pengantar big data - arumprimandari.files.wordpress.com filein may 2011, mckinsey & company, ......
TRANSCRIPT

PENGANTAR BIG DATA Arum Handini Primandari
BIG DATA
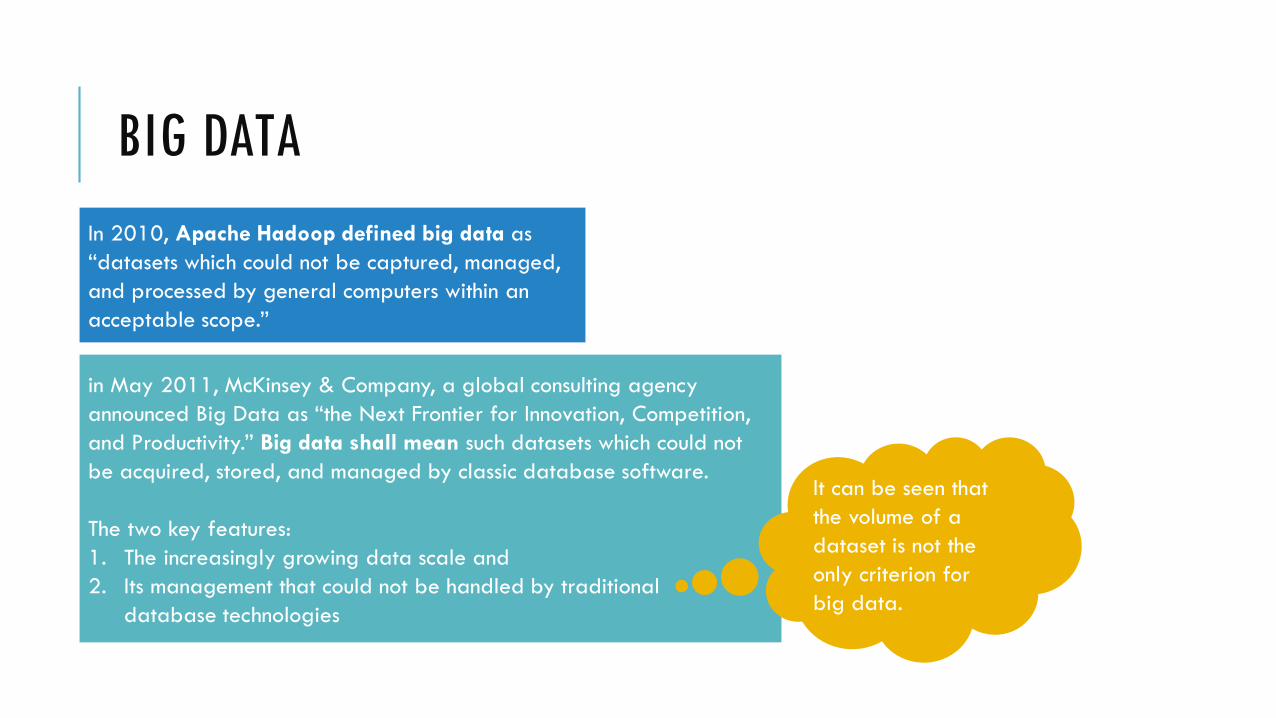
In 2010, Apache Hadoop defined big data as
“datasets which could not be captured, managed,
and processed by general computers within an
acceptable scope.”
in May 2011, McKinsey & Company, a global consulting agency
announced Big Data as “the Next Frontier for Innovation, Competition,
and Productivity.” Big data shall mean such datasets which could not
be acquired, stored, and managed by classic database software.
The two key features:
1. The increasingly growing data scale and
2. Its management that could not be handled by traditional
database technologies
It can be seen that
the volume of a
dataset is not the
only criterion for
big data.

FEATURES OF BIG DATA
Volume
• Enormous volumes of data
• Data is generated by machines, networks, and human interactive (e.g trough social media, e-commerce transaction, etc)
Variety
• Many sources and types of data (structure or unstructured)
• Data comes in the form of emails, photos, videos, monitoring devices, PDFs, audio, etc
Velocity
• The pace of data flows, that is massive and continuous
Veracity
• Big Data Veracity refers to the biases, noise and abnormality in data
Validity
• Meaning that the data correct and accurate for the intended use
• Valid data is key to making the right decisions
Volatility
• Refers to how long is data valid and how long should it be stored
• Determine, when the data no longer relevant to the current analysis
https://insidebigdata.com/2013/09/12/beyond-volume-
variety-velocity-issue-big-data-veracity/

FEATURES BIG DATA http://www.ibmbigdatahub.com/inf
ographic/four-vs-big-data
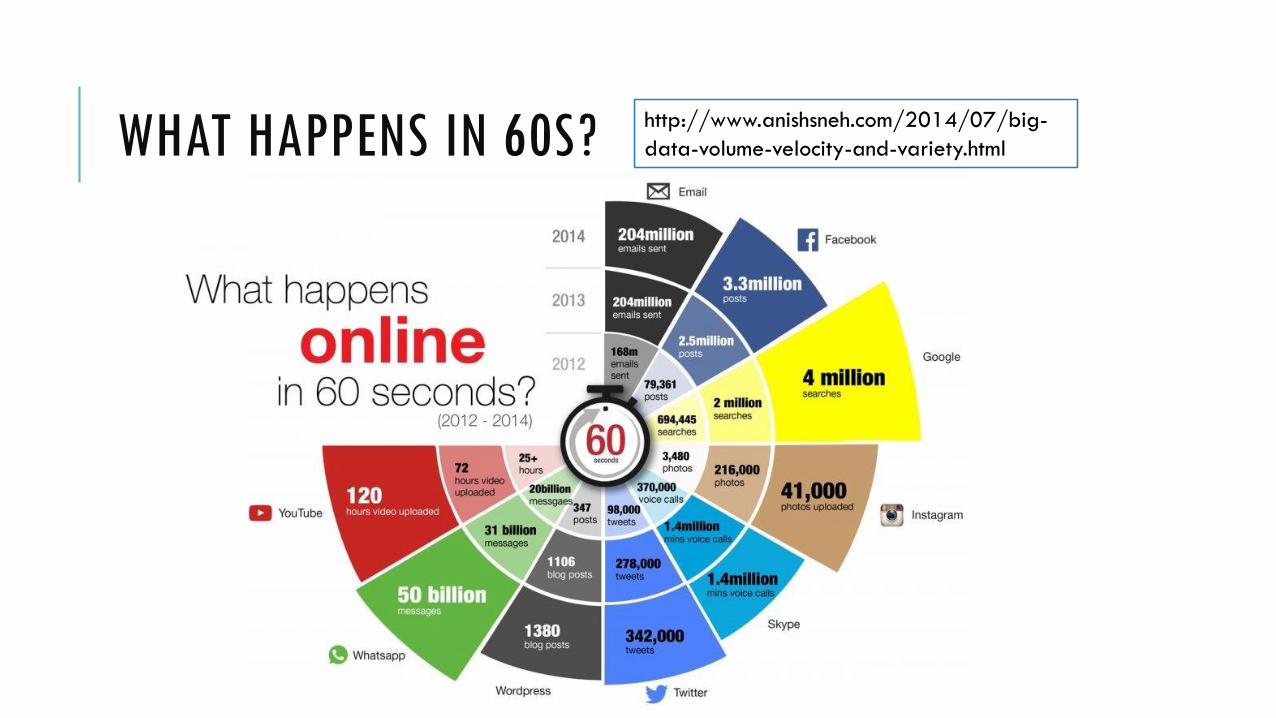
WHAT HAPPENS IN 60S?http://www.anishsneh.com/2014/07/big-
data-volume-velocity-and-variety.html

THE 7V’S BIG DATA https://www.impactradius.com/blog/7-vs-big-data/
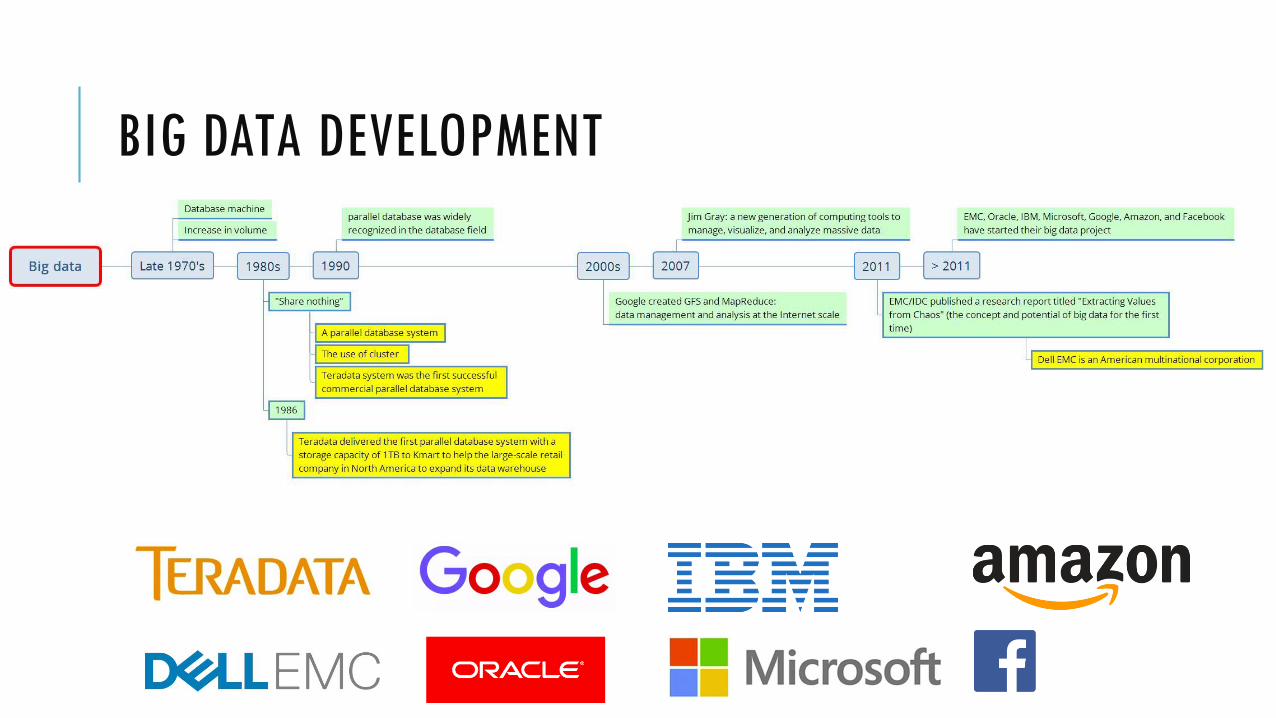
BIG DATA DEVELOPMENT

BIG DATA, BIG OPPORTUNITIES
Big Data bisa berarti Big Opportunity
Sebuah tweet mungkin hanya lelucon, tapisejuta tweet bisa saja berarti trend yang penting
Sebuah review product mungkin hanyaopini, tapi sejuta review bisamengungkapkan cacat desain
Sebuah diagnosis terhadap pasien mungkinhanya kasus khusus, tapi sejuta informasimedis bisa mengarah ke penyembuhan
(Gandhi Manalu, 2016: Workhop Big Data UII)
http://www.ey.com/gl/en/services/advisory/
ey-big-data-big-opportunities-big-challenges

CHALLENGE TO BIG DATA
Tantangan Big Data:
Mengelola volume, velocity, dan variety dari data secara cost-effective
Mendapatkan “insight” dari data yang terstruktur dan tidak terstruktur
Adaptif terhadap perubahan dan dapatterintegrasi dengan tipe dan sumberdata baru
(Gandhi Manalu, 2016: Workhop Big Data UII)
Challenge to data acquisition, storage, management and analysis
• Traditional data management and analytics systems are based on the relational database management system (RDBMS) <- only apply on structured data
• How about unstructured data?(large-scale disordered datasets, distributed file
systems and NoSQL databases)
SQL VS NOSQL
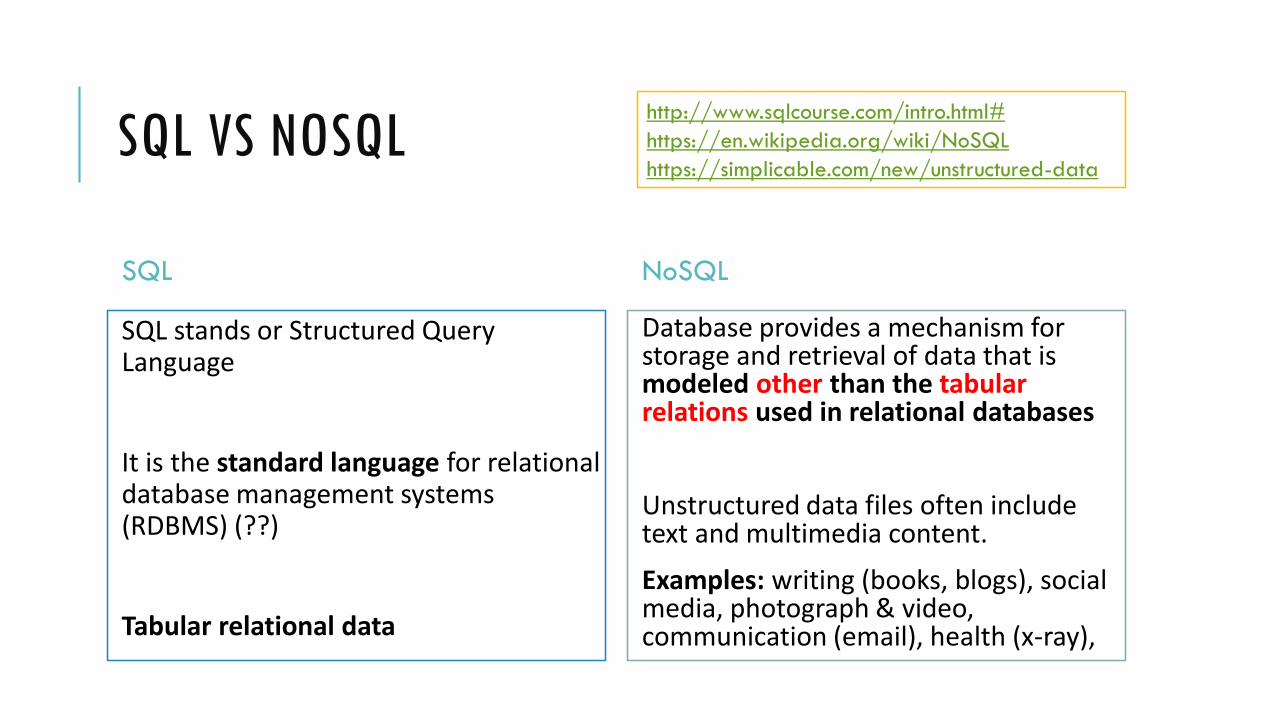
SQL
SQL stands or Structured Query Language
It is the standard language for relational database management systems (RDBMS) (??)
Tabular relational data
NoSQL
Database provides a mechanism for storage and retrieval of data that is modeled other than the tabular relations used in relational databases
Unstructured data files often include text and multimedia content.
Examples: writing (books, blogs), social media, photograph & video, communication (email), health (x-ray),
http://www.sqlcourse.com/intro.html#
https://en.wikipedia.org/wiki/NoSQL
https://simplicable.com/new/unstructured-data
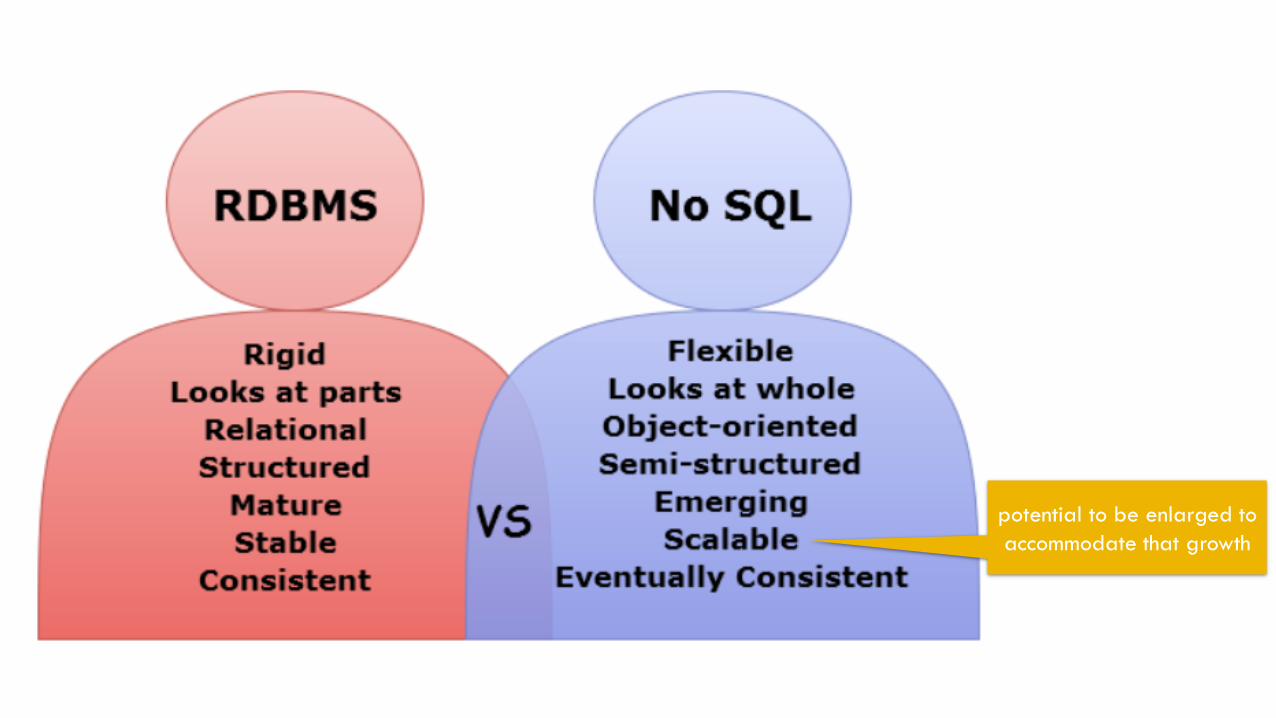
potential to be enlarged to
accommodate that growth

NOSQL
NoSQL adalah jenis basis data yang tidak menggunakanperintah SQL dalam memanipulasi (menyimpan maupunmengambil data) basis data tersebut.
Dilihat dari cara penyimpanan data saja basis data NoSQL tersebar dari cara penyimpanan: Key-Value based (disimpan dalam bentuk kunci-isi berpasangan)
Document based (disimpan dalam dokumen-dokumen)
Column based (disimpan dalam kolom-kolom)
Graph based (disimpan dalam bentuk graf)
7 jenis basis data NoSQL yang paling populer digunakandiseluruh dunia: MongoDB, CouchDB, Cassandra, Redis, Riak, Neo4j, dan OrientDB.
https://www.codepolitan.com/7-basis-data-
nosql-populer
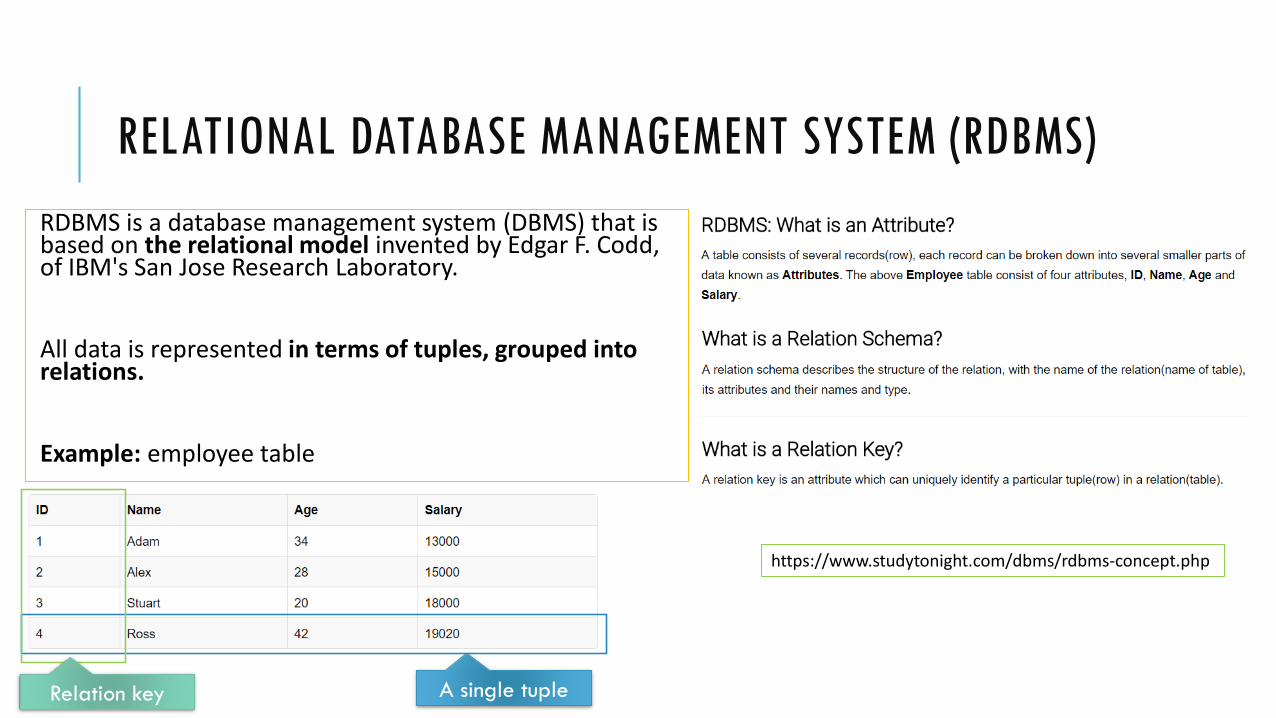
RELATIONAL DATABASE MANAGEMENT SYSTEM (RDBMS)
RDBMS is a database management system (DBMS) that is based on the relational model invented by Edgar F. Codd, of IBM's San Jose Research Laboratory.
All data is represented in terms of tuples, grouped into relations.
Example: employee table
A single tupleRelation key
https://www.studytonight.com/dbms/rdbms-concept.php

DATA LAKE
“Data Lake” mampu menjawab tantangan “Big Data”
A data lake is a storage repository that holds a vast amount of raw data in its native format until it is needed.
While a hierarchical data warehouse stores data in files or folders, a data lake uses a flat architecture to store data.
Each data element in a lake is assigned a unique identifier and tagged with a set of extended metadata tags.
When a business question arises, the data lake can be queried for relevant data, and that smaller set of data can then be analyzed to help answer the question.
Konsep “Data Lake” terkait erat dengan Apache Hadoop dan ekosistem open source nya

HADOOP
“In pioneer days they used oxen for heavy pulling, and when one ox couldn’t budge a log, we didn’t try to grow a larger ox” ~ Grace Hopper, early advocate of distributed computing

HADOOP
Sistem komputasi high-performance modern bersifat terdistribusi: Komputasi disebar di berbagai mesin secara paralel
Banyak digunakan untuk aplikasi scientific

HADOOP
Dua masalah pokok: Bagaimana menyimpan data yang besar dengan reliable dan cost yang reasonable
Bagaimana memproses semua data yang sudah disimpan tadi
Apache Hadoop adalah: Penyimpanan dan pemrosesan data yang scalable
Distributed dan Fault-Tolerant
Berjalan di hardware standard
Dua komponen utama Penyimpanan: HDFS
Pemrosesan: MapReduce
Hadoop cluster Terdiri atas komputer-komputer yang dinamakan node
Cluster bisa terdiri dari 1 node atau beberapa ribu node
HADOOP

HADOOP
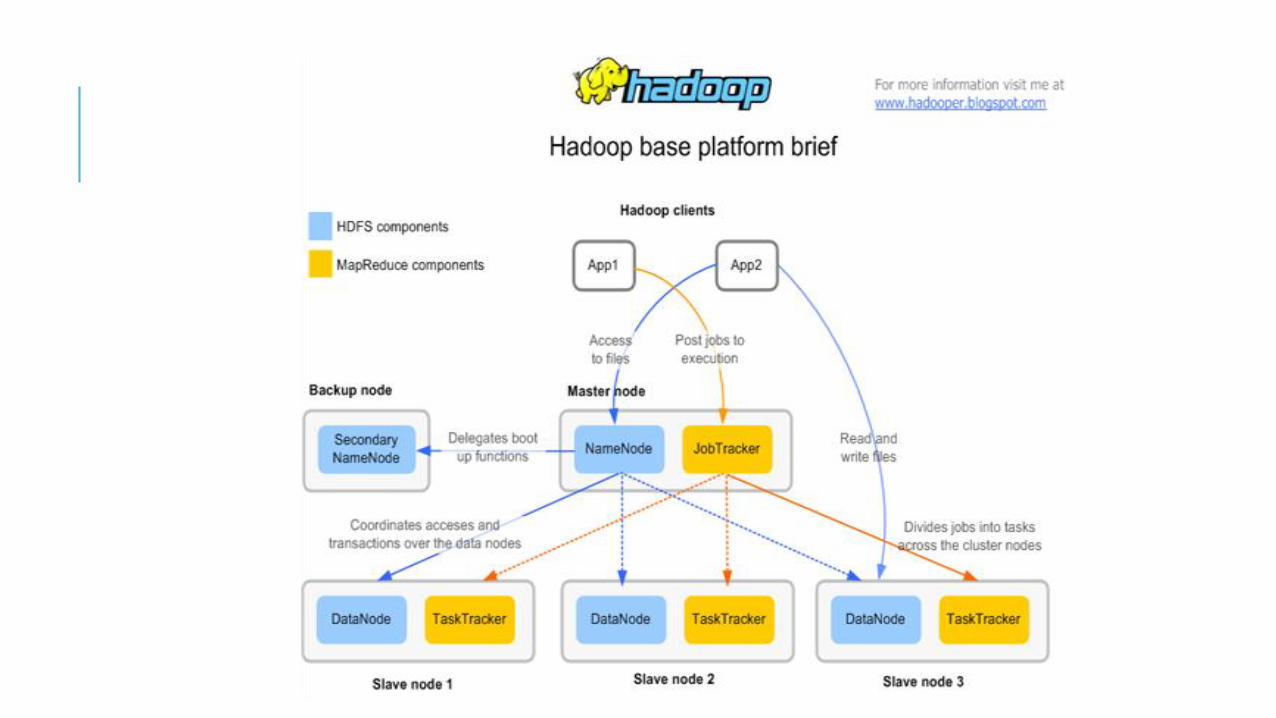
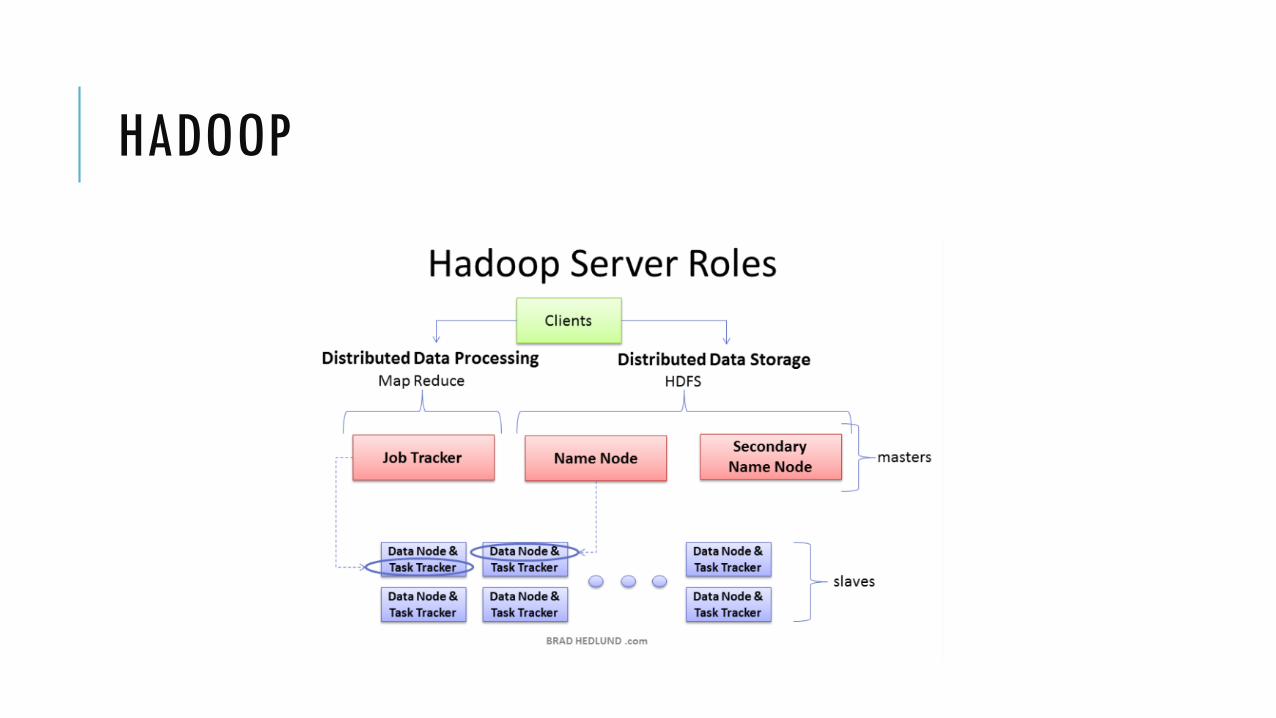
The three major categories of machine roles in a Hadoop deployment are Client machines, Masters nodes, and Slave nodes.
The Master nodes have two task: storing lots of data (HDFS), and
running parallel computations on all that data (Map Reduce)
Slave Nodes make up the vast majority of machines and do all the dirty work of storing the data and running the computations.
Client machines have Hadoop installed, but are neither a Master or a Slave.
http://bradhedlund.com/2011/09/10/understanding-hadoop-
clusters-and-the-network/

HADOOP
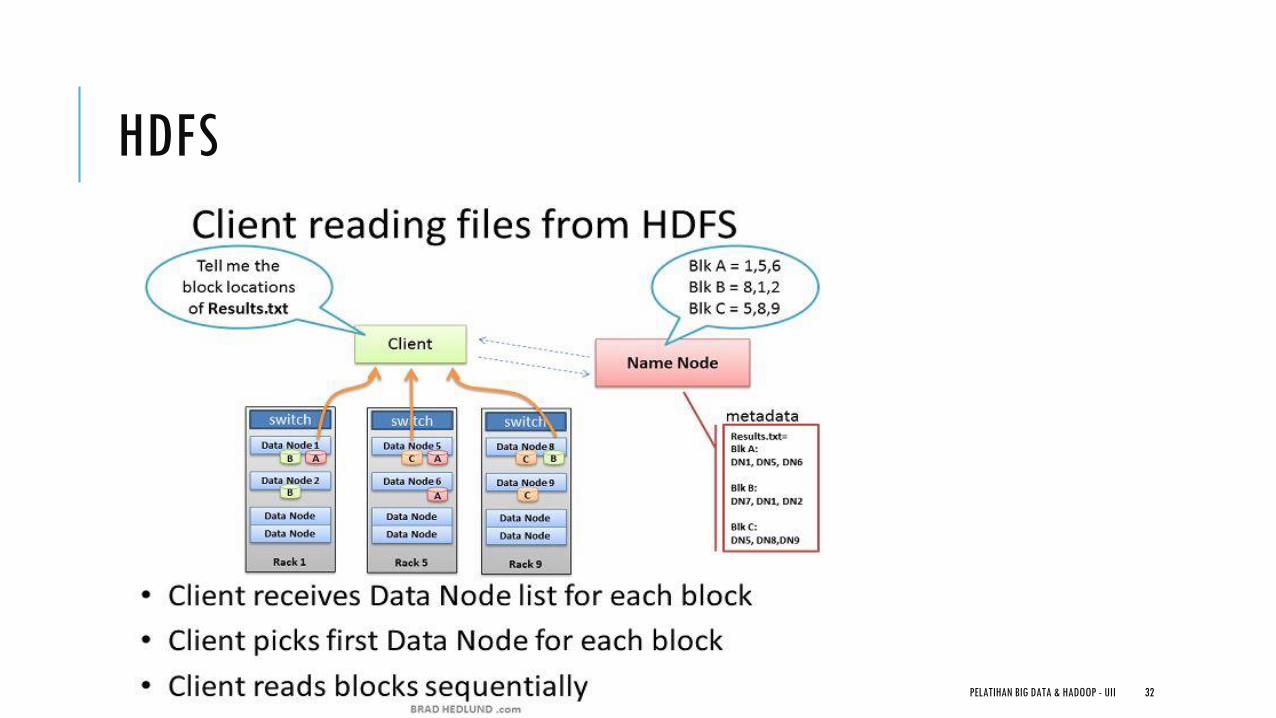
Arsitektur Hadoop NameNode
Master dari HDFS yang mengkoordinasikan DataNode untuk melakukan proses I/O
Menyimpan informasi/metadata tentang HDFS
Secondary NameNode Berkomunikasi dengan NameNode untuk mengambil ‘snapshot’ dari metadata tentang HDFS
Bukanlah ‘hot standby’ untuk NameNode
Akan menghubungi NameNode setiap jam
Tujuannya untuk ‘housekeeping’, melakukan backup terhadap metadata dari NameNode
DataNode Membaca dan Menulis blok-blok HDFS ke file pada filesystem lokal

HADOOP
JobTracker Menentukan rencana eksekusi dengan menentukan file yang akan diproses, ‘task’ yang akan dikerjakan setiap
node, dan memonitor semua ‘task’ yang sedang berjalan
TaskTracker Bertanggungjawab untuk mengeksekusi task yang di-assign oleh JobTracker
HADOOP

HDFS
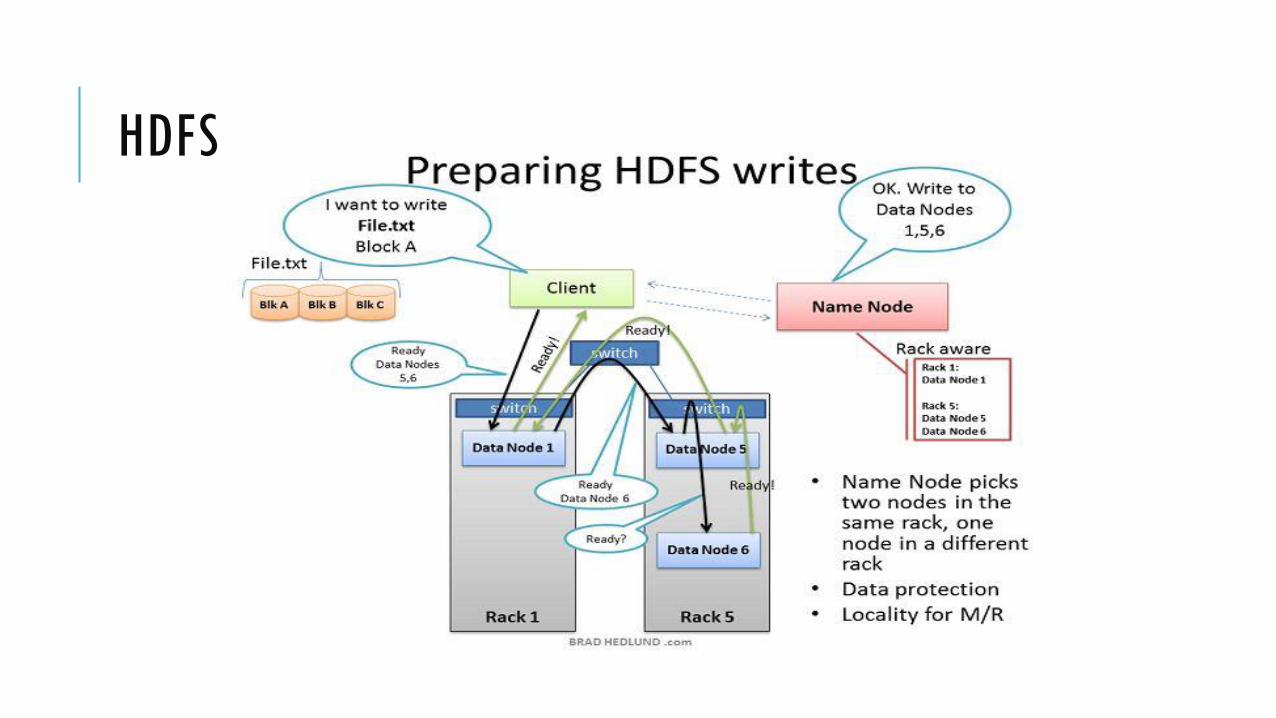
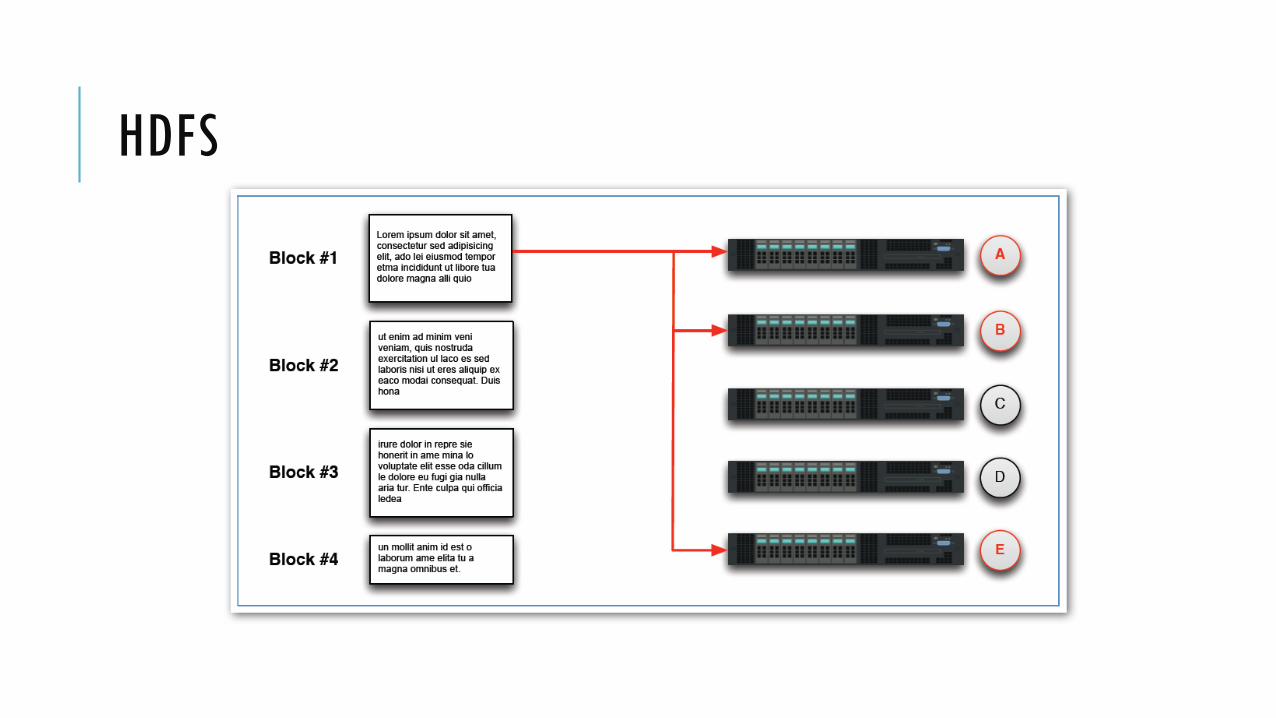
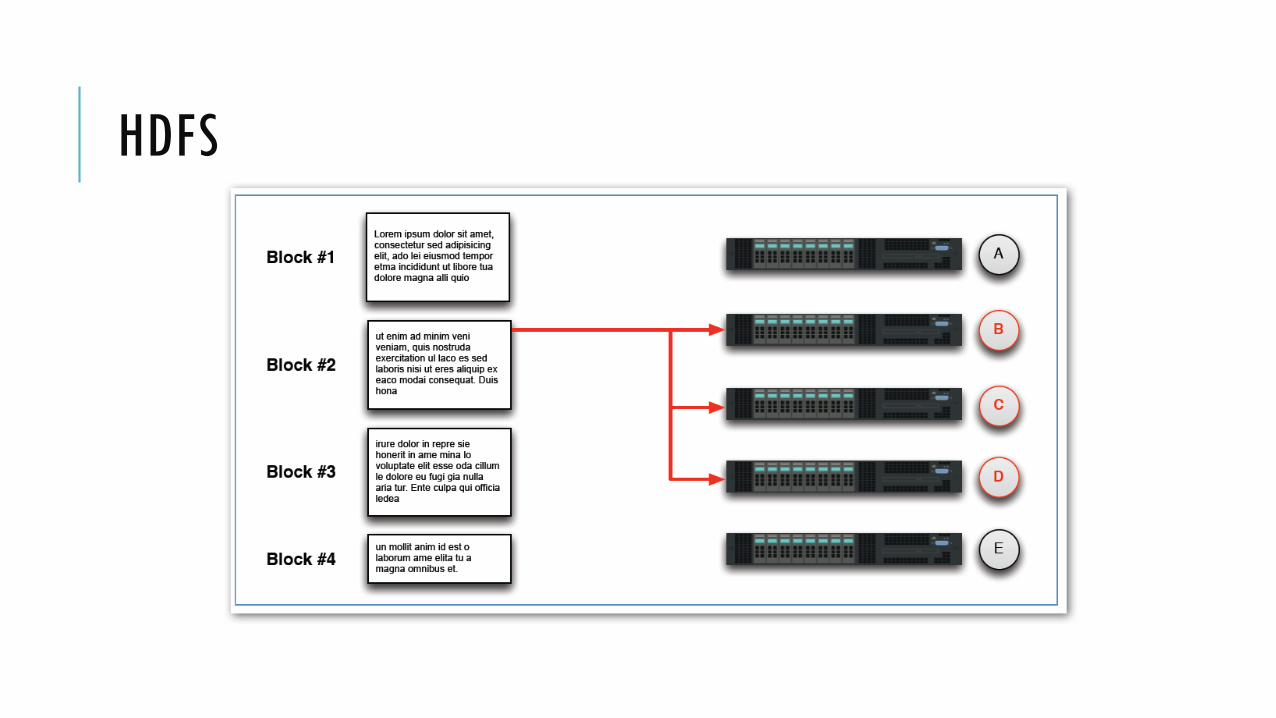
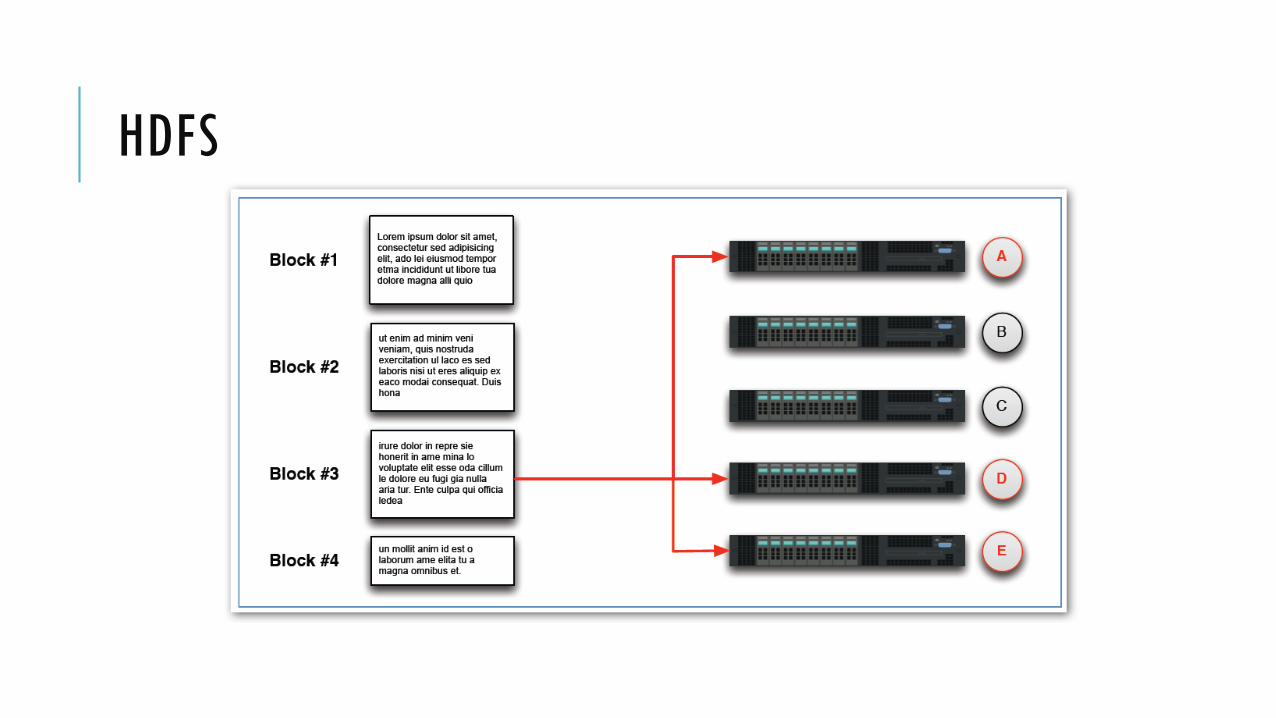
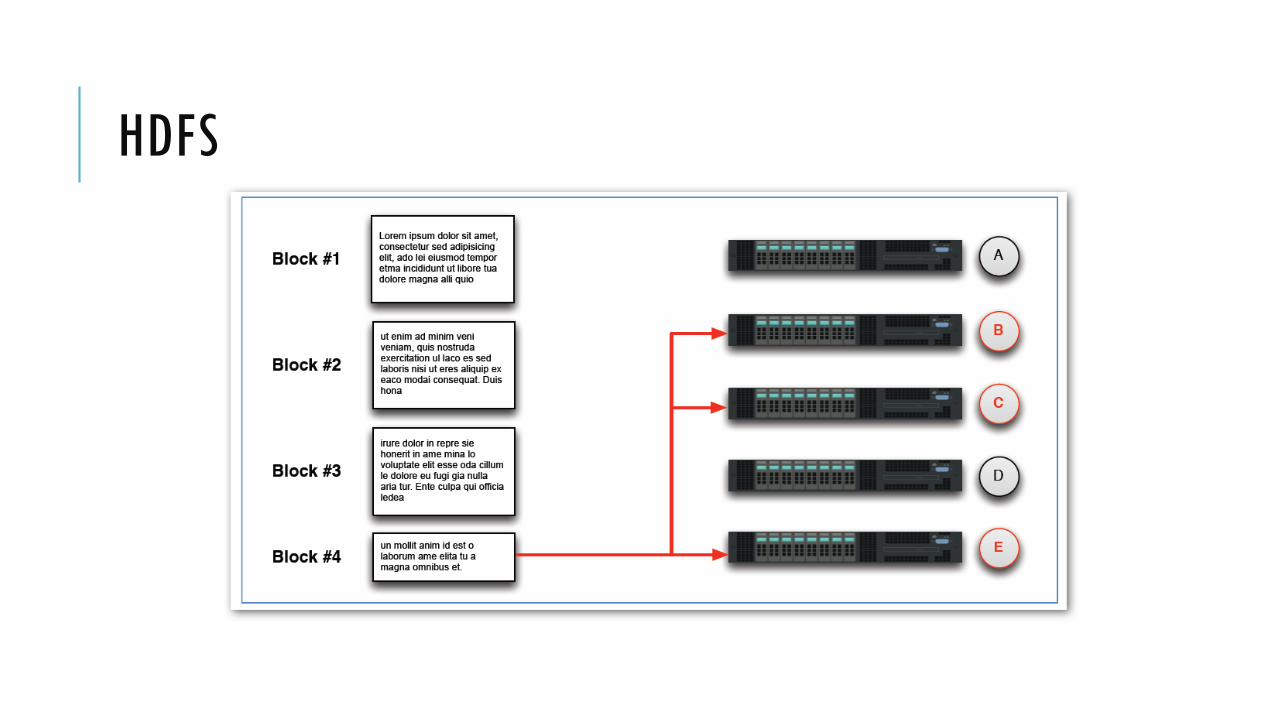
Setiap blok di-replikasi ke beberapa node Replication factor dapat dikonfigurasi, default adalah 3
Kegunaan replikasi: Availability: data tidak hilang ketika sebuah node fail
Reliability: HDFS membandingkan dengan replika dan memperbaiki data yang korup
Performance: data locality

HDFS
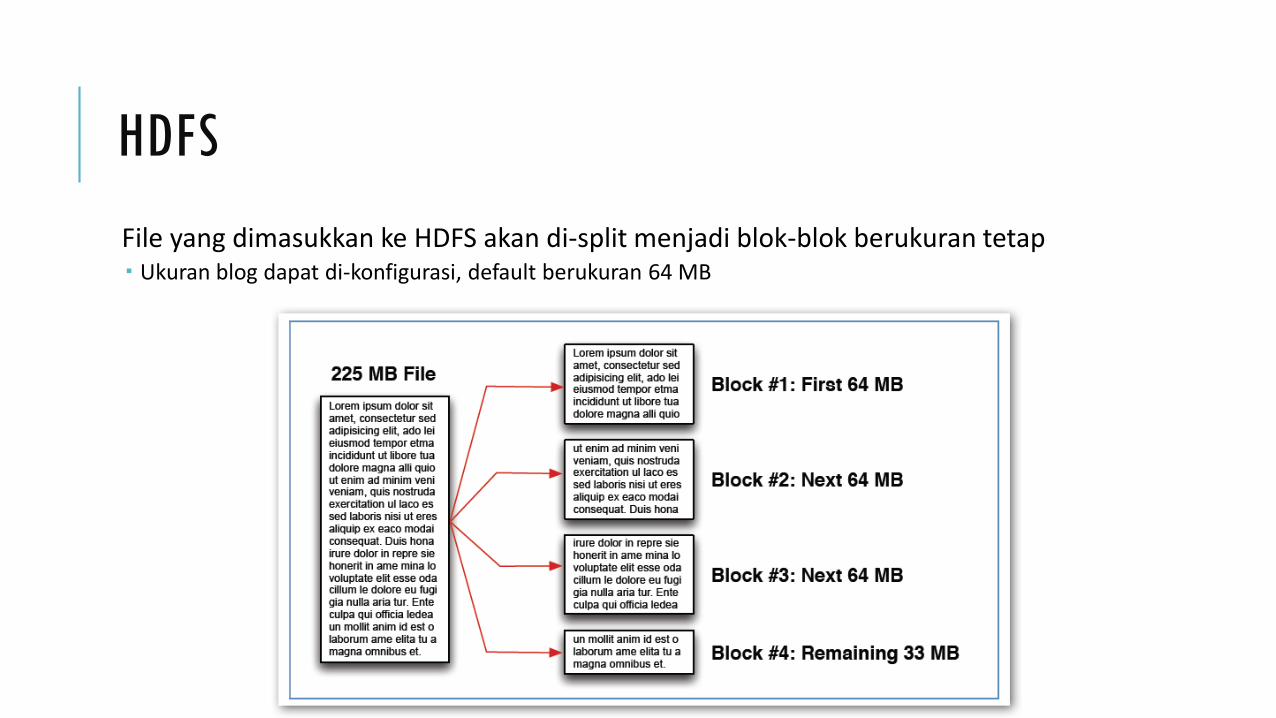
HDFS menyimpan file pada cluster dengan memecah menjadi blok-blok
Ukuran default dari HDFS blok adalah 64 MB (tapi mungkin berbeda pada distribusi-distribusi Hadoop)
Apabila file yang akan disimpan berukuran sangat besar, maka ukuran blok yang besar akan membuat performansi menjadi lebih efektif
Perilaku default dari Hadoop adalah menciptakan sebuah task Map untuk setiapblok dari file input
Dikonfigurasi dengan meng-edit file hdfs-site.xml
HDFS
HDFS
File yang dimasukkan ke HDFS akan di-split menjadi blok-blok berukuran tetap Ukuran blog dapat di-konfigurasi, default berukuran 64 MB
HDFS
HDFS
HDFS
HDFS
HDFS
PELATIHAN BIG DATA & HADOOP - UII 32

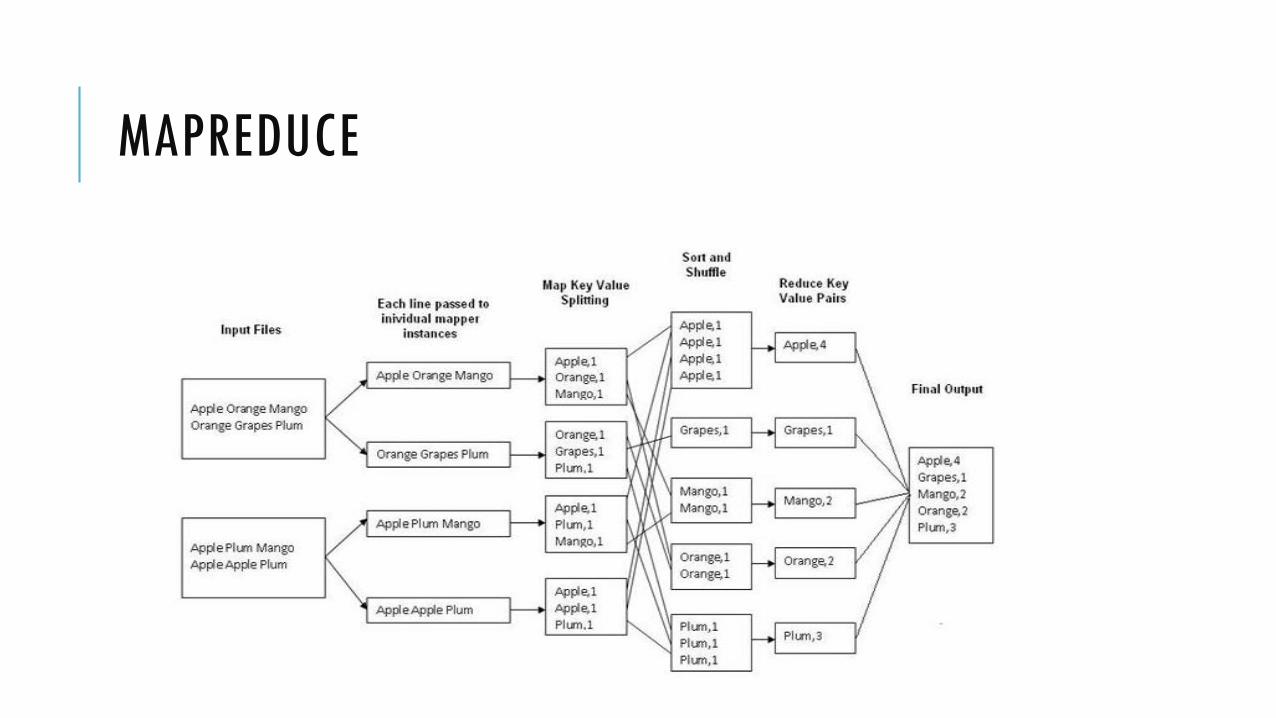
MAPREDUCE
MapReduce adalah sebuah model pemrograman Adalah cara untuk memproses data
MapReduce dapat di-implemen dengan berbagai bahasa (Java, Scala, Python, shell, dll)
Ada dua function untuk memproses data: Map dan Reduce Map: umumnya digunakan untuk transform, parse, atau filter data
Reduce: umumnya digunakan untuk men-summary-kan hasil
Function Map selalu jalan pertama kali Function Reduce jalan setelahnya, tapi bisa optional
Setiap bagian biasanya sederhana, tapi akan sangat powerful kalau dikombinasikan
MAPREDUCE

