pycon 2016: personalised emails with spark and python
TRANSCRIPT

Analytics for the fastest growing companies

Personalised emails with Python and Spark
Tomáš Sirný, 12. 3. 2016 @junckritter

Agenda
● MapReduce
● Introduction to Apache Spark
● Spark + Python
● Use-case: Personalisation of email newsletters

About me
● Python developer
● Web development in Django
● Movie search with Elasticsearch
● Data Science

Problem of Big Data
● data are “BIG” and on lot of places
● hard and costly to get it all together at once
● slow to process

MapReduce
● MR is programming paradigm that allows for massive scalability
across hundreds or thousands of servers in a cluster
● do something with every small chunk
● choose only wanted ones
● put them together
● collect & save result

Hadoop
● Open-source implementation of Google’s BigTable
● Uses MapReduce
● In version 2 introduced YARN (Yet Another Resource Negotiator)
framework for managing resources
● Inputs and results of each phase are saved to files
● Complex configuration of jobs, not easy connection from non-JVM
languages

Apache Spark
Apache Spark™ is a fast and general engine for large-scale data
processing
● fast - faster MR than Hadoop, data are in memory
● general engine - multipurpose (data transformation, machine
learning, …)
● large-scale - runs in parallel on large clusters
● processing - filter, transform, save or send

RDD Resilient Distributed Dataset
● basic data structure in Spark
● immutable distributed collection of objects
● divided into logical partitions
● computed on different nodes of the cluster
● equivalent of table in SQL database

Python shell included(spark)tomas@Fenchurch:~/personal$ spark-1.5.2-bin-hadoop2.6/bin/pysparkPython 2.7.10 (default, Oct 23 2015, 18:05:06)[GCC 4.2.1 Compatible Apple LLVM 7.0.0 (clang-700.0.59.5)] on darwinType "help", "copyright", "credits" or "license" for more information.16/03/11 22:16:12 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable16/03/11 22:16:16 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.16/03/11 22:16:16 WARN MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set.Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 1.5.2 /_/
Using Python version 2.7.10 (default, Oct 23 2015 18:05:06)SparkContext available as sc, HiveContext available as sqlContext.>>> sc<pyspark.context.SparkContext object at 0x1071bb810>>>> x = sc.parallelize([1, 2, 3, 4, 5])>>> x.count()5>>> x.sortBy(lambda item: item, ascending=False).collect()[5, 4, 3, 2, 1]

Run from python in virtualenvos.environ['SPARK_HOME'] = os.path.join(config['spark_home'])os.environ['PYTHONPATH'] = os.path.join(config['spark_home'], 'python')os.environ['PYSPARK_PYTHON'] = config['python']sys.path.insert( 0, os.path.join(config['spark_home'], "python") # pysparksys.path.insert( 0, os.path.join(config[‘spark_home’], 'python/lib/py4j-0.8.2.1-src.zip')) #py4j
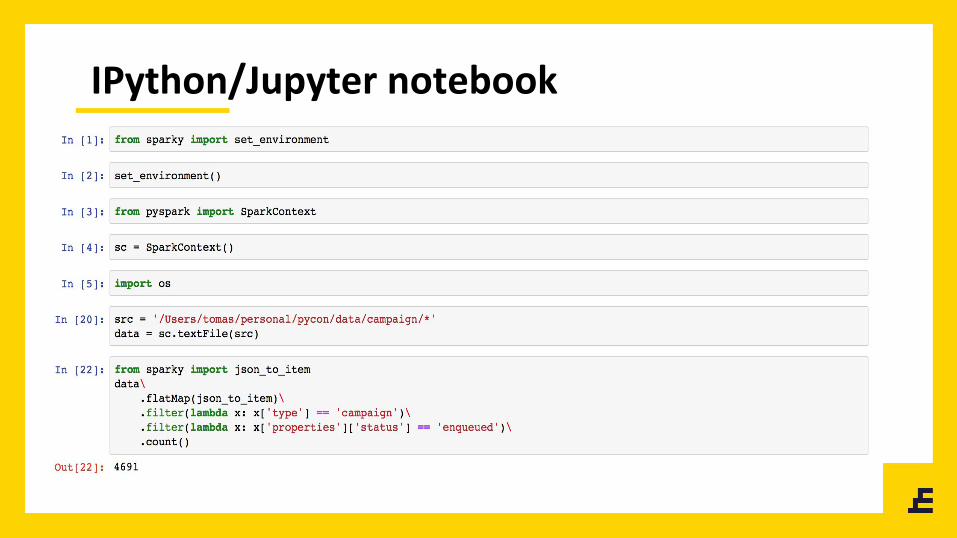
IPython/Jupyter notebook

IPython/Jupyter notebook

Define SparkContext
sc = SparkContext( appName='GenerateEmails', master='yarn-client’, pyFiles='emails.zip')
zip -r emails.zip * -x "*.pyc" -x "*.log"

Simple example
def get_delivered_rdd(data, date_str, mailing=None): delivered_rdd_raw = data \ .filter(lambda x: x['type'] == 'campaign') \ .filter(lambda x: x['properties']['status'] == 'delivered') \ .filter(clicked_actual_date(date_str)) if mailing: delivered_rdd_raw = delivered_rdd_raw \ .filter(lambda x: mailing in x['properties']['mailing']) return delivered_rdd_raw

Complex exampledef get_updated_customers( sc, base_path, project_id, dates='*', user_filter=None, customers=None): if customers is None: customers = sc.emptyRDD() src = os.path.join(base_path, project_id, "update_customer", dates) updates_raw = sc.textFile(src) updates = updates_raw \ .flatMap(json_to_item) \ .sortBy(lambda x: x['timestamp']) \ .filter(lambda x: x is not None) \ .groupByKey() \ .map(filter_manual_customers(user_filter)) \ .filter(lambda x: x is not None) \ .leftOuterJoin(customers) \ .map(join_values) return updates.collectAsMap()

General rule: do as much as possible in Spark
● count()● take(n)● combineByKey()● distinct()● countByKey()● foreach()
● groupBy()● union(), intersection()● join(), leftOuterJoin(), ● reduceByKey()● sortBy(), sortByKey()

Use case:personalised emails

Requirements:
● Set of defined sections in email - items from categories● Set of customers subscribed to different newsletters● Choose best N sections for each customer, based on her
activity
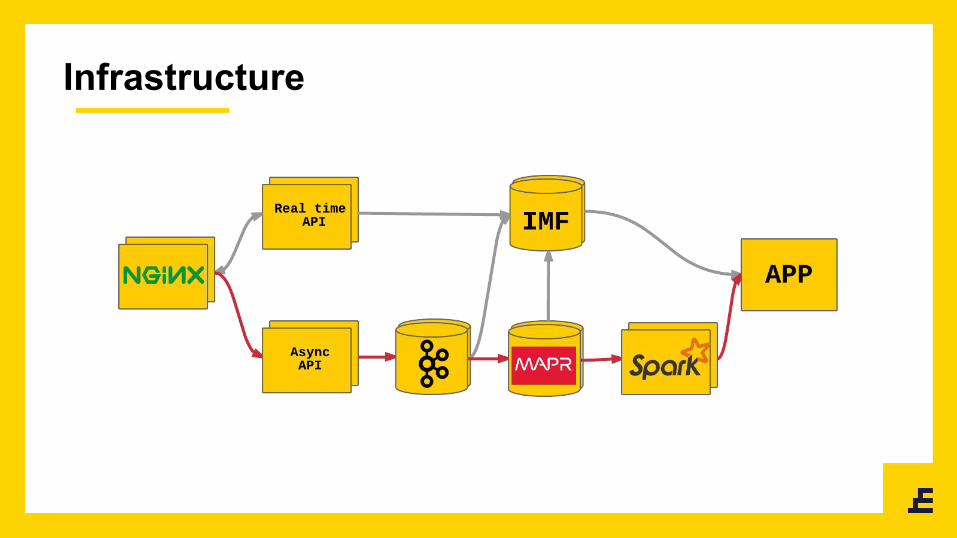
Infrastructure

Event{
"type": "add_event","data": {
"timestamp": 1444043432.0,"customer_id": "c1","type": "campaign","company_id": "ffe66a48-f341-11e4-8cbf-b083fedeed2e","properties": {
"status": "enqueued","sections": {
"s-test1": ["164377", "157663", "165109", "159075", "153851", "161695"],"s-test2": ["162363", "152249", "162337", "156861", "162109", "165021"],"s-test3": ["115249", "150349", "148291", "148265", "157581", "159479"]
}}
}}

AlgorithmS-01 S-02 S-03 S-04 S-05 S-06 S-07 S-08 S-09 S-10
C-01 0.5 0.555 0.23 0.11 0.734 0.93 0.34 0.66 0.85 0.15
C-02 0.4 0.955 0.13 0.76 0.833 0.53 0.74 0.84 0.585 0.45
C-42 0.67 0.555 0.73 0.11 0.234 0.93 0.34 0.66 0.85 0.15
C-43 0.8 0.555 0.33 0.51 0.79 0.43 0.14 0.46 0.55 0.85
C-103 0.9 0.335 0.27 0.11 0.734 0.93 0.34 0.86 0.65 0.15

AlgorithmS-01 S-02 S-03 S-04 S-05 S-06 S-07 S-08 S-09 S-10
C-01 0.5 0.555 0.23 0.11 0.734 0.93 0.34 0.66 0.85 0.15
C-02 0.4 0.955 0.13 0.76 0.833 0.53 0.74 0.84 0.585 0.45
C-42 0.67 0.555 0.73 0.11 0.234 0.93 0.34 0.66 0.85 0.15
C-43 0.8 0.555 0.33 0.51 0.79 0.43 0.14 0.46 0.55 0.85
C-103 0.9 0.335 0.27 0.11 0.734 0.93 0.34 0.86 0.65 0.15

Spark job
● Load data from JSON files on MapR-FS (distributed file-system)
● Create profile of each customer - email address, subscriptions, history of
actions (clicks, views, purchases, …)
● Filter by attributes (subscription, preferences)
● Create customer-specific parameters for main algorithm (which sections
she clicked, which mails she opened)

Python program
● Run Spark job
● Read customer records
● Feed them to main optimisation algorithm
● Generate & send personalised emails

Take-aways
● It’s easy to start with Spark through Python
● Few lines of code can process massive data ○ Map-Reduce, SQL, Graphs, Machine Learning
● Quickly becoming standard for data-science and data-science is a future of web applications

Thanks!