presentation_parallel grasp algorithm for job shop scheduling
TRANSCRIPT

Parallel GRASP algorithm for job shop
scheduling
Fiscarelli Antonio Maria 820571
Advanced algorithms project

Nome relatore
Problem definition
In the job shop scheduling problem (JSP), a finite set of jobs
is processed on a finite set of machines under certain
constraints, such that the maximum completion time of the
jobs is minimized.

Nome relatore
Problem definition
o Each job is required to complete a set of operations in a
fixed order.
o Each operation is processed on a specific machine for a
fixed duration.
o Each machine can process at most one operation at time
and once an operation initiates processing on a given
machine it must complete processing on that machine
without interruption.
A schedule is a mapping of operations to time slots on the
machines.
The objective of the JSP is to find a schedule that
minimizes the makespan.

Nome relatore
Problem definition
Minimize Cmax
Subject to:
Cmax ≥ t(σj,k) + p(σj,k) ∀ σj,k ∈ O
t(σj,k) > t(σj,l) + p(σj,l) ∀ σj,l ≺ σi,k
t(σj,k) > t(σi,l) + p(σi,l) ⋀ t(σi,l) > t(σj,k) + p(σj,k)
∀ σi,l, σj,k ∈ O such that Mσi,l = Mσk,j
t(σj,k) ≥ 0 ∀ σj,k ∈ O

Nome relatore
GRASP algorithm
GRASP is an iterative process, where each iteration consists
of:
o construction of a feasible solution
• A restricted candidate list (RCL) is made up of
candidate operations with a greedy function value
above a specific threshold.
• The next element to be included is selected at
random.
• Since its inclusion alters the greedy function and the
set of operations included, the RCL is updated.
The greedy function is the makespan resulting from the
inclusion of operation σj,k to the already scheduled
operations

Nome relatore
GRASP algorithm
o local search (exploration of solution’s neighborhood)
• A disjunctive graph is build, where nodes are operations (weighted
with its duration) and edges are precedences between operations.
• Edges connecting consecutive operations of the same job are
directed.
• Edges connecting operations sharing the same machine are
undirected.

Nome relatore
GRASP algorithm
• A feasible solution corresponds to an orientation of edges of the
graph.
• The makespan of the schedule can be computed by finding the
critical (longest) path from node S to node T.
• All arcs connecting operations sharing the same machine are
tentatively changed direction.
• This exchange might make the graph cyclic, meaning that the
schedule is unfeasible. To check so, the graph is topologically
ordered.
• A new makespan is computed.
• If the exchange doesn’t make the graph acyclic and improves
the makespan, it is accepted. Otherwise, the exchange is
undone.
• The schedule corresponding to the minimum longest path is a
locally optimal.

Nome relatore
GRASP algorithm
Procedure GRASP
READ_DATASET(datasetName);
for i=1, …, numItr do
BUILD_INITIAL_SOLUTION();
BUILD_GRAPH();
makespan = LOCAL_SEARCH();
if(makespan < optimalMakespan)
optimalMakespan = makespan;
fi
rof
WRITE_SOLUTION();

Nome relatore
Parallelization
OpenMP, an API for multi-platform shared memory
multiprocessing programming, has been used to implement
parallelization.
o Extents C/C++ and Fortran
o Supported by multi-platform compiler
o Provides compiler directives, library routines
environment variables.
Significant parallelism can be implemented just by using few
Directives.

Nome relatore
Parallelization
OpenMP is an implementation of multithreading:
o A master thread “forks” a number of slave threads
o The code of parallel region is duplicated and all
threads will execute that code
o Slaves run concurrently as the runtime environment
allocating threads to different processors

Nome relatore
Parallelization
For this implementation, the main loop takes advantage of
parallelization. This is possible since each GRASP iteration
is indipendent from the previous ones.
o Parallelization is performed on the main loop and
dynamically extents to the entire call tree of
subroutines called in it
o Loop iterations are divided into blocks of size
numItr/numThreads and dynamically executed among
the threads.

Nome relatore
Benchmarks
Tests have been performed on two different machines:
o Samsung NP350V5C-S01IT
CHIPSET: Intel HM76
CPU: Intel Core i7-3610QM (2.30 GHz, 4 core, 6 MB
CACHE L3)
RAM: 4 GB DDR3 1600Mhz
o Dell Poweredge T620
CPU: 2 x Intel Xeon Processor E5-2620 v2 (2.10 GHz,
6 cores, 12 threads,15M Cache)
RAM: 32 GB RDIMM 1600MHz

Nome relatore
Benchmarks
4 different datasets has been used to perform tests.
o Dataset 1: 9 operations, 3 machines
o Dataset 2: 16 operations, 3 machines
o Dataset 3: 16 operations, 5 machines
o Dataset 4: 25 operations, 7 machines
Parallelization is performed among 1, 2, 4, 6, 8,10,12
threads

Nome relatore
Benchmarks
0
0,5
1
1,5
2
2,5
3
3,5
4
4,5
1 2 3 4
dataset1
dataset2
dataset3
Seconds
Threads
Samsung NP350V5C-S01IT
100 iterations

Nome relatore
Benchmarks
0
5
10
15
20
25
30
35
40
1 2 3 4
dataset1
dataset2
dataset3
Seconds
Threads
Samsung NP350V5C-S01IT
1000 iterations
Nome relatore
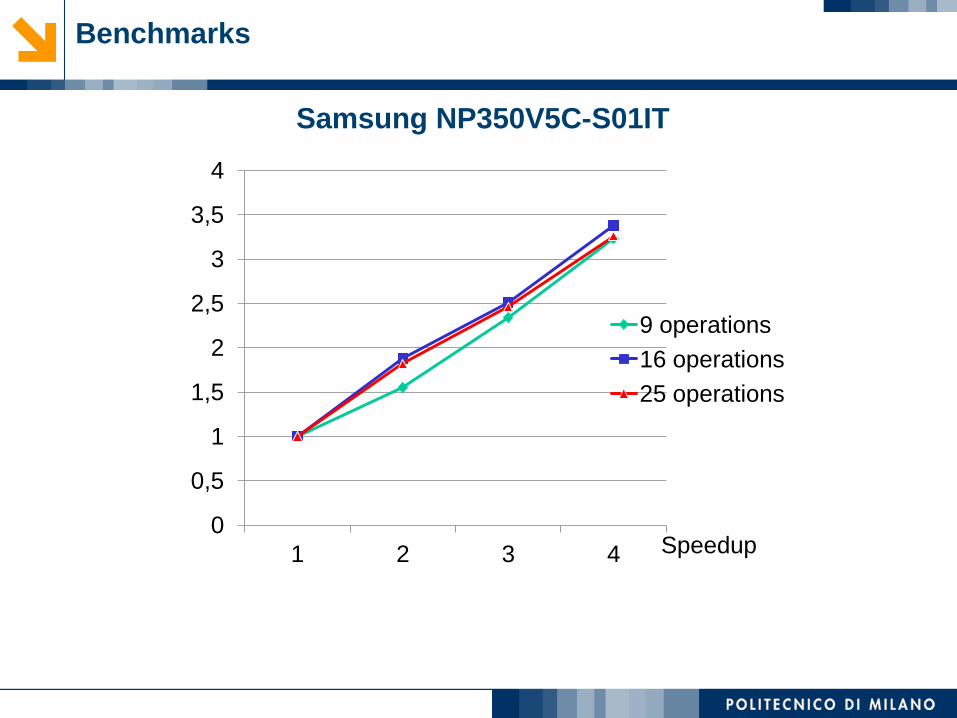
Benchmarks
0
0,5
1
1,5
2
2,5
3
3,5
4
1 2 3 4
9 operations
16 operations
25 operations
Speedup
Samsung NP350V5C-S01IT

Nome relatore
Benchmarks
0
10
20
30
40
50
60
70
80
90
1 2 4 6 8 10 12
Dataset 1
Dataset 2
Dataset 3
Dataset 4
Dell Poweredge T620
500 iterations
Threads
Seconds

Nome relatore
Benchmarks
0
1
2
3
4
5
6
7
8
9
1 2 4 6 8 10 12
Dataset 1
Dataset 2
Dataset 3
Dataset 4
Dell Poweredge T620
500 iterations
Threads
Speedup
Absolute speedup with respect to sequential time

Nome relatore
Benchmarks
0
0,5
1
1,5
2
2,5
2 4 6 8 10 12
Dataset 1
Dataset 2
Dataset 3
Dataset 4
Dell Poweredge T620
500 iterations
Threads
Speedup
Relative speedup among different number of threads

Nome relatore
Benchmarks
0
2
4
6
1 2 3 4 5 6 7 8 9 10
0
20
40
60
80
1 2 3 4 5 6 7 8 9 10
0
50
100
150
200
1 2 3 4 5 6 7 8 9 10
9 operations 16 operations
25 operations
Number of iterations needed to
reach the best solution found

Nome relatore
Benchmarks
Tests show some interesting points:
o absolute speedup is slightly linear with respect to the
number of threads.
o relative speedup decreases while increasing the
number of threads
o the algorithm converges slower as the number of
operations gets bigger and faster as the number of
machines gets bigger.