preserving digital culture: tools & strategies for building web archives : tools and strategies...
TRANSCRIPT
Preserving Digital Culture: Tools & Strategies for Building Web
Archives : Tools and Strategies for Building Web Archives
Internet Librarian 2009Tracy Seneca – California Digital Library

Session Outline• Web content – why we’re building archives• Web crawling - under the hood• Tools available• Web Archiving Service Demo• Solutions for tough times - collaboration
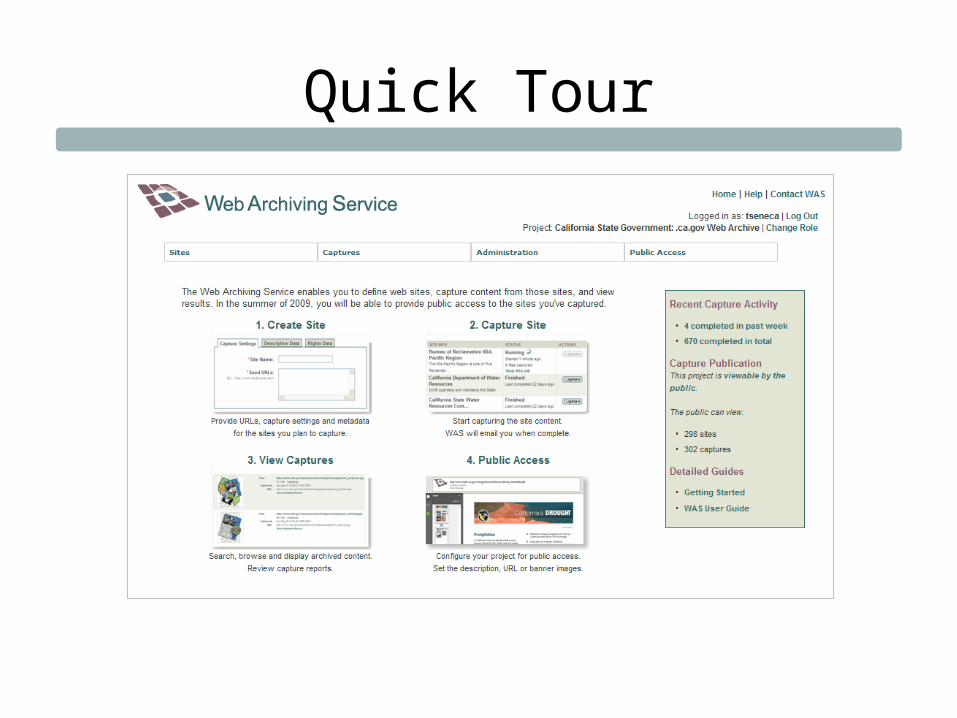
Quick Tour
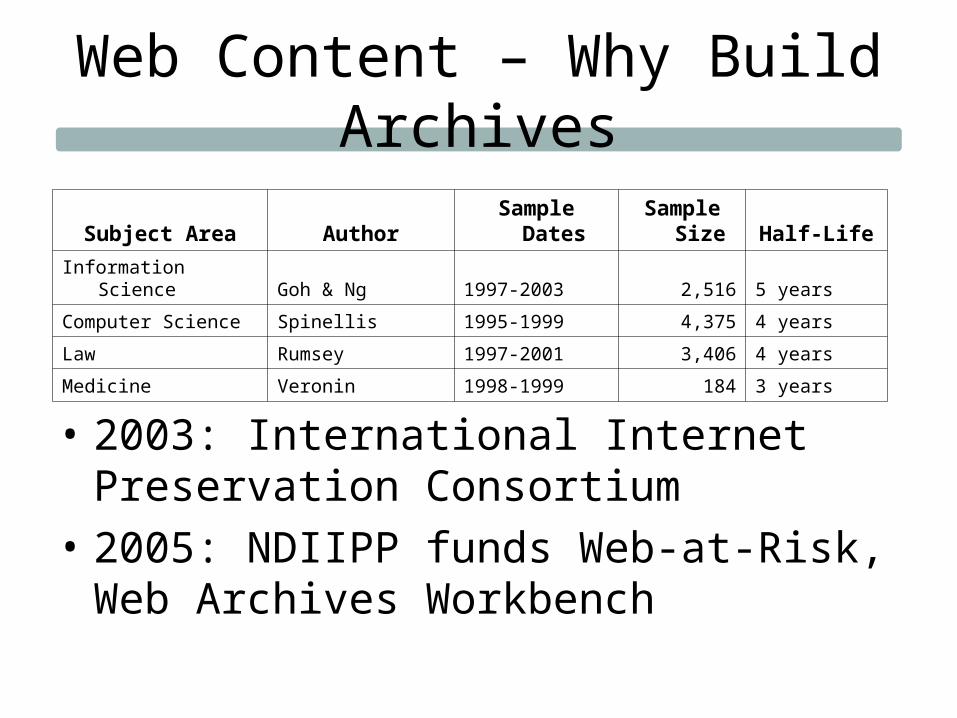
Web Content – Why Build Archives
Subject Area Author Sample DatesSample
Size Half-Life
Information Science Goh & Ng 1997-2003 2,516 5 years
Computer Science Spinellis 1995-1999 4,375 4 years
Law Rumsey 1997-2001 3,406 4 years
Medicine Veronin 1998-1999 184 3 years
• 2003: International Internet Preservation Consortium
• 2005: NDIIPP funds Web-at-Risk, Web Archives Workbench

Threats to Web Content
• Delivery model (many people access one copy)
• Site redesigns• Normal maintenance • Political change
– change of administration– policy changes
• Format

Researcher’s Perspective
• Study the topic / event• Study site change or web-based communication• Create stable citations for publications• Locate archived documents via catalog• Treat archive as a data set

What Makes an Archive
• Collection development – site selection
• Capture – harvesting content
• Curation – description and QA
• Publication – end user access

Archive Types
• Topical• Event• Domain• Document• Personal

Under the Hood
• Heritrix crawler• NutchWAX indexer• Open Source Wayback viewer
Open source tools from the Internet Archive

The Crawler1. Where do I start?2. Can I find that URL?3. Is there a robots.txt?4. What do I need to render that page? (CSS, graphics)5. What links can I find?6. Do those links fit the rules I was given?7. Do I have a flash / PDF / javascript file?8. Does that file have any links?9. For every link that fits the rules, start over!10. Keep going until I can’t find any more links or I hit my
time limit.

What the Crawler Spits Out
• ARC / WARC files– All of the content lumped together in large files– Keeps the archive simple and manageable – Need special tools to search and display
• NutchWAX• Open Source Wayback
• Massive amounts of content!

Why Should I Care?
• When you navigate a web archive, you’re interacting with a very different file structure
• These tools are constantly improving– Crawler gets better at capturing– Indexer gets better at ranking & scaling
• The Web is constantly changing– New technologies, new obstacles

Tools Available: Considerations
• Hosted vs. local
• Cost
• Public access
• Discovery / search options
• Capture configuration
• QA / Analysis Tools
• Metadata options
• Training & Support
• Ease of use
• Limits to:– Users– Archives– Sites– Storage
• Data Transfer
• Data Configuration
• Collaboration
• Rights management

Tools Available
• Hosted– Archive-It– Web Archiving Service– OCLC Web Harvester /
CONTENTdm
– Hanzo Web
• Local Installation– Web Curator Tool– CONTENTdm– NetArchive Suite

Archive-It• Hosted by the Internet Archive
• User-friendly interface, documentation, training
• Capture target = entire collection
• Public access automatic
• Dublin core metadata at seed level
• Limits = storage, # collections, # seeds
• Search full text, not metadata
• Highlight: “Scope It”
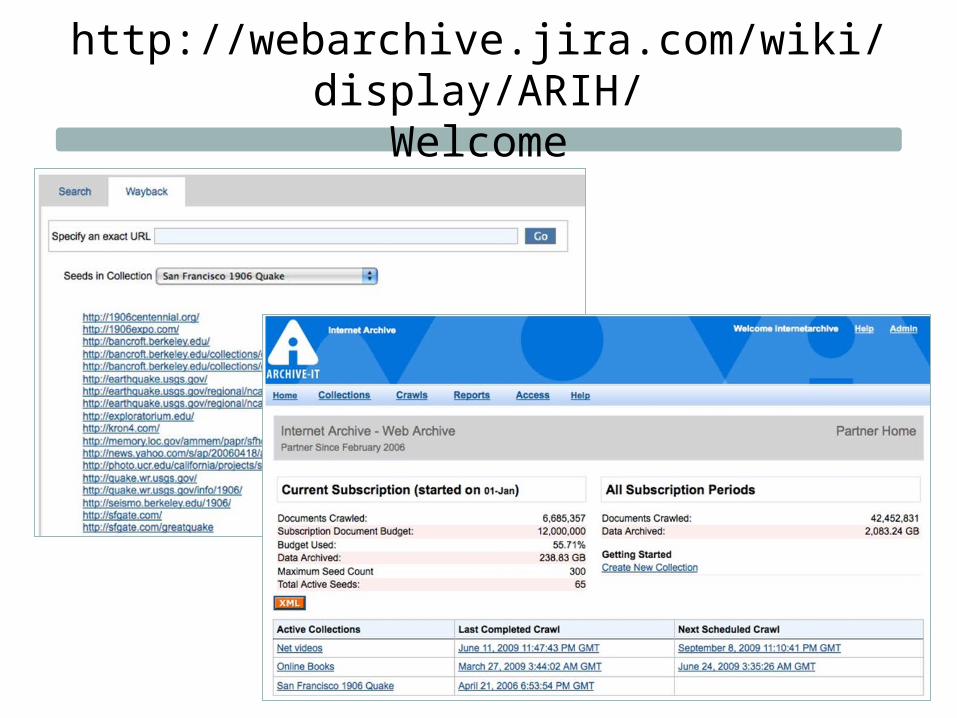
http://webarchive.jira.com/wiki/display/ARIH/Welcome

Web Curator Tool• Developed by National Library of New Zealand with input from the British Library
and other IIPC members
• User-friendly interface, strong user documentation for both technical staff and curators
• Rights management module
• Basic capture settings offered with access to all settings if needed
• Assumes a strong division of labor / specific order of events
• Capture target is flexible (sites or groups of sites)
• Dublin Core metadata
• Highlight: “Prune” tool
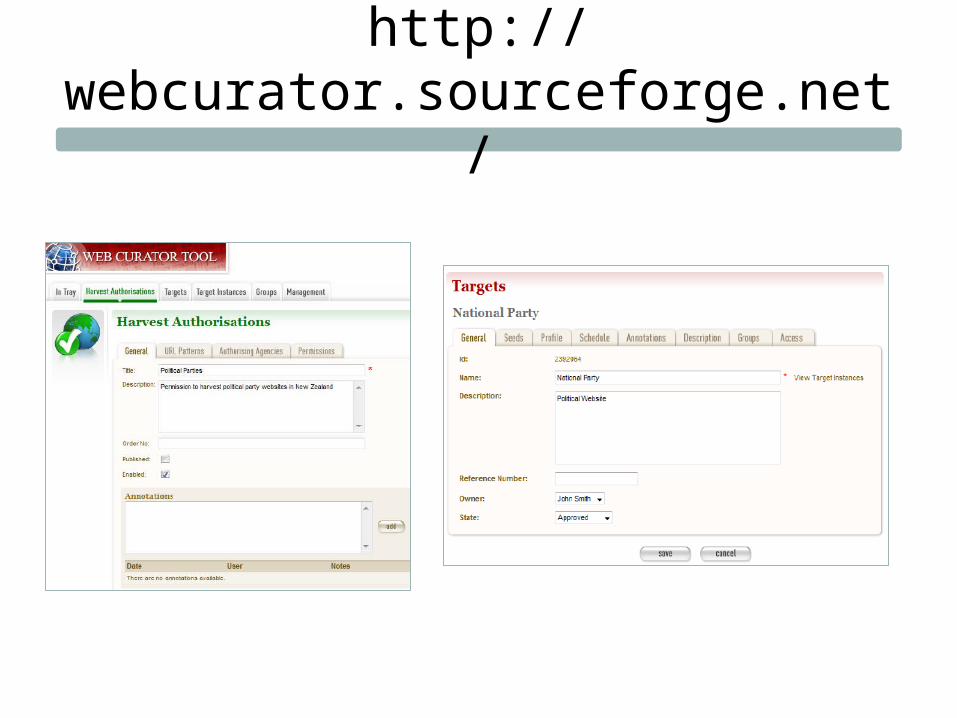
http://webcurator.sourceforge.net/

Web Archiving Service• Hosted by the California Digital Library
• User-friendly interface, documentation, training
• Capture target = site (flexible capture settings)
• Public access (optional)
• Some rights management features
• Limits = storage
• Search full text, not metadata
• Highlight: “show me all the new PDF files”

http://was.cdlib.org
• Web-based demos• User guides

Web Harvester / CONTENTdm
• Harvester hosted by OCLC• Access either hosted or local• Flexible metadata• Search metadata, not full text (except PDF)• Same public access interface as CONTENTdm

NetArchive Suite
• In use at Danish Royal Library 2004• OS release 2007• Tools developed for large scale and comprehensive
domain capture• High degree of control over crawlers• High degree of in-house expertise required• Documentation targets technical staff, not curators
• Highlight: QA tool that lets you click to grab missing images, files
Why have curatorial tools?

Web Archiving Service Demo

Rights Issues: Section 108 Study Group
• No advance permission needed to capture freely available web content
• “Freely available” = no login / fee
• Content owners can prevent capture via robots.txt and may request take down– Except government agencies
• Embargo period observed before archives are published

Large Scale Collaboration
• International Internet Preservation Consortium– Improving capture & display tools– Beginning registry of archives
• APIs to allow searches against different archives, no matter which archiving tool was used

End-of-Term Harvest
• Library of Congress, Internet Archive, California Digital Library, University of North Texas, GPO
• Nomination tool for managing 3000+ URLs for government agency sites
• Captures run at 4 institutions• Content replicated by partner institutions• Public access via Internet Archive
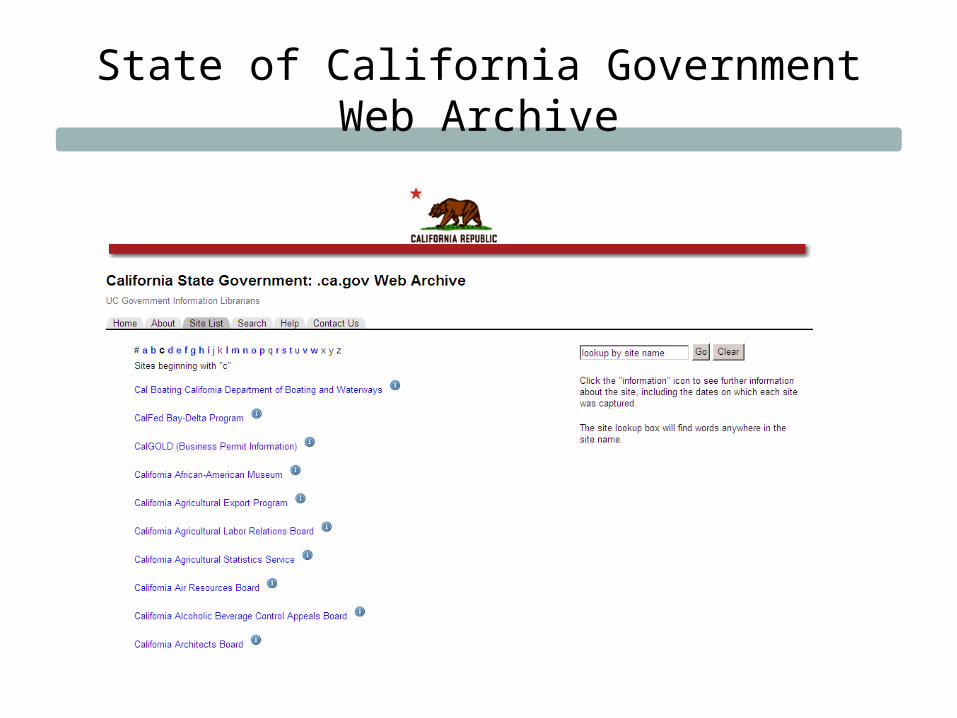
State of California Government Web Archive

Collaboration between
• State agencies/site owners and libraries• Across libraries• Librarians and faculty• Individual researchers
