msis5633 cfb presentation
TRANSCRIPT

Predictive Measures in College Football
By David AffentrangerMSIS 5633 OSU Fall 2012

Project Outline
Project Research
Data Sources and Tools
Data Transformation
Decision Tree
Decision Tree Results
Classification Predictive Modeling
Prediction Results
Future Efforts

Project Research
Projecting Point Spreads◦ http://cs229.stanford.edu/proj2010/LiuLai-BeatingTheNCAAFootballPointSpread.pdf
Predicting individual games◦ http://cfbpredictions.com/
Predicting BCS Rankings◦ http://harvardsportsanalysis.wordpress.com/2011/
11/24/making-sense-of-the-chaos-a-bcs-prediction-model/

Data Sources and Tools
Data Sources◦ http://www.cfbstats.com
Tools◦ Microsoft Excel
◦ Rapid Miner

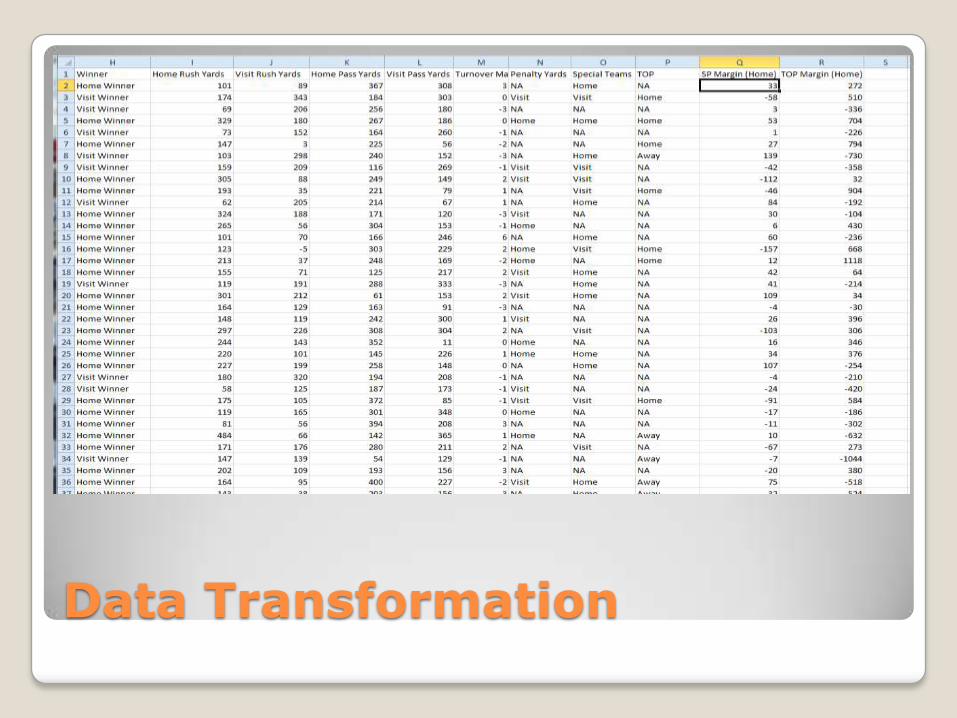
Data Transformation
Data Challenges◦ Data home/away teams listed in separate spreadsheet
◦ Data rows lacked visiting team statistics
◦ Data rows lacked who won the game
◦ Many numerical fields difficult for classification
Data Solutions◦ Used Excel vlookups to pull in visiting team statistics into
the tuples
◦ Used the “Points” field to compare home vs away to create a “Winner” classification field.
◦ Built Formula fields to transform numerical values into a text classification (TOP, Special Teams, Penalty Yards)
Data Transformation
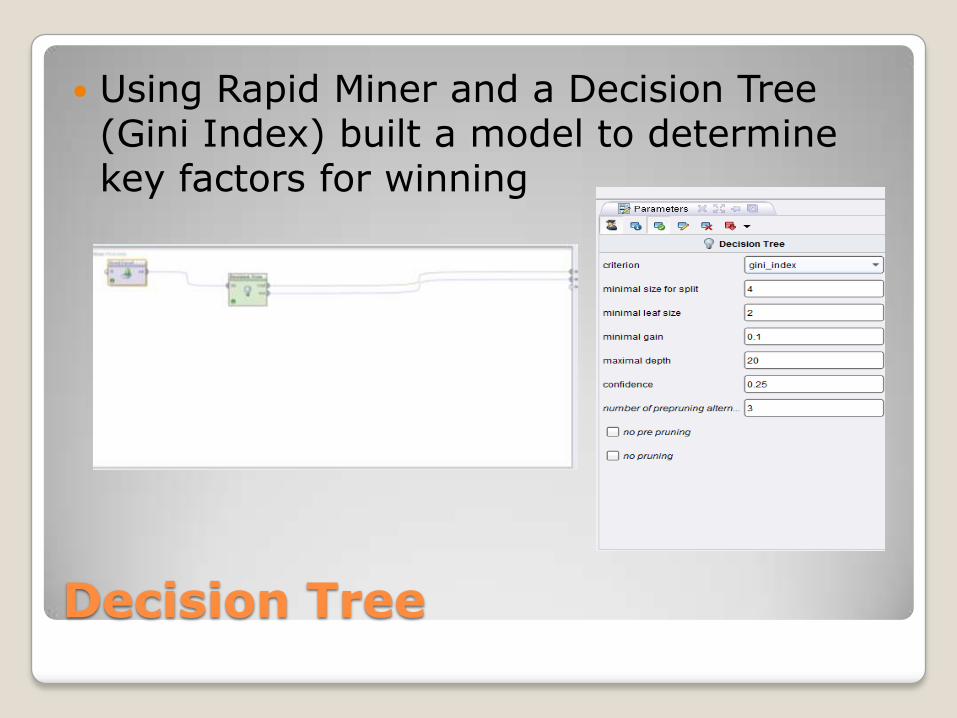
Decision Tree
Using Rapid Miner and a Decision Tree (Gini Index) built a model to determine key factors for winning

Decision Tree Results
Visit Rush Yards Most important Factor in the model >= 165 Yards Visit Winner 66% of the time
<= 165 Yards Home Winner 79% of the time

Decision Tree Results

Classification Predictive Modeling
Predictive Model Plan◦ Predict winner of an individual game based upon key statistics
◦ Use same data set as the decision tree
◦ Split the data into Testing and Training
◦ Evaluate different data elements and there affects on prediction

Classification Predictive Modeling
Using Rapid Miner◦ Naïve-Bayes Classification Model
◦ Split Example set into 2 sets using X-Validation
◦ Analyzed using Performance Tool
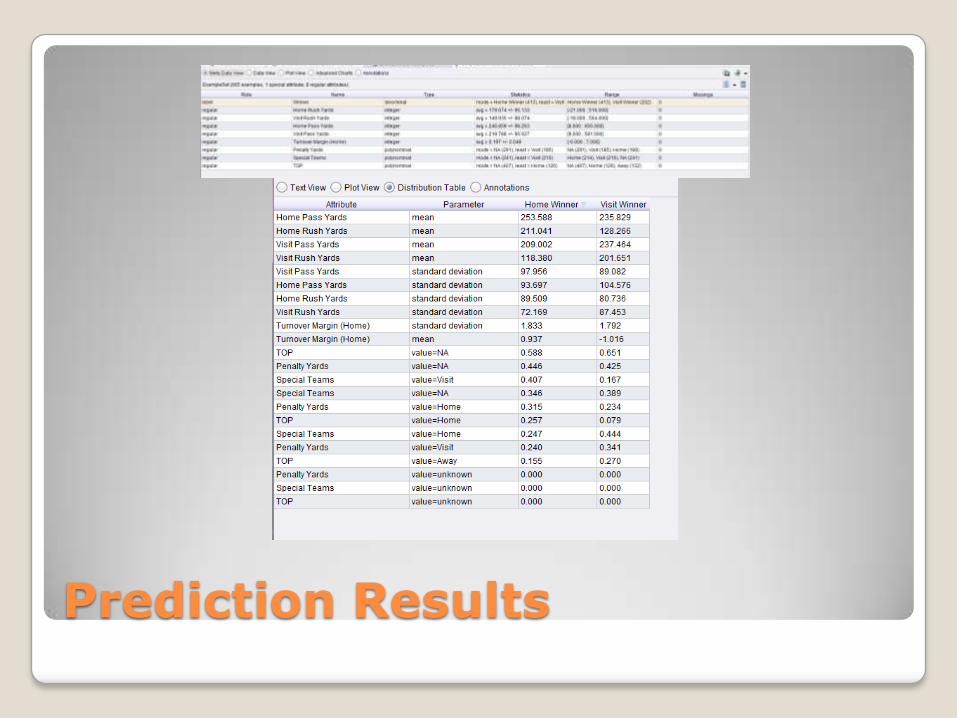
Prediction Results

Prediction Results
85.58% Home Winner precision
78.93% Visit Winner precision

Future Efforts
Model currently relies on a user manually entering key statistical information for a game
Model could be enhanced for a full predictive solution ◦ Using a neural network statistical data could be predicted for an individual team for a particular game
◦ Data from the neural network could feed the classification model to predict a game or series of games

References
http://www.cfbstats.com
http://espn.go.com/college-football/
http://cs229.stanford.edu/proj2010/LiuLai-BeatingTheNCAAFootballPointSpread.pdf