nonparametric motion characterization for robust classification of camera motion patterns
TRANSCRIPT

IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 8, NO. 2, APRIL 2006 323
Nonparametric Motion Characterization for RobustClassification of Camera Motion Patterns
Ling-Yu Duan, Jesse S. Jin, Member, IEEE, Qi Tian, Senior Member, IEEE, and Chang-Sheng Xu, Senior Member, IEEE
Abstract—Motion characterization plays a critical role in videoindexing. An effective way of characterizing camera motion facil-itates the video representation, indexing and retrieval tasks. Thispaper describes a novel nonparametric motion representation toachieve an effective and robust recognition of parts of the videoin which camera is static, or panning, or tilting, or zooming,etc. This representation employs the mean shift filtering and thevector histograms to produce a compact description of a motionfield. The basic idea is to perform spatio–temporal mode-seekingin the motion feature space and use the histograms-based spatialdistributions of dominant motion modes to represent a motionfield. Unlike most existing approaches, which focus on the esti-mation of a parametric motion model from a dense optical flowfield (OFF) or a block matching-based motion vector field (MVF),the proposed method combines the motion representation andmachine learning techniques (e.g., support vector machines) toperform camera motion analysis from the classification point ofview. The main motivation lies in the impossibility of uniformlysecuring a proper parametric assumption in a wide range of videoscenarios. The diverse camera shot sizes and frequent occurrencesof bad OFF/MVF necessitates a learning mechanism, which cannot only capture the domain-independent parametric constraints,but also acquire the domain-dependent knowledge to tolerate theinfluence of bad OFF/MVF. In order to improve performance, wecan use this learning-based method to train enhanced classifiersaiming at a certain context (i.e., shot size, neighbor OFF/MVFs,and video genre). Other visual cues (e.g., dominant color) can alsobe incorporated for further motion analysis. Our main aim is touse a generic feature space analysis method to explore a flexibleOFF/MVF representation in a nonparametric technique, whichcould be fed into a learning framework to robustly capture theglobal motion by incorporating the context information. Resultson videos with various types of content (23 191 MVFs culledfrom MPEG-7 dataset, and 20 000 MVFs culled from broadcasttennis, soccer, and basketball videos) are reported to validate theproposed approach.
Index Terms—Camera motion, nonparametric motion analysis,video databases, video indexing.
Manuscript received September 16, 2004; revised April 28, 2005. The as-sociate editor coordinating the review of this manuscript and approving it forpublication was Dr. Deepak S. Turaga.
L.-Y. Duan is with the Institute for Infocomm Research, Singapore 119613and also with the School of Design, Communication, and Information Tech-nology, University of Newcastle, Callaghan, NSW 2308, Australia (e-mail:[email protected]).
J. S. Jin is with the School of Design, Communication, and InformationTechnology, University of Newcastle, Callaghan, NSW 2308, Australia (e-mail:[email protected]).
Q. Tian and C.-S. Xu are with the Institute for Infocomm Research, Singapore119613 (e-mail: [email protected]; [email protected]).
Digital Object Identifier 10.1109/TMM.2005.864344
I. INTRODUCTION
V IDEO provides rich information about scenes. It extendsthe image capabilities of a still camera by extending spa-
tial area and recording the evolution of events over time. How-ever, interesting information is buried inside the raw or editedvideo materials at the cost of high temporal redundancy. Asdigital video becomes more pervasive, efficient access, storage,and manipulation of video data has become increasingly impor-tant. In particular, the need to index, retrieve and browse videosby their content is imminent. In this paper, we develop an ap-proach for robustly analyzing camera motion patterns based onthe dense optical flow field (OFF) or the block matching-basedmotion vector field (MVF) available directly from MPEG com-pressed video streams, as motion is intrinsic to video structureand content, and camera movement is widely utilized to guidethe viewers’ attention.
Motion characterization plays a critical role in video in-dexing. The use of dynamic information differentiates content-based video indexing and retrieval [1]–[3] from content-basedvisual queries of still images [4], [5]. Camera movements andmobile objects are two main sources of dynamic informationcontained in the video. Compared with appearance-based vi-sual features (e.g., color, edge, texture, shape), motion indicesprovide the natural access to temporal dimension in the video.Motion content has been used as a powerful clue for structuringvideo data [6], [7], similarity-based video retrieval [1], [8]–[10],and video abstraction [11]–[13]. In [6] and [7], the estimation ofdominant image motion was employed to detect shot changes.The statistical distribution of motion vectors was utilized todiscriminate video clips [8]. In [9], a statistical method wasproposed to characterize the local motion’s temporal cooccur-rence (e.g., caused by motion of rivers, flames or crowds) inthe neighborhood structure aiming at the motion-based videoindexing and retrieval. Chang et al. [1] used the trajectories ofmoving regions to facilitate video retrieval. As motion is anindicator of content changes or an author’s intention, Zhang etal. [11] and Wolf [13] proposed the use of motion to select keyframes. Ma et al. [12] further analyzed camera motion transitionmodels for video summarization. As the motion features are ofkey significance in video indexing, MPEG-7 has selected a setof motion descriptors including motion activity, camera move-ment, mosaic, trajectory, and parametric motion [14]. In thecontext of multimedia description interfaces, these descriptorsprovide a complete and coherent set of motion content rangingfrom simple movements to complex ones. However, motionanalysis and understanding is still a complicated problem inmachine vision.
1520-9210/$20.00 © 2006 IEEE

324 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 8, NO. 2, APRIL 2006
Fig. 1. Learning-based nonparametric motion characterization scheme.
We present in this paper an original approach for nonpara-metric motion characterization and apply it to the classificationof camera motion patterns. A preliminary version was presentedin [15], [46]. This method is motivated by three facts. Firstly,although the parametrical approaches [two-dimensional (2-D),2.5-D, and three-dimensional (3-D) affine transformations] havethe advantage of simplicity, they are based on the global esti-mation. There are many constraints over the content of videostreams. Diverse sizes of camera shots (e.g., close-up, mediumshot, long shot, etc.) and scene contents make it infeasible to se-cure a proper parametric assumption in large amounts of videodata. Secondly, the use of context information (e.g., video genre,camera shot size, and a priori knowledge about the scenes) canimprove the robustness of motion characterization. Currently,camera motion pattern recognition algorithms are not matureenough to scale up against such a large problem domain, as thiswould require an excellent resilience to the presence of mobileobjects of significant size and of frequent occurrences of badOFF/MVF. We argue that genre context and scene context canjointly boost the performance with an appropriate representationof estimated motion fields. Thirdly, it is very difficult to employany parametric model for representing knowledge in context.We thus resort to machine learning algorithms. A learning-basedapproach enables the incorporation of other visual cues (e.g.,dominant color) to further improve performance or to infer se-mantic events supported by multiple evidences.
As illustrated in Fig. 1, we deal with motion characterizationfrom two aspects: representation and recognition (see [53] forall color illustrations). Our aim is to employ an effective featurespace analysis method to seek for a compact representation of anOFF/MVF, which can be incorporated into a statistical learningframework to qualitatively recognize camera motion patterns orinfer semantic meanings for a given video segment. Instead ofmodeling local motion (e.g., a mobile object’s trajectory, tem-poral texture [9], [10]), our approach focuses on the capture ofglobal motion (e.g., camera motion, dominant object motion).Literatures [8], [12], and [16] have shown that the global mo-
tion information, in combination with other visual cues, con-tributes to content-based video indexing. At the representationphase, we employ the mean shift filtering [17], [18] to search forrepresentative modes (we shall call this process mode-seeking)in the motion feature space. A modes-based measurement isthen developed to construct a set of compact features. As in-dicated in Fig. 1, we can map one frame or multiple consecu-tive frames of OFF/MVF into a feature space for mode-seeking.Since a motion pattern is usually persistent for a certain pe-riod, the mode-seeking amongst multiple frames is expected toincorporate the neighborhood information. A histogram is uti-lized to represent the spatial distribution of those motion vectorsbelonging to a common mode. The resulting features comprisethe properties of representative modes and their associated his-tograms. Accordingly, only dominant features of an OFF/MVFare captured. We thus call it a compact representation. At therecognition phase, we may employ supervised learning to trainindividual classifiers for different camera motion patterns, ormotion related semantic segments (e.g., semantic shot classesin sports video [16]) or events (e.g., play/break in soccer video[19]). As shown in Fig. 1, other visual cues may be exploited.Existing work [8], [16], [19] has revealed that in practice it isless effective to analyze motion irrespective of other visual cueseven in the sports video domain with rich motion as a key role. Alearning-based method enables the fusion of multiple cues. Dueto other cues, the term motion characterization in our paper isin the broad sense. At the recognition phase we currently focuson the robust classification of camera motion patterns. A set ofmeaningful camera motion patterns have been predefined.
Our proposed approach for motion characterization can beclaimed as nonparametric in two ways. Firstly, the compact rep-resentation of an OFF/MVF is learned from the data itself byseeking motion modes with the mean shift procedure, whichis derived from nonparametric kernel density estimation. Sec-ondly, the learning-based camera motion classification (or othertasks) does not rely on any parametric transformations. We ex-ploit these qualities to capture the global motion in a generic

DUAN et al.: NONPARAMETRIC MOTION CHARACTERIZATION FOR ROBUST CLASSIFICATION 325
way through combining unsupervised feature space analysis andtask-driven supervised learning in an application context.
The remainder of this paper is organized as follows. Sec-tion II reviews existing literatures devoted to motion analysisin the context of video indexing and retrieval. In Section III,we introduce a hierarchy of camera motion patterns. The robustclassification of camera motion patterns is to discover this hier-archy from large video databases. In Section IV, we describe themean shift based nonparametric motion representation. This in-volves mode-seeking from a single or multiple OFF/MVF, and ahistogram-based representation of spatial information for eachrepresentative mode. Section V discusses the issue on how toevaluate the advantages of our nonparametric motion character-ization in terms of robustness improvements of camera motionanalysis. A user-friendly tool is introduced to facilitate the toughlabeling work of motion patterns. The empirical results are pre-sented in Section VI. We conclude this paper in Section VII.
II. PREVIOUS WORK
In the context of video indexing and retrieval, there exists agreat deal of research work on motion analysis [6]–[10], [15],[20]–[32]. To distinguish our work from other related work,we review the state-of-the-art in motion analysis from the per-spectives of global motion versus local motion, nonparametricversus parametric, learning versus nonlearning, and context de-pendent versus context independent. Our aim is to develop a mo-tion field representation in a nonparametric fashion, which canbe fed into a statistical learning framework to robustly capturethe global motion by taking into account context information.
A. Global Motion versus Local Motion
In terms of MPEG-7 visual motion descriptors [14], most ex-isting work can be categorized into four classes: camera mo-tion [6], [7], [15], [20]–[26], motion activity [8]–[10], [28], [30],trajectory [1], [27], [29], and mosaic [20], [32]. Intuitively, wecan think of the trajectory as a representation of local motion,whereas the camera motion describes global motion. Althoughthe information of a moving object’s trajectories has shown itsimportant role in video indexing, the requirements of a robustspatio–temporal region segmentation and tracking, and effectivetrajectory matching have limited the wide applications of thetrajectory-based indexing methods in a generic sense. Cameramotion is, by contrast, a generic and distinct feature for char-acterizing a shot content and discovering the intention of videoproducers, which has attracted much research effort. We thusfocus on the robust classification of camera motion patterns.
Unlike camera motion and trajectory, motion activity at-tempts to provide a global interpretation of the dynamic contentwithin a video segment such as the intensity of activity [28],[30], the special distributions of directions and magnitudes [8],[30], the temporal cooccurrences of textures with motion [9],[10], etc. To some extent, motion activity can be treated as astatistical measurement (ranging from a simple histogram [8]to a complicated causal Gibbs model [9]) of a video segment,which is applicable for representing both local motion andglobal motion. For example, Fablet et al. [9] introduced acausal Gibbs model to represent the temporal cooccurrences of
the local motion-related measurements obtained by eliminatingthe dominant motion. Jain et al. [8] simply used a histogram torepresent the distributions of motion vectors for discriminatingvideo clips, irrespective of local or global one.
B. Nonparametric versus Parametric
A long-standing problem in statistics and related areas is howto find a suitable representation of multivariate data. Represen-tation means that we somehow transform the data so that its es-sential structure is made more visible or accessible. A good mo-tion representation is usually a central goal of many motion anal-ysis techniques. We may summarize existing work according tothe representation in the parametric or nonparametric form. Theterm “nonparametric” here is used to describe motion represen-tation functions for which the functional form is not specified inadvance, but depends on the data itself. The parametric approachis to represent motion in terms of a specific functional form whichcontains a number of adjustable parameters. The values of thoseparameters can then be optimized to give the best fit to the data.
Parametric methods have been widely used for camera mo-tion and mosaic. A global 2-D parametric transformation (e.g.,2-D affine [6], 2-D quadratic [32], or 2-D projective [23]), 2.5-Daffine [47] and 3-D affine [48], [49] are usually used to modelthe transformation between two successive images. Robust sta-tistics is employed to estimate the dominant motion. There aresome approaches estimating motion directly from MPEG mo-tion vectors [23], [26] in order to reduce the processing time. Al-though parametric methods seem theoretically unified, it is lessinfeasible to uniformly secure a proper parametric assumptionin diverse video scenarios. The 2-D models assume that the dis-tance from the camera to the scene is far from the depth varia-tion inside the scene. It will produce large errors for rotationalestimations if there are large depth variations within scenes andthe translation of the camera is not very small. Jin et al. [47] pro-posed three 2.5-D models to resolve the problem by classifyingcamera motion into three clusters and processing each clusterusing a different model. The restriction of the 2.5-D models isthe accuracy of motion classification. Duric et al. [48] and Yao etal. [49] dealt with depth problem by detecting faraway-horizonlines in scenes since the motion of horizon lines is not affected bysmall translation of video camera. Their model assumed that longstraight horizon line would exist in common outdoor videos andit will have large gradients in gray scale images. This assumptionworks only if there was a horizon line and the points around thathorizon line were further away. It will fail in many cases wherethe horizon line is not very clear or just cannot be seen, or thepoints along the horizon line are not so far away. Moreover,parametric models are deficient in incorporating neighbor infor-mation along the temporal axis. Neither of them is applicable toanalyzing motion activities for a video segment. We thus focuson nonparametric motion representation and recognition.
Unlike parametric methods, nonparametric methods concen-trate more on a statistical measurement of global or local motionfrom the exploratory data analysis point of view. A histogram isthe simplest method to represent the distribution of motion vec-tors for camera motion analysis [21] and clip-based similaritymeasure [8]. In [7] and [25], a template matching method is em-ployed to recognize camera motion. The basic idea is to partition

326 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 8, NO. 2, APRIL 2006
Fig. 2. Hierarchy of predefined camera motion patterns.
an OFF/MVF into sub-regions and derive a set of decision rulesto compare with basic camera motion templates according to thelower-order statistics (e.g., average, deviation) of the angularand magnitude distributions of motion vectors in subregions.These approaches depend, however, on many thresholds. Ngoet al. [20] analyzed the orientated patterns in a spatio–temporalimage slice to capture the dominant motion by detecting thepeak of the orientation histogram along the temporal dimen-sion. Ma et al. [22] utilized moment functions to describe theangular distributions of motion vectors from directional slicesalong the temporal axis. The resulting descriptor is used for clas-sifying motion patterns. Although the nonparametric methodslack a unified representation framework, they possess valuableflexibilities of accumulating temporal information and being in-corporated into a statistical learning framework (e.g., the causalGibbs model in [9]) for recognizing motion patterns.
Aiming at a nonparametric representation, our approach doesnot manually introduce heuristic knowledge like subregions par-tition [7], [25] and directional slicing [22]. Rather we emphasizethe unsupervised feature space analysis (i.e., mean shift) to cap-ture dominant modes in single or multiple OFF/MVFs for char-acterizing motion. This point has differentiated our approachfrom most existing nonparametric motion representations.
C. Learning versus Nonlearning
As mentioned in Section I, we deal with the problem ofmotion characterization from two aspects: representation andrecognition. From the machine learning point of view, these twoaspects can be mapped to unsupervised learning and supervisedlearning. For the former, the goal of the machine is to buildrepresentations of data that can be used for reasoning, decisionmaking, predicting things, communicating, etc. For the latter,the goal of the machine is to learn to produce the correct outputgiven a new input, namely, classification and regression. Withthe increasing uncertainty from large video corpus, currentresearch efforts are geared toward using statistical learningto model video structures [19] and high-level semantic con-cepts [16], [33]. However, many existing motion analysisapproaches rely on a nonlearning mechanism such as [7], [10],[20], [23]–[26], [32]. In the context of video indexing, thesenonlearning methods are limited by vulnerable parametric as-sumptions, the choice of appropriate thresholds, and the ad-hoc
approaches for representing domain knowledge. Therefore, wefocus on learning-based methods for motion analysis.
Two recent learning-based methods were reported in [9], [22].A causal spatio–temporal Gibbs model was proposed in [9] tolearn the cooccurrences of a sequence of local motion-relatedmeasurements to discriminate motion classes of interest. An as-sumption has been made that the evolution of motion contentsis by nature causal along the time axis. In [22], support vectormachines (SVM) was used to train classifiers for different mo-tion patterns according to the moment measurements of the an-gular distributions of motion vectors. Compared with these ap-proaches, our learning scheme is unique in terms of the modeseeking to represent a single or multiple OFF/MVFs and thedominant modes-based motion pattern recognition.
D. Context Dependent versus Context Independent
A key issue in the design of complex media processing systemis the engineering of knowledge. These systems need to storeinformation about the environment and objects of interest, insuch a manner that an operational recognition scheme can be en-acted [34]. Context is the larger environmental knowledge thatincludes the laws of biology and physics and common sense.The focus of multimedia research has been geared toward ap-plications that incorporate correlated media, fuse data from dif-ferent sources, and use context to improve application perfor-mance [35]. As indicated in Section I, we emphasize the robust-ness of camera motion pattern classification. The context de-pendent training is one way to improve robustness. The contextinformation in this paper includes video genre, camera shot sizeand a priori knowledge about the scenes. Comparison experi-ments in Section VI will show how to improve robustness byusing context. To our best knowledge, most existing works havenot explicitly compared the performances between context de-pendent training and context independent training, although thecontext constraint has been more or less exploited to facilitatemotion analysis [16], [23], [27].
III. A HIERARCHY OF CAMERA MOTION PATTERNS
Fig. 2 illustrates the hierarchy of predefined camera motionpatterns. This hierarchy intuitively delineates the logical flow ofanalyzing camera motion pattern. A “#” followed by a numberis used to denote a classification task. At the first phase, we

DUAN et al.: NONPARAMETRIC MOTION CHARACTERIZATION FOR ROBUST CLASSIFICATION 327
want to roughly determine the characteristics of an OFF/MVF.Is it a random motion field (RMF) (#1)? Is there any prominentcamera motion (PCM) (#2)? Is there any prominent object mo-tion (POM) (#3)? Is it a still camera shot (ST) (#4)? Note thatthe RMF is mainly caused by erroneous block matching or erro-neous optical flow estimation within a large low textured region.There is an overlap between PCM and POM as a prominent ob-ject motion may be accompanied by a prominent camera motionin the cases of a medium shot or a closeup shot. For PCM andPOM, we want to further determine camera motion patterns, i.e.,Zooming (ZM) (#5), Panning (PN) (#6), Tilting (TT) (#7), andRotating (RT) (#8). A real camera motion can be a combina-tion of ZM, PN, TT, and RT. For ZM, PN, and TT, we furtherdecide the motion directions, and then have Zooming In (ZI)(#9), Zooming Out (ZO) (#9), Panning Left (PL) (#10), Pan-ning Right (PR) (#10), Tilting Up (TU) (#11), and Tilting Down(TD) (#11). In terms of binary classification, we have to design11 binary classifiers (#1–#11) to accomplish the recognition ofthese camera motion patterns.
The hierarchy of camera motion patterns is motivated by twoaspects. Firstly, the qualitative analysis of camera motion is ef-fective for content based video indexing, such as event detection[16], [23] and shot content characterization [6], [21]. For thesetasks, a user usually does not care precise parameters. Even ifthe parameters have been recovered well, researchers [6], [23],[26] tend to derive simple decision rules by imposing sceneconstraints to resolve the relationships between parameters andcamera motion patterns for the purposes of video indexing. Sec-ondly, since a video segment may exhibit only one kind of dom-inant motion or may contain a series of motion types, a reason-able idea is to perform a temporal segmentation before classifi-cation, e.g., Patel et al.’s work [21]. However, it is not straight-forward to develop a generic segmentation algorithm, as motionis complex and may exhibit different persistent characteristics interms of different “atom” actions and different temporal-scales.Our alternative is to employ a hierarchical structure to predefinea set of basic camera motion patterns. The combination of basicmotion patterns is used to determine different persistent prop-erties. Moreover, when using multiframes to improve the clas-sification performance, we employ a learning-based method toseek for neighborhood supports in different ways based on thebasic motion patterns.
IV. NONPARAMETRIC MOTION FIELD REPRESENTATION
As illustrated in Fig. 1, we summarize the nonparametricmotion field representation (NMFR) in three stages includingOFF/MVF visualization, spatio–temporal mode seeking, andmode-based feature extraction.
At the OFF/MVF visualization stage, we utilize the HSVcolor space to display a motion vector. Hue represents the mo-tion direction, saturation represents the motion intensity, andvalue represents the confidence of correct motion vector esti-mation. The visualization provides us an intuitive aid to under-stand, analyze, and compare different kinds of motion charac-teristics. Then we apply the concept of “dominant feature” tocapture the modes of a single OFF/MVF or a volume of consec-utive OFF/MVFs at the spatio–temporal mode seeking stage.
The representative motion modes are finally used to constructa feature vector, which can be fed into a learning algorithm tocharacterize motion content.
As the OFF/MVF visualization is only used to facilitate thelaborious labeling of motion data, it does not directly affectthe performance of NMFR. In this section, we focus on thespatio–temporal mode seeking and the mode-based feature ex-traction. The visualization stage will be presented in Section V.
A. Dominant Feature versus Mode Seeking
Many studies [38], [39] have discovered that, when viewinga global color content, the human visual system eliminates finedetails and averages colors within small areas. Consequently,on the global level, humans perceive images as a combinationof few most prominent colors. These findings have motivatedthe extraction of visual dominant colors in conjunction with ametric to measure color similarity between two images for re-trieval [37]–[39]. It is natural to extend the concept of “dominantfeature” from color to other low-level visual features such as tex-ture, local shape, etc. In this paper, we explore the capability ofdominant motion feature in distinguishing camera motion pat-terns.
Generally speaking, a feature space is the results of mappinginput obtained through processing data in small subsets at atime. For each subset, a parametric representation of the featureof interest is obtained and the result is mapped into a point in themultidimensional space of the parameters. After the entire inputis processed, significant features correspond to denser regions inthe feature space, i.e., to clusters, and the goal of the analysis isthe delineation of these clusters. Dense regions in the featurespace thus correspond to local maximum of the empirical prob-ability density function (p.d.f.), that is, to the modes of the un-known density. Once the location of a mode is determined, thecluster associated with it is delineated based on the local struc-ture of the feature space. The mode seeking is to climb the gra-dient of a p.d.f. to find the nearest dominant mode (peak). Withthis paradigm, we can benefit from the global nature of the de-rived representation of the input, providing excellent toleranceto a noise level which may make local decisions unreliable [18].
The nature of a feature space is application dependent. Anal-ysis of a feature space is application independent. In analyzinga motion feature space, we have to take into account the spatialconstraint due to the characteristics of an OFF/MVFs such aspiece-wise homogeneity (see Fig. 3). Moreover, in order to cap-ture the persistence of a motion pattern, we have to extend thefeature space analysis from a single OFF/MVF to a sequenceof consecutive OFF/MVFs. This is different from the mode-seeking within a single image for image segmentation [18].
B. Mean Shift Procedure
The mean shift algorithm is a nonparametric technique thatclimbs the gradient of a p.d.f. to find the nearest dominant mode(peak) in a feature space. The so-called mean shift is a simpleiterative procedure that shifts each data point to the average ofdata points within its neighborhood. The mean shift procedureis derived by the density gradient estimation.
It is well known that the histogram is the oldest and mostwidely used density estimator. However, the discontinuity of a

328 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 8, NO. 2, APRIL 2006
Fig. 3. Examples of mean shift based MVF representation. First row: frames overlapped with a MVF; second row: representations in MVS space; third row:results from mean shift filtering.
histogram requires appropriately selecting the boundaries of thebins before exploring data points. It is unlikely to represent atrue distribution. Another serious problem is with the require-ment of a huge number of data points to estimate the p.d.f. in ahigh-dimensional space. Most of the bins would be empty, andthus it leads to inefficient use of the data. Most importantly, thediscontinuity of a histogram produces an extreme difficulty ifderivates of the p.d.f are required.
Apart from the histogram, the kernel estimator [50] is very el-egant and of wide applicability. The mean shift procedure is de-rived by estimating density gradients from the kernel estimator.More details can be found in [17], [18]. We briefly review itsderivation as below.
Assume that is the given multivariate data set inthe -dimensional Euclidean space . The multivariate kerneldensity estimator with kernel and window width is definedas
(1)
The term obtained by estimating the Epanechnikov kernel baseddensity gradient:
(2)
is called the mean shift at , where the region is ahyper-sphere of radius having the volume , centered at
, containing data points. The repeated movement of datapoints to the sample means is called the mean shift procedure.
The mean shift vector always points toward the direction ofthe maximum increase in the density. The mean shift is shownto be a mode-seeking process on a surface constructed with a“shadow” kernel and the convergence of mean shift iterationshas been proved in [17].
C. Mean Shift Filtering in a Single OFF/MVF
An OFF/MVF is typically represented as a 2-D lattice of -di-mensional vectors (motion vectors), where , i.e., magni-tude and direction, and if we consider the confidence
of correct motion vector estimation. The space of the lattice isknown as the spatial domain, while the motion vector is rep-resented in the range domain. As an OFF/MVF contains largeamounts of motion vectors, it is infeasible to directly feed anOFF/MVF into a learning algorithm for training or recognition.Dimension reduction is required. As illustrated in Fig. 3, we em-ploy a so-called mean shift filtering to transform an OFF/MVFinto a “mosaic” comprising a set of colored pieces. The recogni-tion of a motion pattern is to learn the spatial-range compositionknowledge of the colored pieces for each predefined motion pat-tern from training samples.
To incorporate the spatial-range constraints, we concatenatethe location and range vectors in the joint spatial-range domainof dimension . Let and ,be the -dimensional input and filtered motion vectors in thejoint spatial-range domain, where and are the spatial partand the range part, respectively. For each motion vector, we per-form the mean shift filtering as follows.
Step 1) Initialize and .Step 2) Compute according to (2) until convergence,
.Step 3) Assign .
Such stationary points are the modes of the density. Thefiltered data at the spatial location will have the range com-ponent of the mode . The set of all locations that convergeto the same mode defines the basin of attraction of that mode.To delineate homogeneous tiles as shown in Fig. 3, we have toconcatenate the basins of attraction of the corresponding modes.Let be the clusters obtained by grouping togetherall which are closer than in the spatial domain and in therange domain, where and are the employed kernel band-widths. For each , we thus assign the label of the thmotion vector in the filtered OFF/MVF as: .According to , we will derive a compact feature set to repre-sent an OFF/MVF in Section E.
The mean shift procedure is an elegant way to locate themodes without estimating the density. However, we have toaddress two important issues: the shape of the kernel and themetric of the feature space. Two radially symmetric kernels,i.e., the Epanechnikov kernel and the truncated normal kernel,

DUAN et al.: NONPARAMETRIC MOTION CHARACTERIZATION FOR ROBUST CLASSIFICATION 329
Fig. 4. Example of modes-based motion feature extraction (the total number of selected modes N = 5; the pair of histograms contain the bin number of I = 5and k = 6, respectively; the final feature dimension = 4 � 5 + (5 + 6) � 5 = 75).
will suffice for most applications we are interested in. Note thatthe Epanechnikov kernel is the shadow of the uniform kernel,i.e., the -dimensional unit sphere, while the normal kernel andits shadow have the same expression. The term of mean shiftin (2) is derived by the Epanechnikov kernel. In the normalkernel case, the term of mean shift is the difference betweenthe weighted mean, using the normal kernel for weights, and ,the center of the kernel (window). All the OFF/MVF filteringin this paper were performed using uniform kernels.
The resolution of the mean shift analysis is controlled onlyby the kernel bandwidth. In practice, the bandwidth matrix ischosen as diagonal or proportional to the identity matrix. Theclear advantage of the later case is that only one bandwidth pa-rameter must be provided. An Euclidean metric for the featurespace has been assumed. As discussed above, the -dimensionalinput concatenates the location and range information. For bothdomains, Euclidean metric is assumed. Their different naturehas to be compensated by proper normalization. Thus, we em-ploy the joint domain multivariate kernel, which is defined asthe product of two radially symmetric kernels and the Euclideanmetric allows a single bandwidth parameter for each domain
(3)
where is the location vector, is the range vector, thecommon profile used in both domains, and the kernelbandwidths, and the normalization constant. An Epanech-nikov or a truncated normal kernel always provides satisfactoryperformance. An efficient computation of the mean shift pro-cedure in the joint domain first requires the definition of a dataset that is on a 2-D lattice. A search on the data set using thelattice is performed. To compute the mean shift vector by using
(2), all points found to lie within the spatial search window andthe range search window defined using a uniform kernel aresummed and counted. The amount of time needed to computethe mean shift vector using such a data set is much less than thatof an arbitrary -dimensional data set.
D. Mean Shift Filtering in Multiple OFF/MVFs
To capture the contextual support from neighbor OFF/MVFs,we consider the mean shift filtering in multiple OFF/MVFs. Be-sides the spatio–range constraints, the temporal constraint is tobe incorporated. It is assumed that a sequence of the camera mo-tion-related quantities tend to remain stable over a few frames.As we concern persistent motion patterns, it seems pertinent toanalyze the pattern of an OFF/MVF based on the accumulatedfeature points collected from its temporal neighbor frames. Anillustration of spatio–temporal constraints imposed by multipleframes can be found in [51].
Consider a sequence of OFF/MVFsconsisting of
neighbor frames within a symmetric window of . Letand be
the -dimensional input and filtered motion vectors in ,each OFF/MVF containing motion vectors, whereand are the spatial part and the range part. The totalnumber of accumulated motion feature points is .The joint domain kernel (3) is employed to carry out modeseeking amongst these feature points. Note that eachmotion vector is projected into the -dimensional feature spaceirrespective of the temporal order of its original OFF/MVF. Itenables to compute the mean shift vector in a fairly similarway as that in a single OFF/MVF. In the multiple OFF/MVFscase, a search on the data set using the lattice is also executed.To compute the mean shift vector by using (2), we firstly locate

330 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 8, NO. 2, APRIL 2006
feature points lying within the spatial search window for eachOFF/MVF of . Among them, those feature points lyingwithin the range search window are further determined. Allpoints satisfying the spatial and range constraints are finallysummed and counted.
As far as dynamic video content characterization is con-cerned, it is critical to reasonably represent the temporalconstraint. The complexity of a temporal constraint dependson the application. In terms of camera motion analysis, wesimply make an assumption of persistent patterns. The accu-mulated effects (irrespective of the temporal order) of multipleframes do not reflect the interaction (e.g., acceleration, causalmodeling, etc.) between temporally successive OFF/MVFs.Moreover, the -dimensional input does not include anytemporal measurement at the range part . The empirical re-sults in Section VI will show that this simple assumption workswell for camera motion analysis. Comparatively speaking, acomplicated temporal constraint was represented by a causalspatio–temporal Gibbs model in [9], which assumes that theevolution of the local motion-related measurements is by naturecausal along the time axis. The basic idea is to model the cooc-currence probability distribution of the temporal pairs of siteswithin the temporal neighborhood by analyzing a series of pairsof consecutive local motion maps in a given video sequence.Maximum likelihood estimation is employed to achieve theclique’s potentials configuration associated to the greatestcooccurrence values, which gives the highest probabilities. Theestimated models’ Kullback–Leibler (KL) divergence is usedto measure the similarity between two video sequences.
The mean shift filtering in multiple OFF/MVFs tends to char-acterize the global motion, while the casual Gibbs model excelsat capturing the delicate local motion. Both methods have as-sumed the motion persistence along the time axis. For the first,the persistence of intraframe features is assumed. For the latter,the persistence of interframe features is assumed. The persis-tence implies an appropriate choice of temporal window size.The sequence of OFF/MVFs is currently chopped into a se-ries of overlapped and symmetric windows with a fixed sizeof one second. It is assumed that a camera movement usuallylasts for more than one second. As discussed in Section III,we do not perform a temporal segmentation before classifica-tion. Instead the combination of a set of basic camera patternscan be used to represent different persistent properties. Sincewe use a set of binary classifiers to recover the hierarchy ofbasic camera motion patterns, the case of more than one classwithin the temporal window can be easily handled by the com-bination of the outputs of those binary classifiers. An exceptionoccurs when the temporal window is sliding to the ends of a seg-ment consisting of a basic motion pattern, as those distracting“nonpattern” OFF/MVFs may cause the missed ones. When thetemporal window is extended to the shot level, it is natural toimagine that the mean shift filtering may produce an abstractionof the motion content within a whole shot. However, a too longduration of the temporal window could decrease the physicalmeanings like dominant camera motion. It is worth to note thatthe mean shift filtering in multiple OFF/MVFs mostly would nothelp when the range part includes the interframe features,as the clustering process cannot capture the complex dynamics.
E. Mode-Based Motion Feature Extraction
In this section, we discuss how to utilize the representativemotion modes to construct a feature vector. Although the meanshift procedure has provided a general approach to seek modes,the construction of a modes-based feature vector is domaindependent.
In terms of camera motion analysis, the feature vector is ex-pected to numerically describe the spatial-range information ofcolored “mosaics” for distinguishing camera motion patterns asillustrated in Figs. 3 and 4. Aiming at a uniform feature vectorfor all OFF/MVFs, we need to solve two issues: 1) how to elimi-nate the variability due to a variable number of motion modes indifferent OFF/MVFs and 2) how to represent the mode-relatedspatial information.
A selection criterion of modes is introduced to solve theproblem of variability. Currently, the mode selection is basedon the priority decided by the cluster size. The mode of a largersize is the first to be chosen. The total number of selected modes
is predefined. If the real number of resulting modes is lessthan , we augment the feature vector with zero to a requireddimension. Cross validation can be performed to determine asuitable .
The histogram is utilized to represent the spatial distribu-tion for each chosen mode. Let and
, be the -dimensional input of an OFF/MVF and thefiltered motion vector. Let and bethe set of motion modes and their associated percentages, where
. For each , we assign thelabel of the th motion vector in the filtered OFF/MVF as
. Let and denote the projectedpositions of at the horizontal and vertical axis, respectively.For each mode , we get a pair of histograms, and , con-taining and bins respectively, i.e.,
(4)
where denotes the set size, .It is straightforward to extend (4) to deal with the sequence of
OFF/MVFs .As introduced in Section D, the mode seeking on thefeature points has produced a set of motion modes denoted by
.We assign the label of the th motion vectorin the as . Let anddenote the projected positions of at the horizontal and ver-tical axis, respectively. For each mode , we also get a pairof histograms, and , containing and bins respectively,i.e.,
(5)
where . Likewise, cross validation can be em-ployed to determine the bin numbers and .

DUAN et al.: NONPARAMETRIC MOTION CHARACTERIZATION FOR ROBUST CLASSIFICATION 331
With (4) and (5), we construct the feature vector as follows:
(6)
where the dimension equals denotesthe dimension of the range part . Note that and havethe dimensions of and . An illustration of constructing thenonparametric motion representation is given in Fig. 4.
V. CAMERA MOTION PATTERN CLASSIFICATION
The task of robust camera motion pattern classification is car-ried out to evaluate the nonparametric motion representation.In order to support our arguments of global versus local, non-parametric versus parametric, learning versus nonlearning, andcontext dependent versus context independent, a series of com-parison experiments are required. Since the learning capabilityis one of distinguished features endued by the proposed mo-tion representation, the evaluation job is mainly focused on thetraining and testing of context dependent and context indepen-dent motion recognizers. Comparisons are employed to demon-strate the capability of capturing domain dependent and domainindependent knowledge for robustness improvements.
A. Key Design Considerations of a Series of ComparisonExperiments
We design the experiments as follows.
• T1: Train a series of general motion recognizers. Thetraining and testing MVFs are extracted from a large anddiverse video dataset including education, sports, drama,news, surveillance, etc. The training phase does not ex-plicitly consider any context information, i.e., genre, shotsize, neighbor OFF/MVFs. The performance of T1 istreated as the baseline to compare with other recognizershaving incorporated certain context.
• T2: Train a series of shot size (i.e., long shot, mediumshot, and close-up) dependent motion recognizers. Fordifferent shot sizes, the object-induced independent mo-tion has different effects on the recognition of camera mo-tion. The performance comparison between T1 and T2 isexpected to show the role of the shot size knowledge inrecognizing camera motion patterns. Since it is difficult toautomatically identify video shot size in a generic sense,we manually label the shot size.
• T3: Train a series of multiframes based motion rec-ognizers. The performance improvement against T1 isexpected to show that the mean shift filtering in multipleOFF/MVFs can capture the contextual support fromneighbor frames. Since the camera induced motion is akind of global motion, the multiframes mode seeking caneliminate outliers and represent the persistent cameramotion through accumulated effects.
• T4: Train a series of genre dependent motion recognizers.The video genres are currently limited to broadcast sportsvideo, i.e., tennis, soccer, and basketball. A big improve-ment against T1 is expected. This fact may indicate that al-though the domain independent knowledge (e.g., a global2-D parametric transformation model) is applicable in a
generic sense, other domain dependent knowledge (e.g.,the setting of a court/playing field) can further contributeto more robust performance. Learning is an effective wayto incorporate domain dependent knowledge.
• T5: Compare with three previous algorithms includingangular component projection [21], subregions partition[7], and direction slices based moment measure [22].Since the collection of experimental MVFs is ad-hocmore or less, the comparisons with representative algo-rithms on the same dataset helps show the advantage ofmodes based representation.
B. A Tool to Facilitate OFF/MVF Labeling
Much laborious labeling work is required for training a rec-ognizer in a supervised way. To efficiently and easily label anOFF/MVF, a user-friendly tool [40] is developed. Its user inter-face is shown in Fig. 5. It enables fast random access to neighborOFF/MVFs. Moreover, a semi-automatic mechanism is intro-duced to facilitate labeling. A small number (around 20% of thewhole data set) of OFF/MVFs are first selected and manually la-beled to train classifiers. These trained classifiers are applied topredict motion patterns of an unlabeled OFF/MVF. The outputis delivered for judging whether the prediction is correct or not,which is followed by manual modifications if necessary. Sinceany motion pattern is usually persistent, this tool can not onlyfacilitate the labeling, but alleviate the subjectivity of decidingthe patterns of an OFF/MVF.
In particular, a cone-shaped motion vector space (MVS) is in-troduced to display a motion vector. Traditional superimposedarrows on a static image add clutter and give no intuitive sense ofmotion. In MVS, Hue represents the direction, Saturation repre-sents the intensity, and Value represents the confidence of correctmotion vector estimation. Fig. 6(a) illustrates the cone-shapedMVS. Fig. 6(b) shows the polar coordinates Angle (the angularcoordinate) and Magnitude (the radial coordinate) of a motionvector. A motion vector can be converted to MVS as follows:
(7)
where and are normalizing thresholds. The con-fidence measure Value simply assumes that a motion vector iswell estimated at high textured regions. Spatial and temporalconfidence measures [36] may be employed. However, a con-stant Value is taken in this paper.
Fig. 7 gives several illustrative examples of MVS. The domi-nant right-panning with a player-induced local motion is delin-eated in Fig. 7(a). Especially in the presenceofcluttered andover-lapped arrows in Fig. 7(a), (b), and (d), the color hint clearly iden-tifies the motion direction. In Fig. 7(c), the arrows are too short toindicate camera motion patterns. However, the zooming patternis delineated by using colored “mosaic.” The MVS is also suit-able for delineating an independent moving region. For example,the contour of a walking player is clearly produced in Fig. 7(d).Moreover, the regions with different color (i.e., green, red, blue)are even associated to three walking individuals in Fig. 7(e).

332 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 8, NO. 2, APRIL 2006
Fig. 5. User-interface of a semi-automatic motion annotation tool for camera motion pattern classification.
Fig. 6. (a) Cone-shaped MVS space, (b) the polar coordinates of a motionvector.
VI. EXPERIMENTS
A. Classifier Choice
Various supervised learning algorithms can be employedto train a motion pattern recognizer. Support vector machines(SVM) [43] is used in our experiments. SVM has been suc-cessfully applied to a wide range of pattern recognition andclassification problems including face detection, handwritingrecognition, etc. SVM finds an optimal separating hyper plane
between data points of different classes in a (possibly) highdimensional space. The actual support vectors are the pointsthat form the decision boundary between the classes. The SVMalgorithm is based on the idea of structural risk minimization.Its generation error is bound by the sum of training error and theVC-dimension of a classifier. By minimizing the upper bound,SVM can achieve a higher generalization performance. Com-pared with artificial neural networks (ANNs), SVM is faster,more interpretable, and deterministic. Advantages of SVMover other methods consists of 1) providing better predictionon unseen test data, 2) providing a unique optimal solution fora training problem, 3) containing fewer parameters comparedto other methods, and 4) working well for data with a largenumber of features.
We employ the C-Support Vector Classification (C-SVC)[44]. Given training vectors in twoclasses, and a vector such that , C-SVCsolved the following primal problem:
(8)

DUAN et al.: NONPARAMETRIC MOTION CHARACTERIZATION FOR ROBUST CLASSIFICATION 333
Fig. 7. Comparison between the traditional OFF/MVF representation in arrows and that in MVS space.
The radial basis function (RBF) kernelis used to map training vectors into a high dimen-
sional feature space for classification. Two parameters andare determined by cross validation.
SVM was originally designed for binary classification. Tosupport multiclass classification, several methods (e.g., “one-against-all”, “one-against-one,” and DAG methods [45]) havebeen proposed. Although the tasks illustrated in Fig. 2 appear tobe a multiclass classification problem, we reduce them to solvebinary classifications indexed by #1–#11. Eleven SVM modelsare constructed. For the tasks #1–#8, the th SVM is trainedwith all of the examples in the th class (i.e., RMF, PCM, POM,ST, ZM, PN, TT, and RT) with positive labels, and all other ex-amples with negative labels. For the tasks #9–#11, three binaryclassifications (i.e., ZI versus ZO, PL versus PR, and TU versusTD) are further applied to the outputs of the tasks #5, #6, and #7.
B. T1: Training General Motion Recognizers
We have manually labeled 23 191 P-frame MVFs extractedfrom the culled MPEG-7 video dataset for motion activity anal-ysis [30]. This dataset is rich in content including sports, drama,education, news, surveillance, etc. Note that bi-directional pre-dicted frames (B-frames) are not considered in our experiments.However, in order to achieve a uniform presentation of a motionvector independent of frame type, a normalization procedurewas introduced in [52] to represent each motion vector asa backward-predicted vector with respect to the next framethrough some intuitive reasoning. This procedure may be useful
TABLE ISTATISTICS OF DIFFERENT MOTION PATTERNS OF 23 191 MVFS
EXTRACTED FROM MPEG-7 VIDEO DATASET
TABLE IISTATISTICS OF DIFFERENT CAMERA MOTION PATTERNS OF 7618 MVFS IN THE
PRESENCE OF PCM ON THE DATASET LISTED IN TABLE I
for multiframes based recognizers (See T3) when there arefewer P-frames within a GOP.
Tables I and II summarize the motion label related statistics.For each category, the number of MVFs is listed by different

334 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 8, NO. 2, APRIL 2006
TABLE IIICLASSIFICATION RESULTS OF 11 MOTION PATTERNS
camera shot sizes. As shown in Table I, ST and PCM are twomajor classes. The majority of PCM come from a long shot (LS).The majority of RMF come from a close-up shot (CU) due to theout of focus brought by fast moving regions. The POM class in-dicates the presence of prominent object motion. The concept of“prominent” is subjective. However, the MVFs of POM mostlyhappen in a CU as listed in Table I. For the PCM class, an MVFis labeled by ZM, PN, TT, and RT. The first three classes are fur-ther labeled by six subclasses, respectively, as listed in Table II.RT is a minor class. Compared with ZM and TT, PN is morefrequently used. A camera and an object jointly cause the com-plexity of an OFF/MVF. The labeling work is thus subjectivemore or less. An alternative is to decide the pattern of an MVFthrough observing a sequence of neighbor frames. It is facili-tated by the tool shown in Fig. 5.
As introduced in T1, 11 binary classifiers are trained. Thedata of training and testing sets are randomly selected from thewhole dataset with the ratios of and , respectively. Asthis random process produces different settings, 20 runs are car-ried out for each classifier and the average performance is usedfor evaluation. At the training stage, three-fold cross validationand automatic parameters ( and ) selection strategies are per-formed on the whole training set. A weighted SVM [45] is takento handle unbalanced data. Refer to (6), is set to 6, andare both set to 4. The dimension of the range part is 2 by set-ting the confidence measure constant. The final feature dimen-sion thus equals . The kernelparameters andare determined according to the cross-validation results through
compositions. is mostly or is mostly .Table III summarizes the results. The recall-precision mea-
sure is used. Note that the accuracy measure is used for eval-uating the tasks of #9–#11, as both classes are of interest. Thevalues of recall and precision are combined as follows to mea-sure the overall performance, namely F1 measure:
(9)
The value of RP is high only when both recall and precisionare high. Table III shows that compared with RMF and POM,PCM and ST get higher performance. This is due to the uni-form and invariant characteristics of MVFs in the presence ofPCM or ST. ZM has achieved better results than PN, RT, and inparticular TT. The observation reveals that the inherent charac-
teristics of ZM are insensitive to an independent object motionor an incomplete and noisy OFF/MVF. TT is otherwise becausethe vertical (upwards or downwards) motion induced by an in-dependent moving object can cause many false alarms (with therecall of 70.82%, but the precision of 53.64% only). Since thewell-handled horizontal tracking is usually used to keep movingobjects in the central view, an object induced horizontal mo-tion cause fewer false alarms for PN. For RT, there is a promi-nent difference between recall and precision. A probable reasonis the lack of samples. The higher precision of 96.27% but alower recall of 63.90% is supported by its unique characteris-tics to other patterns. Satisfactory performance is achieved forZI versus ZO, PL versus PR, and TU versus TD. The highestaccuracy (95.82%) of PL versus PR may reveal much more di-rection distinguishability even in the presence of an independentobject motion. The lower accuracy (92.52%) of ZI versus ZO isdue to the pattern complexity of ZM, which requires the com-pleteness of an OFF/MVF. For the vertical object motion, theaccuracy of TU versus TD is only 88.20%.
C. T2: Training Shot Size Dependent Motion Recognizers
Different from T1, we classify an OFF/MVF according to thecamera shot size and individually train recognizers under dif-ferent shot sizes, i.e., CU, MS, and LS. Results are listed inTable IV. To compare with T1, Table IV lists the results (i.e.,“ ”) without considering shot size. The experi-ment setup is similar to T1, e.g., the construction of training andtesting sets, three-fold cross-validation, and weighted SVM.
The performance of “ ” is higher than “CU” butlower than “LS” except POM, ZI versus ZO. This fact indicatesthe negative effects of an independent object motion on cameramotion pattern classification. The RP differences between “CU”and “LS” are 4.26% (RMF), 25.62% (PCM), 6.43% (POM),5.95% (ST), 27.03% (ZM), 20.25% (PN), and 12.48% (TT),respectively. For RT, the RP difference between “CU” and “LS”is not considered due to the serious lack of samples for “CU”and “MS”. The accuracy differences between “CU” and “LS”are 4.66% (ZI versus ZO), 4.65% (PL versus PR), and 9.67%(TU versus TD), respectively. These RP or accuracy differencesreveal the necessity of applying the prior knowledge of shot sizeto improve the robustness. The direction related classification(the tasks #9–#11) is more or less insensitive to shot size (unlikethe tasks #2–#8).
Let us further study the figures about the tasks #9–#11.For “LS”, the accuracy ranking is %
% % (ZI versus ZO). Thereason is twofold: 1) the effect of an independent object motionin “LS” is very weak or even zero; 2) the incompleteness orerror of an estimated OFF/MVF is normal and it may notsuffice for the pattern complexity of a ZM related motion.For “MS” and “CU”, the accuracy ranking is in the order of
.This also indicates the role of an independent object.
D. T3: Training Multiframes Based Motion Recognizers
T3 is expected to analyze whether the neighbor context has apositive contribution to the recognition of various camera mo-
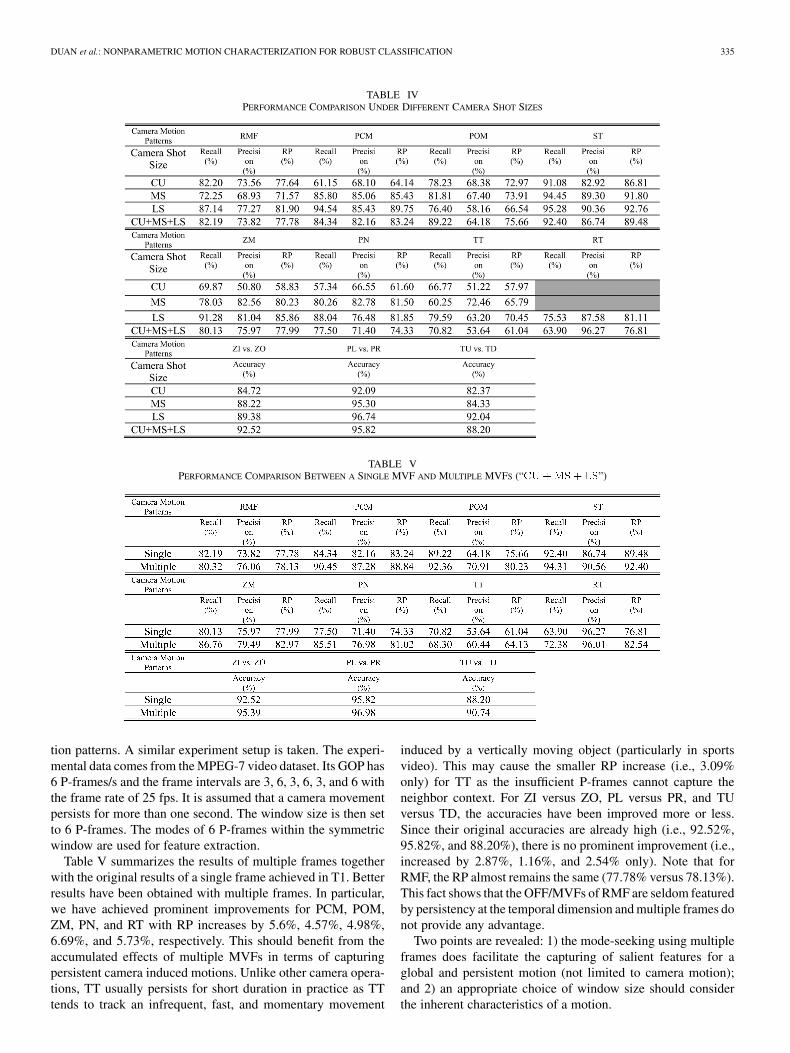
DUAN et al.: NONPARAMETRIC MOTION CHARACTERIZATION FOR ROBUST CLASSIFICATION 335
TABLE IVPERFORMANCE COMPARISON UNDER DIFFERENT CAMERA SHOT SIZES
TABLE VPERFORMANCE COMPARISON BETWEEN A SINGLE MVF AND MULTIPLE MVFS (“CU +MS + LS”)
tion patterns. A similar experiment setup is taken. The experi-mental data comes from the MPEG-7 video dataset. Its GOP has6 P-frames/s and the frame intervals are 3, 6, 3, 6, 3, and 6 withthe frame rate of 25 fps. It is assumed that a camera movementpersists for more than one second. The window size is then setto 6 P-frames. The modes of 6 P-frames within the symmetricwindow are used for feature extraction.
Table V summarizes the results of multiple frames togetherwith the original results of a single frame achieved in T1. Betterresults have been obtained with multiple frames. In particular,we have achieved prominent improvements for PCM, POM,ZM, PN, and RT with RP increases by 5.6%, 4.57%, 4.98%,6.69%, and 5.73%, respectively. This should benefit from theaccumulated effects of multiple MVFs in terms of capturingpersistent camera induced motions. Unlike other camera opera-tions, TT usually persists for short duration in practice as TTtends to track an infrequent, fast, and momentary movement
induced by a vertically moving object (particularly in sportsvideo). This may cause the smaller RP increase (i.e., 3.09%only) for TT as the insufficient P-frames cannot capture theneighbor context. For ZI versus ZO, PL versus PR, and TUversus TD, the accuracies have been improved more or less.Since their original accuracies are already high (i.e., 92.52%,95.82%, and 88.20%), there is no prominent improvement (i.e.,increased by 2.87%, 1.16%, and 2.54% only). Note that forRMF, the RP almost remains the same (77.78% versus 78.13%).This fact shows that the OFF/MVFs of RMF are seldom featuredby persistency at the temporal dimension and multiple frames donot provide any advantage.
Two points are revealed: 1) the mode-seeking using multipleframes does facilitate the capturing of salient features for aglobal and persistent motion (not limited to camera motion);and 2) an appropriate choice of window size should considerthe inherent characteristics of a motion.

336 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 8, NO. 2, APRIL 2006
Fig. 8. Illustration of major shot classes in soccer, tennis, and basketball, respectively, together with the percentages.
TABLE VISTATISTICS OF DIFFERENT MOTION PATTERNS FROM SOCCER VIDEO DATASET (“CU +MS + LS”)
TABLE VIISTATISTICS OF DIFFERENT MOTION PATTERNS FROM BASKETBALL VIDEO DATASET (“CU +MS + LS”)
TABLE VIIISTATISTICS OF DIFFERENT MOTION PATTERNS FROM TENNIS VIDEO DATASET (“CU +MS + LS”)
E. T4: Training Genre Dependent Motion Recognizers
The experimental results on the general video dataset havebeen presented. In this section, we focus on three typical kindsof broadcast sports video (i.e., soccer, tennis and basketball) tostudy the genre-dependent motion recognizers. Compared witheducation, drama, surveillance, and news videos, sports videosare much richer in motion contents including object motionand camera induced motion. Although these three sports are offield-ball game, they are featured by different environmentalsettings and motion characteristics. Basketball and tennis areundertaken upon a relatively small area while soccer takes placein an open and large area. In basketball video, frequent and fastactions are accompanied by frequent occurrences of prominentcamera movements. In spite of frequent camera following opera-tions, the intensity of PCM in soccer video is mostly weaker thanthat in basketball video. Unlike soccer or basketball video, tennis
video has fewer OFF/MVFs of PCM in a long shot. Moreover, thelow textured regionwithina playing field/court in soccer or tennisvideo tends to produce an incomplete or erroneous OFF/MVF.
With a similar rule as T1, we have manually labeled 20 000MVFs, i.e., 8000 MVFs from soccer video, 8000 MVFs frombasketball video, and 4000 MVFs from tennis video. Thesevideo data has ever been used in the semantic sports video shotclassification [16], [41]. As introduced in [41], we predefinea small number of semantic shot classes for each sport, aboutfive to ten, which covers 90–95% of broadcast sports video.Different from the labeling work in T1, we select the sampleMVFs from three major shot classes in soccer, basketball, andtennis as shown in Fig. 8. Such major classes are associatedto the shots of CU, MS, and LS, respectively. Since rotating isseldom used in these sports video, RT is not considered. Thestatistics of sample MVFs are summarized in Tables VI–VIII.
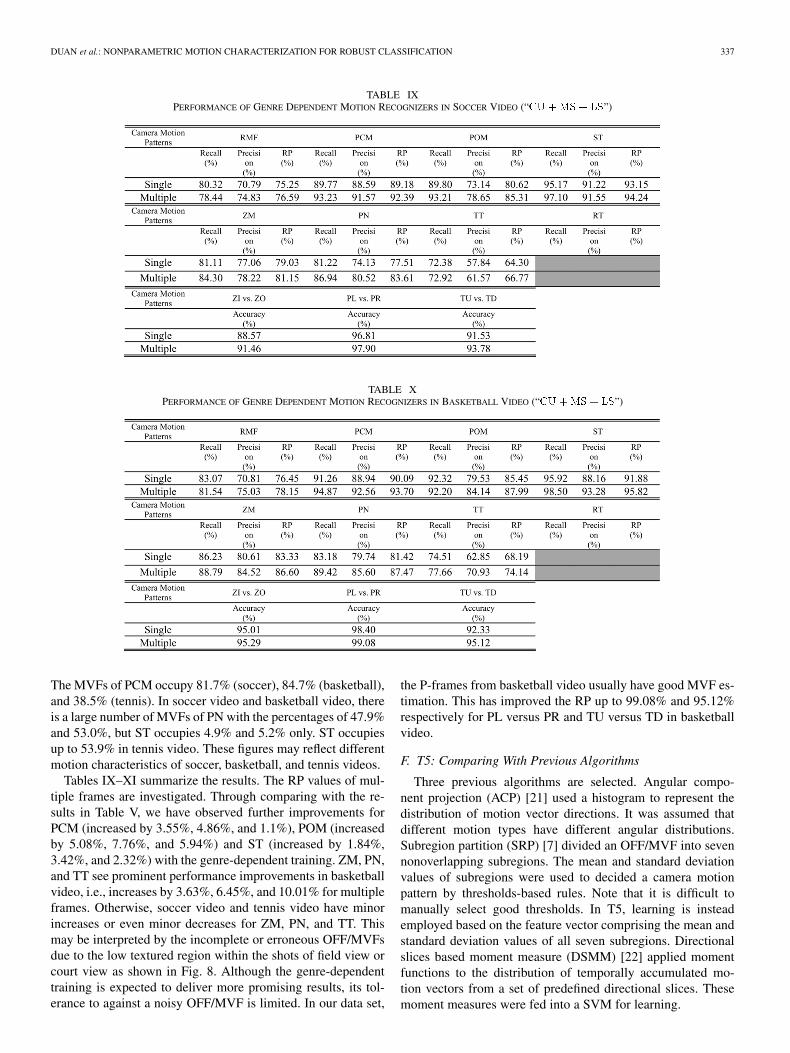
DUAN et al.: NONPARAMETRIC MOTION CHARACTERIZATION FOR ROBUST CLASSIFICATION 337
TABLE IXPERFORMANCE OF GENRE DEPENDENT MOTION RECOGNIZERS IN SOCCER VIDEO (“CU +MS + LS”)
TABLE XPERFORMANCE OF GENRE DEPENDENT MOTION RECOGNIZERS IN BASKETBALL VIDEO (“CU +MS + LS”)
The MVFs of PCM occupy 81.7% (soccer), 84.7% (basketball),and 38.5% (tennis). In soccer video and basketball video, thereis a large number of MVFs of PN with the percentages of 47.9%and 53.0%, but ST occupies 4.9% and 5.2% only. ST occupiesup to 53.9% in tennis video. These figures may reflect differentmotion characteristics of soccer, basketball, and tennis videos.
Tables IX–XI summarize the results. The RP values of mul-tiple frames are investigated. Through comparing with the re-sults in Table V, we have observed further improvements forPCM (increased by 3.55%, 4.86%, and 1.1%), POM (increasedby 5.08%, 7.76%, and 5.94%) and ST (increased by 1.84%,3.42%, and 2.32%) with the genre-dependent training. ZM, PN,and TT see prominent performance improvements in basketballvideo, i.e., increases by 3.63%, 6.45%, and 10.01% for multipleframes. Otherwise, soccer video and tennis video have minorincreases or even minor decreases for ZM, PN, and TT. Thismay be interpreted by the incomplete or erroneous OFF/MVFsdue to the low textured region within the shots of field view orcourt view as shown in Fig. 8. Although the genre-dependenttraining is expected to deliver more promising results, its tol-erance to against a noisy OFF/MVF is limited. In our data set,
the P-frames from basketball video usually have good MVF es-timation. This has improved the RP up to 99.08% and 95.12%respectively for PL versus PR and TU versus TD in basketballvideo.
F. T5: Comparing With Previous Algorithms
Three previous algorithms are selected. Angular compo-nent projection (ACP) [21] used a histogram to represent thedistribution of motion vector directions. It was assumed thatdifferent motion types have different angular distributions.Subregion partition (SRP) [7] divided an OFF/MVF into sevennonoverlapping subregions. The mean and standard deviationvalues of subregions were used to decided a camera motionpattern by thresholds-based rules. Note that it is difficult tomanually select good thresholds. In T5, learning is insteademployed based on the feature vector comprising the mean andstandard deviation values of all seven subregions. Directionalslices based moment measure (DSMM) [22] applied momentfunctions to the distribution of temporally accumulated mo-tion vectors from a set of predefined directional slices. Thesemoment measures were fed into a SVM for learning.
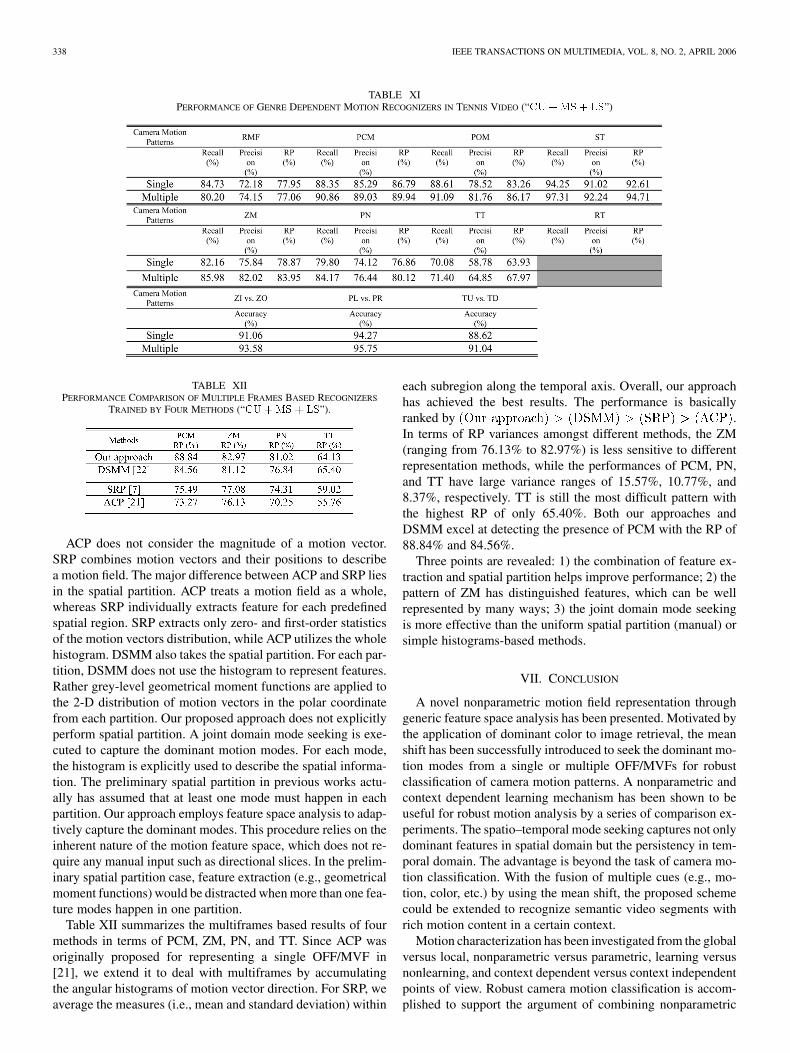
338 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 8, NO. 2, APRIL 2006
TABLE XIPERFORMANCE OF GENRE DEPENDENT MOTION RECOGNIZERS IN TENNIS VIDEO (“CU +MS + LS”)
TABLE XIIPERFORMANCE COMPARISON OF MULTIPLE FRAMES BASED RECOGNIZERS
TRAINED BY FOUR METHODS (“CU +MS + LS”).
ACP does not consider the magnitude of a motion vector.SRP combines motion vectors and their positions to describea motion field. The major difference between ACP and SRP liesin the spatial partition. ACP treats a motion field as a whole,whereas SRP individually extracts feature for each predefinedspatial region. SRP extracts only zero- and first-order statisticsof the motion vectors distribution, while ACP utilizes the wholehistogram. DSMM also takes the spatial partition. For each par-tition, DSMM does not use the histogram to represent features.Rather grey-level geometrical moment functions are applied tothe 2-D distribution of motion vectors in the polar coordinatefrom each partition. Our proposed approach does not explicitlyperform spatial partition. A joint domain mode seeking is exe-cuted to capture the dominant motion modes. For each mode,the histogram is explicitly used to describe the spatial informa-tion. The preliminary spatial partition in previous works actu-ally has assumed that at least one mode must happen in eachpartition. Our approach employs feature space analysis to adap-tively capture the dominant modes. This procedure relies on theinherent nature of the motion feature space, which does not re-quire any manual input such as directional slices. In the prelim-inary spatial partition case, feature extraction (e.g., geometricalmoment functions) would be distracted when more than one fea-ture modes happen in one partition.
Table XII summarizes the multiframes based results of fourmethods in terms of PCM, ZM, PN, and TT. Since ACP wasoriginally proposed for representing a single OFF/MVF in[21], we extend it to deal with multiframes by accumulatingthe angular histograms of motion vector direction. For SRP, weaverage the measures (i.e., mean and standard deviation) within
each subregion along the temporal axis. Overall, our approachhas achieved the best results. The performance is basicallyranked by .In terms of RP variances amongst different methods, the ZM(ranging from 76.13% to 82.97%) is less sensitive to differentrepresentation methods, while the performances of PCM, PN,and TT have large variance ranges of 15.57%, 10.77%, and8.37%, respectively. TT is still the most difficult pattern withthe highest RP of only 65.40%. Both our approaches andDSMM excel at detecting the presence of PCM with the RP of88.84% and 84.56%.
Three points are revealed: 1) the combination of feature ex-traction and spatial partition helps improve performance; 2) thepattern of ZM has distinguished features, which can be wellrepresented by many ways; 3) the joint domain mode seekingis more effective than the uniform spatial partition (manual) orsimple histograms-based methods.
VII. CONCLUSION
A novel nonparametric motion field representation throughgeneric feature space analysis has been presented. Motivated bythe application of dominant color to image retrieval, the meanshift has been successfully introduced to seek the dominant mo-tion modes from a single or multiple OFF/MVFs for robustclassification of camera motion patterns. A nonparametric andcontext dependent learning mechanism has been shown to beuseful for robust motion analysis by a series of comparison ex-periments. The spatio–temporal mode seeking captures not onlydominant features in spatial domain but the persistency in tem-poral domain. The advantage is beyond the task of camera mo-tion classification. With the fusion of multiple cues (e.g., mo-tion, color, etc.) by using the mean shift, the proposed schemecould be extended to recognize semantic video segments withrich motion content in a certain context.
Motion characterization has been investigated from the globalversus local, nonparametric versus parametric, learning versusnonlearning, and context dependent versus context independentpoints of view. Robust camera motion classification is accom-plished to support the argument of combining nonparametric

DUAN et al.: NONPARAMETRIC MOTION CHARACTERIZATION FOR ROBUST CLASSIFICATION 339
techniques and learning towards robust content analysis. Thismethodology helps derive semantic concepts since a context de-pendent learning approach may bridge the gap between low-level features and high-level semantics. A typical example isthe semantic sports video shot classification [46] where domainknowledge is incorporated to improve robustness.
There are still some limitations in our scheme. It cannot suf-fice for other tasks such as motion texture modeling, foregroundsegmentation, mosaic representation and so on. However, the ro-bust classification of camera motion can be treated as a front-endmodule followed by sophisticated but noise sensitive parametrictechniques. We are developing diverse motion-related modes toaccomplish other interesting tasks. Choosing an appropriate sta-tistical learning framework to autonomously deal with a longvideo sequence is in the list of future research.
REFERENCES
[1] S.-F. Chang, W. Chen, H. J. Meng, H. Sundaram, and D. Zhong, “A fullyautomated content-based video search engine supporting spatiotemporalqueries,” IEEE Trans. Circuits Syst. Video Technol., vol. 8, no. 5, pp.602–615, May 1998.
[2] A. Hamrapur et al., “Virage video engine,” in Proc. SPIE Storage andRetrieval for Image and Video Databases, San Jose, CA, Jan. 1997, pp.188–197.
[3] H. Wactlar, S. Stevens, M. Smith, and T. Kanade, “Intelligent access todigital video: The informedia project,” IEEE Computer, vol. 29, no. 3,pp. 46–52, 1996.
[4] M. Flickner et al., “Query by image and video content: The QBICsystem,” IEEE Computer, vol. 28, no. 9, pp. 23–32, 1995.
[5] A. Pentland, R. W. Picard, and S. Sclaroff, “Photobook: Tools for con-tent-based manipulation of image databases,” in Proc. SPIE Storage andRetrieval for Image & Video Databases II, San Jose, CA, 1994, pp.34–47.
[6] P. Bouthemy, M. Gelgon, and F. Ganansia, “A unified approach toshot change detection and camera motion characterization,” IEEETrans. Circuits Syst. Video Technol., vol. 9, no. 7, pp. 1030–1044,Jul. 1999.
[7] W. Xiong and J. C. M. Lee, “Efficient scene change detection and cameramotion annotation for video classification,” Comput. Vis. Image Under-stand., vol. 71, no. 2, pp. 166–181, 1998.
[8] A. K. Jain, A. Vailaya, and W. Xiong, “Query by video clip,” MultimediaSyst., vol. 7, no. 5, pp. 369–384, 1999.
[9] R. Fablet, P. Bouthemy, and P. Perez, “Nonparametric motion charac-terization using casual probabilistic models for video indexing and re-trieval,” IEEE Trans. Image Process., vol. 11, no. 4, pp. 393–407, Apr.2002.
[10] M. Szummer and R. W. Picard, “Temporal texture modeling,” inProc. Int. Conf. Image Processing, Lausanne, Switzerland, 1996, pp.823–826.
[11] H.-J. Zhang, C. Y. Low, S. W. Smoliar, and J. H. Wu, “Video parsing,retrieval, and browsing: An integrated and content-based solution,” inProc. ACM Multimedia, San Francisco, CA, 1995, pp. 15–24.
[12] Y.-F. Ma, L. Lu, H.-J. Zhang, and M. Li, “An attention model for videosummarization,” in Proc. ACM Multimedia, France, 2002, pp. 533–542.
[13] W. Wolf, “Key frame selection by motion analysis,” in Proc. Int. Conf.Acoustics, Speech, and Signal Processing (ICASSP), Atlanta, GA, 1996,pp. 1228–1231.
[14] S. Jeannin and A. Divakaran, “MPEG-7 visual motion descriptors,”IEEE Trans. Circuits Syst. Video Technol., vol. 11, no. 6, pp. 720–724,Jun. 2001.
[15] L.-Y. Duan, M. Xu, Q. Tian, and C.-S. Xu, “Mean shift based nonpara-metric motion characterization,” in Proc. Int. Conf. Image Processing(ICIP), Singapore, 2004, pp. 1597–1600.
[16] L.-Y. Duan, M. Xu, T.-S. Chua, Q. Tian, and C.-S. Xu, “A mid-levelrepresentation framework for semantic sports video analysis,” in Proc.ACM Multimedia, Berkeley, CA, 2003, pp. 33–44.
[17] Y. Cheng, “Mean shift, mode seeking, and clustering,” IEEE Trans. Pat-tern Anal. Mach. Intell., vol. 17, no. 8, pp. 790–799, Aug. 1995.
[18] D. Comaniciu and P. Meer, “Mean shift: A robust approach toward fea-ture space analysis,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 24,no. 5, pp. 603–619, May 2002.
[19] L. Xie, P. Xu, S.-F. Chang, A. Divakaran, and H. Sun, “Structure analysisof soccer video with domain knowledge and hidden markov models,”Pattern Recognit. Lett., vol. 25, no. 7, pp. 767–775, 2004.
[20] C.-W. Ngo, T.-C. Pong, and H.-J. Zhang, “Motion-based video repre-sentation for scene change detection,” Int. J. Comput. Vis., vol. 50, no.2, pp. 127–142, 2002.
[21] N. Patel and I. K. Sethi, “Video shot detection and characterizationfor video databases,” Pattern Recognit., vol. 30, no. 4, pp. 583–592,1997.
[22] Y.-F. Ma and H.-J. Zhang, “Motion pattern based video classificationand retrieval,” EURASIP J. Appl. Signal Process., vol. 2003, no. 2, pp.199–208, 2003.
[23] Y.-P. Tan, D. D. Saur, S. R. Kulkarni, and P. J. Ramadge, “Rapid estima-tion of camera motion from compressed video with application to videoannotation,” IEEE Trans. Circuits Syst. Video Technol., vol. 10, no. 1,pp. 133–146, Jan. 2000.
[24] G. Sudhir and J. C. M. Lee, “Video annotation by motion interpretationusing optical flow streams,” J. Vis. Commun. Image Represent., vol. 7,no. 4, pp. 354–368, 1996.
[25] S. K. Lee and M. H. Hayes, “Real-time camera motion classification forcontent-based indexing and retrieval using templates,” in Proc. ICASSP,Orlando, FL, 2002, pp. 3664–3667.
[26] J.-G. Kim, H. S. Chang, J. Kim, and H.-M. Kim, “Efficient camera mo-tion characterization for MPEG video indexing,” in Proc. Int. Conf. Mul-timedia & Expo, New York, 2000, pp. 1171–1174.
[27] X. Yu et al., “Trajectory-based ball detection and tracking with appli-cations to semantic analysis of broadcast soccer video,” in Proc. ACMMultimedia, Berkeley, CA, 2003, pp. 11–20.
[28] K. A. Peker and A. Divakaran, “Framework for measurements of theintensity of motion activity of video segments,” J. Vis. Commun. ImageRepresent., vol. 14, no. 4, p. 2003.
[29] K. W. Lee, W. S. You, and J. Kim, Quantitative Analysis for theMotion Trajectory Descriptor in MPEG-7, Dec. 1999. ISO/ICEMPEG99/m5400.
[30] A. Divaranran et al., Report on the MPEG-7 Core Experiments on theMotion Activity Feature, Melbourne, Australia, Oct. 2000. ISO/ICEMPEG99/m5030.
[31] C.-W. Ngo, T.-C. Pong, and H.-J. Zhang, “On clustering and retrieval ofvideo shots,” in Proc. ACM Multimedia, Ottawa, ON, Canada, 2001, pp.51–60.
[32] M. Irani and P. Anandan, “Video indexing based on mosaic representa-tions,” Proc. IEEE, vol. 86, no. 5, pp. 905–921, May 1998.
[33] M. Naphade et al., The IBM TRECVID Concept Detection: Some NewDirections and Results.
[34] T. Caelli and W. F. Bischof, Machine Learning and Image Interpreta-tion. New York: Plenum, 1997, pp. 189–224.
[35] ACM SIGMM Retreat Report on Future Directions in MultimediaResearch, L. A. Rowe and R. Jain. [Online]. Available: www.acm.org/sigmm/main/events/sigmm_retreat/sigmm-retreat03-final.pdf
[36] R. Wang, H. J. Zhang, and Y. Q. Zhang, “A confidence measurebased moving object extraction system built for compressed domain,”in Proc. Int. Symp. Circuits and Systems, Geneva, Switzerland, 2000,pp. 21–24.
[37] Y. Rubner, C. Tomasi, and L. J. Guibas, “A metric for distribution withapplications to image databases,” in Proc. Int. Conf. Computer Vision,Bombay, India, 1998, pp. 59–64.
[38] A. Mojsilovic, J. Hu, and E. Soljanin, “Extraction of perceptuallyimportant colors and similarity measurement for image matching,retrieval, and analysis,” IEEE Trans. Image Process., vol. 11, no. 11,pp. 1238–1248, Nov. 2002.
[39] A. Mojsilovic, J. Kovacevic, J. Hu, R. J. Safranek, and K. Ganapathy,“Matching and retrieval based on the vocabulary and grammar of colorpatterns,” IEEE Trans. Image Process., vol. 9, no. 1, pp. 38–54, Jan.2000.
[40] L.-Y. Duan, M. Xu, Q. Tian, and C.-S. Xu, “Nonparametric motionmodel,” in Proc. ACM Multimedia, New York, 2004, pp. 754–755.
[41] L.-Y. Duan, M. Xu, Q. Tian, C.-S. Xu, and J. S. Jin, “A unified frame-work for semantic shot classification in sports video,” IEEE Trans. Mul-timedia, vol. 7, no. 6, pp. 1066–1083, Dec. 2005.
[42] L.-Y. Duan, M. Xu, Q. Tian, and C.-S. Xu, “Nonparametric color char-acterization using mean shift,” in Proc. ACM Multimedia, Berkeley, CA,2003, pp. 243–246.
[43] V. Vapnik, The Nature of Statistical Learning Theory. New York:Springer-Verlag, 1995.

340 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 8, NO. 2, APRIL 2006
[44] C. Cortes and V. Vapnik, “Support-vector network,” Mach. Learn., vol.20, no. 3, pp. 273–297, 1995.
[45] C.-W. Hsu and C.-J. Lin, “A comparison of methods for multi-class sup-port vector machines,” IEEE Trans. Neural Networks, vol. 13, no. 2, pp.415–425, Mar. 2002.
[46] L.-Y. Duan, M. Xu, Q. Tian, and C.-S. Xu, “Nonparametric motionmodel with applications to camera motion pattern classification,” inProc. ACM Multimedia, New York, 2004, pp. 328–331.
[47] J. S. Jin, Z. Zhu, and G. Y. Xu, “A stable vision system for movingvehicles,” IEEE Trans. Intell. Transport. Syst., vol. 1, no. 1, pp. 32–39,Mar. 2000.
[48] Z. Duric and A. Rosenfeld, “Stabilization of Image Sequences,” Univ.Maryland, College Park, 1995. Tech. Rep. CAR-TR-778.
[49] Y. S. Yao and R. Chellappa, “Electronic Stabilization and FeatureTracking in Long Image Sequences,” Univ. Maryland, College Park,1995. Tech. Rep. CAR-TR-790.
[50] B. W. Silverman, Density Estimation for Statistics and Data Anal-ysis. New York: Chapman and Hall, 1986.
[51] D. DeMenthon and D. Doermann, “Video retrieval using spatio–tem-poral descriptors,” in Proc. ACM Multimedia, Berkeley, CA, 2003, pp.508–517.
[52] V. Kobla, D. DeMenthon, and D. Doermann, “Identification of sportsvideos using replay, text, and camera motion features,” in Proc. SPIEStorage and Retrieval for Media Databases, San Jose, CA, 2000, pp.332–343.
[53] (2005, Feb.) I2R Tech. Rep.. Inst. Infocomm Research. [Online]. Avail-able: http://www1.i2r.a-star.edu.sg/~lingyu/reports/cameramotion.pdf
Ling-Yu Duan received the B.E. degree in appliedphysics from Dalian University of Technology(DUT), Dalian, China, in 1996, the M.S. degreein automation from University of Science andTechnology (USTC), Hefei, China, in 1999, andthe M.S. degree in computer science from NationalUniversity of Singapore (NUS), Singapore, in 2002,respectively. He is currently pursuing the Ph.D.degree in the School of Design, Communication, andInformation Technology, University of Newcastle,Australia.
He is a Research Scientist at the Institute for Infocomm Research, Singapore.His current research interests include image/video processing, multimedia, com-puter vision and pattern recognition, and machine learning.
Jesse S. Jin (M’98) was born in Beijing, China in1956. He received the B.E. degree from ShanghaiJiao Tong University, China, the M.E. from ChinaTextile University, and the Ph.D. degree from Uni-versity of Otago, New Zealand, in 1982, 1987, and1992 respectively, all in computer science.
He held academic positions at the University ofOtago, University of New South Wales, and Univer-sity of Sydney, and is the Chair Professor of IT inthe School of Design, Communication and IT, Uni-versity of Newcastle, Callaghan, NSW, Australia. He
has published 175 articles, has one patent and is in the process of filing threemore patents. His research interests include multimedia, medical imaging, com-puter vision and pattern recognition.
Prof. Jin is a member of ACM, ASTS, and IS&T. He established a spinoffcompany and the company won the 1999 ATP Vice-Chancellor New BusinessCreation Award.
Qi Tian (S’83–M’86–SM’90) received the B.S. andM.S. degrees from Tsinghua University, Beijing,China, and the Ph.D. degree from the Universityof South Carolina, Columbia, all in electrical andcomputer engineering. He was a post-doctor at theUniversity of California, San Diego, in 1985.
He is a Principal Scientist at the Institute forInfocomm Research, Singapore. His main researchinterests are image/video/audio analysis, multimediacontent indexing and retrieval, computer vision,pattern recognition and machine learning. He is
also an Adjunct Professor at Beijing University. He joined the research staff,Institute of System Science, National University of Singapore, in 1992, andsubsequently was the Program Director for the Media Engineering Program atthe Kent Ridge Digital Labs, then Laboratories for Information Technology,Singapore (2001–2002). He has published over 110 papers in peer reviewedinternational journals and conferences. He has two U.S. patents issued withfour pending.
Dr. Tian served as an Associate Editor for the IEEE TRANSACTIONS ON
CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (1997–2003), and servedas chair and member of the technical committees of several internationalconferences, including the IEEE Pacific-Rim Conference on Multimedia(PCM), the IEEE International Conference on Multimedia and Expo (ICME),nd Multimedia Modeling (MMM).
Chang-Sheng Xu (M’97–SM’99) received the Ph.D.degree in electric engineering from Tsinghua Univer-sity, Beijing, China, in 1996.
From 1996 to 1998, he was a Research AssociateProfessor with the National Lab of Pattern Recog-nition, Institute of Automation, Chinese Academyof Sciences, Beijing. He joined the Institute forInfocomm Research (I2R), Singapore, in March1998. Currently, he is Head of Media Analysis Labat I2R. His research interests include multimediacontent analysis, indexing and retrieval, digital
watermarking, computer vision and pattern recognition. He published morethan 100 papers in those areas.