progressive hedging and tabu search applied to mixed integer (0,1) multistage stochastic programming
TRANSCRIPT

Journal of Heuristics, 2:111-128 (1996) (~) 1996 Kluwer Academic Publishers
Progressive Hedging and Tabu Search Applied to Mixed Integer (0, 1) Multistage Stochastic Programming ARNE LOKKETANGEN Molde College, Britvn. 2, 6400 Molde, Norway email: [email protected]
DAVID L. WOODRUFF Graduate School qt'Management, UC Davis, Davis, CA 95616, USA email: [email protected]
Abs trac t
Many problems faced by decision makers are characterized by a multistage decision process with uncertainty about the future and some decisions constrained to take on values of either zero or one (for example, either open a facility at a location or do not open it). Although some mathematical theory exists concerning such problems, no general-purpose algorithms have been available to address them. In this article, we introduce the first imple- mentation of general purpose methods for finding good solutions to multistage, stochastic mixed-integer (0, 1) programming problems. The solution method makes use of Rockafellar and Wets' progressive hedging algorithm that averages solutions rather than data. Solutions to the induced quadratic (0, 1) mixed-integer subproblems are obtained using a tabu search algorithm. We introduce the notion of integer convergence for progressive hedg- ing. Computational experiments verify that the method is effective. The software that we have developed reads standard (SMPS) data files.
Key Words: stochastic programming, integer programming, progressive hedging, tabu search
Many problems faced by decis ion makers are characterized by a mult istage decision process with uncertainty about the future, recourse, and some decisions constrained to take on values
of either zero or one (for example, either open a facility at a location or do not open it). By multistage we mean that there are a series of decisions to be made. By the word recourse we mean that at each addit ional decision point additional information is available (that is, some random variables have been realized). Since these decision stages typically correspond to
t ime points, we index them by t = 1 . . . . , r a n d call this index set T. Even though we are required only to implement decisions needed "right now," we want to take into account the
fact that we will be making additional decisions in the future. In other words, we may want to "hedge" against uncertainty about the future.
By incorporat ing integer variables, uncertainty, and recourse we enable very realistic models for the extremely c o m m o n situations where systems must be designed and operated over a period of t ime and the design may evolve if needed. For example, product ion
and distr ibution formulat ions such as those found in textbooks (e.g., Fourer, Gay, and Kernighan, 1993, Sec. 4.3) can be extended to take into account fixed costs associated with

112 LOKKETANGEN AND WOODRUFF
opening or closing facilities by using integers and more realistic modeling of the multistage decision process by including uncertainty and recognizing that future decisions can depend on information that will become available in the future. For example, we may decide to open a smaller facility now if know that we can decide to open another one in the future after we have new information. Similar opportunities abound in problems concerning telecommunications network design, oil field development, real estate development, and host of other disparate problem domains.
At the heart of this increased modeling power is the representation of uncertain events using random variables. In theory, these random variables can take on a very large number of values; it may not be reasonable or useful to consider distribution functions. It may not be reasonable because there may not be sufficient data to estimate entire multivariate distributions (especially with no reason to expect or require independence). It may not be useful because in many cases the essence of the stochastics can be captured by specifying a reasonable number of representative scenarios. We assume that scenarios are specified giving a full set of random variable realizations and a corresponding probability. We index the scenario set S by s and refer to the probability of occurrence of s (or, more accurately, a realization "near" scenario s) as Pr(s). Let the number of scenarios be given by S.
For each scenario s and each stage t we are given a row vector c(s, t) of length n(t), a re(t) x n(t) matrix A(s, t), and a column vector b(s, t) of length m(t). Let N(t) be the index set 1 . . . . . n(t) and M(t) be the index set 1 . . . . . m(t). For notational convenience let A(s) be (A(s, 1) . . . . . A(s, r)) and let b(s) be (b(s, 1) . . . . . b(s, r)).
_.;.The decision variables are a set of n(t) vectors x(t) with one vector for each scenario. Notice that the solution is allowed to depend on the scenario. Let X(s) be (x(s, 1) . . . . . x(s, r)). We will use X as shorthand for the entire solution system of x vectors (that is, (X=x(1 , 1) . . . . . x(S, r)).
If we were prescient enough to know which scenario would be the realization (call it s) and therefore the values of the random variables, we would want to minimize
f(s; X(s)) =- ~_, ~ [ci(s, t)xi(s, t)] (P.,,) tET i~N(t)
subject to
A(s)X(s) > b(s)
x i ( s , t ) E {0,1}i E l ( t ) , t E T
xi(s, t) > 0 i E N(t ) - l ( t ) , t E T,
(1)
(2)
(3)
where l ( t ) defines the set of integer variables in each time stage. Discounting could easily be added. The notation A X is used to capture the usual sorts of single period and period linking constraints that one typically finds in multistage linear programming formulations.
Since we are not prescient, we must require solutions that do not require foreknowledge and that will be feasible no matter which scenario is realized. We refer to solution systems

PROGRESSIVE HEDGING AND TABU SEARCH 113
that satisfy constraints with probability one as admissible. We refer to a system of solution vectors as implementable if, for scenario pairs s and s' that are indistinguishable up to time t, it is true that xi(s, t') =x i ( s ' , t') for all 1 < t' < t and each i in each N(t) . We refer to the set of all such solution systems as N's for a given set of scenarios S
rain ~[Pr(s)f(s; X(s))] (P), sES
subject to
A(s )X ( s ) > b(s) s E S
x i (S , t ) E {O, 1}i E I ( t ) , t E T, s E S
x i ( s , t ) > 0 i E N ( t ) - l ( t ) , t E T , s E S
x ~Ns.
(4)
(5)
(6)
(7)
Unless time travel becomes possible, only solutions that are implementable are useful. Solutions that are not admissible, on the other hand, may have some value. Although some constraints may represent laws of physics, others may be violated slightly without serious consequence. The progressive hedging algorithm (PH) ensures implementable solutions at all iterations and admissibility on convergence.
Although ours is the first reported use of PH for multistage integer problems, there have been some applications to other problems. Mulvey and Vladimirou have reported success solving network problems (see, e.g., Mulvey and Vladimirou, 1991, 1992). Helgason and Wallace (1991) (as well as Wallace and Helgason, 1991) have reported success solving fishery problems and have suggested the use of tree-based data structures for managing PH data.
Approaches other than PH are possible for some types of integer problems. A straight- forward solution method is based on a reformulation called the deterministic equivalent (DE). The DE is produced by reformulating the original problem so that dependence on scenarios is eliminated implicitly. This will be defined in a rigorous fashion after more nota- tion has been developed, but for now we note that for mixed-integer problems the resulting instance will typically be too large to solve exactly. Additional approaches have been dis- cussed for some classes of stochastic programming problems with integer variables in the first stage (see, e.g., Averbakh, 1990) and for classes of two-stage problems with integers (see Laparte and Louveaux, 1993).
However, we are interested in the more general case where there can be any number of integer variables in any and all stages and where any of the data can be stochastic. We also are interested in methods that can accommodate more than two stages and instances that are potentially too large for exact methods, even for one scenario. In order to have all of these features, we must abandon exact methods and make use of heuristics.
In Section 1 we describe progressive hedging and the tabu search algorithm used to solve subproblems. Computational experiments are discussed in Section 2. The final section offers conclusions and directions for further research.

114 LOKKETANGEN AND WOODRUFF
1. Solution methods
1.1. Progressive hedging
The progressive hedging algorithm proposed by Rockafellar and Wets (199 l) is intuitively appealing and has desirable theoretical properties: it converges to global optimum in the convex case, there is a linear convergence rate in the case of a linear stochastic problem, and if it converges in the nonconvex case (and if the subproblems are solved to local optimality), then it converges to a local optimal solution. We describe our application of PH here. For a more general description see Rockafellar and Wets (1991).
To begin the PH implementation for (P), we organize the scenarios and decision times into a tree. The leaves correspond to scenario realizations. The leaves are grouped for connection to nodes at time r. Each leaf is connected to exactly one time r node, and each of these nodes represents a unique realization up to time r. The time r nodes are connected to time z - 1 nodes so that each scenario connected to the same node at time r - I has the same realization up to time r - 1. This is continued back to time 1 (that is, "now"). Hence, two scenarios whose leaves are both connected to the same node at time t have the same realization up to time t. Clearly, then, in order for a solution to be implementable it must be true that if two scenarios are connected to the same node at some time t, then the values of xi (t') must be the same under both scenarios for all i and for t ' _< t.
To illustrate the notation developed thus far, we consider a very small example with three decision epochs (so r = 3 and T = {1,2, 3}) and two decisions per period, one of which is integer and the other of which is bounded above zero and only three additional constraints. For any given scenario s the problem (Ps) is to minimize
cl (s, 1)Xl (s, 1) + c2(s, 1)x2(s, 1) + cl (s, 2)xj (s, 2) + c2(s, 2)Xz(S, 2)
q- Cl (s, 3)Xl (s, 3) + c2(s, 3)xz(s, 3),
subject to
all(s, 1)xl(s, 1) +a l2(s , 1)x2(s, 1 ) < b l ( s , 1)
a21 (s, 1)xl(s, 1 ) + a22(s, l)x2(s, 1 )< bz(s, 1)
ajl (s, l)xl (s, 1) + al2(s, 1)xz(s, 1) -k- all (s, 2)xl (s, 2)
+ al2(S, 2)xz(s, 2) + all (s, 3)Xl (s, 3) + al2(s, 3)x2(s, 3) < bl (s, 3)
xl(s, t) 6{O, 1}, t = 1 , 2 , 3
xz(s , t )>O t = 1 , 2 , 3 .
Suppose that all data for t = 1 are known and the data for t > 1 will become available before we will have to commit to the decision variables for these times. Further suppose that the only data that are stochastic for t > 1 are c2 and a12. Now suppose that at t = 2 we will have c2 = 2 and al2 = 3, with probability 6 and c2 = 3, a12 = 3.7 as the only other possibility. If the first case occurs, then we will know with certainty that for t = 3 the values of c2 and al2 will both be 6, but in the second case there is a 0.5 chance that they will be

PROGRESSIVE HEDGING AND TABU SEARCH 1 15
Figure 1.
F]
Scenario tree for the small example problem.
unchanged from t = 2 values and a 0.5 chance that they will both be 6. This is seen much more easily with a scenario tree graph as shown in Figure 1. This graph uses a circle for both nodes and leaves. For each circle, this graph shows the pair (c2, a12) along with the unconditional probability of realizing the scenario(s) for the circle.
The solution for any particular scenario may not be of any value to us. Ultimately, we want to be able to solve the problem of minimizing the expected objective function value subject to meeting the constraints for all of the scenarios and also subject to the constraint that the solution system be implementable.
The way we obtain such solutions is to use progressive hedging. For each scenario s, approximate solutions are obtained for the problem of minimizing, subject to the constraints, the deterministic f~, plus terms that penalize lack ofimplementability. These terms strongly resemble those found when the method of augmented Lagrangians is used (Bertsekas, 1982). They make use of a system of row vectors w that have the same dimension as the column vector system X, so we use the same shorthand notation. For example, w(s) means (w(s, 1) . . . . . w(s, r)) for the multiplier system.
In order to give a formal algorithm statement, we need to formalize some of the scenario tree concepts. We use Pr(.A) to denote the sum of Pr(s) over all s for scenarios emanating from node ..4 (that is, those s that are the leaves of the subtree having ..4 as a root also referred to as s ~ ..4). We use t(.A) to indicate the time index for node ..4 (that is, node A corresponds to time t).
HS(x';x) Let the operator < mean "assign the result of a heuristic search optimization that
attempts to find the argument x that minimizes the right side of the expression with the

116 LOKKETANGEN AND WOODRUFF
HS(e;x) search beginning at x'." This is described in detail in the next subsection. We use when the PH algorithm does not suggest a starting solution for the search.
For typesetting convenience, we consider the constraints (1), (2), and (3) for (P,.) to be represented by the symbol ~s. We use X(t; .4) on the left side of a statement to indicate assignment to the vector (xl(s, t) . . . . . XN(t)(s, t)) for each s 6 .4. We refer to vectors at each iteration using a superscript--for example, w (°) (s) is the multiplier vector for scenario s at PH iteration zero. The PH iteration counter is k.
If we defer briefly the discussion of termination criteria, a formal version of the algorithm can be stated as follows taking r > 0 as a parameter.
1. k +--0. 2. For all scenario indexes, s ~ S
X(°l(s)tts(°;X(s)) f (s; X(s)) " X(s) E f2s (8)
and
w(°~(s) ~ O.
3. k + - - k + l . 4. For each node .4 in the scenario tree and for t = t (.A),
A) +-- Z Pr(s)X(t; s)(k-l) /Pr(.A). sEA
5. For all scenario indexes s 6 S,
w(k)(s) +-- w(k-I)(S) -~ (r)(X(k-l)(s) --x(k-l)(s))
and
X ~ (s) Hs(x'~ -~ %);xc°) L (X(s)) + w (t) (s)X(s) + r/2 IIX(s) - 2 ~ - 1 (s)I12 :X(s) E ~"2 s . (9)
6. If the termination criteria are not met, then go to Step 3.
The termination criteria are based mainly on convergence, but we must also terminate based on time because nonconvergence is a possibility. Iterations are continued until k reaches some predetermined limit K or the algorithm has converged, which we take to mean 5t'k (s) is sufficiently close to ~(~-1 (s) for all s. One possible definition of"sufficiently close" is to require the distance (for example, Euclidean) to be less than some parameter. A much better choice is to consider only integer components of X" and require equality. This requires no metric or parameter and typically occurs after far fewer iterations. Once the integer components of a solution are (assumed) known, the real valued variables are obtained by solving the deterministic equivalent problem (DE) with the integer values fixed.

PROGRESSIVE HEDGING AND TABU SEARCH 117
Although the DE is much larger than the original subproblems, fixing all the integers can more than mitigate this when there are even a modest number of integer variables. (It would also be possible to solve the problem once the integers have been fixed using any other method for multistage, linear, stochastic optimization). The only potential drawback to convergence based only on integers (integer convergence) is that there is no theoretical guarantee that a better solution would not be obtained by waiting for convergence of the entire solution system (full convergence).
The vectors w can be interpreted as a dual price for the (implied) implementability constraints (see, e.g., Wets, 1989). In other words, they have an interpretation as a value of information. The algorithm is often classified as a dual method because we are essentially searching for good values of w. In our case the direct search will be for X, and the values of w will be implied.
1.2. Heuristic search
The statement of the algorithm PH gives rise to the two search problems labeled as (8) and (9). The first is a linear mixed-integer problem, and the second is similar but has quadratic terms in the objective function. We will refer to (8) as MIP and the corresponding problem generated by relaxing the integer requirements as LP. Similarly, we will refer to (9) as QMIP and a corresponding problem without integer requirements as QP. A MIP must be solved once for each scenario and QMIP for each scenario for each iteration of PH. We make use of heuristics based on Glover's tabu search (Glover, 1989). The PH algorithm is parameterized to allot a ff times n iterations for the search devoted to each scenario in PH iteration 0 and ~7 times n tabu search iterations at every other PH iteration. Response to these parameters is explored in the next section, but typical values of ~" and rl are 4 and 1, respectively.
A variety of zero-one mixed-integer programming (MIP) problems with special structures have been successfully treated by tabu search (TS). For an overview of TS and its application areas, see, for example, the application survey in Glover and Laguna (1993) and Glover, Laguna, Taillard, and de Werra (1993). Tabu search has also been applied to solving general zero-one MIP problems by superimposing the TS framework on the "pivot and complement" heuristic by Balas and Martin (1980) (Aboudi and J(Srnsten, 1994) and by embedding TS within the pivot and complement heuristic (Lckketangen, J6rnsten and Stor~y, 1994). A more direct approach is used by L~kketangen and Glover (1996) using a standard bounded variable simplex method as a subroutine, to exploit the fact that an optimal solution to the zero-one MIP may be found at an extreme point of the LP feasible set (see also Glover and Lckketangen, 1995). This technology constitutes the foundations of the methods that we employ.
In order to combine discussion of the two problems (MIP and QMIP), we will refer to the objective function value as z whether the function is linear or quadratic. Also, let x * denote the best solution seen so far, and let z* denote its objective function value. The startup of the search algorithm varies considerably depending on whether it is for (8) or (9). For (8) we begin by solving the LP relaxation using MINOS (Murtagh and Saunders, 1993) to obtain an optimal LP basic (extreme point) solution. For (9), we use the starting

118 LOKKETANGEN AND WOODRUFF
point X (k-l) (s) to fix the value of all integer variables and then solve the resulting QP using MINOS to obtain a good basis. Thereafter, for both problems, the algorithm proceeds as follows:
1. Consider the pivot moves that lead to adjacent solutions that are feasible for the re- laxed problem. If a candidate move would lead to an integer feasible solution x whose associated z value yields z < z*, record x as the new x* and update z*.
2. Select the pivot move with the highest move evaluation, applying tabu restrictions and aspiration criteria.
3. Execute the selected pivot, updating the associated tabu search memory and guidance structures. Unless the stopping criterion is met (for example, the allotted number of search iterations has been executed), return to step 1.
4. (QP only) Fix the integer values to match those of the best solution seen during the search, and solve the resulting QP to obtain values for the continuous values.
The move evaluation functions used in step 1 and the tabu search mechanisms employed in step 2 are described in detail by Lckketangen and Glover (1995). We include a descrip- tion of our implementation in Appendix A along with computational results that support the contention that the algorithm's performance is extremely robust with respect to the pa- rameters that control move selection and tabu status. In the appendix we define a set of tabu search parameters that are the r e c o m m e n d e d set and used for the experiments described in the next section.
J
2. Computational experience
Since ours is the first reported general-purpose implementation of a solution method for general, multistage, mixed-integer stochastic programs, we face a paucity of instances and competition. In the introduction we introduced the notion of the deterministic equiv- alent formulation, which we now formalize. Rather than providing nonanticipatitivity constraints--such as x i ( s , t ' ) - x i ( s ' , t ') = 0 for all i ~ N ( t ' ) , 1 __< t' < r and s -~ s ' but {s, s'} C A with t' = t(.A) for all nodes .A in the scenario t ree - -we simply convert all occurrences of xi (s, t ') to Yi (t') for all s 6 A with t' = t (A) for all nodes A in the scenario tree. We can also factor variables out of the probability summation in the objective function if we wish to or let the preprocessor provided by a commercial solver do it, which is our preference. Although this formulation is somewhat smaller than (P), it can be very large when the number of scenarios is large. Progressive hedging is a method based on repeatedly solving problems that are roughly as large as the problem for one scenario. When there are integer variables, reductions in problem size can be critical.
To verify that the computer implementation of the PH algorithm is working correctly we make use of an "integerized" version of a continuous instance that happens to have a number of {0, 1 } integer values in its (known) optimal solution. We refer to this instance as INT0110. To study parameter sensitivities and performance as compared to CPLEX version 3.0 (CPLEX Optimization Inc., 1994) applied to the DE (let this algorithm be called CDE), we make use of a family of instances from a production planning problem. We refer to

PROGRESSIVE HEDGING AND TABU SEARCH 119
these instances collectively as SIZESxx where xx is replaced by the number of scenarios. The CPU times given are for a DEC Alpha 3000/700 (SPECfp92 225).
2.1. INTOllO
The APPxxxx family of instances are provided as test problems for prerelease versions of SP/OSL (King, 1994). They are multistage stochastic programs with continuous variables. The instance APP0110 has nine scenarios each with 60 bounded variables and 26 additional constraints and three time periods. It can be solved in less than a second using, for example, SP/OSL. The resulting optimal solution has a number of vector elements that are zero or one. With r = 0.8 our implementation of PH requires 64 iterations in 30 seconds to get convergence sufficient for all constraints to be within 0.01 (70 iterations and 33 seconds for r = 0.6 and 79 iterations and 36 seconds if r = 0.4). Note that Rockafeller and Wets proved that the convergence rate is linear, which implies that the time required depends very strongly on the definition of convergence. We are not interested in comparison of methods for continuous problems (and there are certainly techniques that result in better continuous problem performance with PH that will be mentioned in the conclusions section), but instance APP0110 does provide some verification of the correctness of our computer coding and indicates that there is hope that it will be reasonably robust with respect to the parameter r.
We created instance INT0110 by changing 10 of the first-stage variables that are either zero or one in the optimal solution to be {0, 1 } variables. Clearly the best way to solve this problem is to solve its relaxation, but we pretend that we do not know this and treat the instance as a multistage zero one problem. We were not able to achieve full convergence on these instances due to a combination of the requirement for a very large number of iterations (more than 100) and an inability to maintain good scaling for MINOS (if the vector w changes a lot over time, so do the nonlinear terms on the objective function). Optimal integer convergence, on the other hand, is achieved after 11 iterations requiring a total of 83 seconds with r =0 .8 , ~" --4, and q = 1. If r is changed to 0.4, 10 iterations requiring a total of 78 seconds are needed.
These results are very encouraging. Convergence of the integer variables to their optimal values implies the optimal solution and with the 10 integers fixed, the resulting continuous problem is even smaller than the original app0110, which was easy to solve in the first place. The lack of sensitivity to r over a fairly large range of values is also encouraging. We can get little more than encouragement and verification of computer coding from a problem where we are just "pretending" that there are integer constraints. For serious parametric sensitivity investigation and comparison with CDE, we turn to a more appropriate family of instances.
2.2. SIZESxx
A recent paper by Jorjani, Scott, and Woodruff (1995) introduces a family of two-stage instances with 20 {0, 1} integer variables, 130 bounded real variables, and 64 additional

120 LOKKETANGEN AND WOODRUFF
constraints per scenario. The integer variables occur in both stages. The details of the prob- lem and the instances we used are described in Appendix B. We considered problems with 3, 5, and 10 scenarios named SIZES3, SIZES5, and SIZES 10, respectively. For this family of instances, the relaxation of the integer constraints results in optimal solutions where all of the formerly integer variables take on small, nonzero values. Hence, these instances must be solved as integer problems.
Our first experiments involved the use of 83 different parameter configurations to test sensitivities to tabu search parameters and the PH parameters ~', rl, and r. These tests were done on the SIZES3 instance. In order to conduct simple statistical tests we made use of linear models. Clearly, the objective function responses to these parameters will not be linear, and one would also question the assumption of a linear model as a predictor of execution time. However, to get an idea of gross sensitivity, a linear model seems useful.
A linear regression using r as a predictor of either the objective function value obtained or the time required results in P-values that suggest insignificance (. 17 for the objective function and .28 for time) and the 95 percent confidence interval for the coefficient spans zero in both cases. The results are qualitatively the same when other parameters are included as predictors in the regression along with r.
The regression model results in P-values very near zero for both ff and 77 as predictors of time, which is hardly surprising. As predictors of the objective function value found, when considered together, ~" gets a P-value of 0.00996 and 0 gets 0.0934. Too much faith in the linear model would be required in order to make use of the coefficients themselves, but we no gle that the 95 percent confidence interval for 0 does span zero, while ~" is solidly negative as expected. We summarize by concluding that rl is somewhat important as a predictor of quality while ~" is very important.
When one considers the details of PH, this makes sense. If the tabu search during the zeroth iteration of PH fails to produce a good, integer-feasible solution for some or all scenarios, then the resulting w vector will be quite bad, and the search in subsequent iterations will have to start with a solution that is not integer feasible and furthermore with a w and perhaps an ,~ that tend to keep ~he solution away from integer feasibility. Even if integer feasible solutions are discovered on subsequent PH iterations, it will take a number of additional iterations to get the w vector to reflect the new, superior solutions. Note that a solution that is feasible for a scenario for the first PH iteration is feasible for that scenario in all other iterations because only the objective function changes with PH iterations. Qualitative analysis of the runs used for parametric sensitivity analysis indicates that ~" = 1 is not reliable, while ~" = 4 is. These results are no doubt valid only for this family of instances, but we use them in the experiments that follow and defer discussion of a more adaptive means of terminating the searches during PH iteration zero.
Figure 2 is a plot of objective function values versus CPU times for CDE (using CPLEX 3.0 to attach the deterministic equivalent) and PH. Times are varied for CDE by increasing the node limit for the CPLEX branch and bound algorithm. Varied times for PH are the result in variations in the parameters; consequently there is no monotonicity in the PH results, and the points are not connected with a line. The parametric variations and results used for this graph are shown in Table 1. For this instance, runs of CPLEX significantly

PROGRESSIVE HEDGING AND TABU SEARCH 121
S=5
2 ~ e o o
=
~" 225S00
Figure 2.
I I I i SO0 1000 1500 2000
11me (*ec)
CDE versus PH for the SIZES5 instance.
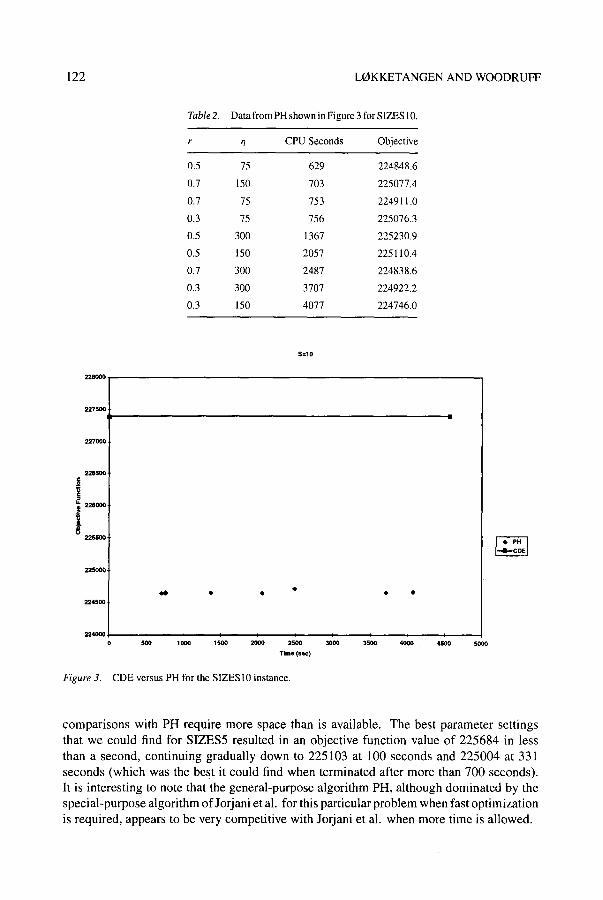
longer than 5000 seconds where problematic due to virtual memory thrashing on a machine with over 130MB of main memory. Table 2 and Figure 3 show the results for SIZES10.
One can see that PH obtains better solutions than CDE and the level of domination seems to increase with the problem size, which is prointuitive. However, PH cannot provide integer feasible solutions nearly as quickly. Actually, if one wants integer feasible solutions quickly for SIZESxx, the algorithm of Jorjani, Scott, and Woodruff (1995), which is a special purpose algorithm for the problem class SIZESxx, dominates CDE (as an aside, we note that the Jorjani et al. algorithm uses CPLEX to solve subproblems). The Jorjani et al. heuristic takes three parameters and is not a general-purpose algorithm, so extensive
Table 1. Data from PH shown in Figure 2 for SIZES5.
r ~ CPU Seconds Objective
0.7 75 230 224643.2
0.5 75 252 224643.2
0.7 150 271 224652.8
0.7 300 355 224652.8
0.3 150 356 224643.2
0.3 75 405 224710.9
0.5 150 523 224652.8
0.3 300 695 224660.8
122 LOKKETANGEN AND WOODRUFF
Table2. Data from PH shown in Figure 3 for SIZES 10.
r ~7 CPU Seconds Objective
0.5 75 629 224848.6
0.7 150 703 225077.4
0.7 75 753 224911.0
0.3 75 756 225076.3
0.5 300 1367 225230.9
0.5 150 2057 225110.4
0.7 300 2487 224838.6
0.3 300 3707 224922.2
0.3 150 4077 224746.0
228000
S=10
227500
22700(
2 2 6 5 O O
i
u. 226000 _>.
2 2 5 5 0 0
225000
224500¸
224000
Figure 3.
4 0 • • • •
i , i i t i i i i
500 100~ 1500 2000 2500 3000 3500 4000 4500 5000
T i m e (s ic )
CDE versus PH for the SIZES I0 instance.
comparisons with PH require more space than is available. The best parameter settings that we could find for SIZES5 resulted in an objective function value of 225684 in less than a second, continuing gradually down to 225103 at 100 seconds and 225004 at 331 seconds (which was the best it could find when terminated after more than 700 seconds). It is interesting to note that the general-purpose algorithm PH, although dominated by the special-purpose algorithm of Jorjani et al. for this particular problem when fast optimization is required, appears to be very competitive with Jorjani et al. when more time is allowed.

PROGRESSIVE HEDGING AND TABU SEARCH 123
3. Conclusions
In this article, we have introduced the first implementation of general-purpose methods for finding good solutions to multistage, stochastic mixed-integer (0, 1) programming prob- lems. This has been accomplished using tabu search for subproblems and progressive hedging to coordinate blending the subproblem solutions and notion of integer convergence that we have introduced. Computational experiments verify that the method is effective. More instances are needed to establish effective parameter ranges and to study the algo- rithm's performance. The presence of a solver should help to spur creation of such instances.
The software that we have developed reads standard (SMPS) input files (Birge et al., 1987; Gassman and Schweitzer, 1996). Interested readers may contact the authors if they wish to use the software as a benchmark for testing improved methods. It is clear that computational improvements are possible.
Perhaps the most striking improvements can be obtained by bundling multiple scenarios, solving the resulting smaller number of larger subproblems, and blending these solutions. One research issue concerns the criterion for partitioning the scenarios. Should they be partitioned to facilitate easy solution of the resulting subproblems (as suggested by Wets, 1989) or to accelerate convergence (as suggested by Wets, 1991)? Either method promises to result in huge reductions in computational effort provided that the larger subproblems can be solved effectively.
Improvements in search for solutions to quadratic 0-1 problems will produce benefits and schemes for metacontrol of PH may also be productive. In this category, it seems that there is a critical need for an adaptive stopping criterion to be used by the tabu search for good solutions during PH iteration zero. This would eliminate or replace the parameter ~" and instead stop the search only after an integer feasible solution has been found and perhaps only after there is "no reasonable chance of further improvement in the near future" Such adaptive stopping rules are less important in the later PH iterations, but they would seem to be very important as means of reducing the importance of parameter tuning for the zeroth iteration. Other potential improvements in the methodology for finding good QMIP solutions include enhancements to move evaluation and tabu memory structures.
The algorithm described in this article provides a starting point for such improvements and a benchmark for testing them. It also provides a practical means of attacking a large and important class of problems.
Appendix A: Tabu search description
Complete details and justification of the search methods are described by Lckketangen and Glover (1996), but in the interest of repeatability we give a summary here. We assume the reader is familiar with tabu search (e.g., Glover and Laguna, 1993) and with basic concepts of the simplex method.
The neighborhood used is induced by extreme point pivoting using a bounded variable simplex subroutine provided by MINOS. The attribute of moves used for tabu status is the index of the variable leaving the basis. Once a variable has left the basis, it may not reenter until a number of iterations, the tabu tenure has expired. The tabu tenure begins at n~ 15

124 LOKKETANGEN AND WOODRUFF
Table 3. Move classifications and ranking functions.
Type Defining Conditions Ranking Function
I z(h) < 1, u(h) > 0 (Az(h) /Au(h)) /R
11 z(h) > 0, u(h) < 0 (Au(h)/13z(h)) * R
Ill z(h) > O, u(h) > 0 - A u ( h ) * Az(h)
IV All others - A u ( h ) * Az(h)
and every TLPeriod iterations it is changed to a value selected at random from the interval (n/15, n/7) .
The move evaluation considers both the objective function value and a measure of integer infeasibility. For a potential move from solution 0 to h, we define Az(h) = z(0) - z(h)
and Au(h) = u(h) - u(O) where z is the objective function value and u is the sum of the difference between the value of each integer variable and the nearest integer (that is, the total integer infeasibility). Table 3 shows the different move types and the ranking function for each. The value of R is
R -- y]~ abs(z(h)) y]~ abs(u(h)) '
where the summations are over all moves, h, that are Type I or Type II (this is a special casa~e of R as defined in Lckketangen and Glover, 1996). Moves are sorted with Type III moves in the first group, followed by a group with Types I and II, and the third group is Type IV moves. Within each group, the moves are sorted by decreasing values of the ranking function. Moves are selected in probabilistic fashion by repeating the following steps until a move is selected:
1. Take the tope move from the sorted list. 2. Subject the move to the sequence of tests shown in Table 3.
a. Accept if the move would be the best seen. b. Reject if tabu, and place the move at the end of list, removing its tabu status for the
current iteration. c. If degenerate, reject the move and remove it from the list. d. Generate a pseudorandom deviate r from a uniform(0, 1) distribution. If r > p, reject
and remove it from list then go to Step 1. If r > p, accept the move,where p is the program parameter ProbMoveAcceptance.
Using the 83 program runs mentioned in Section 2.2, we added TLPeriod and Prob- MoveAcceptance as predictors. Regardless of the other predictors included, they are both insignificant as predictions of the final objective function value achieved (P-values greater than 0.2 and 95 percent confidence intervals for coefficients that span zero). Although further research that makes use of additional (as yet nonexistent) problems may yield instances classes where the settings of these parameters is critical, we feel comfortable at this time making use of the recommended settings of n~ 15 and 0.8, respectively.

PROGRESSIVE HEDGING AND TABU SEARCH 125
Appendix B: The sizes problem
Complete details of the problem are provided by Jorjani, Scott, and Woodruff (1995), but we give a summary here.
Single-period model
Suppose a product is available in a finite number N of sizes where 1 is the smallest size and N is the largest size. Further, suppose size i is substitutable for size j if i > j - - t h a t is, larger sizes may fulfill demand for a smaller size. Let di, i = l . . . . . N denote the demand for size i.
We introduce a cost structure for the production of the product. Let Pi, i = 1 . . . . . N be the unit production cost for size i. Generally Pi > Pj for i > j . Let cr be the setup cost for producing units of any size and q be the unit penalty cost of meeting demand for size j with a larger size i.
We need the following decision variables:
l if we produce sizei
zi = 0 otherwise
Yi = number of units of size i produced
xij = number of units of size i cut to meet demand for size j , j < i.
Hence, in order to find the optimal subset of the N sizes to produce so as to satisfy demand, we solve the following integer linear program:
N
min Z ( c r z i + PiYi) + q Z xij, i=1 j < I
subject to
Yi = d i - - y ~ X k i + Z x i t i = 1 , . . . , X , (I0) k>i l<i
y i - M z i ' < O i = 1 . . . . . N, (11)
zi E {0,1} i = 1 . . . . . N, (12)
xi, Yi E {nonnegative integers} i = 1 . . . . . N, (13)
The base data set is shown in Table 4.
Multiperiod, stochastic formulation
To produce a multiperiod formulation, variables and data are subscripted with a period index t that takes on values up to T and we add an index for the scenario.

126 LOKKETANGEN AND WOODRUFF
Table 4. The one-period data set.
Unit Production
Index Cost ($) Demand
I 0.748 2500
2 0.7584 7500
3 0.7688 12500
4 0.7792 10000
5 0.7896 35000
6 0.8 25OOO
7 0.8104 15000
8 0.8208 12500
9 0.8312 12500
10 0.8416 5000
Unit reduction cost, q = $0.008
Setup cost, c~ = $453
To model the idea that items produced in one period can be used as-is or reduced in subsequent periods, we use xijt to indicate that product i is to be used without reduction in period t if i = j and with reduction otherwise. The y vector gives production quantities
,for each product in each period without regard to the period in which they will be used (and perhaps reduced for use). The formulation is essentially an extension of the single- period formulation except that a capacity constraint must be added in the multiple-period formulation:
] min Z Pr(s) ~ ( c r z i , s + p i Y i t . ~ ) + q ~ j ~ x i j , . , . s~S L i=1 j<i
subject to
Z Xijts >_ dit s s c S , i = 1 . . . . . N , t = 1 . . . . . T .j ~_i
' - L j<i
Yits -- MZi t s ~ 0 N
Z Yits ~ Cts i=1
Z[t.,. E {0, 1}
( 1 4 )
s ~ , .3 , i = 1 . . . . . N , t = 1 . . . . . T ( 1 5 )
s ~ S , i = 1 . . . . . N , t = 1 . . . . . T ( 1 6 )
s ~ S , i = 1 . . . . . T ( 1 7 )
s E S , i = 1 . . . . . N , t = 1 . . . . . T . ( 1 8 )
We create a family of related instances. Each has costs and first-period demands given by Table 4 and stochastic second-period demands with a mean given by Table 4, a capacity

PROGRESSIVE HEDGING AND TABU SEARCH 127
of 200,000, and a symmetric set of scenarios. For each instance, each scenario has equal probability. The instances are specified by a vector of multipliers--one multiplier for each scenario that is multiplied times the demand vector from Table 4 to give the demand vector for the scenario. Each instance is given a short ID that indicates the number of scenarios. Instance SIZE3 is defined by (.7, 1, 1.3), SIZE5 by (0.6, 0.8, 1, 1.2, 1.4), and SIZEI0 by (.5, .6, .7, .8, .9, 1.1, 1.2, 1.3, 1.4, 1.5).
Acknowledgments
We are grateful for the comments of H.I. Gassman and the many improvements suggested by an anonymous referee. This work was supported in part by the National Science Foundation under grant DMS-94.06193.
References
Aboudi, R., and K. J6msten. (1994). "Tabu Search for General Zero-One Integer Programs Using the Pivot and Complement Heuristic." ORSA Journal on Computing 6, 82-93.
Averbakh, I.L. (1990). "An Additive Method for Optimization of Two-Stage Stochastic Systems with Discrete Variables." Soviet Journal (~f'Computer and System Sciences 28, 161-165.
Balas, E., and C. Martin. (1980). "Pivot and Complement: Heuristic for 0-1 Programming." Management Science 26, 86-96.
Bertsekas, D.P. (1982). Constrained Optimization and Lagrange Multiplier Methods. New York: Academic Press. Birge, J.R., M.A. Dempster, H.I. Gassman, E.A. Gunn, A.J. King, and S.W. Wallace. (1987). "A Standard Input
Format for Multiperiod Stochastic Linear Program." COAL (Math. Prog. Soc., Comm. on Algorithms) Newsletter 17, 1-19.
CPLEX Optimization, Inc. (1994). Using the CPLEX Callable Library. CPLEX Optimization, Inc., Suite 279, 930 Tahoe Blvd. Building 802, Incline Village, NV 89451-9436.
Fourer, R., D.M. Gay, and B.W. Kernighan. (1993). AMPL. San Francisco: Scientific Press. Gassman, H.I., and E. Schweitzer. (1996). "Proposed Extensions to the SMPS Input Format for Stochastic Linear
Programs." WP-96-1, School of Business, Dalhousie University, Halifax, Canada. Glover, E (1989). "Tabu Search--Part I." ORSA Journal on Computing 1, 190-206. Glover, E, and M. Laguna. (1993). "Tabu Search." In C. Reeves (Ed.), Modern Heuristics tbr Combinatorial
Problems. Blackwell Scientific Publishing. Glover, E, M. Laguna, E. Taillard, and D. de Werra (Eds.). (1993). Annals ~/Operations Research 41. Glover, E, and A. Lckketangen. (1995). "Solving Zero-One Mixed Integer Programming Problems Using Tabu
Search." Technical Report, Molde College, 6400 Molde Norway. Helgason, "12, and S.W. Wallace. (1991). "Approximate Scenario Solutions in the Progressive Hedging Algorithm:
A Numerical Study with an Application to Fisheries Management." Annals ~[ OR 30, 425444. Jorjani, S., C.H. Scott, and D.L. Woodruff. (1995). "Selection of and Optimal Subset of Sizes." Technical Report,
GSM, UC lrvine, Irvine, CA. King, A.J. (1994). "SP/OSL Version 1.0 Stochastic Programming Interface Library User's Guide." IBM Research
Division, T.J. Watson Research Center, Yorktown Heights, NY 10598. Laporte, G., and EV. Louveaux. (1993). "The Integer L-Shaped Method for Stochastic Integer Programs with
Complete Recourse." OR Letters 13, 133-142. Lckketangen, A., and F. Glover. (1996). "Probabilistic Move Selection in Tabu Search for Zero-One Mixed Integer
Programming Problems." In Metaheuristics: Theory and Applications, 1995. Kluwer. L~kketangen, A., K. J6rnsten, and S. Stor~y. (1994). "Tabu Search Within a Pivot and Complement Framework."
International Transactions qf Operations Research 1,305-316.

128 LOKKETANGEN AND WOODRUFF
Mulvey, J.M., and H. Vladimirou. ( 1991). "Applying the Progressive Hedging Algorithm to Stochastic Generalized Networks." Annals ¢~f'OR 30, 399-424.
Mulvey, J.M., and H. Vladimirou. (1992)~ "Stochastic Network Programming for Financial Planning Problems." Management Science 38, 1642-1664.
Murtagh, B.A., and M.A. Saunders. (1993). "MINOS 5.4 User's Guide." Technical Report SOL83-20R, SOL, OR, Stanford University, Stanford, CA 94305.
Rockafellar, R.T., and R.J.-B. Wets. (1991). "Scenarios and Policy Aggregation in Optimization Under Uncer- tainty." Math. qlOR 16, 119-147.
Wallace, S.W., and T. Helgason. (1991 ). "Structural Properties of the Progressive Hedging Algorithm." Annals qr OR 30, 445-456.
Wets, R.J.-B. (1989). "The Aggregation Principle in Scenario Analysis and Stochastic Optimization." In S.W. Wallace (Ed.), Algorithms and Model Formulations in Mathematical Programming. Berlin: Springer.
Wets, R.J.-B. (1991). "Decomposition by Stratification for Multistage Stochastic Programs." Internal Note, I B M Watson Research Center, Yorktown, NY.