presentazione tetris
TRANSCRIPT


PROGRAMMA OPERATIVO NAZIONALE RICERCA E COMPETITIVITÀ 2007-2013Azione di formazione
Servizi innovativi Open Source su TETRA Modelli per la gestione della mobilità urbana.
Gruppo di lavoroRocco Picarelli Nicola Procopio Raffaele Vumbaca

Obiettivi:Attività:
Analisi esplorative su dati di mobilità dell’area di CosenzaRealizzazione di modelli finalizzati alla gestione della mobilità cittadina.
Obiettivo:Fornire un supporto alle decisioni per la gestione ed il coordinamento dei mezzi di trasporto pubblico.

Dati
Dati del TPL di Cosenza. I dati riguardano gli itinerari delle linee nella città, i diari dei viaggi degli autobus. Periodo: Statici + Log 2012. Fornitore: AMACO + ITALIA DISPLAY
Dati di telefonia mobile. I Call Data Record (CDR) sono relativi ad eventi di chiamata degli utenti che si trovano, nel periodo di analisi, nell’area di Cosenza. Periodo Ottobre 2012 e Novembre 2012. Fornitore: Wind.
Traiettorie GPS di veicoli privati che transitano nell’area urbana di Cosenza e in tutta la provincia. Periodo: Luglio e Ottobre 2012 Fornitore: OctoTelematics. Disponibilità: In consegna.

Obiettivi1. Costruzione di una Time-table reale estratta dalle tracce degli
autobus
2. Identificazione dei comportamenti frequenti degli autobus
3. Analisi di raggiungibilità TPL
4. Analisi di raggiungibilità con mezzi privati (TP) e confronto con TPL
5. Analisi di presenza e profilazione degli utenti nell’area cosentina

Tecnologie:
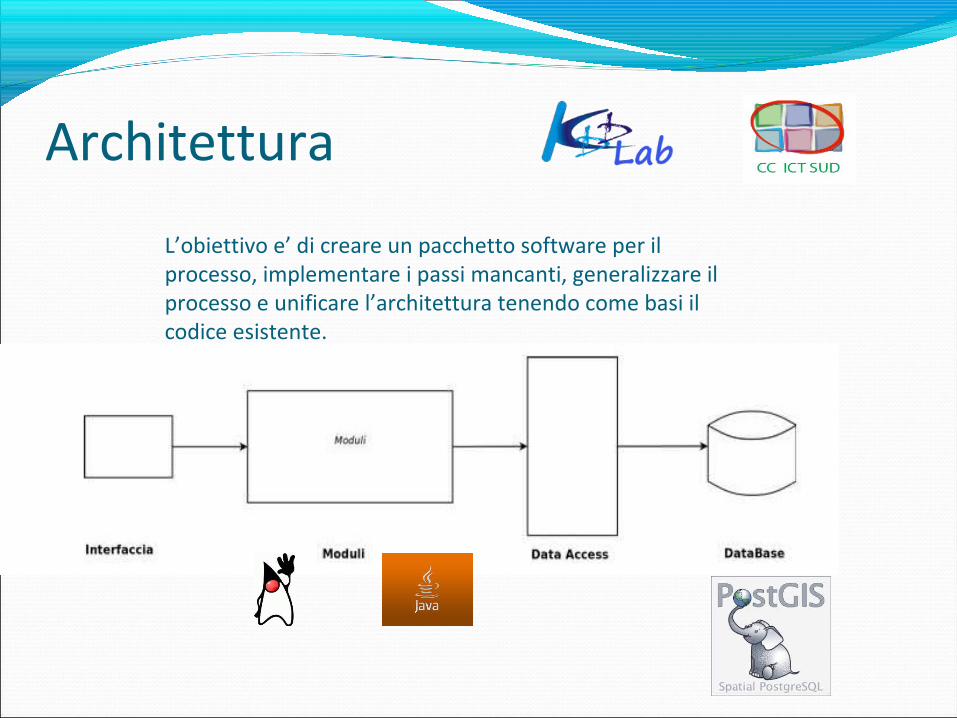
Architettura
L’obiettivo e’ di creare un pacchetto software per il processo, implementare i passi mancanti, generalizzare il processo e unificare l’architettura tenendo come basi il codice esistente.
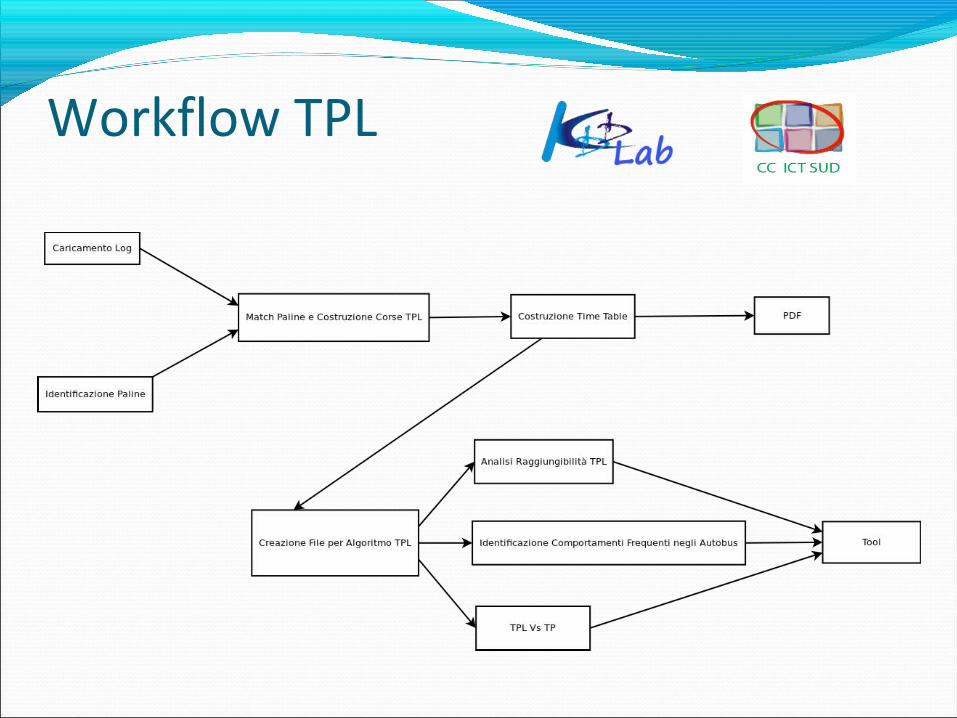
Workflow TPL

Analisi
Raggiungibilità: Come le differenti zone della città sono raggiungibili con i mezzi pubblici ?Dati: TPL - GSM - GPS
Comportamenti frequentiCi sono tratte e/o periodi in cui gli autobus subiscono ritardi frequenti?Analisi dei percorsi, le corse sono “ottimizzate”? Dati: TPL
Utenza Privata vs TPLCome il trasporto può pubblico servire il trasporto privato? Dati: TPL - GPS
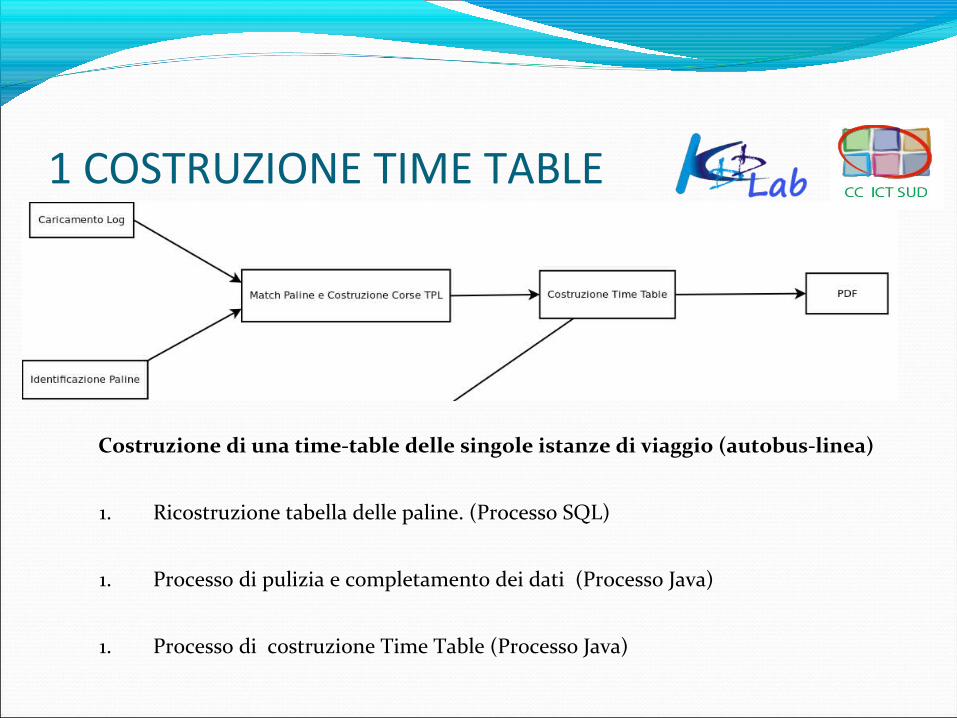
1 COSTRUZIONE TIME TABLE
Costruzione di una time-table delle singole istanze di viaggio (autobus-linea)
1. Ricostruzione tabella delle paline. (Processo SQL)
1. Processo di pulizia e completamento dei dati (Processo Java)
1. Processo di costruzione Time Table (Processo Java)

Ricostruzione Tabella PalinePer identificare una posizione univoca per paline con stesso identificativo è stata utilizzata una
metodologia density-based.
Per associare un'unica posizione alla fermata è stata utilizzata una metodologia che assegna maggior peso a rilevamenti vicini. Costruendo un buffer di 50 m. attorno ad ogni fermata, si selezionano i rilevamenti i cui buffer si intersecano. Delle fermate che hanno un’intersezione a comune, si calcola il punto medio e si associa a quel punto la posizione effettiva della palina (Figura 2). Questa metodologia permette di escludere punti molto lontani che possono essere generati da errori nel gps o di trascrizione.
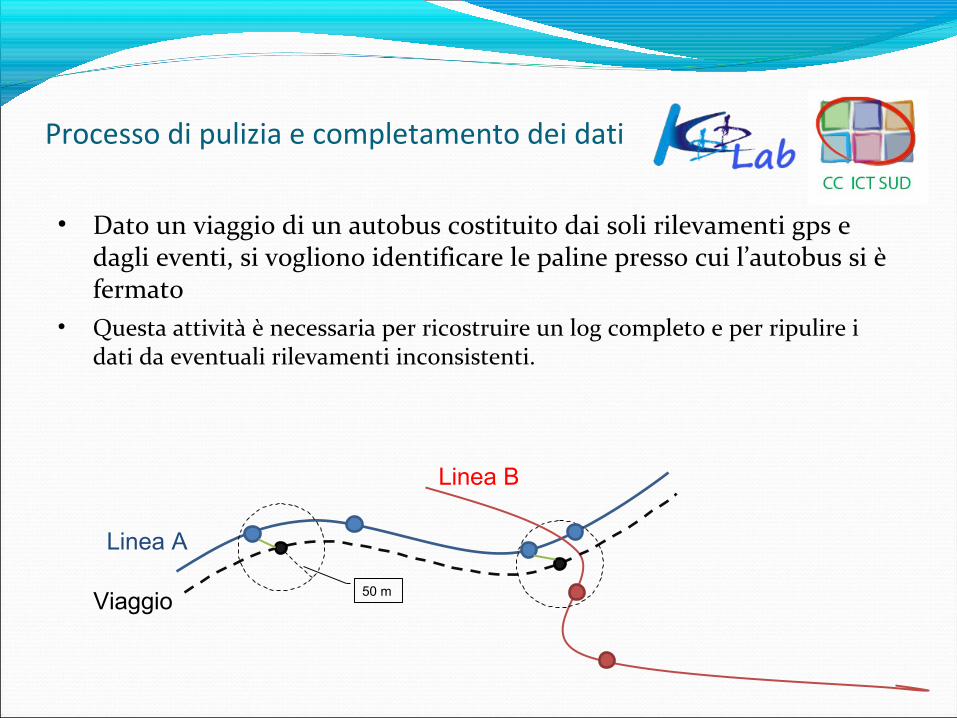
Processo di pulizia e completamento dei dati
• Dato un viaggio di un autobus costituito dai soli rilevamenti gps e dagli eventi, si vogliono identificare le paline presso cui l’autobus si è fermato
• Questa attività è necessaria per ricostruire un log completo e per ripulire i dati da eventuali rilevamenti inconsistenti.
Linea A
Viaggio
Linea B
50 m

Processo di pulizia e completamento dei dati
Sono ordinati i log in base al time stamp selezionando per ogni linea, autobus e giorno i
diversi gruppi di log. Da questi, si sono suddivisi i viaggi (sequenze di rilevamenti in un giorno) in corse
giornaliere, tagliando le varie traiettorie in base a 3 criteri:
• Raggiungimento dell’ultima fermata della linea.
• Partenza dalla prima fermata della linea.
• Distanza temporale tra rilevamenti successivi maggiore di una soglia MAX_TIME_GAP = 30
minuti.
Linea A
Viaggio
Linea B
50 m
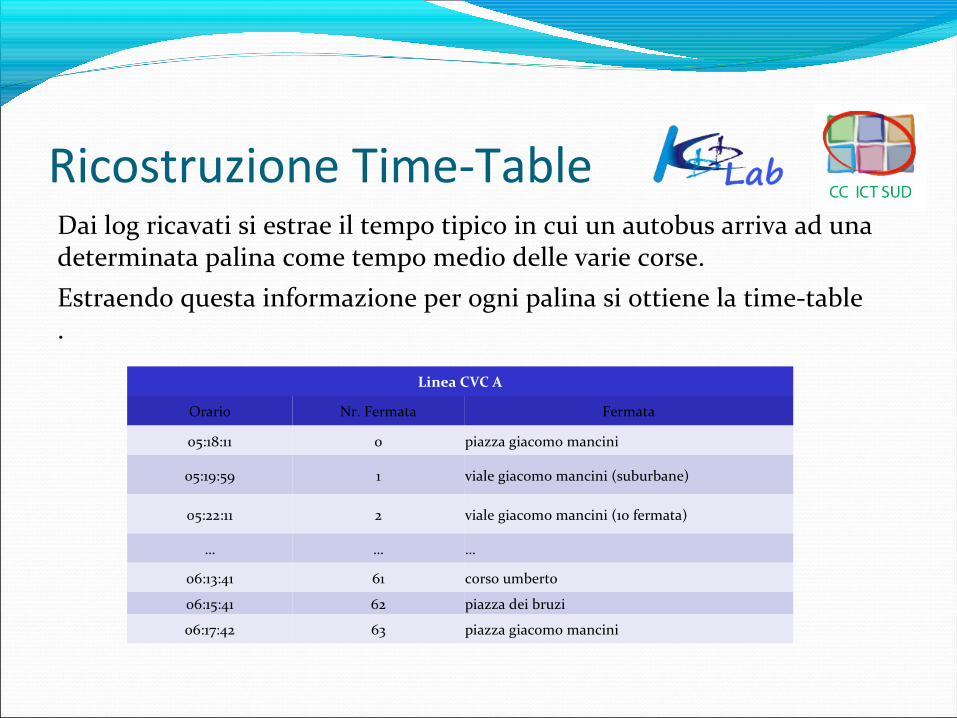
Ricostruzione Time-TableDai log ricavati si estrae il tempo tipico in cui un autobus arriva ad una determinata palina come tempo medio delle varie corse. Estraendo questa informazione per ogni palina si ottiene la time-table .
Linea CVC A
Orario Nr. Fermata Fermata
05:18:11 0 piazza giacomo mancini
05:19:59 1 viale giacomo mancini (suburbane)
05:22:11 2 viale giacomo mancini (1o fermata)
… … …
06:13:41 61 corso umberto
06:15:41 62 piazza dei bruzi
06:17:42 63 piazza giacomo mancini

2 Identificazione comportamentifrequenti degli autobus
15
Lo scopo è analizzare i percorsi AMACO per verificare se esistono schemi ricorrenti per quanto riguarda:
•Sovrabbondanza o carenza di linee su un’area;•Tratte e/o periodi in cui gli autobus subiscono ritardi frequenti;•Eccessivo carico su una palina.
Metodo:
•Processo SQL e DMQL per visualizzare graficamente le linee;•Analisi di densità.
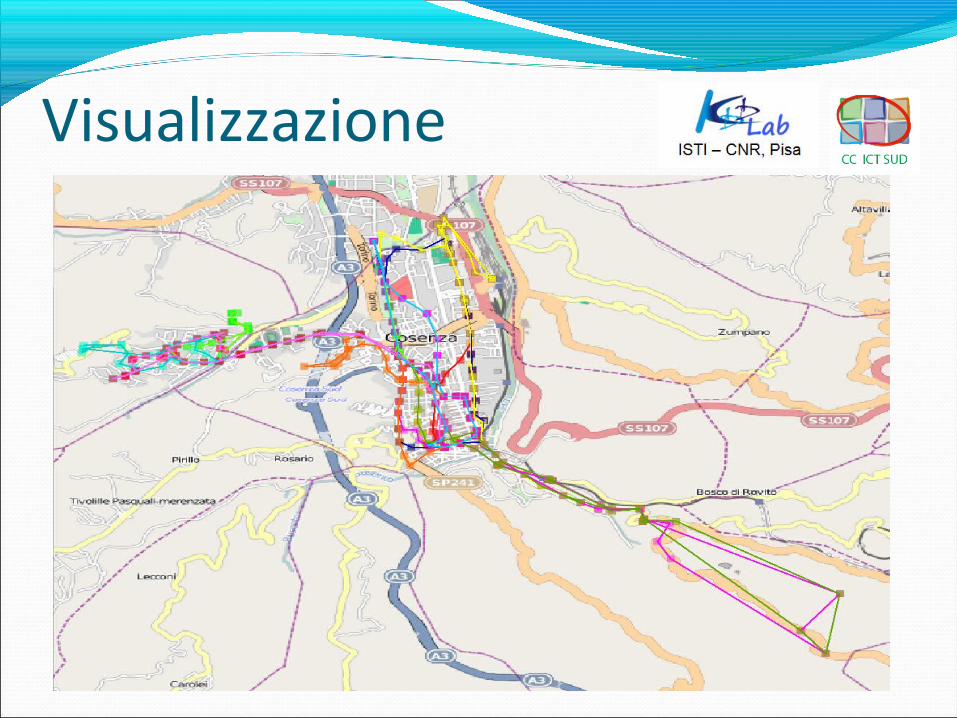
Visualizzazione
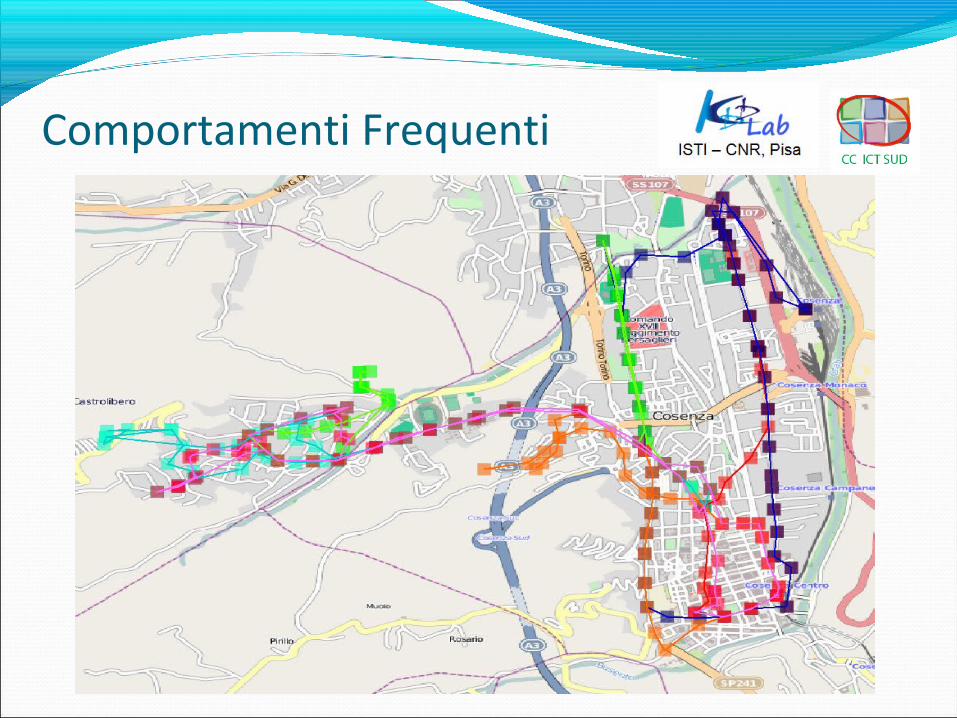
Comportamenti Frequenti
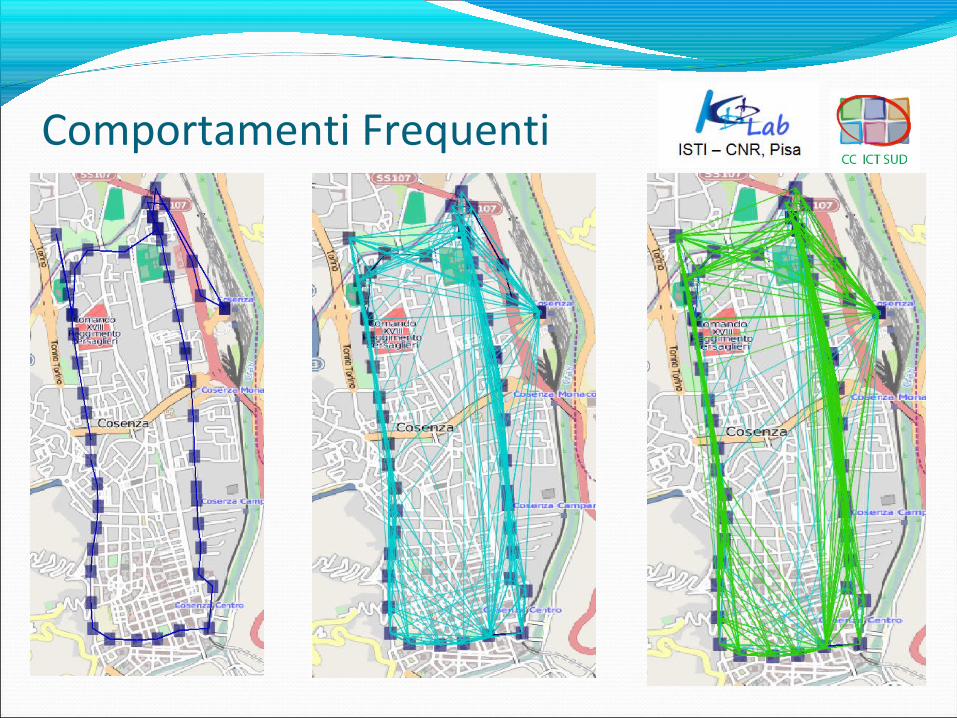
Comportamenti Frequenti
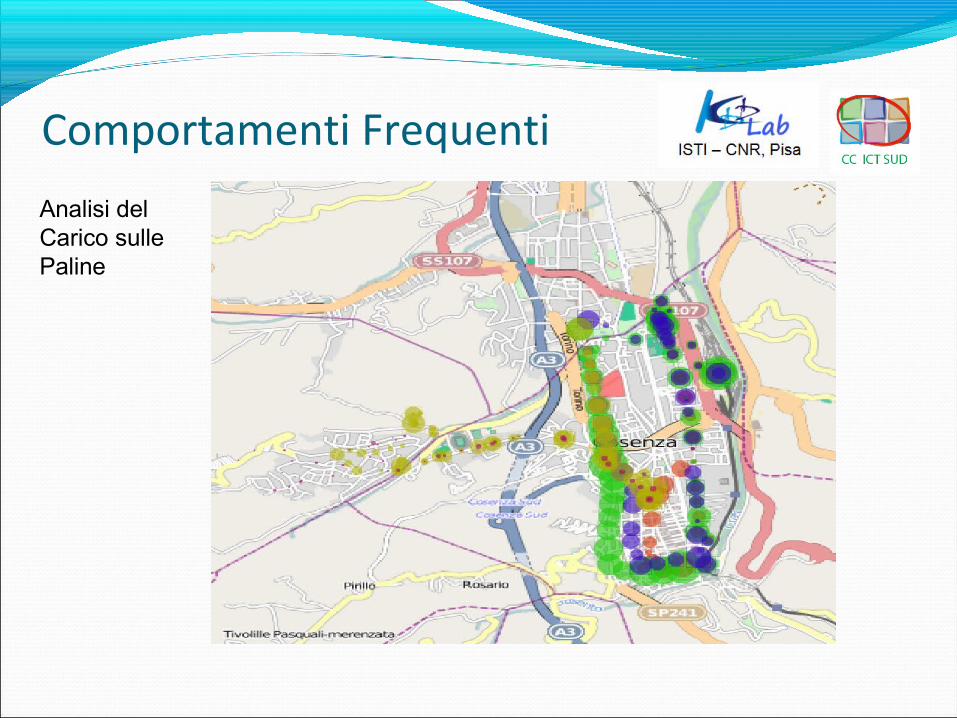
Comportamenti Frequenti
Analisi del Carico sulle Paline
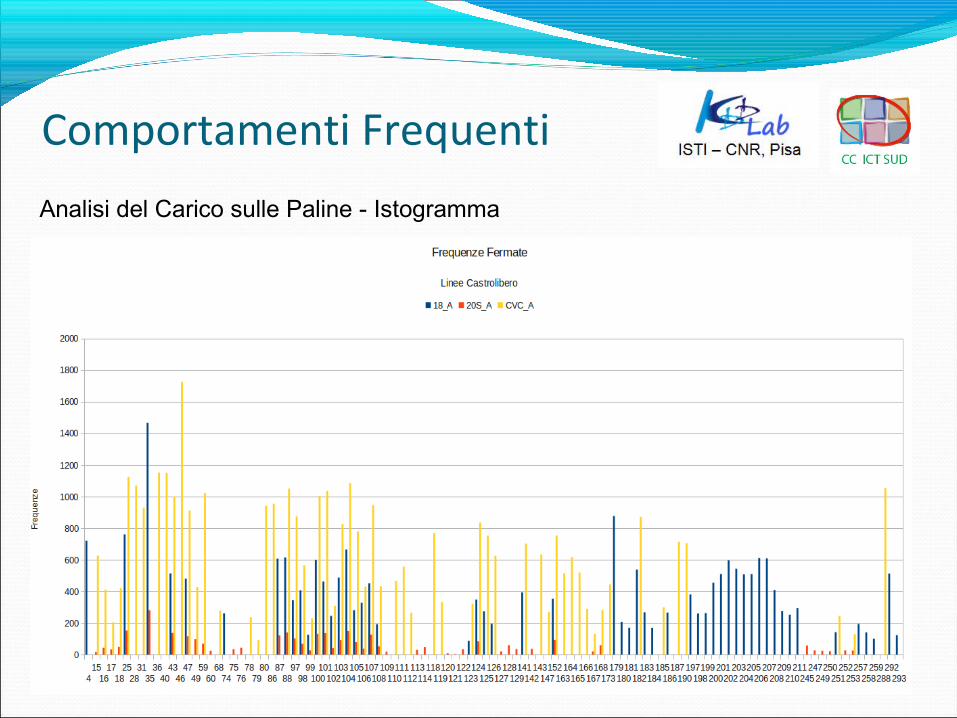
Comportamenti Frequenti
Analisi del Carico sulle Paline - Istogramma

Analisi di raggiungibilità
Lo scopo è quello di calcolare i luoghi raggiungibili con il TPL dato:Luogo partenza (una palina TPL).
Orario di partenza.
Tempo massimo di viaggio.
Metodo: Codifica della rete TPL come un grafo diretto, dove:
Nodi: paline del TPL con associato il tempo di arrivo.
Archi: segmenti che formano una linea di TPL
Implementazione di un algoritmo di esplorazione su grafi per calcolare le paline raggiungibili dato l’insieme di constraints.
21

Analisi di raggiungibilitàBuffer Variabile – più è vicina la palina più il buffer è piccolo
Buffer Fisso
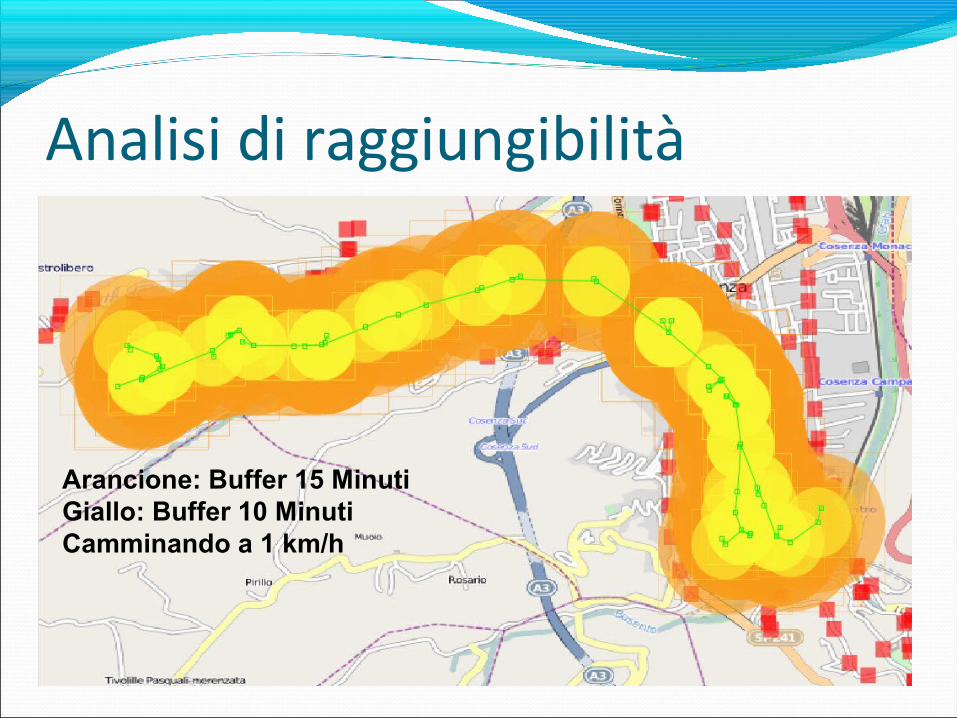
Analisi di raggiungibilità
Arancione: Buffer 15 MinutiGiallo: Buffer 10 MinutiCamminando a 1 km/h

Analisi di raggiungibilità con mezzi privati e TPL
1. Non essendo disponibili i log OctoTelematics sono stati generati dei percorsi con il Simulatore di Mobilita’ SumoTrack
1. Altra attività è costruire un parser per associare i percorsi generati con i dati di OpenStreetMap
1. Una volta ottenuto il risultato si ha a disposizione i dati per confrontare i tempi.
24

Analisi di raggiungibilità con mezzi privati e TPL
5 Profilazione utenti
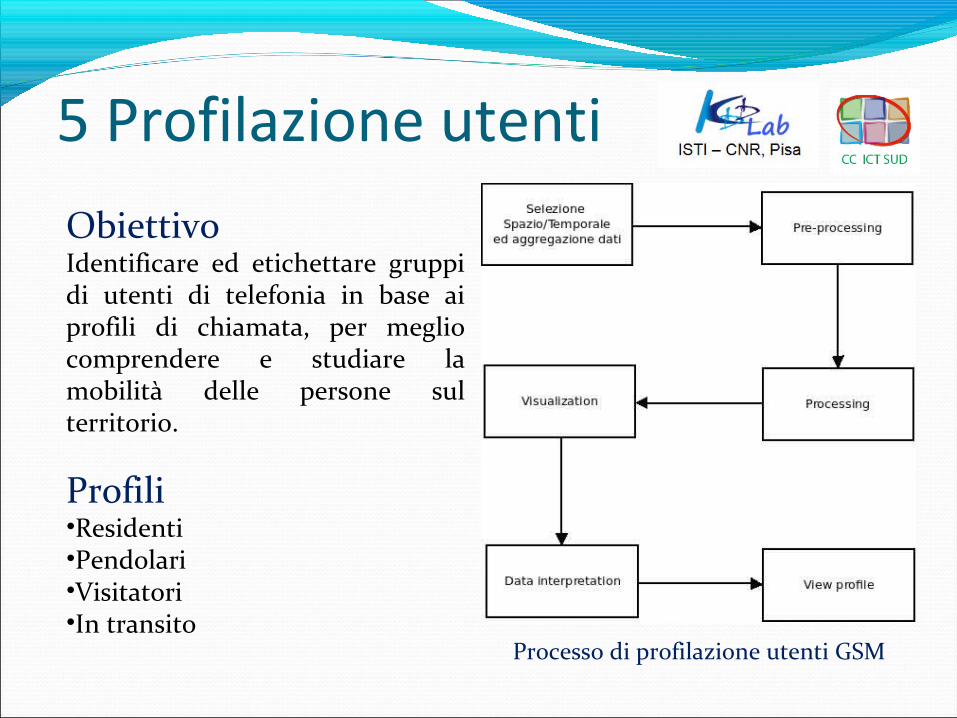
ObiettivoIdentificare ed etichettare gruppi di utenti di telefonia in base ai profili di chiamata, per meglio comprendere e studiare la mobilità delle persone sul territorio.
Profili•Residenti•Pendolari•Visitatori•In transito
Processo di profilazione utenti GSM
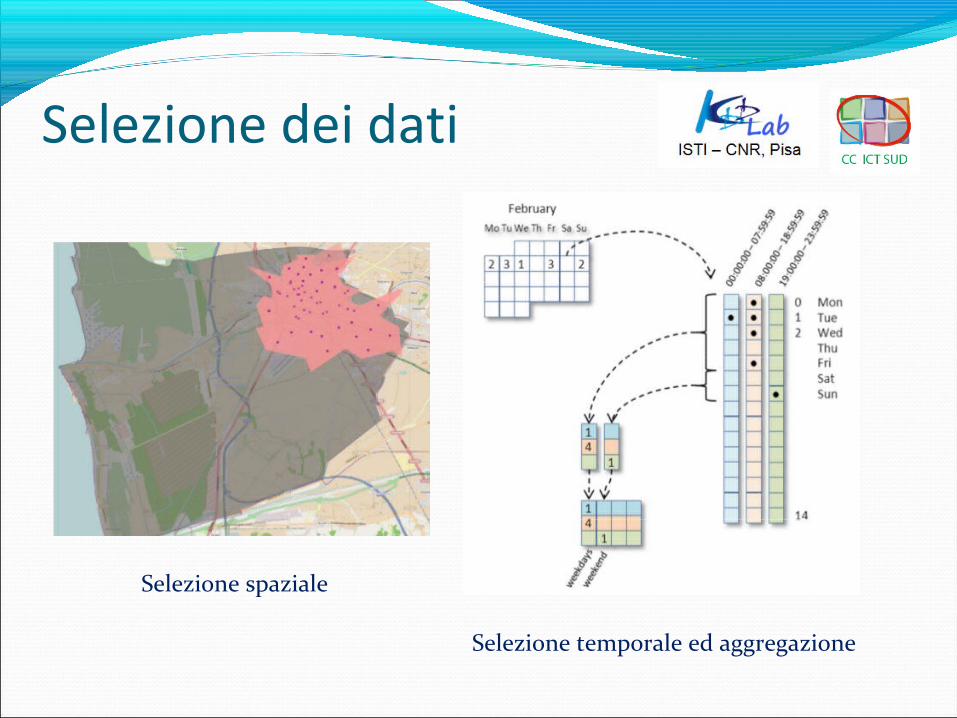
Selezione dei dati
Selezione spaziale
Selezione temporale ed aggregazione

Pre-ProcessingPreparazione dei dati per l'algoritmo di clustering
Algoritmo utilizzato: Clustering basato su Self Organizing Map (SOM)
Prima di eseguire l'algoritmo è necessario preparare i dati di input nel formato accettato.Questo passo è effettuato attraverso un wrapper java che seleziona i dati dalla tabella dei profili e crea un file xml.
Pre-processingPre-processing
Serie temporali in XMLSerie temporali da DB
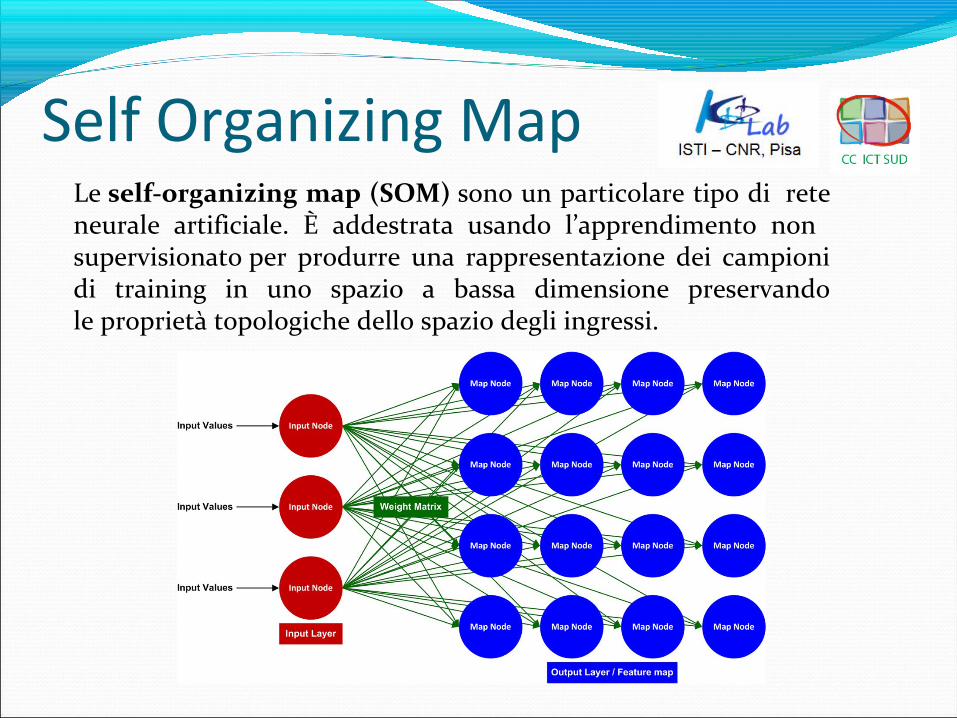
Self Organizing MapLe self-organizing map (SOM) sono un particolare tipo di rete neurale artificiale. È addestrata usando l’apprendimento non supervisionato per produrre una rappresentazione dei campioni di training in uno spazio a bassa dimensione preservando le proprietà topologiche dello spazio degli ingressi.
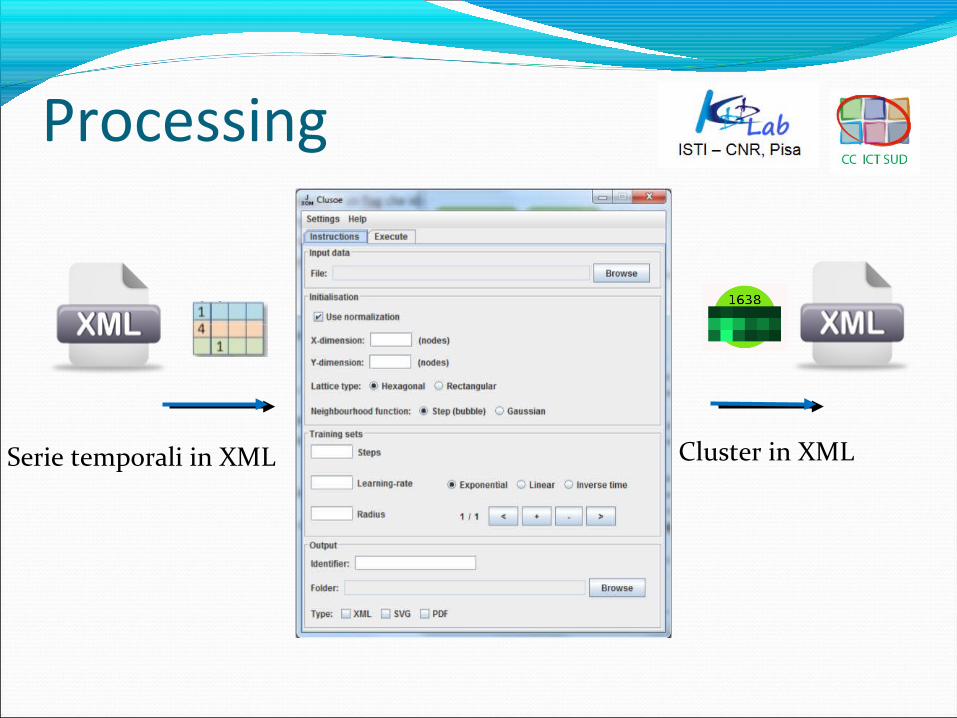
Processing
Serie temporali in XML Cluster in XML
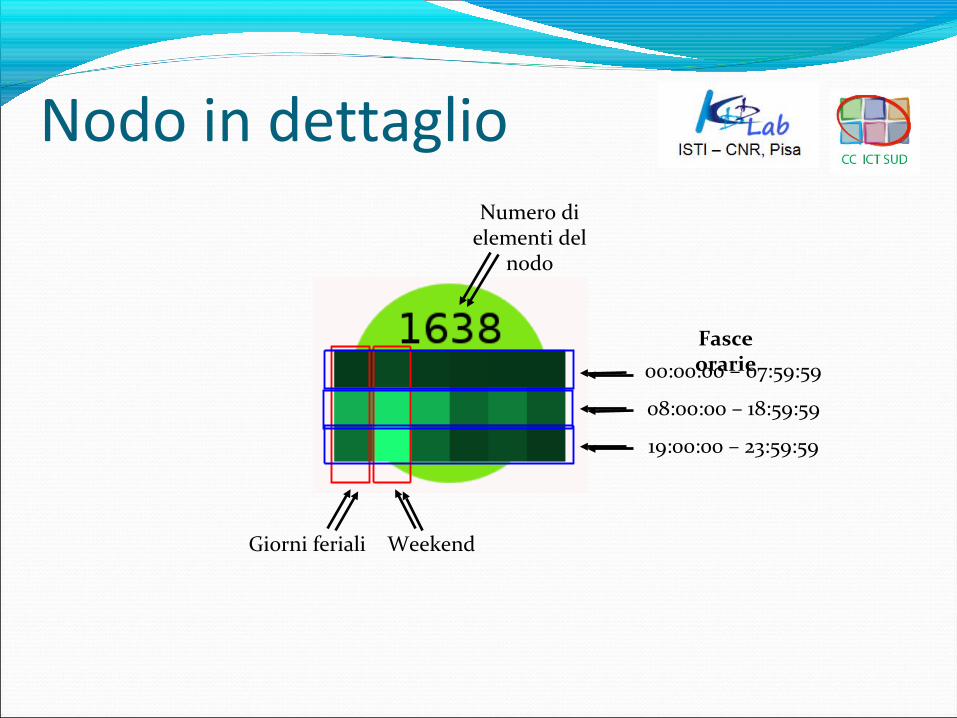
Nodo in dettaglio
Giorni feriali Weekend
Numero di elementi del
nodo
Fasce orarie00:00:00 – 07:59:59
08:00:00 – 18:59:59
19:00:00 – 23:59:59

Visualizzazione risultato

Interpretazione dei datiMetodologia di classificazione
• creazione di un prototipo per ogni profilo;
• discretizzazione dei valori che caratterizzano i nodi;
• calcolo della similarità (coseno di similarità);
• affinamento dell’indice di similarità;
• assegnamento del profilo più simile al nodo.

Interpretazione dei dati
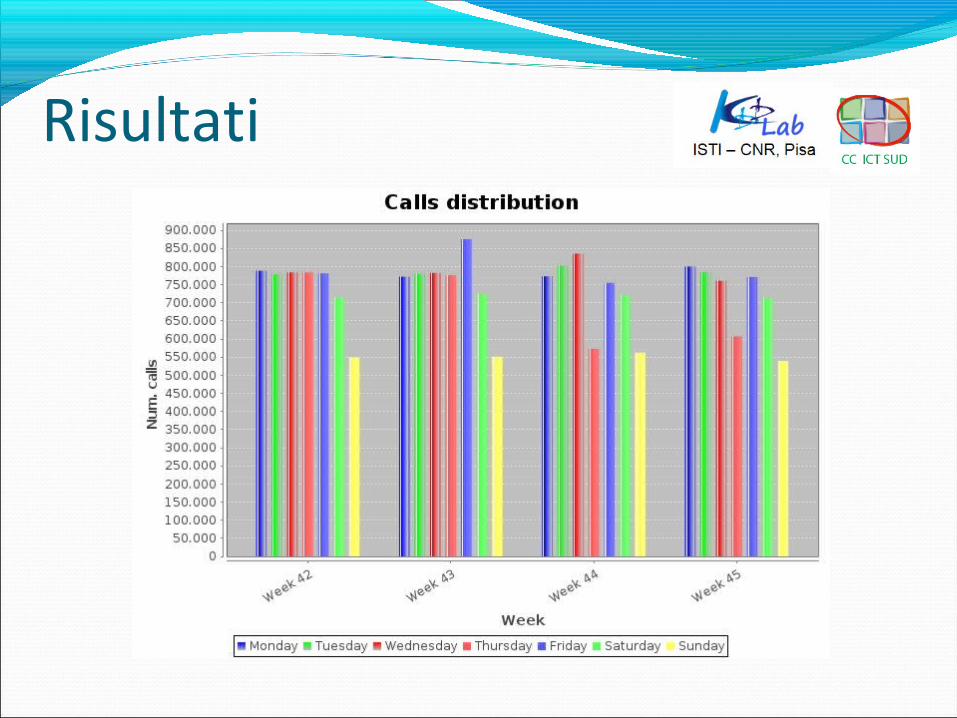
Risultati

Grazie per l’attenzione