monika henzinger supercomputing challenge for indexing the ... · m. henzinger indexing the web 13...
TRANSCRIPT

Indexing the Web – A Challenge for
SupercomputingMonika Henzinger

M. Henzinger Indexing the Web 2
The Web
� 2-10 billion pages – doubling every 8 months� 260 million users per month [Nielson/NetRatings]� 80% of them issue searches [Jupiter Media Metrix]
� How can they find what they need:
Smart algorithms + parallelism =

M. Henzinger Indexing the Web 3
Let’s first talk about the smart
algorithms …

M. Henzinger Indexing the Web 4
Classic Information Retrieval
� Input: Document collection
� Goal: Retrieve documents or text with information content that is relevant to user’s information need
� Two aspects:
1. Processing the collection
2. Processing queries (searching)

M. Henzinger Indexing the Web 5
Determining query results
� Ranking is a function of query term frequency within the document and across all documents
� This works because of the following assumptions in classical IR:– Queries are long and well specified
“What is the impact of the Falklands war on Anglo-Argentinean relations”
– Documents (e.g., newspaper articles) are coherent, well authored, and are usually about one topic
– The vocabulary is small and relatively well understood

M. Henzinger Indexing the Web 6
IR on the Web
� Input:The publicly accessible Web� Goal: Retrieve high quality pages that are relevant to
user’s need– Static (files: text, audio, … )– Dynamically generated on request: mostly data base
access� Two aspects:
1. Gathering and processing the collection 2. Processing queries (searching)

M. Henzinger Indexing the Web 7
What’s different about the Web?
(1) Pages:� Bulk …………………… >2B � Vocabulary size………. 10s-100s million of words� Lack of stability……….. Estimates: 23%/day, 38%/week [CG’99]� Diversity
– Type of documents .. Text, pictures, audio, scripts,…– Quality ……………… Lots of misinformation… – Language ………….. 100+
� Duplication– Syntactic……………. 30% (near) duplicates – Semantic……………. ??
� Non-running text……… many home pages, bookmarks, ...
M. Henzinger Indexing the Web 8
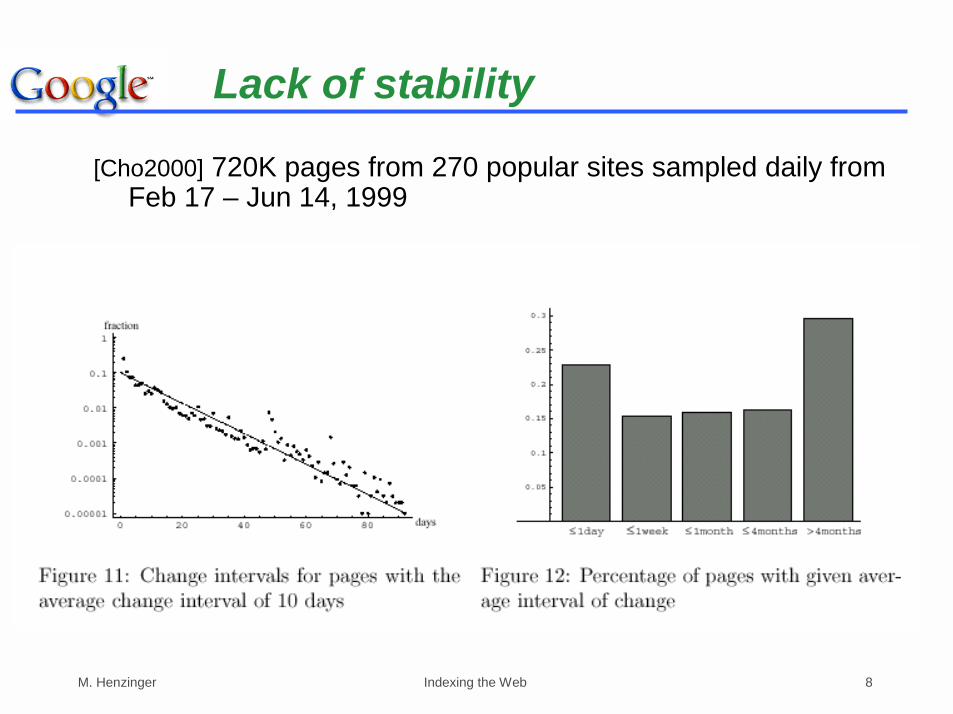
Lack of stability
[Cho2000] 720K pages from 270 popular sites sampled daily from Feb 17 – Jun 14, 1999

M. Henzinger Indexing the Web 9
Misinformation (Spam)http://www.Safari-iafrica.com/diana.htm<META name="keywords"
content="diana,di,princess,princess diana,princess di,princess DIANA,PRINCES di,princess of wales,princess of wales, death,condolences, royal, royal family,british,spencer,harry,william,charles,prince,william,prince harry,prince charles,queen elizabeth,">
Other tricks:Keyword hiding, Link spam,Cloaking, Doorways, DNS cloaking,Domain hijacking, …

M. Henzinger Indexing the Web 10
The big challenge
Meet the user needs given
the heterogeneity of Web pages

M. Henzinger Indexing the Web 11
What’s different about the Web? (2) Users:� Bulk ……………………. > 93.5 million unique users [3/2002,
MediaMetrics USA data]� Diversity
– Topics of interest…… Arts, computers, …– Knowledge & needs.. – Language …………… 100+
� Sub-optimal queries– Short…………………. 2.35 terms avg– Sub-optimal syntax….. ~80% without operators *
� Search behavior……… – Few results studied…. 85% of users look only at top 10 results *– Query modification….. 78% of queries are not modified *
* [SHMM’98]

M. Henzinger Indexing the Web 12
The bigger challenge
Meet the user needs given
the heterogeneity of Web pagesand
the sub-optimal queries.

M. Henzinger Indexing the Web 13
The bright side:Web advantages vs. classic IR
Collection/tools� Redundancy� Hyperlinks� Statistics
– Easy to gather– Large sample sizes
� Interactivity (give hints to the user)
User� Many tools available� Interactivity (refine the
query if needed)

M. Henzinger Indexing the Web 14
Determining query results on the web
� Ranking based on query term frequency within the document and across all documents does not work well:– Misinformation– Variety in page quality– Huge vocabulary– Short queries

M. Henzinger Indexing the Web 15
Google’s approach
� Assumption: A link from page A to page B is a recommendation of page B by the author of A(we say B is successor of A)
�Quality of a page is related to its in-degree
� Recursion: Quality of a page is related to– its in-degree, and to – the quality of pages linking to it
�PageRank [BP ‘98]

M. Henzinger Indexing the Web 16
Definition of PageRank [BP’98]
� Consider the following infinite random walk (surf):
– Initially the surfer is at a random page
– At each step, the surfer proceeds
• to a randomly chosen web page with probability d
• to a randomly chosen successor of the current page with probability 1-d
� The PageRank of a page p is the fraction of steps the surfer spends at p in the limit.

M. Henzinger Indexing the Web 17
PageRank (cont.)
Said differently:� PageRank = stationary probability for this Markov chain,
i.e.
where n is the total number of nodes in the graph
∑∈
−+=Euv
voutdegreevPageRankdnduPageRank
),()(/)()1()(
M. Henzinger Indexing the Web 18
PageRank (cont.)
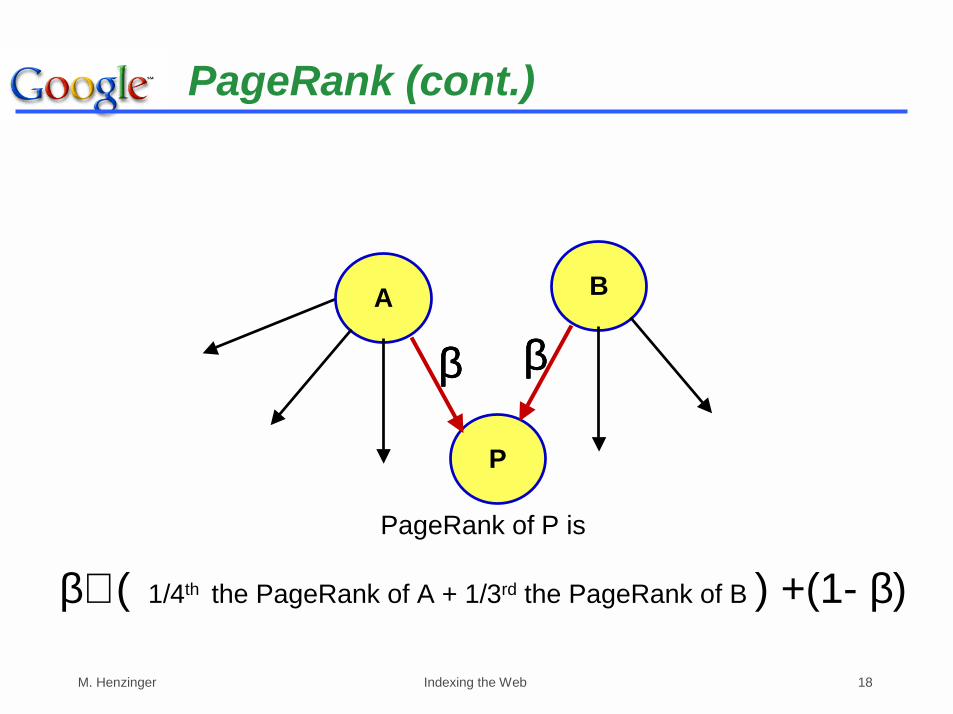
P
A B
PageRank of P is
β∗ ( 1/4th the PageRank of A + 1/3rd the PageRank of B ) +(1- β)
ββββββββ

M. Henzinger Indexing the Web 19
PageRank advantages
� Query-independent
� Summarizes the “web opinion” of the page importance
� Highly spam-resistant
� Patented

M. Henzinger Indexing the Web 20
Now let’s talk about parallelism …

M. Henzinger Indexing the Web 21
Search engine components
� Crawler (Spider): collects the documents
� Indexer: processes and represents the data
� Query handler: processes user queries
M. Henzinger Indexing the Web 22
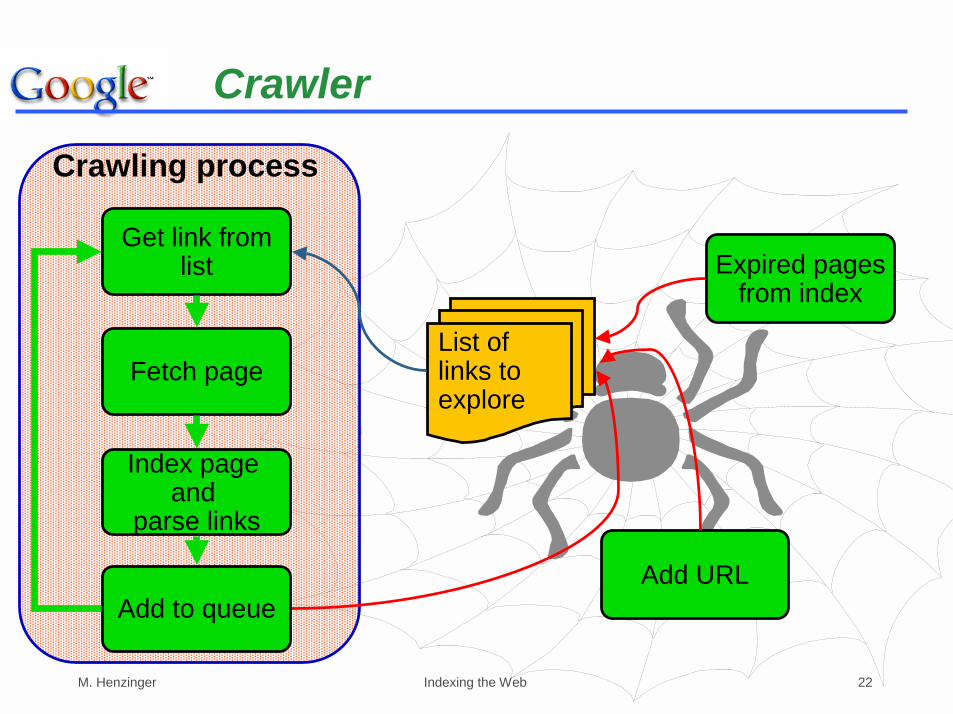
Crawler
List of links to explore
Expired pagesfrom index
Add URL
Get link fromlist
Fetch page
Add to queue
Index page and
parse links
Crawling process

M. Henzinger Indexing the Web 23
Issues with Parallelization
� Crawling order
� Avoid re-crawling
– Session-ids
� Should not overload any server or connection
– virtual hosting
� Avoid infinite spaces
� Content types (Google: 23 different types)

M. Henzinger Indexing the Web 24
Search engine components
� Crawler (Spider): collects the documents �
� Indexer: processes and represents the data
� Query handler: processes user queries

M. Henzinger Indexing the Web 25
Indexer� Inverted index data structure: Consider all documents concatenated
into one huge document– For each word keep an ordered array of all positions in
document, compressed
� Indexing = a huge parallel sort� Issues
– Redirects– Anchor text– Incremental updates
...last position1st positionWord 1
......
…

M. Henzinger Indexing the Web 26
Search engine components
� Crawler (Spider): collects the documents �
� Indexer: processes and represents the data �
� Query handler: processes user queries

M. Henzinger Indexing the Web 27
Google’s query handler
� Over 150 million queries per day
� Sub-second response time
� Powered by more than 10,000 Linux-based systems
(over 10 teraflops)

M. Henzinger Indexing the Web 28
Issues
� Scalability with:
– traffic growth
– web data growth
� Hardware faults

M. Henzinger Indexing the Web 29
Scalability (Data)
� Size of web is growing exponentially� No matter how big your machine, it’s going to be too
small� Solution: distribute index across multiple machines
(“sharding”)

M. Henzinger Indexing the Web 30
Scalability (Traffic)
� Replicate everything
� Index is read-only, so no consistency problems
� Search is embarrassingly parallel, so linear speedup

M. Henzinger Indexing the Web 31
Reliability / Fault Tolerance
� PCs are unreliable, especially if you have thousands
� But they are cheap and fast
� Strategy:
– Again: Replication is your friend
• Failure only reduces capacity
• Anyway needed for scalability
– Make it reliable in software

M. Henzinger Indexing the Web 32
New developments at Google
� Google Web APIs
� Distributed computing: part of folding@home project at
Stanford for protein analysis
� Voice search (+1 650 318 0165)
� …

M. Henzinger Indexing the Web 33
Google Web APIs (beta)
� SOAP interface to Google:– Searches– Spelling requests– Cached pages
� Client examples in Java, Perl, .NET� Open developer program (http://www.google.com/apis/)� Examples:
– Professor verifier– Google velocity indicator
M. Henzinger Indexing the Web 34
Where Our Users Are...