multidimensional binary partitions: distributed data structures for spatial partitioning
TRANSCRIPT

This article was downloaded by: [University of Auckland Library]On: 05 December 2014, At: 14:35Publisher: Taylor & FrancisInforma Ltd Registered in England and Wales Registered Number: 1072954 Registered office: Mortimer House,37-41 Mortimer Street, London W1T 3JH, UK
International Journal of ControlPublication details, including instructions for authors and subscription information:http://www.tandfonline.com/loi/tcon20
Multidimensional binary partitions: distributed datastructures for spatial partitioningGEORGE CYBENKO a & THOMAS G. ALLEN ba Center for Supercomputing Research and Development , University of Illinois , Urbana, IL,61801, U.S.A.b ALPHATECH, Inc. , 50 Mall Road, Burlington, MA, 01803, U.S.A.Published online: 27 Mar 2007.
To cite this article: GEORGE CYBENKO & THOMAS G. ALLEN (1991) Multidimensional binary partitions: distributed datastructures for spatial partitioning, International Journal of Control, 54:6, 1335-1352, DOI: 10.1080/00207179108934215
To link to this article: http://dx.doi.org/10.1080/00207179108934215
PLEASE SCROLL DOWN FOR ARTICLE
Taylor & Francis makes every effort to ensure the accuracy of all the information (the “Content”) containedin the publications on our platform. However, Taylor & Francis, our agents, and our licensors make norepresentations or warranties whatsoever as to the accuracy, completeness, or suitability for any purpose of theContent. Any opinions and views expressed in this publication are the opinions and views of the authors, andare not the views of or endorsed by Taylor & Francis. The accuracy of the Content should not be relied upon andshould be independently verified with primary sources of information. Taylor and Francis shall not be liable forany losses, actions, claims, proceedings, demands, costs, expenses, damages, and other liabilities whatsoeveror howsoever caused arising directly or indirectly in connection with, in relation to or arising out of the use ofthe Content.
This article may be used for research, teaching, and private study purposes. Any substantial or systematicreproduction, redistribution, reselling, loan, sub-licensing, systematic supply, or distribution in anyform to anyone is expressly forbidden. Terms & Conditions of access and use can be found at http://www.tandfonline.com/page/terms-and-conditions

INT. J. CONTROL, 1991, VOL. 54, No.6, 1335-1352
Multidimensional binary partitions: distributed data structures forspatial partitioning
GEORGE CYBENKOt and THOMAS G. ALLENt
A multidimensional binary partition (MBP) is a data structure determined by a setof points in n-dimensional space. On certain parallel architectures, this datastructure can be easily distributed across the processing nodes of the machine andcan provide a natural technique for load balancing and partitioning of applicationproblems that depend on a distribution of dynamically changing points in multidimensional space. This paper describes parallel algorithms for generating andusing MBPs on a hypercube parallel machine. It is also shown how these distributeddata structures allow efficient parallel searches of the data set. The performance ofan implementation of these algorithms on an NCUBE hypercube is presented.
1. Introduction
1.1. The load balancing problem
Load balancing and problem partitioning commonly encounter difficulties in theparallel processing of applications when the work load distribution among processors changes dynamically as the computation progresses. In this paper, we assumethat the distribution of work is explicitly determined by an underlying distributionof points on multidimensional space and that the position of these points changesover time. That is, the amount of processing per point is approximately equal.Applications where such dynamically changing point distributions occur includemultiobject tracking (Allen et al. 1987), domain decomposition methods for ellipticpartial differential equations (Keyes and Gropp 1987), vortex methods for fluiddynamics problems (Baden 1986) and n-body problems (Greengard 1987). In suchsituations, we can abstract load balancing and partitioning issues into the problemof distributing points as equally as possible among the processors in a parallelcomputer. Moreover, points that are close in space are more likely to interact in theunderlying computation so that we have the added condition that points close inspace should be allocated to either the same processor or to processors that cancommunicate with minimal overhead. Hence, in these situations, the problem ofload balancing and partitioning becomes the problem of dynamically partitioning aset of points and then allocating them to processing nodes in an appropriate way.
Multidimensional binary partitions (MBPs) are distributed data structures thataddress such geometrically based load balancing and problem partitioning issues onparallel computers. They have already been shown to be effective data structures forhandling dynamic data distributions (Allen et al. 1987, Baden 1986, Berger andBokhari 1987). The main contribution of this paper is the derivation of parallelalgorithms for computing and searching these data structures on a hypercube
Received 10 April 1991.t Center for Supercomputing Research and Development, University of Illinois, Urbana
IL 61801, U.S.A.t ALPHATECH, Inc., 50 Mall Road, Burlington, MA 01803, U.S.A.
0020-7179/91 $3.00 © 1991 Taylor & Francis Ltd
Dow
nloa
ded
by [
Uni
vers
ity o
f A
uckl
and
Lib
rary
] at
14:
35 0
5 D
ecem
ber
2014

1336 G. Cybenko and T. G. Allen
parallel computer, although it will become clear that the basic ideas carryover toother parallel architectures as well. The algorithms that we derive have beenimplemented on an NCUBE hypercube and their performance is presented andanalysed. We also present some analytic properties on the locality of the ensuingallocation of points to processors in a hypercube.
As noted above, we can recast the load balancing and partitioning problem interms of decomposing point sets into subsets that get allocated to processing nodes.Suppose we are given a set of points S in k-dimensional euclidean space, s«. AnMBP is a data structure that determines a partition PI' P2 , ••• , PN of S with theproperty that different elements of the partition are allocated to different processorsin a hypercube parallel computer (so that N = 2d for some d). This partition andallocation should satisfy the following loosely stated criteria.
(I) Equity-each element of the partition should have almost the same numberof points from S.
(2) Proximity-points that are close in space are allocated to processors thatare close in the hypercube.
Criterion I is usually precise enough in an application context and will not bediscussed further. Criterion 2 is more vague by comparison and requires additionalcomment. First of all, closeness in a distributed memory multiprocessor networkrefers to the notion of distance given by shortest communication paths in thenetwork. Any simple attempt to formalize the closeness criterion by requiring somesort of optimality will likely lead to NP-hard problems (Cybenko et al. 1987).Because of this observation, we do not impose a formal optimality criterion formapping points close in space to points close in the hypercube and choose insteadto use Criterion 2 as a guideline. In fact, part of the contribution of this paper isa concrete result on the dilation that does in fact result from the MBP mapping.
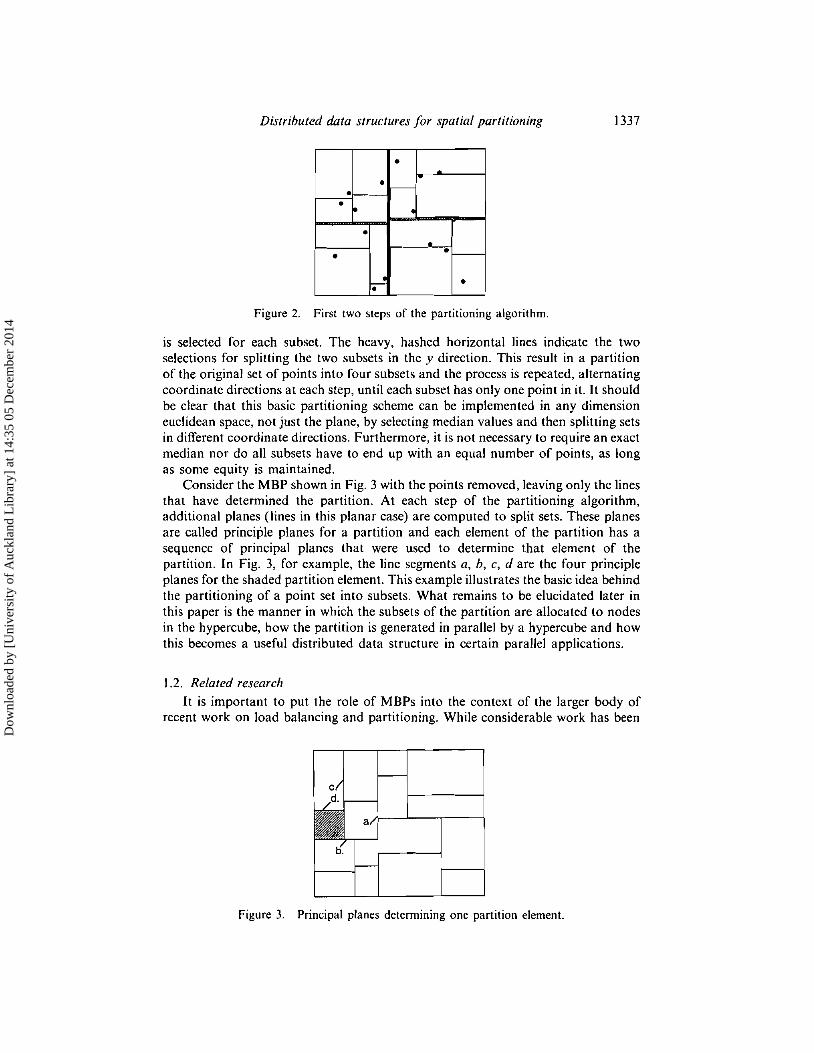
Before introducing a formal definition of multidimensional binary partitions, wegive a simple example that illustrates the basic idea. Below, in Fig. I, we display adistribution of 16 points in the plane and overlay it with a multidimensional binarypartition. Each rectangle in the figure is an element of the partition so that the setof 16 points is decomposed into 16 singleton subsets. The idea behind the partitioning algorithm is illustrated in Fig. 2 where the heavy vertical line shows the firstsplitting of the whole set. That vertical line is determined by the median value of thex-coordinates of the point set. Using that vertical line as a dividing line, we get twosubsets-one to the left of the dividing line and one to the right of the dividing line.The two subsets can now be processed independently and the median y-coordinate
•• -••
• ." "-
~ ••Figure I. An example of a multidimensional binary partition.
Dow
nloa
ded
by [
Uni
vers
ity o
f A
uckl
and
Lib
rary
] at
14:
35 0
5 D
ecem
ber
2014
Distributed data structures for spatial partitioning
0
0o~
0~ •
0
a
00-
~ ••Figure 2. First two steps of the partitioning algorithm.
1337
is selected for each subset. The heavy, hashed horizontal lines indicate the twoselections for splitting the two subsets in the y direction. This result in a partitionof the original set of points into four subsets and the process is repeated, alternatingcoordinate directions at each step, until each subset has only one point in it. It shouldbe clear that this basic partitioning scheme can be implemented in any dimensioneuclidean space, not just the plane, by selecting median values and then splitting setsin different coordinate directions. Furthermore, it is not necessary to require an exactmedian nor do all subsets have to end up with an equal number of points, as longas some equity is maintained.
Consider the MBP shown in Fig. 3 with the points removed, leaving only the linesthat have determined the partition. At each step of the partitioning algorithm,additional planes (lines in this planar case) are computed to split sets. These planesare called principle planes for a partition and each element of the partition has asequence of principal planes that were used to determine that element of thepartition. In Fig. 3, for example, the line segments a, b, c, d are the four principleplanes for the shaded partition element. This example illustrates the basic idea behindthe partitioning of a point set into subsets. What remains to be elucidated later inthis paper is the manner in which the subsets of the partition are allocated to nodesin the hypercube, how the partition is generated in parallel by a hypercube and howthis becomes a useful distributed data structure in certain parallel applications.
1.2. Related research
It is important to put the role of MBPs into the context of the larger body ofrecent work on load balancing and partitioning. While considerable work has been
Figure 3. Principal planes determining one partition element.
Dow
nloa
ded
by [
Uni
vers
ity o
f A
uckl
and
Lib
rary
] at
14:
35 0
5 D
ecem
ber
2014

1338 G. Cybenko and T. G. Allen
devoted to the study of dynamic load balancing for parallel computing (Cybenko1989, Chou and Abraham 1982, Hajjar and Carlson 1989, Fox 1986, Fox andFurmanski 1986, Price 1981) it is only recently that researchers have focusedattention on applications where work must be balanced with special care beingtaken with regard to the relative position of the target processor within a multiprocessor system.
Geometric partitioning problems arise naturally in a variety of applicationsquite independently of parallel computing and load balancing. The partitioningproblem occurs in computational geometry (Preparata and Shamos 1985) whereone uses the partition as a standard sequential data structure that permits efficientsearching strategies. It was in this context that Bentley first developed the notion ofa multidimensional binary tree that is so fundamental to the notion of an MBP(Benlley 1975,1980). Tn fact the partition we have shown in Fig. I is essentiallyidentical to the construction of Bentley. More recently, considerable research hasgone into the use of binary tree partitions for classification in large sparse data setsarising in statistical applications (Breiman et al. 1984). In a similar spirit, somework has been devoted to the use of binary partitions of data sets for fastclassification and interpolation as an alternative to neural network structures(Omohundro 1987).
The importance of geometric partitioning as a basis for load balancing inparallel computing has been recognized by numerous researchers. Using Bentley'Sconstruction of multidimensional binary trees, Berger and Bokhari (1987) made thefirst thorough study of how multidimensional binary trees can be mapped tostandard multiprocessor network topologies. Their work generates bounds andestimates for communications costs when embedding binary partitions into grids,trees and hypercubes of processors. Their motivation for studying the partitioningproblem arises primarily from numerical solutions of elliptic and hyperbolic partialdifferential equations using domain decomposition techniques. A general discussionof that application can be found in the work of Keyes and Gropp (1987). Recently,Baden used binary partitions for dynamic load balancing in implementing vortexmethods for some fluid mechanics problems (Baden 1986). Boris (1986) hasdeveloped a multidimensional ordering of points in high dimensional space thatturns out to be easily derivable from binary partitions of space. That multidimensional ordering has been coined a 'monotonic logical grid'. Our own interest in thisproblem arose in our implementation of parallel algorithms for tracking (Allen etal. 1987). In that application, the point set that underlies the work distribution isthe set of objects that are being tracked by some type of sensor. Each objectrequires a certain amount of fixed computation to update estimates of variousparameters such as position and velocity. This accounts for the need to allocatepoints (objects) to processors in an equitable manner. Moreover, the problem ofresolving new measurements by associating them with existing objects requires thatobjects close in space (and therefore contending for the same measurements) arehandled by processors close in the parallel machine. This leads to the secondcriterion, namely that of proximity.
1.3. OvervielV of paperThis paper is organized as follows. Section 2 is an introduction to MBPs as
distributed data structures while § 3 presents a parallel algorithm for computing
Dow
nloa
ded
by [
Uni
vers
ity o
f A
uckl
and
Lib
rary
] at
14:
35 0
5 D
ecem
ber
2014

Distributed data structures for spatial partitioning 1339
them dynamically on a hypercube. Section 4 deals with the problem of using theresulting distributed data structure for efficient parallel searching. Section 5 presentsthe performance of an implementation of these algorithms on an NCUBE hypercube. Section 6 is a discussion and summary.
2. Multidimensional binary partitions
2.1. Recursive binary partitions
As illustrated above, MBPs are created by recursively splitting a given point setinto disjoint pairs of subsets. More generally, this action defines a class of partitionsin which MBPs are a special case. We will refer to this class of partitions asrecursive binary partitions (RBPs). The following simple algorithm serves as adefinition of RBPs.
Recursive binary partition algorithm
INPUT DATA: a point set S.
PROGRAM:Define the following recursive procedure:
procedure RBP (S, depth);begin
if (termination) thenP=S
elsebegin
(SI, S2) = split (S, depth);RBP (S',; depth + I);RBP (S2, depth + I);
endend
Initiate the program with the following calling sequence:
RBP (S, I)
OUTPUT: A partition PI' P2 , ••• , PN of the original point set S.
Two seperate criteria, termination and splitting, must be specified to determine aspecific RBP. By using various termination and splitting schemes, many of thecurrently used partitioning methods can be generated. Splitting techniques thatconsider only the geometry of the underlying space and ignore the point distribution result in standard grid partitions. Such grid partitions, when combined with aconstant depth termination criterion, result in uniform grids; and, when combinedwith variable depth termination criteria, result in a combination of course and fineuniform grid patches.
Uniform grid partitions, due to their disregard of the point set distribution,cannot satisfy our stated equity requirement. This requirements suggests the use ofsplitting schemes based on partitioning the point set input to the partition procedure into two comparably sized subsets.
Dow
nloa
ded
by [
Uni
vers
ity o
f A
uckl
and
Lib
rary
] at
14:
35 0
5 D
ecem
ber
2014

1340 G. Cybenko and T. G. Allen
2.2. M BP definition
Multidimensional binary partitions are a class of RBPs that recursively split theinput point set into (almost) equally sized subsets. This partitioning is accomplishedby computing the median of the coordinate values in a given direction and splittingthe set into points whose coordinates fall above and below this value. Thiscoordinate direction is specified from a sequence dependent only on the currentpartition depth. Note that since MBPs are binary partitions, and since we arepartitioning based on medians, the equity requirement is satisfied. The terminationrule is to continue until the depth exceeds a maximum value. Therefore, the MBPcan be characterized by a depth, d, and a sequence of coordinate directionsj( 1),j(2),j(3), ...,j(d).
Multidimensional binary partition algorithm
INPUT DATA: a point set S, maximum depth d, and a sequence ofcoordinate directions, j( I),j(2),j( 3), ...,j(d).
PROGRAM:Define the following recursive procedure:
procedure MBP (S, depth);begin
if (depth> d) thenP=S
elsebegin
-compute the median of the j(depth)coordinates of the points in S;
-partition S into those points above(S,) and below (S2) the median;
MBP (S" depth + I);MBP (S2' depth + I);
endend
Initiate the program with the following calling sequence:
MBP (S, I)
OUTPUT: A partition P" P2 , ... , PN of the original point set S, whereN=2 d
.
The planar MBP shown above (Fig. I) was created with the following definitions
d = 4 and j(depth) = depth mod 2 + I
The sequence of coordinate directions here is simply to alternate the direction. Figure4 shows an MBP with the same underlying point distribution and depth as Fig. I,but with the following sequence of coordinate directions
j(depth) = L(depth - 1)/2J mod 2 + I
Dow
nloa
ded
by [
Uni
vers
ity o
f A
uckl
and
Lib
rary
] at
14:
35 0
5 D
ecem
ber
2014

Distributed data structures for spatial partitioning
•• •
•••f-- • ••
•• •
I---
• •e----.-Figure 4. MBP with different coordinate sequence.
1341
2.3. MBPs as distributed data structures
One property of the MBP that will prove important for hypercube implementation is its ability to be expressed as a distributed data structure. A necessarycharacteristic of such structures is the distribution of the information required todefine each point set and its corresponding region. The point sets themselves can bedistributed given their disjoint nature. The regions can be described in a distributedmanner by exploiting the binary partitioning nature of MBP.
At each stage (depth) of the MBP algorithm a median is computed and used topartition the input point set. We refer to these median values as principal planes. Asequence of d (the depth of the MBP) principal planes is employed to create eachregion. Three sets of information are required to specify the relation between anyone region and its principle planes. These are the values of the principle planes(given by the calculated medians), the orientations of the principle planes (given bythe coordinate directions), and whether the region falls above or below eachprinciple plane (given by whether set S, or S2 was used to create the region). Thisinformation can be distributed within the MBP algorithm in the same manner asthe point sets-merely pass additional arguments that are stored in arrays using thevalue of depth as an index.
Figure 5 is an example of the definition of a single region for a MBP with d = 4.The four sets of principle plane information define a unique spatial region.
Figure 5. Principal planes for a single region.
Dow
nloa
ded
by [
Uni
vers
ity o
f A
uckl
and
Lib
rary
] at
14:
35 0
5 D
ecem
ber
2014

1342 G. Cybenko and T. G. Allen
3. Hypercube generation of multidimensional binary partitions3.1. Hypercube parallel computers-a review
Inorder to discuss hypercube algorithms for creating MBPs we need to recall somebasic facts and properties of binary hypercube computers (see Heath 1986 for moreinformation). A d-dimensional hypercube is constructed by taking 2d processing nodesand labelling them with the 2d binary integer labels ranging from 0 to 2d
- 1.Processorswhose binary integer labels differ in exactly one bit are connected by a direct communications channel. Let I be a processor label (that is, a binary integer with d bits) andfor I <r;j <r; d, let L(I,j) be the binary integer identical to I except in the jth bit whereit differs from I. (Our convention is to order the bits from least significant to mostsignificant-that is from right to left-although this is of course quite arbitrary.)By construction of the hypercube, processors I and L(I,j) are directly connected.Moreover, the pairing {I, L(/,j)} partitions the cube into 2d - 1 pairs and taking thenode from each pair with its jth bit cleared, we obtain a d - I dimensional cube.
It is well known that if we take a hypercube node label and hold some bits fixedwhile letting the others vary we get a subcube of the whole hypercube. We need someterminology to help us identify such subcubes. Specifically, for a node label I, letH(I,j) be the subcube of the d-dimensional hypercube that consists of the nodeswhose labels agree with label I in the first j least significant bits. Thus H(/,O) isprecisely the whole hypercube while H(/, I) is the (d - I)-dimensional subcube ofnodes whose labels have the same least significant bit as I.
3.2. The hypercube algorithm for generating M BPsThe basic algorithm for computing multidimensional binary partitions involves
recursively splitting sets into two subsets using some coordinate value as a splittingcriterion. We call this coordinate value a pseudo-median. The idea behind paralielizing this process is quite intuitive-a set stored in the nodes of a hypercube is splitso that the resulting two subsets are stored on disjoint subcubes of the originalhypercube. The recursive structure of the algorithm clearly matches the recursivestructure of the hypercube.
This general algorithmic approach involves a number of choices. First of all, asequence of coordinate directions in which splitting occurs has to be specified-thesecan be chosen quite arbitrarily. Secondly, some protocol is needed for deciding whichsubcubes get points above which pseudo-median and which subcubes get pointsbelow that pseudo-median. This protocol must be chosen carefully if we want tosatisfy the proximity criterion. The key lies in the selection of a mapping of ann-dimensional grid to a hypercube determined by binary reflected Gray codes in eachcoordinate direction.
There is a wealth of literature on the embeddings of grids into hypercubes, butusing them would lead us to a detailed discussion of binary reflected Gray codes andspecial embeddings of grids into hypercubes and their properties. Instead, we identifya simple protocol that dynamically generates the desired embeddings directly fromthe selection of coordinate directions. This makes the procedure for generating MBPsa truly distributed algorithm with no centralized control except for the computationof pseudo-medians.
Before describing the protocol for assigning sides of the principal planes to nodes,we summarize the hypercube MBP algorithm while leaving the protocol, mediancomputation and resulting embedding indeterminate.
Dow
nloa
ded
by [
Uni
vers
ity o
f A
uckl
and
Lib
rary
] at
14:
35 0
5 D
ecem
ber
2014

Distributed data structures for spatial partitioning 1343
Hypercube MBP partitioning algorithm for node I
INPUT DATA: a point set S, resident on node I (known only to node l) anda sequence of coordinate directions,f( I),f(2),f( 3), ...,f(d) (known to allnodes).
PROGRAM:for j = I to d dobegin
-compute a pseudo-median of the f(j) coordinates of the points inH(l,j - I);
-assign this pseudo-median to the jth principle plane, mj,l, on nodeI',
-send to L(/,j) the points in S, that belong on the L(/,j) side of mj .,
and receive from L(l,j) and put into S, points that belong on theI side of mj,l;
end
OUTPUT: the point set S, resident on node I that is an element of the MBPand a sequence of principle planes, ml.l, m2.l> ... , md,l'
The two ingredients of this algorithm that remain unspecified are the method ofpseudo-median calculation and the protocol for deciding which nodes retain whichpoints. We now discuss these two issues separately.
3.3. Pseudo-median selection
If we were able to compute medians exactly then the resulting allocation ofpoints to processing nodes would satisfy the equity criterion as closely as possible.In practice, our implementation uses an approximation of the true median becauseexact median computations are expensive and turn out to be unnecessary forgood load balancing. We now briefly describe three possibilities for pseudo-medianselection.
Exact medians
Exact median splitting is the basis for computing balanced multidimensionalbinary partitions. It requires computing the exact median of some subset of pointsthat are distributed over a subcube of processors. The exact median computation isexpensive on a distributed memory multiprocessor since all algorithms for findingexact medians appear to require a great deal of global information. Accordingly, wedo not advocate the use of the exact median.
Exact means
Means are easy to compute in an hypercube and could in principle be used aspseudo-medians. A drawback of using means is that in the presence of outliers amean can be arbitrarily far from the median. In applications where some wellunderstood statistical mechanism is generating the points, it may be possible to usemeans for effective splitting.
Dow
nloa
ded
by [
Uni
vers
ity o
f A
uckl
and
Lib
rary
] at
14:
35 0
5 D
ecem
ber
2014

1344 G. Cybenko and T. G. Allen
Approximate medians
There are many possible methods for estimating a good pseudo-median and wedescribe one that was used in our implementation. This splitting scheme involvesfirst computing the exact median of the points on each processor and thencomputing the median of these medians. Suppose that each processor contains atleast Q points-it can be easily checked that the derived approximate median hasthe property that at least Q!4 points are less than it and at least Q!4 points aregreater than it. The local computation of the exact local median requires no morethan O(Q) steps using the algorithm of Blum et al. (1973). Computing the medianof these local medians involves exchanging data among the processors withinsubcubes. This approach is attractive since it requires gathering only one point fromeach processor as opposed to a gather operation of all or many points whichappears to be necessary for exact median computation. This second-order mediancan be refined by iterating a bisection search.
The idea behind iterative improvement through bisection lies in tallying thenumber of points that are on either side of the estimated pseudo-median. This alsoinvolves gathering point counts within subcubes. If the point counts are too far apart,an updated pseudo-median is selected and the point counts are recomputed. Whenthe point counts on either side are within an acceptable tolerance, the process stops.
3.4. The protocol [or splitting sets between processorsWhat remains to be addressed is the proximity condition and in particular the
protocol for determining which nodes receive which subset of points in each step ofthe iteration. To this end, we introduce the notion of a parity function.
Take the function f, mapping {I, ...; d} into {I, ..., k} that determines thesequence of coordinate directions used in the above algorithm. Thus J(i) specifiesthe coordinate axis in which the pseudo-medians are computed and sets are split atthe ith level of the iteration. Define the (f,j)-parity of a node as follows. Recallthat the node labels are finite strings of zeros and ones. Let I, be the ith bit of I. (Wecontinue to use the convention that I, is the least significant bit while Id is the mostsignificant bit.) Define
Pl.)!) = I{i such that I <;; i <;;j, t, = IJ(i) =J(j)}1 mod 2
and call it the (f,j)-parity of a label l. In words, the value of PfJ(l) is determinedby first looking at J(j) and selecting the bits, Ii, of the node label I to the right ofthe jth bit (inclusively) for which J(i) = J(j). Now we simply count the number ofbits which are ones. If this number is even, then the value of P/.j(l) is 0, while if itis odd the value is I. Notice that by definition of L(l,j), we must have that P/./l)and PJJ(L(/,j» are different. For example, if we are partitioning points fromtwo-dimensional space and we alternate the coordinate direction in which we arecomputing medians then
J(i) = i mod 2 + I
For the label I = 1001101 the (f, 7)-parity is
P/.7(l) = I{ I, 5, 7}1 mod 2 = I
while the (f, 6)-parity is
PI. 6(/) = 1{4}1 mod 2 = I
Dow
nloa
ded
by [
Uni
vers
ity o
f A
uckl
and
Lib
rary
] at
14:
35 0
5 D
ecem
ber
2014

Distributed data structures for spatial partitioning 1345
The (f,j)-parity of a node label determines our protocol for deciding which nodereceives the points above a pseudo-median and which node receives points belowthe pseudo-median. In particular, between the pair I and L(/,j), the node with(f,j)-parity of I will receive the points above the median while the node with(f,j)-parity of 0 will receive points below the median. Since the (f,j)-parities of Iand L(/,j) are different, there is no ambiguity in such a protocol.
We now state the hypercube MBP generation algorithm with this protocolincluded.
The hypercube MBP algorithm for node I
INPUT DATA: a point set Sf resident on node I and a sequence ofcoordinate directions, f( 1),/(2),/(3), ...,/(d).
PROGRAM:for j = I to d dobegin
-compute a pseudo-median of thef(j) coordinates of the points inH(/,j - I);
-assign this pseudo-median to the jth principle plane, mj ./> on nodet.,
-if PfJ (/ ) = 0 send to L(/,j) the points from Sf that are above m j J;-if Pfil) = I send to L(/,j) the points from Sf that are below mjJ;
-delete the points sent to L(/,j) from Sf;-receive points from L(/,j) and put them in Sf;
end
OUTPUT: the point set Sf resident on node I that is an element of the MBPand a sequence of principle planes, ml./, m 2J, ...• mdJ'
The reason we introduce the parity function and resultant protocol is to addressthe proximity criterion but it is probably not immediately obvious what impact theparity function has on proximity. In the next subsection, we show, among otherthings, that the parity function generates binary Gray codes in each coordinatedirection. The Gray code, by mapping a linear array into a hypercube, results inpartitions that are close in space being mapped to processor nodes that are close inthe hypercube.
3.5. Properties of the MBP
The desire to partition sets into almost equally sized subsets is completelyhandled by the use of pseudo-medians. In particular, the better the pseudo-mediansapproximate the true medians, the closer the partitioning scheme approximatesexact equity. On the other hand, we also seek to have points that are physicallyclose together end up being in the same partition subsets or at least in subsets thatare mapped to processors close together in a hypercube network. This condition ishandled by the use of the above parity function to decide which processors getwhich half of a set when the set is split by a pseudo-median. We now examine moreclosely the implications of this protocol on the proximity condition.
When referring to distance between points on physical euclidean space we usethe adjective 'physical' so that 'physically' close points are points close together in
Dow
nloa
ded
by [
Uni
vers
ity o
f A
uckl
and
Lib
rary
] at
14:
35 0
5 D
ecem
ber
2014

1346 G. Cybenko and T. G. Allen
the metric of the underlying coordinate space. The natural distance measure in ahypercube is the so-called 'Hamming' distance which counts the number of bits bywhich two binary node labels differ. This metric measures the amount of communication delay arising between processing nodes. We use the adjective 'logical' to referto distance in a hypercube. Thus if we have two elements of an MBP, we say theyare logically close if the Hamming distance between the nodes where they reside isrelatively small. In this terminology, the original proximity goal of partitioning is toallocate physically close points to logically close processing nodes.
Logical distance in a hypercube is a notion relevant to performance. The largerthe distance, the longer a message spends being propagated and forwarded in thenetwork. Ideally, one seeks to assign frequently communicating pairs of processorsclose to one another in the hypercube to minimize the effect of this latency. Thegeneral problem of mapping an arbitrary graph into a hypercube to achieve this isNP-complete (Cybenko et al. 1987).
Our basic partitioning algorithm determines a sequence of d principal planes for-each hypercube node. Each of these principle planes together with the parity
function determine half-space in which the points on that node must be contained.These planes and half-spaces vary from node to node. The points that a processingnode ends up with at the end of the 'hypercube partitioning algorithm' are preciselythe points contained in the intersection of all those half-spaces. Hence we canassociate hypercube processing nodes with elements of the partition. We want toexamine how elements in the partition are mapped to nodes in the hypercube,especially with respect to their distance in the hypercube.
The first observation we make comes directly from the algorithm. At the jth stepof the algorithm, every node, I, determines a principle plane so that the points thatits neighbour L(l,j) stores are on the opposite side of the principle plane. Thus byconstruction we have the following basic fact.
Theorem I
For every hypercube node and for every of that node's principle planes, there isa neighbouring node that lies on the opposite side of that principle plane. 0
This result tells us that given the element of the MBP stored on node I, we canfind another element of the MBP that is on the opposite side of a principal plane,Inj./' by simply going to L(l,j).
A more complicated result concerns the logical proximity of the physicalneighbours of the partition. First of all, each physical boundary of a partitionelement is a principle plane computed in some iteration of the partitioning algorithm. (Not every principle plane is a physical boundary of a partition elementhowever.) The question is, what partition elements are physically adjacent to agiven partition element? How far away are those adjacent partition elements in thehypercube? Our result on the logical proximity of physically adjacent neighbours issummarized in the following.
Theorem 2
Suppose that two partition elements are physically adjacent and are separatedby a principle plane at depth i. I ,,;;j ,,;; d. Then the logical distance between the
Dow
nloa
ded
by [
Uni
vers
ity o
f A
uckl
and
Lib
rary
] at
14:
35 0
5 D
ecem
ber
2014

Distributed data structures for spatial partitioning
hypercube nodes storing those two partition elements is less than or equal to
1 + l{i such that j + I :;;; i :;;; d,f(J) # f(i)}1
1347
o
Proof
This bound is straightforward to establish once we make a couple of simpleobservations. Since the two partition elements are separated by a principal plane atthe jth level, they must be in the intersection of the first j - 1 half-planesdetermined by the first j - 1 principle planes for those partition elements. Hence thefirst j - 1 least significant bits of both node labels must be identical. The firstprincipal plane for which the two partition elements lie on opposite sides istherefore the jth. The constant term I in the above expression is needed to traversethis jth principle plane separating the two nodes. Any additional logical distance isgained by looking at partitioning steps that follow the jth level.
The second term in the above expression is obtained by counting only thesplittings in dimensions other than the one at the jth level. Note that by assumption, at the jth level of the iteration the two partition elements in the theorem areadjacent but on different sides of the jth principle plane. Call the two nodes storingthese partition elements, nand m, with m lying below the jth plane and n lyingabove the jth plane. We must have that PfJ(m) = 0 and PfJ(n) = 1 or else theywould have been on the same side of the jth principle plane. Now suppose thati > i. withf(i) = f(J), with the ith bit being the first bit in which m and n differ withthese properties. Then Pj.i(m) = I = Pj.,(n) or Pj.i(m) = 0 = Pj.i(n) since the ith bitsdiffer. But this means that the two nodes must either both be below their principleplanes at the ith level or both be above their principle planes at that level. This inturn means that there is another principle plane that separates the two partitionelements, which contradicts our assumption that the two regions are adjacent.Hence all bits following the jth bit that correspond to partitioning in the directionof f(J) must be the same. 0
As an example, consider the RBP obtained by cycling between 3 dimensions for12 steps. This yields a partition with 4096 subsets and is mappable to a 12dimensional hypercube. The maximal logical distance between any two physicallyadjacent subsets of the partition is I + 8 = 9. The maximal logical distance betweentwo sets separated by a plane at the ninth level is similarly I + 2 = 3.
In general, it can be shown that for a two dimensional set S that is partitionedto a depth d, the average logical distance between physically adjacent regions(defined in an appropriate way) is bounded by 380/189 (see Allen and Cybenko1987) independently of the depth d for d < 40. Similar results for MBPs of higherdimensional euclidean space can also be found in the work of Allen and Cybenko( 1987).
4. Using MBPs for parallel searchingThe distributed data structure that the hypercube MBP algorithm computes can
be used not only for load balancing a work distribution that depends on a pointdistribution in physical space but also for searching. For example, in the applicationthat motivated this work (Allen et al. 1987), we encountered the problem of
Dow
nloa
ded
by [
Uni
vers
ity o
f A
uckl
and
Lib
rary
] at
14:
35 0
5 D
ecem
ber
2014

1348 G. Cybenko and T. G. AI/en
matching new data with points that were present in the point set that determinedthe MBP. Since the data structure is distributed, there is no centralized informationabout which processor is storing which points or what regions of space areallocated to which processors, for that matter. However, we now see that theinformation about the principle planes that each processor has stored in thegeneration of the MBP is sufficient to get a new data point to the region of thepartition which it belongs. We now make these ideas precise.
Suppose that we have generated an MBP using the hypercube MBP algorithm.The algorithm allocates regions of space to processors in such a way that thenumber of points from the initial point set in each region is almost the same. Nowsuppose that an arbitrary processor has a new point and this new point must besent to the processor responsible for the region of space to which the point belongs.No global information is available.
The algorithm for routing the new point to its appropriate processor can bemultiplexed-that is, it is just as easy conceptually to imagine each processorhaving a new set of points and each of these points must be routed to the hypercubenode managing its region of space. We write down the algorithm and then discussits effectiveness. It should be evident that it closely follows the hypercube MBPalgorithm itself.
The hypercube data distribution algorithm for node I
ASSUMPTION: an MBP has already been computed using the coordinateselection function f, and the principle planes IllJ.l, 1ll2,!' ... , Illd'! for thisMBP are known and stored on node I;
INPUT DATA: an arbitrary point set N, of new points resident on node I;
PROGRAM:for j = I to d dobegin
-if PfJ(I) = 0 send to L(I,j) the points from N, that are above Illp;
-if PfJ(/) = I send to L(I,j) the points from N, that are below Illj ,!;-delete the points sent to L(/,j) from N,;-receive points from L(/,j) and put them in N,;
end
OUTPUT: the point set N, of new points that are in the partition elementof the MBP on node I.
The effectiveness of this procedure follows readily from the effectiveness of the MBPgeneration algorithm itself. In fact, we can consider this algorithm as runningconcurrently with the hypercube MBP generation algorithm, with these new points'tagging' along. The routing of the new points mimics the routing of the points thatdetermine the MBP. Therefore, these new points end up being on processors thatcontain the MBP element that contains them.
The power of MBPs as distributed data structures that allow efficient searchingis thus seen. In particular, it takes a sequence of 2d communication steps to routethe points from an arbitrarily distributed point set to the appropriate nodes in thehypercube. The performance and analysis of an implementation of both the MBPgeneration algorithm and this data distribution algorithm are given in the next section.
Dow
nloa
ded
by [
Uni
vers
ity o
f A
uckl
and
Lib
rary
] at
14:
35 0
5 D
ecem
ber
2014

Distributed data structures for spatial partitioning 1349
5. Implementation performance and analysisAssume there are N points to be partitioned among 2" processors and that each
processor has N12" points locally. Our algorithm for computing MBPs on ahypercube consists of a number of steps-each step involves the determination ofa single principal plane. The bisection approach we use requires that each processorreport its point distribution with respect to a candidate principle plane. In a ddimensional cube, this reporting requires d transmissions and the number ofbisections required depends on the data distribution. We do not attempt to modelthis number of bisections.
Let us outline the work required at the kth step of the partition generationalgorithm in a d dimensional cube. First of all, a principle plane must be foundwithin the appropriate d - k + 1 dimensional cube. This requires bisections usmgglobal communication within the d - k + 1 cube, say a total of c bisection steps.Thus there are c(d - k + I) total communications of only a pair of bytes and wemodel this time as
»cid - k + I)
Where l' is the data dependent communication overhead time (1'~ 500 us for theNCUBE hypercube employed in our research). For each bisection step, we need tocompare all N12" local points with the candidate plane leading to an additional
acNl2"
time, where a is the time required per point to perform one comparison. Once themedian coordinate is found, processors exchange points with neighbours and weassume as before that half the points must be exchanged. Thus fJN 12"+ I time isspent exchanging points, where fJ is the communication time required per byte(fJ~ 3 us for the NCUBE hypercube). Collecting these times, we get
acNI2"+ fJN/2"+! +1'c(d -k + I)
time at the kth step. Summing over k = 1,2, ..., d, we get
acdNl2" + fJdN/2"+! + vcdtd + 1)/2
Fixing the hypercube and varying the number of points per node, we see thereis linear growth in time. This trend is clearly suggested in Fig. 6 where each
PARTITIONING - NCUBECPU TIME YS. POINTS PER NODE
400
3S0 60
300
250 SOrow.TIME 200(lIl$ec:)
ISO 40
100 30
SO 2010
0
10 20 30 40 SO
f'OIrITS PER NODE
Figure 6. Partitioning performance (points per node).
Dow
nloa
ded
by [
Uni
vers
ity o
f A
uckl
and
Lib
rary
] at
14:
35 0
5 D
ecem
ber
2014

1350 G. Cybenko and T. G. Allen
PARTITIONING - NCUBECPU TIME vs. HYPERCUBE DIMENSION
'00
350
300
250CPUTIME 200(msec)
ISO
100
'0O+--- -----.----..----~---__<
1 3'HYPEIlCUBEDIM~SION
Figure 7. Partitioning performance (hypercube dimension).
connected line is for a fixed hypercube dimension. Keeping the total number ofpoints fixed and varying the cube dimension is shown in Fig. 7. While the formulasuggests that there is a nominal increase in required time when going from d = I tod =2, the observed increase seems larger to us than it should be. As d increases, theterms with d/2d contribute less while the quadratic term increases.
We now turn to the problem of data distribution. Suppose we have N points todistribute in an MBP on a d-dimensional hypercube. We again assume that eachnode has N/2 d points locally. Recall that data distribution requires the repeatedcomparison of points with a principal plane and the exchange with a neighbour ofthese points found to be on the wrong side of the plane. Let us suppose that at eachstage of this process, every processor has half of its points on the correct side of theappropriate plane and half on the wrong side. This requires a communication ofN/2 d + 1 points between neighbours per dimension. The general formula for the timerequired for data distribution, under these assumptions, is
N Nex 2d+fJ 2d + 1 +y
time per step, one for each dimension. Multiplying this expression by d gives thetotal time:
Nyd + d( ex + fJ/2) 2d
which indicates a linear growth as a function of d if N /2d is held fixed. The growthis affine in N /2d if d is fixed. For fixed N and varying d, the time depends linearlyon d with a decaying term involving d/2 d.
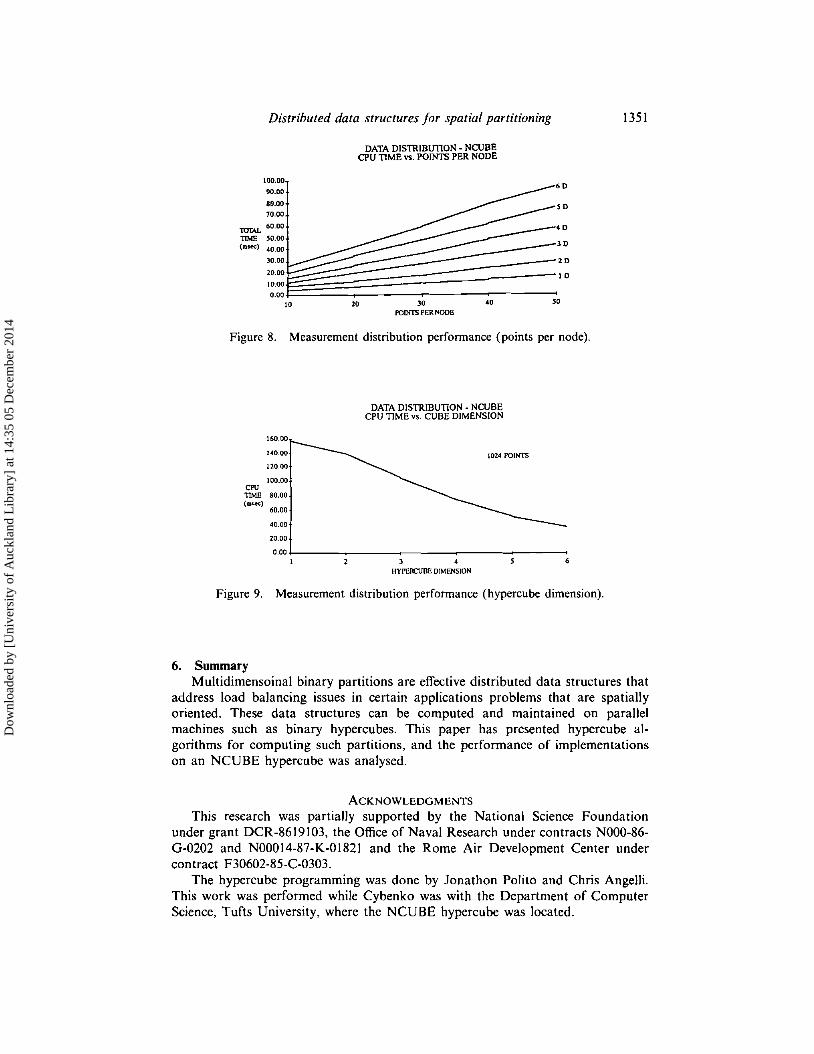
The linear growth of the time as a function of the number of points per node forconstant dimension hypercubes is illustrated in Fig. 8. Figure 9 shows the time fordata distribution when the total number of points is held fixed at 1024 and thedimension of the hypercube (and hence depth of the MBP) is varied. This graphclearly illustrates the exponential decay in the time as a function of hypercubedimension. These performance figures indicate that data distribution using MBPs isquite efficient-distributing 3200 points in a 6 dimensinal hypercube requires lessthan 100 milliseconds.
Dow
nloa
ded
by [
Uni
vers
ity o
f A
uckl
and
Lib
rary
] at
14:
35 0
5 D
ecem
ber
2014
Distributed data structures for spatial partitioning 1351
DATA DISTRIBUTION - NCUBECPU TIME vs. POINTS PER NODE
60
.0
'0
'0.0
:-_----30
30PO~PERNODE
'0
100.00
90.00
80.00
70.00
1UI'AL 60.00
TIME 50.00(Illsec) 40.00
30'OO~~~~.'O20.00 10
10.000.00
10
Figure 8. Measurement distribution performance (points per node).
DATA DISTRIBUTION - NCUBECPU TIME vs. CUBE DIMENSION
160.00
1024 POI!'ITS
3 •HYPEJOJDEDrMF.NSIOH
40.00
20.00
0.00l---_~---~---~---_--~
1
CPUTIME 80.00(-l
60.00
100.00
120.00
Figure 9. Measurement distribution performance (hypercube dimension).
6. SummaryMultidimensoinal binary partitions are effective distributed data structures that
address load balancing issues in certain applications problems that are spatiallyoriented. These data structures can be computed and maintained on parallelmachines such as binary hypercubes. This paper has presented hypercube algorithms for computing such partitions, and the performance of implementationson an NCUBE hypercube was analysed.
ACKNOWLEDGMENTS
This research was partially supported by the National Science Foundationunder grant DCR-8619103, the Office of Naval Research under contracts NOOO-86G-0202 and NOOOI4-87-K-OI821 and the Rome Air Development Center undercontract F30602-85-C-0303.
The hypercube programming was done by Jonathon Polito and Chris Angelli.This work was performed while Cybenko was with the Department of ComputerScience, Tufts University, where the NCUBE hypercube was located.
Dow
nloa
ded
by [
Uni
vers
ity o
f A
uckl
and
Lib
rary
] at
14:
35 0
5 D
ecem
ber
2014

1352 Distributed data structures for spatial partitioning
REFERENCES
ALLEN. T. G .• and CYBENKO, G .• 1987, Recursive binary partitions. Department ofComputer Science, Tufts University, Technical Report 87-14.
ALLEN, T. G .. CYBENKO, G., ANGELLI. Ci M; and POLITO, J., 1987. Hypercube Implementation of Tracking Algorithms. Proceedings of the 1987 Command and ControlResearch Symposium, pp. 145-153.
BADEN, S. B.. 1986, Dynamic load balancing of a vortex calculation running on multiprocessors. Lawrence Berkeley Laboratory, Research Report, Vol. 22584.
BENTLEY, J. L.. 1975. Multidimensional binary search trees used for associative searching.Communications of the ACM, 18,509-516; 1980, Multidimensional divide-and-conquer. Communications of the ACM, 23, 214-228.
BERGER, M. J.. and BOKIIARI, S.. 1987, A partitioning strategy for non-uniform problemson multiprocessors. I.E.E.E. Transactions on Computers, 26, 570-580.
BLUM, M .. FLOYD, R. W.. PRAlT, V. R., RIVEST, R. L., and TARJAN. R. E., 1973. Timebounds for selection. Journal of Computer and Systems Sciences, 9, 448-461.
BORIS, J., 1986, A vectorized 'ncar neighbors' algorithm of order N using a monotoniclogical grid. Journal of Computational Physics, 66, 1-20.
BREIMAN, L.. FRIEDMAN, J. H.. OLSHEN, R. A., and STONE, C J., 1984, Classification andRegression Trees (Belmont, Calif.: Wadsworth).
CHOU, T. C K., and ABRAHAM, J. A., 1982, Load balancing in distributed systems. IEEETransactions Oil Software Engineering, 8, 401-412.
CYIlENKO, G., 1989, Dynamic load balancing for distributed memory multiprocessors.Journal ,,( Parallel and Distributed Computing, 7, 279-301.
CYIlENKO, G., KRUMME, D. W., and VENKATARAMAN. K. N., 1987, Fixed hypercubeembedding. Information Processing Leiters, 25, 35-39.
Fox, G. C .. 1986, A review of automatic load balancing and decomposition methods forhypercubes, Caltech Concurrent Computing Project, Vol. C3 P-385.
Fox, G. C, and FURMANSKI, W.. 1986, Load balancing by neural networks. CaltechConcurrent Computing Project, Vol. C3 P-363.
GREENGARD, L., 1987, The rapid evaluation of potential fields in particle systems. Ph.D.thesis, Department of Computer Science, Yale University. Research Report 533.
HAJJAR, J. E., and CARLSON, D. A., 1989, Assigning modules to processors in linear arraysand rings. Proceedings of the Eighth Annual I.E.E.E. International Conference onComputers and Communications. pp. 510-514.
HEATH, M. T., (editor), 1986, Hypercube multiprocessors 1986 (Philadelphia: SIAM).KEYES, D. E., and GROPP, W. D., 1987, A comparison of domain decomposition techniques
for elliptic partial differential equations and their implementation. SIA M Journal ofScientific and Statistical Computing, 8, sI66-s202.
OMOHUNDRO, S., 1987, Efficient algorithms with neural network behavior. Complex Systcms, I, 273-347.
PREPARATA, F. P.. and SHAMOS. M. I., 1985, Computational Geometry (New York:Springer-Verlag).
PRICE, C, 1981, The assignment of computational tasks among processors in a distributedsystem. Proceedings of the National Computer Conference, pp. 291-296.
Dow
nloa
ded
by [
Uni
vers
ity o
f A
uckl
and
Lib
rary
] at
14:
35 0
5 D
ecem
ber
2014