projeto jedi - sistema operacional - solaris - java - 110 páginas
TRANSCRIPT

Módulo 8Sistema Operacional
Lição 1Introdução ao Solaris
Versão 1.0 - Mar/2008

JEDITM
Autor-
EquipeRommel FeriaJohn Paul Petines
Necessidades para os ExercíciosSistemas Operacionais SuportadosNetBeans IDE 5.5 para os seguintes sistemas operacionais:
• Microsoft Windows XP Profissional SP2 ou superior• Mac OS X 10.4.5 ou superior• Red Hat Fedora Core 3 • Solaris™ 10 Operating System (SPARC® e x86/x64 Platform Edition)
NetBeans Enterprise Pack, poderá ser executado nas seguintes plataformas:• Microsoft Windows 2000 Profissional SP4• Solaris™ 8 OS (SPARC e x86/x64 Platform Edition) e Solaris 9 OS (SPARC e
x86/x64 Platform Edition) • Várias outras distribuições Linux
Configuração Mínima de HardwareNota: IDE NetBeans com resolução de tela em 1024x768 pixel
Sistema Operacional Processador Memória HD Livre
Microsoft Windows 500 MHz Intel Pentium III workstation ou equivalente
512 MB 850 MB
Linux 500 MHz Intel Pentium III workstation ou equivalente
512 MB 450 MB
Solaris OS (SPARC) UltraSPARC II 450 MHz 512 MB 450 MB
Solaris OS (x86/x64 Platform Edition)
AMD Opteron 100 Série 1.8 GHz 512 MB 450 MB
Mac OS X PowerPC G4 512 MB 450 MB
Configuração Recomendada de Hardware
Sistema Operacional Processador Memória HD Livre
Microsoft Windows 1.4 GHz Intel Pentium III workstation ou equivalente
1 GB 1 GB
Linux 1.4 GHz Intel Pentium III workstation ou equivalente
1 GB 850 MB
Solaris OS (SPARC) UltraSPARC IIIi 1 GHz 1 GB 850 MB
Solaris OS (x86/x64 Platform Edition)
AMD Opteron 100 Series 1.8 GHz 1 GB 850 MB
Mac OS X PowerPC G5 1 GB 850 MB
Requerimentos de SoftwareNetBeans Enterprise Pack 5.5 executando sobre Java 2 Platform Standard Edition Development Kit 5.0 ou superior (JDK 5.0, versão 1.5.0_01 ou superior), contemplando a Java Runtime Environment, ferramentas de desenvolvimento para compilar, depurar, e executar aplicações escritas em linguagem Java. Sun Java System Application Server Platform Edition 9.
• Para Solaris, Windows, e Linux, os arquivos da JDK podem ser obtidos para sua plataforma em http://java.sun.com/j2se/1.5.0/download.html
• Para Mac OS X, Java 2 Plataform Standard Edition (J2SE) 5.0 Release 4, pode ser obtida diretamente da Apple's Developer Connection, no endereço: http://developer.apple.com/java (é necessário registrar o download da JDK).
Para mais informações: http://www.netbeans.org/community/releases/55/relnotes.html
Sistema Operacional 2

JEDITM
Colaboradores que auxiliaram no processo de tradução e revisãoAécio JúniorAlberto Ivo da Costa VieiraAlexandre MoriAlexis da Rocha SilvaAllan Wojcik da SilvaAntonio José Rodrigues Alves RamosAngelo de OliveiraBruno da Silva Bonfim
Carlos Fernandes GonçalvesDenis Mitsuo NakasakiFelipe GaúchoJacqueline Susann BarbosaJoão Vianney Barrozo CostaLuiz Fernandes de Oliveira Junior Marco Aurélio Martins BessaMaria Carolina Ferreira da Silva
Massimiliano GiroldiPaulo Oliveira Sampaio ReisRonie DotzlawSeire ParejaThiago Magela Rodrigues DiasVinícius Gadis Ribeiro
Auxiliadores especiais
Revisão Geral do texto para os seguintes Países:
• Brasil – Tiago Flach• Guiné Bissau – Alfredo Cá, Bunene Sisse e Buon Olossato Quebi – ONG Asas de Socorro
Coordenação do DFJUG
• Daniel deOliveira – JUGLeader responsável pelos acordos de parcerias• Luci Campos - Idealizadora do DFJUG responsável pelo apoio social• Fernando Anselmo - Coordenador responsável pelo processo de tradução e revisão,
disponibilização dos materiais e inserção de novos módulos• Rodrigo Nunes - Coordenador responsável pela parte multimídia• Sérgio Gomes Veloso - Coordenador responsável pelo ambiente JEDITM (Moodle)
Agradecimento Especial
John Paul Petines – Criador da Iniciativa JEDITM
Rommel Feria – Criador da Iniciativa JEDITM
Original desta por – McDougall e Mauro – Solaris Internals. Sun Microsystems. 2007.
Sistema Operacional 3

JEDITM
1. Objetivos
Neste módulo utilizaremos o Sistema Operacional Solaris desenvolvido pela Sun Microsystems.
Figura 1: Tela de Login no Solaris
A linha Solaris foi lançada em 1992, quando a versão 4 do SunOS - baseada no Free BSD - foi substituída por uma nova versão chamada de Solaris 2, baseada em UNIX System V. Internamente, a nova versão continuou sendo chamada de SunOS versão 5.0, mas foi promovida no mercado como Solaris 2, com a versão anterior SunOS v.4.1 renomeada para Solaris 1. A primeira versão do Solaris 10 (SunOS 5.10) foi lançada em janeiro de 2005 e vem recebendo periódicas atualizações. A versão mais atual é a Solaris 10 8/07 (referente a outubro de 2007).
Ao final desta lição, o estudante será capaz de:
• Conhecer os principais aspectos de segurança do Solaris
• Aprender boas práticas de segurança do Solaris
• Observar as práticas de segurança do Solaris aplicadas à linguagem Java
Sistema Operacional 4

JEDITM
2. Sistema Operacional Solaris
O desenvolvimento do sistema operacional Solaris baseia-se nas seguintes áreas chave:
● Confiabilidade – desenvolvimento baseado em detecção de falhas e erros, isolamento e recuperação, e gerenciamento de serviços combinado com um rigoroso conjunto de padrões estritamente reforçados para a integração de novos códigos no sistema operacional Solaris.
● Desempenho e Escalabilidade – grande habilidade em rodar uma ampla gama de processos em sistemas, desde sistemas para computadores mono processados e servidores montados em paralelo a servidores multiprocessados de alta demanda.
● Gerenciabilidade – ferramentas e aplicações para apoiar a administração de tarefas cotidianas e também para gerenciar o sistema Solaris.
● Observabilidade – características que combinam o software administração para monitorar, analisar o desempenho e comportamento de aplicações com o núcleo do Solaris.
● Gerenciamento de Recursos – gerenciamento dos recursos disponíveis de hardware para atender eficientemente aos requisitos de desempenho, habilitando uma variedade de processos a rodar no sistema operacional Solaris.
Sistema Operacional 5

JEDITM
3. Introdução ao Solaris 10
Discutiremos algumas características da última versão do Sistema Operacional Solaris.
● Auto-Tratamento – combina as ferramentas Solaris Fault Manager e Solaris Service Manager, que são capazes de agir quando ocorre um problema de hardware ou software. Existem mecanismos para detectar e isolar os eventos. Uma vez que o erro for detectado, pode ser feita uma desativação dinâmica dos componentes afetados.
● Framework de Gerenciamento de Serviço (SMF – Service Manager Framework) – fornece um conjunto de comandos organizados que auxiliam a iniciar, interromper e reiniciar os serviços do sistema.
● Zonas do Solaris – permite a criação e o gerenciamento de computadores virtuais co-existentes em uma única instância dentro do núcleo do Solaris. Cada zona tem seu próprio ambiente, além de processos e usuários que são independentes uns dos outros. Também pode ser criada uma zona para rodar uma aplicação específica, fornecendo um ambiente virtual especificamente customizado para esta aplicação.
● União dos Recursos Dinâmicos – permite aos usuários designar um processador em particular ou partes de tempo do processador a um usuário em particular. Um administrador pode definir, por exemplo, um usuário pode destinar para um conjunto de recursos setenta por cento do tempo da CPU de dois processadores, aos quais podem ser atribuídos para um processo em particular.
● Controle de Memória Física – usuários podem limitar a quantidade de memória física que um processo pode usar.
● Mecanismo de Rastreamento Dinâmico – permite que os usuários testem o comportamento das aplicações e do núcleo enquanto rodam os aplicativos, sem a necessidade de modificação no código.
● Gerenciamento de Direitos a Processos – permite ao administrador atribuir direitos específicos a usuários específicos, não apenas as permissões “tudo ou nada” do administrador em relação ao usuário.
● Desempenho da Rede – foi implementada uma melhora significativa na rede TCP/IP, com ênfase no aumento no rendimento e na eficiência.
● Suporte a Arquitetura x64 – foi ampliado o suporte para o novo processador Intel de 64 bits, permitindo que o Solaris 10 suporte tanto o processamento em 32 bits quanto o novo de 64 bits.
Sistema Operacional 6

JEDITM
4. Esquema geral da arquitetura do núcleo do Solaris
Figura 2: Arquitetura do núcleo do Solaris
O núcleo do Solaris é dividido em módulos que fornecem as seguintes funcionalidades:
● Interface de Chamada de Sistema – fornece uma interface para que programas do usuário acessem funções do núcleo do sistema.
● Execução de Processo e Planejamento – executa o gerenciamento de processos. Os processos são programas em execução, aos quais é atribuído um tempo do processador, de acordo com um determinado algoritmo de planejamento. Este módulo lida também com a criação e limpeza do processo, quando um processo finaliza a execução.
● Gerenciamento de Memória – o sistema de memória não apenas lida com a alocação física da memória para os processos, mas também gerencia a memória virtual armazenada no disco rígido, bem como com a alocação de memória para os processos do núcleo.
● Camada de Tradução de Endereço de Hardware – esta seção fornece um mapeamento do espaço de endereço de diferentes dispositivos, não apenas da memória física. Por exemplo, um endereço de memória poderia, ao invés de apontar para um endereço físico de memória, apontar para a memória virtual armazenada no disco rígido. Além disso, dispositivos podem ser mapeados para endereços de memória; a recuperação de um valor de um endereço deste tipo é na verdade uma requisição de leitura no dispositivo. A tradução do hardware em endereços de memória abstrai a complexidade da camada de gerenciamento de memória.
● Gerenciamento de Recursos – o gerenciamento de recursos suporta a alocação de recursos do sistema como memória, dispositivos de leitura e escrita (I/O) e tempo de processamento (CPU). Este módulo tenta maximizar a utilização dos recursos do sistema. Utilizado com fuso horário, este módulo pode fornecer um ambiente isolado de recursos disponíveis apenas a um determinado fuso horário.
● Gerenciamento de Sistema de Arquivos – gerencia a entrada e saída (I/O) de dados do sistema de arquivos. O Solaris 10 pode manipular diferentes sistemas de arquivos ao mesmo tempo.
● I/O Bus e Drivers Nexus – o acesso direto a dispositivos é gerenciado por este módulo. Para cada dispositivo conectado ao sistema, o Solaris carrega um arquivo específico para as nuances do dispositivo. O resultado deste gerenciamento é uma visão consistente do sistema de entrada e saída para o resto do núcleo.
● Serviços do Núcleo (ciclos, temporizador, entre outros) – este módulo fornece as funcionalidades utilizadas regularmente pelo núcleo, tais como ciclos de máquina, e bibliotecas de sincronização.
● Rede – gerencia a comunicação do sistema operacional com outros computadores através de uma rede de computadores.
Sistema Operacional 7

Módulo 8Sistema Operacional
Lição 2Instalação do Solaris
Versão 1.0 - Mar/2008

JEDITM
1. Objetivos
A palavra mudança, para muitas pessoas, é terrível. É incrível pensar que estamos em uma área que sofre mudanças constantes. Entretanto, a grande maioria das pessoas nesta área não está acostumada a estas. Analise se está nesta categoria respondendo às seguintes perguntas:
● Como desenvolvedor de Java, consegue usar desde um bloco de notas até o NetBeans, não se importando em mudar de editor quando necessário?
● Quando sai uma nova versão de qualquer aplicativo, não se preocupa em fazer a atualização pois já está a muito tempo usando a versão BETA ou DEVELOPER?
● Já leu e executou alguns exemplos em outros ambientes Java (JSE, JEE e JME) e pesquisou sobre tecnologias decorrentes, como, por exemplo, JavaFX ou JavaSpot?
Se respondeu “não” a pelo menos uma dessas pergunta, cuidado, repito que esta é uma área em constante mudança e com certeza precisamos nos adaptar rapidamente a qualquer ambiente.
Ao final desta lição, o estudante será capaz de:
• Particionar o HD com fdisk ou GParted para criar uma partição Solaris
• Instalar o Solaris em conjunto com o Windows
Sistema Operacional 4

JEDITM
2. Tarefas de Pré-instalação
Trocar de sistema operacional não é uma decisão simples como escolher almoçar um prato de salada ao invés de um sanduíche em uma Fast-Food, pois podemos voltar ao sanduíche quando desejarmos e sem complicação. Então, o que queremos lhe propor é uma convivência pacífica entre os sistemas operacionais Windows XP e o Solaris no mesmo computador. Deste modo, podemos nos adaptar de uma forma tranqüila e sem pressões.
Entretanto a instalação de um Sistema Operacional, mesmo atualmente, com todas as facilidades dos programas, não é um processo simples para um usuário leigo. Recomendamos fortemente que estes processos sejam realizados somente com total certeza do que está fazendo. Existe o risco da perda total dos dados contidos no computador.
Como primeiro passo, iremos preparar seu HD para a instalação através de uma das seguintes maneiras:
1. Particionar o HD usando o software fdisk
2. Reparticionar o HD usando o software Norton PartitionMagictm da Symantec
3. Reparticionar o HD usando o software gratuito GParted que pode ser encontrado no CD de recuperação do Linux (SystemRescueCD)
Para segundo passo, precisamos instalar o Solaris, que pode ser feita:
1. Através do DVD de instalação
2. Através do download realizado nos endereços:
1. http://www.sun.com/solaris/get
2. http://opensolaris.org/os/downloads
2.1. Particionar o HD usando o software fdisk
Este é um processo que só deve ser executado em um computador que ainda não tenha um sistema operacional ou que possua espaço no HD. Para executar o aplicativo fdisk, é necessário o CD original do Windows XP. Após reiniciar o computador através do CD do Windows selecione a opção "Iniciar com suporte a CD-ROM".
ATENÇÃO – todo o processo pode causar perda dos dados.
Após acessar a console do computador, execute o comando fdisk e as seguintes opções serão mostradas:
1. Criar uma partição ou uma unidade lógica do DOS – para criar uma nova partição
2. Definir uma partição ativa – quando o computador for iniciado, este irá procurar pela partição ativa do HD para iniciar o sistema operacional
3. Excluir uma partição ou unidade lógica do DOS – elimina uma partição
4. Exibir as informações sobre as partições – mostra as partições do seus HD
Ao acessar a opção 1, surgem as seguintes opções:
1. Criar uma partição primária do DOS
2. Criar uma partição estendida do DOS
3. Criar unidades lógicas na partição estendida do DOS
ATENÇÃO, o aplicativo fdisk só deve ser usado quando seu HD não estiver completamente particionado, pois o aplicativo não realiza uma recolocação do espaço.
Sistema Operacional 5

JEDITM
2.2. Usar o software Norton PartitionMagictm
Para utilizar um reparticionador recomenda-se que primeiro seja realizada uma desfragmentação no HD, isso permite que os arquivos particionados sejam concentrados.
ATENÇÃO – pode causar perda de dados.
O Norton PartitionMagictm da Symantec permite a reorganização do HD através da criação, redimensionamento, cópia e mesclagem das partições do disco. Permite também separar sistemas operacionais, aplicativos e documentos, entre outros.
Para maiores informações e aquisição do produto consulte o endereço:
http://www.symantec.com/region/br/home_office/products/system_performance/pm80/
2.3. Usar o software gratuito GParted
ATENÇÃO! É recomendado que, antes de prosseguir, seja realização de uma cópia de segurança de todos os dados no computador.
Para utilizar um reparticionador recomenda-se que primeiro seja realizada uma desfragmentação no HD, isso permite que os arquivos particionados sejam concentrados.
ATENÇÃO! O processo a seguir pode causar a perda dos dados contidos no computador.
Após realizar a desfragmentação do HD, faça download da imagem ISO do SystemRescueCD no endereço http://www.sysresccd.org/ e grave um CD-R com esta imagem. Reinicie seu computador através deste CD e a seguinte janela será mostrada:
Figura 1: Janela inicial do SystemRescueCD
Pressione Enter para continuar o processo.
Sistema Operacional 6

JEDITM
Figura 2: Selecionar o KeyMap
Selecione o KeyMap apropriado a seu teclado. E pressione Enter.
Figura 3: Selecionar o KeyMap
Após a busca das informações, entramos no sistema propriamente dito, digite Xorg ou Xvesa para entrar no ambiente gráfico. Caso não funcione, digite startx.
Sistema Operacional 7

JEDITM
Figura 4: Menu principal
Na janela do xterm digite gparted. Com o aplicativo aberto, selecione o botão Resize/Move para redimensionar o tamanho do HD.
Figura 5: Janela do gparted
Utilize o mouse para redimensionar o tamanho do HD.
Sistema Operacional 8

JEDITM
Figura 6: Redimensionando o espaço no HD
Selecione o novo espaço aberto.
Figura 7: Definindo a nova partição
No menu selecione a opção Partition/New.
Sistema Operacional 9

JEDITM
Figura 8: Criando uma nova partição
Uma nova partição será alocada no espaço.
Figura 9: Partição criada
Selecione o botão Apply.
Sistema Operacional 10
JEDITM
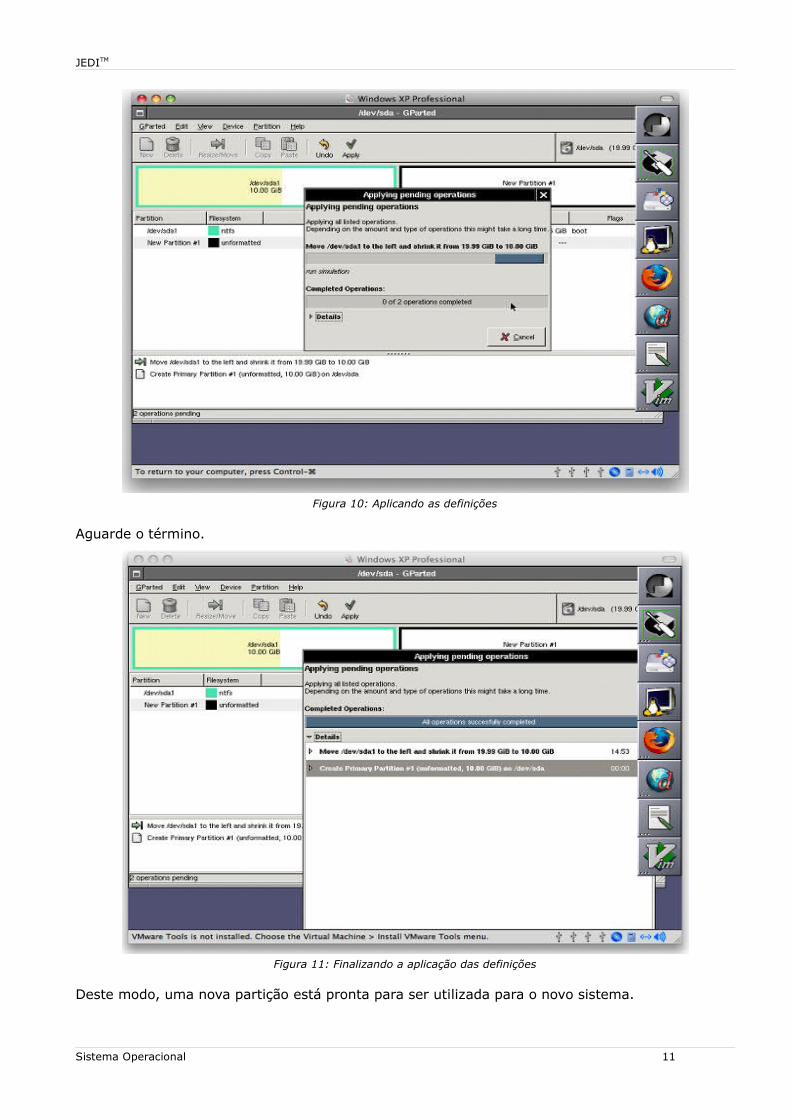
Figura 10: Aplicando as definições
Aguarde o término.
Figura 11: Finalizando a aplicação das definições
Deste modo, uma nova partição está pronta para ser utilizada para o novo sistema.
Sistema Operacional 11

JEDITM
Figura 12: Pronta para instalação
Sistema Operacional 12

JEDITM
3. Instalação do Solaris
ATENÇÃO! Os passos a seguir podem causar a perda de dados contidos na partição do Windows. Recomenda-se a execução de uma cópia de segurança.
Agora que já temos uma partição livre e disponível, podemos instalar sem problemas o novo sistema operacional. Reinicie o computador com o DVD do Solaris no driver.
A seguinte janela será mostrada para iniciarmos todo o processo.
Figura 13: Selecionando o tipo de instalação
Selecionar o modo de instalação.
Figura 14: Selecionando o modo de instalação
Em seguida será verificada as condições do seu computador e os locais de instalação.
Sistema Operacional 13

JEDITM
Figura 15: Verificando o espaço para instalação
Pressione 1 e aguarde a conclusão da operação e abertura da seguinte janela:
Figura 16: Selecionando o teclado
Selecionar o tipo do teclado e aguarde o ambiente gráfico ser aberto.
Sistema Operacional 14
JEDITM
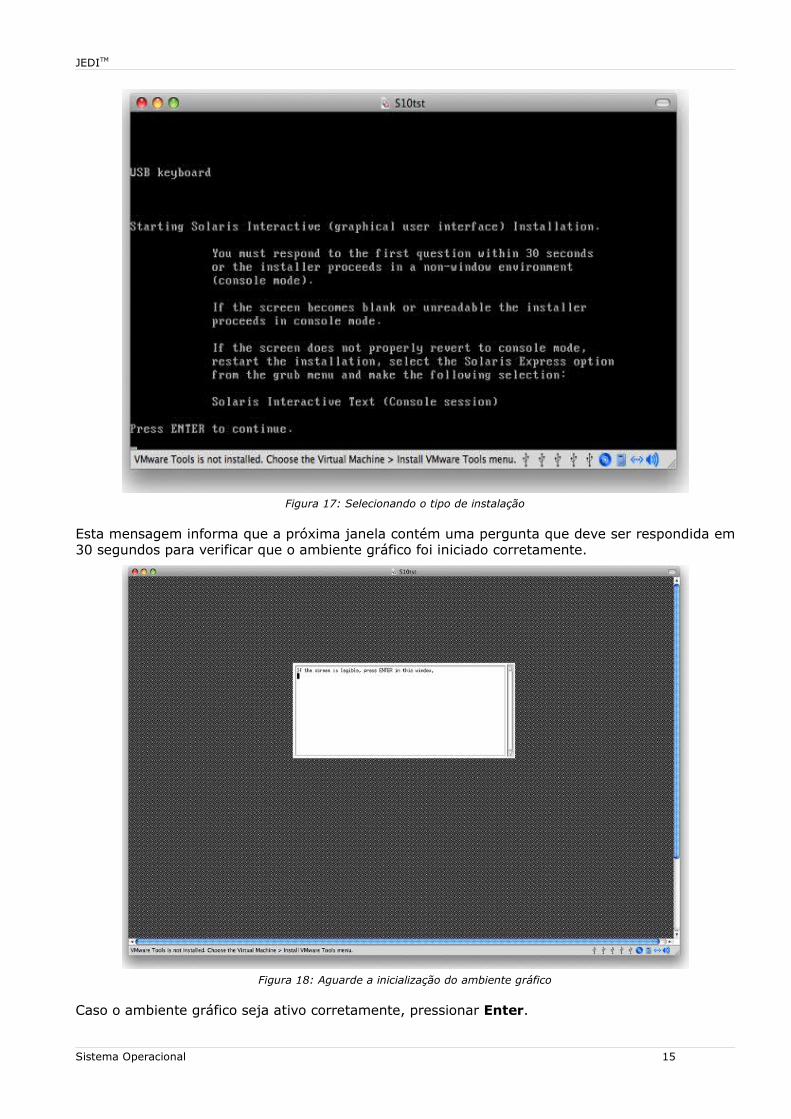
Figura 17: Selecionando o tipo de instalação
Esta mensagem informa que a próxima janela contém uma pergunta que deve ser respondida em 30 segundos para verificar que o ambiente gráfico foi iniciado corretamente.
Figura 18: Aguarde a inicialização do ambiente gráfico
Caso o ambiente gráfico seja ativo corretamente, pressionar Enter.
Sistema Operacional 15

JEDITM
Figura 19: Selecionando o idioma
Selecionar o idioma padrão para o processo de instalação.
Figura 20: Iniciando a instalação
Selecionar a partição para o Solaris. Atenção.
Sistema Operacional 16
JEDITM
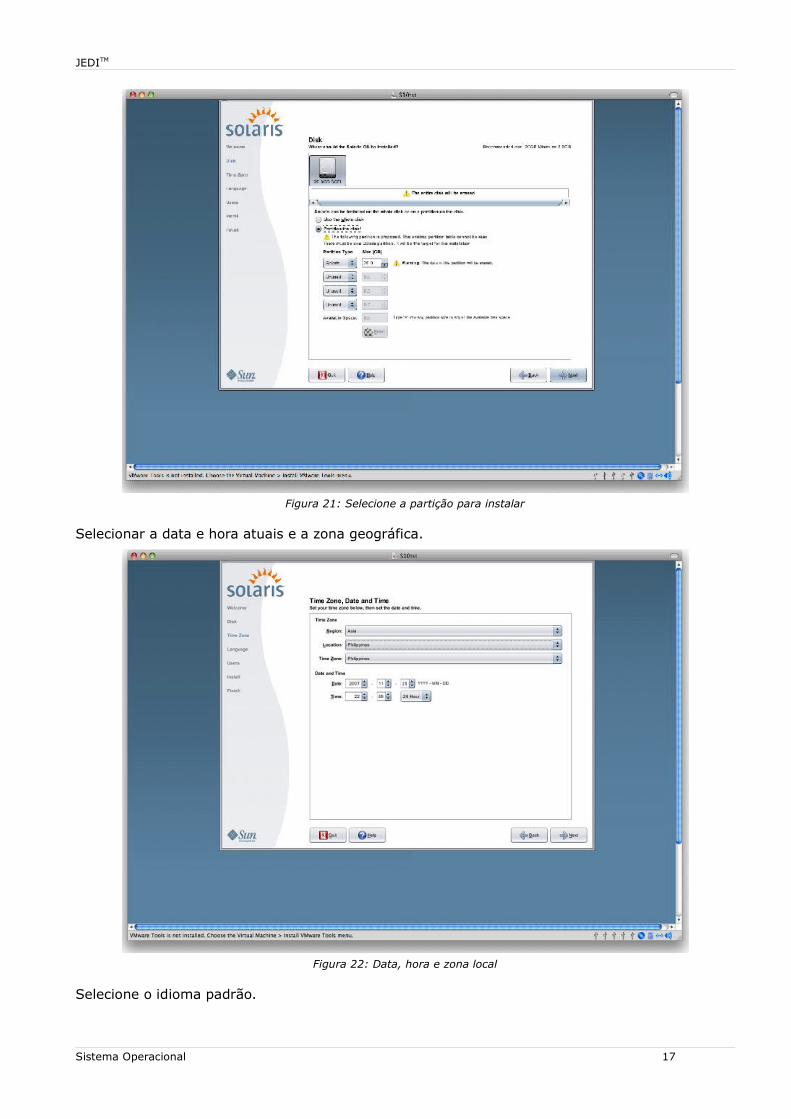
Figura 21: Selecione a partição para instalar
Selecionar a data e hora atuais e a zona geográfica.
Figura 22: Data, hora e zona local
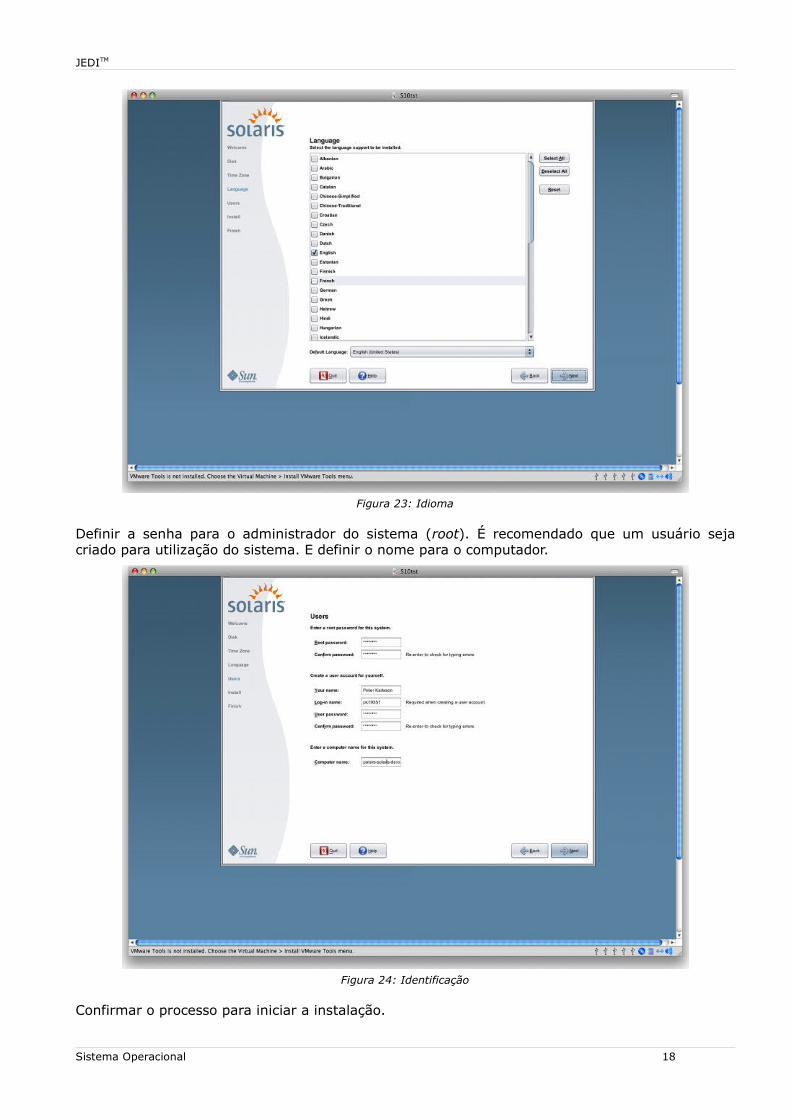
Selecione o idioma padrão.
Sistema Operacional 17
JEDITM
Figura 23: Idioma
Definir a senha para o administrador do sistema (root). É recomendado que um usuário seja criado para utilização do sistema. E definir o nome para o computador.
Figura 24: Identificação
Confirmar o processo para iniciar a instalação.
Sistema Operacional 18

JEDITM
Figura 25: Pronto para instalar
Aguardar o término do processo.
Figura 26: Aguarde a finalização do processo
Seja bem-vindo a um novo mundo de mudanças.
Sistema Operacional 19

Módulo 8Sistema Operacional
Lição 3Comandos Básicos e Scripting
Versão 1.0 - Mar/2008

JEDITM
1. Objetivos
A aprendizagem de um sistema operacional vai além do conhecimento da interface gráfica. A interface gráfica é o bastante para usuários comuns, mas o terminal permite a execução de comandos mais poderosos. Nessa lição veremos alguns comandos básicos do terminal do Solaris e também uma introdução sobre shell scripting.
Ao final desta lição, o estudante será capaz de:
• Utilizar alguns comandos básicos em um Terminal
• Discutir a criação de scripts básicos e avançados
• Executar comandos básicos para administração do ambiente
Sistema Operacional 4

JEDITM
2. Terminal
Podemos abrir um terminal pressionando o botão direito no desktop e selecionando a opção 'Open Terminal'. O prompt é onde os comandos serão executados. Nos exemplos mostrados, iremos representar o comando de terminal pelo símbolo $. O símbolo $ não deve ser digitado.
Figura 1: Janela de Terminal no Solaris
Mais à frente nessa lição, será solicitado a troca para o usuário definido por padrão como root. O usuário root, também conhecido como superusuário, é o administrador do sistema, com acesso a comandos que afetam a todo o sistema. O prompt do terminal para o superusuário muda de forma a refletir isso. Para representar o terminal do superusuário, usaremos o símbolo #. De modo semelhante, não devemos digitar o símbolo # inicial.
Comandos e nomes de arquivos um ambiente Unix, como o caso do Solaris e Linux, são sensíveis a letras maiúsculas e minúsculas. Ao executar, por exemplo, o comando para mostrar os arquivos de um diretório como Ls, ao invés de ls, será mostrado um erro informando que o comando não existe.
2.1. Comandos de ajuda
Cada comando no ambiente terminal possui uma documentação de ajuda. Podemos acessar essa ajuda através do comando man (manual) seguido pelo comando. Por exemplo, para solicitar a ajuda sobre o comando ls.
$ man ls
Podemos navegar pelo editor de ajuda utilizando as teclas para cima e para baixo. Para finalizar o editor de ajuda, pressionamos a tecla q (quit).
Sistema Operacional 5

JEDITM
2.2. Navegar no sistema de arquivos
2.2.1. Visualizar os arquivos do diretório Atual
O comando ls (list sources) lista arquivos no diretório corrente. Podemos também mostrar os arquivos selecionados utilizando o comando ls. Da seguinte forma:
ls jedi.txt
Se nenhum arquivo no diretório corrente tiver o nome jedi.txt, então o comando não produz nenhuma saída.
O comando ls permite a utilização de curingas para visualizar arquivos que atendam a um certo critério. Apresentamos a seguir alguns curingas mais utilizados:
● * - representa nenhum ou vários caracteres. Por exemplo:
○ ls a* - mostrar os arquivos iniciados pela letra a
○ ls *.java - listar os arquivos que terminem com .java
○ ls * - listar os arquivos, neste caso o curinga é desnecessário pois este é o comportamento padrão deste comando
● ? - representa um único caractere. Por exemplo:
○ ls ?a? - mostrar os arquivos que contém uma letra a no meio de um nome
Como a maioria dos comandos, o comando ls pode ter opções adicionais, que são iniciadas com o símbolo '-' (sinal de menos). Por exemplo, para visualizar arquivos no formato longo, que mostra informações adicionais do arquivo, devemos usar a opção -l. Para ver todos os arquivos (incluindo arquivos ocultos) podemos usar a opção -a. Para ambas, podemos digitar:
$ ls -a -l
Ou então:
$ ls -al
Executar o comando ls com a opção -a faz com que os arquivos ocultos sejam incluídos na listagem. Arquivo ocultos são arquivos cujo o nome é iniciado por um ponto. Por exemplo, o arquivo .bashrc é um arquivo oculto, um script que é executado sempre que uma janela de terminal é aberta. Podemos criar arquivos ocultos simplesmente utilizando um ponto no inicio do nome do arquivo.
Algumas opções consistem de palavras ao invés de letras simples. Algumas opções podem necessitar de parâmetros, os quais são especificados por um símbolo '=' (sinal de igual). O seguinte exemplo que mostra todos os arquivos, utiliza a opção –sort, com o parâmetro size, para ordenar pelo tamanho dos arquivos.
$ ls -al –sort=size
Existem muitas outras opções para o comando ls que podem ser verificadas utilizando o comando man.
2.2.2. Permissões de arquivos
Uma breve descrição da saída do comando ls -l é necessária. Em particular, iremos discutir permissões de arquivos.
Figura 2: Sistema de Permissões
Sistema Operacional 6

JEDITM
O primeiro espaço na lista de controle de acesso descreve o tipo do arquivo que está sendo listado:
● Um espaço em branco indica que é um arquivo comum
● Um d indica um diretório
● Um I ou s indica um caminho simbólico, do tipo hardware ou software, para outro arquivo, respectivamente
● Exclusivamente para dispositivos, um b indica que o arquivo representa um dispositivo de bloco enquanto que um c indica que o arquivo aponta para um dispositivo de caractere
Existem três permissões possíveis para as listas de controle:
● Para um arquivo ser lido, deve possuir a permissão r
● Para um arquivo ser alterado, deve possuir a permissão w
● Para um arquivo ser executado, deve possuir a permissão x (em ambiente tipo Unix não existe a diferença entre um arquivo executável é um arquivo texto, diferente de ambiente tipo DOS)
A lista de controle de acesso é dividida em três partes:
● Os primeiros três caracteres referem-se ao usuário que criou o arquivo
● Os próximos três caracteres contém a permissão do grupo de usuários que pertencem ao mesmo grupo do usuário que criou o arquivo
● As últimas três letras indicam as permissões para usuários que não estão no grupo do usuário que criou o arquivo
Considere as seguintes permissões de acesso para um arquivo qualquer: rwxrw-r--
As primeiras três letras determinam as permissões do usuário. O r nesse grupo de letras significa que o arquivo é legível pelo criador do arquivo. O w que o arquivo pode ter seu conteúdo modificado (não sendo apenas de leitura). A permissão x significa que o arquivo pode ser executado. No exemplo, o usuário que criou o arquivo pode ler, escrever e executar este.
Usuários nos sistemas UNIX podem pertencer a grupos de usuários. Os próximos três caracteres determinam quais permissões outros usuários que pertencem ao mesmo grupo do criador do arquivo possuem. No exemplo, a permissão ausente, caractere x, significa que os outros usuários do grupo não podem executar o arquivo.
Para finalizar, os últimos três caracteres determinam as permissões para os usuários que não pertencem ao grupo do criador do arquivo. No exemplo, podem apenas ler o arquivo.
Permissões de arquivos podem ser modificadas com o comando chmod (change mode). Aceita dois parâmetros, o nome do arquivo a ser modificado e a nova permissão utilizando três dígitos em formato octal.
Se um digito octal for convertido para binário, então o número binário consiste de três dígitos. O comando chmod necessita de três dígitos em formato octal:
● O primeiro para a permissão do usuário● O segundo para permissões do grupo● O terceiro para permissões de outros usuários.
Na montagem final da lista de controle de acesso convertendo o conjunto para binários, o binário 1 significa que a permissão é concedida e o binário 0 que não existe permissão para a posição.
Por exemplo, para um arquivo hello.txt, a permissão rwxrw-r pode ser configurada usando:
$ chmod 764 hello.txt
A seguir temos uma tabela para a conversão do tipos:
Octal Binário Permissões0 000 ---
Sistema Operacional 7

JEDITM
1 001 --x2 010 -w-3 011 -wx4 100 r--5 101 r-x6 110 rw-7 111 rwx
Figura 3: Conversão Binário, Octal e Permissões
E a permissão rw-r-xr-- pode ser configura usando:
$ chmod 654 hello.txt
2.2.3. Obter a localização atual e mudar de diretório
Ao entrar no terminal, por padrão, o diretório corrente é o home. Para descobrir qual é o diretório corrente, usamos o comando pwd (present work directory):
$ pwd/export/home/alice
O sistema de arquivo do Solaris começa no diretório root, ou diretório /. Para alcançar o diretório home do usuário logado a partir do diretório /, primeiramente devemos acessar o diretório export, e em seguida o diretório home, e nesse diretório acessar o diretório do usuário logado (que possui o mesmo nome deste).
Para mudar o diretório corrente, utilizamos o comando cd (change diretory) seguido do nome do diretório que deve ser acessado. Como não existe nenhum diretório dentro do diretório home, primeiramente devemos ir para o diretório /, conforme o comando a seguir:
$ cd /
Ao executar o comando ls nesse diretório, serão mostrado todos os diretórios e arquivos que estão no nível mais alto dos diretórios do sistema. A figura a seguir mostra um sistema de arquivo típico para sistemas baseados em UNIX, tal como o Solaris.
Figura 4: Sistema de arquivos padrão
Sistema Operacional 8

JEDITM
Por exemplo, para acessar o diretório etc, a partir da raiz, podemos digitar:
$ cd etc
Ao executar o comando pwd, será mostrado o caminho do diretório etc. Como forma de exercitar estes comandos, entre nos subdiretórios de etc e verifique quais são seus arquivos.
Para subir um nível de diretório, podemos digitar o seguinte comando:
$ cd ..
Ponto seguido de ponto é uma referência para o diretório pai do diretório atual. Sendo assim, se o usuário estiver, por exemplo, em etc, poderá digitar esse comando para retornar ao diretório /.
Há duas maneiras para especificar um diretório. Podemos especificar seu nome relativo. Por exemplo, para navegar do diretório / ao diretório defaults, que está dentro do diretório etc, podemos digitar:
$ cd etc/defaults
Podemos também especificar o nome absoluto de um diretório, que é o caminho completo do diretório sempre a partir da raiz. Por exemplo, estando em qualquer diretório do sistema, o usuário pode retornar ao diretório home através do comando:
$ cd /export/home/<username>
Se o nome do usuário for “alice”, então o comando seria da seguinte forma:
$ cd /export/home/alice
Observe que digitando apenas o comando cd fará com que o diretório home se torne o diretório corrente.
2.2.4. Sistema de arquivos Solaris
Voltemos à raiz do sistema Solaris. Embora existam muitos diretórios que podem mudar de acordo com a instalação, os seguintes diretórios são padrões:
● /export/home – O diretório home para todos os usuários. Pode também ser apenas /home
● /usr – Arquivos executáveis do sistema
● /etc – Arquivos de configuração
● /var – Diretório para arquivos temporários
● /proc – Diretório especial do sistema de arquivos para mostrar todas as aplicações que estão rodando no momento
● /mnt – Diretório onde as mídias removíveis são montadas, tais como, disquetes, CDs e pen drives
● /dev – Dispositivos são representados como arquivos no sistema Solaris e contidos neste diretório
2.2.5. Obter a utilização e o espaço livre no disco
O comando du (disk usage) mostra quanto espaço está sendo gasto pelos arquivos num determinado diretório, incluindo sub-diretórios. Geralmente é usado com o atributo -h, para mostrar uma listagem mais completa.
$ du -h /etc 5K /etc/certs 5K /etc/cron.d 5K /etc/crypto/certs 1K /etc/crypto/crls 11K /etc/crypto 63K /etc/default
Sistema Operacional 9

JEDITM
3K /etc/devices...56M /etc
O comando df (disk free) mostra, para cada disco, sua capacidade, quanto está em uso e quanto está livre. Assim como o comando du, o comando df também é, normalmente, utilizado com a opção -h.
$ df -hFilesystem size used avail capacity Mounted on/dev/dsk/c0t0d0s0 13G 3.8G 9.3G 30% //devices 0K 0K 0K 0% /devicesctfs 0K 0K 0K 0% /system/contractproc 0K 0K 0K 0% /procmnttab 0K 0K 0K 0% /etc/mnttabswap 2.4G 1.1M 2.4G 1% /etc/svc/volatileobjfs 0K 0K 0K 0% /system/objectfd 0K 0K 0K 0% /dev/fdswap 2.4G 0K 2.4G 0% /tmpswap 2.4G 48K 2.4G 1% /var/run/dev/dsk/c0t0d0s7 19G 8.1G 11G 43% /export/home
2.2.6. Localizar arquivos
Para procurar um arquivo, o usuário pode utilizar o comando find o qual procura pelo nome do arquivo (especificado com a opção -name) de um dado diretório, e, recursivamente, por todos os subdiretórios. É permitido o uso de curingas neste comando.
O exemplo abaixo procura todos os arquivos que começam pela palavra profile e estão dentro do diretório /etc.
$ find /etc -name profile*
Existem muitas opções para se usar juntamente com este comando. Para maiores informações, basta rodar o comando man.
2.3. Modificar o sistema de arquivos
Usuários podem fazer mudanças apenas em seus diretórios. Somente o usuário root pode fazer mudanças nos diretórios do sistema.
2.3.1. Copiar arquivos
O usuário pode copiar arquivos através do comando cp (copy), o qual possui dois argumentos: o arquivo fonte e o de destino. Lembrando que pode conter diretórios e curingas nos nomes dos arquivos.
Por exemplo, para copiar o arquivo passwd do diretório /etc para o diretório atual, executamos:
$ cp /etc/passwd .
No comando o “.” é uma referência ao diretório atual. E para copiar todos os arquivos do diretório /etc para o diretório /home:
$ cp /etc/* /export/home/<username>
Se o destino for um nome de arquivo e não um diretório, o comando cp copia o arquivo e o renomeia. Por exemplo, para um arquivo chamado a.txt, podemos realizar uma cópia para um arquivo chamado b.txt:
$ cp a.txt b.txt
Também podem ser feitas cópias de diretórios inteiros, usando a opção -r (recursive). Cópias recursivas incluem subdiretórios do diretório especificado. Por exemplo, para copiar todo o conteúdo do /etc para o diretório home do usuário:
Sistema Operacional 10

JEDITM
$ cp -r /etc /export/home/<username>
Uma vez copiado, aparecerá um novo diretório /etc no diretório /home.
2.3.2. Mover arquivos
Para mover arquivos, usamos o comando mv (move) que contém opções e funcionalidades similares ao comando cp, só que ao término de uma cópia bem sucedida, o comando exclui os arquivos ou diretórios originais.
Por exemplo, para mover o arquivo a.txt para c.txt:
$ mv a.txt c.txt
2.3.3. Eliminar arquivos
Para eliminar arquivos, usamos o comando rm (remove) e o nome do arquivo a ser eliminado. Por exemplo, o seguinte comando elimina o arquivo c.txt:
$ rm c.txt
o comando rm pode ser usado com curingas. Por exemplo, para remover todos os arquivos que estão em um diretório tempo, dentro do diretório home do usuário:
$ rm /export/home/<username>/temp/*
Note que isto remove apenas arquivos. A remoção de diretórios será discutida a seguir.
2.3.4. Criar e eliminar diretórios
Para criar diretórios, usamos o comando mkdir (make directory). Por exemplo, criar um diretório lesson1:
$ mkdir lesson1
Também é possível especificar o caminho completo, a partir da raiz. Por exemplo, criar um subdiretório exercise1 dentro do diretório lesson1:
$ mkdir /export/home/<username>/lesson1/exercise1
Para eliminar diretórios, usamos o comando rmdir (remove directory). Este comando permite usar o caminho relativo ou absoluto. Por exemplo, remover o diretório exercise1:
$ rmdir /export/home/<username>/lesson1/exercise1
Note que o comando rmdir só pode ser utilizado se o diretório já estiver vazio, sem arquivos. Para remover um diretório, devemos primeiro utilizar o comando rm e em seguida o comando rmdir para remover o diretório.
No entanto, existe uma solução para este problema. Usar o comando rm com as opções -rf. A opção -r indica recursividade, isso significa que todos subdiretórios serão removidos, e a opção -f é utilizada para forçar essa remoção, sem perguntas de confirmação. O seguinte exemplo remove o diretório lesson1 com todo seu conteúdo sem questionar a ação.
$ rm -rf /export/home/<username>/lesson1
Note que este é um comando bastante perigoso. Se o usuário estiver no diretório raiz e rodar o comando 'rm -rf .', pode remover todo o sistema de arquivos se tiver permissão para tal. E não existe nenhuma forma simples para desfazer essa ação no Solaris. Portanto, o usuário deve ter EXTREMO cuidado ao utilizar este comando e ter total certeza do que está fazendo.
2.4. Direcionar a saída de um comando para um arquivo
2.4.1. Redirecionamentos
As saídas dos comandos podem ser redirecionadas para arquivos. Por exemplo, a listagem completa do conteúdo do diretório /etc pode exceder a capacidade da tela, então, o usuário pode
Sistema Operacional 11

JEDITM
salvar esta saída em um arquivo texto para ser visualizado através de um editor de texto. Para isto, basta usar o comando junto ao operador “>” (sinal de maior que) seguido do nome do arquivo texto onde a saída será armazenada. Por exemplo, para listar todos os arquivos do diretório /etc e colocar seu conteúdo no arquivo list.txt:
$ ls -l /etc > list.txt
Depois de executado, o usuário pode visualizá-lo através de qualquer editor de texto e até guardá-lo para uma análise posterior. Este redirecionamento funciona com qualquer comando.
O operador “>” sobrescreve o conteúdo antigo do arquivo destino. Para concatenar a saída para um arquivo que já possui um conteúdo, utilizamos o operador “>>”. Por exemplo, adicionar a saída de um novo comando ls ao arquivo list.txt (criado no exemplo anterior), sem eliminar o conteúdo anterior:
$ ls -l /usr >> list.txt
O comando para concatenar é geralmente usado durante um processo de log, na qual a saída dos programas, tais como, mensagens do sistema operacional, são armazenadas por um longo período de tempo para uma eventual auditoria.
O comando echo, mostra (na tela ou em arquivo) o parâmetro passado. Por exemplo:
$ echo 'Hello world!'Hello world!$ echo 'Listing the contents of /etc' > list.txt $ ls -l /etc >> list.txt$ echo 'Listing the contents of /usr' >> list.txt$ ls -l /usr >> list.txt
Para ignorar totalmente a saída de um comando, o usuário pode redirecioná-la para um arquivo especial chamado /dev/null. Este é um arquivo especial que simplesmente descarta qualquer saída enviada para ele. Suprimir uma saída de comando pode mudar a forma como um programa se comporta. Por exemplo, o seguinte comando suprime totalmente a saída do comando ls.
$ ls /etc > /dev/null 2> /dev/null
2.4.2. Error streams
Output stream e Error stream agem de formas diferentes nos sistemas UNIX. Output stream é a saída esperada pelo usuário enquanto que Error stream é a saída quando ocorre um determinado problema.
Linguagens de programação freqüentemente oferecem comandos para enviar informação. Java possue dois objetos diferentes: System.out para uma saída comum e System.err para uma saída com erros.
É possível ver em ação o error stream quando executamos o seguinte comando:
$ ls nosuchfile.txt > output.txtls: nosuchfile.txt: No such file found
O erro do comando ls é enviado para a saída padrão, e não para o arquivo output.txt. O operando “>” redireciona somente o output stream do comando. Se também for necessário redirecionar o error stream, utilizamos o operando “2>”:
$ ls nosuchfile.txt > output.txt 2> error.txt
2.4.3. Paginar a saída de conteúdo
O comando more pode ser utilizado para visualizar conteúdo na tela. Este comando paralisa a saída de forma que seja possível ver uma tela cheia por vez. É possível concatenar o comando more com o comando ls utilizando o comando “|” (sinal de pipe).
$ ls -l /etc | more
Sistema Operacional 12

JEDITM
O comando more, no entanto, é limitado podendo ser visualizado somente no sentido para a frente. O comando less é similar ao comando more, entretanto permite a visualização da saída em ambos sentidos, para frente e para trás.
$ ls -l /etc | less
2.5. Variáveis de ambiente
Variáveis de ambiente são definidas para uso pelo sistema operacional. As variáveis são identificadas pelo símbolo $ (sinal de cifrão) em seu início. Por exemplo, a variável $PATH lista os diretórios nos quais o terminal procura por arquivos executáveis quando o usuário executa algum comando. O seguinte exemplo verifica o valor da variável $PATH:
$ echo $PATH
Outros exemplos de variáveis de ambiente são $HOME, $USER e $PWD que mostram o diretório padrão, o usuário atual e o diretório atual, respectivamente. Para descobrir seus valores, execute o comando echo no terminal. A seguir vemos como mostrar esses valores, e também como mesclar mensagens com as variáveis em um único comando echo:
$ echo 'Olá! Sou ' $USER '. ' $HOME ' é meu diretório padrão.'
Resultando, por exemplo:
Olá! Sou alice. /export/home/alice é meu diretório padrão.
É possível utilizar aspas simples ou duplas no comando echo. A diferença é que ao colocar uma variável dentro de aspas duplas, seu valor é retornado.
$ echo 'Olá! Meu nome é $USER'Olá! Meu nome é $USER$ echo "Olá! Meu nome é $USER"Olá! Meu nome é alice.
Como pode ser visto, colocando o símbolo $ entre aspas duplas no comando echo significa que as palavras sejam consideradas como variáveis. Para o símbolo $ ser impresso, basta colocar um símbolo \ (sinal de barra contrária) antes do símbolo $, isto é, \$.
As variáveis também podem ser definidas. Por exemplo, para uma variável de boas-vindas definida pelo próprio usuário, basta digitar:
$ greeting='Bem Vindo!'
Note que não é necessário colocar o símbolo $ se estiver atribuindo um valor a uma variável (cuidado pois o símbolo $ exibido acima corresponde ao prompt). Também não poderá haver espaços entre os dois lados do operador de atribuição. Os nomes das variáveis são sensíveis a maiúsculas e minúsculas.
É possível utilizar as variáveis criadas da mesma forma que as variáveis de ambiente.
$ echo $greeting ' Como está ' $USER '?'Bem Vindo! Como está alice?
É possível também mudar o valor das variáveis existentes. Por exemplo, se for desejável adicionar o diretório /home à variável $PATH, basta digitar:
$ PATH=$PATH:/export/home/<username>
Deve ser observado que as variáveis definidas pelo usuário são acessíveis somente dentro do terminal onde foram declaradas. Se houver outras janelas de terminal abertas, não será possível acessar estas variáveis definidas. Além disso, assim que o terminal é fechado, as variáveis criadas desaparecerão e as variáveis ambiente retornarão aos seus valores originais.
Sistema Operacional 13

JEDITM
3. Scripts
Um script é um arquivo que pode conter diversas instruções seqüenciais para execução no terminal (comparando com o ambiente DOS, é um arquivo .bat). Algumas tarefas dos sistemas envolvem um encadeamento sucessivo de comandos simples e, ao colocá-los em um único script, economiza-se tempo e esforço ao executar um único comando.
O script vai além de uma simples cadeia de comandos. A maioria das linguagens de script tem suas próprias construções de programação, tais como sentenças com comandos de decisão e repetição, e podem aceitar entrada de dados do usuário.
Na interface de console existe o que chamamos de interpretador de comandos, conhecido como shell. Existem vários tipos de shells, tais como, ksh ou korn shell, ou csh (c shell), cada um possui uma sintaxe distinta. Utilizaremos aqui a linguagem denominada bash. Bash é uma sigla para Bourne-again shell, que é uma revisão da linguagem Bourne shell. Entretanto, o conhecimento aprendido pode ser aplicável a outros shells.
3.1. Criando um Bash Script
Em exemplos anteriores listamos o conteúdo dos diretórios /etc e /usr e enviamos para um arquivo chamado list.txt. Abaixo vemos um script que executa as instruções de uma forma conjunta. Pode ser utilizado em qualquer editor de texto para escrever este arquivo que receberá o nome de myscript.
#!/bin/bash# this is my first bash script.echo 'Listing the contents of /etc' > list.txtls -l /etc >> list.txtecho 'Listing the contents of /usr' >> list.txtls -l /usr >> list.txt
Para executar este arquivo, devemos primeiro modificar suas permissões. Para descobrir quais são as permissões do script, usa-se o comando ls -l.
$ ls -l myscript-rw-r--r-- 1 alice alice 6 Nov 12 8:40 myscript
As permissões para myscript são de leitura e escrita para o proprietário do arquivo (alice) e somente de leitura para outros usuários. Para tornar o script executável, adicionamos a permissão através do comando chmod, da seguinte maneira:
$ chmod 755 myscript$ ls -l myscript-rwxr-xr-x 1 alice alice 6 Nov 12 8:42 myscript
Agora todos usuários possuem a permissão para executar o arquivo myscript. Para executar o script, digitamos:
$ ./myscript
3.1.1. Comentários
No arquivo myscript, vemos linhas que são iniciadas pelo símbolo #. Estas linhas são comentários. No entanto, a primeira linha, iniciada pelo símbolo #! do script indica que este é um script bash, cujo o executável está no diretório /bin. Deve haver pelo menos um espaço entre o símbolo # e a primeira letra do comentário.
A primeira linha do script bash não é exatamente um comentário mas um indicador da linguagem de script a ser utilizada:
● #!/bin/bash - informa ao SO para executar o script utilizando o bash
● #!/bin/ksh - informa ao SO para executar o script utilizando o korn shell (outro tipo de linguagem de script)
Sistema Operacional 14

JEDITM
3.1.2. Bash Scripts embutidos
A maioria dos sistemas baseados em UNIX utilizam scripts extensivamente durante sua execução. Por exemplo, quando o bash é iniciado durante o boot do sistema, ele executa comandos do /etc/profile. A variável $PATH e outras são definidas neste momento.
Quando o usuário realiza a entrada no sistema, os arquivos ocultos .bash_profile, .bash_login e .profile são lidos e executados. Quando um terminal é iniciado, são executados os comandos do script .bashrc do usuário corrente. Quando uma sessão é finalizada, o bash executa os comandos do arquivo .bash_logout.
3.2. Scripting avançado
Iremos agora descobrir como as variáveis, sentenças de decisão e de repetição podem ser utilizadas. Também veremos como conseguir entrada de dados pelo executor do script.
3.2.1. Substituição de variáveis
Conforme discutido anteriormente, uma variável é indicada pelo símbolo $. O símbolo $ é um comando que indica que o valor da variável deve ser substituído naquela posição quando o comando for executado.
Por exemplo, considere os seguintes comandos
$ x=42$ echo $x
A variável x contém o valor 42. O comando echo $x é substituído internamente por echo 42. Como na maioria das vezes as variáveis são utilizadas desta maneira, é necessário lembrar que o símbolo $ não aparece durante a atribuição de uma variável ou quando uma variável for exportada.
Esta substituição pode ser vista com o caractere de nova linha. Como na maioria das linguagens de programação, uma nova linha pode ser impressa com uma barra contrária e o caractere n (isto é, \n). Entretanto, colocar \n em uma string no comando echo não produz uma nova linha. Para se fazer isto, deve-se utilizar $'\n'. Será inserida uma nova linha na posição onde \n aparecer.
$ echo 'hello \n world'hello \n world$ echo 'hello' $'\n' 'world'Helloworld
É possível utilizar variáveis para armazenar a saída de alguns programas colocando o símbolo “'” (sinal de aspas simples) no comando a ser executado. Por exemplo, o script a seguir armazena a saída do comando ls /etc em uma variável e a exibe.
#!/bin/bashx='ls /etc'echo "Our variable contains the following files"echo $x
3.2.2. Variáveis regulares
As variáveis em scripts são declaradas de forma usual. Contudo, não são visíveis fora do escopo do script a menos que sejam exportadas. Por exemplo, pode-se notar no script /etc/profile que ele exporta a variável $PATH.
3.2.3. Variáveis posicionais da entrada de dados pelo usuário
As variáveis especiais $1 a $9 substituem argumentos no arquivo de script. Os argumentos são as palavras informadas e separadas por espaços após o nome do script (assim como na linguagem Java). Esta é uma das formas pelas quais o usuário pode entrar com dados. Vejamos o script abaixo, salvo em um arquivo chamado argtest. A quantidade de argumentos passados
Sistema Operacional 15

JEDITM
para o script é representado pela variável $#.
#!/bin/bashecho 'My first argument' $1echo 'My second argument' $2echo 'Number of arguments passed' $#
Abaixo estão alguns exemplos para o argtest.
$ ./argtestMy first argumentMy second argumentNumber of arguments passed 0$ ./argtest helloMy first argument helloMy second argumentNumber of arguments passed 1$ ./argtest hello world starMy first argument helloMy second argument worldNumber of arguments passed 3
Para variáveis posicionais acima de $9, o valor deverá ser colocado dentro de colchetes, por exemplo ${10}, ${11} e assim por diante.
3.2.4. Comando read
Podemos obter entradas para o script através do comando read. Por exemplo, o script abaixo solicita um nome:
#!/bin/bashecho "Enter name"read necho "Hello," $n "!"
3.2.5. Código de erro
Todos os comandos na maioria de sistemas UNIX possuem código de erro. O valor do código de erro varia entre 0 e 255. Por convenção, um programa retorna 0 após uma execução com sucesso. Qualquer outro valor informa que ocorreram problemas.
Em bash, para se obter o código de erro da última execução, utilizamos a variável $?. Por exemplo, o script a seguir mostra o código de erro do comando ls após a procura por um arquivo específico.
#!/bin/bashls $1echo 'The errorcode of ls command is: ' $?
Abaixo temos a saída da execução (o arquivo foi salvo como lstest)
$ ./lstest<list of files>The errorcode of ls command is: 0$ ./lstest nosuchfile.txtNo such file or directoryThe errorcode of ls command is: 1
Especificamos o código de erro do script pelo comando exit. Por exemplo, no final do lstest, retornamos o código de erro do script como sendo o código de erro do comando ls. Observe que salvamos o valor da variável $? em outra variável, pois $? retorna o código de erro do último comando executado. Se não fosse salva, seria retornado o código de erro do comando echo.
#!/bin/bashls $1
Sistema Operacional 16

JEDITM
output=$?echo 'The errorcode of ls command is: ' $outputexit $output
3.2.6. Operadores
Os operadores aritméticos são usualmente +, -, * ou /. O operador % retorna o resto de uma divisão. O resultado de uma expressão aritmética pode ser atribuída a uma variável usando o comando let. Por exemplo:
$ x=5$ let "x = $x + 1"$ echo $x6
Podemos utilizar também o operador ((<expressão>)), que avalia a expressão dentro dos parênteses duplos. Note que o $ encontra-se antes do abrir parênteses para ocorrer a substituição do valor.
$ x=$((5 + 5))$ echo $x10
A linguagem bash não utiliza números decimais e os transforma para valores do tipo Strings.
3.2.7. Estrutura condicional
Em bash, 0 é um valor verdadeiro e 1 representa falso. Isto reflete o valor de retorno de todos os comandos no Solaris. Por convenção, um programa retorna 0 após uma execução com sucesso e 1 caso contrário.
Podemos testar uma determinada condição utilizando a sentença if. Diferente de outras linguagens de programação, a condição lógica é envolvida por um conjunto de colchetes e o comando é encerrado com fi. De modo similar a outras linguagens de programação, podemos ter a declaração if, if-else e if-elseif-else. A seguir a sintaxe da sentença if-elseif-else:
if [condition] then <statements>elseif [condition] then <statements>else <statements>fi
A seguir mostramos algumas condições que podem fazer parte da estrutura condicional if. Observe que "$a" e "$b" podem ser variáveis ou números.
Operador Definiçãoif ["$a" -eq "$b"] Igualdade entre números (igual a)if ["$a" = "$b"] Igualdade entre Strings (igual a)if ["$a -ne "$b"] Diferença entre números (não igual a)if ["$a" != "$b"] Diferença entre Strings (não igual a)-gt, -ge, -lt, -le Maior que, maior ou igual a, menor que, menor ou igual a -n, -z Comparação de não nulo ou nulo. Por exemplo, if [-n "$1"] verifica se o
primeiro argumento não é nulo. if [<cond1>] && [<cond2>] Operador Eif [<cond1>] || [<cond2>] Operador OUif [!<cond>] Operador de negação. Por exemplo, if [! "$a" -gt "$b"] significa que estamos
perguntando se a negação do valor de a é maior que o valor de b-f Verifica se um nome especifico de arquivo existe. Por exemplo if [-f
"hello.txt"] verifica se o arquivo hello.txt existe.-r, -w, -x verifica se o arquivo possui privilégios de leitura, escrita e execução.
Figura 5: Condições para o comando if
Sistema Operacional 17

JEDITM
Por exemplo, retornando ao script myscript, podemos passar como argumento o nome do arquivo que desejamos salvar, o conteúdo de /etc e /usr. Se nenhum argumento for passado, isto é, $1 será nulo, então devemos retornar um erro.
#!/bin/bash# this is my first bash script.if [-n $1] then echo 'Listing the contents of /etc' > $1 ls -l /etc >> $1 echo 'Listing the contents of /usr' >> $1 ls -l /usr >> $1else echo 'You should specify a parameter'fi
3.2.8. Estruturas de repetição
Em linguagem bash, temos duas estruturas de repetição: for e while.
Estrutura de repetição for
A sintaxe do comando for é:
for <var> in <list> do <statements>done
O parâmetro list é uma lista de valores, no qual cada valor desta lista será repassado para a variável var. Na primeira interação, var assume o valor do primeiro elemento da lista, na segunda interação var assume o segundo elemento da lista e deste modo sucessivamente.
A seguir um exemplo do comando for que percorre os dias da semana.
for days in "Seg" "Ter" "Qua" "Qui" "Sex" "Sab" "Dom" do echo $daysdone
Estrutura de repetição while
Realiza a interação enquanto uma condição for verdadeira. A sintaxe para o comando while é:
while [condition] do <statements>done
Por exemplo, o código a seguir mostra o texto "hello world" um determinado número de vezes, baseado no argumento passado.
#!/bin/bashy=0while [$y -lt $1] do echo 'hello world' let "y = y + 1"done
Sistema Operacional 18

JEDITM
4. Comandos básicos de administração
4.1. Alterar para o super usuário: root
A administração do sistema só pode ser realizada pelo super usuário, isto é, o usuário root. Por exemplo, a edição dos arquivos scripts de profile de configuração no diretório /etc só pode ser feito pelo usuário root. Para acessar a conta root, devemos iniciar o sistema com este usuário ou utilizar o comando su (substitute user ou switch user) para modificar o usuário.
$ suEnter password: *******#
Note que o sinal do prompt foi modificado para refletir que agora o usuário possui o status do super usuário. O comando su também pode ser utilizado para alterar para qualquer usuário.
$ su bobEnter password: *******$ (<-- bob é o usuário corrente)
4.2. Administração de usuários
A seguir veremos alguns comandos que o usuário root pode utilizar para administrar os usuários do sistema.
Adicionar novos usuários
Para adicionar novos usuários, utilizamos o comando useradd (user add). Por exemplo, a instrução a seguir adiciona o usuário “alice”
# useradd -d /export/home/alice -m -s /bin/bash aliceAs opções adicionais são:
● -d especifica um diretório home para o usuário. Deve ser configurado em /export/home● -m o diretório será criado manualmente● -s especifica o tipo shell que será utilizado pelo usuário alice, nesse caso o bash
Eliminar usuários
Para eliminar usuários, utilizamos o comando userdel (user delete). Por exemplo, para remover o usuário “alice”.
# userdel -r alice
As opções adicionais são:
● -r se deve ocorrer a remoção do diretório do usuário
Trocar a senha dos usuários
Para trocar a senha do usuário utilizamos o comando passwd (password). Por exemplo, para trocar a senha do usuário “alice” digite:
# passwd alice
Se nenhum parâmetro for passado para o comando, então é trocada a senha do usuário corrente. Esta é a forma utilizada pelos usuários que não possuem privilégio de administradores do sistema para trocar suas senhas.
Resumidamente, usamos:
● useradd <username> - para criar novo determinado usuário● userdel <username> - para eliminar um determinado usuário● passwd <username> - para modificar a senha de um determinado usuário.
Sistema Operacional 19

Módulo 8Sistema Operacional
Lição 4Processo no Solaris
Versão 1.0 - Mar/2008

JEDITM
1. Objetivos
Um processo pode ser definido como um programa em execução. Conforme já discutido anteriormente, programas existem apenas como instruções em um arquivo até que sejam executados pela CPU. Quando um programa é executado, as instruções são carregados para a memória principal e, assim, torna-se um processo. Este capítulo discute como Solaris implementa processos.
Ao final desta lição, o estudante será capaz de:
• Conhecer sobre os componentes de um processo
• Compreender como funciona a estrutura de processos no Solaris
Sistema Operacional 4

JEDITM
2. Componentes do Processo
Um serviço que está sendo executado no sistema Solaris é definido como processo. O sistema operacional mantém o controle de múltiplos processos. Estes podem ser provenientes de um usuário com múltiplos processos ou de múltiplos usuários de um modo simultâneo. Cada processo, no sistema Solaris, recebe uma identificação única, denominada PID. Uma lista de processos é armazenada em uma tabela de processos. A tabela de processo pode ser visualizada através do comando ps (processes).
# ps -ef UID PID PPID C STIME TTY TIME CMDroot 0 0 0 Nov 20 ? 0:11 schedroot 1 0 0 Nov 20 ? 0:02 /sbin/initroot 2 0 0 Nov 20 ? 0:00 pageoutroot 3 0 0 Nov 20 ? 11:05 fsflushroot 215 1 0 Nov 20 ? 0:00 /usr/sbin/cronroot 7 1 0 Nov 20 ? 0:13 /lib/svc/bin/svc.startdroot 9 1 0 Nov 20 ? 0:28 /lib/svc/bin/svc.configdroot 124 1 0 Nov 20 ? 0:26 /usr/sbin/nscdroot 101 1 0 Nov 20 ? 0:00 /usr/lib/snmp/snmpdx -y -c /etc/snmp/confroot 1840 1836 0 22:17:30 pts 0:00 sh
Um processo pode consistir de vários serviços (threads) de usuários. Um serviço é um trecho de código em execução que roda dentro de um processo. Um processo tradicional (tal como um programa em linguagem Java) teria um único serviço executando. Um processo em Solaris pode suportar mais de um serviço executando simultaneamente (característica multithread). Posteriormente discutiremos a forma de programar aplicações multithread.
Figura 1: Processos do Sistema Solaris
Cada processo do usuário está associado no núcleo do sistema Solaris através de um Light Weight Process ou LWP. Um LWP permite que cada processo acesse as funções do Kernel de modo independente de outros processos.
Cada LWP é executado por um Kernel Thread. O Kernel Thread é a menor unidade de sincronização no Solaris. Em essência, processos, embora construídos com LWP, serão executados no Kernel Threads.
De modo a otimizar o tempo de início de um processo, o Kernel mantém LWP's sempre prontos para aceitar um novo processo.
Sistema Operacional 5

JEDITM
3. Estrutura de Processos
O Solaris armazena informações sobre cada processo em execução. A informação armazenada é resumida pela figura a seguir.
Figura 2: Sistema de Permissões
● Source File - contém as informações sobre o arquivo executável deste processo.
● Memory – indica as páginas de memória onde reside o processo.
● Process Family Tree – mostra toda a estrutura de processos, o processo que criou este (processo pai) e os processos filhos gerados por este.
● Credentials - indica o código e grupo id do usuário que iniciou o processo. Isto pode ser usado para verificar a política de segurança do sistema.
● CPU Utilization - indica o tempo que o processo está executando, seja em modo usuário ou executando no núcleo do sistema.
● Session – os processos também podem ser agrupados por sessões, por exemplo, processos que pertencem aos usuários. Este campo é utilizado para armazenar informações sobre a origem de sessão que este processo pertencente.
● PID – Process ID. Cada processo possui um identificador numérico único no sistema.
● Signal Support – os sinais são uma forma de um processo poder ser informado sobre determinado evento, por exemplo, quando o sistema está para ser finalizado. Este é um ponteiro para uma estrutura que indica como os sinais estão sendo manipulados.
● /proc Support - processos são representados no sistema de arquivos como arquivos no diretório /proc. O nome do arquivo deste processo é o PID.
● Thread List - um ponteiro para uma estrutura que mantém a lista de serviços do usuário que compõem este processo.
● Pooling - armazena informações sobre comportamento do processo, tais como, o estado de monitoramento do processo e o uso de recursos.
● Resources – armazena informações sobre quais recursos estão em uso e quais serão disponibilizados para o processo.
● Open File List - lista de arquivos que o processo está utilizando.
Sistema Operacional 6

Módulo 8Sistema Operacional
Lição 5Java Thread
Versão 1.0 - Mar/2008

JEDITM
1. Objetivos
Nesta lição discutiremos sobre Threads na linguagem Java. Veremos os comandos de sincronização e soluções para os problemas de sincronização discutidos na lição anterior.
Ao final desta lição, o estudante será capaz de:
• Criar Threads em Java
• Fazer o uso da palavras-chave synchronized
• Utilizar os métodos wait e notify de java.lang.Object
• Manipular objetos de concorrência de alto nível
Sistema Operacional 4

JEDITM
2. Criando uma Thread em Java
Thread, em linguagem Java, é a capacidade de diferentes partes de seu programa poder ser executada de modo simultâneo. Por exemplo, pode-se criar uma aplicação que aceite entradas de diferentes usuários ao mesmo tempo, cada um deles manipulando uma thread. A maior parte de aplicações de rede envolvem threads. Poderíamos necessitar criar uma thread que espere por uma determinada entrada enquanto o programa gera um relatório de saída.
Há duas maneiras para se criar threads, por herança da classe thread ou pela implementação de uma interface chamada Runnable. Ao ser iniciada, a thread executa as instruções contidas no método run().
2.1. Estendendo a classe Thread (is a)
Criaremos uma thread que mostrará 500 vezes um determinado número passado como argumento pelo construtor da classe.
class MyThread extends Thread { private int i; MyThread(int i) { this.i = i; } public void run() { for (int ctr=0; ctr < 500; ctr++) { System.out.print(i); } }}
Primeiramente veremos a diferença entre uma execução paralela e não-paralela. Vejamos a seguinte classe:
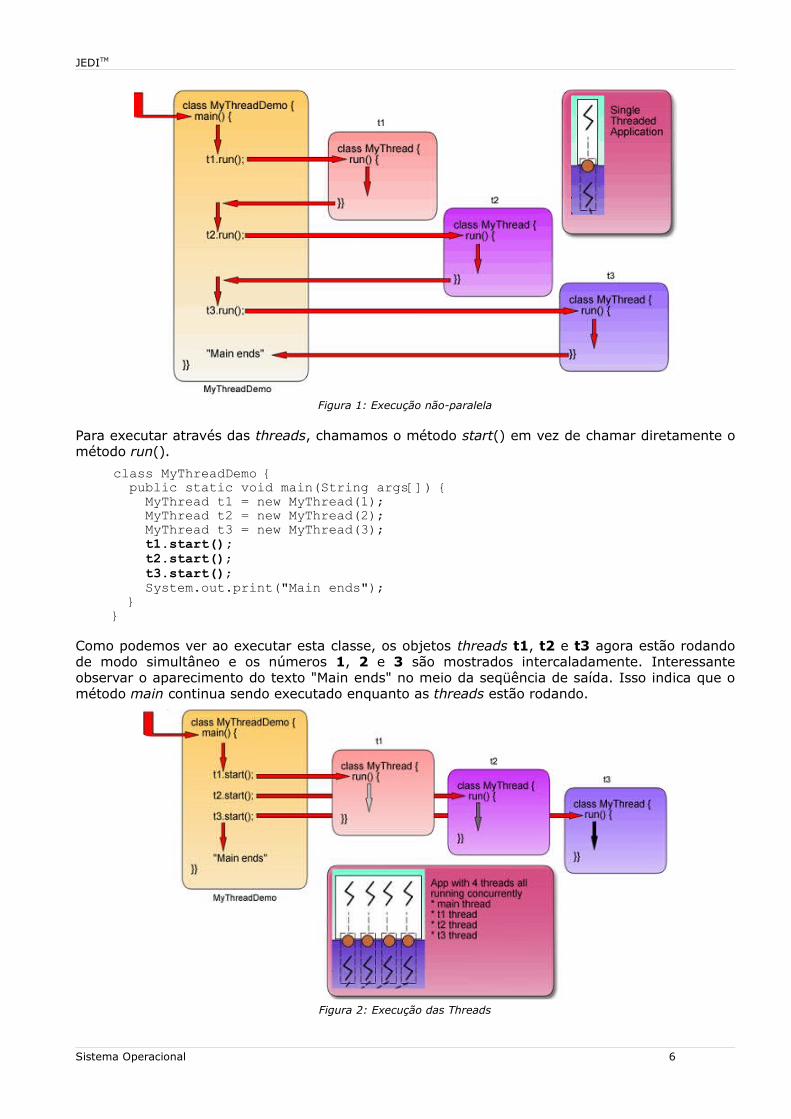
class MyThreadDemo { public static void main(String args[]) { MyThread t1 = new MyThread(1); MyThread t2 = new MyThread(2); MyThread t3 = new MyThread(3); t1.run(); t2.run(); t3.run(); System.out.print("Main ends"); }}
Conforme visto, após a execução da classe MyThreadDemo, foi chamado o método run do objeto t1 que mostra 500 números 1. Em seguida, a chamada ao método run do objeto t2 que mostra 500 números 2. Por fim, a chamada ao método run do objeto t3 que mostra 500 números 3. O texto “Main ends” aparece na parte final, como última mensagem da execução desta classe. Não ocorre nenhuma execução simultânea, isto é o que denominamos de execução não-paralela, conforme pode ser visto na figura a seguir.
Sistema Operacional 5
JEDITM
Figura 1: Execução não-paralela
Para executar através das threads, chamamos o método start() em vez de chamar diretamente o método run().
class MyThreadDemo { public static void main(String args[]) { MyThread t1 = new MyThread(1); MyThread t2 = new MyThread(2); MyThread t3 = new MyThread(3); t1.start(); t2.start(); t3.start(); System.out.print("Main ends"); }}
Como podemos ver ao executar esta classe, os objetos threads t1, t2 e t3 agora estão rodando de modo simultâneo e os números 1, 2 e 3 são mostrados intercaladamente. Interessante observar o aparecimento do texto "Main ends" no meio da seqüência de saída. Isso indica que o método main continua sendo executado enquanto as threads estão rodando.
Figura 2: Execução das Threads
Sistema Operacional 6

JEDITM
2.2. Implementando a interface Runnable (has a)
Outra maneira para se obter os benefícios de uma thread é implementar a interface runnable. Isto pode ser útil se sua classe necessita de herança. Lembre-se que a linguagem Java não permite herança múltipla. Modificamos nossa classe MyThread para implementar a interface runnable. Esta interface possui um único método abstrato que, obrigatoriamente, deve ser implementar, o método public void run().
class MyThread implements Runnable {... <thread body is mostly the same>}
A diferença principal está na construção do objeto da classe Thread que possuem um objeto da classe MyThread.
Thread t1 = new Thread(new MyThread(1));
Um objeto de MyThread agora é passado como um argumento para o construtor de um objeto Thread.
2.3. Pausar threads
Threads podem ser pausadas pelo método sleep(). Por exemplo, para interromper a execução de MyThread por meio segundo antes de imprimir o próximo número, adiciona-se as seguintes linhas de código:
for (int ctr=0; ctr < 500; ctr++) { System.out.print(i); try { Thread.sleep(500); // 500 milissegundos } catch (InterruptedException e) { }}
O método sleep(long time) é estático dentro da classe Thead e pode ser invocado por qualquer thread, inclusive a do método principal. Por exemplo, se quisermos pausar por um segundo o processo antes de iniciar o objeto t2 no nosso método principal, podemos ter:
public static void main(String args[]) { ... t1.start(); try { Thread.sleep(1000); } catch (InterruptedException e) { } t2.start(); ...}
2.4. Concordância de Threads
É possível interromper uma thread até que outra termine sua execução, chamamos, para isso, o método join(). Por exemplo, para fazer a thread principal parar de rodar até que o objeto t1 termine, podemos escrever:
public static void main(String args[]) { ... t1.start(); try { t1.join(); } catch (InterruptedException e) { } t2.start(); ...}
Isto determina que a thread t1 termine de executar antes de iniciar a thread t2.
Sistema Operacional 7

JEDITM
3. Palavra-chave Synchronized
Implementaremos uma solução para um problema de Sessão Crítica usando Java. Lembre-se que somente um processo pode entrar na sessão crítica do sistema, todos os outros processos devem aguardar. Nenhum chaveamento de contexto é permitido na sessão crítica.
Vejamos o seguinte problema: em vez de mostrar uma contínua sucessão de números, MyThread chama o método print10() na classe MyPrinter. O método print10() imprime números contínuos em uma única linha antes de iniciar uma nova linha.
Nossa meta é ter estes 10 números contínuos impressos sem que ocorra nenhum chaveamento de contexto. Em outras palavras, nossa saída deve ser:
...11111111111111111111222222222233333333331111111111...
3.1. Definir a solução
A seguir, definimos a classe MyPrinter que possui o método print10():
class MyPrinter { public void print10(int value) { for (int i = 0; i < 10; i++) { System.out.print(value); } System.out.println(""); // uma nova linha após 10 números }}
Em vez de imprimir os números diretamente, utilizamos o método print10() na classe MyThread, como mostrado a seguir:
class MyThread extends Thread { int i; MyPrinter p; MyThread(int i) { this.i = i; p = new MyPrinter(); } public void run() { for (int ctr=0; ctr < 500; ctr++) { p.print10(i); } }}
Visualizamos a saída de uma única thread.
class MyThreadDemo { public static void main(String args[]) { MyThread t1 = new MyThread(1); // MyThread t2 = new MyThread(2); // MyThread t3 = new MyThread(3); t1.start(); // t2.start(); // t3.start(); System.out.print("Main ends"); }}
Ao ser executada a classe MyThread, teremos:
Sistema Operacional 8

JEDITM
> java MyThreadDemo11111111111111111111111111111111111111111111111111...
Contudo, ao rodar as outras threads, podemos ter uma saída semelhante a esta:
> java MyThreadDemo1111111111111112222222111122233333332...
Não alçamos nosso objetivo de imprimir os 10 números de forma consecutiva quando todas as threads executam o método print10 ao mesmo tempo. O resultado final é que teremos mais de um número aparecendo em uma única linha.
Não deve haver um interruptor do contexto ao mostrarmos os 10 números consecutivos. Assim, uma solução para este problema é também uma solução para o problema de sessão crítica.
3.2. Monitores em Java
Java usa uma construção de monitor para resolver o problema de sessão crítica. Somente uma única thread pode funcionar dentro de um monitor. Para alternar um objeto em um monitor, colocamos a palavra-chave synchronized sobre as assinaturas dos métodos. Somente uma única thread pode executar em um método sincronizado dentro de um objeto.
class MyPrinter { public synchronized void print10(int value) { for (int i = 0; i < 10; i++) { System.out.print(value); } System.out.println(""); // nova linha depois de 10 números }}
Entretanto, se transformarmos nosso método print10() em um método sincronizado, ainda assim este não trabalhará como esperado. Para encontrar um modo de fazê-lo funcionar corretamente, necessitamos descobrir como a palavra-chave synchronized trabalha.
Cada objeto em Java possui um bloqueio. Quando uma thread é executada em um método sincronizado, o objeto é bloqueado. Ao obter um bloqueio a thread começa a funcionar no método sincronizado, caso contrário, espera até que a thread que possui o bloqueio seja liberada.
Figura 3: Método sincronizado
Nosso exemplo não trabalha corretamente, pois cada thread possui uma cópia própria do objeto MyPrinter.
Sistema Operacional 9

JEDITM
class MyThread extends Thread { int i; MyPrinter p; MyThread(int i) { this.i = i; p = new MyPrinter(); // cada MyThread cria sua MyPrinter! } public void run() { for (int ctr=0; ctr < 500; ctr++) { p.print10(i); } }}
Como podemos ver na figura a seguir, cada thread possui seu próprio bloqueio, deste modo, todas funcionam através de um método sincronizado:
Figura 4: Diagrama dos objetos
A solução é um único objeto MyPrinter para compartilhamento por todas as threads.
Figura 5: Solução com um único objeto
Uma maneira de visualizar todos os objetos é através de portas. Uma thread tenta ver se uma
Sistema Operacional 10

JEDITM
porta está aberta. Uma vez que a thread atravessa esta porta, esta é travada. Nenhuma outra thread pode entrar nesta porta porque a primeira a travou por dentro. As outras thread podem entrar se a thread que está dentro destravar a porta e sair. Um alinhamento ocorrerá somente se todos os objetos tiverem uma única porta na sessão crítica.
Reinterando, somente uma única thread pode rodar no método sincronizado de um objeto. Se um objeto tiver um método sincronizado e um método não-sincronizado, somente uma thread pode rodar no método sincronizado e múltiplas threads podem rodar no método não-sincronizado. Threads a serem sincronizadas devem compartilhar o mesmo objeto monitor. Ao executar agora a classe MyThreadDemo, o resultado é mostrado corretamente através dos métodos sincronizados.
3.3. Blocos sincronizados
Além dos métodos sincronizados, Java permite blocos sincronizados. Podemos especificar um bloqueio intrínseco. Os blocos sincronizados permitem a flexibilidade de que o bloqueio intrínseco venha de outro objeto ao invés do objeto atual. Também podemos ter partes de um método que possui um bloqueio diferente de outro.
Considere a seguinte classe MyPrinter:
class MyPrinter { Object lock1 = new Object(); Object lock2 = new Object(); public void print10(int value) { synchronized(lock1) { for (int i = 0; i < 10; i++) { System.out.print(value); } System.out.println(""); // nova linha após 10 números } } public int squareMe(int i) { synchronized (lock2) { return i * i; } }}
Somente uma thread pode rodar dentro do bloco sincronizado dentro dos métodos print10() e squareMe(). Entretanto, duas threads diferentes podem rodar em ambos os blocos sincronizados ao mesmo tempo pois usamos bloqueios diferentes para cada um deles (porque não interferem realmente um com o outro). Os blocos sincronizados permitem também que outra parte de um método sejam executadas em paralelo com outras, como mostrado na figura a seguir:
Figura 6: Diagrama de Sincronização
Sistema Operacional 11

JEDITM
4. Métodos wait e notify
Neste ponto, já é possível utilizar algumas implementações para problemas relacionados a sincronização. Discutiremos o problema do produtor-consumidor. O produtor irá armazenar em um array compartilhado um valor inteiro gerado de forma aleatória que será obtido pelo consumidor. Para propósitos de discussão, será permitido que este array armazene um número muito grande de números inteiros. O produtor irá produzir, desta forma, um total de 100 números inteiros.
4.1. Blocos sincronizados
Primeiramente, criamos a classe para que possa ser realizado o armazenamento do array. Não será aceito que os métodos insertValue() e getValue() sejam executados simultaneamente. Assim, estes métodos serão sincronizados (terão o modificador synchronized). Tanto o produtor quanto o consumidor estarão tratando do mesmo objeto.
class SharedVars { int array[] = new int[100]; int top; // Método responsável pela atribuição do valor public synchronized void insertValue(int value) { if (top < array.length) { array[top] = value; top++; } } // Método responsável por recuperar o valor public synchronized int getValue() { if (top > 0) { top--; return array[top]; } else { return -1; } }}
A seguir, será definida a classe que representa o produtor.
class Producer extends Thread { SharedVars sv; Producer(SharedVars sv) { // Referência de Produtor para os objetos SharedVars this.sv = sv; } public void run() { for (int i = 0; i < 100; i++) { // Atribui um número aleatório entre 0 a 200 int value = (int)(Math.random() * 200); System.out.println("Producer inserts " + value); sv.insertValue(value); try { // Espera um determinado tempo antes de realizar uma nova inserção Thread.sleep((int)(Math.random() * 10000)); } catch (InterruptedException e) { } } }}
E a classe que representa o consumidor:
class Consumer extends Thread { SharedVars sv; Consumer(SharedVars sv) {
Sistema Operacional 12

JEDITM
// Referência de Consumidor para os objetos SharedVars this.sv = sv; } public void run() { for (int i = 0; i < 100; i++) { int value = sv.getValue(); System.out.println("Consumer got:" + value); try { // Espera um tempo antes antes de obter o valor novamente Thread.sleep((int)(Math.random() * 10000)); }catch (InterruptedException e) { } } }}
Para finalizar, temos a seguinte classe principal:
class ProducerConsumerDemo { public static void main(String args[]) { SharedVars sv = new SharedVars(); Producer p = new Producer(sv); Consumer c = new Consumer(sv); p.start(); c.start(); }}
A execução desta classe pode gerar a seguinte saída:
Producer inserts value: 15Consumer got: 15Consumer got: -1Producer inserts value: 50Producer inserts value: 75Consumer got: 75...
É importante notar que, caso seja realizada uma tentativa de recuperar um valor em uma posição no array que não possua nenhum valor, será obtido o valor -1. É possível notar isto se o produtor gerar um novo valor a cada 10 segundos e caso o consumidor recuperar este valor a cada 5 segundos. Em algum ponto o consumidor irá tentar realizar o acesso a uma posição vazia do array.
Então, é melhor que o consumidor espere até que o produtor gere algum valor no lugar de obter o valor -1.
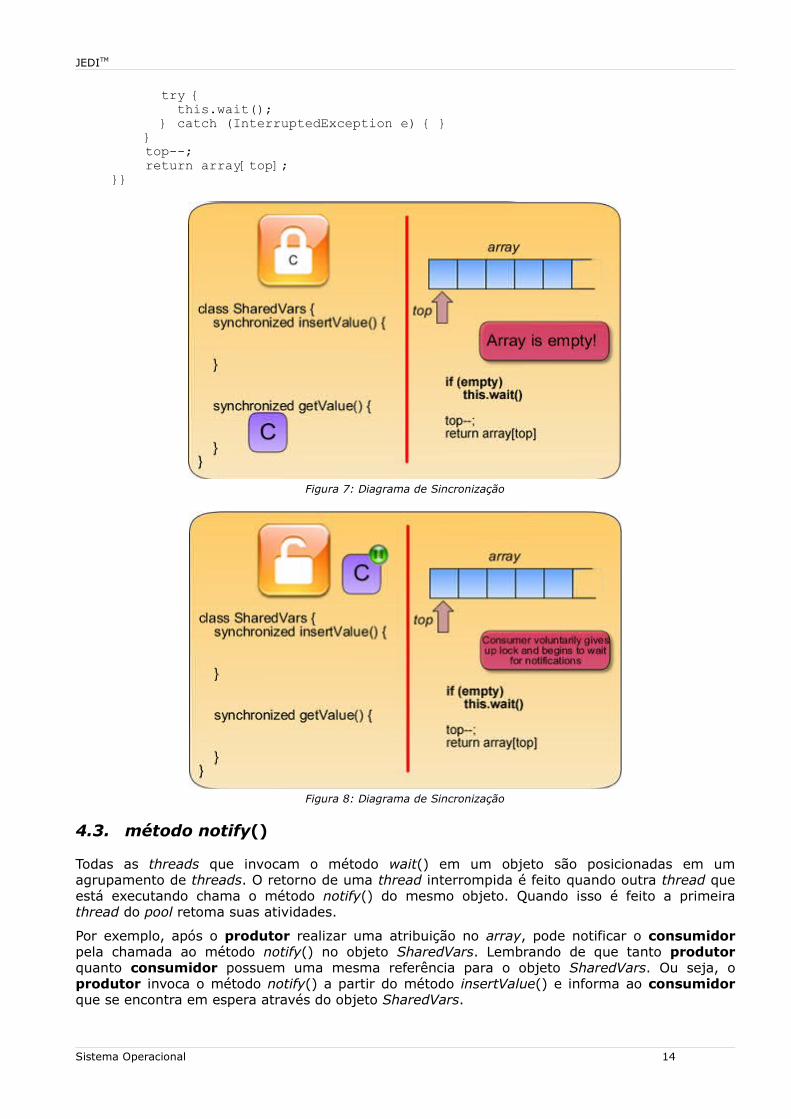
4.2. método wait()
O método wait() é definido na classe java.lang.Object e é herdado por todos os objetos. A chamada a este método fará com que a thread suspenda suas atividades. Entretanto, se uma thread realizada uma chamada a este método, esta possuir um bloqueio para o objeto que está realizando esta chamada. Se for realizada uma chamada na forma this.wait() este deve estar em um bloco sincronizado, da seguinte forma:
synchronized(this);
De modo semelhante, outros métodos que realizam uma interrupção da execução de uma thread, tais como, join() e sleep(), o método wait() deve estar protegido por um bloco try-catch que controle a exceção tipo InterruptedException.
O código a seguir mostra a modificação para o método getValue() na classe SharedVars:
// chamado pela thread consumidorpublic int getValue() { synchronized(this) { if (top <= 0) {
Sistema Operacional 13
JEDITM
try { this.wait(); } catch (InterruptedException e) { } } top--; return array[top];}}
Figura 7: Diagrama de Sincronização
Figura 8: Diagrama de Sincronização
4.3. método notify()
Todas as threads que invocam o método wait() em um objeto são posicionadas em um agrupamento de threads. O retorno de uma thread interrompida é feito quando outra thread que está executando chama o método notify() do mesmo objeto. Quando isso é feito a primeira thread do pool retoma suas atividades.
Por exemplo, após o produtor realizar uma atribuição no array, pode notificar o consumidor pela chamada ao método notify() no objeto SharedVars. Lembrando de que tanto produtor quanto consumidor possuem uma mesma referência para o objeto SharedVars. Ou seja, o produtor invoca o método notify() a partir do método insertValue() e informa ao consumidor que se encontra em espera através do objeto SharedVars.
Sistema Operacional 14

JEDITM
A seguir, teremos o novo método insertValue():
// Chamado pela Produtorpublic void insertValue(int value) { synchronized(this) { if (top < array.length) { array[top] = value; top++; if (top == 1) { // Se o array estiver vazio this.notify(); } } }}
Figura 9: Diagrama de Sincronização
Figura 10: Diagrama de Sincronização
Ao executar novamente o exemplo, podemos observar que, mesmo se produtor estiver lento, o consumidor será obrigado a esperar até que seja gerado um valor antes de obtê-lo.
Devemos considerar também que podemos ter um array lotado, desta forma, será a vez do produtor esperar até que consumidor obtenha alguns valores antes de gerar novos valores. Realize esta implementação como uma forma de exercício.
Sistema Operacional 15

JEDITM
5. Alto Nível de Concorrência dos Objetos
Os métodos discutidos até o momento, foram inseridos desde as primeiras versões da linguagem Java. Entretanto, com a chegada da Java 5.0 novas classes foram adicionadas ao pacote java.util.concurrent para auxiliar na criação e manipulação de threads.
5.1. Bloquear Objetos
Qualquer objeto em linguagem Java pode ser usado para efetuar um bloqueio durante uma sincronização. Porém, o pacote java.util.concurrent.locks define classes que possuem adicionais características para proceder este bloqueio. A interface básica deste pacote é a Lock.
Um objeto que implementa Lock só pode ser utilizado por uma única thread de cada vez. Para efetuar um bloqueio, a thread deve chamar o método lock(). Para liberar este bloqueio, deve chamar o método unlock(). Em vez de fechar implicitamente e destravar um bloco sincronizado ou método, um bloqueio explícito provê a flexibilidade de chamar manualmente os métodos lock() e unlock().
Um bloqueio poderá também chamar um método tryLock(). Este método retorna um valor lógico. Verdadeiro se conseguiria realizar um bloqueio, ou falso se não. O programa não irá bloquear enquanto tryLock() não obtiver sucesso, diferente do método lock() e do comportamento de uma thread que tenta entrar em um bloco ou método sincronizado. Além disso, um polimórfico do método tryLock() permite especificar a quantidade de tempo que uma thread deve esperar para estabelecer um bloqueio antes de retornar verdadeiro ou falso.
A seguir teremos uma classe de implementação para MyPrinter (em nosso exemplo de MyThread2) usando bloqueios. Observe que não existe nenhum desbloqueio implícito, isso acontece quando o bloco sincronizado termina. Assim, qualquer chamada aos métodos lock() ou tryLock() deve ser seguida por uma chamada ao método unlock().
import java.util.concurrent.locks.*;class MyPrinter { // ReentrantLock é uma implementação da interface lock final Lock l = new ReentrantLock(); public void print10(int value) { boolean gotLock = false; while (!gotLock) { gotLock = l.tryLock(); if (!gotLock) { System.out.println("Unable to get lock, try again next time"); try { Thread.sleep((int)(Math.random() * 1000)); } catch (InterruptedException e) { } } } for (int i = 0; i < 10; i++) { System.out.print(value); } System.out.println(""); // Uma nova linha após 10 números l.unlock(); }}
Os métodos wait() e notify() só podem ser chamados no bloqueio intrínseco de um método ou bloco sincronizado. Para fazer isso, podemos usar seu método newCondition() que devolve um objeto do tipo Condition. Um objeto Condition tem um método denominado await() que é o equivalente a chamada ao método wait(). Para retornar uma thread que está em espera o objeto Condition tem um método denominado signal() que é o equivalente a uma chamada ao método notify().
Por exemplo, adicionaremos as seguintes linhas a classe SharedVars usando bloqueios e
Sistema Operacional 16

JEDITM
Conditions.
import java.util.concurrent.locks.*;class SharedVars { final Lock l = new ReentrantLock(); final Condition emptyCondition = l.newCondition(); int array[] = new int[100]; int top;
// método para inserir um novo valor public void insertValue(int value) { l.lock() // realiza o bloqueio if (top < array.length) { array[top] = value; top++; if (top == 1) { emptyCondition.signal(); } } l.unlock(); } // método para obter um valor public int getValue() { l.lock(); if (top <= 0) { try { emptyCondition.await(); } catch (InterruptedException e) { } } top--; l.unlock(); return array[top]; }}
Existem outras classes no pacote java.util.concurrent.locks. Uma delas é a classe ReentrantReadWriteLock que classifica os métodos que retornam os bloqueios. Estes bloqueios podem ser usados como uma solução ao problema produtor-consumidor.
5.2. Executores
Ao criamos uma thread, declaramos manualmente quando esta thread será executada. Por exemplo, a thread seguinte:
class MyThread implements Runnable { ... }
Manualmente, iniciamos a thread através das seguintes instruções:
Thread t1 = new Thread(mt1);t1.start();
Uma classe que implementa a interface Executor pode iniciar automaticamente uma thread. Por exemplo, em vez das instruções anteriores, teríamos:
MyThread mt1 = new MyThread();Executor e = new ThreadPoolExecutor(10); // accepts max 10 threadse.execute(mt1);e.execute(otherThreads);
Nosso exemplo utiliza uma classe denominada ThreadPoolExecutor. Esta classe executa nossas threads inseridas (pelo método execute()) através de um pool de threads em execução. Estas threads em execução reduz a necessidade do overhead para a criação de uma thread, uma threads é passada como um parâmetro para uma linha que já se encontra em execução.
Um parâmetro especificado no construtor indica quantas threads podem rodar no Executor de
Sistema Operacional 17

JEDITM
modo simultâneo. Se um Executor não for usado, então as threads são executadas no momento em que são iniciadas. Se houver muitas threads executando simultaneamente, o sistema pode chegar a não suportar e todas as threads serão interrompidas. Um executor permite que um número de máximo de threads em execução seja especificado e permite que o sistema controle este número, criando um agrupamento daquelas que não pode.
Métodos adicionais indicam como novas threads devem ser colocadas no pool ou quando terminar as threads que estão inativas. Uma subclasse de ThreadPoolExecutor, é a ScheduledThreadPoolExecutor que possui métodos para permitir que uma thread em particular inicie em um determinado momento, e seja repetida periodicamente.
5.3. Coleções Concorrentes
O pacote java.util.concurrent inclui uma coleção de classes que podem ser usadas com programas multithread, sem termos que nos preocupar com problemas de sincronização. Por exemplo, a classe de BlockingQueue cria uma FIFO (first in – first out) que bloqueia automaticamente threads que tentam entrar em um pool cheio ou retorna valores vazio. A execução retoma automaticamente quando outra thread remove um valor em um pool cheio ou acrescenta novos dados a um vazio.
5.4. Variáveis Atômicas
Como vimos no problema produtor-consumidor, as instruções:
array[top] = <new value>;top++;
Devem ser executadas sem intervalos. Este processo é chamado de execução atômica. Cada linha de instrução deve ser executada como um todo. Porém, nem mesmo únicas instruções são atômicas. Considere a seguinte instrução:
top++;
Esta instrução está dividida em três partes quando é executada na CPU:
1. Obtém o valor de top
2. Adiciona 1 para o valor
3. Salva o valor no endereço de top
Estas três instruções devem ser executadas sem deixar que nenhuma outra instrução seja executada. Um modo para assegurarmos isso, é proteger estas instruções por um método sincronizado.
class SharedVars { int top; public synchronized inctop() { top++; }}
A maioria das outras operações aritméticas não são atômicas, isso significa que cada operação matemática deve lidar com variáveis compartilhadas, e tem que estar em um bloco sincronizado para serem seguras. Entretanto, isto pode incluir instruções para tarefas compartilhadas. Para evitar todo este trabalho, o pacote java.util.concurrent.atomic fornece classes preparadas para trabalhar de forma segura em ambiente multithread, ou seja, são thread-safe.
Por exemplo, a classe AtomicInteger fornece os seguintes métodos:
● void incrementAndGet() – executa atomicamente uma operação de incremento
● void addAndGet(int delta) – acrescenta um valor delta a AtomicInteger
Também existem implementações, tais como, um array de tipos inteiros ou um objeto de referência. A maioria das classes em java.util é thread-safe.
Sistema Operacional 18

Módulo 8Sistema Operacional
Lição 6Observabilidade
Versão 1.0 - Mar/2008

JEDITM
1. Objetivos
A Sun fornece freqüentemente aos desenvolvedores acesso imediato às novas tecnologias, assim como ferramentas para rastreabilidade. Estas permitem que os usuários possam analisar profundamente os detalhes da implementação interna do software, do núcleo e do usuário.
Neste ponto já discutimos os conceitos teóricos do sistema operacional. Nesta lição veremos comandos que torna possível observar como estes conceitos são executados no sistema operacional. Discutiremos alguns comandos básicos do poderoso conjunto de ferramentas DTrace.
Ao final desta lição, o estudante será capaz de:
• Trabalhar com o conjunto de ferramentas DTrace
• Realizar comandos no Solaris que permitem ver em ação: CPU, processos, memória e E/S
Sistema Operacional 4

JEDITM
2. DTrace
DTrace é uma poderoso conjunto de ferramentas que foi incluído no Solaris 10 e permite visualizar o comportamento atual de um sistema durante sua execução. Dtrace foi desenvolvido como uma ferramenta para diagnóstico do sistema. Antes do DTrace, para tentar ver como determinado programa executava, era necessário inserir diversas instruções na saída de seu código. Essa prática é difícil de ser realizada quando necessitamos conhecer como um programa está em área de memória ou quão freqüentemente o arquivo executável chama uma determinada função do núcleo do sistema, ou mesmo como o programa acessa o disco rígido. Isso pode envolver realmente a edição do código fonte do próprio sistema operacional.
Para evitar esses problemas, DTrace usa probes (sondas) que estão conectados dentro do Sistema Operacional Solaris. Estes probes mantêm um registro de tudo, desde processos em uso de memória a quão frequentemente interrupções são chamadas pelo programa e a dados que são gravados no disco. Existem mais de 30.000 probes no Solaris. Probes não interferem na execução. Habilitar certos probes com DTrace nos permite um olhar dentro do núcleo do sistema operacional enquanto este está sendo executado.
2.1. Probes BEGIN e END
Iniciaremos o aprendizado com um comando muito simples. Vamos chamar o DTrace com a opção -n:
# dtrace -n BEGINdtrace: description 'BEGIN' matched 1 probeCPU ID FUNCTION:NAME 0 1 :BEGIN
O probe BEGIN é iniciado quando um processo é iniciado. É necessário pressionar CTRL+C para sair do DTrace. Agora consideraremos outro probe, chamado END, que é ativado sempre que um processo finaliza. Quando é executado, o probe END não aparece imediatamente. Pois o processo ainda não acabou.
É necessário parar o DTrace para ver a ativação do probe END pressionando CTRL+C:
# dtrace -n BEGIN -n ENDdtrace: description 'BEGIN' matched 1 probedtrace: description 'END' matched 1 probeCPU ID FUNCTION:NAME 2 1 :BEGIN ^C 2 2 :END
Até agora, vimos apenas probes que são ativados quando DTrace começa ou termina, sem nenhuma funcionalidade adicional. Escreveremos um script para que o DTrace possa executar quando o probe BEGIN ou END for iniciado.
2.2. Alô mundo
DTrace aceita um script escrito na linguagem D, similar à linguagem C ou C++. A sintaxe básica de um script em D se parece com:
<probe description>/<predicate>/{ <código>}
A sessão será executada quando o probe listado na descrição for ativado e o predicado (que é uma expressão condicional) for verdadeiro. Com essa idéia, considere o script a seguir para
Sistema Operacional 5

JEDITM
DTrace, o qual será salvo com o nome de alo.d. Podemos ver que a instrução “Alô Mundo” será executada quando o probe BEGIN iniciar, e a instrução “Adeus” na ativação do probe END.
BEGIN{ trace("Alô Mundo!");}END{ trace("Adeus!");}
Executaremos agora o DTrace utilizando a opção -s para informar o nome do arquivo script que iremos rastrear.
# dtrace -s alo.ddtrace: script 'alo.d' matched 2 probesCPU ID FUNCTION:NAME 0 1 :BEGIN Alô Mundo! ^C 2 2 :END Adeus!
Note como modificamos o comportamento do DTrace para mostrar seu início e fim. Rastrear um programa significava ter que modificá-lo, editando-o para inserir instruções de saída. Com DTrace, podemos rastrear um programa sem ter que modificar isso simplesmente utilizando o probe correto.
2.3. Organização dos probes
Podemos listar todos os probes através da opção -l. Existem mais de 30.000 probes disponíveis no Solaris.
# dtrace -l ID PROVEDOR MÓDULO NOME DA FUNÇÃO 1 dtrace BEGIN 2 dtrace END 3 dtrace ERROR 4 vminfo fasttrap fasttrap_uwrite softlock 5 vminfo fasttrap fasttrap_uread softlock 6 nfsmapid229 nfsmapid check_domain daemon-domain
Probes são identificados pelos ID e pelo seu nome, que é composto pelos seguintes valores separados por dois-pontos:
● Provedor
● Módulo
● Função
● Nome
Por exemplo, probe de ID 5, pode ser também referido como:
vminfo:fasttrap:fasttrap_uread:softlock
Provedores são módulos do núcleo que contêm o código dos probes. Módulo e Função indicam o módulo do núcleo, biblioteca do usuário ou nome de função que o probe é projetado para rastrear. A última parte e o Nome do probe é a descrição do que é designado a fazer.
Aqui estão alguns exemplos de Provedores:
● DTrace – probes relacionados ao DTrace
● Lockstat – probes para sincronização em nível de núcleo do sistema
● Profile – probes que executam todos os intervalos especificados que podem ser usados
Sistema Operacional 6

JEDITM
para obter uma amostra do sistema em execução
● Syscall – probes para cada entrada e retorno de cada chamada de sistema no programa
● VMinfo – probes de memória virtual
● Proc – probes de processo, threads e criação e finalização de LWP
● Sched – probes de agendamento de processo
Para especificar um probe em um script D, simplesmente coloque seu nome completo na parte de descrição do probe. Caso não seja preeenchida partes da descrição, o código iniciará todos os probes que coincidam.
Por exemplo, o script a seguir roda o código sempre que uma página for carregada da memória virtual para a memória principal, bem como o código que irá executar em qualquer probe provido pelo syscall.
vminfo:genunix:pageio_setup:pgin{ trace("Pagina em que ocorreu");}syscall:::{ trace("Rodando um probe syscall");}
2.4. Variáveis
Variáveis no DTrace não possuem tipos de dados, isso significa que este é determinado durante a primeira atribuição de valor. Por exemplo, i = 0 cria uma variável, do tipo inteiro, denominada i com o valor 0, enquanto msg = "Alô" cria uma variável denominada msg do tipo String com o valor "Alô".
O dtrace:::BEGIN é comumente usado para inicializar variáveis e são acessíveis somente enquanto o processo estiver rodando.
Para mostrar as variáveis em ação, o script DTrace a seguir, chamado countdown.d, mostra o funcionamento de variáveis, e o probe profile:::tick-1sec, que roda a cada segundo.
dtrace:::BEGIN{ ctr = 10;}profile:::tick-1sec{ trace(ctr); ctr--;}dtrace:::END{ trace("Obrigado por usar meu programa.");}
A saída de countdown.d é a seguinte:
# dtrace -s countdown.ddtrace: script 'countdown.d' find 3 probesCPU ID FUNCTION:NAME 2 41214 :tick-1sec 10 2 41214 :tick-1sec 9 2 41214 :tick-1sec 8 2 41214 :tick-1sec 7 2 41214 :tick-1sec 6 2 41214 :tick-1sec 5 2 41214 :tick-1sec 4
Sistema Operacional 7

JEDITM
2 41214 :tick-1sec 3 2 41214 :tick-1sec 2 2 41214 :tick-1sec 1 2 41214 :tick-1sec 0 2 41214 :tick-1sec -1 2 41214 :tick-1sec -2^C 2 2 :END Obrigado por usar meu programa
2.5. Predicados
Predicados agem como uma instrução para um script. O código do script só é executado juntamente com o probe e o predicado é então comparado.
Realizamos a seguinte modificação no script countdown.d:
dtrace:::BEGIN{ ctr = 10;}profile:::tick-1sec/ ctr > 0 /{ trace(ctr); ctr--;}profile:::tick-1sec/ ctr == 0/{ trace(ctr); exit(0); }dtrace:::END{ trace("O tempo acabou!");}
Nosso primeiro profile:::tick-1sec executará quando a condição "ctr maior que 0" for verdadeira, enquanto o segundo só irá rodar quando a condição "ctr igual a 0" for verdadeira. A função exit() finaliza o trace.
# dtrace -s countdown.d
dtrace: script 'countdown.d' encontrou 4 probesCPU ID FUNCTION:NAME 2 41214 :tick-1sec 10 2 41214 :tick-1sec 9 2 41214 :tick-1sec 8 2 41214 :tick-1sec 7
2.6. printf
O comando printf mostra o valor de um determinado atributo na tela. Sua sintaxe é semelhante à da linguagem C/C++. Para mostrar uma lista de strings utilizando a função printf(), utilizamos uma vírgula para separá-las:
printf("O tempo restante é %d segs. O que posso dizer é %s", ctr, msg);
O formato String é apresentado na tela através da substituição dos atributos denotados pelo símbolo %, seguido de um caractere que identifica o tipo de atributo.
● %d significa que um valor inteiro será exibido naquela posição.
Sistema Operacional 8

JEDITM
● %s significa que uma String será exibida naquela posição.
● %f significa que um número decimal será exibido naquela posição.
● %x exibe números inteiros como caracteres em hexadecimal.
● %% imprime um percentual na posição.
Modificamos o script countdown.d para exemplificar o uso da função printf():
dtrace:::BEGIN{ ctr = 10; msg = "Adeus"}profile:::tick-1sec/ ctr > 0 /{ printf("Tempo restante de %d segs\n",ctr); ctr--;}profile:::tick-1sec/ ctr == 0/{ printf("Tempo restante de %d segs\n", ctr); exit(0); }dtrace:::END{ printf("Tempo acabando! %d segs. Tudo que posso dizer é %s\n", ctr, msg);}
Para melhorar a visualização, podemos utilizar a opção -q para listar as strings.
# dtrace -q -s countdown.dTempo restante 10 segsTempo restante 9 segsTempo restante 8 segsTempo restante 7 segsTempo restante 6 segsTempo restante 5 segsTempo restante 4 segsTempo restante 3 segsTempo restante 2 segsTempo restante 1 segsTempo restante 0 segsTempo acabado! 0 segs. Tudo que posso dizer é Adeus
2.7. Scripts no DTrace – parte 1
Considere o seguinte script salvo com o nome syscall.d. Syscall:::entry é o conjunto de probes disparados sempre que uma aplicação chama uma função do núcleo do sistema. Execname, PID e probefunc são atributos no DTrace. Execname é o nome do processo que originou este probe. PID é a identificação do processo. Probefunc é o nome da função do probe, indicando qual função do sistema foi chamada.
Adicionaremos um predicado para considerar apenas os processos em bash.
syscall:::entry/ execname == “bash” /{ printf("%s(%d) chamado %s\n", execname, pid, probefunc);}
Executando o script, é possível que não ocorre nenhuma saída inicial. Isto porque o script bash
Sistema Operacional 9

JEDITM
atual que está em execução é o DTrace. Para se obter uma saída inicie outra janela do terminal e execute alguns comandos em bash. Como por exemplo:
# dtrace -q -s syscall.dBash(1035) chamado readBash(1035) chamado readBash(1035) chamado writeBash(1035) chamado readBash(1091) chamado getpidBash(1091) chamado lwp_selfBash(1091) chamado lwp_sigmaskBash(1091) chamado getpidBash(1091) chamado schedctl...
Para investigar essas chamadas de sistema ao núcleo e descobrir como o sistema funciona, uma boa dica é verificar o código-fonte dessas funções.
2.8. Funções agregadas
Talvez seja necessário saber quais funções foram chamadas, mas como saber quantas vezes cada função foi chamada? Podemos utilizar funções agregadas para analisar os dados.
Para ilustrar um exemplo, modificamos o script syscall.d para produzir um total de probefunc que foram chamadas pelo bash.
syscal:::entry/execname == "bash"/{ printf("%s(%d) chamado %s\n", execname, pid, probefunc); @[probefunc] = count();}
A execução prossegue normal, mas no final do script obtemos a seguinte saída, que mostra quantas vezes cada função do sistema foi chamada.
^C exece 1 fork1 1 lwp_self 1 schedctl 1 setcontext 1 stat64 1 waitsys 1 getpid 2 gtime 3 read 3 write 4 setpgrp 6 ioctl 15 lwp_sigmask 22 sigaction 33
A sintaxe básica da função agregada é:
@name[key] = aggfunc(args)
A parte esquerda da expressão cria um array. Um vetor agregado é um conjunto que, em vez de índices, utiliza strings para referenciar seus elementos. Por exemplo, @vendas["seg"]=14; if (@vendas["ter"]> 10), etc.
O @ indica que estamos definindo uma função agregada. O name é um nome qualquer para o agregado e key é um atributo cujos valores tornam-se índices do array.
O lado direito da expressão que define uma função agregada, pode ser:
● count() - quantas vezes ocorreu um evento.
Sistema Operacional 10

JEDITM
● sum(exp) – executa a soma da expressão.
● avg(exp) – executa a média aritmética da expressão.
● min(exp), max(exp) – mínimo e máximo, respectivamente, de uma expressão.
● quantize(exp) – cria um gráfico de uma expressão.
Não é necessário exibir explicitamente uma função agregada, pois o DTrace automaticamente assume que, todas as funções agregadas são impressas no final da execução do script.
2.9. Scripts no DTrace – parte 2
Em vez de apenas contar quantas vezes uma chamada ao sistema foi executada, também podemos conhecer quanto tempo levou para executar. Para tornar isso simples, consideraremos apenas a função read. Nosso próximo script timestamp.d utiliza dois probes, syscall::read:entry e syscall::ready:exit. Também utilizamos o atributo timestamp que retorna a hora atual.
Para achar a duração, gravamos a timestemp na syscall:::entry e a subtraímos da nova timestamp localizada na syscall:::exit.
syscall::read:entry{ t = timestamp;}syscall::read:return{ delay = timestamp - t; printf("%s(%d) tempo em %s: %d nsecs\n", execname, pid, probefunc, delay); t = 0;}
O problema com este código é que vários processos o chamam e modificam o valor do atributo t, que corresponde ao tempo em que o sistema começou a funcionar.
Para resolver este problema, DTrace verifica sua estrutura de atributos. Qualquer atributo inserido no DTrace é exclusivo de uma thread. Por exemplo, ao declarar um atributo self->t, então este é único para cada thread.
A seguir, o script timestamp.d modificado:
syscall::read:entry{ self->t = timestamp;}syscall::read:return{ self->delay = timestamp - self->t; printf("%s(%d) tempo no método %s: %d nsecs\n", execname, pid, probefunc, self->delay); self->t = 0;}
O código de saída poderia ser mostrado da maneira:
# dtrace -q -s timestamp.dXsun(485) tempo em read: 33261 nsecsXsun(485) tempo em read: 23697 nsecsXsun(485) tempo em read: 25137 nsecssshd(1405) tempo em read: 46509 nsecsXsun(485) tempo em read: 27892 nsecsXsun(485) tempo em read: 21706 nsecssshd(1405) tempo em read: 26893 nsecssshd(1405) tempo em read: 13417 nsecssshd(1405) tempo em read: 21497 nsecs...
Sistema Operacional 11

JEDITM
Para tornar os dados mais significativos, podemos utilizar a função agregada quantize.
syscall::read:entry{ self->t = timestamp;}syscall::read:return{ self->delay = timestamp - t; @[execname] = quantize[self->delay]; self->t = 0;}
A saída do código é:
# dtrace -q -s timestamp.d^C nfsmapid valor ------------- Distribuição ------------- count 4096 | 0 8192 |@@@@@@@@@@@@@@@@@@@@ 1 16384 | 0 32768 |@@@@@@@@@@@@@@@@@@@@ 1 65536 | 0 sshd valor ------------- Distribuição ------------- count 8192 | 0 16384 |@@@@@@@@@@@@@@@@@@@@ 1 32768 |@@@@@@@@@@@@@@@@@@@@ 1 65536 | 0 Xsun valor ------------- Distribuição ------------- count 8192 | 0 16384 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ 41 32768 |@@@@ 4 65536 | 0
2.10. DTrace toolkit
Não iremos só discutir uma visão geral do DTrace através da linguagem D. Para saber mais sobre o DTrace, acesse o manual em:
http://docs.sun.com/app/docs/doc/817-6223
Para tornar as coisas simples, um toolkit do DTrace pode ser baixado e instalado. O toolkit DTrace contém uma grande quantidade de scripts prontos, que monitoram diversos probes.
O toolkit DTrace pode ser baixado no endereço:
http://www.opensolaris.org/os/community/dtrace/dtracetoolkit/
Vejamos como instalar e executar a versão DTraceToolkit-0.99.tar.gz. Uma vez realizado o download do arquivo, execute os seguintes comandos:
gunzip DtraceToolkit-0.99.tar.gztar xvf DTraceToolkit-0.99.tarcd DTraceToolkit-0.99./install
DTraceToolkit será instalado por padrão no diretório /opt/DDT. Analisaremos a seguir o conteúdo deste diretório:
● apps/ - scripts específicos de aplicação
Sistema Operacional 12

JEDITM
● cpu / - scripts para análise de CPU
● disk/ - scripts para análise de I/O
● docs/ - documentação
● mem/ - scripts para análise de memória
● proc/ - scripts para análise de processos
Casa script possui uma página principal associada, embora não seja automaticamente instalado. Para acessar a página principal dos scripts, executamos o comando man com as seguintes opções:
# man -M <DTT Man directory> <command>
Por padrão, o diretório é /opt/DTT/Man. Por exemplo, para solicitar auxílio sobre o script runocc.d, que verifica o pool de ocupação da CPU, executamos o seguinte comando:
# man -M /opt/DTT/Man runocc.d
Atualmente, está em desenvolvimento o monitoramento para programas Java, bem como monitoramento para JavaScript e aplicações WEB. Quando estiverem prontos, poderão ser usado para rastrear programas Java sem ter de modificar o código fonte.
Sistema Operacional 13

JEDITM
3. Informações da CPU
3.1. Comando vmstat
O comando vmstat lista informações sobre o comportamento global da CPU desde a sua inicialização. Executando este comando, podemos produzir a seguinte saída:
# vmstatkthr memory page disk faults cpur b w swap free re mf pi po fr de sr f0 s0 s2 s6 in sy cs us sy id0 0 0 2678760 1842984 0 1 0 0 0 0 0 0 0 0 0 508 30 46 0 1 99
Veremos com mais detalhes estes campos:
● kthr – número de threads nos seguintes estados:
○ r – número de threads no núcleo executando queue
○ b – número de threads bloqueadas esperando, por exemplo, I/O, recursos do sistema, entre outros
○ w – número de pares de troca LWP que estão esperando para finalizar o processo de um recurso
● memory – memória utilizada em kilobytes
○ swap – espaço em área de troca
○ free – memória livre
● page – informação sobre como a memória está sendo utilizada
● disk – informação sobre as operações em disco por segundo
● faults – informação sobre os traps do sistema
● cpu – percentual de uso da CPU
○ us – utilizada pelo usuário
○ sy – tempo do sistema
○ id – tempo livre
Também é possível executar o vmstat com a informação do intervalo de saída, que executa o comando após cada intervalo específico, para obter uma visão global dos processos que estão em execução.
# vmstat 5kthr memory page disk faults cpur b w swap free re mf pi po fr de sr f0 s0 s2 s6 in sy cs us sy id0 0 0 2678752 1842968 0 1 0 0 0 0 0 0 0 0 0 508 30 46 0 1 990 0 0 2657392 1820800 0 5 0 0 0 0 0 0 0 0 0 503 50 49 0 1 990 0 0 2657392 1820800 0 0 0 0 0 0 0 0 0 0 0 502 34 44 0 1 990 0 0 2657392 1820800 0 0 0 0 0 0 0 0 0 0 0 504 44 50 0 1 990 0 0 2657392 1820800 0 0 0 0 0 0 0 0 0 0 0 508 70 67 0 1 990 0 0 2657384 1819848 2 24 234 0 0 0 0 0 0 33 0 609 663 153 0 2 980 0 0 2656272 1815528 3 27 2557 0 0 0 0 0 0 328 0 1471 4262 722 1 6 930 0 0 2649720 1791392 0 0 3103 0 0 0 0 0 0 438 0 1896 4418 890 1 7 920 0 0 2644960 1771032 0 0 3289 0 0 0 0 0 0 459 0 1880 4639 960 1 7 920 0 0 2639400 1750232 3 0 2773 0 0 0 0 0 0 395 0 1671 6227 844 1 10 89
Podemos computar o uso da CPU utilizada, subtraindo o tempo livre (cpu id) de 100.
3.2. uptime
Para descobrir há quanto tempo seu computador está ativo, bem como a média de carga na CPU, executamos simplesmente o comando uptime:
Sistema Operacional 14

JEDITM
# uptime10:50am up 3 day(s), 5 min(s), 2 users, load average: 0.11, 0.04, 0.02
Note a coluna que contém a média de carga (load average): está em 1, 5 e 15 minutos de média para carregar na CPU. Estes números são um reflexo de como muitos processos são executados no computador. Por exemplo, 1.00 é 100% de utilização de CPU em um único processador, mas seria a metade em um computador com dois processadores. Se for obtido mais do que o processador consegue executar, significa que está ocorrendo uma saturação de CPU.
3.3. Scripts no DTrace – Parte 3
No diretório /opt/DTT/cpu, podemos executar um script em DTrace para recuperar as informações sobre a CPU dos computadores:
● cputypes.d – lista a informação sobre cada CPU
● loads.d – mostra a média de carga
● intbycpu.d – mostra o número de interrupções manipuladas por cada CPU
● runocc.d – mostra as execuções que estão em uma queue
3.4. Script shellsnoop
A aplicação shellsnoop usa o DTrace para mostrar o que está sendo exibido em outros terminais. A saída a seguir mostra um usuário alterando sua senha:
# ./shellsnoop PID PPID CMD DIR TEXT 1412 1411 bash W # 1412 1411 bash R p 1412 1411 bash W p 1412 1411 bash R a 1412 1411 bash W a 1412 1411 bash R s 1412 1411 bash W s 1412 1411 bash R s 1412 1411 bash W s 1412 1411 bash R w 1412 1411 bash W w 1412 1411 bash R d 1412 1411 bash W d 1412 1411 bash R 1412 1411 bash W 1734 1412 passwd W passwd 1734 1412 passwd W : Changing password for 1734 1412 passwd W mario 1734 1412 passwd W 1734 1412 passwd W New Password: 1734 1412 passwd W 1734 1412 passwd W Re-enter new Password: 1734 1412 passwd W 1734 1412 passwd W passwd: password successfully changed for mario 1734 1412 passwd W 1412 1411 bash W #
A senha não é exibida, shellsnoop mostra unicamente o que aparece na tela do terminal.
Sistema Operacional 15

JEDITM
4. Processos
4.1. Comando ps
O comando ps é um comando padrão para listar informações dos processos.
# ps -ef UID PID PPID C STIME TTY TIME CMD root 0 0 0 Dec 10 ? 0:12 sched root 1 0 0 Dec 10 ? 0:01 /sbin/init root 2 0 0 Dec 10 ? 0:00 pageout root 3 0 1 Dec 10 ? 6:29 fsflush root 1412 1411 0 08:14:12 pts/3 0:01 bash root 7 1 0 Dec 10 ? 0:09 /lib/svc/bin/svc.startd root 9 1 0 Dec 10 ? 0:24 /lib/svc/bin/svc.configd root 95 1 0 Dec 10 ? 0:00 /usr/lib/snmp/snmpdx -y -c /etc/snmpdaemon 220 1 0 Dec 10 ? 0:00 /usr/sbin/rpcbind root 214 1 0 Dec 10 ? 0:00 /usr/sbin/cron ...
A opção -e mostra todos os processos, e a opção -f lista os processos que contém as colunas completas.
● UID – identificação do usuário do processo
● PID – identificação do processo
● PPD – identificação do processo pai
● C – coluna obsoleta. Corresponde à utilização do processo agendado
● STIME – tempo de inicialização de um processo
● TTY – terminal de controle (? se não for controlado por um terminal)
● TIME – tempo que um processo está executando na CPU
● CMD – comando usado para inicializar o processo
4.2. Scripts no DTrace – Parte 4
Os scripts de processo são encontrados no diretório /opt/DTT/proc. Vejamos a seguir alguns dos mais usados para monitorar os processos:
● sampleproc – um arquivo executável que usa DTrace para a inspeção em muitas CPUs na qual a aplicação é executada
● writebytes.d e readbytes.d – como os bytes são lidos e escritos pelo processo
● syscallbyproc.d e syscallbypid.d – sistema de chamadas por processo ou por identificação do processo
● filebyproc.d – lista de arquivos abertos por um processo
● crash.d – relatório sobre aplicações que falharam
Sistema Operacional 16

JEDITM
5. Memória
5.1. pmap -x
O comando pmap associado à opção -x mostra uma visão da memória com a identificação do processo. O exemplo a seguir mostra um mapa de um processo na memória com ID 1412. Para explorar o endereço de memória de um processo em particular, temos que usar o comando ps para procurar o próprio ID do processo.
# pmap -x 14121412: bash Address Kbytes RSS Anon Locked Mode Mapped File00010000 648 624 - - r-x-- bash000C0000 80 48 16 - rwx-- bash000D4000 168 168 64 - rwx-- [ heap ]FF100000 864 856 - - r-x-- libc.so.1...
5.2. Scripts no DTrace – Parte 5
Os scripts de memória são encontrados no diretório /opt/DTT/mem. A seguir são mostrados alguns scripts mais comumente utilizados para analisar a memória:
● vmstat.d – utilizado para escrever em D
● xvmstat – um arquivo executável (./xvmstat) que usa DTrace para mostrar mais informações em relação ao vmstat, tais como memória RAM livre, memória virtual livre entre outros
● swapinfo.d – mostra informações da memória virtual
● minfbypid.d – detecta um grande consumidor de memória
Sistema Operacional 17

JEDITM
6. Disco Rígido
6.1. Scripts no DTrace – Parte 6
Scripts para controle do disco rígido são localizados em /opt/DTT/disk. A seguir, são mostrados alguns scripts mais utilizados para analisar o disco rígido:
● iofile.d – mostra o tempo de espera para entrada e saída● diskhits – uma queue sendo executada, através de um filename, verifica a entrada e
saída e a média de carga de um arquivo● iotop – um arquivo executável que lista os eventos de entrada e saída do disco por
processo● iosnoop – um arquivo executável que monitora eventos de entrada e saída para um
determinado userid, processid ou filename
A seguir um exemplo de saída de um iosnoop mostrando os arquivos editados por um determinado comando:
# ./iosnoop UID PID D BLOCK SIZE COMM PATHNAME 0 3 W 28720 2560 fsflush <none> 0 1726 R 71712 8192 vi /export/home/alice/temp.txt 0 1726 R 12227792 8192 vi /export/home/alice/temp.txt 0 1726 R 11606832 8192 vi <none> 0 1726 R 12227936 8192 vi /export/home/alice/temp.txt 0 1726 W 1081232 8192 vi /var/tmp/ExtBaWxd 0 1726 W 1372256 90112 vi /var/tmp/ExtBaWxd 0 1726 W 11627936 958464 vi /var/tmp/ExtBaWxd 0 1726 R 12228880 8192 vi /export/home/alice/temp.txt 0 1726 R 12229184 8192 vi /export/home/alice/temp.txt
6.2. Chime
Chime é uma interface gráfica para visualizar DTrace.
Figura 1: Janelas do Chime
O pacote, bem as instruções para instalação podem ser encontrados no site da comunidade Open Solaris. No endereço: http://www.opensolaris.org/os/project/dtrace-chime/.
Sistema Operacional 18

Módulo 8Sistema Operacional
Lição 7ZFS
Versão 1.0 - Mar/2008

JEDITM
1. Objetivos
ZFS foi desenvolvido pela equipe de Jeff Bonwick como um novo sistema de arquivo para o Solaris. Seu desenvolvimento foi anunciado em setembro de 2004, foi incluído como parte da distribuição oficial do OpenSolaris em novembro de 2005 e distribuído com a atualização 6/06 do Solaris 10 em junho de 2006.
ZFS promete para ser a “última palavra em sistemas de arquivos”. Desenvolvedores de ZFS o descrevem na página WEB da comunidade Solaris como “um novo tipo de sistema de arquivo que provê uma administração simples, semântica transacional, integridade de dados end-to-end e melhor escalabilidade”1.
Discutiremos nesta lição estas características do ZFS e mostraremos suas melhorias sobre o sistema de arquivo atualmente em uso.
Ao final desta lição, o estudante será capaz de:
• Compreender o conceito de sistema de arquivos
• Utilizar o aplicativo ZFS
• Realizar agrupamento, espelhamento, fotografias e clones no disco de sistema Solaris
1 http://www.opensolaris.org/os/community/zfs/ publicado em 21 de agosto de 2007.
Sistema Operacional 4

JEDITM
2. Capacidade
A capacidade de um sistema de arquivo pode ser descrita pelo número de bits em uso pelo sistema que é utilizado para armazenar informações sobre de arquivos. Atualmente os sistemas de arquivo são de 64 bits. Isso significando que são usados 64 bits de dados para armazenar a informação de cada arquivo, como local para o dispositivo, permissões de arquivo, conteúdos de diretório, entre outros. Sendo que um sistema de arquivo de 64 bits denota um arquivo de tamanho máximo teórico de sistema com 264 bytes, temos aproximadamente 1011 Gb ou 1 bilhão de discos rígidos (de 100 Gb cada).
Este é um tamanho máximo teórico. A seguir temos as limitações de sistema de arquivos para cada sistema conhecido.
Sistema de Arquivo Sistema Operacional CapacidadeFAT16 DOS-Win3.11 2 GbFAT32 Win95-WinME 8 Tb (ou 8000 Gb)ext3 Linux 32 Tb (32000Gb)NTFS WinXP-Vista 2 Tb (2000 Gb)
Figura 1: Capacidade teórica dos sistemas de arquivos
Isto pode parecer bastante grande, entretanto atualmente existem algumas companhias que possuem dados na escala de petabyte, aproximadamente 106 no valor de GB de espaço armazenado. Se a tendência na Lei de Moore continuar, então, na metade da próxima década podemos ver que o limite de 64 bits será suplantado1. Realmente o armazenamento mundial já excedeu os 161 exabytes (1018 bytes) e alcançará 988 exabytes antes de 20102. Nosso armazenamento mundial já foi além dos 1011 Gb do limite teórico de sistemas de 64 bits, ou seja, um bilhão de vezes acima.
ZFS é o primeiro sistema de arquivos de 128 bits. Sendo que um sistema de arquivos de 128 bits que pode armazenar teoricamente 2128 bytes. Isto corresponde a 1024 Gb, ou seja, um trilhão de trilhão de gigabytes ou 10.000 vezes maior do que o tamanho total de armazenamento mundial. Os desenvolvedores usam limites físicos de computação para armazenar 128-bits completos em um sistema de arquivo, um usuário iria necessitar de um dispositivo de armazenamento com uma massa mínima de 136 bilhões quilogramas, e isso seria energia mais do que suficiente para ferver os oceanos.
1 http://blogs.sun.com/bonwick/entry/128_bit_storage_are_you de 22 de agosto de 2007.
2 Cooporação EMC. The Expanding Digital Universe: A Forecast of Worldwide Information Growth Through 2010
Sistema Operacional 5

JEDITM
3. Armazenamento Agrupado
3.1. O novo problema do disco rígido
Suponhamos a situação de um computador com um longo tempo de vida, este está conectado à internet, provavelmente, ocorreria o problema de falta de espaço em disco. Considerando a compra de um novo disco rígido, podemos adotar duas estratégias:
Como uma primeira estratégia configuramos o novo dispositivo como um disco rígido secundário, (como um novo drive para o sistema operacional Windows ou montado como um novo diretório em sistemas do tipo Unix, tais como Linux e Solaris). Poderíamos colocar grandes arquivos ou aplicações neste disco rígido novo. E, se este for o caso, então os usuários de computador devem lembrar do drive para guardar os arquivos. As aplicações começariam a manipular diferentes diretórios e seu filesystem ficaria completamente desorganizado.
Para evitarmos esse problema descrito, a segunda estratégia consistiria em copiar o conteúdo do antigo disco rígido para o novo (ou, pelo menos, os documentos do usuário). Porém, deste modo teríamos alguns problemas. Se o usuário ou uma aplicação não puder localizar um determinado arquivo porque foi movido para outro diretório (nenhum problema para computadores com Linux ou Solaris). Entretanto, e se alguns arquivos fossem deixados para trás?
No fim, acrescentar um novo disco rígido no seu computador causa uma grande quantidade de dores de cabeça devido a uma nova reorganização.
3.2. A resposta através de ZFS: Armazenamento agrupado
Em outros sistemas de arquivo existe um único dispositivo, e meios de dispositivos múltiplos que possuem um Gerenciador de Volume. Gerenciadores de volume mostram os dispositivos diferentes como "drives" em sistemas Windows. Em sistemas Linux, o diretório raiz atravessa todos os dispositivos, e estes dispositivos (ou diretórios nesses dispositivos) podem ser montados como diretórios no diretório de raiz.
Por outro lado, ZFS usa um sistema de armazenamento agrupado. Durante a organização de um agrupamento de ZFS, é possível nomear um, dois ou mais dispositivos a este. Toda a capacidade de todos os dispositivos é acessível pelo agrupamento.
Este agrupamento permite que seja montado como um diretório no filesystem regular do Solaris. Do ponto de vista do usuário, estará economizando um diretório no sistema de Solaris. Porém, internamente, podem ser economizados dados em um dispositivo e podem ser estendidos ao próximo dispositivo se houver espaço faltando. Isto pode ser refletido até mesmo para outro disco ou ser distribuído para vários discos rígidos obtendo uma maior redundância. O usuário deve apenas se preocupar onde e como o dados são armazenados.
Para colocar isto de forma simples, “ZFS faz com o armazenamento o que a memória virtual fez com a RAM”1. Como visto em lições anteriores, a memória virtual pode ser resumida em: detalhes de aplicações e como elas são armazenadas. Uma aplicação não sabe onde está em memória, se foi alocada em memória contínua ou não. De fato, está na memória, entretanto pode estar temporariamente armazenada no disco rígido. Ocorre o mesmo com arquivos ZFS. O usuário não necessita se preocupar como o arquivo é armazenado de fato, a menos que este diretório possa ser acessado.
Adicionar um novo dispositivo ao ZFS significa que estamos adicionando no agrupamento do armazenamento. O computador irá automaticamente pegar esta nova capacidade disponível e usá-lo sem a necessidade de transferir ou reorganizar o filesystem. É possível ter no máximo 264 dispositivos em um único agrupamento.
1 Jeff Bonwick. ZFS: The Last Word in File Systems. Sun Microsystems
Sistema Operacional 6
JEDITM
4. Integridade de Dados
Armazenamento secundário está longe de ser um meio seguro de manter seus dados intactos. Problemas podem ocorrer e destruir a informação a qualquer momento.
A perda de bits acontece quando se desgasta o meio magnético, seu disco rígido começa a falhar devido a este desgaste. Pode ocorrer o que denominamos de fantasma. Um fantasma pode escrever e o disco rígido reivindicar a escrita com dados que de fato não existem. Resultado que pode acidentalmente tentar ler ou escrever dados em uma porção errada do disco. Isto acaba tornando áreas completas do disco ilegíveis.
ZFS tem diversas características que mantêm a integridade dos dados.
4.1. Checksums end-to-end1
Sistema de arquivo armazenam informação em blocos. Sistemas de arquivo tradicionais acrescentam blocos em checksums aos arquivos e estes blocos podem prover correções de erro. Isto é, podem descobrir trechos com problemas de fantasmas, como o que acontece quando os dados e o checksum não são compatíveis.
Figura 2: Dados não emparelhados com o checksum
Porém, o que acorre quando são colocados os dados corretos com o checksum correto na porção errada do disco rígido? Na realidade, este sistema pode descobrir um único pedaço com problema de fantasmas e nada mais.
Figura 3: Pedaço errado do sistema de arquivos
ZFS vai um passo adiante e coloca um checksum em cada nível do bloco.
Inserindo checksums em todo o caminho até o bloco pai não só asseguramos que cada dado é bloqueado de forma consistente, mas também mantemos um agrupamento inteiro de forma
1 Summation Check - verificação do numérica dos bits que estão sendo transferidos para descobrir erros na transferência
Sistema Operacional 7

JEDITM
consistente. Qualquer operação que resulte em qualquer lugar em um checksum errado ao longo dos meios da árvore indica que o agrupamento inteiro está de alguma forma incompatível e necessita de correção.
Figura 4: Agrupamento inválido
E ainda, ZFS separa os dados do checksum. Em sistemas de arquivo tradicionais, onde os dados e o checksum são armazenados no mesmo bloco, existe uma chance de um erro se o disco rígido modificar tanto os dados quanto o checksum de forma que o sistema não pode mais determinar se ocorreu algum erro. Fisicamente separados, dados e checksum, erros no disco rígido irão afetar somente os dados ou o checksum, sendo fácil de serem detectados.
4.2. Limpeza do disco
Para assegurar que os dados continuem consistentes, ZFS faz uma verificação continua de todos os blocos de dados em um processo conhecido como “Limpeza do Disco” (disk scrubbing). ZFS percorre o disco inteiro verificando se os dados combinam com os respectivos checksums. Em caso de erros, ZFS está apto a corrigir a informação automaticamente, derivando a partir do checksum, ou através de um espelho.
4.3. Transações de escrita e leitura na entrada e saída
Já aconteceu que ao salvar um documento (normalmente muito importante) ocorre uma falha de energia? Para nosso horror, descobrimos que o arquivo do documento foi corrompido e devemos refazê-lo do zero.
O arquivo foi corrompido porque o arquivo foi deixado em um estado inconsistente. O arquivo consiste de diversos blocos de dados de uma nova versão assim como os dados da antiga versão, os quais deveriam ser sobrescritos se não ocorresse a falha de energia.
Alguns sistemas tradicionais de arquivo fazem uso de um sistema de notícias (journal). Todas as operações de entrada e saída são escritas primeiramente neste sistema de publicação antes de serem executadas. Isso garante que em caso de falha de energia ou outro erro, o sistema simplesmente continue suas operações escrevendo no arquivo de publicação antes que se torne inconsistente novamente. As operações devem ser atômicas. Ou todas são executadas com sucesso, ou são novamente executadas a partir do arquivo de publicação em caso de estar
Sistema Operacional 8

JEDITM
corrompido, ou não são executadas.
Fazer uso do sistema de publicação, entretanto, diminui a velocidade da execução de entrada e saída devido ao passo extra de se tomar nota de todas as instruções que serão executadas. Após um longo período de tempo, o arquivo de publicação ocupará um espaço significante no disco rígido.
ZFS dá um passo extra para implementar este tipo de transação. Nenhum dado está de fato sendo sobrescrito pelo ZFS, quaisquer modificações do sistema toma o lugar de uma cópia dos dados. Qualquer falha de sistema irá afetar somente a cópia dos dados. No caso de uma falha, o sistema recupera os blocos de dados originais antes de executar as operações. Apenas quando as modificações atingem o bloco raiz é que ocorre a gravação e conclusão das modificações no sistema. Ou todas as instruções de entrada e saída agrupadas são executadas ou a transação não acontece.
Figura 5: Novos dados chegam e os antigos não são alterados
Figura 6: Modificações são realmente gravadas
Sistema Operacional 9

JEDITM
Figura 7: Em caso de falha permanece os dados consistentes
4.4. Fotografias de tempo linear
Como efeito colateral dos sistemas de escrita e leitura, fotografias de sistema de arquivo são automaticamente realizadas depois de qualquer operação do sistema. Fotografias são uma cópia do sistema em algum momento no passado as quais podem ser usadas para propósitos de backup. Cada operação em ZFS automaticamente cria uma fotografia do antigo sistema. De fato é mais rápido criar uma fotografia do que ter aquele passo extra de substituir os dados antigos.
Sistema Operacional 10

JEDITM
5. Espelhamento e RAID-Z
5.1. Espelhamento
ZFS possibilita, sem muito esforço, configurar um sistema de arquivo espelhado. Um sistema de arquivo espelhado usa um segundo disco rígido para replicar completamente os dados de um outro disco rígido. Espelhos são freqüentemente usados se o primeiro disco rígido falhar, o sistema continua operando com dados contidos no segundo disco rígido. Além disso, espelhos tornam a leitura duas vezes mais rápida, os dados podem ser retornados do segundo disco rígido enquanto o primeiro estiver ocupado.
Implementações de espelhamento tradicionais não diferenciam blocos ruins. Mesmo que uma cópia backup exista no espelho, isso não possibilita dizer se um bloco foi, de algum modo, corrompido. Ao fazer o checksum de todos os blocos, o ZFS determina silenciosamente se um bloco foi corrompido. Se isso ocorre, o ZFS recupera automaticamente o bloco correto do segundo disco e repara o bloco ruim do primeiro disco. Isso é feito de modo transparente, sem informar ao usuário qualquer problema.
5.2. RAID-Z
RAID é uma sigla para Redundant Array of Inexpensive Disks (Conjunto Redundante de Discos Baratos). Configurar um sistema RAID significa adicionar novos discos rígidos, seguindo um esquema particular (chamado nível RAID) de como a informação será armazenada nestes discos.
Há 5 níveis tradicionais de RAID:
● RAID 0 – os dados são simplesmente colocados em trilhas de múltiplos discos. Uma trilha consiste de vários blocos agrupados de dados. Fornece a vantagem de melhor performance, pois as leituras podem ser feitas em paralelo. No entanto, não provê nenhum tipo de segurança ao dado, uma falha no disco resulta em falha de todos os dados.
● RAID 1 – os dados são espelhados ou completamente duplicados em um segundo disco, ou múltiplos. Leituras podem também ser feitas em paralelo, assim como prover segurança aos dados já que se um disco falhar os dados podem ainda ser lidos de um segundo disco. Entretanto, esse nível de RAID é caro, necessitamos ter o dobro da quantidade de disco rígido para armazenar os dados.
● RAID 2 – os dados são escritos um bit por vez em cada disco, com um disco dedicado especialmente para armazenar a informação de paridade para a recuperação desses dados. Esse nível não é usado já que é inviável armazenar bit a bit.
● RAID 3 – assim como o RAID 2, divide os dados entre discos com uma paridade de disco especial. Entretanto, os dados dessa vez são divididos em trilhas.
● RAID 4 – divide os dados em blocos de dados do sistema de arquivo ao invés de colocar os blocos em trilhas de múltiplos discos. Um disco de paridade dedicado contém informação que pode ser usada para detectar e corrigir erros de dados nos discos.
O problema com o RAID 4 é que qualquer escrita feita em um bloco de dados significa ter que novamente computar a paridade. Isso significa que qualquer escrita irá envolver o processo de duas escritas, a escrita dos dados e a da uma nova paridade no bloco. Isso causa um gargalo na paridade de disco. Um novo tipo denominado de RAID 5 distribui a paridade de disco e permite um tempo mais rápido de escrita.
O problema com RAID 4 e 5 é que sempre que qualquer bloco de dados for escrito, outros blocos na mesma trilha devem ser lidos para recalcular o bloco de paridade. E isso diminui a velocidade de escrita. Os dados podem se tornar corrompidos se uma falha de energia ocorrer enquanto o bloco de paridade estiver sendo computado. Como o novo bloco de paridade ainda não foi escrito corretamente, então os blocos de dados não batem com o bloco de paridade. Quando isso ocorre, RAID assume incorretamente que o dado está corrompido.
ZFS inclui o modelo RAID-Z. RAID-Z é uma implementação modificada do RAID 5. Este novo
Sistema Operacional 11

JEDITM
modelo configura cada bloco de dados do sistema de arquivo para ser sua própria trilha. Dessa forma, para se recalcular a paridade, é preciso ter que carregar somente um único bloco de dados, não é mais necessário ler qualquer outro bloco. E como as operações do sistema de arquivo são agora baseadas em transações, a questão de paridade é evitada, ou o bloco inteiro (incluindo a paridade) é escrito, ou ainda, não é escrito de forma alguma.
Striping dinâmico também é uma característica adicional de RAID-Z. Antigas implementações de RAID faziam que, uma vez fixado o número de discos rígidos, quando o sistema era organizado, sua faixa de tamanho também era. Quando um novo disco for adicionado, todos os novos dados são acertados para usar este novo disco. Não existe nenhuma necessidade de se migrar os antigos dados, com o passar do tempo estes dados migram para o novo formato de faixa. Esta migração é feita automaticamente.
Sistema Operacional 12

JEDITM
6. Administração ZFS
6.1. Convenção de nomes do disco
Antes de podermos discutir a administração do ZFS, devemos nos familiarizar primeiro com a notação de disco usada no sistema Solaris.
Todos os dispositivos em Solaris são representados como arquivos. Estes arquivos são armazenados no diretório /devices.
# ls /devicesiscsi pci@1f,2000:devctl pci@1f,4000:devctl pseudo:devctliscsi:devctl pci@1f,2000:intr pci@1f,4000:intr scsi_vhcioptions pci@1f,2000:reg pci@1f,4000:reg scsi_vhci:devctlpci@1f,2000 pci@1f,4000 pseudo
Estes são todos os dispositivos que estão conectados ao sistema, inclusive o teclado, monitor, dispositivos de USB e outros. Para diferenciar entre discos rígidos (inclusive drives de CD) e outros dispositivos, Solaris provê um diretório separado para os discos rígidos, denominado /dev/rdsk.
Ao listar o conteúdo deste diretório, veremos os seguintes arquivos com formatos do tipo: c#d#s# ou c#t#d#s# ou c#d#p#. Estes descrevem o endereço completo de um trecho do disco.
# ls /dev/dsk c0d0p0 c0d0s7 c1t0d0s4 c1t1d0s15 c1t2d0s12 c1t3d0s1 c1t4d0p3 c0d0p1 c0d0s8 c1t0d0s5 c1t1d0s2 c1t2d0s13 c1t3d0s10 c1t4d0p4 c0d0p2 c0d0s9 c1t0d0s6 c1t1d0s3 c1t2d0s14 c1t3d0s11 c1t4d0s0 c0d0p3 c1t0d0p0 c1t0d0s7 c1t1d0s4 c1t2d0s15 c1t3d0s12 c1t4d0s1 c0d0p4 c1t0d0p1 c1t0d0s8 c1t1d0s5 c1t2d0s2 c1t3d0s13 c1t4d0s10 c0d0s0 c1t0d0p2 c1t0d0s9 c1t1d0s6 c1t2d0s3 c1t3d0s14 c1t4d0s11 c0d0s1 c1t0d0p3 c1t1d0p0 c1t1d0s7 c1t2d0s4 c1t3d0s15 c1t4d0s12 c0d0s10 c1t0d0p4 c1t1d0p1 c1t1d0s8 c1t2d0s5 c1t3d0s2 c1t4d0s13 c0d0s11 c1t0d0s0 c1t1d0p2 c1t1d0s9 c1t2d0s6 c1t3d0s3 c1t4d0s14 c0d0s12 c1t0d0s1 c1t1d0p3 c1t2d0p0 c1t2d0s7 c1t3d0s4 c1t4d0s15 c0d0s13 c1t0d0s10 c1t1d0p4 c1t2d0p1 c1t2d0s8 c1t3d0s5 c1t4d0s2 c0d0s14 c1t0d0s11 c1t1d0s0 c1t2d0p2 c1t2d0s9 c1t3d0s6 c1t4d0s3 c0d0s15 c1t0d0s12 c1t1d0s1 c1t2d0p3 c1t3d0p0 c1t3d0s7 c1t4d0s4 c0d0s2 c1t0d0s13 c1t1d0s10 c1t2d0p4 c1t3d0p1 c1t3d0s8 c1t4d0s5 c0d0s3 c1t0d0s14 c1t1d0s11 c1t2d0s0 c1t3d0p2 c1t3d0s9 c1t4d0s6 c0d0s4 c1t0d0s15 c1t1d0s12 c1t2d0s1 c1t3d0p3 c1t4d0p0 c1t4d0s7 c0d0s5 c1t0d0s2 c1t1d0s13 c1t2d0s10 c1t3d0p4 c1t4d0p1 c1t4d0s8 c0d0s6 c1t0d0s3 c1t1d0s14 c1t2d0s11 c1t3d0s0 c1t4d0p2 c1t4d0s9
● c# - representa o número de controlador. Eles são numerados c0, c1, c2 e assim sucessivamente. E conectam discos rígidos a um controlador.
● d# - representa número de discos para aquele controlador.
● s# - representa número de trechos. Estes números podem ir de 0 a 15.
● p# - representa número da partição, algumas vezes é usado ao invés do número de trechos. Números de partição podem ir de 0 a 4.
A seção de inicialização mostra normalmente quatro dispositivos. Estes dispositivos são: master primário, slave primário, master secundário e slave secundário. Seu disco rígido primário é freqüentemente o dispositivo de master primário. Um drive de CD ou DVD é colocado freqüentemente como o dispositivo slave primário. Ao possuir discos rígidos adicionais, estes normalmente são o master e o slave secundário.
Para Solaris, esta poderia ser uma anotação para estes discos:
● mestre primário: c0d0s0 (controlador 0, disco 0, parte 0) ● escravo primário: c0d1s0 (controlador 0, disco 1, parte 0) ● mestre secundário: c1d0s0 (controlador 1, disco 0, parte 0) ● escravo secundário: c1d1s0 (controlador 1, disco 1, parte 0)
Sistema Operacional 13

JEDITM
Alguns computadores podem ter uma interface SCSI. SCSI permite até 16 dispositivos conectados a um único controlador. Freqüentemente, os controladores SCSI começam com o número 2, já que 0 e 1 são, respectivamente, os controladores primários e secundários.
Computadores SCSI usam o valor t# para indicar um disco. Este pode variar de 0 a 15. Endereços SCSI também podem usar a notação d#, mas sempre é fixo para zero (d0). por exemplo, o arquivos de c2t2d0s0 até c2t2d0s15 representam todas as partes do dispositivo nomeados para o t2 no controlador 2.
6.2. Administração do agrupamento
Agrupamentos são mantidos pelo comando zpool. Comandos de zpool permitem criação, exclusão e adição de novos dispositivos, inscrição e modificação de agrupamentos.
Para criar um agrupamento básico em ZFS, executamos o comando zpool. A sintaxe básica é:
# zpool create <poolname> <vdev> <dispositivos>
Poolname é o nome do agrupamento a criar. O parâmetro vdev descreve que característica de armazenamento deve usar o agrupamento. Dispositivos indicam que discos rígidos devem ser usados no agrupamento. É possível criar agrupamento de pedaços de disco (ou até mesmo arquivos) entretanto, isso é feito normalmente com discos inteiros.
Observe que é possível utilizar parte de um disco para formatá-lo como agrupamento do disco. Por exemplo, o seguinte comando cria um zpool básico nomeado como myfirstpool1 que usa o disco master secundário.
# zpool create myfirstpool1 disk c1d0
Para criar um agrupamento espelho, simplesmente substituímos a palavra-chave disk por mirror. Devemos prover mais que um disco para criar um espelho.
# zpool create mymirroedpool mirror c1d0 c1d1
Uma coleção de discos pode ser organizada em uma configuração do tipo RAID-Z inserindo o valor raidz no parâmetro <vdev>. O número indicado de discos para RAID-Z está entre 3 a 9.
# zpool create myraidzpool raidz c0d1 c1d0 c1d1
ZFS permite criar agrupamentos de arquivos regulares. Em vez de especificar um disco, pode-se especificar um arquivo regular. Por exemplo:
# zpool create mypool1 file /export/home/alice/mypoolfile# zpool create mypool2 mirror /export/home/alice/p1 /export/home/alice/p2
Esta característica permite testar as características do ZFS sem precisar ter discos adicionais. Usaremos isto em futuros exercícios. Para acrescentar um dispositivo a um agrupamento:
# zpool add myfirstpool disk c1d0
Pode-se acrescentar um espelho ou um dispositivo adicional de RAID-Z a um agrupamento existente simplesmente substituindo o disco por um espelho ou raidz. O comando a seguir lista todos os agrupamentos ZFS disponíveis e as informações de uso espacial e ßstatus:
# zpool list
Um agrupamento pode ter 3 valores de estado: online, degraded ou faulted. Um zpool online tem todos seus dispositivos em bom estado de funcionamento. Um agrupamento degraded tem um dispositivo falho que ainda pode ser recuperado por redundância. Um dispositivo faulted significa que falhou e seus dados não podem mais ser recuperados.
Exportar um agrupamento significa por os dispositivos em uma área de transferência. Para exportar um agrupamento, executamos o comando:
# zpool export mypool
Sistema Operacional 14

JEDITM
E devemos importar os dispositivos a um novo computador, através do comando:
# zpool import mypool
E finalmente, para eliminar um agrupamento, executamos o comando:
# zpool destroy mypool
Isto elimina um agrupamento e faz com que os dispositivos que faziam parte deste fiquem disponíveis para outros usos.
6.3. Uso Básico de Agrupamento em ZFS
Uma vez que criamos um agrupamento, podemos montá-lo para fazer parte permanente do sistema de arquivos do Solaris. Os usuários economizariam a montagem do diretório a partir do momento que não precisam conhecer que este diretório está usando o ZFS. Também é desnecessário saber que os diretórios são espelhados ou armazenados usando RAID-Z.
Para montar um agrupamento como parte do sistema de arquivos do Solaris, usamos o comando:
# zfs set mountpoint=/target/directory/in/regular/filesystem poolname
Por exemplo, montaremos um agrupamento mypool para guardar o diretórios dos usuários.
# zfs set mountpoint=/export/home mypool
Podemos criar diretórios adicionais em mypool. Por exemplo, criamos diretórios para user1 e user2:
# zfs create mypool/user1# zfs create mypool/user2
Como já montamos mypool para /export/home, user1 está automaticamente montado como /export/home/user1 e user2 como /export/home/user2.
Há outras opções adicionais, tais como, compressão, cotas de disco e garantias espaciais de disco que podem ser ativadas com os seguintes comandos.
# zfs set compression=on mypool# zfs set quota=5g mypool/user1# zfs set reservation=10g mypool/user2
6.4. Fotografias e Clones
Como foi discutido, ZFS permite a criação de fotografias (snapshots). Fotografias são cópias de leitura de um sistema de arquivo em um determinado ponto que pode ser usado para propósitos de backup.
Para criar uma fotografia, executamos o comando zfs snapshot. Indicamos o diretório ZFS que desejamos obter uma fotografia juntamente com um nome deste. Por exemplo, o seguinte comando cria uma fotografia do diretório de projetos de user1 e nomeado como ver3backup.
# zfs snapshot mypool/user1/projects@ver3backup
Devido ao modo como ZFS armazena dados, são criadas fotografias imediatamente e não demandam nenhum espaço adicional. Não existe nenhum processo adicional necessário, ZFS preserva os dados originais e os bloqueia sempre que são feitas mudanças no diretório informado.
Todas as fotografias são armazenadas dentro do diretório zfs/snapshot localizado na raiz de cada filesystem. Isto permite que os usuários possam conferir suas fotografias sem ter que ser um administrador do sistema. Por exemplo, a fotografia que criamos está armazenada em:
/export/home/user1/.zfs/snapshot/ver3backup
Na qual o user1 pode acessar sem ter que ser um administrador de sistema.
Além disso, podemos executar um rollback no diretório a partir de uma fotografia. Rollback quer
Sistema Operacional 15

JEDITM
dizer que podemos, a qualquer momento, desfazer todas as mudanças realizadas no diretório a partir da fotografia. Por exemplo, user1 pode cometer diversos erros na versão 4 do projeto, deste modo, haveria uma necessidade de retornar à versão 3. Para reverter a situação a uma fotografia denominada ver3backup, executamos o comando:
# zfs rollback -r mypool/user1/projects@ver3backup
Clones em ZFS são cópias de fotografias que podem ser escritas. Para se criar um clone, indicamos a fotografia e o diretório para a cópia.
# zfs clone mypool/user1/project@ver3backup mypool/user1/project/ver3copy
Existem ainda muitos comandos para o aplicativo ZFS. Podemos verificar como utilizá-los acessando o manual, através do comando:
# man zfs
Sistema Operacional 16

Módulo 8Sistema Operacional
Lição 8Regiões no Solaris
Versão 1.0 - Mar/2008

JEDITM
1. Objetivos
Uma região (zone) é um ambiente virtualizado no sistema operacional criado por uma única instância. Na essência, é criado um "computador dentro de um computador"; um sistema completamente virtual que existe sobre o sistema físico.
Nesta seção, discutiremos as regiões do Solaris. Começaremos com uma discussão sobre o que às regiões são e quais vantagens de sua utilização sobre um sistema provedor de serviços. Essa lição fornece uma visão geral ao mostrar quais comandos são necessários para criar uma região. Finalmente, terminaremos com uma discussão sobre algumas opções de regiões comumente utilizadas.
Ao final desta lição, o estudante será capaz de:
• Explicar o que são regiões no Solaris
• Criar uma região básica
• Estar familiarizado com alguns comandos avançados para a criação de regiões
Sistema Operacional 4

JEDITM
2. Introdução
2.1. Utilização típica para regiões
As regiões permitem múltiplas instâncias separadas do Solaris existindo independentemente uma da outra em um só computador, o que pode ser bem vantajoso em certas situações. Considere um escritório que necessite de um servidor WEB, de banco de dados, de desenvolvimento, de email e de arquivo. Essa companhia possui duas opções:
● Opção 1: Um computador por serviço. Uma companhia executando esta opção não teria escolha a não ser obter cinco computadores.
● Opção 2: Ter todos esses serviços em um só computador ou mais de um serviço por computador. Nessa opção, há margem para haver alguns problemas de configuração, particularmente se alguns desses serviços tiverem conflitos uns com os outros.
As regiões permitem uma terceira opção. Os serviços podem ser instalados cada um em sua própria instância do Solaris, sendo executados em um único computador físico. Isso combina o melhor dos dois mundos. Primeiramente, não há mais necessidade de comprar computadores múltiplos já que as regiões permitem computadores virtuais sendo executados em um só sistema autônomo. Em segundo lugar, como cada serviço existe em seu próprio sistema autônomo, não há mais necessidade de se preocupar com conflitos de configuração; um serviço pode ser instalado em uma região que está configurada precisamente com as necessidades desse serviço.
2.2. Vantagens
A utilização de regiões fornece as seguintes vantagens:
2.2.1. Segurança
Se um serviço de rede é feito para ser executado em uma região, invasores que pretendam utilizar as vulnerabilidades deste serviço para ganhar acesso ao sistema somente poderão acessar a região do serviço. Qualquer dano causado será limitado a essa região. Acessar outra região seria como invadir um segundo computador, apesar do fato de que essas regiões na verdade são executadas no mesmo computador físico.
Uma região pode ter usuários diferentes de outras regiões. O administrador do sistema global pode escolher dar acesso aos usuários apenas a serviços específicos e não a todo sistema.
A utilização de regiões permite um segundo nível de administração, o superusuário da região. Este usuário tem direitos de administrar apenas para uma região específica. Isso permite que o administrador do sistema global (o superusuário da região global principal) delegue tarefas administrativas da região de outros usuários enquanto mantém a habilidade de promover as grandes mudanças necessárias no sistema.
2.2.2. Isolamento
As regiões trabalham isoladamente, não estão cientes da existência de outras regiões. Desta forma, processos sendo executados em uma determinada região são incapazes de influenciar processos em outras regiões. A configuração de uma região é importante apenas para esta região e não afeta outras regiões. Uma aplicação sendo executada em uma região pode ter o benefício de ser executada em um ambiente criado especificamente para ela, por isso, não há mais necessidade de preocupações com detalhes de configurações.
2.2.3. Virtualização
A configuração do sistema global é irrelevante para uma região. As regiões podem ter suas próprias customizações de ambiente virtual. Este ambiente pode até mesmo ser copiado em diferentes máquinas, permitindo assim que uma região tenha o mesmo ambiente virtual mesmo em diferentes máquinas com diferentes configurações.
Sistema Operacional 5

JEDITM
2.2.4. Granularidade
Há muitas opções disponíveis para configurar o nível de isolamento de uma região. Uma região pode ter sua própria CPU, memória, espaço de disco rígido, ou ter estes recursos compartilhados entre diferentes regiões mesmo sem saber que nenhum compartilhamento está sendo feito.
2.2.5. Ambiente
Uma aplicação não precisa ser recompilada para ser executada em outra região. O Solaris fornece as mesmas bibliotecas e interfaces para todas as regiões. Existem apenas algumas restrições que não permitem programas executar grandes mudanças enquanto dentro de uma região.
Adicionalmente, uma aplicação não é afetada pela existência de outras regiões, e é praticamente inconsciente dessas outras regiões. As regiões são criadas para que uma aplicação possa ser executada em uma instalação autônoma do Solaris.
2.3. Os dois tipos de região
Existem dois tipos de região no Solaris. A região global e as regiões não-globais.
A região global é a instalação padrão que é utilizada pelo Solaris. Toda a administração do sistema é executada a partir desta região. Esta é a única região que está ciente de todas as outras regiões que estão sendo executadas no sistema. É a partir desta região que a administração de regiões é realizada.
As regiões não-globais são as regiões adicionais que são configuradas a partir da região global. Essas são as regiões que são executadas sobre a região global. As regiões não-globais não estão cientes de que são regiões ou da existência de outras regiões. Assim, a manutenção desta região não é possível a partir de uma região não-global.
O superusuário em uma região global pode ser considerado o superusuário global, habilitado a executar grandes mudanças no sistema, incluindo mudanças que afetam as outras regiões. O superusuário em uma região não-global só pode administrar aquela região.
2.4. Mapeamento de tarefas por região
Para configurar regiões para um computador, as seguintes tarefas precisam ser realizadas:
1. Identificar quais aplicações serão executadas na região.
2. Determinar quantas regiões serão configuradas (pode-se ter um máximo de 8.192 regiões. Quanto menos regiões, melhor para o sistema).
3. Determinar se uma região requer características de gerenciamento avançado de recursos.
4. Executar os passos de pré-configuração, tais como, determinar o endereço de IP da região, nome do servidor, usuários para esta região, entre outros.
5. Gravar a configuração da região utilizando o comando zonecfg.
6. Configurar e instalar a região.
7. Carregar a região utilizando o comando zoneadm.
8. Acessar a região utilizando zlogin e customizar cada uma de acordo com o planejamento inicial de configuração.
Sistema Operacional 6

JEDITM
3. Configurando uma região básica
Veremos agora como configurar uma região básica no Solaris. Mostraremos os comandos necessários para realizar esta tarefa e conheceremos mais informações sobre regiões enquanto a configuramos.
3.1. Iniciação do zonecfg
Para configurar uma região utilizarmos o comando zonecfg. Para executar este comando é necessário estar conectado como superusuário e executá-lo com as seguintes opções:
# zonecfg -z myfirstzone
A opção -z indica o nome da região que se deseja configurar; neste caso, myfirstzone. Após executar este comando, a tela exibirá o alerta do zonecfg do seguinte modo:
zonecfg:myfirstzone>
Indicando que o zonecfg está sendo executado e pronto para receber comandos. Configurar uma região quer dizer executar comandos zonecfg. Como o alerta indica, esses comandos serão utilizados para configurar myfirstzone.
Há dois modos do zonecfg:
1. Modo global – comandos zonecfg que são executados no modo global são comandos que configuram os atributos da região, tais como onde a região deve ser instalada ou se uma região deve ou não ser automaticamente carregada ao iniciar.
2. Modo recurso – significa que os próximos comandos são utilizados para descrever recursos na região, tais como os arquivos de sistema ou rede.
Configurar uma região implica alternar entre estes dois modos, executando comandos que indicam os atributos da região e comandos que descrevem seus recursos. Quando o zonecfg é iniciado, está automaticamente no modo global.
3.2. Configuração de região básica
A figura seguinte mostra os diferentes comandos necessários para configurar myfirstzone. A seguir discutiremos estes comandos de forma mais detalhada.
zonecfg:myfirstzone> createzonecfg:myfirstzone> set zonepath=/export/home/myfirstzonezonecfg:myfirstzone> set autoboot=truezonecfg:myfirstzone> add fszonecfg:myfirstzone:fs> set dir=/usr/localzonecfg:myfirstzone:fs> set special=/opt/localzonecfg:myfirstzone:fs> set type=lofszonecfg:myfirstzone:fs> endzonecfg:myfirstzone> add netzonecfg:myfirstzone:net> set address=192.168.0.1/24zonecfg:myfirstzone:net> set physical=hme0zonecfg:myfirstzone:net> endzonecfg:myfirstzone> add attrzonecfg:myfirstzone:attr> set type=stringzonecfg:myfirstzone:attr> set value="my first zone"zonecfg:myfirstzone:attr> endzonecfg:myfirstzone> verifyzonecfg:myfirstzone> commitzonecfg:myfirstzone> exit
3.3. Criação da configuração de uma região
Inicia-se a criação da configuração de um região com o comando create.
Sistema Operacional 7

JEDITM
zonecfg:myfirstzone> create
Caso seja informado o nome de uma região não existente no comando zonecfg, o sistema solicitará a execução do comando create.
3.4. Configuração da raiz de diretório da região
A raiz de diretório de uma região existe em um subdiretório do arquivo de sistema da região global. Podemos especificá-la através do comando zonepath:
zonecfg:myfirstzone> set zonepath=/export/home/myfirstzone
O comando informa ao zonecfg que a raiz do diretório myfirstzone estará localizada em /export/home/myfirstzone. Necessariamente este diretório deve existir.
3.5. Carregamento automático
O comando set autoboot especifica quando uma região será ou não iniciada automaticamente quando a região global for iniciada.
zonecfg:myfirstzone> set autoboot=true
Se esta opção não for enviada, então a região deverá ter uma inicialização manual usando o comando zoneadm.
3.6. Arquivo de sistema da região
Por padrão, certos diretórios da região global são herdados pelas regiões não-globais para fornecer um sistema de trabalho à região. O diretórios inherit-pkg-dir (/lib, /platform, /sbin e /usr) não são copiados para dentro da região. O que a região recebe é um endereço somente de leitura para esses diretórios na região global. Permite que a região economize espaço de arquivo. Fora isso, quaisquer mudanças na região global particularmente para estes diretórios também refletirão nos arquivos de sistema das regiões não-globais.
Para adicionar arquivos de sistemas, utilizamos o comando add fs:
zonecfg:myfirstzone> add fs
O comando add fs alterna do modo global para o modo de recurso. Como dito, o modo de recurso significa que comandos adicionais especificados são utilizados para descrever um recurso para a região. O alerta zonecfg também muda para mostrar que está sendo editado um recurso de arquivo de sistema.
zonecfg:myfirstzone> add fszonecfg:myfirstzone:fs>
3.7. Adicionar um sistema de arquivos
A seguir estão os comandos para definir um recurso de sistema de arquivos para myfirstzone:
zonecfg:myfirstzone> add fszonecfg:myfirstzone:fs> set dir=/usr/localzonecfg:myfirstzone:fs> set special=/opt/localzonecfg:myfirstzone:fs> set type=lofszonecfg:myfirstzone:fs> end
O comando especial set especifica qual diretório da região global deve ser adicionado. Este diretório é colocado na região de sistema de arquivos no diretório especificado pelo set dir. No nosso exemplo, /opt/local, situado na região global, é colocado em /usr/local em myfirstzone.
O comando set type indica qual o tipo de sistema de arquivos do diretório a ser montado. O tipo de sistema de arquivos explica como o núcleo lidará com este diretório. O sistema de arquivos virtual loopback (lofs) indica que o diretório montado é o mesmo diretório no sistema de arquivos
Sistema Operacional 8

JEDITM
global, entretanto, é acessado através de um caminho diferente. Isto é semelhante ao inherit-pkg-directories.
Devido a isso, todas as mudanças feitas no diretório global refletem também no diretório da região. Para o exemplo, se um arquivo for adicionado ao diretório /opt/local na região global seguido de /usr/local em myfirstzone este irá mudar também.
Observamos que o diretório /opt/local na região global deve ser um diretório existente.
Para terminar a configuração do sistema de arquivo, temos o comando:
zonecfg:myfirstzone:fs> endzonecfg:myfirstzone>
Isto muda a zonecfg de volta ao modo global como indicado pela mudança do prompt. Podemos agora adicionar novos sistemas de arquivos com comando add fs.
3.8. Adicionar uma rede
Uma região pode ter seu próprio endereço IP individual. Não há necessidade de interfaces de rede adicionais para cada novo endereço IP definido; a região global gerencia automaticamente o roteamento. Podemos usar o comando add net para definir este gerenciamento.
Vejamos a seqüência de instruções para configurar a rede myfirstzone.
zonecfg:myfirstzone> add netzonecfg:myfirstzone:net> set address=192.168.0.1/24zonecfg:myfirstzone:net> set physical=hme0zonecfg:myfirstzone:net> end
Nosso exemplo configura o endereço IP de myfirstzone para 192.168.0.1 com uma máscara de rede definida como /24 (255.255.255.0). Este endereço IP está vinculado a uma placa de rede hme0 (este resultado pode ser diferente nas diversas configurações).
3.9. Descrição da região
Um recurso para a especificação da região é o comando add attr, que podemos utilizar para acrescentar um comentário para a região.
zonecfg:myfirstzone> add attrzonecfg:myfirstzone:attr> set type=stringzonecfg:myfirstzone:attr> set value="my first zone"zonecfg:myfirstzone:attr> end
3.10. Finalizar a configuração
Podemos utilizar os seguintes comandos para finalizar a configuração.
zonecfg:myfirstzone> verifyzonecfg:myfirstzone> commitzonecfg:myfirstzone> exit
O comando verify verifica se a configuração da região foi digitada corretamente. Este comando permite visualizar erros. O comando commit salva a configuração da região. A região ainda não está instalada, apenas a configuração é armazenada. E o comando exit sai de zonecfg.
3.11. Eliminar atributos
Se errar a configuração de uma região, é possível utilizar o comando remove. Este comando possui duas maneiras que dependem da modalidade de zonecfg.
No modo global, remove <resource-type> especifica a eliminação de um determinado recurso. Por exemplo, o seguinte comando elimina o comentário:
zonecfg:myfirstzone> remove attr
Sistema Operacional 9

JEDITM
No modo de recurso, remove <property-name> <property-value> elimina um elemento daquela descrição dos recursos. Por exemplo, podemos eliminar um endereço IP com este comando. Para fazer isso precisamos estar no recurso net.
zonecfg:myfirstzone:net> remove address=192.168.0.1/24
Este é o mesmo formato do comando remove quando se deseja eliminar qualquer um dos atributos globais. O exemplo a seguir elimina o atributo autoboot:
zonecfg:myfirstzone> remove autoboot=true
Quaisquer alterações feitas à configuração devem ser atualizadas.
3.12. Comandos zonecfg adicionais
Para visualizar a configuração de uma região, pode-se utilizar o comando export.
O comando zonecfg inclui um auxílio para seus comandos internos, que podemos utilizar para pedir informações adicionais. Digitando simplemente help exibirá todos seus comandos. Digitando help <comando> exibirá todas as informações sobre um comando específico.
Sistema Operacional 10

JEDITM
4. Zoneadm
O comando zoneadm é usado para administrar as regiões. Este comando vem com sub-comandos que são utilizados para indicar o que fazer com uma região específica (por meio da opção -z). Discutiremos esses comandos com os quais continuaremos com a configuração básica da região.
4.1. Instalação e inicialização
Depois de uma região ter sido configurada corretamente, esta pode ser instalada através do comando:
# zoneadm -z myfirstzone install
O sistema irá instalar a myfirstzone. Na tela serão mostrados os pacotes que estão sendo copiados para a nova região. Após o término da instalação, podemos iniciar a região através do comando:
# zoneadm -z myfirstzone boot
Se não definirmos a propriedade da região para um autoboot, este deverá ser o comando que utilizaremos para iniciar a região.
4.2. Listagem de regiões
Para listar as regiões existentes podemos utilizar o sub-comando list:
#zoneadm list -vID NAME STATUS0 global running1 myfirstzone installed
O status pode assumir um dos seguintes valores para a região:
● configured – foi devidamente configurada com zonecfg, entretanto ainda não foi instalada
● incomplete – está no processo de instalação
● installed – foi instalada, entretanto ainda não está funcionando (não foi atribuída uma plataforma virtual à região)
● ready – foi atribuída a uma plataforma virtual e está pronta para aceitar processos de usuário
● running – está rodando com processos de usuário
● shutting down – está sendo encerrada
4.3. Comandos zoneadm adicionais
● zoneadm -z myfirstzone halt – interrompe a região (e a coloca em estado ready)
● zoneadm -z myfirstzone reboot – reinicializa a região
● zoneadm -z myfirstzone uninstall – remove a instalação da região
● zoneadm -z myfirstzone delete – remove a configuração da região
Sistema Operacional 11

JEDITM
5. Logging in
Nesta fase, a instalação de myfirstzone ainda não está concluída. Para concluirmos sua instalação, devemos acessar a região através do comando:
# zlogin -C myfirstzone
A opção -C é a forma para acessar uma região que não está em estado running. Mais tarde, quando a instalação for concluída, não será mais necessário informar esta opção.
Como primeiro acesso, será necessário inserir informações sobre o sistema, semelhante às caixas de diálogo encontradas durante a instalação do Solaris. São feitas perguntas como a linguagem do sistema, o hostname da região, a senha do administrador (para o administrador da região). Depois desse diálogo ter sido concluído, a região vai agora entrar em estado running e pode aceitar processos do usuário.
Nesta fase, é possível acessar uma região e realizar sua personalização. Tais como, adicionar novos usuários, instalar novos programas e configurar os serviços que serão necessários.
Sistema Operacional 12

JEDITM
6. Eliminar uma região
Executamos os seguintes passos para eliminar uma região.
Primeiro devemos encerrar a região:
# zlogin myfirstzone shutdown
Em seguida, eliminar a instalação da região. A opção -F corresponde forçar uma desinstalação:
# zoneadm -z myfirstzone uninstall -F
E eliminar a configuração da região:
# zoneadm -z myfirstzone delete -F
Sistema Operacional 13

Módulo 8Sistema Operacional
Apêndice AExercícios
Versão 1.0 - Mar/2008

JEDITM
1. Objetivos
Neste apêndice veremos exercícios que podem ser realizados para reforçar o conhecimento sobre cada lição deste módulo.
Não será apresentada a resolução dos mesmos, cabe ao estudante tirar suas próprias conclusões.
Sistema Operacional 4

JEDITM
2. Exercícios
2.1. Lição 1 – Introdução ao Solaris
1. Abrir a lista de processos no seu sistema operacional atual (Ctrl-Alt-Del no WindowsXP, ps aux no terminal em sistemas Unix) e observe os diferentes processos que estão sendo executados no sistema. Pesquise cada um desses processos. Quais processos são parte do sistema operacional, e quais não são? Por que?
2. Além dos objetivos aqui discutidos para um sistema operacional, que outros objetivos deveriam ser incluídos?
3. Sistemas Operacionais, tais como, Linux, MacOS, Windows e Solaris são conhecidos. Entretanto, existem muitos outros sistemas operacionais. Pesquise e faça uma lista de pelo menos outros cinco sistemas e uma breve descrição de cada.
4. Uma técnica chamada de virtualização permite um sistema operacional rodar como uma aplicação sobre um outro sistema operacional. Leia mais sobre este assunto e o descreva com suas palavras.
2.2. Lição 2 - Instalação
1. Considerar o efeito da Internet no seu cotidiano. Como deveriam evoluir os sistemas operacionais considerando este fato?
2. Que outras aplicações um sistema robusto demandaria? E um sistema distribuído?
2.3. Lição 3 – Comandos Básicos e Scripting
1. Criar um script para copiar um arquivo. Deverá mostrar uma mensagem de erro caso o arquivo não exista. Por exemplo:
$ ./politecp /etc/passwd /export/home/aliceDeseja que eu copie o arquivo /etc/passwd para /export/home/aliceCópia finalizada! Tenha um bom dia.
2. Criar um script para aceitar um número informado pelo usuário e verificar se este é maior ou menor do que um determinado número.
Entre o número [0-100]: 53Muito grandeEntre o número [0-100]: 23Muito pequenoEntre o número [0-100]: 42Parabéns, você acertou em 3 tentativas!
3. Criar um script para listar todo o conteúdo do diretório /usr/sbin em ordem decrescente de tamanho e direcionar a saída para um determinado arquivo.
4. Criar um script para modificar a lista de controle de acesso de um arquivo por meio de um conjunto de perguntas. Exemplo:
$ ./mychangemod test.txtVocê quer que este arquivo possa ser lido pelo usuário [s/n]? sVocê quer que este arquivo possa ser gravado pelo usuário [s/n]? sVocê quer que este arquivo possa ser executado pelo usuário [s/n]? nVocê quer que este arquivo possa ser lido pelo grupo [s/n]? sVocê quer que este arquivo possa ser gravado pelo grupo [s/n]? sVocê quer que este arquivo possa ser executado pelo grupo [s/n]? nVocê quer que este arquivo possa ser lido por outros [s/n]? sVocê quer que este arquivo possa ser gravado por outros [s/n]? nVocê quer que este arquivo possa ser executado por outros [s/n]? nRodando chmod 664 test.txtOk
Sistema Operacional 5

JEDITM
5. Criar um programa Java que use System.out e System.err. Use os comandos de redirecionamento para mostrar qual saída é a regular e qual é a de erro.
2.4. Lição 4 – Processo no Solaris
1. Dados os seguintes processos e seus tempos de de CPU, todos chegando ao tempo 0.
● P1 – 5 segundos
● P2 – 15 segundos
● P3 – 9 segundos
● P4 – 6 segundos
● P5 – 2 segundos
Apresente a tabela de execução de processos para esses processos, segundo o esquema de escalamento abaixo:
a) Primeiro a chegar e primeiro servido
b) Trabalho mais curto
c) Cíclico com Quantum de Tempo de 2
2. Bob, que é um barbeiro que corta cabelos de acordo com um esquema de prioridades, com preempção, mas sem envelhecimento, recebeu os seguintes clientes ao abrir a barbearia às 8 da manhã:
Nome Tempo de Corte Prioridade Hora de Chegada
Alfred 50 min. Média 8:00
Eugene 5 min. Muito alta 8:30
Vincent 10 min. Média 8:45
Dennis 5 min. Baixa 9:00
Jerico 25 min. Alta 9:10
Apresente o Gráfico de Execução de Cortes de Cabelo de Bob, tempo de espera e tempo de troca por cliente, e Utilização do Barbeiro (utilização de CPU) dados os seguintes fatos adicionais:
● Divida a execução de Cortes de Cabelo em fatias de 5 minutos cada
● Se tiver que escolher entre clientes de mesma prioridade, escolher o que chegou primeiro
● Tempo de mudança de contexto de Bob: 5 min. A mudança de contexto acontece sempre que Bob muda de cliente, independente de ter ou não terminado o corte do cliente
● No início de cada fatia de 5 minutos, Bob escolhe a próxima pessoa para cortar o cabelo, ou seja, a decisão de cortar o cabelo de alguém é tomada antes que a mudança de contexto ocorra
● Se o seu cabelo não está sendo cortado então você está esperando, incluir este tempo de Mudança de Contexto
3. Charlie, parceiro de Bob, que faz alocação de tempo por processo cíclico com intervalo de tempo de 20 minutos e 5 minutos de tempo de mudança de contexto, recebeu os seguintes clientes um dia, na seguinte ordem, às 8 da manhã:
Nome Tempo de Corte
Sistema Operacional 6

JEDITM
Steve 50 min.
Bert 5 min.
John 10 min.
Mark 5 min.
Henry 25 min.
4. Apresente o Gráfico de Execução de Cortes de Cabelo de Charlie, tempo de espera e tempo de troca por cliente, e Utilização do Barbeiro.
2.5. Lição 5 – Java Thread
1. Há três crianças querendo usar um balanço. Contudo, somente uma delas pode usar o balanço por vez. Cada criança alterna entre ter vontade de se balançar ou fazer uma pausa para recuperar o fôlego, enquanto outra criança usa o balanço. Implemente isto com o uso de threads. Faça com que cada thread de criança tenha um nome associado via construtor (i.e., Kid k1 = new Kid(“alice”)). Use um retardo aleatório de no máximo 10 segundos para usar o balanço e para tomar fôlego. A saída deverá ser como a mostrada abaixo:
Alice: Eu quero usar o balançoAlice: Eu uso o balanço por 5940 mili-segundosBob: Eu quero usar o balançoCharlie: Eu quero usar o balançoAlice: Eu me cansei. Pausa de 4430 mili-segundosBob: Eu uso o balanço por 4361 mili-segundosAlice: Eu quero usar o balançoBob: Eu me cansei. Pausa de 6940 mili-segundosCharlie: Eu uso o balanço por 4301 mili-segundos...
2. Crie duas threads, MyInput e MyOutput. MyInput é uma thread que aceita nomes de usuários. As entradas deste usuário são impressas por MyOutput. (Note que MyOutput tem que esperar que você digite seus comandos antes de você poder imprimi-los). MyInput e MyOutput fazem isto sucessivamente até você digitar fim.
MyOutput: Aguardando entrada do usuárioMyInput: Por favor entre um nome: AliceMyOutput: Olá Alice!MyOutput: Aguardando entrada do usuárioMyInput: Por favor entre um nome: BobMyOutput: Olá Bob!MyOuput: Aguardando entrada do usuárioMyInput: Por favor entre um nome: fimMyInput terminando...MyOutput terminando...
3. Alice e Bob estão no escritório. Há uma porta pela qual eles têm que passar de vez em quando. Como Bob é bem educado, se ele chega até à porta, ele se assegura de sempre abrir a porta e esperar que Alice passe pela porta antes dele. Alice, por si só, simplemente passa pela porta. Sua tarefa é escrever uma thread Alice e Bob que imite este comportamento. Para simular ter que passar por aquela porta, inclua um retardo aleatório em cada thread, de no máximo 5 segundos. A saída do seu código deve ser como se segue:
Alice: Eu passo pela portaAlice: Eu passo pela portaBob: Eu chego até a porta e espero por Alice...Alice: Eu passo pela portaBob: Eu sigo a AliceAlice: Eu passo pela portaBob: Eu chego até a porta e espero por Alice......
Sistema Operacional 7

JEDITM
4. Modifique o problema Produtor-Consumidor para considerar o cenário de buffer cheio pela limitação do tamanho do vetor em 10 e fazendo o Consumidor mais lento do que o Produtor.
5. Implemente uma solução para o problema Leitores-Escritores através da criação de 2 threads de Leitor e 2 threads de Escritor e um objeto compartilhado MyFile com os métodos read() e write(). Novamente, muitas threads poderiam estar lendo o arquivo, mas somente uma das threads poderá estar escrevendo no arquivo. Para simular os retardos de “leitura” e “escrita”, use Thread.sleep() fazendo com que cada thread pause por no máximo 10 segundos (retardo aleatório) durante a leitura e a escrita. Sua saída deverá se parecer com a seguinte:
Reader1: Eu quero ler o arquivoReader1: Lendo arquivo por 1420 mili-segundosReader2: Eu quero ler o arquivoReader2: Lendo arquivo por 4504 mili-segundosWriter1: Eu quero escrever no arquivoWriter2: Eu quero escrever no arquivoReader1: Leitura do arquivo terminadaReader2: Leitura do arquivo terminadaWriter1: Escrevendo no arquivo por 5930 mili-segundosReader1: Eu quero ler o arquivoReader2: Eu quero ler o arquivoWriter1: Escrita no arquivo terminadaWriter2: Escrevendo no arquivo por 6041 mili-segundosWriter2: Escrita no arquivo terminadaReader1: Lendo arquivo por 9543 mili-segundosReader2: Lendo arquivo por 3461 mili-segundos...
2.6. Lição 6 – Observabilidade
1. Há uma ponte de faixa única perto da sua escola. Um dia você encontrou ao acaso o seguinte cenário, envolvendo 6 carros.
a) Qual é o Gráfico de Alocação de Recursos para esta ponte? (Dica: A ponte tem o comprimento exato de seis recursos)
b) A situação foi resolvida empurrando dois carros para fora da ponte. Que esquema de recuperação de Deadlock é este?
c) Dê dois esquemas para prevenir esta situação de ocorrer novamente no futuro. Indique que condição necessária é eliminada.
2. Você ganhou uma quantidade expressiva de dinheiro numa loteria e decidiu aplicar em um banco. Seu critério primário na escolha do banco é se há dinheiro suficiente para satisfazer todas as suas necessidades.
Nome Empréstimo Atual Teto do Empréstimo
Alice $ 5000 $ 7000
Verde-2 $ 0 $ 9000
Azul-3 $ 3000 $ 15000
Amarelo-4 $ 1000 $ 20000
Rosa-5 $ 1000 $ 2000
Sistema Operacional 8

JEDITM
Quantia disponível: $ 3000
2.7. Lição 7 – ZFS
1. Crie um nome de usuário douglas com o diretório home em /export/home/douglas. Agora, faça deste diretório um zpool espelhado usando dois arquivos, pool1 e pool2, localizados no diretório raiz (root). Além disso, faça com que este pool tenha uma cota de disco de 1GB.
2.8. Lição 8 – Zonas no Solaris
1. Prepare uma zona cujo diretório raiz esteja armazenado no diretório /mysecondzone na zona global. Faça com que esta zona monte um diretório especial chamado /shared tanto no diretório raiz da zona global quanto na zona local. Demonstre (depois da instalação) que quaisquer mudanças feitas na zona global são também vistas na zona local.
Sistema Operacional 9

JEDITM
Parceiros que tornaram JEDITM possível
Instituto CTSPatrocinador do DFJUG.
Sun MicrosystemsFornecimento de servidor de dados para o armazenamento dos vídeo-aulas.
Java Research and Development Center da Universidade das FilipinasCriador da Iniciativa JEDITM.
DFJUGDetentor dos direitos do JEDITM nos países de língua portuguesa.
PolitecSuporte e apoio financeiro e logístico a todo o processo.
Instituto GaudiumFornecimento da sua infra-estrutura de hardware de seus servidores para que os milhares de alunos possam acessar o material do curso simultaneamente.
Sistema Operacional 10