Perdomo-Ortiz (2015): Estimation of effectivetemperatures in quantum annealers for sampling applications: A case study with possibleapplicationsindeeplearning;Phys.Rev.A94,022308
[3] V. N. Smelyanskiy, D. Venturelli, A. Perdomo-Ortiz, S. Knysh,M. I. Dykman (2015): Quantumannealingviaenvironment-mediatedquantumdiffusion;Phys.Rev.Lett.118,066802
[4] D.Venturelli,D.J.J.Marchand,G.Rojo(2015):QuantumAnnealingImplementationofJob-ShopScheduling;arXiv:1506.08479v2[quant-ph]
[5] Z. Jiang, E. G. Rieffel (2015): Non-commuting two-local Hamiltonians for quantum errorsuppression;QuantumInfProcess(2017)16:89.
[6] S. V. Isakov, G. Mazzola, V. N. Smelyanskiy, Z. Jiang, S. Boixo, H. Neven, M. Troyer (2015):Understanding Quantum Tunneling through QuantumMonte Carlo Simulations (2015); PhysRevLett.2016Oct28;117(18):180402
[7] B.O’Gorman,A.Perdomo-Ortiz,R.Babbush,A.Aspuru-Guzik,V.Smelyanskiy(2014):BayesianNetworkStructureLearningUsingQuantumAnnealing;Eur.Phys.J.Spec.Top.(2015)224:163.
[8] E.G.Rieffel,D.Venturelli,B.O’Gorman,M.B.Do,E.Prystay,V.N.Smelyanskiy(2014):Acasestudyinprogrammingaquantumannealerforhardoperationalplanningproblems;QuantumInfProcess(2015)14:1.
[9] D. Venturelli, S. Mandr, S. Knysh, B. O’Gorman, R. Biswas, V. Smelyanskiy (2014): QuantumOptimizationofFully-ConnectedSpinGlasses;Phys.Rev.X5,031040

15
[10] A. Perdomo-Ortiz, J. Fluegemann, S. Narasimhan, R. Biswas, V. N. Smelyanskiy (2014): AQuantumAnnealingApproachforFaultDetectionandDiagnosisofGraph-BasedSystems;Eur.Phys.J.Spec.Top.(2015)224:131.
[11] S.Boixo,T. F.Ronnow, S.V. Isakov, Z.Wang,D.Wecker,D.A. Lidar, J.M.Martinis,M.Troyer(2014):Evidence forquantumannealingwithmore thanonehundredqubits;NaturePhysics10,218224(2014)
[12] R. Babbush, A. Perdomo-Ortiz, B. O’Gorman, W. Macready, A. Aspuru-Guzik (2012):Construction of Energy Functions for Lattice Heteropolymer Models: Efficient Encodings forConstraint Satisfaction Programming andQuantumAnnealing Advances in Chemical Physics;arXiv:1211.3422v2[quant-ph]
[13] J.A.Smolin,G.Smith(2013):Classicalsignatureofquantumannealing;Front.Phys.2:52.[14]A.Perdomo-Ortiz, N. Dickson, M. Drew-Brook, G. Rose, A. Aspuru-Guzik (2012): Finding low-energy conformations of lattice protein models by quantum annealing; Scientific Reports 2,Articlenumber:571
[14] NeukartF,VonDollenD,SeidelCandCompostellaG(2018)Quantum-EnhancedReinforcementLearning for Finite-Episode Games with Discrete State Spaces.Front. Phys. 5:71. doi:10.3389/fphy.2017.00071
[15] Los Alamos National Laboratory (2016): D-Wave2X Quantum Computer; URL: http://www.lanl.gov/projects/national-security-education-center/information-sciencetechnology/dwave/
[16] F.Neukart,C. Seidel,G.Compostella,D.VonDollen, S.Yarkoni,B.Parney (2017):Traffic flowoptimizationusingaquantumannealer;Front.ICT4:29.
[17] A.Lucas(2014):IsingformulationsofmanyNPproblems;Front.Physics2:5.
[18] D. Korenkevych, Y. Xue, Z. Bian, F. Chudak, W. G. Macready, J. Rolfe, E. Andriyash (2016):Benchmarking Quantum Hardware for Training of Fully Visible Boltzmann Machines;arXiv:1611.04528v1[quant-ph]
[19] T. Lanting, A.J. Przybysz, A.Yu. Smirnov, F.M. Spedalieri,M.H. Amin, A.J. Berkley, R. Harris, F.Altomare,S.Boixo,P.Bunyk,N.Dickson,C.Enderud,J.P.Hilton,E.Hoskinson,M.W.Johnson,E.Ladizinsky,N.Ladizinsky,R.Neufeld,T.Oh, I.Perminov,C.Rich,M.C.Thom,E.Tolkacheva,S.Uchaikin,A.B.Wilson,G.Rose(2013):EntanglementinaQuantumAnnealingProcessor;Phys.Rev.X4,021041
[20] M.Wiering, M. van Otterlo (2012): Reinforcement Learning andMarkov Decision Processes;Wiering M., van Otterlo M. (eds) Reinforcement Learning. Adaptation, Learning, andOptimization,vol12,pp.3-42.Springer,Berlin,Heidelberg
[21] R.S.Sutton,A.G.Barto(1998):ReinforcementLearning:anIntroduction;MITPress,Cambridge

16
[22] F.Neukart,S.M.Moraru(2013):OnQuantumComputersandArtificialNeuralNetworks;SignalProcessingResearch2(1),1-11,ISSN2327-171X
[23] F.Neukart,S.M.Moraru(2014):OperationsonQuantumPhysicalArtificialNeuralStructures;ProcediaEngineering69,1509-1517
[24] Springer Professional: Volkswagen Trials Quantum Computers (2017); URL:https://www.springerprofessional.de/en/automotive-electronics—software/companies—institutions/volkswagen-trials-quantum-computers/12170146?wtmc=offsi.emag.mtz-worldwide.rssnews.-.x
[25] F.Neukart(2017):Quantumphysicsandthebiologicalbrain.In:ReverseEngineeringtheMind.AutoUniSchriftenreihe,vol94,pp.221-229.Springer,Wiesbaden
[26] A. Levit, D. Crawford, N. Ghadermarzy, J. S. Oberoi, E. Zahedinejad, P. Ronagh (2017): Free-Energy-basedReinforcementLearningUsingaQuantumProcessor;arXiv:1706.00074v1[cs.LG]
[27] D. Crawford, A. Levit, N. Ghadermarzy, J. S. Oberoi, P. Ronagh (2016): ReinforcementLearningUsingQuantumBoltzmannMachines;arXiv:1612.05695[quant-ph]
[28] A. B. Finilla, M. A. Gomez, C. Sebenik and J. D. Doll, "Quantum annealing: A newmethod forminimizingmultidimensionalfunctions"Chem.Phys.Lett.219,343(1994)
[29] F.Neukart (2017):Anoutlineofartificialneuralnetworks. In:ReverseEngineering theMind.AutoUniSchriftenreihe,vol94,pp.91-93.Springer,Wiesbaden
[30] AnderbergMichaelR.(1973):ClusterAnalysisforApplications,NewYork:AcademicPressInc.
[31] Chamoni Peter, Gluchowski Peter (2006): Analytische Informationssysteme: BusinessIntelligence-Technologienund–Anwendungen,3rd.ed.,p.265,Springer,Berlin
[32] MacQueen J. B. (1967): Some Methods for Classification and Analysis of MultivariateObservations; Proceedings of 5th Berkeley Symposium on Mathematical Statistics andProbability;Berkeley:UniversityofCaliforniaPress,1:281-297
[33] Oracle:O-Cluster:ScalableClusteringofLargeHighDimensionalDatasets[2018-02-28];OracleCorporation;URL:https://docs.oracle.com/cd/B28359_01/datamine.111/b28129/algo_oc.htm
[34] RitterHelge,MartinezThomas,SchultenKlaus(1991):NeuronaleNetze.EineEinführungindieNeuroinformatikselbstorganisierenderNetzwerke;AddisonWesley
[35] KramerOliver(2009):ComputationalIntelligence:EineEinführung,p.141,Springer,Berlin
[36] Scikit-learn:MachineLearninginPython,Pedregosaetal.,JMLR12,pp.2825-2830,2011.
[37] Von Dollen David (2017): Identifying Similarities in Epileptic Patients for Drug ResistancePrediction;arXiv:1704.08361

17
[38] KumarVaibhaw,BassGideon,TomlinCasey,Dulny III Joseph(2018):QuantumAnnealing forCombinatorialClustering;arXiv:1708.05753v2