procedural skill unlearning
TRANSCRIPT

Procedural Skill Unlearning
Matthew J. Crossley
Department of Psychological and Brain Sciences University of California, Santa Barbara, 93106

• Build and test a computational cognitive neuroscience (CCN) model of procedural skill learning and unlearning
• CCN models predict neurobiology and behavior
Talk Goals

• Procedural Skills
• Model Architecture
• Instrumental Conditioning Applications
• Category Learning Applications
• Closing Remarks
Outline

• Procedural Skills
• Model Architecture
• Instrumental Conditioning Applications
• Category Learning Applications
• Closing Remarks
Outline

• Learned incrementally from feedback
• E.g., riding a bike or playing an instrument
• E.g., radiology
Procedural Skills
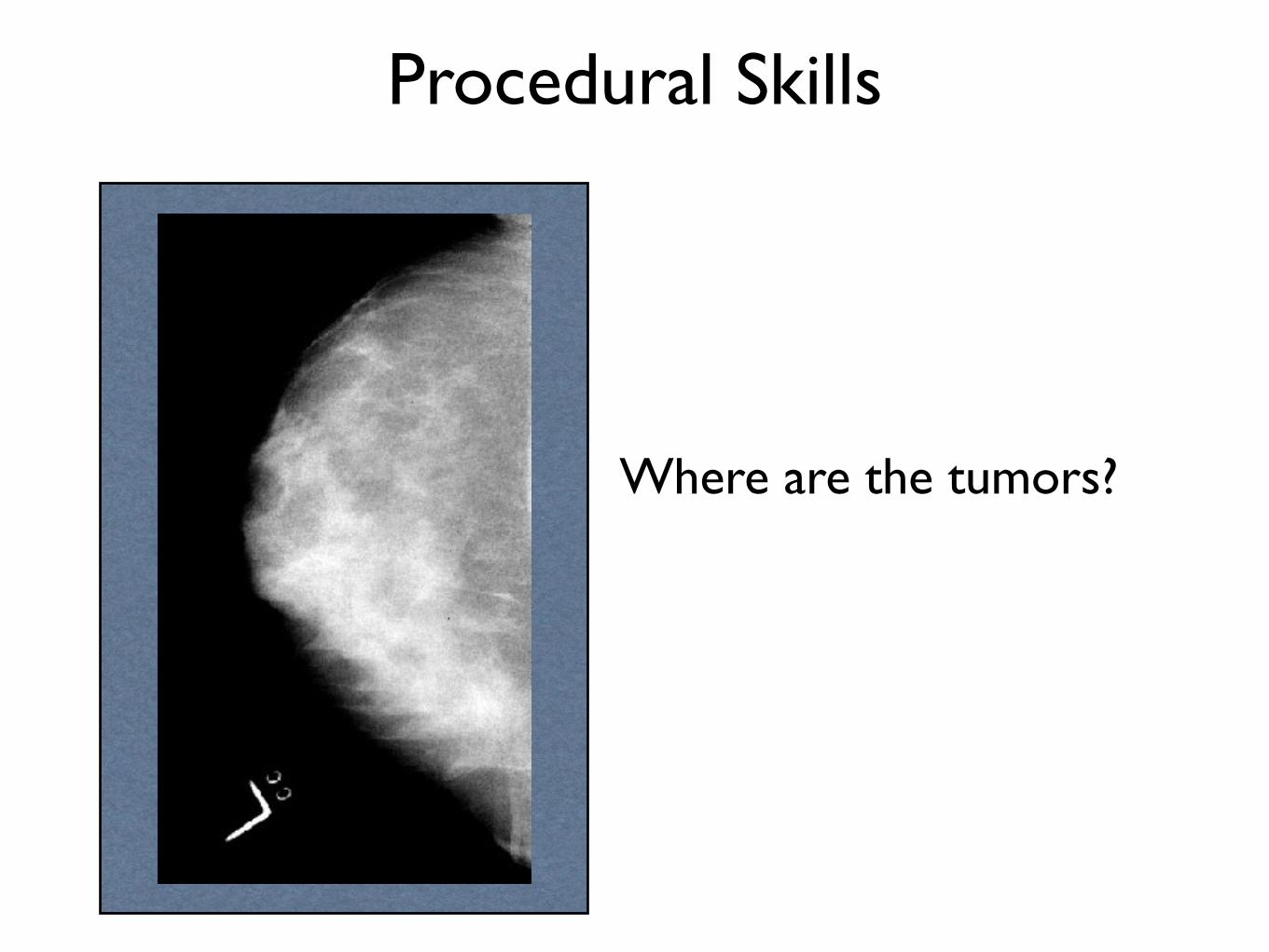
Procedural Skills
Where are the tumors?
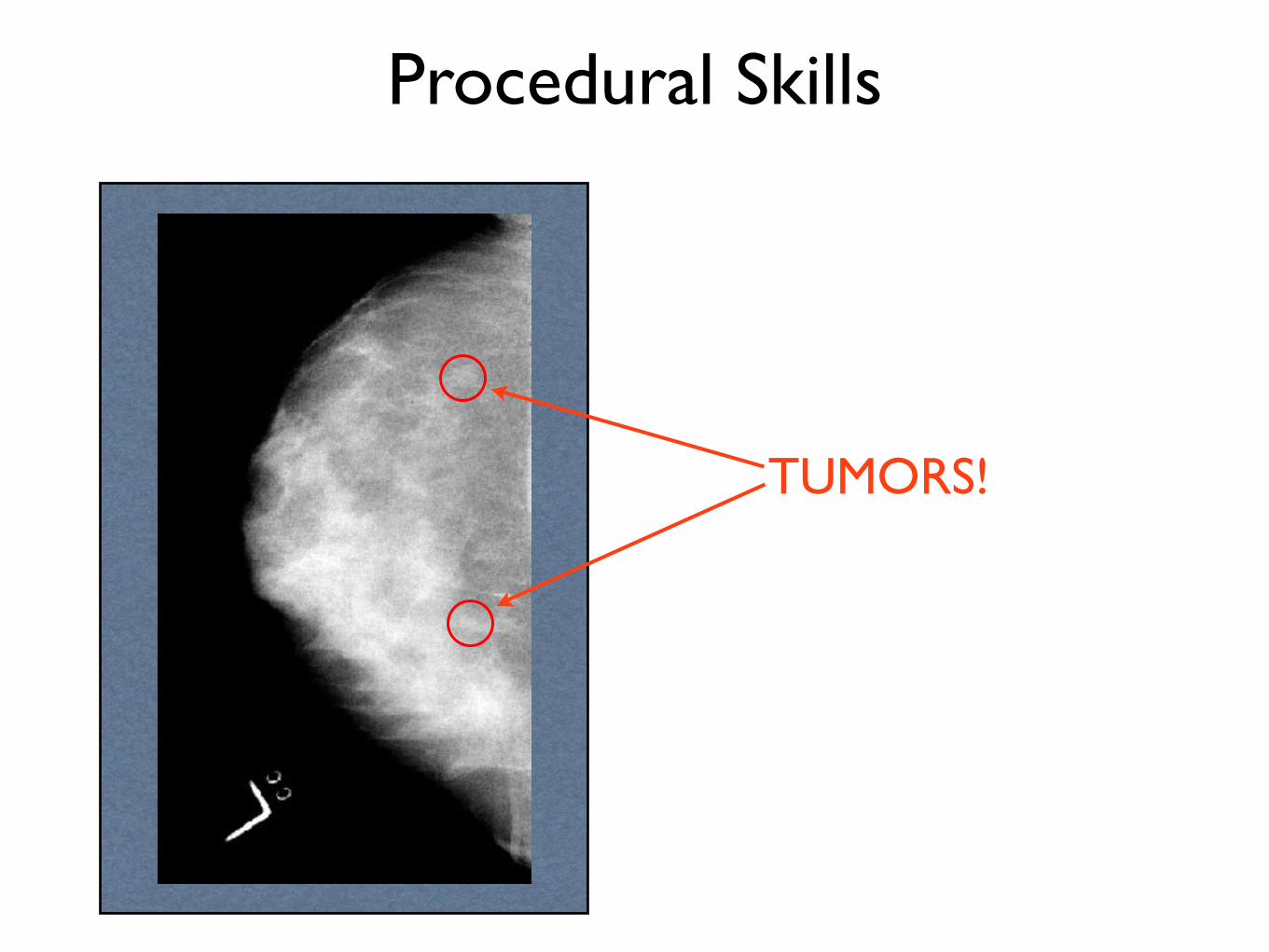
Procedural Skills
TUMORS!

Procedural Skills in the Lab
• Appetitive Instrumental Conditioning
• II Category Learning

Appealing Choices
• Much is known about the relevant neurobiology for each
• Each has investigated unlearning
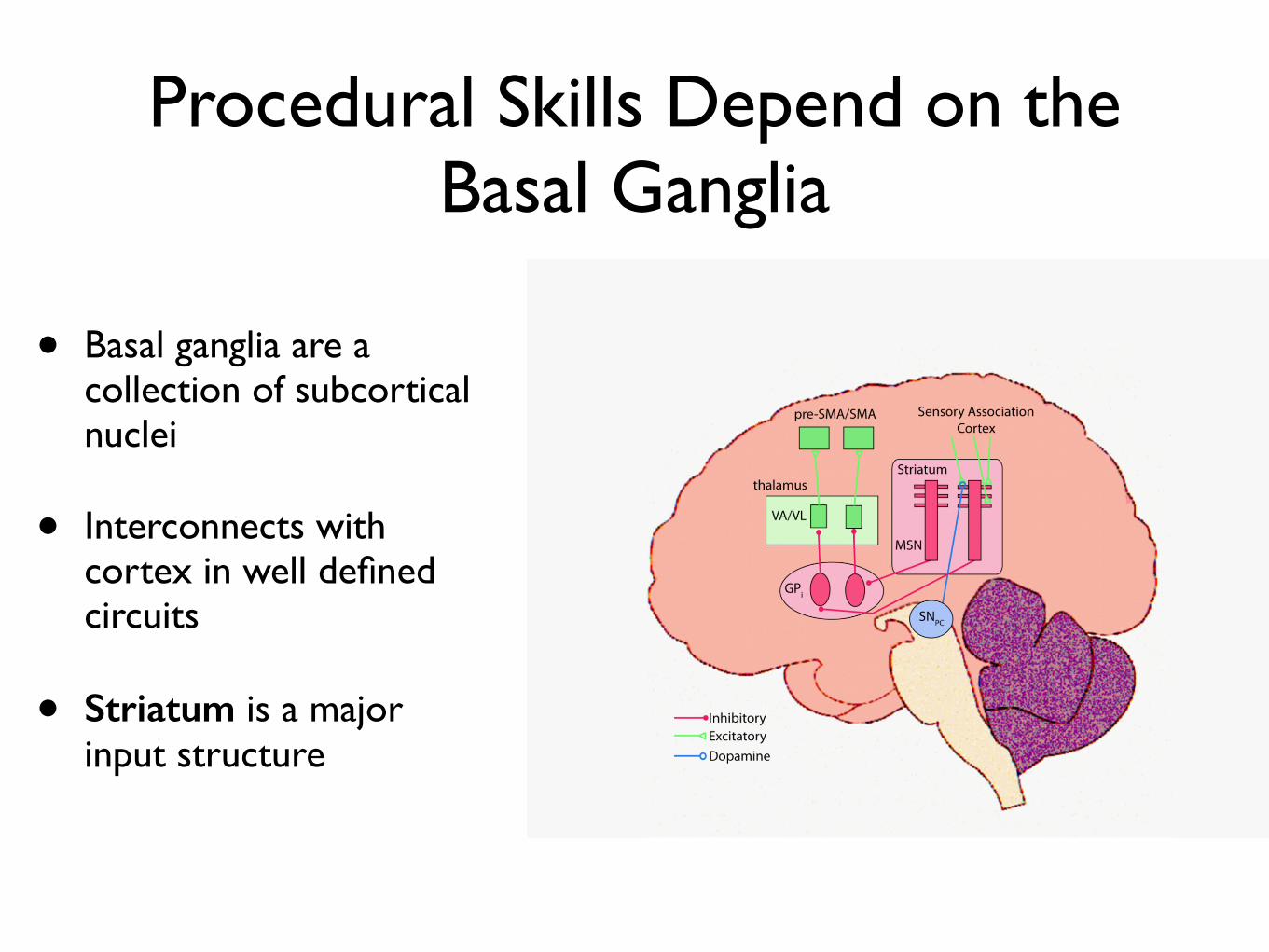
Procedural Skills Depend on the Basal Ganglia
• Basal ganglia are a collection of subcortical nuclei
• Interconnects with cortex in well defined circuits
• Striatum is a major input structure
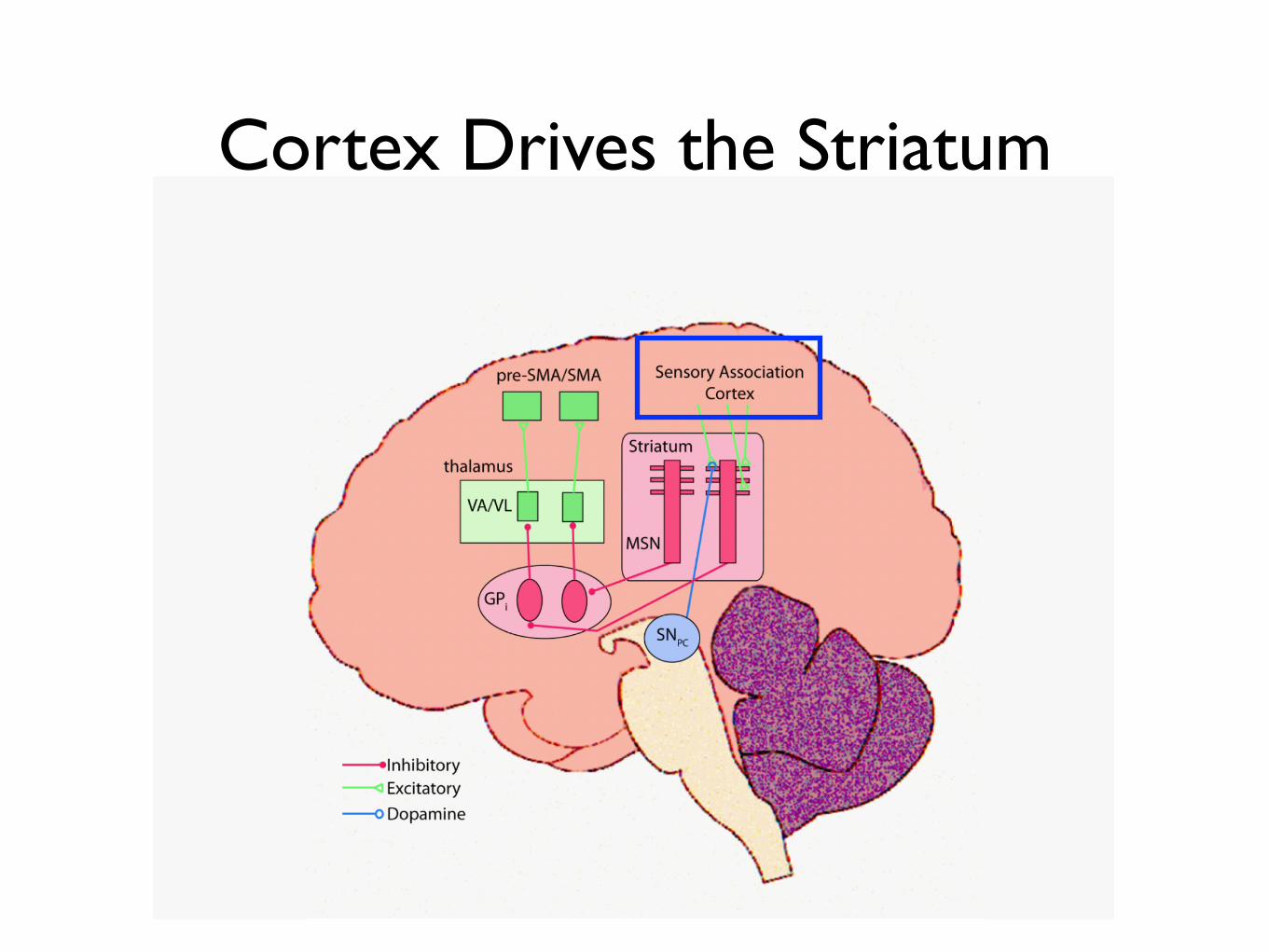
Cortex Drives the Striatum

Striatum Inhibits the GPi
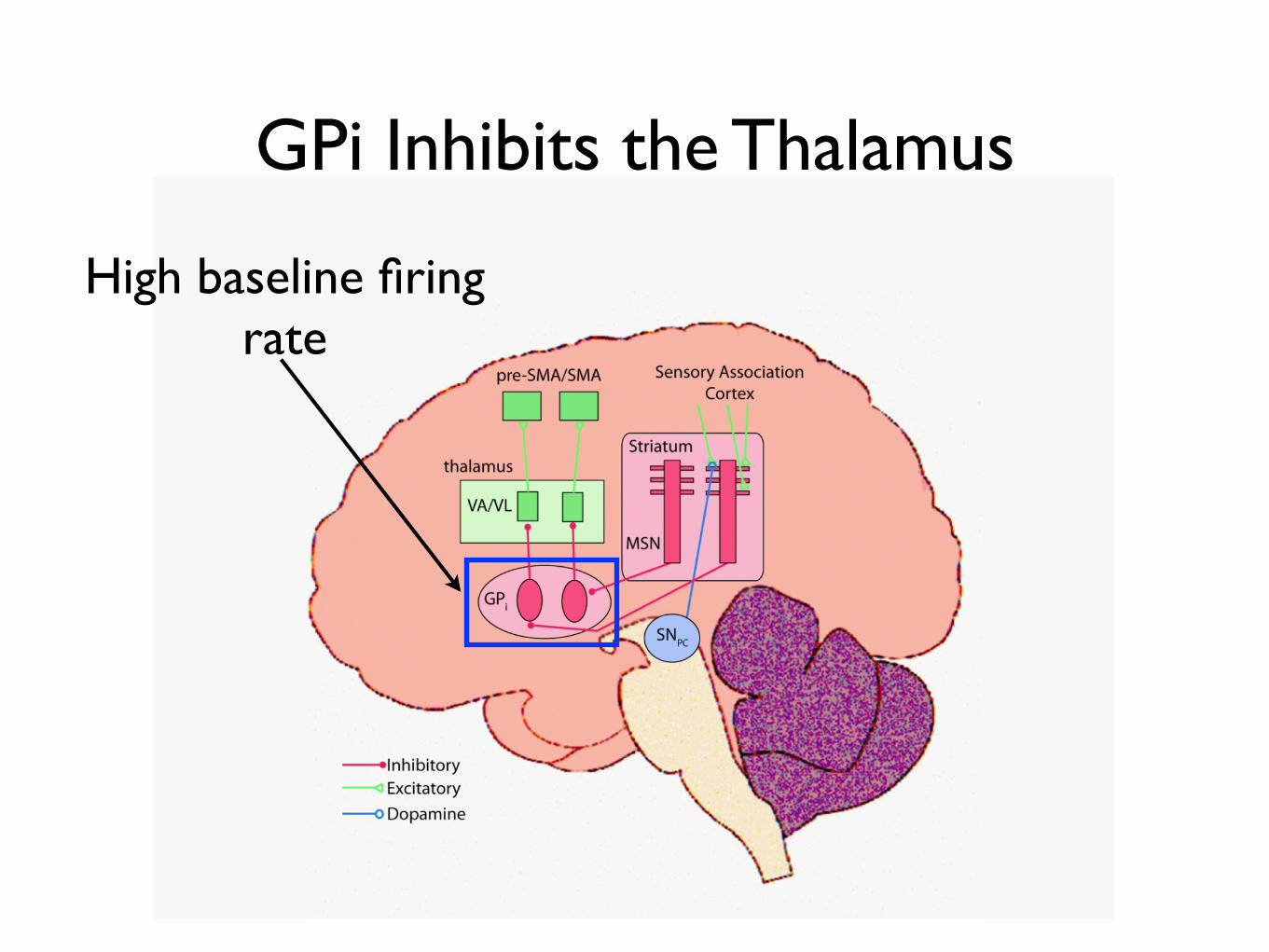
GPi Inhibits the Thalamus
High baseline firing rate
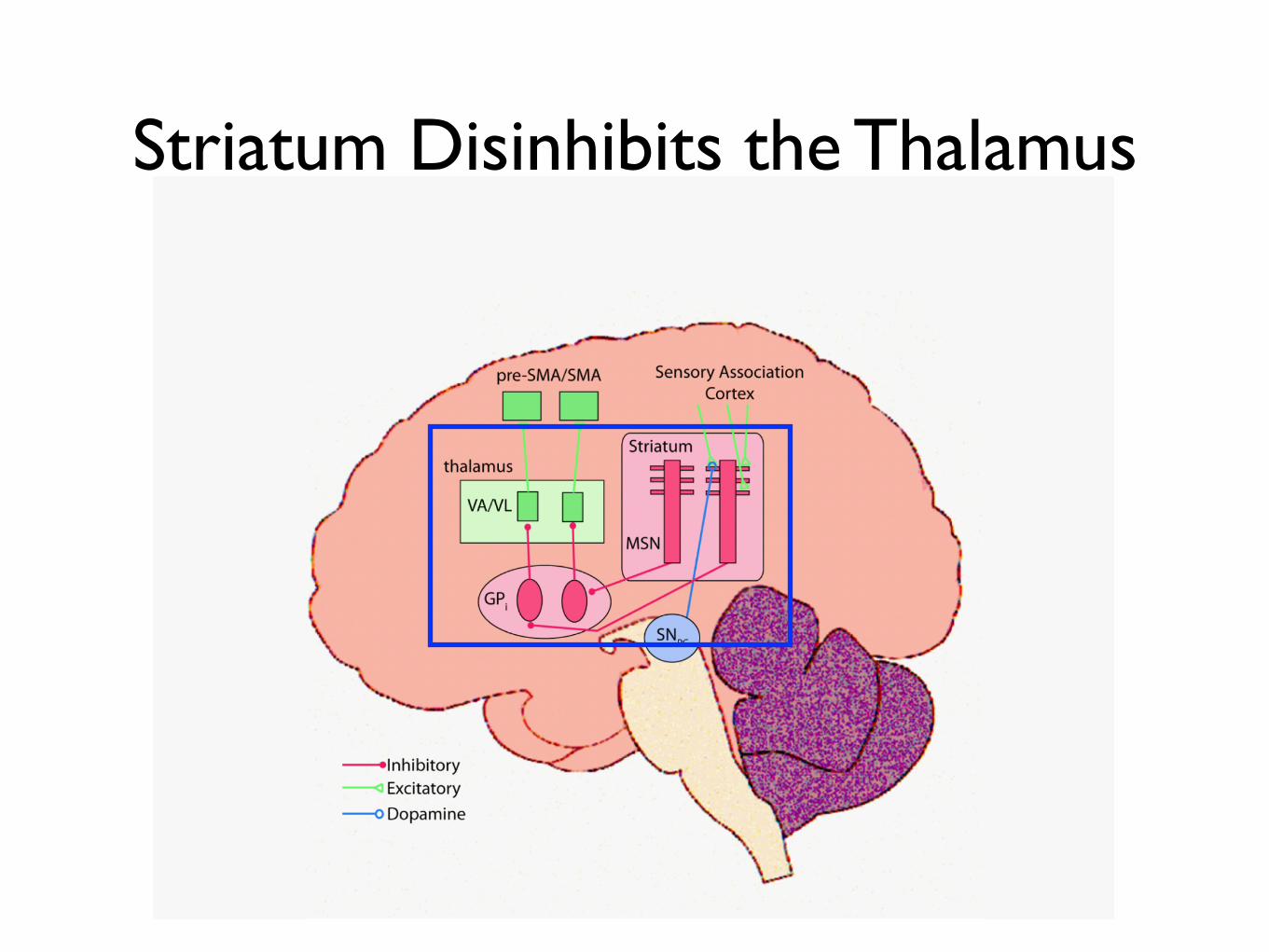
Striatum Disinhibits the Thalamus
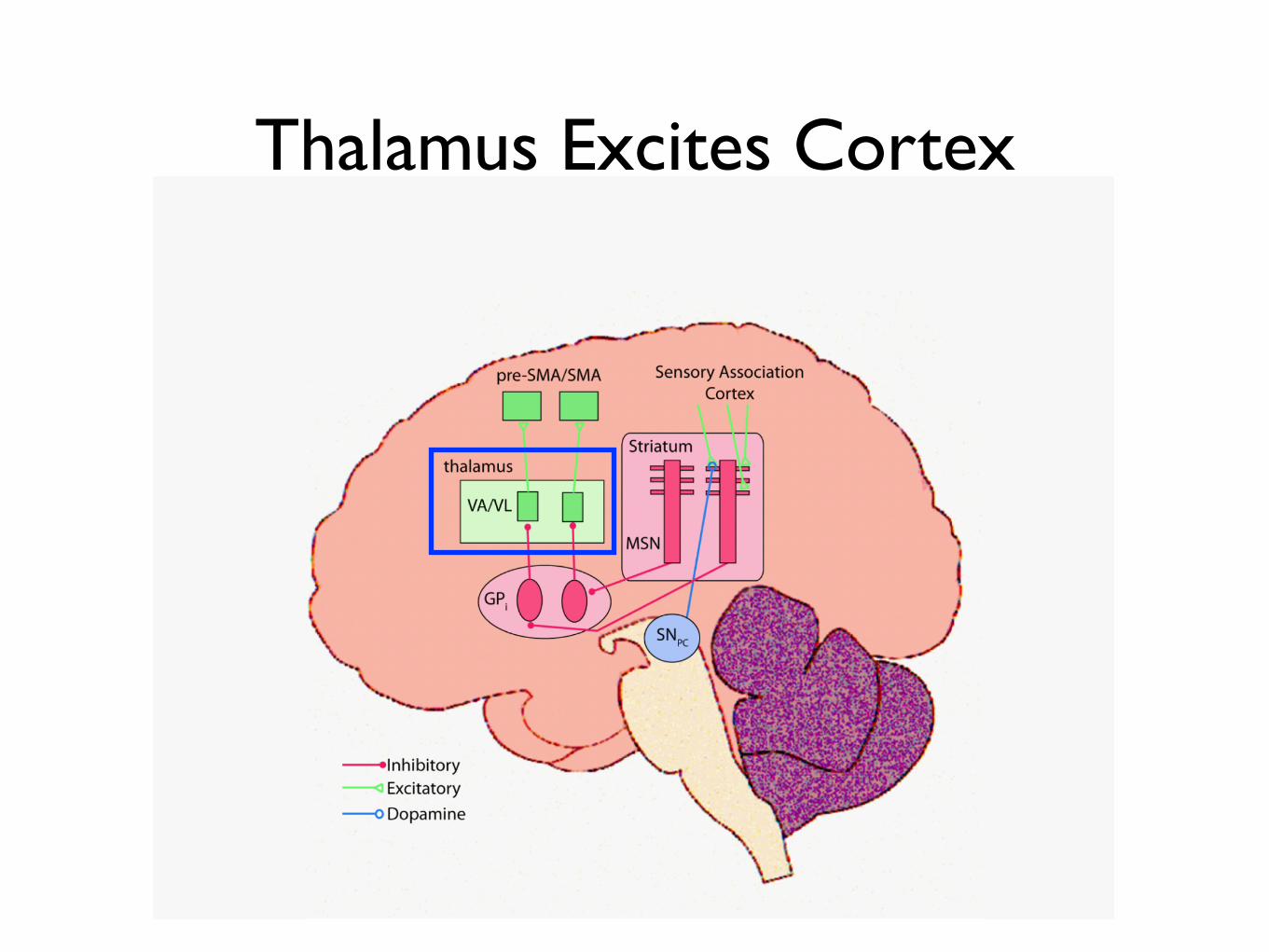
Thalamus Excites Cortex

Dopamine Modulates Activity

Procedural Learning Depends on the Striatum
• Single-cell recordings Carelli, Wolske, & West, 1997; Merchant, Zainos, Hernadez, Salinas, & Romo, 1997; Romo, Merchant, Ruiz, Crespo, & Zainos, 1995
• Lesion studies Eacott & Gaffan, 1991; Gaffan & Eacott, 1995; Gaffan & Harrison, 1987; McDonald & White, 1993, 1994; Packard, Hirsch, & White, 1989; Packard & McGaugh, 1992
• Neuropsychological patient studies Filoteo, Maddox, & Davis, 2001; Filoteo, Maddox, Salmon, & Song, 2005; Knowlton, Mangels, & Squire, 1996
• Neuroimaging Nomura et al., 2007; Seger & Cincotta, 2002; Waldschmidt & Ashby, 2011
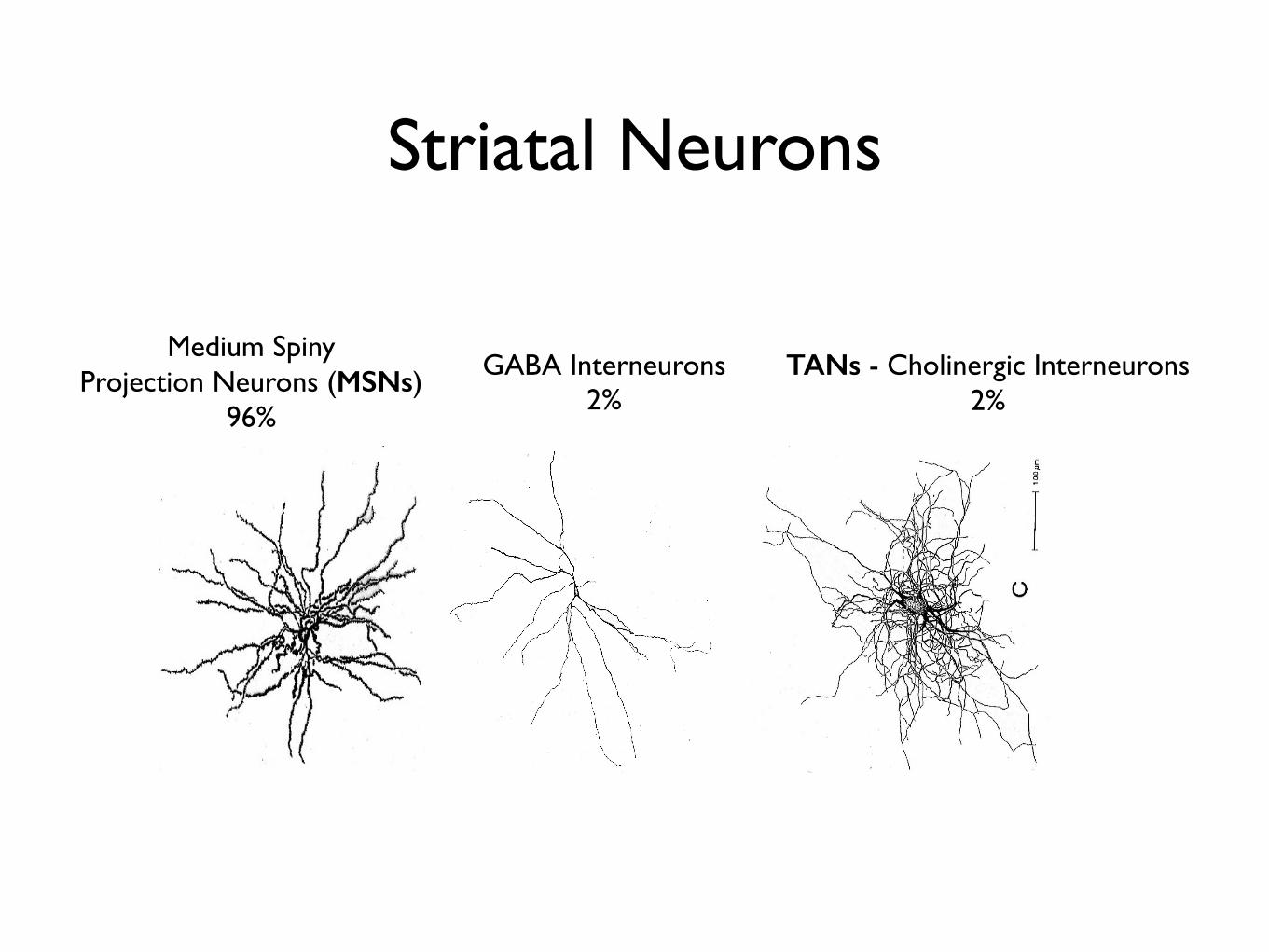
Striatal Neurons
Medium Spiny Projection Neurons (MSNs)
96%
GABA Interneurons 2%
TANs - Cholinergic Interneurons 2%

The TANs are of Particular Interest
• Tonically active and pause to excitatory input
• Presynaptically inhibit cortical input to MSNs
• Get major input from CM-Pf
• Learn to pause to stimuli that predict reward (requires dopamine)

• Procedural Skills
• Model Architecture
• Instrumental Conditioning Applications
• Category Learning Applications
• Closing Remarks
Outline
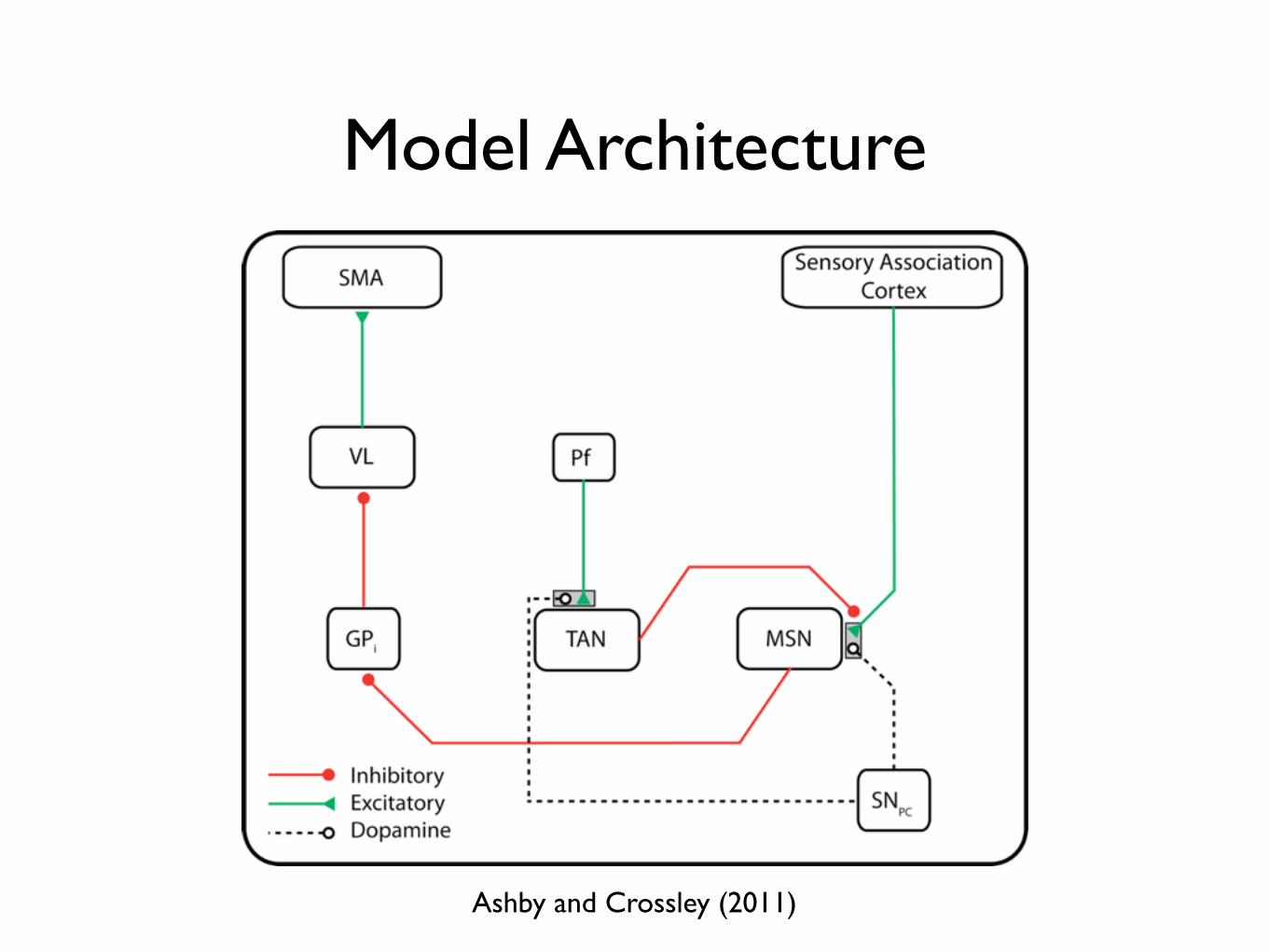
Model Architecture
Ashby and Crossley (2011)

Learning Occurs at the CTX-MSN Synapse and at Pf-TAN Synapses
Pf-TAN Synapse
CTX-MSN Synapse
Ashby and Crossley (2011)
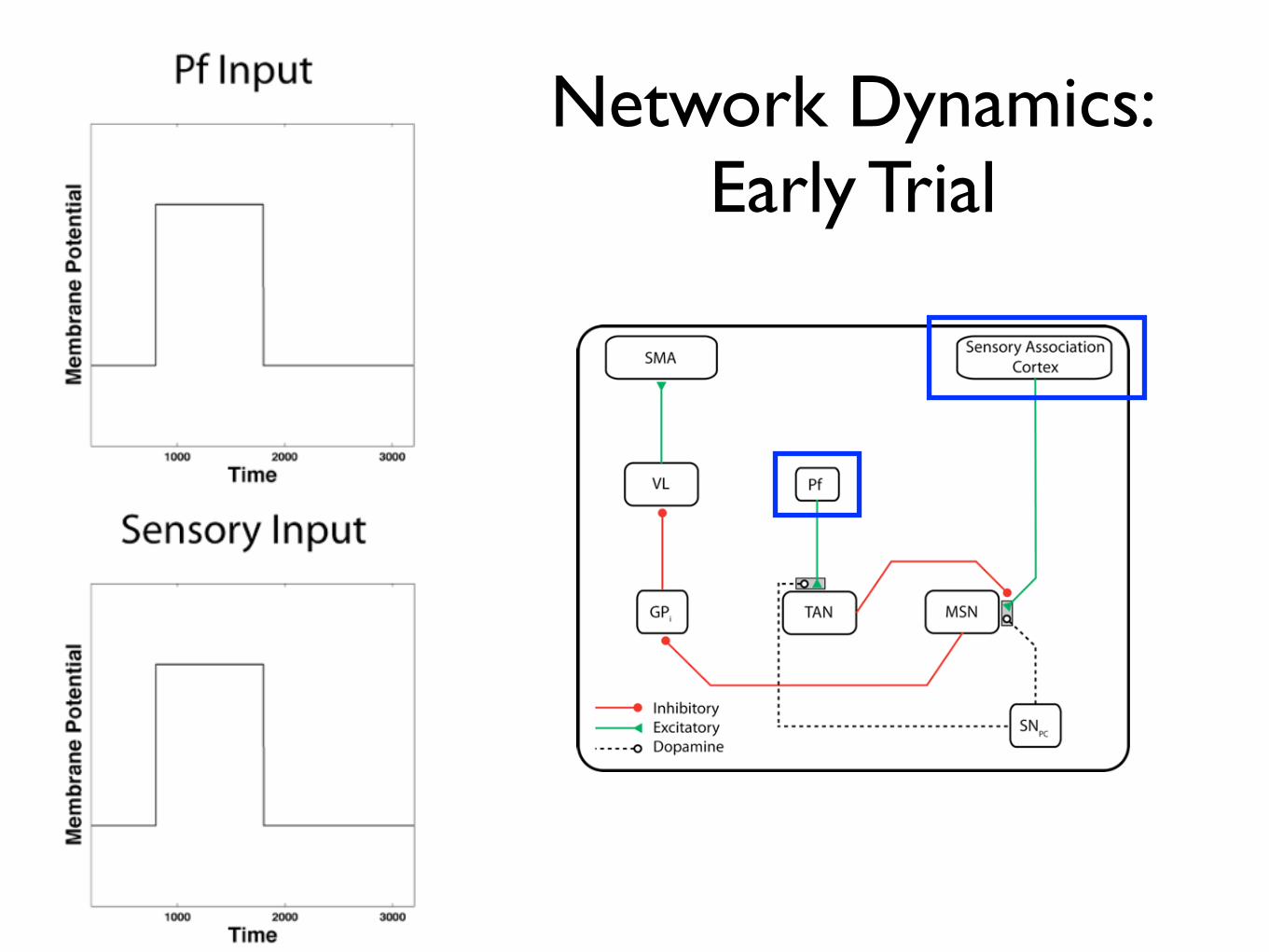
Network Dynamics: Early Trial

Network Dynamics: Early Trial

Network Dynamics - Early Trial
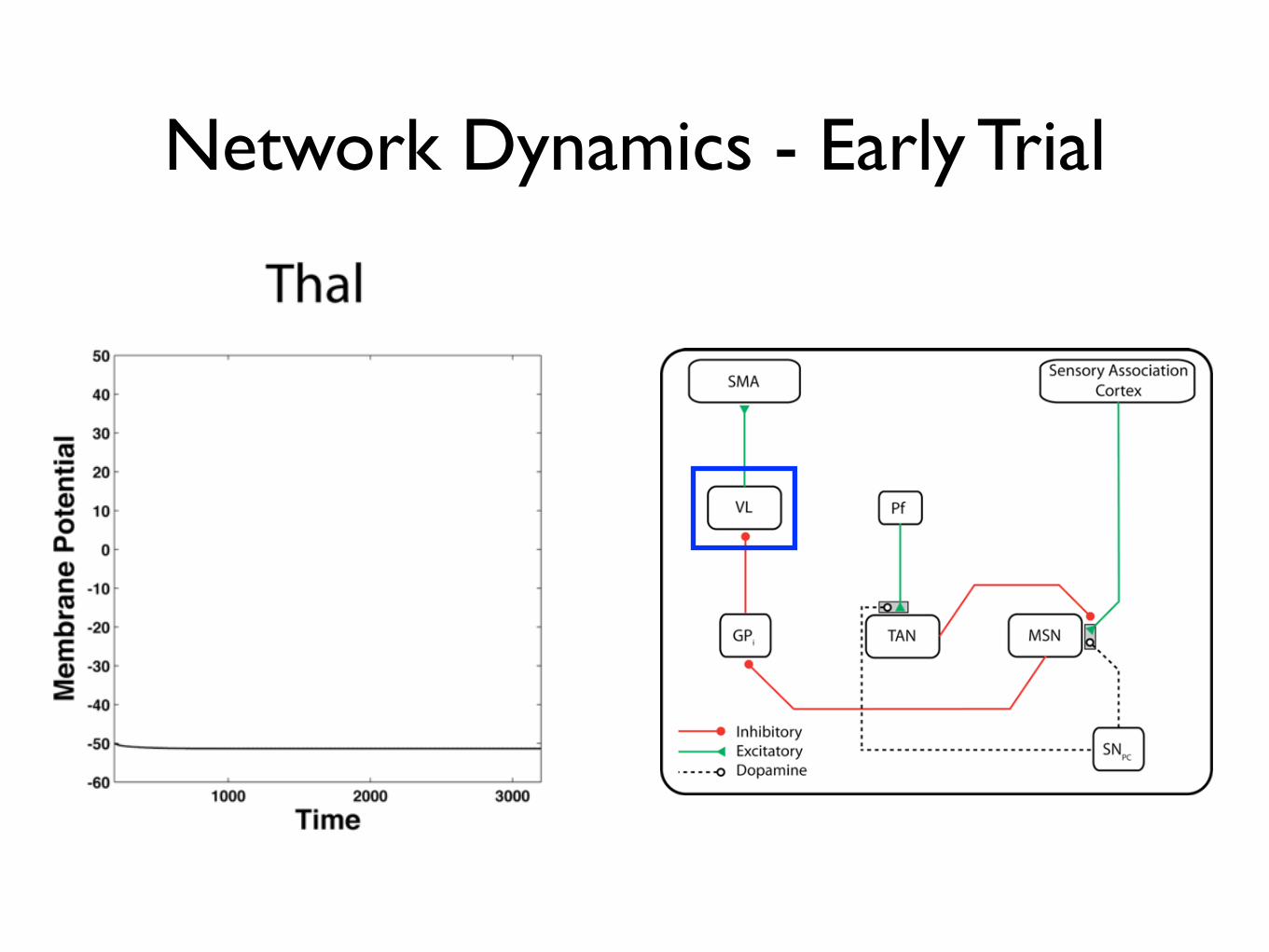
Network Dynamics - Early Trial
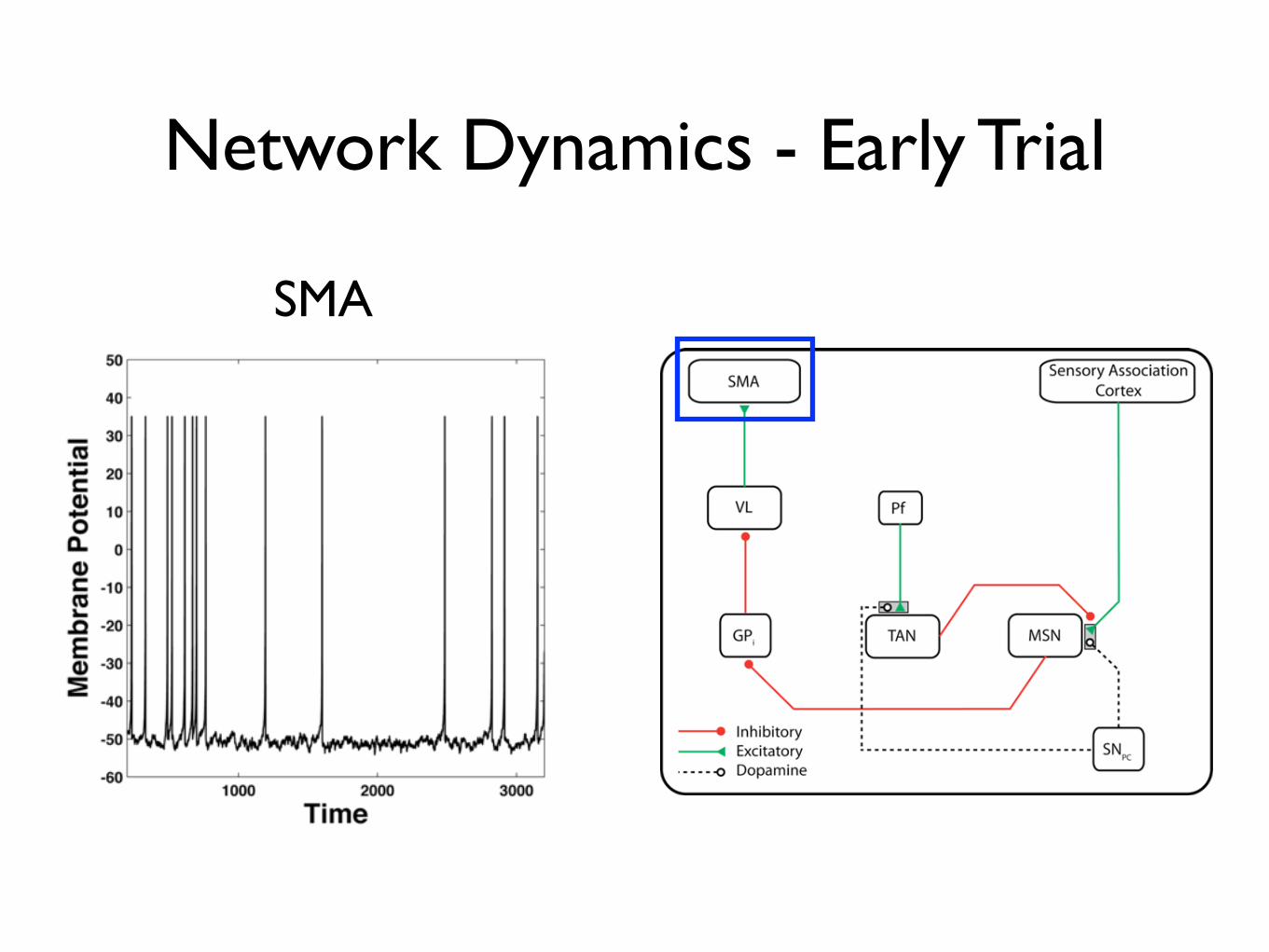
Network Dynamics - Early Trial
SMA

Response and Feedback
• Model responds if SMA crosses threshold
• Model is given feedback after every trial

Learning Occurs at the CTX-MSN Synapse and at Pf-TAN Synapses
Pf-TAN Synapse
CTX-MSN Synapse
Ashby and Crossley (2011)

CTX-MSN Synaptic Modification Requires a TANs Pause
• Synaptic Strengthening:
- Strong presynaptic activation
- Strong postsynaptic activation
- Elevated DA levels
• Synaptic Weakening:
- Strong presynaptic activation
- Strong postsynaptic activation
- Depressed DA levels
Arbuthnott, Ingham, & Wickens (2000) Calabresi, Pisani, Mercuri, & Bernardi (1996) Reynolds & Wickens (2002)

Synaptic Plasticity in the Striatum Depends on Dopamine (DA)
• Synaptic Strengthening:
- Strong presynaptic activation
- Strong postsynaptic activation
- Elevated DA levels
• Synaptic Weakening:
- Strong presynaptic activation
- Strong postsynaptic activation
- Depressed DA levels
Arbuthnott, Ingham, & Wickens (2000) Calabresi, Pisani, Mercuri, & Bernardi (1996) Reynolds & Wickens (2002)
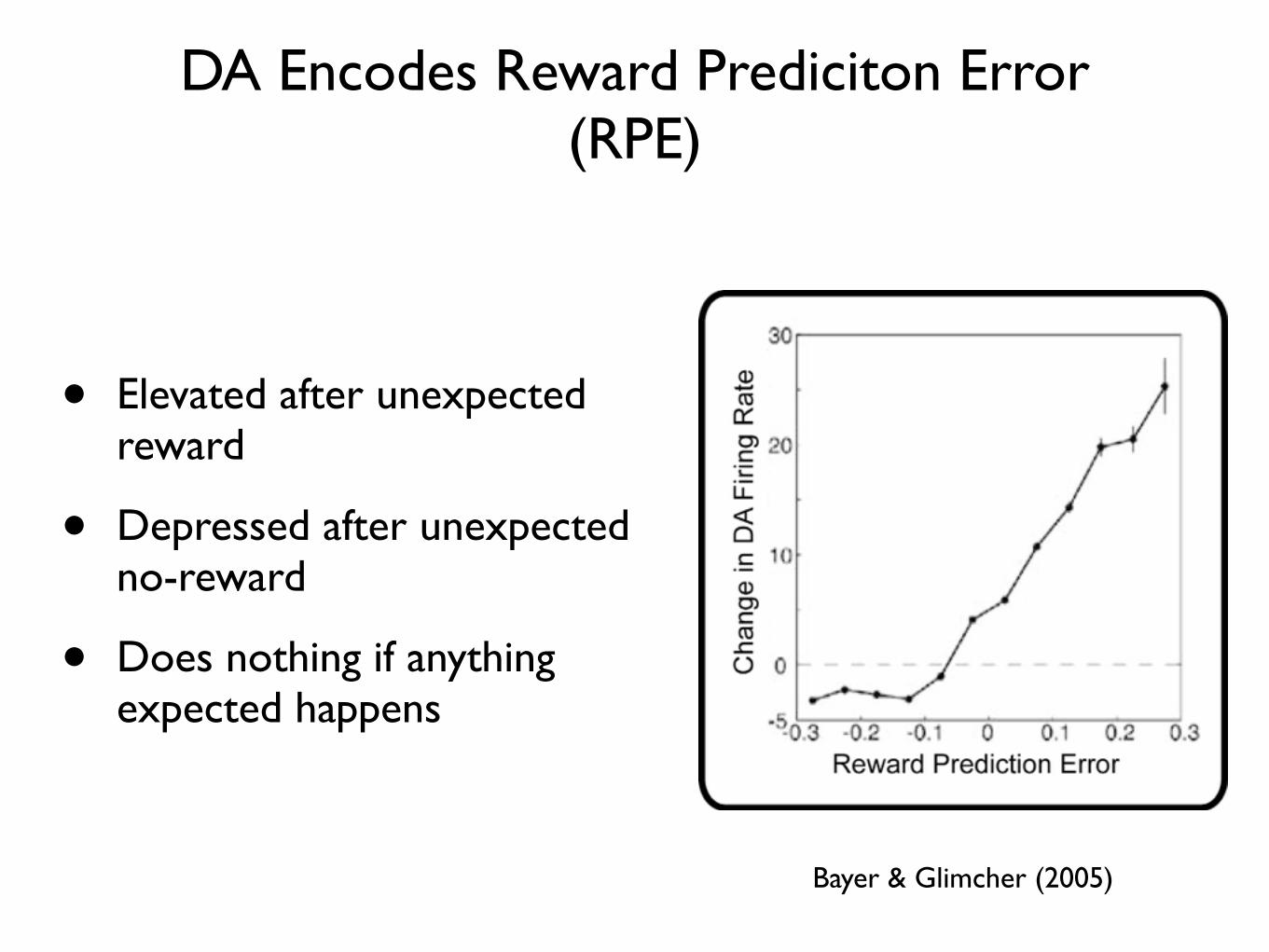
DA Encodes Reward Prediciton Error (RPE)
• Elevated after unexpected reward
• Depressed after unexpected no-reward
• Does nothing if anything expected happens
Bayer & Glimcher (2005)

Computing RPE
Obtained feedback on trial n:
Predicted feedback on trial n:
Rn =
�1 if positive feedback0 otherwise
Pn = Pn�1 + �(Rn�1 � Pn�1)
RPE on trial n:
RPE(n) = Rn � Pn
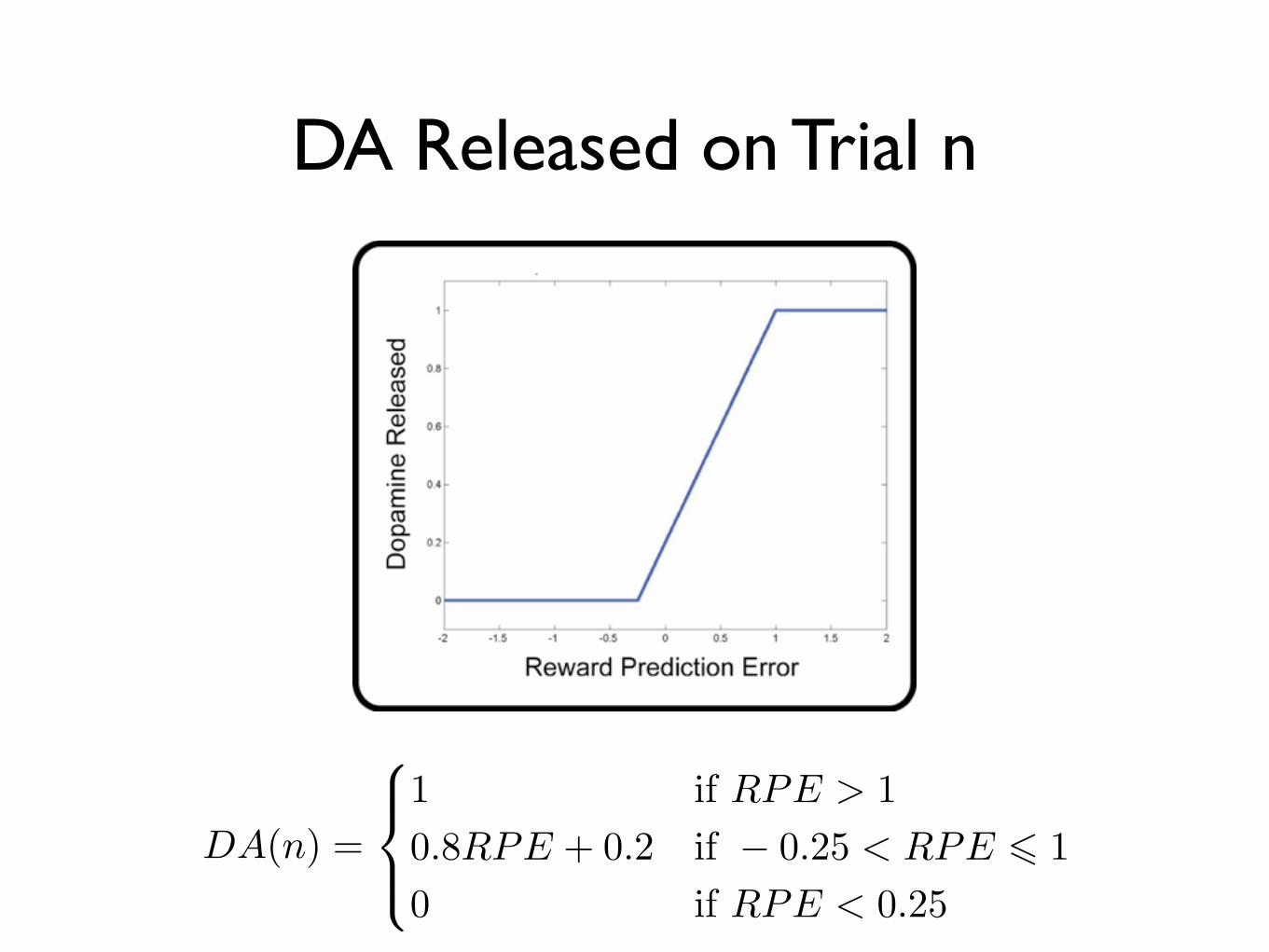
DA Released on Trial n
DA(n) =
�⌅⇤
⌅⇥
1 if RPE > 10.8RPE + 0.2 if � 0.25 < RPE � 10 if RPE < 0.25

Updating Synapses in the Model
!
wK ,J
(n +1) = wK ,J
(n)
+"wIK
(n) SJ(n) #$
NMDA[ ]+D(n) #D
base[ ]+
1# wK ,J
(n)[ ]
#%wIK
(n) SJ(n) #$
NMDA[ ]+Dbase
#D(n)[ ]+wK ,J
(n)
# &wIK
(n) $NMDA
# SJ(n)[ ]
+' S
J(n) #$
AMPA[ ]+wK ,J
(n).
Presynaptic Activity
Presynaptic Activity
Synaptic Strengthening
Synaptic Weakening

Updating Synapses in the Model
!
wK ,J
(n +1) = wK ,J
(n)
+"wIK
(n) SJ(n) #$
NMDA[ ]+D(n) #D
base[ ]+
1# wK ,J
(n)[ ]
#%wIK
(n) SJ(n) #$
NMDA[ ]+Dbase
#D(n)[ ]+wK ,J
(n)
# &wIK
(n) $NMDA
# SJ(n)[ ]
+' S
J(n) #$
AMPA[ ]+wK ,J
(n).
Postsynaptic Activation
Postsynaptic Activation
Synaptic Strengthening
Synaptic Weakening
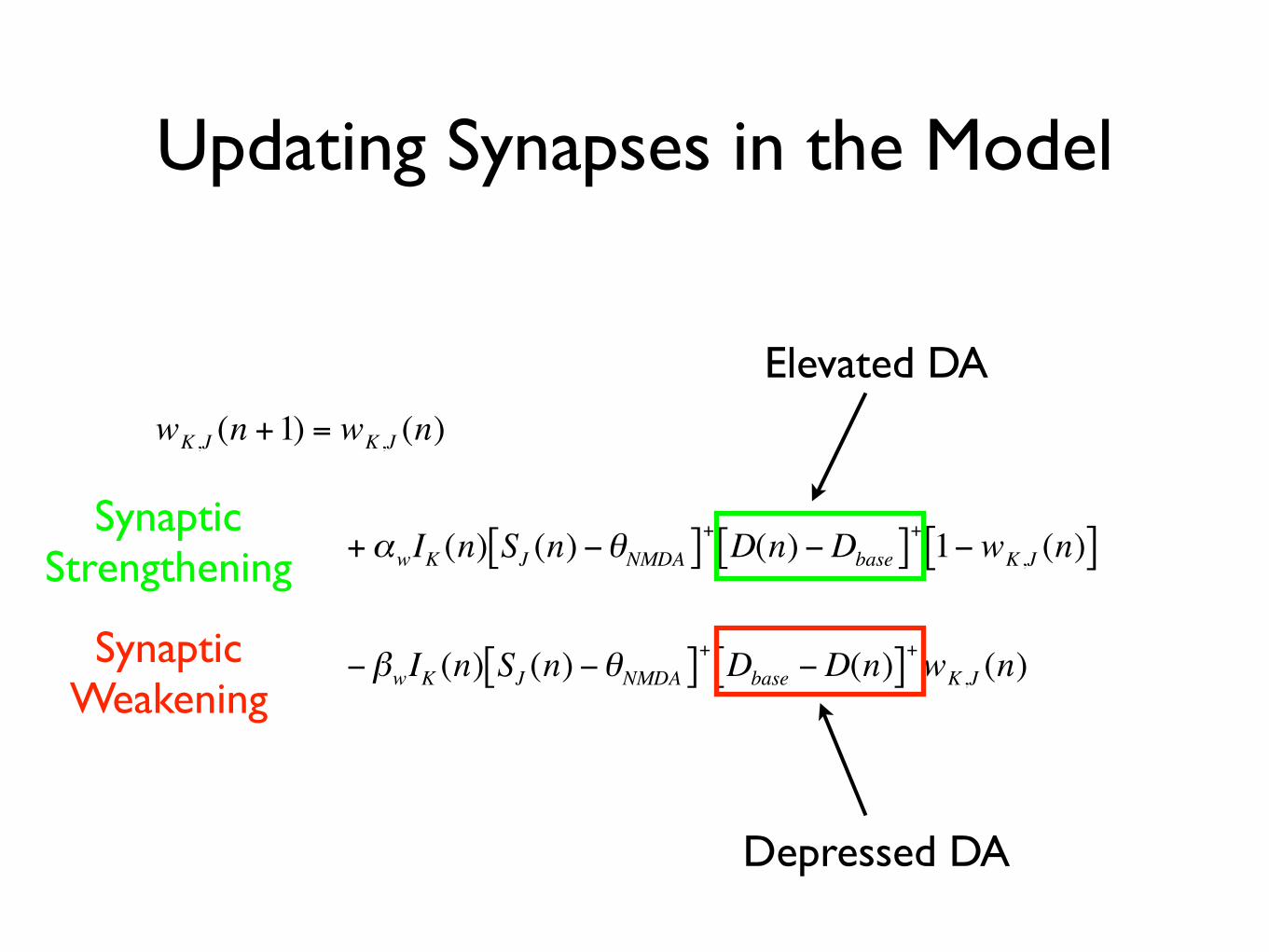
Updating Synapses in the Model
!
wK ,J
(n +1) = wK ,J
(n)
+"wIK
(n) SJ(n) #$
NMDA[ ]+D(n) #D
base[ ]+
1# wK ,J
(n)[ ]
#%wIK
(n) SJ(n) #$
NMDA[ ]+Dbase
#D(n)[ ]+wK ,J
(n)
# &wIK
(n) $NMDA
# SJ(n)[ ]
+' S
J(n) #$
AMPA[ ]+wK ,J
(n).
Elevated DA
Depressed DA
Synaptic Strengthening
Synaptic Weakening
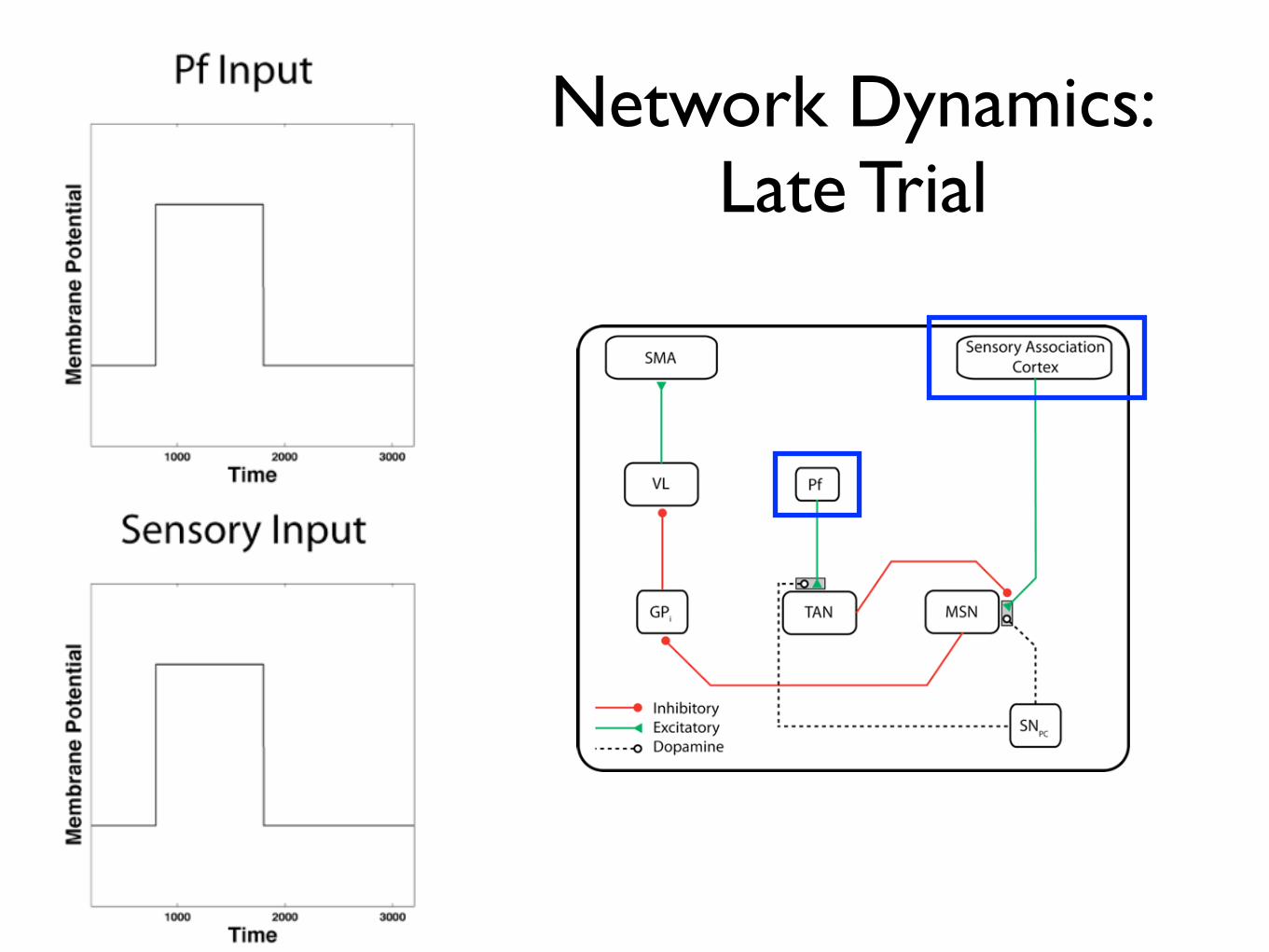
Network Dynamics: Late Trial

Network Dynamics: Late Trial
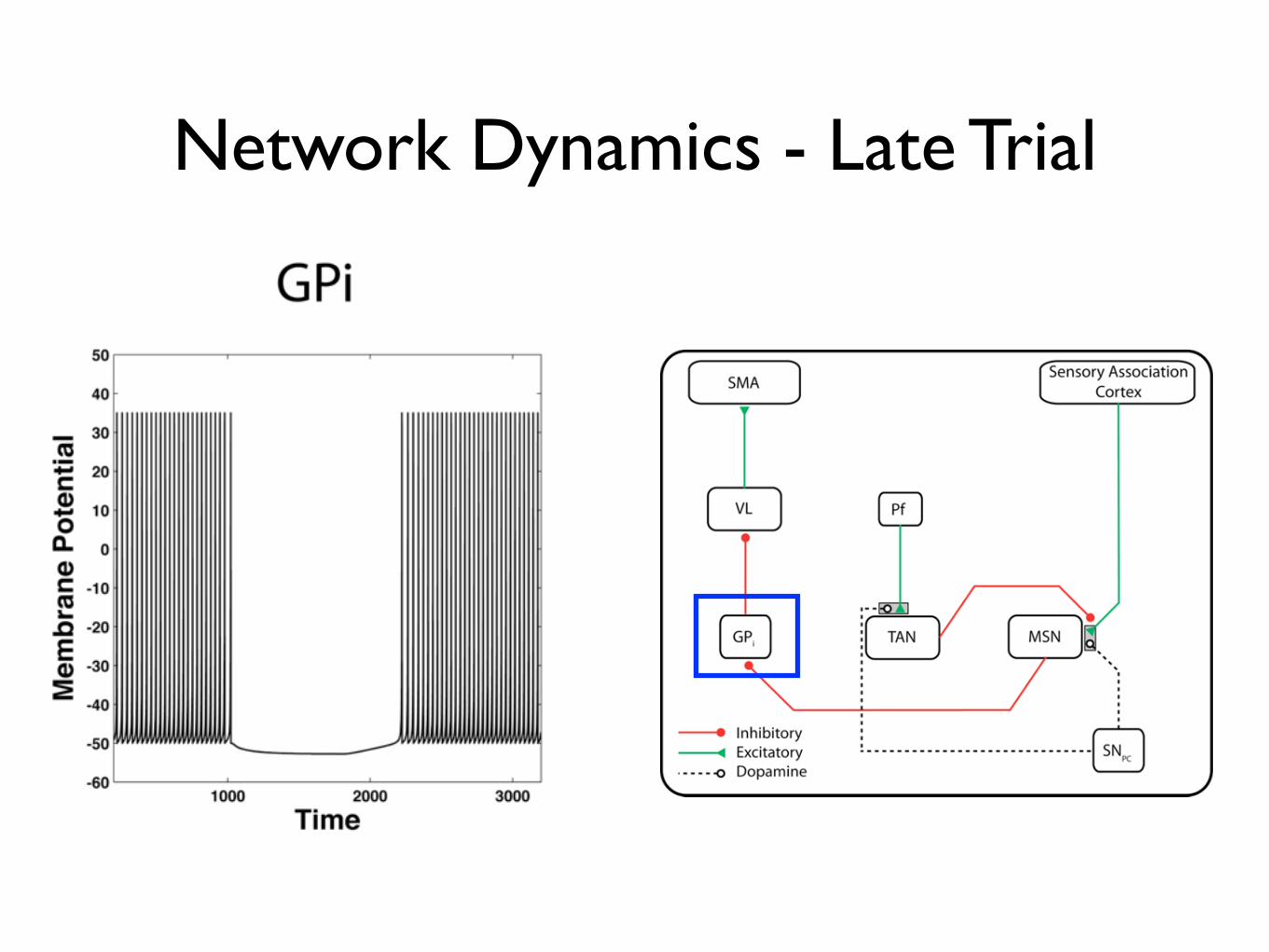
Network Dynamics - Late Trial
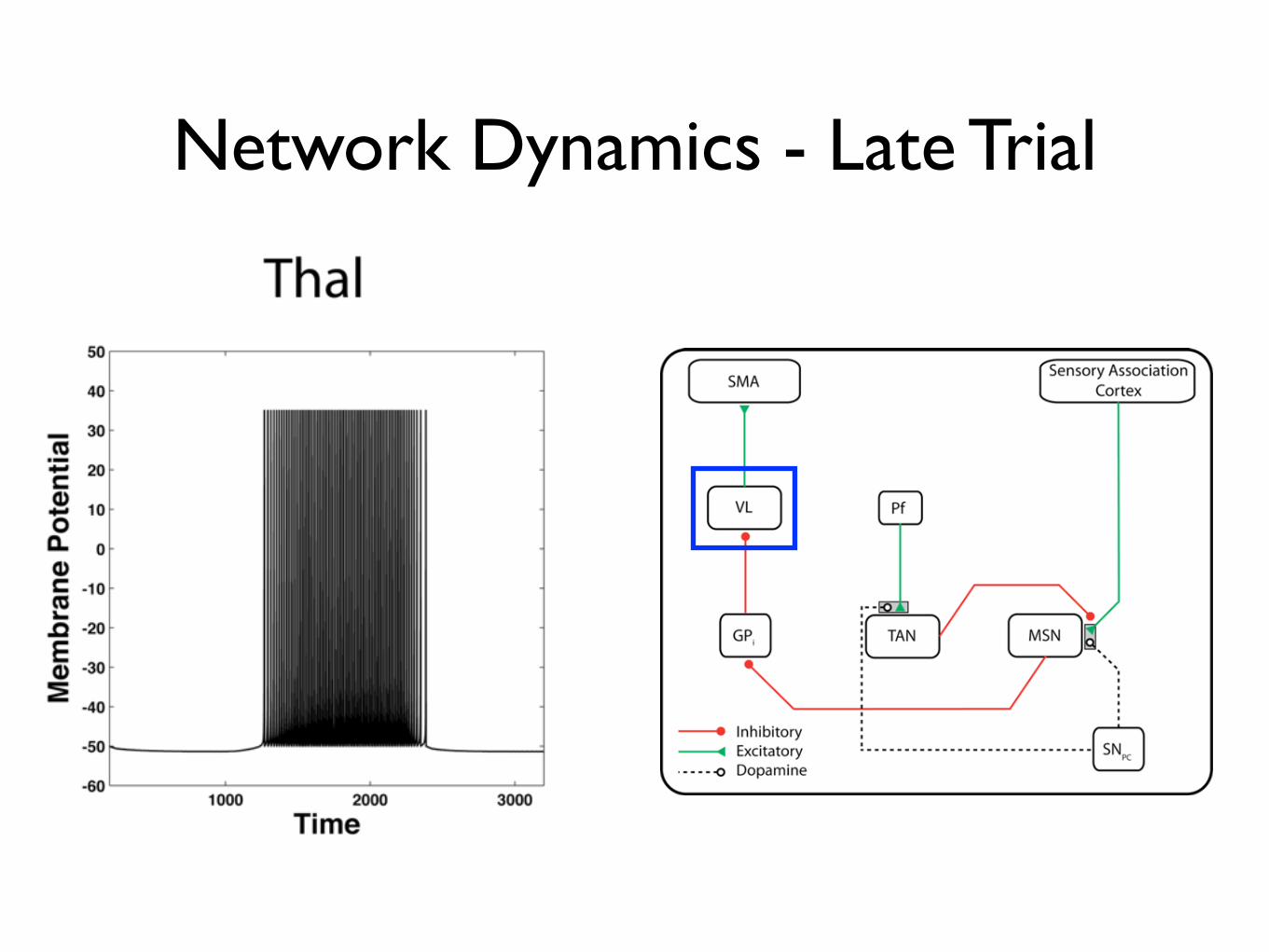
Network Dynamics - Late Trial

Network Dynamics - Late Trial
SMA
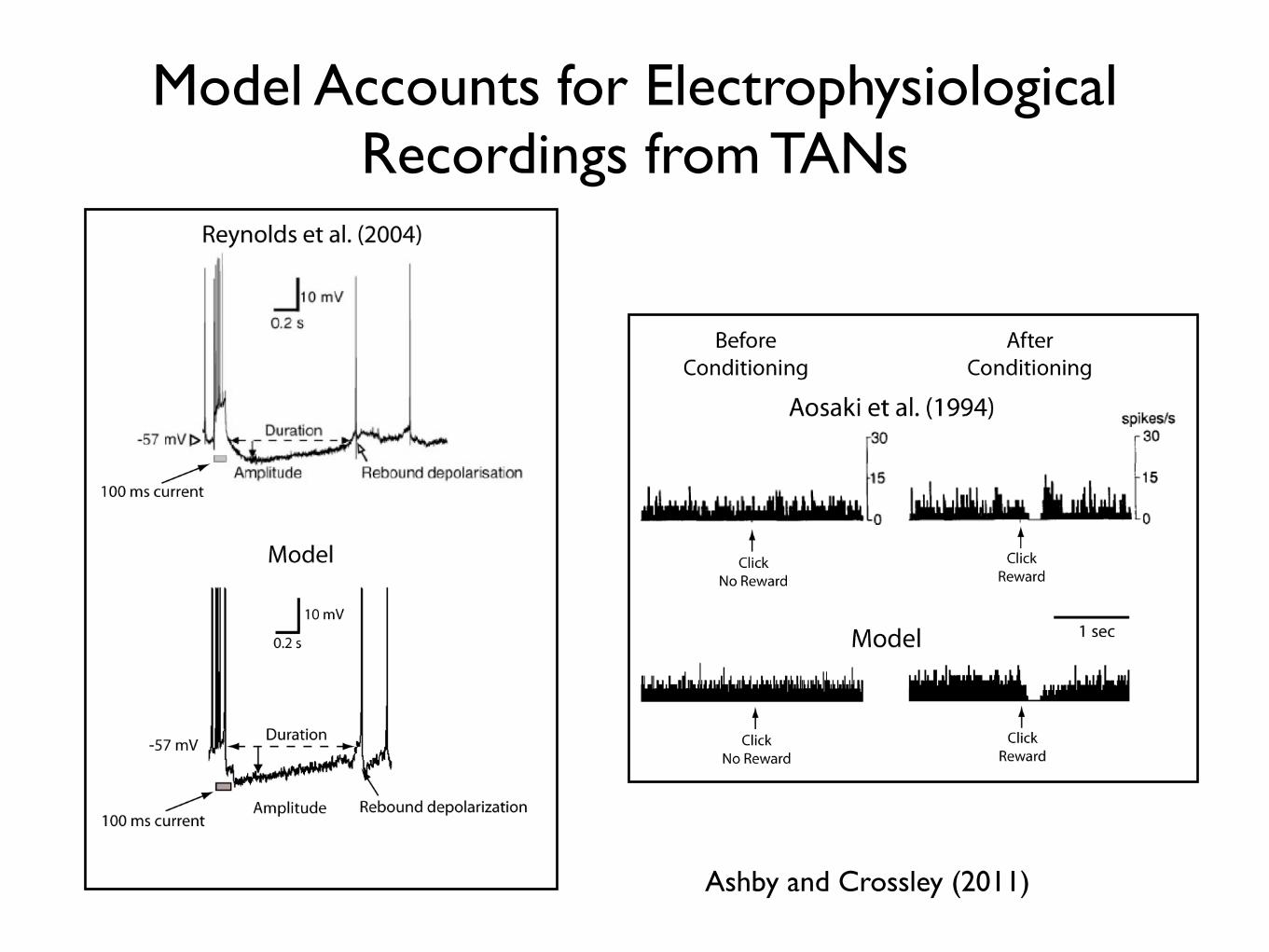
Model Accounts for Electrophysiological Recordings from TANs
Ashby and Crossley (2011)
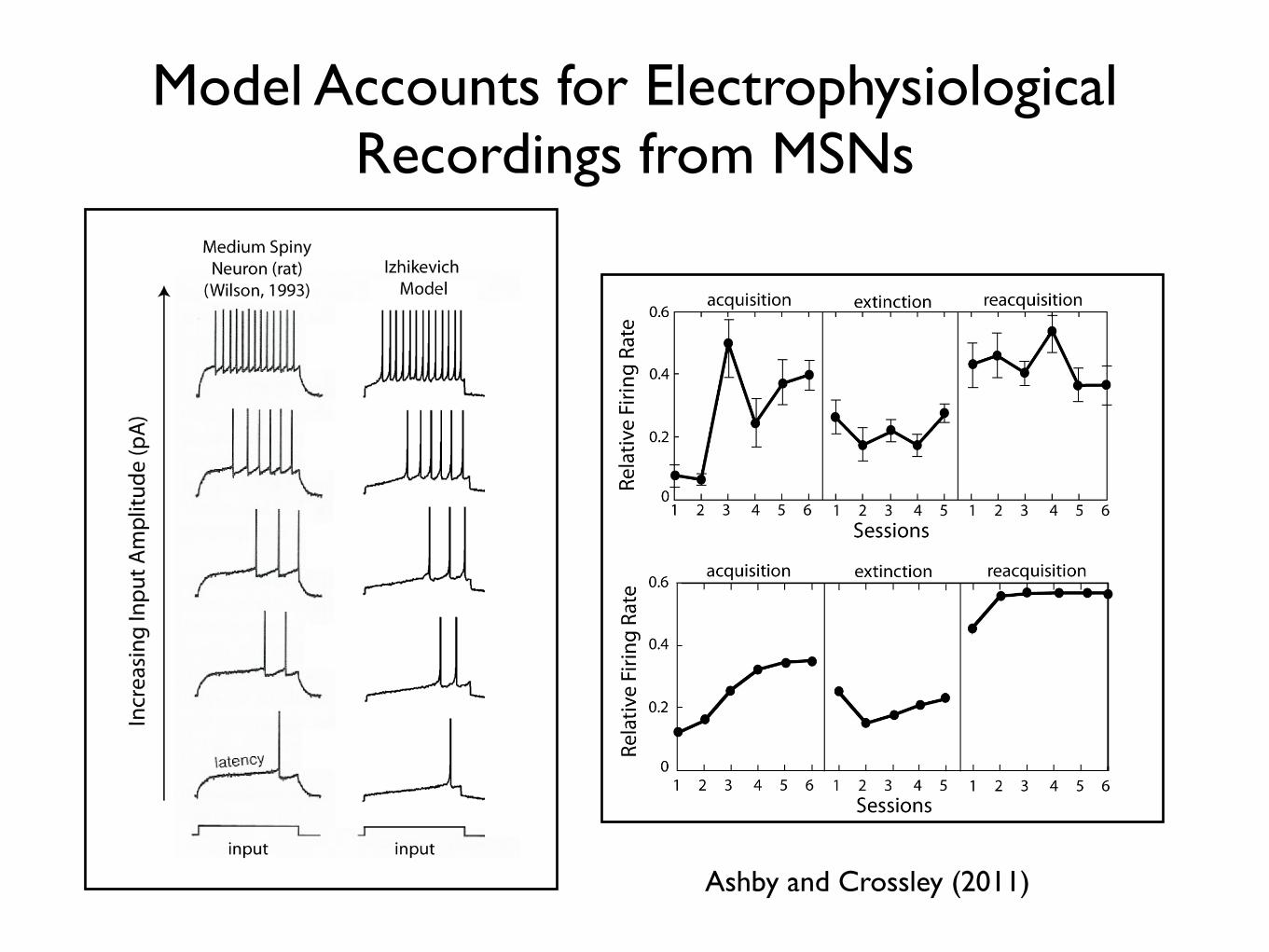
Model Accounts for Electrophysiological Recordings from MSNs
Ashby and Crossley (2011)
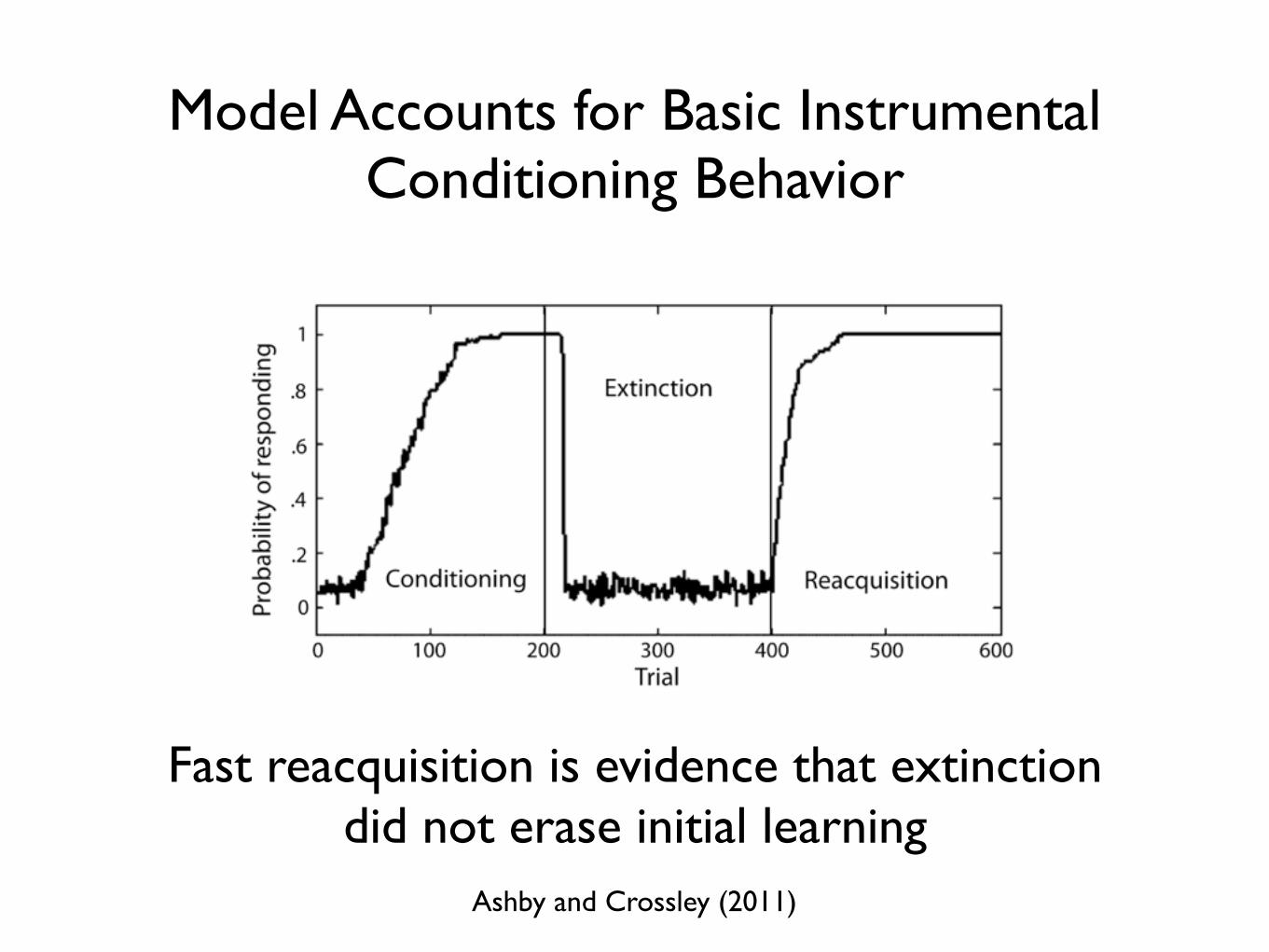
Model Accounts for Basic Instrumental Conditioning Behavior
Ashby and Crossley (2011)
Fast reacquisition is evidence that extinction did not erase initial learning

• Procedural Skills
• Model Architecture
• Instrumental Conditioning Applications
• Category Learning Applications
• Closing Remarks
Outline
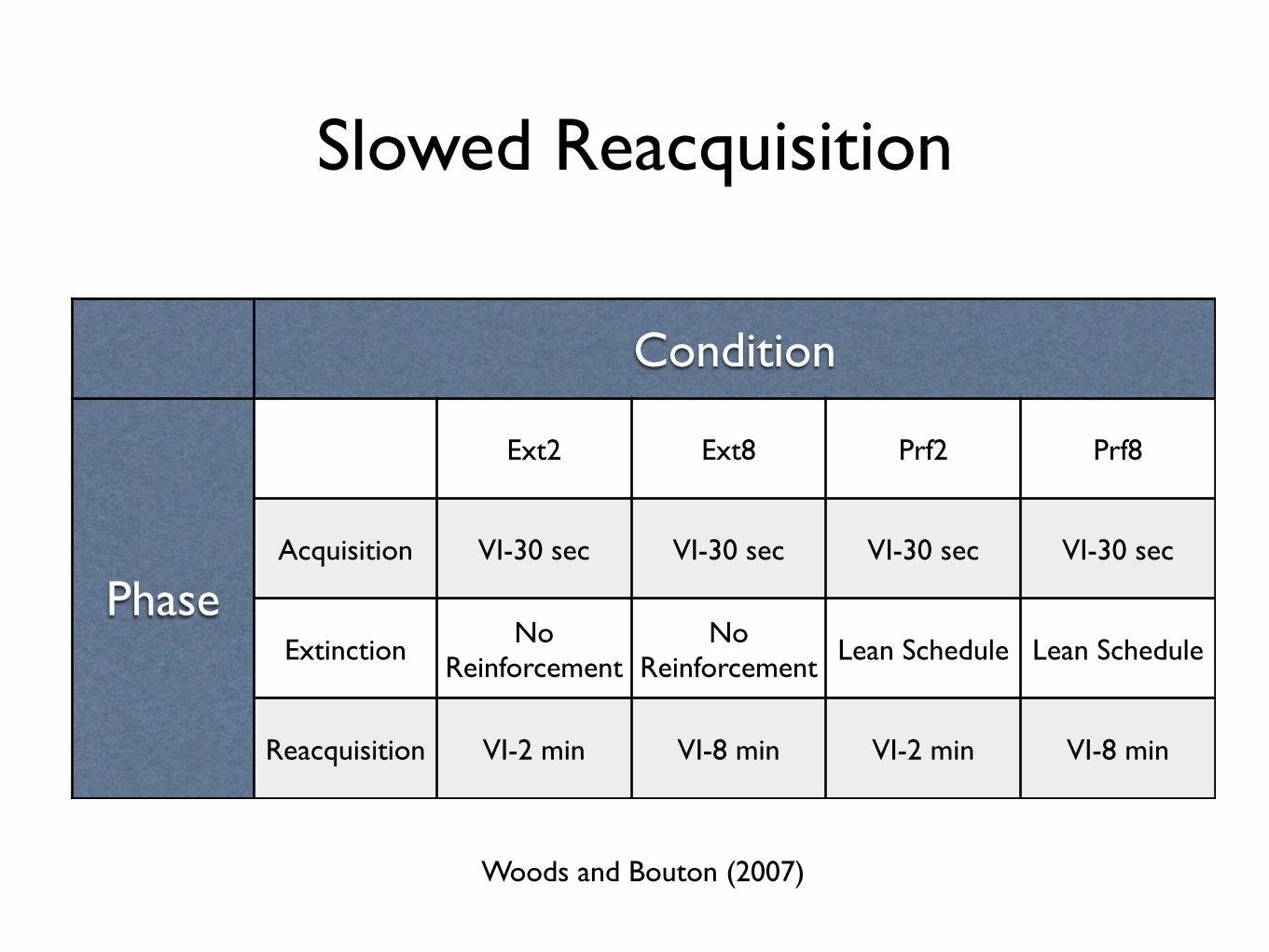
Slowed Reacquisition
Condition
Phase
Ext2 Ext8 Prf2 Prf8
Acquisition VI-30 sec VI-30 sec VI-30 sec VI-30 sec
ExtinctionNo
ReinforcementNo
ReinforcementLean Schedule Lean Schedule
Reacquisition VI-2 min VI-8 min VI-2 min VI-8 min
Woods and Bouton (2007)
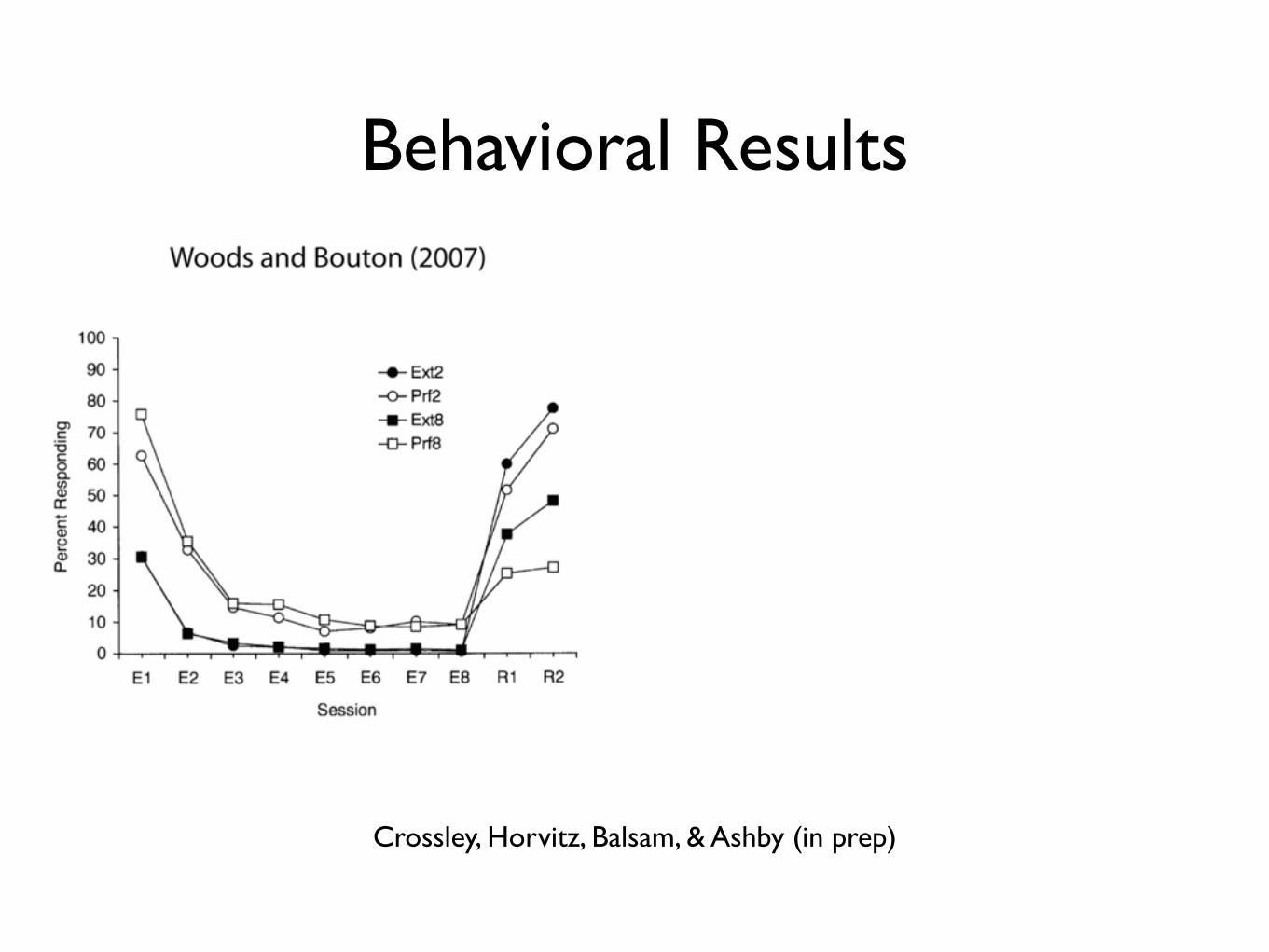
Behavioral Results
Crossley, Horvitz, Balsam, & Ashby (in prep)
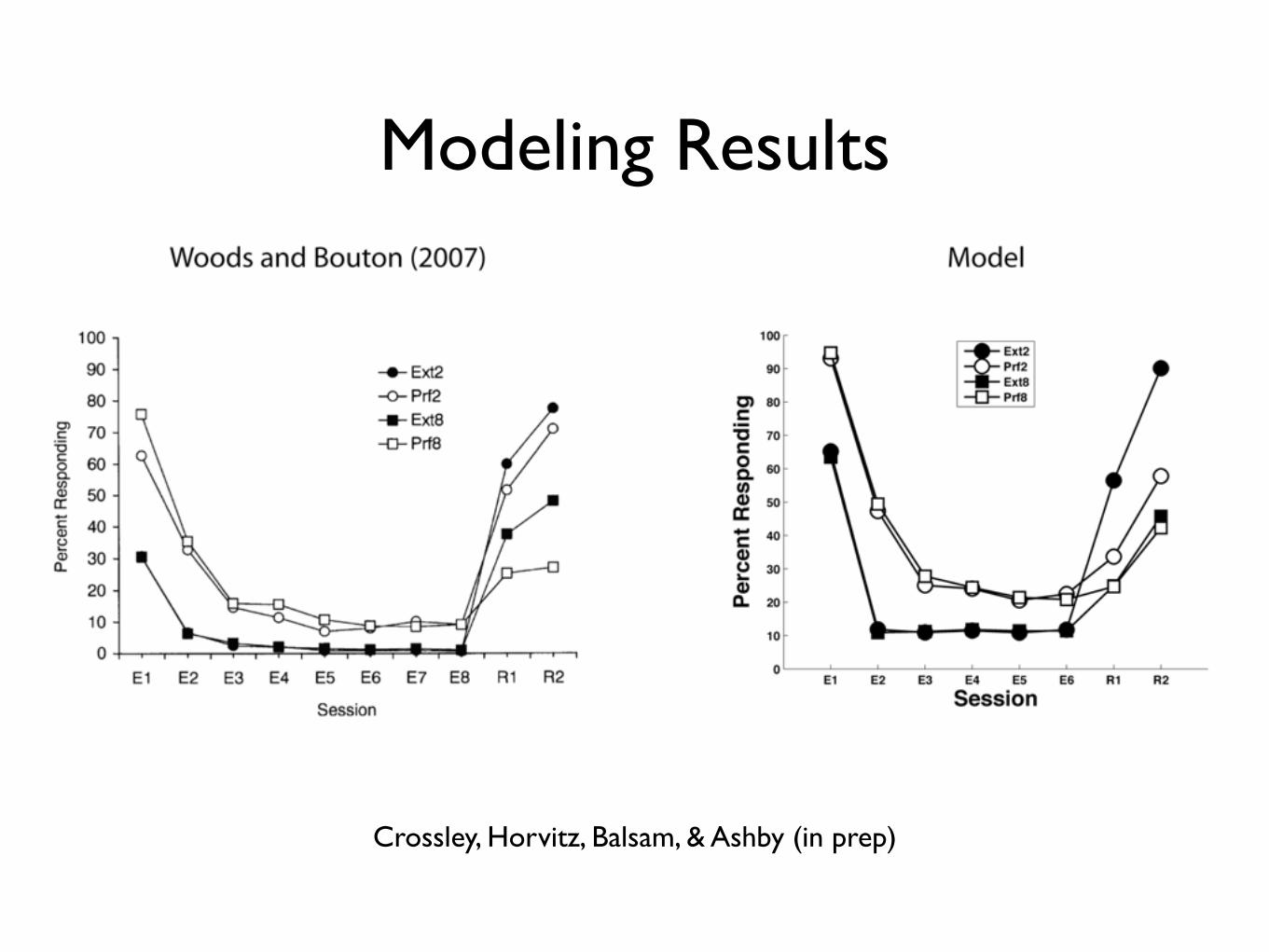
Modeling Results
Crossley, Horvitz, Balsam, & Ashby (in prep)
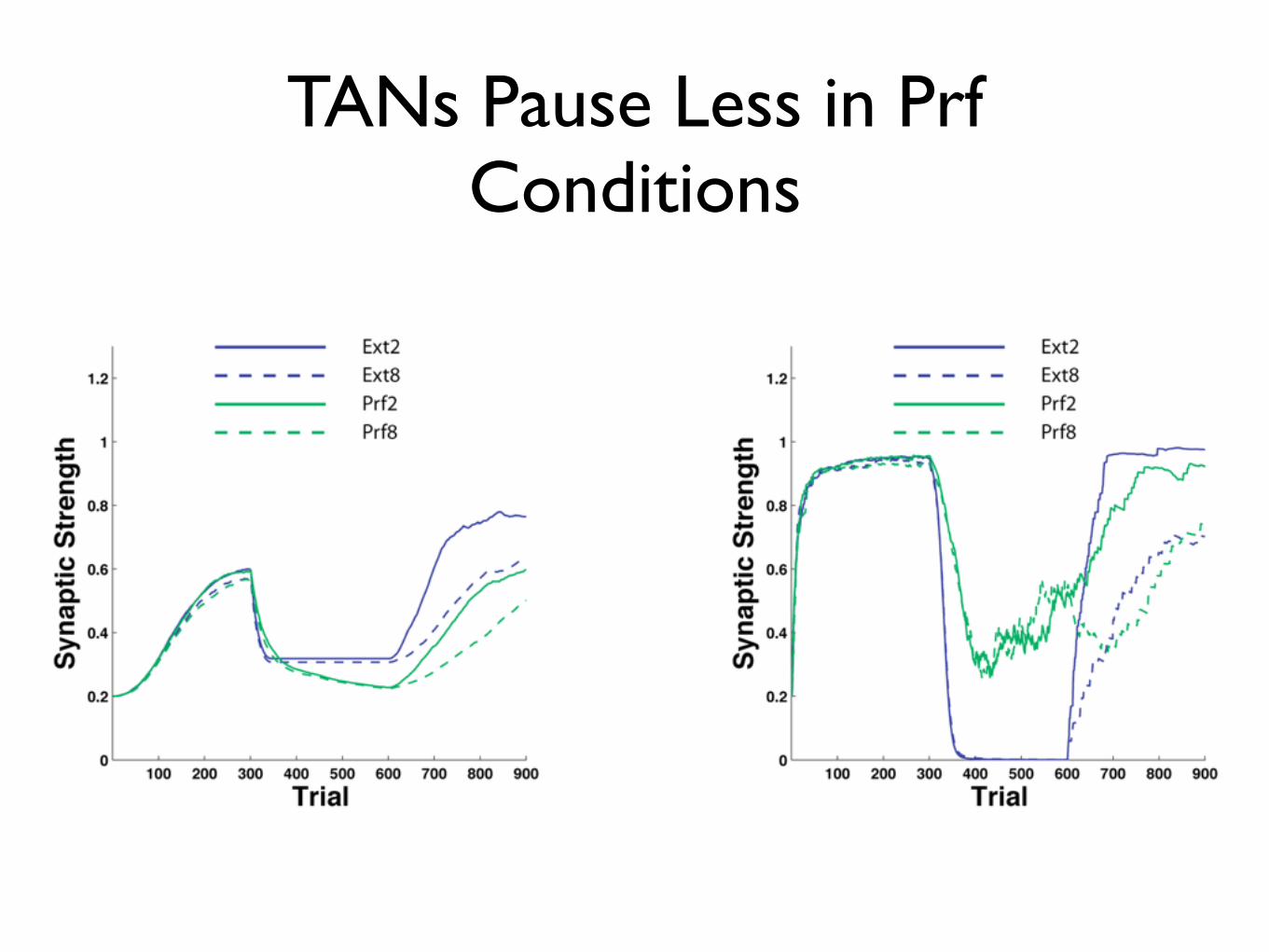
TANs Pause Less in Prf Conditions

Renewal - Basic Design
Condition
Phase
ABA AAB ABC
Acquisition Environment A Environment A Environment A
Extinction Environment B Environment A Environment B
Renewal (Extinction)
Environment A Environment B Environment C
Bouton et al. (2011)
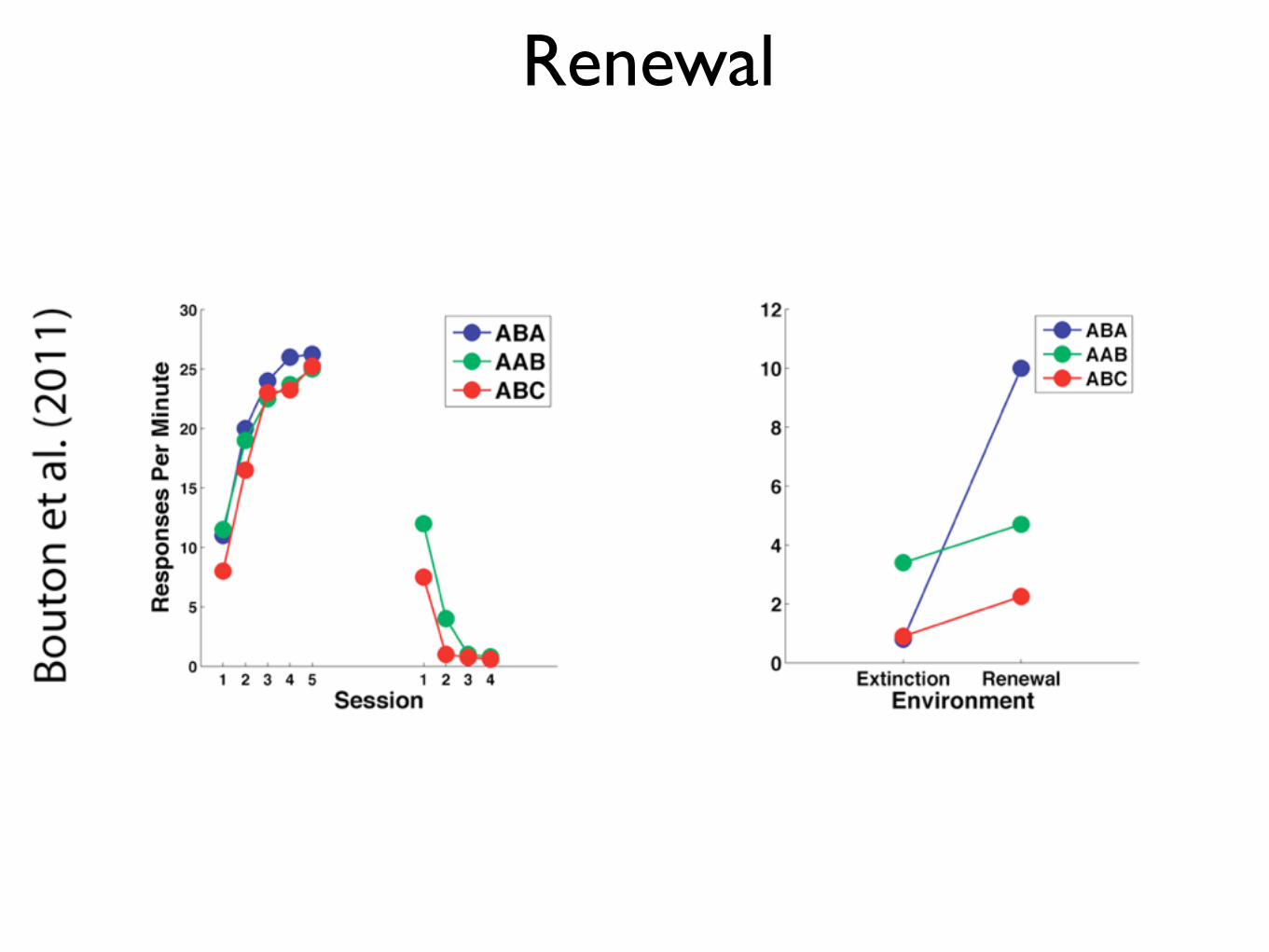
Renewal
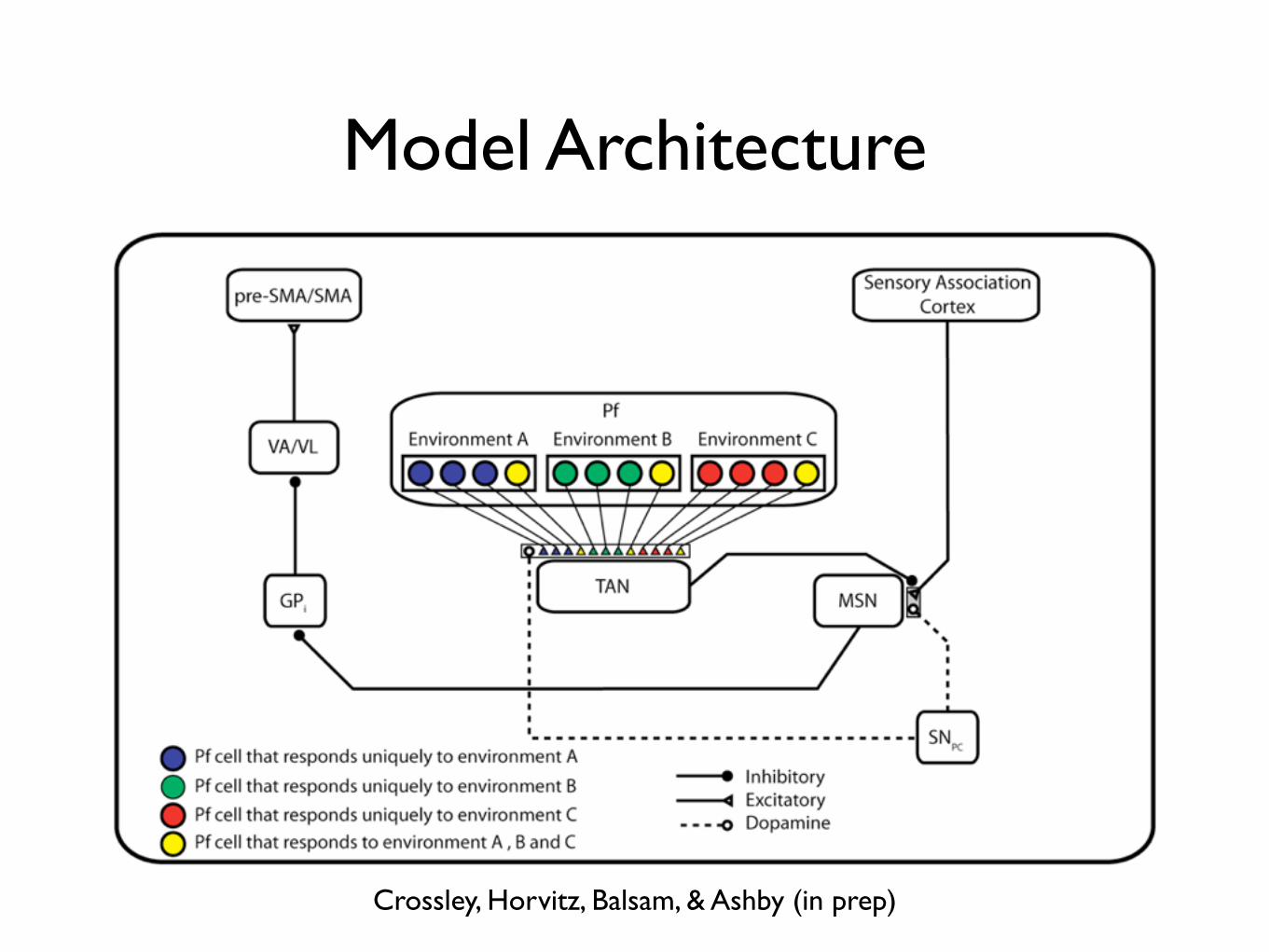
Model Architecture
Crossley, Horvitz, Balsam, & Ashby (in prep)
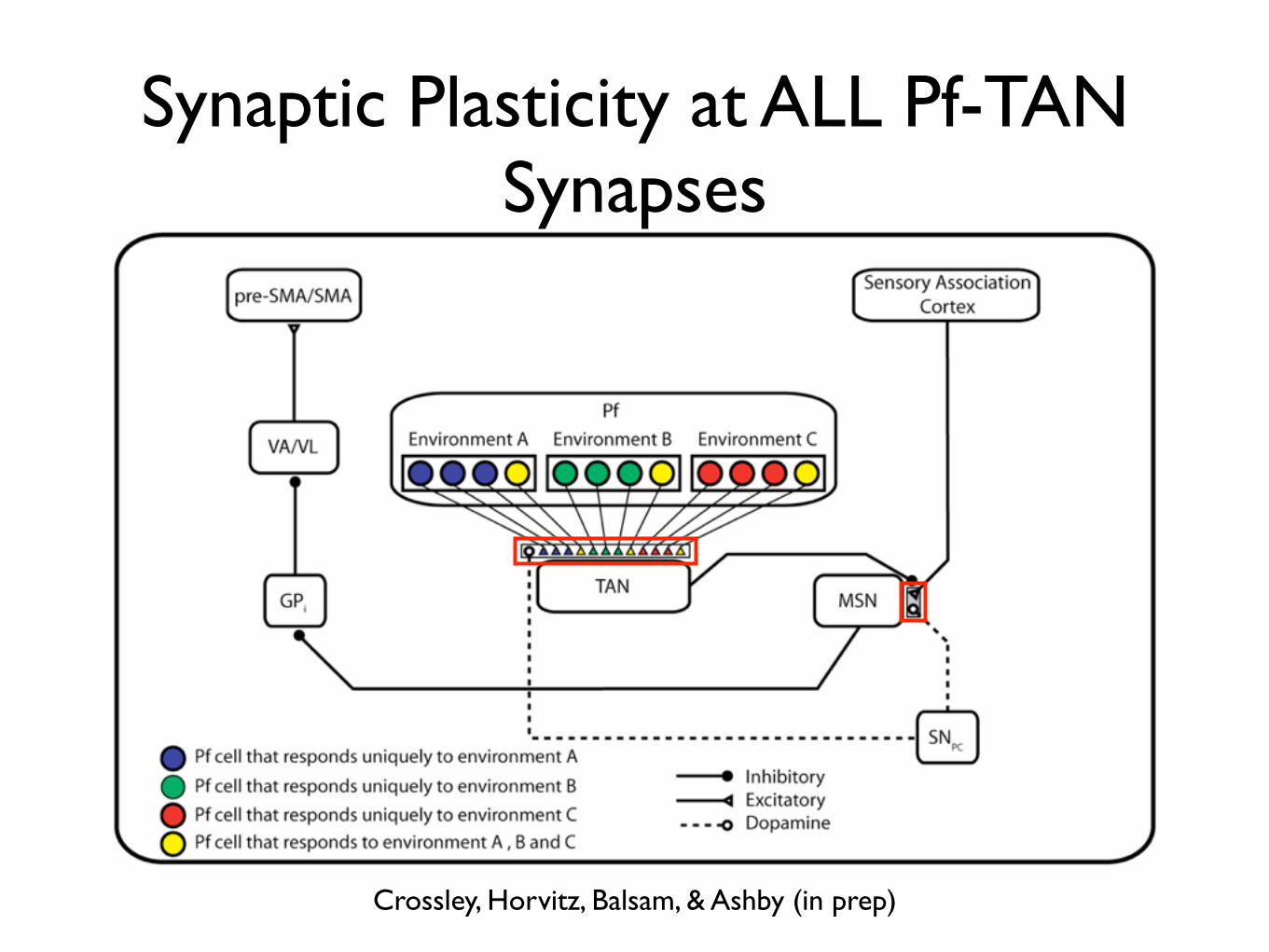
Synaptic Plasticity at ALL Pf-TAN Synapses
Crossley, Horvitz, Balsam, & Ashby (in prep)

Renewal
Crossley, Horvitz, Balsam, & Ashby (in prep)
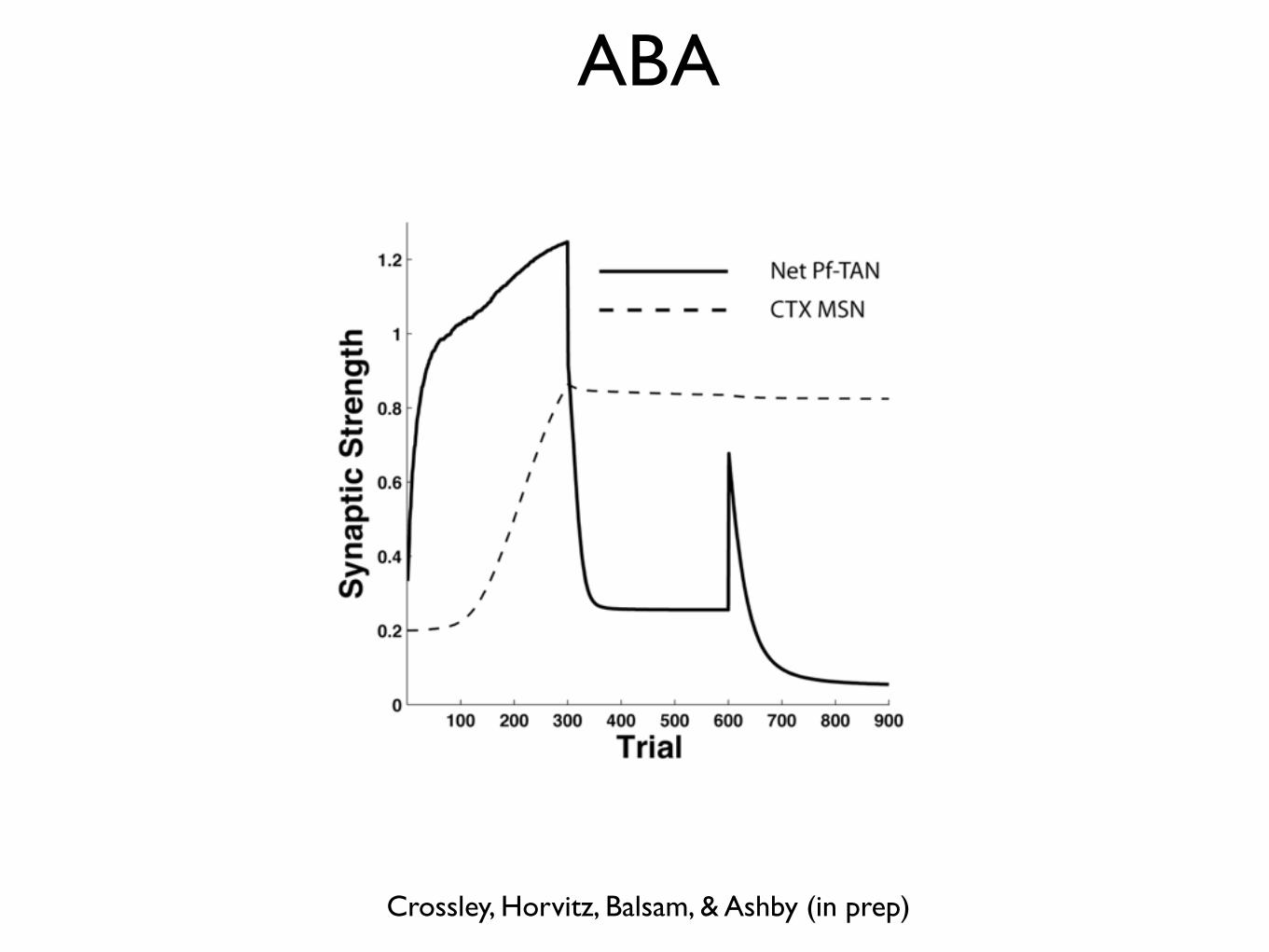
ABA
Crossley, Horvitz, Balsam, & Ashby (in prep)

Instrumental Conditioning Summary
• The TANs protect learning at CTX-MSN synapses.
• Manipulations that keep the TANs paused during extinction leave learning at the CTX-MSN synapse subject to change.

• Procedural Skills
• Model Architecture
• Instrumental Conditioning Applications
• Category Learning Applications
• Closing Remarks
Outline
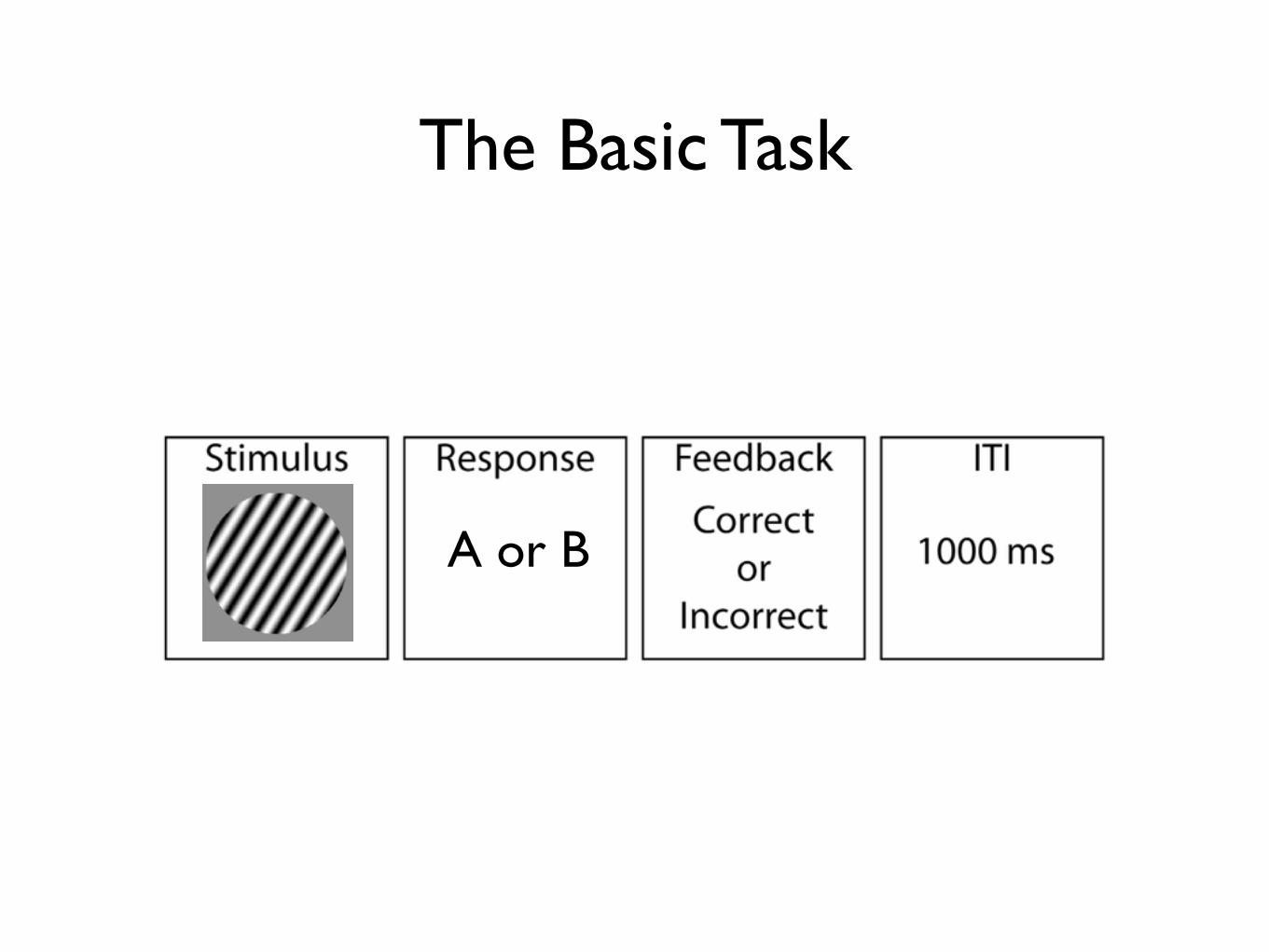
The Basic Task
A or B
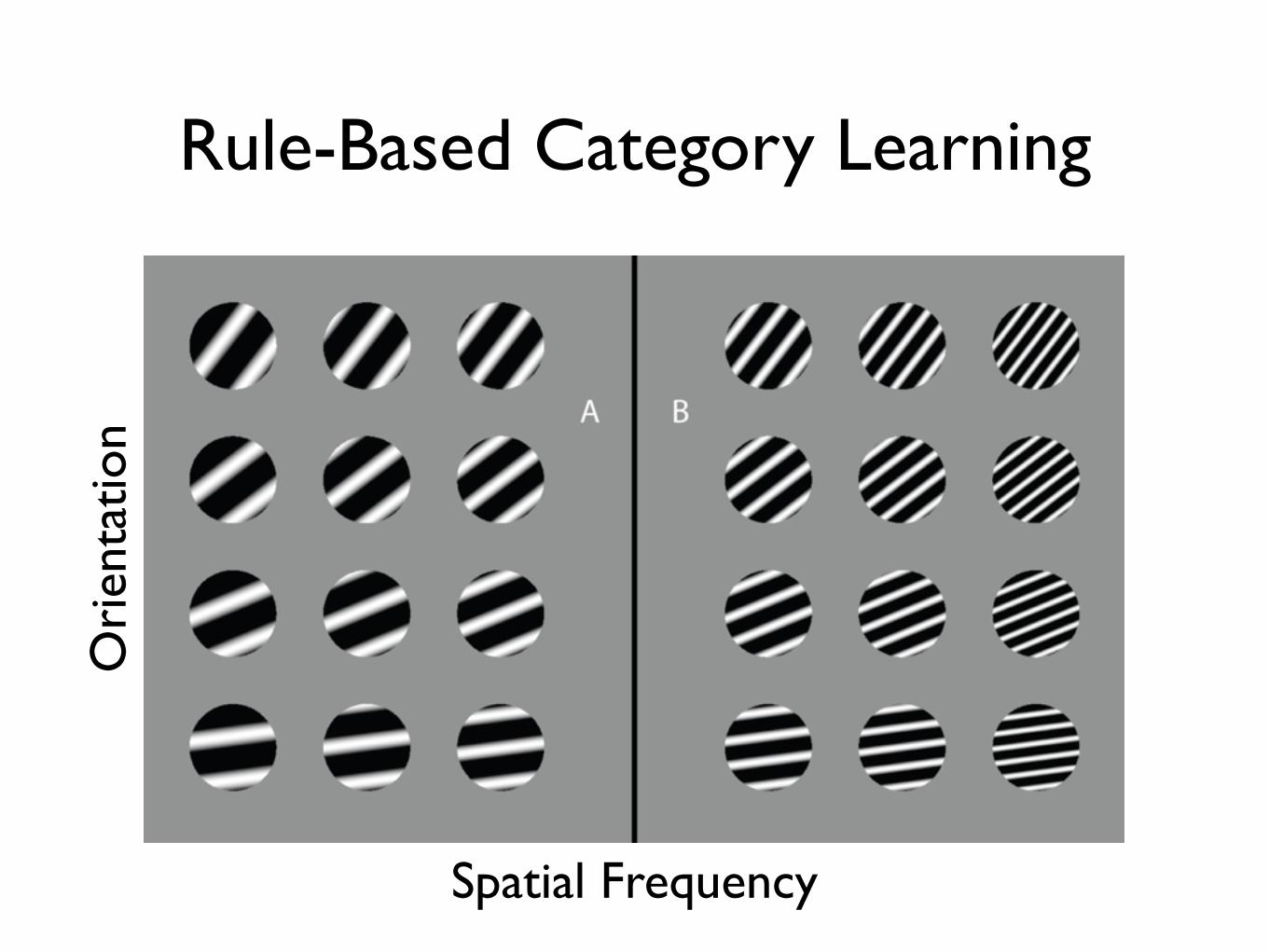
Rule-Based Category Learning
Spatial Frequency
Ori
enta
tion
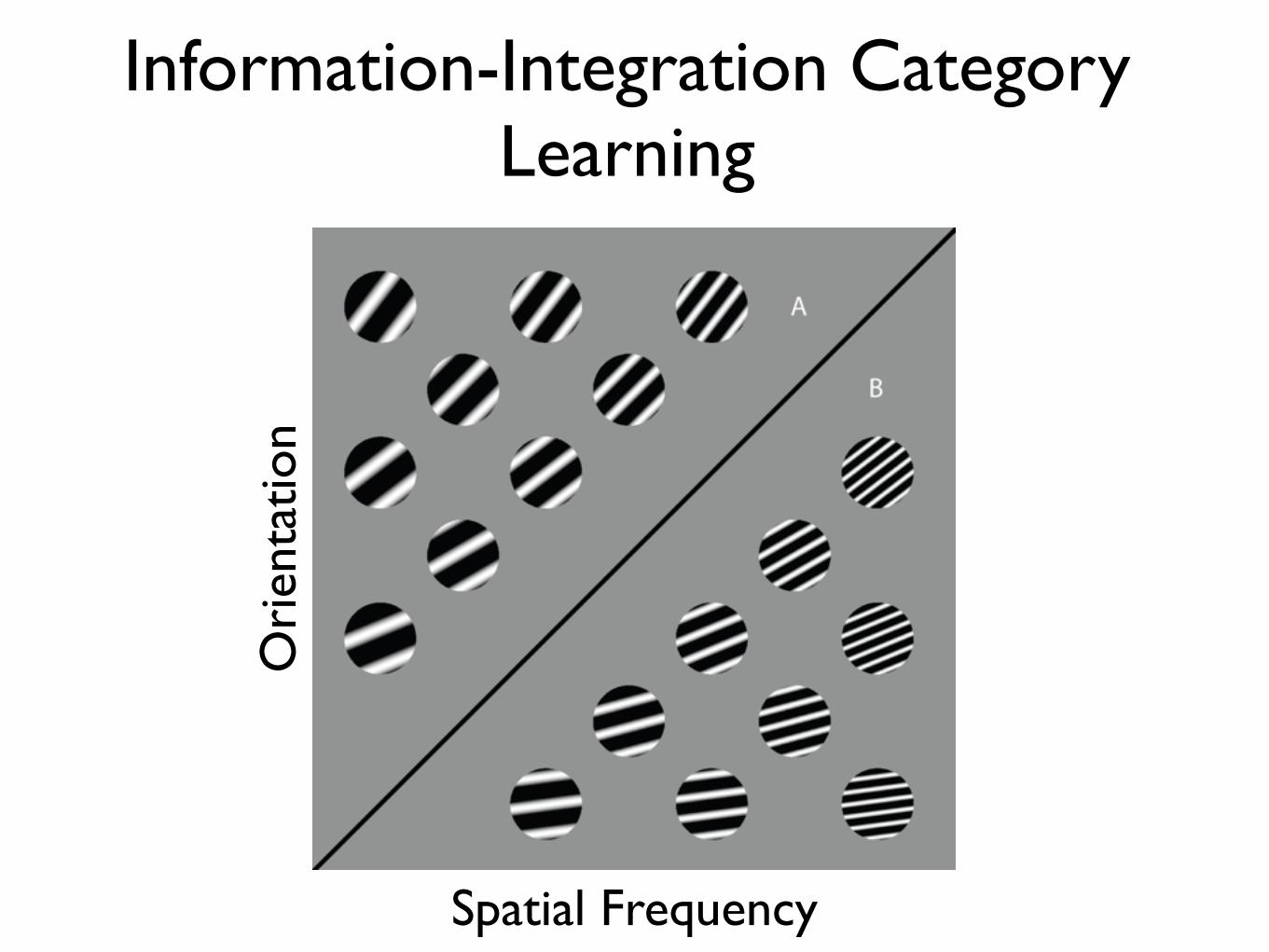
Information-Integration Category Learning
Spatial Frequency
Ori
enta
tion
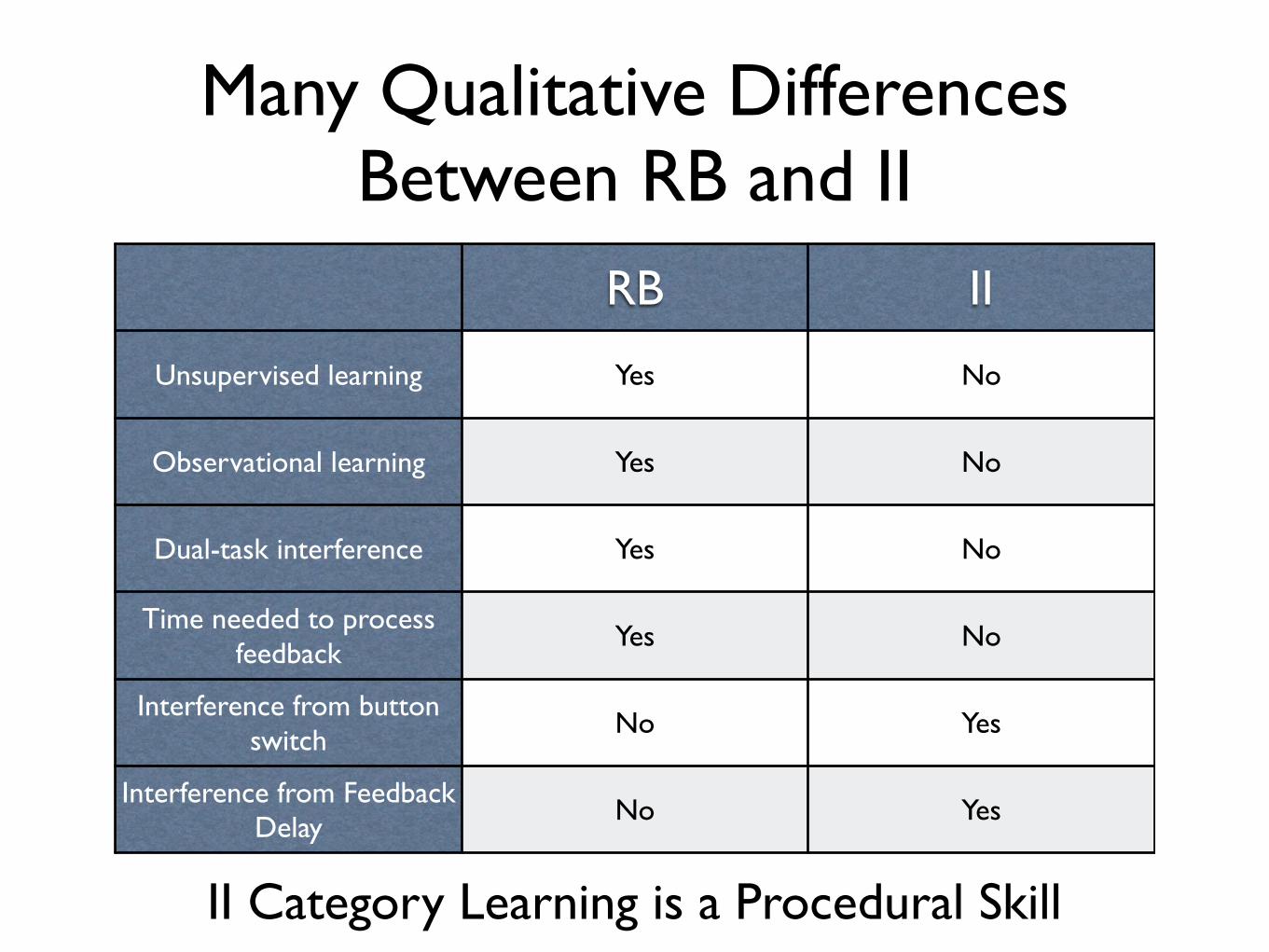
Many Qualitative Differences Between RB and II
RB II
Unsupervised learning Yes No
Observational learning Yes No
Dual-task interference Yes No
Time needed to process feedback
Yes No
Interference from button switch
No Yes
Interference from Feedback Delay
No Yes
II Category Learning is a Procedural Skill
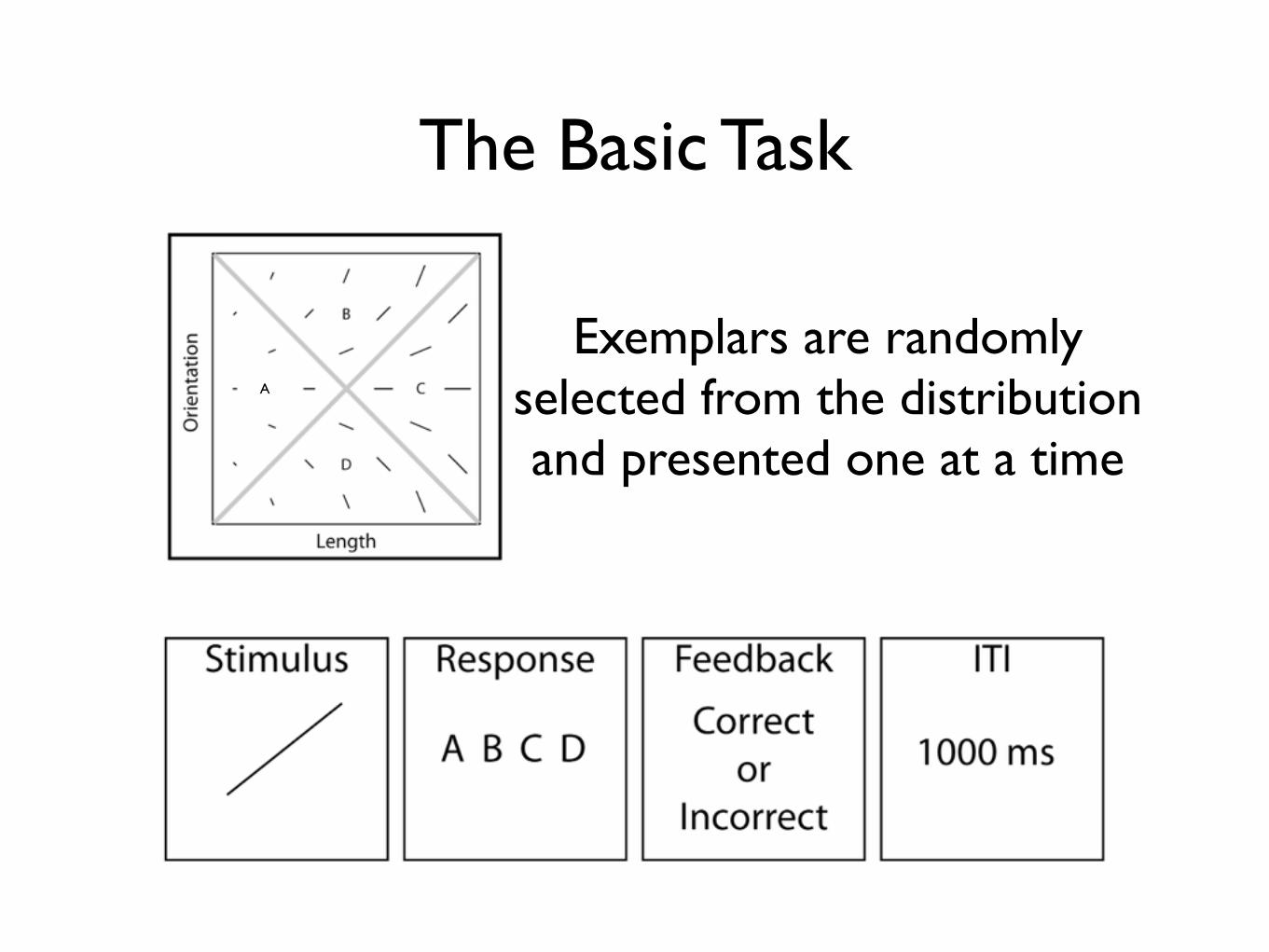
The Basic Task
Exemplars are randomly selected from the distribution and presented one at a time
A
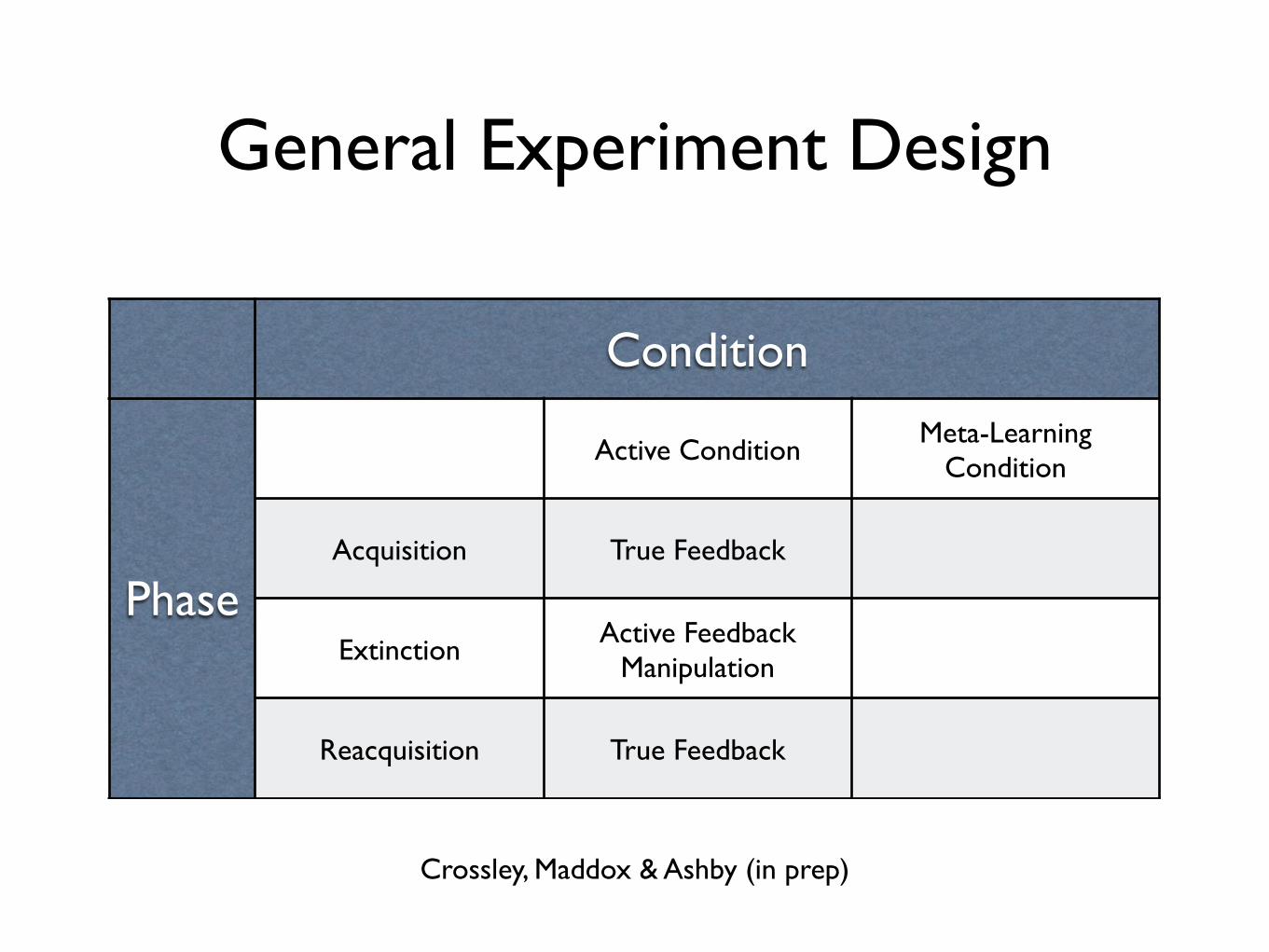
General Experiment Design
Crossley, Maddox & Ashby (in prep)
Condition
Phase
Active ConditionMeta-Learning
Condition
Acquisition True Feedback
ExtinctionActive Feedback
Manipulation
Reacquisition True Feedback
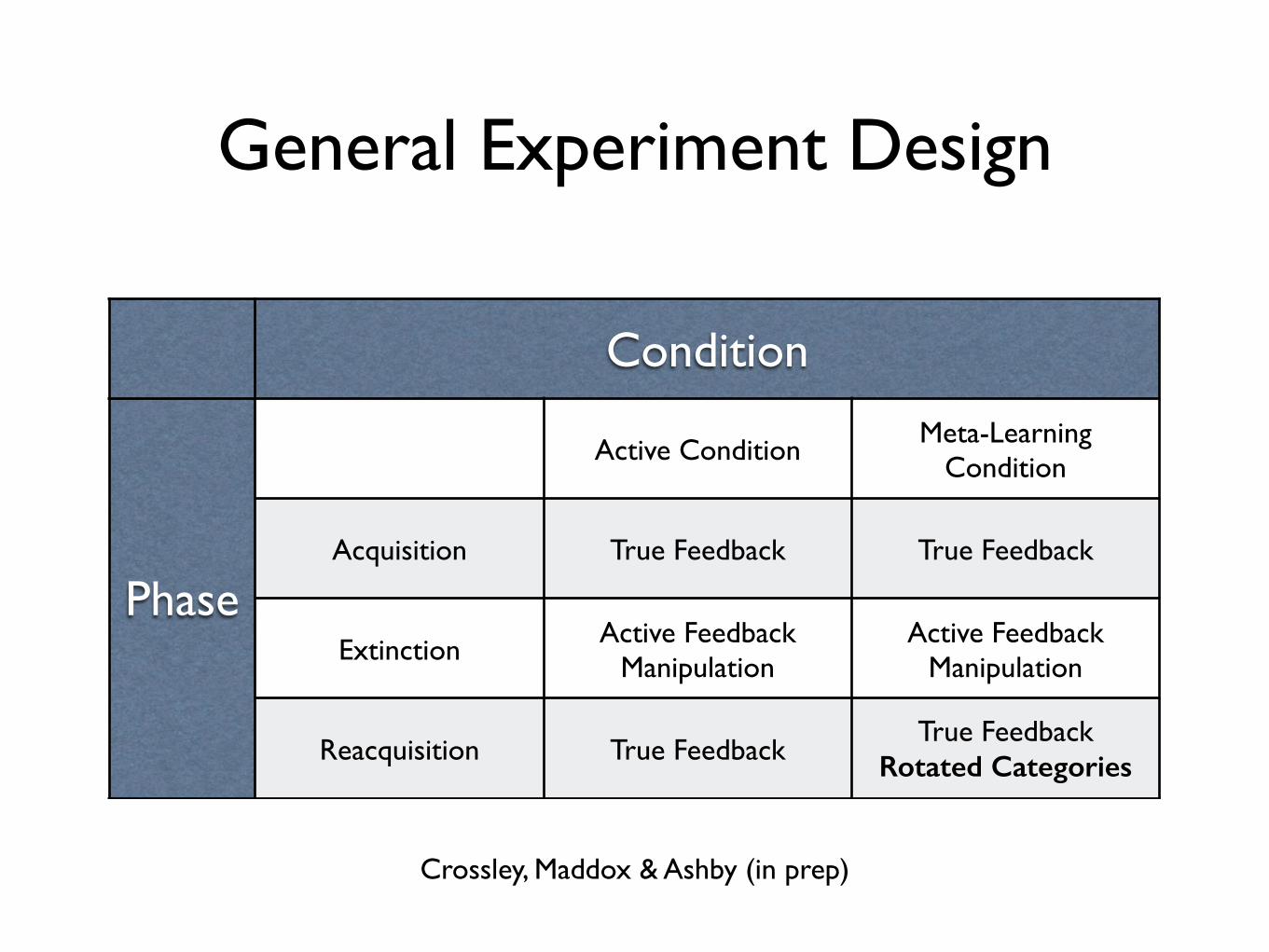
General Experiment Design
Crossley, Maddox & Ashby (in prep)
Condition
Phase
Active ConditionMeta-Learning
Condition
Acquisition True Feedback True Feedback
ExtinctionActive Feedback
ManipulationActive Feedback
Manipulation
Reacquisition True FeedbackTrue Feedback
Rotated Categories

II Category-Unlearning
Rotation of this kind massively interferes with category learning performance (Maddox, Glass, O’Brien, Filoteo & Ashby, 2010)
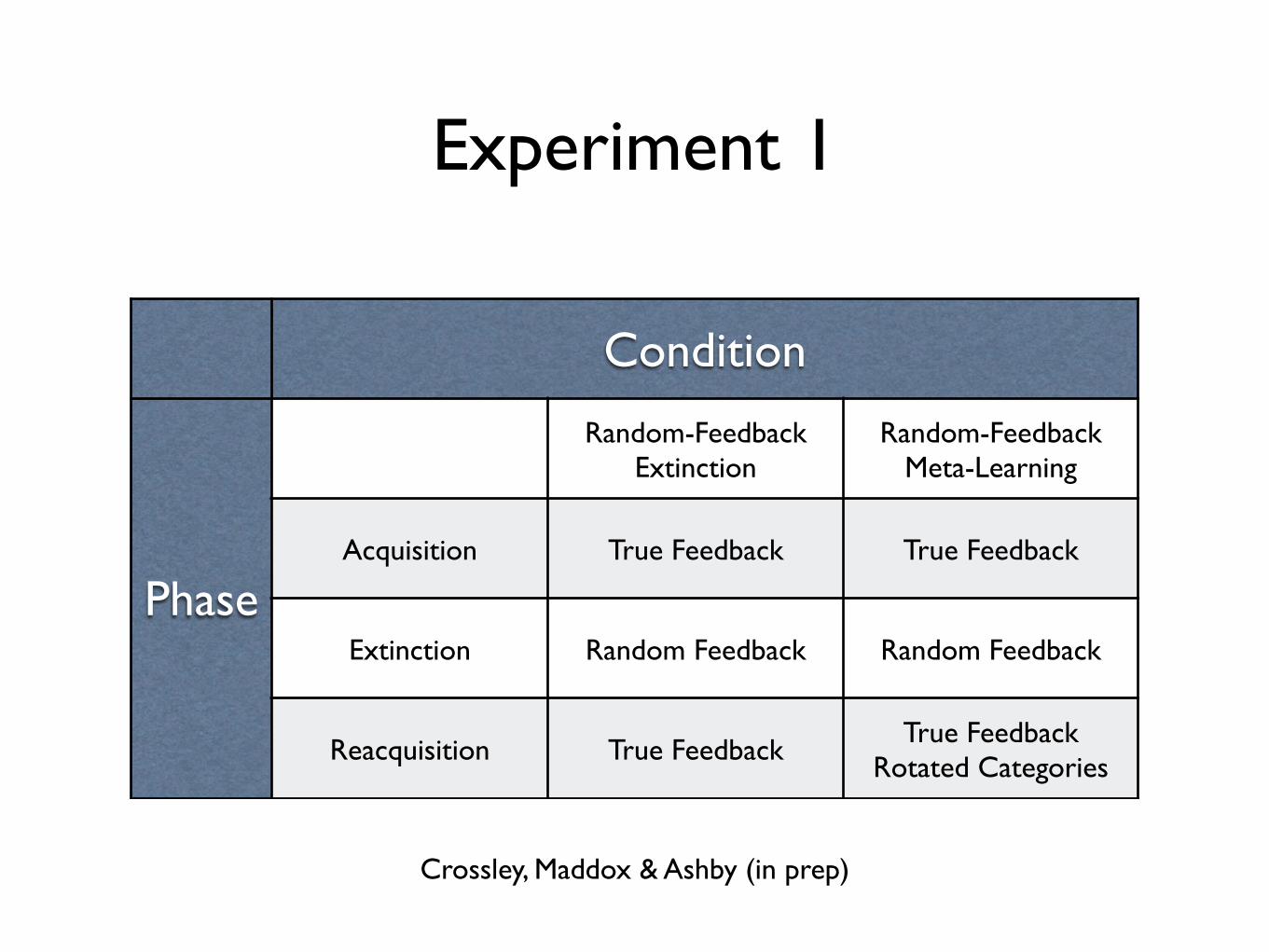
Experiment 1
Crossley, Maddox & Ashby (in prep)
Condition
Phase
Random-Feedback Extinction
Random-Feedback Meta-Learning
Acquisition True Feedback True Feedback
Extinction Random Feedback Random Feedback
Reacquisition True FeedbackTrue Feedback
Rotated Categories
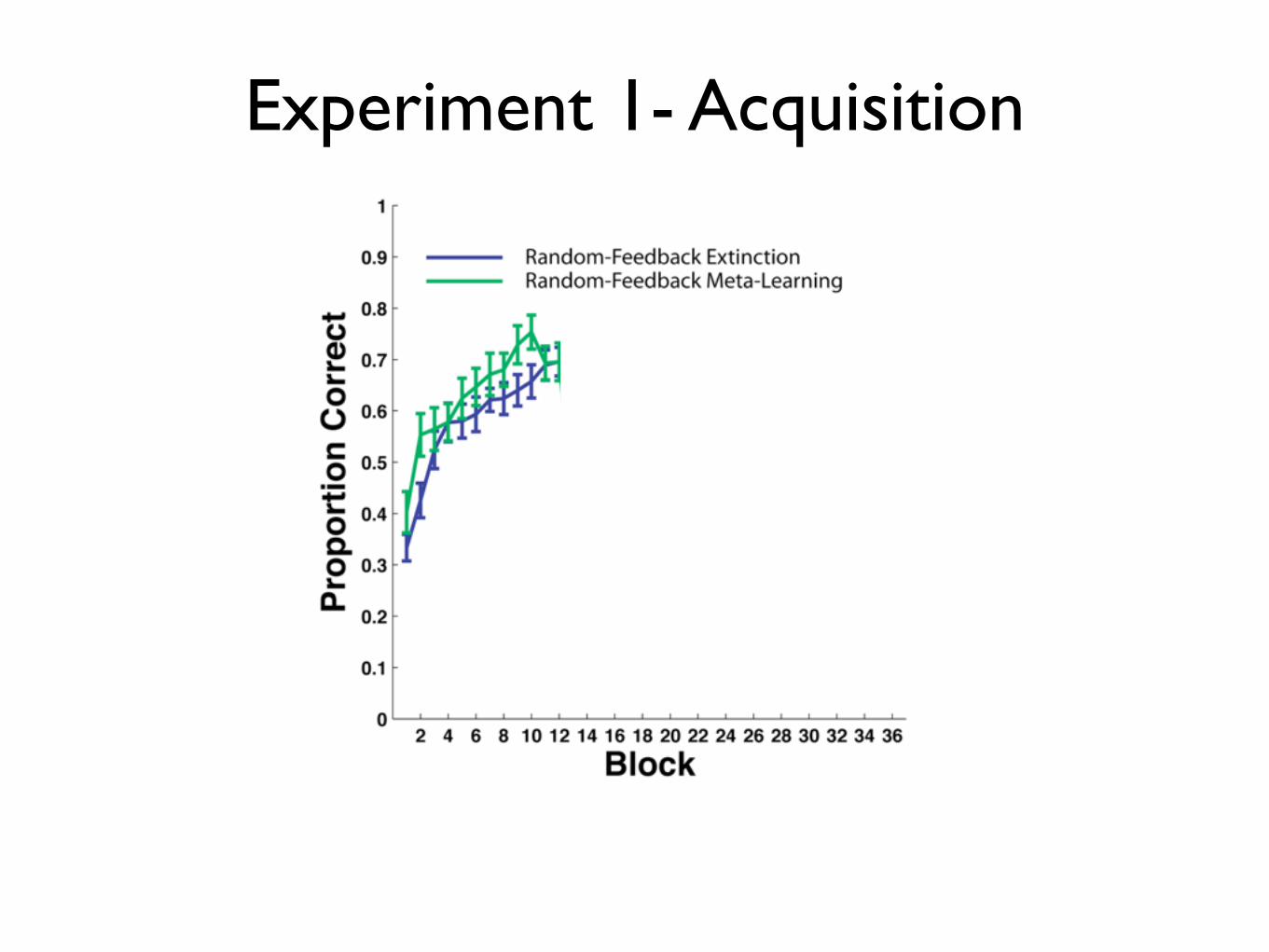
Experiment 1- Acquisition
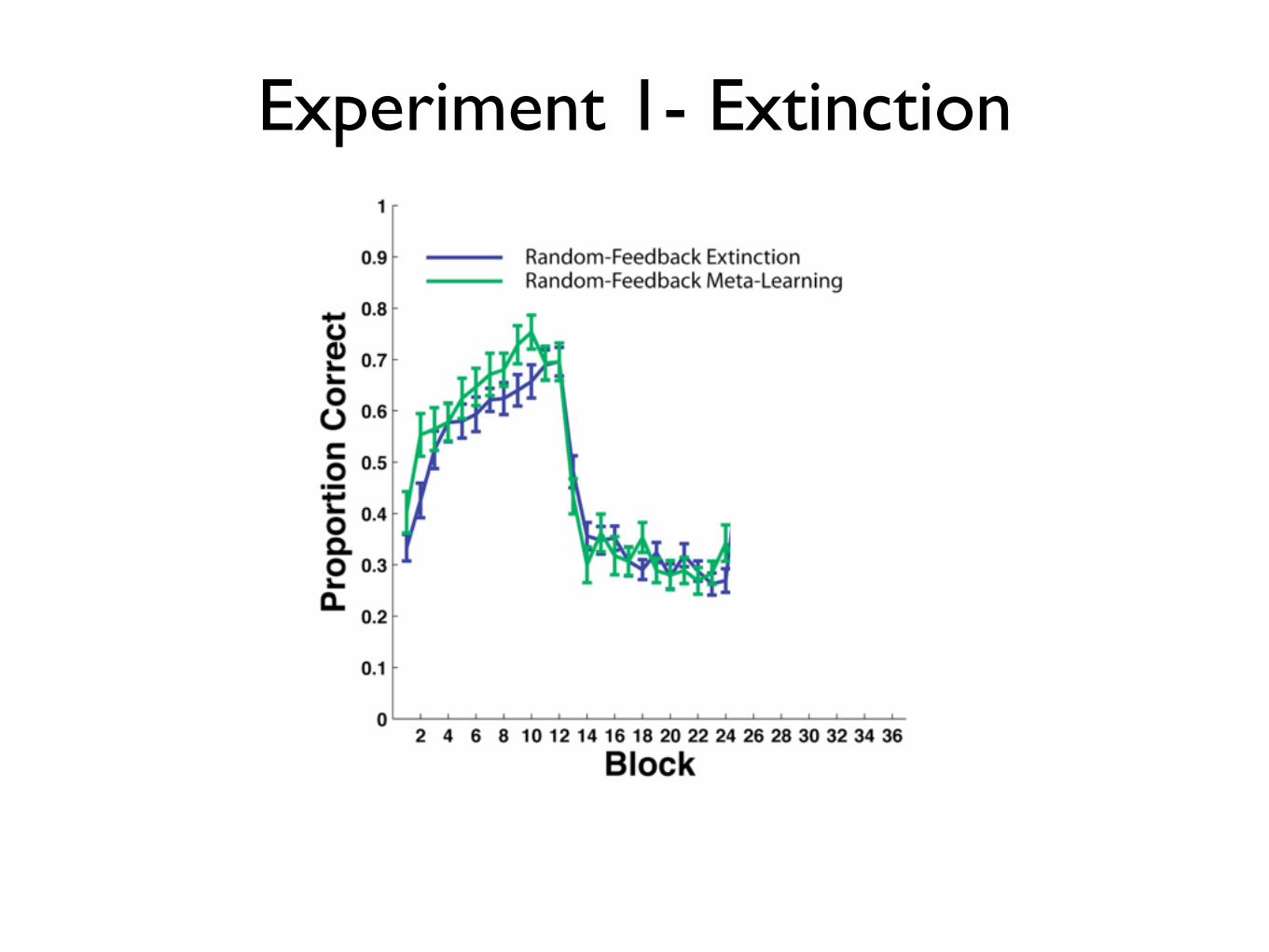
Experiment 1- Extinction

Experiment 1- Reacquisition
Fast Reacquisition: Random feedback does not interfere with initial learning
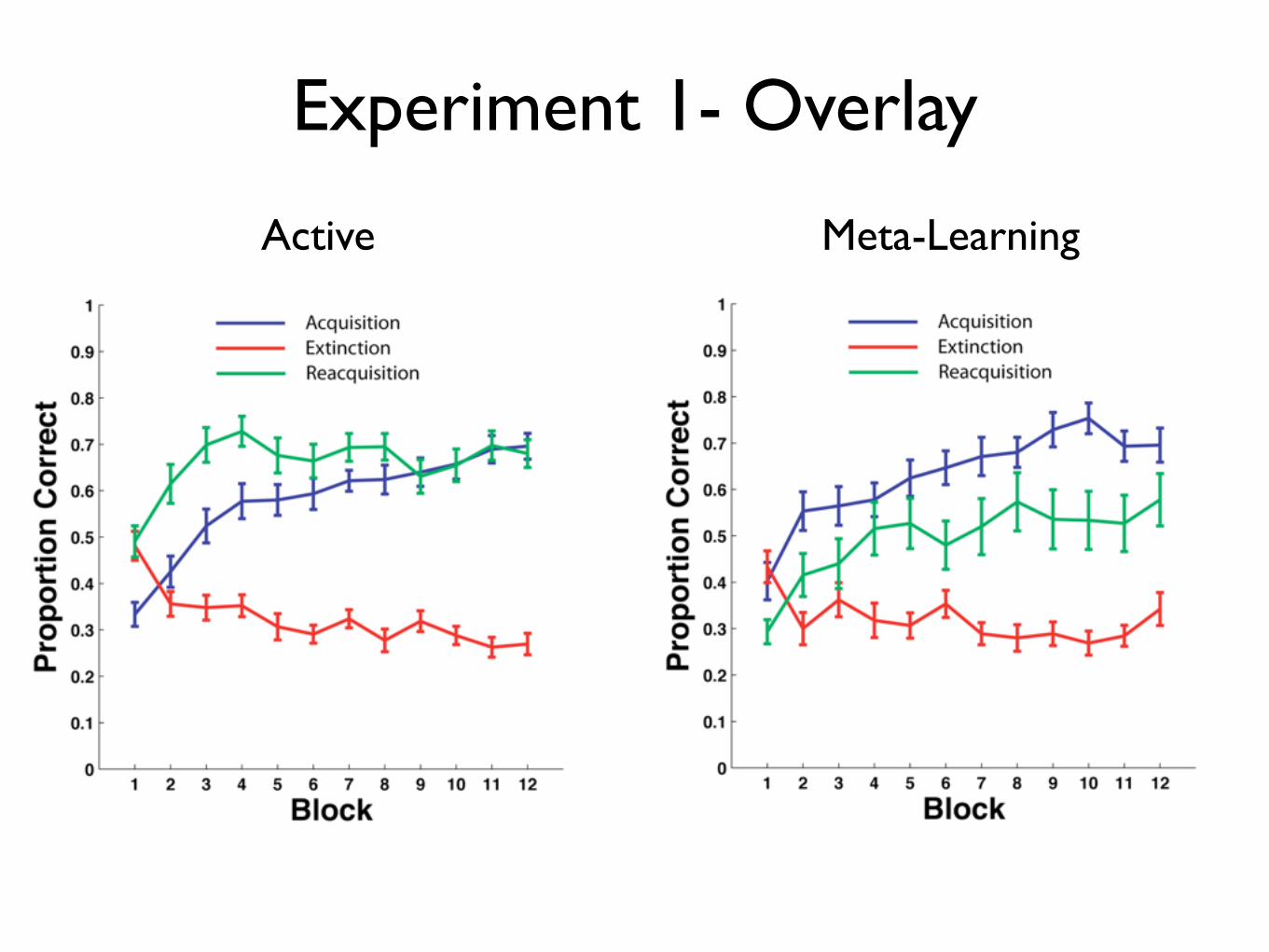
Experiment 1- Overlay
Active Meta-Learning

The results of experiment 1 are inconsistent with all existing theories of category learning
Importance

Theoretical AccountNetwork Architecture
Crossley, Maddox & Ashby (in prep)
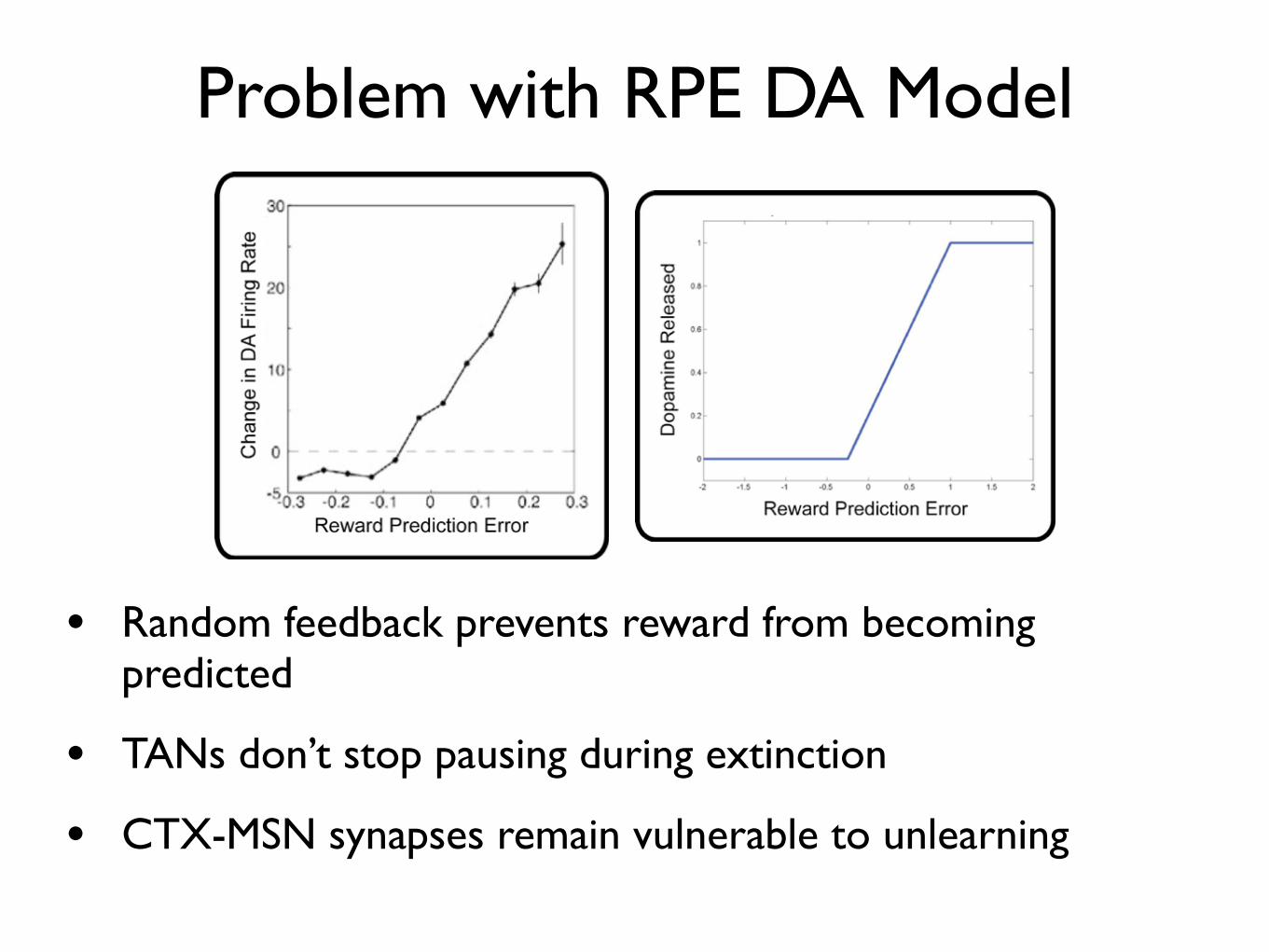
Problem with RPE DA Model
• Random feedback prevents reward from becoming predicted
• TANs don’t stop pausing during extinction
• CTX-MSN synapses remain vulnerable to unlearning
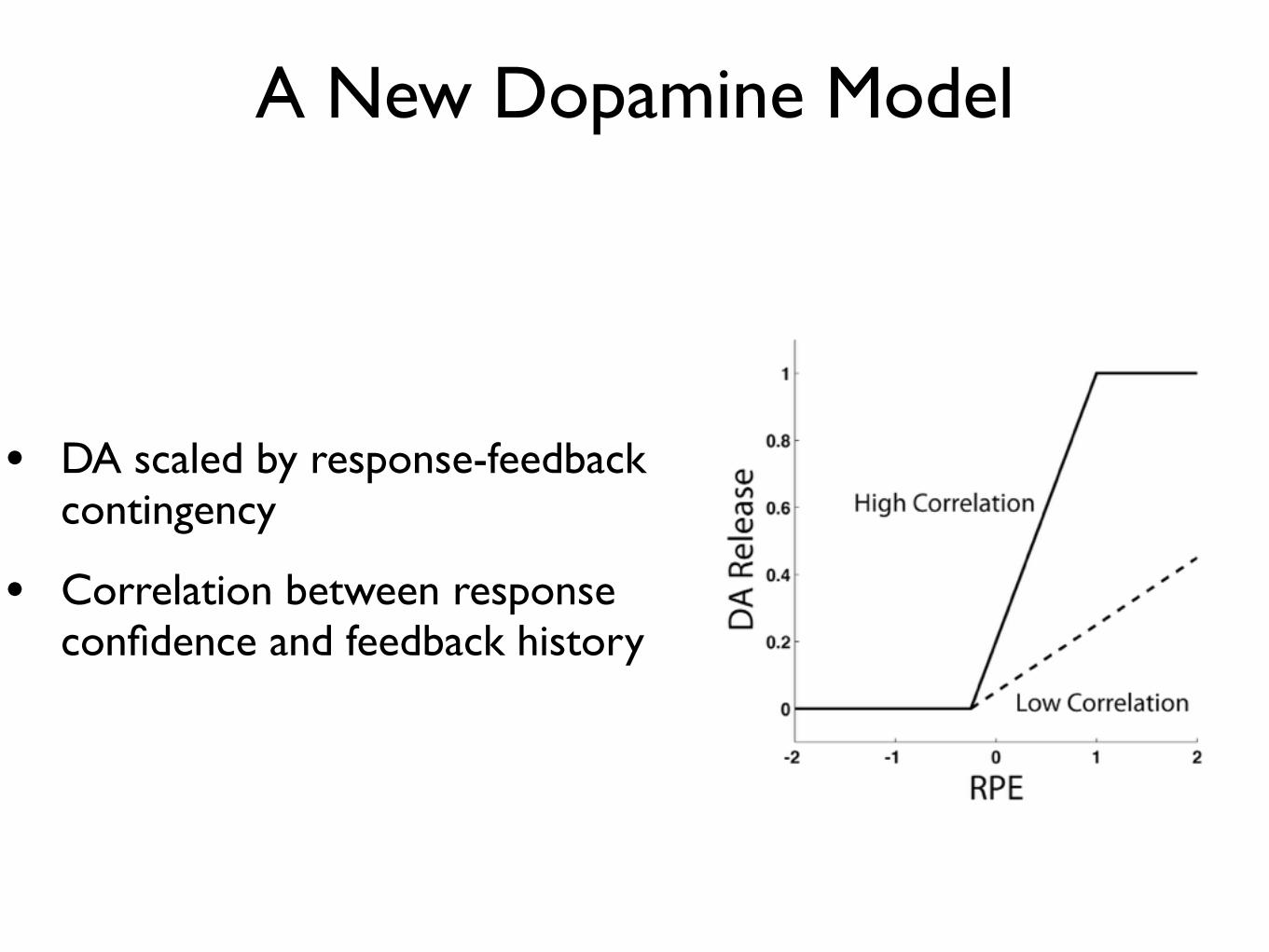
• DA scaled by response-feedback contingency
• Correlation between response confidence and feedback history
A New Dopamine Model
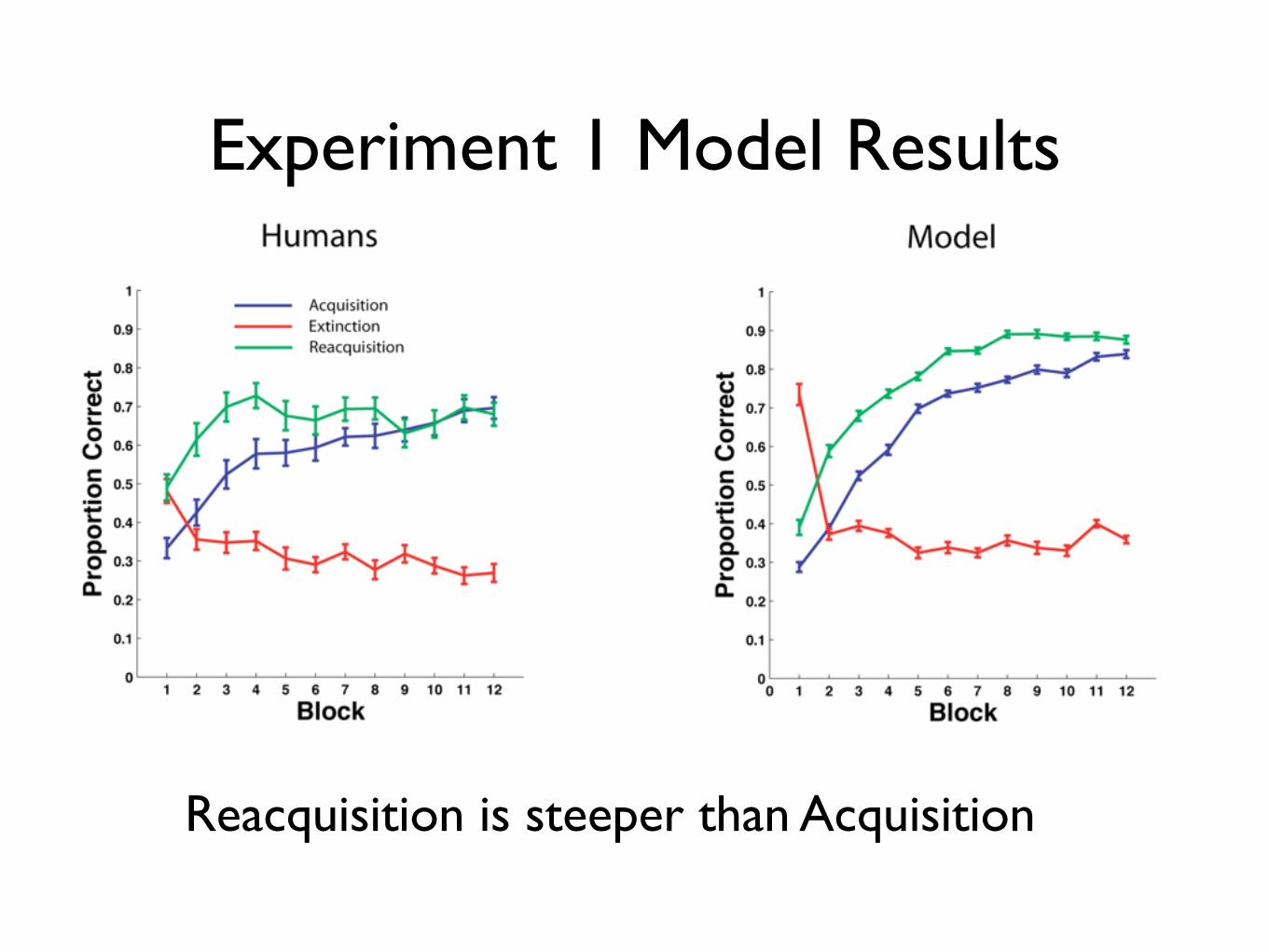
Experiment 1 Model Results
Reacquisition is steeper than Acquisition

DA model suggests the important factor to keep the TANs paused is
response-feedback contingency
Using the Model to Develop an Effective Unlearning Protocol

Experiment 2
Crossley, Maddox & Ashby (in prep)
Condition
Phase
Partially-Contingent Extinction
Partially-Contingent Meta-Learning
Acquisition True Feedback True Feedback
Extinction Partially-Contingent Partially-Contingent
Reacquisition True FeedbackTrue Feedback
Rotated Categories
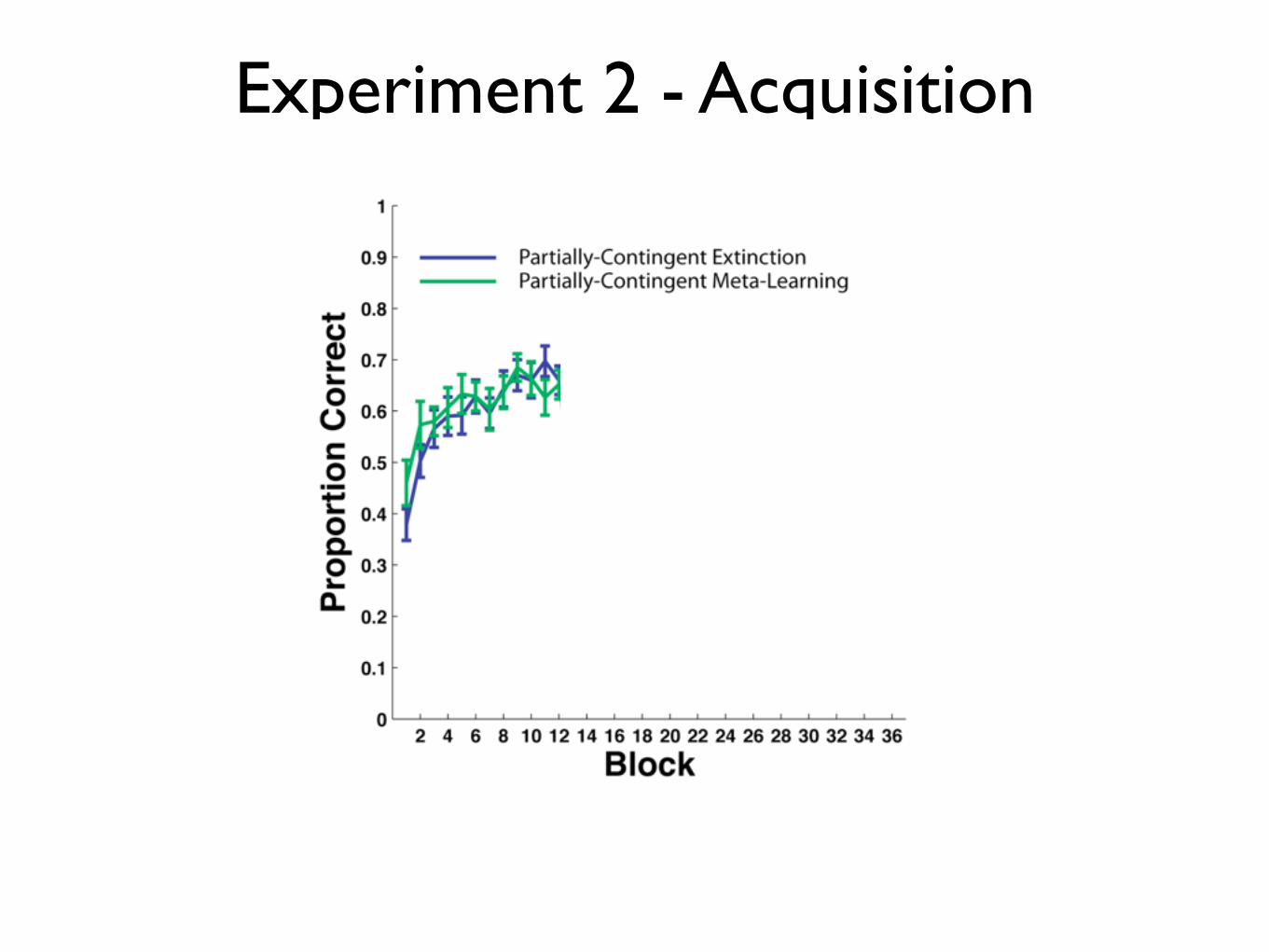
Experiment 2 - Acquisition
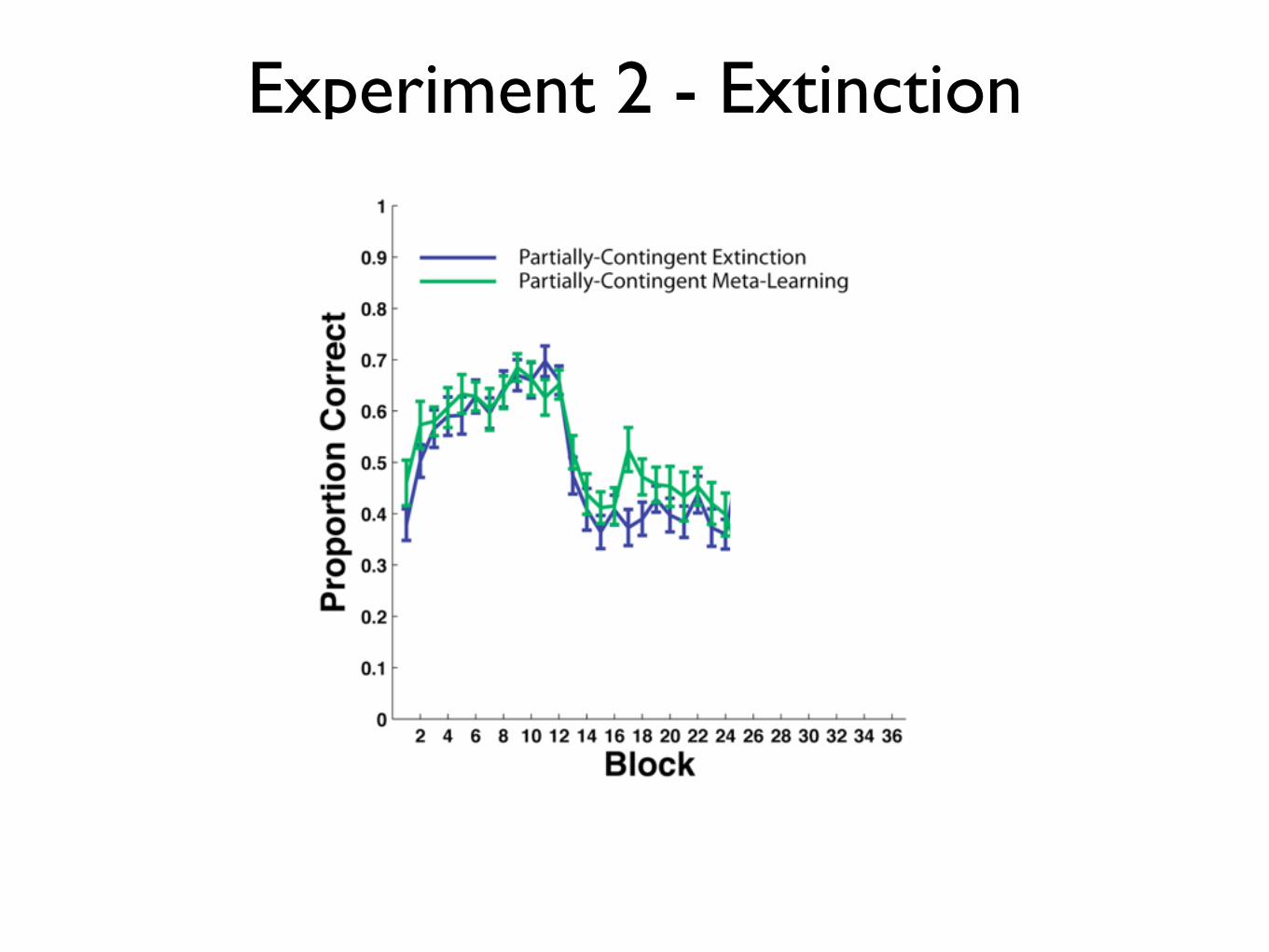
Experiment 2 - Extinction

Experiment 2 - Reacquisition
Slow Reacquisition: Partially-Contingent Random feedback interferes with initial learning
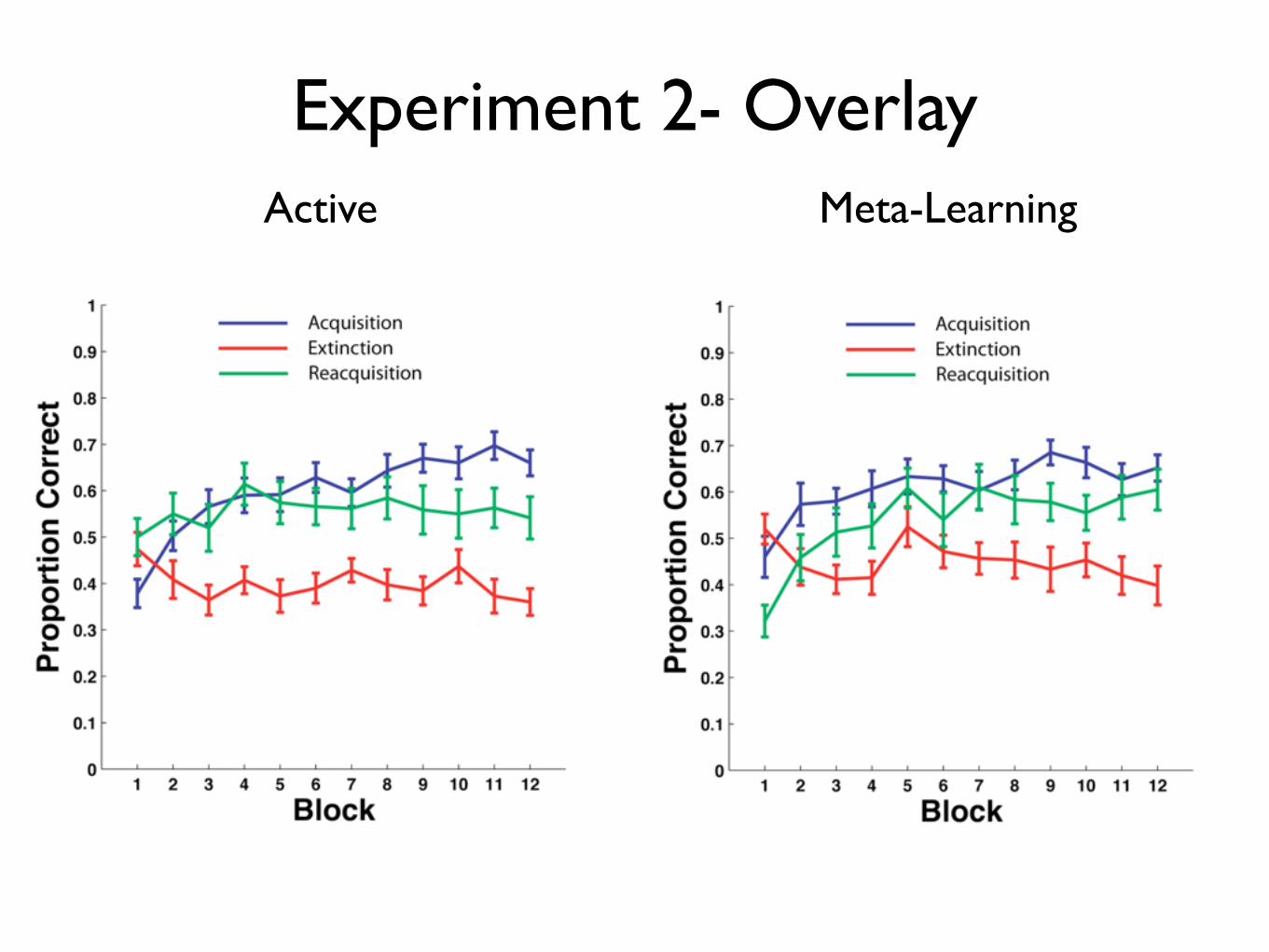
Experiment 2- OverlayActive Meta-Learning
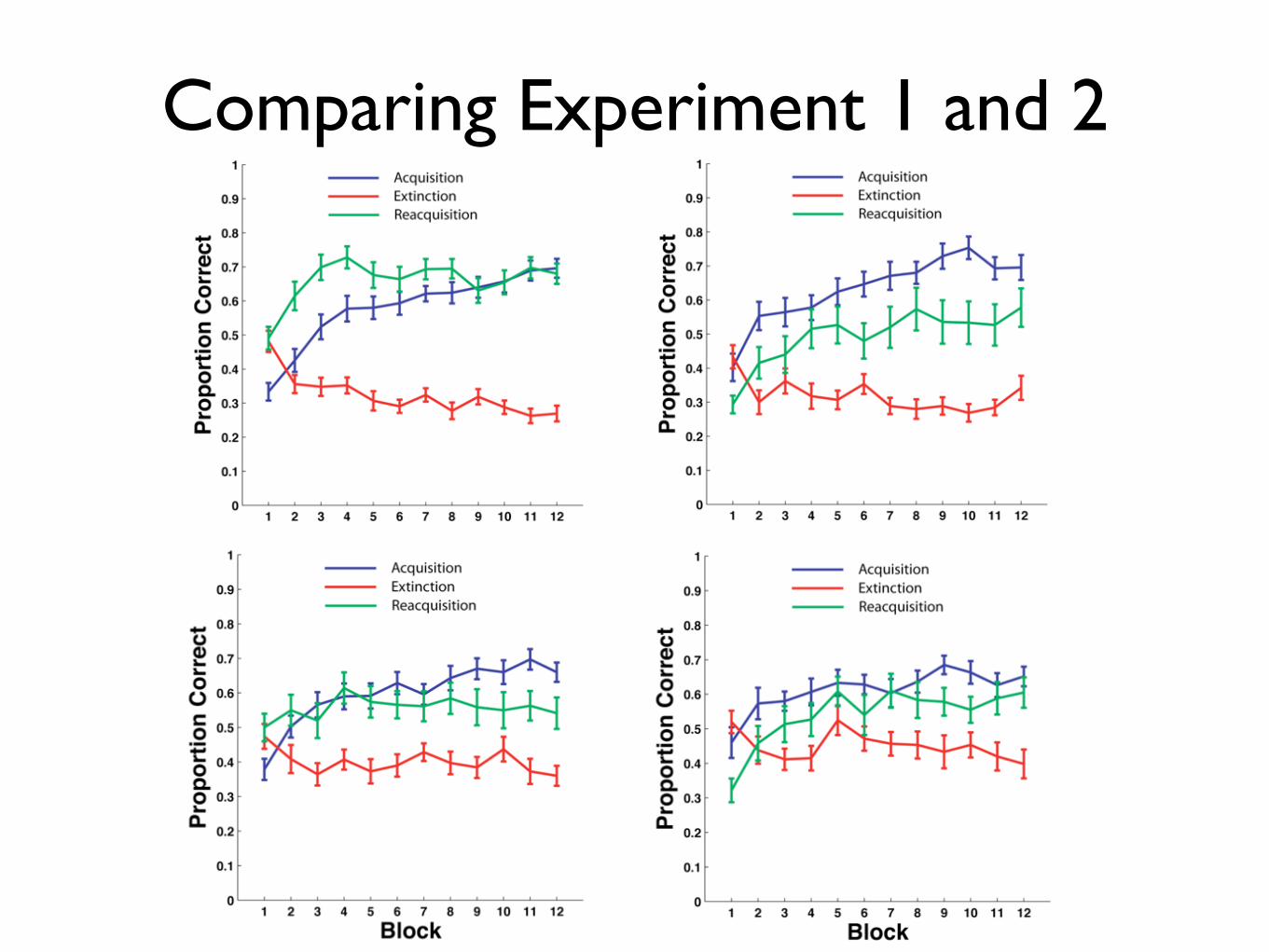
Comparing Experiment 1 and 2
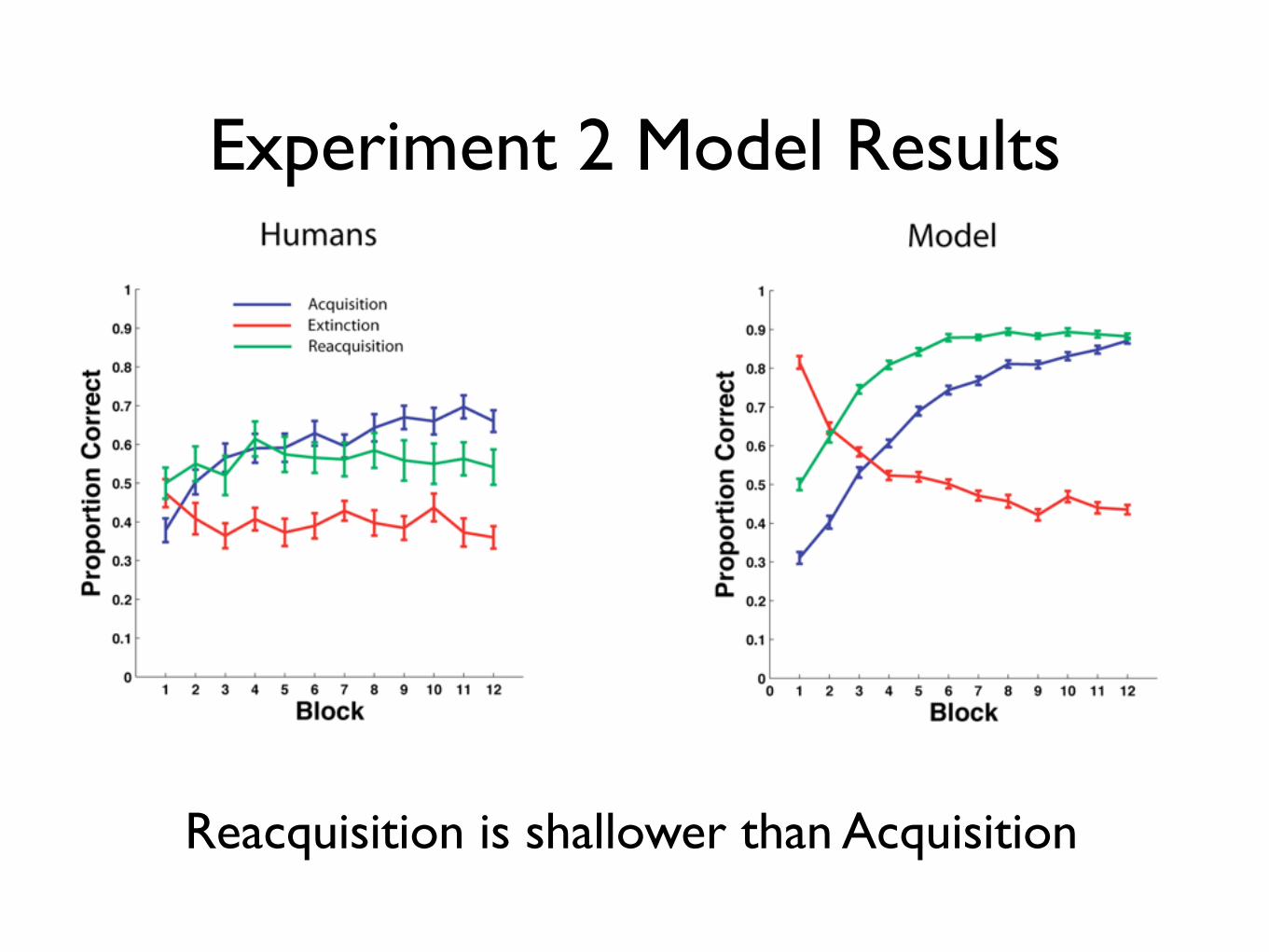
Experiment 2 Model Results
Reacquisition is shallower than Acquisition
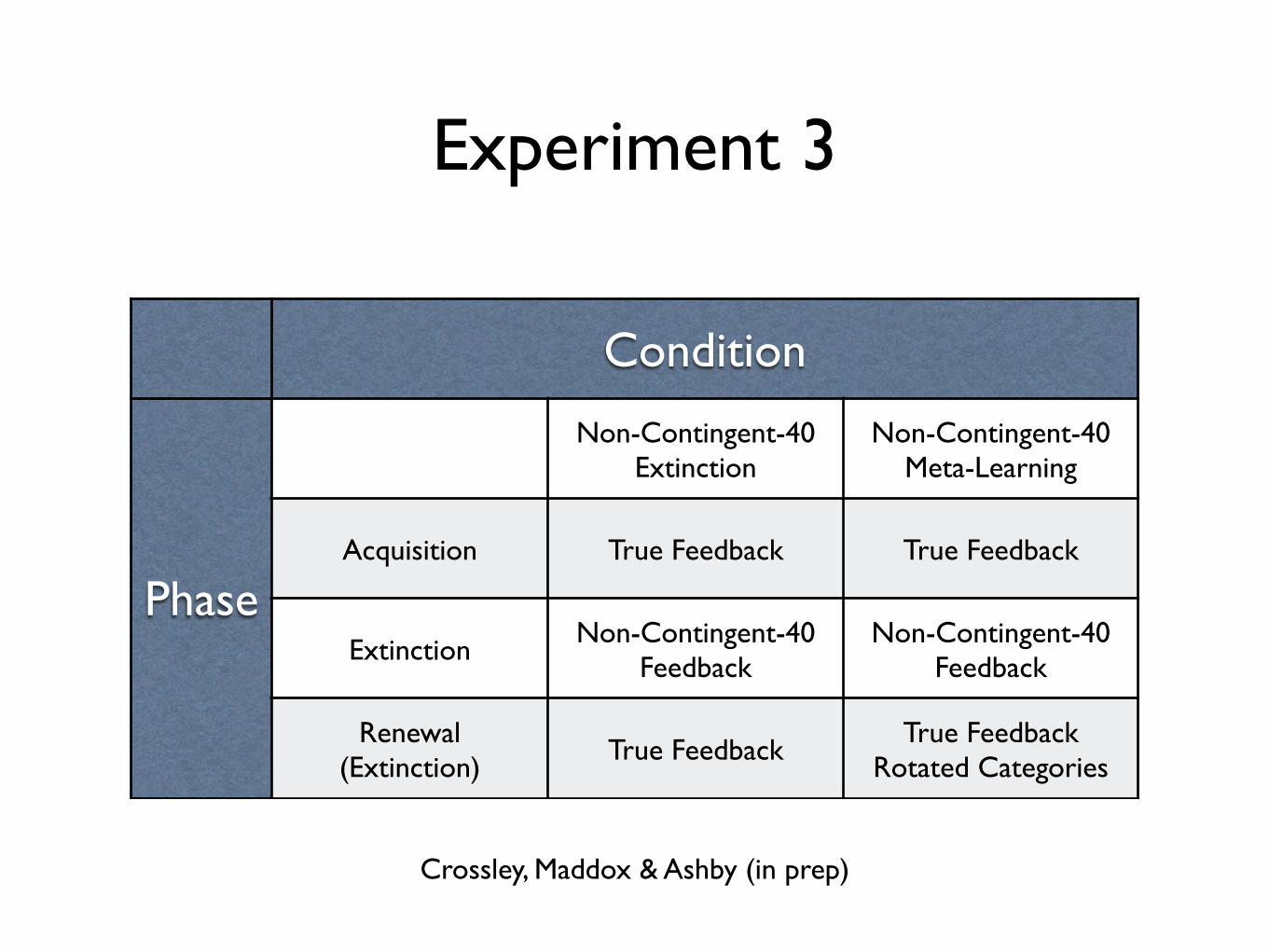
Experiment 3
Crossley, Maddox & Ashby (in prep)
Condition
Phase
Non-Contingent-40 Extinction
Non-Contingent-40 Meta-Learning
Acquisition True Feedback True Feedback
ExtinctionNon-Contingent-40
FeedbackNon-Contingent-40
Feedback
Renewal (Extinction)
True FeedbackTrue Feedback
Rotated Categories
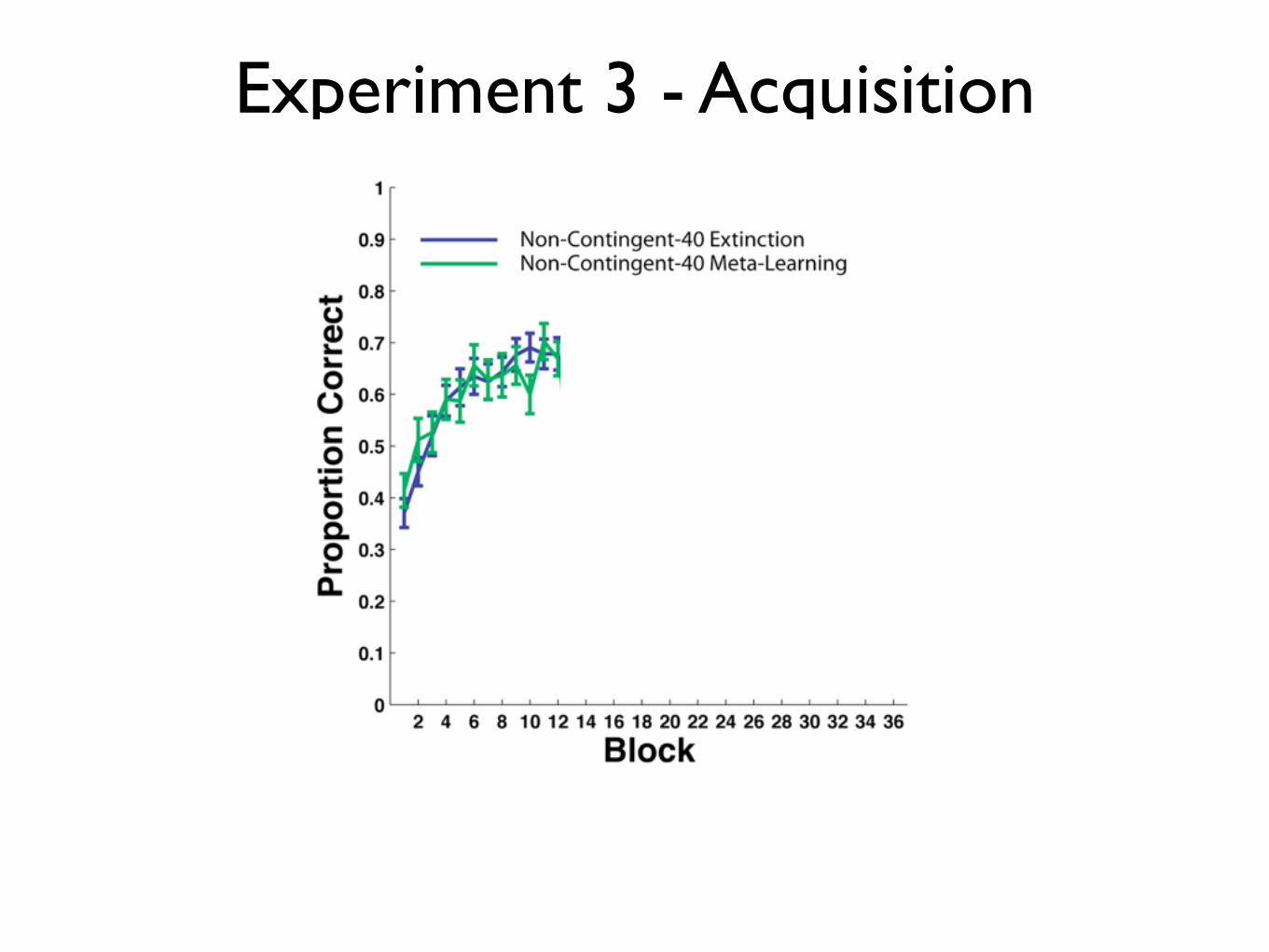
Experiment 3 - Acquisition
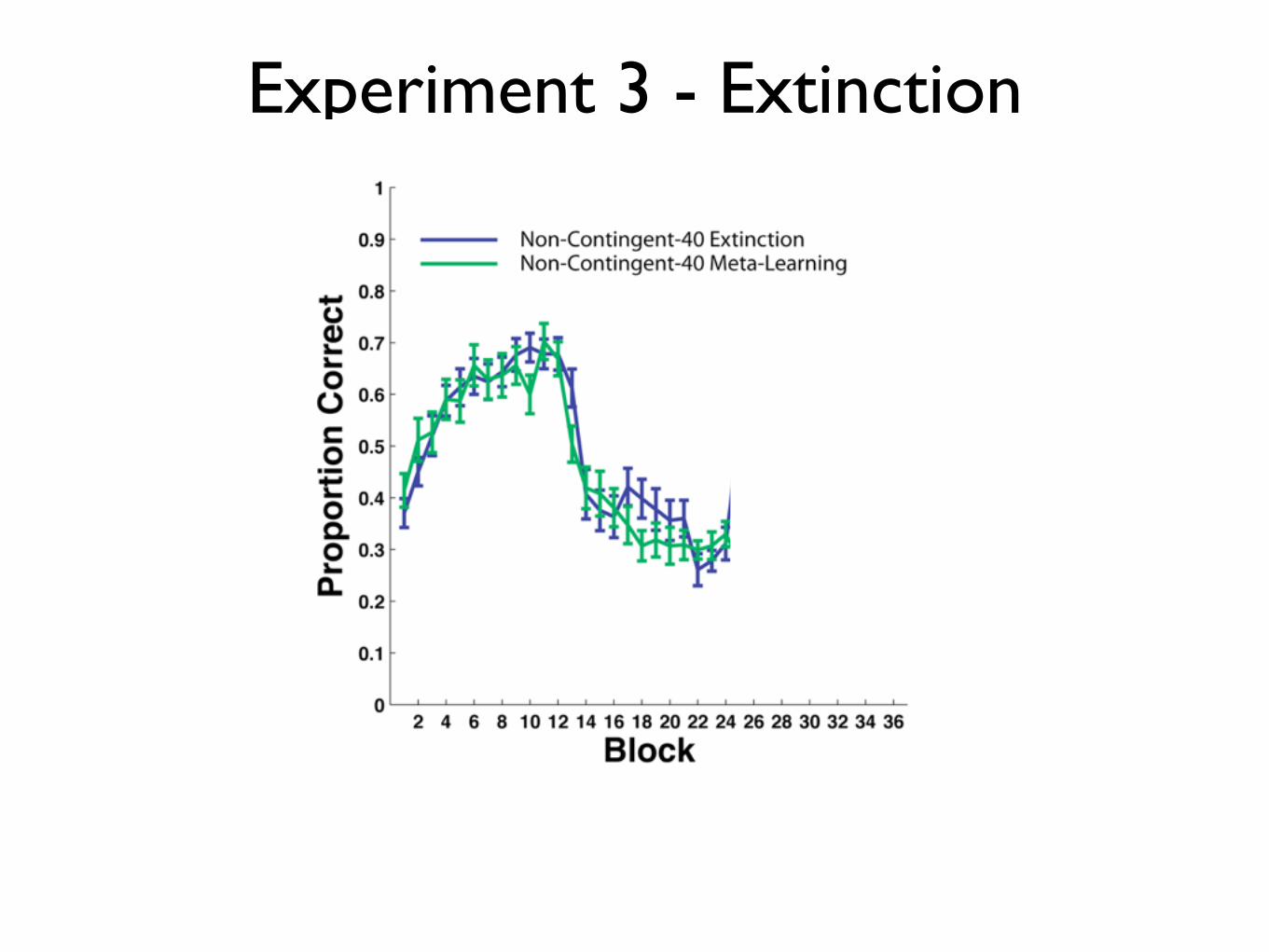
Experiment 3 - Extinction

Experiment 3 - Acquisition
Fast Reacquisition: Non-Contingent-40 feedback does not erase initial learning

Experiment 3- OverlayActive Meta-Learning

Experiment 3 Model Results
Reacquisition is Steeper than Acquisition

Summary
• TANs protect cortical-striatal synapses during periods when reward delivery is not contingent on behavior
• RPE may not be sufficient to capture DA behavior under noisy feedback conditions
• Key to unlearning may be to simulate a TAN pause (e.g., with drugs) or trick the TANs into pausing (e.g., with partial reliable feedback) during the unlearning process

Acknowledgments Collaborators:
Greg Ashby
Todd Maddox
Jon Horvitz
Peter Balsam
!
Funding:
NIMH Grant MH3760-2, Army Research Laboratory Todd Wilkinson