network traffic analysis & cluster analysis€¦ · network traffic analysis & cluster...
TRANSCRIPT

NetworkTrafficAnalysis&ClusterAnalysis
ExploringHadoopClustersusingFreeTools

BackgroundandGoals:
• ApacheSpotwasstartedrecently• DNS,Netflow,PCAPdataisanalyzed• Thegoalistoidentify:”suspicous connections”or:“dangerousactivity”.
• Whatissuspicious?• ApacheSpotusesatopic-modelapproach,toclassifytraffic.
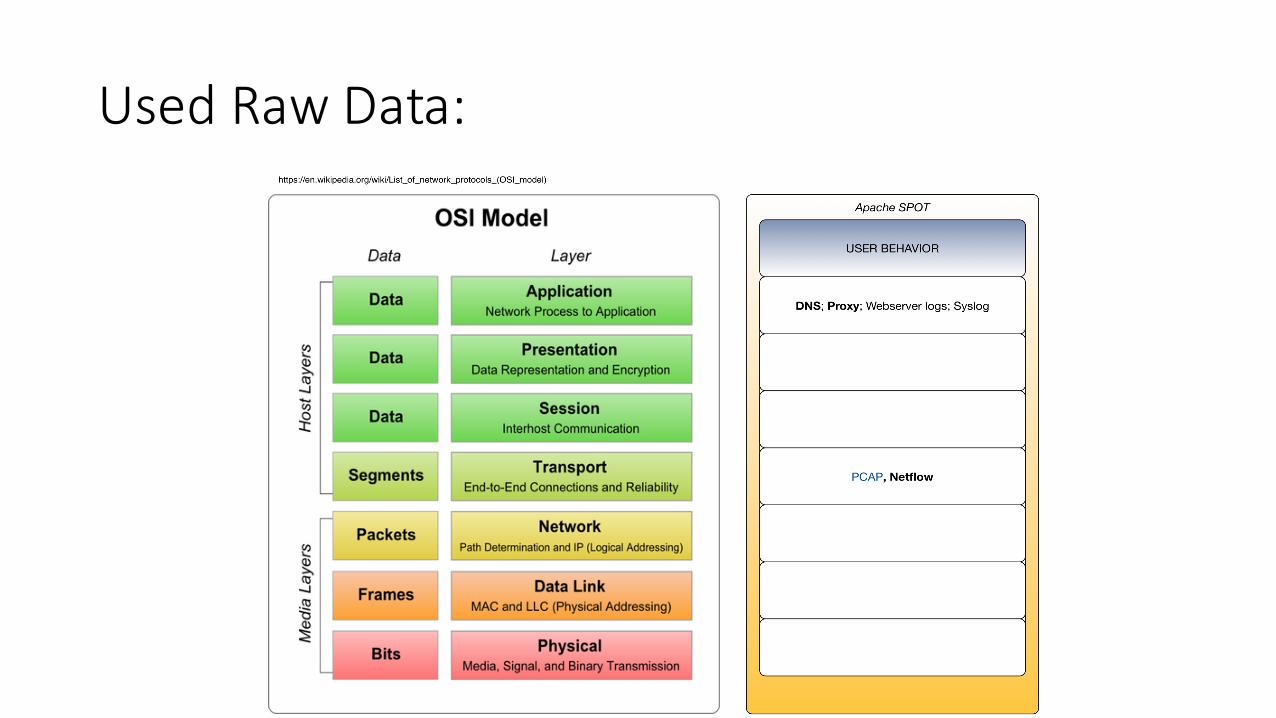
UsedRawData:

OurGoals(midterm):
• Uselocalcontext informationinsteadofsinglepackagedataonly.
(A)Temporalcommunicationnetworks(B)Vectorization ofmeasuredpropertiesfrommultiplesources
• Consideradditionalcommunicationlayers:• Syslog• Webserverlogs• ClouderaManagerevents• ClouderaNavigatorevents

AboutEventProcessing:
• Kafka givesanorderonlywithinapartition• Post-processinginSpark
• HBase sortsrowsbykey• Tabledesignisnowstrictlytimerelated,whichisnotaveryuniversalapproach.
• Kudu usesPrimaryKeysEachKudutablemustdeclareaprimarykeycomprisedofoneormorecolumns.Primarykeycolumnsmustbenon-nullable,andmaynotbeaboolean orfloating-pointtype.Everyrowinatablemusthaveauniquesetofvaluesforitsprimarykeycolumns.AswithatraditionalRDBMS,primarykeyselectioniscriticaltoensuringperformantdatabaseoperations.• But:Eventshavetimestampswhicharenot reallyunique!!!

OurActivities
• Implementadatapipeline:• Kafka=>Spark=>HDFS=>Notebook• Kafka=>Spark=>Kudu• Kudu=>Spark=>HDFS=>(Notebook)
• Createreferencedatasets• ScenarioA:Terrasort (Big-Batch-Workload)• ScenarioB:HDFSPUT,GET;HUE(InteractiveWorkload)• ScenarioC:Idlecluster(Vacationtime)• ScenarioD:Kafka=>Spark=>Kudu(RealisticproductionWorkload)• ScenarioE:Twitter=>Spark=>Kudu(RealisticproductionWorkload)

Results
• ScenarioA:Batchworkload• ScenarioD:Externaldataacquisition• ScenarioE:Idlecluster
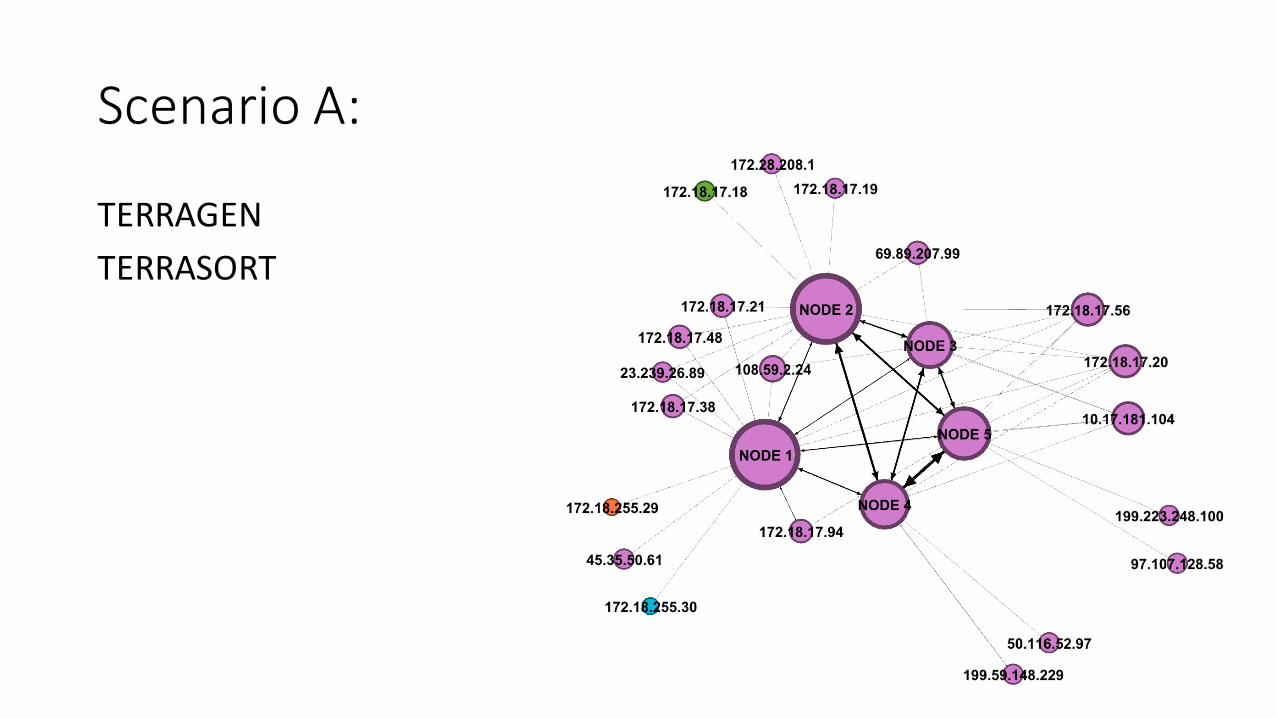
ScenarioA:
TERRAGENTERRASORT
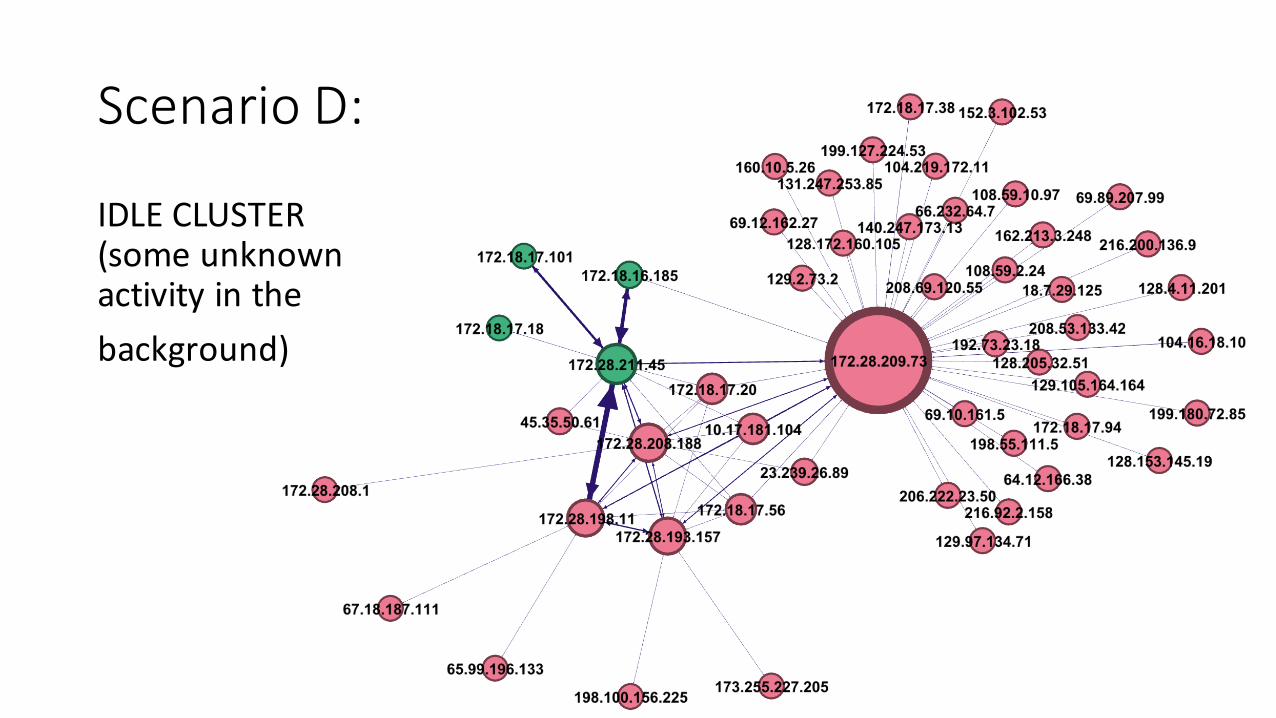
ScenarioD:
IDLECLUSTER(someunknownactivityinthebackground)

FirstIteration:
• Weorganizedourworkin3phases:• Dataanddomaininspection+solutionproposals• Environmentsetup
• Toolcentric:Jupyter,Eclipse,IntlliJ,CloudCat cluster,Git repository• Datacentric:,Datacollectortool,Demodatageneration,Dataformats
• Datacapturinganddatageneration• Analyzingthedatainawelldefinedenvironment
• ResultsareavailableinGit repos:• http://github.mtv.cloudera.com/kamir/Snaffer• https://github.com/mbalassi/packet-inspector
• Increasefunctionalityandknowledgebydoingsmalliterations• Sharecodeandknowledge

Howitworks…
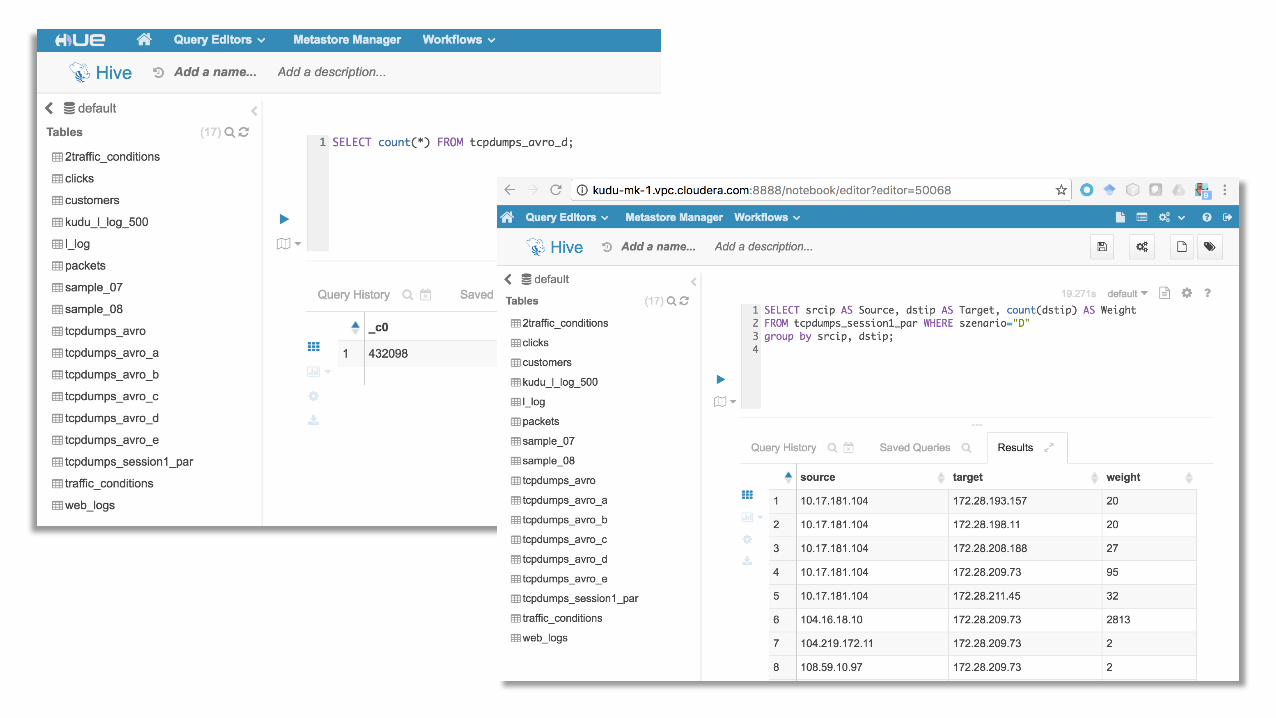
• WecollectrawdatainAvroformat,usingtheSnaffer script.• Wetransformtheeventstonetworks,usingHive.• WeanalyzeandvisualizethenetworksusingGephi.
Outlook

EntropyofTemporalNetwork
• Timeevolutionofthenetworkproperties• Topology• Topologicalnodeproperties

MilestoneOne:
• FollowacommonDSPmodel (datascienceprocessmodel)• UseCDHdefaulttoolsandgainexperience• WorkwithKafka(forinput)andHivetables(forinputandoutput)• Implementadatasetprofilingprocedure,usingSpark• Presentresults,usingJupiternotebook• Increasefunctionalityandknowledgebydoingsmalliterations• Sharecodeandknowledge

TODO(1)
• Definedatasourcesaccordingtoinspectionmethods• DefineAvroschemaandSOLRschema• Automaticdatasetinitalization /validation
• DESCRIBEasWIKIandthaninstantiateviaANSIBLE

TODO(2)
• SNAProfiler• SQLforNetworkcreation• Topologypertimeslice
• Envelop:• AllowsustohookintheSNAProfiler componentasaJAR.

TODO(3)
• TimeSlicePreparation• KAFKA=>Hbase• App—controled timeslicemanagement:
• (K,V):(EXP_METRIC_TS,NETWORKDATA_as_edgelist)• OppositetoTIMESERIESpresentation

References
• https://docs.google.com/document/d/12SHvTGJWtewk8CpUClOy22mh7cUow18F_Jg2ZNNE3h8/edit#heading=h.r4wlzr2ctack• https://docs.google.com/document/d/1sD0_T2fQ7J5k7Ttx1vmAkYkMljMySgKFimm4hNVXxgA/edit#• http://research.ijcaonline.org/volume74/number17/pxc3890233.pdf• https://www.cs.princeton.edu/~blei/papers/BleiNgJordan2003.pdf